
Properties of a Random Bipartite Geometric Associator Graph Inspired by Vehicular Networks

1
Department of Electrical Engineering, Indian Institute of Technology Kanpur, Kanpur 208016, India
2
Wireless@VT, Bradley Department of Electrical and Computer Engineering, Virginia Tech, Blacksburg, VA 24061, USA
*
Author to whom correspondence should be addressed.
Entropy 2023, 25(12), 1619; https://doi.org/10.3390/e25121619
Submission received: 7 August 2023
/
Revised: 18 November 2023
/
Accepted: 24 November 2023
/
Published: 4 December 2023
(This article belongs to the Section Statistical Physics)
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:We consider a point process (PP) generated by superimposing an independent Poisson point process (PPP) on each line of a 2D Poisson line process (PLP). Termed PLP-PPP, this PP is suitable for modeling networks formed on an irregular collection of lines, such as vehicles on a network of roads and sensors deployed along trails in a forest. Inspired by vehicular networks in which vehicles connect with their nearest wireless base stations (BSs), we consider a random bipartite associator graph in which each point of the PLP-PPP is associated with the nearest point of an independent PPP through an edge. This graph is equivalent to the partitioning of PLP-PPP by a Poisson Voronoi tessellation (PVT) formed by an independent PPP. We first characterize the exact distribution of the number of points of PLP-PPP falling inside the ball centered at an arbitrary location in as well as the typical point of PLP-PPP. Using these distributions, we derive cumulative distribution functions (CDFs) and probability density functions (PDFs) of kth contact distance (CD) and the nearest neighbor distance (NND) of PLP-PPP. As intermediate results, we present the empirical distribution of the perimeter and approximate distribution of the length of the typical chord of the zero-cell of this PVT. Using these results, we present two close approximations of the distribution of node degree of the random bipartite associator graph. In a vehicular network setting, this result characterizes the number of vehicles connected to each BS, which models its load. Since each BS has to distribute its limited resources across all the vehicles connected to it, a good statistical understanding of load is important for an efficient system design. Several applications of these new results to different wireless network settings are also discussed.
1. Introduction
1.1. Background and Motivation
To provide control and connectivity to a network of devices, a set of control/access nodes are often deployed that form a control/communication network where each device (acting as a user node) is connected to one control/access node (acting as a master node). Consider, for instance, a wireless cellular network consisting of several base stations (BSs) providing connectivity to a set of mobile users, where each user is connected to a BS to receive channel access control and exchange data. Which user connects with which BS (termed cell or BS association) is a function of the network geometry (since users usually connect with their proximate BSs). A specific example of this setting is when each user node is associated with its closest master node. The association between these two types of nodes can be represented using a simple bipartite many-to-one associator graph with edges from the user nodes to master nodes with each edge representing an association.
Given the natural irregularity in the node locations, tools from stochastic geometry (SG) have been used extensively to model and analyze such networks. The underlying idea is to model the locations of these two types of nodes as realizations of appropriately selected point processes (PPs) [1]. Therefore, the associator graph on this network can be thought of as a variant of AB random geometric graph and is hence termed the random bipartite geometric associator graph in this paper. As we will discuss in the sequel, the properties of this graph are of key importance in the modeling and analysis of control/communication networks. For instance, the degree of a master node provides the number of user nodes associated with this master node, which we term as its load. Since the amount of resources allocated by a master node to each of its user nodes will depend upon its load (such as bandwidth assigned to each user in the cellular network example above), it is easy to deduce that the load directly impacts the performance of each user node.
Before going further, it is useful to note that models from stochastic geometry (such as point and line processes) have also been used extensively in statistical physics. Therefore, one can find numerous examples of PPs and related models that were originally inspired by networks but later found interest in the statistical physics community, such as [2,3,4,5,6,7,8]. Our hope is that the current contribution will also lie in the same category. In general, SG has found applications in many diverse fields, such as forestry, geophysics, economics, biology, and telecommunications, e.g., see [1,9,10,11,12] for a small sample.
1.2. PLP-PPP Random Bipartite Geometric Associator Graph
Now we introduce the main object of this paper, which is inspired by vehicular networks. We first describe the underlying PP of interest using which the random associator graph will be constructed.
If we consider a single road, the locations of vehicles on a road can be modeled using a Poisson point process (PPP). However, a general vehicular network consists of multiple vehicles distributed on multiple roads located throughout the city. A popular model for this setting involves modeling the underlying road network as a Poisson line process (PLP) and then distributing vehicles on each road as a 1D PPP. Since conditioned on the road locations, the vehicles form a PPP with density determined by the realization of the roads (equivalently the PLP), the overall process is a Cox process with density driven by a PLP [10]. We term this doubly-stochastic point process as a PLP-driven-Poisson Cox point process or a PLP-PPP in short [10]. It was first presented in [13] to model a vehicular mobile communication network and was studied comprehensively in [10].
We now enrich this model by considering an overlaid cellular network of BSs (modeled as an independent 2D PPP), such that each vehicle from the PLP-PPP is associated with the closest BS from this PPP (which will also maximize its received signal-to-noise-plus-interference ratio (SINR)). Such wireless links between vehicles and the BSs are termed vehicle-to-infrastructure (V2I) links. This type of geometry based association results in an interesting random bipartite geometric associator graph where the nodes from PLP-PPP (representing vehicles) connect to the nearest control nodes forming an independent PPP (representing BSs). We term this the PLP-PPP Random Bipartite Geometric Associator Graph, which is the main topic of this paper.
For completeness, note that the association can also be seen as a partition of PLP-PPP by an independent Poisson Voronoi (PV) tessellation. Here, the load on a master node is simply the number of user nodes lying in its PV cell. By definition, this is the same the node degree of a control/access node of the above graph. As discussed above already, the load on each BS will impact the amount of resources allocated to each vehicle and will hence impact the performance of this network. Using the PLP-PPP model, recent works have analyzed coverage probability [14,15,16,17,18], load distribution [19], and other such metrics for vehicular networks.
PLP-PPP can also be used to model other deployments along a set of random lines, e.g., sensors along the trails in a forest. Here, sensors can associate with a fusion node that collects their data. Assuming fusion nodes are distributed as a 2D PPP, the load on each fusion node is given by the node degree of the above graph. We will also consider a case study inspired by this setting.
Note that the PLP-PPP can be further generalized (or restricted) to model various variations of vehicular traffic. In [20], the authors captured platooned vehicular traffic by modeling vehicles on each line of a PLP by a Matérn cluster process, thereby giving rise to a PLP-MCP. As another example, if we restrict the orientation of roads to only two orthogonal directions, the line process reduces to a Manhattan line process (MLP), thereby giving rise to an MLP-PPP model of vehicular traffic. Although our focus in the paper is restricted to PLP-PPP, our results and derivations can also be applied to such variations of the PLP-PPP.
1.3. Context and Contributions
The focus of this paper is on studying several key properties of PLP-PPP and the above-described random bipartite geometric associator graph. We are specifically interested in the Laplace functional (LF), probability generating functional (PGFL), contact distance (CD), and nearest neighbor distance (NND) of this PP. In order to put this contribution in context, we briefly describe directly relevant prior work in this direction. The characteristic properties of PLP-PPP have been studied in [14,15,18,21]. In particular, in [21], authors presented the expressions for the density, CDFs of CD and NND, and LF of PLP-PPP along with their Palm counterparts. Note that the Palm distribution of a PP refers to its distribution conditioned on the occurrence of one of its points at a specific location. The distributions for the number of lines intersecting a convex body and some distances in PLP-PPP are presented in [14]. The asymptotic properties of PLP-PPP along with the void probability (the probability that no point is located in a given set) are presented in [15]. In [18], authors presented the CDF and PDF of CD and NND of PLP-PPP.
Despite these existing works, there are some knowledge gaps that this paper will attempt to fill. First, the k-th CD and NND distributions of PLP-PPP have not been reported in the literature for general values of . Second, the load distribution analyses described in the literature have their own constraints and limitations in the sense that they cannot be easily extended to a general Cox process in which general 1D PPs are used to model vehicle locations on each line of a PLP. Further, the study of rate coverage reported in the literature is inadequate, and metrics such as meta distribution of rate coverage, which quantifies the rate coverage of an individual link for a specific realization, have not been presented for the PLP-PPP model. Inspired by these gaps, this paper provides a comprehensive treatment of PLP-PPP as well as the corresponding associator graph described in Section 1.2. We also investigate some applications of these new results to wireless communications networks. The specific contributions of this paper are summarized next.
- We provide simplified PGFs of the number of points of the PLP-PPP falling in a ball centered at an arbitrary location from and at a randomly selected point of PLP-PPP. Using these results, we provide closed form expressions for the CDFs of k-th CD and NND of PLP-PPP.
- We then derive the node-degree distribution of the typical and tagged control/access node of a random bipartite geometric associator graph that associates a PLP-PPP to an independent PPP (described in Section 1.2). We also provide approximate distributions for the same.
- As a key intermediate result, we present the empirical PDF of the perimeter of the zero-cell of the Poisson Voronoi (PV) cell for this setup as well as an approximate distribution of the length of any randomly selected chord of the zero-cell.
- Finally, we discuss several applications of the new node degree distribution result in wireless networks. Examples include the simple closed form expressions for load distribution, rate coverage, meta distribution of rate, and coverage as well as content caching analysis in vehicular networks. We also provided a direct application of the derived node degree result to the analysis of a wireless sensor network.
1.4. Notation
Now, we present the important notations that we use throughout the paper. A vector in and is denoted by bold style letter () and bold italic style () with their norms and , respectively. A ball in 1D and 2D centered at and of radius r is denoted by and , respectively. For a set , denotes its Lebesgue measure, for example . For a PP , the notation denotes the number of points of falling inside the set . The PGF, CDF, and PDF of a random variable (RV) X is denoted by , and , respectively. The expected value and variance of RV X is denoted by and , respectively. The notation denotes the k-th derivative of function f with respect to x. For a RV X with PGF , the mean and the variance can be computed as
The PDF of a generalized Gamma RV X with parameters , and c is
with its mean and variance being and , respectively. The Faà di Bruno’s formula [22] states that the k-th derivative of with respect to s is given as
where the sum is over set consisting of all -tuples with and . The notation denotes a line in , where is the length of the normal from the origin to the line, and is the angle that the normal subtends from the -axis in the counter-clockwise direction. The point is the point on the line that is nearest to the origin, which is termed the base of line .
The line can also be represented as an element in the representation space . Let denote the transformation of to the given as
Here, denotes the 2D location of a point located at the -axis (i.e., ) with coordinates after getting transformed to a line as seen in Figure 1. This also shows the absolute 2D location of a point of line which is located at a distance x from the line’s base. The notation denotes the Palm probability, which is the probability that the PP satisfies a property conditioned on there being a point located at the origin. Further, denotes the reduced Palm probability which is the distribution of the PP excluding a point at the origin conditioned on the presence of that point at the origin, i.e., .
2. System Model
In this work, the object of interest for us is a graph associating nodes of a PLP-PPP with the nodes of an independent PPP on a 2D space. In order to define this graph rigorously, we first provide the definitions of PLP and PLP-PPP.
Definition 1.
(PLP) A random set of lines with and as the length and orientation of the perpendicular to the i-th line from the origin, is a PLP if the pairs form a PPP in the representation space .
Note that an i-th line can be uniquely defined using the two parameters and which is essentially a 2D coordinate in the representation space . Therefore, each line can be represented as a point in , hence, a set of lines can be equivalently seen as a PP in . The above definition says that a PLP is equivalently a PPP in . Further, the PLP is characterized using the density parameter (denoted by ) such that number of lines hitting a convex body of perimeter is Poisson distributed with mean [10].
Definition 2.
(PLP-PPP) Let is a PLP with density . Let be independent and identically distributed PPPs in with density . We assign i-th PPP to the i-th line and transform the points of to be on the line to get
where is defined in (4). Now, Consider a point process Ψ formed as the union of all the , i.e.,
which includes all points located on each line of . The PP Ψ is a Cox process driven by PLP [10]. This has also been termed the Poisson line Cox process and also PLP-PPP.
It is easy to check that is a stationary PP [21] with density . Owing to stationarity, the analysis of the average properties of the PP can be performed by placing the typical point at the origin. In this work, we consider two types of nodes. The first set of nodes is distributed as a PLP-PPP with density in the space on a random network of lines, distributed as a PLP with density . The second set of nodes is distributed as an independent 2D PPP with density on the same space.
Further, each node of the first type (PP ) is connected with one (and only one) node of the second type (PP ). Hence, we call the nodes of the first type (PP ) as the associate nodes and the second (PP ) as the master nodes. Further, the association is based on the mutual distance, where each associate node is connected to the closest master node. This association is commonly used in selecting access points in wireless networks or fusion nodes in sensor networks in order to maximize network performance. In general, in any scenario where the quality of an interaction between two nodes decreases with the distance between them, this association would be practically relevant. This association results in a simple graph with edges from the points of to where each association is represented as an edge. The scenario is illustrated in Figure 2. As mentioned earlier, we term this graph the random bipartite geometric associator graph.
The above association can also be visualized in terms of Voronoi partitions. In order to understand that, consider the space partitioned by the Voronoi tessellation generated by the master nodes . In , each master node is associated with a Voronoi cell (region). In particular, the Voronoi cell associated with the typical master node is termed as the typical cell. The Voronoi cell of a node located at , is defined as
This Poisson Voronoi (PV) tessellation partitions the PLP-PPP into smaller PPs associated with master nodes where is comprised of points of falling inside Voronoi cell . It is clear from this construction that is the same as the set of the associate nodes connected with the master node in graph . Let denote the number of edges associated with the typical master node of , which essentially denotes its node degree. It is the same as the number of points of falling in the typical cell of which can also be understood as the load on the typical cell in many applications (such as wireless cellular networks).
Note that the points in are located at the chords formed by in . This brings us to the notion of the typical chord of the typical Voronoi cell which is defined as any randomly drawn chord in the typical Voronoi cell without any selection bias.
For this setup, we are interested in deriving the distribution of the node degree along with various statistics including its mean and variance. In order to do that, we need several intermediate results, which is derived in the next section.
3. Cell Perimeter, Area and Chord Distribution under PV Tessellation
In this section, we will present some important expressions including the PDF of the area, and perimeter of the Voronoi cell, and the chord length distribution in the Voronoi cell, which will be useful in the subsequent sections of this paper.
3.1. Area, Perimeter, and Chord Length Distribution of the Typical Cell
The analytical distributions for the area and perimeter for the typical cell defined above are presented in [23]. Since the analytical expressions are not in closed form and hence unwieldy to work with, we will instead use the empirical PDFs of area and perimeter presented in [24]. Let the Voronoi region associated with the typical cell be denoted by with area and perimeter Z. The empirical PDFs of and Z are given as
where denotes the generalized Gamma distribution presented in (2). Further, , .
Since the points of lie on the lines, we need to understand the statistics of the chords formed by the intersection of the PLP and the typical cell . For that, we focus on the typical chord and provide useful results related to this typical chord length. The PDF of the length C of the typical chord is [25]
where is the area of union of two disk of radius y and with centers c distance away, denotes the k-th derivative of with respect to c and . Further, [25]. For the completeness of (9), we now present the and its first and second derivatives with respect to c in the following lemma.
Lemma 1.
The area of the union of two disks of radius y and with centers c distance away is
where , further
We also provide a result about the dependence of the chord length of a convex polygon on the perimeter of the polygon in the following propositions. For the proofs, please refer to Appendix A and Appendix B.
Proposition 1.
The length of any chord in a convex polygon is upper bounded by half of its perimeter.
Proposition 2.
The lengths of random chords of a convex polygon conditioned on the perimeter of the polygon are dependent RVs.
3.2. Area, Perimeter, and Chord Length Distribution of the Zero-Cell
We now derive the same set of results for the zero-cell, which is defined as the Voronoi cell that contains the typical point of . Due to the stationarity of , we can assume that the typical point is located at the origin. Mathematically, the zero-cell can be written as
Here, the expression represents the master node that serves the associate node located at . If this master node is the same as the master node serving the origin, i.e., , it indicates that the location falls within the serving region of the master node closest to the origin, or in other words, it falls in the zero cell. Therefore, all locations satisfying the above condition constitute the zero cell. The master node with which the zero-cell is associated with is termed the tagged master node. The area distribution of the zero-cell can be obtained using the area bias sampling [1] and can be expressed as
where note that for , , . Now, we present the empirical PDF of the zero-cell’s perimeter. Inspired by the well-accepted empirical distributions presented in the literature to find the PDF of the area perimeter of typical cell [24], we have also used a three-variable generalized gamma distribution to fit the distribution of perimeter of the zero-cell of PVT. These empirical approximations are common (and necessary) while dealing with Voronoi tessellations. Using simulations, we generate samples of zero-cells and compute the empirical PDF of the zero-cell’s perimeter. We fit a generalized Gamma distribution’s PDF (2) via maximum likelihood estimation (MLE) to determine the parameters (, and c). Consequently, the fitted PDF of the zero-cell’s perimeter is
where is given in (2). Further, .
To quantify the accuracy of the PDF presented in (10), we plot the Bhattacharya’s coefficient (BC) [26] between the PDF given in (10) and the empirical PDF obtained using simulations. The BC coefficient measures the similarity between the two PDFs of continuous RV or two PMFs of discrete RV. Let the PDFs and PMFs for continuous and discrete probability distributions are defined as and , respectively, then the between the continuous PDFs and discrete PMFs is
respectively. Here, we would like to highlight that the BC ranges from 0 to 1, and a value close to 1 denotes the higher similarity between the distributions. Figure 3 presents the BC coefficient between the fitted and the empirical PDF of the perimeter of the zero-cell. As the BC coefficient is close to 1, the derived PDF is close to the exact PDF of the perimeter of the zero-cell.
For the chord distribution of the zero-cell, we can easily identify that there are two types of chords for the zero-cell (i) the tagged chord that goes through the typical point (in our case, the origin) with its length denoted as , and (ii) the randomly selected chord of zero-cell with length . The length distribution of is presented in [20] as
where
where is given in Lemma 1 and
and and . We now give the approximate length distribution of in the following Lemma. Please see Appendix C for the proof.
Lemma 2.
The length distribution of of any randomly selected chord is approximately given as with .
In the next section, we present the distance distributions for PLP-PPP which are not only useful on their own right but will also play a role in our subsequent analysis.
4. Distance Distributions for PLP-PPP
In this section, we present the PDFs and CDFs of the k-th CD and NND for the PLP-PPP.
4.1. Distribution of the k-th CD
The k-th CD is defined as the distance of the k-th point of from an arbitrary point in . Let denote the number of points of falling in . From the definition of k-th CD [27], the CDF is
Hence, we first derive the PGF followed by the PMF for , i.e., the number of points of falling in ball . Note that an alternative formula for the PMF of is presented in [10] (Lemma 4.4) which is slightly more complicated compared to the one presented here. Please see Appendix D for the proof of the following result.
Theorem 1.
The PGF for is
where
Let denote the m-th derivative of at and . In the next result, we derive the PMF of using (3).
Corollary 1.
The last expression of the above Corollary is obtained by substituting . From Theorem 1, we obtain the distribution of k-th CD as given below.
Corollary 2.
The CDF of k-th CD for Ψ is
Now, before deriving the CDFs and PDFs for some special cases such as and 2, we derive the first derivative of denoted by with respect to r which is crucial for computing the PDF of CD.
Corollary 3.
The CDF and PDF of CD for and 2 are
4.2. Distribution of the k-th NND
Along the same lines as the k-th CD, the k-th NND is defined as the distance of k-th nearest point from the typical point of . Without loss of generality, we assume that the typical point is located at the origin, hence . Let denote the number of points of falling in . From the definition [27], CDF of k-th NND is
where denotes the probability under the reduced Palm version of . Before deriving the CDF of k-th NND, we first derive the PGF of . For the proof of the following results please refer to Appendix E.
Theorem 2.
The PGF of is
Corollary 4.
The PMF of is
Using the PMF of , we may derive the CDFs and PDFs of k-th NND as
Corollary 5.
Corollary 6.
The approach that we utilized to determine the distance distribution for PLP-PPP is rather general and has several uses in a vehicular network modeled as a PLP-PPP, such as deriving the load on the BSs which we will revisit in subsequent sections.
5. Node Degree Distribution for the Typical Master Node in the Associator Graph
We now derive the distribution of the node degree of the typical master node in graph which is equal to the number of points falling in the typical Voronoi cell of . For the exact analysis, one can adopt the following approach.
- S–1
- Conditioned on the perimeter Z of the typical Voronoi cell, using the property of PLP, the number of lines n intersecting the Voronoi cell is Poisson RV with mean . The empirical distribution of Z is provided in [24] and stated above in (8).
- S–2
- Conditioned on the perimeter Z and n, we compute the length distribution (PDF) of all chords of the typical Voronoi cell.
- S–3
- Once the PDF of the sum of lengths of the n chords is obtained in S-2, we can decondition it using the distribution of n conditioned on Z. Finally, using the distribution of Z, we obtain the PGF for the node degree of the typical master node.
Note that Proposition 1 states that the chord length depends on the perimeter while Proposition 2 states that conditioned on the perimeter Z, the lengths of the chords are not independent, which requires us to derive the joint PDF. Since the joint distribution of chord lengths conditioned on Z is not available, the exact analysis is difficult. Therefore, we present two methods of approximating the node degree for the typical Voronoi cell below.
5.1. Approximation-1-typical () Approach
In the approach to obtain the approximate value , we make the following approximation in the S-2 step above. Conditioned on the perimeter Z and n, we assume that the chord length distribution of the typical Voronoi cell is independent of the perimeter, i.e., and conditioned on the perimeter Z, the lengths of the chords are independent of each other, i.e., . Due to these two assumptions, the PGF of is the product of the PGF’s of the number of points on each chord inside the typical Voronoi cell. The following theorem provides the PGF of along with its PMF and key moments. Please see Appendix F for the proof.
Theorem 3.
() The PGF for the approximated node degree on the typical Voronoi cell is
The PMF of is
where and are
Further, the mean and the variance of are
A similar approach to finding the approximate distribution in such models has been used in [19,20]. In particular, in [19] authors first derive the Laplace functional (LF) of sum W of the length of all chords falling inside the typical Voronoi cell conditioned on the perimeter Z. In [20] authors assumed that the chord lengths in the typical Voronoi cell are independent RVs and then derived the load distribution for the Cox process driven by PLP by superimposing the 1D MCP on each line of PLP. It is important to note that in both papers, the lengths of these chords conditioned on the perimeter are assumed to be independent RVs which is an approximation as shown in the Propositions 1 and 2. Then, using the PGFL of PLP and deconditioning with the perimeter Z’s distribution, the PMF of the load is obtained in terms of the derivative of LF. Here, we would like to highlight that the PGFs and corresponding PMFs of the node degree presented in this paper are simpler as compared to [19]. For example, in [19] the PMF of load involves a higher-order derivative of a function; however, the PMF presented in the paper is in closed form. Due to the simple and closed-form nature of the PMFs, the numerical implementation of PMFs is much faster in this case. Moreover, we are able to obtain the mean and variance of the ode degree easily from the PGF, which may not always be as easy from the PMF. Another significant advantage of the proposed techniques for deriving the node degree distribution in both approximations is that we primarily utilized the two PGFLs, namely the PGFL of PLP and PPP. An important consequence of this observation is that these approximations can be easily extended to the variants of the model used in this paper in which the PP used to describe the placement of points on lines does not have to be a PPP as long as it has a known PGFL. Therefore, it is possible to extend these results to the settings in which vehicles exhibit clustering or repulsion as long as the PP used to describe these placements has a known PGFL.
5.2. Approximation-2-typical () Approach
In this approach, is approximated by , which is the number of points in the ball of area equal to the area of the typical Voronoi cell. Hence, the radius of the ball is a random variable given as with the distribution
Here, is given in (7). Therefore, where is given in Theorem 1. The PGF and corresponding PMF of the approximate node degree are given below.
Theorem 4.
() The PGF and PMF for are
where PGF and PMF of is given in Theorem 1.
Using the properties of PGF stated in (1), we can compute the mean and the variance of the approximate node degree as given in the following. Please see Appendix G for the proof.
Corollary 7.
The mean and the variance of are
where , , and .
It can be seen that the expressions obtained via are simpler than the . We will numerically compare the accuracy of the two approaches in Section 9.2.
6. Node Degree Distribution for the Tagged Master Node in the Associator Graph
We now derive the distribution of node degree of the master node of the zero-cell in graph which is equal to the number of points falling in the zero-cell. It can also be seen as the load on the zero cell. Just like the approach discussed in the previous section for the typical cell, one can adopt the following approach for this derivation.
- S–1
- As soon as we condition on the typical point of , we know that there is a line passing through that location (since points of lie on the lines). Recall that the chord corresponding to this line has been defined as the tagged chord above. In addition, there are other chords in the zero-cell, on which points are located. Hence, the node degree is the sum of the number of points on the tagged chord and the other chords of zero-cell.
- S–2
- Hence, the PGF for is the product of the PGF of the number of points falling on the tagged chord and the PGF for the number of points falling on the rest of the chords of the zero-cell.
- S–3
- The length distribution of the tagged chord is presented in (12). Using that, we can compute the PGF of the number of points falling on the tagged chord.
- S–4
- Conditioned on the perimeter of the zero-cell, the number of other chords is Poisson distributed. Using the distribution of the sum of their lengths conditioned on the perimeter of the zero-cell and their number, the PGF of the number of points on them can be computed which can be further averaged over the two.
As we discussed in the case of the typical cell in the previous section, the exact analysis is intractable because of the lack of joint distribution of the chord lengths. In order to overcome this challenge, we present two approximations similar to the typical cell case.
6.1. Approximation-1-zero ()
In this approach, we approximate by by assuming that the length of the other chords (other than the tagged chord) in the zero-cell are independent RVs whose distributions do not depend on the perimeter. Further, owing to symmetry, these lengths are identically distributed. The length distribution of each chord can then be given by the distribution of the typical chord length of the zero-cell. We derive this distribution conditioned on the zero-cell perimeter. Averaging over the distribution of the perimeter, we obtain the following result. Please see Appendix H for the proof.
Theorem 5.
As the PGF of is the product of the PGFs of two independent RVs, the mean of is the summation of the mean number of points on the tagged chord and the other chords of the zero cell. The next corollary presents this result.
Corollary 8.
The mean of node degree on the zero-cell is approximated as
Similarly, we can derive the variance of .
6.2. Approximation-2-zero () Approach
Similar to the typical cell, we can approximate the zero-cell with a ball of equal area. Here, is the location of the master node corresponding to . For equal area which gives . Hence, the PDF of is
where is given in (29). Under this approximation, the node degree corresponding to the zero-cell will be equal to the sum of two independent RVs. One RV represents the number of points falling on the tagged chord and the second denotes the number of points in the equivalent ball. This gives us the following PGF. The proof is given in Appendix I.
Theorem 6.
Corollary 9.
The mean of the node degree corresponding to the zero-cell can be approximated as
where is due to . The second derivative of the PGF at is
Using the second derivative and (1), we obtain the variance of .
Similar to , and . The approach that we utilized to determine the distributions of distances and node degree for PLP-PPP is rather general and has several applications in wireless applications including load distribution on each BS in a vehicular network modeled as a PLP-PPP.
The rest of this paper is devoted to several applications of the models and results discussed so far to problems of practical interest in wireless networks.
7. Application Area 1: Vehicular Communications Networks
The associator graph studied in this paper is largely inspired by vehicular networks. Therefore, it is quite befitting to consider this as our primary application area. A vehicular communication network consists of multiple vehicles located on a system of roads and a wireless network deployed in the same space to provide connectivity to these vehicles (Figure 4). Because of its ubiquity, we will assume this wireless network to be a cellular network that provides cellular connectivity to the vehicular nodes. As discussed next, this setup can be directly mapped to the model introduced in this paper. This will allow us to use the mathematical properties of the model explored in this paper to study several practical aspects of vehicular communications networks.
- The spatial layout of roads is modeled a PLP with density .
- We model the vehicles on the i-th road by an independent PPP with density . Therefore, the union of all the vehicles located on each road of forms PLP-PPP.
- The BS locations are modeled as a 2-D PPP with density . The role of the BS is to provide infrastructure connectivity (V2I) to the vehicles.
- Further, we assume that the association of a vehicle to its serving BS is based on the maximum average received power. Assuming the same transmit power for all the BSs, this is the same as associating each vehicle with its closest BS. In other words, each vehicle will connect to the BS whose Voronoi cell it falls in. Therefore, if we consider a PV tessellation with the BSs as master nodes, each Voronoi cell will denote the service region of the respective BS.
Owing to their tractability and accuracy, such stochastic geometry based models have gained popularity within the context of vehicular networks. For instance, the authors in [28] have illustrated that these models are, at a minimum, as precise as the grid-based models utilized for wireless standardization by 3GPP. This provides a robust rationale for their incorporation, especially in foundational theoretical studies, such as the one described in this paper.
Note, further that since the vehicular users are confined on the road, it is important to incorporate the impact of roads in the modeling of vehicular users. Hence, the PLP-PPP turns out to be a suitable choice as it accurately captures the randomness in the both components. Modeling these users as PPP may lead to simpler expressions; however, it may not be accurate for a general case as will be seen in the numerical section. Now we construct an associator graph with BSs as master nodes and vehicles as associate nodes where the association represents the BS each vehicle connects with.
7.1. The Load on the Typical BS
For the setting described above, the load served by the typical BS of is defined as the number of vehicles that are connected to it at any given time. Due to the association law discussed above, these are the vehicles falling inside the typical Voronoi cell. Since the resources at the BSs will be shared by these vehicles, it is important to understand the distribution of load. Owing to the stationarity of this setup, the typical point can be placed at the origin. Therefore, the aforementioned load is exactly the node degree of the typical master node in the graph or the load (i.e., the number of points of ) on the typical Voronoi cell as studied in the paper. Hence, we denote this load also by the RV . Its two approximate distributions were presented in Theorems 3 and 4, respectively.
7.2. The Load on the Tagged BS
In addition to the load on the typical BS, the load on the tagged BS is also important to understand (especially when we are interested in the performance of the typical user that is located in the tagged cell). Owing to the stationarity of , without loss of generality, we assume that the typical user is located at the origin. Due to the association law described above, this user will be associated with the zero-cell of the underlying PV tessellation. The associated BS is termed the tagged BS. Therefore, the load on the tagged BS is exactly the load (number of points of ) on the zero-cell of the PV tessellation as studied in the paper. Hence, we denote this load by the RV . Its two approximate distributions are given in Theorems 5 and 6, respectively.
7.3. Rate Coverage
Let us consider the typical vehicular user located at the origin. It is associated with the tagged BS located at distance R. Let all the BSs transmit at the same power, which is considered unity without loss of generality. Furthermore, we assume that a BS with zero load remains silent and hence does not cause interference at the typical user. We assume the standard path-loss model [1]. For this setting, the signal-to-interference ratio (SIR) of the typical user is
where is PP consisting of active BSs with density , is the path loss exponent, and , respectively, denote the fading gains of the link from the serving BS to the typical user and the BS at to the typical user. Further, we assume Rayleigh fading. As a consequence, the fading coefficients h are exponentially distributed with unit mean. Assuming that the bandwidth B is equally shared by all users associated with the tagged BS, the achievable rate of the typical user is given by
A key performance indicator for such networks is the rate coverage of the typical user, which is defined as the probability that the achievable rate by the typical user is greater than a certain threshold . Hence, the rate coverage for the typical receiver is defined as
Now, the probability that a BS is active is . Using this, we can approximate the PP of active BSs as a PPP with density [1,29]. Hence, the SIR coverage can be derived as [29]
where (a) is achieved by substituting and . Now using (39)–(41), we obtain the following result.
Theorem 7.
The rate coverage for the typical user is
where .
We can now approximate by or to immediately obtain reasonable approximations for the above result.
7.3.1. Meta Distribution of Rate Coverage
The rate coverage, as defined above, averages over all sources of randomness simultaneously regardless of the scale at which they are changing. While this results in a convenient metric, it is often desirable to obtain more fine-grained information about the variability of performance across the network. A rigorous way of doing that is through meta distributions [30]. Interested readers are advised to refer to [31,32] for a pedagogical treatment of this concept. For the purpose of this paper, it is sufficient to understand that the meta distribution of the rate coverage is defined as the probability that the typical vehicle’s conditional rate coverage (conditional on the PP realization) at a certain threshold is greater than a certain reliability target x, i.e., [30,31,32]
where is the probability that achievable rate at the typical user is greater than threshold conditioned on a realization of the BS PP and load on the tagged BS, i.e.,
It is difficult to directly derive the meta-distribution of the rate coverage. Hence, first, we derive the moments of , and then, using the Gill Pelaez inversion theorem [33], we derive the meta distribution of rate coverage. The qth moment of is related to the meta distribution of rate coverage as
Note, that for , denotes the coverage probability.
Theorem 8.
The q-th moment of the downlink coverage probability and the qth moment of rate coverage, respectively, is
where .
The proof of the above theorem is provided in Appendix J.
Using Theorem 8, the definition of meta distribution and Gil-Pelaez lemma inversion theorem [33], we can derive the meta distribution for the rate coverage which is given in the following theorem. The proof is given in Appendix K.
Theorem 9.
The meta distribution for rate coverage is
where
and and and .
7.3.2. Approximation for the Meta Distribution
Another simple yet tractable approach is to use the approximation to obtain the meta distribution [30]. For this, we can use for to obtain the meta distribution as [30,34]
where is the regularized incomplete beta function and and are given as
Now, we present the two important applications where the distance distribution can be directly used for the analysis of vehicular networks modeled by PLP-PPP.
7.4. Coverage under V2I Line of Sight (LOS) Only Communication
In a vehicular network, BS may transmit messages to the other vehicles to communicate various data including critical updates and traffic information [35]. Various blockages can block a link making it non-LOS (NLOS). The wireless propagation along urban roads is usually different for LOS and NLOS links [36] (Figure 5). Especially at higher frequencies, NLOS may result in total loss of connection. The probability that a link with length r is LOS is given as where is the blockage parameter [1] dependent on blockage density. Now, consider V2I communication between a BS and its k-th nearest vehicle. If this link is LOS, the corresponding signal to noise ratio () is
Here, is the distance of the k-th nearest vehicle from the BS and hence, has the distribution equal to that of the k-th CD of a PLP-PPP. The probability that this link is LOS and it is in coverage (i.e., is above the threshold ) is given as
which can be computed using the CD distribution derived earlier in (18).
7.5. Content Caching in V2V within Communication Range
As the number of vehicles on the road increases, the data content requirements for various vehicular applications and services increase commensurately. According to [37,38], the majority of mobile multimedia traffic consists of duplicate downloads of a limited number of popular content files. As current automobiles have large storage capacities, it is possible to cache frequently accessed files closer to the user [39]. Furthermore, in self-driving cars, the information related to traffic may be learned through the nearby vehicles using decentralized learning [40]. Therefore, to reduce the file access time and data dependency on the BS the vehicles may implement data caching, where a vehicle can access the data available at other vehicles within its communication range [27]. To characterize the performance of such networks, we can define a metric termed cache hitting probability as the probability that at least k neighbors are in the communication range of the typical vehicle. This gives
where is the k-th NND and denotes the probability under the reduced Palm distribution. Further, we can simplify using the Corollary 5.
8. Application Area 2: Wireless Sensor Networks
As the second representative application area, we consider a wireless sensor network (WSN), which is a popular choice for sensing vast areas where human interventions are mostly limited or unwanted, such as forests. Let us consider a WSN where the sensors are deployed over a set of lines (for example in a forest along the trails) forming a PLP-PPP. Let PPP denote the locations of the fusion centers that compile information coming from these sensors for data collection, monitoring, organizing, or taking further action. For example, in the barrier coverage [41] application, where the sensors are deployed by dropping along a line using an aircraft, the sensors’ data may be collected using a network of unmanned aerial vehicles (UAVs) distributed as a 2D PPP. To minimize power consumption, it is reasonable to assume that the sensors connect to their nearest fusion nodes. This results in a graph connecting sensor nodes to associated fusion nodes which is equivalent to discussed in the paper. Hence, the number of sensors each fusion center needs to control can be seen as the load on the fusion center which is given as the number of sensors falling in its serving region. The information about this load will be useful for proper dimensioning of the system, such as determining the system bandwidth as well as the power requirement at the fusion centers. We can see that the distribution of this load is the same as the approximate load distribution given in Theorems 3 and 4.
Now, let us inspect the uplink connection carrying data from the sensors to the connected fusion node. Owing to limited capability and energy constraints, we can realistically assume that each sensor node can connect with a fusion center within a certain range around it. The radius of this communication disk (ball) depends on the sensors’ transmit power and the path loss. Hence, the i-th fusion node’s serving region is given by the intersection of its Voronoi cell with its communication ball . This results in a slightly different graph connecting sensor nodes to associated fusion nodes as shown in Figure 5. We can model the resultant tessellation using a germ grain process with fusion centers as germs and the corresponding serving regions as grains. Note that under the approximation, the Voronoi cell is approximated as a ball . Hence, the serving region is given as Hence, similar to Theorem 4, the distribution of the uplink load on the typical fusion center can be obtained as
Due to the limited communication range, some of the sensors may not be able to send their data to fusion centers. It is evident that a sensor is able to communicate if it falls inside the serving region of a fusion center which is equivalent to the event that it falls in the communication ball of at least one fusion center. For the setup described above, this probability is simply .
Clearly, one can map the above setup consisting of sensors and fusion centers with the model discussed in this paper. Hence all the foundational results are either directly applicable to this setting or can be applied with simple variations.
9. Numerical Results
In this section, we first validate the presented approximations of load distribution by comparing them with the exact results obtained from Monte Carlo simulations. We have used the numerical software MATLAB (R2023a) to obtain the numerical results. We kept the simulation window size at . For the load distribution results, we perform iterations with each iteration generating a PPP representing the BS deployment, selecting the typical and tagged cell, generating a PLP-PPP for user distribution and counting the number of points of PLP-PPP for load inside each of the two cells. Similarly, realizations of PLP-PPP are generated for getting the CDFs of kth CD and NND for PLP-PPP. Other parameter values, such as bandwidth, line density (), and BS density (), are declared wherever they are used. We present some useful results related to the network performance of the applications discussed above.
9.1. CD and NND Distributions
In Figure 6a,b, we present the CDF of k-th CD and NND derived in this paper along with the results obtained from simulations. The purpose of this comparison is to simply verify the analysis for a variety of settings.
9.2. Validation of the Approximations Proposed in the Load Distributions
To verify the proposed approximations, the BC of the approximate expression against the exact values (obtained via simulation) are presented in Figure 7. It can be readily observed that the BC for both the approximations is closer to 1 for both the typical and zero-cell cases. Additionally, we see that and are closer to 1 than and , respectively. Since and approximations are also simpler and easier to deal with, we will use them in the subsequent numerical analyses. Furthermore, we observe that BC increases with an increase in the BS density which indicates that the accuracy of the approximations improves as the BS density increases.
9.3. Mean and Variance of the Load on the Typical and Zero-Cell
The mean and variance of the load in the typical cell under both approximations are plotted in Figure 8a, along with their respective exact values (i.e., obtained via simulations). Both the results are remarkably accurate for both the typical and the zero-cells. The mean load obtained under both approximations is accurate. The variance values obtained under are accurate for all values of , whereas the values obtained under exhibit slight differences from the respective simulation-based values in the regime of smaller .
Similarly, the mean and variance of the zero-cell load under approximations are shown in Figure 8b. As was the case above, the variance under is accurate for all values of . We have omitted the variance result for since it is not as accurate as the result obtained under .
9.4. Validation of Rate Coverage and Meta Distribution
Figure 9a shows the variation of the rate coverage with respect to the BS density for two different values of threshold. We have also plotted the active probability with the BS density . We see that the active probability obtained using closely approximates the true results obtained from simulations. With an increase in the BS’s density, the active probability reduces and hence, more BSs remain silent, which reduces the power consumption. Figure 9b presents the meta distribution for the rate coverage. We have also shown the values obtained via the beta approximation.
9.5. Comparison with PPP Based Models
Please note that PLP-PPP can be approximated using a 2D PPP to reduce complexity at the cost of accuracy. It was shown in [15] (Theorem-1) that the PLP-PPP converges to a PPP with the same density asymptotically when the line density of PLP-PPP while keeping the density constant. Hence, such approximation is accurate for a high line density . However, such an approximation may not be valid at lower line density. To further investigate it, in Figure 10a, we show the variance of load distribution in a vehicular communication network, where vehicular users are distributed as PLP-PPP and PPP, respectively, with respect to the road density while keeping total vehicular density constant and the same for the two cases. For higher line density, vehicles in a single cell are still spread over many roads and hence PLP-PPP resembles PPP. Hence, we observe that both PPP and PLP-PPP provide the same load distribution. However, for lower line density, usually only a single line falls inside a cell. Hence, the variance reduces for PLP-PPP. Further, in Figure 10b, we compare the rate coverage of PLP-PPP and PPP distributed vehicular users with respect to the road density while keeping total vehicular density the same. We observe that for higher line density, both PPP and PLP-PPP provide the same rate coverage. However, for lower line density, rate coverage decreases. This discussion highlights the importance of PLP-PPP-based models. As stated earlier, PLP-PPP can be approximated by PPPs to simplify analysis; however, such models may have lower accuracy, especially at lower line densities.
9.6. Distribution and Cache Hitting Probability
The distributions for the ten closest LOS vehicles from the typical BS are shown in Figure 11a. We observe a significant difference between the distributions for the closest and second-closest vehicles, but the difference between SNR distributions from k and -th closest vehicles decreases with the order k. In Figure 11b, the cache content probability is shown with respect to the vehicular density . We observe that in a situation with heavy traffic (growing vehicle density), the cache striking probability increases. With an increase in , the content is made accessible to nearby vehicles, which may lower the burden on the BSs in a scenario with heavy traffic. Thus, content caching and broadcasting could be potentially advantageous in high-traffic situations.
10. Conclusions
In this paper, we explored several important properties of the PLP-PPP as well as its random bipartite geometric associator graph in which each point of the PLP-PPP connects with its closest point of an independent PPP. This graph is equivalent to partitioning the PLP-PPP with a PVT formed by an independent PPP. Key contributions related to PLP-PPP involve the distributions of its k-th CD and NND. We then presented an empirical distribution for the perimeter distribution of the zero-cell of the aforementioned PVT. The accuracy of this result is validated by using the BC coefficient for a range of values of the PPP density. Additionally, we presented the distribution of the length of any randomly selected chord of a zero-cell of this PVT. Using these results, we provided two approximate distributions of the node degree of the associator graph mentioned above. We then applied these results to several wireless network settings. For instance, we presented the distributions of the load on the typical and the tagged BS in a vehicular network in which the vehicles are modeled as a PLP-PPP and the BSs are modeled as an independent PPP (and each vehicle connects to its closest BS). Using this load distribution, we then presented the rate coverage and the meta-distribution of the rate coverage for a vehicle. We also presented the coverage probability for a vehicle and content hitting probability using the k-th CD and NND of PLP-PPP, respectively. We numerically compared the PLP-PPP and PPP-based models to discuss the accuracy vs complexity trade-off. We concluded the paper by rigorously demonstrating that the results of this paper can also be applied to wireless sensor networks in which sensors are deployed over a set of lines (for example in a forest along the trails) forming a PLP-PPP.
Author Contributions
Conceptualization, K.P., A.K.G. and H.S.D.; Formal analysis, K.P., A.K.G., H.S.D. and K.R.P.; Investigation, K.P.; Writing—original draft, K.P.; Writing—review & editing, A.K.G., H.S.D.; Visualization, K.P.; Supervision, A.K.G. and H.S.D.; Funding acquisition, A.K.G. and H.S.D. All authors have read and agreed to the published version of the manuscript.
Funding
A. K. Gupta greatly acknowledges the support of DST SERB (Grants MTR/2022/000390 and CRG/2023/005206). H. S. Dhillon gratefully acknowledges the support of the US National Science Foundation (Grant CNS-1923807).
Data Availability Statement
No new data were created or analyzed in this study. Data sharing is not applicable to this article.
Conflicts of Interest
The authors declare no conflict of interest. The funders had no role in the design of the study; in the writing of the manuscript, or in the decision to publish the results.
Appendix A. Proof of Proposition 1
We consider an irregular convex polygon with perimeter Z as shown in the Figure A1a. Let there be an arbitrary chord intersecting the polygon at two points and . Now using the triangular inequality, we can obtain the following inequalities
From the above, it can be concluded that
Similarly, we can prove that
Taking the summation of (A2) and (A3), we obtain the following
which completes the proof of Proposition 1.
Figure A1.
(a) An irregular convex polygon with perimeter Z and an arbitrary chord PQ. (b) An irregular convex polygon with perimeter Z featuring two non intersecting chords PQ and RS.
Figure A1.
(a) An irregular convex polygon with perimeter Z and an arbitrary chord PQ. (b) An irregular convex polygon with perimeter Z featuring two non intersecting chords PQ and RS.

Appendix B. Proof of Proposition 2
Consider the polygon shown in Figure A1b. Now consider two non intersecting chords and of lengths and , respectively. To prove this result, we will show that the length of the chord depends on . Let us join the opposite edges of chords to create line segments and . By applying the sine rule to the triangle , we get
Similarly, by applying the sine rule to the triangle , we get
where and are the radii of the circumcircles of triangles and , respectively. Furthermore, these circumcircles fall inside the convex polygon, and therefore, the perimeters of both the circumcircles are upper bounded by the perimeter of polygon [42], which is assumed to be Z. Therefore, the ratio is dependent on Z. Consequently, is proportional to , which establishes that and are dependent RVs.
Appendix C. Proof of Corollary 2: Proof of Length Distribution of Tagged Chord
To derive the PDF , we use the fact that the area of a zero-cell is larger than the area of the typical cell. Hence, is a scaled version of and can be written as
To obtain the approximate value of , we equate the mean load on the tagged BS obtained by two methods. The first method is using the stationarity property of PP [1]. The second method is using the PGF of . In the first method, we know that the average number of vehicles falling in the zero-cell is the product of the density of and the average size of the zero-cell [43]. Hence, the mean is equal to . In the second method, we observe from Corollary 8 that the mean of is the summation of the mean number of points falling in the zero-cell which is equal to and the mean number of points on the tagged chord. Therefore, equating with , we get
where is obtained by replacing the mean of obtained in (10). Solving further, we obtain the value of .
Appendix D. Proof of Theorem 1: PGF and Corresponding PMF of S(r)
To obtain the PGF of the number of points of falling in an arbitrary ball of radius r, we first compute the PGF of the number of points on each line of PLP that intersects the ball. Due to independence among the lines of PLP, we take the product of the PGFs conditioned on the number of lines N that are intersecting the ball. Since N is a Poisson RV, we derive the PGF by deconditioning with the distribution of N. Hence the number of points is
The length of the segment of road is . Hence, the number of vehicles on have Poisson distribution with mean . Therefore, conditioned on the PGF for number of points falling inside is
Note that, is a uniform RV in the range . Hence, deconditioning over the PGF expression reduces to
where step (a) follows from a definite integral property. Let there be N such lines intersecting , hence the joint PGF is the product of individual PGFs which is equal to
Here, N is a Poisson RV with mean . From the law of total probability, deconditioning over N, we obtain the PGF as
Appendix E. Proof of Theorem 2: The PGF and Corresponding PMF for M(r)
Without loss of generality, we assume that the typical point of is located at the origin. Hence the number of points of falling inside a circle of radius r conditioned on can be divided into two parts. The first is the number of points falling on the line passing through the origin of length , for which the PGF is . The second is the number of points of falling in ball for which the PGF is provided in Theorem 1. Taking the product of the two PGFs, we obtain the desired PGF.
Appendix F. Proof of Theorem 3: Proof of PGF, PMF, Mean and Variance of
The number of points falling in the typical Voronoi cell is
Let N be the number of chords intersecting the typical Voronoi cell. The PGF expression is
where . Note that the number of chords N intersecting the typical Voronoi cell is a Poisson RV with mean , where Z denotes the perimeter of . Hence, conditioned on , deconditioning with the distribution of N, we obtain the PGF as
Finally, deconditioning with the distribution of Z provided in (8), we obtain the PGF. Note that, the conditional PGF is in the form of . Further to find the PMF, we need the k-th derivative of conditional PGF. After obtaining the k-th derivative, we obtain the PMF of as
To derive the mean of , we need the first derivative of the PGF which is
Solving further, we obtain the mean of . To obtain the variance of , we need the second derivative of , which is given as
Using (1), we obtain the variance of .
Appendix G. Proof of Corollary 7: Proof of Mean and Variance of
The mean number of points of falling in ball is . Substituting , we obtain the mean of . To derive the variance of , we need the second derivative of the PGF that is given as
Using (1) and the second derivative, we derive the variance of .
Appendix H. Proof of Theorem 5: Proof of PGF of
The number of points falling in the zero-cell is the sum of two RVs. First is the number of points falling on the tagged chord and second is the number of points falling on any other chords of zero-cell conditioned on the perimeter of the zero-cell. We further assume that the two RVs are independent hence we write their PGFs separately. The PGF for the number of points on the tagged chord is
The PGF for the number of points falling in the zero-cell of perimeter can be derived similar to Theorem 3. The PGF is given by
Taking the product of (A8) and (A9), we obtain the PGF of .
Appendix I. Proof of Theorem 6: Proof for PGF of
The is the sum of two independent RV, the first is the number of points falling on chord of length and the second is number of vehicles falling inside ball of radius . Hence,
where denotes the number of points on zero chord of length with PGF and denotes the number of points of falling inside a ball of radius , and . The PGF of can be determined using Theorem 4. The product of these two PGFs provides the PGF of .
Appendix J. Proof of Theorem 8: Proof for qth Moment of Rate Coverage
The coverage probability conditioned on the nearest BS distance R is
where is obtained using the Laplace transform of interference [1]. Hence, the qth moment of is
Using the PGFL of PPP and deconditioning over R, we obtain the q-th moment of the coverage probability as
which can be further simplified by substituting and , which completes the proof of Theorem 8. Further the q-th moment of the rate coverage is
where . Deconditioning over , we obtain the qth moment of rate coverage probability.
Appendix K. Proof of Theorem 9: Proof for the Meta Distribution of Rate Coverage
From the definition of the meta distribution of rate coverage, we get
where step is obtained using the Gill-Pelaez lemma for the inversion of the -th moment of which turns out to be the function of the -th moment , of the rate coverage and step is obtained by substituting from (45). After step , we can further simplify by extracting the imaginary part of . First, we determine the imaginary part of . The is
Now in (A12) the term can be written as
Substituting the above in (A12) and simplifying further, we get
In order to provide a compact form of the equations, let and . Now, we can easily extract the imaginary term, , that appears in (A11) as
By substituting this in (A11), we obtain the meta distribution as
where step is obtained by apply and then using the following integral identity
Solving further from step , we obtain the meta distribution of the rate coverage.
References
- Andrews, J.G.; Gupta, A.K.; AlAmmouri, A.; Dhillon, H.S. An Introduction to Cellular Network Analysis Using Stochastic Geometry; Morgan and Claypool Publishers: Williston, VT, USA, 2023. [Google Scholar]
- Koufos, K.; Dettmann, C.P. Distribution of cell area in bounded Poisson Voronoi tessellations with application to secure local connectivity. J. Stat. Phys. 2019, 176, 1296–1315. [Google Scholar] [CrossRef]
- Mankar, P.D.; Parida, P.; Dhillon, H.S.; Haenggi, M. Distance from the Nucleus to a Uniformly Random Point in the 0-Cell and the Typical Cell of the Poisson–Voronoi Tessellation. J. Stat. Phys. 2020, 181, 1678–1698. [Google Scholar] [CrossRef]
- Černỳ, R.; Funken, S.; Spodarev, E. On the Boolean model of Wiener sausages. Methodol. Comput. Appl. Probab. 2008, 10, 23–37. [Google Scholar] [CrossRef]
- Chetlur, V.V.; Dhillon, H.S.; Dettmann, C.P. Shortest path distance in manhattan Poisson line cox process. J. Stat. Phys. 2020, 181, 2109–2130. [Google Scholar] [CrossRef]
- Parida, P.; Dhillon, H.S. Multilayer Random Sequential Adsorption. J. Stat. Phys. 2022, 187, 1–22. [Google Scholar] [CrossRef]
- Subramaniam, S. Statistical representation of a spray as a point process. Phys. Fluids 2000, 12, 2413–2431. [Google Scholar] [CrossRef]
- Lowen, S.B.; Teich, M.C. Doubly stochastic Poisson point process driven by fractal shot noise. Phys. Rev. A 1991, 43, 4192. [Google Scholar] [CrossRef]
- Chiu, S.N.; Stoyan, D.; Kendall, W.S.; Mecke, J. Stochastic Geometry and its Applications; John Wiley & Sons: Chichester, UK, 2013. [Google Scholar]
- Dhillon, H.S.; Chetlur, V.V. Poisson Line Cox Process: Foundations and Applications to Vehicular Networks; Morgan & Claypool Publishers: Williston, VT, USA, 2020. [Google Scholar]
- Sabu, N.V.; Gupta, A.K. Analysis of diffusion based molecular communication with multiple transmitters having individual random information bits. IEEE Trans. Mol. Biol. Multi-Scale Commun. 2019, 5, 176–188. [Google Scholar] [CrossRef]
- Deng, Y.; Noel, A.; Guo, W.; Nallanathan, A.; Elkashlan, M. 3D Stochastic Geometry Model for Large-Scale Molecular Communication Systems. In Proceedings of the 2016 IEEE Global Communications Conference (GLOBECOM), Washington, DC, USA, 4–8 December 2016; pp. 1–6. [Google Scholar]
- Baccelli, F.; Zuyev, S. Stochastic geometry models of mobile communication networks. In Frontiers in Queueing: Models and Applications in Science and Engineering; CRC Press: Boca Raton, FL, USA, 1996. [Google Scholar]
- Chetlur, V.V.; Dhillon, H.S. Coverage analysis of a vehicular network modeled as Cox process driven by Poisson line process. IEEE Trans. Wirel. Commun. 2018, 17, 4401–4416. [Google Scholar] [CrossRef]
- Chetlur, V.V.; Dhillon, H.S. Coverage and rate analysis of downlink cellular vehicle-to-everything (C-V2X) communication. IEEE Trans. Wirel. Commun. 2019, 19, 1738–1753. [Google Scholar] [CrossRef]
- Guha, S. Cellular-Assisted Vehicular Communications: A Stochastic Geometric Approach. Master’s Thesis, Virginia Polytechnic Institute and State University, Blacksburg, VA, USA, 2016. [Google Scholar]
- Choi, C.S.; Baccelli, F. An analytical framework for coverage in cellular networks leveraging vehicles. IEEE Trans. Commun. 2018, 66, 4950–4964. [Google Scholar] [CrossRef]
- Sial, M.N.; Deng, Y.; Ahmed, J.; Nallanathan, A.; Dohler, M. Stochastic geometry modeling of cellular V2X communication over shared channels. IEEE Trans. Veh. Technol. 2019, 68, 11873–11887. [Google Scholar] [CrossRef]
- Chetlur, V.V.; Dhillon, H.S. On the load distribution of vehicular users modeled by a Poisson line Cox process. IEEE Wirel. Commun. Lett. 2020, 9, 2121–2125. [Google Scholar] [CrossRef]
- Pandey, K.; Perumalla, K.R.; Gupta, A.K.; Dhillon, H.S. Fundamentals of Vehicular Communication Networks with Vehicle Platoons. IEEE Trans. Wirel. Commun. 2023. early access. [Google Scholar] [CrossRef]
- Choi, C.S.; Baccelli, F. Poisson Cox point processes for vehicular networks. IEEE Trans. Veh. Technol. 2018, 67, 10160–10165. [Google Scholar] [CrossRef]
- Johnson, W.P. The Curious History of Faà di Bruno’s formula. Am. Math. Mon. 2002, 109, 217–234. [Google Scholar]
- Calka, P. Precise formulae for the distributions of the principal geometric characteristics of the typical cells of a two-dimensional Poisson-Voronoi tessellation and a Poisson line process. Adv. Appl. Probab. 2003, 35, 551–562. [Google Scholar] [CrossRef]
- Tanemura, M. Statistical distributions of Poisson Voronoi cells in two and three dimensions. Forma 2003, 18, 221–247. [Google Scholar]
- Muche, L.; Stoyan, D. Contact and chord length distributions of the Poisson Voronoi tessellation. J. Appl. Probab. 1992, 29, 467–471. [Google Scholar] [CrossRef]
- Bhattacharyya, A. On a measure of divergence between two multinomial populations. Sankhyā Indian J. Stat. 1946, 7, 401–406. [Google Scholar]
- Pandey, K.; Gupta, A.K. kth Distance distributions of n-dimensional Matérn cluster process. IEEE Commun. Lett. 2021, 25, 769–773. [Google Scholar] [CrossRef]
- Chetlur, V.V.; Dhillon, H.S. Spatial Models for Networks on Roads: Bridging the Gap Between Industry and Academia. IEEE Netw. 2022, 36, 26–31. [Google Scholar] [CrossRef]
- Gupta, A.K.; Zhang, X.; Andrews, J.G. Potential throughput in 3D ultradense cellular networks. In Proceedings of the Asilomar Conference on Signals, Systems and Computers, Pacific Grove, CA, USA, 8–11 November 2015; pp. 1026–1030. [Google Scholar]
- Haenggi, M. The meta distribution of the SIR in Poisson bipolar and cellular networks. IEEE Trans. Wirel. Commun. 2015, 15, 2577–2589. [Google Scholar] [CrossRef]
- Haenggi, M. Meta distributions—Part 1: Definition and examples. IEEE Commun. Lett. 2021, 25, 2089–2093. [Google Scholar] [CrossRef]
- Haenggi, M. Meta distributions—Part 2: Properties and interpretations. IEEE Commun. Lett. 2021, 25, 2094–2098. [Google Scholar] [CrossRef]
- Gil-Pelaez, J. Note on the inversion theorem. Biometrika 1951, 38, 481–482. [Google Scholar] [CrossRef]
- Deng, N.; Haenggi, M. A Fine-grained analysis of millimeter-wave device-to-device networks. IEEE Trans. Commun. 2017, 65, 4940–4954. [Google Scholar] [CrossRef]
- Choi, C.S.; Baccelli, F. Modeling and analysis of vehicle safety message broadcast in cellular networks. IEEE Trans. Wirel. Commun. 2021, 20, 4087–4099. [Google Scholar] [CrossRef]
- Andersen, J.B.; Rappaport, T.S.; Yoshida, S. Propagation measurements and models for wireless communications channels. IEEE Commun. Mag. 1995, 33, 42–49. [Google Scholar] [CrossRef]
- Wang, X.; Chen, M.; Taleb, T.; Ksentini, A.; Leung, V.C. Cache in the air: Exploiting content caching and delivery techniques for 5G systems. IEEE Commun. Mag. 2014, 52, 131–139. [Google Scholar] [CrossRef]
- Afshang, M.; Dhillon, H.S.; Chong, P.H.J. Fundamentals of cluster-centric content placement in cache-enabled device-to-device networks. IEEE Trans. Commun. 2016, 64, 2511–2526. [Google Scholar] [CrossRef]
- Wu, H.; Xu, W.; Chen, J.; Wang, L.; Shen, X. Matching-based content caching in heterogeneous vehicular networks. In Proceedings of the GLOBECOM, Abu Dhabi, United Arab Emirates, 9–13 December 2018. [Google Scholar]
- Niknam, S.; Dhillon, H.S.; Reed, J.H. Federated learning for wireless communications: Motivation, opportunities, and challenges. IEEE Commun. Mag. 2020, 58, 46–51. [Google Scholar] [CrossRef]
- Saipulla, A.; Westphal, C.; Liu, B.; Wang, J. Barrier coverage of line-based deployed wireless sensor networks. In Proceedings of the INFOCOM, Rio de Janeiro, Brazil, 19–25 April 2009; pp. 127–135. [Google Scholar]
- Glazyrin, A.; Morić, F. Upper bounds for the perimeter of plane convex bodies. Acta Math. Hung. 2014, 142, 366–383. [Google Scholar] [CrossRef]
- Gupta, S.K.; Malik, V.; Gupta, A.K.; Andrews, J.G. Impact of Blocking Correlation on the Performance of mmWave Cellular Networks. IEEE Trans. Commun. 2022, 70, 4925–4939. [Google Scholar] [CrossRef]
Figure 1.
Illustration showing transformation of the point located on -axis to the line .

Figure 2.
Illustration of a PLP-PPP partitioned by a PV tessellation resulting in a graph .
Figure 3.
The plot showing the BC coefficient between the empirical (Emp.) PDF and the PDF obtained from simulation (Simul.) of the perimeter of the zero-cell. The plot demonstrates a high accuracy of our result for a range of values of .
Figure 3.
The plot showing the BC coefficient between the empirical (Emp.) PDF and the PDF obtained from simulation (Simul.) of the perimeter of the zero-cell. The plot demonstrates a high accuracy of our result for a range of values of .
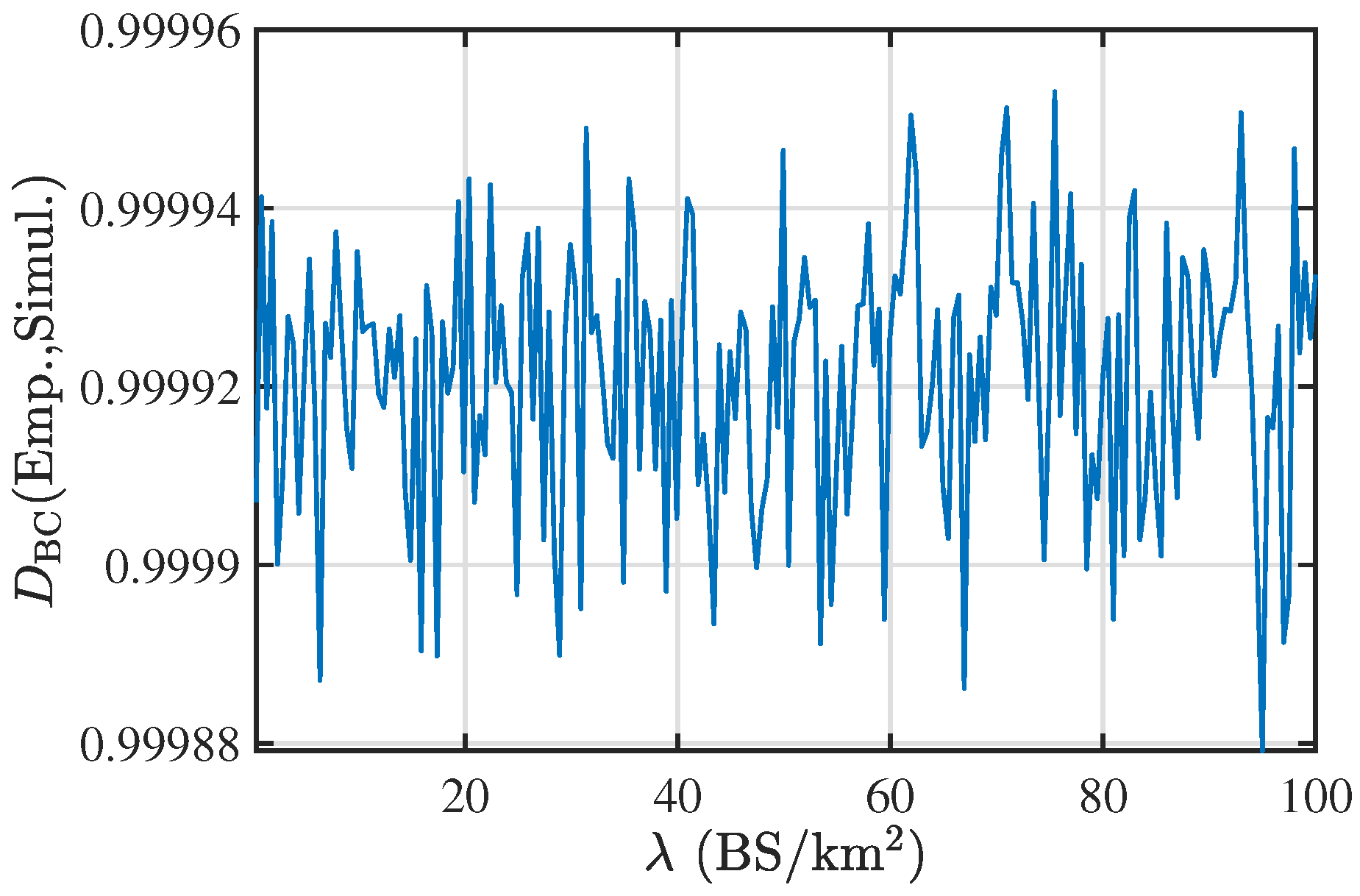
Figure 4.
Illustration of a scenario where the vehicles connect with their nearest BSs.
Figure 5.
Illustration showing a graph connecting sensor nodes to associated fusion nodes under minimum distance based association and finite communication range.
Figure 5.
Illustration showing a graph connecting sensor nodes to associated fusion nodes under minimum distance based association and finite communication range.

Figure 6.
(a) CDF of k-th CD for PLP-PPP. (b) CDF of k-th NND for the PLP-PPP. The parameters are , and .
Figure 6.
(a) CDF of k-th CD for PLP-PPP. (b) CDF of k-th NND for the PLP-PPP. The parameters are , and .
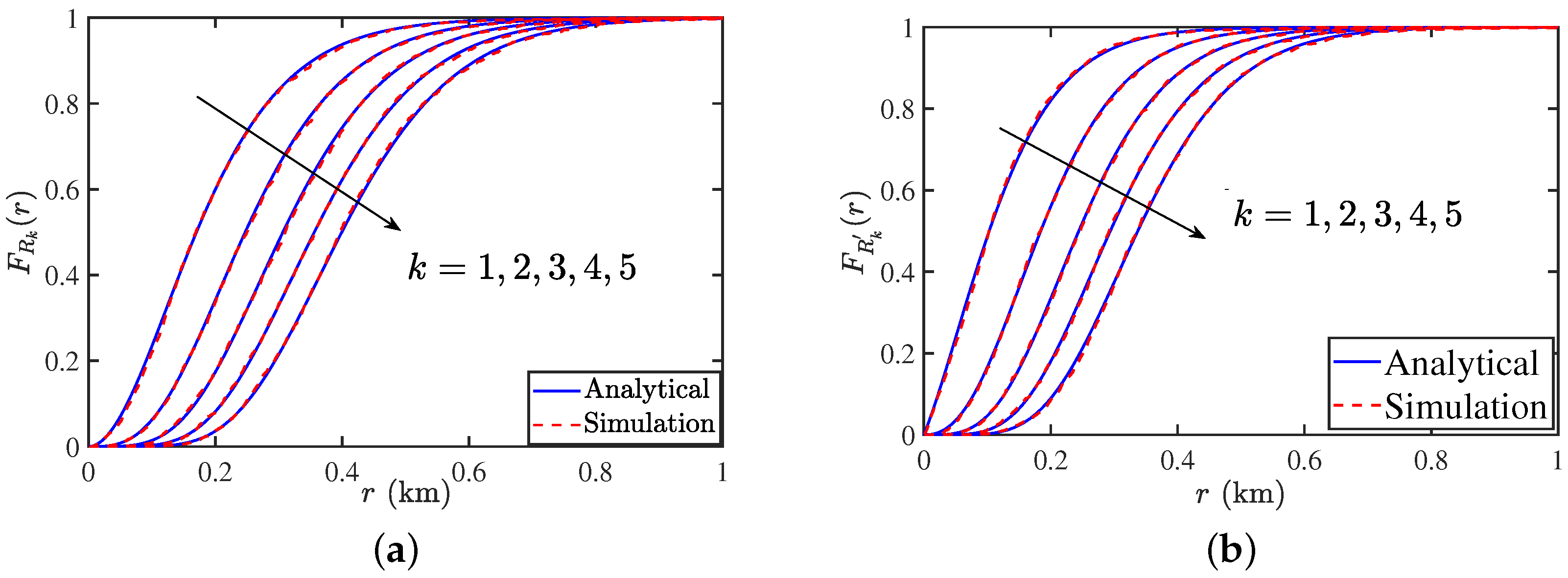
Figure 7.
The analytical expressions obtained for the load distributions in both the typical and the zero-cell are accurate since the BC is close to 1.
Figure 7.
The analytical expressions obtained for the load distributions in both the typical and the zero-cell are accurate since the BC is close to 1.
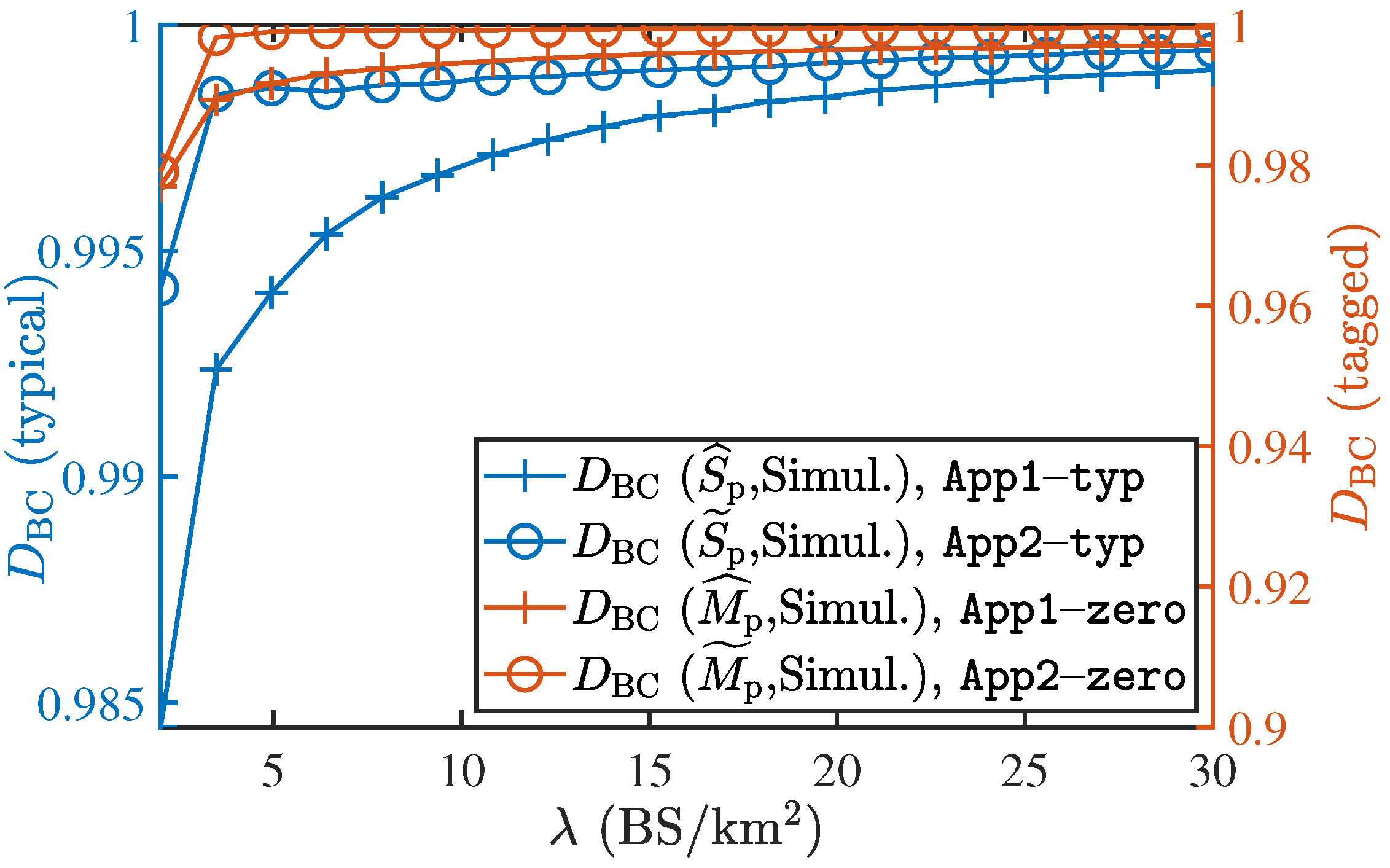
Figure 8.
(a) Plot of the mean and variance of the load on the typical cell. (b) Plot of the mean and variance of the load on the zero-cell. It can be observed that is more accurate compared to . The parameters are , .
Figure 8.
(a) Plot of the mean and variance of the load on the typical cell. (b) Plot of the mean and variance of the load on the zero-cell. It can be observed that is more accurate compared to . The parameters are , .

Figure 9.
(a) Plot showing the rate coverage for two different values of threshold, it also shows the probability that a BS is active with varying BS density. We consider , . (b) presents the meta distribution for the PLP-PPP process with . The parameters are , , and . For both the plots, the load distribution on the zero-cell is obtained under .
Figure 9.
(a) Plot showing the rate coverage for two different values of threshold, it also shows the probability that a BS is active with varying BS density. We consider , . (b) presents the meta distribution for the PLP-PPP process with . The parameters are , , and . For both the plots, the load distribution on the zero-cell is obtained under .
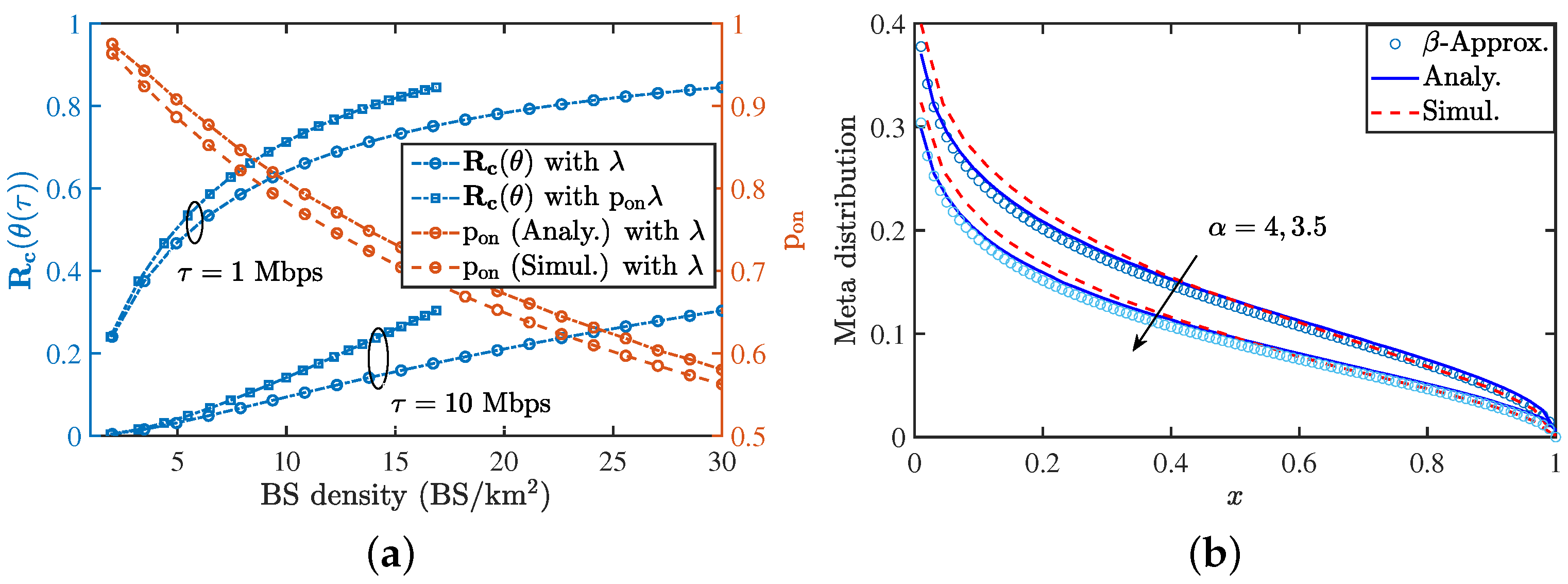
Figure 10.
(a) Variance of the load distribution vs the line density for different values of the BS density for the cases where users are modeled using PLP-PPP and PPP (b) the rate coverage vs line density for different values of the BS density for the cases where users are modeled using PLP-PPP and PPP. The vehicular density , bandwidth , and .
Figure 10.
(a) Variance of the load distribution vs the line density for different values of the BS density for the cases where users are modeled using PLP-PPP and PPP (b) the rate coverage vs line density for different values of the BS density for the cases where users are modeled using PLP-PPP and PPP. The vehicular density , bandwidth , and .

Figure 11.
(a) Probability that the LOS link is in coverage as a function of blockage probability with , , , and the road density . (b) Variation of the cache hitting probability with road vehicular density . The road density , the broadcast range and .
Figure 11.
(a) Probability that the LOS link is in coverage as a function of blockage probability with , , , and the road density . (b) Variation of the cache hitting probability with road vehicular density . The road density , the broadcast range and .
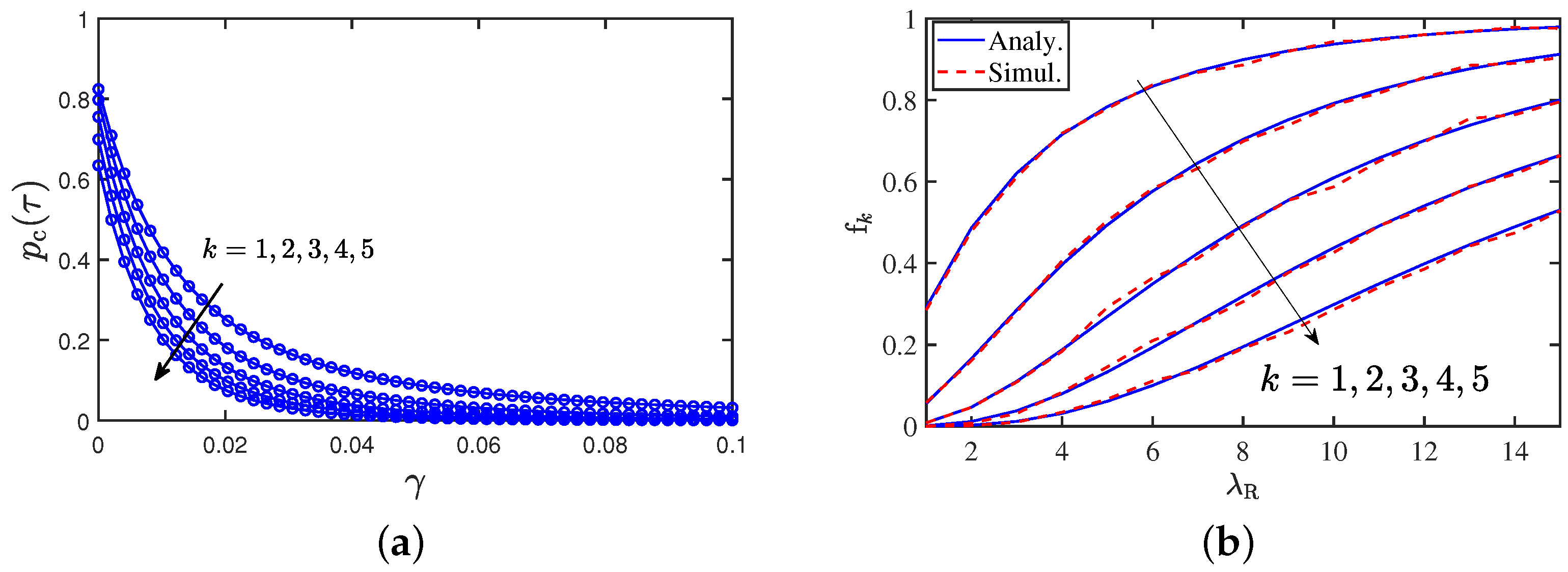
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Pandey, K.; Gupta, A.K.; Dhillon, H.S.; Perumalla, K.R. Properties of a Random Bipartite Geometric Associator Graph Inspired by Vehicular Networks. Entropy 2023, 25, 1619. https://doi.org/10.3390/e25121619
AMA Style
Pandey K, Gupta AK, Dhillon HS, Perumalla KR. Properties of a Random Bipartite Geometric Associator Graph Inspired by Vehicular Networks. Entropy. 2023; 25(12):1619. https://doi.org/10.3390/e25121619
Chicago/Turabian StylePandey, Kaushlendra, Abhishek K. Gupta, Harpreet S. Dhillon, and Kanaka Raju Perumalla. 2023. "Properties of a Random Bipartite Geometric Associator Graph Inspired by Vehicular Networks" Entropy 25, no. 12: 1619. https://doi.org/10.3390/e25121619
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.