Kernel Risk-Sensitive Mean p-Power Error Algorithms for Robust Learning


1
College of Electronic and Information Engineering, Southwest University, Chongqing 400715, China
2
Chongqing Key Laboratory of Nonlinear Circuits and Intelligent Information Processing, Chongqing 400715, China
*
Author to whom correspondence should be addressed.
Entropy 2019, 21(6), 588; https://doi.org/10.3390/e21060588
Submission received: 8 May 2019
/
Revised: 11 June 2019
/
Accepted: 12 June 2019
/
Published: 13 June 2019
(This article belongs to the Special Issue Information Theoretic Learning and Kernel Methods)
Abstract
:As a nonlinear similarity measure defined in the reproducing kernel Hilbert space (RKHS), the correntropic loss (C-Loss) has been widely applied in robust learning and signal processing. However, the highly non-convex nature of C-Loss results in performance degradation. To address this issue, a convex kernel risk-sensitive loss (KRL) is proposed to measure the similarity in RKHS, which is the risk-sensitive loss defined as the expectation of an exponential function of the squared estimation error. In this paper, a novel nonlinear similarity measure, namely kernel risk-sensitive mean p-power error (KRP), is proposed by combining the mean p-power error into the KRL, which is a generalization of the KRL measure. The KRP with reduces to the KRL, and can outperform the KRL when an appropriate p is configured in robust learning. Some properties of KRP are presented for discussion. To improve the robustness of the kernel recursive least squares algorithm (KRLS) and reduce its network size, two robust recursive kernel adaptive filters, namely recursive minimum kernel risk-sensitive mean p-power error algorithm (RMKRP) and its quantized RMKRP (QRMKRP), are proposed in the RKHS under the minimum kernel risk-sensitive mean p-power error (MKRP) criterion, respectively. Monte Carlo simulations are conducted to confirm the superiorities of the proposed RMKRP and its quantized version.
1. Introduction
Online kernel-based learning is to extend the kernel methods to online settings where the data arrives sequentially, which has been widely applied in signal processing thanks to its excellent performance in addressing nonlinear issues [1]. The development of kernel methods is of great significance for practical applications. In kernel methods, the input data are transformed from the original space into the reproducing kernel Hilbert space (RKHS) using the kernel trick [2]. As the representative of the kernel methods, kernel adaptive filters (KAFs) provide an effective way to transform a nonlinear problem into a linear one, which have been widely introduced in system identification and time-series prediction [3,4,5]. Generally, KAFs are designed for Gaussian and non-Gaussian noises from the aspect of cost function, respectively.
For Gaussian noises, the second-order similarity measures of errors are generally used as a cost function of KAFs to achieve desirable filtering accuracy. Therefore, in the Gaussian noise environment, KAFs based on the second-order similarity measures of errors are mainly divided into three categories, i.e., the kernel least mean square (KLMS) algorithm [6], the kernel affine projection algorithm (KAPA) [7], and the kernel recursive least square algorithm (KRLS) [8]. However, the network size of KAFs increases linearly with the length of training, leading to large computational and storage burdens. To curb this structure growth, many sparsification methods are required, such as the surprise criterion (SC) [9], novelty criterion (NC) [10], coherence criterion [11], and approximate linear dependency (ALD) criterion [8]. However, these sparsification methods only discard the redundant data, leading to reduction of filtering accuracy. Unlike the aforementioned sparsification methods, the vector quantization (VQ) utilizes the redundant data to update the weights for accuracy improvement. The VQ is combined into KAFs to generate quantized KAFs, e.g., the quantized kernel least mean square algorithm (QKLMS) [12] and quantized kernel recursive least squares algorithm (QKRLS) [13].
However, the second-order similarity measures used in the aforementioned algorithms merely contain the second order statistics of errors, which cannot address non-Gaussian noises or outliers, efficiently [14]. Thus, it is very important to design a cost function beyond the second-order statistics of errors for combating non-Gaussian noises. The non-second order similarity measures can be divided into three categories, i.e., the mean p-power error (MPE) criterion [15], information theoretic learning (ITL) [14], and risk-sensitive loss (RL) based criteria [16,17]. The MPE criterion based on the pth absolute moment of the error can deal with non-Gaussian data with a proper p-value, efficiently. In general, MPE is robust to large outliers when [15], generating robust adaptive filters [15], e.g., the kernel least mean p-power (KLMP) algorithm [18] and the kernel recursive least mean p-power (KRLP) algorithm [18]. ITL can incorporate the complete distribution of errors into the learning process, resulting in the improvement of filtering precision and robustness to outliers. The most widely used ITL criterion is the maximum correntropy criterion (MCC) [19,20,21,22,23,24]. As a local similarity measure defined as a generalized correlation in the RKHS, the correntropy used in MCC can leverage higher order statistics of data to combat outliers [25]. However, the performance surface of the correntropic loss (C-Loss) is highly non-convex, which may lead to poor convergence performance. In the RL-based criteria, e.g., minimum risk-sensitive loss [16] and minimum kernel risk-sensitive loss (MKRL) [17,26], the risk-sensitive loss in the RKHS is convex extremely, which is more efficient for combating non-Gaussian noises or outliers than MCC [17,26]. However, since the MKRL uses the stochastic gradient descent (SGD) method to update its weights, the desirable filtering performance cannot be achieved for some complex nonlinear issues. The recursive update rules with excellent tracking ability can improve the filtering performance of adaptive filtering algorithms [21]. For example, KRLS based on the recursive update rule can improve the filtering performance of KLMS based on the SGD, significantly. To the best of our knowledge, however, it has not yet been proposed to design a recursive MKRL algorithm for desirable filtering performance in the RKHS by a recursive update rule.
In this paper, to inherit the advantages of both KRL and MPE for robustness improvement, we propose the risk-sensitive mean p-power error (RP) defined as the expectation of an exponential function of the pth absolute moment of the estimation error, and its kernel RP (KRP). The KRP can outperform the KRL by setting an appropriate p-value for robust learning, and the KRP with reduces to the KRL. The proposed KRP criterion is used to derive a novel recursive minimum kernel risk-sensitive mean p-power error (RMKRP) algorithm for desirable filtering performance by combining the weighted output information. Furthermore, to curb the growth of network size in the RMKRP, the VQ is combined into RMKRP to generate quantized RMKRP (QRMKRP).
The rest of this paper is organized as follows. In Section 2, we define the KRP, and give some basic properties. The KRP criterion is derived to develop a recursive adaptive algorithm by combining the weighted output information, called RMKRP algorithm in Section 3. To further reduce the network size of RMKRP, the vector quantization method is applied in RMKRP, thus generating the quantized RMKRP (QRMKRP) in Section 3. In Section 4, Monte Carlo simulations are conducted to validate the superiorities of the proposed algorithms in nonlinear examples. The conclusion is summarized in Section 5.
2. Kernel Risk-Sensitive Mean p-Power Error
2.1. Definition
According to [17], the risk-sensitive loss is defined in RKHS, called the kernel risk-sensitive loss (KRL). Given two arbitrary scalar random variables X and Y, where , the KRL is defined by
where is a risk-sensitive scalar parameter; is a nonlinear mapping induced by a Mercer kernel , which transforms the data from the original space into the RKHS equipped with an inner product satisfying ; denotes the mathematical expectation; denotes the norm in RKHS ; denotes the joint distribution function of . A shift-invariant Gaussian kernel with bandwidth is given as follows:
However, the joint distribution of is usually unknown, and only N samples are available. Hence, the nonparametric estimate of is obtained by applying the Parzen windows [19] as . Note that the inner product in the RKHS for the same input is calculated by using kernel trick and (2), i.e, .
In this paper, we define a new non-second order similarity measure in the RKHS, i.e., the kernel risk-sensitive mean p-power error (KRP) loss. Given two random variables X and Y, the KRP loss is defined by
where is the power parameter. Note that the KRL can be regarded as a special case of the KRP with .
However, the joint distribution of X and Y is usually unknown in practice. Hence, the empirical KRP is defined as follows:
where denotes the available finite number of samples. The empirical KRP can be regarded as a distance between both and .
2.2. Properties
In the following, we give some important properties of the proposed KRP.
Property 1.
is symmetric that is .
Proof.
Straightforward since . □
Property 2.
is positive and bounded, i.e., , and reaches its minimum if .
Proof.
Straightforward since , and if . □
Property 3.
As λ is small enough, it holds that .
Proof.
For a small enough , we have , i.e.,
Therefore, we can obtain
□
Property 4.
As σ is large enough, it holds that .
Proof.
Since is approximated by for a small enough x, for the case of large enough , i.e., . Thus, we can obtain the approximation as
Similarly, when for large enough , we can also obtain the approximation as
Remark 1.
Property 5.
As p is small enough, it holds that .
Proof.
Property 5 holds because of . □
Property 6.
Let , where . The empirical KRP as a function of is convex at any point satisfying and . When , the empirical KRP is also convex if the risk-sensitive parameter and power parameter .
Proof.
Since , the Hessian matrix of with respect to can be derived as
where
with . When , we have if . From (11), if and , or and , we have . Therefore, we have if
where . Thus, we have . □
Remark 2.
According to Property 6, the empirical KRP as a function of is convex at any point satisfying and . For the case , the empirical KRP can still be convex at a point if the risk-sensitive parameter and power parameter .
Property 7.
As or , , it holds that
where denotes an N-dimensional zero vector.
Proof.
□
Remark 3.
According to Property 7, the empirical KRP behaves like an norm of when kernel bandwidth σ is large enough.
3. Application to Adaptive Filtering
In this section, to combat non-Gaussian noises, two recursive robust adaptive algorithms under the proposed KRP criterion are proposed in the RKHS using the kernel trick and vector quantization technique, respectively.
3.1. RMKRP
The recursive strategy is introduced into the KRP loss function, namely the recursive minimum kernel risk-sensitive mean p-power error (RMKRP) algorithm. The offline solution to minimum of the KRP loss is first obtained. Based on the obtained offline solution, the recursive solution or online solution to minimum of the KRP loss is then derived using some matrix operations, which generates the RMKRP algorithm. The details of RMKRP are shown as follows.
Consider the prediction of a continuous input-output model based on adaptive filtering shown in Figure 1, where is the ith D-dimensional input vector, is the ith scalar desired output contaminated by a noise , i.e., . A sequence of training samples is used to perform the prediction of in an adaptive filter. The nonlinear mapping of input is denoted by for simplicity. Hence, in the RKHS , the training samples are changed to , where the desired output vector is and the input kernel mapping matrix is . The prediction denoted by in the RKHS is therefore given as , where is the weight vector in a high dimensional feature space .
An exponentially-weighted loss function is used here to put more emphasis on recent data and to de-emphasize data on the remote past [28]. When are available, the weight vector is obtained as the offline solution to minimizing the following weighted cost function:
where denotes the forgetting factor in the interval , is the regularization factor, , and denotes the jth estimate error. The second term is a norm penalizing term, which is to guarantee the existence of the inverse of the input data autocorrelation matrix especially during the initial update stages. In addition, the regularization term is weighted by , which deemphasizes regularization as time progresses. According to Property 6, the empirical KRP as a function of is convex at any point satisfying , , and . To obtain the minimum of (15), its gradient is calculated, i.e.,
Setting (16) to zero, i.e., , we can obtain the offline solution to minimum of (15) as follows:
where with , , and denotes an identity matrix with an appropriate dimension.
To obtain an efficient recursive solution to the minimum of (15), a Mercer kernel is used to construct the RKHS. Here, the Gaussian kernel is used as a Mercer kernel, which is denoted as with being the kernel width. The inner product in the RKHS can be calculated by using the kernel trick [28], i.e., , efficiently, which can avoid the direct calculation of nonlinear mapping .
Note that in (19) can be computed by the kernel trick, efficiently. The weight vector is therefore described explicitly as a linear combination of the input data in the RKHS, i.e.,
where denotes the coefficients vector.
It can be seen from (20) that the recursive form of is changed to that of . Hence, in the following, the key for finding a recursive solution to the minimum of (15) is to obtain the recursive form of .
The coefficients vector is calculated using the kernel trick as
For simplicity, we obtain the update form of indirectly by defining as
where . Then, the update form of can be further obtained
where . By using some matrix operations, we further simplify (23) as
where . By using the following block matrix inversion identity [18,21,28]
then, we can obtain the update equation for the inverse of the growing matrix in (24) as
where and . Combining (21) with (26), the coefficients vector of the weight vector is shown as follows:
where denotes the difference between the desired output and the system output . is the jth element of and all the previous data are the centers. The coefficients and all the previous data should be stored at each iteration. Finally, the RMKRP algorithm is summarized in Algorithm 1.
| Algorithm 1: The RMKRP Algorithm. |
| Initialization: . . . Computation: While { available do 1) 2) 3) 4) 5) 6) 7) 8) end while |
3.2. QRMKRP
The RMKRP algorithm generates a linearly growing network owing to the used kernel trick. The online vector quantization (VQ) method [12] has been successfully applied in KAFs to curb its network growth efficiently. Thus, we incorporate the online VQ method into the RMKRP to develop the quantized RMKRP (QRMKRP) algorithm, which is shown as follows.
Suppose that the dictionary contains L vectors at discrete time i, i.e., , , which means that there are L distinctive quantization regions. In the RKHS, the prediction is therefore expressed as , where is the weight vector in RKHS . The cost function of QRMKRP based on is denoted as
where denotes the number of input data those lie in the kth quantization region of and satisfies and , and is the desired output corresponding to the nth element within the kth quantization region.
The offline solution to the minimization of (28) can be described by
where with elements; denotes a accumulated diagonal matrix; denotes a accumulated weighted output vector; denotes corresponding to the nth entry of the kth quantization region; denotes an identity matrix with an appropriate dimension. Since (29) has a similar form to (17), we simplify (29) as
where . To obtain the recursive solution to the minimization of (28), we let and denote
To update in (30) recursively, two cases are therefore considered.
(1) First, Case: dis: In this case, we have and , which means the input is therefore quantized to the th element of dictionary , where = . The matrix and the vector have a similar form to [13]. Here, and can be shown as
where is a -dimensional column vector whose th element is 1 and all other elements are 0. Combining (32) into (31), the matrix can be expressed as . By using the matrix inversion lemma [28], we obtain
where and represent the th columns of the matrices and , respectively. Therefore, in (30) can be calculated as
(2) Second Case: dis: In this case, we have , , and we have
where is the null column vector with a compatible dimension; and . Combining (31), (35), , and the block matrix inversion identity [28], we obtain
where
Furthermore, due to , we obtain
The QRMKRP algorithm is summarized in Algorithm 2, where L denotes the dictionary size.
| Algorithm 2: The QRMKRP algorithm. |
| Initialization: , , . , . Computation: While { available do 1) Compute the distance between and : dis, where = . 2) If dis: Keep the dictionary unchanged: , Update by (32), by (33), by (34). 3) Otherwise: The dictionary changes: , Update by (35), by (36), by (38). end while |
4. Simulation
In this section, to validate the performance of the proposed RMKRP algorithm and its quantized version, two examples, i.e., Mackey–Glass (MG) chaotic time series prediction and nonlinear system identification, are used to validate the performance superiorities of the proposed two algorithms.
In this example, the noise environment considered is the impulsive noise, which is modeled by the combination of two independent noise processes [17], i.e.,
where is an ordinary noise disturbance with small variance and represents large outliers with large variance; is of binary distribution random process over with and ( is an occurrence probability). Here, we select . The distribution of is considered as a Binary distribution over with probability mass . In addition, is modeled by the -stable process, owing to its heavy-tailed probability density function. The -stable process is described by the following characteristic function [29]:
where
with being the characteristic factor, being the symmetry parameter, being the dispersion parameter, denotes the sign function, , and being the location parameter. Generally, a smaller generates a heavier tail and a smaller generates fewer large outliers. The characteristic function denoted as is chosen as to model the impulse noise in the simulations.
4.1. Chaotic Time Series Prediction
The MG chaotic time series is generated from the following differential equation [9]:
where . Here, we set , , and . The time series is discretized at a sampling period of six seconds. The training set includes a segment of 2000 samples corrupted by the additive noises which are shown in (39), and another 200 samples without noise are used as the testing set. The kernel size in the Gaussian kernel is set to 1. The filter length is set at , which means that is used to predict .
To evaluate the filtering accuracy, the testing mean square error (MSE) is defined as follows:
where is the estimate of , and N is the length of testing data.
The KLMS [6], KMCC [22], MKRL [26], KRMC [21], and KRLS [8] algorithms are chosen for performance comparison with RMKRP thanks to their excellent filtering performance. The other sparsification algorithms, i.e., the QKLMS [12], QKMCC [30], QMKRL [26], QKRLS [13], and KRMC-NC [21] algorithms are used for performance comparison with QRMKRP owing to their modest space complexities and excellent performance. All simulation results are averaged over 50 independent Monte Carlo runs.
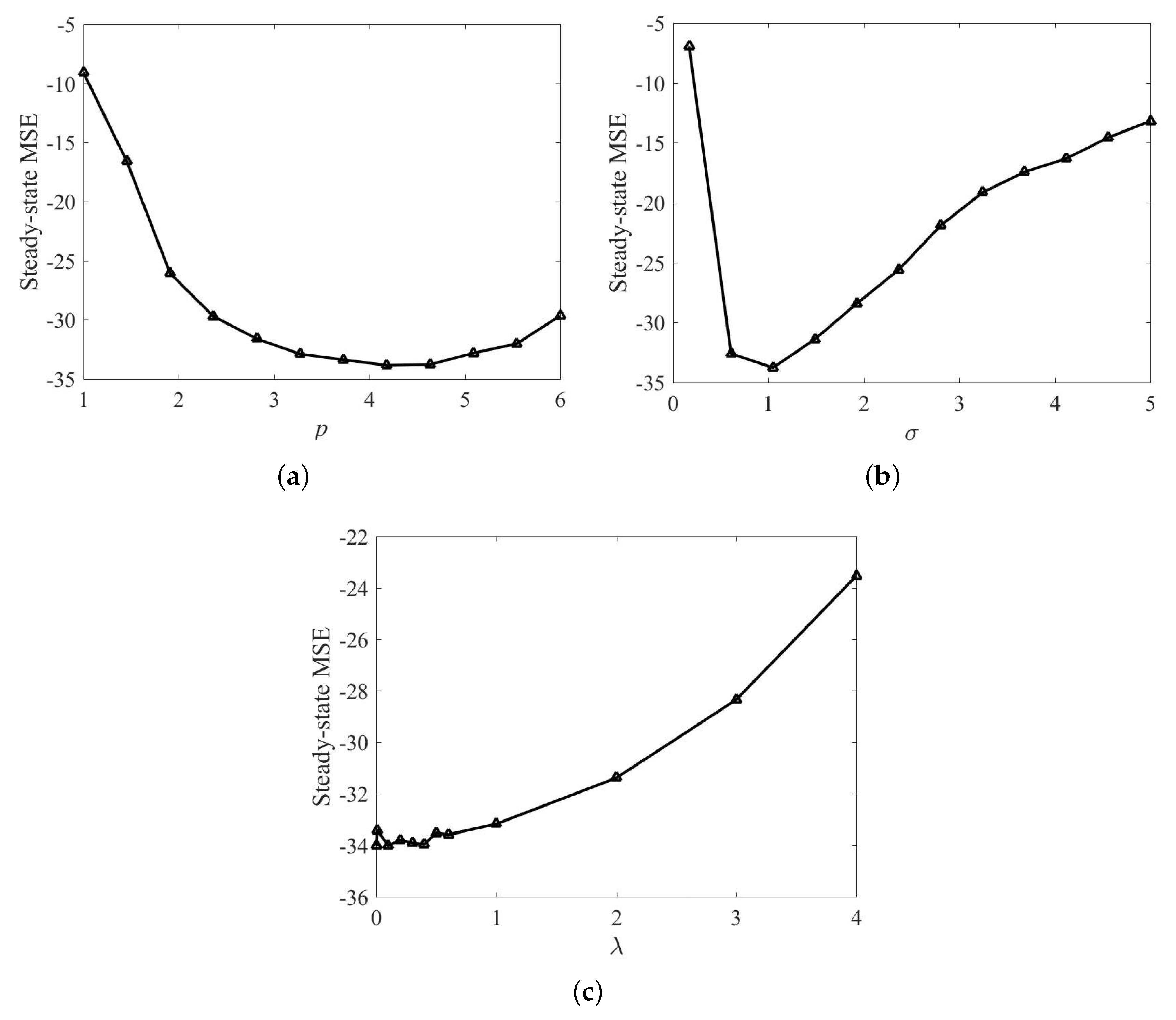
Since power parameter p, risk-sensitive parameter , and kernel width are crucial parameters in the proposed RMKRP and QRMKRP algorithms, the influence of these parameters on the performance is first discussed. In the simulations, we take 12 points evenly in the close interval and , respectively. The influence of p on the steady-state performance of RMKRP is shown in Figure 2a, where the steady-state MSEs are obtained as averages over the last 100 iterations. The parameters are set as: p is set within ; risk-sensitive parameter in the KRP is set as 1; and ; kernel size in the KRP is set as 1. As can be seen from Figure 2a, we have that the filtering accuracy of RMKRP is the highest when and decreases gradually when p is either too small or too large. Then, the influence of on the filtering performance of RMKRP with is shown in Figure 2b, where the steady-state MSEs are obtained as averages over the last 100 iterations. The parameters are set as: risk-sensitive parameter is fixed at 1; lies in . From Figure 2b, we see that RMKRP can achieve the highest filtering accuracy when is about 1. It is reasonable to note that RMKRP are sensitive to outliers when the kernel width is large, and decreases its ability of error-correction when the kernel width is small. Finally, the influence of on the filtering performance of RMKRP with and is shown in Figure 2c, where the steady-state MSEs are obtained as averages over the last 100 iterations. The parameters are set as: the range of is selected as . From Figure 2c, we see that has a slight influence on the filtering accuracy when is small, and a large can increase the steady-state MSE obviously. Therefore, from Figure 2, the parameters of RMKRP can be chosen by trials to obtain the best performance in practice. Similarly, the parameters of QRMKRP can be chosen by the same method as that in RMKRP.
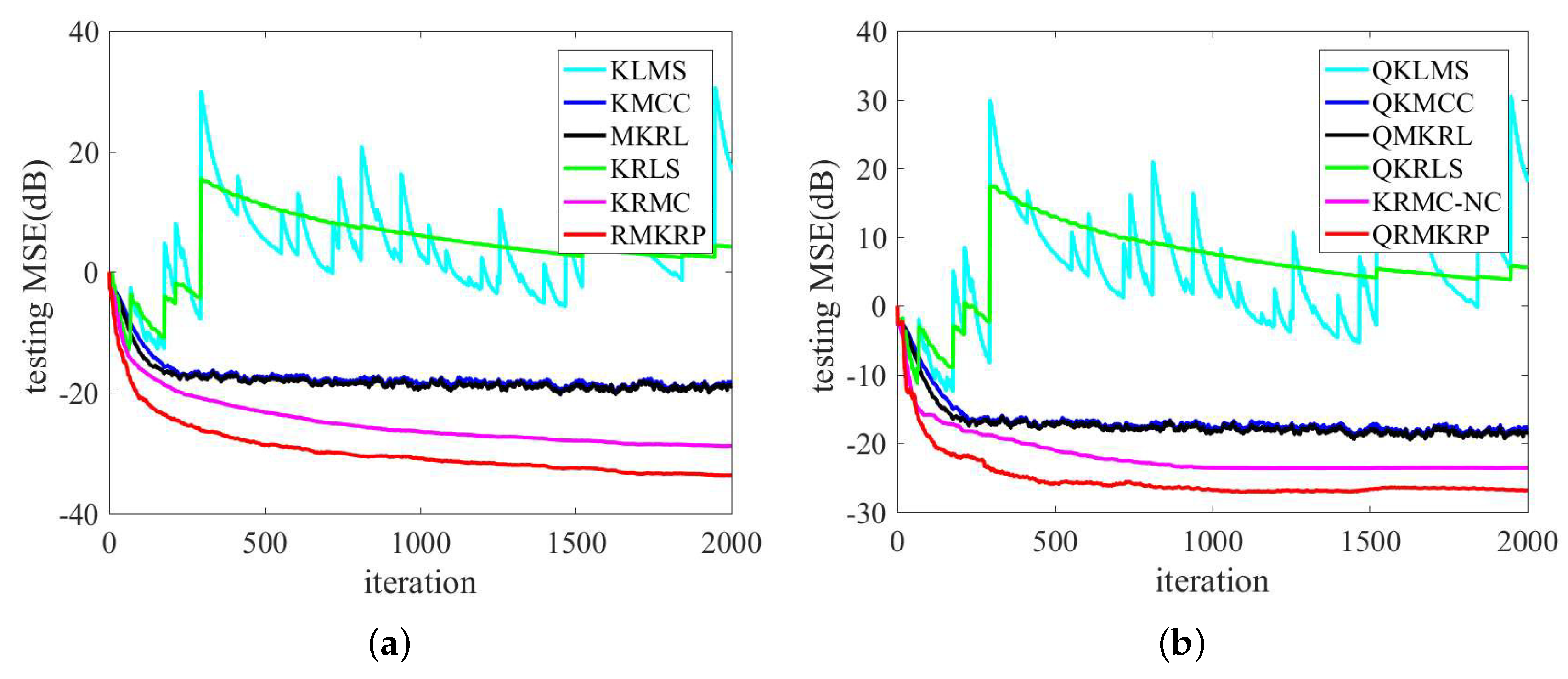
The performance comparison of QKLMS, QKMCC, QMKRL, KLMS, KMCC, MKRL, KRLS, KRMC, KRMC-NC, and QKRLS is conducted in the same environments as in (39). The parameters of the proposed algorithms are selected by trials to achieve desirable performance, and the parameters of compared algorithms are chosen such that they have almost the same convergence rate. , , and are set for RMKRP; , , , and for QRMKRP; for KLMS; and for KMCC; , , and for MKRL; and for QKLMS; , , and for QKMCC; , , , and for QMKRL; , , and for KRMC; the novelty criterion thresholds , , , , and for KRMC-NC; for KRLS; and for QKRLS. Figure 3 shows the compared MSEs of RMKRP, QRMKRP, and the compared algorithms. As can be seen from Figure 3, RMKRP achieves a better filtering accuracy than KRLS, KRMC, KLMS, KMCC, and MKRL. QRMKRP achieves a better steady-state testing MSE than the sparsification algorithms including QKRLS, KRMC-NC, QKLMS, QKMCC, and QMKRL. We also see from Figure 3 that the proposed algorithms provide good robustness to impulsive noises. For detailed comparison, the dictionary size, consumed time, and steady-state MSEs in Figure 3 are shown in Table 1. Note that the steady-state MSEs of KLMS, QKLMS, KRLS, and QKRLS are not shown in Table 1 since they cannot converge in such impulsive noise environment. From Table 1, we see that RMKRP has similar consumed time to KRLS and KRMC but provides better filtering accuracy. In addition, QRMKRP provides the highest filtering accuracy in all the compared sparsification algorithms and approaches the filtering accuracy of RMKRP with a significantly lower network size.
4.2. Nonlinear System Identification
To further validate the performance superiorities of the proposed RMKRP and QRMKRP algorithms, the nonlinear system identification is considered. Here, the nonlinear system is of the following form [31].
where denotes the output at discrete time t with the initial and . The two previous outputs are utilized as the input to estimate the current output . The training set includes a segment of 2000 samples corrupted by the additive noises shown in (39), and another 200 samples without noise are used as the testing set. The kernel width is set to 1 for the Gaussian function. All simulation results are averaged over 50 independent Monte Carlo runs.
Similar to MG chaotic time series prediction, the influence of power parameter p, risk-sensitive parameter , and kernel width on the performance of RMKRP is also discussed in nonlinear system identification. The influence of p on the steady-state performance of RMKRP is shown in Figure 4a, where the steady-state MSEs are obtained as averages over the last 100 iterations. The parameters are set as: p is set within ; is set as ; and ; kernel size in the KRP is set as 1. The influence of on the filtering performance of RMKRP is shown in Figure 4b, where risk-sensitive parameter is fixed at ; lies in ; p is set as 4. The influence of on the filtering performance of RMKRP is shown in Figure 4c, where the range of is selected as ; is set as 1; p is set as 4. As can be seen from Figure 4, we can obtain the same conclusions as those in Figure 2.
We compare the filtering performance of QKLMS, QKMCC, QMKRL, KLMS, KMCC, MKRL, KRLS, KRMC, KRMC-NC, and QKRLS in the same environments as in (39). The parameters of the proposed algorithms are selected by trials to achieve desirable performance, and the parameters of compared algorithms are chosen such that they have almost the same convergence rate. , , and are set for RMKRP; , , , and for QRMKRP; for KLMS; and for KMCC; , , and for MKRL; and for QKLMS; , , and for QKMCC; , , , and for QMKRL; , , and for KRMC; the novelty criterion thresholds , , , , and for KRMC-NC; for KRLS; and for QKRLS. Figure 5 shows the compared MSEs of RMKRP, QRMKRP, and the compared algorithms. For detailed comparison, the dictionary size, consumed time, and steady-state MSEs in Figure 5 are also shown in Table 2, where the steady-state MSEs of KLMS, QKLMS, KRLS, and QKRLS are not shown since they cannot converge in such impulsive noise environments. From Figure 5 and Table 2, we can obtain the same conclusions as those in Figure 3 and Table 1.
5. Conclusions
In this paper, the kernel risk-sensitive mean p-power error (KRP) criterion is proposed by constructing mean p-power error (MPE) into kernel risk-sensitive loss (KRL) in RKHS, and some basic properties are presented. The KRP criterion with power parameter p is more flexible than KRL to handle the signal corrupted by impulsive noises. Two kernel recursive adaptive algorithms are derived to obtain desirable filtering accuracy under the minimum KRP (MKRP) criterion, i.e., the recursive minimum KRP (RMKRP) and quantized RMKRP (QRMKRP) algorithms. The RMKRP can achieve higher accuracy but with almost identical computational complexity as that of the KRLS and KRMC. The vector quantization method is introduced into RMKRP, thus generating QRMKRP, and QRMKRP can effectively reduce network size while maintaining the filtering accuracy. Simulations conducted in Mackey–Glass (MG) chaotic time series prediction and nonlinear system identification under impulsive noises illustrate the superiorities of RMKRP and QRMKRP from the aspects of robustness and filtering accuracy.
Author Contributions
Conceptualization, T.Z. and S.W.; methodology, T.Z. and H.Z.; software, T.Z. and L.W.; validation, S.W. and T.Z.; formal analysis, T.Z. and H.Z.; investigation, T.Z. and K.X.; resources, S.W.; data curation, S.W. and T.Z.; writing—original draft preparation, T.Z.; writing—review and editing, S.W. and H.Z.; visualization, T.Z.; supervision, S.W.; project administration, S.W. and L.W.; funding acquisition, S.W. and K.X.
Funding
This work was supported by the National Natural Science Foundation of China (61671389), Fundamental Research Funds for the Central Universities (XDJK2019B011), and the Research Fund for Science and Technology Commission Foundation of Chongqing (cstc2017rgzn-zdyfX0002).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Kivinen, J.; Smola, A.J.; Williamson, R.C. Online learning with kernels. IEEE Trans. Signal Process. 2004, 52, 1540–1547. [Google Scholar] [CrossRef]
- Chen, B.; Li, L.; Liu, W.; Príncipe, J.C. Nonlinear adaptive filtering in kernel spaces. In Springer Handbook of Bio-/Neuroinformatics; Springer: Berlin, Germany, 2014; pp. 715–734. [Google Scholar]
- Nakajima, Y.; Yukawa, M. Nonlinear channel equalization by multi-kernel adaptive filter. In Proceedings of the IEEE 13th International Workshop on Signal Processing Advances in Wireless Communications, Cesme, Turkey, 17–20 June 2012; pp. 384–388. [Google Scholar]
- Jiang, S.; Gu, Y. Block-sparsity-induced adaptive filter for multi-clustering system identification. IEEE Trans. Signal Process. 2015, 63, 5318–5330. [Google Scholar] [CrossRef]
- Zheng, Y.; Wang, S.; Feng, J.; Tse, C.K. A modified quantized kernel least mean square algorithm for prediction of chaotic time series. Digital Signal Process. 2016, 48, 130–136. [Google Scholar] [CrossRef]
- Liu, W.; Príncipe, P.P.; Príncipe, J.C. The kernel least mean square algorithm. IEEE Trans. Signal Process. 2008, 56, 543–554. [Google Scholar] [CrossRef]
- Liu, W.; Príncipe, J.C. Kernel affine projection algorithms. IEEE Trans. Signal Process. 2004, 52, 2275–2285. [Google Scholar]
- Engel, Y.; Mannor, S.; Meir, R. The kernel recursive least-squares algorithm. IEEE Trans. Signal Process. 2004, 52, 2275–2285. [Google Scholar] [CrossRef]
- Liu, W.; Park, I.; Príncipe, J.C. An information theoretic approach of designing sparse kernel adaptive filters. IEEE Trans. Neural Netw. 2009, 20, 1950–1961. [Google Scholar] [CrossRef]
- Platt, J. A resource-allocating network for function interpolation. Neural Comput. 1991, 3, 213–225. [Google Scholar] [CrossRef]
- Richard, C.; Bermudez, J.C.M.; Honeine, P. Online prediction of time series data with kernels. IEEE Trans. Signal Process. 2009, 57, 1058–1067. [Google Scholar] [CrossRef]
- Chen, B.; Zhao, S.; Zhu, P.; Príncipe, J.C. Quantized kernel least mean square algorithm. IEEE Trans. Neural Netw. Learn. Syst. 2012, 23, 22–32. [Google Scholar] [CrossRef]
- Chen, B.; Zhao, S.; Zhu, P.; Príncipe, J.C. Quantized kernel recursive least squares algorithm. IEEE Trans. Neural Netw. Learn. Syst. 2013, 24, 1484–1491. [Google Scholar] [CrossRef] [PubMed]
- Príncipe, J.C. Information Theoretic Learning: Renyi’s Entropy and Kernel Perspectives; Springer: New York, NY, USA, 2010. [Google Scholar]
- Pei, S.-C.; Tseng, C.-C. Least mean p-power error criterion for adaptive FIR filter. IEEE J. Sel. Areas Commun. 1994, 12, 1540–1547. [Google Scholar]
- Boel, R.K.; James, M.R.; Petersen, I.R. Robustness and risk sensitive filtering. IEEE Trans. Autom. Control 2002, 47, 451–461. [Google Scholar] [CrossRef]
- Chen, B.; Xing, L.; Xu, B.; Zhao, H.; Zheng, N.; Príncipe, J.C. Kernel risk-sensitive loss: Definition, properties and application to robust adaptive filtering. IEEE Trans. Signal Process. 2017, 65, 2888–2901. [Google Scholar] [CrossRef]
- Ma, W.; Duan, J.; Man, W.; Zhao, H.; Chen, B. Robust kernel adaptive filters based on mean p-power error for noisy chaotic time series prediction. Eng. Appl. Artif. Intell. 2017, 58, 101–110. [Google Scholar] [CrossRef]
- Liu, W.; Pokharel, P.P.; Príncipe, J.C. Correntropy: Properties and applications in non-gaussian signal processing. IEEE Trans. Signal Process. 2007, 55, 5286–5298. [Google Scholar] [CrossRef]
- Chen, B.; Xing, L.; Liang, J.; Zheng, N.; Príncipe, J.C. Steady-state mean-square error analysis for adaptive filtering under the maximum correntropy criterion. IEEE Signal Process. Lett. 2014, 21, 880–884. [Google Scholar]
- Wu, Z.; Shi, J.; Zhang, X.; Ma, W.; Chen, B. Kernel recursive maximum correntropy. Signal Process. 2015, 117, 11–16. [Google Scholar] [CrossRef]
- Zhao, S.; Chen, B.; Príncipe, J.C. Kernel adaptive filtering with maximum correntropy criterion. In Proceedings of the International Joint Conference on Neural Network, San Jose, CA, USA, 31 July–5 August 2011; Volume 31, pp. 2012–2017. [Google Scholar]
- He, R.; Hu, B.; Zheng, W.; Kong, X. Robust principal component analysis based on maximum correntropy criterion. IEEE Trans. Image Process. 2011, 20, 1485–1494. [Google Scholar]
- He, R.; Zheng, W.; Hu, B. Maximum correntropy criterion for robust face recognition. IEEE Trans. Patt. Anal. Mach. Intell. 2011, 33, 1561–1576. [Google Scholar]
- Santamaría, I.; Pokharel, P.P.; Príncipe, J.C. Generalized correlation function: Definition, properties, and application to blind equalization. IEEE Trans. Signal Process. 2006, 54, 2187–2197. [Google Scholar] [CrossRef]
- Luo, X.; Deng, J.; Wang, W.; Wang, J.-H.; Zhao, W. A Quantized Kernel Learning Algorithm Using a Minimum Kernel Risk-Sensitive Loss Criterion and Bilateral Gradient Technique. Entropy 2017, 19, 365. [Google Scholar] [CrossRef]
- Chen, B.; Xing, L.; Wang, X.; Qin, J.; Zheng, N. Robust learning with kernel mean p-power error loss. IEEE Trans. Cybern. 2017, 48, 2101–2113. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Príncipe, J.C.; Haykin, S. Kernel Adaptive Filtering: A Comprehensive Introduction; Wiley: New York, NY, USA, 2010. [Google Scholar]
- Weng, B.; Barner, K.E. Nonlinear system identification in impulsive environments. IEEE Trans. Signal Process. 2005, 53, 2588–2594. [Google Scholar] [CrossRef]
- Wang, S.; Zheng, Y.; Duan, S.; Wang, L.; Tan, H. Quantized kernel maximum correntropy and its mean square convergence analysis. Dig. Signal Process. 2017, 63, 164–176. [Google Scholar] [CrossRef]
- Fan, H.; Song, Q. A linear recurrent kernel online learning algorithm with sparse updates. Neural Netw. 2014, 50, 142–153. [Google Scholar] [CrossRef] [PubMed]
Figure 1.
Block diagram of adaptive filtering.

Figure 2.
Steady-state MSE of RMKRP with different p in MG time series prediction (a); steady-state MSE of RMKRP with different in MG time series prediction (b); steady-state MSE of RMKRP with different in MG time series prediction (c).
Figure 2.
Steady-state MSE of RMKRP with different p in MG time series prediction (a); steady-state MSE of RMKRP with different in MG time series prediction (b); steady-state MSE of RMKRP with different in MG time series prediction (c).

Figure 3.
Comparison of the MSEs of KLMS, KMCC, MKRL, KRLS, KRMC, and RMKRP in MG time series prediction (a); comparison of the MSEs of QKLMS, QKMCC, QMKRL, QKRLS, KRMC-NC, and QRMKRP in MG time series prediction (b).
Figure 3.
Comparison of the MSEs of KLMS, KMCC, MKRL, KRLS, KRMC, and RMKRP in MG time series prediction (a); comparison of the MSEs of QKLMS, QKMCC, QMKRL, QKRLS, KRMC-NC, and QRMKRP in MG time series prediction (b).

Figure 4.
Steady-state MSE of RMKRP with different p in nonlinear system identification (a); steady-state MSE of RMKRP with different in nonlinear system identification (b); steady-state MSE of RMKRP with different in nonlinear system identification (c).
Figure 4.
Steady-state MSE of RMKRP with different p in nonlinear system identification (a); steady-state MSE of RMKRP with different in nonlinear system identification (b); steady-state MSE of RMKRP with different in nonlinear system identification (c).

Figure 5.
Comparison of the MSEs of KLMS, KMCC, MKRL, KRLS, KRMC, and RMKRP in nonlinear system identification (a); comparison of the MSEs of QKLMS, QKMCC, QMKRL, QKRLS, KRMC-NC, and QRMKRP nonlinear system identification (b).
Figure 5.
Comparison of the MSEs of KLMS, KMCC, MKRL, KRLS, KRMC, and RMKRP in nonlinear system identification (a); comparison of the MSEs of QKLMS, QKMCC, QMKRL, QKRLS, KRMC-NC, and QRMKRP nonlinear system identification (b).


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Simulation results of QKLMS, QKMCC, QMKRL, QKRLS, KRMC-NC, KLMS, KMCC, MKRL, KRLS, KRMC, RMKRP, and QRMKRP in MG time series prediction.
Table 1.
Simulation results of QKLMS, QKMCC, QMKRL, QKRLS, KRMC-NC, KLMS, KMCC, MKRL, KRLS, KRMC, RMKRP, and QRMKRP in MG time series prediction.
| Algorithms | Size | Time (s) | MSE (dB) |
|---|---|---|---|
| KLMS [6] | 2000 | 30.9501 s | N/A |
| QKLMS [12] | 28 | 2.1011 s | N/A |
| KRLS [8] | 2000 | 58.5358 s | N/A |
| QKRLS [13] | 28 | 2.3374 s | N/A |
| KMCC [22] | 2000 | 30.8285 s | −18.5063 |
| QKMCC [30] | 28 | 2.0995 s | −17.8707 |
| MKRL [26] | 2000 | 30.9117 s | −18.7312 |
| QMKRL [26] | 28 | 2.1063 s | −18.1037 |
| KRMC [21] | 2000 | 58.1229 s | −25.1618 |
| KRMC-NC [21] | 462 | 2.8045 s | −21.5183 |
| QRMKRP | 28 | 2.3443 s | −24.9326 |
| RMKRP | 2000 | 58.2196 s | −28.1802 |
Table 2.
Simulation results of QKLMS, QKMCC, QMKRL, QKRLS, KRMC-NC, KLMS, KMCC, MKRL, KRLS, KRMC, RMKRP, and QRMKRP in nonlinear system identification.
Table 2.
Simulation results of QKLMS, QKMCC, QMKRL, QKRLS, KRMC-NC, KLMS, KMCC, MKRL, KRLS, KRMC, RMKRP, and QRMKRP in nonlinear system identification.
| Algorithms | Size | Time (s) | MSE (dB) |
|---|---|---|---|
| KLMS [6] | 2000 | 21.2447 s | N/A |
| QKLMS [12] | 14 | 1.7284 s | N/A |
| KRLS [8] | 2000 | 48.6055 s | N/A |
| QKRLS [13] | 14 | 1.9643 s | N/A |
| KMCC [22] | 2000 | 21.1328 s | −19.233 |
| QKMCC [30] | 14 | 1.763 s | −17.9723 |
| MKRL [26] | 2000 | 21.0313 s | −19.5390 |
| QMKRL [26] | 14 | 1.7243 s | −18.5748 |
| KRMC [21] | 2000 | 48.7601 s | −28.7583 |
| KRMC-NC [21] | 496 | 2.6874 s | −23.671 |
| QRMKRP | 14 | 1.9681 s | −27.3128 |
| RMKRP | 2000 | 48.6101 s | −34.0790 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Zhang, T.; Wang, S.; Zhang, H.; Xiong, K.; Wang, L. Kernel Risk-Sensitive Mean p-Power Error Algorithms for Robust Learning. Entropy 2019, 21, 588. https://doi.org/10.3390/e21060588
AMA Style
Zhang T, Wang S, Zhang H, Xiong K, Wang L. Kernel Risk-Sensitive Mean p-Power Error Algorithms for Robust Learning. Entropy. 2019; 21(6):588. https://doi.org/10.3390/e21060588
Chicago/Turabian StyleZhang, Tao, Shiyuan Wang, Haonan Zhang, Kui Xiong, and Lin Wang. 2019. "Kernel Risk-Sensitive Mean p-Power Error Algorithms for Robust Learning" Entropy 21, no. 6: 588. https://doi.org/10.3390/e21060588
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.