
Mixture-Based Probabilistic Graphical Models for the Label Ranking Problem †


1
Departamento de Sistemas Informáticos, Universidad de Castilla-La Mancha, 02071 Albacete, Spain
2
Laboratorio de Sistemas Inteligentes y Minería de Datos, Instituto de Investigación en Informática de Albacete, 02071 Albacete, Spain
3
Departamento de Matemáticas, Universidad de Castilla-La Mancha, 02071 Albacete, Spain
*
Author to whom correspondence should be addressed.
†
This is an extended version in proceedings of the 15th European Conference on Symbolic and Quantitative Approaches with Uncertainty, Belgrade, Serbia, 18–20 September 2019.
Entropy 2021, 23(4), 420; https://doi.org/10.3390/e23040420
Submission received: 9 March 2021
/
Revised: 26 March 2021
/
Accepted: 27 March 2021
/
Published: 31 March 2021
(This article belongs to the Special Issue Bayesian Inference in Probabilistic Graphical Models)
Abstract
:The goal of the Label Ranking (LR) problem is to learn preference models that predict the preferred ranking of class labels for a given unlabeled instance. Different well-known machine learning algorithms have been adapted to deal with the LR problem. In particular, fine-tuned instance-based algorithms (e.g., k-nearest neighbors) and model-based algorithms (e.g., decision trees) have performed remarkably well in tackling the LR problem. Probabilistic Graphical Models (PGMs, e.g., Bayesian networks) have not been considered to deal with this problem because of the difficulty of modeling permutations in that framework. In this paper, we propose a Hidden Naive Bayes classifier (HNB) to cope with the LR problem. By introducing a hidden variable, we can design a hybrid Bayesian network in which several types of distributions can be combined: multinomial for discrete variables, Gaussian for numerical variables, and Mallows for permutations. We consider two kinds of probabilistic models: one based on a Naive Bayes graphical structure (where only univariate probability distributions are estimated for each state of the hidden variable) and another where we allow interactions among the predictive attributes (using a multivariate Gaussian distribution for the parameter estimation). The experimental evaluation shows that our proposals are competitive with the start-of-the-art algorithms in both accuracy and in CPU time requirements.
1. Introduction
Preferences are comparative judgments about a set of alternatives or choices. The Label Ranking (LR) problem [1,2,3] is a well-known non-standard supervised classification problem [4,5], whose goal is to learn preference models that predict the preferred ranking over a set of class labels for a given unlabeled instance. Practical applications of the LR problem are found in cases where an order of preference (or ranking) for the class labels is required given an input instance. Particular examples can be ranking a set of genes from their expression level, ranking the set of relevant topics for a given document, ranking a set of available machine learning algorithms for a given dataset and prediction task, etc. [6,7].
Formally, we consider a problem domain defined over npredictive variables (also known as attributes), , and a class variableC with m labels, . We are interested in predicting the ranking of the labels for an unlabeled instance given a dataset with N labeled instances. Therefore, the LR problem consists in learning a LR-Classifier from which generalizes well on unseen data.
In other words, the goal of the LR problem is to induce a model able to predict a permutation of the class labels by taking advantage of all the available information during the learning process. Different approaches have been proposed to tackle this problem:
- Transformation methods. They transform the ranking-based prediction problem into a set of single-class classifiers, whose outcomes must be later aggregated in order to obtain a ranking. Various approaches have been considered, such as labelwise [8] and pairwise approaches [9,10], chain classifiers [11], etc.
- Adaptation methods. They adapt well-known machine learning algorithms to cope with the new class structure. Cheng et al. in [2] introduced a model-based algorithm that induces a decision tree (Label Ranking Trees (LRT)) and a model-free algorithm which uses k-nearest neighbors (Instance-Based Label Ranking (IBLR)). Other techniques, like association rules [12] or neural networks [13], have also been adapted.
In this paper, we propose a new model-based LR-classifier which belongs to the adaptation methods family. Our motivation is twofold:
- Although fine-tuned instance-based algorithms have exhibited remarkable performance (especially when the model is trained with complete rankings), they may demand a great amount of computational resources (memory and time) during model selection and inference when the size of the dataset grows.
- Although Probabilistic Graphical Models (PGMs; e.g., Bayesian networks) [18,19] constitute a standard approach in machine learning, they have not been used in this problem because of the difficulty in coping with permutations in this framework [2,20]. In this work, we successfully introduce the use of PGMs to deal with the LR problem, obtaining results which are competitive with the state-of-the-art IBLR and LRT algorithms.
The proposed probabilistic LR-classifier relies on the use of a hybrid Bayesian network [21] where different probability distributions are used to conveniently model variables of a different nature: Multinomial for discrete variables, Gaussian for numerical variables, and Mallows for permutations [22]. The Mallows probability distribution is usually considered to model a set of permutations and, in fact, is the core of the decision tree algorithm (LRT) proposed in [2].
To overcome the constraints regarding the topology of the network when dealing with different types of variables, in the preliminary version of this study, we proposed a mixture-based structure where the root is a hidden discrete variable. In [23], we based our proposal on a Naive Bayes graphical structure, where only univariate probability distributions are estimated for each state of the hidden variable. Learning and inference schemes were also designed in [23], based on the use of well-known Expectation-Maximization (EM) algorithm for parameter estimation and a combination of probabilistic inference with the Kemeny Ranking Problem (KRP) [24], respectively. Nonetheless, the proposed methods performed somewhat unevenly when dealing with the different datasets. With this more comprehensive paper, we successfully overcome the main weaknesses of our former proposal. Specifically, the main contributions of this study are as follows:
- After identifying early stopping as the main problem in our previous learning algorithm (Method A), we propose a new learning scheme (see Method B in Section 3) to search for the number of components in the mixture.
- For our Hidden Naive Bayes model, we explore discretization as an alternative to modeling numerical variables as Gaussian distributions.
- We extend the complexity of the naive Bayes-based structure model in order to allow interactions among the predictive attributes. In this new model, only numerical predictive attributes are allowed, and interactions are managed by using a multivariate Gaussian distribution.
- We perform an exhaustive experimental analysis over the standard benchmark for the label ranking problem.
The rest of the paper is structured as follows. In Section 2, we review some basic notions needed to deal with rank data. In Section 3, we formally describe the proposed Hidden Naive Bayes (HNB) as well as the algorithms to induce it from data and to carry out inference. Then, in Section 4, we extend our proposal to allow interactions between the (numerical) predictive attributes, by using a multivariate Gaussian mixture. In Section 5, we set out the empirical study conducted to evaluate the methods designed in this paper. In Section 6, we briefly comment on some limitations of the presented approach. Finally, in Section 7, we provide the conclusions and future research lines.
2. Background
In this section, we review the background to our proposal. In particular, we briefly describe some permutation-based notions, such as the Kemeny Ranking Problem [24] and the Mallows probability distribution [22]. We also revise the Naive Bayes model [18] and the two competing methods to tackle the LR problem used in this study: the Label Ranking Trees and the Instance-Based Label Ranking algorithms [2].
2.1. Kemeny Ranking Problem
Let be the set of permutations defined over m elements . The Kemeny Ranking Problem (KRP) [24] consists in obtaining the consensus permutation (mode) that best represents a sample with N permutations , .
Formally, the KRP looks for the consensus permutation that minimizes
where , is a distance measure between two permutations and . Normally, the Kendall distance [25] is used, which counts the number of pairwise disagreements between the two permutations, and the (greedy) Borda count algorithm [26] is employed to solve the KRP, because of its trade-off between efficiency and accuracy. The Borda count algorithm basically assigns m points to the item ranked first, to the second one, and so on. Once all the input rankings have been computed, the items are sorted according to the number of accumulated points.
When not all rankings are equally important, a weight can be associated with each one to reflect its relevance. Then, a generalized version of the Borda method called weighted Borda count is used, which basically balances the points received by a permutation taking its weight into account.
2.2. Kendall Rank Correlation Coefficient
In our learning process (see Section 3.3), the Kendall rank correlation coefficient is used as goodness score [27]. Given the class variable C with and permutations of the values in , the Kendall rank correlation coefficient is given by
where
for . Here, means that is ranked before in .
The Kendall rank correlation coefficient lies in the range . In particular, means a total positive correlation between and (), whereas indicates a total negative correlation (actually this occurs when is the inverse of ). Values of close to 0 mean a poor correlation between the permutations.
2.3. Mallows Probability Distribution
The Mallows probability distribution (also known as the Mallows model) [22] is an exponential probability distribution over permutations based on distances. The Mallows model, , is parametrized by two parameters: the central permutation (mode) and the spread parameter (dispersion) . Given a distance D in , the probability assigned to a permutation by the Mallows distribution is
where is a normalization constant. The spread parameter quantifies the concentration of the distribution around . For , a uniform distribution is obtained, while for the model assigns a probability of 1 to and of 0 to the rest of the permutations. Both and can be estimated accurately in polynomial time [28]. For consensus permutation (), the Borda count is usually employed. For the spread (), there is no closed form, so numerical algorithms (e.g., Newton–Raphson) are normally used.
2.4. Naive Bayes
Naive Bayes (NB) models are well-known probabilistic classifiers based on the strong independence hypothesis that, given the class variable, every pair of features is considered conditionally independent [30]. This assumption allows an efficient factorization of the join probability distribution (see Equation (1)) as well as efficient learning and inference procedures. Figure 1 shows the graphical structure of an NB model.
Like most probabilistic classifiers, NB models follow the maximum a posteriori (MAP) principle, that is, they return the most probable class label given the input instance as evidence. Formally, given an input instance and being C the class variable with , a Naive Bayes Classifier returns
according to Bayes’ theorem and the conditional independence hypothesis, respectively. The above conditional distributions may be multinomial for discrete attributes and Gaussian for continuous attributes.
2.5. Instance-Based Label Ranking
The Instance-Based Label Ranking (IBLR) algorithm [2] is based on the nearest neighbors estimation principle. It takes, as input, an instance to be classified, a training dataset with N labeled instances and the number of nearest neighbors , , to be considered. Using an appropriate distance, the IBLR algorithm then compares the input instance with all the N training ones, obtains the k nearest neighbors from , , and takes the rankings associated with these instances, . Then, the IBLR algorithm applies the Borda count algorithm to the permutations in and the obtained consensus permutation is returned as output.
The main advantage of instance-based learning is its local behavior, which allows it to locally estimate a different target function for each new instance to be classified instead of estimating a single target function for the entire instance space. On the other hand, its main disadvantage is its high computational cost in the inference stage, as it must compare the input instance against all the instances in the training dataset.
2.6. Label Ranking Trees
Decision trees are usually constructed by recursively partitioning the dataset. The Label Ranking Trees (LRT) algorithm [2] receives, at each call, a set of instances with and , and must decide whether to stop the recursive call by creating a leaf node, or go on with the branching process by splitting the received training dataset into several subsets according to the value of an attribute .
The stopping and splitting criteria used in LRT are as follows:
- Stopping criterion. If we consider as the rankings associated with the instances in , the LRT algorithm stops the splitting process and creates a leaf node if either of the following two conditions hold:
- -
- All the rankings are consistent. For all the pairs of class labels , they maintain the same preference relation or through all the rankings in which rank both and .
- -
- . This condition is introduced as a pre-pruning operation to prevent overfitting.
The leaf created is labeled with the consensus ranking obtained by applying the Borda count algorithm over the rankings in . - Splitting criterion. The LRT algorithm uses the spread parameter of the Mallows model (see Section 2.3) to measure the scattering of the rankings associated with a partition with respect to the consensus one. Formally, given an attribute with domain , the uncertainty associated with a partition of is inversely proportional towhere is the spread parameter estimated from the rankings of the instances in , which can be computed by means of standard numerical optimization methods [2,29].The LRT algorithm proceeds in a standard way, that is, sorting the values of the attributes in and analyzing all the possible thresholds . Thus, it deals with the resulting two-state discrete attribute with domain , and selects the threshold of the attribute that maximizes (2).
Then, an instance is classified by following the path from the root to the corresponding leaf, selecting, at each decision node, the branch corresponding to the value of the attribute in the instance to be classified. Thus, once a leaf node is reached, the permutation assigned to the leaf node is returned.
3. Hidden Naive Bayes for Label Ranking
In this section, we propose an NB-based model to deal with the LR problem. We start by defining the proposed PGM structure and then describe the parameter estimation process and two different methods for training the model.
3.1. Model Definition
To overcome the constraints regarding the topology of the network when dealing with different types of variables, the model proposed here combines an NB structure with a hidden (latent) variable.
This idea is not new, and has been used, for instance, for unsupervised clustering [21,31], to improve the performance (accuracy) of the base classifier [32], relax some of the independence statements increasing the classifier modeling capability [33,34,35], or obtain models for efficient probabilistic inference [36].
In this paper, the introduction of the hidden variable stems from the need to model the join probability distribution involving variables of a different nature: discrete, continuous, and permutation-based.
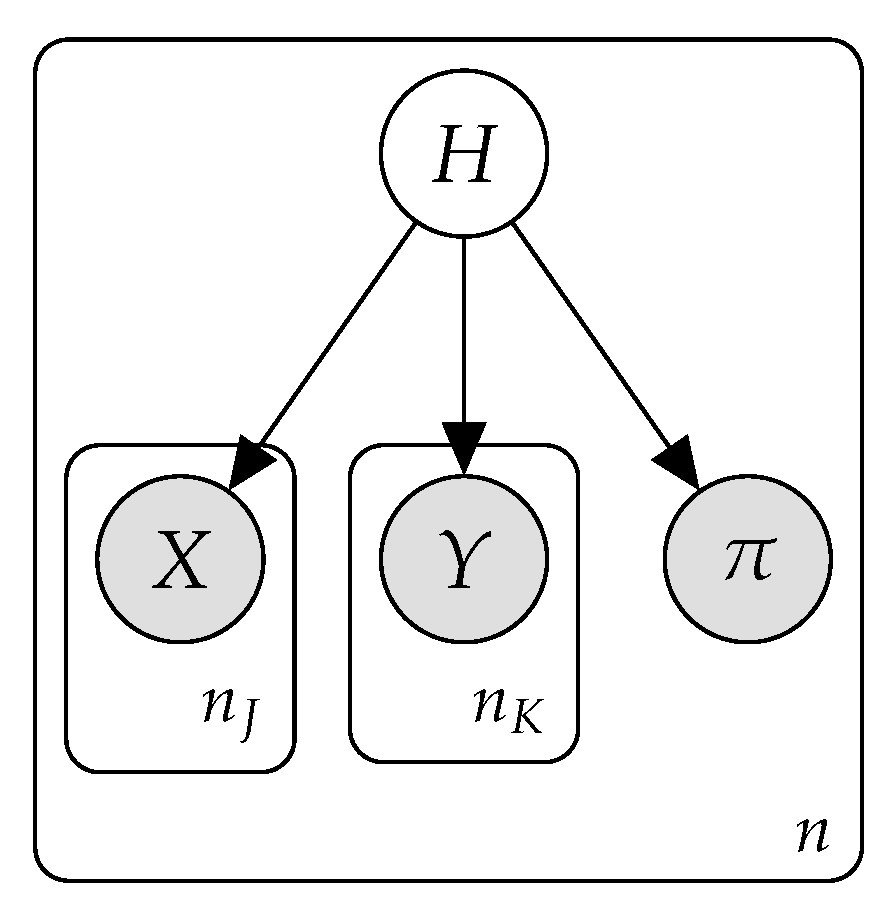
In the proposed NB model graphical structure, the root element of the model is a discrete hidden variable, which we will denote as H, with being the total number of mixture models. The rest of the variables are observed variables. We consider two types of observed variables:
- The feature variables, observed both in the training and in the test phase. We consider two kinds: discrete variables, denoted as , and , and continuous variables, denoted as , .
- The ranking variable, denoted as , which takes values in , this being the set of permutations defined over the class labels . This variable is used only during the training stage and is the target to be inferred.
Figure 2 shows a plate-based representation of the proposed model with the different types of variables described above (). The model assumes that each of these variable types follows a different conditional distribution given the root variable:
- Discrete variables follow a Multinomial distribution,
- Continuous variables follow a Normal or univariate Gaussian distribution,
- The ranking variable follows a Mallows distribution,
- The hidden variable follows a Multinomial distribution,
The parameters for each of the conditional distributions need to be estimated to perform inference using the model.
3.2. Parameter Estimation
As is common in most machine learning papers, we assume i.i.d. data. Furthermore, we also assume complete data, i.e., without missing values, both in the predictive and in the ranking variables. If there are missing values in the training data, they must be imputed previously to learn the model. The ranking variable can be imputed as described in [2]. Thus, we only deal with a hidden variable, H, and base our approach on the use of the Expectation-Maximization (EM) algorithm to estimate jointly the parameters of both the observed and hidden variables.
The EM algorithm [37] consists of two steps: the expectation step (E step), where the values for the hidden variable are estimated, and the maximization step (M step), where the parameters for the conditional distributions are obtained. Below, we describe these steps:
- E step: Under the assumption that the parameters of the model , , , , , , , , , are known, the probability of an example being in a mixture isHere, is the normalization constant.
- M step: Under the assumption that the probabilities of belonging to each mixture for all examples are known, the parameters of the model can be estimated as follows:
- -
- Multinomial parameters for the discrete variables. Each multinomial parameter is estimated by using MLE, where the count for each instance is weighted by the probability of given the instance.
- -
- Gaussian distribution parameters for the continuous variables. The parameters and of the Gaussian distribution are estimated through MLE for each , weighting each instance by the probability of it being in the mixture.
- -
- Mallows distribution parameters for the ranking variable. For each component of the mixture of H, a Mallows distribution must be estimated (see Section 2.3). In particular, is computed by applying a weighted version of the Borda count algorithm (points assigned to items are weighted by the probability of given the instance), and is calculated by using the Newton–Raphson numerical optimization method.
- -
- The mixture model probabilities are computed according to the weights for each mixture of H (see Equation (3)) by means of MLE.
Stopping condition: The EM algorithm can easily accommodate different types of stop conditions, most of them based on checking the convergence of some score (logarithm likelihood, accuracy, etc.).
3.3. Learning Process
In addition to the graphical structure and the parameter estimation already described, we also need to determine some kind of structural learning in order to find the inner structure of H, that is, its cardinality or number of states.
Basically, we follow a greedy technique by initializing to a certain number and then running consecutive executions of the EM algorithm with an increasing number of mixtures.
There are several points to discuss regarding the learning process: the initial value for , the value used to increment between two consecutive iterations, the way the components of the mixture are initialized, and how the goodness of the model is evaluated and the final value of is selected. Below, we describe the two proposed schemes.
3.3.1. Method A: HNBE-LR
First, we describe the scheme proposed in the preliminary (conference) version of this study [23], based on the learning process used in [36] and which basically wraps the EM method for parameter estimation. In Algorithm 1, we show our adaptation from the NB estimation algorithm [31] to the LR problem. The main characteristics of this method are as follows:
| Algorithm 1: Method A: HNBE-LR |
 |
- It is a wrapper method. Thus, the data received is divided into training and validation datasets, using the Kendall coefficient to assess the models and parameterizations explored during the search.
- The search for the number of components of the mixture is carried out greedily. We start with an initial number of components and a new component is added at each iteration. However, low probability components are pruned both during the search and during the EM-based parameter estimation. The search stops when the obtained model does not improve the best one in a given number of consecutive iterations. The improvement is assessed by evaluating the current parameterized model over the training dataset .
- Every time a new component is added to the mixture, the model parameters corresponding to this component are initialized from a set of instances of obtained by using sampling with replacement.
- For each number of components in the mixture tried, an EM is run for parameter estimation. After each iteration (E and M steps), the model is evaluated using the Kendall coefficient for the training data . A threshold on the difference between this value and the previous one is used to check convergence.
- When the number of components changes (either because of pruning low probability ones or because of the addition of a new one), the component weights are properly rescaled.
3.3.2. Method B: HNB-LR
The results obtained in [23] shed light on certain drawbacks. The main one is that the algorithm reaches the stopping condition too soon, which results in a small number of components for the mixture. As the authors in [36] noted, in contrast to clustering (e.g., AutoClass [31]), a high number of mixture components is required to obtain an accurate approximation of the joint probability estimation.
Bearing this in mind, and also that the number of different values tried for must be small for reasons of efficiency, we propose an alternative scheme that we call Method B. As in Method A, the main idea is to wrap the EM algorithm by a search procedure to look for the number of components to be included in the mixture. In order to do that, we introduce important design modifications. Algorithms 2 and 3 show the scheme of this approach. Below, we comment on their main characteristics and differences with respect to Method A.
- In Method B, low probability components are not pruned, and so the EM algorithm is carried out in the search process (see Algorithm 2). Furthermore, the convergence of the EM algorithm is checked by using the log-likelihood () of the data () given the model, that is, no wrapper evaluation is carried out to compute inside EM.
- The search process works in a wrapper style. Thus, we divide the data received into a training and validation datasets, and use to assess the models explored during the search.
- The search for the number of components is carried out greedily, but we now split it into two phases. The first is a forward search, where we evaluate the model with . We then select the best value according to and run a binary search between and . Finally, the best value found in the binary search (see Section 5.2) according to is returned as the number of components for our model.The intuition behind this greedy search is to be efficient (at most, 20 values are tested) and to quickly try large values for , as we identified this point as a shortcoming of Method A.
- Each time a new value for is tried, the process starts from scratch, that is, all the components are initialized simultaneously, instead of being added to the model as in Algorithm 1. To initialize the component parameters (probabilities and weights), k-means clustering processes [38] with are run, and the better one according to the minimal sum of distances between points and clusters centroids is selected. The instances associated with each cluster are used to initialize the corresponding mixture component.
| Algorithm 2: Method: EM |
 |
| Algorithm 3: Method B: HNB-LR |
 |
3.4. Inference Process
In the inference process, the method needs to predict the ranking associated with a given instance . In our proposal, the probability of a ranking given can be obtained by marginalizing out variables until we obtain an expression for the posterior probability
The outcome can then be obtained by using the MAP principle, that is, choosing the ranking which maximizes the score
However, due to the possible high cardinality of , we propose an approximate method:
- Compute the probability a posteriori of each component of the mixture given the instance :
- Solve a generalized aggregation problem by using the weighted Borda count over the set of weighted rankings , that is, the consensus rankings associated with the components of the mixture, and taking as weight , the probability a posteriori computed for the mixture component .
4. Gaussian Mixture-Based Semi-Naive Bayes for Label Ranking
In this section, we go one step further by allowing interactions between the predictive variables. However, in order to maintain the complexity of the learning process under control, we decided to use a model in which, apart from identifying the number of mixture components, no structural learning is needed. Our proposal falls in the so-called Semi-Naive Bayes approach [30,39], and we restrict our study to continuous predictive variables. This constraint is quite natural in the LR problem, as all the benchmark datasets contain only continuous variables. In the future, we plan to adapt our method to also allow discrete predictive attributes, which, in general, means learning constrained graphical structures by limiting the number of dependencies allowed [30] or even dealing with hybrid Bayesian networks [40]. Learning PGMs with hidden variables is not an easy task, but there are several approaches in the literature, most based on the use of the Structural EM (SEM) algorithm [41].
4.1. Model Definition
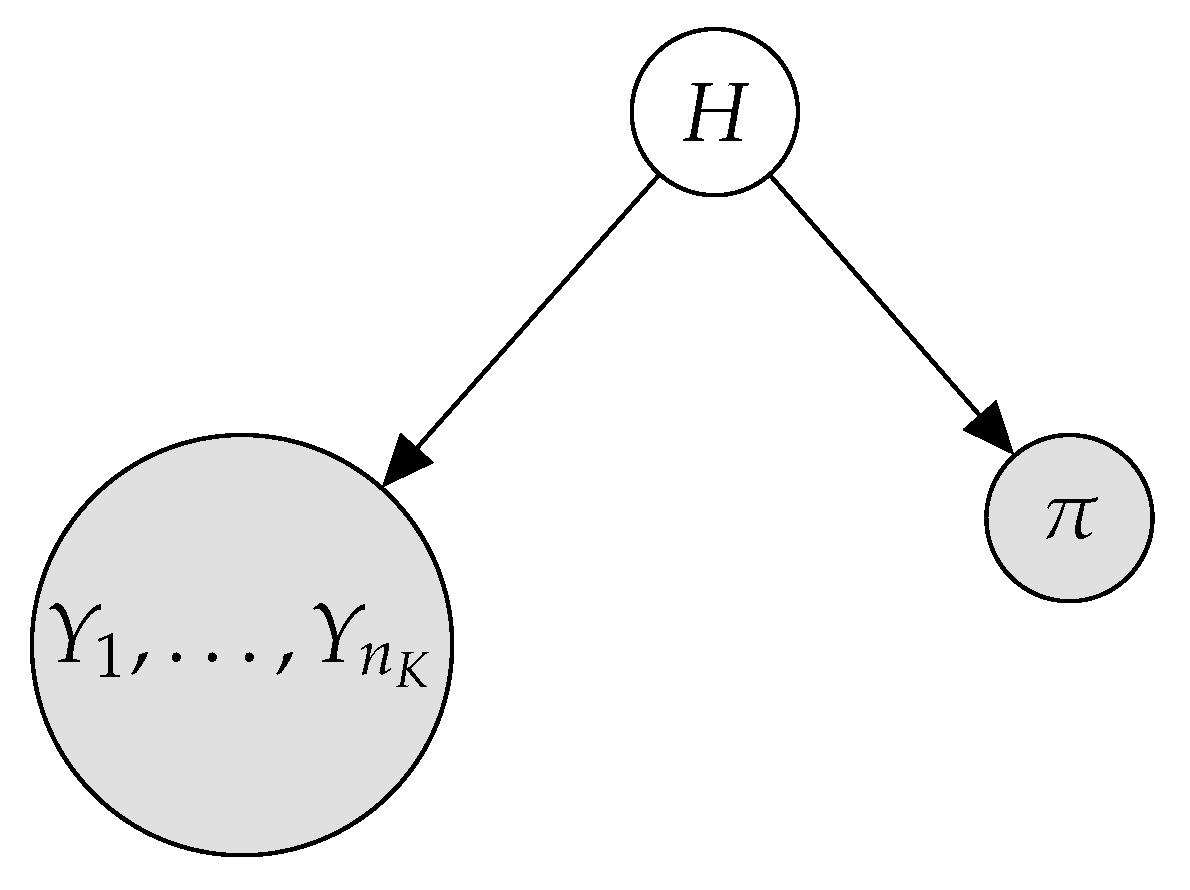
Once we limit our model to contain only continuous predictive attributes , , and H, and also avoid structural learning apart from , we have to deal with representing the interactions between the variables. We maintain the interaction between and the predictive variables to be channeled through the hidden variable H. Thus, explicit interactions are only allowed between the continuous attributes. As no structural learning of these relations is desired, we decided to model them by using a multivariate Gaussian distribution, . This has the advantage of having to estimate only parameters, as are the values in the vector of means and in the covariance matrix.
In the literature, a Gaussian Mixture Model (GMM) [42] is a parametric probability density function represented as a weighted sum of Gaussian component densities, where each component density is a multivariate Gaussian function. Therefore, we take advantage of the widely used GMM to plug them into our PGM to deal with the LR problem. In the literature, we can find several variants of the GMM, which differ in the way the covariance matrix is constrained or not constrained. In particular, the standard or full GMM estimates a covariance matrix for each component with no additional constraint. On the other hand, in the diag variant, such a covariance matrix is constrained to be diagonal, which is equivalent to the NB assumption. The third option is to use a tied covariance matrix, which means estimating an unconstrained covariance matrix, but using it for all the components.
Figure 3 shows the graphical representation of the proposed semi-naive Bayes (SNB) model, where the large node including all the continuous attributes emphasizes the idea of modeling them jointly. The difference regarding the HNB presented in Section 3 is that the continuous variables now follow a multivariate Gaussian distribution given the root variable
where Y is the set of continuous variables , is the vector of means for , and is the covariance matrix.
4.2. Parameter Estimation
As in the case of the proposed HNB algorithm, we use the EM algorithm to estimate the model parameters. Next, we point out the differences between this method and the univariate case (see Section 3.2).
- E step: Under the assumption that the parameters of the model , , , , , , are known, the probability of an example being in a mixture iswhere is the normalization constant and stands for the probability density function of the multinormal distribution with parameters and given byHere, is a configuration of values for variables , is the determinant of , and and T denote the inverse and transpose matrix operators, respectively.
- M step: Under the assumption that the probabilities of belonging to each mixture for all the examples are known, the parameters of the model can be estimated as follows:
- -
- Continuous variables. Empirical means and covariance matrices are calculated in the standard way, using each instance being weighted by according to the expressionsHere, × stands for the usual matrix product.In the tied case, where all the components share the same covariance matrix, , it is estimated as [43] (p. 71):
4.3. Learning Process
Method B, described in Section 3.3, is used to estimate the number of components for the mixture H. To do so, Algorithm 2 is modified as follows:
- In the M step, the expressions in Section 4.2 are used instead of the respective ones in Section 3.2.
4.4. Inference Process
The same inference process is used as in the HNB model (see Section 3.4). The only difference is that we now compute the posterior probability of each component of the mixture given the instance by using the multivariate probability density function instead of Equation (4).
5. Experimental Evaluation
In this section, we assess the mixture-based algorithms proposed to solve the LR problem. Below, we detail the datasets used, the algorithms tested, the methodology adopted, and the results obtained.
5.1. Datasets
Table 1 shows the main characteristics of the 21 datasets widely used as benchmark for the LR problem. The first 16 datasets were turned from multi-class (Type A) and regression (Type B) problems into the LR problem [2], while the last 5 datasets (Type R) correspond to real-world biological problems [10]. The columns #rankings and max #rankings represent the actual number of different rankings in the dataset and the maximum number of different rankings according to the number of classes (#classes), respectively. In the 21 datasets considered, all the predictive attributes (features) are continuous variables. A more detailed description of the datasets is provided at: https://scikit-lr.readthedocs.io/en/latest/user_guide/datasets.html#datasets (accessed on 29 March 2021).
5.2. Algorithms
In this study, we considered the following algorithms:
- The IBLR algorithm introduced in [2] (see Section 2.5). To identify the nearest neighbors, the Euclidean distance was used. To compute the prediction, the permutations associated with the k-nearest neighbors were weighted according to the neighbor’s (inverse) distance to the input instance. Although the IBLR algorithm belongs to the lazy paradigm of machine learning, we carried out model learning to select the number k of nearest neighbors. We applied the following process using a fivefold cross-validation method (5-cv) over the training dataset to assess the goodness of each candidate value:
- We started with and doubled it while the score was improving. From this process, we obtained and , that is, the number of nearest neighbors leading to the best score (the penultimate value tested) and the one stopping the iterative process (the last value tested), respectively.
- We applied a binary search in the range [, ]. In this process, we took , and if the score improved for with respect to , we then repeated this recursive process using the range . Otherwise, the range was used.
We kept the number of nearest neighbors that led to the best score. - The LRT algorithm introduced in [2] (see Section 2.6).
- The HNBE-LR algorithm introduced in [23] (see Section 3.3.1). Note that all the attributes of the datasets are continuous variables. Thus, the parameters of the model were estimated by means of Gaussian distribution parameters (HNBE-LR-G). The hyperparameter values were , , , . The holdout for the training and validation datasets was 75%/25%.
- The HNB-LR algorithm (see Section 3.3.2). As in the previous case, we estimated the conditional probability distributions with Gaussian univariate distributions (HNB-LR-G). Furthermore, we binned the continuous variables using equal-frequency (HNB-LR-F), equal-width (HNB-LR-W), and entropy-based [44] (HNB-LR-E) discretization techniques, estimating the parameters of the model with Multinomial distribution parameters. The number of bins was set to 5 for equal-width and equal-frequency cases. The holdout for the training and validation datasets was 80%/20%. The value was fixed to 10.
- The GMSNB-LR algorithm (see Section 4), with a different covariance matrix for each component, full approach (GMSNB-LR-F), and sharing the same covariance matrix between all the components of the mixture, tied approach (GMSNB-LR-T). The holdout for the training and validation datasets was 80%/20%. The value was fixed to 10.
5.3. Methodology
We adopted the following design decisions:
- We used five repetitions of a tenfold cross-validation method (5 × 10-cv) to assess the algorithms.
- We used the Kendall rank correlation coefficient as goodness score: the higher, the better (see Section 2.2).
- To properly analyze the results, we carried out the standard statistical analysis procedure for machine learning [45,46], using the exreport tool [47]. The procedure is divided into two steps:
- First, we carried out a Friedman test [48] with significance level . If the obtained p-value , then we rejected the null hypothesis and concluded that at least one algorithm is not equivalent to the rest.
- Second, once the previous step rejected , we applied a post hoc test using the Holm’s procedure [49] to discover the outstanding algorithms. This test compares all the algorithms against the control algorithm, that is, the one ranked first by the Friedman test.
- We executed the experiments on computers running the CentOS Linux 7 operating system with an Intel(R) Xeon(R) E5–2630 CPU running at 2.40 GHz, and with 16 GB of RAM memory.
5.4. Results
In this section, we present and analyze the results obtained. We focus on accuracy ( score) and CPU time.
5.4.1. Accuracy
First, we analyze the results obtained by the HNB-LR algorithms. The accuracy results for this family of algorithms are shown in Table 2. The cells contain the average and standard deviation over the test sets of the cross validation method for the rank correlation coefficient between the real and predicted permutations. The boldfaced values correspond to the algorithm(s) achieving the best mean accuracy for each dataset.
We base our analysis on the statistical procedure described in Section 5.3:
- The p-value obtained in the Friedman test was 3.613 ×). Therefore, the null hypothesis () was rejected, and at least one of the tested algorithms was different.
- Table 3 shows the results for the post hoc test by taking HNB-LR-G, the algorithm ranked first by the Friedman test, as the control. The columns rank and p-value represent the ranking obtained by the Friedman test and the p-value adjusted by Holm’s procedure, respectively. The columns win, tie, and loss contain the number of times that the control algorithm wins, ties, and loses with respect to the row-wise algorithm. The p-values for the non-rejected null hypothesis are boldfaced.
According to these results and the statistical analysis performed, we can conclude the following.
- The HNBE-LR-G algorithm is the worst method. The reason is obvious if we analyze Table 4, where we show the number of components (on average) selected for each algorithm. It is clear that this number is too small for HNBE-LR-G, which clearly suffers from premature early stopping. Furthermore, we must recall that this algorithm is the only one which prunes low weight components during its performance. As a consequence, HNBE-LR-G does not obtain a good probability estimation.
- The HNB-LR-G algorithm is ranked first and is statistically different to the HNB-LR-W and HNBE-G algorithms. In the case of HNB-LR-W, the reason is not the number of selected components, but the equal-width discretization carried out, which produces poor binning in comparison, for example, with the supervised entropy-based method.
- Although the HNB-LR-G algorithm is ranked first, the post hoc test reveals no significant difference with respect to the HNB-LR-E and HNB-LR-F algorithms. This opens the door to future research on more complex Bayesian network structures.
- As stated in [36], a large number of components are required to obtain a good probability estimation and, in our problem, a good ranking prediction.
Once we have determined that the best HNB-LR algorithms are HNB-LR-G, HNB-LR-E, and HNB-LR-F, we introduce the two algorithms allowing interactions among the predictive attributes in the study, that is, those based on the use of the multivariate Gaussian distribution to jointly model the (numerical) attributes: GMSNB-LR-F and GMSNB-LR-T. The results are shown in the two leftmost columns of Table 5. To complete the comparison, we also show the results for the two state-of-the-art LR classifiers [2] described in Section 2.5 and Section 2.6.
Again, we applied the statistical analysis procedure described in Section 5.3, including also the three HNB-LR algorithms selected from the previous study:
- The p-value obtained for the Friedman test was 2.503 × . Therefore, we rejected the null hypothesis (), i.e., at least one algorithm is different to the rest.
- As IBLR is ranked first by the Friedman test, we took it as the control and performed a post hoc test using Holm’s procedure. Table 6 shows the results for the post hoc test.
Considering these results, we can conclude the following.
- The IBLR algorithm is ranked first, being statistically different to all the tested algorithms except GMSNB-LR-T. Note that IBLR is a fine-tuned algorithm, as can be observed from the number of neighbors selected for each dataset (see Table 4), which are far from standard values ().
- The GMSNB-LR-T algorithm has a remarkable performance, being non-significantly different to IBLR. This is a very important finding because, as recognized in the literature, the instance-based algorithm generally outperforms the model-based algorithms, being necessary to use ensembles of the LRT algorithm to compete with it [14].
- The GMSNB-LR-T algorithm also has in its favor that it is able to cope with all the tested datasets, while the experiments for IBLR cannot finish in a maximum of 168 h (one week) for fried dataset (notice the empty cell in Table 5). As can be observed, fried is the largest dataset in our experiments, which reveals the disadvantage of using IBLR for larger domains.
- The GMSNB-LR-T algorithm behaves better than GMSNB-LR-F, which is also ranked behind HNB-LR-G. Two explanations are plausible for this behavior: First, the amount of data considered is limited, so it can be scarce for the estimation of many covariance matrices when the number of components grows. Second, it is well known that increasing the number of components can be enough to model the correlations between the features. In fact, if we observe Table 4, we realize that the numbers of components selected for GMSNB-LR-T and HNB-LR-G are noticeably greater than that selected for GMSNB-LR-F.
5.4.2. Time
In this study, we consider model-based and instance-based machine learning algorithms, which clearly distribute the CPU time for the learning and inference steps differently. Although the CPU time for the whole process (learning from the training dataset and validating with test dataset) is generally reported, we separate the CPU time for the learning and inference steps because (i) a model is learnt once but queried many times and (ii) most real-world applications require online predictions but allow for offline fitting. Table 7 and Table 8 show the average CPU time for the learning and inference steps. In light of these results, we can conclude the following.
- The HNBE-LR-G algorithm is the fastest method during the learning step because it suffers from premature early stopping, which gives rise to a fast but poor algorithm. On the other hand, the LRT algorithm is the fastest method during the inference step, which is a common situation for tree-based algorithms.
- The IBLR algorithm is faster than the HNB-LR and GMSNB-LR algorithms in the learning step. However, during inference, the IBLR algorithm computes the distance between the input instance and the instances in the training dataset, which clearly increases the CPU time required by the algorithm.
- The GMSNB-LR-F algorithm is generally faster than the GMSNB-LR-T algorithm, both in learning and inference. This is due to the number of components selected by the GMSNB-LR-F algorithm in comparison to the GMSNB-LR-T algorithm. In a similar way, the HNB-LR-G algorithm is faster than the HNB-LR-F, HNB-LR-W, and HNB-LR-E algorithms, as the the latter ones apply a discretization procedure prior to the learning and inference steps.
6. Limitations
As observed in the previous section, allowing interactions between the predictive variables represents a crucial issue with respect to the univariate case. Actually, our mixture-based model emerges as competitive with IBLR. However, there are still some weaknesses in our study/proposal:
- The CPU time data shown in Table 7 suggest that our method does not scale as would be desirable. In fact, it seems that the number of instances has a greater influence on the CPU time than the number of variables. However, more analysis is needed to clarify this point. Feature subset selection and stratification could lead to scalability improvements.
- Currently, the method only works with complete rankings. Nevertheless, in real-world applications it is usual to allow the agent to rank only certain labels. We think our techniques can be adapted to deal with incomplete rankings.
7. Conclusions
This study explores the use of mixture-based algorithms to solve the LR problem. The main problem is to model the target variable, as it takes values in the set of permutations defined over the class variable. We solve this shortcoming by introducing a hidden variable as root, so all the variables can be modeled by using conditional distributions. In particular, we base our approach on the Naive Bayes structure, with the hidden variable being the root of the model. We then go a step further by allowing interactions between the (numerical) predictive variables, thus designing a Semi-Naive Bayes model. Learning algorithms based on the well-known EM estimation principle are proposed for both cases. The inference is designed as a combination of probabilistic inference and rank aggregation.
From the experimental evaluation, we observe that the Naive Bayes approach is comparable in score to the decision trees for the LR problem, while the Semi-Naive Bayes approach (in particular, the one sharing a single covariance matrix among all the components) outperforms the Naive Bayes and decision tree-based algorithms, being also competitive with the state-of-the-art model-free algorithm based on the nearest neighbors method (IBLR). The good performance of this algorithm (GMSNB-LR-T) with respect to IBLR is reinforced by its better behavior at the inference stage, where IBLR needs a great amount of time when facing large datasets.
As future research, we propose two possible extensions to this work: First, we plan to extend our approach to cope with incomplete data in the ranking variable, that is, cases in which not all the labels are ranked in the instances of the training set. In the literature, this step is solved by completing those rankings before learning the model. However, we think this step can be introduced in the EM algorithm. In fact, model-based algorithms have shown better behavior than model-free ones when learning from incomplete rankings, so open the door to future promising research. Second, we plan to extend the mixture-based algorithms to the LR problems whose target ranking is a partial or bucket order, that is, a ranking in which some labels can be tied. This problem, which is generally termed the Partial Label Ranking (PLR) problem [51,52], introduces new challenges, such as the infeasibility of using the Mallows distribution to model the target variable.
Author Contributions
Conceptualization, E.G.R., J.C.A., J.A.A., and J.A.G.; Formal analysis, E.G.R., J.C.A., J.A.A., and J.A.G.; Funding acquisition, J.A.G.; Investigation, E.G.R., J.C.A., J.A.A., and J.A.G.; Methodology, E.G.R., J.C.A., J.A.A., and J.A.G.; Software, E.G.R., and J.C.A.; Supervision, J.A.A. and J.A.G.; Validation, E.G.R., J.C.A., J.A.A., and J.A.G.; Writing—original draft, E.G.R., J.C.A., J.A.A., and J.A.G.; Writing—review and editing, E.G.R., J.C.A., J.A.A., and J.A.G. All authors have read and agreed to the published version of the manuscript.
Funding
This study has been partially funded by the Spanish Government, FEDER funds and the JCCM through the projects PID2019–106758GB–C33/AEI/10.13039/501100011033, TIN2016–77902–C3–1–P, and SBPLY/17/180501/000493. Juan C. Alfaro has also been funded by the FPU scholarship FPU18/00181 by MCIU.
Institutional Review Board Statement
Not applicable.
Informed Consent Statement
Not applicable.
Data Availability Statement
The running examples of the paper together with other basic models are available at: https://github.com/alfaro96/scikit-lr (accessed on 30 March 2021).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Vembu, S.; Gärtner, T. Label Ranking Algorithms: A Survey. In Preference Learning; Springer: Berlin/Heidelberg, Germany, 2010; pp. 45–64. [Google Scholar]
- Cheng, W.; Hühn, J.; Hüllermeier, E. Decision tree and instance-based learning for label ranking. In Proceedings of the 26th Annual International Conference on Machine Learning, Montreal, QC, Canada, 14–18 June 2009; pp. 161–168. [Google Scholar]
- Dery, L. Multi-label Ranking: Mining Multi-label and Label Ranking Data. arXiv 2021, arXiv:2101.00583. [Google Scholar]
- Hernández, J.; Inza, I.; Lozano, J.A. Weak supervision and other non-standard classification problems: A taxonomy. Pattern Recognit. Lett. 2016, 69, 49–55. [Google Scholar] [CrossRef]
- Charte, D.; Charte, F.; García, S.; Herrera, F. A snapshot on nonstandard supervised learning problems: Taxonomy, relationships, problem transformations and algorithm adaptations. Prog. Artif. Intell. 2019, 8, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Werbin-Ofir, H.; Dery, L.; Shmueli, E. Beyond majority: Label ranking ensembles based on voting rules. Expert Syst. Appl. 2019, 136, 50–61. [Google Scholar] [CrossRef]
- Esmeli, R.; Bader-El-Den, M.; Abdullahi, H. Session Similarity Based Approach for Alleviating Cold-start Session Problem in e-Commerce for Top-N Recommendations. In Proceedings of the 12th International Joint Conference on Knowledge Discovery, Knowledge Engineering and Knowledge Management, Setubal, Portugal, 2–4 November 2020; pp. 179–186. [Google Scholar]
- Cheng, W.; Henzgen, S.; Hüllermeier, E. Labelwise versus Pairwise Decomposition in Label Ranking. In Proceedings of the Workshop on Lernen, Wissen & Adaptivität, Bamberg, Germany, 7–9 October 2013; pp. 129–136. [Google Scholar]
- Gurrieri, M.; Fortemps, P.; Siebert, X. Alternative Decomposition Techniques for Label Ranking. In Proceedings of the 15th International Conference on Information Processing and Management of Uncertainty in Knowledge-Based Systems, Montpellier, France, 15–19 July 2014; pp. 464–474. [Google Scholar]
- Hüllermeier, E.; Fürnkranz, J.; Cheng, W.; Brinker, K. Label ranking by learning pairwise preferences. Artif. Intell. 2008, 172, 1897–1916. [Google Scholar] [CrossRef] [Green Version]
- Har-Peled, S.; Roth, D.; Zimak, D. Constraint Classification for Multiclass Classification and Ranking. In Proceedings of the 2002 Neural Information Processing Systems Conference, Vancouver, BC, Cabada, 9–14 December 2002; pp. 785–792. [Google Scholar]
- de Sá, C.R.; Soares, C.; Jorge, A.M.; Azevedo, P.; Costa, J. Mining Association Rules for Label Ranking. In Advances in Knowledge Discovery and Data Mining; Springer: Berlin/Heidelberg, Germany, 2011; pp. 432–443. [Google Scholar]
- Ribeiro, G.; Duivesteijn, W.; Soares, C.; Knobbe, A.J. Multilayer Perceptron for Label Ranking. In Proceedings of the 22nd international conference on Artificial Neural Networks and Machine Learning, Lausanne, Switzerland, 11–14 September 2012; pp. 25–32. [Google Scholar]
- Aledo, J.; Gámez, J.; Molina, D. Tackling the supervised label ranking problem by bagging weak learners. Inf. Fusion 2017, 35, 38–50. [Google Scholar] [CrossRef]
- de Sá, C.R.; Soares, C.; Knobbe, A.; Cortez, P. Label Ranking Forests. Expert Syst. 2017, 34, e12166. [Google Scholar] [CrossRef] [Green Version]
- Zhou, Y.; Qiu, G. Random forest for label ranking. Expert Syst. Appl. 2018, 112, 99–109. [Google Scholar] [CrossRef] [Green Version]
- Dery, L.; Shmueli, E. BoostLR: A Boosting-Based Learning Ensemble for Label Ranking Tasks. IEEE Access 2020, 8, 176023–176032. [Google Scholar] [CrossRef]
- Koller, D.; Friedman, N. Probabilistic Graphical Models: Principles and Techniques—Adaptive Computation and Machine Learning; MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Jensen, F.V.; Nielsen, T.D. Bayesian Networks and Decision Graphs; Springer: Berlin/Heidelberg, Germany, 2007. [Google Scholar]
- Cheng, W.; Dembczynski, K.; Hüllermeier, E. Label Ranking Methods based on the Plackett-Luce Model. In Proceedings of the 27th Annual International Conference on Machine Learning, Haifa, Israel, 21–24 June 2010; pp. 215–222. [Google Scholar]
- Fernández, A.; Gámez, J.A.; Rumí, R.; Salmerón, A. Data clustering using hidden variables in hybrid Bayesian networks. Prog. Artif. Intell. 2014, 2, 141–152. [Google Scholar] [CrossRef] [Green Version]
- Mallows, C.L. Non-Null Ranking Models. Biometrika 1957, 44, 114–130. [Google Scholar] [CrossRef]
- Alfaro, J.C.; González, E.; Aledo, J.A.; Gámez, J.A. A Probabilistic Graphical Model-Based Approach for the Label Ranking Problem. In Proceedings of the 15th European Conference on Symbolic and Quantitative Approaches with Uncertainty, Belgrade, Serbia, 18–20 September 2019; pp. 351–362. [Google Scholar]
- Kemeny, J.; Snell, J. Mathematical Models in the Social Sciences; MIT Press: Cambridge, MA, USA, 1972. [Google Scholar]
- Kendall, M.G. Rank Correlation Methods; Griffin: Hong Kong, China, 1948. [Google Scholar]
- Borda, J. Memoire Sur Les Elections au Scrutin; Histoire de l’Academie Royal des Sciences: Paris, France, 1770. [Google Scholar]
- Kendall, M.G. A New Measure of Rank Correlation. Biometrika 1938, 30, 81–93. [Google Scholar] [CrossRef]
- Irurozk, E.; Calvo, B.; Lozano, J.A. PerMallows: An R Package for Mallows and Generalized Mallows Models. J. Stat. Softw. 2016, 71, 1–30. [Google Scholar]
- Ali, A.; Meilă, M. Experiments with Kemeny ranking: What works when? Math. Soc. Sci. 2012, 64, 28–40. [Google Scholar] [CrossRef]
- Bielza, C.; Larrañaga, P. Discrete Bayesian Network Classifiers: A Survey. ACM Comput. Surv. 2014, 47. [Google Scholar] [CrossRef]
- Stutz, J.; Cheeseman, P. Autoclass—A Bayesian Approach to Classification. In Maximum Entropy and Bayesian Methods; Skilling, J., Sibisi, S., Eds.; Springer: Berlin/Heidelberg, Germany, 1996; pp. 117–126. [Google Scholar]
- Stewart, B. Improving performance of naive bayes classifier by including hidden variables. In Proceedings of the 11th International Conference on Industrial and Engineering Applications of Artificial Intelligence and Expert Systems: Methodology and Tools in Knowledge-Based Systems, Castellon, Spain, 1–4 June 1998; pp. 272–280. [Google Scholar]
- Flores, M.J.; Gámez, J.A.; Martínez, A.M.; Puerta, J.M. HODE: Hidden One-Dependence Estimator. In Proceedings of the 15th European Conference on Symbolic and Quantitative Approaches to Reasoning with Uncertainty, Belgrade, Serbia, 18–20 September 2009; pp. 481–492. [Google Scholar]
- Langseth, H.; Nielsen, T.D. Classification using Hierarchical Naïve Bayes models. Mach. Learn. 2006, 63, 135–159. [Google Scholar] [CrossRef]
- Jiang, L.; Zhang, H.; Zhihua, C. A Novel Bayes Model: Hidden Naive Bayes. IEEE Trans. Knowl. Data Eng. 2009, 21, 1361–1371. [Google Scholar] [CrossRef]
- Lowd, D.; Domingos, P. Naive Bayes models for probability estimation. In Proceedings of the 22nd International Conference on Machine Learning, Bonn, Germany, 7–11 August 2005; pp. 529–536. [Google Scholar]
- Dempster, A.P.; Laird, N.M.; Rubin, D.B. Maximum Likelihood from Incomplete Data Via the EM Algorithm. J. R. Stat. Soc. Ser. B Methodol. 1997, 39, 1–22. [Google Scholar]
- Wu, X.; Kumar, V. The Top Ten Algorithms in Data Mining; Chapman and Hall: London, UK, 2009. [Google Scholar]
- Flores, M.; Gámez, J.A.; Martínez, A. Supervised Classification with Bayesian Networks: A Review on Models and Applications. In Intelligent Data Analysis for Real-Life Applications: Theory and Practice; IGI Global: Hershey, PA, USA, 2012; pp. 72–102. [Google Scholar]
- Salmerón, A.; Rumí, R.; Langseth, H.; Nielsen, T.D.; Madsen, A.L. A Review of Inference Algorithms for Hybrid Bayesian Networks. J. Artif. Intell. Res. 2018, 62, 799–828. [Google Scholar] [CrossRef] [Green Version]
- Friedman, N. The Bayesian Structural EM Algorithm. In Proceedings of the Fourteenth Conference on Uncertainty in Artificial Intelligence, Madison, WI, USA, 24–26 July 1998; pp. 129–138. [Google Scholar]
- Reynolds, D. Gaussian Mixture Models. In Encyclopedia of Biometrics; Springer: Berlin/Heidelberg, Germany, 2009; pp. 659–663. [Google Scholar]
- McLachlan, G.; Krishnan, T. The EM algorithm and Extensions, 2nd ed.; Wiley: Hoboken, NJ, USA, 2008. [Google Scholar]
- Fayyad, U.M.; Irani, K.B. Multi-interval discretization of continuous-valued attributes for classification learning. Artif. Intell. 1993, 13, 1022–1027. [Google Scholar]
- Demšar, J. Statistical Comparisons of Classifiers over Multiple Data Sets. J. Mach. Learn. Res. 2006, 7, 1–30. [Google Scholar]
- García, S.; Herrera, F. An Extension on “Statistical Comparisons of Classifiers over Multiple Data Sets” for all Pairwise Comparisons. J. Mach. Learn. Res. 2008, 9, 2677–2694. [Google Scholar]
- Arias, J.; Cózar, J. ExReport: Fast, Reliable and Elegant Reproducible Research. CRAN. 2016. Available online: https://cran.r-project.org/web/packages/exreport (accessed on 21 March 2021).
- Friedman, M. A comparison of alternative tests of significance for the problem of m rankings. Ann. Math. Stat. 1940, 11, 86–92. [Google Scholar] [CrossRef]
- Holm, S. A Simple Sequentially Rejective Multiple Test Procedure. Scand. J. Stat. 1979, 6, 65–70. [Google Scholar]
- Pérez-Bernabé, I.; Maldonado, A.D.; Salmerón, A.; Nielsen, T.D. MoTBFs: An R Package for Learning Hybrid Bayesian Networks Using Mixtures of Truncated Basis Functions. R J. 2020, 12, 321. [Google Scholar] [CrossRef]
- Alfaro, J.C.; Aledo, J.A.; Gámez, J.A. Averaging-Based Ensemble Methods for the Partial Label Ranking Problem. In Proceedings of the 15th International Conference on Hybrid Artificial Intelligence Systems, Gijón, Spain, 11–13 November 2020; pp. 410–423. [Google Scholar]
- Alfaro, J.C.; Aledo, J.A.; Gámez, J.A. Learning decision trees for the partial label ranking problem. Int. J. Intell. Syst. 2021, 36, 890–918. [Google Scholar] [CrossRef]
Figure 1.
Naive Bayes model structure.

Figure 2.
The proposed HNB model.

Figure 3.
The proposed GMSNB model.


{kind=link}
{kind=link}
{kind=link}
Table 1.
Description of the datasets.
| Dataset | Type | #Instances | #Features | #Classes | #Rankings | Max #Rankings |
|---|---|---|---|---|---|---|
| authorship | A | 841 | 70 | 4 | 17 | 4! |
| bodyfat | B | 252 | 7 | 7 | 236 | 7! |
| calhousing | B | 20,640 | 4 | 4 | 24 | 4! |
| cpu | B | 8192 | 6 | 5 | 119 | 5! |
| elevators | B | 16,599 | 9 | 9 | 131 | 9! |
| fried | B | 40,769 | 9 | 5 | 120 | 5! |
| glass | A | 214 | 9 | 6 | 30 | 6! |
| housing | B | 506 | 6 | 6 | 112 | 6! |
| iris | A | 150 | 4 | 3 | 5 | 3! |
| pendigits | A | 10,992 | 16 | 10 | 2081 | 10! |
| segment | A | 2310 | 18 | 7 | 135 | 7! |
| stock | B | 950 | 5 | 5 | 51 | 5! |
| vehicle | A | 846 | 18 | 4 | 18 | 4! |
| vowel | A | 528 | 10 | 11 | 294 | 11! |
| wine | A | 178 | 13 | 3 | 5 | 3! |
| wisconsin | B | 194 | 16 | 16 | 194 | 16! |
| spo | R | 2465 | 24 | 11 | 2361 | 11! |
| heat | R | 2465 | 24 | 6 | 622 | 6! |
| dtt | R | 2465 | 24 | 4 | 24 | 4! |
| cold | R | 2465 | 24 | 4 | 24 | 4! |
| diau | R | 2465 | 24 | 7 | 967 | 7! |
Table 2.
Mean accuracy for each HNB-LR algorithm.
| Dataset | HNBE-LR-G | HNB-LR-G | HNB-LR-F | HNB-LR-W | HNB-LR-E |
|---|---|---|---|---|---|
| authorship | 0.907 (±0.028) | 0.919 (±0.018) | 0.905 (±0.021) | 0.905 (±0.019) | 0.909 (±0.017) |
| bodyfat | 0.078 (±0.074) | 0.128 (±0.063) | 0.115 (±0.066) | 0.116 (±0.062) | 0.117 (±0.068) |
| calhousing | 0.171 (±0.018) | 0.303 (±0.024) | 0.278 (±0.009) | 0.198 (±0.011) | 0.343 (±0.013) |
| cpu | 0.360 (±0.023) | 0.435 (±0.013) | 0.461 (±0.013) | 0.334 (±0.016) | 0.459 (±0.013) |
| elevators | 0.646 (±0.025) | 0.728 (±0.014) | 0.695 (±0.011) | 0.664 (±0.013) | 0.688 (±0.016) |
| fried | 0.489 (±0.105) | 0.895 (±0.034) | 0.367 (±0.308) | 0.404 (±0.303) | 0.812 (±0.014) |
| glass | 0.788 (±0.067) | 0.793 (±0.061) | 0.849 (±0.051) | 0.834 (±0.057) | 0.846 (±0.048) |
| housing | 0.400 (±0.116) | 0.734 (±0.034) | 0.667 (±0.045) | 0.639 (±0.041) | 0.711 (±0.044) |
| iris | 0.963 (±0.060) | 0.962 (±0.048) | 0.845 (±0.082) | 0.900 (±0.056) | 0.866 (±0.086) |
| pendigits | 0.721 (±0.026) | 0.914 (±0.003) | 0.916 (±0.002) | 0.912 (±0.003) | 0.920 (±0.003) |
| segment | 0.656 (±0.096) | 0.926 (±0.008) | 0.909 (±0.009) | 0.928 (±0.008) | 0.939 (±0.007) |
| stock | 0.791 (±0.040) | 0.910 (±0.016) | 0.852 (±0.022) | 0.861 (±0.016) | 0.885 (±0.016) |
| vehicle | 0.744 (±0.054) | 0.790 (±0.038) | 0.806 (±0.037) | 0.798 (±0.059) | 0.810 (±0.033) |
| vowel | 0.545 (±0.067) | 0.817 (±0.046) | 0.865 (±0.027) | 0.863 (±0.028) | 0.616 (±0.092) |
| wine | 0.935 (±0.044) | 0.935 (±0.054) | 0.927 (±0.064) | 0.915 (±0.076) | 0.928 (±0.053) |
| wisconsin | 0.295 (±0.070) | 0.355 (±0.050) | 0.373 (±0.046) | 0.334 (±0.055) | 0.324 (±0.093) |
| cold | 0.071 (±0.039) | 0.080 (±0.035) | 0.080 (±0.037) | 0.073 (±0.037) | 0.076 (±0.030) |
| diau | 0.215 (±0.023) | 0.219 (±0.022) | 0.215 (±0.025) | 0.219 (±0.024) | 0.217 (±0.023) |
| dtt | 0.119 (±0.034) | 0.120 (±0.034) | 0.114 (±0.033) | 0.107 (±0.030) | 0.119 (±0.031) |
| heat | 0.054 (±0.025) | 0.061 (±0.028) | 0.057 (±0.026) | 0.055 (±0.027) | 0.059 (±0.024) |
| spo | 0.147 (±0.016) | 0.146 (±0.015) | 0.148 (±0.016) | 0.146 (±0.015) | 0.148 (±0.015) |
Table 3.
Results of the post hoc test for the mean accuracy of HNB-LR algorithms.
| Method | Rank | p-Value | Win | Tie | Loss |
|---|---|---|---|---|---|
| HNB-LR-G | 2.05 | - | - | - | - |
| HNB-LR-E | 2.33 | 5.5818 × | 14 | 0 | 7 |
| HNB-LR-F | 2.86 | 1.9422 × | 14 | 0 | 7 |
| HNB-LR-W | 3.62 | 3.8394 × | 16 | 0 | 5 |
| HNBE-LR-G | 4.14 | 7.0206 × | 18 | 0 | 3 |
Table 4.
Mean number of components for each mixture-based algorithm and mean number of nearest neighbors for the IBLR algorithm.
Table 4.
Mean number of components for each mixture-based algorithm and mean number of nearest neighbors for the IBLR algorithm.
| Dataset | HNBE-LR-G | HNB-LR-G | HNB-LR-F | HNB-LR-W | HNB-LR-E | GMSNB-LR-F | GMSNB-LR-T | IBLR |
|---|---|---|---|---|---|---|---|---|
| authorship | 5.82 (±0.87) | 28.66 (±24.98) | 25.08 (±21.39) | 22.18 (±21.95) | 38.60 (±45.37) | 3.26 (±0.44) | 44.92 (±49.51) | 6.52 (±1.62) |
| bodyfat | 5.88 (±0.90) | 36.74 (±27.42) | 21.04 (±17.29) | 24.92 (±23.04) | 20.14 (±32.20) | 20.66 (±14.57) | 42.20 (±30.10) | 28.68 (±13.49) |
| calhousing | 7.12 (±1.67) | 280.78 (±103.40) | 357.72 (±84.48) | 119.56 (±59.87) | 461.96 (±81.83) | 257.90 (±116.43) | 453.58 (±88.94) | 27.24 (±6.85) |
| cpu | 6.60 (±1.84) | 142.62 (±106.17) | 153.10 (±83.49) | 17.40 (±12.02) | 230.06 (±116.99) | 60.94 (±45.28) | 372.62 (±129.13) | 46.52 (±8.61) |
| elevators | 5.44 (±0.67) | 216.10 (±78.63) | 95.30 (±42.99) | 105.98 (±45.74) | 134.12 (±49.31) | 52.12 (±18.61) | 219.50 (±75.32) | 27.10 (±5.43) |
| fried | 7.14 (±2.19) | 500.82 (±36.01) | 167.34 (±138.34) | 171.58 (±131.69) | 408.98 (±105.35) | 257.62 (±21.08) | 475.22 (±92.00) | |
| glass | 5.34 (±0.56) | 14.72 (±11.81) | 74.56 (±37.55) | 42.40 (±17.82) | 26.14 (±10.63) | 5.84 (±5.63) | 48.32 (±13.45) | 5.26 (±0.53) |
| housing | 5.56 (±0.67) | 64.08 (±19.45) | 79.46 (±47.78) | 68.52 (±47.02) | 38.76 (±36.03) | 45.94 (±25.61) | 116.60 (±28.84) | 39.88 (±6.94) |
| iris | 5.78 (±0.71) | 14.44 (±9.45) | 21.46 (±14.90) | 17.12 (±10.96) | 16.36 (±12.78) | 8.50 (±2.39) | 21.62 (±16.59) | 8.46 (±2.00) |
| pendigits | 6.22 (±1.31) | 503.20 (±29.99) | 484.00 (±55.38) | 451.62 (±87.11) | 484.00 (±49.35) | 126.16 (±6.82) | 509.44 (±18.10) | 6.18 (±0.56) |
| segment | 5.56 (±0.61) | 166.98 (±55.22) | 341.02 (±138.26) | 303.68 (±145.76) | 383.14 (±139.14) | 45.10 (±16.55) | 371.08 (±109.12) | 8.16 (±1.74) |
| stock | 6.16 (±1.54) | 123.42 (±48.48) | 99.66 (±33.97) | 56.60 (±31.58) | 95.54 (±30.49) | 45.96 (±13.12) | 244.78 (±107.07) | 5.66 (±1.15) |
| vehicle | 6.92 (±1.63) | 48.06 (±48.45) | 239.58 (±169.52) | 179.26 (±171.77) | 111.72 (±114.48) | 10.34 (±4.96) | 191.38 (±154.49) | 8.80 (±2.22) |
| vowel | 6.04 (±1.19) | 96.70 (±27.75) | 239.58 (±32.12) | 231.36 (±38.00) | 132.70 (±60.35) | 13.28 (±4.44) | 251.86 (±13.70) | 5.98 (±0.98) |
| wine | 5.48 (±0.65) | 11.76 (±13.61) | 12.22 (±12.34) | 16.30 (±17.10) | 11.40 (±13.93) | 3.68 (±1.25) | 9.58 (±12.81) | 7.16 (±2.48) |
| wisconsin | 5.88 (±1.24) | 23.10 (±14.23) | 21.10 (±13.76) | 49.90 (±41.21) | 45.38 (±27.82) | 4.60 (±1.85) | 35.84 (±15.83) | 14.24 (±4.75) |
| cold | 6.28 (±1.40) | 84.84 (±107.13) | 72.00 (±99.91) | 84.70 (±109.52) | 98.42 (±148.12) | 83.00 (±143.73) | 229.26 (±134.65) | 23.44 (±22.88) |
| diau | 5.76 (±1.04) | 13.24 (±20.64) | 23.50 (±50.16) | 15.92 (±23.00) | 14.58 (±14.84) | 18.40 (±15.89) | 35.76 (±48.31) | 132.04 (±40.12) |
| dtt | 5.50 (±0.84) | 104.22 (±154.80) | 82.84 (±118.50) | 120.76 (±148.76) | 20.50 (±27.44) | 36.52 (±46.53) | 116.42 (±152.29) | 101.80 (±27.78) |
| heat | 6.24 (±1.15) | 71.08 (±133.42) | 74.44 (±116.93) | 66.44 (±128.37) | 77.72 (±127.87) | 31.48 (±80.92) | 79.68 (±135.62) | 23.14 (±13.40) |
| spo | 5.90 (±0.95) | 10.16 (±9.16) | 9.24 (±12.53) | 11.26 (±13.44) | 12.62 (±15.67) | 18.28 (±31.55) | 6.96 (±5.76) | 354.66 (±314.51) |
Table 5.
Mean accuracy for the GMSNB-LR, IBLR, and LRT algorithms.
| Dataset | GMSNB-LR-F | GMSNB-LR-T | IBLR | LRT |
|---|---|---|---|---|
| authorship | 0.838 (±0.033) | 0.925 (±0.019) | 0.935 (±0.014) | 0.883 (±0.024) |
| bodyfat | 0.080 (±0.078) | 0.151 (±0.074) | 0.230 (±0.055) | 0.151 (±0.066) |
| calhousing | 0.295 (±0.020) | 0.284 (±0.017) | 0.351 (±0.010) | 0.319 (±0.012) |
| cpu | 0.418 (±0.016) | 0.432 (±0.027) | 0.506 (±0.013) | 0.404 (±0.014) |
| elevators | 0.774 (±0.017) | 0.780 (±0.009) | 0.730 (±0.006) | 0.668 (±0.010) |
| fried | 0.908 (±0.025) | 0.927 (±0.014) | 0.727 (±0.103) | |
| glass | 0.790 (±0.061) | 0.879 (±0.059) | 0.864 (±0.051) | 0.902 (±0.040) |
| housing | 0.695 (±0.044) | 0.782 (±0.029) | 0.716 (±0.031) | 0.811 (±0.029) |
| iris | 0.925 (±0.053) | 0.962 (±0.035) | 0.963 (±0.042) | 0.953 (±0.044) |
| pendigits | 0.891 (±0.003) | 0.927 (±0.002) | 0.943 (±0.002) | 0.942 (±0.002) |
| segment | 0.884 (±0.015) | 0.947 (±0.008) | 0.961 (±0.005) | 0.955 (±0.006) |
| stock | 0.894 (±0.015) | 0.922 (±0.014) | 0.926 (±0.014) | 0.898 (±0.016) |
| vehicle | 0.721 (±0.051) | 0.802 (±0.042) | 0.860 (±0.026) | 0.818 (±0.040) |
| vowel | 0.589 (±0.039) | 0.906 (±0.015) | 0.889 (±0.018) | 0.753 (±0.033) |
| wine | 0.937 (±0.054) | 0.944 (±0.042) | 0.941 (±0.048) | 0.870 (±0.078) |
| wisconsin | 0.244 (±0.085) | 0.336 (±0.108) | 0.499 (±0.041) | 0.374 (±0.040) |
| cold | 0.072 (±0.036) | 0.090 (±0.042) | 0.090 (±0.035) | 0.048 (±0.031) |
| diau | 0.222 (±0.025) | 0.219 (±0.025) | 0.234 (±0.026) | 0.129 (±0.022) |
| dtt | 0.124 (±0.030) | 0.119 (±0.032) | 0.159 (±0.033) | 0.080 (±0.033) |
| heat | 0.064 (±0.029) | 0.046 (±0.025) | 0.070 (±0.022) | 0.039 (±0.023) |
| spo | 0.148 (±0.016) | 0.148 (±0.015) | 0.149 (±0.017) | 0.090 (±0.018) |
Table 6.
Results of the post hoc test for the mean accuracy of the algorithms.
| Method | Rank | p-Value | Win | Tie | Loss |
|---|---|---|---|---|---|
| IBLR | 1.76 | - | - | - | - |
| GMSNB-LR-T | 2.93 | 8.012 × | 14 | 0 | 7 |
| HNB-LR-G | 3.98 | 1.791 × | 19 | 0 | 2 |
| LRT | 4.52 | 1.029 × | 18 | 0 | 3 |
| HNB-LR-E | 4.67 | 5.271 × | 20 | 0 | 1 |
| GMSNB-LR-F | 5.00 | 5.955 × | 19 | 0 | 2 |
| HNB-LR-F | 5.14 | 2.369 × | 20 | 0 | 1 |
Table 7.
Mean CPU time (in seconds) for the learning step of each algorithm.
| Dataset | HNBE-LR-G | HNB-LR-G | HNB-LR-F | HNB-LR-W | HNB-LR-E | GMSNB-LR-F | GMSNB-LR-T | IBLR | LRT |
|---|---|---|---|---|---|---|---|---|---|
| authorship | 1.705 | 61.196 | 89.829 | 87.027 | 89.588 | 45.615 | 63.305 | 0.750 | 6.417 |
| bodyfat | 0.242 | 5.225 | 14.765 | 19.063 | 26.695 | 4.178 | 7.411 | 0.408 | 0.459 |
| calhousing | 24.985 | 4460.303 | 934.879 | 549.931 | 924.278 | 2477.003 | 1640.548 | 222.602 | 617.978 |
| cpu | 10.822 | 832.624 | 434.776 | 284.175 | 334.790 | 880.115 | 1469.499 | 53.066 | 119.613 |
| elevators | 15.681 | 2252.878 | 3878.157 | 2912.576 | 1822.243 | 3696.911 | 1974.011 | 154.594 | 1685.996 |
| fried | 51.613 | 6783.099 | 3050.954 | 8534.450 | 3255.716 | 3836.842 | 7345.125 | 6049.934 | |
| glass | 0.139 | 4.784 | 21.871 | 24.472 | 21.390 | 5.001 | 12.855 | 0.142 | 0.439 |
| housing | 0.278 | 33.743 | 74.223 | 77.063 | 72.623 | 12.118 | 37.575 | 1.011 | 0.843 |
| iris | 0.119 | 5.103 | 5.940 | 8.612 | 10.060 | 2.891 | 3.740 | 0.146 | 0.024 |
| pendigits | 14.921 | 4958.630 | 7526.738 | 3363.739 | 2181.268 | 1370.683 | 2171.361 | 37.522 | 137.337 |
| segment | 1.893 | 306.300 | 614.536 | 297.176 | 633.483 | 155.155 | 680.656 | 3.290 | 43.915 |
| stock | 1.153 | 78.335 | 206.016 | 203.993 | 215.489 | 51.965 | 110.541 | 0.678 | 1.767 |
| vehicle | 1.361 | 46.526 | 75.399 | 131.554 | 187.489 | 28.025 | 120.622 | 0.784 | 2.614 |
| vowel | 0.581 | 39.580 | 72.241 | 76.060 | 189.684 | 22.197 | 47.121 | 0.364 | 5.231 |
| wine | 0.125 | 1.565 | 4.887 | 5.235 | 6.360 | 1.264 | 1.614 | 0.132 | 0.250 |
| wisconsin | 0.265 | 17.549 | 13.207 | 20.881 | 40.325 | 6.196 | 13.596 | 0.287 | 2.414 |
| cold | 3.400 | 318.876 | 373.824 | 287.441 | 212.068 | 309.730 | 342.582 | 5.489 | 558.146 |
| diau | 2.485 | 234.570 | 296.337 | 175.379 | 273.500 | 266.421 | 176.723 | 14.260 | 509.939 |
| dtt | 2.308 | 320.371 | 440.020 | 317.019 | 155.423 | 246.605 | 228.628 | 11.159 | 436.914 |
| heat | 3.444 | 323.654 | 359.967 | 243.728 | 293.548 | 250.223 | 226.749 | 6.322 | 149.847 |
| spo | 3.106 | 345.584 | 364.797 | 238.538 | 357.678 | 338.189 | 218.729 | 33.453 | 330.353 |
Table 8.
Mean CPU time (in seconds) for the inference step of each algorithm.
| Dataset | HNBE-LR-G | HNB-LR-G | HNB-LR-F | HNB-LR-W | HNB-LR-E | GMSNB-LR-F | GMSNB-LR-T | IBLR | LRT |
|---|---|---|---|---|---|---|---|---|---|
| authorship | 0.007 | 0.012 | 0.062 | 0.057 | 0.044 | 0.008 | 0.025 | 0.022 | 0.002 |
| bodyfat | 0.001 | 0.002 | 0.012 | 0.008 | 0.007 | 0.003 | 0.005 | 0.006 | 0.001 |
| calhousing | 0.053 | 0.409 | 0.682 | 0.376 | 0.617 | 0.348 | 0.354 | 3.675 | 0.116 |
| cpu | 0.024 | 0.069 | 0.219 | 0.068 | 0.263 | 0.067 | 0.260 | 0.713 | 0.033 |
| elevators | 0.059 | 0.152 | 0.321 | 0.252 | 0.128 | 0.214 | 0.345 | 2.620 | 0.243 |
| fried | 0.124 | 0.779 | 0.328 | 1.016 | 1.009 | 0.437 | 1.250 | 0.264 | |
| glass | 0.001 | 0.002 | 0.021 | 0.015 | 0.008 | 0.003 | 0.009 | 0.004 | 0.001 |
| housing | 0.002 | 0.011 | 0.026 | 0.018 | 0.014 | 0.006 | 0.024 | 0.012 | 0.001 |
| iris | 0.001 | 0.004 | 0.005 | 0.005 | 0.003 | 0.003 | 0.004 | 0.003 | 0.001 |
| pendigits | 0.055 | 0.533 | 1.380 | 0.648 | 0.346 | 0.166 | 0.570 | 1.266 | 0.025 |
| segment | 0.011 | 0.049 | 0.093 | 0.135 | 0.191 | 0.045 | 0.190 | 0.085 | 0.005 |
| stock | 0.003 | 0.015 | 0.029 | 0.021 | 0.033 | 0.022 | 0.072 | 0.020 | 0.002 |
| vehicle | 0.004 | 0.007 | 0.065 | 0.097 | 0.069 | 0.006 | 0.064 | 0.018 | 0.002 |
| vowel | 0.003 | 0.012 | 0.084 | 0.075 | 0.046 | 0.013 | 0.041 | 0.011 | 0.002 |
| wine | 0.001 | 0.001 | 0.007 | 0.006 | 0.007 | 0.001 | 0.002 | 0.003 | 0.001 |
| wisconsin | 0.002 | 0.007 | 0.016 | 0.027 | 0.019 | 0.004 | 0.007 | 0.005 | 0.001 |
| cold | 0.011 | 0.033 | 0.071 | 0.096 | 0.122 | 0.048 | 0.128 | 0.099 | 0.017 |
| diau | 0.012 | 0.023 | 0.047 | 0.042 | 0.034 | 0.031 | 0.045 | 0.148 | 0.011 |
| dtt | 0.010 | 0.034 | 0.083 | 0.129 | 0.039 | 0.033 | 0.076 | 0.121 | 0.011 |
| heat | 0.012 | 0.025 | 0.054 | 0.097 | 0.102 | 0.036 | 0.065 | 0.101 | 0.006 |
| spo | 0.014 | 0.022 | 0.032 | 0.043 | 0.033 | 0.036 | 0.028 | 0.310 | 0.006 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Rodrigo, E.G.; Alfaro, J.C.; Aledo, J.A.; Gámez, J.A. Mixture-Based Probabilistic Graphical Models for the Label Ranking Problem. Entropy 2021, 23, 420. https://doi.org/10.3390/e23040420
AMA Style
Rodrigo EG, Alfaro JC, Aledo JA, Gámez JA. Mixture-Based Probabilistic Graphical Models for the Label Ranking Problem. Entropy. 2021; 23(4):420. https://doi.org/10.3390/e23040420
Chicago/Turabian StyleRodrigo, Enrique G., Juan C. Alfaro, Juan A. Aledo, and José A. Gámez. 2021. "Mixture-Based Probabilistic Graphical Models for the Label Ranking Problem" Entropy 23, no. 4: 420. https://doi.org/10.3390/e23040420
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.