As a result of the research carried out on Kaggle, three different networks were selected to be examined. These networks are Basic CNN, VGG16Net, and DenseNet. Then, the data percentage to be used in the training phase was determined on the chosen data set: 80% of the data is reserved for use during the training phase and 20% for the testing phase. During the training phase, the accuracy rates of architectural structures, validation accuracy rates, and changes in loss functions were examined and tabulated at each step. These changes were examined separately for each model. It was learned that the same errors occurred in certain classes during the classification in the previously trained models. In the simple CNN network, classification errors arose due to deficiencies in the layers. These errors were reduced to minimum levels in the modified CNN network, and high accuracy rates were obtained during the training phase.
4.2.1. Basic CNN Architecture
During the literature research phase of the study, the models in other studies were examined. As a result of this research, it was concluded that the popularities of the classical CNN model, VGG16Net, and DenseNet models in the studies were high, so it was decided to examine studies of these models. In the classical CNN architecture, firstly, the structure of the layers was examined. There is only one convolutional layer and a pooling layer in this structure. Then, classification is performed by passing information to the classical neural network. In the proposed approach, convolutional and pooling layers have been developed and inserted into the classical neural network after multiple preprocessing steps.
As a result of the research carried out on Kaggle, it was decided that the first structure to be examined would be a simple CNN architecture. The purpose of choosing this architectural structure is to observe how successful the CNN architecture will be without changing the layers. As a result of these observations, it was decided how changes should be made in the layers. The system was operated with a total of 10 epochs, and the resulting values were examined. These values are shown in
Table 4.
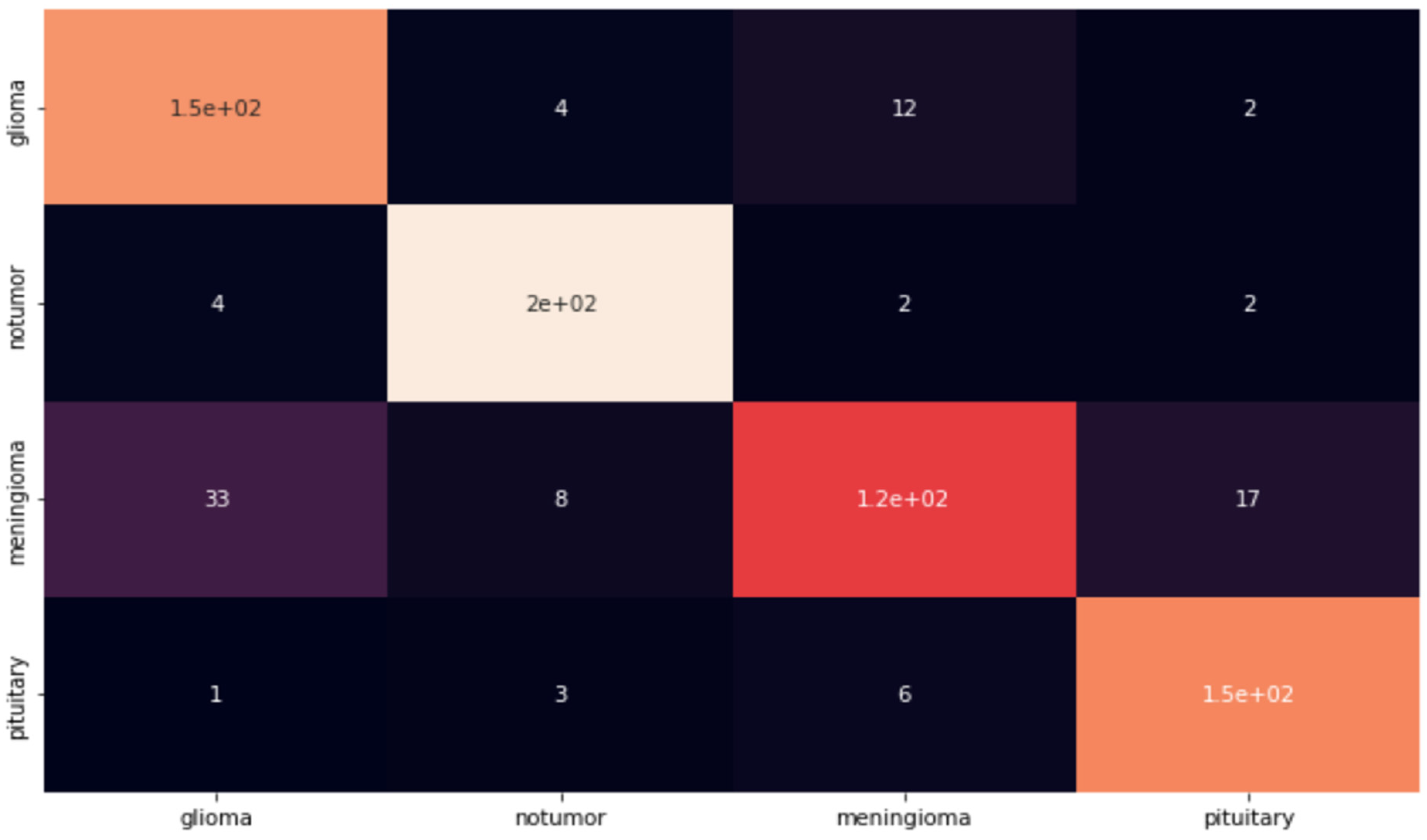
As can be seen from the graphics, the accuracy of the system is up to 92%. However, to test the reliability of the system, an application was made using the test data set. The reason for this is that even if the success rates of the created models are high during the training phase, their inadequacy in the testing phase has been observed before. As a result of this application, and as can be seen in
Figure 4, an error matrix was created, and Precision, Sensitivity, and F1 Scores were examined over this error matrix.
As can be seen from the error matrix in
Figure 4, the simple CNN model works well for two classes (Healthy Individual and Pituitary). However, the success rate in other classes was less than expected. Even if the success rate in other classes is sufficient as a result of a normal examination, a success rate of 89–90% is not sufficient in a study on cancer in the field of health. For this reason, this model is not a model that can achieve the necessary success in real life. The weak points of this model were examined, and it was determined which parts were missing. Even though the success rate in MRI images of healthy individuals and patients with the pituitary disease was at the expected rate, the success rates in MRI images in the glioma and meninglioma tumor classes were below the expected levels.
In order to examine the reliability of the model in detail, the values of each tumor class at the test stage were examined separately. In this way, it has become easier to detect the model’s weak points. As we have previously examined in the error matrix, although the success rate in healthy individuals and patients with a pituitary brain tumor was 97–98%, the success rate in meninglioma and glioma tumor types remained below 90%, as shown in
Table 5. This ratio is not sufficient for application in the field of health. The reason for this low success rate is the equation we use to calculate the F1 score. While calculating the F1 score, the value that affects the ratio the most is the “False Positive” value. This value occurs when people’s test results are negative, but they have a disease, and it is the most important value in medical applications. This is the weakest point of this system since this value is too high in the case of meninglioma.
4.2.2. VGG16Net Architecture
The VGG16Net architectural structure uses convolutional layers in groups of two or three, and it is different from CNN model structures. At the same time, the VGG16Net architecture functions as a previously trained model. The reason for making a comparison between VGG16Net and the proposed model is that the complexity in the former’s network structure is higher than the proposed model. We also want to see how much a pre-trained model will affect the success rate.
As the second model, it was decided to examine the VGG16Net architectural structure. A new model was created using the VGG16 transfer learning method. The purpose of this model is to increase its reliability by applying training with large datasets. This model was run at the same epoch number with the simple CNN architecture, and its values during the training phase are given in
Table 6.
As seen in
Table 6, the accuracy rate of the model regularly increases throughout the training phase. However, during the validation stage, that is, the pre-test phase, the accuracy values could not meet the expected values and did not show a regular increase. The validation accuracy decreased again in some epochs. Afterward, the trained model was tested, and an error matrix was created. A table was created to examine this matrix in detail and to see the “Sensitivity,” “Precision,” and “F1 Score” values. As seen on the confusion matrix, the VGG 16 Model worked with a lower success rate than the simple CNN model, and the success rate decreased in the same classes. The model that made many mistakes in the glioma brain tumor class was determined as a model that is unlikely to be used in the health field as a success rate.
Later, when we examined the performance of
Table 7 according to their classes, it made too many mistakes and examined the deficiencies in meninglioma and glioma tumor types similar to the previous model. It did not achieve the expected success in distinguishing tumor classes at the classification stage, as shown in
Figure 5.
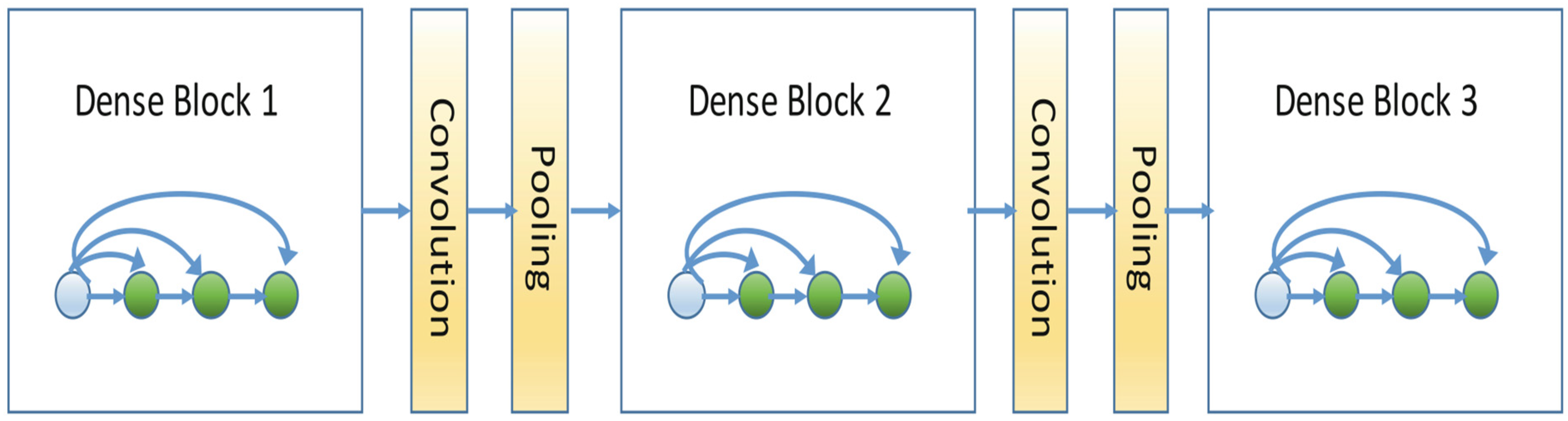
4.2.3. DenseNet Architectural Structure
The reason for examining the DenseNet architecture is that in DenseNet, each layer receives inputs from the previous layers and transfers all feature maps to the next layers. The aim here is to compare the CNN architectural structure and the DenseNet architectural structure, which transfers collective information. This way, the operation of feature maps will be compared, and the differences between the models will be examined.
Finally, a different transfer learning model was examined based on the VGG16 transfer learning model. The reason for choosing the DenseNet architecture is that it can better learn the details in the inputs and outputs by using dense layers. The DenseNet model is also a model that has been previously trained with different data sets. It was run on the same data set, with the same number of epochs as the other models. The values at the training stage are given in
Table 8.
Like the VGG16 model, the DenseNet model showed a regular increase in accuracy during the training phase. However, also like the VGG16 model, there is a tide in the accuracy rates in the pre-test phase, causing a loss of confidence. After some epochs, there were decreases. In order to examine the success rates in the test phase, a table showing the “Sensitivity”, “Precision,” and “F1 Score” values was created.
As can be seen in
Table 9, unlike the VGG16 architecture, DenseNet’s architecture failed to detect meninglioma and glioma tumors, although the Sensitivity ratio was high in healthy individuals and pituitary tumor patients. Likewise, the apparent insufficiency in F1 scores is due to the high number of “False Positives.”
4.2.4. Modified CNN Architecture
As a result of the examination of the three models, deficiencies in each model were determined. Afterward, a CNN model was created in order to eliminate these deficiencies. In this model, unlike the simple CNN model, a more advanced network is created, and images are analyzed in more detail in this network. The values of the model operated in the form of 20 epochs during the training phase are given in
Table 10.
As can be seen in
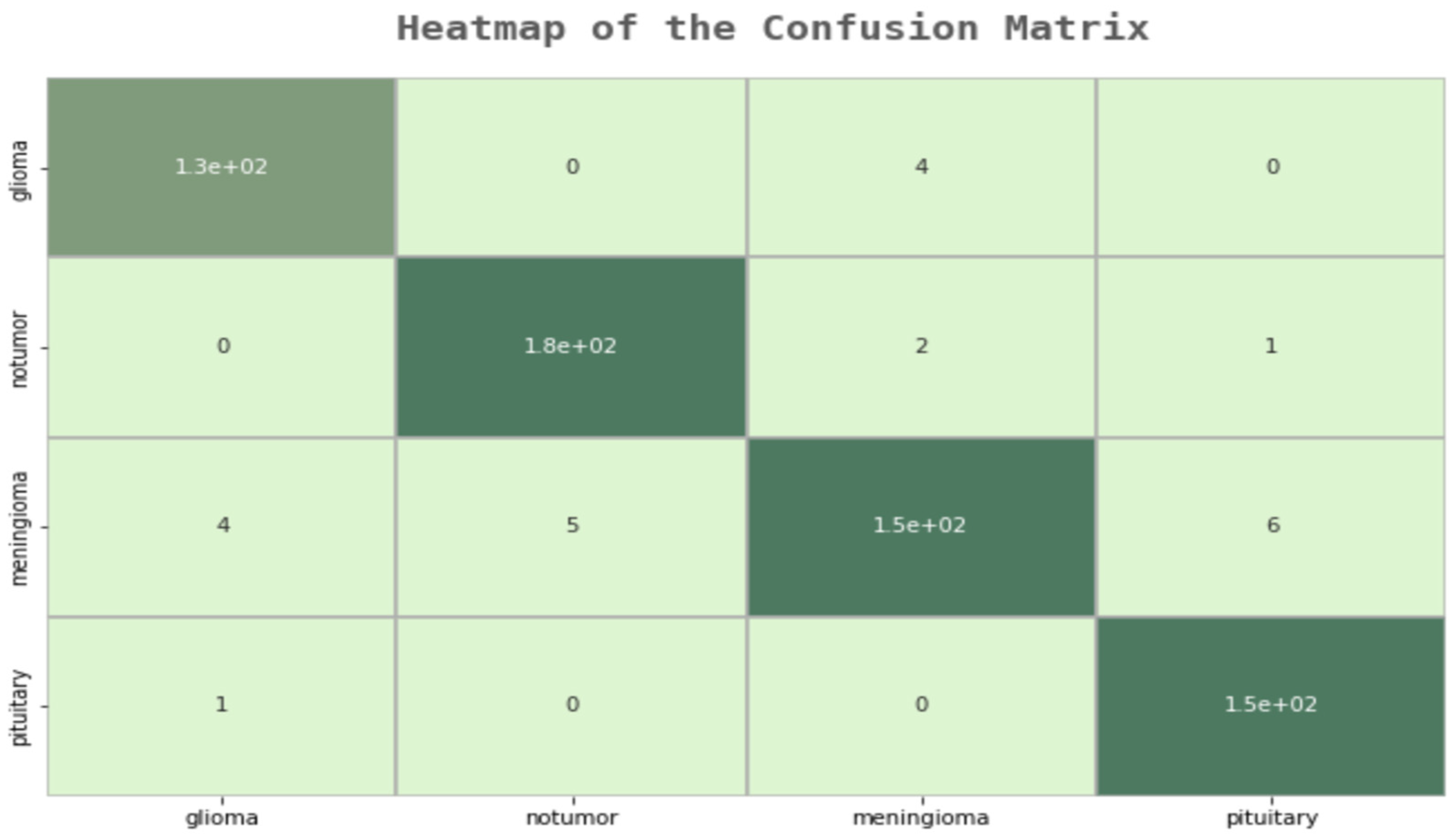
Table 10, a 99% success rate was achieved in the training phase, unlike other models. In the pre-test phase, this rate increased to 95%. In order to test this model and examine in which parts it makes mistakes, an error matrix, followed by a “Sensitivity”, “Precision”, and “F1 Score” table, was created.
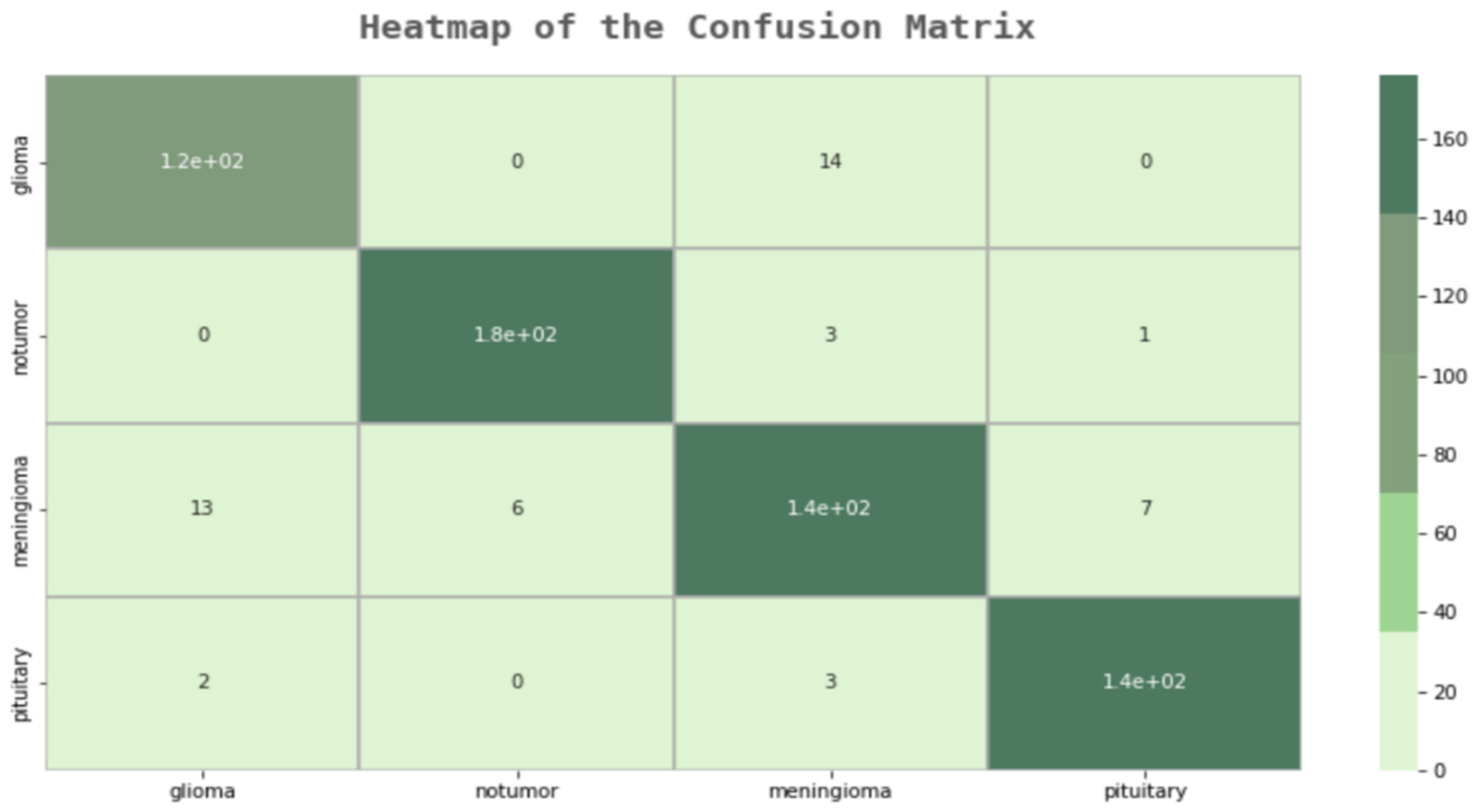
As a result of the examinations on the error matrix, all MR images were correctly classified, except for 23 images in total. A “False Positive”, which is the most important for us, was only made in three images. In the developed model, many of the deficiencies of the other models were eliminated, and the F1 score was examined to check the model’s reliability, as shown in
Figure 6. In
Table 11, additional evaluation metrics are provided for each class. These metrics convey useful information regarding the modified model’ predictive power for each class.
In order to prove this increase and to ensure the reliability of the model, a K-fold cross-validation method was also added, and the results of this method were examined. As a result of the cross-validation process, it has been proven that the model’s work with independent data sets does not reduce its success rate, and it works better than other models.
In the K-fold cross-validation, K was determined as 10. In the first stage, K was determined as five, and the results were examined. After the K-fold application, an increase in the success rate was observed. The reason why five-fold cross-validation was chosen first is to determine how it would affect the operation of the system. Later, due to the increase in the success rate, K was determined as ten and run again. The reason for this was to observe whether there would be an increase in the success rate as a result of 10-fold cross-validation. However, success rates continued to rise between 97 and 95. It was decided to use Google Colab during the operations. This is because the model that is running on Jupyter has been shown to have a very long processing time. The fast transaction service provided via Google Colab was utilized. The comparative results for the brain tumor databases are depicted in
Table 12.
The developed CNN architectural structure showed a higher success than other architectural structures. The classical CNN architectural structure could not reach the desired success rate due to the low number of layers. In the examination of the model, it was observed that there were some deficiencies in feature extraction due to the number of layers, and for this reason, the success rate decreased in some classes.
In the VGG16Net architectural structure, it has been observed how to measure the success rate of pre-trained models and how increasing the number of convolutional layers will affect the success rate. It was concluded that the previously trained models had a low overshoot rate on health data. For this reason, the margin of error is high in the classification stage of such architectural structures.
Finally, the reason for examining the DenseNet architectural structure is to observe how the use of denser layers in the transfer learning method and the collective knowledge transfer will yield results. Although dense layers are more effective than the VGG16Net architectural structure, the error rate was high in some classes due to the transfer learning method.
The conclusion that is understood as a result of these examinations is that the layers should be used intensively and that the training phase should be carried out without using transfer learning methods. For this reason, an intensive CNN model was created in the proposed method, in which 80% of the data was used in the training phase and the model was self-trained without using transfer learning methods.
Table 13 was created to compare and examine the average values of precision, sensitivity, and F1 Scores of all models
Table 14 gives average evaluation metrics (F1 Score, Precision, and Recall) for a comparison of the results having the same dataset as the state-of-the-art studies.
When the table is examined, it can be observed that our research is in close proximity with the studies that reach high accuracy among modern studies. There is also some consistency between all three scales. Detailed interventions that can be carried out in the data preparation and cleaning stages can raise the values a little higher.


 ,
, 







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}