The Reconciliation of Multiple Conflicting Estimates: Entropy-Based and Axiomatic Approaches


1
Institute of Environmental Sciences CML, Leiden University, Einsteinweg 2, 2333 CC Leiden, The Netherlands
2
Edward J. Bloustein School of Planning & Public Policy, Rutgers, The State University of New Jersey, 33 Livingston Avenue, New Brunswick, NJ 08901-1982, USA
*
Author to whom correspondence should be addressed.
Entropy 2018, 20(11), 815; https://doi.org/10.3390/e20110815
Submission received: 3 September 2018
/
Revised: 18 October 2018
/
Accepted: 19 October 2018
/
Published: 23 October 2018
(This article belongs to the Special Issue The 20th Anniversary of Entropy - Recent Advances in Entropy and Information-Theoretic Concepts and Their Applications)
Abstract
:When working with economic accounts it may occur that multiple estimates of a single datum exist, with different degrees of uncertainty or data quality. This paper addresses the problem of defining a method that can reconcile conflicting estimates, given best guess and uncertainty values. We proceeded from first principles, using two different routes. First, under an entropy-based approach, the data reconciliation problem is addressed as a particular case of a wider data balancing problem, and an alternative setting is found in which the multiple estimates are replaced by a single one. Afterwards, under an axiomatic approach, a set of properties is defined, which characterizes the ideal data reconciliation method. Under both approaches, the conclusion is that the formula for the reconciliation of best guesses is a weighted arithmetic average, with the inverse of uncertainties as weights, and that the formula for the reconciliation of uncertainties is a harmonic average.
1. Introduction
With improvements in information technology, the world has become more unified and interconnected. Information is now typically shared quickly and easily from all over the globe, such that barriers formed by linguistic and geographic boundaries essentially have been torn down. This has enabled people from disparate cultures and backgrounds to share ideas and information. One outcome of this regime change has been a boosting of the perceived benefits of statistical information. While some benefits of such statistical information have been known since at least Quetelet’s (1835) tome on so-called “social physics” was published, today’s massive socio-economic statistical repositories in Europe, North America, and East Asia are enabling a data revolution of sorts. Indeed, the fields of data mining and data analytics are fast becoming important fields of academic study. Mirroring the rise of data availability and the nature of some of the data itself, the term “big data” has been coined [1] to refer to the extremely voluminous and complex data sets that require specialized processing application software to deal with them.
The most prominent stewards of socio-economic data are government statistical agencies, which focus on producing and disseminating data products secured via surveys (for example the American Community Survey), censuses (such as Japan’s 2015 Population Census), and administrative procedures (like information needed to get an academic promotion in Spain). As a result, data storage is now ubiquitously electronic, replicated offsite to guard against storage failure, and measured in petabytes. Electronic storage enables low-cost dissemination of data. It also facilitates the integration of records across disparate databases—for example, into a system of national accounts, which is what countries use to generate their estimates of gross domestic product, as suggested by the United Nations. Both lead to concerns about confidentiality of data and how it can be protected [2].
Our point in broaching the above is that data producers, disseminators, and users alike can run into the problem of having access to multiple estimates for a single quantity of interest. In the particular experience of the authors, which motivated the present study, these multiple estimates are a consequence of non-disclosure by a statistical office in order to ensure confidentiality. Hence we act as what Duncan et al. [2] called “data snooper”. For concreteness, in such instances we are interested in obtaining number of employees at county level from the U.S. Bureau of Statistics’s Quarterly Census of Employment and Wages (QCEW) data and U.S. Bureau of the Census’s County Business Patterns. In both datasets these figures are suppressed for selected sectors in some counties and even states. But information is provided for larger spatial and sectoral units, so it is possible to use this higher-level information to obtain multiple estimates of the quantities of interest. It is common for official statistical data to have a hierarchical structure so this problem is quite general. Garfinkel et al. [3] note that the increasing ability of data snoopers is making ever more data stewards reluctant to provide certain data products because they are finding it increasingly difficult to ensure confidentiality to the agents from whom they obtain the data. This is despite some use of noise as a disclosure limitation [4].
In this paper, we focus on the problem of combining such multiple estimates into a single value. In the case of economic accounts, Miller and Blair [5] (pp. 384–386) have called it “the reconciliation issue”. The reconciliation issue considered here should not be confused with the more general problem of data balancing, in which a set of multiple data points need to satisfy a set of constraints: That problem is addressed in other studies, such as Kruithof [6], Stone et al. [7], Byron [8], Van Der Ploeg [9], Lahr and Mesnard [10], Chen [11]. General solutions to confidentiality disclosure or data censoring issues are provided by [12,13]. Herein we set out to assist current and future data snoopers and miners, by identifying what a data reconciliation method should be from first principles when a fairly general formulation of the reconciliation constraints is possible.
In particular, we consider that the multiple estimates for a particular datum can be characterized by a best guess and uncertainty. If we interpret each estimate as a random variable with an underlying probability distribution, the best guess is the expected value and the uncertainty is standard deviation. In the case of multiple data sources, the conflict enabling the multiple estimates is self-evident. When numbers are published with some data censored and for which estimates can be obtained using partial information [14], the conflict can arise from a higher (or lower) hierarchical spatial or sectoral level (e.g., average employee number if the number of establishments is available). To the best of our knowledge no first-principle approach to this problem has yet been published, although more heuristic approaches can be found in Bourque et al. [15], Miernyk et al. [16], Jensen and McGaurr [17], Gerking [18], Gerking [19], Weale [20], Boomsma and Oosterhaven [21], Rassier et al. [22]. We tackle the same problem from two different angles.
Using concepts and techniques from Bayesian inference [23] and in particular the minimum cross-entropy method [24], we first address the problem of data reconciliation as a particular case of more general data balancing [25]. That is, we consider there are two or more initial estimates for a particular datum, but this datum is itself embedded in a set of constraints connecting it to other data that are potentially unbalanced. We look for simplifications of the general setting under which this original problem can be transformed into another balancing problem where the multiple estimates are replaced by a single one. We prove that, if the initial uncertainty estimates are close to one another, the data reconciliation method of best guesses is a weighted arithmetic average and the data reconciliation method of uncertainties is a harmonic average.
Afterwards we address the same problem from an axiomatic perspective, laying out the desirable properties of a data reconciliation method. Such an approach has roots in different fields, from table deflation [26] and supply-use transformations [27] to environmental responsibility [28]. It turns out that the canonical data reconciliation method, i.e., the one that satisfies all required properties, is none other than a suitable generalization of the entropy-based method as derived earlier. That generalization centers on the introduction of the number of previously combined priors and a ranking of estimates by their relative quality.
2. Entropy-Based Approach
2.1. Basic Concepts
Bayesian inference was first developed by Laplace [29] and later expanded by others, such as Jeffreys [30], Jaynes [31] and Jaynes [23]. According to the Bayesian paradigm, a probability is a degree of belief about the likelihood of an event, and should reflect all relevant available information about that event. According to Weise and Woger [32], if an empirical quantity is subject to measurement errors, it must be described by a random variable, whose expectation is the best guess and whose standard-deviation is the uncertainty estimate.
More formally, a prior datum is characterized by a probability distribution , which expresses the degree of belief that the datum takes realization . The best guess is and the uncertainty is . When multiple data are considered, e.g., and , it is necessary to introduce the correlation between them, . Rodrigues [33] further provides a series of rules to determine the properties of a strictly positive prior datum, using the maximum-entropy principle [34].
The type of data we are interested in are connected to one another through accounting identities of the form:
where is an aggregate datum and the ’s are disaggregate data. If the set of data is arranged in a vector of length , the set of accounting identities can be defined through a concordance matrix , where, for a given accounting identity i, if is a disaggregate datum, if is an aggregate datum and otherwise.
If the prior configuration is unbalanced, then , where is a vector of zeros. Rodrigues [25] derives an analytical solution and a series of approximations that, given a concordance matrix and prior configuration, provide a posterior configuration, , such that . The notational convention used here is that Greek letters refer to priors while Latin cognates will refer to posteriors, i.e., , and are, respectively, the best guess and uncertainty of and correlation between and .
2.2. Problem Formulation
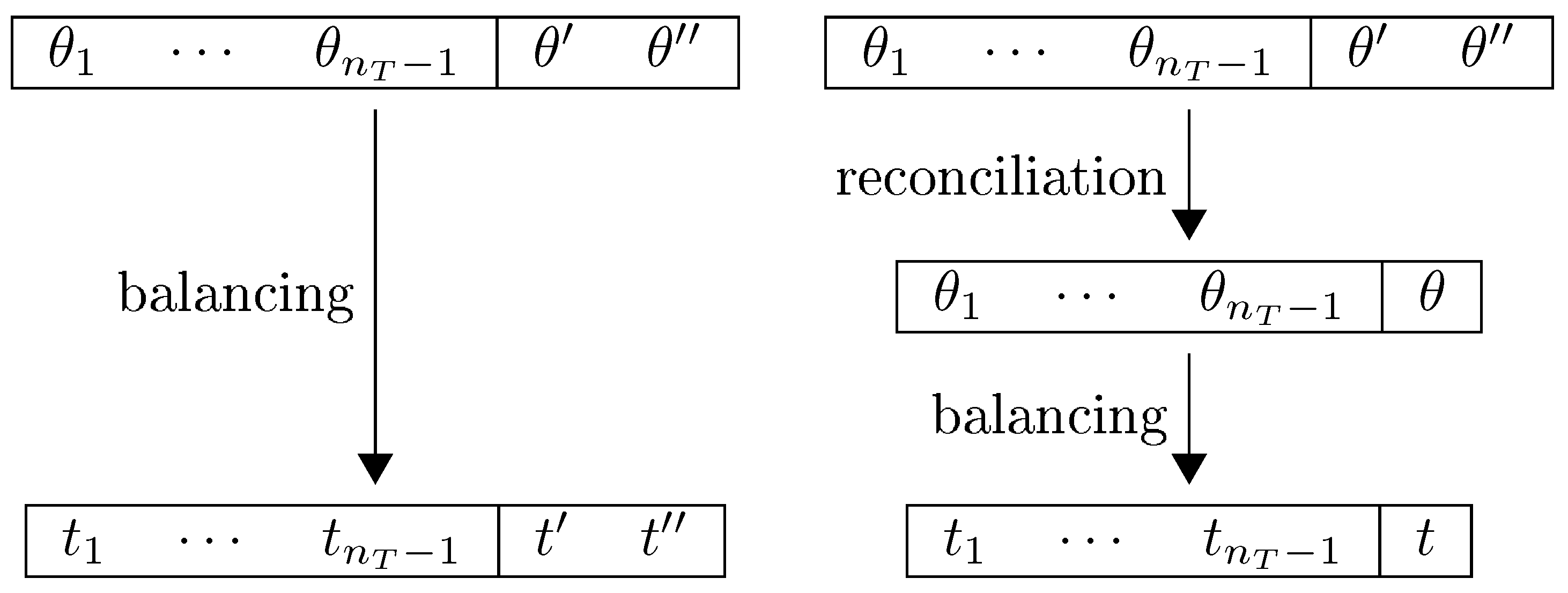
We are now in position to formulate the data reconciliation problem. Given initial priors and and a system with numerical data , and accounting identities, where accounting identity takes the form , our goal is to determine the final prior , in a new system with numerical data, and the first accounting identities of the original system, in which the posteriors are identical in both data balancing problems, and . Conceptually, we are approaching data reconciliation as a form of preliminary data balancing, as illustrated in Figure 1. The conflicting estimates are initial priors of the same datum, and the reconciled value is a final prior. Note the following notational convention: while other variables (and their properties) are denoted with subscripts, initial priors/posteriors (and their properties) are denoted with one () or two () primes, and the final prior/posterior is denoted with neither subscripts nor primes.
Three situations emerge: Either the datum to be reconciled is only a disaggregate datum; it is only an aggregate datum; or it is both a disaggregate and an aggregate datum, in different accounting identities. We will deal with the three cases separately.
We now present simple systems to illustrate the three possible cases. As a benchmark consider a tabular system (i.e., with data organized in rows and columns) with no multiple estimates consisting of a table with row sums and columns sums . Furthermore, consider that the sum of both and is known as d. If is a vector of ones of appropriate length, all vectors are in column format by default, and prime () adjoined to a matrix or vector denotes transpose, then the previous set of constraints means that:
The vectorized form of this system and the concordance table is presented in Table 1. In the baseline system there is a total of twelve variables (columns of the concordance matrix ) and seven constraints (rows thereof). The first six variables are disaggregate values (corresponding to the initial matrix), the following five are mixed (row and column sums and ), and the last one is an aggregate datum (d). The first two constraints (rows of ) are the row sums of , the following three are its columns sums, and the last two are the sums of and . To understand how is constructed let us consider the first constraint, which is the row sum of . Formally, this is:
hence in the first row of the entries corresponding to the columns of , and have 1s, the entry corresponding to the column of has and all entries are zero.
We are now in position to formalize the three situations of multiple estimates of a single datum as variants of Table 1 in which an additional row and column has been added to .
The case of disaggregate datum occurs if the datum for which multiple estimates exist is an interior point, which for concreteness we consider to be element : The set of constraints is shown in Table 2. As an illustration of the case of there being two estimates of an aggregate datum consider it to be d: The set of constraints is shown in Table 3. Finally, consider as example of an element that is both aggregate and disaggregate that of : The set of constraints is shown in Table 4.
It is perhaps instructive to describe how the reconciliation problems differ from the features of the baseline system. The three variants of the baseline are constructed by adding a single variable, the conflicting estimate, which by convenience is always appended to the original system. It is also necessary to add an extra constraint, connecting the two conflicting estimates. Finally, the baseline system is also changed so that in one of the original occurrences of the datum to be reconciled is the first conflicting estimate and the second occurrence is the other conflicting estimate.
Note that in this simple example there are only two constraints affecting each datum, but that naturally is not generally the case. The number of constraints per datum is arbitrary and can be either one or larger than two. An example of what this system might represent is employment count by region and sector, with an extra dimension being type of ownership (private or local, state, or federal government), as reported in the QCEW database.
2.3. From Balancing to Reconciliation
Rodrigues [25] shows that if the posterior configuration is balanced, then its first- and second-moment constraints are:
where and are the posterior best-guess vector and covariance matrix, and the latter is defined as , where is the vector of posterior uncertainties and is the vector of posterior correlations, and denotes diagonal matrix. Likewise and are the prior best guess vector and covariance matrix, and the latter is defined as .
The analytical solution of the data-balancing problem is:
Notice that Equations (3) and (4) contain symbols adjoined with (which we refer to as Gaussian parameters) while Equations (1) and (2) do not. The connection between the Gaussian parameters and the corresponding observable quantities is described in Rodrigues [25]: When relative uncertainty, or , is low, then the Gaussian parameter and the observable are identical. When relative uncertainty is high, the best guess Gaussian parameter tends to and the uncertainty Gaussian parameter tends to ∞, in such a way that if relative uncertainty is unitary, and . There is no closed-form expression between observables and Gaussian parameters in the multivariate case.
If both the prior uncertainty of aggregate data and initial prior correlations are high, we obtain a simplified weighted least-squares (WLS) method in which the weights are prior uncertainties:
and posterior correlations are set by considering that relative uncertainty is constant, , where ⊙ and ⊘ are Hadamard (or entrywise) product and division, and the update takes place in small steps.
This WLS method is a generalization of the standard biproportional balancing method (RAS) for arbitrary structure and uncertainty data [25]. However, it is in a way too simple for the data reconciliation problem, because it keeps relative uncertainty constant. In the data reconciliation problem this assumption is untenable, whenever the relative uncertainty of the initial priors differs.
Thus, we now look for a simplification of the general solution (Equations (3) and (4)) that is still feasible and that allows both for best guess and uncertainty reconciliation. Let us consider that correlations change little from prior to posterior, so that only uncertainties are adjusted. Equations (3) and (4) become:
where we dropped the , meaning that all variables are observables. If correlations are not adjusted, then , and if variances change little The previous expressions become:
For convenience, consider now that a datum corresponding to entry in the tabular matrix is , while the sums of row or column i is , and the Lagrange parameters of a row sum or column sum are adjoined with superscript R or C. For a particular entry, the previous matrix equation reads:
where and . If the adjustment from prior to posterior is small, then . If , and , then the previous expression matrix expressions simplify to:
where the derivation of Equation (7) follows along identical lines to that of Equation (6). We now use these expressions to obtain a tentative solution of the data reconciliation problem, even though they were derived under rather strict assumptions.
2.4. A Tentative Solution
We now examine the implications of applying Equations (6) and (7) to different data reconciliation configurations as described in Section 2.2: multiple estimates of (a) an aggregate datum; (b) a disaggregate datum; and (c) a datum that is both aggregate and disaggregate. We shall see that the same expression applies to all these problems.
For clarity, the analysis is carried out using scalar expressions, and, for brevity, only to the case of two constraints per datum. The strategy of the proof is the same for all configurations: to derive constraints connecting prior and posterior in the original problem and in a modified problem in which there is only a single datum where originally there were the conflicting estimates.
2.4.1. Aggregate Datum
Consider that there are two initial priors of a datum, and and that the datum is involved in two accounting identities, the first summing over elements 1 to and the second summing over to :
where each , for , can be affected by other accounting identities. The Lagrange parameters associated with these three expressions in Equation (6) are denoted, respectively, by , and . We wish to determine a final prior , such that:
Equation (6) reads, for the original problem:
where … refers to other Lagrange parameters. And in the modified problem:
Notice that for every datum the original and modified problem are identical. Because the posteriors of the aggregate datum are all identical, , we can write:
A similar expression can be obtained from Equation (7) for the final prior best guess, leading to the solution:
Thus, both the final prior of the absolute uncertainty, , and the relative uncertainty, , are obtained as the harmonic average of the initial prior absolute and relative uncertainties.
2.4.2. Disaggregate Datum
Consider now that there are two initial priors of an interior point, and , which is affected by two accounting identities, such that the posteriors satisfy:
The Lagrange parameters associated with these three expressions are, as before, , and . We wish to determine a final prior , such that:
As before, the data for which there are no conflicting estimates (, and with ) are subject to the same set of constraints in the original and in the modified problem. Because the posteriors of the disaggregate datum are all identical, , we can write:
At this stage it becomes clear that we will encounter exactly the same solution as in the case of an aggregate datum:
2.4.3. Mixed Datum
Consider now that there are two initial priors, and , of a datum that is both aggregate and disaggregate, in different accounting identities, and whose posteriors satisfy:
As before the Lagrange parameters are denoted as , and . We wish to determine a final prior , such that:
As has become routine, for datum 0 and for every datum the original and modified problem are identical. Because , we can write:
Thus, it is clear that the solution is again identical.
3. Axiomatic Approach
3.1. Axiomatic Formulation
In Section 2 we obtained a data reconciliation algorithm from first principles, as an operation of data balancing under a particular structure. However, we can also reason about the data reconciliation algorithm in terms of its properties, i.e., we will not determine what it is, but what it ought to be.
If and are two initial priors, the data reconciliation algorithm is a function that generates a final prior , where each prior is characterized by a best guess, , an absolute uncertainty, , and a relative uncertainty, , which can take values in the range . Let and , where x can be , or u.
We now propose a series of properties that define the data reconciliation method.
Property 1 (Lower and upper bounds).
The parameters of the final prior lie within the range set by the parameters of the initial priors, , and .
Property 2 (Commutativity).
The order in which the initial priors are combined does not matter, .
Property 3 (Associativity).
Several initial priors can be combined and the resulting final prior is invariant to the order of reconciliation, .
Property 4 (Identity).
If the initial prior best guesses are identical, then the final prior best guess is identical, . If the initial prior uncertainties are identical, then the final prior uncertainty is identical, .
Property 5 (Monotonicity).
The relative adjustment from initial to final prior increases with the relative magnitude of initial uncertainty:
where and .
Property 6 (Absorption).
If initial prior is known with minimal uncertainty, , and is not, , then the final prior is identical to the first initial prior, . If initial prior is known with maximal uncertainty, , and is not, , then the final prior is identical to the second initial prior, .
We believe that these six properties are uncontroversial and self-explanatory. However, it turns out that the problem as formulated here has no solution, i.e., no formula can satisfy all of the above properties. We later overcome this hurdle by generalizing the problem formulation, to include two additional concepts: A hierarchy of data quality and the number of combined priors.
3.2. The Canonical Data Reconciliation Method
The properties outlined in Section 3.1 constrain the range of data reconciliation algorithms but do not define a unique solution. However, Equations (8) and (9) suggests how it may be possible to obtain a solution. Let us consider that and take the simple yet flexible form of and .
The condition of identity (Property 4), in the case of and leads to the indeterminacy:
But if the limit is approached as and , when , then:
Thus, under the condition of identity, Equations (8) and (9) imply that:
so . Let us further consider the simplest possible case , so that and are the identity lines. Applying and to Equations (8) and (9) leads to:
Rearranging terms:
Recalling that we obtain the canonical data reconciliation method as:
Thus, if the ratio of relative adjustment of best guesses and uncertainties is identical to the ratio of absolute uncertainties of the initial priors, the best-guess data reconciliation method is a weighted average, where the weights are proportional to the inverse of absolute uncertainty, and the absolute and relative uncertainty data reconciliation methods are harmonic averages.
Does this data reconciliation method satisfy the properties of Section 3.1? It is trivial to check that Properties 1, 2, 4 and 5 are satisfied. But this is not the case for Properties 3 and 6. In the following subsections we present suitable extensions of the canonical data reconciliation method to address these problems.
3.3. The Number of Combined Priors
The canonical data reconciliation method is not associative. The properties of are:
While the properties of are:
Thus, . But upon some reflection, this result is in fact reasonable. The final prior is the combination of two initial priors with equal weights. If some of these initial priors are themselves a combination of other initial priors, this information has to be considered explicitly.
Let us introduce a new quantity, n, as the number of combined priors, so that now a prior is defined by a best guess, , an absolute uncertainty, , and n. Consider the following data reconciliation rule:
This data reconcilation rule satisfies the first five properties of Section 3.1.
3.4. Ranking of Data Quality
The canonical data reconciliation method satisfies the absorption property of minimal uncertainty. If and , then:
and Equations (10) and (11) become:
so and . However, it does not satisfy the absorption property of maximal uncertainty. If and , then and Equations (10), (11) and (13) become:
and thus and .
In order to ensure that the absorption of maximal uncertainty is satisfied, we use the concept of data quality, introduced in Rodrigues [25]. The idea is that, besides an uncertainty estimate, which formalizes quantitatively a degree of confidence in the accuracy of the best guess of a datum, it is also possible to formalize qualitatively a degree of confidence in the accuracy of a datum relative to others.
For the purpose of data balancing, Rodrigues [25] suggests that a datum that is considered to be of higher quality should be kept fixed while lower quality data are adjusted. The natural corollary, in the problem of data reconciliation, is to consider that when one wishes to combine two initial priors of differing levels of data quality, the prior of lower quality should be disregarded.
If a datum has unitary relative uncertainty, then it is maximally uninformative, and it is reasonable to disregard it. After all, a maximally uninformative prior should only be used if no better alternative is available. We therefore suggest that, if and , then directly, without using Equations (10) and (11).
3.5. Summary
We now present the expressions for the combination of n initial priors, , with into a single final prior . Addressing this problem requires the specification, for each prior, , of its best guess, , its absolute uncertainty, , and the number of previously combined priors, .
If all relative uncertainties, , are in the range , then the final prior properties are defined as:
Equation (19) can be expressed as:
If some initial priors have zero relative uncertainty, , then all other initial priors should be disregarded. If some initial priors have unitary relative uncertainty, , then it is they which should be disregarded.
In Figure 2 we illustrate the behaviour of Equation (19), when and . The plot shows different curves of the combined posterior best guess as a function of the prior best guess , where each curve corresponds to a different ratio of uncertainties, . When both uncertainties are identical, the posteriod best guess is the arithmetic average of the two prior best guesses. When the uncertainties differ, the best guess prior with the largest uncertainty contributes the least to combined best guess: in the limit case in which the prior is ignored and the posterior is similar to ; when the reverse occurs and .
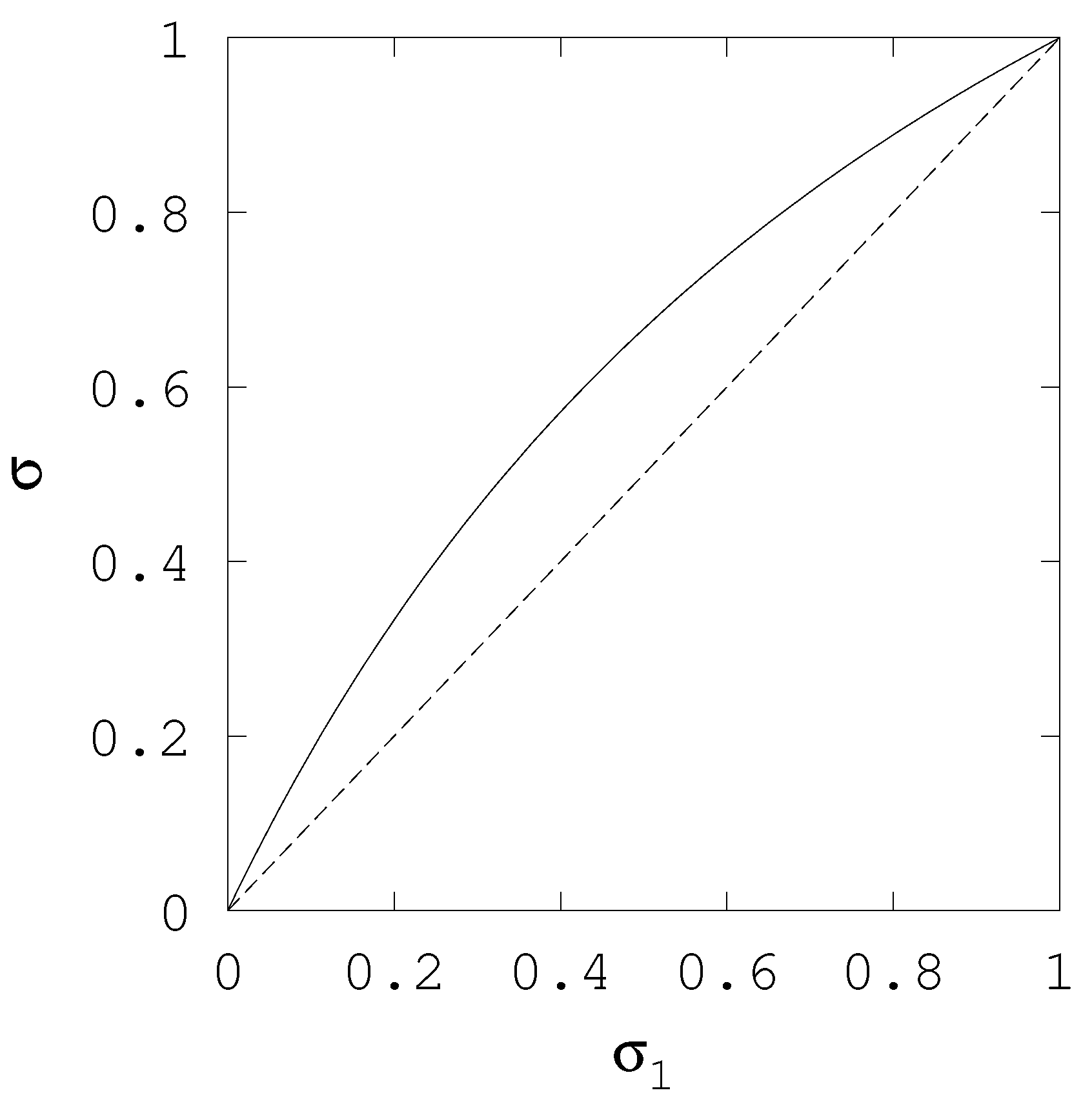
In turn, Figure 3 we illustrate the behaviour of Equation (20). We still consider that and but now no explicit assumption about best guesses is necessary. Instead, the uncertainty of the second variable is fixed, , and the curve shows the value of the combined posterior as a function of prior uncertainty . The figure describes an arc slightly above the diagonal line. When both prior uncertainties are identical (), then the posterior equals the priors, as expected. As becomes smaller than the combined prior becomes closer to than to , but always larger, , except in the limit case , in which case .
4. Conclusions and Discussion
Herein we investigated using two distinct pathways the problem of reconciling multiple conflicting estimates in the course of database development. We assume that the developer (data snooper) is tooled with a best guess and uncertainty for each of those conflicting estimates.
First, we apply a maximum-entropy Bayesian inference method, under the limiting condition that the adjustment from prior to posterior uncertainties is small. Second, we obtain a canonical data reconciliation method through an axiomatic approach that is as simple as possible but satisfied important qualitative properties. Each approach verifies the other.
The resulting formula for the best guess, Equation (19), is a weighted average showing that, as the count of conflicting priors underlying a particular prior rises, the value of that prior increases in importance in terms of obtaining a solution. We get a similar result with the inverse of the uncertainty, that is, the narrower the uncertainty of an estimate the more it contributes to the final solution. The resulting formula for the uncertainty, Equation (20), is a harmonic average where the same factors are present: As the count of conflicting priors underlying a particular prior rises, the value of that prior increases in importance; and the narrower the uncertainty of a prior, the more it contributes to the final solution.
Of course, limitations to our approach must be mentioned. And the key limitation is certainly that, in some practical applications, the data snooper will lack information on, either or both, best guess and uncertainty. It may be that instead, one only has upper and lower bounds for the datum of interest to inform its best guess and uncertainty. This is certainly the case in some instances when data are censored, e.g., the anti-suppression problem of Gerking et al. [13] and Isserman and Westervelt [12]. Future work using variable ranges with externally informed priors would be a natural extension of what is presented here. Indeed, some initial forays into this line of investigation are already underway, see, e.g., Makarkina and Lahr [35].
It should be mentioned that although the focus of attention here was on conflicting estimates arising from economic accounts there are other circumstances in which a formally identical problem arises, for example in expert elicitation [36].
Author Contributions
J.R. performed the conceptualization and formal analysis, M.L. provided the motivation and both J.R. and M.L. wrote the manuscript.
Funding
Research funded by Leiden University.
Acknowledgments
Any errors the paper may contain are the sole responsibility of the authors.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Lohr, S. The Origins of ‘Big Data’: An Etymological Detective Story. New York Times. 2013. Available online: https://bits.blogs.nytimes.com/2013/02/01/the-origins-of-big-data-an-etymological-detective-story/ (accessed on 22 October 2018).
- Duncan, G.T.; Elliot, M.; Salazar-Gonzalez, J.J. Statistical Confidentiality: Principles and Practice; Springer: New York, NY, USA, 2011. [Google Scholar]
- Garfinkel, R.; Gopal, R.; Goes, P. Privacy Protection of Binary Confidential Data against Deterministic, Stochastic, and Insider Attack. Manag. Sci. 2002, 48, 749–764. [Google Scholar] [CrossRef]
- Evans, T.; Zayatz, L.; Slanta, J. Using Noise for Disclosure Limitation of Establishment Tabular Data. Off. Stat. 1998, 14, 537–551. [Google Scholar]
- Miller, R.E.; Blair, P.D. Input-Output Analysis: Foundations and Extensions, 2nd ed.; Cambridge University Press: Cambridge, UK, 2009. [Google Scholar]
- Kruithof, R. Telefoonverkeersrekening. De Ingenieur 1937, 52, E15–E25. (In Dutch) [Google Scholar]
- Stone, R.; Meade, J.E.; Champernowne, D.G. The Precision of National Income Estimates. Rev. Econ. Stud. 1942, 9, 111–125. [Google Scholar] [CrossRef]
- Byron, R. The Estimation of Large Social Account Matrices. Stat. Soc. Ser. A 1978, 141, 359–367. [Google Scholar] [CrossRef]
- Van Der Ploeg, F. Reliability and the Adjustment of Sequences of Large Economic Accounting Matrices. Stat. Soc. Ser. A 1982, 145, 169–194. [Google Scholar] [CrossRef]
- Lahr, M.L.; Mesnard, L.D. Biproportional Techniques in Input-Output Analysis: Table Updating and Structural Analysis. Econ. Syst. Res. 2004, 16, 115–134. [Google Scholar] [CrossRef] [Green Version]
- Chen, B. A Balanced System of U.S. Industry Accounts and Distribution of the Aggregate Statistical Discrepancy by Industry. Bus. Econ. Stat. 2012, 30, 202–211. [Google Scholar] [CrossRef]
- Isserman, A.; Westervelt, J. 1.5 Million Missing Numbers: Overcoming Employment Suppression in County Business Patterns Data. Int. Reg. Sci. Rev. 2006, 29, 311–335. [Google Scholar] [CrossRef]
- Gerking, S.; Isserman, A.; Hamilton, W.; Pickton, T.; Smirnov, O.; Sorenson, D. Anti-suppressants and the Creation and Use of Non-Survey Regional Input-Output Models. In Regional Science Perspectives in Economic Analysis: A Festschrift in Memory of Benjamin H. Stevens; Lahr, M., Miller, R., Eds.; Elsevier: New York, NY, USA, 2001; pp. 379–406. [Google Scholar]
- Rodrigues, J.; Marques, A.; Wood, R.; Tukker, A. A network approach for assembling and linking input-output models. Econ. Syst. Res. 2016, 28, 518–538. [Google Scholar] [CrossRef]
- Bourque, P.J.; Chambers, E.J.; Chiu, J.S.Y.; Denman, F.L.; Dowdle, B.; Gordon, G.; Thomas, M.; Tiebout, C.; Weeks, E.E. The Washington Economy: An Input-Output Study; University of Washington: Seattle, WA, USA, 1967. [Google Scholar]
- Miernyk, W.H.; Shellhammer, K.L.; Brown, D.M.; Coccari, R.L.; Gallagher, C.J.; Wineman, W.H. Simulating Regional Economic Development: An Interindustry Analysis of the West Virginia Economy; D.C. Heath and Co.: Lexington, KY, USA, 1970. [Google Scholar]
- Jensen, R.C.; McGaurr, D. Reconciliation of purchases and sales estimates in an Input-Output table. Urban Stud. 1976, 13, 59–65. [Google Scholar] [CrossRef]
- Gerking, S. Reconciling ‘rows only’ and ‘columns only’ coefficients in an Input-Output model. Int. Reg. Sci. Rev. 1976, 1, 623–626. [Google Scholar] [CrossRef]
- Gerking, S. Reconciling reconciliation procedures in regional Input-Output Analysis. Int. Reg. Sci. Rev. 1979, 4, 23–36. [Google Scholar] [CrossRef]
- Weale, M. The reconciliation of values, volumes and prices in national accounts. Stat. Soc. Ser. A 1988, 151, 211–221. [Google Scholar] [CrossRef]
- Boomsma, P.; Oosterhaven, J. A double-entry method for the construction of bi-regional Input-Output tables. Reg. Sci. 1992, 32, 269–284. [Google Scholar] [CrossRef]
- Rassier, D.; Howells, T.; Morgan, E.; Empey, N.; Roesch, C. Implementing a Reconciliation and Balancing Model in the U.S. Industry Accounts; Working Paper WP2007-4; Bureau of Economic Analysis: Washington, DC, USA, 2007.
- Jaynes, E.T. Probability Theory: The Logic of Science; Cambridge University Press: Cambridge, UK, 2003. [Google Scholar]
- Kullback, S.; Leibler, R.A. On Information and Sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Rodrigues, J.F.D. A Bayesian Approach to the Balancing of Statistical Economic Data. Entropy 2014, 16, 1243–1271. [Google Scholar] [CrossRef] [Green Version]
- Persons, W.M. Fisher’s Formula for Index Numbers. Rev. Econ. Stat. 1921, 3, 103–113. [Google Scholar] [CrossRef]
- Kop Jansen, P.; Raa, T.T. The Choice of Model in the Construction of Input-Output Coefficients Matrices. Int. Econ. Rev. 1990, 31, 213–227. [Google Scholar] [CrossRef]
- Schneider, J.R.T.D.S.G.F. Designing an indicator of environmental responsibility. Ecol. Econ. 2006, 59, 256–266. [Google Scholar]
- Laplace, P.S. Essai Philosophique sur les Probabilités; Courcier Imprimeur: Paris, France, 1814. [Google Scholar]
- Jeffreys, H. Theory of Probability; Clarendon Press: Oxford, UK, 1939. [Google Scholar]
- Jaynes, E.T. Papers on Probability, Statistics and Statistical Physics; Kluwer Academic Publishers: Dordrecht, The Netherlands, 1983. [Google Scholar]
- Weise, K.; Woger, W. A Bayesian theory of measurement uncertainty. Meas. Sci. Technol. 1992, 4, 1–11. [Google Scholar] [CrossRef]
- Rodrigues, J.F.D. Maximum-Entropy Prior Uncertainty and Correlation of Statistical Economic Data. Bus. Econ. Stat. 2016, 34, 357–367. [Google Scholar] [CrossRef] [Green Version]
- Jaynes, E.T. Information Theory and Statistical Mechanics I. Phys. Rev. 1957, 106, 620–630. [Google Scholar] [CrossRef]
- Makarkina, G.V.; Lahr, M.L. Estimating Nationwide Impacts using an Input-Output Model with Fuzzy Parameters. In Proceedings of the 25th International Input-Output Conference, Atlantic, NJ, USA, 19–23 June 2017. [Google Scholar]
- Keane, E.A.L.M.J. Inconsistency reduction in decision making via multi-objective optimisation. Eur. Oper. Res. 2018, 267, 212–226. [Google Scholar]
Figure 1.
On the left-hand side balancing in a single step, with multiple initial estimates (priors) of the same datum, and , balanced to the same quantity (posterior), . On the right-hand side balancing in two steps: First the reconciliation procedures combines the multiple initial estimates (initial priors), and , into a final prior, ; afterwards the full system is balanced, leading to posterior t. We impose that the result from both procedures is the same, .
Figure 1.
On the left-hand side balancing in a single step, with multiple initial estimates (priors) of the same datum, and , balanced to the same quantity (posterior), . On the right-hand side balancing in two steps: First the reconciliation procedures combines the multiple initial estimates (initial priors), and , into a final prior, ; afterwards the full system is balanced, leading to posterior t. We impose that the result from both procedures is the same, .

Figure 2.
Best guess of the combined prior as a function of initial prior best guess, , when , for diferent values of : Solid line (–) when , solid line with circle markers (–○–) when , and solid line with triangle markers (–△–) when .
Figure 2.
Best guess of the combined prior as a function of initial prior best guess, , when , for diferent values of : Solid line (–) when , solid line with circle markers (–○–) when , and solid line with triangle markers (–△–) when .

Figure 3.
Solid line (–) and relative uncertainty, uncertainty of the final prior, , as a function of initial prior uncertainty, , when . Dashed line (--) is the identity line.
Figure 3.
Solid line (–) and relative uncertainty, uncertainty of the final prior, , as a function of initial prior uncertainty, , when . Dashed line (--) is the identity line.


{kind=link}
{kind=link}
{kind=link}
Table 1.
Prior vector and concordance matrix, with no multiple estimates.
| d | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 0 | 0 | 0 | −1 | 0 | 0 | 0 | 0 | 0 | |
| 0 | 0 | 0 | 1 | 1 | 1 | 0 | −1 | 0 | 0 | 0 | 0 | |
| 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | −1 | 0 | 0 | 0 | |
| 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | −1 | 0 | 0 | |
| 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | −1 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | −1 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | −1 |
Table 2.
Prior vector and concordance matrix, with multiple estimates of .
| d | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 0 | 0 | 0 | −1 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 0 | 0 | 0 | 1 | 1 | 1 | 0 | −1 | 0 | 0 | 0 | 0 | 0 | |
| 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | −1 | 0 | 0 | 0 | 0 | |
| 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | −1 | 0 | 0 | 0 | |
| 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | −1 | 0 | 1 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | −1 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | −1 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | 0 | −1 |
Table 3.
Prior vector and concordance matrix, with multiple estimates of d.
| 1 | 1 | 1 | 0 | 0 | 0 | −1 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 0 | 0 | 0 | 1 | 1 | 1 | 0 | −1 | 0 | 0 | 0 | 0 | 0 | |
| 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | −1 | 0 | 0 | 0 | 0 | |
| 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | −1 | 0 | 0 | 0 | |
| 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | −1 | 0 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 0 | 0 | 0 | −1 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | 0 | −1 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | −1 |
Table 4.
Prior vector and concordance matrix, with multiple estimates of .
| d | |||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 1 | 1 | 0 | 0 | 0 | −1 | 0 | 0 | 0 | 0 | 0 | 0 | |
| 0 | 0 | 0 | 1 | 1 | 1 | 0 | −1 | 0 | 0 | 0 | 0 | 0 | |
| 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | −1 | 0 | 0 | 0 | 0 | |
| 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | −1 | 0 | 0 | 0 | |
| 0 | 0 | 1 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | −1 | 0 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | −1 | 1 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 0 | 0 | 1 | 1 | 1 | −1 | 0 | |
| 0 | 0 | 0 | 0 | 0 | 0 | 1 | 0 | 0 | 0 | 0 | 0 | −1 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Rodrigues, J.F.D.; Lahr, M.L. The Reconciliation of Multiple Conflicting Estimates: Entropy-Based and Axiomatic Approaches. Entropy 2018, 20, 815. https://doi.org/10.3390/e20110815
AMA Style
Rodrigues JFD, Lahr ML. The Reconciliation of Multiple Conflicting Estimates: Entropy-Based and Axiomatic Approaches. Entropy. 2018; 20(11):815. https://doi.org/10.3390/e20110815
Chicago/Turabian StyleRodrigues, João F. D., and Michael L. Lahr. 2018. "The Reconciliation of Multiple Conflicting Estimates: Entropy-Based and Axiomatic Approaches" Entropy 20, no. 11: 815. https://doi.org/10.3390/e20110815
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.