A Relationship between the Ordinary Maximum Entropy Method and the Method of Maximum Entropy in the Mean

{kind=link}
{kind=link}
{kind=link}
Abstract
: There are two entropy-based methods to deal with linear inverse problems, which we shall call the ordinary method of maximum entropy (OME) and the method of maximum entropy in the mean (MEM). Not only does MEM use OME as a stepping stone, it also allows for greater generality. First, because it allows to include convex constraints in a natural way, and second, because it allows to incorporate and to estimate (additive) measurement errors from the data. Here we shall see both methods in action in a specific example. We shall solve the discretized version of the problem by two variants of MEM and directly with OME. We shall see that OME is actually a particular instance of MEM, when the reference measure is a Poisson Measure.1. Introduction
During the last quarter of the XIX-th century Boltzmann proposed a way to study convergence to equilibrium in a system of interacting particles through a quantity that was that was a Lyapunov functional for the dynamics of the system, and increased as the system tended to equilibrium. A related idea was used at the beginning of the XX-th century by Gibbs to propose a theory of equilibrium statistical mechanics. The difference between the approaches was in the nature of the microscopic description. In the late 1950s, Jaynes in [1] turned the idea into a variational method to determine a probability distribution given the expected value of a few random variables (observables to use the physical terminology). This procedure is called the method of maximum entropy. This methodology has proven useful in a variety of problems well removed from the standard statistical physics setup. See Kapur (1989) [2] for example, or the Kluwer Academic Press collection of Maximum Entropy and Bayesian Methods or the volume by Jaynes (2003) [3].
As it turns out, similar procedures had come up in the actuarial and statistical literature, see for example the works by Esscher (1932) [4] and by Kullback (1957) [5]. Jaynes’s procedure was further extended in Decarreau et al. (1992) [6], and Dacunha-Castelle and Gamboa (1990) [7]. Such extension has proven a powerful tool to deal with linear inverse problems with convex constraints. See Gzyl and Velásquez (2011) [8] for example. This method uses the standard variational technique as a stepping stone in a peculiar way.
Besides providing a more general type of solutions to the OME problem, we shall verify in two different ways that the standard solution of the OME is actually a particular case of the more general MEM approach to solve linear inverse problems with convex constraints.
The paper is organized as follows. In the remainder of this section we shall state the two problems whose solutions we want to relate. These consists in obtaining a positive, continuous function satisfying some integral constraints. In the next section we shall recall the basics of MEM. In section three we continue with the same theme and examine specific choices of set up to implement the method. Section 4 is devoted to the issue of obtaining the problem by the OME from the solution by the MEM.
In section five we implement both approaches numerically to compare their performance in one simple example. The idea of using two different choices of prior is to emphasize the flexibility of the MEM.
1.1. Statement of the First Problem
Even though the problem considered is not in its most general form, it is enough for our purposes and can be readily extended. We want to find a continuous positive function x(t) : [0, 1] → [0, ∞) such that
1.2. Statement of the Second Problem
Clearly Equation (1) is a particular case of the following more general problem: Let k(s, t) : [a, b] × [0, 1] → ℝ. Let ⊂ ([0, 1]) be a cone contained in the class of continuous functions, and let m(s) : [a, b] → ℝ be some continuous function. We want to find x(t) ∈ satisfying the integral constraints
We remark that when x(t) is a density and k(s, t) ≡ 1, them m(s) ≡ 1. Clearly the integral constraints could be incorporated into , but it is convenient to keep both separated. For what comes below, and to relate to the first problem, we shall restrict ourselves to the convex set of continuous density functions. Such type of problems were considered for example in [9] or in much grater generality in [10] or and more recently in [11] where applications and further references to related work are collected. As mentioned above, the setup can be relaxed considerable at the expense of technicalities. For example, one can consider the kernel k to be defined on the product S1 × S2 of two locally compact, separable metric spaces, and dt could be replaced by some σ–finite measure ν(dt) on (S2, (S2)). But let us keep it as simple as possible.
2. The Maximum Entropy in the Mean Approach
The basic intuition behind the MEM goes as follows. We search for a stochastic process with independent increments {X(t)|t ∈ [0, 1]} defined on some auxiliary probability space (Ω, , Q) such that
As we want to implement the scheme numerically, it is more convenient to discretize Equation (2) and then to bring in the MEM. It is at this point where the regularity properties of k(s, t) and x(t) come in to make life easier. Consider a partition of [a, b] into M equal adjacent intervals and a partition of [0, 1] into N adjacent intervals. Let {si|i = 1, ..., M} and respectively {tj|j = 1, ..., N} be the center points of those intervals. Let us set Aij = A(i, j) = k(si, tj). Also, set xj ≡ x(j) = x(tj)/N and finally mi ≡ m(i) = m(si).
Comment We chose xj = x(tj)/N because when x(t) is a density, we want its discretized version to satisfy ∑j xj = 1.
With these changes, the discretized version of the second problem becomes: Given M real numbers mi : i = 1, ..., M, determine positive numbers xj : j = 1, ..., N such that
3. Solution of Equation (7) by MEM
The notation will be as at the end of the previous section. For the purpose of comparison, we shall solve Equation (7) using two different measures. First we shall consider a product of exponential distributions on Ω and then we shall consider a product of Poisson distributions. Let us first develop the generic procedure, and then particularize for each choice of reference measure.
At this point we mention that the only requirement on the reference measure is the following:
Assumption We shall require the closure of the convex hull generated by the support of Q to be exactly Ω.
Let us consider the convex set (Q) = {P measure on(Ω, ), P << Q} on which we define the following concave functional
Lemma 3.1. Suppose that P, Q and R are probability measures on (Ω, ) such that P << Q, P << R and R << Q, then SR(P) ≤ 0, and
We want to consider the following consequence of this lemma. Let us define R by dRλ(ξ) = ρλ(ξ)dQ(ξ) where
The idea behind the maximum entropy method, comes from the realization that for such R, when P satisfies the constraints, substituting Equation (10) in the integral term in Equation (9), we obtain that
Proposition 3.1. Suppose that a measure P satisfying (7) exists and that the minimum of Σ(λ) is reached at λ* in the interior of {λ ∈ ℝM |Z(λ) < ∞}, then the probability P* that maximizes SQ(P) and satisfies Equation (7) is given by
Let us now examine two possible choices for Q.
3.1. Exponential Reference Measure
Since we want positive xj, we shall first try all factor q(dξ) = μe−μξdξ, which has [0, ∞) as support. A simple computation yields that
3.2. Poisson Reference Measure
This time, instead of a product of exponentials, we shall consider a product of Poisson measures, i.e., we take
3.3. The MEM Approach to the Original Problem
Consider Equation (1) again. This time we shall consider a Poisson point process on ([0, 1], ([0, 1]) with intensity dt. By this we mean a base probability space (Ω, , Q) on which a collection of random measures {N(A) : A ∈ ([0, 1])} (the point process) is given, which has the following properties:
- (1)
N(A) is a Poisson random variable with intensity (mean)|A|,
- (2)
Q – almost everywhere A → N(A) is an integer valued measure
- (3)
For any disjoint A1, ..., Ak the N(A1), ..., N(Ak) are independent
From these, it is clear that for any λ ∈ ℝM the random variable , k(t) > N(dt) satisfies
4. OME from MEM
4.1. Discrete Case
We shall now relate the last result to the standard (ordinary) method of maximum entropy. Suppose that the unknown quantities xj in Equation (3) are indeed probabilities, and that m1 = 1 and A1j = 1 for all j = 1, ..., N. It is easy to verify using the first equation of the set Equation (3) that where λr = (λ2, ..., λM) and
4.2. Continuous Case as Limit of the Discrete Case
This is the second place in which our discretization procedure enters. First rewriteEquation (15) as x*(tj)/N, from which Equation (15) becomes
For each N denote by Aj(N) the blocks of the partition of [0, 1], and suppose that the partitions refine each other as N increases (consider dyadic partitions for example). For each N denote the maxentropic solution described in Equation (17) by and define the piecewise constant (continuous) density
4.3. The Full Continuous Case
Here we show how to obtain the OME solution to Equation (1) from the MEM solution Equation (16) without the labor described in the previous section. The argument is similar to the one mentioned above. As k1(t) = 1, we can isolate and rewrite as
5. Numerical Examples
To compare the output of the three methods, we consider a simple example in which the data consists in a few values of the Laplace transform of the density of a Γ(a, b) density. Observe that if S denotes the original random variable, then T = e−S denotes the corresponding random variable with range mapped onto [0, 1]. The values of the Laplace transform of S are the fractional (non-necessarily integer) moments of T. The maxentropic methods yield the density x(t) of T, from which the density of S is to be obtained by the change of variable fS(s) = e−sx(e−s).
If we let {α1 = 0, α2, ..., αM} and ki(t) = tαi be M given powers of T, the corresponding moments to be used in Equation (1) are mi = (b/(αi + b))a, with m1 = 1. To be specific, let us consider a = b = 1, and α2 = 1/5, α3 = 1/4, α4 = 1/3, α5 = 1/2, α6 = 5, α7 = 10, α8 = 15, α9 = 20 from which we readily obtain the values of the 9 generalized moments mi. To finish, we take N = 100 partition points of [0, 1].
5.1. Exponential Reference Measure
We shall set μ = 10 as a number high enough so that the positivity conditions mentioned in Section (3.1) holds. The function to be minimized to determine the λs is
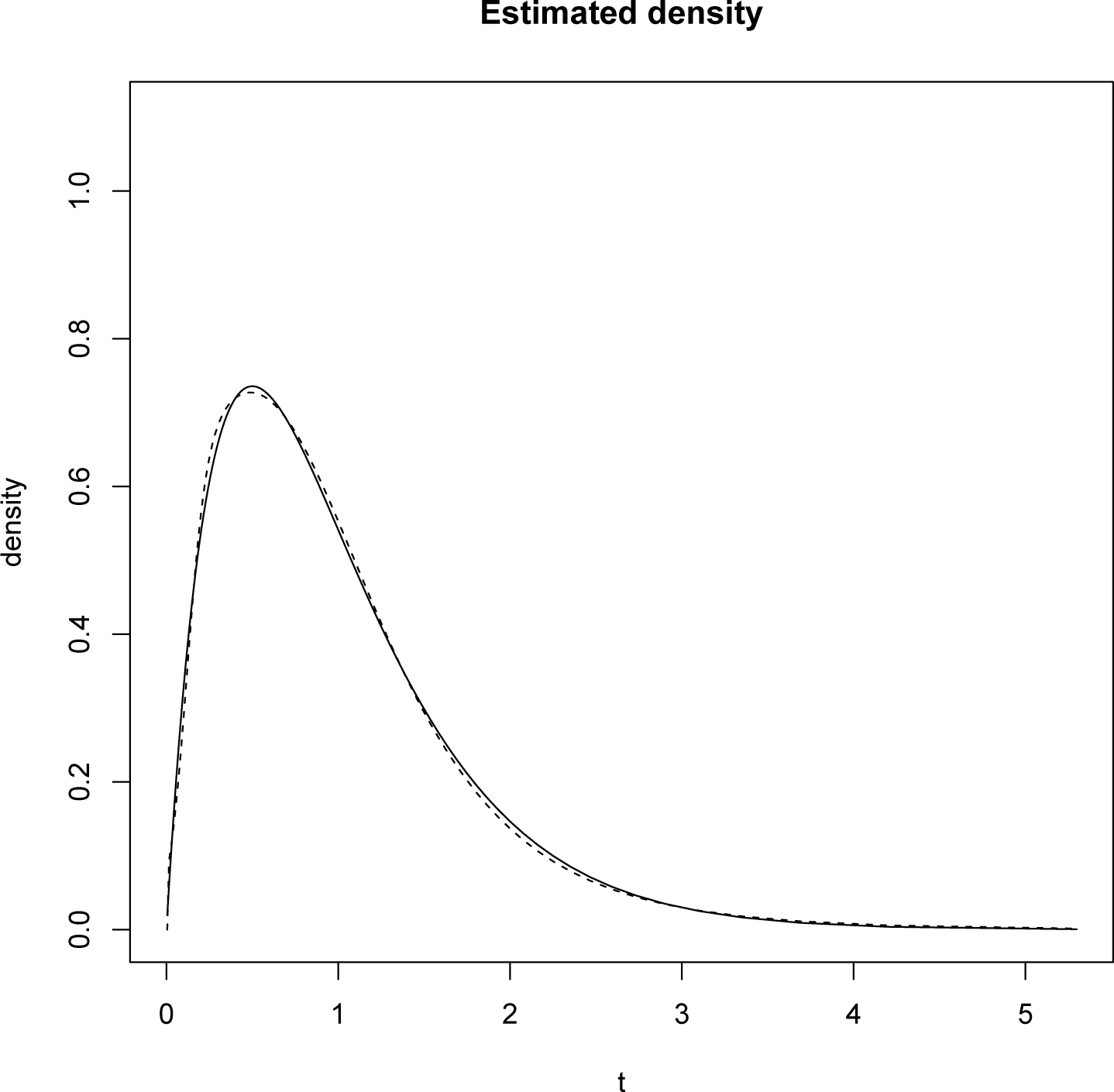
To find the minimizer, we use the Barzilai-Borwein code available for R, see [15]. Once the optimal λ is obtained it is inserted in Equation (14). That is the density of T on [0, 1]. To plot the density on [0, ∞) we perform the change of variables mentioned above and the result is plotted in the Figure 1.
We point out that the L1 norm of the difference between the reconstructed and the original densities is 0.0283 rounding at the fourth decimal place.
5.2. The Poisson Reference Measure
In reference to the setup of Section 3.3 we set μ = 5 this time. The function to be minimized this time is
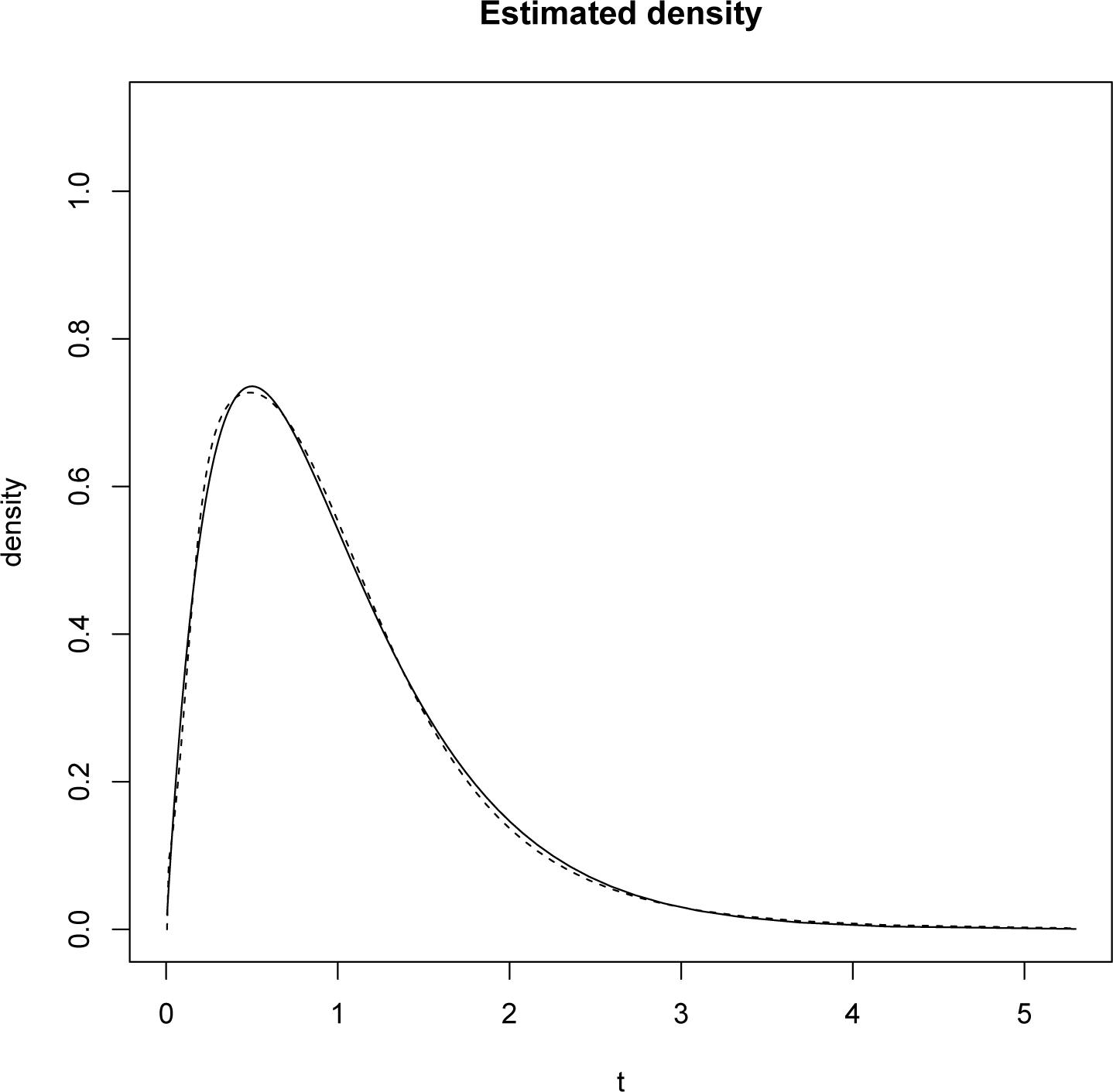
Once the minimizing λ* has been found, the routine is as above: the density on [0, 1] is mapped onto a density on [0, ∞) by means of a change of variables. The result obtained is displayed on Figure 2.
The L1 norm of the difference between the reconstructed and the original densities is 0.00524.
5.3. The OME Method
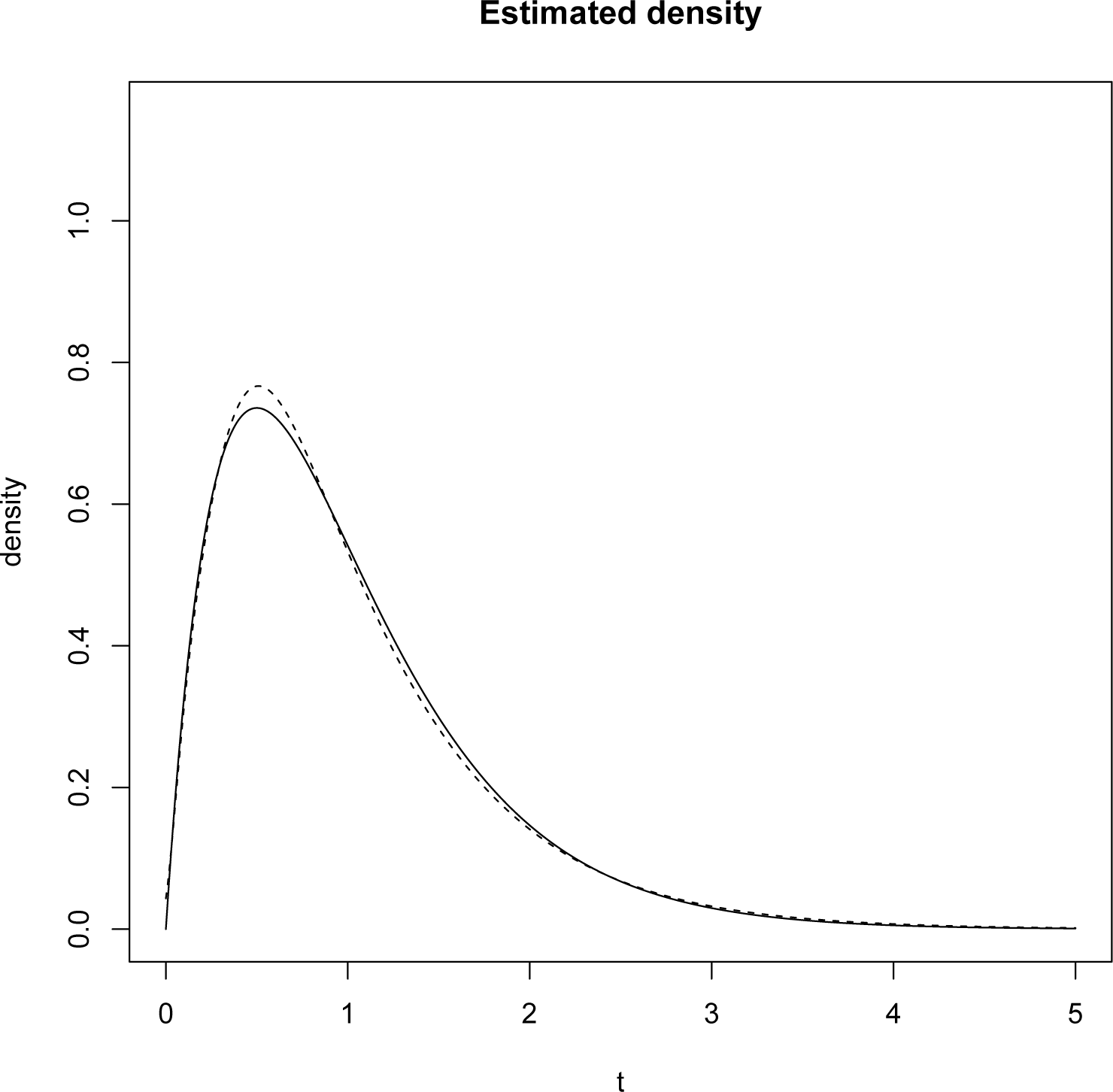
In this case, to determine λ* we have to minimize
The L1 norm of the difference between the reconstructed and the original densities is 0.03479.
Acknowledgments
We greatly appreciate the comments by the referees. They certainly contributed to improve our presentation.
Conflicts of Interest
The authors declare no conflicts of interest.
Bibliographycal Comment
The literature on the OME method is very large, consider this journal for example. Even though the literature on the MME method is not that large, we cited only a few foundational papers and a very small sample of recent papers that apply the method to interesting problems.
References
- Jaynes, E. Information theory and statistical physics. Phys. Rev 1957, 106, 171–197. [Google Scholar]
- Kapur, J. Maximum Entropy Models in Science and Engineering; Wiley Eastern Ltd.: New Delhi, India, 1989. [Google Scholar]
- Jaynes, E. Probability Theory: The Logic of Science; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Escher, F. On the probability function in the collective theory of risk. Scan. Aktuarietidskr 1932, 15, 175–195. [Google Scholar]
- Kullback, S. Information Theory and Statistics; Dover Pubs: New York, NY, USA, 1968. [Google Scholar]
- Decarreau, A.; Hilhorst, D.; Demarechal, C.; Navaza, J. Dual Methods in Entropy Maximization. Application to Some Problems in Crystallography. SIAM J. Optim 1992, 2, 173–197. [Google Scholar]
- Dacunha-Castelle, D.; Gamboa, F. Maximum d’entropie et problème des moments. Ann. Inst. Henri Poincaré 1990, 26, 567–596. [Google Scholar]
- Gzyl, H.; Velásquez, Y. Linear Inverse Problems: The Maximum entropy Connection; World Scientific Pubs: Singapore, Singapore, 2011. [Google Scholar]
- Gzyl, H. Maxentropic reconstruction of Fourier and Laplace transforms under non-linear constraints. Appl. Math. Comput 1995, 25, 117–126. [Google Scholar]
- Gamboa, F.; Gzyl, H. Maxentropic solutions of linear Fredholm equations. Math. Comput. Model 1997, 25, 23–32. [Google Scholar]
- Gallon, S.; Gamboa, F.; Loubes, M. Functional Calibration estimation by the maximum entropy in the mean principle. 2013. arXiv: 1302.1158[math.ST].. [Google Scholar]
- Csiszar, I. I-divergence geometry of probability distributions and minimization problems. Ann. Probab 1975, 3, 148–158. [Google Scholar]
- Csiszar, I. Generalized I-projection and a conditional limit theorem. Ann. Probab 1984, 12, 768–793. [Google Scholar]
- Cherny, A.; Maslov, V. On minimization and maximization of entropy functionals in various disciplines. Theory Probab. Appl 2003, 17, 447–464. [Google Scholar]
- Varadhan, R.; Gilbert, P. An R package for solving large system of nonlinear equations and for optimizing a high dimensional nonlinear objective function. J. Stat. Softw 2009, 32, 1–26. [Google Scholar]



© 2014 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Gzyl, H.; Ter Horst, E. A Relationship between the Ordinary Maximum Entropy Method and the Method of Maximum Entropy in the Mean. Entropy 2014, 16, 1123-1133. https://doi.org/10.3390/e16021123
Gzyl H, Ter Horst E. A Relationship between the Ordinary Maximum Entropy Method and the Method of Maximum Entropy in the Mean. Entropy. 2014; 16(2):1123-1133. https://doi.org/10.3390/e16021123
Chicago/Turabian StyleGzyl, Henryk, and Enrique Ter Horst. 2014. "A Relationship between the Ordinary Maximum Entropy Method and the Method of Maximum Entropy in the Mean" Entropy 16, no. 2: 1123-1133. https://doi.org/10.3390/e16021123
APA StyleGzyl, H., & Ter Horst, E. (2014). A Relationship between the Ordinary Maximum Entropy Method and the Method of Maximum Entropy in the Mean. Entropy, 16(2), 1123-1133. https://doi.org/10.3390/e16021123