3.2. Upgrading of the Feature Pyramid Structure
To enhance the effectiveness of target detection, the receptive field must be expanded due to the large size of the targets in the dataset used in this study. Most studies tend to increase the receptive field by increasing the convolutional layer and increasing the downsampling ratio [
39]. However, in convolutional neural networks, the feature maps obtained by deep convolution are more semantic, but the location information is lost and the computational effort is increased. Therefore, in this paper, we increase the downsampling rate based on the original algorithm [
40,
41] and stack the feature pyramid network structure one level up, i.e., the original P3–5 structure is improved to a P4–6 structure. The newly added P6 detection layer is more suitable for detecting larger targets and can achieve higher accuracy under higher-resolution training conditions [
42].
Due to the small number of downsampling layers of YOLOv5s, the detection effect on large-sized objects is not ideal. Therefore, we add a 64× downsampling feature fusion layer P6 in the Backbone, which is output by the backbone network with 64× downsampling and 1024 output channels, generating a feature map of size 10 × 10. The smaller the feature map, the sparser the newly generated feature map’s segmented grid, the more advanced the semantic information contained in every grid, and the larger the receptive field obtained, which is conducive to the recognition of large-sized targets [
43]. At the same time, the original 8× downsampling feature fusion layer is removed, i.e., only P4, P5, and P6 are used to downsample the image. In this way, the original image is sent to the feature fusion network after 16×, 32×, and 64× downsampling to obtain 40 × 40, 20 × 20, and 10 × 10 feature maps in the detection layer. Three sizes of feature maps are used to detect targets of different sizes, and the original feature extraction model is shown in
Figure 3.
As shown in
Figure 3, P4, P5, and P6 are three different layers of feature maps, corresponding to 16, 32, and 64 times downsampling magnification, respectively. Feature maps P4, P5, and P6 carry out feature fusion through feature pyramids, i.e., fusing the high-level and low-level feature maps by passing high-level information from top to bottom and location information from bottom to top, combining the location information of the low-level network with the semantic information of the high-level network. The model can be used to enhance the detection function of targets of different sizes and strengthen the multi-scale prediction capability of the network for targets. P6 has a higher downsampling multiplier and contains a larger receptive field per pixel, which provides more sufficient information on large-sized targets during the fusion of feature information transfer, thus, enhancing the learning capability of the network. The feature map then enters the detection layer for prediction, which consists of three detection heads and is responsible for identifying feature points on the feature map and determining whether there is a target corresponding to it.
We carry out ablation experiments because target detection layers add more parameters. The experimental findings demonstrate that the number of parameters increases only slightly after the P4–P6 structure is improved due to the addition of only feature layers and not a significant number of extra convolutional layers; however, the detection accuracy is improved. In conclusion, by increasing the downsampling multiplier to obtain a smaller feature map, the feature map receptive field is larger, which is helpful for fully refining the image feature information, reducing the information loss, and strengthening the network’s learning capability, thus, improving the accuracy of target detection and recognition while decreasing the computational effort.
3.3. GSConv
Although P4–6 are improved, it still introduces a certain number of parameters, which is not optimal for the creation of lightweight networks even if it leads to significant accuracy advances. The design of lightweight networks often favors the use of depth-wise separable convolution (DSC). The greatest advantage of DSC is its efficient computational power, with approximately one-third of the number of parameters and computational effort of conventional convolution, but the channel information of the input image is separated during the calculation. This deficiency leads to a much lower feature extraction and fusion capability of DSC than even the standard convolution (SC). To make up for this deficiency, MobileNets first compute channel information independently and then fuse it with a large number of dense convolutions; ShuffleNets use shuffle to achieve channel information interaction; GhostNet only inputs half of the number of channels for ordinary convolution to retain the interaction information. Many lightweight networks are limited to similar thinking, but all three approaches use only DSC or SC independently, ignoring the joint role of DSC and SC and, thus, cannot fundamentally solve the problems of DSC [
44].
To make effective use of the computational power of DSC and, at the same time, make the detection accuracy of DSC reach the standard of SC, this paper proposes a new hybrid convolutional approach, GSConv, based on research on lightweight networks. The GSConv module is a combination of SC, DSC, and shuffle, and its structure is shown in
Figure 4. Firstly, a feature map with the input channel number
is input, half of the channel number is divided for deep separable convolution, and the remaining channel is convolved for normal convolution, after which the two are joined for feature concatenation. Then, the information generated by SC is infiltrated into the various parts of the information generated by DSC using shuffle, and the number of output channels in the feature map is
. Shuffle is a channel-mixing technique that was first used in ShuffleNets [
45]. It enables channel information interaction by allowing information from the SC to be fully blended into the DSC output by transferring its feature information on various channels.
During the convolution process, the spatial information of feature maps is gradually transferred to the number of channels, i.e., the number of channels increases while the width and height of the feature map decrease, thus, making the semantic information stronger and stronger. In contrast, each spatial compression and channel expansion of the feature map results in a partial loss of semantic information, which affects the accuracy of target detection. SC retains the hidden connections between each channel to a greater extent, which can reduce the loss of information to a certain extent, but the time complexity is greater; on the contrary, DSC completely cuts off these connections, causing the channel information of the input image to be completely separated during the calculation process, that is, the feature map is separable with minimal time complexity. GSConv retains as many of these connections as possible while keeping the time complexity small, which reduces information loss and enables faster operation, achieving a degree of unity between SC and DSC.
The time complexity of the convolution calculation is usually defined by FLOPs, and the time complexity of SC, DSC, and GSConv is calculated as follows:
where W and H are the width and height of the output feature map, respectively;
and
are the size of the convolution kernel;
is the number of channels of the input feature map;
is the number of channels of the output feature map.
Applying each of the three convolution patterns to the same image of the dataset in this paper, the visualization results for SC, DSC, and GSConv are as shown in
Figure 5. Compared to DSC, the feature maps output by GSConv are more similar to those output by SC, and, in some cases, the detection of the target is even better than SC with the highest detection accuracy; some of the output colors of DSC are darker, and there is a lack of detection accuracy.
Further, the convolutional kernel size of the DSC used in the original GSConv is 5 × 5, which is replaced with a 7 × 7 sized convolutional kernel to adapt it to the detection of large targets so we can obtain a larger scale of features and receptive field. This study reduces the network parameters and computation, minimizing the drawbacks of DSC, reducing its detrimental effects on the model, and making full use of the effective computational capacity of DSC to make the model easier to deploy to the endpoints.
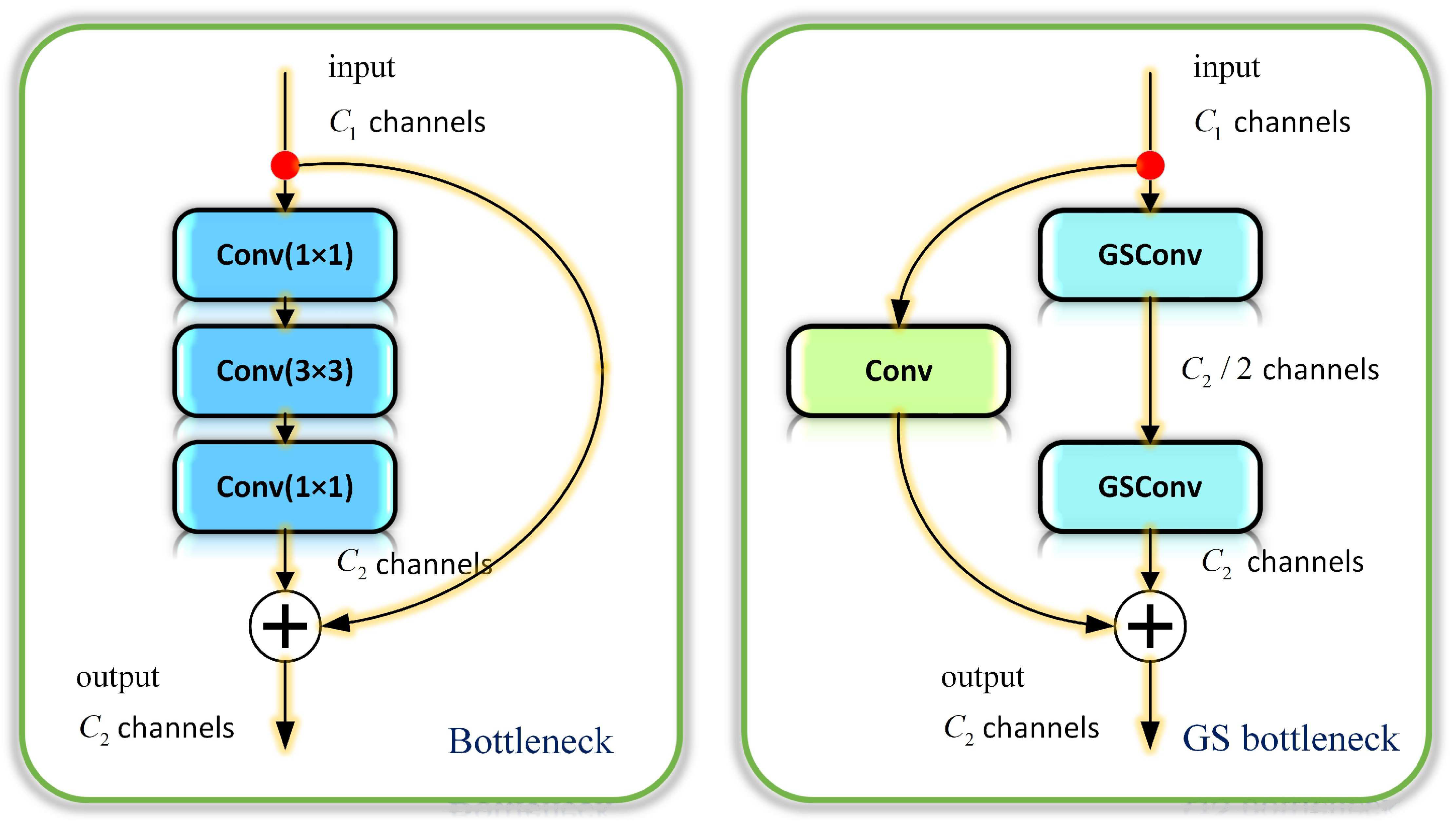
3.4. VoVGSCSP
Based on a new hybrid convolutional approach, GSConv, we introduce a GS bottleneck based on Bottleneck and replace Bottleneck in C3 with GS bottleneck to improve C3. Bottleneck originally comes from Resnet and is proposed for high-level Resnet networks. It consists of three SCs with convolutional kernels of sizes 1 × 1, 3 × 3, and 1 × 1, respectively, where the 1 × 1 convolutional kernel serves to reduce and recover dimensionality, and the 3 × 3 is the bottleneck layer with smaller input and output dimensions. The special structure of Bottleneck means that it is easy to change dimensionality and achieve feature dimensionality reduction, thus, reducing the computational effort [
46].
A comparison of the structure of Bottleneck and GS bottleneck is shown in
Figure 6. Compared to Bottleneck, GS bottleneck replaces the two 1 × 1 SCs with GSConv and adds a new skip connection. The two branches of GS bottleneck, thus, perform separate convolutions without sharing weights and by splitting the number of channels so that the number of channels is propagated via different network paths. The propagated channel information thus gains greater correlation and discrepancy, which not only ensures the accuracy of the information but also reduces the computational effort [
47].
In this paper, we use an aggregation method to embed the GS bottleneck in C3 to replace Bottleneck and design a newly structured VoVGSCSP module. A comparison of the structure of C3 and VoVGSCSP is shown in
Figure 7.
In VoVGSCSP, the input feature map splits the number of channels into two parts, the first part first passing through the Conv for convolution, after which the features are extracted by the stacked GS bottleneck module. The other part is connected as residuals and passes through only one Conv to convolve. The two parts are fused and connected according to the number of channels and finally output by Conv convolution. VoVGSCSP is not only compatible with all the advantages of GSConv but also has all the advantages that GS bottleneck brings. Thanks to the new skip-connected branch, VoVGSCSP has a stronger non-linear representation compared to C3, solving the problem of gradient disappearance. Meanwhile, similar to the segmentation gradient flow strategy of a cross-stage partial network (CSPNet), VoVGSCSP’s split-channel approach enables rich gradient combinations, avoiding the repetition of gradient information and improving learning ability. Ablation experimental results showed that VoVGSCSP reduces the computational effort and improves the accuracy of the model [
48,
49].
Combining the above improvements in the Backbone of YOLOv5s, we replace the SPP module with the SPPF module to improve the pooling efficiency while adding the Conv module to achieve 64× downsampling output; in the Head of YOLOv5s, we replace all the Conv modules with GSConv modules to reduce the number of parameters and computation brought by the upgrade of the feature pyramid structure. The C3 module is replaced with VoVGSCSP module, and the features are extracted by the stacked GS bottleneck for better compatibility with the GSConv module; at the same time, the original 8-fold downsampling feature fusion layer is deleted, and a 64-fold downsampling feature fusion layer is added to strengthen the learning capability of the network and give full play to the efficient computational capability of GSConv. The rest of the original modules of YOLOv5s remain unchanged [
25]. Since all the improvements in this paper have good compatibility for different numbers of residual components and convolutional kernels and are not affected by the deepening of the network structure, for the YOLOv5m, YOLOv5l, and YOLOv5x models, which differ only at the network size and depth levels, the same improvements are also applicable. In this paper, we only take YOLOv5s as an example, and the improved network structure is shown in
Figure 8.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}