1. Introduction
This paper is concerned with the calculation of mutual information for spike trains using the data that are available in a typical in vivo electrophysiology experiment in the sensory system. It uses a kernel-based estimation of probability distributions.
In particular, this paper is concerned with computing the mutual information, , between two random variables, R and S. The motivating neuroscience example is a typical sensory pathway electrophysiology experiment in which the corpus of sensory stimuli are presented over multiple trials, so there is a set of recorded responses for each of a number of stimuli. The stimuli are drawn from a discrete space, the corpus, but the responses are spike trains. The space of spike trains is peculiar; locally, it is like a smooth manifold, with the spike times behaving like coordinates; but, globally, it is foliated into subspaces, each with a different number of spikes. The space of spike trains does, however, have a metric. As such, S takes values in a discrete set, , and models the stimulus, and R takes values in a metric space, , and models the response.
is not a discrete space, and so, to calculate the mutual information between S and R, it is necessary to either discretize or to use differential mutual information. In the application of information theory to electrophysiological data, it is common to take the former route and discretize the data. Here, the latter alternative is chosen, and the differential mutual information is estimated.
The mutual information between two random variables,
R and
S, is a measure of the average amount of information that is gained about
S from knowing the value of
R. With
S, a discrete random variable taking values in
and
R, a continuous random variable, the mutual information is:
where
is the measure on
: computing the differential mutual information between
R and
S requires integration over
. Integration requires a measure, and when there are coordinates on a space, it is common to use the integration measure derived from these coordinates.
The space of spike trains has no system of coordinates, and so, there is no coordinate-based measure. This does not mean that the space has no measure. As a sample space, it has an intrinsic measure corresponding to the probability distribution; thus, there is a measure, just not one derived from coordinates. The probability of an event occurring in a region of sample space gives a volume for that region. In other words, the volume of a region, , can be identified with . This is the measure that will be used throughout this paper; it does not rely on coordinates, and so, can be applied to the case of interest here.
Of course, in practice, the probability density is not usually known on the space of spike trains, but
can be estimated from the set of experimental data. A Monte-Carlo-like approach is used: the volume of a region is estimated by counting the fraction of data points that lie within it:
This is exploited in this paper to estimate the volume of square kernels, making it possible to estimate conditional probabilities using kernel density estimation.
The classical approach to the problem of estimating
is to map the spike trains to binary words using temporal binning [
1,
2], giving a histogram approximation for
. This approach is very successful, particularly when supplemented with a strategically chosen prior distribution for the underlying probability distribution of words [
3,
4]. This is sometimes called the plug-in method, and that term is adopted here. One advantage of the plug-in method is that the mutual information it calculates is correct in the limit: in the limit of an infinite amount of data and an infinitesimal bin size, it gives the differential mutual information.
Nonetheless, it is interesting to consider other approaches, and in this spirit, an alternate approach is presented here. This new method exploits the inherent metric structure of the space of spike trains, it is very natural and gives an easily implemented algorithm, which is accurate on comparatively small datasets.
2. Methods
This section describes the proposed method for calculating mutual information. Roughly, the conditional probability is approximated using kernel density estimation and, by using the unconditioned probability distribution as a measure, integration is approximated by the Monte-Carlo method of summing over data points.
Since this is a kernel-based approach, a review of kernel density estimation is given in
Section 2.1. This also serves to establish notation. The two key steps used to derive the kernel-based estimate are a change of measure and a Monte-Carlo estimate. The change of measure, described in
Section 2.2, permits the estimation of probabilities by a simple Monte-Carlo method. The new measure also simplifies the calculation of
, resulting in a formula involving a single conditional distribution. This conditional distribution is estimated using a Monte-Carlo estimate in
Section 2.3.
2.1. Kernel Density Estimation
The non-parametric kernel density estimation (KDE) method [
5,
6,
7] is an approach to estimating probability densities. In KDE, a probability density is estimated by filtering the data with a kernel. This kernel is normalized with an integral of one and is usually symmetric and localized. For an
n-dimensional distribution with outcome vectors
and a kernel,
, the estimated distribution is usually written:
where, because the argument is
, there is a copy of the kernel centered at each data point. In fact, this relies on the vector-space structure of
n-dimensional space; in the application considered here, a more general notation is required, with
denoting the value at
of the kernel when it is centered on
. In this situation, the estimate becomes:
The square kernel is a common choice. For a vector space, this is:
where
V is chosen, so that the kernel integrates to one. The kernel is usually scaled to give it a bandwidth:
This bandwidth,
h, specifies the amount of smoothing. The square kernel is the most straight-forward choice of kernel mathematically, and so, in the construction presented here, a square kernel is used.
In the case that will be of interest here, where and are not elements of a vector space, the condition must be replaced by , where is a metric measuring the distance between and . Calculating the normalization factor, V, is more difficult, since this requires integration. This problem is discussed in the next subsection.
2.2. Change of Measure
Calculating the differential mutual information using KDE requires integration, both the integration required by the definition of the mutual information and the integration needed to normalize the kernel. As outlined above, these integrals are estimated using a Monte-Carlo approach; this relies on a change of measure, which is described in this section.
For definiteness, the notation used here is based on the intended application to spike trains. The number of stimuli is , and each stimulus is presented for trials. The total number of responses, , is then . Points in the set of stimuli are called s and in the response space, r; the actual data points are indexed, , and is a response-stimulus pair. As above, the random variables for stimulus and response are S and R, whereas the set of stimuli and the space of responses are denoted by a calligraphic and , respectively. It is intended that when the method is applied, the responses, , will be spike trains.
The goal is to calculate the mutual information between the stimulus and the response. Using the Bayes theorem, this is:
Unlike the differential entropy, the differential mutual information is invariant under the choice of measure. Typically, differential information theory is applied to examples where there are coordinates,
, on the response space and the measure is given by
. However, here, it is intended to use the measure provided by the probability distribution,
. Thus, for a region,
, the change of measure is:
so:
The new probability density relative to the new measure,
, is now one:
Furthermore, since
and
are both densities,
is invariant under a change of measure and:
where, again,
and
are the values of the densities,
and
, after the change of measure.
The expected value of any function,
, of random variables,
R and
S, is:
and this can be estimated on a set of outcomes,
, as:
For the mutual information, this gives:
Now, an estimate for
is needed; this is approximated using KDE.
2.3. A Monte-Carlo Estimate
One advantage to using
as the measure is that
, and this simplifies the expression for
. However, the most significant advantage is that under this new measure, volumes can be estimated by simply counting data points. This is used to normalize the kernel. It is useful to define the support of a function: if
is a function, then the support of
, supp
, is the region of its domain where it has a non-zero value:
Typically, the size of a square kernel is specified by the radius of the support. Here, however, it is specified by volume. In a vector space where the volume measure is derived from the coordinates, there is a simple formula relating radius and volume. That is not the case here, and specifying the size of a kernel by volume is not equivalent to specifying it by radius. Choosing the volume over the radius simplifies subsequent calculations and, also, has the advantage that the size of the kernel is related to the number of data points. This also means that the radius of the kernel varies across
.
The term, bandwidth, will be used to describe the size of the kernel, even though here, the bandwidth is a volume, rather than a radius. Since
is a probability measure, all volumes are between zero and one. Let
h be a bandwidth in this range. If
is the value at
of a square kernel with bandwidth
h centered on
r, the support will be denoted as
:
and the volume of the support of the kernel is vol
. The value of the integral is set at one:
and so, since the square kernel is being used,
has a constant value of
throughout
.
Thus, volumes are calculated using the measure,
, based on the probability density. However, this density is unknown, and so, volumes need to be estimated. As described above, using
, the volume of a region is estimated by the fraction of data points that lie within it. In other words, the change of measure leads to a Monte-Carlo approach to calculating the volume of any region. In the Monte-Carlo calculation, the volume of the support of a kernel is estimated as the fraction of data points that lie within it. A choice of convention has to be made between defining the kernel as containing
or
points, that is, on whether to round
down or up. The former choice is used, so, the kernel around a point,
r, is estimated as the region containing the nearest
points to
r, including
r itself. Thus, the kernel around a point,
, is defined as:
and the support,
, has
if
, or, put another way,
is one of the
nearest data points. In practice, rather than rounding
up or down, the kernel volume in a particular example can be specified using
rather than
h.
Typically, kernels are balls: regions defined by a constant radius. As such, the kernel described here makes an implicit assumption about the isotropic distribution of the data points. However, in the normal application of KDE, special provision must be made near boundaries, where the distribution of data points is not isotropic [
8]. Here, these cases are dealt with automatically.
Since
, here, the conditional distribution,
, is estimated by first estimating
. As described above, a kernel has a fixed volume relative to the measure based on
. Here, the kernel is being used to estimate
:
where
is the number of data points evoked to stimulus
for which
is one of the
closest points:
This gives the estimated mutual information:
Remarkably, although this is a KDE estimator, it resembles a
k-, or, here,
-, nearest-neighbors estimator. Basing KDE on the data available for spike trains appears to lead naturally to nearest neighbor estimation.
The formula for
behaves well in the extreme cases. If the responses to each stimulus are close to each other, but distant from responses to all other stimuli, then
for all stimulus-response pairs
. That is, for each data point, all nearby data points are from the same stimulus. This means that the estimate will be:
This is the correct value, because, in this case, the response completely determines the stimulus, and so, the mutual information is exactly the entropy of the stimulus. On the other hand, if the responses to each stimulus have the same distribution, then
, so the estimated mutual information will be close to zero. This is again the correct value, because in this case, the response is independent of the stimulus.
3. Results
As a test, this method has been applied to a toy dataset modelled on the behavior of real spike trains. It is important that the method is applied to toy data that resemble the data type, electrophysiological data, on which the method is intended to perform well. As such, the toy model is selected to mimic the behavior of sets of spike trains. The formula derived above acts on the matrix of inter-data-point distances, rather than the points themselves, and so, the dataset is designed to match the distance distribution observed in real spike trains [
9]. The test dataset is also designed to present a stiff challenge to any algorithm for estimating information.
The toy data are produced by varying the components of one of a set of source vectors. More precisely, to produce a test dataset, a variance,
, is chosen uniformly from
, and
sources are chosen uniformly in a
-dimensional box centered at the origin with unit sides parallel to the Cartesian axes. Thus, the sources are all
-dimensional vectors. The data points are also
-dimensional vectors; they are generated by drawing each component from a normal distribution about the corresponding component of the source. Thus, data points with a source
are chosen as
, where the
are all drawn from normal distributions with variance
centered at the corresponding
:
data points are chosen for each source, giving
data points in all.
Each test uses 200 different datasets; random pruning is used to ensure that the values of mutual information are evenly distributed over the whole range from zero to
; otherwise, there tends to be an excess of datasets with a low value. The true mutual information is calculated using a Monte-Carlo estimate sampled over 10,000 points. The actual probability distributions are known: the probability of finding a point
generated by a source,
, depends only on the distance
and is given by the
χ-distribution:
There is a bias in estimating the mutual information, in fact, bias is common to any approach to estimating mutual information [
10]. The problem of reducing bias, or defining the mutual information, so that the amount of bias is low, is well studied and has produced a number of sophisticated approaches [
4,
10,
11,
12,
13,
14]. One of these, quadratic estimation, thanks to [
11,
13], is adapted to the current situation. Basically, it is assumed that for large numbers of data points,
, the estimated information,
, is related to the true mutual information
by:
This asymptotic expansion is well-motivated in the case of the plug-in approach to spike train information [
10,
11,
15,
16,
17], and since the sources of bias are presumably similar, it is assumed the same expansion applies. In fact, this assumption is supported by plots of
against
. To extract
, the estimate,
, is calculated for
with
λ taking values from 0.1 to one in 0.1 increments. Least squares fit is used to estimate
from these ten values.
The new method works well on these toy data. It is compared to a histogram approach, where the -dimensional space is discretized into bins and counting is used to estimate the probability of each bin. This is an analog of the plug-in method, and the same quadratic estimation technique is used to reduce bias.
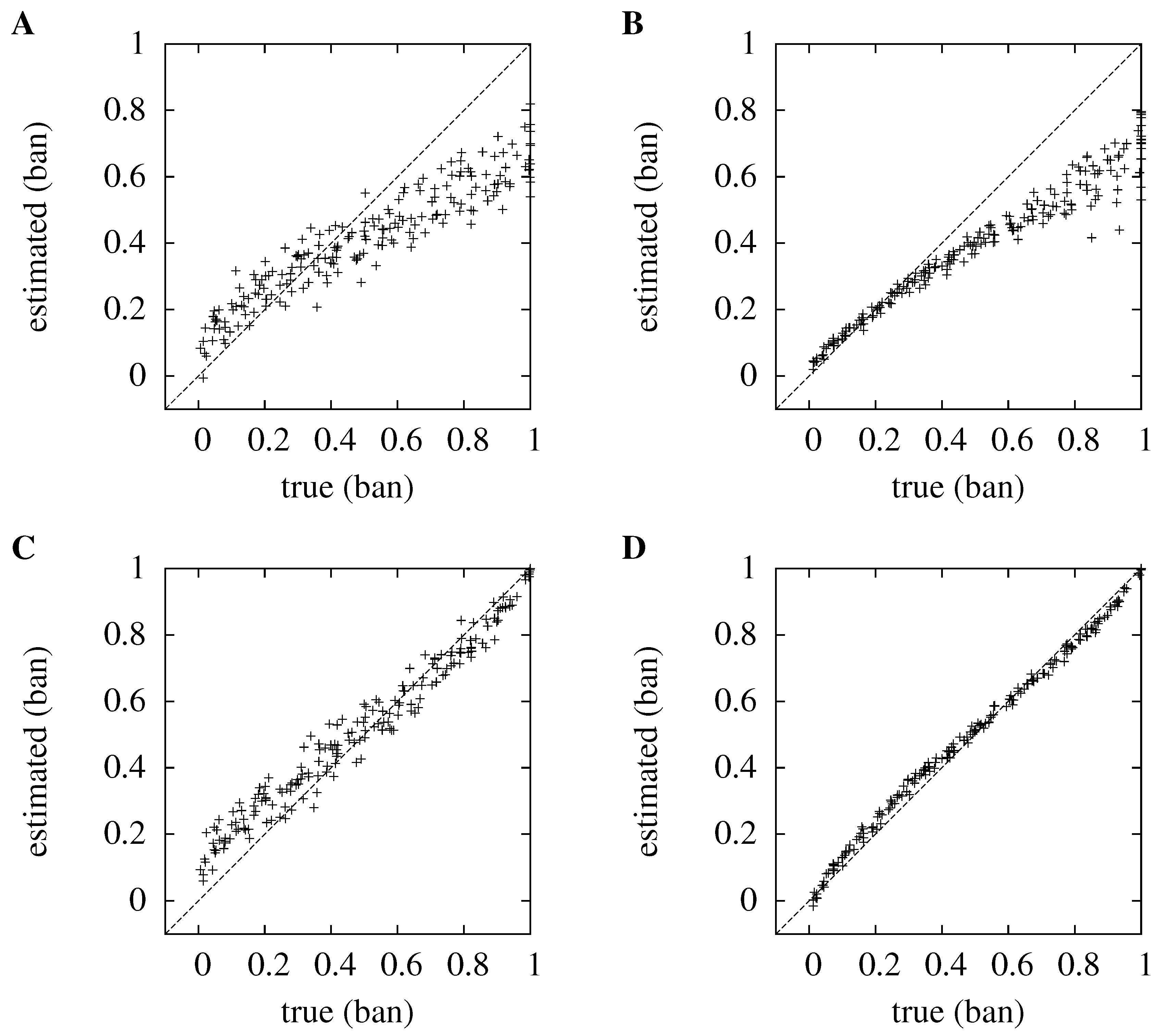
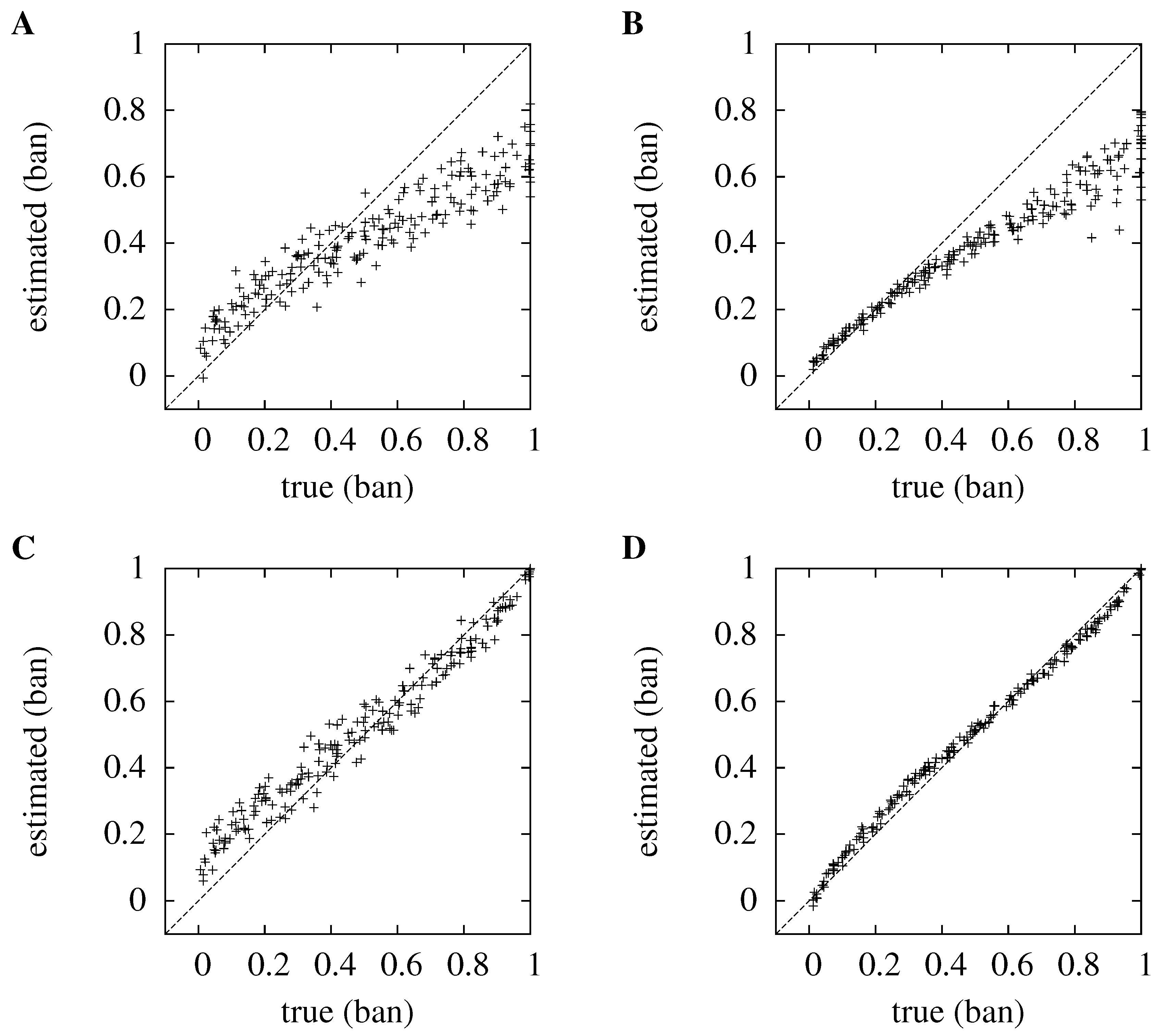
Figure 1.
Comparing kernel density estimation (KDE) to the histogram method for ten sources, , and three dimensions, . In each case, the true information is plotted against the estimated information; the line, , which represents perfect estimation, is plotted for clarity. For convenience, the mutual information has been normalized, so in each case, the value plotted is the estimate of , with a maximum value of one; in the cases plotted here, that means the information is measured in ban. (A) and (B) show the distribution for the histogram method for and ; (C) and (D) show the kernel method.
Figure 1.
Comparing kernel density estimation (KDE) to the histogram method for ten sources, , and three dimensions, . In each case, the true information is plotted against the estimated information; the line, , which represents perfect estimation, is plotted for clarity. For convenience, the mutual information has been normalized, so in each case, the value plotted is the estimate of , with a maximum value of one; in the cases plotted here, that means the information is measured in ban. (A) and (B) show the distribution for the histogram method for and ; (C) and (D) show the kernel method.
In
Figure 1, the new method is compared to the histogram method when
and
, and for both low and high numbers of trials,
and
. For the histogram method, the optimum discretization width is used. This optimal width is large,
in each case; this roughly corresponds to a different bin for each octant of the three-dimensional space containing the data. In the new method, the bandwidth is not optimized on a case by case basis; instead, the kernel bandwidth,
, is chosen as being equal to the number of trials,
. It can be seen that the new method is better at estimating the information: for
, it has an average absolute error of
bits, compared to
bits for the histogram method; for
, the average absolute error is
bits, compared to
bits for the histogram approach.
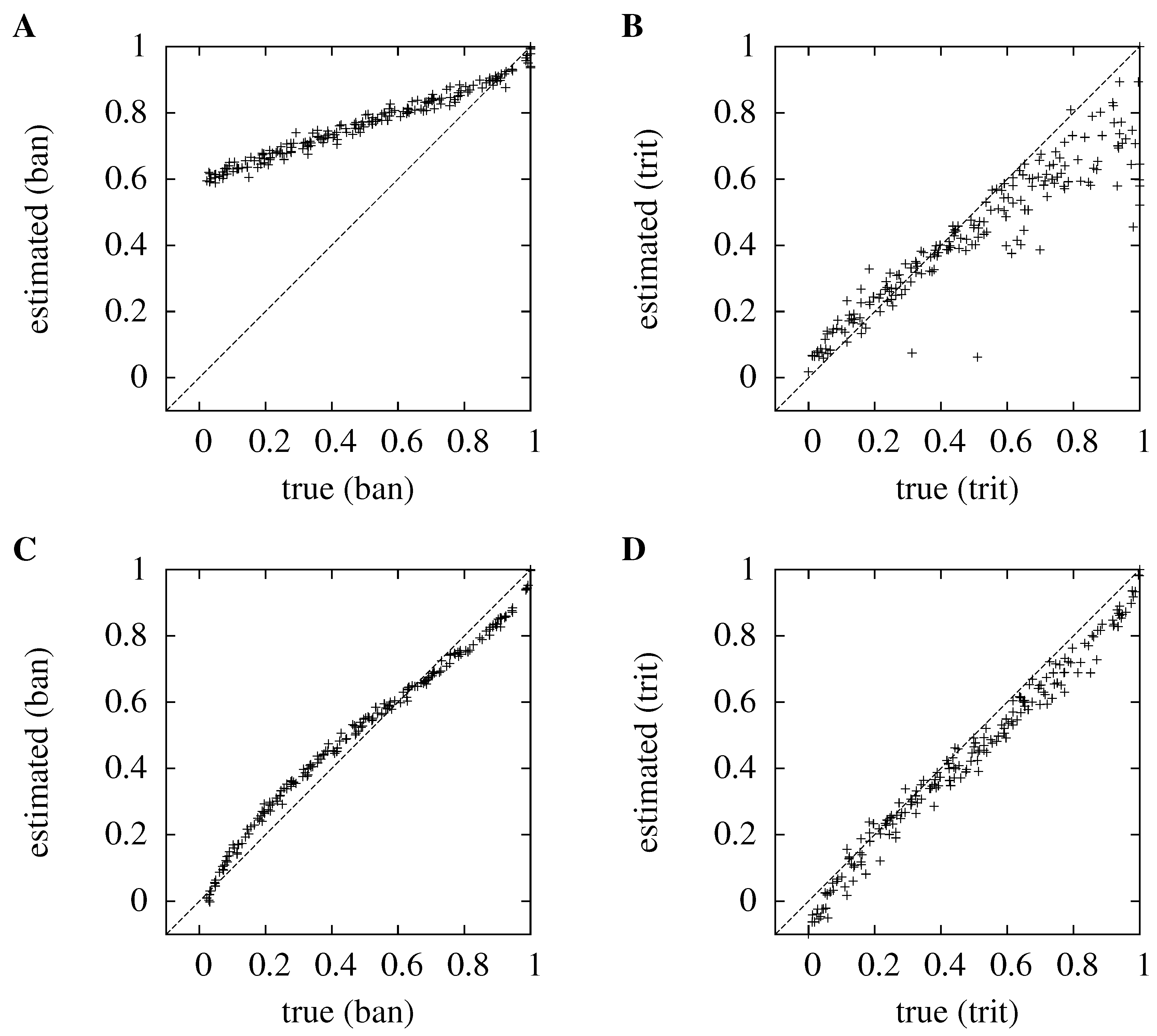
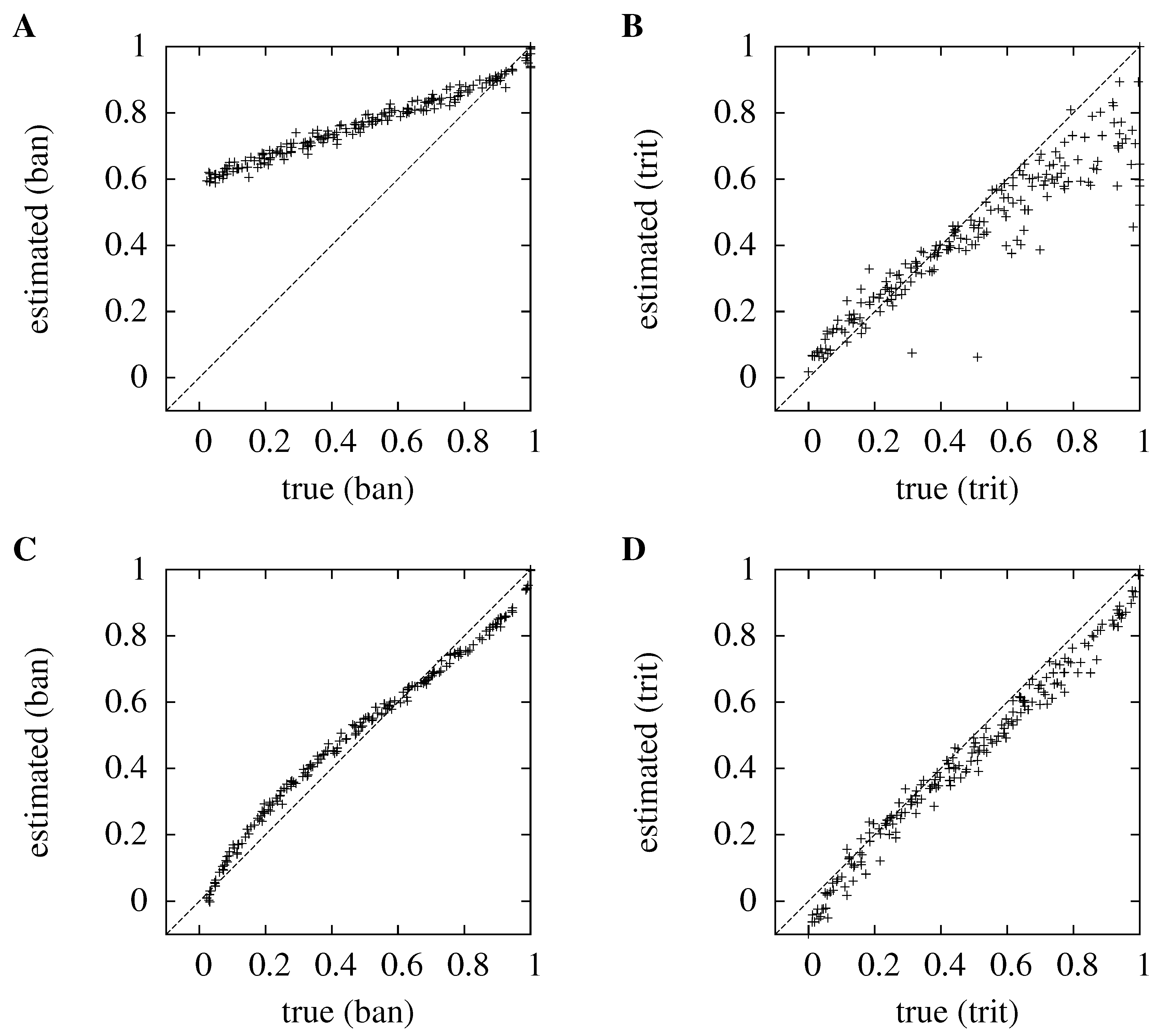
Figure 2.
Comparing the KDE to the histogram method for high and low numbers of sources and dimensions. The true information is plotted against the estimated information; in (A) and (C), and ; in (B) and (D), and . The top row, (A) and (B), is for the histogram method, the bottom row, (C) and (D), is for the kernel method. As before, the normalized information, , is plotted. So, for , the information is in ban, for , in trit, and in each case, the maximum mutual information is one. for all graphs.
Figure 2.
Comparing the KDE to the histogram method for high and low numbers of sources and dimensions. The true information is plotted against the estimated information; in (A) and (C), and ; in (B) and (D), and . The top row, (A) and (B), is for the histogram method, the bottom row, (C) and (D), is for the kernel method. As before, the normalized information, , is plotted. So, for , the information is in ban, for , in trit, and in each case, the maximum mutual information is one. for all graphs.
In
Figure 2, the histogram and kernel methods are compared for
and
and for
and
; the number of trials is
in each case. The kernel method outperforms the histogram method. When
and
, the average absolute error for the kernel method is 0.139 bits, compared to 0.876 bits for the histogram method; for
and
, its average absolute error is 0.076 bits compared to 0.141 bits for the histogram. Furthermore, the errors for the kernel method are less clearly modulated by the actual information, which makes the method less prone to producing misleading results.
4. Discussion
Although the actual method presented here is very different, it was inspired in part by the transmitted information method for calculating mutual information using metric-based clustering described in [
18] and by the novel approach introduced in [
19], where a kernel-like approach to mutual information is developed. Another significant motivation was the interesting technique given in [
20], where the information is estimated by measuring how large a sphere could be placed around each data point without it touching another data point. In [
20], the actual volume of the sphere is required, or, rather, the rate the volume changes with diameter. This is calculated by foliating the space of spike trains into subspaces with a fixed spike number and interpreting the spike times as coordinates. This is avoided here by using the Monte-Carlo estimate of volumes. Finally, the copula construction is related to the approach described here. In fact, the construction here can be thought of as a reverse copula construction [
21].
An important part of the derivation of the kernel method is the change of measure to one based on the distribution. Since the kernel size is defined using a volume based on this measure, the radius of the kernel adapts to the density of data points. This is similar to the adaptive partitioning described, for example, in [
22]. Like the plug-in method of computing mutual information for spike trains, adaptive partitioning is a discretization approach. However, rather than breaking the space into regions of fixed width, the discrete regions are chosen dynamically, using estimates of the cumulative distribution, similar to what is proposed here.
One striking aspect of KDE seen here is that it reduces to a
kth nearest-neighbor (kNN) estimator. The kNN approach to estimating the mutual information of variables lying in metric spaces has been studied directly in [
23]. Rather than using a KDE of the probability distribution, a Kozachenko-Leonenko estimator [
24] is used. To estimate
, where
X and
Y are both continuous random variables taking values in
and
, Kozachenko-Leonenko estimates are calculated for
,
and
; by using different values of
k in each space, the terms that would otherwise depend on the dimension of
and
cancel.
This approach can be modified to estimate
, where
S is a discrete random variable. Using the approach described in [
23] to estimate
and
gives:
where
is the digamma function,
is an integer parameter and
is similar to
above. Whereas
counts the number of responses to
for which
is one of the
closest data points,
is computed by first finding the distance,
d, from
to the
th nearest spike-train response to stimulus
; then,
counts the number of spike trains, from any stimulus, that is at most a distance of
d from
.
is the mutual information with base
e, so
. During the derivation of this formula, expressions involving the dimension of
appear, but ultimately, they all cancel, leaving an estimate which can be applied in the case of interest here, where
has no dimension. Since the digamma function can be approximated as:
for large
x, this kNN approach and the kernel method produce very similar estimates. The similarity between the two formulas, despite the different routes taken to them, lends credibility to both estimators.
Other versions of the kernel method can be envisaged. A kernel with a different shape could be used or the kernel could be defined by the radius rather than by the volume of the support. The volume of the support and, therefore, the normalization would then vary from data point to data point. This volume could be estimated by counting, as it was here. However, as mentioned above, the volume-based bandwidth has the advantage that it gives a kernel that is adaptive: the radius varies as the density of data points changes. Another intriguing possibility is to investigate if it would be possible to follow [
20] and [
23] more closely than has been done here and use a Monte-Carlo volume estimate to derive a Kozachenko and Leonenko estimator. Finally, KDE applied to two continuous random variables could be used to derive an estimate for the mutual information between two sets of spike trains or between a set of spike trains and a non-discrete stimulus, such as position in a maze.
There is no general, principled approach to choosing bandwidths for KDE methods. There are heuristic methods, such as cross-validation [
25,
26], but these include implicit assumptions about how the distribution of the data is itself drawn from a family of distributions, assumptions that may not apply to a particular experimental situation. The KDE approach developed here includes a term analogous to bandwidth, and although a simple choice of this bandwidth is suggested and gives accurate estimates, the problem of optimal bandwidth selection will require further study.
Applying the KDE approach to spike trains means it is necessary to specify a spike train metric [
18,
27,
28]. Although the metric is only used to arrange points in the order of proximity, the dependence on a metric does mean that the estimated mutual information will only include mutual information encoded in features of the spike train that affect the metric. As described in [
20], in the context of another metric-dependent estimator of mutual information, this means the mutual information may underestimate the true mutual information, but it does allow the coding structure of spike trains to be probed by manipulating the spike train metrics.
It is becoming increasingly possible to measure large number spike trains from large numbers of spike trains simultaneously. There are metrics for measuring distances between sets of multi-neuron responses [
29,
30,
31], and so, the approach described here can also be applied to multi-neuronal data.

{kind=link}
{kind=link}