
A Genetic Algorithm Optimized RNN-LSTM Model for Remaining Useful Life Prediction of Turbofan Engine

Abstract
:1. Introduction
1.1. Related Works
1.2. Research Gaps and Motivations
- Cross-validation was omitted in some studies [9,10,11,14,16] which may create a bias interpretation for the performance of model. For instance, certain training and testing datasets could be selected to produce smaller RMSE. In addition, some of the data may not be tested and thus lowering the generalization and robustness of model.
- A 10-fold cross-validation is adopted for performance evaluation of RUL prediction model.
- We combine recurrent neural network (RNN) and LSTM which take the advantages in managing both short-term and long-term RUL predictions.
- NSGA-II is adopted to optimally design the RNN-LSTM model.
1.3. Research Contributions
- The combined model RNN-LSTM takes the advantages in RUL prediction of turbofan engine under short-term and long-term conditions. Results reveal that it reduces RMSE by 6.07–14.72% compared with stand-alone RNN and stand-alone LSTM.
- The combination of complete ensemble empirical mode decomposition (CEEMD) and wavelet packet transform (WPT) as two-step decomposition for feature extraction takes the advantages in capturing both time and frequency information. It reduces the RMSE by 5.14–27.15% compared with CEEMD, EEMD, EMD, WPT, EEMD-WPT, and EMD-WPT.
- Non-dominated sorting genetic algorithm II (NSGA-II) optimally designs the RNN-LSTM for optimal performance on short-term and long-term predictions.
- The proposed NSGA-II optimized RNN-LSTM model outperformed related works by 12.95–39.32% in terms of RMSE.
2. Methodology of Proposed NSGA-II Optimized RNN-LSTM Model
2.1. Feature Extraction
2.2. NSGA-II Optimized RNN-LSTM Model
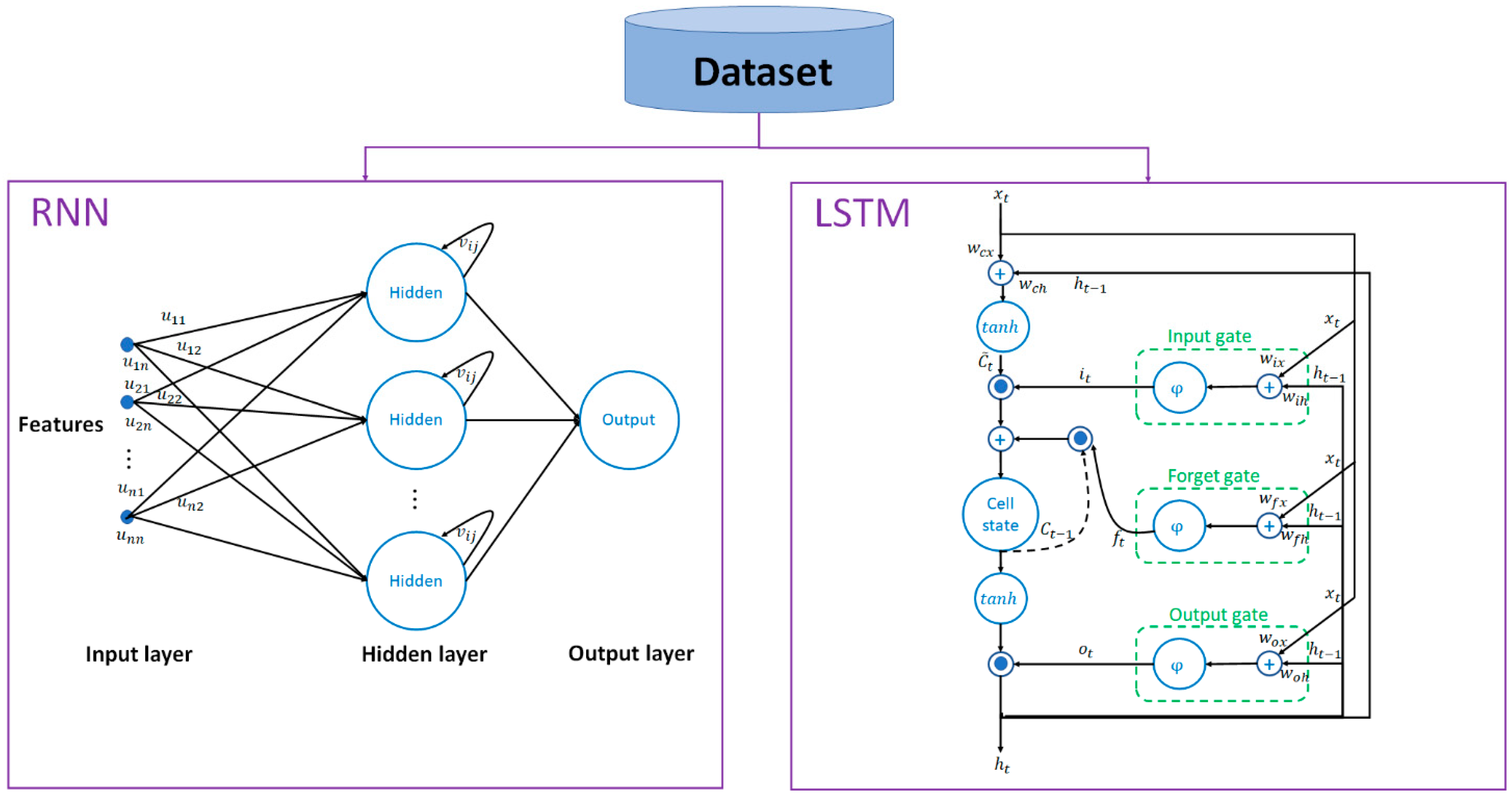
2.2.1. Formulation of RNN
- Power-sigmoid activation function:where and .
- Bipolar-sigmoid activation function:where .
2.2.2. Formulation of LSTM
- Forget gate:The forget gate takes the latest input and previous output of memory block . The activation function of the forget gate is chosen to be logistic sigmoid as common practice, determines how much information is reserved the upper cell.
- Input gate:The information flowing into the cell is controlled by the input gate .
- Output gate:The output of the memory cell is regulated by the output gate .
- Memory cell:A tanh layer creates a vector of new candidate values that could be added to the state.
2.2.3. Optimal Design of RNN-LSTM Using NSGA-II
| Algorithm 1 | |
| Input: Training datasets | |
| Output: RUL Prediction Model | |
| |
3. Results
3.1. Commercial Modular Aero-Propulsion System Simulation Turbonfan Degradation (C-MAPSS-TD) Dataset
3.2. Comparison between Feature Extraction Approaches
3.3. Comparison between Stand-Alone RNN, Stand-Alone LSTM, and Proposed NSGA-II Optimized RNN-LSTM
3.4. Comparison between Proposed Work and Existing Works
4. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bokrantz, J.; Skoogh, A.; Berlin, C.; Wuest, T.; Stahre, J. Smart maintenance: A research agenda for industrial maintenance management. Int. J. Prod. Econ. 2020, 224, 107547. [Google Scholar] [CrossRef]
- Tewari, A.; Gupta, B.B. Security, privacy and trust of different layers in Internet-of-Things (IoTs) framework. Future Gener. Comput. Syst. 2020, 108, 909–920. [Google Scholar] [CrossRef]
- Gupta, B.B.; Quamara, M. An overview of Internet of Things (IoT): Architectural aspects, challenges, and protocols. Concurr. Comput. Pr. Exp. 2020, 32, 4946. [Google Scholar] [CrossRef]
- Zhang, W.; Yang, D.; Wang, H. Data-driven methods for predictive maintenance of industrial equipment: A survey. IEEE Syst. J. 2019, 13, 2213–2227. [Google Scholar] [CrossRef]
- Carvalho, T.P.; Soares, F.A.; Vita, R.; Francisco, R.D.P.; Basto, J.P.; Alcalá, S.G. A systematic literature review of machine learning methods applied to predictive maintenance. Comput. Ind. Eng. 2019, 137, 106024. [Google Scholar] [CrossRef]
- Airline Maintenance Cost Executive Commentary Edition 2019; The International Air Transport Association: Montreal, QC, Canada, 2019. Available online: https://www.iata.org/contentassets/bf8ca67c8bcd4358b3d004b0d6d0916f/mctg-fy2018-report-public.pdf (accessed on 2 November 2020).
- Mosallam, A.; Medjaher, K.; Zerhouni, N. Data-driven prognostic method based on Bayesian approaches for direct remaining useful life prediction. J. Intell. Manuf. 2016, 27, 1037–1048. [Google Scholar] [CrossRef]
- Fan, Y.; Nowaczyk, S.; Rögnvaldsson, T. Transfer learning for remaining useful life prediction based on consensus self-organizing models. Reliab. Eng. Syst. Saf. 2020, 203, 107098. [Google Scholar] [CrossRef]
- Zhao, Z.; Liang, B.; Wang, X.; Lu, W. Remaining useful life prediction of aircraft engine based on degradation pattern learning. Reliab. Eng. Syst. Saf. 2017, 164, 74–83. [Google Scholar] [CrossRef]
- Ordóñez, C.; Sánchez-Lasheras, F.; Roca-Pardiñas, J.; Juez, F.J.D.C. A hybrid ARIMA–SVM model for the study of the remaining useful life of aircraft engines. J. Comput. Appl. Math. 2019, 346, 184–191. [Google Scholar] [CrossRef]
- Cai, H.; Feng, J.; Li, W.; Hsu, Y.M.; Lee, J. Similarity-based Particle Filter for Remaining Useful Life prediction with enhanced performance. Appl. Soft Comput. 2020, 106474. [Google Scholar] [CrossRef]
- Ellefsen, A.L.; Bjørlykhaug, E.; Æsøy, V.; Ushakov, S.; Zhang, H. Remaining useful life predictions for turbofan engine degradation using semi-supervised deep architecture. Reliab. Eng. Syst. Saf. 2019, 183, 240–251. [Google Scholar] [CrossRef]
- Wu, Y.; Yuan, M.; Dong, S.; Lin, L.; Liu, Y. Remaining useful life estimation of engineered systems using vanilla LSTM neural networks. Neurocomputing 2018, 275, 167–179. [Google Scholar] [CrossRef]
- Wu, J.; Hu, K.; Cheng, Y.; Zhu, H.; Shao, X.; Wang, Y. Data-driven remaining useful life prediction via multiple sensor signals and deep long short-term memory neural network. ISA Trans. 2020, 97, 241–250. [Google Scholar] [CrossRef] [PubMed]
- Lu, Y.W.; Hsu, C.Y.; Huang, K.C. An Autoencoder Gated Recurrent Unit for Remaining Useful Life Prediction. Processes 2020, 8, 1155. [Google Scholar] [CrossRef]
- Li, X.; Ding, Q.; Sun, J.Q. Remaining useful life estimation in prognostics using deep convolution neural networks. Reliab. Eng. Syst. Saf. 2018, 172, 1–11. [Google Scholar] [CrossRef] [Green Version]
- Turbofan Engine Degradation Simulation Data Set; NASA Ames Prognostics Data Repository, NASA Ames Research Center: Moffett Field, CA, USA, 2008.
- Saxena, A.; Goebel, K.; Simon, D.; Eklund, N. Damage propagation modeling for aircraft engine run-to-failure simulation. In Proceedings of the 2008 International Conference on Prognostics and Health Management, Denver, CO, USA, 6–9 October 2008. [Google Scholar]
- Chen, D.; Lin, J.; Li, Y. Modified complementary ensemble empirical mode decomposition and intrinsic mode functions evaluation index for high-speed train gearbox fault diagnosis. J. Sound Vib. 2018, 424, 192–207. [Google Scholar] [CrossRef]
- Torres, M.E.; Colominas, M.A.; Schlotthauer, G.; Flandrin, P. A complete ensemble empirical mode decomposition with adaptive noise. In Proceedings of the 2011 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Prague, Czech Republic, 22–27 May 2011; pp. 4144–4147. [Google Scholar]
- Gokhale, M.Y.; Khanduja, D.K. Time domain signal analysis using wavelet packet decomposition approach. Int. J. Commun. Netw. Syst. Sci. 2010, 3, 321–329. [Google Scholar] [CrossRef] [Green Version]
- Rhif, M.; Ben Abbes, A.; Farah, I.R.; Martínez, B.; Sang, Y. Wavelet transform application for/in non-stationary time-series analysis: A review. Appl. Sci. 2019, 9, 1345. [Google Scholar] [CrossRef] [Green Version]
- Plaza, E.G.; López, P.N. Application of the wavelet packet transform to vibration signals for surface roughness monitoring in CNC turning operations. Mech. Syst. Signal Process 2018, 98, 902–919. [Google Scholar] [CrossRef]
- Xiao, L.; Liao, B.; Li, S.; Chen, K. Nonlinear recurrent neural networks for finite-time solution of general time-varying linear matrix equations. Neural Netw. 2018, 98, 102–113. [Google Scholar] [CrossRef]
- Xiao, L.; Zhang, Z.; Li, S. Solving time-varying system of nonlinear equations by finite-time recurrent neural networks with application to motion tracking of robot manipulators. IEEE Trans. Syst. Man Cybern. Syst. 2019, 49, 2210–2220. [Google Scholar] [CrossRef]
- Hyndman, R.J.; Athanasopoulos, G. Forecasting: Principles and Practice; OTexts: Melbourne, Australia, 2018. [Google Scholar]
- Deb, K.; Pratap, A.; Agarwal, S.; Meyarivan, T.A.M.T. A fast and elitist multiobjective genetic algorithm: NSGA-II. IEEE Trans. Evol. Comput. 2002, 6, 182–197. [Google Scholar] [CrossRef] [Green Version]
- Cai, X.; Wang, P.; Du, L.; Cui, Z.; Zhang, W.; Chen, J. Multi-objective three-dimensional DV-hop localization algorithm with NSGA-II. IEEE Sens. J. 2019, 19, 10003–10015. [Google Scholar] [CrossRef]
- Harrath, Y.; Bahlool, R. Multi-Objective Genetic Algorithm for Tasks Allocation in Cloud Computing. Int. J. Cloud Appl. Comput. 2019, 9, 37–57. [Google Scholar] [CrossRef]
- Marcot, B.G.; Hanea, A.M. What is an optimal value of k in k-fold cross-validation in discrete Bayesian network analysis? Comput. Stat. 2020, 1–23. [Google Scholar] [CrossRef]
- Jain, A.K.; Gupta, B.B. A machine learning based approach for phishing detection using hyperlinks information. J. Ambient Intell. Hum. Comput. 2019, 10, 2015–2028. [Google Scholar] [CrossRef]
- Chui, K.T.; Tsang, K.F.; Chi, H.R.; Ling, B.W.K.; Wu, C.K. An accurate ECG-based transportation safety drowsiness detection scheme. IEEE Trans. Ind. Inform. 2016, 12, 1438–1452. [Google Scholar] [CrossRef]
- Chen, X.; Duan, Y.; Houthooft, R.; Schulman, J.; Sutskever, I.; Abbeel, P. Infogan: Interpretable representation learning by information maximizing generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; pp. 2172–2180. [Google Scholar]
- Zhang, H.; Sindagi, V.; Patel, V.M. Image de-raining using a conditional generative adversarial network. IEEE Trans. Circuits Syst. Video Technol. 2020, 30, 3943–3956. [Google Scholar] [CrossRef] [Green Version]
- Xia, X.; Togneri, R.; Sohel, F.; Huang, D. Auxiliary classifier generative adversarial network with soft labels in imbalanced acoustic event detection. IEEE Trans. Multimed. 2018, 21, 1359–1371. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Subset | ||||
|---|---|---|---|---|
| FD001 | FD002 | FD003 | FD004 | |
| Number of engine units (Total) | 200 | 519 | 200 | 497 |
| Number of engine units (Training) | 180 in 1st–10th folds | 468 in 1st–9th folds and 459 in 10th folds | 180 in 1st–10th folds | 450 in 1st–7th folds and 441 in 10th folds |
| Number of engine units (Testing) | 20 in 1st–10th folds | 51 in 1st–9th folds and 60 in 10th folds | 20 in 1st–10th folds | 47 in 1st–7th folds and 56 in 8th–10th folds |
| Number of operating conditions | 1 | 6 | 1 | 6 |
| Number of fault modes | 1 | 1 | 2 | 2 |
| FD001 | FD002 | FD003 | FD004 | |
|---|---|---|---|---|
| Method | RMSE/MAE | |||
| EMD | 14.96/14.18 | 22.82/22.36 | 15.35/14.47 | 23.28/22.38 |
| EEMD | 14.53/13.71 | 22.35/21.83 | 14.92/13.91 | 22.89/22.05 |
| CEEMD | 14.29/13.37 | 22.27/21.42 | 14.68/13.78 | 22.44/21.84 |
| WPT | 15.36/14.32 | 23.53/22.61 | 15.63/14.77 | 23.69/22.83 |
| EMD-WPT | 12.82/11.67 | 20.98/19.69 | 13.01/12.02 | 20.73/20.13 |
| EEMD-WPT | 12.66/11.35 | 20.74/19.28 | 12.85/11.68 | 20.31/19.74 |
| Proposed CEEMD-WPT | 11.19/10.28 | 19.33/18.50 | 11.47/10.66 | 19.74/18.82 |
| FD001 | FD002 | FD003 | FD004 | |
|---|---|---|---|---|
| Method | RMSE/MAE | |||
| Stand-alone RNN | 13.08/11.74 | 21.77/20.71 | 13.45/12.06 | 21.87/20.93 |
| Stand-alone LSTM | 12.04/11.17 | 20.58/19.65 | 12.39/11.39 | 21.15/20.46 |
| Proposed NSGA-II optimized RNN-LSTM | 11.19/10.28 | 19.33/18.50 | 11.47/10.66 | 19.74/18.82 |
| Work | Methodology | Cross-Validation | RMSE | |||
|---|---|---|---|---|---|---|
| FD001 | FD002 | FD003 | FD004 | |||
| [7] | Hybrid discrete Bayesian filter and k-nearest neighbors | 3-fold | 27.57 | |||
| [8] | k nearest neighbors-based transfer learning and random forest regression | 4-fold | 26 | |||
| [9] | Back propagation neural network | No | 42.6 | |||
| [10] | Auto-regressive integrated moving average-based support vector regression | No | 47.63 | |||
| [11] | Maximum Rao–Blackwellized particle filter, kernel two sample test, and maximum mean discrepancy | No | 15.94 | 17.15 | 16.17 | 20.72 |
| Average (18.2) | ||||||
| [12] | LSTM | 10-fold | 12.56 | 22.73 | 12.10 | 22.66 |
| Average (19.8) | ||||||
| [13] | Vanilla LSTM | 5-fold | 19.76 | 27.26 | 24.04 | 34.72 |
| Average (28.4) | ||||||
| [14] | Adam adaptive learning optimized LSTM | No | 18.43 | N/A | 19.78 | N/A |
| Average (19.1) | ||||||
| [15] | Autoencoder gated recurrent unit | 5-fold | 20.07 | |||
| [16] | Deep convolution neural networks | No | 12.61 | 22.36 | 12.64 | 23.31 |
| Average (19.9) | ||||||
| Proposed | NSGA-II optimized RNN-LSTM | 10-fold | 11.19 | 19.33 | 11.47 | 19.74 |
| Average (17.2) | ||||||
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chui, K.T.; Gupta, B.B.; Vasant, P. A Genetic Algorithm Optimized RNN-LSTM Model for Remaining Useful Life Prediction of Turbofan Engine. Electronics 2021, 10, 285. https://doi.org/10.3390/electronics10030285
Chui KT, Gupta BB, Vasant P. A Genetic Algorithm Optimized RNN-LSTM Model for Remaining Useful Life Prediction of Turbofan Engine. Electronics. 2021; 10(3):285. https://doi.org/10.3390/electronics10030285
Chicago/Turabian StyleChui, Kwok Tai, Brij B. Gupta, and Pandian Vasant. 2021. "A Genetic Algorithm Optimized RNN-LSTM Model for Remaining Useful Life Prediction of Turbofan Engine" Electronics 10, no. 3: 285. https://doi.org/10.3390/electronics10030285