2.1. Motivation
As previously mentioned, air traffic management of the future will make an intensive use of 4D trajectories as a basic object. Full automation is a far-reaching concept that will probably not be implemented before 2040–2050, and even in such a situation, it will be necessary to keep humans in the loop so as to gain a wide societal acceptance of the concept. Starting from SESAR or Nextgen initial deployment and aiming towards this ultimate objective, a transition phase with human-system cooperation will take place. Since ATC controllers are used to a well-structured network of routes, it is advisable to post-process the 4D trajectories issued by automated systems in order to make them as close as possible to line segments connecting beacons. To perform this task, in an automatic way, flight paths will be deformed so as to minimize an entropy criterion that enforces avoidance of low density areas and at the same time penalizes length. Compared to already available bundling algorithms [
3] that tend to move curves to high density areas, this new procedure generates geometrically-correct curves, without excess curvature.
Let a set of smooth curves be given that will be aircraft flight paths for the air traffic application. It will be assumed in the sequel that all curves are smooth mappings from to a domain Ω of with everywhere non-vanishing derivatives in . This last condition allows one to view them as smooth immersions with boundaries and is sound from the application point of view, as aircraft velocities are bounded below by the efficiency consideration and ultimately by the stall and, therefore, cannot vanish expect at the endpoints. In air traffic applications, the dimension of the state space is generally two and sometimes three when the evolution of the aircraft in the vertical plane is of interest.
The approach taken in this work is first to get a sound definition of spatial density associated with a curve system, then to derive from it an entropy that will be minimized.
2.2. Spatial Density of a System of Curves
Due to the fact that aircraft positions are acquired through radar measurements, a trajectory is known only at discrete sampling times. In the operational context, the sampling period ranges from 4 to 10 s, which corresponds roughly to a 100–250-m traveling distance. Derived from that, a classical performance indicator used in ATM is the aircraft density [
4], obtained from the sampled positions
on each flight path
. It is constructed from a partition
of Ω by counting the number of samples occurring in a given
, then dividing out by the total number of samples
. More formally, the density
in the subset
of Ω is expressed as:
with
the characteristic function of the set
. It seems natural to extend the density obtained from samples to another one based on the trajectories themselves using an integral form:
where the normalizing constant
λ is chosen so that
is a discrete probability distribution:
and since
is a partition:
so that
.
Density can be viewed as an empirical probability distribution with the
considered as bins in an histogram. It is thus natural to extend the above computation so as to give rise to a continuous distribution on Ω. For that purpose, local weighting techniques, such as kernel density estimation methods, are well known in nonparametric statistics, because they are a useful data-driven way to yield continuous density estimation. Many references may be found in the literature as in [
5,
6]. Given the observations, the resulting estimation will be the sum of weights taking into account the distance between the observations and the location
x at which the density has to be estimated; the more an observation is close to
x, the greater is the weighting. The weights are defined by selecting a summable function centered on the observations, called a kernel, usually denoted by
in the univariate case, and a smoothed version of the Parzen–Rosenblatt density estimator [
7,
8] is used. Standard choices for the
K function are the ones used for nonparametric kernel estimation, like the Epanechnikov function [
9]:
There exists a large variety of kernel functions, and any density function satisfying the normalization condition can be considered, so that the estimation is a probability density. Moreover, the kernel function is a symmetric positive function, with the first moment equal to zero and a finite second order moment. In the multivariate case, a multivariate kernel function
is selected that can be expressed by means of a real kernel
K associated with a norm, denoted by
, in
as follows:
The normalization condition becomes:
A kernel version of the density is then defined as a mapping
d from Ω to
:
Normalizing the kernel is not mandatory, as the normalization occurs with the definition of
d. It is nevertheless easier to consider these kinds of kernels, as is done in nonparametric density estimation. Note that when
K is compactly supported, which is the case of the Epanechnikov function and all of its relatives, it becomes:
provided that Ω contains the set:
where the interval
contains the support of
K. The case of kernels with unbounded support, like Gaussian functions, may be dealt with provided
. In the application considered, only compactly-supported kernels are used, mainly to allow fast machine implementation of the density computation.
Using the polar coordinates
and the rotation invariance of the integrand, the relation becomes:
which yields a normalizing constant of
for the Epanechnikov function in dimension two, instead of the usual
in the real case. When the normalization condition is fulfilled, the expression of the density simplifies to:
The normalizing constant is the same as in (
2).
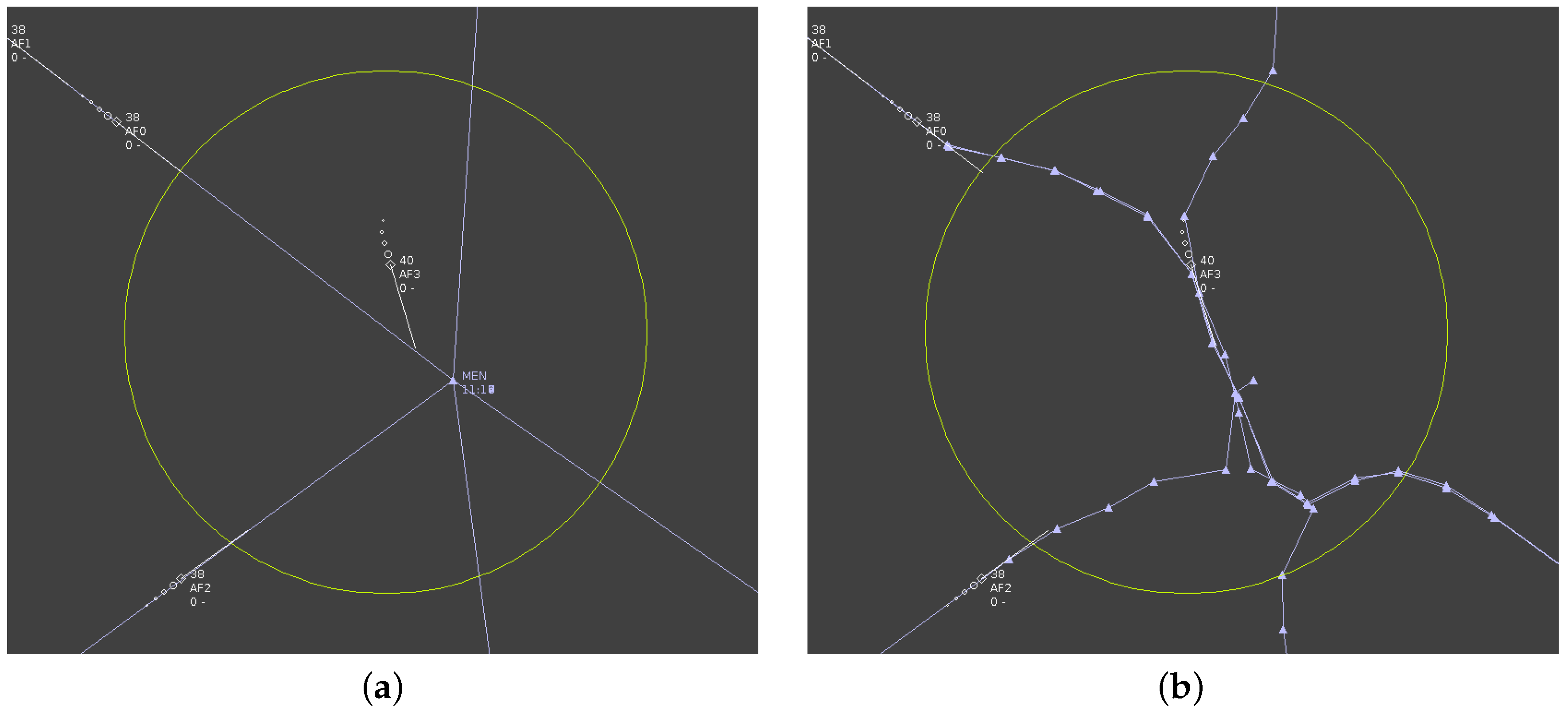
As an example, one day of traffic over France is considered and pictured in
Figure 1 with the corresponding density map, computed on an evenly-spaced grid with a normalized Epanechnikov kernel.
Unfortunately, density computed this way suffers a severe flaw for the ATM application: it is not related only to the shape of trajectories, but also to the time behavior. Formally, it is defined on the set
of smooth immersions from
to
while the space of primary interest will be the quotient by smooth diffeomorphisms of the interval
,
. Invariance of the density under the action of
is obtained as in [
10] by adding a term related to velocity in the integrals. The new definition of
d becomes:
Assuming again a normalized kernel and letting
be the length of the curve
, the expression of the density simplifies to:
The new Diff-invariant density is pictured in
Figure 2 along with the standard density. While the overall aspect of the plot is similar, one can observe that routes are more apparent in the right picture and that the density peak located above the Paris area is of less importance and less symmetric due to the fact that near airports, aircraft are slowing down, and this effect exaggerates the density with the non-invariant definition.
The extension of the two-dimensional defined that way to the general case of curves in an arbitrary space is straightforward.
2.3. Further Properties of the Density
In this section, the curves considered are a smooth mapping from the closed interval to , with a non-vanishing derivative in . All multivariate kernels will be assumed smooth, positive, with a unit integral and of the form . However, it is not required that they are compactly supported unless explicitly stated. All results are presented for the whole space , but apply almost verbatim to an open subset.
Definition 1. Let f be a smooth summable mapping from to . The scaling of f is defined, for each , to be the mapping: It is clear that the -norm of the original mapping is preserved by the scaling. Given a summable kernel function K from to , it defines a multivariate kernel on that maps x to . One may derive from it a parametrized family of kernels in by mapping each ν in to the scaled kernel . If the original K is of unit integral, so are all of the .
Proposition 1. Let be a smooth path with a non-vanishing derivative in . Let be a parametrized family of unit integral kernels. The family of Borel measures defined for any Borel set A by:is tight and converges narrowly to the Lebesgue measure on . Proof. Let
be given. By the summability of
K, there exists a positive real number
r, such that:
with
the open ball of radius
r centered at the origin. Since
for
, the same holds for all of the family
. Let
be an open ball containing
. Then:
where
denotes the length of
γ. This proves the tightness of the family
.
Let
be a bounded continuous mapping. It becomes:
and since
f is bounded, the dominated convergence theorem shows that:
proving the second part of the claim. ☐
The density in (
7) is for a single curve of the form
with
the length of the curve
γ. It is invariant under the change of the parameter and can be written in a more concise way as:
where
η is the arclength times
.
This form allows a simple probabilistic interpretation of the density
d: if a point
u is drawn on the curve
γ according to a uniform distribution and independently a vector
v in
with a density
(the multivariate kernel corresponding to
K), then the density of
is given by Equation (
10).
Proposition 2. If the multivariate kernel has a finite second moment, that is the univariate kernel K is such that:then the Wasserstein distance between the densities associated with smooth curves is bounded by:with :where each curve is parametrized by the scaled arclength as in (10). Proof. Let us consider the plan [
11] given by the density:
where each curve is parametrized by the scaled arclength. The associated transport cost is given by:
letting
and using Fubini gives:
The inner term can be written as:
The integral:
is zero and, using spherical coordinates:
with
. Putting back this value in the expression of the cost gives:
Finally:
As before, the middle term vanishes, and the first one integrates to:
so that:
☐
This result indicates that the densities associated with curves using the smoothing process described above cannot be too far (with respect to the Wasserstein distance) from each other if the geometric distance is small. In fact, the upper bound in Proposition 2 can be interpreted as the cost of moving the smoothed density around to the uniform distribution on the curve, then moving to , keeping points with equal scaled arclength in correspondence, and finally, moving the uniform distribution on to the smoothed density.
Having the density at hand, the entropy of the system of curves
is defined the usual way as:
The entropy is dependent on the particular choice of the kernel K. As mentioned before, it is a common practice in the field of non-parametric statistics to introduce a tuning parameter in the kernel, called bandwidth, so that it is expressed as a scaled version of a given function . The value of ν is the most influential parameter in the estimation of the density and must be selected carefully. For curve clustering applications, it is defined by the desired interaction length: if ν tends to zero, the curves will behave as independent objects, while on the other end of the scale, very high bandwidth will tend to remove the influence of the curves themselves. For the moment, no automated means of finding an optimal ν was used, although it will be part of a future work.
2.4. Minimizing the Entropy
In order to fulfill the initial requirement of finding bundles of curve segments as straight as possible, one seeks after the system of curves minimizing the entropy
, or equivalently maximizing:
The reason why this criterion gives the expected behavior will become more apparent after derivation of its gradient at the end of this part. Nevertheless, when considering a single trajectory, it is intuitive that the most concentrated density distribution is obtained with a straight segment connecting the endpoints: this point will be made rigorous later.
Letting
ϵ be a perturbation of the curve
, such that
, the first order expansion of
will be computed in order to get a maximizing displacement field, analogous to a gradient ascent (the choice has been made to maximize the opposite of the entropy, so that the algorithm will be a gradient ascent one) in the finite dimensional setting. The notation:
will be used in the sequel to denote the derivative of a function
F of the curve
in the sense that for a perturbation
ϵ:
First of all, please note that since
has integral one over the domain Ω:
so that:
Starting from the expression of
given in Equation (
7), the first order expansion of
with respect to the perturbation
ϵ of
is obtained as a sum of a term coming from the numerator:
and a second one coming from the length of
in the denominator. This last term is obtained from the usual first order variation formula of a curve length:
Using an integration by parts, the first order term can be written as:
with:
the normal component of:
Please note that when dealing with planar curves (i.e., with values in ), it is with (resp. ) the curvature (resp. the unit normal vector) of .
The integral in (
15) can be expanded in a similar fashion. Using as above the notation
for normal components, the first order term is obtained as:
From the expressions in (
16) and (
17), the first order variation of the entropy is:
As expected, only moves normal to the trajectory will change at first order the value of the criterion: the displacement of the curve
will thus be performed at
t in the normal bundle to
and is given, up to the
term, by:
The first term in the expression will favor moves towards areas of high density, while the second and third ones are moving along normal vector and will straighten the trajectory. This last point can be enlightened by considering the case of a single planar curve with fixed endpoints.
Proposition 3. Let be fixed points in and K be a kernel as in (7). The segment is a critical point for the entropy associated with the curve system in consisting of single smooth paths with endpoints . Proof. Let the segment
be parametrized as
with
v the vector
. Starting with the expression (
19), it is clear that the second and third terms occurring in the formula will vanish as the second derivative of
γ is zero. Let
u be the unit normal vector to
γ. Any point
x in
can be written as
,
, so that
and
. The change of variables
has Jacobian
. For a fixed
, it becomes:
The density
for the
γ curve is expressed in
coordinates as:
and is an even function in
ξ. The same is true for
. Finally, the mapping:
is odd for a fixed
θ, so that the whole integrand is odd as a function of
ξ. By the Fubini theorem, integrating first in
ξ will therefore yield a vanishing integral, proving the assertion. ☐
The result still holds in , the only different aspect being that x is now expanded as with an orthonormal basis of the orthogonal complement of in . Rewriting and , the same parity argument can be applied on any of the components , showing that the integral is vanishing.
The effect of curve straightening is present when minimizing the entropy of a whole curve system, but is counterbalanced by the gathering effect. Depending on the choice of the kernel bandwidth, one or the other effect is dominant: straightening is preeminent for low values, being the only remaining effect in the limit, while gathering dominates at high bandwidths. For the air traffic application, a rule of the thumb is to take 2–3-times the separation norm as an effective support for the kernel. Using an adaptive bandwidth may be of some interest also: starting with medium to high values favors curve gathering; then, gradually reducing it will straighten the trajectories.
Using the scaled arclength in the entropy gives an equivalent, but somewhat easier to interpret result. Starting with the expression (
7) that takes in this case the form:
Let
be fixed. An admissible variation of the curve
is a smooth mapping from
to
, with
satisfying the following properties:
- (a)
.
- (b)
with the length of the curve .
- (c)
.
Taking the derivative with respect to tat zero of Equation (b) yields:
Letting
be the unit tangent vector to
at
η and noting that
, it becomes:
This relation puts a constraint on the variation of the tangential component of the curve derivative and shows that it has to be constant in η.
Proposition 4. Let D be the mapping from to defined by:where η refers collectively to the scaled arclength parameter for each curve. The partial derivative is given by: The proof is straightforward and is omitted. From Proposition 4, the variation of the entropy is derived:
This relation is equivalent to (
18): it can be seen by splitting the terms into a normal and a tangential component. The first one yields:
For the tangential part, the starting point is the relation:
where the subscript
stands for tangential component. It becomes:
With an integration by parts, the first integral in the right-hand side becomes:
Gathering terms, the expression (
18) is recovered. As expected, only the normal components enter the relation, but it has to be noted that the tangential component of
is not arbitrary and can be deduced from (
22). The gradient with respect to the
i-th curve is obtained from the expression of the entropy variation and can be written in its simplest form as:
where
is the estimated spatial density. One must keep in mind the constraint on
that is hidden within the apparent simplicity of the expression.


{kind=link}
{kind=link}
{kind=link}
{kind=link}



