1. Introduction
The modern chicken breeding industry presents the characteristics of high intensification and integration. With the requirements and challenges of the food crisis, environmental protection, biosecurity and animal welfare, the modern chicken breeding industry urgently needs to be transformed from labor-intensive to intelligent [
1].
The day-age of a chicken is a concept similar to human age [
2]. It is an important indicator of its growth. The day-age of a chicken plays an essential role in modern chicken farming, which is related to feed conversion, reproduction traits and slaughter performance. These indexes also directly affect the production management of chickens and achieve optimal poultry production. Therefore, many chicken breeding enterprises will regularly recognize the day-age of chickens and conduct group management in order to realize precision feeding, which can help enterprises to reduce costs and increase efficiency.
Generally, chickens can be divided into laying hens and broilers by their production specialists. Broiler production mainly adopts the system named “all in, all out” without involving herd transfer. Laying hens [
3] can be divided into reserve chickens which are from newborn to 126 day age and laying hens which are from 127 to 504 day age. Reserve chicken is a crucial essential stage in laying hen production. Different types of laying hens not only directly affect the growth and development of laying hens, but also affect the production performance during the laying period. For laying hens, it also affects the breeding value, the renewal of the flock and the smooth completion of the production plan. According to the different environmental conditions and nutritional needs of breeding, detailed classification information of reserve chickens is displayed in
Table 1.
By dividing chickens into different stages according to their day-age, this paper carries out targeted feeding management, which is of great significance to improve feeding efficiency. These significance is mainly reflected in the following aspects:
- 1.
Determine the utilization cycle of breeding chickens [
4], the feeding cycle of laying hens and the best slaughter time of broilers [
1].
- 2.
Improve the efficiency of feed utilization [
5] and reduce the feed cost and the environmental pollution caused by chicken excreta.
- 3.
Predict possible diseases at each stage [
6,
7] and administer the targeted prevention programs.
- 4.
Provide precision feeding for the differences in light [
8], temperature and drinking water needs at each stage.
In traditional chicken farming, the day-age of chickens is usually estimated by the experience of the poultry feeders. The most intuitive index is the weight of chickens. Under the same rearing conditions, the weight of chickens of the same sex at a certain day-age is within a certain range. Some physical features can also be used to judge the day-age. Here are four traditional methods of determining the day-age of a chicken:
- 1.
Beak. In free-ranging flocks, the beak of the short-day-age chickens is taper, narrow and thin and there is no hard horn; As a result of long-term outdoor foraging, the beak of the long-day-age chicken is thick and short, the end becomes hard and smooth and the two sides are broad and rough.
- 2.
Crest. The crests of chickens with a short day-age are smaller, while the crests grow larger with the increase in day-age.
- 3.
The length of the feather. The feather length of chickens will elongate with the increase in the day-age of chickens and the day-age of chickens can be roughly judged by the main wing feathers [
9].
- 4.
Metatarsus. The metatarsal length is positively correlated with chicken day-age and elongates with the increase in chicken day-age. Metatarsal scales are soft when young and keratinized when adults. The larger the day-age, the harder the scales and they even protrude laterally.
However, these methods are derived from experience, which may have large personal errors and poor accuracy. They can only be used as rough judgment and cannot accurately determine the day-age of chickens, so they are not suitable for the needs of precision feeding in the chicken breeding industry.
In large-scale farms, physical barriers are often used to separate flocks of chickens of different day-ages, strict production records are made to ensure accurate monitoring of the day-age of chickens and regular inspections are carried out to eliminate or transfer the chickens that do not conform to the uniformity of the flock. However, this is undoubtedly labor-intensive and will bring about a series of animal welfare problems [
10]. With the development of computer vision and its application in the chicken breeding industry, the optical density assay method has been used to measure the emission density of bone [
11] to infer the day-age of chickens. However, this method of measuring bone density cannot be applied to live chickens.
Based on this, modern chicken breeding needs a method that can get rid of the empirical aspect and accurately identify the day-age of chickens. Therefore, utilizing artificial intelligence to establish a set of less personal errors and a human contact chicken day-age identification method has positive significance for modern chicken farming [
12]. There are great differences in the feeding and management methods of laying hens at different day-ages [
13]. During the reserve chicken period, the requirement of different amino acids is different in different periods, which needs to be accurately grasped [
14]. Thirdly, the accurate identification of chicken day-age is helpful to accurately determine the broiler production time and the elimination time of laying hens, which can improve the economic benefits. The meat quality of broilers varies depending on the different day-age at which they are slaughtered, divided and sold [
15]. By determining the slaughter time through the accurate day-age judgment, the texture needs of different chicken products can be grasped dynamically in the market, so that they can provide chickens suitable in terms of day-age [
16].
In recent years, researchers have developed a variety of digital image processing and pattern recognition techniques that use camera traps for objection detection and classification, which identify species accurately and concisely in agriculture [
17,
18,
19,
20,
21,
22,
23]. In Ref. [
2], Ren et al. improved the accuracy of chicken day-age detection. They proposed an attention encoder structure to extract chicken image features, trying to improve the detection accuracy. To cope with the imbalance of the dataset, various data enhancement schemes such as Cutout, CutMix and MixUp were proposed to verify the effectiveness of the proposed attention encoder. By applying the attention encoder structure, they can improve the accuracy of chicken age detection to 95.2% and they also designed a complete image acquisition system for chicken houses and a detection application configured for mobile. However, when the number of captured cameras proliferates, the strategy based on single-point training will lead to long training time and how to utilize the large amount of edge computing power will be the key to solving this problem.
These studies provide the basis for research on classification of chickens based on computer vision and point the way forward. Based on the above discussion, this paper proposes a high-precision federated learning-based chicken 100-day-old classification model that can be applied to edge computing scenarios. The main contributions of this paper are as follows:
- 1.
This paper proposes a dual-ended adaptive federal learning framework that can be adapted to clients with different computing powers.
- 2.
In order to adapt to edge computing scenarios, the mainstream classification models have been lightened to run on low computing power platforms.
- 3.
This paper conducted extensive experiments to validate and analyze the robustness of the proposed method and finally achieved 95.3% accuracy on our dataset.
2. Related Work
Federated learning was first proposed by Google in 2016 [
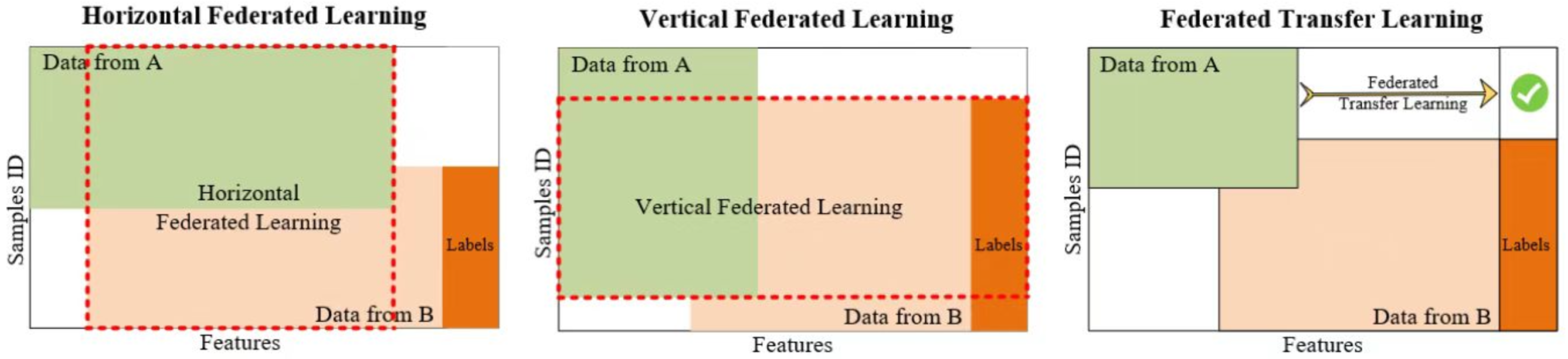
24] and was originally used to solve the problem of updating models locally for Android phone end users. It is essentially a distributed machine learning technique or machine learning framework. The goal of federated learning is to enable co-modeling and improve the effectiveness of AI models while ensuring data privacy and security and legal compliance. Each entity involved in joint modeling is called a participant and based on the distribution of data across multiple participants, joint learning is divided into three categories: horizontal vertical joint learning, joint transfer learning and joint learning, as shown in
Figure 1.
2.1. Horizontal Federal Learning
The essence of cross-sectional federation learning is the union of samples, which apply to the scenario when the participants have the same business model but reach different customers, i.e., more overlapping features and less overlapping users, e.g., banks in different regions have a similar business (similar features) but different users (different samples). The learning process is shown below:
- 1.
The participants each download the latest model from server A.
- 2.
Each participant trains the model using local data and the encrypted gradients are uploaded to Server A, which aggregates the gradients of each user to update the model parameters.
- 3.
Server A returns the updated model to each participant.
- 4.
Each participant updates his model.
In traditional machine learning modeling, the data needed to train a model is usually collected in a data center prior to training the model and making further predictions. Horizontal composite learning is a sample-based distributed model training where all the data for this training are distributed across different computers. Each computer downloads the model from the server, then trains the model based on the local data and sends any parameters that need to be updated back to the server. Based on the parameters returned by the different computers, the server compiles and updates the model and then sends the latest model to the different computers.
In this process, there is no communication and dependency between machines, each machine can also predict independently when predicting and the models under each machine are identical and complete, which can be said to be sample-based distributed model training. Google first uses horizontal federation to solve the model local update problem for Android mobile end users.
2.2. Vertical Federal Learning
The essence of vertical federation learning is the union of features, which is suitable for scenarios with more overlapping users and less overlapping features, such as a superstore and a bank in the same area, where they reach users who are both residents of the area (same sample) but have different businesses (different features). In the traditional machine learning modeling process, two parts of data need to be pooled into one data center and then the features of each user are joined into one piece of data for training the model, so both sides must have user intersection and one side to have a label. The first step is to encrypt the sample alignment. This is done at the system level so that non-intersecting users are not exposed at the enterprise perception level; the second step is to align the samples for model encryption training, as shown below:
- 1.
The public key sent by the third party C to A and B, which is used to encrypt the data to be transmitted.
- 2.
A and B compute the intermediate results of the features associated with themselves, respectively, and encrypt the interactions, which are used to derive the respective gradients and losses.
- 3.
A and B compute their respective encrypted gradients and add masks to send to C, while B computes the encrypted losses to send to C.
- 4.
C decrypts the gradient and loss and passes it back to A and B. A and B remove the mask and update the model.
2.3. Federated Transfer Learning
Federated transfer learning can be considered when there is little feature and sample overlap among participants, such as the federation between banks and supermarkets in different regions. It is mainly applicable to scenarios where deep neural networks are the base models. The steps of federated transfer learning are similar to those of longitudinal federated learning, except that the intermediate transfer results are different (in fact, the intermediate transfer results are different for each model). The process of federation migration is shown in
Figure 2.
Federated learning is reflected in the fact that A and B can learn a model together by securely interacting with intermediate results and transfer learning is reflected in the fact that B migrates the classification ability of A.


 ,
, 









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}