Transfer Entropy Expressions for a Class of Non-Gaussian Distributions


{kind=link}
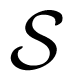{kind=link}
1. Introduction
Granger causality is a well-known concept based on dynamic co-dependence [1]. In the framework of Granger causality, the cause precedes and contains unique information about the effect. The concept of Granger causality has been applied in a wide array of scientific disciplines from econometrics to neurophysiology, from sociology to climate research (see [2,3] and references therein), and most recently in cell biology [4].
Information theory has increasingly become a useful complement to the existing repertoire of methodologies in mathematical statistics [5,6]. Particularly, in the area of Granger causality, transfer entropy [7], an information theoretical measure of co-dependence based on Shannon entropy, has been applied extensively in non-parametric analysis of time-resolved causal relationships. It has been shown that (conditional) mutual information measured in nats and transfer entropy coincide in definition [8–10]. Moreover, for Gaussian-distributed variables, there is a tractable equivalence by a factor of two between transfer entropy and a linear test statistic for Granger causality [11]. Although similar equivalences for non-Gaussian variables have been given in [8], it should be remarked that such equivalences cannot be generalized to non-Gaussian distributions as the linear models underlying the construction of linear test statistics for Granger causality are rendered invalid under assumptions of non-Gaussianity.
The aim of this paper is to present closed-form expressions for transfer entropy for a number of non-Gaussian, unimodal, skewed distributions used in the modeling of occurrence rates, rare events and ‘fat-tailed’ phenomena in biological, physical and actuarial sciences [12]. More specifically, we will derive expressions for transfer entropy for the multivariate exponential, logistic, Pareto (type –
 ) and Burr distributions. As for real-world applications, the exponential distribution is the naturally occurring distribution for describing inter-arrival times in a homogeneous Poisson process. In a similar manner, the exponential distribution can be used to model many other change of state scenarios in continuous settings, e.g., time until the occurrence of an accident given certain specifications. The logistic distribution is of great utility given its morphological similarity to the Gaussian distribution and is frequently used to model Gaussian-like phenomena in the presence of thicker distribution tails. The Pareto distribution (in either of its forms) is used in modeling of size related phenomena such as size of incurred casualties in non-life insurance, size of meteorites, and size of trafficked files over the Internet. The Burr distribution is another distribution used in non-life insurance to model incurred casualties, as well as in econometrics where it is used to model income distribution.
) and Burr distributions. As for real-world applications, the exponential distribution is the naturally occurring distribution for describing inter-arrival times in a homogeneous Poisson process. In a similar manner, the exponential distribution can be used to model many other change of state scenarios in continuous settings, e.g., time until the occurrence of an accident given certain specifications. The logistic distribution is of great utility given its morphological similarity to the Gaussian distribution and is frequently used to model Gaussian-like phenomena in the presence of thicker distribution tails. The Pareto distribution (in either of its forms) is used in modeling of size related phenomena such as size of incurred casualties in non-life insurance, size of meteorites, and size of trafficked files over the Internet. The Burr distribution is another distribution used in non-life insurance to model incurred casualties, as well as in econometrics where it is used to model income distribution.
The specific choice of these distributions is contingent upon the existence of unique expressions for the corresponding probability density functions and Shannon entropy expressions. A counter-example is given by the multivariate gamma distribution, which although derived in a number of tractable formats under certain preconditions [12,13], lacks a unique and unequivocal multivariate density function and hence a unique Shannon entropy expression.
Another remark shall be dedicated to stable distributions. Such distributions are limits of appropriately scaled sums of independent and identically distributed variables. The general tractability of distributions with this property lies in their “attractor” behavior and their ability to accommodate skewness and heavy tails. Other than the Gaussian distribution (stable by the Central Limit Theorem), the Cauchy-Lorentz distribution and the Lévy distribution are considered to be the only stable distributions that can be expressed analytically. However, the latter lacks analytical expressions for Shannon entropy in the multivariate case. Expressions for Shannon entropy and transfer entropy for the multivariate Gaussian distribution have been derived in [14] and [11], respectively. Expressions for Shannon entropy and transfer entropy for the multivariate Cauchy-Lorentz distribution can be found in the Appendix.
As a brief methodological introduction, we will go through a conceptual sketch of Granger causality, the formulation of the linear models underlying the above-mentioned test statistic, and the definition of transfer entropy before deriving the expressions for our target distributions.
2. Methods
Employment of Granger causality is common practice within cause-effect analysis of dynamic phenomena where the cause temporally precedes the effect and where the information embedded in the cause about the effect is unique. Formulated using probability theory, under H0, given k lags and the random variables A and B and the set of all other random variables C in any arbitrary system, B is said to not Granger-cause A at observation index t, if
where ⫫ denotes probabilistic independence. Henceforth, for the sake of convenience, we implement the following substitutions: X = At, and . It is understood that all formulations in what follows are compatible with any multivariate setting. Thus, one can parsimoniously reformulate the hypothesis in Equation (1) as:
The statement above can be tested by comparing the two conditional probability densities: fX|Z and fX|Y Z [15].
2.1. Linear Test Statistics
In parametric analysis of Granger causality, techniques of linear regression have been the dominant choice. Under fulfilled assumptions of ordinary least squares’ regression and stationarity, the hypothesis in Equation (2), can be tested using the following models:
where the β and γ terms are the regression coefficients, and the residuals ε and η are independent and identically distributed following a centered Gaussian N(0, σ2). Traditionally, the F-distributed Granger-Sargent test [1], equivalent to the structural Chow test [16], has been used to examine the statistical significance of the reduction in residual sum of squares in the latter model compared to the former. In this study however, we will focus on the statistic G(X, Y |Z) = ln(Varε/Varη) [11,17]. This statistic is χ2-distributed under the null hypothesis, and non-central χ2-distributed under the alternate hypothesis. There are two types of multivariate generalizations of G(X, Y |Z); one by means of total variance, using the trace of covariance matrices [18], and one by generalized variance, using the determinant of covariance matrices [11,17]. For a thorough discussion on the advantages of either measure we refer the reader to [18,19]. Choosing the latter extension, the test statistic in G(X, Y |Z) can be reformulated as:
where the last equality follows the scheme presented in [11].
2.2. Transfer Entropy
Transfer entropy, a non-parametric measure of co-dependence is identical to (conditional) mutual information measured in nats (using the natural logarithm). Mutual information is a basic concept, based on the most fundamental measure in information theory, the Shannon entropy, or, more specifically, the differential Shannon entropy in the case of continuous distributions. The differential Shannon entropy of a random variable S with a continuous probability density fS with support on
 is
is
where b is the base of the logarithm determining the terms in which the entropy is measured; b = 2 for bits and b = e for nats [14,20]. The transfer entropy for the hypothesis in Equation (2) is defined as [7]:
Interestingly, for Gaussian variables one can show that G(X, Y |Z) = 2 · T(Y → X|Z) [11]. Naturally, such equivalences fail when using other types of distributions that do not meet the requirements of linear models used to construct G(X, Y |Z).
In the following, we shall look at closed-form expressions for transfer entropy for the multivariate exponential, logistic, Pareto (type –
) and Burr distributions. Before deriving the results, it should be noted that all marginal densities of the multivariate density functions in this study are distributed according to the same distribution; i.e., the marginal densities of a multivariate exponential density are themselves exponential densities.
3. Results
In this section we will derive the expression for transfer entropy for the multivariate exponential distribution. The remaining derivations follow an identical scheme and are presented in the Appendix. The differential Shannon entropy expressions employed in this study can be found in [21].
The multivariate exponential density function for a d-dimensional random vector S is:
where S ∈ ℝd, si > λi, θi > 0 for i = 1, ..., d and α > 0. For the multivariate exponential distribution the differential Shannon entropy of S is:
Thus, transfer entropy for a set of multivariate exponential variables can be formulated as:
which, after simplifications, reduces to
where dX represents the number of dimensions in X, and where α is the multivariate distribution parameter. As stated previously, the expression in Equation (11) holds for the multivariate logistic, Pareto (type –
) and Burr distributions as proven in the Appendix. For the specific case of dX = dY = dZ = 1, the transfer entropy expression reduces to:
In any regard, T(Y → X|Z) depends only on the number of involved dimensions and the parameter α. The latter parameter, α, operates as a multivariate distribution feature and does not have a univariate counterpart. This result indicates that the value assigned to the conditional transfer of information from the cause to the effect decreases with increasing values of α. However, the impact of the multivariate distribution parameter α in this decrease, shrinks rather rapidly as the numbers of dimensions increase.
4. Conclusions
The distributions discussed in this paper are frequently subject to the modeling of natural phenomena, and utilized frequently within biological, physical and actuarial engineering. Events distributed according to any of the discussed distributions are not suitable for analysis using linear models and require non-parametric models of analysis or transformations where feasible.
The focus of this paper has been on non-parametric modeling of Granger causality using transfer entropy. Our results show that the expressions for transfer entropy for the multivariate exponential, logistic, Pareto (type –
) and Burr distributions coincide in definition and are dependent on the multivariate distribution parameter α, and the number of dimensions. In other words, the transfer entropy expressions are independent of other parameters of the multivariate distributions.
As underlined by our result, the value of transfer entropy depends in a declining manner on the multivariate distribution parameter α as the number of dimensions increase.
Acknowledgments
The authors wish to thank John Hertz for insightful discussions and feedback. MJM has been supported by the Magnussons Fund at the Royal Swedish Academy of Sciences and the European Unions Seventh Framework Programme (FP7/2007-2013) under grant agreement #258068, EU-FP7-Systems Microscopy NoE. MJM and JT have been supported by the Swedish Research Council grant #340-2012-6011.
Conflicts of Interest
The authors declare no conflicts of interest.
- Author ContributionsMehrdad Jafari-Mamaghani and Joanna Tyrcha designed, performed research and analyzed the data; Mehrdad Jafari-Mamaghani wrote the paper. All authors read and approved the final manuscript.
References
- Granger, C.W.J. Investigating causal relations by econometric models and cross-spectral methods. Econometrica 1969, 37, 424–438. [Google Scholar]
- Hlaváčková-Schindler, K.; Paluš, M.; Vejmelka, M.; Bhattacharya, J. Causality detection based on information-theoretic approaches in time series analysis. Phys. Rep 2007, 441, 1–46. [Google Scholar]
- Guo, S.; Ladroue, C.; Feng, J. Granger Causality: Theory and Applications. In Frontiers in Computational and Systems Biology; Springer: Berlin/Heidelberg, Germany, 2010; pp. 83–111. [Google Scholar]
- Lock, J.G.; Jafari-Mamaghani, M.; Shafqat-Abbasi, H.; Gong, X.; Tyrcha, J.; Strömblad, S. Plasticity in the macromolecular-scale causal networks of cell migration. PLoS One 2014, 9, e90593. [Google Scholar]
- Soofi, E.S. Principal information theoretic approaches. J. Am. Stat. Assoc 2000, 95, 1349–1353. [Google Scholar]
- Soofi, E.S.; Zhao, H.; Nazareth, D.L. Information measures. Wiley Interdiscip. Rev. Comput. Stat 2010, 2, 75–86. [Google Scholar]
- Schreiber, T. Measuring information transfer. Phys. Rev. Lett, 2000, 85. http://dx.doi.org/10.1103/PhysRevLett.85.461. [Google Scholar]
- Hlaváčková-Schindler, K. Equivalence of Granger causality and transfer entropy: A generalization. Appl. Math. Sci 2011, 5, 3637–3648. [Google Scholar]
- Seghouane, A.-K.; Amari, S. Identification of directed influence: Granger causality, Kullback-Leibler divergence, and complexity. Neural Comput 2012, 24, 1722–1739. [Google Scholar]
- Jafari-Mamaghani, M. Non-parametric analysis of Granger causality using local measures of divergence. Appl. Math. Sci 2013, 7, 4107–4136. [Google Scholar]
- Barnett, L.; Barrett, A.B.; Seth, A.K. Granger causality and transfer entropy are equivalent for Gaussian variables. Phys. Rev. Lett 2009, 103, 238701. [Google Scholar]
- Johnson, N.L.; Kotz, S.; Balakrishnan, N. Continuous Multivariate Distributions, Models and Applications; Volume 1, Wiley: New York, NY, USA, 2002. [Google Scholar]
- Furman, E. On a multivariate gamma distribution. Stat. Probab. Lett 2008, 78, 2353–2360. [Google Scholar]
- Cover, T.M.; Thomas, J.A. Elements of information theory; Wiley: New York, NY, USA, 1991. [Google Scholar]
- Florens, J.P.; Mouchart, M. A note on noncausality. Econometrica 1982, 50, 583–591. [Google Scholar]
- Chow, G.C. Tests of equality between sets of coefficients in two linear regressions. Econometrica 1960, 28, 591–605. [Google Scholar]
- Geweke, J. Measurement of linear dependence and feedback between multiple time series. J. Am. Stat. Assoc 1982, 77, 304–313. [Google Scholar]
- Ladroue, C.; Guo, S.; Kendrick, K.; Feng, J. Beyond element-wise interactions: Identifying complex interactions in biological processes. PLoS One 2009, 4, e6899. [Google Scholar]
- Barrett, A.B.; Barnett, L.; Seth, A.K. Multivariate Granger causality and generalized variance. Phys. Rev. E 2010, 81, 041907. [Google Scholar]
- Shannon, C.E. A mathematical theory of communication. Bell Syst. Tech. J 2001, 1, 3–55. [Google Scholar]
- Zografos, K.; Nadarajah, S. Expressions for Rényi and Shannon entropies for multivariate distributions. Stat. Prob. Lett 2005, 71, 71–84. [Google Scholar]
- Abe, S.; Rajagopal, A.K. Information theoretic approach to statistical properties of multivariate Cauchy-Lorentz distributions. J. Phys. A 2001, 34. [Google Scholar] [CrossRef]
A. Appendix
A.1. Multivariate Logistic Distribution
The multivariate logistic density function for a d-dimensional random vector S is:
with S ∈ ℝd, θi > 0 for i = 1, ..., d and α > 0. For the multivariate logistic distribution the differential Shannon entropy of S is:
where is the digamma function. Thus, the transfer entropy for the multivariate logistic distribution can be formulated as:
which, after simplifications, using the identity
reduces to
A.2. Multivariate Pareto Distribution
The multivariate Pareto density function of type –
for a d-dimensional random vector S is:
with S ∈ ℝd, si > μi, γi > 0 and θi > 0 for i = 1, ..., d and α > 0. Other types of the multivariate Pareto density function are obtained as follows:
Pareto by setting α = 1 in Equation (18).
Pareto by setting γi = 1 in Equation (18).
Pareto by setting γi = 1 and μi = θi in Equation (18).
For the multivariate Pareto distribution in Equation (18) the differential entropy of S is:
Thus, the transfer entropy for the multivariate Pareto density function of type –
can be formulated as:
which, after simplifications, reduces to
A.3. Multivariate Burr Distribution
The multivariate Burr density function for a d-dimensional random vector S is:
with S ∈ ℝd, si > 0, ci > 0, di > 0 for i = 1, ..., n and α > 0. For the multivariate Burr distribution the differential entropy of S is:
Thus, the transfer entropy for the multivariate Burr distribution can be formulated as:
which, after simplifications, reduces to
B. Appendix
B.1. Multivariate Cauchy-Lorentz Distribution
The multivariate Cauchy-Lorentz density function for a d-dimensional random vector S is:
for S ∈ ℝd. Interestingly, Equation (26) is equivalent to the multivariate t-distribution with one degree of freedom, zero expectation, and an identity covariance matrix [21]. For the case of d = 1, Equation (26) reduces to the univariate Cauchy-Lorentz density function [22]. The differential entropy of S is:
Thus, the transfer entropy T(Y → X|Z) for the multivariate Cauchy-Lorentz distribution can be formulated as:
which, after simplifications, using the identity in Equation (16), reduces to
where
is obtained after a simplification of the digamma function.
© 2014 by the authors; licensee MDPI, Basel, Switzerland This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Jafari-Mamaghani, M.; Tyrcha, J. Transfer Entropy Expressions for a Class of Non-Gaussian Distributions. Entropy 2014, 16, 1743-1755. https://doi.org/10.3390/e16031743
Jafari-Mamaghani M, Tyrcha J. Transfer Entropy Expressions for a Class of Non-Gaussian Distributions. Entropy. 2014; 16(3):1743-1755. https://doi.org/10.3390/e16031743
Chicago/Turabian StyleJafari-Mamaghani, Mehrdad, and Joanna Tyrcha. 2014. "Transfer Entropy Expressions for a Class of Non-Gaussian Distributions" Entropy 16, no. 3: 1743-1755. https://doi.org/10.3390/e16031743