Deep Convolutional Neural Network-Based Approaches for Face Recognition



Abstract
:1. Introduction
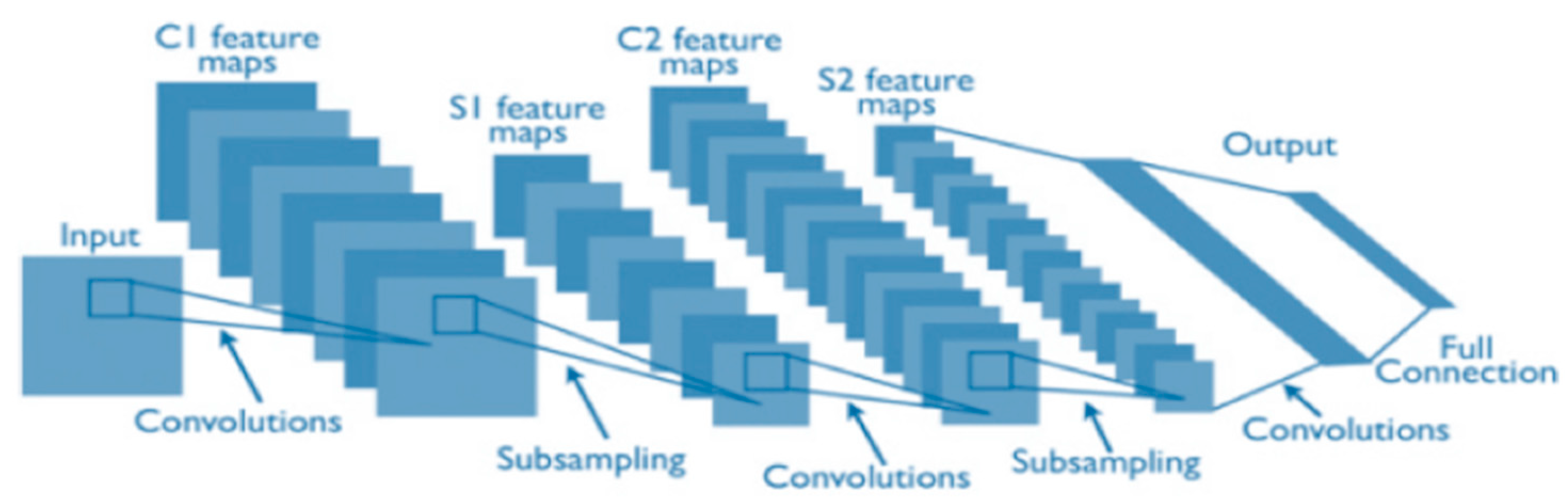
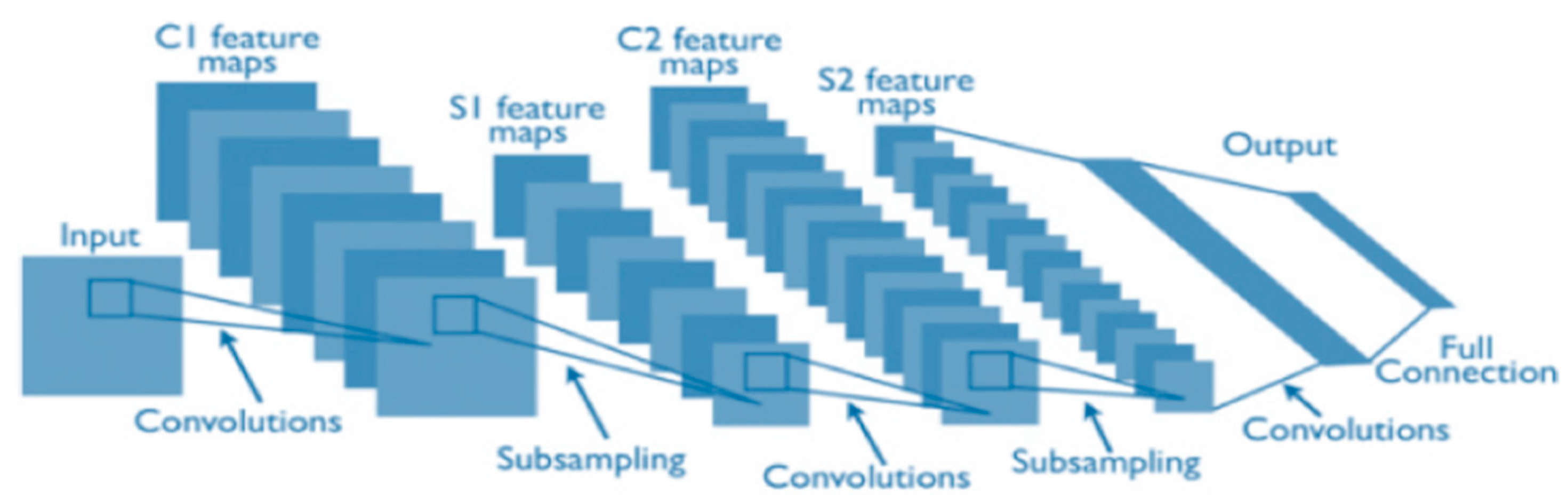
2. CNNs Preliminaries
2.1. CNN Pre-Trained Models
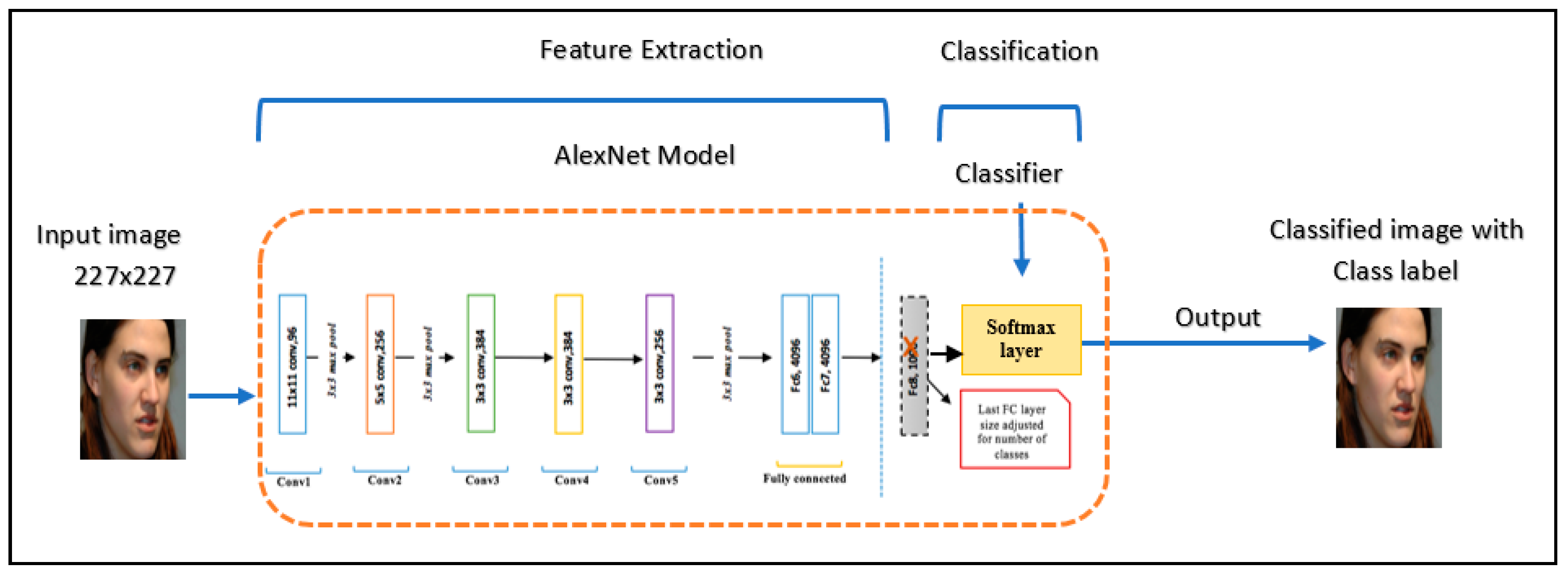
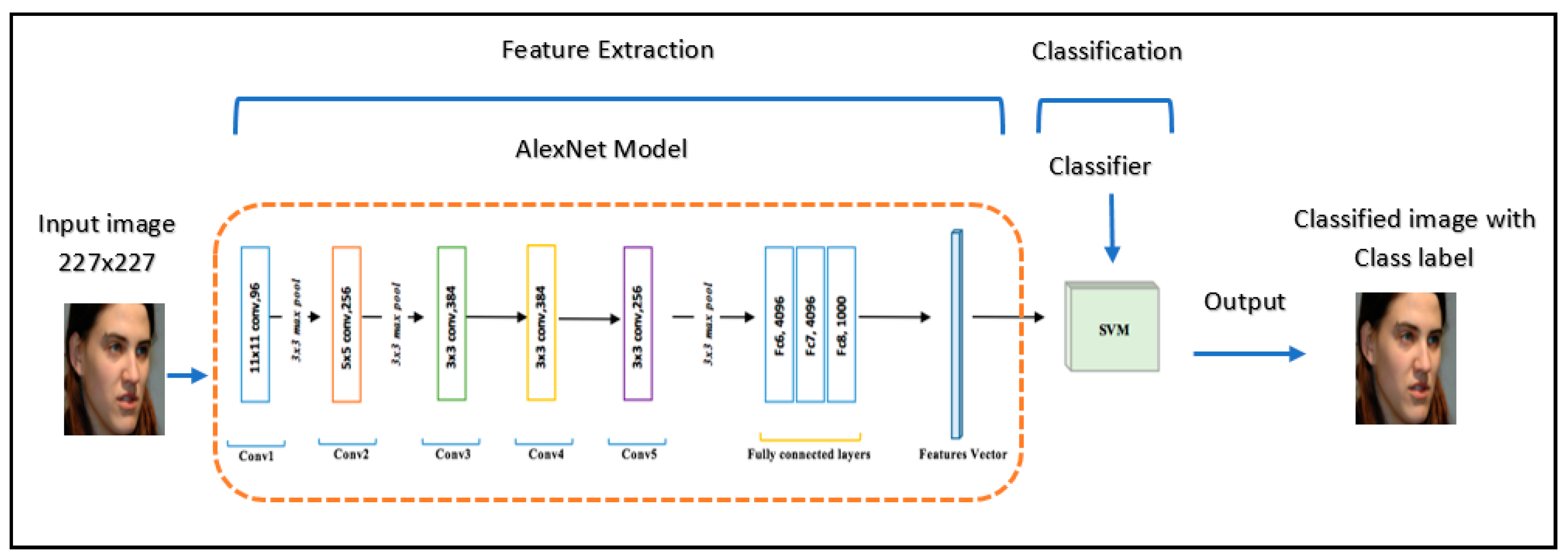
2.1.1. AlexNet
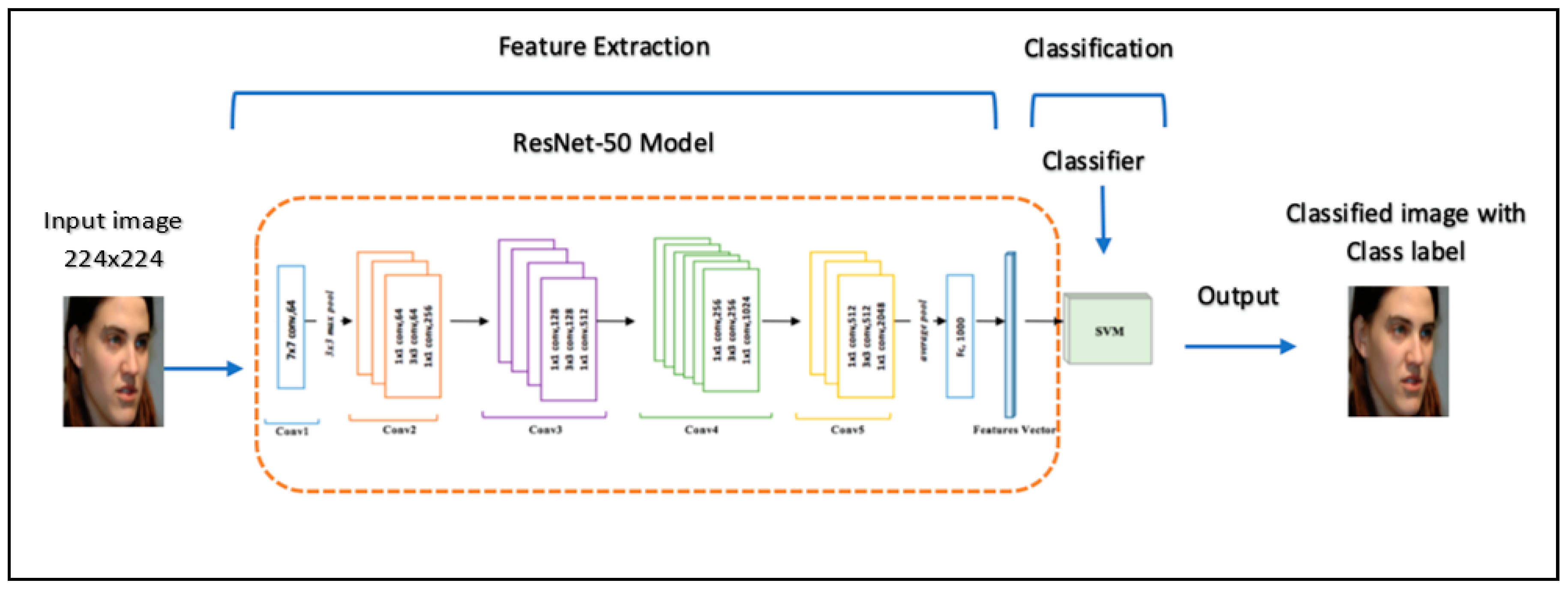
2.1.2. ResNet-50
3. Related Work
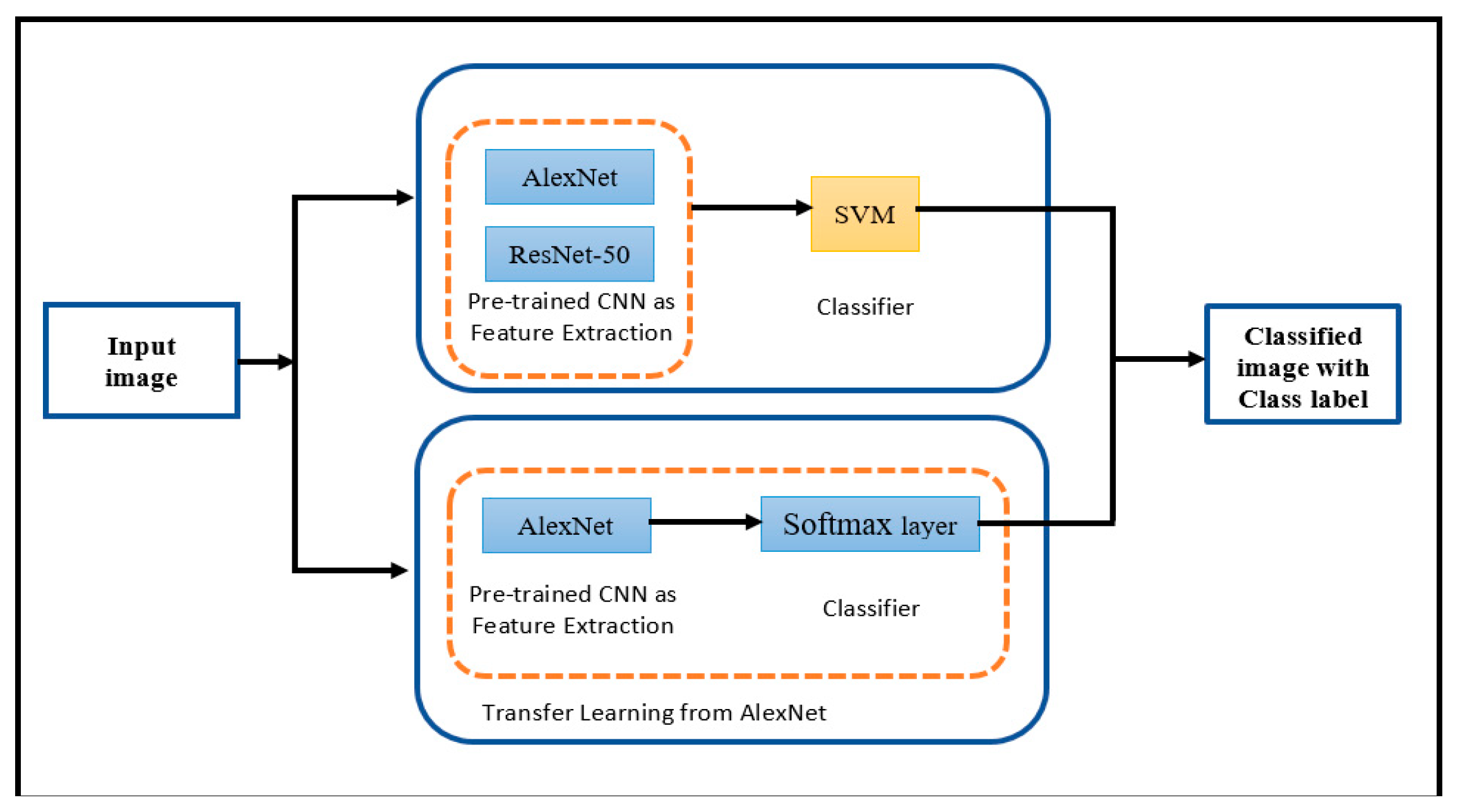
4. Methodology and Experiments
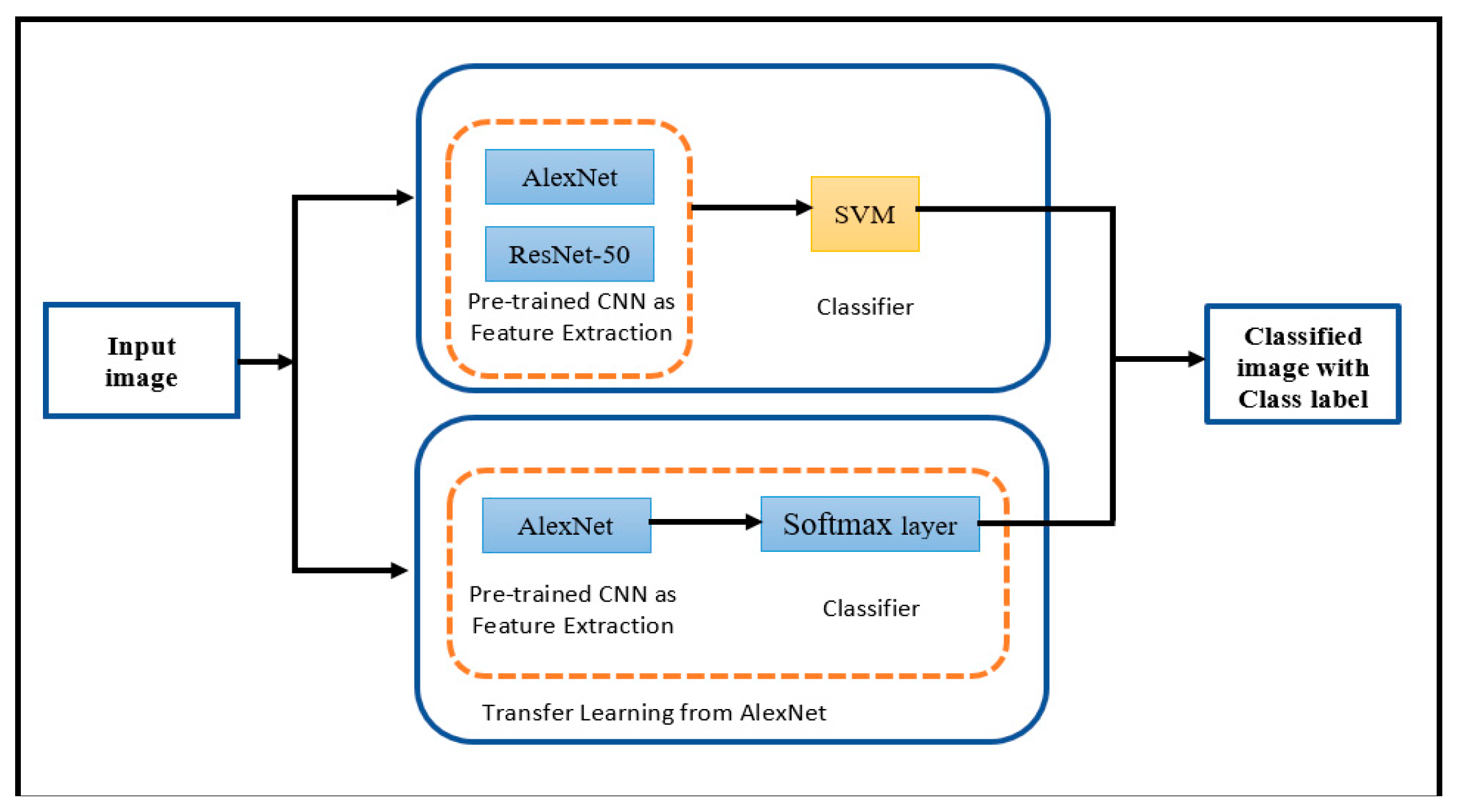
- First approach: Applying the pre-trained CNN for extracting features and support vector machine (SVM) for classification.
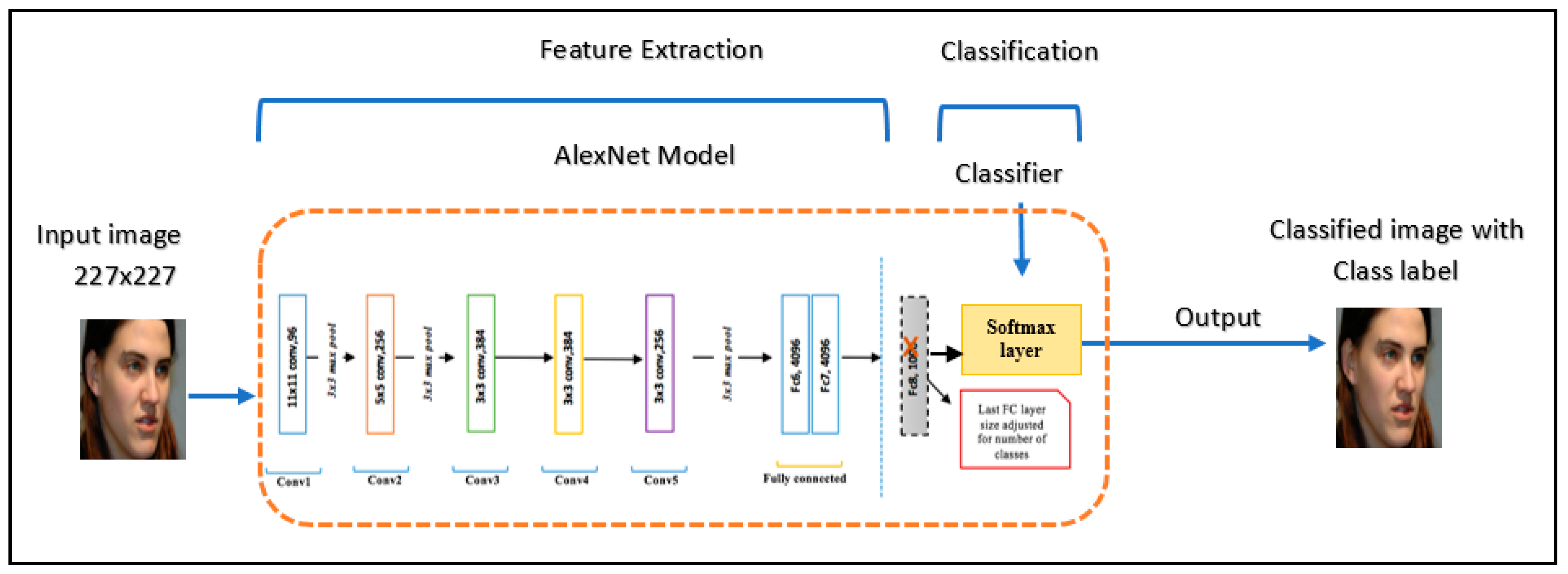
- Method 1: Pre-trained CNN AlexNet with SVM.
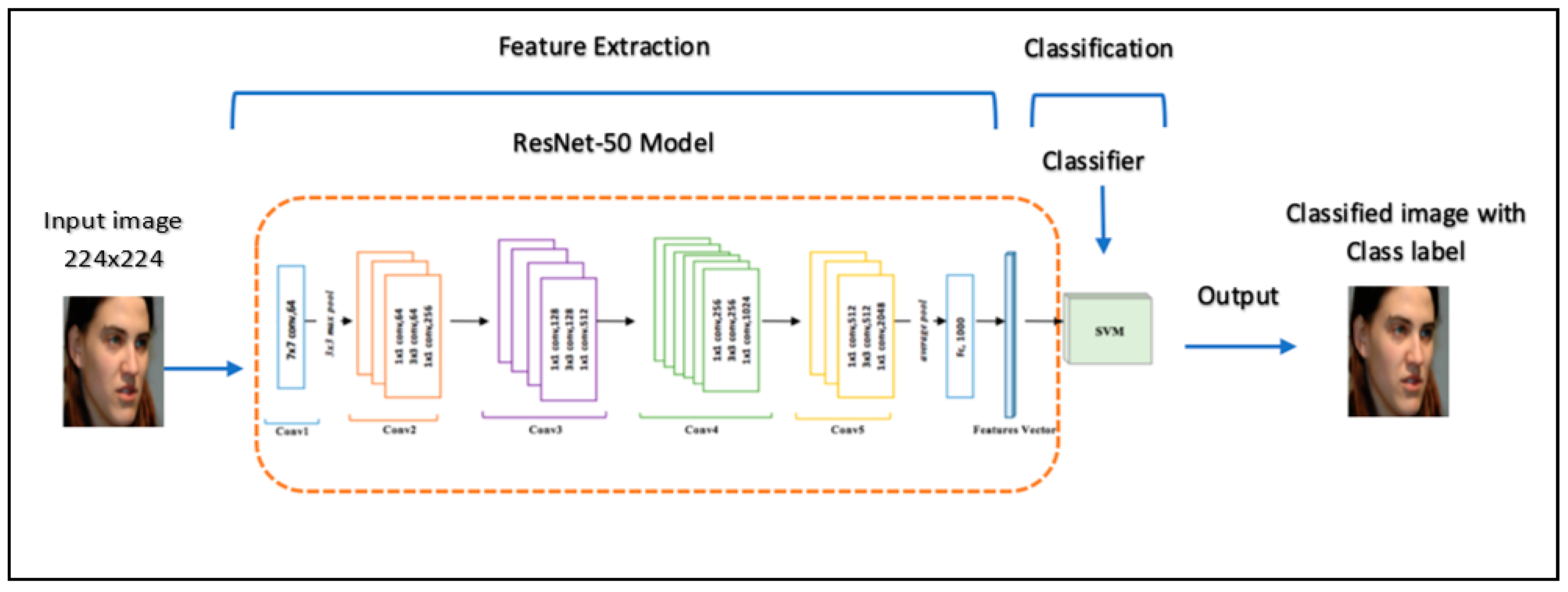
- Method 2: Pre-trained CNN ResNet-50 with SVM.
- Second approach: Applying transfer learning from AlexNet model for extracting features and classification.
4.1. Setting
Dataset Description
- ORL [16]: The database utilized in recognition experiments. It contains 10 unique images of 40 individuals, adding up to a total of 400 images that have different face angles, facial expressions, and facial details. The dataset has a collection at the Olivetti Research Laboratory at Cambridge University for some individuals.
- GTAV face database [17]: The database contains images for 44 individuals, which were taken on different pose views (0º, ±30º, ±45º, ±60º and 90º) for three illuminations (environment or natural light, strong light source from an angle of 45º, and an almost frontal mid-strong light source with environment or natural light). In our study, 34 images per each person in the dataset were chosen.
- Georgia Tech face database [18]: This database contains sets of images for 50 individuals, and there are 15 color pictures for each person. Most of the pictures were taken in two different sessions to consider the variations in illumination conditions, appearance, and facial expression. Also, the images in the datasets were taken at different orientations and scales.
- FEI face [19]: The database has 14 image sets for every individual among all the 200 people, totaling up to 2800 images. In our study, we chose frontal images for each individual. The total number of images that were chosen in the study was 400 images. In our experiment, we chose images for 50 individuals in a total of 700 images.
- Labeled faces in the wild (LFW) [20]: This dataset was designed for studying the problem of unconstrained face recognition. The dataset contains more than 13,000 images of faces collected from the web. Each face has been labeled with the name of the person pictured. A total of 1680 of the people pictured have two or more distinct photos in the dataset.
- YouTube face (YTF) [22]: The dataset contains 3425 videos collected from YouTube. The videos are a subset of the celebrities in the LFW. The videos contain 1595 individuals. In our study, we used images taken from video.
- DB_Collection: This dataset contains images combined from all datasets used in this study. We selected images for 30 people from each dataset, a total of 2880 images.
4.2. Experiments and Results
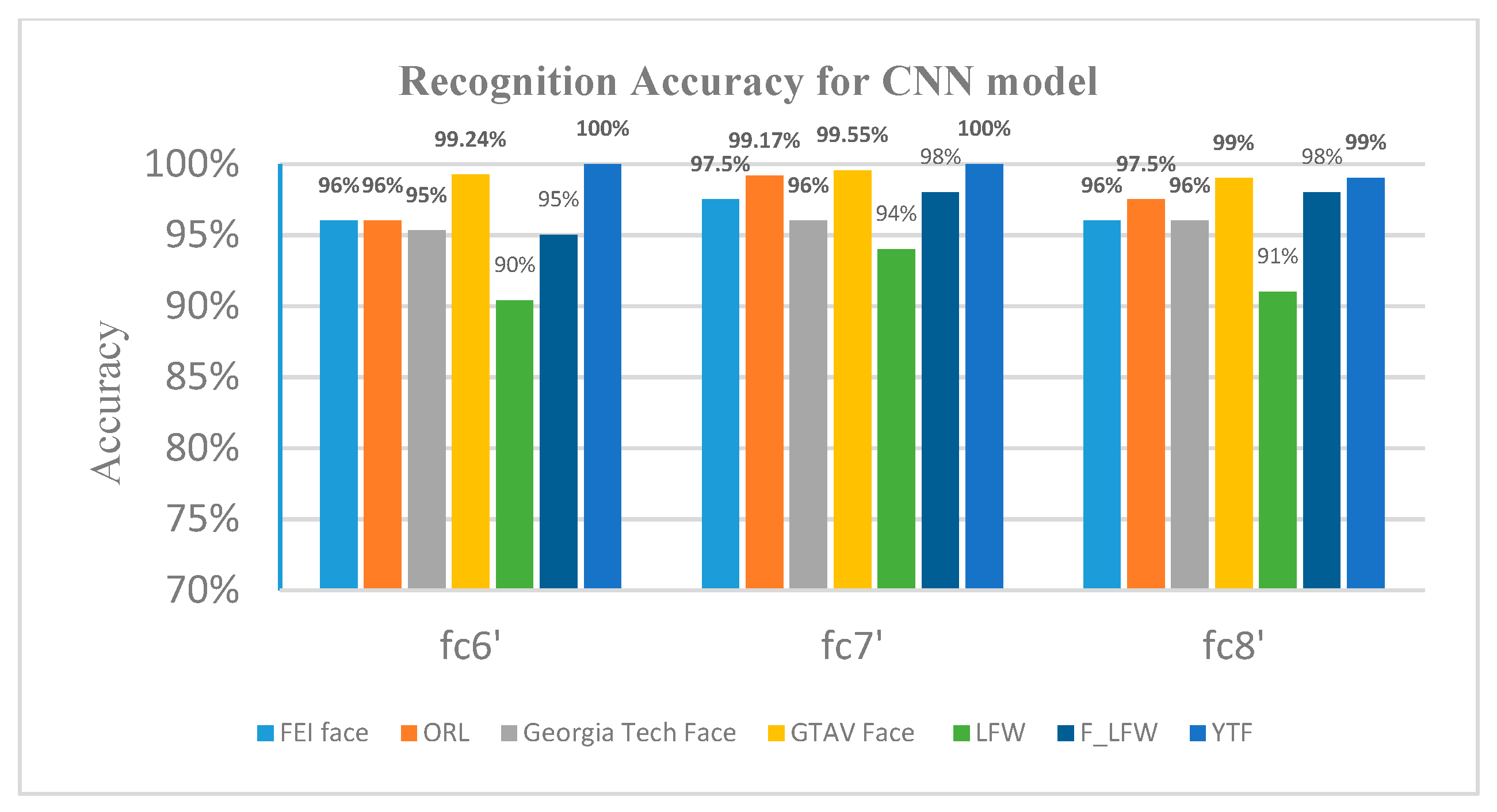
4.2.1. First Experiment: Pre-Trained CNN AlexNet with SVM
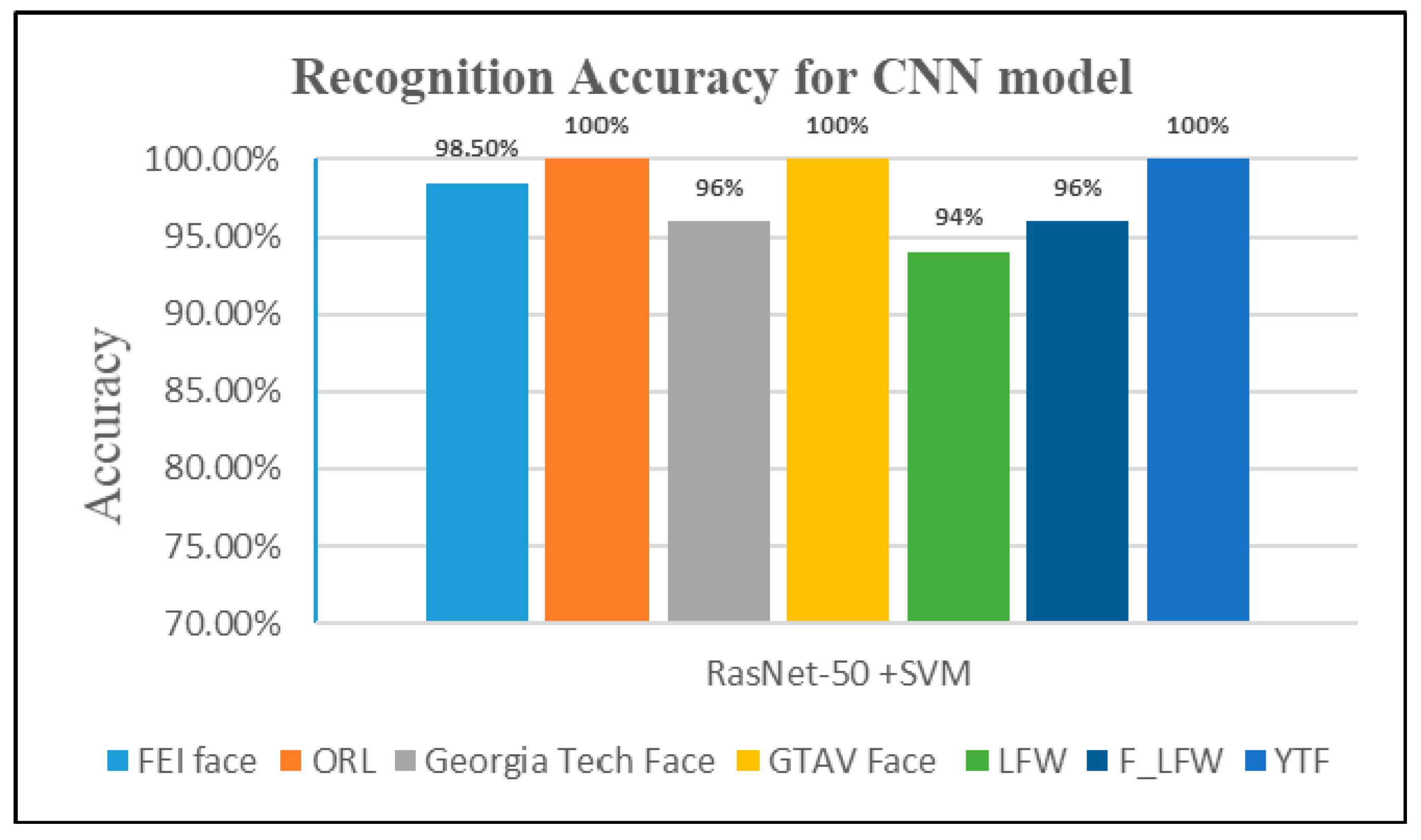
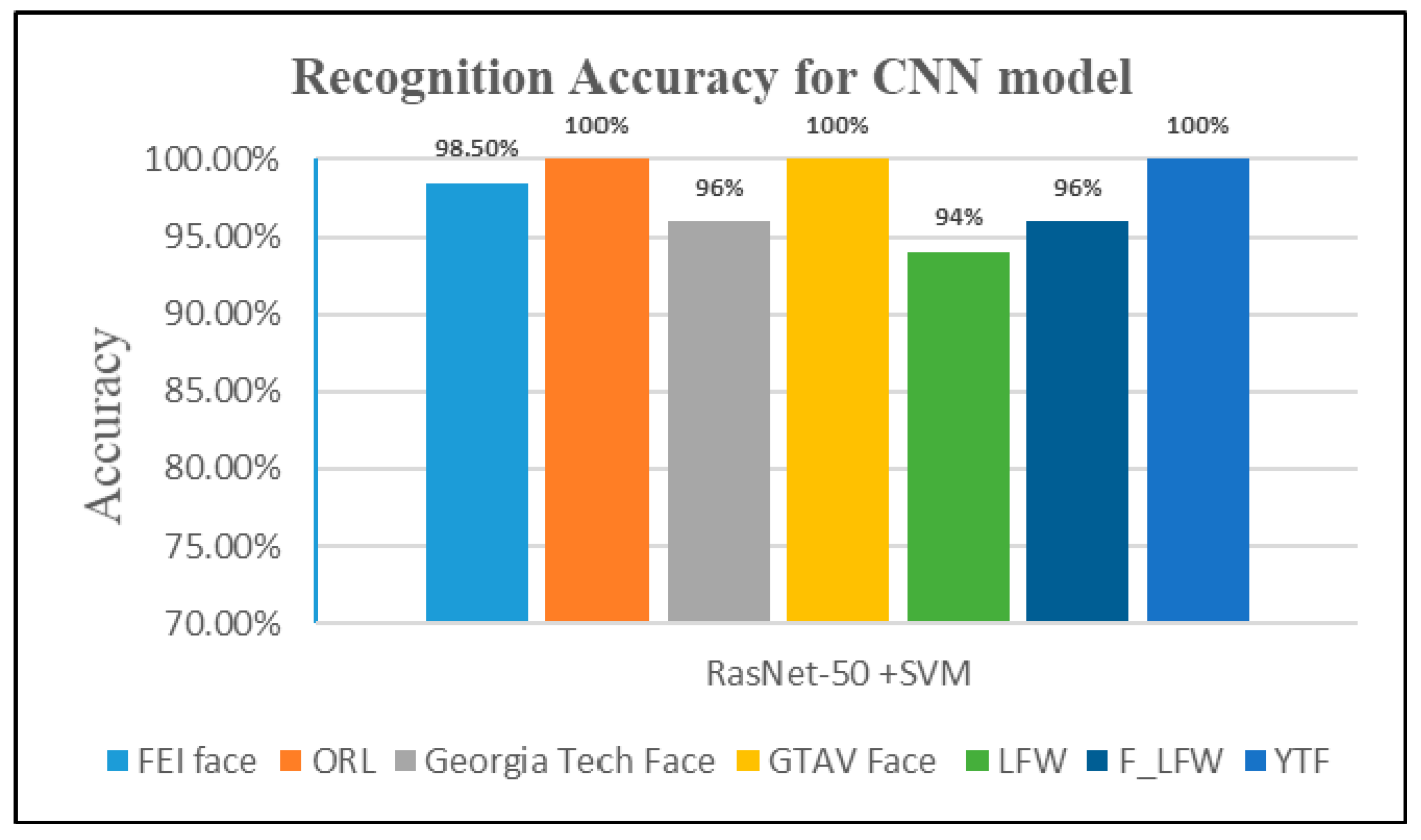
4.2.2. Second Experiment: Pre-Trained ResNet-50 Model with SVM
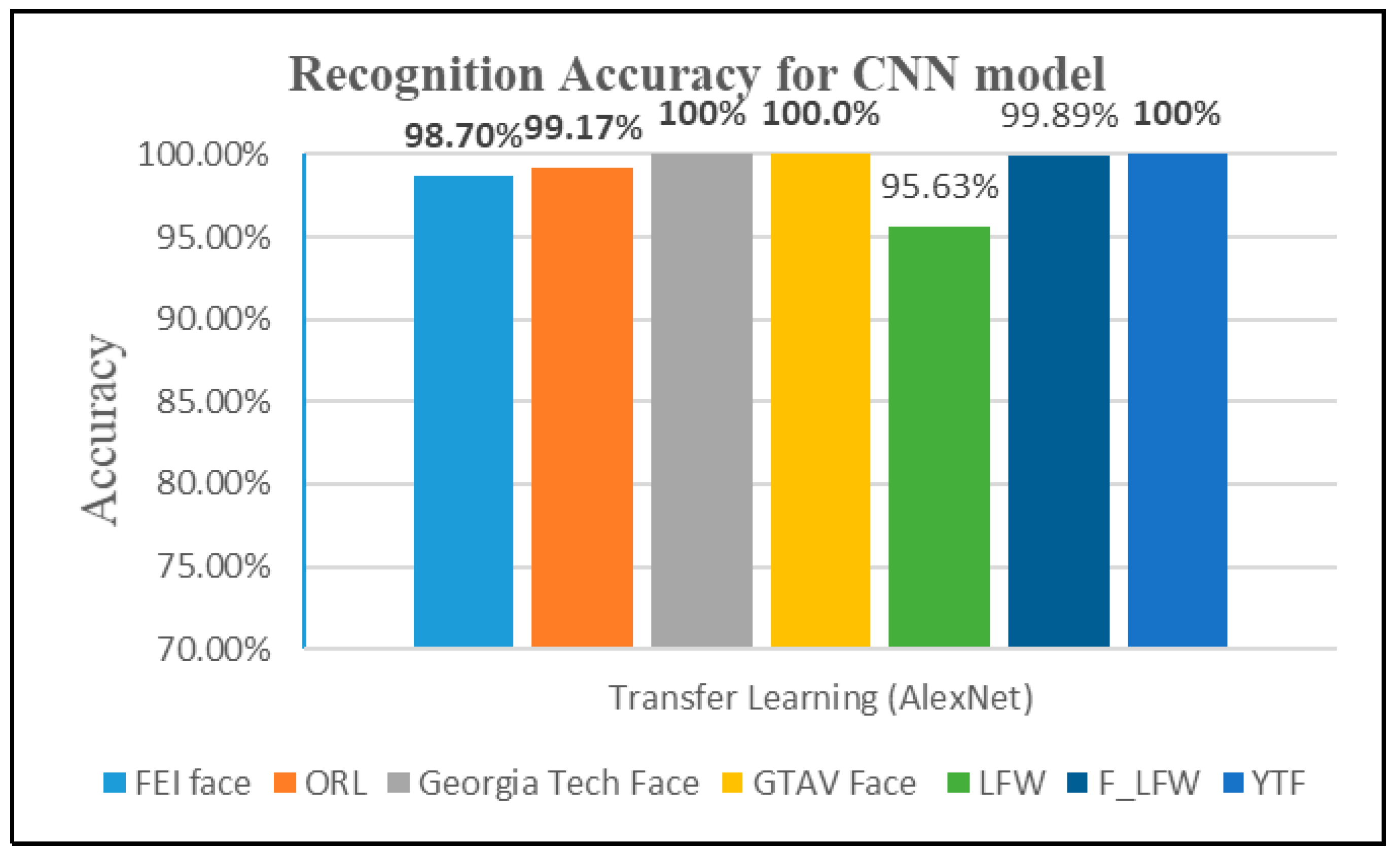
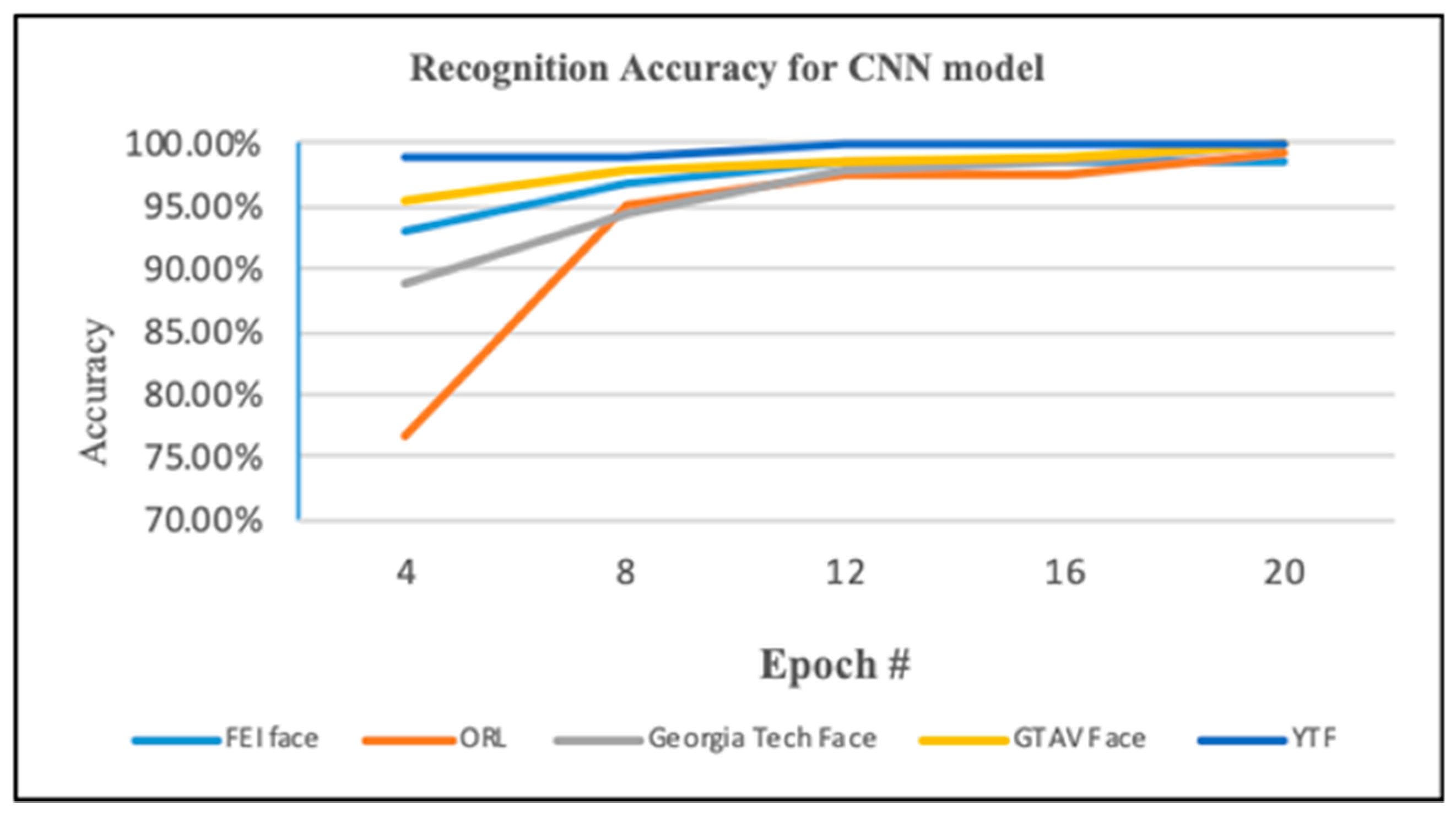
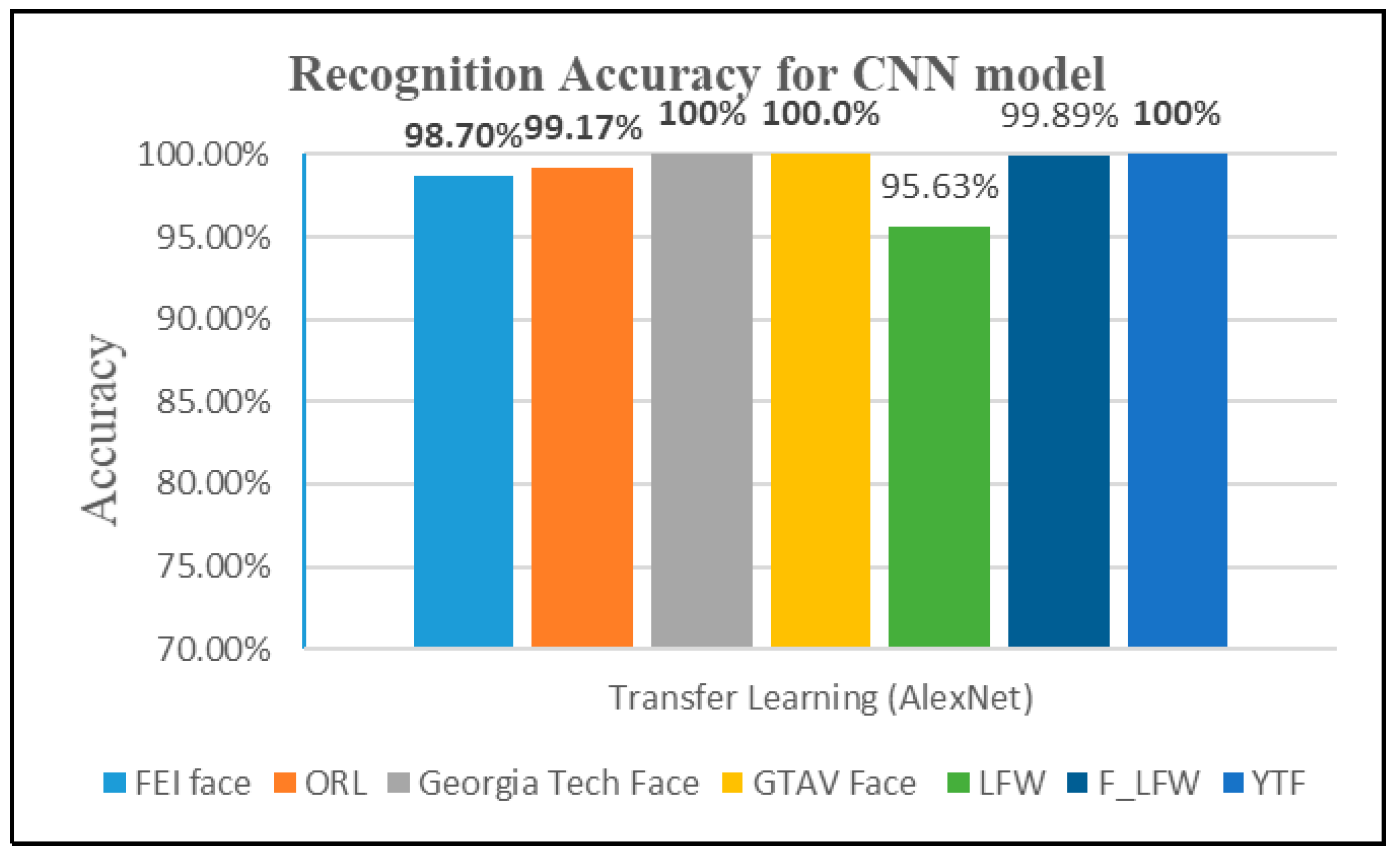
4.2.3. Third Experiment: Transfer Learning from AlexNet for Extracting Features and Classification
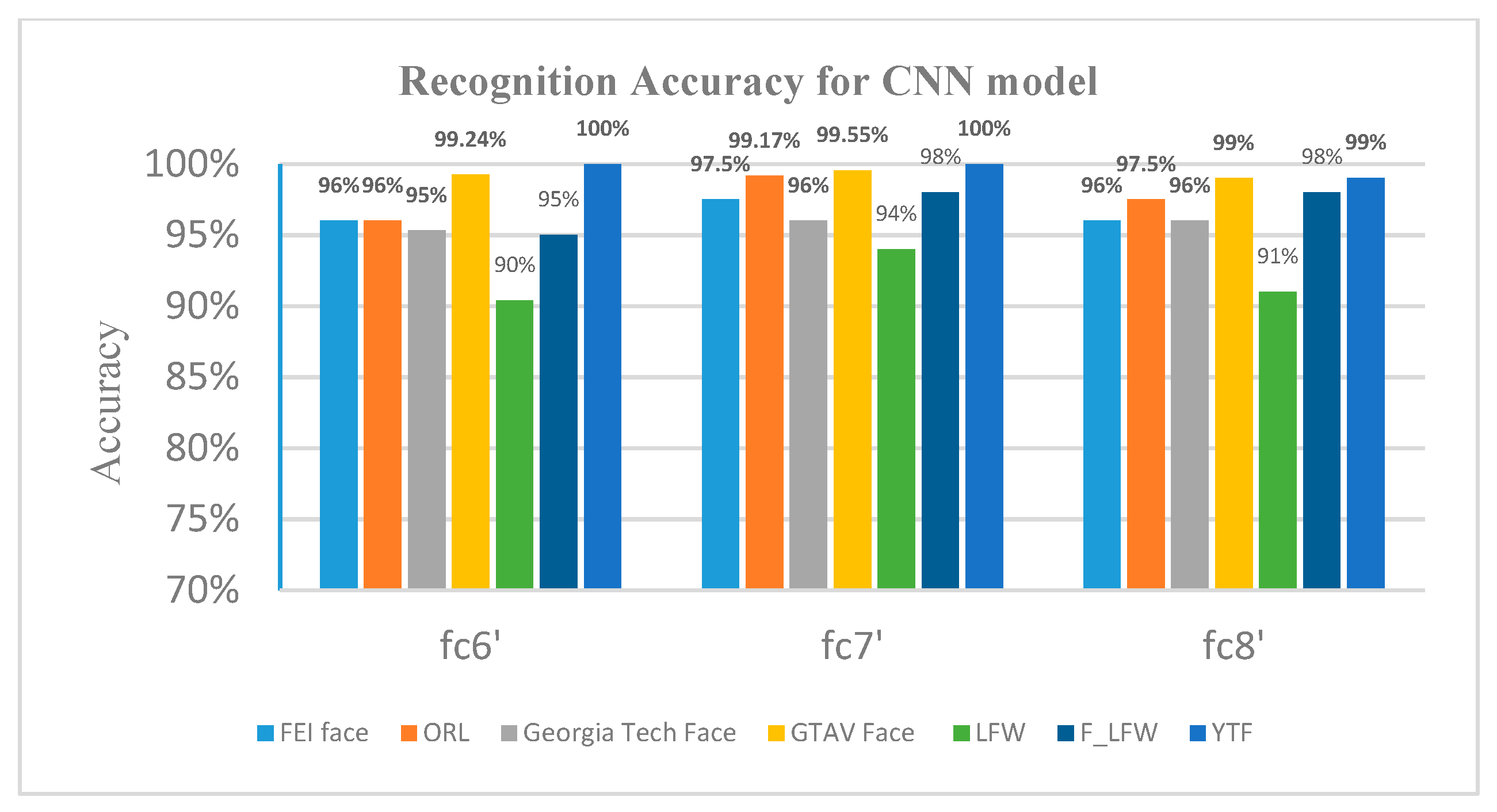
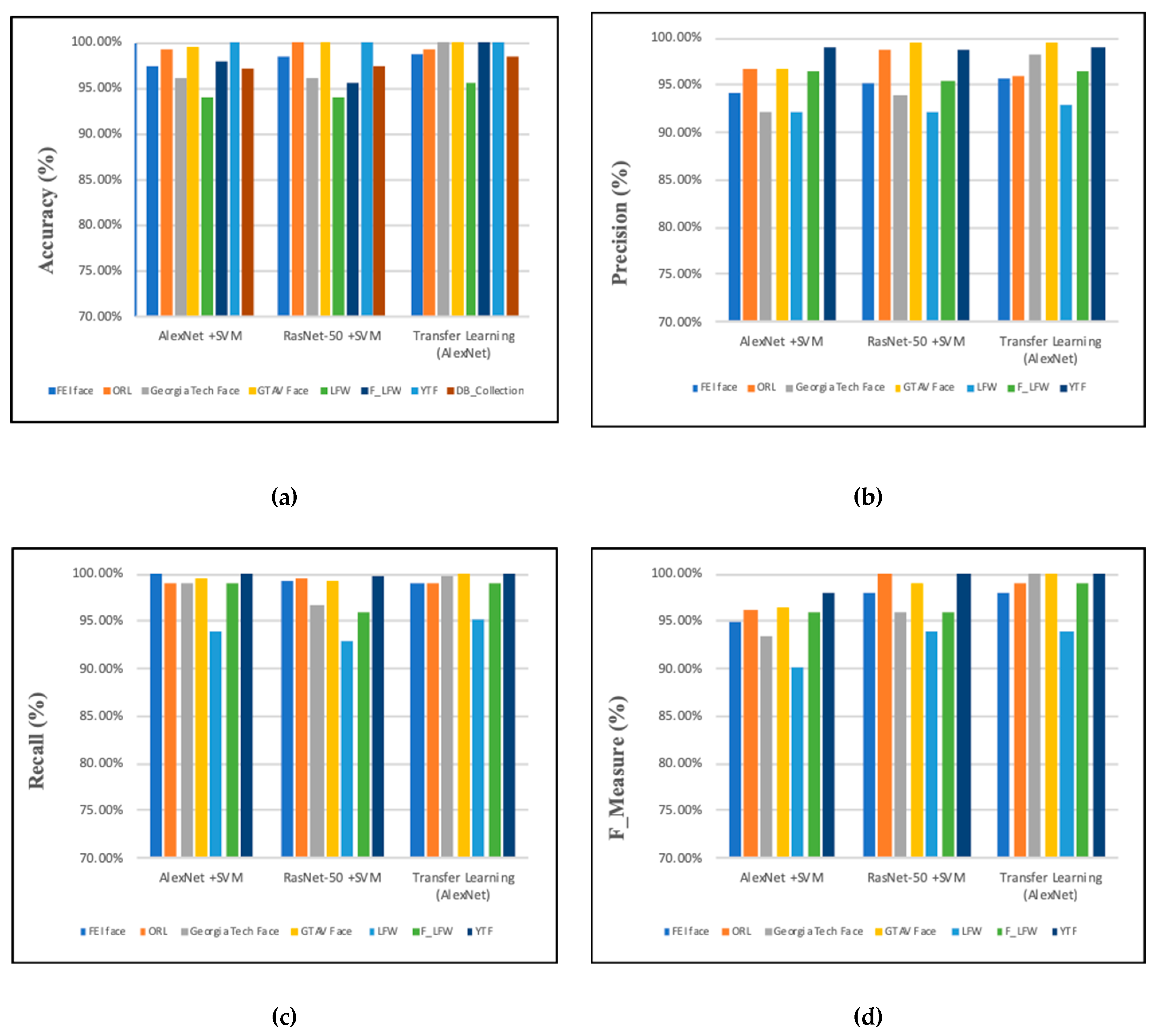
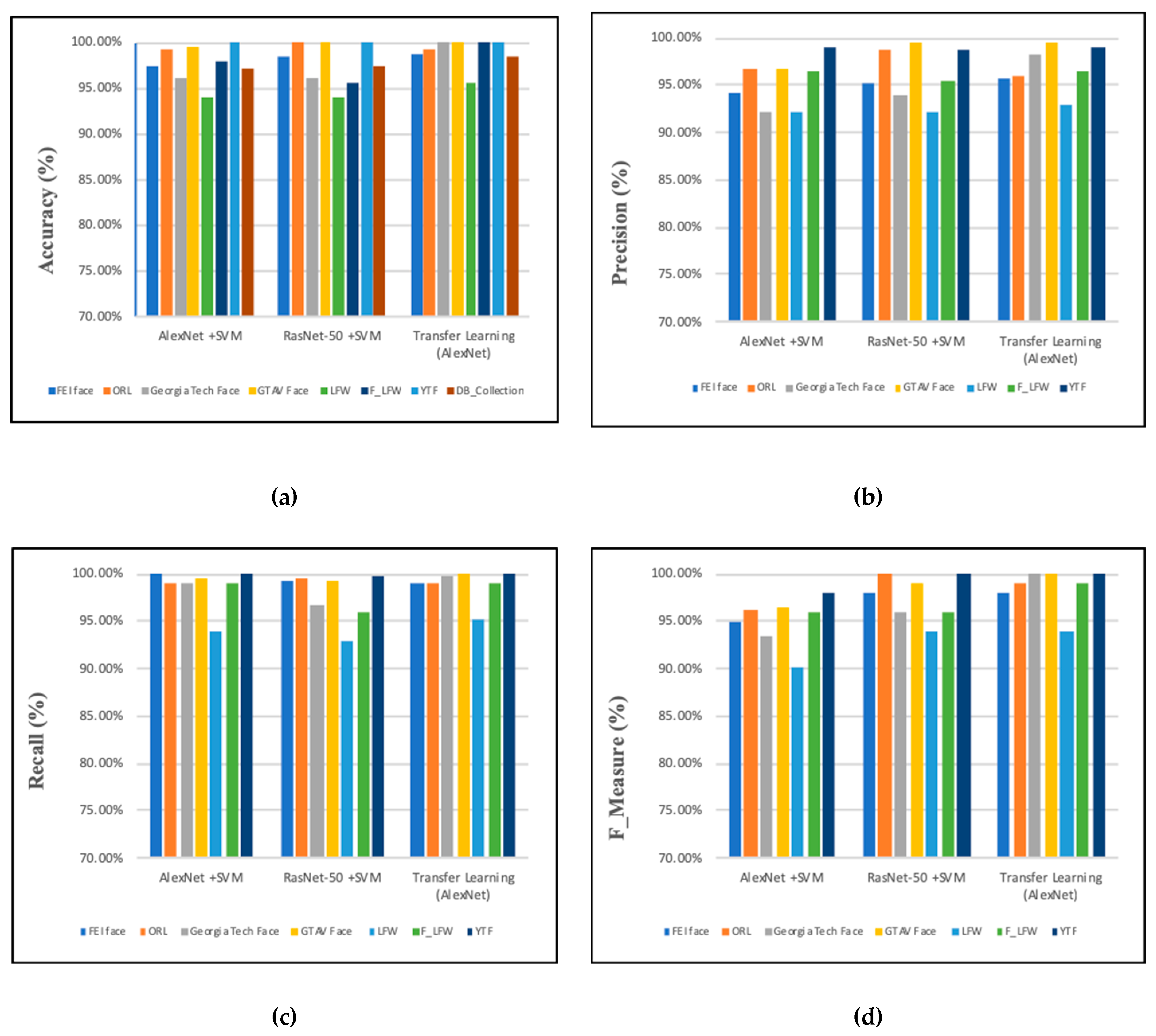
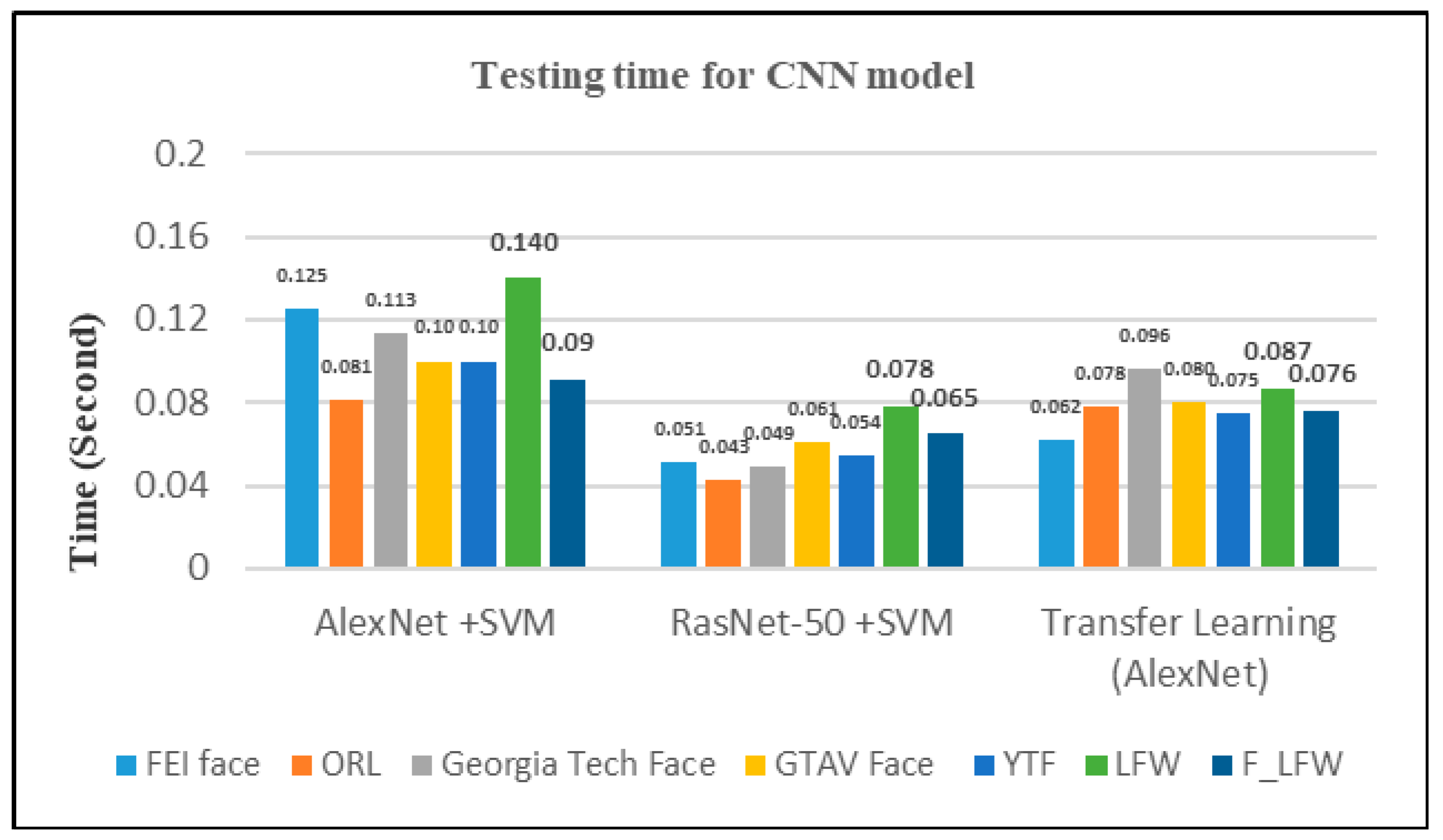
4.2.4. Performance Analysis
4.3. Comparison with the State-of-the-Art Models
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- Purwins, H.; Li, B.; Virtanen, T.; Chang, S.; Sainath, T. Deep Learning for Audio Signal Processing. IEEE J. Sel. Top. Signal Process. 2019, 14, 206–219. [Google Scholar] [CrossRef]
- Bao, Y.; Tang, Z.; Li, H. Computer vision and deep learning–based data anomaly detection method for structural health monitoring. Struct. Health Monit. 2018, 18, 401–421. [Google Scholar] [CrossRef]
- Xue, J.; Han, J.; Zheng, T.; Gao, X.; Guo, J. A Multi-Task Learning Framework for Overcoming the Catastrophic Forgetting in Automatic Speech Recognition. arXiv 2019, arXiv:1904.08039. [Google Scholar]
- Imran, J.; Raman, B. Deep motion templates and extreme learning machine for sign language recognition. Vis. Comput. 2019. [Google Scholar] [CrossRef]
- Ravi, S.; Suman, M.; Kishore, P.V.V.; Kumar, K.; Kumar, A. Multi Modal Spatio Temporal Co-Trained CNNs with Single Modal Testing on RGB–D based Sign Language Gesture Recognition. J. Comput. Lang. 2019, 52, 88–102. [Google Scholar] [CrossRef]
- Al-Emadi, S.; Al-Ali, A.; Mohammad, A.; Al-Ali, A. Audio Based Drone Detection and Identification using Deep Learning. In Proceedings of the 2019 15th International Wireless Communications & Mobile Computing Conference (IWCMC), Tangier, Morocc, 24–28 June 2019; pp. 459–464. [Google Scholar]
- Prasad, P.S.; Pathak, R.; Gunjan, V.K.; Rao, H.V.R. Deep Learning Based Representation for Face Recognition; Springer: Berlin, Germany, 2019; pp. 419–424. [Google Scholar]
- Hu, G.; Yang, Y.; Yi, D.; Kittler, J.; Christmas, W.; Li, S.Z.; Hospedales, T. When face recognition meets with deep learning: An evaluation of convolutional neural networks for face recognition. In Proceedings of the IEEE International Conference on Computer Vision Workshops, Santiago, Chile, 11–12 December 2015; pp. 142–150. [Google Scholar]
- Kshirsagar, V.P.; Baviskar, M.R.; Gaikwad, M.E. Face recognition using Eigenfaces. In Proceedings of the 2011 3rd International Conference on Computer Research and Development, Shanghai, China, 11–13 March 2011; Volume 2, pp. 302–306. [Google Scholar]
- Bartlett, M.S.; Movellan, J.R.; Sejnowski, T.J. Face recognition by independent component analysis. IEEE Trans. Neural Netw. 2002, 13, 1450–1464. [Google Scholar] [CrossRef]
- Ojala, T.; Pietikainen, M.; Maenpaa, T. Multiresolution gray-scale and rotation invariant texture classification with local binary patterns. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 971–987. [Google Scholar] [CrossRef]
- Liu, Y.; Lin, M.; Huang, W.; Liang, J. A physiognomy based method for facial feature extraction and recognition. J. Vis. Lang. Comput. 2017, 43, 103–109. [Google Scholar] [CrossRef]
- Taigman, Y.; Yang, M.; Ranzato, M.; Wolf, L. Deepface: Closing the gap to human-level performance in face verification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1701–1708. [Google Scholar]
- Boufenar, C.; Kerboua, A.; Batouche, M. Investigation on deep learning for off-line handwritten Arabic character recognition. Cogn. Syst. Res. 2018, 50, 180–195. [Google Scholar] [CrossRef]
- Boser, B.E.; Guyon, I.M.; Vapnik, V.N. A training algorithm for optimal margin classifiers. In Proceedings of the Fifth Annual Workshop on Computational Learning Theory, Pittsburgh, PA, USA, 27–29 July 1992; pp. 144–152. [Google Scholar]
- ORL Face Database. Available online: http://www.uk.research.att.com/facedatabase.html (accessed on 6 April 2019).
- Tarres, F.; Rama, A. GTAV Face Database. 2011. Available online: https://gtav.upc.edu/en/research-areas/face-database (accessed on 6 April 2019).
- Nefian, A.V. Georgia Tech Face Database. Available online: http://www.anefian.com/research/face_reco.htm (accessed on 6 April 2019).
- Thomaz, C.E. FEI Face Database. 2012. Available online: https://fei.edu.br/~cet/facedatabase.html (accessed on 6 April 2019).
- Huang, G.B.; Ramesh, M.; Berg, T.; Learned-Miller, E. Labeled Faces in the Wild: A Database for Studying Face Recognition in Unconstrained Environments. 2007. Available online: https://hal.inria.fr/inria-00321923 (accessed on 1 September 2019).
- Frontalized Faces in the Wild. 2016. Available online: https://www.micc.unifi.it/resources/datasets/frontalized-faces-in-the-wild/ (accessed on 6 April 2019).
- Wolf, L.; Hassner, T.; Maoz, I. Face recognition in unconstrained videos with matched background similarity. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Colorado Springs, CO, USA, 20–25 June 2011; pp. 529–534. [Google Scholar]
- LeCun, Y.; Kavukcuoglu, K.; Farabet, C. Convolutional networks and applications in vision. In Proceedings of the 2010 IEEE International Symposium on Circuits and Systems, Paris, France, 30 May–2 June 2010; pp. 253–256. [Google Scholar]
- LeCun, Y.; Boser, B.E.; Denker, J.S.; Henderson, D.; Howard, R.E.; Hubbard, W.E.; Jackel, L.D. Handwritten digit recognition with a back-propagation network. In Proceedings of the Advances in Neural Information Processing Systems, Denver, CO, USA, 26–29 November 1990; pp. 396–404. [Google Scholar]
- Postorino, M.N.; Sarne, G.M.L. A neural network hybrid recommender system. In Proceedings of the 2011 Conference on Neural Nets WIRN10, Salerno, Italy, 27–29 May 2011; pp. 180–187. [Google Scholar]
- Ciresan, D.C.; Meier, U.; Masci, J.; Gambardella, L.M.; Schmidhuber, J. Flexible, high performance convolutional neural networks for image classification. In Proceedings of the Twenty-Second International Joint Conference on Artificial Intelligence, Catalonia, Spain, 16–22 June 2011; Volume 22, pp. 1237–1242. [Google Scholar]
- Xie, Y.; Le, L.; Zhou, Y.; Raghavan, V.V. Deep Learning for Natural Language Processing. In Handbook of Statistics; Elsevier: Amsterdam, The Netherlands, 2018. [Google Scholar]
- Kumar, R. Natural language processing. In Machine Learning and Cognition in Enterprises; Kumar, R., Ed.; Springer: Berlin, Germany, 2017; pp. 65–73. [Google Scholar]
- Rojas, R. Neural Networks: A Systematic Introduction; Springer: Berlin, Germany, 2013. [Google Scholar]
- Karpathy CS231n Convolutional Neural Networks for Visual Recognition. 2018. Available online: http://cs231n.github.io/convolutional-networks/ (accessed on 8 May 2019).
- Boureau, Y.-L.; Ponce, J.; LeCun, Y. A theoretical analysis of feature pooling in visual recognition. In Proceedings of the 27th International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 111–118. [Google Scholar]
- Scherer, D.; Müller, A.; Behnke, S. Evaluation of pooling operations in convolutional architectures for object recognition. In Proceedings of the International Conference on Artificial Neural Networks, Thessaloniki, Greece, 15–18 September 2010; pp. 92–101. [Google Scholar]
- Wu, H.; Gu, X. Max-pooling dropout for regularization of convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing, Istanbul, Turkey, 9–12 November 2015; pp. 46–54. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Spatial pyramid pooling in deep convolutional networks for visual recognition. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 1904–1916. [Google Scholar] [CrossRef]
- Ouyang, W.; Wang, X.; Zeng, X.; Qiu, S.; Luo, P.; Tian, Y.; Tang, X. Deepid-net: Deformable deep convolutional neural networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2403–2412. [Google Scholar]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Proceedings of the Advances in Neural Information Processing Systems, Lake Tahoe, CA, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Yu, J.; Sun, K.; Gao, F.; Zhu, S. Face biometric quality assessment via light CNN. Pattern Recognit. Lett. 2018, 107, 25–32. [Google Scholar] [CrossRef]
- Sun, Y.; Wang, X.; Tang, X. Hybrid deep learning for computing face similarities. Int. Conf. Comput. Vis. 2013, 38, 1997–2009. [Google Scholar]
- Singh, R.; Om, H. Newborn face recognition using deep convolutional neural network. Multimed. Tools Appl. 2017, 76, 19005–19015. [Google Scholar] [CrossRef]
- Guo, K.; Wu, S.; Xu, Y. Face recognition using both visible light image and near-infrared image and a deep network. CAAI Trans. Intell. Technol. 2017, 2, 39–47. [Google Scholar] [CrossRef]
- Hu, H.; Afaq, S.; Shah, A.; Bennamoun, M.; Molton, M. 2D and 3D Face Recognition Using Convolutional Neural Network. In Proceedings of the TENCON 2017 IEEE Region 10 Conference, Penang, Malaysia, 5–8 November 2017; pp. 133–138. [Google Scholar]
- Nam, G.P.; Choi, H.; Cho, J. PSI-CNN: A Pyramid-Based Scale-Invariant CNN Architecture for Face Recognition Robust to Various Image Resolutions. Appl. Sci. 2018, 8, 1561. [Google Scholar] [CrossRef]
- Khan, S.; Javed, M.H.; Ahmed, E.; Shah, S.A.A.; Ali, S.U. Networks and Implementation on Smart Glasses. In Proceedings of the 2019 International Conference on Information Science and Communication Technology (ICISCT), Karachi, Pakistan, 9–10 March 2019; pp. 1–6. [Google Scholar]
- Qin, C.; Lu, X.; Zhang, P.; Xie, H.; Zeng, W. Identity Recognition Based on Face Image. J. Phys. Conf. Ser. 2019, 1302, 032049. [Google Scholar] [CrossRef]
- Menotti, D.; Chiachia, G.; Pinto, A.; Schwartz, W.R.; Pedrini, H.; Falcao, A.X.; Rocha, A. Deep Representations for Iris, Face, and Fingerprint Spoofing Detection. IEEE Trans. Inf. Forensics Secur. 2015, 10, 864–879. [Google Scholar] [CrossRef] [Green Version]
- Simón, M.O.; Corneanu, C.; Nasrollahi, K.; Nikisins, O.; Escalera, S.; Sun, Y.; Greitans, M. Improved RGB-D-T based face recognition. IET Biom. 2016, 5, 297–303. [Google Scholar] [CrossRef]
- Parkhi, O.M.; Vedaldi, A.; Zisserman, A. Deep Face Recognition. BMVC 2015, 1, 6. [Google Scholar]
- Zhu, Z.; Luo, P.; Wang, X.; Tang, X. Recover canonical-view faces in the wild with deep neural networks. arXiv 2014, arXiv:1404.3543. [Google Scholar]
- Guo, S.; Chen, S.; Li, Y. Face recognition based on convolutional neural network & support vector machine. In Proceedings of the 2016 IEEE International Conference on Information and Automation (ICIA), Ningbo, China, 1–3 August 2016; pp. 1787–1792. [Google Scholar]
- Lawrence, S.; Giles, C.L.; Tsoi, A.C.; Back, A.D. Face recognition: A convolutional neural-network approach. IEEE Trans. Neural Netw. 1997, 8, 98–113. [Google Scholar] [CrossRef] [PubMed]
- Sun, Y.; Wang, X.; Tang, X. Deep Learning Face Representation from Predicting 10,000 Classes. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 1891–1898. [Google Scholar]
- Sun, Y.; Chen, Y.; Wang, X.; Tang, X. Deep Learning Face Representation by Joint Identification-Verification. In Proceedings of the Advances in Neural Information Processing Systems 27, Montreal, QC, Canada, 8–13 December 2014; pp. 1988–1996. [Google Scholar]
- Sun, Y.; Wang, X.; Tang, X. Deeply Learned Face Representations Are Sparse, Selective, and Robust. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 2892–2900. [Google Scholar]
- Lu, Z.; Jiang, X.; Kot, A.C. Deep Coupled ResNet for Low-Resolution Face Recognition. IEEE Signal Process. Lett. 2018, 25, 526–530. [Google Scholar] [CrossRef]
- Ferrari, C.; Lisanti, G.; Berretti, S.; del Bimbo, A. Effective 3D based frontalization for unconstrained face recognition. In Proceedings of the 2016 23rd International Conference on Pattern Recognition (ICPR), Cancun, Mexico, 4–8 December 2016; pp. 1047–1052. [Google Scholar]
- Zhang, Y.; Zhao, D.; Sun, J.; Zou, G.; Li, W. Adaptive Convolutional Neural Network and Its Application in Face Recognition. Neural Process. Lett. 2016, 43, 389–399. [Google Scholar] [CrossRef]
- Cai, J.; Chen, J.; Liang, X. Single-sample face recognition based on intra-class differences in a variation model. Sensors 2015, 15, 1071–1087. [Google Scholar] [CrossRef]
- Chui, K.; Lytras, M.D. A Novel MOGA-SVM Multinomial Classification for Organ Inflammation Detection. Appl. Sci. 2019, 9, 2284. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Layer | Number of Kernels | Kernel Size | Stride | Padding | Output Size |
|---|---|---|---|---|---|
| Input | [227 × 227 × 3] | ||||
| Conv1 | 96 | 11 × 11 × 3 | 4 | - | [55 × 55 × 96] |
| Max pool1 | 3 × 3 | 2 | - | [27 × 27 × 96] | |
| Norm1 | [27 × 27 × 96] | ||||
| Conv2 | 256 | 5 × 5 × 48 | 1 | 2 | [27 × 27 × 256] |
| Maxpool2 | 3 × 3 | 2 | - | [13 × 13 × 256] | |
| Norm 2 | [13 × 13 × 256] | ||||
| Conv3 | 384 | 3 × 3 × 256 | 1 | 1 | [13 × 13 × 384] |
| Conv4 | 384 | 3 × 3 × 192 | 1 | 1 | [13 × 13 × 384] |
| Conv5 | 256 | 3 × 3 × 192 | 1 | 1 | [13 × 13 × 256] |
| Max pool3 | 3 × 3 | 2 | - | [6 × 6 × 256] | |
| fc6 ReLU Dropout(0.5) | 1 | 4096 | |||
| fc 7 ReLU Dropout(0.5) | 1 | 4096 | |||
| fc8 softmax | 1 | 1000 |
| Layer | Kernel Size | Stride | Padding | Output Size |
|---|---|---|---|---|
| Input | [224 × 224 × 3] | |||
| Conv1 | 7 × 7 × 3 | 2 | 3 | [112 × 112 × 64] |
| Max pool | 3 × 3 | 2 | - | [56 × 56] |
| Conv2 | [1×1conv,64],[3 × 3conv,64],1 × 1conv,256] | 2 | - | [56 × 56] |
| [1×1conv,64],[3 × 3conv,64],1 × 1conv,256] | 1 | - | ||
| [1×1conv,64],[3 × 3conv,64],1 × 1conv,256] | 1 | - | ||
| Conv3 | [1×1conv,128],[3 × 3conv,128],[1 × 1conv,512] | 2 | - | [28 × 28] |
| [1×1conv,128],[3 × 3conv,128],[1 × 1conv,512] | 1 | - | ||
| [1×1conv,128],[3 × 3conv,128],[1 × 1conv,512] | 1 | - | ||
| [1×1conv,128],[3 × 3conv,128],[1 × 1conv,512] | 1 | - | ||
| Conv4 | [1×1conv,256],[3 × 3conv,256],[1 × 1conv,1024] | 2 | - | [14 × 14] |
| [1×1conv,256],[3 × 3conv,256],[1 × 1conv,1024] | 1 | - | ||
| [1×1conv,256],[3 × 3conv,256],[1 × 1conv,1024] | 1 | - | ||
| [1×1conv,256],[3 × 3conv,256],[1 × 1conv,1024] | 1 | - | ||
| [1×1conv,256],[3 × 3conv,256],[1 × 1conv,1024] | 1 | - | ||
| [1×1conv,256],[3 × 3conv,256],[1 × 1conv,1024] | 1 | - | ||
| Conv5 | [1×1conv,512],[3 × 3conv,512],[1 × 1conv,2048] | 2 | - | [7 × 7] |
| [1×1conv,512],[3 × 3conv,512],[1 × 1conv,2048] | 1 | - | ||
| [1×1conv,512],[3 × 3conv,512],[1 × 1conv,2048] | 1 | - | ||
| Average pool | 7 × 7 | 7 | - | [1 × 1] |
| fc1000 softmax | 1000 |
| References | Convolutional Neural Network (CNN) Model | Dataset | Accuracy |
|---|---|---|---|
| Yu et al. (2017) [39] | A novel biometric quality assessment (BQA) method based on light CNN | CASIA, FLW, and YouTube | 99.01% |
| Sun et al. (2016) [40] | Hybrid ConvNet-restricted Boltzmann machine (RBM) | Labeled faces in the wild (LFW), CelebFaces | 97.08% (CelebFaces) 93.83% (LFW) |
| Singh and Om (2017) [41] | DeepCNN | IIT(BHU) newborn database | 91.03% |
| Guo et al. (2017) [42] | DeepFace based on DNN used VGGNet | LFW, YouTube face (YTF) | 97.35% |
| Hu et al. (2017) [43] | CNN-2 model | ORL | 95% |
| G. P. Nam et al. (2018) [44] | PSI-CNN | LFW, CCTV | 98.87% |
| P. S. Prasad et al. (2019) [7] | Deep learning based | AR | - |
| Suleman Khan et al. (2019) [45] | Deep CNN | - | 98.5% |
| Chen Qin et al. (2019) [46] | Deep CNN | - | 94.67% |
| Menotti et al. (2015) [47] | Hyperopt-convnet for architecture optimization (AO) based on CNN Cuda-convnet for filter optimization (FO) based on back-propagation algorithm | Replay-Attack, 3DMAD | |
| Simón et al.(2016) [48] | CNN-based | RGB-D-T | |
| O. M. Parkhi et al. (2015) [49] | Deep CNN | LFW, YTF | 98.95% |
| Z. Zhu et al. (2014) [50] | Facial component-based network | LFW, CelebFaces | 96.45 |
| Guo et al. (2017) [51] | CNN + support vector machine (SVM) | ORL | 97.50% |
| Y. Taigman et al. (2014) [13] | DeepFace system | SFC , LFW, YTF | 97.35% |
| Y. Sun et al. (2014) [53] | DeepID | LFW | 97.45% |
| Y. Sun et al. (2014) [54] | DeepID2 | LFW | 99.15% |
| Y. Sun et al. (2015) [55] | DeepID2+ | LFW, YTF | 99.47% (LFW) 93.2% (YTF) |
| Lu et al. (2018) [56] | Deep coupled ResNet (DCR) | LFW, SCface | 99% |
| Datasets | Identities | Images | Images Per Identities | Images Size | Images Type |
|---|---|---|---|---|---|
| ORL | 40 | 400 | 10 | 92 × 112 | JPEG |
| GTAV face | 44 | 704 | 16 | 240 × 320 | BMP |
| Georgia Tech face | 50 | 700 | 14 | 131 × 206 | JPEG |
| FEI face | 50 | 700 | 14 | 640 × 480 | JPEG |
| Labeled faces in the wild (LFW) | 50 | 700 | 14 | 250 × 250 | JPEG |
| Frontalized labeled faces in the wild (F_LFW) | 50 | 700 | 14 | 272 × 323 | JPEG |
| YouTube face (YTF) | 50 | 700 | 14 | 320 × 240 | JPEG |
| DB_Collection | 210 | 2880 | 10-16 | - | - |
| FEI Face | ORL | Georgia Tech Face | GTAV Face | LFW | F_LFW | YTF | |
|---|---|---|---|---|---|---|---|
| AlexNet + SVM | 97.50% | 99.17% | 96% | 99.55% | 94% | 98% | 100% |
| Transfer learning (AlexNet) | 98.70% | 99.17% | 100% | 100% | 95.63% | 99.3% | 100% |
| References | Model | Datasets | Recognition Accuracy | Mean | Variance | Time |
|---|---|---|---|---|---|---|
| Sun et al. (2016) [40] | Hybrid ConvNet-RBM | LFW | 93.83% | 93.80 | 0.03 | Not available |
| Guo et al. (2017) [42] | DeepFace based on DNN using VGGNet | LWF | 97.35% | 97.32 | 0.03 | Not available |
| Y. Sun et al. (2014) [53] | DeepID | LFW | 97.45% | 97.33 | 0.02 | Not available |
| Y. Sun et al. (2014) [54] | DeepID2 | LFW | 99.15% | 99.12 | 0.03 | Not available |
| Yu et al. (2017) [39] | BQA method based on CNN | YTF | 99.01% | 99.00 | 0.01 | Not available |
| Guo et al. (2017) [42] | DeepFace based on DNN using VGGNet | YTF | 97.35% | 97.32 | 0.03 | Not available |
| O. M. Parkhi et al. (2015) [49] | Deep CNN | YTF | 98.95% | 98.92 | 0.03 | Not available |
| Y. Taigman et al. (2014) [13] | DeepFace system | YTF | 97.35% | 97.32 | 0.03 | Not available |
| Y. Sun et al. (2015) [55] | DeepID2+ | YTF | 93.20% | 93.17 | 0.03 | Not available |
| Y. Zhang (2015) [58] | Global expansion ACNN | ORL | 91.67% | 91.65 | 0.02 | 4.58 min |
| Y. Zhang (2015) [58] | Global + local Expansion ACNN | ORL | 93.30% | 93.27 | 0.03 | 5.7 min |
| S. Guo et al. (2017) [51] | CNN + SVM | ORL | 97.50% | 97.47 | 0.03 | 0.46 min |
| H. Hu et al. (2017) [43] | CNN-2 | ORL | 95.00% | 94.97 | 0.03 | Not available |
| J. Cai et al. (2015) [59] | Sparse representation face recognition | FEI face | 61.31% | 61.30 | 0.01 | Not available |
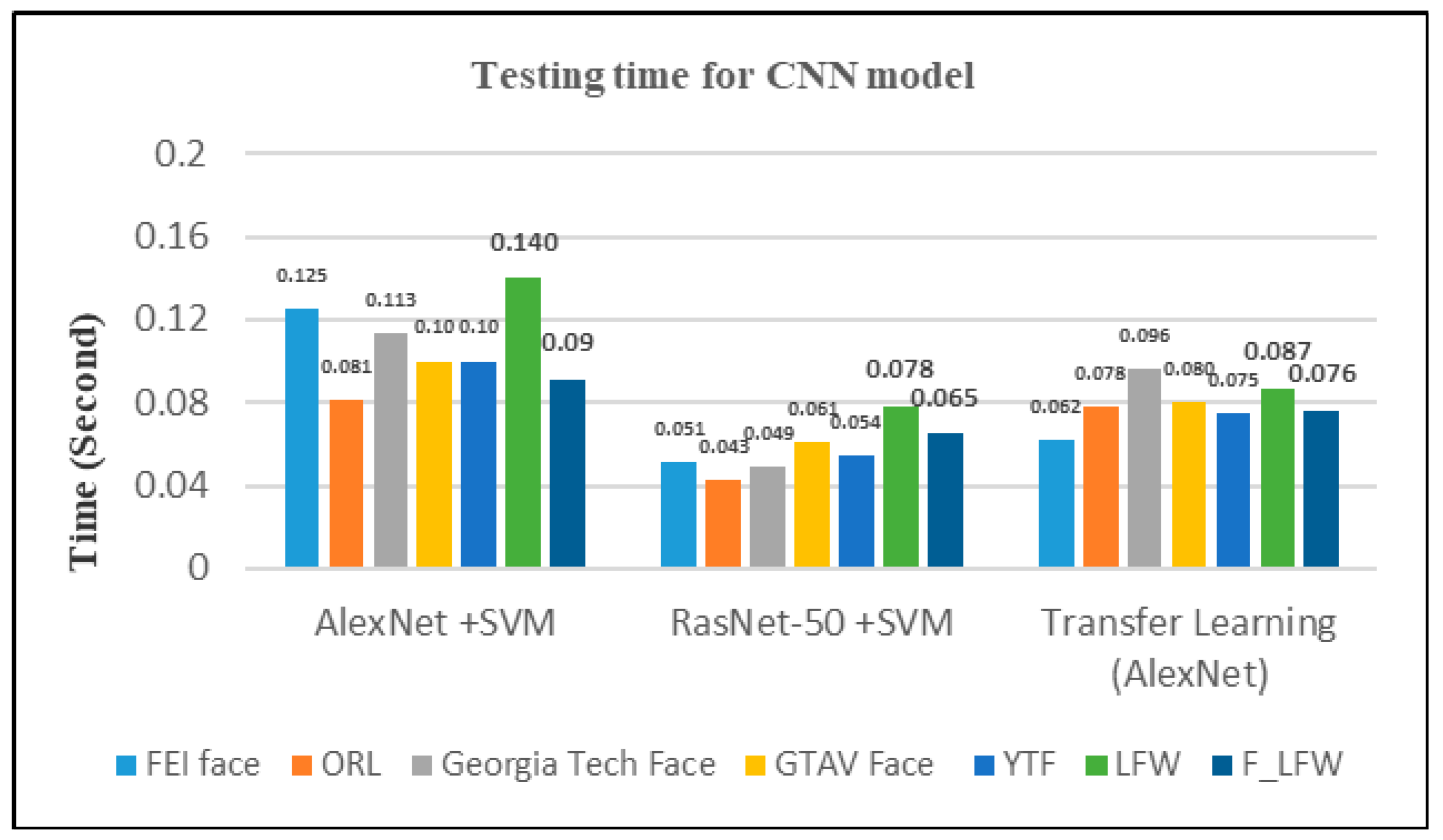
| Our proposed model (2019) | AlexNet + SVM | FEI face | 97.50% | 97.47 | 0.03 | 0.125 s |
| RasNet-50 + SVM | 98.50% | 98.47 | 0.03 | 0.051 s | ||
| Transfer learning (AlexNet) | 98.70% | 98.67 | 0.03 | 0.062 s | ||
| AlexNet + SVM | ORL | 99.17% | 99.15 | 0.02 | 0.081 s | |
| RasNet-50 + SVM | 100% | 100 | 0 | 0.043 s | ||
| Transfer learning (AlexNet) | 99.17% | 99.15 | 0.02 | 0.078 s | ||
| AlexNet + SVM | YTF | 100% | 100 | 0 | 0.10 s | |
| RasNet-50 + SVM | 100% | 100 | 0 | 0.054 s | ||
| Transfer learning (AlexNet) | 100% | 100 | 0 | 0.075 s | ||
| AlexNet + SVM | LFW | 94% | 93.97 | 0.03 | 0.140 s | |
| RasNet-50 + SVM | 94% | 93.97 | 0.03 | 0.078 s | ||
| Transfer learning (AlexNet) | 95.63% | 95.60 | 0.03 | 0.087 s |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Almabdy, S.; Elrefaei, L. Deep Convolutional Neural Network-Based Approaches for Face Recognition. Appl. Sci. 2019, 9, 4397. https://doi.org/10.3390/app9204397
Almabdy S, Elrefaei L. Deep Convolutional Neural Network-Based Approaches for Face Recognition. Applied Sciences. 2019; 9(20):4397. https://doi.org/10.3390/app9204397
Chicago/Turabian StyleAlmabdy, Soad, and Lamiaa Elrefaei. 2019. "Deep Convolutional Neural Network-Based Approaches for Face Recognition" Applied Sciences 9, no. 20: 4397. https://doi.org/10.3390/app9204397
APA StyleAlmabdy, S., & Elrefaei, L. (2019). Deep Convolutional Neural Network-Based Approaches for Face Recognition. Applied Sciences, 9(20), 4397. https://doi.org/10.3390/app9204397