Joint Identification of Genetic Variants for Physical Activity in Korean Population



Abstract
:1. Introduction
2. Results and Discussion
2.1. Results
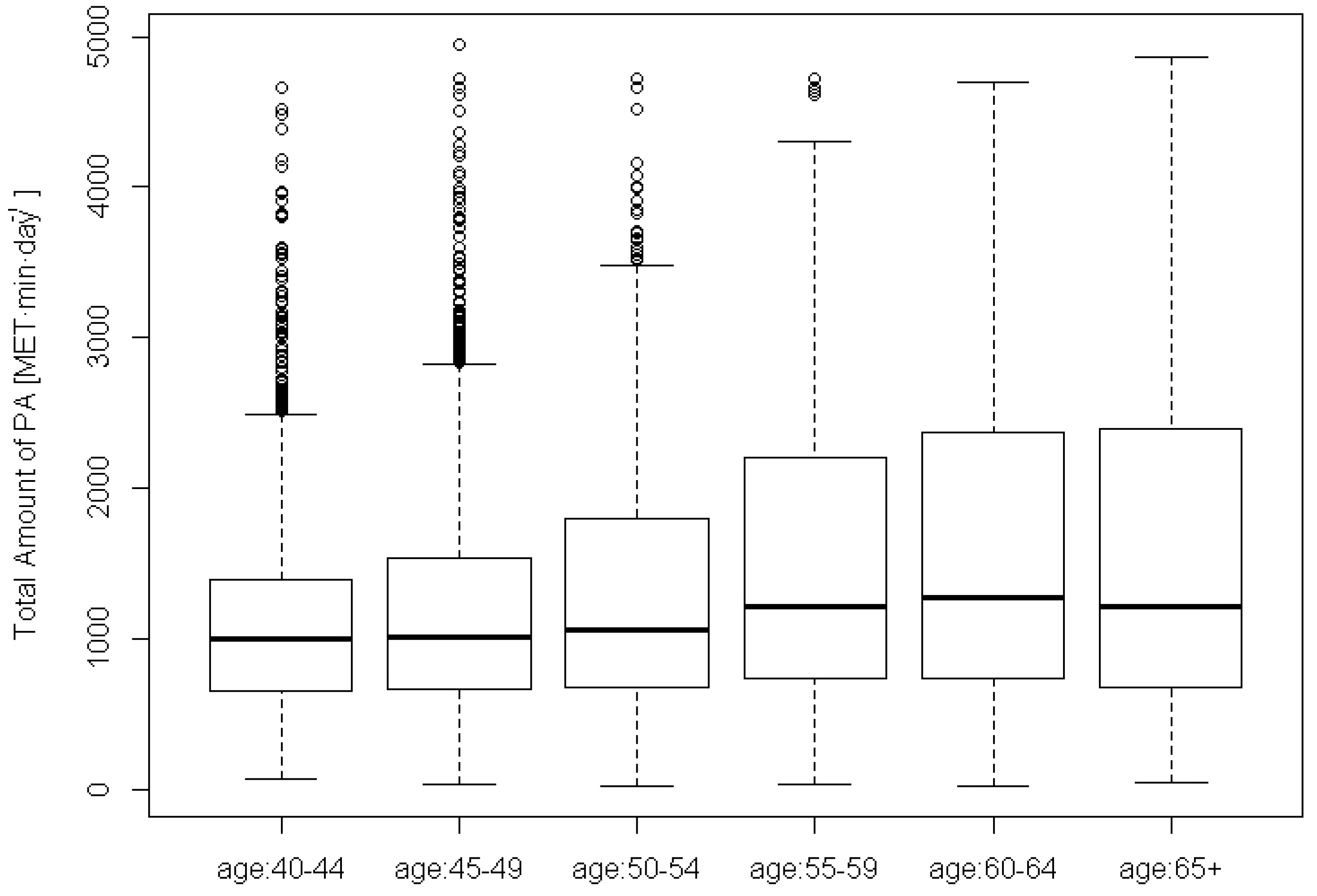
2.1.1. Physical Activity Levels

2.1.2. Individual Single Nucleotide Polymorphism (SNP)-Based Association Analysis


{kind=link}
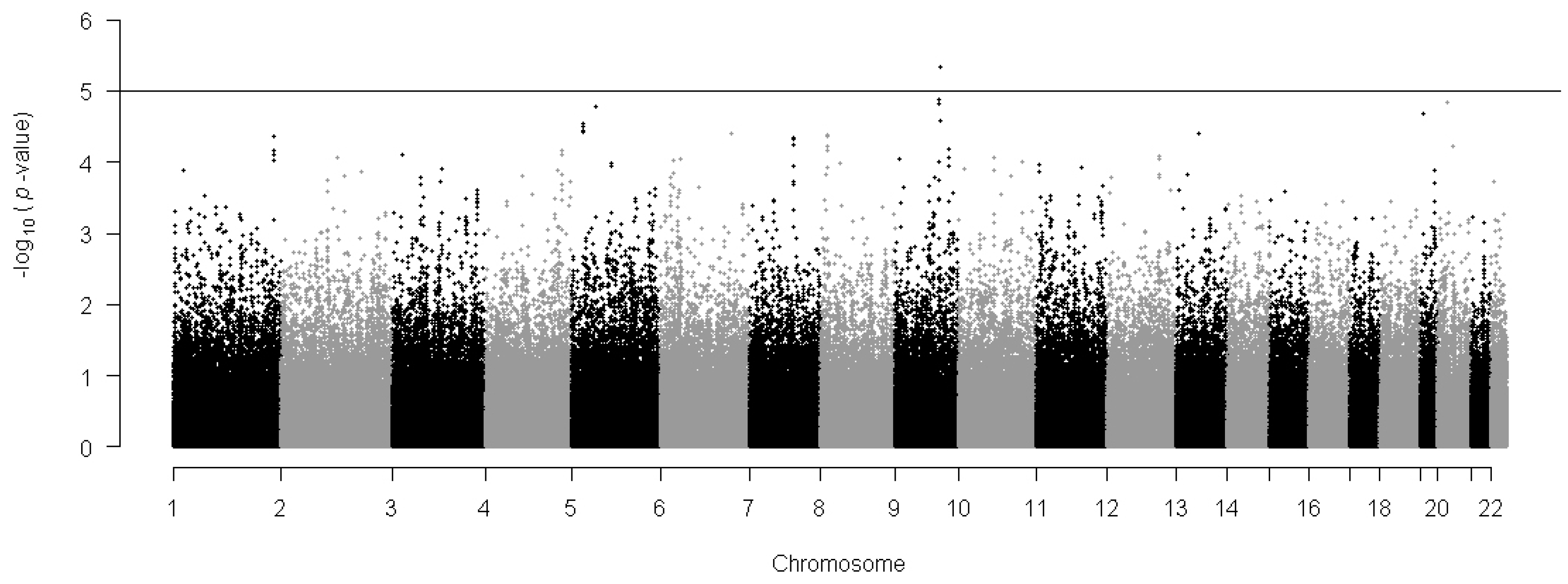{kind=link}
{kind=link}
| rs Number | Gene Symbol | Location of SNP | Cytoband | Minor Allele | MAF a | BETA b | p-Value c |
|---|---|---|---|---|---|---|---|
| rs7023003 | RN7SK, SLC44A1 | intergenic | 9q31.1d | G | 0.2522 | 65.58 | 4.67 × 10−5 |
| rs11791649 | intergenic | 9q31.1b | A | 0.0681 | 107.6 | 1.30 × 10−5 | |
| rs6074898 | MACROD2 | intronic | 20p12.1c | C | 0.0598 | 113.9 | 1.42 × 10−5 |
| rs17228531 | intergenic | 9q31.1b | A | 0.0676 | 107.1 | 1.49 × 10−5 | |
| rs10057067 | ITGA1 | intronic | 5q11.2b | G | 0.4550 | −53.42 | 1.67 × 10−5 |
| rs12462609 | CACNA1A | intronic | 19p13.13b | A | 0.1120 | −83.29 | 2.04 × 10−5 |
| rs7020422 | RN7SK, SLC44A1 | intergenic | 9q31.1d | A | 0.2350 | 61.84 | 2.59 × 10−5 |
| rs11952141 | intergenic | 5p15.1a | C | 0.1833 | 67.73 | 2.92 × 10−5 | |
| rs6867384 | intergenic | 5p15.1a | G | 0.1838 | 67.28 | 3.18 × 10−5 | |
| rs6891956 | intergenic | 5p15.1a | T | 0.1839 | 66.67 | 3.66 × 10−5 | |
| rs6880596 | intergenic | 5p15.1a | A | 0.1767 | 67.66 | 3.78 × 10−5 | |
| rs17069951 | CITED2 | intergenic | 6q24.1b | T | 0.0106 | 246.8 | 3.91 × 10−5 |
| rs10507652 | TDRD3 | intergenic | 13q21.2b | T | 0.0536 | −113.1 | 3.95 × 10−5 |
| rs11781985 | MFHAS1, CLDN23 | intergenic | 8p23.1d | C | 0.0632 | 105.8 | 4.23 × 10−5 |
| rs940031 | CLDN23 | intergenic | 8p23.1d | T | 0.0822 | 92.64 | 4.31 × 10−5 |
| rs11586310 | IRF2BP2 | intergenic | 1q42.3a | G | 0.0625 | −104.3 | 4.38 × 10−5 |
| rs2519580 | TFPI2 | intergenic | 7q21.3a | T | 0.1466 | −71.32 | 4.62 × 10−5 |
| rs2519573 | TFPI2 | intergenic | 7q21.3a | T | 0.1469 | −71.19 | 4.69 × 10−5 |
| rs2724079 | TFPI2 | intergenic | 7q21.3a | A | 0.1475 | −70.25 | 5.77 × 10−5 |
| rs11783707 | MFHAS1,CLDN23 | intergenic | 8p23.1d | T | 0.0627 | 103.9 | 6.10 × 10−5 |
| rs2093145 | CST9 | intergenic | 20p11.21b | A | 0.2963 | −54.71 | 6.10 × 10−5 |
| rs1888286 | ASTN2 | intronic | 9q33.1b | G | 0.3201 | 53.33 | 6.51 × 10−5 |
| rs11587639 | IRF2BP2 | intergenic | 1q42.3a | C | 0.0608 | −103.2 | 6.72 × 10−5 |
| rs11780486 | MFHAS1, CLDN23 | intergenic | 8p23.1d | C | 0.0625 | 103.4 | 6.74 × 10−5 |
| rs337999 | GALNT17 | intronic | 4q34.1b | G | 0.2463 | 57.03 | 6.83 × 10−5 |
| rs2987460 | IRF2BP2 | intergenic | 1q42.3a | T | 0.0727 | −94.17 | 7.74 × 10−5 |
| rs337997 | GALNT17 | intronic | 4q34.1b | T | 0.2458 | 56.61 | 7.82 × 10−5 |
| rs853334 | FGD5, C3ORF20 | intergenic | 3p24.3e | A | 0.4373 | −49.31 | 7.92 × 10−5 |
| rs11111767 | NT5DC3 | intronic | 12q23.3a | A | 0.3923 | 49.77 | 8.12 × 10−5 |
| rs7083122 | RHOBTB1 | intronic | 10q21.2a | A | 0.1486 | 68.83 | 8.67 × 10−5 |
| rs1928980 | ASTN2 | intronic | 9q33.1b | A | 0.3152 | 52.4 | 8.76 × 10−5 |
| rs2421930 | DDX18 | intergenic | 2q14.1d | G | 0.0290 | 147 | 8.77 × 10−5 |
| rs1928984 | ASTN2 | intronic | 9q33.1b | C | 0.3157 | 52.33 | 8.81 × 10−5 |
| rs3751204 | NT5DC3 | utr-variant-3-prime | 12q23.3a | T | 0.3783 | 49.85 | 8.86 × 10−5 |
| rs10124001 | JAK2, RCL1, MIR101-2 | intergenic | 9p24.1c | A | 0.1146 | −76.5 | 9.19 × 10−5 |
| rs1265074 | CCHCR1 | intronic | 6p21.33a | A | 0.3225 | −51.96 | 9.23 × 10−5 |
| rs2493869 | CDKAL1 | intronic | 6p22.3b | A | 0.3373 | −51.44 | 9.39 × 10−5 |
| rs10495350 | IRF2BP2 | intergenic | 1q42.3a | T | 0.0613 | −100.4 | 9.45 × 10−5 |
| rs2446484 | CDKAL1 | intronic | 6p22.3b | G | 0.3213 | −51.99 | 9.66 × 10−5 |
| rs10989864 | intergenic | 9q31.1b | A | 0.0428 | 117.6 | 9.94 × 10−5 | |
| rs4344422 | ADRA2A | intergenic | 10q25.2b | G | 0.0910 | 83.98 | 1.00 × 10−4 |
2.1.3. Multiple SNP-Based Association Analysis
| rs Number | Gene Symbol | Location of SNP | Cytoband | Minor Allele | MAF a | Effect Size (4000) b | BSS (4000) c | p-Value d (4000) | ||
|---|---|---|---|---|---|---|---|---|---|---|
| rs10849033 | CCND2, C12ORF5 | intronic | 12p13.32a | C | 0.4886 | 19.799 | 99.7 | 0.00003 | ||
| rs4252821 | CCNI | Downstream (500 bp) Upstream (5000 bp) | 4q21.1b | G | 0.1013 | 15.281 | 96.9 | 0.00003 | ||
| rs853334 | FGD5, C3ORF20 | intronic | 3p24.3e | A | 0.4373 | −15.166 | 98.3 | 0.00009 | ||
| rs17099857 | ARHGAP26 | intergenic | 5q31.3e | C | 0.0763 | 16.107 | 99.2 | 0.00010 | ||
| rs4906747 | ATP10A | intergenic | 15q12a | G | 0.0640 | 14.613 | 97.4 | 0.00010 | ||
| rs6030844 | RNU6-1, RNU6-2 | intergenic | 20q13.11b | C | 0.1729 | 14.352 | 97.6 | 0.00010 | ||
| rs10978130 | PTPRD | intergenic | 9p23d | C | 0.1523 | 23.022 | 99.9 | 0.00013 | ||
| rs10507652 | TDRD3 | intergenic | 13q21.2b | T | 0.0536 | −19.779 | 99.9 | 0.00015 | ||
| rs7649230 | HES1 | intergenic | 3q29c | C | 0.3382 | 12.115 | 96.4 | 0.00017 | ||
| rs13106655 | TMEM156 | nonsynonymous | 4p14c | G | 0.2674 | 13.811 | 98.2 | 0.00018 | ||
| rs16953182 | UNC13C | intronic | 15q21.3b | G | 0.0165 | 17.941 | 99.2 | 0.00021 | ||
| rs7976955 | VWF, TMEM16B | utr-variant-3-prime | 12p13.31e | T | 0.0230 | 12.674 | 95.5 | 0.00025 | ||
| rs2586038 | MRPS23 | intergenic | 17q22d | G | 0.3314 | −14.089 | 97.1 | 0.00026 | ||
| rs9833833 | UBE2E1 | intergenic | 3p24.3a | T | 0.3393 | 16.227 | 99.3 | 0.00031 | ||
| rs41455146 | ADAM12 | intergenic | 10q26.2a | G | 0.0726 | −12.430 | 96.5 | 0.00033 | ||
| rs2314612 | GPR149, MME | intronic | 3q25.2c | A | 0.4665 | −20.284 | 99.6 | 0.00033 | ||
| rs10513868 | DLGAP1, FLJ35776 | intronic | 18p11.31e | G | 0.2335 | 13.314 | 97.6 | 0.00035 | ||
| rs4131468 | MBD2, DCC, SNORA30, SNORA37 | intergenic | 18q21.2c | T | 0.4954 | −15.354 | 98.8 | 0.00036 | ||
| rs2851651 | intergenic | 11q22.1a | T | 0.2047 | −15.510 | 99 | 0.00039 | |||
| rs2728504 | ZNF521 | intergenic | 18q11.2d | T | 0.2713 | −19.259 | 96.9 | 0.00042 | ||
| rs17339892 | MCTP1 | intergenic | 5q15c | T | 0.1076 | 12.451 | 96.6 | 0.00051 | ||
| rs7997236 | FAM155A | intergenic | 13q33.3a | A | 0.0498 | −20.321 | 99.7 | 0.00054 | ||
| rs1387243 | FAR2, RN5S1, CCDC91 | intergenic | 12p11.22b | C | 0.1766 | 12.015 | 98.4 | 0.00056 | ||
| rs707586 | AJAP1 | intergenic | 1p36.31b | G | 0.2672 | −18.571 | 99.7 | 0.00064 | ||
| rs4978521 | ZFP37, SLC46A2 | intergenic | 9q32b | T | 0.0886 | −19.155 | 96.7 | 0.00066 | ||
| rs2067730 | NRXN3 | utr-variant-3-prime | 14q31.1a | C | 0.0308 | −11.340 | 96.2 | 0.00072 | ||
| rs16967978 | LOC100132540, LOC339047, XYLT1 | intronic | 16p12.3c | A | 0.0427 | 13.550 | 95.2 | 0.00073 | ||
| rs41351947 | EIF2B3 | intergenic | 1p34.1d | C | 0.0291 | −15.446 | 99.2 | 0.00073 | ||
| rs931701 | BOC | intronic | 3q13.2b | A | 0.3798 | −15.920 | 98.9 | 0.00077 | ||
| rs729239 | RNU6-1, RNU6-2 | intronic | 4q21.1b | T | 0.0194 | −15.186 | 98.4 | 0.00080 | ||
| rs10020466 | RN5S1 | intronic | 4q34.3d | C | 0.0739 | −13.149 | 98.4 | 0.00082 | ||
| rs1536053 | C13ORF16 | intronic | 13q34b | T | 0.0393 | −15.016 | 96.8 | 0.00083 | ||
| rs17553316 | RGNEF | intergenic | 5q13.2c | G | 0.0192 | 12.629 | 96.7 | 0.00094 | ||
| rs445942 | C7ORF10, INHBA | intronic | 7p14.1b | C | 0.1666 | −16.716 | 99 | 0.00099 | ||
| rs17058450 | FAM116A | intergenic | 3p14.3a | T | 0.0742 | −12.336 | 96.1 | 0.00103 | ||
| rs11167061 | FLJ43860 | Upstream (5000 bp) | 8q24.3d | A | 0.2238 | −15.508 | 99.2 | 0.00112 | ||
| rs1453282 | intronic | 7p12.3b | C | 0.3057 | −16.260 | 99.5 | 0.00130 | |||
| rs4864029 | RNU6-1, RNU6-2 | intergenic | 4q28.3b | G | 0.1181 | 17.370 | 99.4 | 0.00134 | ||
| rs4620043 | LIFR | intergenic | 5p13.1c | A | 0.2291 | 11.716 | 95.3 | 0.00153 | ||
| rs2140340 | CSMD1 | intronic | 8p23.2c | T | 0.0826 | 15.130 | 98.4 | 0.00177 | ||
| rs3738178 | MOSC1 | intergenic | 1q41d | A | 0.0966 | 13.128 | 96.3 | 0.00189 | ||
| rs7770227 | intergenic | 6q22.1b | T | 0.0781 | 18.199 | 99.7 | 0.00192 | |||
| rs17730347 | MCTP2 | intronic | 15q26.2a | C | 0.2599 | 13.531 | 96.4 | 0.00194 | ||
| rs11024787 | PTPN5 | intronic | 11p15.1c | A | 0.0300 | −18.894 | 99.9 | 0.00200 | ||
| rs1605987 | EDIL3 | intergenic | 5q14.3b | T | 0.1921 | −14.930 | 98.2 | 0.00204 | ||
| rs3802292 | CSMD1 | intronic | 8p23.2d | T | 0.3660 | −15.587 | 99.8 | 0.00238 | ||
| rs2273635 | KIAA1305 | intronic | 14q12a | T | 0.0956 | 13.632 | 97.8 | 0.00243 | ||
| rs7102454 | CFL1, OVOL1, SNX32 | intronic | 11q13.1d | C | 0.3163 | −13.331 | 96.8 | 0.00299 | ||
| rs2725795 | C15ORF53 | intergenic | 15q14d | G | 0.0710 | 17.092 | 99.2 | 0.00323 | ||
| rs2280732 | PLB1 | intergenic | 2p23.2b | C | 0.2716 | 11.855 | 97.2 | 0.00324 | ||
| rs3025365 | DBH, FAM163B | intergenic | 9q34.2a | C | 0.1761 | 11.904 | 95.1 | 0.00326 | ||
| rs6979515 | NXPH1 | intergenic | 7p21.3d | G | 0.3828 | −18.242 | 99.2 | 0.00364 | ||
| rs12332121 | RPS17P2 | intronic | 5q23.1a | C | 0.1237 | −15.236 | 98.4 | 0.00445 | ||
| rs10046269 | EYA4, TCF21 | intergenic | 6q23.2c | C | 0.0454 | 17.753 | 99.4 | 0.00484 | ||
| rs4921144 | MIR146A, ATP10B | Upstream (5000 bp) | 5q33.3d | A | 0.0454 | −12.473 | 96.4 | 0.00495 | ||
| rs888053 | VIT, STRN | intronic | 2p22.2b | A | 0.2656 | 14.279 | 96.5 | 0.00512 | ||
| rs1079082 | ZNF579, FIZ1 | intronic | 19q13.42c | T | 0.1132 | 13.545 | 96.4 | 0.00589 | ||
| rs4531650 | EGLN3, C14ORF147 | intronic | 14q13.1c | C | 0.3818 | −14.878 | 98.3 | 0.00643 | ||
| rs1799884 | GCK, YKT6 | intergenic | 7p13d | A | 0.1892 | −11.829 | 96.7 | 0.00724 | ||

2.2. Discussion
3. Experimental Section
3.1. Subjects
| Cohort | Sex (n) | Age (Mean ± SD) | ||||
|---|---|---|---|---|---|---|
| Male | Female | Both | Male | Female | Both | |
| Ansung (rural) | 1658 | 2240 | 3898 | 55.92 ± 8.66 | 55.65 ± 8.81 | 55.77 ± 8.75 |
| Ansan (urban) | 2337 | 2219 | 4556 | 48.56 ± 7.44 | 49.60 ± 8.22 | 49.07 ± 7.85 |
| Total | 3995 | 4459 | 8454 | 51.61 ± 7.44 | 52.64 ± 9.04 | 52.16 ± 8.92 |
3.2. Physical Activity Information
3.3. Genotypes
3.4. Statistical Analysis
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Ainsworth, B.E.; Haskell, W.L.; Leon, A.S.; Jacobs, D.R.J.; Montoye, H.J.; Sallis, J.F.; Paffenbarger, R.S.J. Compendium of physical activities: Energy costs of human movement. Med. Sci. Sports Exerc. 1993, 25, 71–80. [Google Scholar] [CrossRef]
- Ainsworth, B.E.; Haskell, W.L.; Whitt, M.C.; Irwin, M.L.; Swartz, A.M.; Strath, S.J.; O’Brien, W.L.; Bassett, D.R.J.; Schmitz, K.H.; Emplaincourt, P.O. Compendium of physical activities: An update of activity codes and MET intensities. Med. Sci. Sports Exerc. 2000, 32, S498–S516. [Google Scholar] [CrossRef]
- Struber, J. Considering physical inactivity in relation to obesity. Int. J. Allied Health Sci. Pract. 2004, 2, 1–7. [Google Scholar]
- Bouchard, C.; Malina, R.; Pérusse, L. Genetics of Fitness and Physical Performance; Human Kinetics: Champaign, IL, USA, 1997; pp. 323–334. [Google Scholar]
- Rankinen, T.; Roth, S.M.; Bray, M.S.; Loos, R.; Pérusse, L.; Wolfarth, B.; Hagberg, J.M.; Bouchard, C. Advances in exercise, fitness, and performance genomics. Med. Sci. Sports Exerc. 2010, 42, 835–846. [Google Scholar]
- Stubbe, J.H.; Boomsma, D.I.; Vink, J.M.; Cornes, B.K.; Martin, N.G.; Skytthe, A.; Kyvik, K.O.; Rose, R.J.; Kujala, U.M.; Kaprio, J. Genetic influences on exercise participation in 37,051 twin pairs from seven countries. PLoS One 2006, 1, e22. [Google Scholar] [CrossRef] [Green Version]
- De Moor, M.H.; Liu, Y.J.; Boomsma, D.I.; Li, J.; Hamilton, J.J.; Hottenga, J.J.; Levy, S.; Liu, X.G.; Pei, Y.F.; Posthuma, D. Genome-wide association study of exercise behavior in dutch and american adults. Med. Sci. Sports Exerc. 2009, 41, 1887–1895. [Google Scholar] [CrossRef]
- Kim, J.; Oh, S.; Min, H.; Kim, Y.; Park, T. Practical issues in genome-wide association studies for physical activity. Ann. N. Y. Acad. Sci. 2011, 1229, 38–44. [Google Scholar] [CrossRef]
- Manolio, T.A.; Collins, F.S.; Cox, N.J.; Goldstein, D.B.; Hindorff, L.A.; Hunter, D.J.; McCarthy, M.I.; Ramos, E.M.; Cardon, L.R.; Chakravarti, A. Finding the missing heritability of complex diseases. Nature 2009, 461, 747–753. [Google Scholar] [CrossRef]
- Visscher, P.M. Sizing up human height variation. Nat. Genet. 2008, 40, 489–490. [Google Scholar] [CrossRef]
- Cho, S.; Kim, K.; Kim, Y.J.; Lee, J.K.; Cho, Y.S.; Lee, J.Y.; Han, B.G.; Kim, H.; Ott, J.; Park, T. Joint identification of multiple genetic variants via elastic-net variable selection in a genome-wide association analysis. Ann. Hum. Genet. 2010, 74, 416–428. [Google Scholar] [CrossRef]
- Shi, W.; Wahba, G.; Wright, S.; Lee, K.; Klein, R.; Klein, B. Lasso-pattern search algorithm with application ophthalmology and genomic data. Stat. Interface 2007, 1, 137. [Google Scholar]
- Wu, T.; Chen, Y.; Hastie, T.; Sobel, E.; Lange, K. Genome-wide association analysis by lasso penalized logistic regression. Bioinformatics 2009, 25, 714. [Google Scholar] [CrossRef]
- Tibshirani, R. Regression shrinkage and selection via the lasso. J. R. Stat. Soc. B 1996, 58, 267–288. [Google Scholar]
- Zou, H.; Hastie, T. Regularization and variable selection via the elastic net. J. R. Stat. Soc. B 2005, 67, 201–210. [Google Scholar]
- Brambillasca, S.; Altkrueger, A.; Colombo, S.F.; Friederich, A.; Eickelmann, P.; Mark, M.; Borgese, N.; Solimena, M. CDK5 regulatory subunit-associated protein 1-like 1 (CDKAL1) is a tail-floated protein in the endoplasmic reticulum (ER) of insulinoma cells. J. Biol. Chem. 2012, 287, 41808–41819. [Google Scholar] [CrossRef]
- Hu, C.; Zhang, R.; Wang, C.; Wang, J.; Ma, X.; Lu, J.; Qin, W.; Hou, X.; Wang, C.; Bao, Y. PPARG, KCNJ11, CDKAL1, CDKN2A-CDKN2B, IDE-KIF11-HHEX, IGF2BP2 and SLC30A8 are associated with type 2 diabetes in a Chinese population. PLoS One 2009, 4, e7643. [Google Scholar]
- Hibi, K.; Goto, T.; Kitamura, Y.H.; Yokomizo, K.; Sakuraba, K.; Shirahata, A.; Mizukami, H.; Saito, M.; Ishibashi, K.; Kigawa, G. Methylation of TFPI2 gene is frequently detected in advanced well-differentiated colorectal cancer. Anticancer Res. 2010, 30, 1205–1207. [Google Scholar]
- Hibi, K.; Goto, T.; Shirahata, A.; Saito, M.; Kigawa, G.; Nemoto, H.; Sanada, Y. Detection of TFPI2 methylation in the serum of colorectal cancer patients. Cancer Lett. 2011, 311, 96–100. [Google Scholar] [CrossRef]
- Tiala, I.; Suomela, S.; Huuhtanen, J.; Wakkinen, J.; Hölttä-Vuori, M.; Kainu, K.; Ranta, S.; Turpeinen, U.; Hämäläinen, E.; Jiao, H. The CCHCR1 (HCR) gene is relevant for skin steroidogenesis and downregulated in cultured psoriatic keratinocytes. J. Mol. Med. 2007, 85, 589–601. [Google Scholar] [CrossRef]
- Asumalahti, K.L.; Veal, C.; Laitinen, T.; Suomela, S.; Allen, M.; Elomaa, O.; Moser, M.; de Cid, R.; Ripatti, S.; Vorechovsky, I. Coding haplotype analysis supports HCR as the putative susceptibility gene for psoriasis at the MHC PSORS1 locus. Hum. Mol. Genet. 2002, 11, 589–597. [Google Scholar] [CrossRef]
- Suomela, S.; Elomaa, O.; Asumalahti, K.; Kariniemi, A.L.; Karvonen, S.L.; Peltonen, J.; Kere, J.; Saarialho-Kere, U. HCR, a candidate gene for psoriasis, is expressed differently in psoriasis and other hyper-proliferative skin disorders and is down-regulated by interferon-γ in keratinocytes. J. Investig. Dermatol. 2003, 121, 1360–1364. [Google Scholar] [CrossRef]
- Ramos, S.; Khademi, F.; Somesh, B.P.; Rivero, F. Genomic organization and expression profile of the small GTPases of the RhoBTB family in human and mouse. Gene 2002, 298, 147–157. [Google Scholar] [CrossRef]
- Wang, K.S.; Liu, X.F.; Aragam, N. A genome-wide meta-analysis identifies novel loci associated with schizophrenia and bipolar disorder. Schizophr. Res. 2010, 124, 192–199. [Google Scholar] [CrossRef]
- Jacobsen, J.; Wewer, U.M. Targeting ADAM12 in human disease: Head, body or tail? Curr. Pharm. Des. 2009, 15, 2300–2310. [Google Scholar] [CrossRef]
- Nakamura, T.; Sanokawa, R.; Sasaki, Y.F.; Ayusawa, D.; Oishi, M.; Mori, N. Cyclin I: A new cyclin encoded by a gene isolated from human brain. Exp. Cell Res. 1995, 221, 534–542. [Google Scholar] [CrossRef]
- Yang, C.H.; Huang, C.C.; Hsu, K.S. A critical role for protein tyrosine phosphatase nonreceptor type 5 in determining individual susceptibility to develop stress-related cognitive and morphological changes. J. Neurosci. 2012, 32, 7550–7562. [Google Scholar] [CrossRef]
- Bille, D.S.; Banasik, K.; Justesen, J.M.; Sandholt, C.H.; Sandbæk, A.; Lauritzen, T.; Jørgensen, T.; Witte, D.R.; Holm, J.C.; Hansen, T. Implications of central obesity-related variants in LYPLAL1, NRXN3, MSRA, and TFAP2B on quantitative metabolic traits in adult Danes. PLoS One 2011, 6, e20640. [Google Scholar] [CrossRef]
- Hishimoto, A.; Liu, Q.R.; Drgon, T.; Pletnikova, O.; Walther, D.; Zhu, X.G.; Troncoso, J.C.; Uhl, G.R. Neurexin 3 polymorphisms are associated with alcohol dependence and altered expression of specific isoforms. Hum. Mol. Genet. 2007, 16, 2880–2891. [Google Scholar] [CrossRef]
- Novak, G.; Boukhadra, J.; Shaikh, S.A.; Kennedy, J.L.; le Foll, B. Association of a polymorphism in the NRXN3 gene with the degree of smoking in schizophrenia: A preliminary study. World J. Biol. Psychiatry 2009, 10, 929–935. [Google Scholar] [CrossRef]
- Tattersall, R.B. Mild familial diabetes with dominant inheritance. Q. J. Med. 1974, 43, 339–357. [Google Scholar]
- Tattersall, R.B.; Fajans, S.S. A difference between the inheritance of classical juvenile-onset and maturity-onset type diabetes of young people. Diabetes 1975, 24, 44–53. [Google Scholar] [CrossRef]
- Frayling, T.M.; Evans, J.C.; Bulman, M.P.; Pearson, E.; Allen, L.; Owen, K.; Bingham, C.; Hannemann, M.; Shepherd, M.; Ellard, S. β-cell genes and diabetes: Molecular and clinical characterization of mutations in transcription factors. Diabetes 2001, 50, S94–S100. [Google Scholar] [CrossRef]
- Ledermann, H.M. Maturity-onset diabetes of the young (MODY) at least ten times more common in Europe than previously assumed? Diabetologia 1995, 38, 1482. [Google Scholar] [CrossRef]
- Tremblay, C.S.; Huang, F.F.; Habi, O.; Huard, C.C.; Godin, C.; Lévesque, G.; Carreau, M. HES1 is a novel interactor of the Fanconi anemia core complex. Blood 2008, 112, 2062–2070. [Google Scholar] [CrossRef]
- Cho, Y.S.; Go, M.J.; Kim, Y.J.; Heo, J.Y.; Oh, J.H.; Ban, H.J.; Yoon, D.; Lee, M.H.; Kim, D.J.; Park, M. A large-scale genome-wide association study of Asian populations uncovers genetic factors influencing eight quantitative traits. Nat. Genet. 2009, 41, 527–534. [Google Scholar] [CrossRef]
- Haskell, W.L.; Lee, I.M.; Pate, R.R.; Powell, K.E.; Blair, S.N.; Franklin, B.A.; Macera, C.A.; Heath, G.W.; Thompson, P.D.; Bauman, A. Physical activity and public health: Updated recommendation for adults from the american college of sports medicine and the american heart association. Med. Sci. Sports Exerc. 2007, 39, 1423–1434. [Google Scholar] [CrossRef]
- Scheet, P.; Stephens, M. A fast and flexible statistical model for large-scale population genotype data: Applications to inferring missing genotypes and haplotypic phase. Am. J. Hum. Genet. 2006, 78, 629–644. [Google Scholar] [CrossRef]
- Hosack, D.A.; Dennis, G.J.; Sherman, B.T.; Lane, H.C.; Lempicki, R.A. Identifying biological themes within lists of genes with EASE. Genome Biol. 2003, 4, R70. [Google Scholar] [CrossRef]
- Shaun Purcell. Whole Genome Association Analysis Toolset. Available online: http://pngu.mgh.harvard.edu/purcell/plink/ (accessed on 10 October 2011).
- The R Project for Statistical Computing. Available online: http://www.r-project.org/ (accessed on 15 October 2005).
- Manson, J.E.; Hu, F.B.; Rich-Edwards, J.W.; Colditz, G.A.; Stampfer, M.J.; Willett, W.C.; Speizer, F.E.; Hennekens, C.H. A prospective study of walking as compared with vigorous exercise in the prevention of coronary heart disease in women. N. Engl. J. Med. 1999, 341, 650–658. [Google Scholar] [CrossRef]
- Manson, J.E.; Greenland, P.; LaCroix, A.Z.; Stefanick, M.L.; Mouton, C.P.; Oberman, A.; Perri, M.G.; Sheps, D.S.; Pettinger, M.B.; Siscovick, D.S. Walking compared with vigorous exercise for the prevention of cardiovascular events in women. N. Engl. J. Med. 2002, 347, 716–725. [Google Scholar] [CrossRef]
- US Department of Health & Human Services. Physical Activity and Health: A Report of the Surgeon General; National Center for Chronic Disease Prevention and Health Promotion: Atlanta, GA, USA, 1996; pp. 135–140. [Google Scholar]
© 2014 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/3.0/).
Share and Cite
Kim, J.; Kim, J.; Min, H.; Oh, S.; Kim, Y.; Lee, A.H.; Park, T. Joint Identification of Genetic Variants for Physical Activity in Korean Population. Int. J. Mol. Sci. 2014, 15, 12407-12421. https://doi.org/10.3390/ijms150712407
Kim J, Kim J, Min H, Oh S, Kim Y, Lee AH, Park T. Joint Identification of Genetic Variants for Physical Activity in Korean Population. International Journal of Molecular Sciences. 2014; 15(7):12407-12421. https://doi.org/10.3390/ijms150712407
Chicago/Turabian StyleKim, Jayoun, Jaehee Kim, Haesook Min, Sohee Oh, Yeonjung Kim, Andy H. Lee, and Taesung Park. 2014. "Joint Identification of Genetic Variants for Physical Activity in Korean Population" International Journal of Molecular Sciences 15, no. 7: 12407-12421. https://doi.org/10.3390/ijms150712407
APA StyleKim, J., Kim, J., Min, H., Oh, S., Kim, Y., Lee, A. H., & Park, T. (2014). Joint Identification of Genetic Variants for Physical Activity in Korean Population. International Journal of Molecular Sciences, 15(7), 12407-12421. https://doi.org/10.3390/ijms150712407