Robust Inference after Random Projections via Hellinger Distance for Location-Scale Family


1
Department of Statistics, George Mason University, Fairfax, VA 22030, USA
2
Department of Mathematics and Statistics, Brock University, St. Catharines, ON L2S 3A1, Canada
*
Author to whom correspondence should be addressed.
Entropy 2019, 21(4), 348; https://doi.org/10.3390/e21040348
Submission received: 6 February 2019
/
Revised: 23 March 2019
/
Accepted: 24 March 2019
/
Published: 29 March 2019
(This article belongs to the Special Issue New Developments in Statistical Information Theory Based on Entropy and Divergence Measures)
Abstract
:Big data and streaming data are encountered in a variety of contemporary applications in business and industry. In such cases, it is common to use random projections to reduce the dimension of the data yielding compressed data. These data however possess various anomalies such as heterogeneity, outliers, and round-off errors which are hard to detect due to volume and processing challenges. This paper describes a new robust and efficient methodology, using Hellinger distance, to analyze the compressed data. Using large sample methods and numerical experiments, it is demonstrated that a routine use of robust estimation procedure is feasible. The role of double limits in understanding the efficiency and robustness is brought out, which is of independent interest.
1. Introduction
Streaming data are commonly encountered in several business and industrial applications leading to the so-called Big Data. These are commonly characterized using four V’s: velocity, volume, variety, and veracity. Velocity refers to the speed of data processing while volume refers to the amount of data. Variety refers to various types of data while veracity refers to uncertainty and imprecision in data. It is believed that veracity is due to data inconsistencies, incompleteness, and approximations. Whatever be the real cause, it is hard to identify and pre-process data for veracity in a big data setting. The issues are even more complicated when the data are streaming.
A consequence of the data veracity is that statistical assumptions used for analytics tend to be inaccurate. Specifically, considerations such as model misspecification, statistical efficiency, robustness, and uncertainty assessment-which are standard part of a statistical toolkit-cannot be routinely carried out due to storage limitations. Statistical methods that facilitate simultaneous addressal of twin problems of volume and veracity would enhance the value of the big data. While health care industry and financial industries would be the prime benefactors of this technology, the methods can be routinely applied in a variety of problems that use big data for decision making.
We consider a collection of n (n is of the order of at least ) observations, assumed to be independent and identically distributed (i.i.d.), from a probability distribution belonging to a location-scale family; that is,
We denote by the parameter space and without loss of generality take it as compact since otherwise it can be re-parametrized in a such a way that the resulting parameter space is compact (see [1]).
The purpose of this paper is to describe a methodology for joint robust and efficient estimation of and that takes into account (i) storage issues, (ii) potential model misspecifications, and (iii) presence of aberrant outliers. These issues-which are more likely to occur when dealing with massive amounts of data-if not appropriately accounted in the methodological development, can lead to inaccurate inference and misleading conclusions. On the other hand, incorporating them in the existing methodology may not be feasible due to a computational burden.
Hellinger distance-based methods have long been used to handle the dual issue of robustness and statistical efficiency. Since the work of [1,2] statistical methods that invoke alternative objective functions which converge to the objective function under the posited model have been developed and the methods have been shown to possess efficiency and robustness. However, their routine use in the context of big data problems is not feasible due to the complexity in the computations and other statistical challenges. Recently, a class of algorithms-referred to as Divide and Conquer—have been developed to address some of these issues in the context of likelihood. These algorithms consist in distributing the data across multiple processors and, in the context of the problem under consideration, estimating the parameters from each processor separately and then combining them to obtain an overall estimate. The algorithm assumes availability of several processors, with substantial processing power, to solve the complex problem at hand. Since robust procedures involve complex iterative computations-invoking the increased demand for several high-speed processors and enhanced memory-routine use of available analytical methods in a big data setting is challenging. Maximum likelihood method of estimation in the context of location-scale family of distributions has received much attention in the literature ([3,4,5,6,7]). It is well-known that the maximum likelihood estimators (MLE) of location-scale families may not exist unless the defining function satisfies certain regularity conditions. Hence, it is natural to ask if other methods of estimation such as minimum Hellinger distance estimator(MHDE) under weaker regularity conditions. This manuscript provides a first step towards addressing this question. Random projections and sparse random projections are being increasingly used to “compress data” and then use the resulting compressed data for inference. The methodology, primarily developed by computer scientists, is increasingly gaining attention among the statistical community and is investigated in a variety of recent work ([8,9,10,11,12]). In this manuscript, we describe a Hellinger distance-based methodology for robust and efficient estimation after the use of random projections for compressing i.i.d data belonging to the location-scale family. The proposed method consists in reducing the dimension of the data to facilitate the ease of computations and simultaneously maintain robustness and efficiency when the posited model is correct. While primarily developed to handle big and streaming data, the approach can also be used to handle privacy issues in a variety of applications [13].
The rest of the paper is organized as follows: Section 2 provides background on minimum Hellinger distance estimation; Section 3 is concerned with the development of Hellinger distance-based methods for compressed data obtained after using random projections; additionally, it contains the main results and their proofs. Section 4 contains results of the numerical experiments and also describes an algorithm for implementation of the proposed methods. Section 5 contains a real data example from financial analytics. Section 6 is concerned with discussions and extensions. Section 7 contains some concluding remarks.
2. Background on Minimum Hellinger Distance Estimation
Ref. [1] proposed minimum Hellinger distance (MHD) estimation for i.i.d. observations and established that MHD estimators (MHDE) are simultaneously robust and first-order efficient under the true model. Other researchers have investigated related estimators, for example, [14,15,16,17,18,19,20]. These authors establish that when the model is correct, the MHDE is asymptotically equivalent to the maximum likelihood estimator (MLE) in a variety of independent and dependent data settings. For a comprehensive discussion of minimum divergence theory see [21].
We begin by recalling that the Hellinger distance between two probability densities is the distance between the square root of the densities. Specifically, let, for , denote the norm defined by
The Hellinger distance between the densities and is given by
Let denote the density of valued independent and identically distributed random variables , where ; let be a nonparametric density estimate (typically a kernel density estimator). The Hellinger distance between and is then
The MHDE is a mapping from the set of all densities to defined as follows:
Please note that the above minimization problem is equivalent to maximizing . Hence MHDE can alternatively be defined as
To study the robustness of MHDE, ref. [1] showed that to assess the robustness of a functional with respect to the gross-error model it is necessary to examine the -influence curve rather than the influence curve, except when the influence curve provides a uniform approximation to the -influence curve. Specifically, the -influence function () is defined as follows: for , let , where denotes the uniform density on the interval , where is small, , ; the -influence function is then defined to be
where is the functional for the model with density . Equation (2) represents a complete description of the behavior of the estimator in the presence of contamination, up to the shape of the contaminating density. If is a bounded function of z such that , then the functional T is robust at against contamination by gross errors at arbitrary large value z. The influence function can be obtained by letting . Under standard regularity conditions, the minimum divergence estimators (MDE) are first order efficient and have the same influence function as the MLE under the model, which is often unbounded. Hence the robustness of these estimators cannot be explained through their influence functions. In contrast, the -influence function of the estimators are often bounded, continuous functions of the contaminating point. Finally, this approach often leads to high breakdown points in parametric estimation. Other explanations can also be found in [22,23].
Ref. [1] showed that the MHDE of location has a breakdown point equal to . Roughly speaking, the breakdown point is the smallest fraction of data that, when strategically placed, can cause an estimator to take arbitrary values. Ref. [24] obtained breakdown results for MHDE of multivariate location and covariance. They showed that the affine-invariant MHDE for multivariate location and covariance has a breakdown point of at least . Ref. [18] showed that the MHDE has breakdown in some discrete models.
3. Hellinger Distance Methodology for Compressed Data
In this section we describe the Hellinger distance-based methodology as applied to the compressed data. Since we are seeking to model the streaming independent and identically distributed data, we denote by J the number of observations in a fixed time-interval (for instance, every ten minutes, or every half-hour, or every three hours). Let B denote the total number of time intervals. Alternatively, B could also represent the number of sources from which the data are collected. Then, the incoming data can be expressed as . Throughout this paper, we assume that the density of belongs to a location-scale family and is given by , where . A typical example is a data store receiving data from multiple sources, for instance financial or healthcare organizations, where information from multiple sources across several hours are used to monitor events of interest such as cumulative usage of certain financial instruments or drugs.
3.1. Random Projections
Let be a matrix, where S is the number of compressed observations in each time interval, , and ’s are independent and identically distributed random variables and assumed to be independent of . Let
and set ; in matrix form this can be expressed as . The matrix is referred to as the sensing matrix and is referred to as the compressed data. The total number of compressed observations is much smaller than the number of original observations . We notice here that ’s are independent and identically distributed random matrices of order . Referring to each time interval or a source as a group, the following Table 1 is a tabular representation of the compressed data.
In random projections literature, the distribution of is typically taken to be Gaussian; but other distributions such as Rademacher distribution, exponential distribution and extreme value distributions are also used (for instance, see [25]). In this paper, we do not make any strong distributional assumptions on . We only assume that and , where represents the expectation of the random variable and represents the variance of the random variable. Additionally, we denote the density of by .
We next return to the storage issue. When and , is a sum of J random variables. In this case, one retains (stores) only the sum of J observations and robust estimates of are sought using the sum of observations. In other situations, that is when are not degenerate at 1, the distribution of is complicated. Indeed, even if are assumed to be normally distributed, the marginal distribution of is complicated. The conditional distribution is (given ) is a weighted sum of location scale distributions and does not have a useful closed form expression. Hence, in general for these problems the MLE method is not feasible. We denote by and work with the random variables We denote the true density of to be . Also, when (which implies ) we denote the true density of by to emphasize that the true density is a convolution of J independent and identically distributed random variables.
3.2. Hellinger Distance Method for Compressed Data
In this section, we describe the Hellinger distance-based method for estimating the parameters of the location scale family using the compressed data. As described in the last section, let be a doubly indexed collection of independent and identically distributed random variables with true density . Our goal is to estimate using the compressed data . We re-emphasize here that the density of depends additionally on , the variance of the sensing random variables .
To formulate the Hellinger-distance estimation method, let be a class of densities metrized by the distance. Let be a parametric family of densities. The Hellinger distance functional T is a measurable mapping mapping from to , defined as follows:
When , then under additional assumptions . Since minimizing the Hellinger-distance is equivalent to maximizing the affinity, it follows that
It is worth noticing here that
To obtain the Hellinger distance estimator of the true unknown parameters , expectedly we choose the parametric family to be density of and to be a non-parametric consistent estimator of . Thus, the MHDE of is given by
In the notation above, we emphasize the dependence of the estimator on the variance of the projecting random variables. We notice here that the solution to (1) may not be unique. In such cases, we choose one of the solutions in a measurable manner.
The choice of the density estimate, typically employed in the literature is the kernel density estimate. However, in the setting of the compressed data investigated here, there are S observations per group. These S observations are, conditioned on independent; however they are marginally dependent (if ). In the case when , we propose the following formula for . First, we consider the estimator
With this choice, the MHDE of is given by, for ,
The above estimate of the density chooses observation from each group and obtains the kernel density estimator using the B independent and identically distributed compressed observations. This is one choice for the estimator. Of course, alternatively, one could obtain different estimators by choosing different combinations of observations from each group.
It is well-known that the estimator is almost surely consistent for as long as and as . Hence, under additional regularity and identifiability conditions and further conditions on the bandwidth , existence, uniqueness, consistency and asymptotic normality of , for fixed , follows from the existing results in the literature.
When and , as explained previously, the true density is a –fold convolution of , it is natural to ask the following question: if one lets , will the asymptotic results converge to what one would obtain by taking . We refer to this property as a continuity property in of the procedure. Furthermore, it is natural to wonder if these asymptotic properties can be established uniformly in . If that is the case, then one can also allow to depend on B. This idea has an intuitive appeal since one can choose the parameters of the sensing random variables to achieve an optimal inferential scheme. We address some of these issues in the next subsection.
Finally, we emphasize here that while we do not require , in applications involving streaming data and privacy problems S tends to greater than one. In problems where the variance of sensing variables are large, one can obtain an overall estimator by averaging over various choices of ; that is,
The averaging improves the accuracy of the estimator in small compressed samples (data not presented). For this reason, we provide results for this general case, even though our simulation and theoretical results demonstrate that for some problems considered in this paper, S can be taken to be one. We now turn to our main results which are presented in the next subsection. The following Figure 1 provides a overview of our work.
3.3. Main Results
In this section we state our main results concerning the asymptotic properties of the MHDE of compressed data . We emphasize here that we only store Specifically, we establish the continuity property in of the proposed methods by establishing the existence of the iterated limits. This provides a first step in establishing the double limit. The first proposition is well-known and is concerned with the existence and uniqueness of MHDE for the location-scale family defined in () using compressed data.
Proposition 1.
Assume that is a continuous density function. Assume further that if . Then for every , on a set of positive Lebesgue measure, the MHDE in (4) exists and is unique.
Proof.
The proof follows from Theorem 2.2 of [20] since, without loss of generality, is taken to be compact and the density function is continuous in . □
Consistency: We next turn our attention to consistency. As explained previously, under regularity conditions for each fixed , the MHDE is consistent for . The next result says that under additional conditions, the consistency property of MHDE is continuous in .
Proposition 2.
Let be a continuous probability density function satisfying the conditions of Proposition 1. Assume that
Then, with probability one (wp1) the iterated limits also exist and equals ; that is, for ,
Proof.
Without loss of generality let be compact since otherwise it can be embedded into a compact set as described in [1]. Since is continuous in and is continuous in , it follows that is continuous in and . Hence by Theorem 1 of [1] for every fixed and ,
Thus, to verify the convergence of to as , we first establish, using (6), that
To this end, we first notice that
Hence, using (3),
Hence,
Also, by continuity,
which, in turn implies that
Thus existence of the iterated limit first as and then follows using compactness of and the identifiability of the model. As for the other iterated limit, again notice notice that for each , converges to with probability one as converges to 0. The result then follows again by an application of Theorem 1 of [20]. □
Remark 1.
Verification of condition (6) seems to be involved even in the case of standard Gaussian random variables and standard Gaussian sensing random variables. Indeed in this case, the density of is a fold convolution of a Bessel function of second kind. It may be possible to verify the condition (6) using the properties of these functions and compactness of the parameter space Θ. However, if one is focused only on weak-consistency, it is an immediate consequence of Theorems 1 and 2 below and condition (6) is not required. Finally, it is worth mentioning here that the convergence in (6) without uniformity over Θ is a consequence of convergence in probability of to 1 and Glick’s Theorem.
Asymptotic limit distribution: We now proceed to investigate the limit distribution of as and . It is well-known that for fixed , after centering and scaling, has a limiting Gaussian distribution, under appropriate regularity conditions (see for instance [20]). However to evaluate the iterated limits as and , additional refinements of the techniques in [20] are required. To this end, we start with additional notations. Let and let the score function be denoted by . Also, the Fisher information is given by
In addition, let be the gradient of with respect to , and is the second derivative matrix of with respect to . In addition, let and . Furthermore, let denote when . Please note that in this case, for all The corresponding kernel density estimate of is given by
We emphasize here that we suppress i on the LHS of the above equation since are equal for all .
The iterated limit distribution involves additional regularity conditions which are stated in the Appendix. The first step towards this aim is a representation formula which expresses the quantity of interest, viz., as a sum of two terms, one involving sums of compressed i.i.d. random variables and the other involving remainder terms that converge to 0 at a specific rate. This expression will appear in different guises in the rest of the manuscript and will play a critical role in the proofs.
3.4. Representation Formula
Before we state the lemma, we first provide two crucial assumptions that allow differentiating the objective function and interchanging the differentiation and integration:
Model assumptions on
(D1) is twice continuously differentiable in .
(D2) Assume further that is continuous and bounded.
Lemma 1.
Assume that the conditions (D1) and (D2) hold. Then for every and the following holds:
Proof.
By algebra, note that Furthermore, the second partial derivative of is given by Now using (D1) and (D2) and partially differentiating with respect to and setting it equal to 0, the estimating equations for is
Let be the solution to (14). Now applying first order Taylor expansion of (14) we get
where is defined in (10), and is given by
and is given by
Thus,
By using the identity, , can be expressed as the difference of and , where
and
Hence,
where and are given in (9). □
Remark 2.
In the rest of the manuscript, we will refer to as the remainder term in the representation formula.
We now turn to the first main result of the manuscript, namely a central limit theorem for as first and then . As a first step, we note that the Fisher information of the density is given by
Next we state the assumptions needed in the proof of Theorem 1. We separate these conditions as (i) model assumptions, (ii) kernel assumptions, (iii) regularity conditions, (iV) conditions that allow comparison of original data and compressed data.
Model assumptions on
(D1’) is twice continuously differentiable in .
(D2’) Assume further that is continuous and bounded.
Kernel assumptions
(B1) is symmetric about 0 on a compact support and bounded in We denote the support of by .
(B2) The bandwidth satisfies , .
Regularity conditions
(M1) The function is continuously differentiable and bounded in at .
(M2) The function is continuous and bounded in at . In addition, assume that
(M3) The function is continuous and bounded in at ; also,
(M4) Let be a sequence diverging to infinity. Assume that
where is the support of the kernel density and is a generic random variable with density .
(M5) Let
Assume .
(M6) The score function has a regular central behavior relative to the smoothing constants, i.e.,
Furthermore,
(M7) The density functions are smooth in an sense; i.e.,
(M1’) The function is continuously differentiable and bounded in at .
(M2’) The function is continuous and bounded in at . In addition, assume that
(M3’) The function is continuous and bounded in at . also,
Assumptions comparing models for original and compressed data
(O1) For all ,
(O2) For all ,
Theorem 1.
Assume that the conditions (B1)–(B2), (D1)–(D2) , (D1’)–(D2’), (M1)–(M7), (M1’)–(M3’), and (O1)–(O2) hold. Then, for every the following holds:
where G is a bivariate Gaussian random variable with mean 0 and variance , where is defined in (15).
Before we embark on the proof of Theorem 1, we first discuss the assumptions. Assumptions (B1) and (B2) are standard assumptions on the kernel and the bandwidth and are typically employed when investigating the asymptotic behavior of divergence-based estimators (see for instance [1]). Assumptions (M1)–(M7) and (M1’)–(M3’) are regularity conditions which are concerned essentially with continuity and boundedness of the scores and their derivatives. Assumptions (O1)–(O2) allow for comparison of and . Returning to the proof of Theorem 1, using representation formula, we will first show that , and then prove that in probability. We start with the following proposition.
Proposition 3.
Assume that the conditions (B1), (D1)–(D2), (M1)–(M3), (M1’)–(M3’), (M7) and (O1)–(O2) hold. Then,
where G is given in Theorem 1.
We divide the proof of Proposition 3 into two lemmas. In the first lemma we will show that
Next in the second lemma we will show that first letting and then allowing
We start with the first part.
Lemma 2.
Assume that the conditions (D1)–(D2), (D1’)–(D2’), (M1)–(M3), (M1’)–(M3’) and (O1)–(O2) hold. Then, with probability one, the following prevails:
Proof.
Using representation formula in Lemma 1. First fix . It suffices to show
We begin with . By algebra, can be expressed as
It suffices to show that as , , and . We first consider . By Cauchy-Schwarz inequality and assumption (M2), it follows that there exists ,
where the last convergence follows from the convergence of and . Hence, as , . Next we consider . Again, by Cauchy-Schwarz inequality and assumption (M2), it follows that . Hence . Turning to , by similar argument, using Cauchy-Schwarz inequality and assumption (M3), it follows that . Thus, to complete the proof, it is enough to show that
We start with the first term of (16). Let
We will show that . By algebra, the difference of the above two terms can be expressed as the sum of and , where
converges to zero by Cauchy-Schwarz inequality and assumption (O2), and converges to zero by Cauchy-Schwarz inequality, assumption (M2’) and Scheffe’s theorem. Next we consider the second term of (16). Let
We will show that . By algebra, the difference of the above two terms can be expressed as the sum of and , where
converges to zero by Cauchy-Schwarz inequality and assumption (O1), and converges to zero by Cauchy-Schwarz inequality, assumption (M3’) and Scheffe’s theorem. Therefore the lemma holds. □
Lemma 3.
Assume that the conditions (B1), (D1)–(D2), (D1’)–(D2’), (M1)–(M3), (M3’), (M7) and (O1)–(O2) hold. Then, first letting , and then
Proof.
First fix . Please note that using , we have that
Therefore,
Since ’s are i.i.d. across l, using Cauchy-Schwarz inequality and assumption (B1), we can show that there exists ,
converging to zero as by assumption (M7). Also, the limiting distribution of is as . Now let It is enough to show that as the density of converges to the density of . To this end, it suffices to show that . However, this is established in Lemma 2. Combining the results, the lemma follows. □
Proof of Proposition 3.
The proof of Proposition 3 follows immediately by combining Lemmas 2 and 3. □
We now turn to establishing that the remainder term in the representation formula converges to zero.
Lemma 4.
Assume that the assumptions (B1)–(B2), (M1)–(M6) hold. Then
Proof.
Using Lemma 2, it is sufficient to show that converges to 0 in probability as . Let
Please note that
Then
We first deal with , which can be expressed as the sum of and , where
Now consider . Let be arbitrary but fixed. Then, by Markov’s inequality,
Now since are independent and identically distributed across l, it follows that
Now plugging (19) into (18), interchanging the order of integration (using Tonelli’s Theorem), we get
where C is a universal constant, and the last convergence follows from conditions (M5)–(M6). We now deal with . To this end, we need to calculate . Using change of variables, two-step Taylor approximation, and assumption (B1), we get
Convergence of (21) to 0 now follows from condition (M6). We next deal with . To this end, by writing our the square term of , we have
We will show that the RHS of (22) converges to 0 as We begin with the first term. Please note that by Cauchy-Schwarz inequality,
the last term converges to 0 by (M4). As for the second term, note that, a.s., by Cauchy-Schwarz inequality,
Now taking the expectation and using Cauchy-Schwarz inequality, one can show that
where . The convergence to 0 of the RHS of above inequality now follows from condition (M4). Finally, by another application of the Cauchy-Schwarz inequality,
The convergence of RHS of above inequality to zero follows from (M4). Now the lemma follows. □
Proof of Theorem 1.
Recall that
where and are given in (9). Proposition 3 shows that ; while Lemma 4 shows that in probability. The result follows from Slutsky’s theorem. □
We next show that by interchanging the limits, namely first allowing to converge to 0 and then letting the limit distribution of is Gaussian with the same covariance matrix as Theorem 1. We begin with additional assumptions required in the proof of the theorem.
Regularity conditions
(M4’) Let be a sequence diverging to infinity. Assume that
where is the support of the kernel density and is a generic random variable with density .
(M5’) Let
Assume that .
(M6’) The score function has a regular central behavior relative to the smoothing constants, i.e.,
Furthermore,
(M7’) The density functions are smooth in an sense; i.e.,
Assumptions comparing models for original and compressed data
(V1) Assume that
(V2) is continuous in the sense that implies that , where the expectation is with respect to distribution .
(V3) Assume that for all , .
(V4) Assume that for all , .
Theorem 2.
Assume that the conditions (B1)–(B2), (D1’)–(D2’), (M1’)–(M7’), (O1)–(O2) and (V1)–(V4) hold. Then,
where G is a bivariate Gaussian random variable with mean 0 and variance .
We notice that in the above Theorem 2 that we use conditions (V2)–(V4) which are regularity conditions on the scores of the fold convolution of while facilitates comparison of the scores of the densities of the compressed data and that of the fold convolution. As before, we will first establish (a):
and then (b): in probability. We start with the proof of (a).
Proposition 4.
Assume that the conditions (B1)–(B2), (D1’)–(D2’), (M1’)–(M3’), (M7’), (O1)–(O2), and (V1)–(V2) hold. Then,
We divide the proof of Proposition 4 into two lemmas. In the first lemma, we will show that
In the second lemma, we will show that first let , then let ,
Lemma 5.
Assume that the conditions (B1)–(B2), (D1’)–(D2’), (M1’)–(M3’), (O1)–(O2), and (V1)–(V2) hold. Then,
Proof.
First fix B. Recall that
By algebra, can be expressed as the sum of , , , and , where
We will show that
where
is given in (7). First consider . it converges to zero as by Cauchy-Schwarz inequality and assumption (O2). Next we consider . We will first show that
To this end, notice that by Cauchy-Schwarz inequality and boundedness of in , it follows that there exists a constant C such that
It suffices to show that converges to in . Since
and , by dominated convergence theorem, . Next we will show that
In addition, by Cauchy-Schwarz inequality, boundedness of in and Scheffe’s theorem, we have that converges to zero as Next we consider . it converges to zero by Cauchy-Schwarz inequality and assumption (M2’). Thus (24) holds. Now let we will show that and First consider . It converges to zero by Cauchy-Schwarz inequality and assumption (M2’). Next we consider . It converges to zero by Cauchy-Schwarz inequality and convergence of and . Therefore .
We now turn to show that . First fix B and express as the sum of , , , , and , where
We will show that
First consider . It converges to zero as by Cauchy-Schwarz inequality and assumption (O1). Next consider . By similar argument as above and boundedness of , it follows that (27) holds. Next consider . It converges to zero as by Cauchy-Schwarz inequality and assumption (M3’). Now let we will show that and . First consider . It converges to zero by Cauchy-Schwarz inequality and assumption (M3’) as . Finally consider . It converges to zero by Cauchy-Schwarz inequality and convergence of and . Thus . Now letting , the proof of (23) follows using arguments similar to the one in Lemma 2. □
Lemma 6.
Assume that the conditions (B1)–(B2),(D1’)–(D2’), (M1’)–(M3’), (M7’), (O1)–(O2), and (V1)–(V2) hold. Then, first letting , and then letting
Proof.
First fix B. We will show that as
First observe that
We will show that the RHS of (29) converges to zero as and the RHS of (30) converges to zero in probability as . First consider the RHS of (29). Since
which converges to zero as by assumption (V1). Next consider the RHS of (30). Since
By assumption (V2), it follows that as , (30) converges to zero in probability. Now letting , we have
and
where the last convergence follows by assumption (M7’). Hence, using the Central limit theorem for independent and identically distributed random variables it follows that the limiting distribution of is , proving the lemma. □
Proof of Proposition 4.
The proof of Proposition 4 follows by combining Lemmas 5 and 6. □
Lemma 7.
Assume that the conditions (M1’)–(M6’) and (V1)–(V4) hold. Then,
Proof.
First fix B. Let
we will show that as , . By algebra, can be written as the sum of and , where
First consider . It is bounded above by , which converges to zero as by assumption (V1), where C is a constant. Next consider . We will show that converges to
In fact, the difference of and the above formula can be expressed as the sum of , and , where
First consider . Please note that
which converges to 0 as by assumptions (V3) and (V4). Next we consider . Since
which converges to zero as due to assumption (V2). Finally consider , which can be expressed as the sum of and , where
First consider . Notice that
where the last convergence follows by Cauchy-Schwarz inequality and assumption (V4). Next we consider . By Cauchy-Schwarz inequality, it is bounded above by
Equation (31) converges to zero as by boundedness of and convergence between and , where the convergence has already been established in Lemma 5. Now letting , following similar argument as Lemma 4 and assumptions (M1’)–(M6’), the lemma follows. □
Proof of Theorem 2.
Recall that
Proposition 4 shows that first letting then , ; while Lemma 7 shows that in probability. The theorem follows from Slutsky’s theorem. □
Remark 3.
The above two theorems (Theorems 1 and 2) do not immediately imply the double limit exists. This requires stronger conditions and more delicate calculations and will be considered elsewhere.
3.5. Robustness of MHDE
In this section, we describe the robustness properties of MHDE for compressed data. Accordingly, let , where denotes the uniform density on the interval , where is small, , , and . Also, let , , , , and . Before we state the theorem, we describe certain additional assumptions-which are essentially continuity conditions-that are needed in the proof.
Model assumptions for robustness analysis
(O3) For and all ,
(O4) For and all ,
Theorem 3.
(i) Let and assume that for all , and assume that the assumptions of Proposition 1 hold, also assume that is unique for all z. Then, is a bounded, continuous function of z and
(ii) Assume further that the conditions (V1), (M2)-(M3), and (O3)-(O4) hold. Then,
Proof.
Let denote and let denote We first show that (32) holds. Let be fixed. Then, by triangle inequality,
We will show that the first term of RHS of (33) is equal to zero. Suppose that it is not zero, without loss of generality, by going to a subsequence if necessary, we may assume that as . Since minimizes , it follows that
for every . We now show that as ,
To this end, note that as for every y,
Therefore, as
where
Now, by Cauchy-Schwarz inequality and Scheffe’s theorem, it follows that as , and . Therefore, (35) holds. By Equations (34) and (35), we have
for every . Now consider
where . Since is a non-negative and strictly convex function with as the unique point of minimum. Hence unless on a set of Lebesgue measure zero, which by the model identifiability assumption , is true if and only if . Since , it follows that
Since . This implies that
which contradicts (36). The continuity of follows from Proposition 2 and the boundedness follows from the compactness of . Now let , the second term of RHS of (33) converges to zero by Proposition 2.
We now turn to part (ii) of the Theorem. First fix Since minimizes over . By Taylor expansion of around , we get
where is a point between and ,
and can be expressed the sum of and , where
Therefore,
We will show that
We will first establish (40). Please note that as by definition Thus, In addition, by assumptions (O3) and (O4), is continuous in . Therefore, to prove (40), it suffices to show that
We begin with . Notice that
Thus,
In addition, in order to pass the limit inside the integral, note that, for every component of matrix , we have
where represents the absolute function for each component of the matrix, and
Now choosing the dominating function
and applying Cauchy-Schwarz inequality, we obtain that there exists a constant C such that
which is finite by assumption (M2). Hence, by the dominated convergence theorem, (43) holds. Turning to (42), notice that for each component of the matrix ,
where denotes the absolute function for each component. Now choosing the dominating function
and applying the Cauchy-Schwarz inequality it follows, using (M3), that
Finally, by the dominated convergence theorem, it follows that
Now taking partial derivative of with respect to , it can be expressed as the sum of , and , where
By dominated convergence theorem (using similar idea as above to find dominating functions), we have
We start with (44). Since for fixed , by the above argument, it follows that
it is enough to show
which is proved in Lemma 2. Hence (44) holds. Next we prove (45). By the argument used to establish (40), it is enough to show that
However,
and the RHS of the above inequality converges to zero as from assumption (V1). Hence (46) holds. This completes the proof. □
Our next result is concerned with the behavior of the influence function when first and then or . The following three additional assumptions will be used in the proof of part (ii) of Theorem 4.
Model assumptions for robustness analysis
(O5) For and all , is bounded in .
(O6) For and all , is bounded in .
(O7) For and all ,
Theorem 4.
(i) Let and assume that for all , assume that the assumptions of Proposition 1 hold, also assume that is unique for all z. Then, is a bounded, continuous function of z such that
(ii) Assume further that the conditions (O3)–(O7) hold. Then,
Proof.
Let denote and let denote . First fix ; then by the triangular inequality,
The first term of RHS of (47) is equal to zero due to proposition 2. Now let , then the second term on the RHS of (47) converges to zero using similar argument as Theorem 3 with density converging to . This completes the proof of I). Turning to (ii), we will prove that
Recall from the proof of part (ii) of Theorem 3 that
We will now show that for fixed
It can be seen that converges to zero as by Cauchy-Schwarz inequality and assumption (O3); also, converges to zero as by Cauchy-Schwarz inequality, assumption (O5) and Scheffe’s theorem. Hence (50) follows. Similarly (51) follows as by Cauchy-Schwarz inequality, assumption (O4), assumption (O6) and Scheffe’s theorem.
Now let . Using the same idea as in Theorem 3 to find dominating functions, one can apply the dominated convergence Theorem to establish that
Please can be expressed as the sum of , and , where
It can be seen thatr converges to zero as by Cauchy-Schwarz inequality and assumption (O7); converges to zero as by Cauchy-Schwarz inequality, boundedness of in , and Scheffe’s theorem. Therefore, (52) holds. Finally, letting and using the same idea as in Theorem 3 to find the dominating function, it follows by the dominated convergence theorem and L’Hospital rule that (49) holds. This completes the proof of the Theorem. □
Remark 4.
Theorems 3 and 4 do not imply that the double limit exists. This is beyond the scope of this paper.
In the next section, we describe the implementation details and provide several simulation results in support of our methodology.
4. Implementation and Numerical Results
In this section, we apply the proposed MHD based methods to estimate the unknown parameters using the compressed data. We set J = 10,000 and . All simulations are based on 5000 replications. We consider the Gaussian kernel and Epanechnikov kernel for the nonparametric density estimation. The Gaussian kernel is given by
and the Epanechnikov kernel is given by
We generate and uncontaminated compressed data in the following way:
- Step 1. Generate , where .
- Step 2. Generate , where .
- Step 3. Generate the uncontaminated by calculating .
4.1. Objective Function
In practice, we store the compressed data for all . Hence if follows Normal distribution with mean and variance , the form of the marginal density of the compressed data, viz., is complicated and does not have a closed form expression. However, for large J, using the local limit theorem its density can be approximated by Gaussian density with mean and variance . Hence, we work with , where . Please note that with this transformation, and . Hence, the kernel density estimate of the unknown true density is given by
The difference between the kernel density estimate and the one proposed here is that we include the unknown parameter in the kernel. Additionally, this allows one to incorporate into the kernel. Consequently, only the scale parameter is part of the parametric model. Using the local limit theorem, we approximate the true parametric model by , where is the density of . Hence, the objective function is
and, the estimator is given by
It is clear that is a consistent estimator of In the next subsection, we use Quasi-Newton method with Broyden-Fletcher-Goldfarb-Shanno (BFGS) update to estimate . Quasi-Newton method is appealing since (i) it replaces the complicated calculation of the Hessian matrix with an approximation which is easier to compute ( given in the next subsection) and (ii) gives more flexible step size t (compared to the Newton-Raphson method), ensuring that it does not “jump” too far at every step and hence guaranteeing convergence of the estimating equation. The BFGS update () is a popular method for approximating the Hessian matrix via gradient evaluations. The step size t is determined using Backtracking line search algorithm described in Algorithm 2. The algorithms are given in detail in the next subsection. Our analysis also includes the case where and . In this case, as explained previously, one obtains significant reduction in storage and computational complexity. Finally, we emphasize here that the density estimate contains and is not parameter free as is typical in classical MHDE analysis. In the next subsection, we describe an algorithm to implement our method.
4.2. Algorithm
As explained previously, we use the Quasi-Newton Algorithm with BFGS update to obtain . To describe this method, consider the objective function (suppressing i) , which is twice continuously differentiable. Let the initial value of be and , where I is the identity matrix.
| Algorithm 1: The Quasi-Newton Algorithm. |
Set k = 1.
|
Remark 5.
In step 1, one can directly use the Inverse update for as follows:
Remark 6.
In step 2, the step size t should satisfy the Wolfe conditions:
where and are constants with The first condition requires that t sufficiently decrease the objective function. The second condition ensures that the step size is not too small. The Backtracking line search algorithm proceeds as follows (see [26]):
| Algorithm 2: The Backtracking Line Search Algorithm. |
| Given a descent direction for at , . while , do end while |
4.3. Initial Values
The initial value for are taken to be
Another choice of the initial value for is:
where is an empirical estimate of the variance of .
Bandwidth Selection: A key issue in implementing the above method of estimation is the choice of the bandwidth. We express the bandwidth in the form , where , and is set equal to median .
In all the tables below, we report the average (Ave), standard deviation (StD) and mean square error (MSE) to assess the performance of the proposed methods.
4.4. Analyses Without Contamination
From Table 2, Table 3, Table 4 and Table 5, we let true , and take the kernel to be Gaussian kernel. In Table 2, we compare the estimates of the parameters as the dimension of the compressed data S increases. In this table, we allow S to take values in the set . Also, we let the number of groups , the bandwidth is chosen to be , and . In addition, in Table 2, means that with
From Table 2 we observe that as S increases, the estimates for and remain stable. The case is interesting, since even by storing the sum we are able to obtain point estimates which are close to the true value. In Table 3, we choose and and compare the estimates as changes from 0.01 to 1.00. We can see that as increases, the estimate for remains stable, whereas the bias, standard deviation and MSE for increase.
In Table 4, we fix and and allow the bandwidth to increase. Also, means that the bandwidth is chosen as with Notice that in this case when while which is not small as is required in assumption (B2). We notice again that as decreases, the estimates of and are close to the true value with small MSE and StD.
In Table 5, we let and and let the number of groups B increase. This table implies that as B increases, the estimate performs better in terms of bias, standard deviation and MSE.
In Table 6, we set and keep other settings same as Table 5. This table implies that as B increases, the estimate performs better in terms of bias, standard deviation and MSE. Furthermore, the standard deviation and MSE are slightly smaller than the results in Table 5.
We next move on to investigating the effect of other sensing variables. In the following table, we use Gamma model to generate the additive matrix . Specifically, the mean of Gamma random variable is set as , and the variance is chosen from the set which are also the variances in Table 3.
From Table 7, notice that using Gamma sensing variable yields similar results as Gaussian sensing variable. Our next example considers the case when the mean of the sensing variable is not equal to one and the sensing variable is taken to have a discrete distribution.Specifically, we use Bernoulli sensing variables with parameter p. Moreover, we fix and let . Therefore . Hence as J increases, the variance decreases. Now notice that in this case the mean of sensing variable is p instead of 1. In addition, and . Hence we set the initial value as
Additionally, we take , and to be
Table 8 shows that MHD method also performs well with Bernoulli sensing variable, although the bias of , standard deviation and mean squre error for both estimates are larger than those using Gaussian sensing variable and Gamma sensing variable.
4.5. Robustness and Model Misspecification
In this section, we provide a numerical assessment of the robustness of the proposed methodology. To this end, let
where is a contaminating component, We generate the contaminated reduced data in the following way:
- Step 1. Generate , where .
- Step 2. Generate , where .
- Step 3. Generate uncontaminated by calculating .
- Step 4. Generate contaminated , where with probability , and with probability .
In the above description, the contamination with outliers is within blocks. A conceptual issue that one encounters is the meaning of outliers in this setting. Specifically, a data point which is an outlier in the original data set may not remain an outlier in the reduced data and vice-versa. Hence the concepts such as breakdown point and influence function need to be carefully studied. The tables below present one version of the robustness exhibited by the proposed method. In Table 9 and Table 10, we set . In addition, means that with
From the above Table we observe that, even under contamination the estimate of the mean remains stable; however, the estimate of the variance is affected at high-levels of contamination (beyond ). An interesting and important issue is to investigate the role of on the breakdown point of the estimator.
Finally, we investigate the bias in MHDE as a function of the values of the outlier. The graphs below (Figure 2) describe the changes to MHDE when outlier values () increase. Here we set . In addition, we let and to take values from . We can see that as increases, both and increase up to then decrease, although does not change too much. This phenomenon is because when the outlier value is small (or closer to the observations), then it may not be considered as an “outlier” by the MHD method. However, as the outlier values move “far enough” from other values, then the estimate for and remain the stable.
5. Example
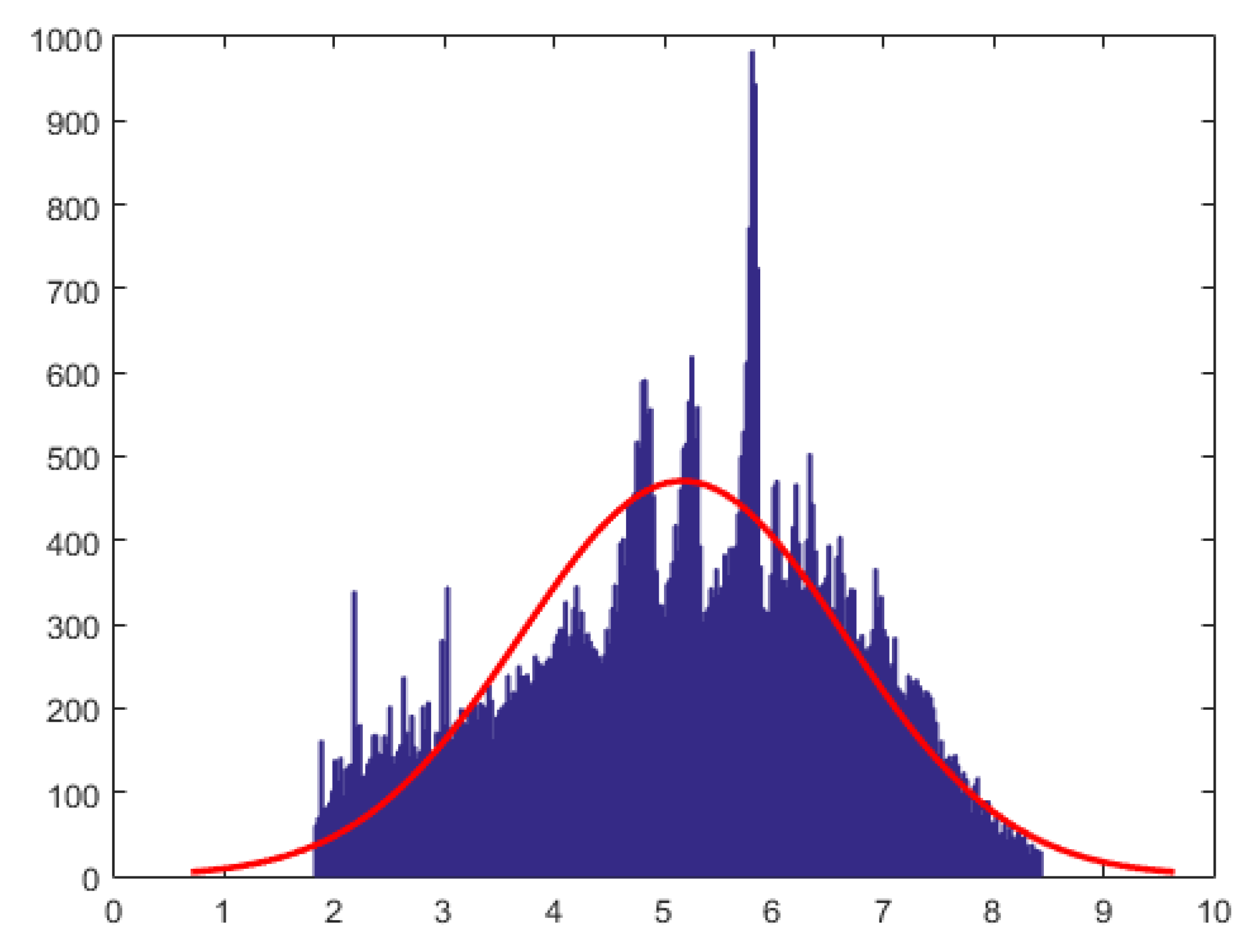
In this section we describe an analysis of data from financial analytics, using the proposed methods. The data are from a bank (a cash and credit card issuer) in Taiwan and the targets of analyses were credit card holders of the bank. The research focused on the case of customers’ default payments. The data set (see [27] for details) contains 180,000 observations and includes information on twenty five variables such as default payments, demographic factors, credit data, history of payment, and billing statements of credit card clients from April 2005 to September 2005. Ref. [28] study machine learning methods for evaluating the probability of default. Here, we work with the first three months of data containing 90,000 observations concerning bill payments. For our analyses we remove zero payments and negative payment from the data set and perform a logarithmic transformation of the bill payments . Since the log-transformed data was multi-modal and exhibited features of a mixture of normal distributions, we work with the log-transformed data with values in the range (6.1, 13). Next, we performed the Box-Cox transformation to the log-transformed data. This transformation identifies the best transformation that yields approximately normal distribution (which belongs to the location-scale family). Specifically, let denote the log-transformed data in range (6.1, 13), then the data after Box-Cox transformation is given by . The histogram for is given in Figure 3. The number of observations at the end of data processing was 70,000.
Our goal is to estimate the average bill payment during the first three months. For this, we will apply the proposed method. In this analysis, we assume that the target model for is Gaussian and split the data, randomly, into blocks yielding observations per block.
In Table 11, “est” represents the estimator, “ CI” stands for confidence interval for the estimator. When analyzing the whole data and choosing bandwidth as , we get the MHDE of to be with confidence interval , and the MHDE of as with confidence interval .
In Table 11, we choose the bandwidth as Also, represents the case where and . In all other settings, we keep . We observe that all estimates are similar as S changes.
Next we study the robustness of MHDE for this data by investigating the relative bias and studying the influence function. Specifically, we first reduce the dimension from to for each of the blocks and obtain the compressed data ; next, we generate the contaminated reduced data from step 4 in Section 4.5. Also, we set ; the kernel is taken to be to be Epanechnikov density with bandwidth . is assumed to takes values in (note that the approximate mean of is around 3600). Let be the Hellinger distance functional. The influence function given by
which we use to assess the robustness. The graphs shown below (Figure 4) illustrate how the influence function changes as the outlier values increase. We observe that for both estimates ( and ), the influence function first increase and then decrease fast. From , the influence functions remain stable and are close to zero, which clearly indicate that MHDE is stable.
Additional Analyses: The histogram in Figure 3 suggests that, may be a mixture of normal distributions may fit the log and Box-Cox transformed data better than the normal distribution. For this reason, we calculated the Hellinger distance between four component mixture (chosen using BIC criteria) and the normal distribution and this was determined to be 0.0237, approximately. Thus, the normal distribution (which belongs to the location-scale family) can be viewed as a misspecified target distribution; admittedly, one does lose information about the components of the mixture distribution due to model misspecification. However, since our goal was to estimate the overall mean and variance the proposed estimate seems to possess the properties described in the manuscript.
6. Discussion and Extensions
The results in the manuscript focus on the iterated limit theory for MHDE of the compressed data obtained from a location-scale family. Two pertinent questions arise: (i) is it easy to extend this theory to MHDE of compressed data arising from non location-scale family of distributions? and (ii) is it possible to extend the theory from iterated limits to a double limit? Turning to (i), we note that the heuristic for considering the location-scale family comes from the fact that the first and the second moment are consistently estimable for partially observed random walks (see [29,30]). This is related to the size of J and can be of exponential order. For such large J, other moments may not be consistently estimable. Hence, the entire theory goes through as long as one is considering parametric models , where , for a known function . The case in point is the Gamma distribution which can be re-parametrized in terms of the first two moments.
As for (ii), it is well-known that existence and equality of iterated limits for real sequences does not imply the existence of the double limit unless additional uniformity of convergence holds (see [31] for instance). Extension of this notion for distributional convergence requires additional assumptions and are investigated in a different manuscript wherein more general divergences are also considered.
7. Concluding Remarks
In this paper we proposed the Hellinger distance-based method to obtain robust estimates for mean and variance in a location-scale model using compressed data. Our extensive theoretical investigations and simulations show the usefulness of the methodology and hence can be applied in a variety of scientific settings. Several theoretical and practical questions concerning robustness in a big data setting arise. For instance, the effect of the variability in the matrix and its effect on outliers are important issues that need further investigation. Furthermore, statistical properties such as uniform consistency and uniform asymptotic normality under different choices for the distribution of would be useful. These are under investigation by the authors.
Author Contributions
The problem was conceived by E.A., A.N.V. and G.D. L.L. is a student of A.N.V., and worked on theoretical and simulation details with inputs from all members at different stages.
Funding
The authors thank George Mason University Libraries for support with the article processing fees; Ahmed’s research is supported by a grant from NSERC.
Acknowledgments
The authors thank the anonymous reviewers for a careful reading of the manuscript and several useful suggestions that improved the readability of the paper.
Conflicts of Interest
The authors declare no conflict of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| MHDE | Minimum Hellinger Distance Estimator |
| MHD | Minimum Hellinger Distance |
| i.i.d. | independent and identically distributed |
| MLE | Maximum Likelihood Estimator |
| CI | Confidence Interval |
| IF | Influence Function |
| RHS | Right Hand Side |
| LHS | Left Hand Side |
| BFGS | Broyden-Fletcher-Goldfarb-Shanno |
| var | Variance |
| StD | Standard Deviation |
| MSE | Mean Square Error |
References
- Beran, R. Minimum Hellinger distance estimates for parametric models. Ann. Stat. 1977, 5, 445–463. [Google Scholar] [CrossRef]
- Lindsay, B.G. Efficiency versus robustness: The case for minimum Hellinger distance and related methods. Ann. Stat. 1994, 22, 1081–1114. [Google Scholar] [CrossRef]
- Fisher, R.A. Two new properties of mathematical likelihood. Proc. R. Soc. Lond. Ser. A 1934, 144, 285–307. [Google Scholar] [CrossRef]
- Pitman, E.J.G. The estimation of the location and scale parameters of a continuous population of any given form. Biometrika 1939, 30, 391–421. [Google Scholar] [CrossRef]
- Gupta, A.; Székely, G. On location and scale maximum likelihood estimators. Proc. Am. Math. Soc. 1994, 120, 585–589. [Google Scholar] [CrossRef]
- Duerinckx, M.; Ley, C.; Swan, Y. Maximum likelihood characterization of distributions. Bernoulli 2014, 20, 775–802. [Google Scholar] [CrossRef]
- Teicher, H. Maximum likelihood characterization of distributions. Ann. Math. Stat. 1961, 32, 1214–1222. [Google Scholar] [CrossRef]
- Thanei, G.A.; Heinze, C.; Meinshausen, N. Random projections for large-scale regression. In Big and Complex Data Analysis; Springer: Berlin, Germany, 2017; pp. 51–68. [Google Scholar]
- Slawski, M. Compressed least squares regression revisited. In Artificial Intelligence and Statistics; Addison-Wesley: Boston, MA, USA, 2017; pp. 1207–1215. [Google Scholar]
- Slawski, M. On principal components regression, random projections, and column subsampling. Electron. J. Stat. 2018, 12, 3673–3712. [Google Scholar] [CrossRef]
- Raskutti, G.; Mahoney, M.W. A statistical perspective on randomized sketching for ordinary least-squares. J. Mach. Learn. Res. 2016, 17, 7508–7538. [Google Scholar]
- Ahfock, D.; Astle, W.J.; Richardson, S. Statistical properties of sketching algorithms. arXiv, 2017; arXiv:1706.03665. [Google Scholar]
- Vidyashankar, A.; Hanlon, B.; Lei, L.; Doyle, L. Anonymized Data: Trade off between Efficiency and Privacy. 2018; preprint. [Google Scholar]
- Woodward, W.A.; Whitney, P.; Eslinger, P.W. Minimum Hellinger distance estimation of mixture proportions. J. Stat. Plan. Inference 1995, 48, 303–319. [Google Scholar] [CrossRef]
- Basu, A.; Harris, I.R.; Basu, S. Minimum distance estimation: The approach using density-based distances. In Robust Inference, Handbook of Statistics; Elsevier: Amsterdam, The Netherlands, 1997; Volume 15, pp. 21–48. [Google Scholar]
- Hooker, G.; Vidyashankar, A.N. Bayesian model robustness via disparities. Test 2014, 23, 556–584. [Google Scholar] [CrossRef]
- Sriram, T.; Vidyashankar, A. Minimum Hellinger distance estimation for supercritical Galton–Watson processes. Stat. Probab. Lett. 2000, 50, 331–342. [Google Scholar] [CrossRef]
- Simpson, D.G. Minimum Hellinger distance estimation for the analysis of count data. J. Am. Stat. Assoc. 1987, 82, 802–807. [Google Scholar] [CrossRef]
- Simpson, D.G. Hellinger deviance tests: Efficiency, breakdown points, and examples. J. Am. Stat. Assoc. 1989, 84, 107–113. [Google Scholar] [CrossRef]
- Cheng, A.; Vidyashankar, A.N. Minimum Hellinger distance estimation for randomized play the winner design. J. Stat. Plan. Inference 2006, 136, 1875–1910. [Google Scholar] [CrossRef]
- Basu, A.; Shioya, H.; Park, C. Statistical Inference: The Minimum Distance Approach; Chapman and Hall/CRC: London, UK, 2011. [Google Scholar]
- Bhandari, S.K.; Basu, A.; Sarkar, S. Robust inference in parametric models using the family of generalized negative exponential dispatches. Aust. N. Z. J. Stat. 2006, 48, 95–114. [Google Scholar] [CrossRef]
- Ghosh, A.; Harris, I.R.; Maji, A.; Basu, A.; Pardo, L. A generalized divergence for statistical inference. Bernoulli 2017, 23, 2746–2783. [Google Scholar] [CrossRef]
- Tamura, R.N.; Boos, D.D. Minimum Hellinger distance estimation for multivariate location and covariance. J. Am. Stat. Assoc. 1986, 81, 223–229. [Google Scholar] [CrossRef]
- Li, P. Estimators and tail bounds for dimension reduction in l α (0 < α ≤ 2) using stable random projections. In Proceedings of the Nineteenth Annual ACM-SIAM Symposium on Discrete Algorithms, San Francisco, CA, USA, 20–22 January 2008; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2008; pp. 10–19. [Google Scholar]
- Boyd, S.; Vandenberghe, L. Convex Optimization; Cambridge University Press: Cambridge, UK, 2004. [Google Scholar]
- Lichman, M. UCI Machine Learning Repository. Available online: https://archive.ics.uci.edu/ml/index.php (accessed on 29 March 2019).
- Yeh, I.C.; Lien, C.H. The comparisons of data mining techniques for the predictive accuracy of probability of default of credit card clients. Expert Syst. Appl. 2009, 36, 2473–2480. [Google Scholar] [CrossRef]
- Guttorp, P.; Lockhart, R.A. Estimation in sparsely sampled random walks. Stoch. Process. Appl. 1989, 31, 315–320. [Google Scholar] [CrossRef]
- Guttorp, P.; Siegel, A.F. Consistent estimation in partially observed random walks. Ann. Stat. 1985, 13, 958–969. [Google Scholar] [CrossRef]
- Apostol, T.M. Mathematical Analysis; Addison Wesley Publishing Company: Boston, MA, USA, 1974. [Google Scholar]
Figure 1.
MLE vs. MHDE after Data Compression.

Figure 2.
Comparison of estimates of (a) and (b) as outlier changes.

Figure 3.
The histogram of credit payment data after Box-Cox transformation to Normality.

Figure 4.
Influence Function of (a) and (b) for MHDE.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Illustration of Data Reduction Mechanism, Here .
| Grp 1 | Grp 2 | ⋯ | Grp B | Grp 1 | Grp 2 | ⋯ | Grp B | ||
|---|---|---|---|---|---|---|---|---|---|
| Original | ⋯ | Compressed | ⋯ | ||||||
| Data | ⋯ | Data | ⋯ | ||||||
| ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ⋮ | ||
| ⋯ | ⋯ |
Table 2.
MHDE as the dimension S changes for compressed data using Gaussian kernel.
| Ave | StD | MSE | Ave | StD | MSE | |
|---|---|---|---|---|---|---|
| 2.000 | 1.010 | 0.001 | 1.016 | 74.03 | 5.722 | |
| 2.000 | 1.014 | 0.001 | 1.018 | 74.22 | 5.844 | |
| 2.000 | 1.005 | 0.001 | 1.019 | 73.81 | 5.832 | |
| 2.000 | 0.987 | 0.001 | 1.017 | 74.16 | 5.798 | |
| 2.000 | 0.995 | 0.001 | 1.019 | 71.87 | 5.525 | |
Table 3.
MHDE as changes for compressed data using Gaussian kernel.
| Ave | StD | MSE | Ave | StD | MSE | |
|---|---|---|---|---|---|---|
| 2.000 | 1.010 | 0.001 | 1.016 | 74.03 | 5.722 | |
| 2.000 | 1.017 | 0.001 | 1.015 | 74.83 | 5.814 | |
| 2.000 | 1.023 | 0.001 | 1.021 | 72.80 | 5.717 | |
| 2.000 | 1.119 | 0.001 | 1.076 | 72.59 | 11.08 | |
| 2.000 | 1.399 | 0.002 | 1.226 | 82.21 | 57.75 | |
Table 4.
MHDE as the bandwidth changes for compressed data using Gaussian kernel.
| Ave | StD | MSE | Ave | StD | MSE | |
|---|---|---|---|---|---|---|
| 2.000 | 1.010 | 0.001 | 1.016 | 74.03 | 5.722 | |
| 2.000 | 1.014 | 0.001 | 1.018 | 74.22 | 5.844 | |
| 2.000 | 1.015 | 0.001 | 1.063 | 79.68 | 10.26 | |
| 2.000 | 1.014 | 0.001 | 1.108 | 82.33 | 18.33 | |
| 2.000 | 1.004 | 0.001 | 1.212 | 93.96 | 53.64 | |
| 2.000 | 1.009 | 0.001 | 1.346 | 110.5 | 132.2 | |
Table 5.
MHDE as B changes for compressed data using Gaussian kernel with .
| Ave | StD | MSE | Ave | StD | MSE | |
|---|---|---|---|---|---|---|
| 2.000 | 2.205 | 0.005 | 1.739 | 378.5 | 688.6 | |
| 2.000 | 1.409 | 0.002 | 1.136 | 125.2 | 34.17 | |
| 2.000 | 1.010 | 0.001 | 1.016 | 74.03 | 5.722 | |
| 2.000 | 0.455 | 0.000 | 0.972 | 32.63 | 1.873 | |
Table 6.
MHDE as B changes for compressed data using Gaussian kernel with .
| Ave | StD | MSE | Ave | StD | MSE | |
|---|---|---|---|---|---|---|
| 2.000 | 2.282 | 0.005 | 1.749 | 381.4 | 706.0 | |
| 2.000 | 1.440 | 0.002 | 1.148 | 125.2 | 37.42 | |
| 2.000 | 1.014 | 0.001 | 1.018 | 74.22 | 5.844 | |
| 2.000 | 0.465 | 0.000 | 0.973 | 31.33 | 1.692 | |
Table 7.
MHDE as variance changes for compressed data using Gaussian kernel under Gamma sensing variable.
Table 7.
MHDE as variance changes for compressed data using Gaussian kernel under Gamma sensing variable.
| Ave | StD | MSE | Ave | StD | MSE | |
|---|---|---|---|---|---|---|
| 2.000 | 1.010 | 0.001 | 1.016 | 74.03 | 5.722 | |
| 2.000 | 1.005 | 0.001 | 1.016 | 74.56 | 5.806 | |
| 2.000 | 1.006 | 0.001 | 1.018 | 73.70 | 5.762 | |
| 2.000 | 1.120 | 0.001 | 1.078 | 73.70 | 11.56 | |
| 2.000 | 1.438 | 0.001 | 1.228 | 81.94 | 58.48 | |
Table 8.
MHDE as J changes for compressed data using Gaussian kernel under Bernoulli sensing variable.
Table 8.
MHDE as J changes for compressed data using Gaussian kernel under Bernoulli sensing variable.
| Ave | StD | MSE | Ave | StD | MSE | |
|---|---|---|---|---|---|---|
| 2.000 | 104.9 | 11.01 | 1.215 | 97.78 | 55.79 | |
| 1.998 | 104.5 | 10.93 | 1.201 | 104.5 | 51.26 | |
| 1.998 | 104.7 | 10.96 | 1.195 | 106.6 | 49.36 | |
| 2.001 | 103.9 | 10.80 | 1.200 | 105.7 | 51.20 | |
| 1.996 | 105.1 | 11.07 | 1.196 | 104.4 | 49.16 | |
Table 9.
MHDE as changes for contaminated data using Gaussian kernel.
| Ave | StD | MSE | Ave | StD | MSE | |
|---|---|---|---|---|---|---|
| 2.000 | 1.010 | 0.001 | 1.016 | 74.03 | 5.722 | |
| 2.000 | 1.014 | 0.001 | 1.018 | 74.22 | 5.844 | |
| 2.000 | 1.002 | 0.001 | 1.022 | 74.89 | 6.079 | |
| 2.000 | 1.053 | 0.001 | 1.023 | 77.86 | 6.599 | |
| 2.000 | 1.086 | 0.001 | 1.034 | 79.30 | 7.350 | |
| 2.000 | 1.146 | 0.001 | 1.073 | 93.45 | 14.06 | |
| 2.001 | 7.205 | 0.054 | 1.264 | 688.2 | 542.5 | |
| 2.026 | 21.60 | 1.100 | 3.454 | 1861 | 9480 | |
| 2.051 | 14.00 | 2.600 | 4.809 | 1005 | 15513 | |
Table 10.
MHDE as changes for contaminated data using Epanechnikov kernel.
| Ave | StD | MSE | Ave | StD | MSE | |
|---|---|---|---|---|---|---|
| 2.000 | 0.972 | 0.001 | 1.008 | 73.22 | 5.425 | |
| 2.000 | 1.014 | 0.001 | 1.018 | 74.22 | 5.844 | |
| 2.000 | 0.978 | 0.001 | 1.028 | 107.4 | 12.19 | |
| 2.000 | 1.264 | 0.002 | 1.025 | 108.7 | 12.35 | |
| 2.000 | 1.202 | 0.001 | 1.008 | 114.7 | 13.09 | |
| 2.000 | 1.263 | 0.002 | 1.046 | 129.8 | 18.76 | |
| 2.001 | 5.098 | 0.026 | 1.104 | 557.8 | 318.9 | |
| 2.021 | 21.80 | 0.900 | 3.004 | 1973 | 7870 | |
| 2.051 | 10.21 | 3.000 | 4.893 | 720.4 | 15669 | |
Table 11.
MHDE from the real data analysis.
| est | 5.171 | 1.362 | |
| CI | (4.904, 5.438) | (1.158, 1.540) | |
| est | 5.171 | 1.391 | |
| CI | (4.898, 5.443) | (1.183, 1.572) | |
| est | 5.172 | 1.359 | |
| CI | (4.905, 5.438) | (1.155, 1.535) | |
| est | 5.171 | 1.372 | |
| CI | (4.902, 5.440) | (1.167, 1.551) | |
| est | 5.171 | 1.388 | |
| CI | (4.899, 5.443) | (1.180, 1.569) |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Li, L.; Vidyashankar, A.N.; Diao, G.; Ahmed, E. Robust Inference after Random Projections via Hellinger Distance for Location-Scale Family. Entropy 2019, 21, 348. https://doi.org/10.3390/e21040348
AMA Style
Li L, Vidyashankar AN, Diao G, Ahmed E. Robust Inference after Random Projections via Hellinger Distance for Location-Scale Family. Entropy. 2019; 21(4):348. https://doi.org/10.3390/e21040348
Chicago/Turabian StyleLi, Lei, Anand N. Vidyashankar, Guoqing Diao, and Ejaz Ahmed. 2019. "Robust Inference after Random Projections via Hellinger Distance for Location-Scale Family" Entropy 21, no. 4: 348. https://doi.org/10.3390/e21040348
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.