Minimax Estimation of Quantum States Based on the Latent Information Priors


1
FANUC Corporation, 3580 Furubaba Shibokusa Oshino-mura, Yamanashi 401-0597, Japan
2
Department of Mathematical Informatics, The University of Tokyo, Hongo 7-3-1, Bunkyo-ku, Tokyo 113-8656, Japan
3
RIKEN Brain Science Institute, 2-1 Hirosawa, Wako-shi, Saitama 351-0198, Japan
*
Author to whom correspondence should be addressed.
Entropy 2017, 19(11), 618; https://doi.org/10.3390/e19110618
Submission received: 13 September 2017
/
Revised: 12 November 2017
/
Accepted: 13 November 2017
/
Published: 16 November 2017
(This article belongs to the Special Issue Transfer Entropy II)
{kind=link}
Abstract
:We develop priors for Bayes estimation of quantum states that provide minimax state estimation. The relative entropy from the true density operator to a predictive density operator is adopted as a loss function. The proposed prior maximizes the conditional Holevo mutual information, and it is a quantum version of the latent information prior in classical statistics. For one qubit system, we provide a class of measurements that is optimal from the viewpoint of minimax state estimation.
1. Introduction
In quantum mechanics, the outcome of a measurement is subject to a probability distribution determined from the quantum state of the measured system and the measurement performed. The task of estimating the quantum state from the outcome of measurement is called the quantum estimation and it is a fundamental problem in quantum statistics [1,2,3]. Tanaka and Komaki [4] and Tanaka [5] discussed quantum estimation using the framework of statistical decision theory and showed that Bayesian methods provide better estimation than the maximum likelihood method. In Bayesian methods, we need to specify a prior distribution on the unknown parameters of the quantum states. However, the problem of prior selection has not been fully discussed for quantum estimation [6].
The quantum state estimation problem is related to the predictive density estimation problem in classical statistics [7]. This is a problem of predicting the distribution of an unobserved variable y based on an observed variable x. Suppose where denotes an unknown parameter. Based on the observed x, we predict the distribution of y using a predictive density . The plug-in predictive density is defined as , where is some estimate of from x. The Bayesian predictive density with respect to a prior distribution is defined as
where is the posterior distribution. We compare predictive densities using the framework of statistical decision theory. Specifically, a loss function is introduced that evaluates the difference between the true density q and the predictive density p. Then, the risk function is defined as the average loss when the true value of the parameter is :
A predictive density is called minimax if it minimizes the maximum risk among all predictive densities:
We adopt the Kullback–Leibler divergence
as a loss function, since it satisfies many desirable properties compared to other loss functions such as the Hellinger distance and the total variation distance [8]. Under this setting, Aitchison [9] proved
where
is called the Bayes risk. Namely, the Bayesian predictive density minimizes the Bayes risk. We provide the proof of Equation (4) in the Appendix A. Therefore, it is sufficient to consider only Bayesian predictive densities from the viewpoint of Kullback–Leibler risk, and the selection of the prior becomes important.
For the predictive density estimation problem above, Komaki [10] developed a class of priors called the latent information priors. The latent information prior is defined as a prior that maximizes the conditional mutual information between the parameter and the unobserved variable y given the observed variable x. Namely,
where
is the conditional mutual information between y and given x. Here,
are marginal densities. The Bayesian predictive densities based on the latent information priors are minimax under the Kullback–Leibler risk:
The latent information prior is a generalization of the reference prior [11] that is a prior maximizing the unconditional mutual information between and y.
Now, we consider the problem of estimating the quantum state of a system based on the outcome of a measurement on a system . Suppose the quantum state of the composed system be where denotes an unknown parameter. We perform a measurement on the system and obtain the outcome x. Based on the measurement outcome x, we estimate the state of the system by a predictive density operator . Similarly to the Bayesian predictive density (1), the Bayesian predictive density operator with respect to the prior is defined as
where is the posterior distribution. Like the predictive density estimation problem discussed above, we compare predictive density operators using the framework of statistical decision theory. There are several possibilities for the loss function in quantum estimation such as the fidelity and the trace norm [12]. In this paper, we adopt the quantum relative entropy
as a loss function, since it is a quantum analogue of the Kullback–Leibler divergence (3). Note that the fidelity and the trace norm correspond to the Hellinger distance and the total variation distance in the classical statistics, respectively. Under this setting, Tanaka and Komaki [4] proved that the Bayesian predictive density operators minimize the Bayes risk:
This is a quantum version of Equation (4).
From Tanaka and Komaki [4], the selection of the prior becomes important also in quantum estimation. However, this problem has not been fully discussed [6]. In this paper, we provide a quantum version of the latent information priors and prove that they provide minimax predictive density operators. Whereas the latent information prior in the classical case maximizes the conditional Shannon mutual information, the proposed prior maximizes the conditional Holevo mutual information. The Holevo mutual information, which is a quantum version of the Shannon mutual information, is a fundamental quantity in the classical-quantum communication [13]. Our result shows that the conditional Holevo mutual information also has a natural meaning in terms of quantum estimation.
Unlike the classical statistics, the measurement is not unique in quantum statistics. Therefore, selection of the measurement also becomes important. From the viewpoint of minimax state estimation, measurements that minimize the minimax risk are considered to be optimal. We provide a class of optimal measurements for one qubit system. This class includes the symmetric informationally complete measurement [14,15]. These measurements and latent information priors provide robust quantum estimation.
2. Preliminaries
2.1. Quantum States and Measurements
We briefly summarize several notations of quantum states and measurements. Let be a separable Hilbert space of a quantum system. A Hermitian operator on is called a density operator if it satisfies
The state of a quantum system is described by a density operator. We denote the set of all density operators on as .
Denote the set of all linear operators on Hilbert space by and the set of all positive linear operators by . Let be a measurable space of all possible outcomes of a measurement and be a -algebra of . A map is called a positive operator-valued measure (POVM) if it satisfies , and where . Any quantum measurement is represented by a POVM on . In this paper, we mainly assume is finite. In such case, we denote and any POVM is represented by a set of positive Hermitian operators such that .
The outcome of a measurement E on a quantum system with the state is distributed with a probability measure
Let , be quantum systems with Hilbert spaces and . The Hilbert space of the composed system is given by the tensor product . Suppose the state of this composed system is . Then, the states of two subsystems can be yielded by the partial trace:
If a measurement is performed on the system and the measurement outcome is x, then the state of the system becomes
where the normalization constant
is the probability of the outcome x. Here, is the identity operator on the space . We call the operator the conditional density operator.
2.2. Quantum State Estimation
We formulate the quantum state estimation problem using the framework of statistical decision theory. Let and be quantum systems with finite-dimensional Hilbert spaces and , where and .
Suppose the state of the composed system be , where denotes unknown parameters. We perform a measurement on , observe the outcome , and estimate the conditional density operator of by a predictive density operator . As discussed in the introduction (1) and (7), the Bayesian predictive density operator based on a prior is defined by
where is the posterior distribution.
To evaluate predictive density operators, we introduce a loss function that evaluates the difference between the true conditional density operator and the predictive density operator . In this paper, we adopt the quantum relative entropy (8) since it is a quantum analogue of the Kullback–Leibler divergence (3). Then, the risk function of a predictive density operator is defined by
where
is the probability of the outcome x. Similarly to the classical case (2), a predictive density operator is called minimax if it minimizes the maximum risk among all predictive density operators [16,17]:
Tanaka and Komaki [4] showed
where
is called the Bayes risk. Namely, the Bayesian predictive density operator minimizes the Bayes risk. This result is a quantum version of Equation (4). Although Tanaka and Komaki [4] considered separable models (), the relation (9) holds also for non-separable models as shown in the Appendix A. Therefore, it is sufficient to consider only Bayesian predictive density operators and the problem of prior selection becomes crucial.
2.3. Notations
For a quantum state family , we define another quantum state family
where
is a density operator in . Since , the state family can be regarded as a subset of the Euclidean space . By identifying with , the parameter space is endowed with the induced topology as a subset of .
Any measurement on the system is represented by a projective measurement , where is an orthonormal basis of . For every , we define as
which is the unnormalized state of conditional on the measurement outcome x. We also define
3. Minimax Estimation of Quantum States
In this section, we develop the latent information prior for quantum state estimation and show that this prior provides a minimax predictive density operator.
In the following, we assume the following conditions:
- is compact.
- For every , .
- For every , there exists such that .
The third assumption is achieved by adopting sufficiently small Hilbert space. Namely, if there exists such that for every , then we redefine the state space as the orthogonal complement of .
Let be the set of all probability measures on endowed with the weak convergence topology and the corresponding Borel algebra. By the Prohorov theorem [18] and the first assumption, is compact.
When x is fixed, the function is bounded and continuous. Thus, for every fixed , the function
is continuous because is endowed with the weak convergence topology and . Let be the eigenvalues and the normalized eigenvectors of the predictive density operator . For every predictive density operator , consider the function from to defined by
The last term in (10) is lower semicontinuous under the definition [10], since each summand takes either zero or infinity and so the set of such that this term takes zero is closed. In addition, the other terms in (10) are continuous since the von Neumann entropy is continuous [12]. Therefore, the function in (10) is lower-semicontinuous.
Now, we prove that the class of predictive density operators that are limits of Bayesian predictive density operators is an essentially complete class. We prepare three lemmas. Lemma 1 is useful for differentiation of quantum relative entropy (see Hiai and Petz [19]). Lemmas 2 and 3 are from Komaki [10].
Lemma 1.
Let be n-dimensional self-adjoint matrices and t be a real number. Assume that is a continuously differentiable function defined on an interval and assume that the eigenvalues of are in if t is sufficiently close to . Then,
Lemma 2
Lemma 3
([10]). Let be continuous, and let μ be a probability measure on Θ such that for every . Then, there is a probability measure in
for every n, such that . Furthermore, there exists a convergent subsequence of and the equality holds, where .
By using these results, we obtain the following theorem, which is a quantum version of Theorem 1 of Komaki [10].
Theorem 1.
- (1)
- Let be a predictive density operator. If there exists a prior such that and for every , then for every .
- (2)
- For every predictive density operator ρ, there exists a convergent prior sequence such that , exists, and for every .
Next, we develop priors that provide minimax predictive density operators. Let x be a random variable, which represents the outcome of the measurement, i.e., . Then, as a quantum analogue of the conditional mutual information (5), we define the conditional Holevo mutual information [13] between the quantum state of Y and the parameter given the measurement outcome x as
which is a function of . Here, we used
and
The conditional Holevo mutual information provides an upper bound on the conditional mutual information as follows.
Proposition 1.
Let be the state of the composed system . Suppose that a measurement is performed on X with the measurement outcome x and then another measurement is performed on Y with the measurement outcome y. Then,
Proof.
Analogous with the latent information priors [10] in classical statistics, we define latent information priors as priors that maximize the conditional Holevo mutual information. It is expected that the Bayesian predictive density operator based on a latent information prior is a minimax predictive density operator. This is true from the following theorem, which is a quantum version of Theorem 2 of Komaki [10].
Theorem 2.
- (1)
- Let be a prior maximizing . If for all ; then, is a minimax predictive density operator.
- (2)
- There exists a convergent prior sequence such that is a minimax predictive density operator and the equality holds.
The proof of Theorems 1 and 2 are deferred to the Appendix A.
We note that the minimax risk depends on the measurement E on . Therefore, the measurement E with minimum minimax risk is desirable from the viewpoint of minimaxity. We define a POVM to be a minimax POVM if it satisfies
In the next section, we provide a class of minimax POVMs for one qubit system.
4. One Qubit System
In this section, we consider one qubit system and derive a class of minimax POVMs satisfying (13).
Qubit is a quantum system with a two-dimensional Hilbert space. It is the fundamental system in the quantum information theory. A general state of one qubit system is described by a density matrix
where . The parameter space for pure states is called the Bloch sphere.
Let be a separable state. We consider the estimation of from the outcome of a measurement on . Here, we assume that the state is separable, since the state of Y changes according to the outcome of the measurement on X and so the estimation problem is not well-defined if the state is not separable.
Let and be Borel sets. From Haapasalo et al. [20], it is sufficient to consider POVMs on . For every probability measure on that satisfies
we define a POVM by
In the following, we identify E with .
Let be a class of POVMs on represented by measures that satisfy the conditions
where is the expectation with respect to a measure . We provide two examples of POVMs in .
Proposition 2.
The POVM corresponding to
where is surface element, is in .
Proof.
From the symmetry of , . Moreover, from and the symmetry of , . ☐
Proposition 3.
Suppose that satisfies . Let μ be a four point discrete measure on Ω defined by
Then, the POVM corresponding to μ belongs to .
Proof.
Let and . From the assumption on ,
where is the identity matrix and is a matrix whose elements are all one. From (16), we have . Therefore, and it implies .
In addition, from (16),
Therefore, . Since , it implies . Then, and . ☐
We note that the POVM (15) is a special case of the SIC-POVM (symmetric, informationally complete, positive operator valued measure) [14,15].
Let be a class of priors on that satisfies the conditions
where is the expectation with respect to a prior .
Proposition 4.
The uniform prior
where is the surface element on the Bloch sphere, belongs to .
Proof.
Same as Proposition 2. ☐
Proposition 5.
Suppose that satisfies . Then, the four point discrete prior
belongs to .
Proof.
Same as Proposition 3. ☐
We obtain the following result.
Lemma 4.
Suppose . Then, for general measurement E, the risk function of the Bayesian predictive density operator is
Proof.
The distribution of the measurement outcome is
Then, since , the marginal distribution of the measurement outcome is
Therefore, the posterior distribution of is
The posterior mean of and are and , respectively.
Thus, the Bayesian predictive density operator based on prior is
and we have
Therefore, the quantum relative entropy loss is
Hence, the risk function is
☐
Theorem 3.
For a measurement , every is a latent information prior:
In addition, the risk of the Bayesian predictive density operator based on is
where h is the binary entropy function .
Proof.
From Lemma 4 and ,
Therefore, the risk depends only on and we have
Since
the function is convex. In addition, we have . Therefore, takes the maximum at .
In other words, takes maximum on the Bloch sphere. In addition, since , the support of is included in the Bloch sphere . Therefore, and it implies that is a latent information prior. ☐
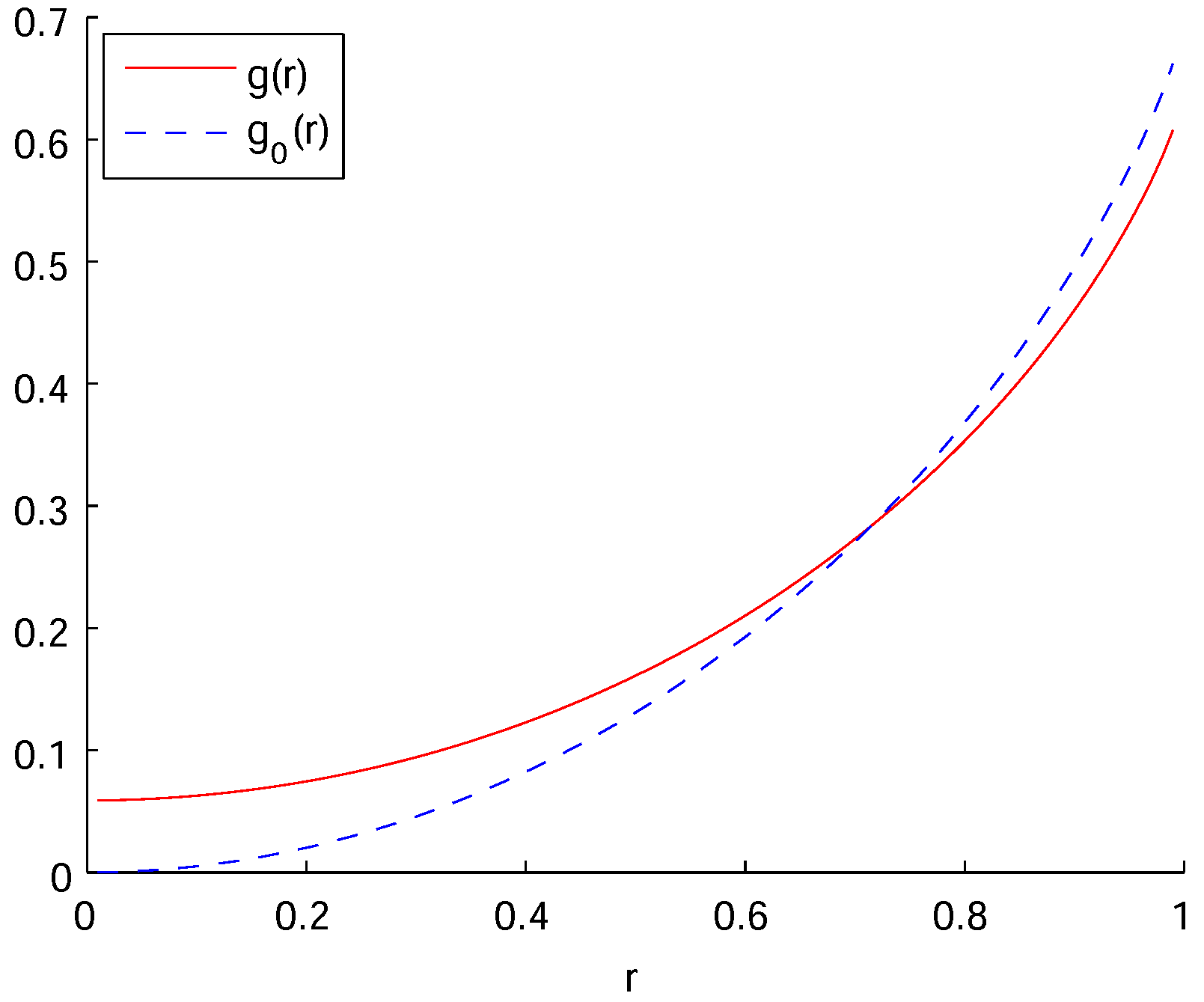
We note that the Bayesian predictive density operator is identical for every . In fact, every also provides the minimax estimation of density operator when there is no observation system X. Figure 1 shows the risk function in (17) and also the minimax risk function when there is no observation:
Whereas around , we can see that around . Both risk functions take the maximum at and
The decrease in the maximum risk corresponds to the gain from the observation X.
Now, we consider the selection of the measurement E. As we discussed in the previous section, we define a POVM to be a minimax POVM if it satisfies (13). We provide a sufficient condition on a POVM to be minimax. Let be a minimax predictive density operator for the measurement E.
Lemma 5.
Suppose is a latent information prior for the measurement . If
then is a minimax POVM.
Proof.
For every , we have
The last equality is from the minimaxity of . Therefore, is a minimax POVM. ☐
Theorem 4.
Every is a minimax POVM.
Proof.
Let . From Theorem 6, is a latent information prior for .
For general measurement E, from Lemma 4, the risk function of the Bayesian predictive density operator is
Hence, the Bayes risk of with respect to is
Now, since the Bayesian predictive density operator minimizes the Bayes risk with respect to among all predictive density operators [4],
for every E. Therefore,
On the other hand,
is obvious.
Hence,
From Lemma 5, is minimax. ☐
Whereas Theorems 1 and 2 are valid even when is not separable, Theorems 3 and 4 assume the separability .
Acknowledgments
We thank the referees for many helpful comments. This work was supported by Japan Society for the Promotion of Science (JSPS) KAKENHI Grant Numbers 26280005 and 14J09148.
Author Contributions
All authors contributed significantly to the study and approved the final version of the manuscript.
Conflicts of Interest
The authors declare no conflict of interest.
Appendix A. Proofs
Proof of (4).
Therefore, for arbitrary ,
which is nonnegative since the Kullback–Leibler divergence in (3) is always nonnegative. ☐
Proof of (9).
Therefore, for arbitrary ,
which is nonnegative since the quantum relative entropy in (8) is always nonnegative. ☐
Proof of Theorem 1.
(1) Let be the orthogonal projection matrix onto the eigenspace of corresponding to eigenvalue 0, and be the set of all probability measures on .
If , the assertion is obvious because for . Therefore, we assume in the following. In this case, . Since if and only if , we have .
Define
for and , where is the probability measure satisfying . Then, , and we have
Thus, if ,
If , . Therefore, for every , the inequality holds.
(2) We note that and are compact subsets of and , respectively.
If , the assertion is obvious, because for every . Therefore, we assume in the following. Let and be a probability measure on such that for every .
Because is continuous as a function of , there exists such that . From Lemma 3, there exists a convergent subsequence of such that where .
Let be the integer satisfying . We can make the subsequence satisfy for some positive constant c.
Since
for every , we have
for every and . Thus,
Hence,
where is the orthogonal projection matrix onto the eigenspace of corresponding to the eigenvalue 0. Here, we have
and
By taking an appropriate subsequence of , we can make the subsequence of density operators converge for all because and .
Then, from (A4), if ,
If , because .
Hence, the risk of the predictive density operator defined by
where is an arbitrary predictive density, is not greater than that of for every .
Therefore, by taking a sequence that converges rapidly enough to 0, we can construct a predictive density operator
as a limit of Bayesian predictive density operators based on priors , where is a measure on such that for every .
Hence, the risk of the predictive density operator (A5) is not greater than that of for every . ☐
Proof of Theorem 2.
(1) Define for all and . Then,
Since for every and if , we have
for every .
On the other hand, we have
Therefore, the predictive density operator is minimax.
(2) Let be a probability measure on such that for every , and let be a prior satisfying . From Lemma 3, there exists a convergent subsequence of and where . Let be the integer satisfying . As in the proof of Theorem 1, we can make the subsequence satisfy for some positive constant c.
Then, for every ,
belongs to for because and .
Thus,
Since for every m and if , we have
Hence,
where is the orthogonal projection matrix onto the eigenspace of corresponding to the eigenvalue 0. Here, we used two equalities
and
since is a bounded continuous function of .
By taking an appropriate subsequence of , we can make converge for every x. Then, for every ,
since for x with .
On the other hand, we have
Here, the first equality is from the fact [4] that the Bayes risk
is minimized when . Although is not uniquely determined for x with , the Bayes risk does not depend on the choice of for such x.
Therefore, the predictive density operator is minimax. ☐
References
- Barndorff-Nielsen, O.E.; Gill, R.D.; Jupp, P.E. On quantum statistical inference. J. R. Stat. Soc. B 2003, 65, 775–804. [Google Scholar] [CrossRef]
- Holevo, A.S. Probabilistic and Statistical Aspects of Quantum Theory; Elsevier: Amsterdam, The Netherlands, 1982. [Google Scholar]
- Paris, M.; Rehacek, J. Quantum State Estimation; Springer: Berlin, Germany, 2004. [Google Scholar]
- Tanaka, F.; Komaki, F. Bayesian predictive density operators for exchangeable quantum-statistical models. Phys. Rev. A 2005, 71, 052323. [Google Scholar] [CrossRef]
- Tanaka, F. Bayesian estimation of the wave function. Phys. Lett. A 2012, 376, 2471–2476. [Google Scholar] [CrossRef]
- Tanaka, F. Noninformative prior in the quantum statistical model of pure states. Phys. Rev. A 2012, 85, 062305. [Google Scholar] [CrossRef]
- Geisser, S. Predictive Inference: An Introduction; Chapman & Hall: London, UK, 1993. [Google Scholar]
- Csiszar, I. Axiomatic characterizations of information measures. Entropy 2008, 10, 261–273. [Google Scholar] [CrossRef]
- Aitchison, J. Goodness of prediction fit. Biometrika 1975, 62, 547–554. [Google Scholar] [CrossRef]
- Komaki, F. Bayesian predictive densities based on latent information priors. J. Stat. Plan. Inference 2011, 141, 3705–3715. [Google Scholar] [CrossRef]
- Bernardo, J.M. Reference posterior distributions for Bayesian inference. J. R. Stat. Soc. B 1979, 41, 113–147. [Google Scholar]
- Petz, D. Quantum Information and Quantum Statistics; Springer: New York, NY, USA, 2008. [Google Scholar]
- Holevo, A.S. Quantum Systems, Channels, Information: A Mathematical Introduction; Walter de Gruyter: Berlin, Germany, 2013. [Google Scholar]
- Appleby, D.M. SIC-POVMs and the extended Clifford group. J. Math. Phys. 2004, 46, 547–554. [Google Scholar]
- Renes, J.M.; Blume-Kohout, R.; Scott, A.J.; Caves, C.M. Symmetric informationally complete quantum measurements. J. Math. Phys. 2004, 45, 2171–2180. [Google Scholar] [CrossRef]
- Ferrie, C.; Blume-Kohout, R. Minimax quantum tomography: Estimators and relative entropy bounds. Phys. Rev. Lett. 2016, 116, 090407. [Google Scholar] [CrossRef] [PubMed]
- Tanaka, F. Quantum minimax theorem. arXiv 2014, arXiv:1410:3639. [Google Scholar]
- Billingsley, P. Convergence of Probability Measures; Wiley: New York, NY, USA, 1999. [Google Scholar]
- Hiai, F.; Petz, D. Introduction to Matrix Analysis and Applications; Springer: New York, NY, USA, 2014. [Google Scholar]
- Haapasalo, E.; Heinosaari, T.; Pellonpää, J.P. Quantum measurements on finite dimensional systems: Relabeling and mixing. Quantum Inf. Process. 2012, 11, 1751–1763. [Google Scholar] [CrossRef]
Figure 1.
Risk functions of predictive density operators. solid line: , dashed line: .

© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Koyama, T.; Matsuda, T.; Komaki, F. Minimax Estimation of Quantum States Based on the Latent Information Priors. Entropy 2017, 19, 618. https://doi.org/10.3390/e19110618
AMA Style
Koyama T, Matsuda T, Komaki F. Minimax Estimation of Quantum States Based on the Latent Information Priors. Entropy. 2017; 19(11):618. https://doi.org/10.3390/e19110618
Chicago/Turabian StyleKoyama, Takayuki, Takeru Matsuda, and Fumiyasu Komaki. 2017. "Minimax Estimation of Quantum States Based on the Latent Information Priors" Entropy 19, no. 11: 618. https://doi.org/10.3390/e19110618
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.