Numerical and Non-Asymptotic Analysis of Elias’s and Peres’s Extractors with Finite Input Sequences †


Abstract
:1. Introduction
1.1. Related Work
1.2. Our Contribution
- (i)
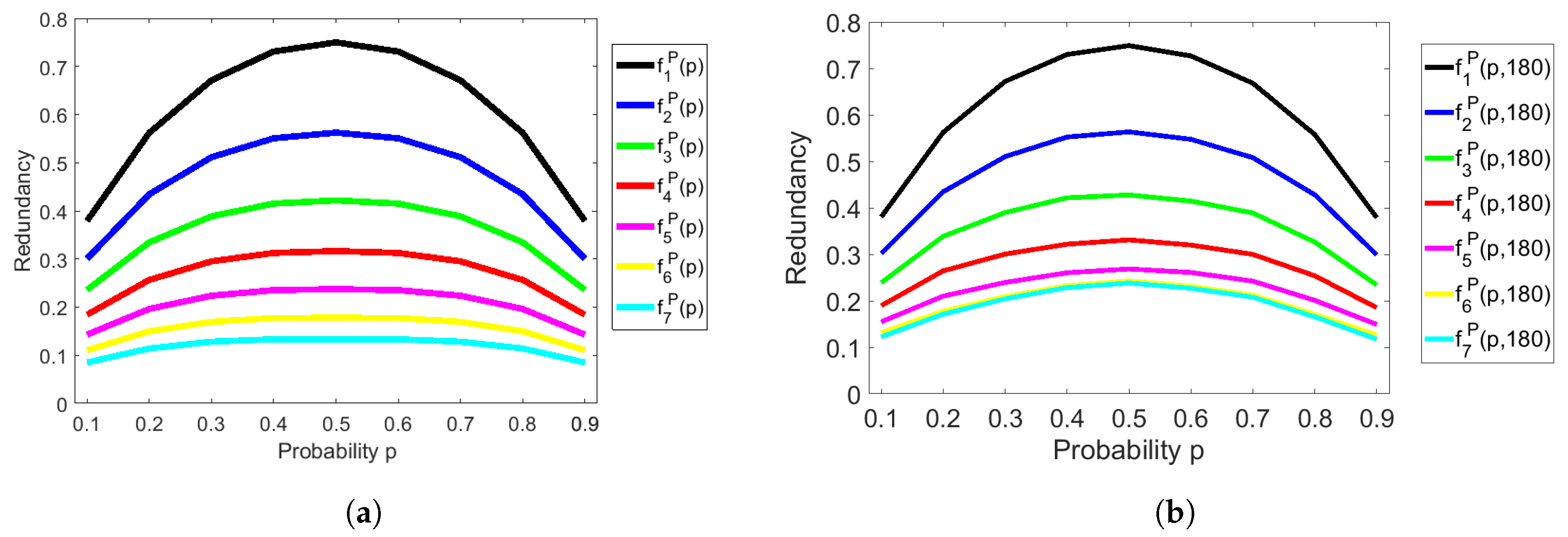
- Based on some heuristics, we derive a lower bound on the maximum redundancy of Peres’s extractor in Section 3. This result shows that the maximum redundancy of Elias’s extractor is superior to Peres’s extractor in general, if we focus only on redundancy (or rates) and we do not pay attention to the time complexity or space complexity.
- (ii)
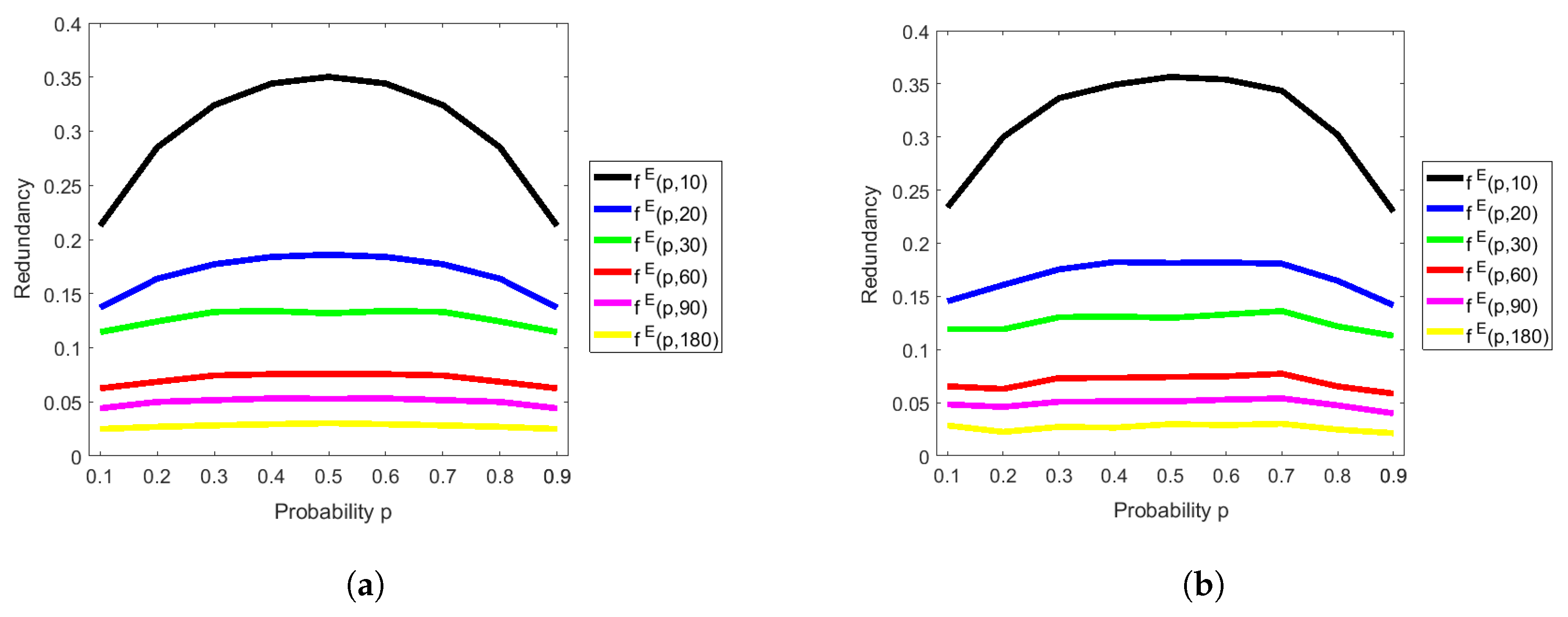
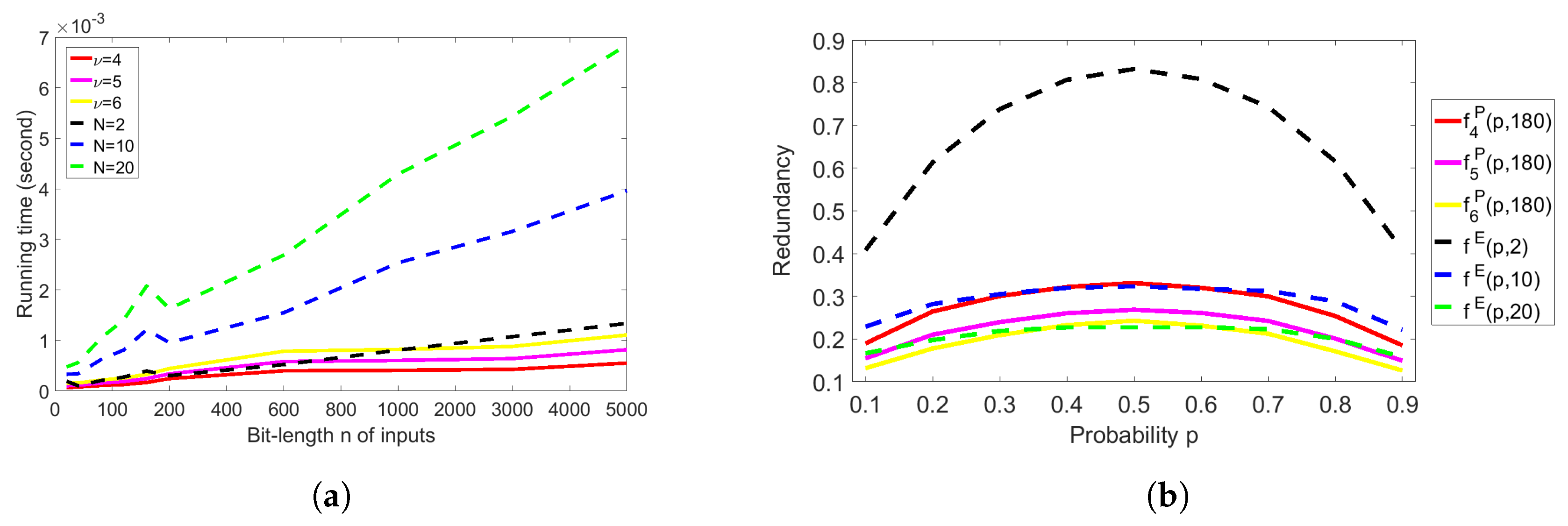
- By numerical analysis, we design our experiments by comparing both extractors with finite input sequences of which each bit occurs with any biased probability under the same environments in terms of practical aspects. Both extractors are implemented on a general PC and do not require any special resources, libraries, or frameworks for computation. Our implementation and results will be explained in Section 4. We calibrate our implementation by comparing the theoretical and experimental redundancy of both extractors. Afterwards, we analyze the time complexity of both extractors with respect to the bit-length of input sequences from 100 to 5000. We compare the redundancy of both extractors, and our implementation shows that Peres’s extractor is much better than Elias’s extractor under a very similar running time. As a result, Peres’s extractor would be more suitable for generating uniformly random sequences for practical use in applications.
2. Preliminaries
2.1. Von Neumann’s Extractor
2.2. Elias’s Extractor
- (i)
- Compute Num in the set , if contains k ones.
- (ii)
- Let for .
- (iii)
- If and Num, then .
- (iv)
- If , then is defined to be the low-order binary string of Num.
- (v)
- If for some , then is defined to be the suffix consisting of the binary string of Num.
2.3. Peres’s Extractor
3. Lower Bound on Redundancy of Peres’s Extractor
4. Implementation and Numerical Analysis
- (1)
- Is theoretical redundancy the same as experimental redundancy in both extractors?
- (2)
- Is the experimental redundancy of Elias’s extractor with the RM method better than the experimental redundancy of Peres’s extractor?
- (3)
- What is the exact running time of both extractors?
- (4)
- Which extractor achieves better redundancy (or rate) under the very similar running time?
- The Schönhage–Strassen multiplication algorithm requires which is asymptotically faster than the normal multiplication requiring ;
- To avoid multiplication, we use only the addition operation because it is simple and makes the basic operation lighter so that it can be used in various applications and environments.
4.1. Analysis of the Redundancy of Peres’s Extractor
4.2. Analysis of the Redundancy of Elias’s Extractor with the RM Method
4.3. Analysis of the Time Complexity of Both Extractors
4.4. Comparison under the Very Similar Running Time
5. Conclusions
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
Appendix A. Proof of Proposition 1
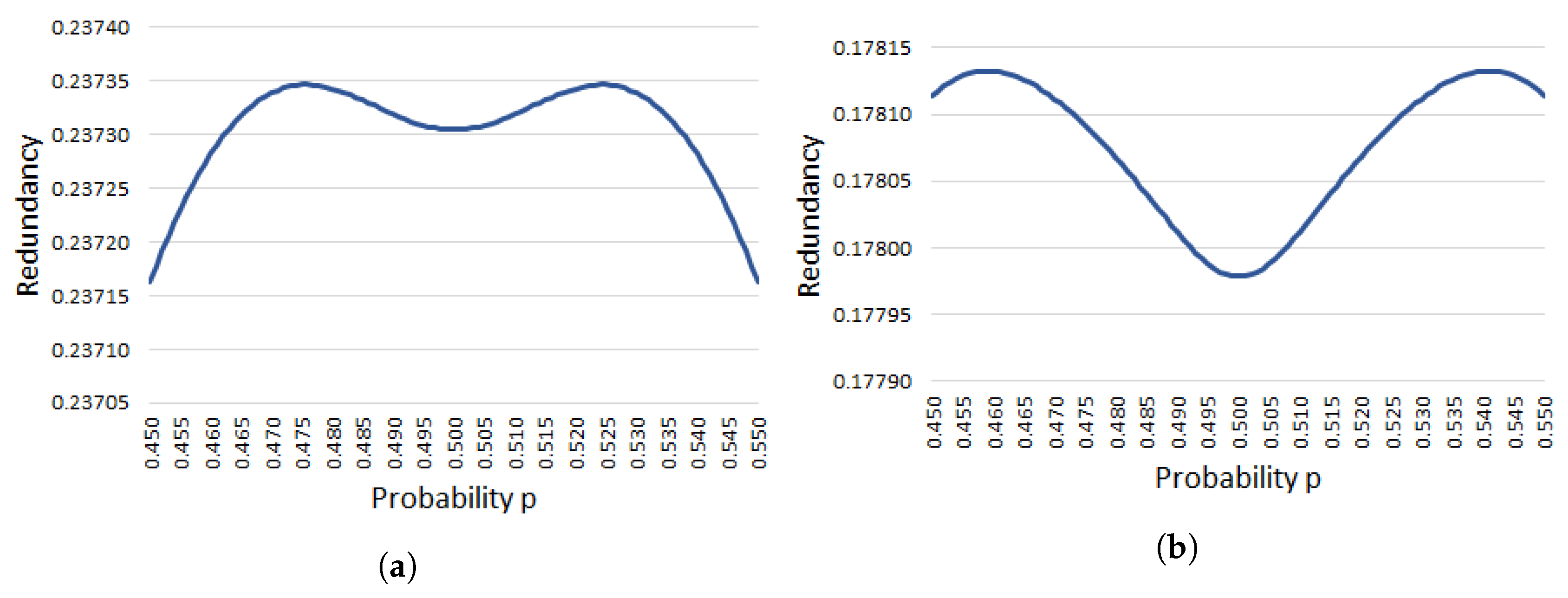
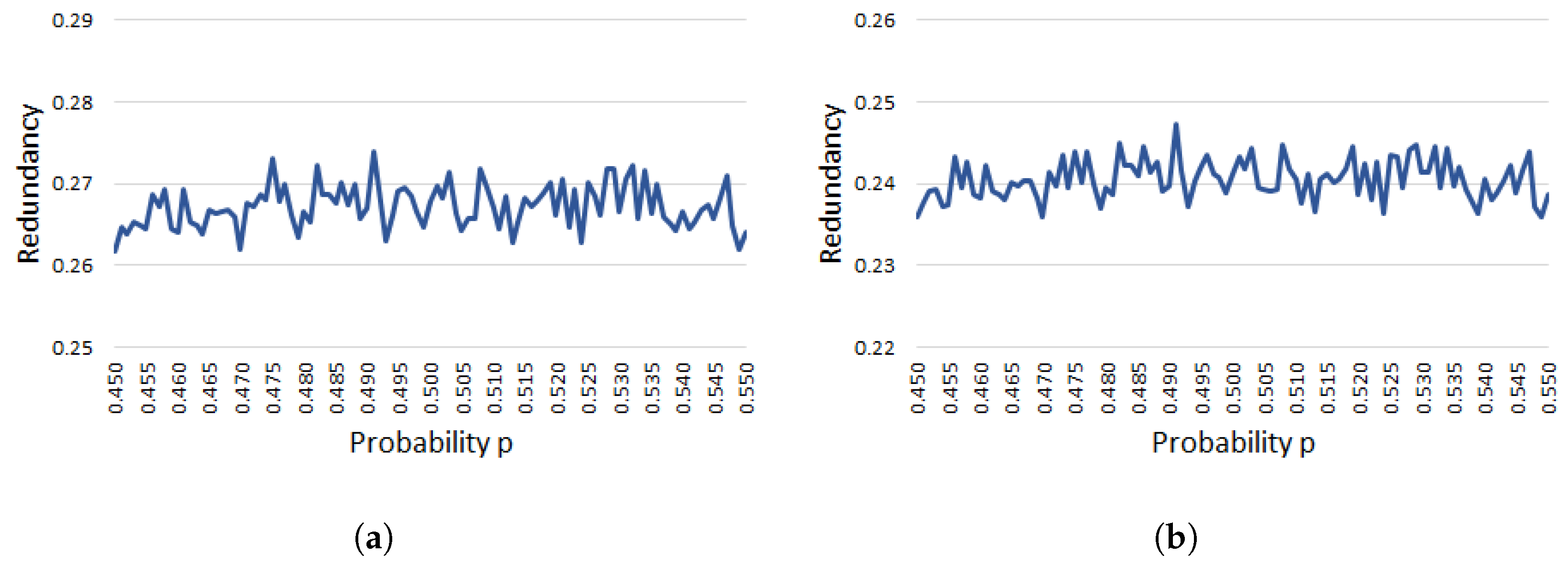
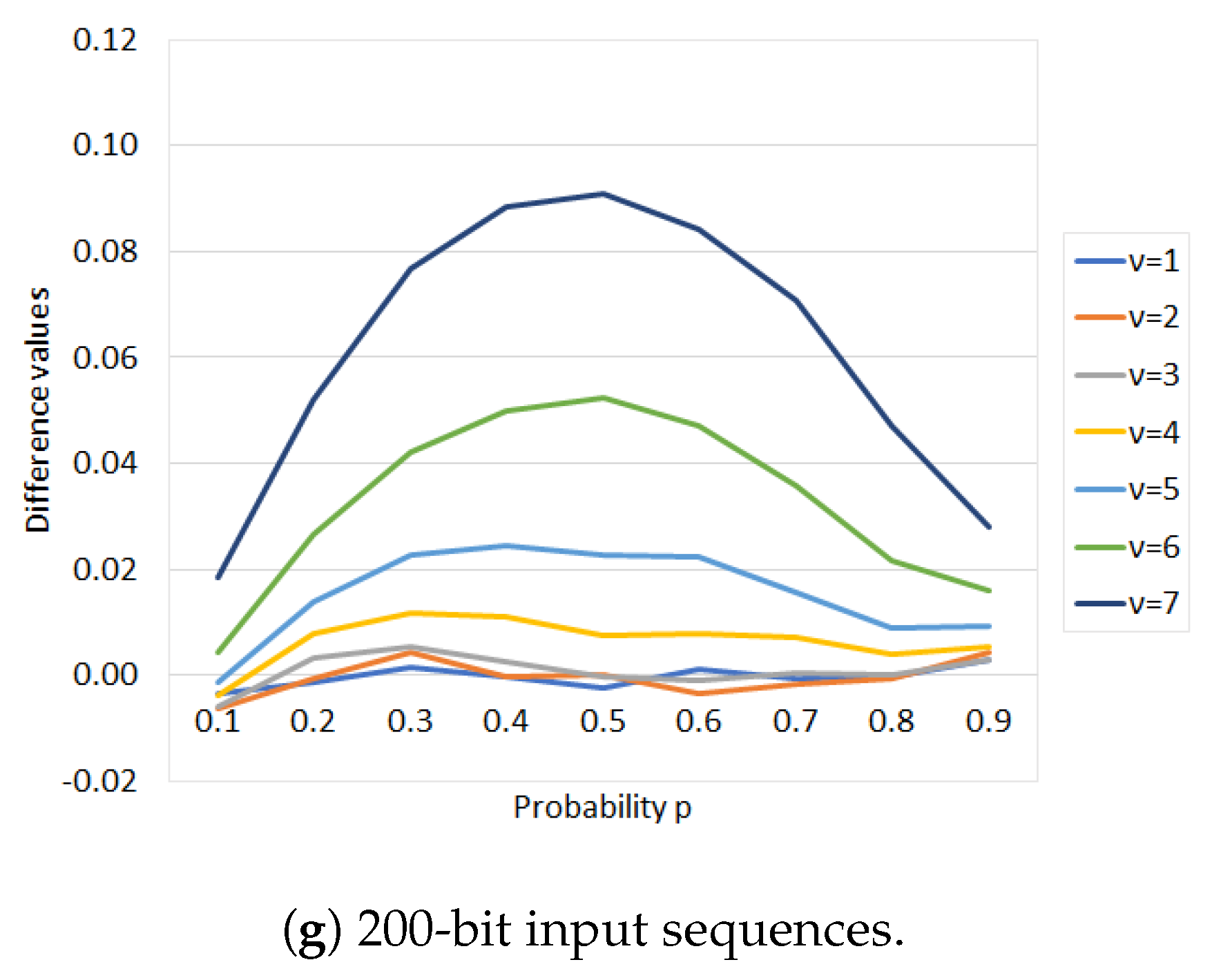
Appendix B. Experimental Results for Proposition 2


References
- Heninger, N.; Durumeric, Z.; Wustrow, E.; Halderman, J.A. Mining Your Ps and Qs: Detection of Widespread Weak Keys in Network Devices. In Proceedings of the 21st USENIX Security Symposium, Bellevue, WA, USA, 8–10 August 2012. [Google Scholar]
- Lenstra, A.K.; Hughes, J.P.; Augier, M.; Bos, J.W.; Kleinjung, T.; Wachter, C. Public Keys. In Advances in Cryptology—ECRYPTO 2012; Safavi-Naini, R., Canetti, R., Eds.; Number 7417 in Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2012; pp. 626–642. [Google Scholar]
- Bendel, M. Hackers Describe PS3 Security As Epic Fail, Gain Unrestricted Access. Available online: Exophase.com (accessed on 20 September 2018).
- Dorrendorf, L.; Gutterman, Z.; Pinkas, B. Cryptanalysis of the Random Number Generator of the Windows Operating System. ACM Trans. Inf. Syst. Secur. 2009, 13, 10. [Google Scholar] [CrossRef]
- Bonneau, J.; Clark, J.; Goldfeder, S. On Bitcoin as a public randomness source. IACR Cryptol. ePrint Arch. 2015, 2015, 1015. [Google Scholar]
- Von Neumann, J. Various Techniques Used in Connection with Random Digits. J. Res. Nat. Bur. Stand. Appl. Math. Ser. 1951, 12, 36–38. [Google Scholar]
- Elias, P. The Efficient Construction of an Unbiased Random Sequence. Ann. Math. Stat. 1972, 43, 865–870. [Google Scholar] [CrossRef]
- Peres, Y. Iterating Von Neumann’s Procedure for Extracting Random Bits. Ann. Stat. 1992, 20, 590–597. [Google Scholar] [CrossRef]
- Abbott, A.A.; Calude, C.S. Von Neumann Normalisation and Symptoms of Randomness: An Application to Sequences of Quantum Random Bits. In Unconventional Computation; Calude, C.S., Kari, J., Petre, I., Rozenberg, G., Eds.; Springer: Berlin/Heidelberg, Germany, 2011; pp. 40–51. [Google Scholar]
- Ryabko, B.; Matchikina, E. Fast and efficient construction of an unbiased random sequence. IEEE Trans. Inf. Theory 2000, 46, 1090–1093. [Google Scholar] [CrossRef]
- Cover, T. Enumerative source encoding. IEEE Trans. Inf. Theory 1973, 19, 73–77. [Google Scholar] [CrossRef]
- Schönhage, A.; Strassen, V. Schnelle Multiplikation großer Zahlen. Computing 1971, 7, 281–292. (In German) [Google Scholar] [CrossRef]
- Pae, S.I. Exact output rate of Peres’s algorithm for random number generation. Inf. Process. Lett. 2013, 113, 160–164. [Google Scholar] [CrossRef]
- Bourgain, J. More on the sum-product phenomenon in prime fields and its applications. Int. J. Number Theory 2005, 1, 1–32. [Google Scholar] [CrossRef]
- Raz, R. Extractors with Weak Random Seeds. In Proceedings of the Thirty-Seventh Annual ACM Symposium on Theory of Computing, Hunt Valley, MD, USA, 22–24 May 2005; ACM: New York, NY, USA, 2005; pp. 11–20. [Google Scholar]
- Cohen, G. Local Correlation Breakers and Applications to Three-Source Extractors and Mergers. In Proceedings of the 2015 IEEE 56th Annual Symposium on Foundations of Computer Science, Berkeley, CA, USA, 17–20 October 2015; pp. 845–862. [Google Scholar]
- Chattopadhyay, E.; Zuckerman, D. Explicit Two-Source Extractors and Resilient Functions. In Proceedings of the 48th Annual ACM SIGACT Symposium on Theory of Computing, Cambridge, MA, USA, 18–21 June 2016; ACM: New York, NY, USA, 2016; pp. 670–683. [Google Scholar]
- Bouda, J.; Krhovjak, J.; Matyas, V.; Svenda, P. Towards True Random Number Generation in Mobile Environments. In Identity and Privacy in the Internet Age; Jøsang, A., Maseng, T., Knapskog, S.J., Eds.; Number 5838 in Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2009; pp. 179–189. [Google Scholar]
- Halprin, R.; Naor, M. Games for Extracting Randomness. In Proceedings of the 5th Symposium on Usable Privacy and Security, Mountain View, CA, USA, 15–17 July 2009; ACM: New York, NY, USA, 2009; p. 12. [Google Scholar]
- Voris, J.; Saxena, N.; Halevi, T. Accelerometers and Randomness: Perfect Together. In Proceedings of the Fourth ACM Conference on Wireless Network Security, Hamburg, Germany, 14–17 June 2011; ACM: New York, NY, USA, 2011; pp. 115–126. [Google Scholar]
- Prasitsupparote, A.; Konno, N.; Shikata, J. Numerical Analysis of Elias’s and Peres’s Deterministic Extractors. In Proceedings of the 51st Annual Conference on Information Sciences and Systems (CISS), Baltimore, MD, USA, 22–24 March 2017. [Google Scholar]
- Graham, R.L.; Knuth, D.E.; Patashnik, O. Concrete Mathematics, 2nd ed.; Addison-Wesley: Boston, MA, USA, 1994; pp. 153–256. [Google Scholar]
- The MathWorks, Inc. Uniformly Distributed Random Numbers—MATLAB Rand. Available online: Mathworks.com/help/matlab/ref/rand.html (accessed on 20 September 2018).
- RANDOM.ORG. RANDOM.ORG—Random Byte Generator. Available online: Random.org/bytes (accessed on 20 September 2018).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Prasitsupparote, A.; Konno, N.; Shikata, J. Numerical and Non-Asymptotic Analysis of Elias’s and Peres’s Extractors with Finite Input Sequences. Entropy 2018, 20, 729. https://doi.org/10.3390/e20100729
Prasitsupparote A, Konno N, Shikata J. Numerical and Non-Asymptotic Analysis of Elias’s and Peres’s Extractors with Finite Input Sequences. Entropy. 2018; 20(10):729. https://doi.org/10.3390/e20100729
Chicago/Turabian StylePrasitsupparote, Amonrat, Norio Konno, and Junji Shikata. 2018. "Numerical and Non-Asymptotic Analysis of Elias’s and Peres’s Extractors with Finite Input Sequences" Entropy 20, no. 10: 729. https://doi.org/10.3390/e20100729
APA StylePrasitsupparote, A., Konno, N., & Shikata, J. (2018). Numerical and Non-Asymptotic Analysis of Elias’s and Peres’s Extractors with Finite Input Sequences. Entropy, 20(10), 729. https://doi.org/10.3390/e20100729