
Protected Geographical Indication Discrimination of Zhejiang and Non-Zhejiang Ophiopogonis japonicus by Near-Infrared (NIR) Spectroscopy Combined with Chemometrics: The Influence of Different Stoichiometric and Spectrogram Pretreatment Methods

 ,
,  and
and
Abstract
:1. Introduction
2. Results and Discussion
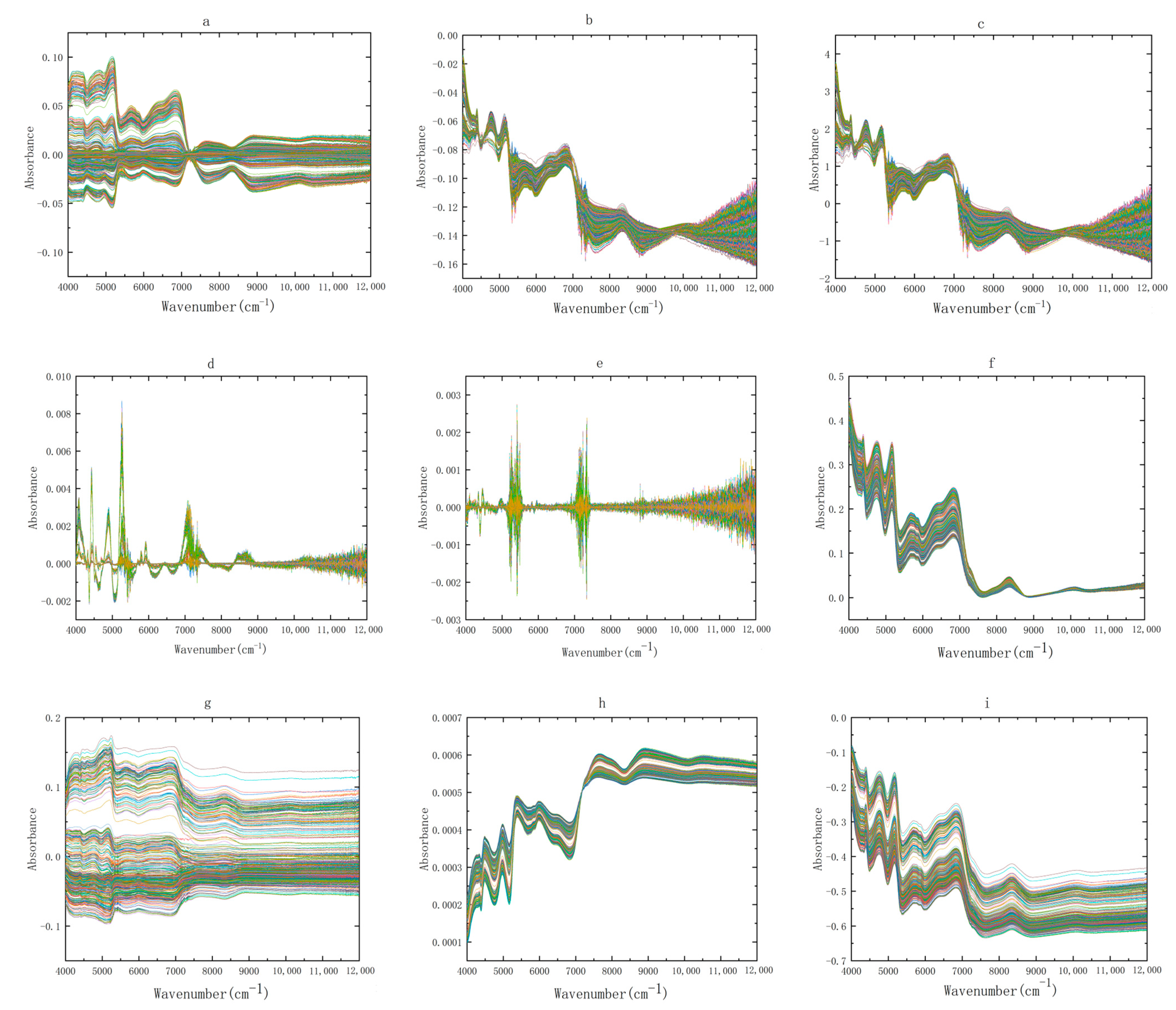
2.1. NIR Spectra
2.2. Preprocessing Method of NIR Spectra
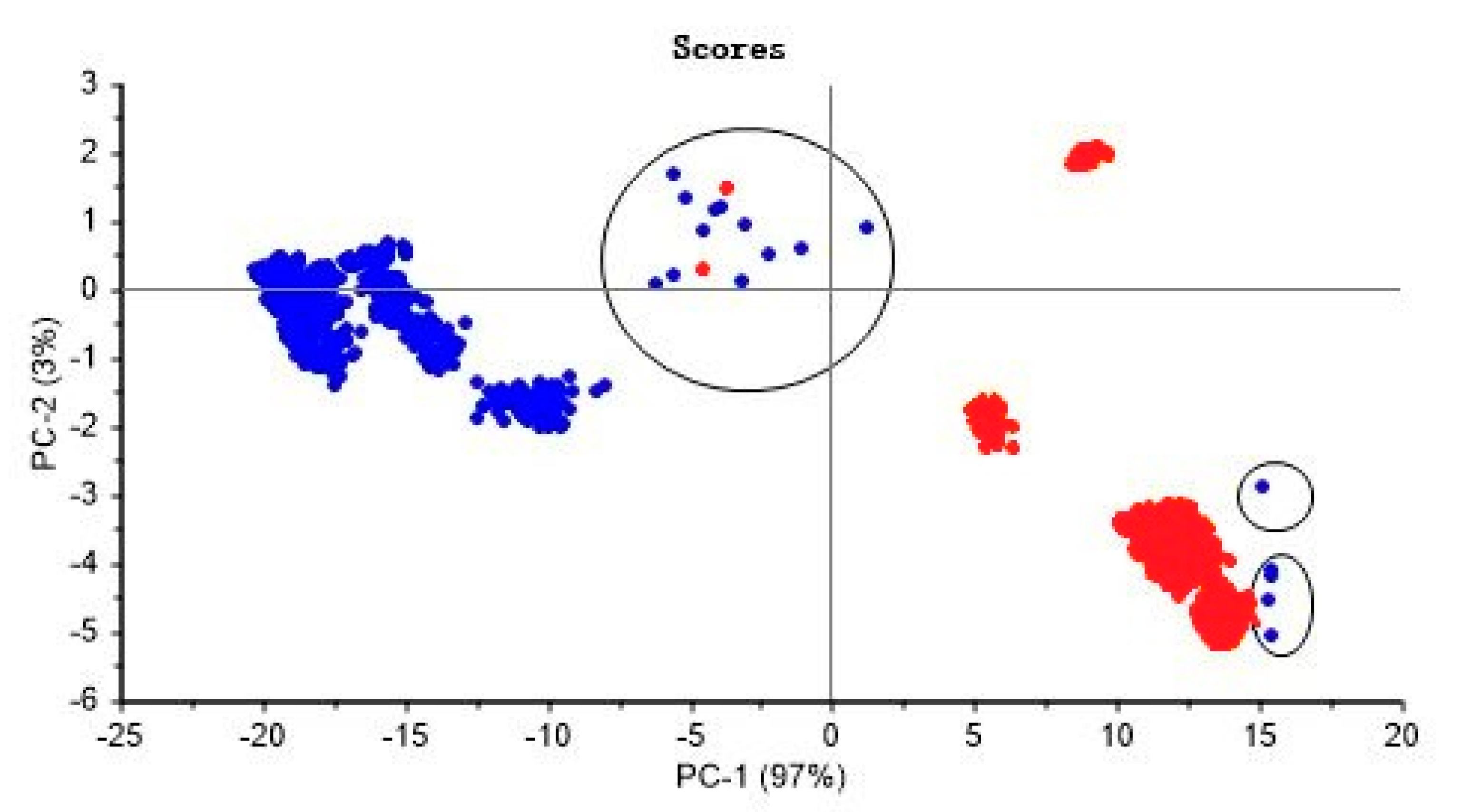
2.3. Outlier Detection
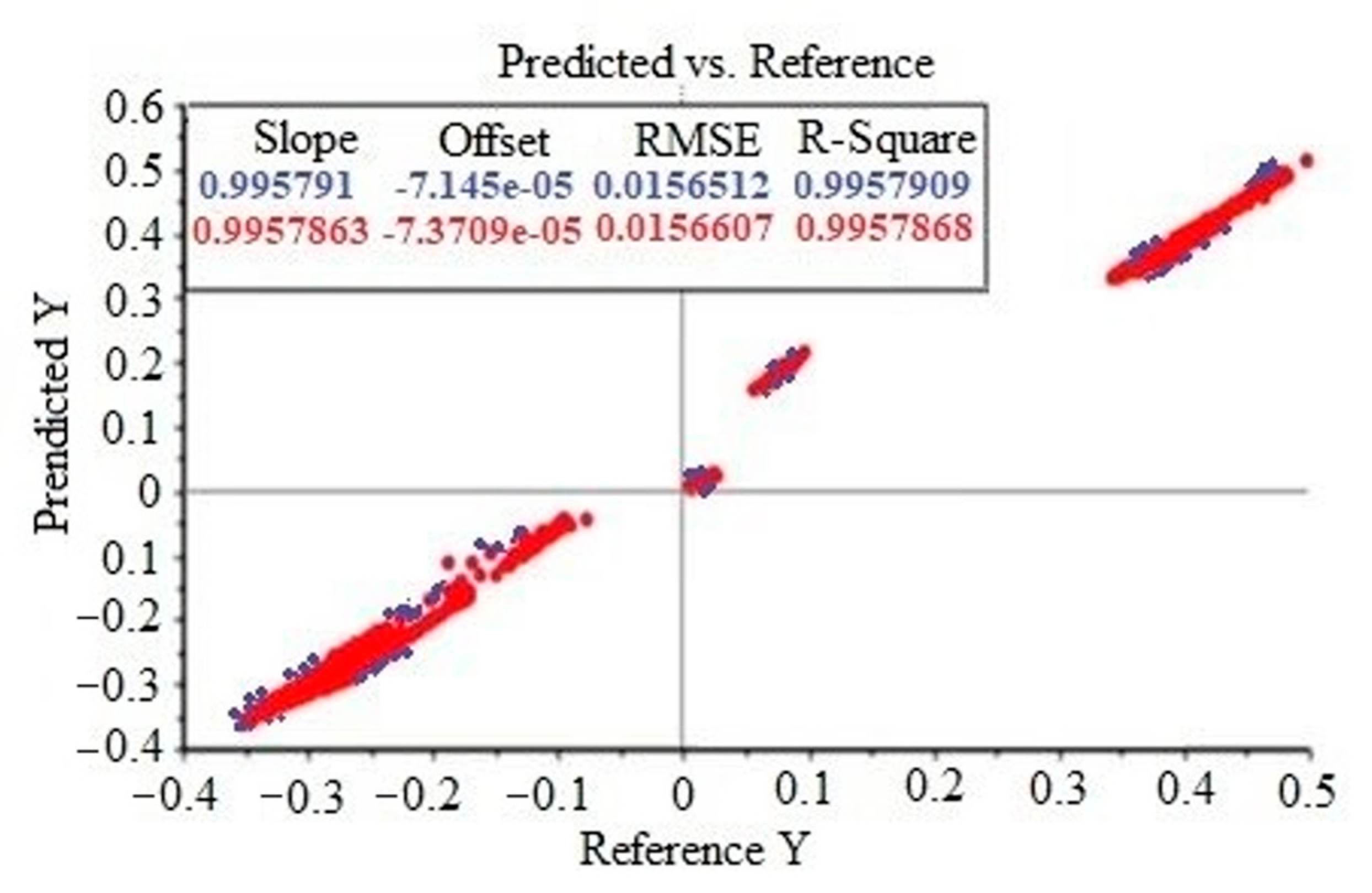
2.4. Partial Least Squares Regression (PLSR)
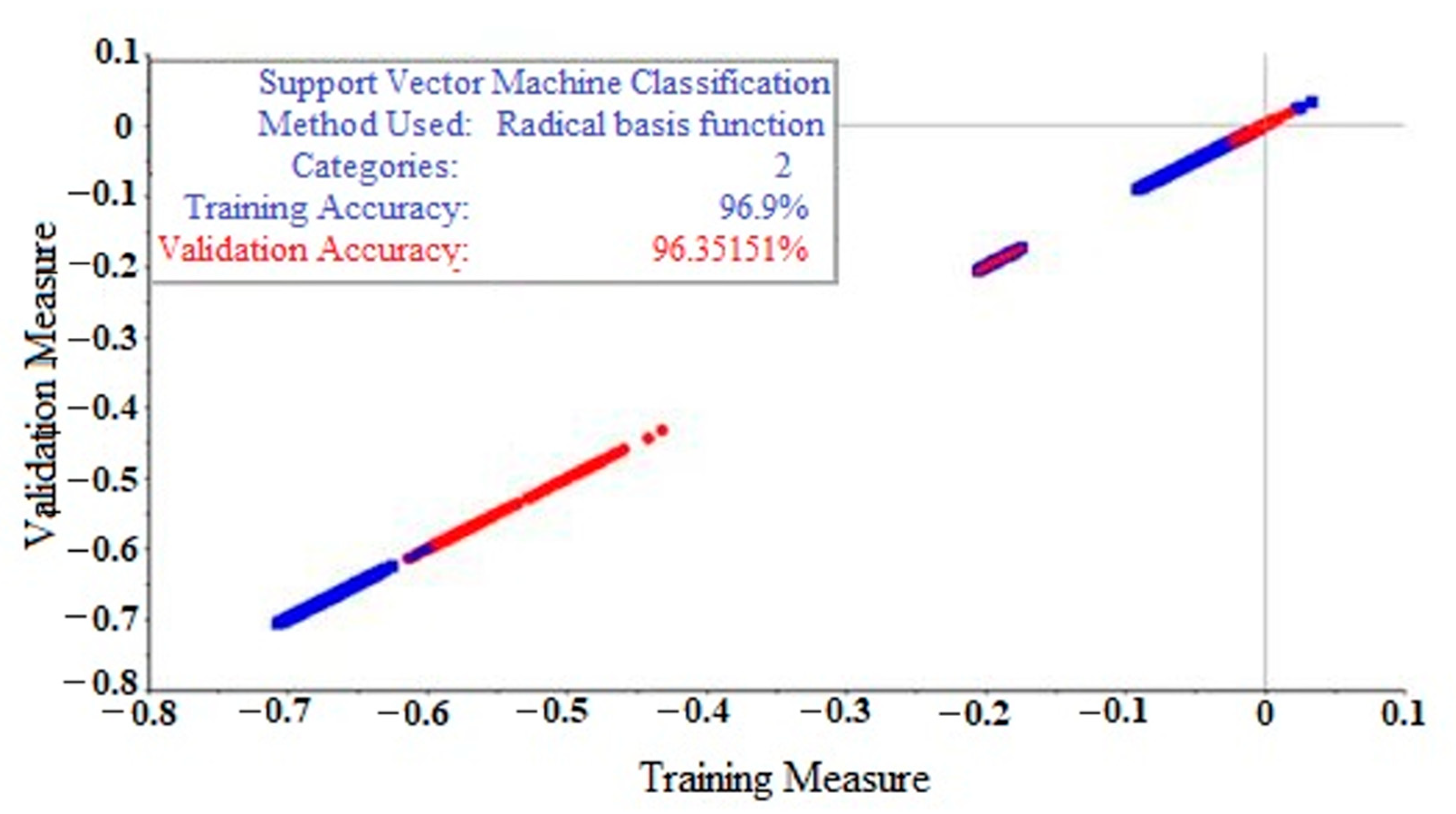
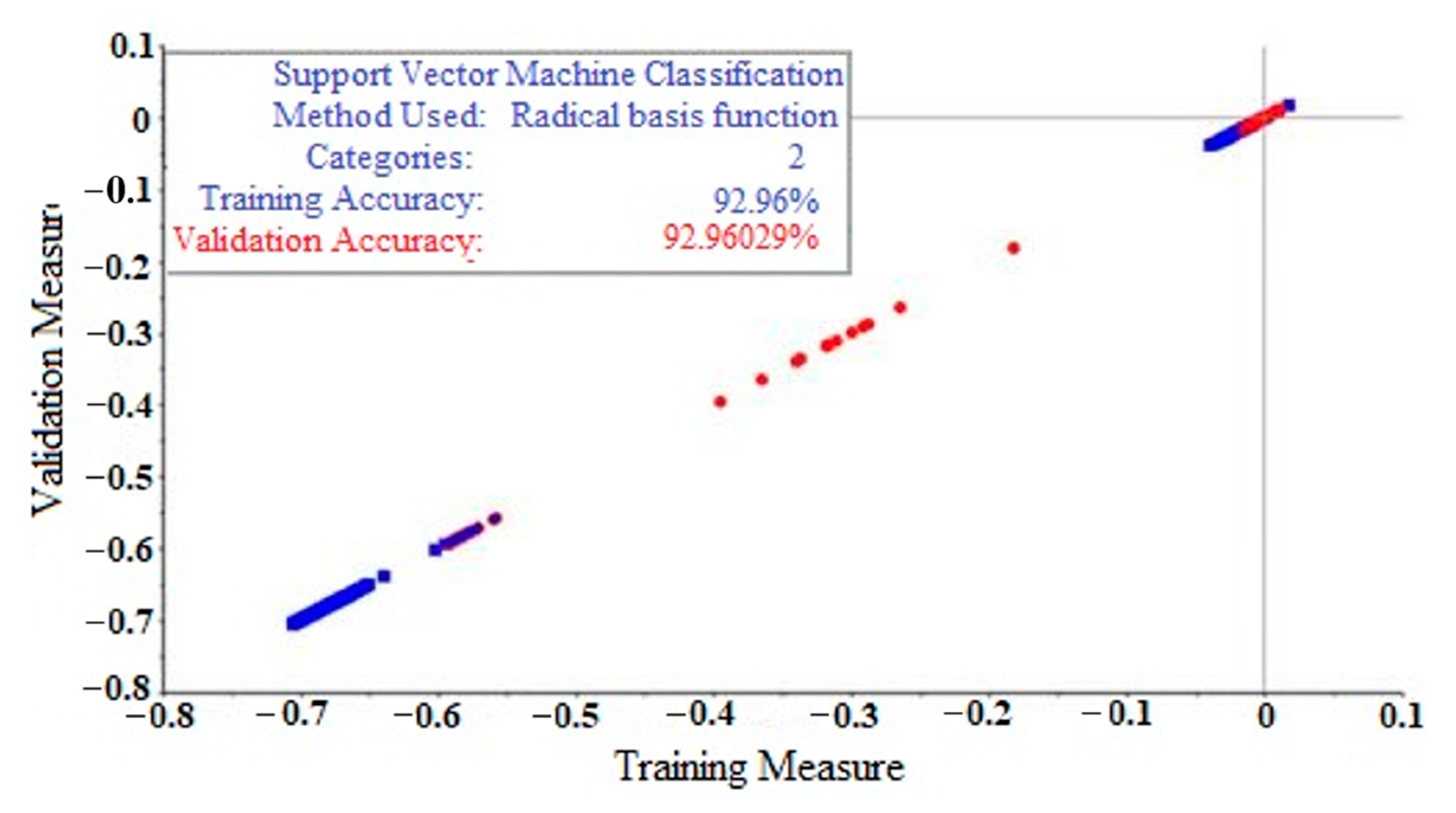
2.5. Support Vector Machine (SVM)
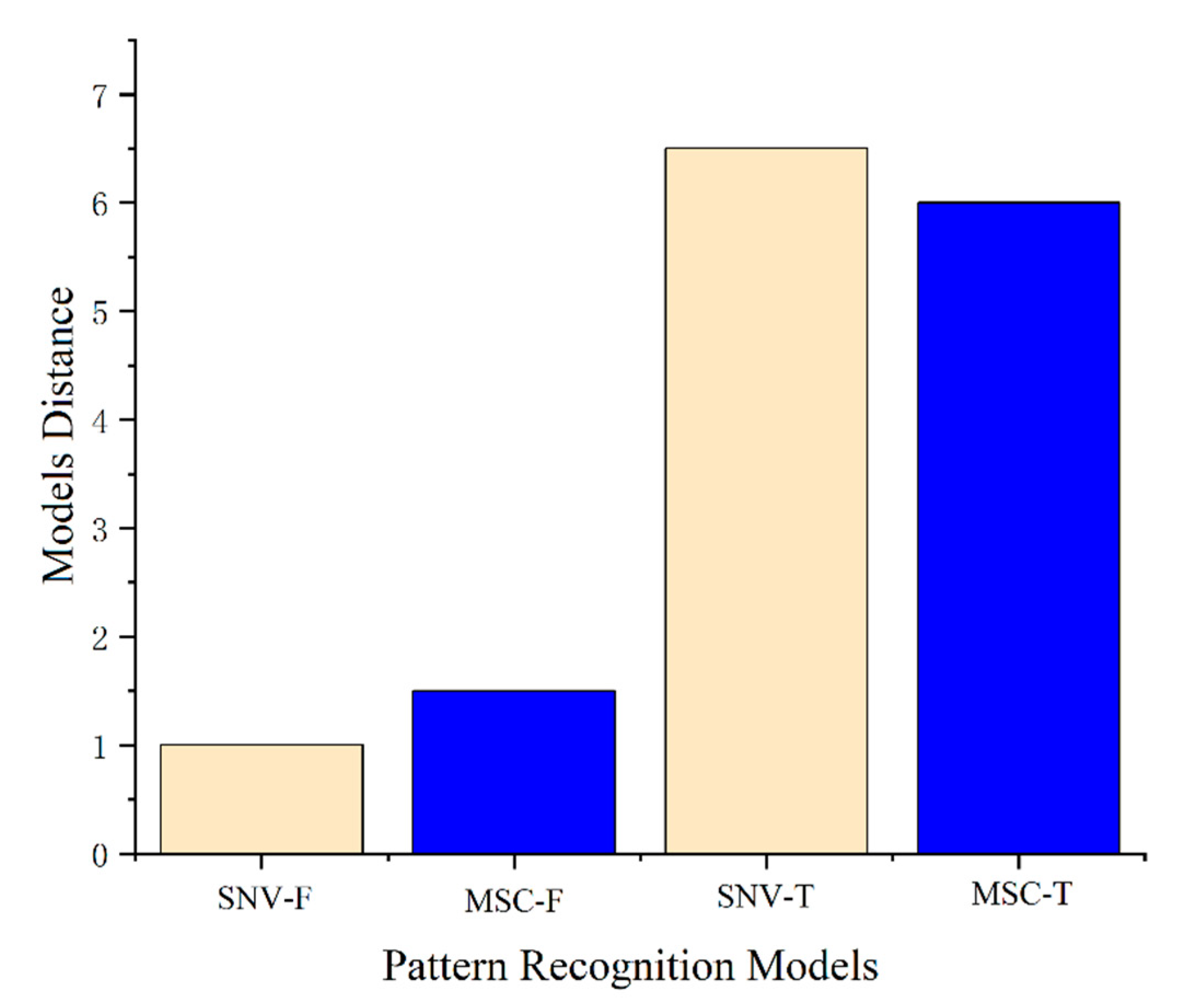
2.6. Soft Independent Modeling of Class Analogies (SIMCA)
3. Materials and Methods
3.1. Ophiopogon japonicus Collection
3.2. Near-Infrared Spectroscopy Detection
3.3. Outlier Detection
3.4. Data Preprocessing
3.5. Three Different Chemometric Analysis
4. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Sample Availability
References
- Xu, Y.; Liu, J.H.; Wang, J.; Zhang, J.; Yu, B.Y. A monoclonal antibody-based competitive ELISA for the determination of ruscogenin in Chinese traditional medicines and biological samples. Chin. J. Nat. Med. 2014, 12, 794–799. [Google Scholar] [CrossRef] [PubMed]
- Wang, L.; Jiang, X.L.; Zhang, W.M.; Li, F.; Khan, A.A.; Liu, X.; Yu, K.; Wang, M.K. Homo-aro-cholestane, furostane and spirostane saponins from the tubers of Ophiopogon japonicus. Phytochemistry 2017, 136, 125–132. [Google Scholar] [CrossRef]
- Zhao, J.W.; Chen, D.S.; Deng, C.S.; Wang, Q.; Zhu, W.; Lin, L. Evaluation of anti-inflammatory activity of compounds isolated from the rhizome of Ophiopogon japonicas. BMC Complem. Altern. Med. 2017, 17, 7. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Wang, H.Y.; Guo, L.X.; Hu, W.H.; Peng, Z.T.; Wang, C.; Chen, Z.C.; Liu, E.Y.L.; Dong, T.T.X.; Wang, T.J.; Tsim, K.W.K. Polysaccharide from tuberous roots of Ophiopogon japonicus regulates gut microbiota and its metabolites during alleviation of high-fat diet-induced type-2 diabetes in mice. J. Funct. Foods 2019, 63, 103593. [Google Scholar] [CrossRef]
- Kai, Z.; Zhang, J.Y.; Wang, X.R.; Wang, L.; Michela, P.; Annamaria, P.; Li, J.X. Cardioprotection of Sheng Mai Yin a classic formula on adriamycin induced myocardial injury in Wistar rats. Phytomedicine 2018, 38, 1–11. [Google Scholar]
- Guo, M.Y.; Jiang, W.J.; Yu, J.S.; Pang, X.H. Investigating the authenticity of Ophiopogonis Radix and its Chinese patent medicines by using a nucleotide signature. J. Ethnopharmacol. 2020, 261, 113134. [Google Scholar] [CrossRef]
- Tan, M.X.; Chen, J.L.; Wang, C.C.; Zou, L.S.; Chen, S.Y.; Shi, J.J.; Mei, Y.Q.; Wei, L.F.; Liu, X.H. Quality Evaluation of Ophiopogonis Radix from Two Different Producing Areas. Molecules 2019, 24, 3220. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Lyu, C.G.; Kang, C.Z.; Kang, L.P.; Yang, J.; Wang, S.; He, Y.L.; Deng, A.P.; Wang, H.Y.; Huang, L.Q.; Guo, L.P. Structural characterization and discrimination of Ophiopogon japonicas (Liliaceae) from different geographical origins based on metabolite profiling analysis. J. Pharmaceut. Biomed. 2020, 18, 113212. [Google Scholar] [CrossRef]
- Li, Z.; Chen, Y.; Ma, L.K.; Zhu, M.; Jiang, L.H. Establish and Discuss the Quality Standard of Ophiopogonis Radix from Zhejiang Province. Chin. J. Mod. Appl. Pharm. 2016, 33, 795–799. [Google Scholar]
- Xiao, X.K.; Ruan, H.S. Research Progress on Difference of Ophiopogonis radix Distributed in Zhejiang Province and Sichuan Province. Chin. Wild Plant Res. 2019, 38, 57–61. [Google Scholar]
- He, J.; Ye, L.H.; Li, J.H.; Huang, W.K.; Huo, Y.J.; Gao, J.X.; Liu, L.; Zhang, W.T. Identification of Ophiopogonis Radix from different producing areas by headspace-gas chromatography-ion mobility spectrometry analysis. J. Food Biochem. 2021, 46, e13850. [Google Scholar] [CrossRef]
- Zhang, T.C.; Li, S.; Wang, Y.H.; Hu, Q.; Wang, C.; Yang, H.; Xu, N.J. Research progress in the application of stable isotope and mineral element analysis in tracing the geographical origin of Chinese medicinal materials. Food Sci Technol. 2022, 42, e08222. [Google Scholar] [CrossRef]
- Hu, L.; Chen, X.F.; Yang, J.; Guo, L.P. Geographic authentication of the traditional Chinese medicine Atractylodes macrocephala Koidz. (Baizhu) using stable isotope and multielement analyses. Rapid Commun. Mass Spectrom. 2019, 33, 1703–1710. [Google Scholar] [CrossRef] [PubMed]
- Fan, C.L.; Deng, J.W.; Yang, Y.Y.; Liu, J.S.; Wang, Y.; Zhang, X.Q.; Fai, K.; Zhang, Q.W.; Ye, W.C. Multi-ingredients determination and fingerprint analysis of leaves from Ilex latifolia using ultra-performance liquid chromatography coupled with quadrupole time-of-flight mass spectrometry. J. Pharmaceut. Biomed. 2013, 84, 20–29. [Google Scholar] [CrossRef] [PubMed]
- Zhong, Y.C.; Wang, H.Y.; Wei, Q.H.; Cao, R.; Zhang, H.L.; He, Y.Z.; Wang, L.Z. Combining DNA Barcoding and HPLC Fingerprints to Trace Species of an Important Traditional Chinese Medicine Fritillariae Bulbus. Molecules 2019, 24, 3269. [Google Scholar] [CrossRef] [Green Version]
- Pei, Y.F.; Zuo, Z.T.; Zhang, Q.Z.; Wang, Y.Z. Data Fusion of Fourier Transform Mid-Infrared (MIR) and Near-Infrared (NIR) Spectroscopies to Identify Geographical Origin of Wild Paris polyphylla var. yunnanensis. Molecules 2019, 24, 2559. [Google Scholar] [CrossRef] [Green Version]
- Li, Y.; Zhang, J.Y.; Wang, Y.Z. FT-MIR and NIR spectral data fusion: A synergetic strategy for the geographical traceability of Panax notoginseng. Anal. Bioanal. Chem. 2018, 410, 91–103. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Wen, B.; Zhang, X.L.; Zhao, Y.; Duan, Y.; Song, X.F.; Ren, S.; Wang, Y.H.; Fang, W.P.; Zhu, X.J. Geographical origin traceability of tea based on multi-element spatial distribution and the relationship with soil in district scale. Food Control. 2018, 90, 18–28. [Google Scholar] [CrossRef]
- Wang, J.; Wang, S.G.; Ge, X.L.; Zhang, M.J. Authentication of American ginseng (Panax quinquefolius L.) from different origins by linear discriminant analysis of multi-elements. Eur. Food Res. Technol. 2021, 247, 2657–2666. [Google Scholar] [CrossRef]
- Meng, J.; Liu, Z.; Gou, C.L.; Rogers, K.M.; Yu, W.J.; Zhang, S.S.; Yuan, Y.W.; Zhang, L. Geographical origin of Chinese wolfberry (goji) determined by carbon isotope analysis of specific volatile compounds. J. Chromatogr. B 2019, 1105, 104–112. [Google Scholar] [CrossRef]
- Li, N.; Che, Y.Y.; Zhang, L.; Zhang, J.Y.; Zhou, Y.; Jiang, Y.; Yu, P.F. Fingerprint analysis of Ophiopogonis Radix by HPLC-UV-ELSD coupled with chemometrics methods. J. Chin. Pharm. Sci. 2013, 22, 1. [Google Scholar] [CrossRef]
- Syed, A.W.; Guo, B.L.; Zhang, X.W.; Imtiaz, H.U.; Wei, Y.M. Recent development in the application of analytical techniques for the traceability and authenticity of food of plant origin. Microchem. J. 2020, 152, 104295. [Google Scholar]
- Zhao, D.Z.; Tian, Z.Z.; Cai, J.; He, J. Microbial spore genetic marker technology, a potential technology for traditional Chinese medicine traceability system. Chin. Med. 2022, 17, 61. [Google Scholar] [CrossRef]
- Giraudo, A.; Grassi, S.; Savorani, F.; Gavoci, G.; Casiraghi, E.; Geobaldo, F. Determination of the geographical origin of green coffee beans using NIR spectroscopy and multivariate data analysis. Food Control. 2019, 99, 137–145. [Google Scholar] [CrossRef] [Green Version]
- Babushkin, V.; Spiridonov, A.; Kozhukhar, A. Application of NIR and FTIR in Food Analysis. J. Phys. Sci. Appl. 2016, 6, 47–50. [Google Scholar] [CrossRef]
- Wang, Y.; Zuo, Z.T.; Wang, Y.Z. Pattern recognition: An effective tool for quality assessment of herbal medicine based on chemical information. J. Chemometr. 2020, 35, e3305. [Google Scholar]
- Lv, C.G.; He, Y.L.; Kang, C.Z.; Zhou, L.; Wang, T.L.; Yang, J.; Guo, L.P. Tracing the Geographical Origins of Dendrobe (Dendrobium spp.) by Near-Infrared Spectroscopy Sensor Combined with Porphyrin and Chemometrics. J. Anal. Methods Chem. 2020, 2020, 8879957. [Google Scholar] [CrossRef]
- Yu, F.Y.; Ma, J.F.; Qi, Y.; Song, H.; Tan, G.L.; Huang, F.R.; Yang, M.X. Geographical Traceability of Clinacanthus nutans with Near-Infrared Pectroscopy and Chemometrics. Am. J. Anal. Chem. 2022, 13, 63–77. [Google Scholar] [CrossRef]
- Meng, W.J.; Xu, X.N.; Cheng, K.K.; Xu, J.J.; Sheng, P.; Wu, Z.D.; Dong, J.Y. Geographical Origin Discrimination of Oolong Tea (TieGuanYin, Camellia sinensis (L.) O. Kuntze) Using Proton Nuclear Magnetic Resonance Spectroscopy and Near-Infrared Spectroscopy. Food Anal. Methods 2017, 10, 3508–3522. [Google Scholar] [CrossRef]
- Li, G.F.; Yin, Q.B.; Zhang, L.; Kang, M.; Fu, H.Y.; Cai, C.B.; Xu, L. Fine classification and untargeted detection of multiple adulterants of Gastrodia elata BI. (GE) by near-infrared spectroscopy coupled with chemometrics. Anal. Methods 2017, 9, 1897–1904. [Google Scholar] [CrossRef]
- Lin, Z.D.; Wang, Y.B.; Wang, R.J.; Wang, L.S.; Lu, C.P.; Zhang, Z.Y.; Song, L.T.; Liu, Y. Improvements of the vis-nirs model in the prediction of soil organic matter content using spectral pretreatments, sample selection, and wavelength optimization. J. Appl. Spectrosc. 2017, 84, 529–534. [Google Scholar] [CrossRef]
- Pennington, A.M.; Okonmah, A.I.; Munoz, D.T.; Tsilomelekis, G.; Celik, F.E. Changes in Polymorph Composition in P25-TiO2 during Pretreatment Analyzed by Differential Diffuse Reflectance Spectral Analysis. J. Phys. Chem. C 2018, 122, 5093–5104. [Google Scholar] [CrossRef]
- Sun, X.D.; Subedi, P.; Walker, R.; Walsh, K.B. NIRS prediction of dry matter content of single olive fruit with consideration of variable sorting for normalisation pre-treatment. Postharvest. Biol. Tec. 2020, 163, 111140. [Google Scholar] [CrossRef]
- Liu, Y.; Liu, Y.L.; Chen, Y.Y.; Zhang, Y.; Shi, T.Z.; Wang, J.J.; Hong, Y.S.; Fei, T.; Zhang, Y. The Influence of Spectral Pretreatment on the Selection of Representative Calibration Samples for Soil Organic Matter Estimation Using Vis-NIR Reflectance Spectroscopy. Remote Sens. 2019, 11, 450. [Google Scholar] [CrossRef] [Green Version]
- Romo-Cárdenas, G.; Avilés-Rodríguez, G.J.; Sánchez-López, J.D.D.; Cosío-León, M.; Luque, P.A.; Gómez-Gutiérrez, C.M.; Nieto-Hipólito, J.I.; Vázquez-Briseño, M.; Navarro-Cotaa, C.X. nNyquist-Shannon theorem application for Savitzky-Golay smoothing window size parameter determination in bio-optical signals. Results Phys. 2018, 11, 17–22. [Google Scholar] [CrossRef]
- Roger, J.M.; Biancolillo, A.; Marini, F. Sequential preprocessing through ORThogonalization (SPORT) and its application to near infrared spectroscopy. Chemom. Intell. Lab. 2020, 199, 103975. [Google Scholar] [CrossRef]
- Chen, H.Z.; Liu, X.K.; Chen, A.; Cai, K.; Lin, B. Parametric-scaling optimization of pretreatment methods for the determination of trace/quasi-trace elements based on near infrared spectroscopy. Spectrochim. Acta A 2020, 229, 117959. [Google Scholar] [CrossRef] [PubMed]
- Hiromi, H.K.; Guillermo, P.H.; Yuko, N.K.; Mutsuki, K.; Hironori, O.; Tomoko, C.; Takeda, S.; Okada, T. Improved transduction of canine X-linked muscular dystrophy with rAAV9-microdystrophin via multipotent mesenchymal stromal cell pretreatment. Mol. Ther.-Meth. Clin. D. 2021, 20, 133–141. [Google Scholar]
- Zhu, M.T.; Long, Y.; Chen, Y.; Huang, Y.S.; Tang, L.J.; Gan, B.; Yu, Q.; Xie, J.H. Fast determination of lipid and protein content in green coffee beans from different origins using NIR spectroscopy and chemometrics. J. Food Compos. Anal. 2021, 102, 104055. [Google Scholar] [CrossRef]
- Zhang, Y.H.; Zhao, W.J.; Shi, J.T. Pretreatment of aircraft spectrum in visible and near infared band based on wavelet transform. In Proceedings of the 2018 3rd International Conference on Mechanical, Control and Computer Engineering (ICMCCE), Huhhot, China, 14–16 September 2018; pp. 368–373. [Google Scholar]
- Biney, J.K.M.; Blöcher, J.R.; Borůvka, L.; Vašát, R. Does the limited use of orthogonal signal correction pre-treatment approach to improve the prediction accuracy of soil organic carbon need attention? Geoderma 2021, 388, 114945. [Google Scholar] [CrossRef]
- Mas, C.; Rubio, L.; Valverde-Som, L.; Sarabia, L.A.; Ortiz, M.C. Impact of the pretreatment of ATR-FTIR signals on the figures of merit when PLS is used. Chemom. Intell. Lab. 2020, 201, 104006. [Google Scholar] [CrossRef]
- Walach, J.; Filzmoser, P.; Hron, K. Chapter Seven—Data Normalization and Scaling: Consequences for the Analysis in Omics Sciences. Compr. Anal. Chem. 2018, 82, 165–196. [Google Scholar]
- Andrić, F.L.J. Towards polypotent natural products: The Derringer desirability approach and nonparametric ranking for mul ticriteria evaluation of essential oils. J. Chemometr. 2018, 32, e3050. [Google Scholar] [CrossRef]
- Gao, X.; Lv, B.; He, K.; Tang, X.Y. Effects of different pretreatment and modeling methods on soil moisture content detected by near infrared spectroscopy. ASABE Annual International Virtual Meeting. Am. Soc. Agric. Biol. Eng. 2021. [Google Scholar] [CrossRef]
- Massaoudi, M.; Refaat, S.S.; Abu-Rub, H.; Chihi, I.; Oueslati, F.S. PLS-CNN-BiLSTM: An End-to-End Algorithm-Based Savitzky–Golay Smoothing and Evolution Strategy for Load Forecasting. Energies 2020, 13, 5464. [Google Scholar] [CrossRef]
- Silalahi, D.D.; Midi, H.; Arasan, J.; Mustafa, M.S.; Caliman, J.P. Robust Generalized Multiplicative Scatter Correction Algorithm on Pretreatment of Near Infrared Spectral Data. Vib. Spectrosc. 2018, 97, 55–65. [Google Scholar] [CrossRef]
- Li, P.; Zhang, X.X.; Zheng, Y.; Yang, F.; Jiang, L.W.; Liu, X.; Ding, S.H.; Shan, Y. A novel method for the nondestructive classification of different-age Citri Reticulatae Pericarpium based on data combination technique. Nutr. Food Sci. 2021, 9, 19. [Google Scholar] [CrossRef]
- Biney, J.K.M.; Borůvka, L.; Agyeman, P.C.; Němeček, K.; Klement, A. Comparison of Field and Laboratory Wet Soil Spectra in the Vis-NIR Range for Soil Organic Carbon Prediction in the Absence of Laboratory Dry Measurement. Remote Sens. 2020, 12, 3082. [Google Scholar] [CrossRef]
- Raju, V.N.G.; Lakshmi, K.P.; Jain, V.M.; Kalidinidi, A.; Padma, V. Study the Influence of Normalization/Transformation process on the Accuracy of Supervised Classification. In Proceedings of the 2020 Third International Conference on Smart Systems and Inventive Technology (ICSSIT), Tirunelveli, India, 20–22 August 2020; pp. 729–735. [Google Scholar]
- Ozaki, Y.; Morisawa, Y. Principles and Characteristics of NIR Spectroscopy. In Near-Infrared Spectroscopy; Springer: Singapore, 2021; pp. 11–35. [Google Scholar] [CrossRef]
- Santana, F.B.; Giuseppe, L.O.; Souza, A.M.; Poppi, R.J. Removing the moisture effect in soil organic matter determination using NIR spectroscopy and PLSR with external parameter orthogonalization. Microchem. J. 2019, 145, 1094–1101. [Google Scholar] [CrossRef]
- Yu, H.; Liu, M.Y.; Du, B.J.; Wang, Z.M.; Hu, L.J.; Zhang, B. Mapping Soil Salinity/Sodicity by using Landsat OLI Imagery and PLSR Algorithm over Semiarid West Jilin Province, China. Sensors 2018, 18, 1048. [Google Scholar] [CrossRef] [Green Version]
- Shirzadifar, A.; Bajwa, S.; Mireei, S.A.; Howatt, K.; Nowatzki, J. Weed species discrimination based on SIMCA analysis of plant canopy spectral data. Biosyst. Eng. 2018, 171, 143–154. [Google Scholar] [CrossRef]
- Cai, S.H.; Li, Q.; Li, S.C.; Yuan, G.; Sun, R.Z. WMFP-Outlier:An Efficient Maximal Frequent-Pattern-Based Outlier Detection Approach for Weighted Data Streams. Inf. Technol. Control. 2019, 48, 505–521. [Google Scholar] [CrossRef]
- Gewers, F.L.; Ferreira, G.R.; Arruda, H.F.D.; Silva, F.N.; Comin, C.H.; Amancio, D.R.; Costa, L.D.F. Principal Component Analysis: A Natural Approach to Data Exploration. ACM Comput. Surv. 2021, 54, 1–34. [Google Scholar] [CrossRef]
- Hu, L.Q.; Yin, C.L.; Ma, S.; Liu, Z.M. Rapid detection of three quality parameters and classification of wine based on Vis-NIR spectroscopy with wavelength selection by ACO and CARS algorithm. Spectrochim. Acta A 2018, 205, 574–581. [Google Scholar] [CrossRef]
- Chai, J.C.; Liang, T.; Lai, K.K.; Zhang, Z.G.; Wang, S.Y. The future natural gas consumption in China: Based on the LMDI-STIRPATPLSR framework and scenario analysis. Energ. Policy 2018, 119, 215–225. [Google Scholar] [CrossRef]
- He, B.L.; Shi, Y.; Wan, Q.; Zhao, X. Prediction of customer attrition of commercial banks based on SVM model. Procedia Comput. Sci. 2014, 31, 423–430. [Google Scholar] [CrossRef] [Green Version]
- Chauhan, V.K.; Dahiya, K.; Sharma, A. Problem formulations and solvers in linear SVM: A review. Artif. Intell. Rev. 2019, 52, 803–855. [Google Scholar] [CrossRef]
- Pomerantsev, A.L.; Rodionova, O.Y. Popular decision rules in SIMCA: Critical review. J. Chemometr. 2020, 34, e3250. [Google Scholar] [CrossRef]
- Lu, X.Q.; Chen, J.; Zhou, X.B. Chemometrics Research Methods; Science Press: Beijing, China, 2012; pp. 83–100. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Pretreatment | RMSE | R2 |
|---|---|---|
| Raw data | 0.015651 | 0.995791 |
| S-G smoothing | 0.015648 | 0.995794 |
| Area normalization | 0.002146 | 0.994077 |
| First derivative | 0.003484 | 0.996229 |
| Second derivative | 0.003019 | 0.965649 |
| Baseline correction | 0.002928 | 0.989924 |
| SNV | 0.001438 | 0.997970 |
| MSC | 0.001812 | 0.997458 |
| Mean centering | 0.016034 | 0.977945 |
| OSC | 0.005945 | 0.997702 |
| First derivative + SNV | 0.002411 | 0.996878 |
| Second derivative + SNV | 0.003043 | 0.997842 |
| S-G Smoothing + SNV | 0.014972 | 0.995860 |
| Detrending + SNV | 0.005477 | 0.978463 |
| SNV + detrending | 0.001562 | 0.997657 |
| SNV + First derivative | 0.001529 | 0.997281 |
| SNV + Second derivative | 0.001617 | 0.986457 |
| SNV + S-G smoothing | 0.001498 | 0.997923 |
| SNV + First derivative + S-G smoothing | 0.001512 | 0.997346 |
| SVM | Training Set Accuracy | Testing Set Accuracy |
|---|---|---|
| Raw data | 96.90% | 92.96% |
| S-G smoothing | 56.73% | 57.40% |
| Area normalization | 56.73% | 57.40% |
| First derivative | 56.73% | 57.40% |
| Second derivative | 89.86% | 93.36% |
| Baseline correction | 97.27% | 96.90% |
| SNV | 99.73% | 98.40% |
| MSC | 98.96% | 97.90% |
| Mean centering | 96.98% | 95.96% |
| OSC | 77.68% | 91.16% |
| First derivative + SNV | 78.56% | 79.03% |
| Second derivative + SNV | 92.75% | 89.15% |
| S-G smoothing + SNV | 65.97% | 66.78% |
| Detrending+ SNV | 80.38% | 82.46% |
| SNV + Detrending | 98.86% | 98.73% |
| SNV + First derivative | 96.43% | 95.74% |
| SNV + Second derivative | 90.17% | 90.33% |
| SNV + S-G smoothing | 99.65% | 98.21% |
| SNV + First derivative + S-G smoothing | 97.25% | 98.57% |
| SIMCA | Training Set Accuracy | Testing Set Accuracy |
|---|---|---|
| Raw data | 85.76% | 54.53% |
| S-G smoothing | 91.20% | 52.81% |
| Area normalization | 65.69% | 67.40% |
| First derivative | 58.95% | 55.68% |
| Second derivative | 71.54% | 60.38% |
| Baseline correction | 77.27% | 76.90% |
| SNV | 100.00% | 100.00% |
| MSC | 100.00% | 100.00% |
| Mean centering | 98.12% | 43.51% |
| OSC | 77.68% | 81.16% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ji, Q.; Li, C.; Fu, X.; Liao, J.; Hong, X.; Yu, X.; Ye, Z.; Zhang, M.; Qiu, Y. Protected Geographical Indication Discrimination of Zhejiang and Non-Zhejiang Ophiopogonis japonicus by Near-Infrared (NIR) Spectroscopy Combined with Chemometrics: The Influence of Different Stoichiometric and Spectrogram Pretreatment Methods. Molecules 2023, 28, 2803. https://doi.org/10.3390/molecules28062803
Ji Q, Li C, Fu X, Liao J, Hong X, Yu X, Ye Z, Zhang M, Qiu Y. Protected Geographical Indication Discrimination of Zhejiang and Non-Zhejiang Ophiopogonis japonicus by Near-Infrared (NIR) Spectroscopy Combined with Chemometrics: The Influence of Different Stoichiometric and Spectrogram Pretreatment Methods. Molecules. 2023; 28(6):2803. https://doi.org/10.3390/molecules28062803
Chicago/Turabian StyleJi, Qingge, Chaofeng Li, Xianshu Fu, Jinyan Liao, Xuezhen Hong, Xiaoping Yu, Zihong Ye, Mingzhou Zhang, and Yulou Qiu. 2023. "Protected Geographical Indication Discrimination of Zhejiang and Non-Zhejiang Ophiopogonis japonicus by Near-Infrared (NIR) Spectroscopy Combined with Chemometrics: The Influence of Different Stoichiometric and Spectrogram Pretreatment Methods" Molecules 28, no. 6: 2803. https://doi.org/10.3390/molecules28062803