One expression for the mutual information is:
where
is Bob’s differential entropy of
θ before he tosses the coin and
is his average differential entropy, once he observes the outcome of the tosses. The right-hand side of Equation (
1) leads to the interpretation of
given above and, thus, accords with the scenario we are imagining, in which Bob is trying to learn about
θ. However, it turns out to be mathematically more convenient to write the mutual information in a different way:
Here,
is the entropy of the number of heads:
and
is the conditional entropy:
where the angular brackets indicate an average over
θ. In these last two equations,
is the probability of getting exactly
n heads when the probability of heads for each toss is
p, and
is the average of
over all values of
θ. Equation (
2) suggests an alternative interpretation of
, namely, that it is the average amount of information one would gain about the value of
n upon learning the value of
θ. Though Equation (
1) and Equation (
2) suggest different interpretations of
, the two expressions are equivalent, and we will continue to think of
as the average amount of information Bob gains about
θ.
2.1. Optimizing When the Number of Trials is Small
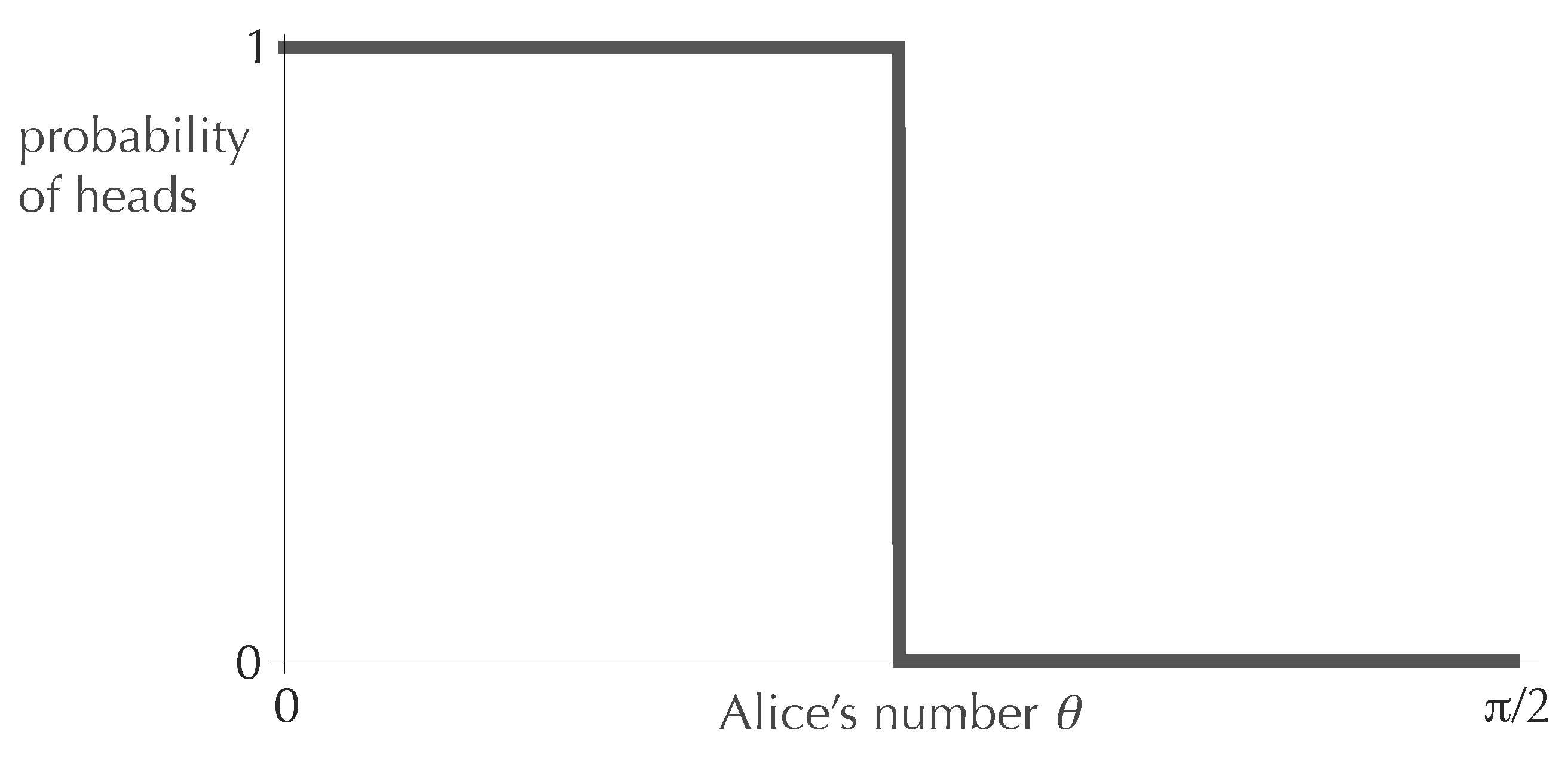
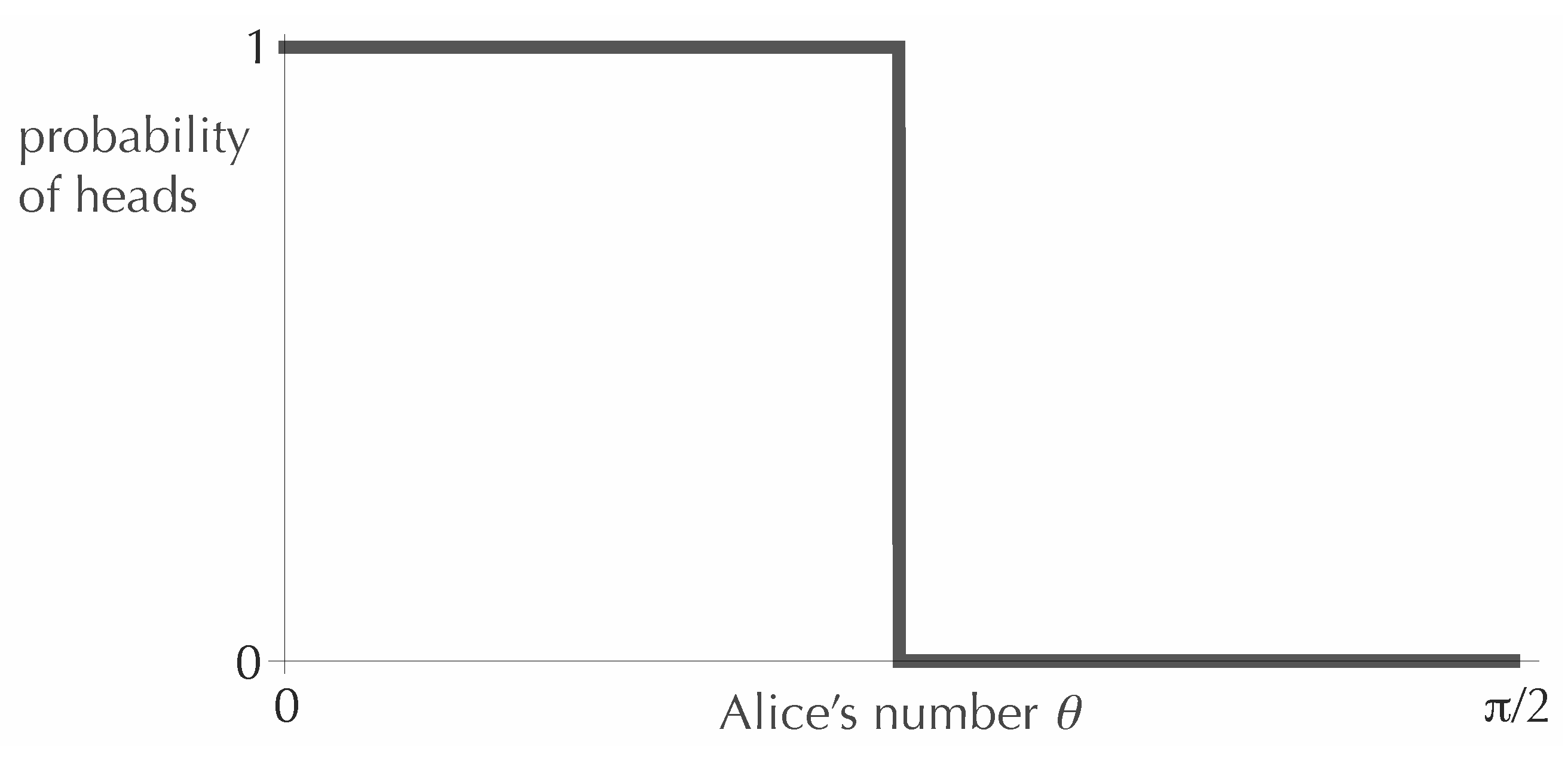
We begin with the simplest case,
. That is, Bob is allowed only a single toss. In this case, it is not hard to see that the optimal strategy is for Alice to send a deterministic coin, with each of the two possible outcomes associated with half of the range of
θ. For example, Alice could adopt the following strategy: for
, she sends Bob a coin that only lands heads, and for
, she sends a coin that only lands tails. Then, from his single toss, Bob gains exactly one bit of information about the value of
θ (that is, 0.693 nats), which is the most one could hope for in a binary experiment. The optimal function defining this strategy is shown in
Figure 1.
Figure 1.
An optimal function for encoding the value of θ in the value of the probability of heads, when the coin will be tossed exactly once.
Figure 1.
An optimal function for encoding the value of θ in the value of the probability of heads, when the coin will be tossed exactly once.
Note that one can obtain other optimal functions by cutting the graph in
Figure 1 into any number of vertical strips and reordering the strips. All that matters is the weight (that is, the fraction of the interval
) assigned to each value of
p. For larger values of
N, there will similarly be many optimal graphs related to each other by a reordering of strips. In what follows, for definiteness, we will typically pick out the unique
non-increasing optimal function.
As we increase the number of tosses, the optimal curve will continue to be a step function, with the number of steps tending to increase as N increases. We show below that the number of distinct probabilities represented in the optimal function will not be larger than , but this bound is likely to be rather weak as N gets large. One might guess that the number of steps instead grows as the square root of N, since the size of the statistical fluctuations in the frequency of occurrence of heads diminishes as . That is, it is plausible that one could distinguish approximately distinct probability values reasonably well in N tosses. However, it is also quite conceivable that the problem is more subtle than this. Fortunately, for our purposes, we do not need to know precisely how the number of steps depends on N.
It is helpful, though, to re-express the mutual information in terms of a discrete set of probabilities
, with
, rather than in terms of the function
. Let
be the weight assigned to the probability
. For the optimal function presented in
Figure 1, for example, the values
are zero and one, and the weight of each is 1/2, since each probability value occupies half of the interval
. In terms of
and
, the mutual information is:
Here, again,
is the binomial distribution given in Equation (
6)—the probability of getting exactly
n heads in
N tosses when the probability of heads in a single toss is
—and
is the overall probability of getting
n heads. Our problem is to maximize
over all values of the parameters
L,
and
, where each
and
lies in the interval
and the
s sum to unity.
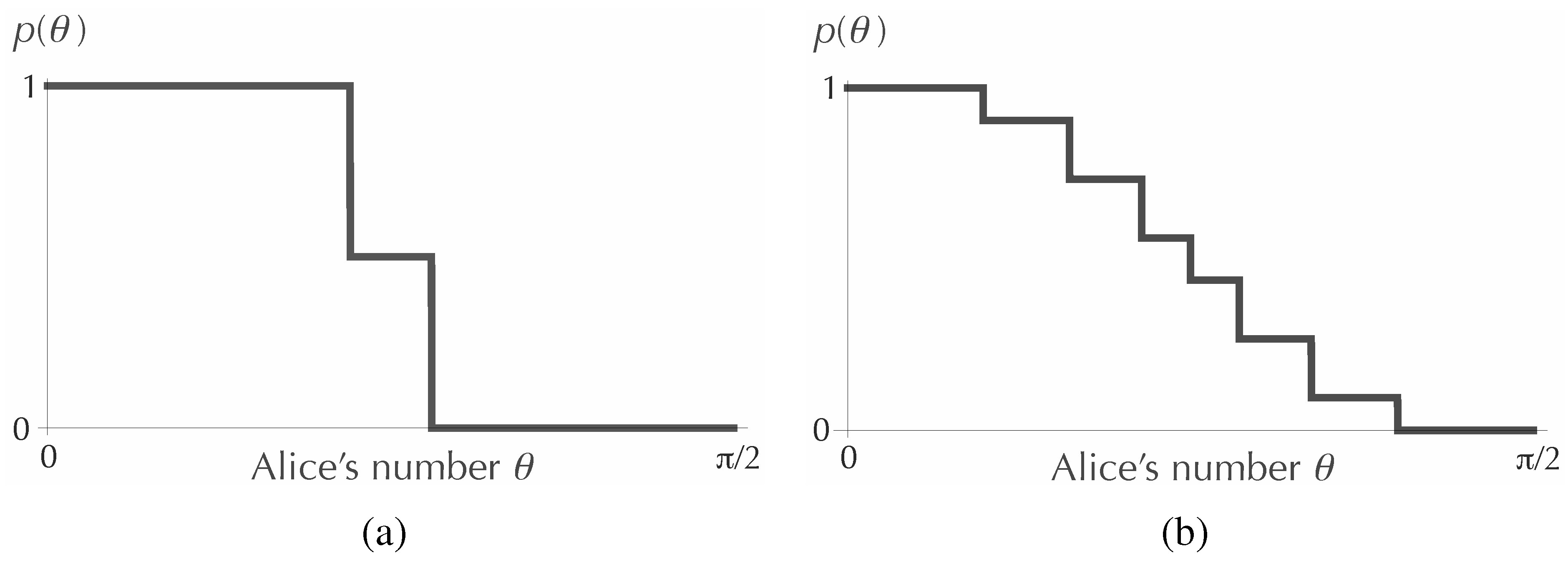
For two tosses of the coin (that is, for
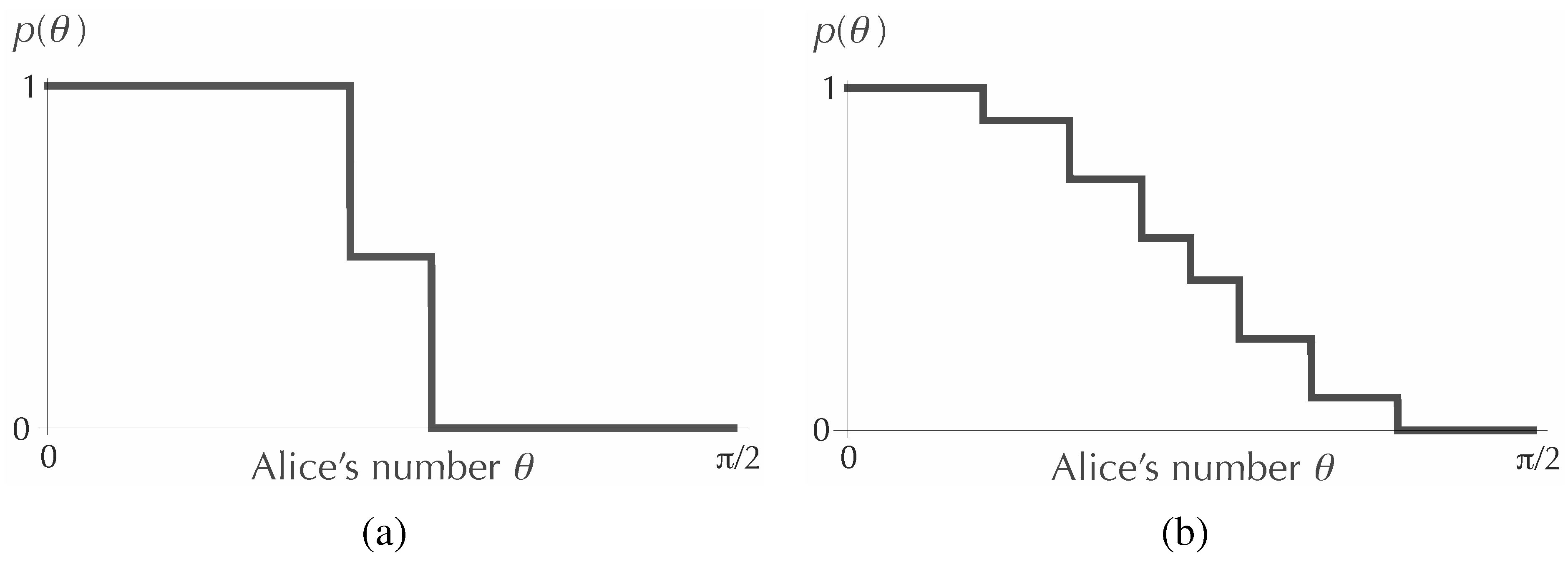
), it is possible to solve the maximization problem analytically. One finds for this case that it is best for Alice to use exactly three probability values, namely, zero, 1/2 and one, with weights 15/34, 4/34 and 15/34, respectively. The first graph in
Figure 2 shows the non-decreasing function
obtained from these values. For larger
N, one can try to find the optimal values of the parameters numerically. The second graph in
Figure 2 shows the function
resulting from a numerical optimization for
. Here, the number of distinct probability values,
L, is also determined numerically. For example, starting from the
graph in
Figure 2, if we offer the computer program an additional probability value, it will simply set the new probability to be equal to one of the values already being used, so that the graph will not change.
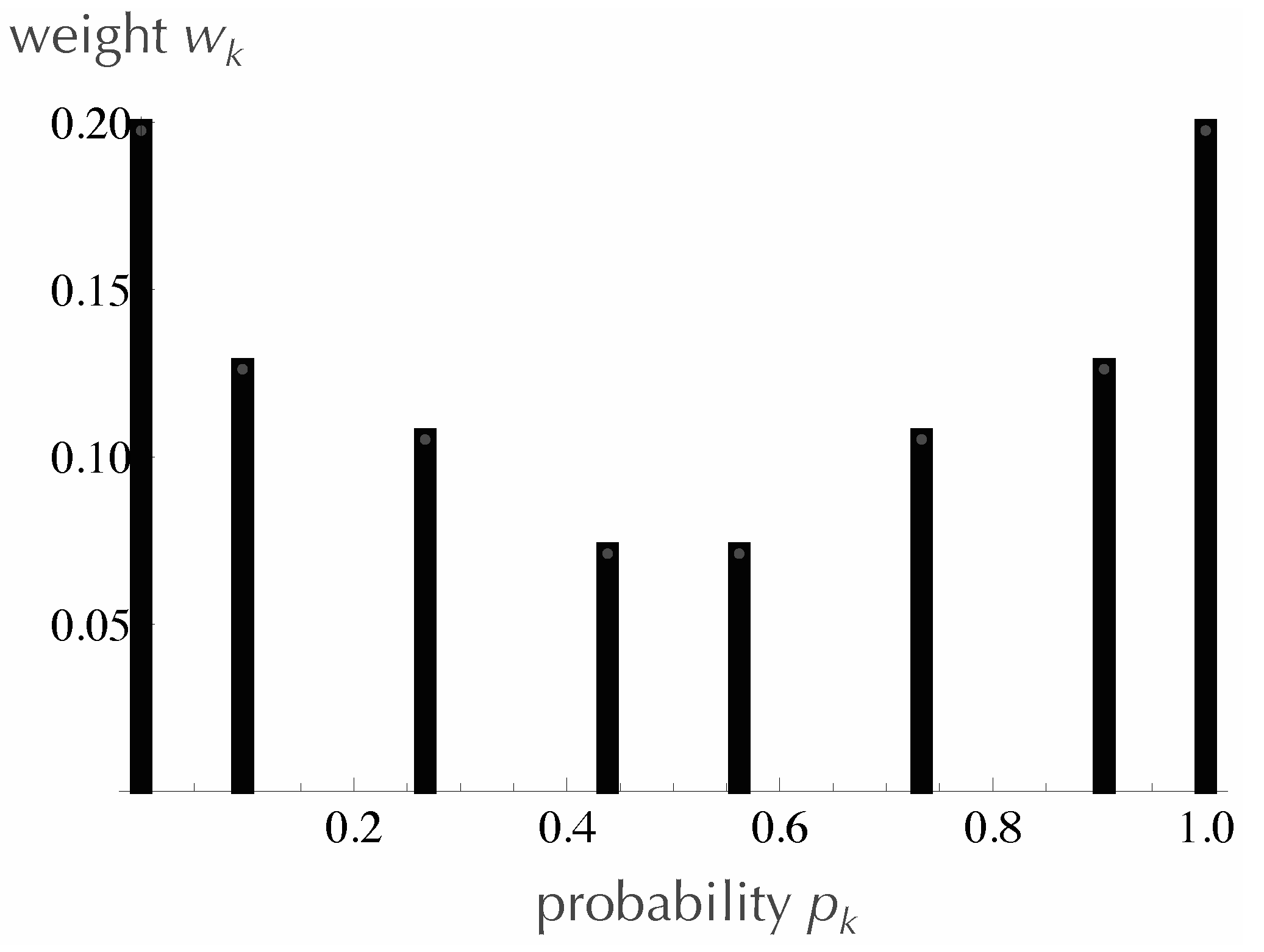
Figure 3 shows explicitly the optimal choices for the
s for
, along with the weight,
, assigned to each.
Figure 2.
Optimal functions for encoding the value of θ in the value of the probability of heads, when the coin will be tossed exactly twice (a) and 25 times (b). The corresponding maximum values of the mutual information are for and for .
Figure 2.
Optimal functions for encoding the value of θ in the value of the probability of heads, when the coin will be tossed exactly twice (a) and 25 times (b). The corresponding maximum values of the mutual information are for and for .
Figure 3.
A bar graph showing the specific probabilities that optimize for the case of 25 tosses, along with the weight assigned to each probability.
Figure 3.
A bar graph showing the specific probabilities that optimize for the case of 25 tosses, along with the weight assigned to each probability.
2.2. An Upper Bound on the Number of Distinct Probability Values
We now show, as promised, that for any value of
N, the number of distinct probability values used in an optimal strategy will not exceed
. For this purpose, it is helpful to write the mutual information in yet another form. Rather than characterizing Bob’s experimental result only by the number of heads, we can think of his result as a specific sequence,
s, of heads and tails. Of course, any details of the sequence beyond the overall number of heads will not help Bob estimate
θ, but including those details helps us with the mathematics. We have:
where
is simply
for a sequence with
n heads and
is the average
. Because each toss is independent, the
N-toss entropy,
, is equal to
N times the one-toss entropy, and we can write:
where
is the binary entropy function,
. It is always optimal to include among the
s the special probabilities, zero and one, so let us fix the values
and
. To look for the other
s, as well as for the
s, we introduce a Lagrange multiplier,
λ, and define:
We now set
equal to zero for each
, and we set
equal to zero for each
. The former condition gives us:
where
is the number of heads in the sequence
s, while the latter condition yields:
Suppose now that we have found a solution,
, to Equation (
12) and Equation (
13). From
, we compute the numbers
. With the values of
fixed, consider the function:
which is defined on the interval
. (The values
and
are defined by taking the limits
and
.) Notice that Equation (
12) and Equation (
13) imply the following facts about the
s:
Thus, it must be the case that each
, including
and
, is a root of the function
, and except at the two endpoints, these roots must occur where the function has zero slope. Therefore, we can get a bound on the number of distinct probability values by finding a bound on the number of values of
x in the interval
for which
is tangent to the
x-axis. (If the maximum of
I occurs at the boundary of the allowed region of the
s, that is, at the boundary of the probability simplex, then the maximum need not satisfy Equation (
12) and Equation (
13). What this means, though, is that we have set
L to be larger than it needs to be. We can reduce the size of
L, until the maximum occurs in the interior of the simplex. Similarly, if a maximum occurs when one of the probabilities
is zero or one, we can achieve the same maximum with a smaller value of
L and with the extreme values taken only by
and
.)
Note that
is of the form
, where
is a polynomial of degree
N. We can write the second derivative of
as:
in which the numerator is also a polynomial of degree
N. Therefore,
can be zero for at most
N distinct values of
x in the interval
. Since
is equal to zero at both endpoints, each point
in the interval
for which
and
must be flanked by two points,
and
, at which the second derivative is zero, and the pairs
and
will not have a point in common if
. Thus, the number of such points
can be at most
. When we add in the roots
and
, we find that the total number
L of distinct probability values must satisfy
, which is what we wanted to show.
Looking again at
Figure 1 and
Figure 2, we see that this bound is saturated for
and
, for which
and
, respectively. However, for
, we have
, which is significantly less than
.
2.3. Letting the Number of Trials Go to Infinity
We now want to consider the limit of a large number of tosses. To do this, we find that it is more convenient to return to the form of
given in Equation (
8), in which the result of Bob’s experiment is characterized simply by the number of heads. Starting from that expression, introducing the Lagrange multiplier,
λ, as before, and setting
equal to zero, we get the condition:
(We do not need the condition
for the asymptotic calculation.) As the number of trials increases, Bob will be able to discriminate among values of
that are more and more closely spaced. We therefore expect the optimal discrete distributions analogous to the one shown in
Figure 3 to approach (in measure) a continuous distribution,
, where
is the weight assigned to an infinitesimal interval of width
around the value
p. We now aim to find this continuous distribution. We proceed by means of a simple heuristic argument. It will turn out that the function
that we find by this method agrees with what has been obtained more rigorously in [
14] and [
15]. (I confess, though, that there is still a mathematical gap—the work in [
14] and [
15] considers from the outset only continuous distributions, whereas we are now thinking of an infinite sequence of discrete distributions.)
First, as
N increases, the binomial distribution,
, given in Equation (
6), becomes highly peaked around the value
. That is, the value of
n will be largely determined by the value
. When we average
over all the values of
k, we should, therefore, find that the distribution
is very close to
. That is, the
a priori distribution of
n should closely mirror the distribution of probability values that Alice will use. (The factor
accounts for the fact that
is normalized by a sum over the values
, whereas
is normalized by an integral over the interval
.) Let us assume that for the purpose of finding the limiting distribution, we may take
to be equal to
. Consider, then, the left-hand side of Equation (
17), which we now write as:
Again, when
N is large, the function
is sharply peaked around the value
, so in the factor
, we replace
with
. Thus, Equation (
17) can be approximated as:
The sum on the right-hand side (including the negative sign) is the entropy of the binomial distribution for
N trials with probabilities
and
. For large
N, this entropy can be approximated as [
16]:
with an error that diminishes as
. Making this substitution in Equation (
19), we get that for each value of
k:
where
C is independent of
k. (Note that
is very different from
, in that
takes into account not just the weights of the values
, but also their spacing, which may vary over the interval
.) Since the values
will become very closely spaced, we conclude that the optimal weighting function, in the limit
, is of the form
. The constant,
C, is determined by the requirement that the integral of
over the interval
is unity, and we arrive at:
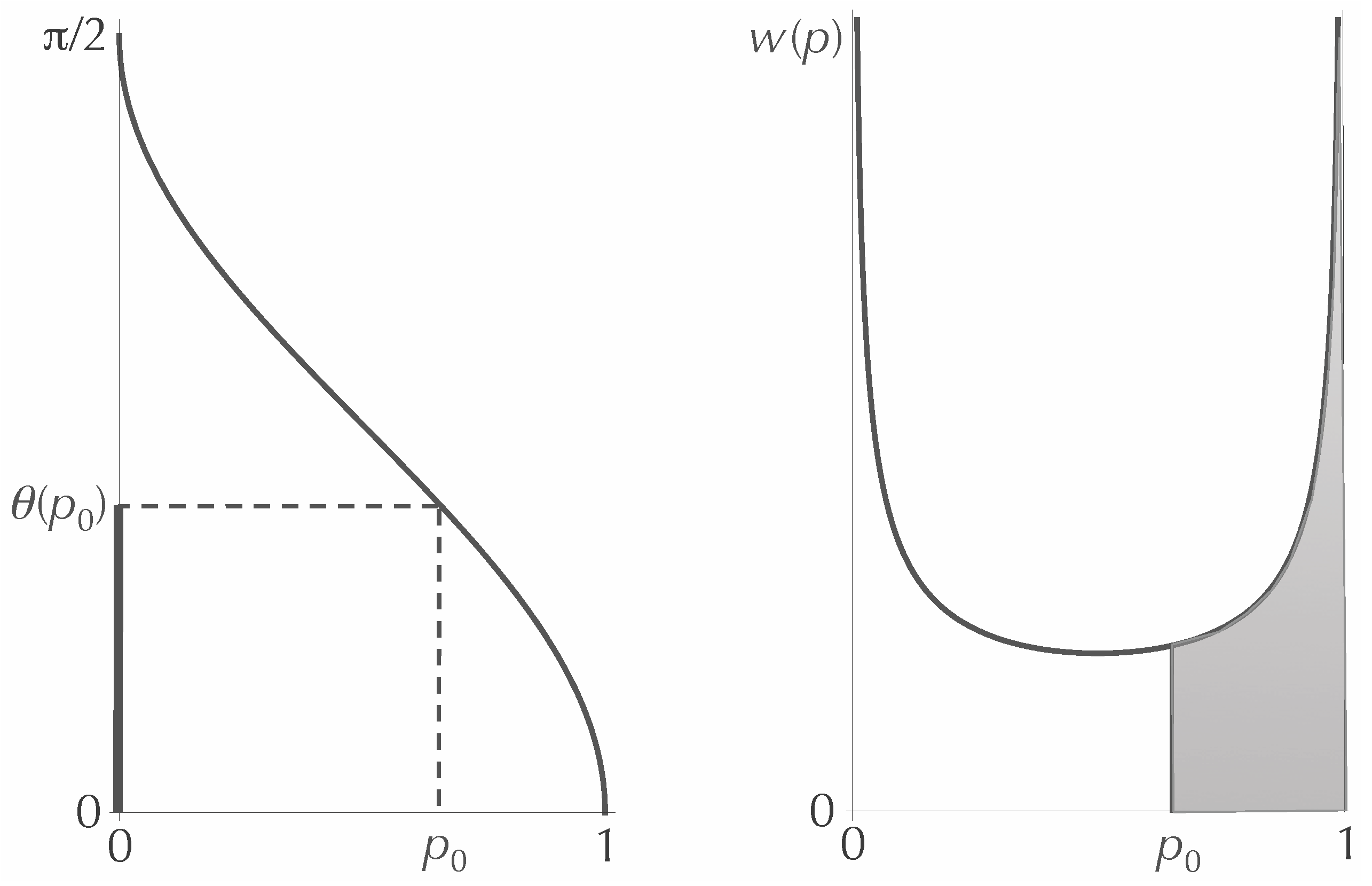
We now work out the unique non-increasing function,
, corresponding to the weighting function,
, of Equation (
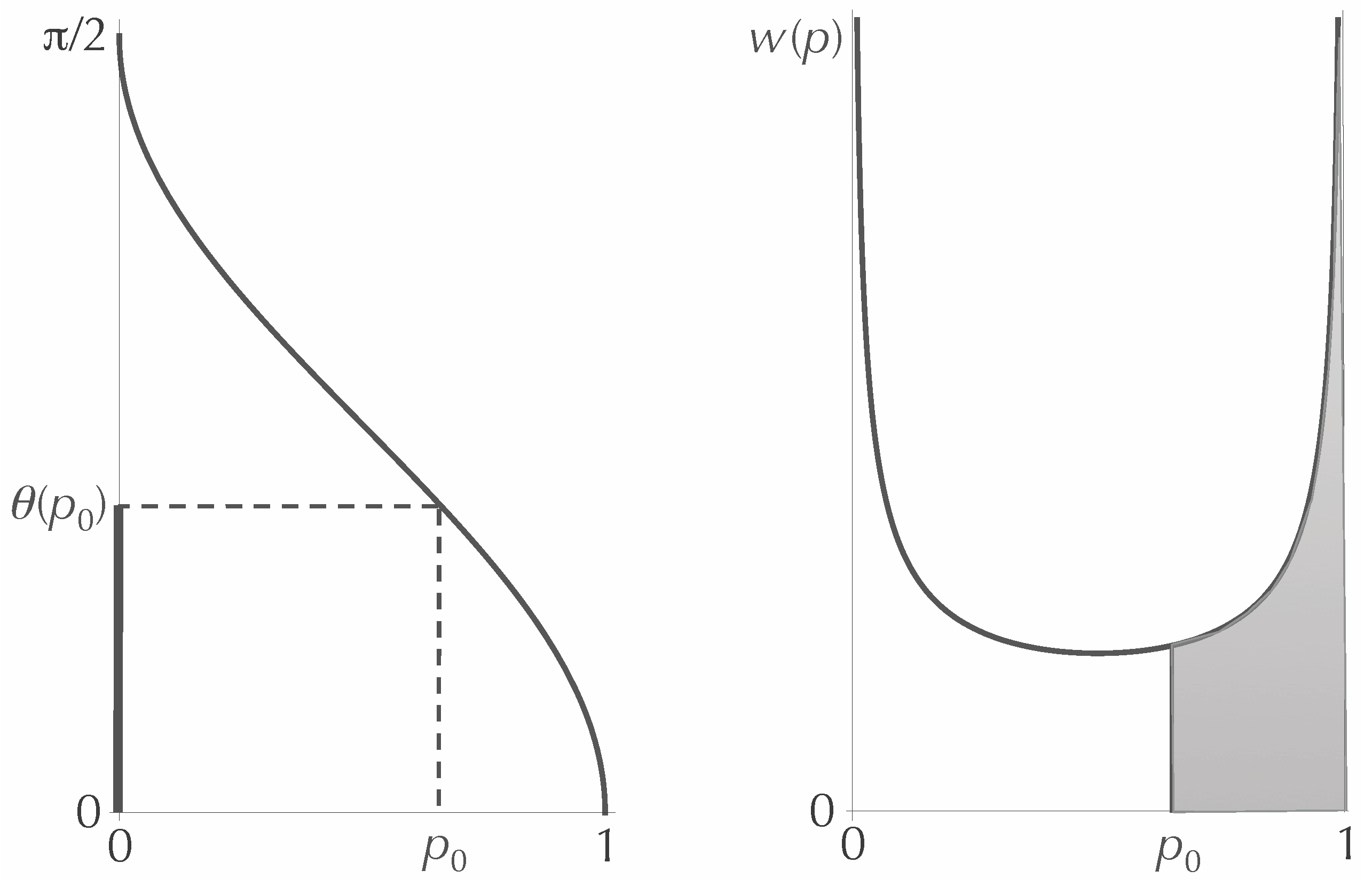
22). First, we find the inverse of
, which we call
. For any
between zero and one, the weight assigned to the interval
is the same as the fraction of the interval
that lies between zero and
(see
Figure 4). That is:
The integral can be evaluated by making the substitution
, and one finds that:
Inverting the function, we get:
That is, if Alice must convey the value of
θ by sending Bob a coin with probability
of heads, in the limit of a large number of tosses, she can convey the most information by choosing the encoding function
.
Figure 4.
The functions and . The ratio of to should be equal to the shaded area under the curve .
Figure 4.
The functions and . The ratio of to should be equal to the shaded area under the curve .
What is intriguing about this result is that the function is the one nature uses to “encode” the polarization angle, θ, of a linearly polarized photon in the probability of the vertical outcome in a horizontal vs. vertical measurement. Thus, in this particular physical situation, nature is using an optimal encoding. Note how very different the above derivation is from the usual derivation of the curve in quantum mechanics. Normally, we obtain this function by squaring the magnitude of the component of the state vector corresponding to the outcome “vertical.” However, in the above argument, there is no state vector.
One might worry that in nature, the angle of polarization is not limited to the range . In order to accommodate all the linear polarizations, we need to let θ go up to π, in which case is not a decreasing function. However, this fact does not affect the optimality of the cosine squared curve. The function maximizes the mutual information (in the limit of infinite N), even when θ ranges over the interval . It is true that with this larger interval, a given value of n will typically lead to a probability distribution over θ that has two peaks, corresponding to the two distinct values of θ for which is equal to . However, the amount of information Bob gains about θ in this case is the same as the amount he gains when his final distribution has only one peak, but extends over only half of the interval. A rough analogy is this: the amount of information one gains by learning that the value shown on a standard six-sided die is either a one or a six is the same as the amount of information one gains by learning that the value shown on a three-sided die is a one. Extending this observation, we can identify other probability functions that achieve, in the large N limit, the same optimal value of the mutual information as the function , namely, functions of the form , where m is a positive integer and θ ranges from zero to . The curve with , that is, , can be recognized as the probability of getting the outcome “vertical” in a spin measurement of a spin-1/2 particle, if the initial direction of spin makes an angle θ with the vertical.
The agreement between the solution to our communication problem and the probability law that appears in quantum theory for the case of linear polarization of photons (or for a measurement of spin for a spin-1/2 particle) might suggest the possibility of deriving at least part of the structure of quantum theory from a “principle of optimal information transfer.” Indeed, as we will see in the next section, the above result generalizes, in a straightforward way, to measurements with more than two possible outcomes. However, as I explain in the following paragraph, the project of finding such a derivation appears to be thwarted, or at least impeded, by the fact that in quantum theory, probability amplitudes are complex rather than real.
The above solution to our communication problem is optimal only under the assumption that the a priori distribution of the variable θ is the uniform distribution. Indeed, if we imagine an observer trying to ascertain the angle of polarization of a beam of linearly polarized light, it is plausible to assume a uniform prior distribution over all angles of polarization. This is the unique distribution that is invariant under rotations and reflections, which are the only unitary transformations that take linear polarizations into linear polarizations. Therefore, one can say that our assumption of a uniform distribution over θ agrees with what is natural in the case of linear polarization. However, with regard to the basic structure of quantum theory, the linear polarizations do not play any special role. They can be represented by state vectors with real components, but to get the full set of pure states, we should use complex state vectors. It is thus much more natural to assume a uniform distribution over the entire sphere of possible polarizations (including elliptical and circular polarizations) on which the linear polarizations form a great circle. (The same issue arises in the case of a spin-1/2 particle, for which the set of pure states again forms a sphere.) The uniform distribution over the sphere is the unique distribution that is invariant under all rotations of the sphere, which correspond to the full set of unitary transformations of the quantum state. Let γ be the angle on the sphere measured from the “north pole.” Then, the uniform distribution over the sphere entails a uniform distribution of the variable over the range ; or, to make the problem more similar to the case considered above, we can say that the variable is distributed uniformly over the interval . Now, according to our solution to the communication problem, the state will be expressed optimally in the probabilities of the two outcomes of an orthogonal measurement (in the limit of a large number of trials) if the probability of one of those outcomes is given by , which, as a function of γ, would be . This is not what nature actually does. If we take the two outcomes of the measurement to correspond to the north and south poles of the sphere, then the probability of the first outcome is, in real life, given by , which is not the same as and is not optimal (because γ is not uniformly distributed).
In
Section 4, we ask whether an alternative version of the problem might be more friendly toward complex amplitudes, but first, we show how the Alice-Bob communication problem generalizes to a measurement with more than two outcomes.

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}