Estimation Bias in Maximum Entropy Models

1
Gatsby Computational Neuroscience Unit, UCL, London WC1N 3AR, UK
2
Max Planck Institute for Biological Cybernetics, Bernstein Center for Computational Neuroscience and Werner Reichardt Centre for Integrative Neuroscience, 72076 Tübingen, Germany
3
School for Informatics, University of Edinburgh, Edinburgh EH8 9AB, UK
*
Author to whom correspondence should be addressed.
Entropy 2013, 15(8), 3109-3129; https://doi.org/10.3390/e15083109
Submission received: 25 June 2013
/
Revised: 25 July 2013
/
Accepted: 29 July 2013
/
Published: 2 August 2013
(This article belongs to the Special Issue Estimating Information-Theoretic Quantities from Data)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:Maximum entropy models have become popular statistical models in neuroscience and other areas in biology and can be useful tools for obtaining estimates of mutual information in biological systems. However, maximum entropy models fit to small data sets can be subject to sampling bias; i.e., the true entropy of the data can be severely underestimated. Here, we study the sampling properties of estimates of the entropy obtained from maximum entropy models. We focus on pairwise binary models, which are used extensively to model neural population activity. We show that if the data is well described by a pairwise model, the bias is equal to the number of parameters divided by twice the number of observations. If, however, the higher order correlations in the data deviate from those predicted by the model, the bias can be larger. Using a phenomenological model of neural population recordings, we find that this additional bias is highest for small firing probabilities, strong correlations and large population sizes—for the parameters we tested, a factor of about four higher. We derive guidelines for how long a neurophysiological experiment needs to be in order to ensure that the bias is less than a specified criterion. Finally, we show how a modified plug-in estimate of the entropy can be used for bias correction.
1. Introduction
Understanding how neural populations encode information about external stimuli is one of the central problems in computational neuroscience [1,2]. Information theory [3,4] has played a major role in our effort to address this problem, but its usefulness is limited by the fact that the information-theoretic quantity of interest, mutual information (usually between stimuli and neuronal responses), is hard to compute from data [5]. That is because the key ingredient of mutual information is the entropy, and estimation of entropy from finite data suffers from a severe downward bias when the data is undersampled [6,7]. While a number of improved estimators have been developed (see [5,8] for an overview), the amount of data one needs is, ultimately, exponential in the number of neurons, so even modest populations (tens of neurons) are out of reach—this is the so-called curse of dimensionality. Consequently, although information theory has led to a relatively deep understanding of neural coding in single neurons [2], it has told us far less about populations [9,10]. In essence, the brute force approach to measuring mutual information that has worked so well on single spike trains simply does not work on populations.
One way around this problem is to use parametric models in which the number of parameters grows (relatively) slowly with the number of neurons [11,12]; and, indeed, parametric models have been used to bound entropy [13]. For such models, estimating entropy requires far less data than for brute force methods. However, the amount of data required is still nontrivial, leading to bias in naive estimators of entropy. Even small biases can result in large inaccuracies when estimating entropy differences, as is necessary for computing mutual information or comparing maximum entropy models of different orders (e.g., independent versus pairwise). Additionally, when one is interested only in the total entropy (a quantity that is useful, because it provides an upper bound on the coding capacity [1]), bias can be an issue. That’s because, as we will see below, the bias typically scales at least quadratically with the number of neurons. Since entropy generally scales linearly, the quadratic contribution associated with the bias eventually swamps the linear contribution, yielding results that tell one far more about the amount of data than the entropy.
Here, we estimate the bias for a popular class of parametric models, maximum entropy models. We show that if the true distribution of the data lies in the model class (that is, it comes from the maximum entropy model that is used to fit the data), then the bias can be found analytically, at least in the limit of a large number of samples. In this case, the bias is equal to the number of parameters divided by twice the number of observations. When the true distribution is outside the model class, the bias can be larger.
To illustrate these points, we consider the Ising model [14], which is the second-order (or pairwise) maximum entropy distribution on binary data. This model has been used extensively in a wide range of applications, including recordings in the retina [15,16,17], cortical slices [18] and anesthetized animals [19,20]. In addition, several recent studies [13,21,22] have used numerical simulations of large Ising models to understand the scaling of the entropy of the model with population size. Ising models have also been used in other fields of biology; for example, to model gene regulation networks [23,24] and protein folding [25].
We show that if the data is within the model class (i.e., the data is well described by an Ising model), the bias grows quadratically with the number of neurons. To study bias out of model class, we use a phenomenological model of neural population activity, the Dichotomized Gaussian [26,27,28]. This model has higher-order correlations which deviate from those of an Ising model, and the structure of those deviations has been shown to be in good agreement with those found in cortical recordings [27,29]. These higher order correlations do affect bias—they can increase it by as much as a factor of four. We provide worst-case estimates of the bias, as well as an effective numerical technique for reducing it.
Non-parametric estimation of entropy is a well studied subject, and a number of very sophisticated estimators have been proposed [5,30,31]. In addition, several studies have looked at bias in the estimation of entropy for parametric models. However, those studies focused on Gaussian distributions and considered only the within model class case (that is, they assumed that the data really did come from a Gaussian distribution) [32,33,34,35]. To our knowledge, the entropy bias of maximum entropy models when the data is out of model class has not be studied.
2. Results
2.1. Bias in Maximum Entropy Models
Our starting point is a fairly standard one in statistical modeling: having drawn K samples of some variable, here denoted, , from an unknown distribution, we would like to construct an estimate of the distribution that is somehow consistent with those samples. To do that, we use the so-called maximum entropy approach: we compute, based on the samples, empirical averages over a set of functions and construct a distribution that exactly matches those averages, but otherwise has maximum entropy.
Let us use to denote the set of functions and to denote their empirical averages. Assuming we draw K samples, these averages are given by:
where is the sample. Given the , we would like to construct a distribution that is constrained to have the same averages as in Equation (1) and also has maximum entropy. Using to denote this distribution (with ), the former condition implies that:
The entropy of this distribution, denoted , is given by the usual expression:
where log denotes the natural logarithm. Maximizing the entropy with respect to subject to the constraints given in Equation (2) yields (see, e.g., [4]):
The (the Lagrange multipliers of the optimization problem) are chosen, such that the constraints in Equation (2) are satisfied, and , the partition function, ensures that the probabilities normalize to one:
Given the , the expression for the entropy of is found by inserting Equation (4) into Equation (3). The resulting expression:
depends only on , either directly or via the functions, .
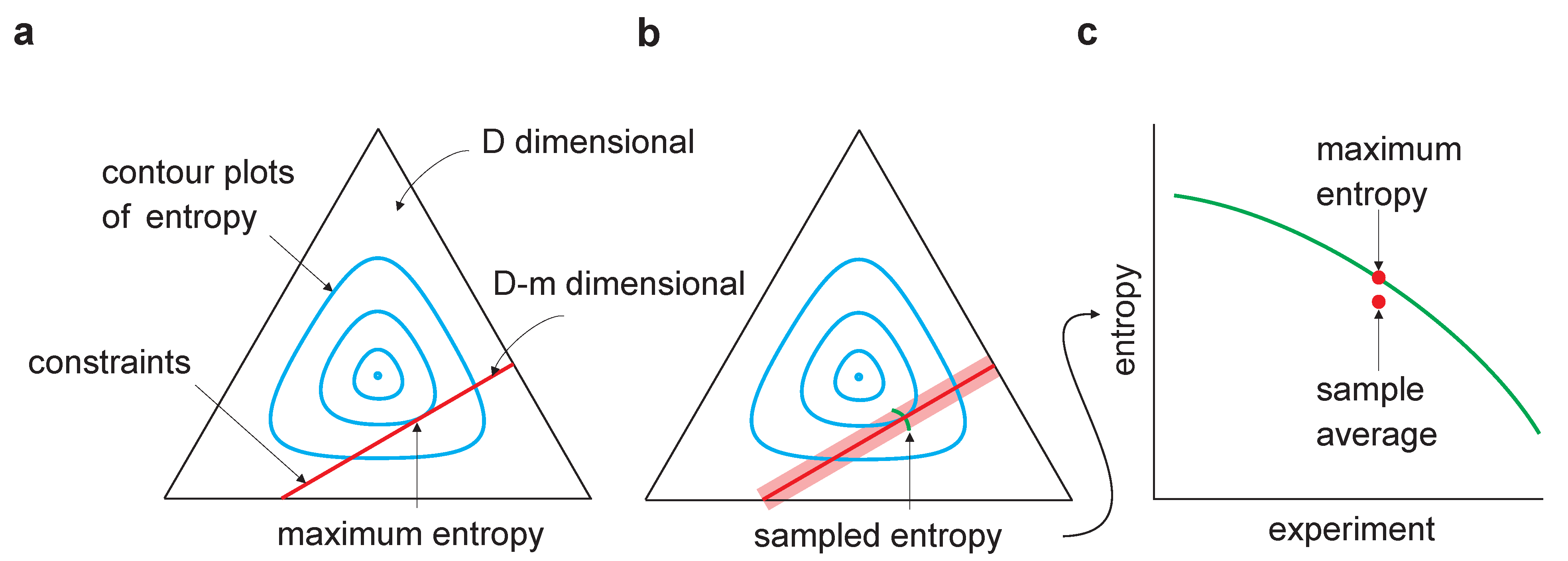
Because of sampling error, the are not equal to their true values, and is not equal to the true maximum entropy. Consequently, different sets of lead to different entropies and, because the entropy is concave, to bias (see Figure 1). Our focus here is on the bias. To determine it, we need to compute the true parameters. Those parameters, which we denote , are given by the limit of Equation (1); alternatively, we can think of them as coming from the true distribution, denoted :
Associated with the true parameters is the true maximum entropy, . The bias is the difference between the average value of and ; that is, the bias is equal to , where the angle brackets indicate an ensemble average—an average over an infinite number of data sets (with, of course, each data set containing K samples). Assuming that is close to μ, we can Taylor expand the bias around the true parameters, leading to:
where:
Because is zero on average [see Equation (7) and Equation (9)], the first term on the right-hand side of Equation (8) is zero. The second term is, therefore, the lowest order contribution to the bias, and it is what we work with here. For convenience, we multiply the second term by , which gives us the normalized bias:
In the Methods, we explicitly compute b, and we find that:
where:
and:
Here, denotes the entry of . Because and are both covariance matrices, it follows that b is positive.
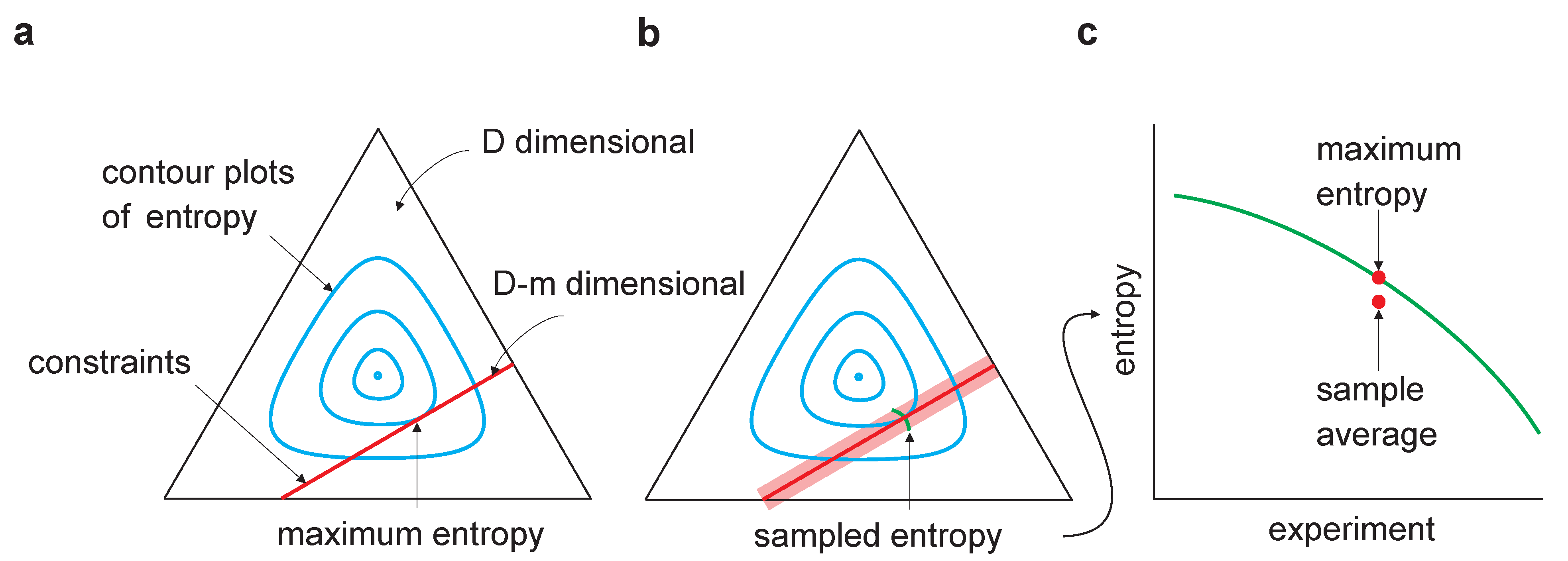
Figure 1.
Sampling bias in maximum entropy models. The equilateral triangle represents a D-dimensional probability space (for the binary model considered here, , where n is the dimensionality of ). The cyan lines are contour plots of entropy; the red lines represent the m linear constraints and, thus, lie in a dimensional linear manifold. (a) Maximum entropy occurs at the tangential intersection of the constraints with the entropy contours. (b) The light red region indicates the range of constraints arising from multiple experiments in which a finite number of samples is drawn in each. Maximum entropy estimates from multiple experiments would lie along the green line. (c) As the entropy is concave, averaging the maximum entropy over experiments leads to an estimate that is lower than the true maximum entropy—estimating maximum entropy is subject to downward bias.
Figure 1.
Sampling bias in maximum entropy models. The equilateral triangle represents a D-dimensional probability space (for the binary model considered here, , where n is the dimensionality of ). The cyan lines are contour plots of entropy; the red lines represent the m linear constraints and, thus, lie in a dimensional linear manifold. (a) Maximum entropy occurs at the tangential intersection of the constraints with the entropy contours. (b) The light red region indicates the range of constraints arising from multiple experiments in which a finite number of samples is drawn in each. Maximum entropy estimates from multiple experiments would lie along the green line. (c) As the entropy is concave, averaging the maximum entropy over experiments leads to an estimate that is lower than the true maximum entropy—estimating maximum entropy is subject to downward bias.
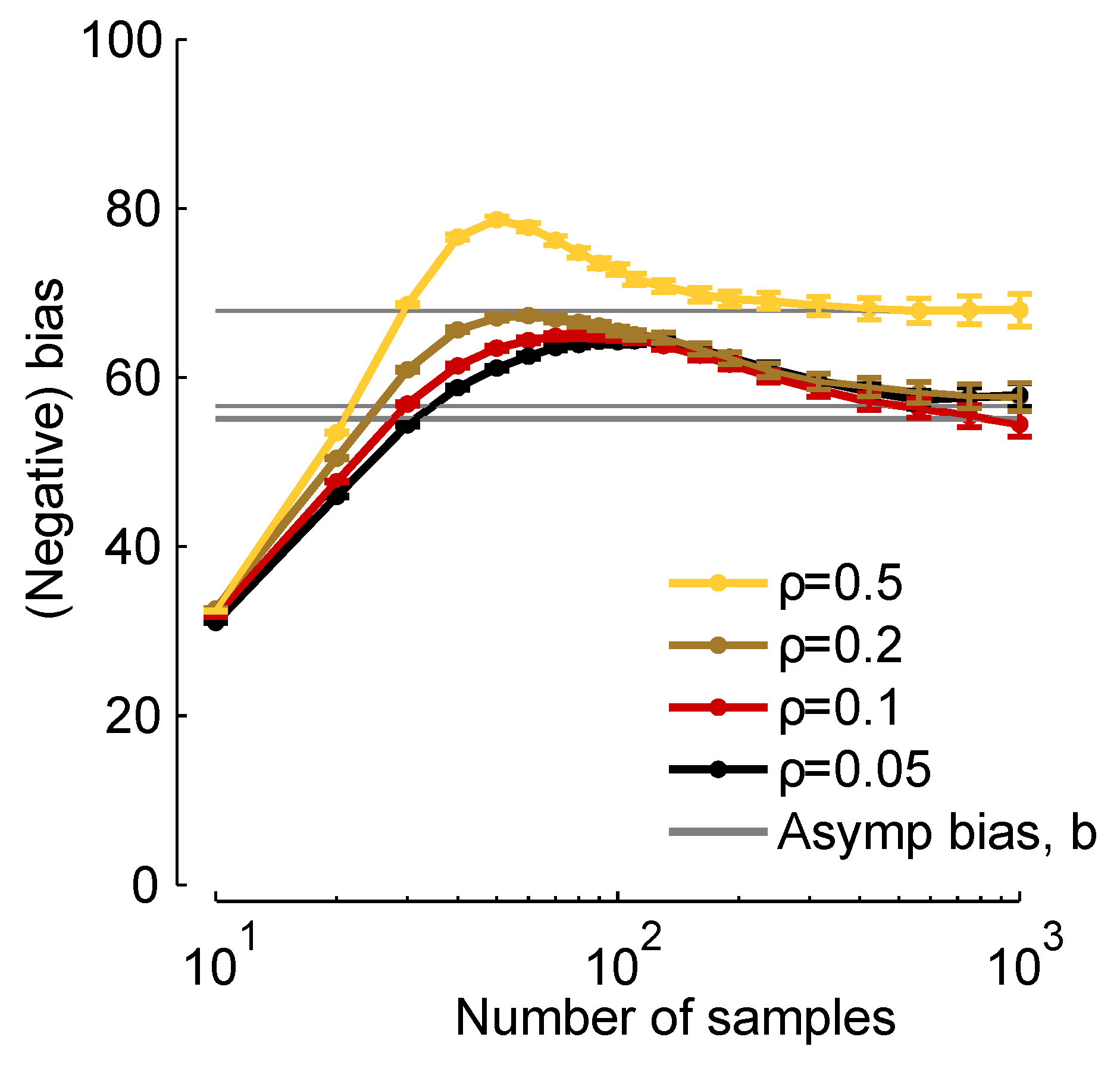
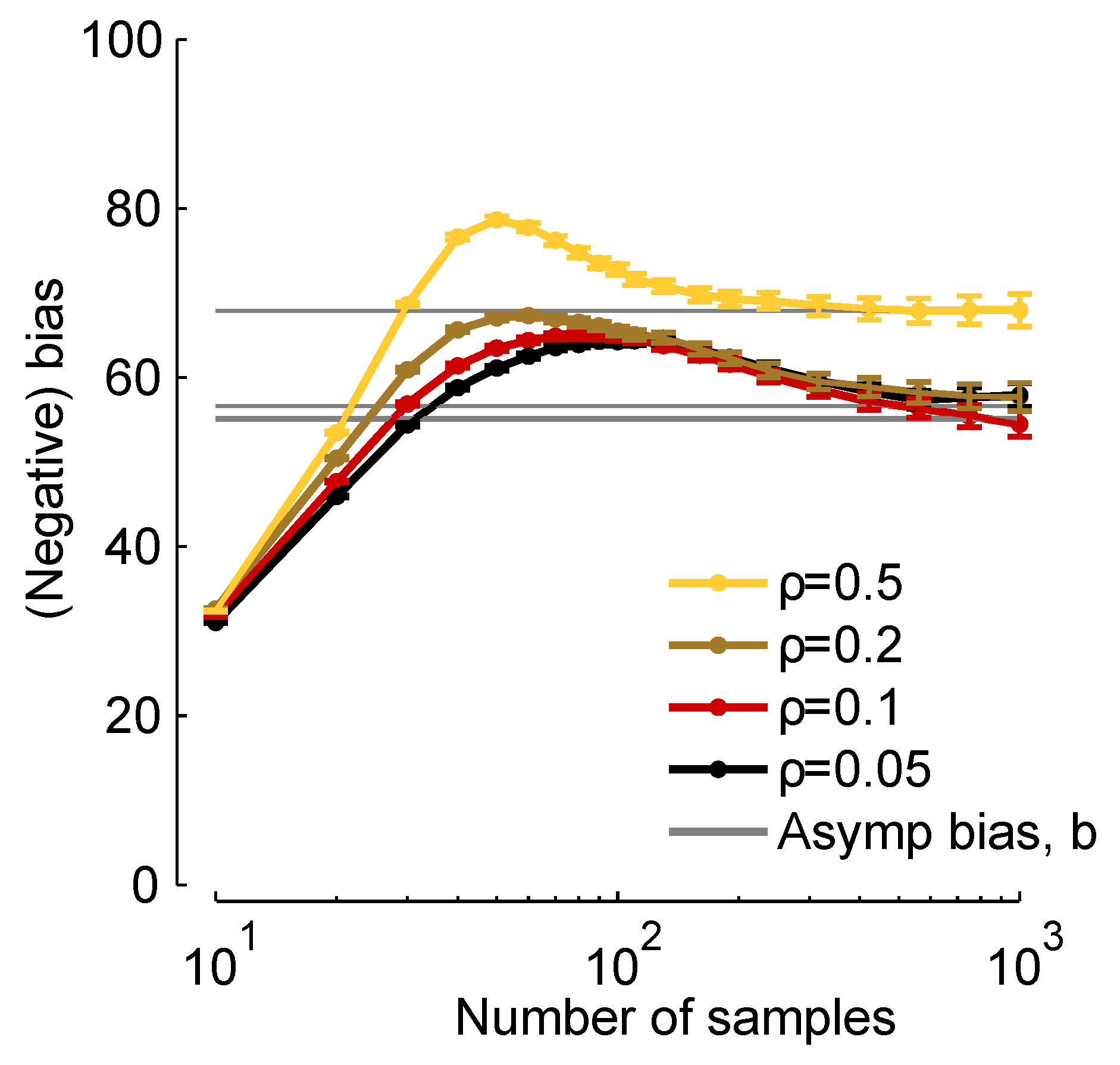
In Figure 2, we plot times the true bias ( times the left-hand side of Equation (8), which we compute from finite samples), and b [via Equation (11)] versus the number of samples, K. When K is about 30, the two are close, and when , they are virtually indistinguishable. Thus, although Equation (11) represents an approximation to the bias, it is a very good approximation for realistic data sets.
Figure 2.
Normalized bias, b, versus number of samples, . Grey lines: , computed from Equation (11). Colored curves: times the bias, computed numerically using the expression on the left-hand side of Equation (8). We used a homogeneous Dichotomized Gaussian distribution with and a mean of 0.1. Different curves correspond to different correlation coefficients [see Equation (19) below], as indicated in the legend.
Figure 2.
Normalized bias, b, versus number of samples, . Grey lines: , computed from Equation (11). Colored curves: times the bias, computed numerically using the expression on the left-hand side of Equation (8). We used a homogeneous Dichotomized Gaussian distribution with and a mean of 0.1. Different curves correspond to different correlation coefficients [see Equation (19) below], as indicated in the legend.
Evaluating the bias is, typically, hard. However, when the true distribution lies in the model class, so that , we can write down an explicit expression for it. That is because, in this case, , so the normalized bias [Equation (11)] is just the trace of the identity matrix, and we have (recall that m is the number of constraints); alternatively, the actual bias is . An important within model-class case arises when the parametrized model is a histogram of the data. If can take on M values, then there are parameters (the “” comes from the fact that must sum to one) and the bias is . We thus recover a general version of the Miller-Madow [6] or Panzeri-Treves bias correction [7], which were derived for a multinomial distribution.
2.2. Is Bias Correction Important?
The fact that the bias falls off as means that we can correct for it simply by drawing a large number of samples. However, how large is “large”? For definitiveness, suppose we want to draw enough samples that the absolute value of the bias is less than ϵ times the true entropy, denoted . Quantitatively, this means we want to choose K, so that . Using Equation (10) to relate the true bias to b, assuming that K is large enough that provides a good approximation to the true bias, and making use of the fact that b is positive, the condition implies that K must be greater than , where is given by:
Let us take to be a vector with n components: ). The average entropy of the components, denoted , is given by , where is the true entropy of . Since , the “independent” entropy of , is greater than or equal to the true entropy, , it follows that obeys the inequality:
Not surprisingly, the minimum number of samples scales with the number of constraints, m (assuming does not have a strong m-dependence; something we show below). Often, m is at least quadratic in n; in that case, the minimum number of samples increases with the dimensionality of .
To obtain an explicit expression for m in terms of n, we consider a common class of maximum entropy models: second order models on binary variables. For these models, the functions constrain the mean and covariance of the , so there are parameters: n parameters for the mean and for the covariance (because the are binary, the variances are functions of the means, which is why there are parameters for the covariances rather than ). Consequently, and, dropping the “” (which makes the inequality stronger), we have:
How big is in practice? To answer that, we need estimates of and . Let us focus first on . For definiteness, here (and throughout the paper), we consider maximum entropy models that describe neural spike trains [15,16]. In that case, is one if there are one or more spikes in a time bin of size and zero, otherwise. Assuming a population average firing rate of , and using the fact that entropy is concave, we have , where is the entropy of a Bernoulli variable with probability p: . Using also the fact that , we see that , and so:
Exactly how to interpret depends on whether we are interested in the total entropy or the conditional entropy. For the total entropy, every data point is a sample, so the number of samples in an experiment that runs for time T is . The minimum time to run an experiment, denoted , is, then, given by:
Ignoring for the moment the factor and the logarithmic term, the minimum experimental time scales as . If one is willing to tolerate a bias of 10% of the true maximum entropy () and the mean firing rate is not so low (say 10 Hz), then s. Unless n is in the hundreds of thousands, running experiments long enough to ensure an acceptably small bias is relatively easy. However, if the tolerance and firing rates drop, say to and Hz, respectively, then s, and experimental times are reasonable until n gets into the thousands. Such population sizes are not feasible with current technology, but they are likely to be in the not so distant future.
The situation is less favorable if one is interested in the mutual information. That is because to compute the mutual information, it is necessary to repeat the stimulus multiple times. Consequently, [Equation (17)] is the number of repeats, with the repeats typically lasting 1–10 s. Again, ignoring the factor and the logarithmic term, assuming, as above, that and the mean firing rate is 10 Hz and taking the bin size to be (a rather typical) 10 ms, then . For , , a number that is within experimental reach. When ; however, . For a one second stimulus, this is about 40 min, still easily within experimental reach. However, for a ten second stimulus, recording times approach seven hours, and experiments become much more demanding. Moreover, if the firing rate is 1 Hz and a tighter tolerance, say , is required, then . Here, even if the stimulus lasts only one second, one must record for about 40 min per neuron—or almost seven hours for a population of 10 neurons. This would place severe constraints on experiments.
So far, we have ignored the factor that appears in Equation (17) and Equation (18). Is this reasonable in practice, when the data is not necessarily well described by a maximum entropy model? We address this question in two ways: we compute it for a particular distribution, and we compute its maximum and minimum. The distribution we use is the Dichotomized Gaussian model [26,36], chosen because it is a good model of the higher-order correlations found in cortical recordings [27,29].
To access the large n regime, we consider a homogeneous model—one in which all neurons have the same firing rate, denoted ν, and all pairs have the same correlation coefficient, denoted ρ. In general, the correlation coefficient between neuron i and j is given by:
In the homogeneous model, all the are the same and equal to ρ.
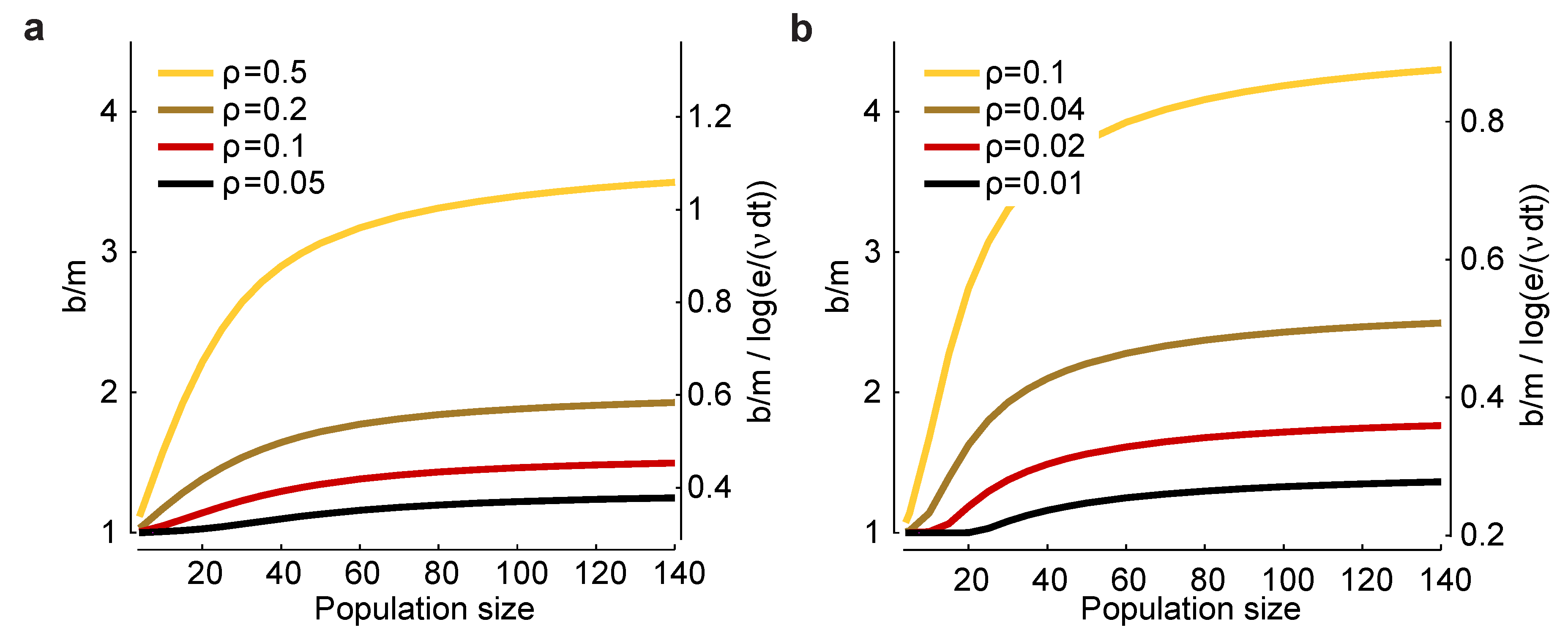
Assuming, as above, a bin size of , the two relevant parameters are the probability of firing in a bin, , and the correlation coefficient, ρ. In Figure 3a,b, we plot (left axis) and (right axis) versus n for a range of values for and ρ. There are two salient features to these plots. First, increases as decreases and as ρ increases, suggesting that bias correction is more difficult at low firing rates and high correlations. Second, the factor that affects the minimum experimental time, , has, for large n, a small range: a low of about 0.3 and a high of about one. Consequently, this factor has only a modest effect on the minimum number of trials one needs to avoid bias.
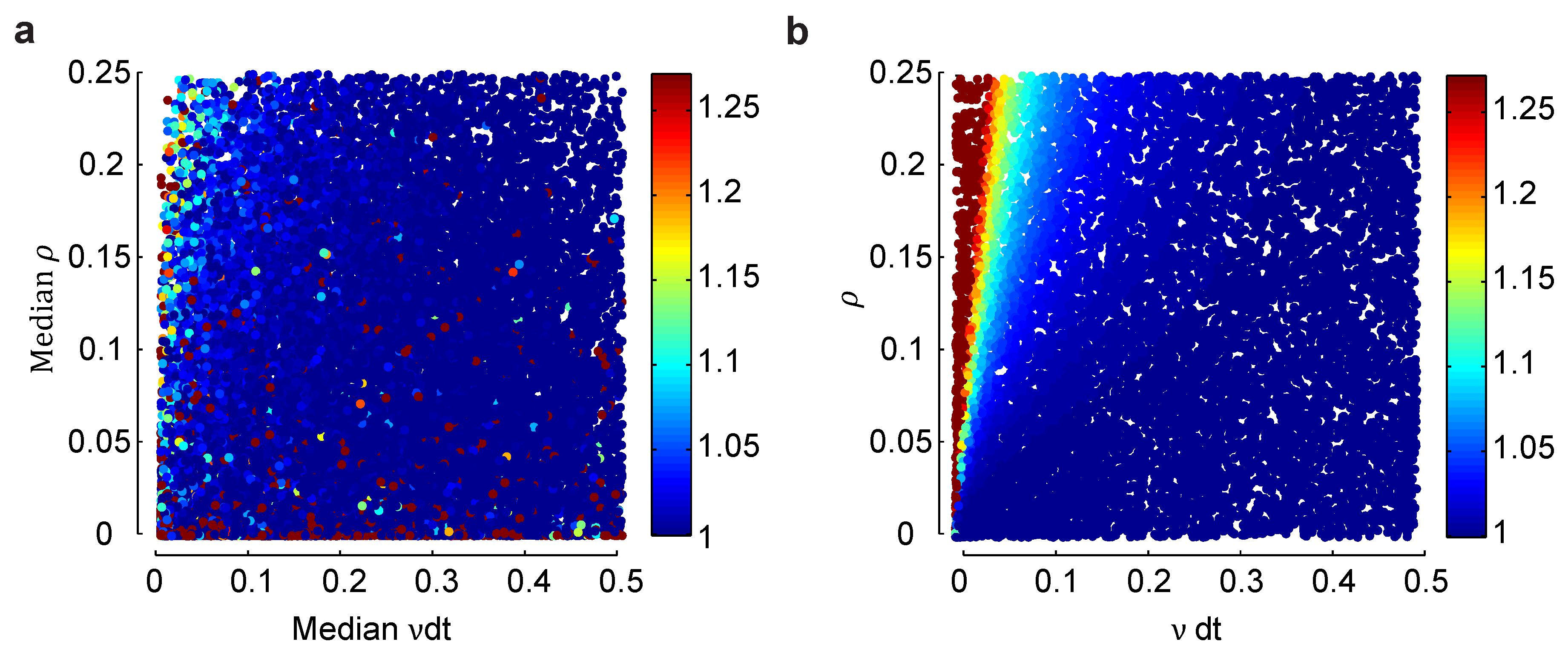
Figure 3 gives us for the homogeneous Dichotomized Gaussian model. Does the general picture—that is largest at low firing rates and high correlations, but never more than about four—hold for an inhomogeneous population, one in which different neurons have different firing rates and different pairs of neurons have different correlation coefficients? To address this question, in Figure 4, we compare a heterogeneous Dichotomized Gaussian model with neurons to a homogeneous model: in Figure 4a, we plot for a range of median firing rates and correlations coefficients in an inhomogeneous model, and in Figure 4b, we do the same for a homogeneous model. At very low firing rates, the homogeneous model is slightly more biased than the heterogeneous one, while at very low correlations, it is the other way around. Overall, though, the two models have very similar biases. Although not proof that the lack of difference will remain at large n, the results are at least not discouraging.
Figure 3.
Scaling of the bias with population size for a homogeneous Dichotomized Gaussian model. (a) Bias, b, for and a range of correlation coefficients, ρ. The bias is biggest for strong correlations and large population sizes; (b) and a range of (smaller) correlation coefficients. In both panels, the left axis is , and the right axis is . The latter quantity is important for determining the minimum number of trials [Equation (17)] or the minimum runtime [Equation (18)] needed to reduce bias to an acceptable level.
Figure 3.
Scaling of the bias with population size for a homogeneous Dichotomized Gaussian model. (a) Bias, b, for and a range of correlation coefficients, ρ. The bias is biggest for strong correlations and large population sizes; (b) and a range of (smaller) correlation coefficients. In both panels, the left axis is , and the right axis is . The latter quantity is important for determining the minimum number of trials [Equation (17)] or the minimum runtime [Equation (18)] needed to reduce bias to an acceptable level.
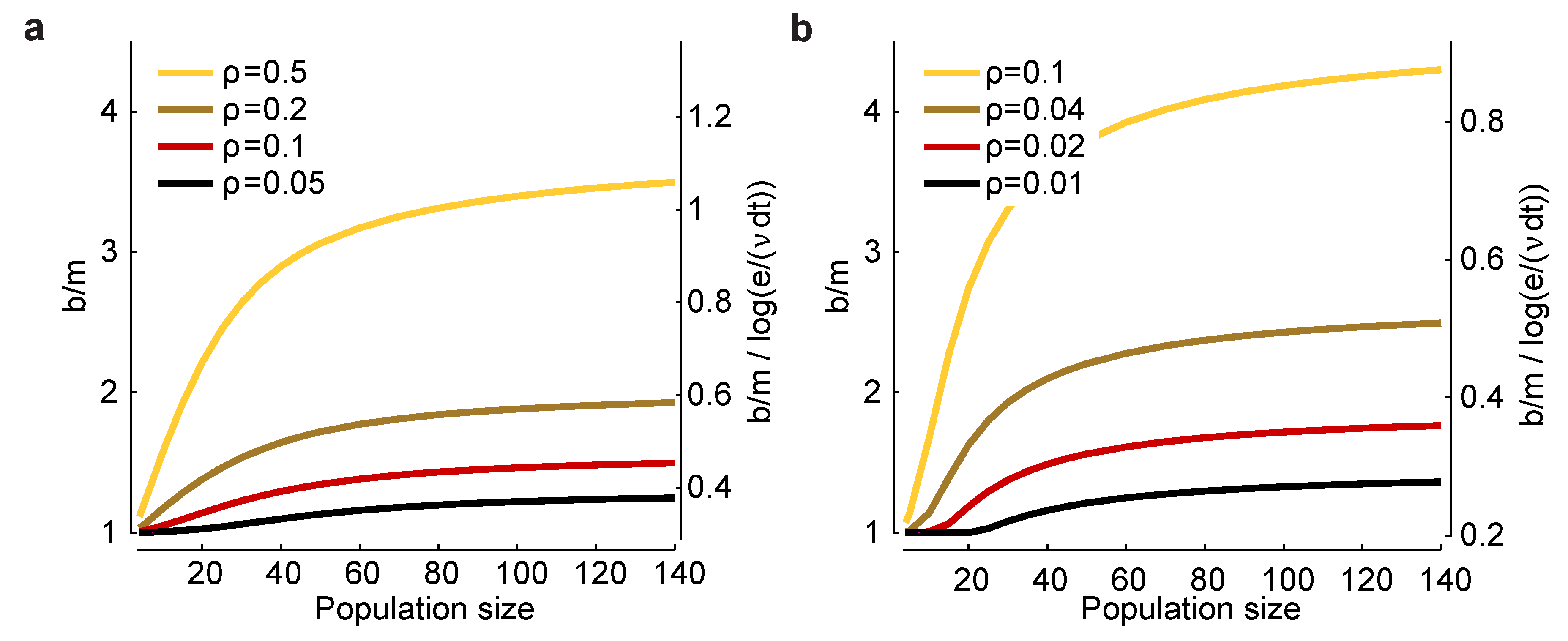
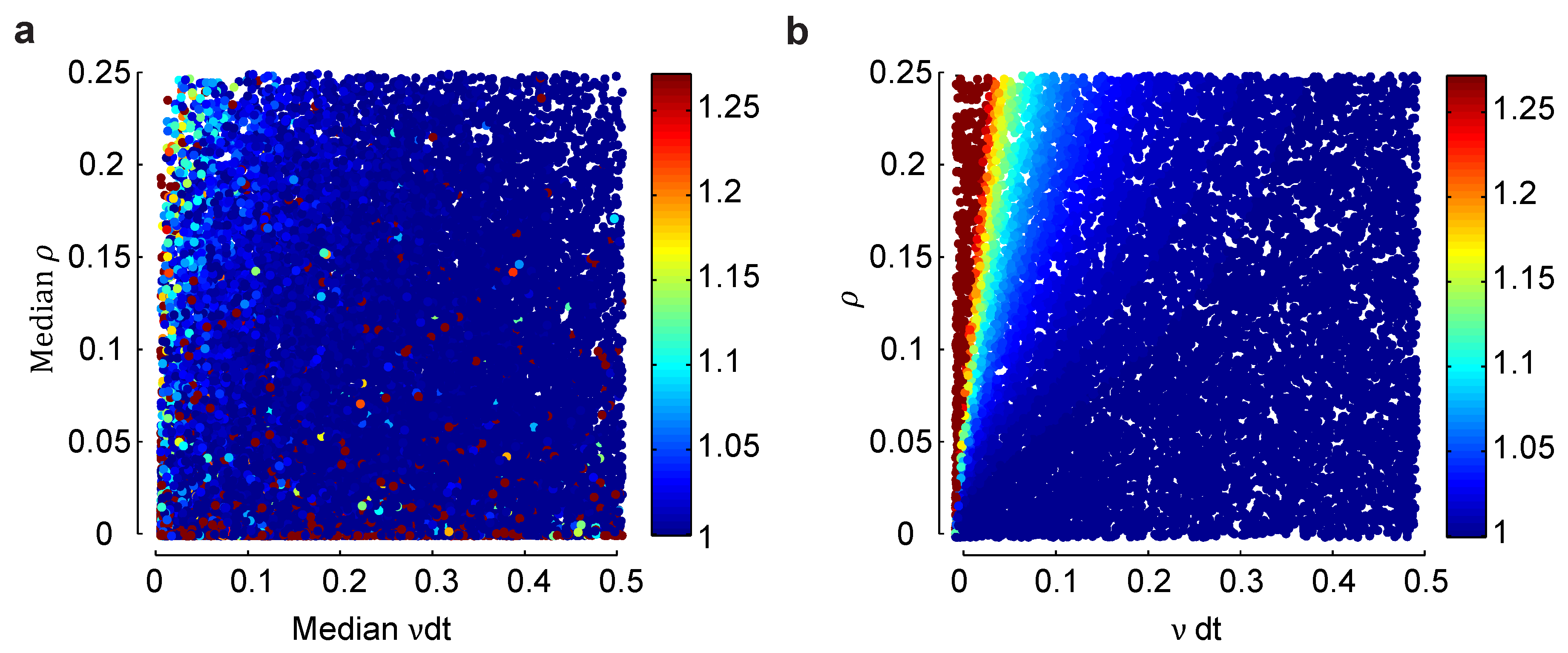
Figure 4.
Effect of heterogeneity on the normalized bias in a small population. (a) Normalized bias relative to the within model class case, , of a heterogeneous Dichotomized Gaussian model with as a function of the median mean, , and correlation coefficient, ρ. As with the homogeneous model, bias is largest for small means and strong correlations. (b) The same plot, but for a homogeneous Dichotomized Gaussian. The difference in bias between the heterogeneous and homogeneous models is largest for small means and small correlations, but overall, the two plots are very similar.
Figure 4.
Effect of heterogeneity on the normalized bias in a small population. (a) Normalized bias relative to the within model class case, , of a heterogeneous Dichotomized Gaussian model with as a function of the median mean, , and correlation coefficient, ρ. As with the homogeneous model, bias is largest for small means and strong correlations. (b) The same plot, but for a homogeneous Dichotomized Gaussian. The difference in bias between the heterogeneous and homogeneous models is largest for small means and small correlations, but overall, the two plots are very similar.
2.3. Maximum and Minimum Bias When the True Model is Not in the Model Class
Above, we saw that the factor was about one for the Dichotomized Gaussian model. That is encouraging, but not definitive. In particular, we are left with the question: Is it possible for the bias to be much smaller or much larger than what we saw in Figure 3 and Figure 4? To answer that, we write the true distribution, , in the form:
and ask how the bias depends on ; that is, how the bias changes as moves out of model class. To ensure that represents only a move out of model class, and not a shift in the constraints (the ), we choose it, so that satisfies the same constraints as :
We cannot say anything definitive about the normalized bias in general, but what we can do is compute its maximum and minimum as a function of the distance between and . For “distance”, we use the Kullback–Leibler divergence, denoted , which is given by:
where is the entropy of . The second equality follows from the definition of , Equation (4) and the fact that , which comes from Equation (21).
Rather than maximizing the normalized bias at fixed , we take a complementary approach and minimize at fixed bias. Since is independent of , minimizing is equivalent to maximizing (see Equation (22)). Thus, again, we have a maximum entropy problem. Now, though, we have an additional constraint on the normalized bias. To determine exactly what that constraint is, we use Equation (11) and (12) to write:
where:
and, importantly, depends on , but not on [see Equation (12a)]. Fixed normalized bias, b, thus corresponds to fixed . This additional constraint introduces an additional Lagrange multiplier besides the , which we denote β. Taking into account the additional constraint, and using the same analysis that led to Equation (4), we find that the distribution with the smallest difference in entropy, , at fixed b, which we denote , is given by:
where is the partition function, the are chosen to satisfy Equation (7), but with replaced by , and β is chosen to satisfy Equation (23), but with, again, replaced by . Note that we have slightly abused notation; whereas, in the previous sections, and Z depended only on μ, now they depend on both μ and β. However, the previous variables are closely related to the new ones: when , the constraint associated with b disappears, and we recover ; that is, . Consequently, , and .
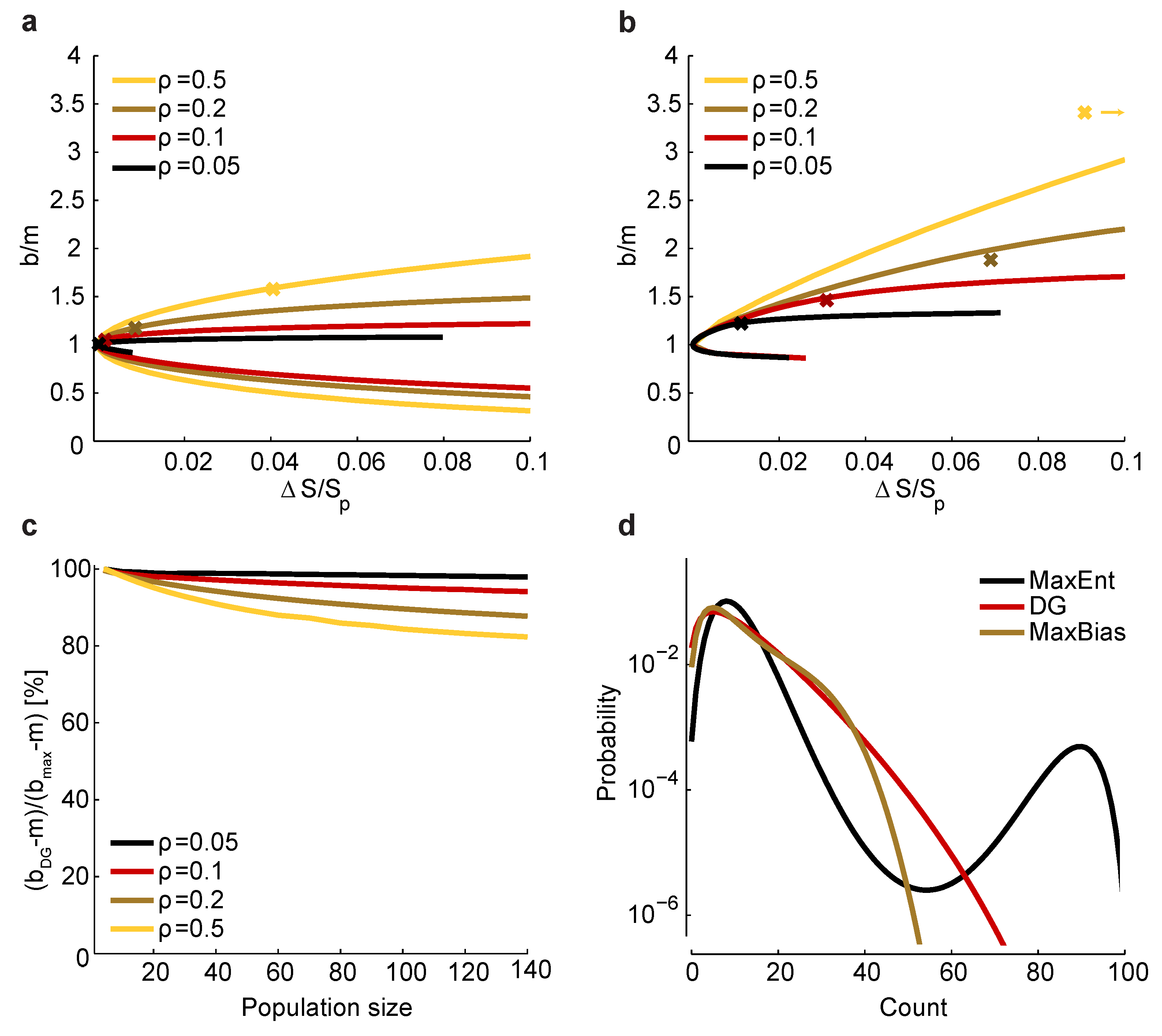
Figure 5.
Relationship between and bias. (a) Maximum and minimum normalized bias relative to m versus (recall that is the entropy of ) in a homogeneous population with size , , and correlation coefficients indicated by color. The crosses correspond to a set of homogeneous Dichotomized Gaussian models with . (b) Same as a, but for . For , the bias of the Dichotomized Gaussian model is off the right-hand side of the plot, at ; for comparison, the maximum bias at and is 3.8. (c) Comparison between the normalized bias of the Dichotomized Gaussian model and the maximum normalized bias. As in panels a and b, we used . Because the ratio of the biases is trivially near one when b is near m, we plot , where and are the normalized bias of the Dichotomized Gaussian and the maximum bias, respectively; this is the ratio of the “additional” bias. (d) Distribution of total spike count () for the Dichotomized Gaussian, maximum entropy (MaxEnt) and maximally biased (MaxBias) models with , and . The similarity between the distributions of the Dichotomized Gaussian and maximally biased models is consistent with the similarity in normalized biases shown in panel c.
Figure 5.
Relationship between and bias. (a) Maximum and minimum normalized bias relative to m versus (recall that is the entropy of ) in a homogeneous population with size , , and correlation coefficients indicated by color. The crosses correspond to a set of homogeneous Dichotomized Gaussian models with . (b) Same as a, but for . For , the bias of the Dichotomized Gaussian model is off the right-hand side of the plot, at ; for comparison, the maximum bias at and is 3.8. (c) Comparison between the normalized bias of the Dichotomized Gaussian model and the maximum normalized bias. As in panels a and b, we used . Because the ratio of the biases is trivially near one when b is near m, we plot , where and are the normalized bias of the Dichotomized Gaussian and the maximum bias, respectively; this is the ratio of the “additional” bias. (d) Distribution of total spike count () for the Dichotomized Gaussian, maximum entropy (MaxEnt) and maximally biased (MaxBias) models with , and . The similarity between the distributions of the Dichotomized Gaussian and maximally biased models is consistent with the similarity in normalized biases shown in panel c.
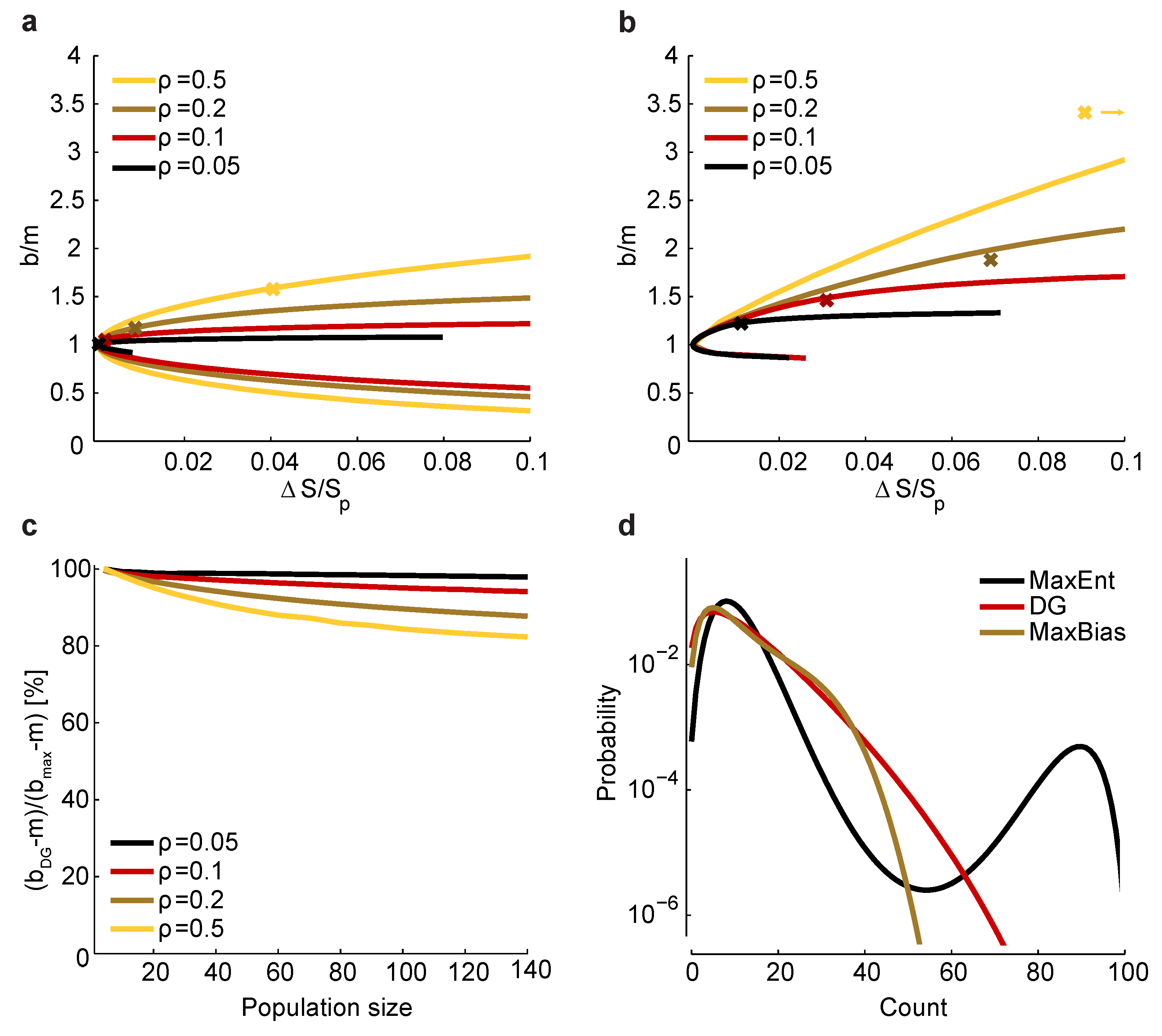
The procedure for determining the relationship between and the normalized bias, b, involves two steps: first, for a particular bias, b, choose the and β in Equation (25) to satisfy the constraints given in Equation (2) and the condition ; second, compute from Equation (22). Repeating those steps for a large number of biases will produce curves like the ones shown in Figure 5a,b.
Since the true entropy, , is maximized (subject to constraints) when , it follows that is zero when and nonzero, otherwise. In fact, in the Methods, we show that has a single global minimum at ; we also show that the normalized bias, b, is a monotonic increasing function of β. Consequently, there are two normalized biases that have the same , one larger than m and the other smaller. This is shown in Figure 5a,b, where we plot versus for the homogeneous Dichotomized Gaussian model. It turns out that this model has near maximum normalized bias, as shown in Figure 5c. Consistent with that, the Dichotomized Gaussian model has about the same distribution of spike counts as the maximally biased models, but a very different distribution from the maximum entropy model (Figure 5d).
The fact that the Dichotomized Gaussian model has near maximum normalized bias is important, because it tells us that the bias we found in Figure 3 and Figure 4 is about as large as one could expect. In those figures, we found that had a relatively small range—from about one to four. Although too large to be used for bias correction, this range is small enough that one could use it to get a conservative estimate of the minimum number of trials [Equation (17)] or minimum run time [Equation (18)] it would take to reduce bias to an acceptable level.
2.4. Using a Plug-in Estimator to Reduce Bias
Given that we have an expression for the asymptotic normalized bias, b [Equation (11)], it is, in principle, possible to correct for it (assuming that K is large enough for the asymptotic bias to be valid). If the effect of model-misspecification is negligible (which is typically the case if the neurons are sufficiently weakly correlated), then the normalized bias is just m, the number of constraints, and bias correction is easy: simply subtract from our estimate of the entropy. If, however, there is substantial model-misspecification, we need to estimate covariance matrices under the true and maximum entropy models. Of course, these estimates are subject to their own bias, but we can ignore that and use a “plug-in” estimator; an estimator computed from the covariance matrices in Equation (11), and , which, in turn, are computed from data. Specifically, we estimate and using:
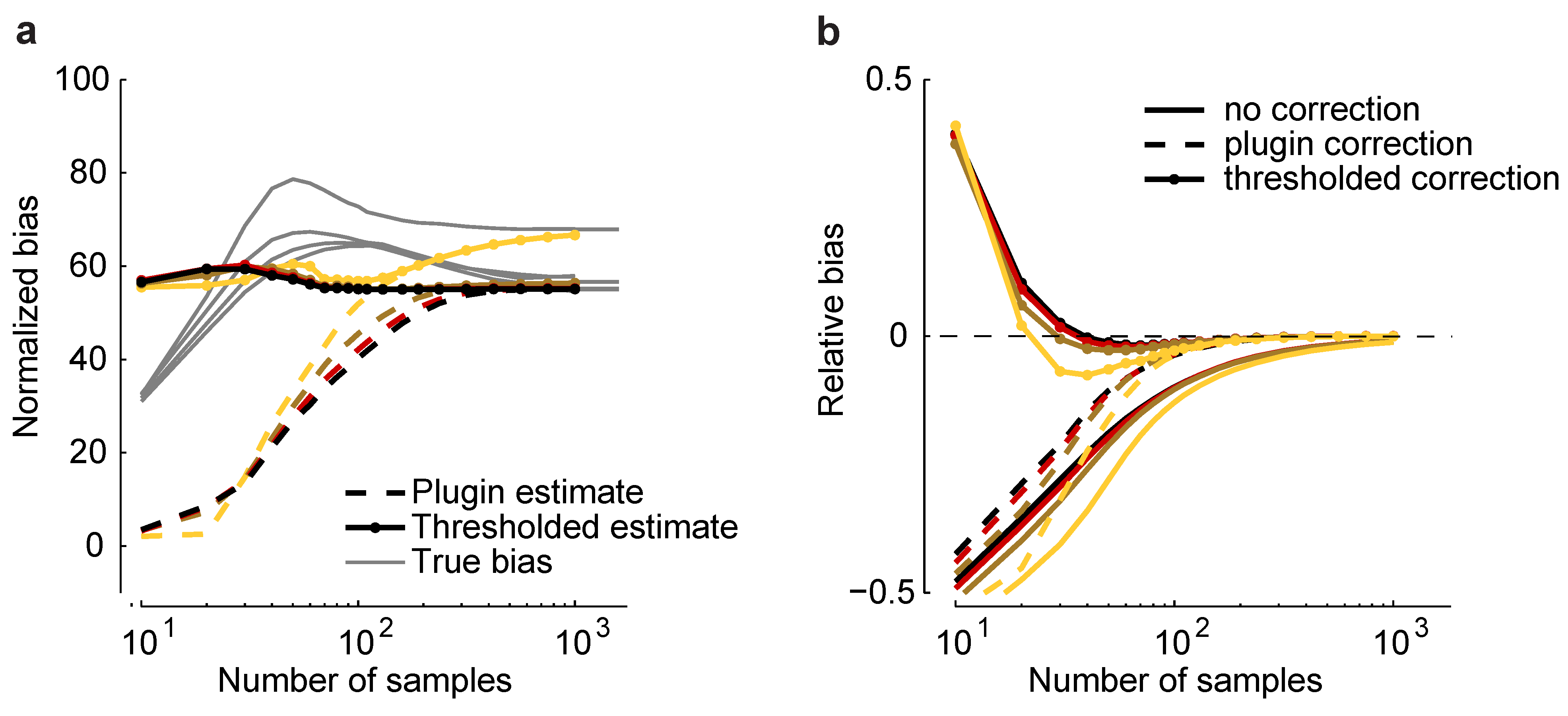
Such an estimator is plotted in Figure 6a for a homogeneous Dichotomized Gaussian with and . Although the plug-in estimator converges to the correct value for sample sizes above about 500, it underestimates b by a large amount, even when . To reduce this effect, we considered a thresholded estimator, denoted , which is given by:
where comes from Equation (11). This estimator is motivated by the fact that we found, empirically, that the additional bias due to model misspecification was almost always greater than m.
Figure 6.
Bias correction. (a) Plug-in, , and thresholded, , estimators versus sample size for a homogeneous Dichotomized Gaussian model with and . Correlations are color coded as in Figure 5. Gray lines indicate the true normalized bias as a function of sample size, computed numerically as for Figure 2. (b) Relative error without bias correction, , with the plug-in correction, , and with the thresholded estimator, .
Figure 6.
Bias correction. (a) Plug-in, , and thresholded, , estimators versus sample size for a homogeneous Dichotomized Gaussian model with and . Correlations are color coded as in Figure 5. Gray lines indicate the true normalized bias as a function of sample size, computed numerically as for Figure 2. (b) Relative error without bias correction, , with the plug-in correction, , and with the thresholded estimator, .
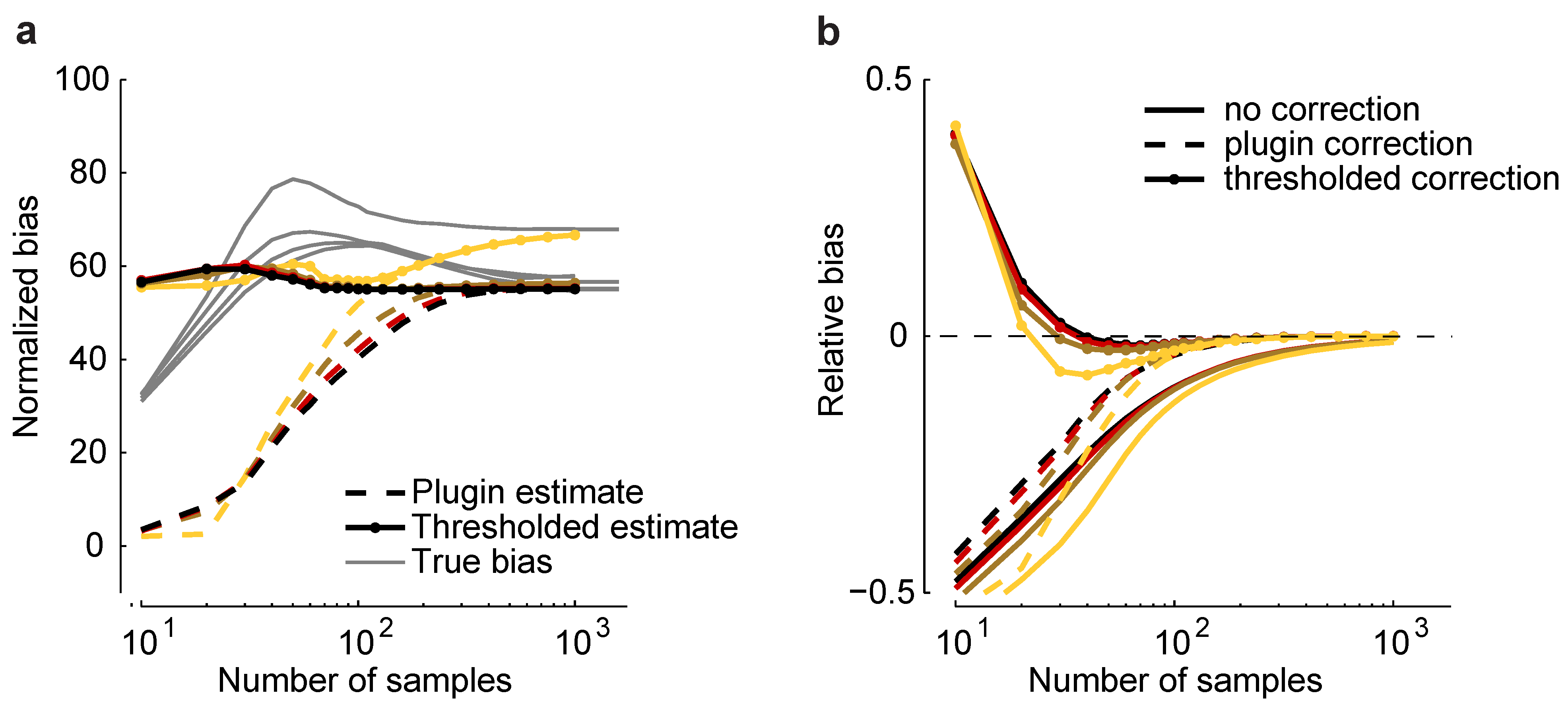
As shown in Figure 6a, is closer to the true normalized bias than . In Figure 6b, we plot the relative error of the uncorrected estimate of the maximum entropy, , and the same quantity, but with two corrections: the plug-in correction, , and the thresholded correction, . Using the plug-in estimator, accurate estimates of the maximum entropy can be achieved with about 100 samples; using the threshold estimators, as few as 30 samples are needed. This suggests that our formalism can be used to perform bias correction for maximum entropy models, even in the presence of model-misspecification.
3. Discussion
In recent years, there has been a resurgence of interest in maximum entropy models, both in neuroscience [13,15,16,18,19,20,21,22] and in related fields [23,24,25]. In neuroscience, these models have been used to estimate entropy. Although maximum entropy based estimators do much better than brute-force estimators, especially when multiple neurons are involved, they are still subject to bias. In this paper, we studied, both analytically and through simulations, just how big the bias is. We focused on the commonly used “naive” estimator, i.e., an estimator of the entropy, which is calculated directly from the empirical estimates of the probabilities of the model.
Our main result is that we found a simple expression for the bias in terms of covariance matrices under the true and maximum entropy distributions. Based on this, we showed that if the true model is in the model class, the (downward) bias in the estimate of the maximum entropy is proportional to the ratio of the number of parameters to the number of observations, a relationship that is identical to that of naive histogram estimators [6,7]. This bias grows quadratically with population size for second-order binary maximum entropy models (also known as Ising models).
What happens when the model is misspecified; that is, when the true data does not come from a maximum entropy distribution? We investigated this question for, again, second-order binary maximum entropy models. We found that model misspecification generally increases bias, but the increase is modest—for a population of 100 neurons and strong correlations (), model misspecification increased bias by a factor of at most four (see Figure 3b). Experimentally, correlation coefficients are usually substantially below 0.1 [15,16,18,20], so a conservative estimate of the minimum number of samples one needs in an experiment can be obtained from Equation (17) with . However, this estimate assumes that our results for homogeneous populations apply to heterogeneous populations, something we showed only for relatively small populations (five neurons).
Has bias been a problem in experiments so far? The answer is largely no. Many of the experimental studies focused on the total entropy, using either no more than 10 neurons [15,16,18,20] or using populations as large as 100, but with a heavily regularized model [17]. In both cases, recordings were sufficiently long that bias was not an issue. There have been several studies that computed mutual information, which generally takes more data than entropy [19,37,38,39]. Two were very well sampled: Ohiorhenuan et al. [19] used about 30,000 trials per stimulus, and Granot-Atedgi et al. [39] used effectively 720,000 trials per stimulus (primarily because they used the whole data set to compute the pairwise interactions). Two other studies, which used a data set with an average of about 700 samples per trial [40], were slightly less well sampled. The first used a homogeneous model (the firing rates and all higher order correlations were assumed to be neuron-independent) [37]. This reduced the number of constraints, m, to at most five. Since there were about 700 trials per stimulus, the approximate downward bias, with , was 0.004 bits. This was a factor of 125 smaller than the information in the population, which was on the order of 0.5 bits, so the maximum error due to bias would have been less than 1%. The other study, based on the same data, considered a third order maximum entropy model and up to eight units [38]. For such a model, the number of constraints, m, is (=). Consequently, the approximate downward bias was . With and , the bias is 0.07 bits. This is more than 10% of information, which was about 0.6 bits. However, the authors applied a sophisticated bias correction to the mutual information [38] and checked to see that splitting the data in half did not change the information, so their estimates are likely to be correct. Nevertheless, this illustrates that bias in maximum entropy models can be important, even with current data sets. Furthermore, given the exponential rate at which recorded population sizes are growing [41], bias is likely to become an increasingly major concern.
Because we could estimate bias, via Equation (10) and Equation (11), we could use that estimate to correct for it. Of course, any correction comes with further estimation problems: in the case of model misspecification, the bias has to be estimated from data, so it too may be biased; even if not, it could introduce additional variance. This is, potentially, especially problematic for our bias correction, as it depends on two covariance matrices, one of which has to be inverted. Nevertheless, in the interests of simplicity, we used a plug-in estimator of the bias (with a minor correction associated with matrix singularities). In spite of the potential drawbacks of our simple estimator (including the fact that it assumes Equation (11) is valid even for very small sample sizes, K), it worked well: for the models we studied, it reduced the required number of samples by a factor of about three—from 100 to about 30. While this is a modest reduction, it could be important in electrophysiological experiments, where it is often difficult to achieve long recording times. Furthermore, it is likely that it could be improved: more sophisticated estimation techniques, such as modified entropy estimates [5], techniques for bias-reduction for mutual information [8,42] or Bayesian priors [30,31,43], could provide additional or more effective bias reduction.
4. Methods
4.1. Numerical Methods
For all of our analysis, we use the Dichotomized Gaussian distribution [26,27,36], a distribution over binary variables, , where can take on the values, 0 or 1. The distribution can be defined by a sampling procedure: first, sample a vector, , from a Gaussian distribution with mean γ and covariance Λ:
then, set to if and 0, otherwise. Alternatively, we may write:
where is given by Equation (28).
Given this distribution, our first step is to sample from it and, then, using those samples, fit a pairwise maximum entropy model. More concretely, for any mean and covariance, γ and Λ, we generate samples (, ); from those, we compute the [Equation (1)]; and from the , we compute the parameters of the maximum entropy model, [Equation (4)]. Once we have those parameters, we can compute the normalized bias via Equation (11).
While this is straightforward in principle, it quickly becomes unwieldy as the number of neurons increases (scaling is exponential in n). Therefore, to access the large n regime, we use the homogeneous Dichotomized Gaussian distribution, for which all the means, variances and covariances are the same: and . The symmetries of this model make it possible to compute all quantities of interest (entropy of the Dichotomized Gaussian distribution model, entropy of the maximum entropy model, normalized bias via Equation (11) and minimum and maximum normalized bias given distance from the model class) without the need for numerical approximations [27].
4.1.1. Parameters of the Heterogeneous Dichotomized Gaussian Distribution
For the heterogeneous Dichotomized Gaussian distribution, we need to specify γ and Λ. Both were sampled from random distributions. The mean, , came from a zero mean, unit variance Gaussian distribution, but truncated at zero, so that only negative s were generated. We used negative s, because for neural data, the probability of not observing a spike (i.e. ) is generally larger than that of observing a spike (i.e. ). Generation of the covariance matrix, Λ, was more complicated and proceeded in several steps. The first was to construct a covariance matrix corresponding to a homogeneous population model; that is, a covariance matrix with 1 along the diagonal and ρ an all the off-diagonal elements. The next step was to take the Cholesky decomposition of the homogeneous matrix; this resulted in a matrix, , with zeros in the upper triangular entries. We then added Gaussian noise to the lower-triangular entries of (the non-zero entries). Finally, the last step was to set Λ to , where is the noise added to the lower-triangular entries and ⊤ denotes the transpose. Because we wanted covariance matrices with a range of median correlation coefficients, the value of ρ was sampled uniformly from the range, . Similarly, to get models that ranged from weakly to strongly heterogeneous, the standard deviation of the noise we added to the Cholesky-decomposition was sampled uniformly from {0.1, 0.25, 0.5, 1, 2}.
4.1.2. Fitting Maximum Entropy Models
To find the parameters of the maximum entropy models (the ), we numerically maximized the log-likelihood using a quasi-Newton implementation [44]. The log likelihood, denoted , is given by:
with the second equality following from Equation (4). Optimization was stopped when successive iterations increased the log-likelihood by less than . This generally led to a model for which all moments were within of the desired empirical moments.
4.1.3. Bias Correction
To compute the normalized bias, b [Equation (11)], we first estimate the covariance matrices under the true and maximum entropy distributions via Equation (26); these are denoted and , respectively. We then have to invert . However, given finite data, there is no guarantee that will be full rank. For example, if two neurons have low firing rates, synchronous spikes occur very infrequently, and the empirical estimate of can be zero for some i and j; say and . In this case, the corresponding λ will be infinity [see Equation (4)]; and so, will be zero for all pairs, and will be zero for all . In other words, will have a row and column of zeros (and if the estimate of is zero for several pairs, there will be several rows and columns of zeros). The corresponding rows and columns of will also be zero, making well behaved in principle. In practice, however, this quantity is not well behaved, and will, in most cases, be close to , where is the number of all-zero rows and columns. In some cases, however, took on very large values (or was not defined). We attribute these cases to numerical problems arising from the inversion of the covariance matrix. We therefore rejected any data sets for which . It is likely that this problem could be fixed with a more sophisticated (e.g., Bayesian) estimator of empirical averages, or by simply dropping the rows and columns that are zero, computing , and then adding back in the number of dropped rows.
4.1.4. Sample Size
When estimating entropy for a particular model (a particular value of γ and Λ), for each K we averaged over data sets. Error bars denote the standard error of the mean across data sets.
4.2. The Normalized Bias Depends Only on the Covariance Matrices
The normalized bias, b, given in Equation (10), depends on two quantities: and . Here, we derive explicit expressions for both. The second is the easier of the two: noting that is the mean of K uncorrelated, zero mean random variables [see Equation (9)], we see that:
where the last equality follows from the definition given in Equation (12a).
For the first, we have:
where we used Equation (6) for the entropy. From the definition of , Equation (5), it is straightforward to show that
Inserting Equation (33) into Equation (32), the first and third terms cancel, and we are left with:
This quantity is hard to compute directly, so instead, we compute its inverse, . Using the definition of :
differentiating both sides with respect to and applying Equation (33), we find that:
The right-hand side is the covariance matrix within the model class.
4.3. Dependence of and the Normalized Bias, b, on β
Here, we show that has a minimum at and that is non-negative, where prime denotes a derivative with respect to β. We start by showing that , so showing that automatically implies that has a minimum at .
Using Equation (22) for the definition of and Equation (25) for and noting that is independent of β, it is straightforward to show that:
Given that [see Equation (23)], it follows that . Thus, we need only establish that . To do that, we first note, using Equation (25) for , that:
where . Then, using the fact that , we see that:
Combining these two expressions, we find, after a small amount of algebra, that:
The right-hand side is non-negative, so we have .
Acknowledgements
Support for this project came from the Gatsby Charitable Foundation. In addition, Jakob H. Macke was supported by an EC Marie Curie Fellowship, by the Max Planck Society, the Bernstein Initiative for Computational Neuroscience of the German Ministry for Science and Education (BMBF FKZ: 01GQ1002); Iain Murray was supported in part by the IST Programme of the European Community under the PASCAL2 Network of Excellence, IST-2007-216886.
Conflict of Interest
The authors declare no conflict of interest.
References
- Rieke, F.; Warland, D.; de Ruyter van Steveninck, R.; Bialek, W. Spikes: Exploring the Neural Code; The MIT Press: Cambridge, MA, USA, 1999. [Google Scholar]
- Borst, A.; Theunissen, F.E. Information theory and neural coding. Nat. Neurosci. 1999, 2, 947–957. [Google Scholar] [CrossRef] [PubMed]
- Shannon, C.; Weaver, W. The Mathematical Theory of Communication; University of Illinois Press: Chicago, IL, USA, 1949. [Google Scholar]
- Cover, T.; Thomas, J. Elements of Information Theory; Wiley: New York, NY, USA, 1991. [Google Scholar]
- Paninski, L. Estimation of entropy and mutual information. Neural Comput. 2003, 15, 1191–1253. [Google Scholar] [CrossRef]
- Miller, G. Note on the Bias of Information Estimates. In Information Theory in Psychology II-B; Free Press: Glencole, IL, USA, 1955; pp. 95–100. [Google Scholar]
- Treves, A.; Panzeri, S. The upward bias in measures of information derived from limited data samples. Neural Comput. 1995, 7, 399–407. [Google Scholar] [CrossRef]
- Panzeri, S.; Senatore, R.; Montemurro, M.A.; Petersen, R.S. Correcting for the sampling bias problem in spike train information measures. J. Neurophysiol. 2007, 98, 1064–1072. [Google Scholar] [CrossRef] [PubMed]
- Averbeck, B.B.; Latham, P.E.; Pouget, A. Neural correlations, population coding and computation. Nat. Rev. Neurosci. 2006, 7, 358–366. [Google Scholar] [CrossRef] [PubMed]
- Quian Quiroga, R.; Panzeri, S. Extracting information from neuronal populations: Information theory and decoding approaches. Nat. Rev. Neurosci. 2009, 10, 173–185. [Google Scholar] [CrossRef] [PubMed]
- Ince, R.A.; Mazzoni, A.; Petersen, R.S.; Panzeri, S. Open source tools for the information theoretic analysis of neural data. Front Neurosci. 2010, 4, 60–70. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Pillow, J.W.; Ahmadian, Y.; Paninski, L. Model-based decoding, information estimation, and change-point detection techniques for multineuron spike trains. Neural Comput. 2011, 23, 1–45. [Google Scholar] [CrossRef] [PubMed]
- Tkačik, G.; Schneidman, E.; Berry, M.J., II; Bialek, W. Spin glass models for a network of real neurons. 2009; arXiv:q-bio/0611072v2. [Google Scholar]
- Ising, E. Beitrag zur Theorie des Ferromagnetismus. Zeitschrift für Physik 1925, 31, 253–258. [Google Scholar] [CrossRef]
- Schneidman, E.; Berry, M.J.; Segev, R.; Bialek, W. Weak pairwise correlations imply strongly correlated network states in a neural population. Nature 2006, 440, 1007–1012. [Google Scholar] [CrossRef] [PubMed]
- Shlens, J.; Field, G.D.; Gauthier, J.L.; Grivich, M.I.; Petrusca, D.; Sher, A.; Litke, A.M.; Chichilnisky, E.J. The structure of multi-neuron firing patterns in primate retina. J. Neurosci. 2006, 26, 8254–8266. [Google Scholar] [CrossRef] [PubMed]
- Shlens, J.; Field, G.D.; Gauthier, J.L.; Greschner, M.; Sher, A.; Litke, A.M.; Chichilnisky, E.J. The structure of large-scale synchronized firing in primate retina. J. Neurosci. 2009, 29, 5022–5031. [Google Scholar] [CrossRef] [PubMed]
- Tang, A.; Jackson, D.; Hobbs, J.; Chen, W.; Smith, J.L.; Patel, H.; Prieto, A.; Petrusca, D.; Grivich, M.I.; Sher, A.; et al. A maximum entropy model applied to spatial and temporal correlations from cortical networks in vitro. J. Neurosci. 2008, 28, 505–518. [Google Scholar] [CrossRef] [PubMed]
- Ohiorhenuan, I.E.; Mechler, F.; Purpura, K.P.; Schmid, A.M.; Hu, Q.; Victor, J.D. Sparse coding and high-order correlations in fine-scale cortical networks. Nature 2010, 466, 617–621. [Google Scholar] [CrossRef] [PubMed]
- Yu, S.; Huang, D.; Singer, W.; Nikolic, D. A small world of neuronal synchrony. Cereb Cortex 2008, 18, 2891–2901. [Google Scholar] [CrossRef] [PubMed]
- Roudi, Y.; Tyrcha, J.; Hertz, J. Ising model for neural data: model quality and approximate methods for extracting functional connectivity. Phys. Rev. E Stat. Nonlin. Soft. Matter Phys. 2009, 79, 051915. [Google Scholar] [CrossRef] [PubMed]
- Roudi, Y.; Aurell, E.; Hertz, J. Statistical physics of pairwise probability models. Front. Comput. Neurosci. 2009, 3. [Google Scholar] [CrossRef] [PubMed]
- Mora, T.; Walczak, A.M.; Bialek, W.; Callan, C.G.J. Maximum entropy models for antibody diversity. Proc. Natl. Acad. Sci. USA 2010, 107, 5405–5410. [Google Scholar] [CrossRef] [PubMed]
- Dhadialla, P.S.; Ohiorhenuan, I.E.; Cohen, A.; Strickland, S. Maximum-entropy network analysis reveals a role for tumor necrosis factor in peripheral nerve development and function. Proc. Natl. Acad. Sci. USA 2009, 106, 12494–12499. [Google Scholar] [CrossRef] [PubMed]
- Socolich, M.; Lockless, S.W.; Russ, W.P.; Lee, H.; Gardner, K.H.; Ranganathan, R. Evolutionary information for specifying a protein fold. Nature 2005, 437, 512–518. [Google Scholar] [CrossRef] [PubMed]
- Macke, J.; Berens, P.; Ecker, A.; Tolias, A.; Bethge, M. Generating spike trains with specified correlation coefficients. Neural Comput. 2009, 21, 397–423. [Google Scholar] [CrossRef] [PubMed]
- Macke, J.; Opper, M.; Bethge, M. Common input explains higher-order correlations and entropy in a simple model of neural population activity. Phys. Rev. Lett. 2011, 106, 208102. [Google Scholar] [CrossRef] [PubMed]
- Amari, S.I.; Nakahara, H.; Wu, S.; Sakai, Y. Synchronous firing and higher-order interactions in neuron pool. Neural Comput. 2003, 15, 127–142. [Google Scholar] [CrossRef] [PubMed]
- Yu, S.; Yang, H.; Nakahara, H.; Santos, G.S.; Nikolic, D.; Plenz, D. Higher-order interactions characterized in cortical activity. J. Neurosci. 2011, 31, 17514–17526. [Google Scholar] [CrossRef] [PubMed]
- Nemenman, I.; Bialek, W.; van Steveninck, R. Entropy and information in neural spike trains: Progress on the sampling problem. Phys. Rev. E 2004, 69, 056111. [Google Scholar] [CrossRef]
- Archer, E.; Park, I.M.; Pillow, J. Bayesian estimation of discrete entropy with mixtures of stick-breaking priors. Adv. Neural Inf. Process. Syst. 2012, 25, 2024–2032. [Google Scholar]
- Ahmed, N.; Gokhale, D.V. Entropy expressions and their estimators for multivariate distributions. IEEE Trans. Inf. Theory 1989, 35, 688–692. [Google Scholar] [CrossRef]
- Oyman, O.; Nabar, R.U.; Bolcskei, H.; Paulraj, A.J. Characterizing the Statistical Properties of Mutual Information in MIMO Channels: Insights into Diversity-multiplexing Tradeoff. In Proceedings of the IEEE Conference Record of the Thirty-Sixth Asilomar Conference on Signals, Systems and Computers, Monterey, CA, USA, 3–6 November 2002; Volume 1, pp. 521–525.
- Misra, N.; Singh, H.; Demchuk, E. Estimation of the entropy of a multivariate normal distribution. J. Multivar. Anal. 2005, 92, 324–342. [Google Scholar] [CrossRef]
- Marrelec, G.; Benali, H. Large-sample asymptotic approximations for the sampling and posterior distributions of differential entropy for multivariate normal distributions. Entropy 2011, 13, 805–819. [Google Scholar] [CrossRef]
- Cox, D.R.; Wermuth, N. On some models for multivariate binary variables parallel in complexity with the multivariate Gaussian distribution. Biometrika 2002, 89, 462–469. [Google Scholar] [CrossRef]
- Montani, F.; Ince, R.A.; Senatore, R.; Arabzadeh, E.; Diamond, M.E.; Panzeri, S. The impact of high-order interactions on the rate of synchronous discharge and information transmission in somatosensory cortex. Philos. Trans. R. Soc. A Math. Phys. Eng. Sci. 2009, 367, 3297–3310. [Google Scholar] [CrossRef] [PubMed]
- Ince, R.A.; Senatore, R.; Arabzadeh, E.; Montani, F.; Diamond, M.E.; Panzeri, S. Information-theoretic methods for studying population codes. Neural Netw. 2010, 23, 713–727. [Google Scholar] [CrossRef] [PubMed]
- Granot-Atedgi, E.; Tkačik, G.; Segev, R.; Schneidman, E. Stimulus-dependent maximum entropy models of neural population codes. PLoS Comput. Biol. 2013, 9, e1002922. [Google Scholar] [CrossRef] [PubMed]
- Arabzadeh, E.; Petersen, R.S.; Diamond, M.E. Encoding of whisker vibration by rat barrel cortex neurons: Implications for texture discrimination. J. Neurosci. 2003, 23, 9146–9154. [Google Scholar] [PubMed]
- Stevenson, I.; Kording, K. How advances in neural recording affect data analysis. Nat. Neurosci. 2011, 14, 139–142. [Google Scholar] [CrossRef] [PubMed]
- Montemurro, M.A.; Senatore, R.; Panzeri, S. Tight data-robust bounds to mutual information combining shuffling and model selection techniques. Neural Comput. 2007, 19, 2913–2957. [Google Scholar] [CrossRef] [PubMed]
- Dudïk, M.; Phillips, S.J.; Schapire, R.E. Performance Guarantees for Regularized Maximum Entropy Density Estimation. In Learning Theory; Shawe-Taylor, J., Singer, Y., Eds.; Springer: Berlin/Heidelberg, Germany, 2004; Volume 3120, Lecture Notes in Computer Science; pp. 472–486. [Google Scholar]
- Schmidt M. minFunc. http://www.di.ens.fr/∼mschmidt/Software/minFunc.html (accessed on 30 July 2013).
© 2013 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
MDPI and ACS Style
Macke, J.H.; Murray, I.; Latham, P.E. Estimation Bias in Maximum Entropy Models. Entropy 2013, 15, 3109-3129. https://doi.org/10.3390/e15083109
AMA Style
Macke JH, Murray I, Latham PE. Estimation Bias in Maximum Entropy Models. Entropy. 2013; 15(8):3109-3129. https://doi.org/10.3390/e15083109
Chicago/Turabian StyleMacke, Jakob H., Iain Murray, and Peter E. Latham. 2013. "Estimation Bias in Maximum Entropy Models" Entropy 15, no. 8: 3109-3129. https://doi.org/10.3390/e15083109