1. Introduction
For half a century, entrepreneurs of South Korea have transformed the originally agriculture-focused country into one with a focus on light and heavy industries, and following the third Industrial Revolution era, South Korea gained a state-of-the-art electronic industry. Furthermore, some South Korean corporate companies that emerged after the 2000s are now top ranking on the global scale. Not only have they established artificial intelligence (AI) research and development (R&D) centers, but they have also aggressively developed professional human resources in order to become global leading companies in the fourth Industrial Revolution era. Notably, amongst construction and transportation industries, the AI-based indoor mapping and positioning technologies developed by Naver Labs are acknowledged as top-tier technologies [
1], and KAKAO BRAIN has developed a technology that allows world-class performance of learning of images without the image labeling process [
2,
3]. According to King et al. [
4], AI will soon be applied to all the industrial sectors around the globe at a fast pace.
The South Korean government-initiated Data Dam project focused on digital infrastructure investment since the mid-2020s [
5]. The South Korean government announced that the Data Dam project would have a total budget of KRW 292.5 billion (equivalent to approximately USD 252 million) for the first half of 2021 and is planning to collect the training data from 84 areas, including vision, geographic information, healthcare, and construction. The aim of this project is to enable research institutes and private companies to focus on AI-related tasks, and the government will develop and establish AI learning datasets, which will take approximately 80% of the total development process time and lead to a delay in AI R&D projects. Consequently, it is expected that this project will have a positive effect on the creation of mass employment as well as on innovations in AI research.
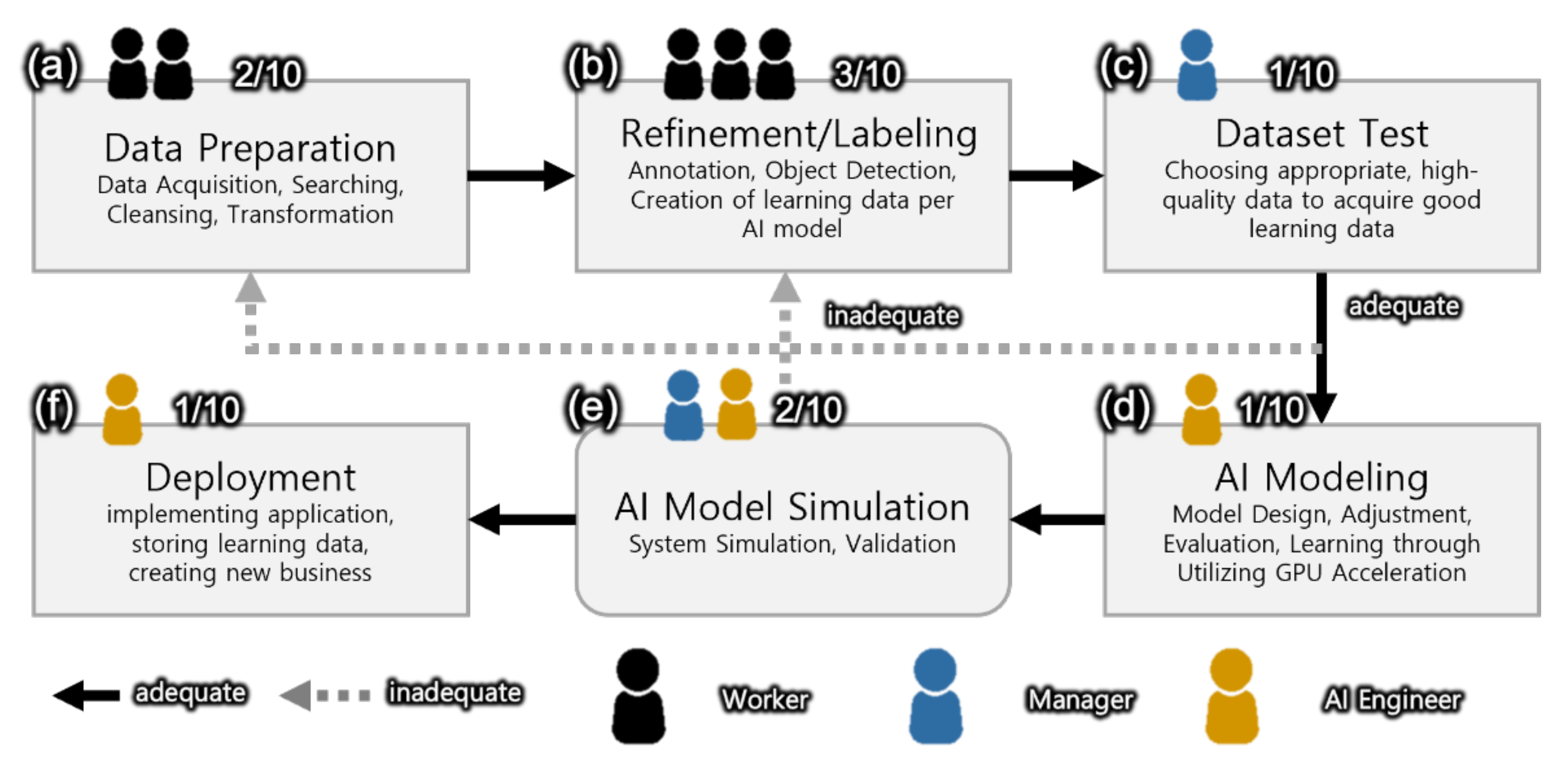
Figure 1 depicts a schematic diagram of data acquisition, refinement, and verification during the execution of AI R&D projects. The set of data in the AI R&D project could be divided into one using image-based data and another using time series data. The overall process of constructing a dataset goes through the process of raw data acquisition, segmentation, and labeling. In general, after collecting the raw data, the refinement process to adjust the size and shape and the labeling process, including annotation and segmentation, are carried out to create the learning dataset based on the two types of data. Additionally, the refined data are re-classified into the weighted model referred to as the brain of AI. The final process of AI dataset construction is quality control to determine what to use in order to ensure the production of optimum results [
6,
7,
8,
9,
10,
11,
12,
13,
14,
15,
16,
17,
18,
19]. While most previous studies divided the construction of the dataset process into the acquisition of raw data, pre-conditioning, data refinement, data labeling, and the composition of the dataset, the process can be simplified into data acquisition, refinement, and labeling steps, excluding the pre-conditioning and composition of the dataset. This is because AI R&D is conducted not by academia but by industrial processes once the data are acquired, and labeling work is carried out to refine the procedure for cost and time reduction. Moreover, subdivided processes performed at research institutes are not followed, as pre-developed models are chosen rather than the development of models for learning on their own, and they swiftly undergo refinement and verification after acquiring data, such as suitable images or videos [
20,
21]. Verification stated here refers to a process that confirms whether refinement was appropriately carried out by utilizing manpower or automation tools, not forming a validation set generally cited in AI research.
It seems that AI R&D could be carried out easily and fast if the above procedures are followed, but there remain two factors to consider in AI research. Firstly, a great deal of high-quality research manpower and equipment are needed at the learning level. In order to verify the performance of training models, numerous variable studies need to be carried out, and researchers who can understand the model structure and change equipment to reduce the training time, as well as manpower to revise labeling, are required. Moreover, a number of studies compared the performance of various AI algorithms in order to verify the optimal model for the construction projects [
22,
23,
24] For example, Chakraborty et al. [
23] tested six different types of machine learning algorithm for predicting the construction costs. Currently, South Korea lacks high-quality manpower that would facilitate a proper understanding and establishment of AI structures, and available personnel are concentrated only in some specific fields. Notably, in minor fields, such as construction and civil engineering, the demand for R&D continues to emerge, but their progress is slow due to a lack of human resources. Problems with development equipment also exist. Hardware, particularly the number of GPUs, is important in the development of the latest AI models [
25]. AI calculation techniques using many GPUs in parallel exist, and, hence, the higher the quantity, the easier the variable research. However, arithmetic disciplines researching minor fields such as construction and civil engineering seem to conduct research with equipment with a budget of USD 4000~10,000 as of 2020 (as shown in
Table 1), and they also use services provided by Google or Amazon without equipment [
26,
27]. As discussed above, AI research may be delayed due to the low performance of computing equipment in non-mainstream sectors.
Secondly, more manpower would be required upon data acquisition and refinement than in the training level. There are limits to searching on the web or reusing existing resources for the acquisition of data, and for special fields, procuring training data itself may be difficult. For instance, in order to acquire data on structure damage due to disasters such as earthquakes and typhoons, research teams must use their time and financial resources at appropriate times and acquire data directly on site. If they are lucky enough to acquire training data after this, refinement is necessary to study the latest AI models, and this requires revision of each data item with human interference. Notably, data refinement that requires expertise may be delayed due to limited manpower.
Although companies carry out AI research by focusing on learning rather than data acquisition and refinement for cost reduction, the outcome is imperfect, as they are unable to procure satisfactory training data. Luckily, South Korea is investing a considerable amount not only in AI model development research but also data acquisition and refinement. In February 2021, the National Information Society Agency (NIA) attempted to standardize the development method by publishing a manual on building data and refinement [
28,
29]. However, the types of data to be acquired consisted of images and video, and simply increasing the quality without considering the development purpose was prioritized; as a result, it is difficult to utilize this model in methods other than the original acquisition purpose. If these data are meaningfully used later, the problem of re-refining the source data by using manpower and financial resources again occurs. Therefore, the aim of this study is to discuss the manpower-dependent problem of the current image-based AI research, its improvement, and its future.
3. What Is the Digital Light Industry?
3.1. Manpower-Dependent Source Data Acquisition Method
AI studies are currently being actively carried out in many fields, but the interest in acquiring training data is relatively small. Acquisition is mostly divided in collection via direct photography or video-shooting and collection via web surfing. Many research engineers are mistaken on the notion that the data acquisition process is not difficult and unimportant due to the incorrect assumptions that infinite data on the Internet can be used and that all objects in the surrounding environment are usable references. In fact, in the case of specialized fields, in order to acquire a datum, bachelor’s degree knowledge and verification in accordance with it are needed. Even if one is fortunate enough to acquire the data, the specialist limit must be considered. In the medical field, for example, where there are numerous clinical cases, effort must be made to prevent leakage of personal information when acquiring image data of wounds, conditions, etc. In the case of the construction field, attention should be paid to not intrude on private property, and all other fields should give attention to copyrights, personal information leakage, and security on the image and acquired data. Thus, although acquisition can be smoothly carried out, blurring parts containing personal information or deleting data violating copyrights from the collected source data in order to abide by R&D ethics regulations should be conducted, which can only be done manually by professionals. If the data are to be used for commercial purposes, much more detailed work is needed.
The digital surfing technique using search engines may appear easy and simple compared to the direct acquisition method, but its usage is being reduced by professional engineers due to its many downsides. In order to transform data into source data after acquisition, inspection of each datum is needed due to overlapping or irrelevant data, format variation, resolution quality, and copyright issues, and research on this subject is required just as much as it is on direct acquisition. Many current beginners who are acquiring AI data believe that numerous training data exist on the web and prefer web-based data acquisition, but when a certain quantity of data is acquired, they become aware of this method’s limit and eventually turn their research toward direct acquisition. However, both methods are means of data acquisition that cannot be overlooked, and a considerable amount of manpower and financial resources are needed in this process due to its trial-and-error nature.
3.2. Necessity for Professional Manpower in Data Processing/Refinement/Labeling
As stated in the previous section, processing and refinement of image data are generally conducted manually using manpower as shown in
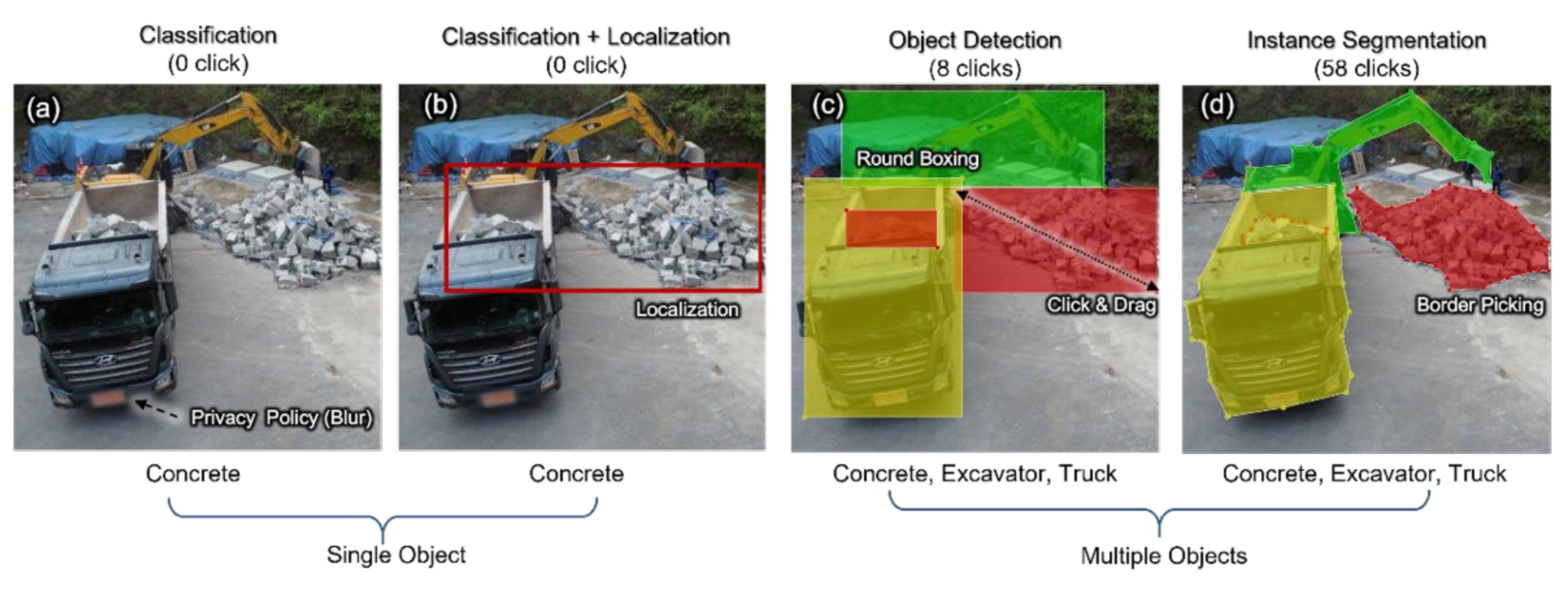
Table 2. If categorizing the acquired data is considered processing and refining, those in charge of the database should classify images one by one at this step. The next steps, namely, cleansing, size transformation, binarizing, and naming, can be solved with a simple program code of the programmer, but the database manager can individually implement the procedures if program personnel are not present. Round boxing and segmentation, which are conducted to utilize the latest AI method, may require professional knowledge depending on the data type, and they may be inefficient in terms of cost if all manpower is gentrified. This issue can be solved by using a method in which a manager with professional knowledge has many ordinary workers, followed by processing and refinement.
During this step, a special program for labeling may be needed. Non-profit research institutes mostly use refinement programs based on open-source software, such as ‘Labelme’ [
36] or ‘VGG annotator’ [
37], whereas business entities utilize self-developed programs and require manpower to manage these. Lastly, in order to manage refined data and utilize them for learning purposes, manpower for professionally developing AI is needed, and specialists with knowledge of at least five knowledge standards in data processing, refinement, and labeling are required, as in
Table 3. It can be clearly observed that programs that automatically assist labeling are released as technology development progresses [
35], and their usages are expected to continue to increase in diversity. However, at this point, human interference must not occur in any of the steps from data acquisition and processing to refinement, and it could be inferred that the AI R&D industry is highly human dependent.
3.3. Acquisition/Process Methods for Low Versatility Data
In general, AI development is not carried out with one-time data refinement. To reach the level of commercialization, training data inevitably have to go through several passes of re-processing, refinement, and labeling, and uneven data management may occur due to the participation of numerous workers. There are three main reasons for re-processing and refinement: the first reason is labeling being carried out in a manner that is not in accordance with the engineer and data managers’ instructions, even if it is performed by professionals. Here, a series of refinements should be conducted again in accordance with the development purpose. The second reason is low accuracy during the training period or when the classified model categorizes unwanted objects. Unlike the problem occurring during model training, the cause cannot be determined in this case, and re-processing and refinement of overall data may be required, which greatly affects the project schedule. This could be due to low precision in the refinement and labeling process (labeling unnecessary data and inserting different data from the development intention) or lack of training data figures. The third reason is the development of a new AI network. Since the training data are composed of a bundle of categories, it is not difficult to add or delete additional categories, but it is difficult to use the bundled data, as they are for the development of AI with a new purpose. For instance, construction material could be a product on-site or rubbish in a dumpsite depending on its usage. Although AI perceiving materials has been successfully developed, it should be able to differentiate between new and used products for resource management, and, in this case, the existing category should be revised. That is, as human beings see and judge, data refinement should be carried out accordingly so as to discern other categories depending on the situation, even if the product is the same. The results of the research team’s trial suggest that the workload lessened considerably when newly labeling from the source data rather than editing the existing labeled data. Research and projects on AI that are currently being developed do not consider subcategories such as the issues above, and as they collect and refine training data, such data are not expected to be used in further developments and would ultimately be considered waste.
3.4. Necessity of Acquisition/Refinement/Labeling Manager
The acquisition/refinement/labeling manager could be defined as the individual who possesses professional knowledge on the specialized field and is capable of making decisions regarding the use of data in training. The advantages gained from hiring such personnel are a shortened development schedule and increased accuracy. If the performance of the model trained with refined data in the absence of a manager is low, it is difficult to find where the cause lies among the training material and AI network. In this case, the AI engineers have to perform the task to identify errors within training data and to improve the network simultaneously, thus leading to the research development schedule being prolonged by twice the amount of time. On the other hand, if the data refinement manager has knowledge of data quality and provides refined data, the AI engineer can concentrate solely on developing the AI network, which may allow for a reduction in R&D time.
4. Solutions
As discussed in
Section 3, many human resources are required for AI R&D. For AIs in specialized fields, the accuracy of the model can only be ensured by highly educated personnel, but such manpower is usually lacking. Moreover, the acquisition and refinement of data, which correspond to the immediate development process but with no consideration in expansion, are used only once in a manner similar to disposable products. In order to avoid such losses, it is necessary to train human resources to consider and manage the expansion from the beginning of the development.
4.1. Solution to the Manpower-Dependent R&D Method
The majority of people in South Korea attend university, and their computer skills are the world’s best. Hence, general human resources required for AI R&D can be considered abundant. However, AI R&D is currently being carried out in an inefficient manner due to notable manpower shortage, and this issue will only be resolved when AI is popularized, which represents the beginning step of the fourth Industrial Revolution. Moreover, Korea is expected to be able to quickly become a powerhouse in this field, as the most efficient R&D is currently being conducted in this country.
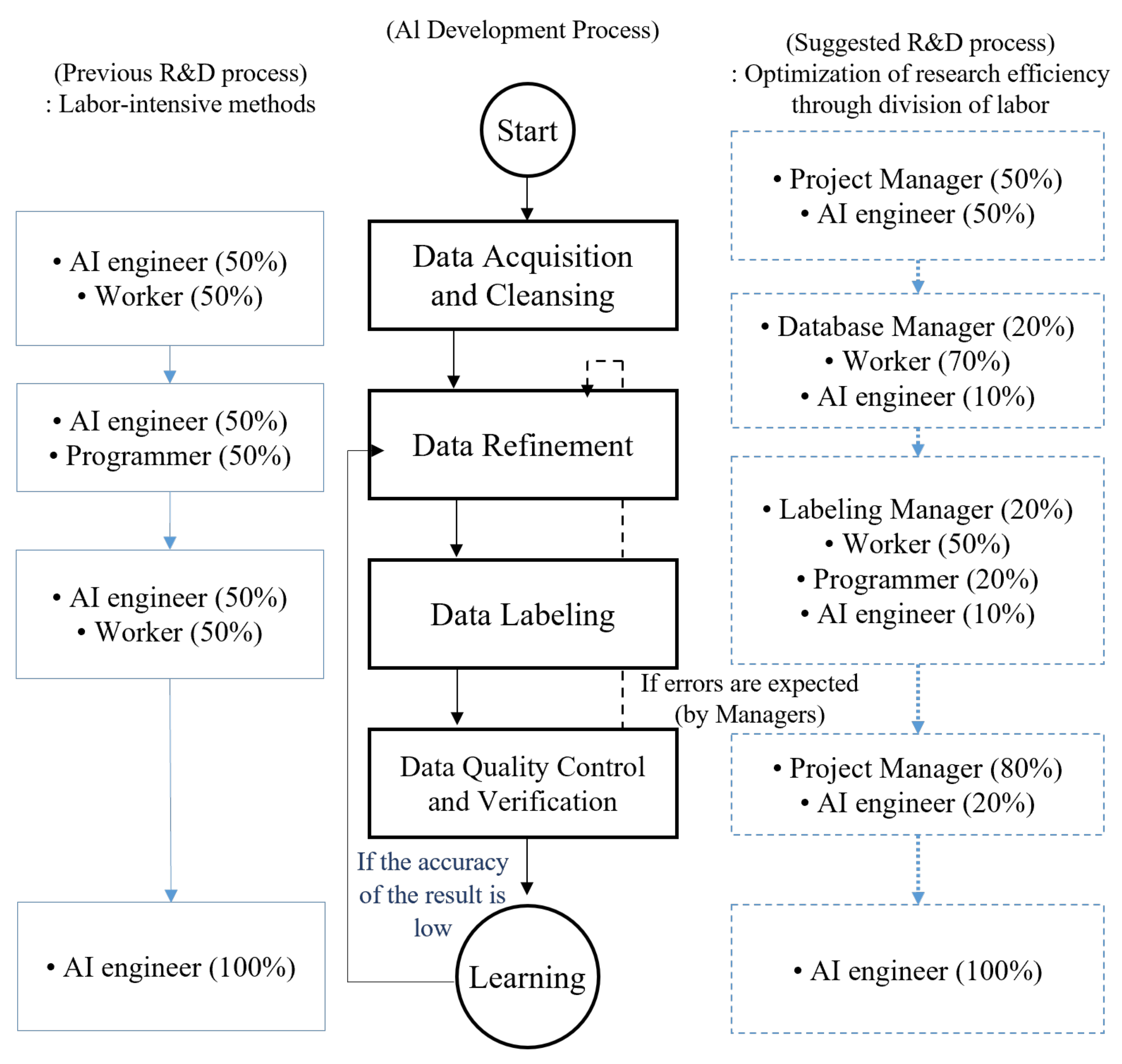
Manpower-related issues can be solved by an AI expert selecting a detailed learning method, data acquisition, refinement, and labeling. Although it is ideal to plan for the consideration of further extendibility, an expert cannot do this alone and, thus, requires AI personnel and an additional general manager. In order to solve this problem, a new type of manpower distribution for the AI development process is suggested, as shown in
Figure 5. The structure and figures of manpower distribution are empirical values obtained by the research team. Aside from their own expertise, general managers play a supporting role, ensuring that R&D is successfully processed by performing tasks in relation to their understanding of the scheme of AI professionals and managing manpower. Should there be insufficient supporting human resources, acquisition, refinement, and labeling managers need to be chosen through professional training and administering manpower, and AI engineers should provide assistance in focusing on enhancement in the capacity of the model. Ultimately, no differences in terms of division could be observed during the Industrial Revolution, and because productivity has dramatically risen as a consequence, AI R&D is expected to produce the same results. For this, large scale learning programs and support are needed for ordinary researchers to become advanced ones through proper education.
4.2. Solution to Concerns Regarding Data Waste
The number of images per project acquired by the Korean government’s Data Dam establishment project is about 200 k~500 k. The cost of this is around KRW 1.8 billion. The likelihood of using these data for other development purposes should be up for reconsideration.
According to a case study of the research team, the same amount of effort required for the existing refined quantity was also required even when adding one simple classification category. Regardless of the selected AI development methods, new category classification and labeling methods should be applied to the model to be developed, and even datasets developed after the consideration of extendibility require half the amount of the pre-existing manpower. Therefore, data should be acquired and refined so as to possess generality by establishing detailed categories, organizing data with extendibility reflected, adopting labeling techniques, starting with a broad development range from the beginning, and reducing cost and time losses.
5. Case Study and Suggestion Regarding Work Index
Three case studies were carried out to support the research team’s argument that AI R&D is similar to a type of light industry. The case studies were carried out in a similar manner to that of the development method performed by general researchers, and the manpower and hours consumed per development step can be observed in
Table 4. Equation (1) presented below is suggested with image quantity, input manpower, and work hours.
Through this equation, the degree of resource consumption in comparison with the data can be quantitatively calculated as a value from 1 to 10 depending on the development method of AI. If a high amount of manpower and hours are input, the index shows a low value; if data generated from other further R&D processes are analyzed, the adequacy of the resource input for data acquisition, refinement, and labeling development can be verified.
5.1. Development on Concrete Surface Crack Recognition
In order to use the object detection method, a total of 20,000 photos showing concrete cracks in 224 × 224 pixels were collected. Concrete cracks were acquired by photographing actual architecture, and the cracks on the image were cropped and saved. It took 200 h under one worker/hour to complete data acquisition and cropping. Special labeling was not required; thus, the work index was 1.4 when compared to a considerable amount of learning data. As a result of learning, the AI models could perceive cracks. While acquiring learning data, the images were amassed around horizontal or vertical cracks, so diagonal cracks were identified, but those intersecting in X were unrecognizable.
5.2. Development in Perceiving Constructional Waste
In order to develop an AI model that differentiates 5 out of 18 constructional wastes being generated from construction sites, namely, concrete, brick, lumber, board, and mixed waste, data were acquired and refined through instant segmentation. A total of 866 images were acquired, and those taken on-site were cropped, collected online at a resolution of 512 × 512 pixels, and refined to 100 kb per photo. Moreover, pixels around the object boundaries were extracted using the polygonal method so as to differentiate the classes for wastes on the images. It took 48 h under three workers/hour to conduct data acquisition, and this time includes all aspects from planning the data acquisition process to taking pictures on-site as well as moving and saving the pictures on a data server. Refinement and labeling were simultaneously carried out, which took 180 h under four workers/hour. The work index for each development step was different, as shown in
Table 4, and it could be observed that many resources were used for data acquisition in this research. Since inaccuracy was observed in some parts after learning, around 60 h under four workers/hour were additionally required for relabeling (segmentation) based on the acquired source data. Relabeling required only one-third of the resources needed to complete the previous work, and it was possible to differentiate five types of wastes after learning with the relabeled data, but it was ultimately decided to increase the amount of learning data due to cases in which board and lumber were being confused for each other.
5.3. Development of Model Identifying the Quantity of Rebar
A model to identify individual bundles of rebar was developed to manage automatized materials on a construction site. Within images of 512 × 512 pixels, 50–250 bundles of rebar were photographed, and the cross-section of rebar was extracted using the polygonal method so as to perceive each bundle of rebar separately. It took 48 h under three manpower/hour to acquire 726 images, and it took 100 h under four manpower/hour to separately segment around 120 k rebars. As a result of learning, the extraction of rebar quantity from the photo, which was achieved by identifying each rebar cross-section individually, was confirmed. However, if more than 300 bundles of rebar were included in one image, some were difficult to differentiate on 512 × 512 pixels, even with the naked eye; thus, a notable decrease in accuracy was observed in some parts with low resolution. This case study had the tendency to a show high work index compared to that of others, and this is considered to be due to no additional labeling being conducted and the development being efficiently carried out by a skilled research team.
6. Conclusions
The fourth Industrial Revolution refers to an intellectualized society with various technologies, such as AI, big data, block chains, and robotics. This study focused on AI among technologies in the fourth Industrial Revolution and examined the development process’s similarities to that of light industry. Compared with the heavy industry, the production efficiency of the light industry is dependent upon manpower and production stages. All processes for AI R&D, from data acquisition to refinement, learning, and quality evaluation, need to be carried out by personnel, an observation that is also highly applicable to the light industry. However, since previous business entities/institutes processed development by only focusing on the AI learning step, manpower supply was not prioritized, which led to low assessment of the importance of human resources in national R&D projects, thus leading to a reality with improper AI R&D. Therefore, this study conducted a detailed analysis of necessary tasks for each AI learning step and examined the urgency of R&D personnel training.
6.1. Data Acquisition Step
Previously, images or time series data were simply copied into the digital form for data acquisition. However, for R&D with commercialization purposes or being conducted in specific professional fields, it is difficult to indiscriminately use existing data due to copyrights and personal information protection, and a process to check the data individually after acquisition is mandatory. A tool to automatize this process exists but cannot be considers as completed; thus, human interference is necessary throughout all processes.
6.2. Data Refinement/Labeling Step
It was verified through a case study that the accuracy of the AI model and reduction in the research period were expectable only with the enhancement of refinement technology. It was observed that a refinement manager and developing personnel who possess academic knowledge of development field were necessary, and it was important that the data were refined by the personnel who received professional education on development rather than by the public recruited through the existing cloud sourcing method. In addition, a refinement manager should be hired to manage R&D projects, and AI engineers should be able to focus on their own tasks, thereby leading to maximized efficiency of labor division.
6.3. Quality Evaluation Step
According to the research results, it appears that managers could carry out quality evaluation for each step. This could lead to quality evaluation focused only on the research purpose, and reutilization of learning data would be impossible. Although it is inessential at this point, reutilization of learning data could serve as a shortcut to reduce the development period for researching and developing similar AI when the golden age of AI research is reached. Hereupon, the necessity of professional manpower to predict development in other fields and manage data would become important.
If a sufficient number of personnel are educated and trained to lead specialized development projects, as per the results above, new value creation in the AI era can be expected. Such an AI industry would increase job opportunities in the short term, and job opportunities in general are not considered to decrease due to AI until a particular point is reached. Labor division and development of mechanisms that emerged during second Industrial Revolution period brought explosive productivity enhancement. The fourth and second Industrial Revolutions show similarities in terms of natural resources (data) and mechanisms (computer). A considerable number of examples verified the increased productivity achieved by using AI, and if human resources are efficiently distributed and utilized, advancement in mankind similar to that observed during the second Industrial Revolution is expected.









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}