Gene–Environment Interactions in Preventive Medicine: Current Status and Expectations for the Future


Abstract
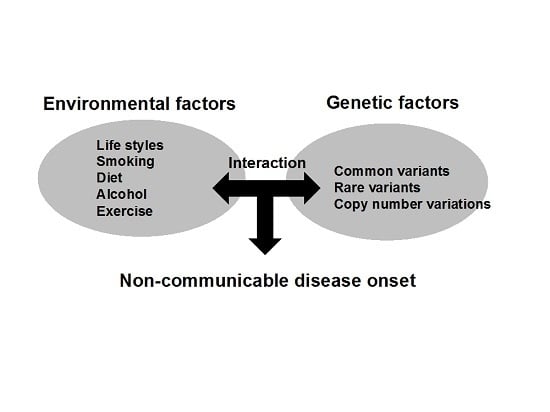
:
{kind=link}
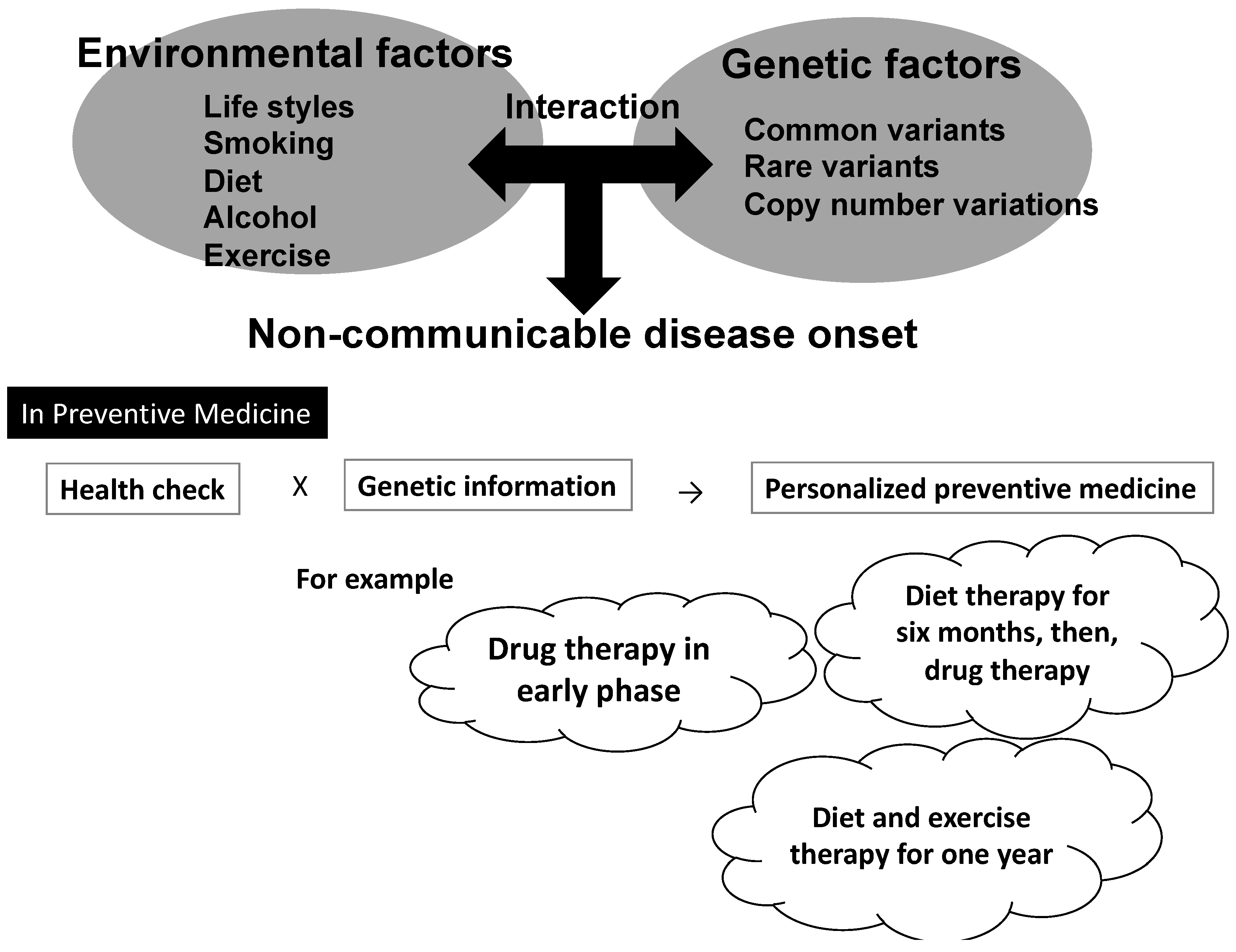{kind=link}
1. Introduction
2. Current Concepts and Study Design for Investigating Gene–Environmental Interactions
2.1. Current Concepts
2.2. Study Designs for Investigating Gene–Environmental Interactions
3. Significance of Gene–Environmental Interactions in Preventive Medicine
3.1. Applying Gene–Environmental Interaction Analyses to Preventive Medicine: Expectations and Limitations
3.2. Gene–Environmental Interactions in Obesity
4. Challenges for Establishing Personalized Preventive Medicine
5. Conclusions
Acknowledgements
Conflicts of Interest
Abbreviations
| BMI | body mass index |
| GWAS | genome-wide association study |
| NCD | non-communicable disease |
| SNP | single nucleotide polymorphism |
References
- Manolio, T.A.; Bailey-Wilson, J.E.; Collins, F.S. Genes, environment and the value of prospective cohort studies. Nat. Rev. Genet. 2006, 7, 812–820. [Google Scholar] [CrossRef] [PubMed]
- Collins, F.S. The case for a US prospective cohort study of genes and environment. Nature 2004, 429, 475–477. [Google Scholar] [CrossRef] [PubMed]
- Manolio, T.A. Genomewide association studies and assessment of the risk of disease. N. Engl. J. Med. 2010, 363, 166–176. [Google Scholar] [PubMed]
- Hamajima, N. The Japan Multi-Institutional Collaborative Cohort Study (J-MICC Study) to detect gene–environment interactions for cancer. Asian Pac. J. Cancer Prev. 2007, 8, 317–323. [Google Scholar] [PubMed]
- Keyes, K.M.; Utz, R.L.; Robinson, W.; Li, G. What is a cohort effect? Comparison of three statistical methods for modeling cohort effects in obesity prevalence in the United States, 1971–2006. Soc. Sci. Med. 2010, 70, 1100–1108. [Google Scholar] [CrossRef] [PubMed]
- Yamagata University Genomic Cohort, C.; Narimatsu, H. Constructing a contemporary gene–environmental cohort: Study design of the Yamagata Molecular Epidemiological Cohort Study. J. Hum. Genet. 2013, 58, 54–56. [Google Scholar]
- Gauderman, W.J. Sample size requirements for matched case-control studies of gene-environment interaction. Stat. Med. 2002, 21, 35–50. [Google Scholar] [CrossRef] [PubMed]
- UK Biobank Home Page. Available online: http://www.ukbiobank.ac.uk/ (accessed on 21 September 2016).
- Barbour, V. UK Biobank: A project in search of a protocol? Lancet 2003, 361, 1734–1738. [Google Scholar] [CrossRef]
- Precision Medicine Initiative Cohort Program. Available online: https://www.nih.gov/precision-medicine-initiative-cohort-program (accessed on 30 September 2016).
- Tohoku Medical Mega Bank. Available online: http://www.megabank.tohoku.ac.jp/english/ (accessed on 4 December 2016).
- Davey Smith, G.; Ebrahim, S.; Lewis, S.; Hansell, A.L.; Palmer, L.J.; Burton, P.R. Genetic epidemiology and public health: Hope, hype, and future prospects. Lancet 2005, 366, 1484–1498. [Google Scholar] [CrossRef]
- Davey Smith, G.; Ebrahim, S. ”Mendelian randomization”: Can genetic epidemiology contribute to understanding environmental determinants of disease? Int. J. Epidemiol. 2003, 32, 1–22. [Google Scholar] [CrossRef]
- Holmes, M.V.; Dale, C.E.; Zuccolo, L.; Silverwood, R.J.; Guo, Y.; Ye, Z.; Prieto-Merino, D.; Dehghan, A.; Trompet, S.; Wong, A.; et al. Association between alcohol and cardiovascular disease: Mendelian randomisation analysis based on individual participant data. BMJ 2014, 349, G4164. [Google Scholar] [CrossRef] [PubMed]
- Brennan, P. Commentary: Mendelian randomization and gene–environment interaction. Int. J. Epidemiol. 2004, 33, 17–21. [Google Scholar] [CrossRef] [PubMed]
- Rudolph, A.; Chang-Claude, J.; Schmidt, M.K. Gene–environment interaction and risk of breast cancer. Br. J. Cancer 2016, 114, 125–133. [Google Scholar] [CrossRef] [PubMed]
- Travis, R.C.; Reeves, G.K.; Green, J.; Bull, D.; Tipper, S.J.; Baker, K.; Beral, V.; Peto, R.; Bell, J.; Zelenika, D.; et al. Gene–environment interactions in 7610 women with breast cancer: Prospective evidence from the Million Women Study. Lancet 2010, 375, 2143–2151. [Google Scholar] [CrossRef]
- Speliotes, E.K.; Willer, C.J.; Berndt, S.I.; Monda, K.L.; Thorleifsson, G.; Jackson, A.U.; Lango Allen, H.; Lindgren, C.M.; Luan, J.; Magi, R.; et al. Association analyses of 249,796 individuals reveal 18 new loci associated with body mass index. Nat. Genet. 2010, 42, 937–948. [Google Scholar] [CrossRef] [PubMed]
- Lu, Y.; Loos, R.J. Obesity genomics: Assessing the transferability of susceptibility loci across diverse populations. Genome Med. 2013, 5, 55. [Google Scholar] [CrossRef] [PubMed]
- Qi, Q.; Chu, A.Y.; Kang, J.H.; Jensen, M.K.; Curhan, G.C.; Pasquale, L.R.; Ridker, P.M.; Hunter, D.J.; Willett, W.C.; Rimm, E.B.; et al. Sugar-sweetened beverages and genetic risk of obesity. N. Engl. J. Med. 2012, 367, 1387–1396. [Google Scholar] [CrossRef] [PubMed]
- Barrio-Lopez, M.T.; Martinez-Gonzalez, M.A.; Fernandez-Montero, A.; Beunza, J.J.; Zazpe, I.; Bes-Rastrollo, M. Prospective study of changes in sugar-sweetened beverage consumption and the incidence of the metabolic syndrome and its components: The SUN cohort. Br. J. Nutr. 2013, 110, 1722–1731. [Google Scholar] [CrossRef] [PubMed]
- Qi, Q.; Chu, A.Y.; Kang, J.H.; Huang, J.; Rose, L.M.; Jensen, M.K.; Liang, L.; Curhan, G.C.; Pasquale, L.R.; Wiggs, J.L.; et al. Fried food consumption, genetic risk, and body mass index: Gene-diet interaction analysis in three US cohort studies. BMJ 2014, 348, G1610. [Google Scholar] [CrossRef] [PubMed]
- Qi, Q.; Li, Y.; Chomistek, A.K.; Kang, J.H.; Curhan, G.C.; Pasquale, L.R.; Willett, W.C.; Rimm, E.B.; Hu, F.B.; Qi, L. Television watching, leisure time physical activity, and the genetic predisposition in relation to body mass index in women and men. Circulation 2012, 126, 1821–1827. [Google Scholar] [CrossRef] [PubMed]
- Li, S.; Zhao, J.H.; Luan, J.; Ekelund, U.; Luben, R.N.; Khaw, K.T.; Wareham, N.J.; Loos, R.J. Physical activity attenuates the genetic predisposition to obesity in 20,000 men and women from EPIC-Norfolk prospective population study. PLoS Med. 2010, 7, e1000332. [Google Scholar] [CrossRef] [PubMed]
- Nakamura, S.; Narimatsu, H.; Sato, H.; Sho, R.; Otani, K.; Kawasaki, R.; Karasawa, S.; Daimon, M.; Yamashita, H.; Kubota, I.; et al. Gene–environment interactions in obesity: Implication for future applications in preventive medicine. J. Hum. Genet. 2016, 61, 317–322. [Google Scholar] [CrossRef] [PubMed]
- Manolio, T.A.; Collins, F.S.; Cox, N.J.; Goldstein, D.B.; Hindorff, L.A.; Hunter, D.J.; McCarthy, M.I.; Ramos, E.M.; Cardon, L.R.; Chakravarti, A.; et al. Finding the missing heritability of complex diseases. Nature 2009, 461, 747–753. [Google Scholar] [CrossRef] [PubMed]
- McCarthy, M.I.; Abecasis, G.R.; Cardon, L.R.; Goldstein, D.B.; Little, J.; Ioannidis, J.P.; Hirschhorn, J.N. Genome-wide association studies for complex traits: Consensus, uncertainty and challenges. Nat. Rev. Genet. 2008, 9, 356–369. [Google Scholar] [CrossRef] [PubMed]
- Schork, N.J.; Murray, S.S.; Frazer, K.A.; Topol, E.J. Common vs. rare allele hypotheses for complex diseases. Curr. Opin. Genet. Dev. 2009, 19, 212–219. [Google Scholar] [CrossRef] [PubMed]
- Mardis, E.R. The impact of next-generation sequencing technology on genetics. Trends Genet. 2008, 24, 133–141. [Google Scholar] [CrossRef] [PubMed]
- Ueki, M.; Tamiya, G. Ultrahigh-dimensional variable selection method for whole-genome gene–gene interaction analysis. BMC Bioinform. 2012, 13, 72. [Google Scholar] [CrossRef] [PubMed]
- Press, N.A.; Yasui, Y.; Reynolds, S.; Durfy, S.J.; Burke, W. Women’s interest in genetic testing for breast cancer susceptibility may be based on unrealistic expectations. Am. J. Med. Genet. 2001, 99, 99–110. [Google Scholar] [CrossRef]

© 2017 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Narimatsu, H. Gene–Environment Interactions in Preventive Medicine: Current Status and Expectations for the Future. Int. J. Mol. Sci. 2017, 18, 302. https://doi.org/10.3390/ijms18020302
Narimatsu H. Gene–Environment Interactions in Preventive Medicine: Current Status and Expectations for the Future. International Journal of Molecular Sciences. 2017; 18(2):302. https://doi.org/10.3390/ijms18020302
Chicago/Turabian StyleNarimatsu, Hiroto. 2017. "Gene–Environment Interactions in Preventive Medicine: Current Status and Expectations for the Future" International Journal of Molecular Sciences 18, no. 2: 302. https://doi.org/10.3390/ijms18020302
APA StyleNarimatsu, H. (2017). Gene–Environment Interactions in Preventive Medicine: Current Status and Expectations for the Future. International Journal of Molecular Sciences, 18(2), 302. https://doi.org/10.3390/ijms18020302