1. Introduction
DNA methylation is a “silencing” epigenetic mark [
1], and its function closely connects with life development and disease formation [
2,
3]. Research about DNA methylation can help us understand the regulation of epigenetic reprogramming [
4,
5,
6], gene expression [
7], and genome imprinting [
8]. When a methyl group is added to the DNA molecule (often to the fifth carbon of a cytosine ring), this cytosine is a 5-methyl-cytosine and the activity of the DNA sequence around it can be changed. The methyl group may affect the transcription of genes [
9,
10] and may cause tumorigenesis and cancer progression [
11]. So, research about DNA methylation can also help disease sub-classification [
12] and biomarker identification [
13].
Some previous studies have shown that DNA methylation has special sequence patterns [
14], and the methylated sites have a strong connection with their sequential contexts [
15]. The sequence constitution of a macromolecule like DNA or protein has a great connection to its polymorphism and phenotype [
16]. Based on the properties of methylation and the abundant information contained in the sequential context, it is possible to identify whether a DNA sequence is methylated according to its nucleotides composition [
17]. Currently, there are several significant research works that have provided computational methods based on simple nucleotide sequences to predict DNA methylation sites [
18]. A common way to do this is by applying a machine learning method, using appropriate functions to extract features from the DNA sequence, and then training a classifier by using the sequence’s feature vector. The trained classifier can predict the methylation state of a new sequence.
Those previous methods use different features to train the classifier. Some use sequence information to extract features, while some apply additional structure properties. Functional expression is also used by some researchers as features. Methylator proposed by Bhasin et al. [
19] simply converts sequences to feature vectors by using conventional binary sparse encoding. HDFINDER proposed by Das et al. [
20] counts the number of specific DNA segments. Liu’s iDNA-Methyl [
21] includes physicochemical properties between nucleotides into its features. Bock et al. [
22] refer to attributes such as structure, conservation, binding sites, and so on. More comprehensively, Previti et al. [
23] combined sequence repeats, structure property, evolutionary conservation, and physicochemical properties together in their method. Other methods also combine several features together to train the classifier. MethCGI proposed by Fang et al. [
24] joins CpG ratios, TpG contents, binding sites, and the distribution of Alu Y. CpGIMethPred proposed by Zheng et al. [
25] takes CpG island, sequence composition, structure patterns, the distribution of conserved binding sites, and histone methylation status into consideration. In the method proposed by Zhang et al. [
26], genome annotation marks and cis-regulatory elements are used as features. Different from the above methods, DeepCpG [
27] uses a deep learning model. Because the deep learning model can generate features from the original sequences, it is not necessary to define features in this method. All of these methods have significantly contributed to the methylation problems, yet they still have some shortcomings and can be improved upon to achieve better results.
In the choosing of classifier, most methods use a support vector machine (SVM) algorithm for its great performance on small datasets with parameter adjustment. Methylator [
19], HDFINDER [
20], iDNA-Methyl [
21], MethCGI [
24], and CpGIMethPred [
25] use SVM to predict methylation states. However, there are also some methods which use other classifiers rather than SVM. The method proposed by Zhang et al. [
26] uses random forests to do prediction. The method proposed by Previti et al. [
23] uses decision tree instead of SVM. Different classifiers are suited to different problems. Thus, choosing the right classifier is important for a method.
In order to propose an effective computational method for DNA methylation prediction, we combined four feature extraction methods:
k-gram, multivariate mutual information (MMI), discrete wavelet transform (DWT), and pseudo amino acid composition (PseAAC). The
k-gram can get an item’s frequency features in a sequence, and has been used in many computational biology problems [
28]. MMI can analyze the correlation information between two nucleotides [
29]. DWT can capture both the frequency and location information [
30]. PseAAC can reflect the covariance between each composition of the sequence [
31]. With those features, we can train a classifier and adjust its parameters to achieve the best performance. Then, the trained sparse Bayesian learning model can predict the methylation state of a sample sequence. We tested our method on a benchmark dataset extracted from MethDB [
32] and two scBS-seq datasets sequenced from scBS-seq profiled mouse embryonic stem cells (mESCs) [
33]. On the benchmark dataset, our method could reach
on area under the receiver operating characteristic curve (AUC),
on accuracy (ACC),
on Matthew’s correlation coefficient (MCC), and
on sensitivity (SN). All of those values are better than the other three methods, and the improvements are significant. When compared with the best of the three methods, the AUC of our method was increased by
, and SN by
. On another two scBS-seq datasets, our method’s AUCs were
and
, which are better than the other two methods. Results show that our method could effectively predict DNA methylation.
2. Method
We used DNA sequence information and physicochemical properties to distinguish methylated sites and non-methylated sites. The sequence features were extracted by
k-gram and multivariate mutual information (MMI) [
29], considering the nucleotide sequences around the candidate methylation sites. The physicochemical features were extracted by discrete wavelet transform (DWT) [
34] and pseudo amino acid composition (PseAAC) [
35], which are associated with the physical structure of nucleotide permutations [
30,
36]. Then, we trained the sparse Bayesian learning model to predict the DNA methylation sites.
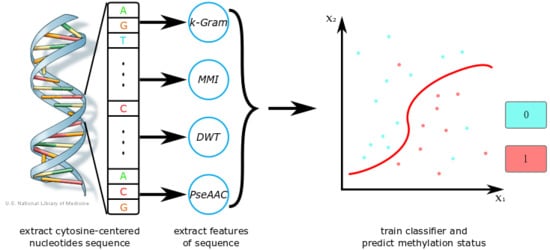
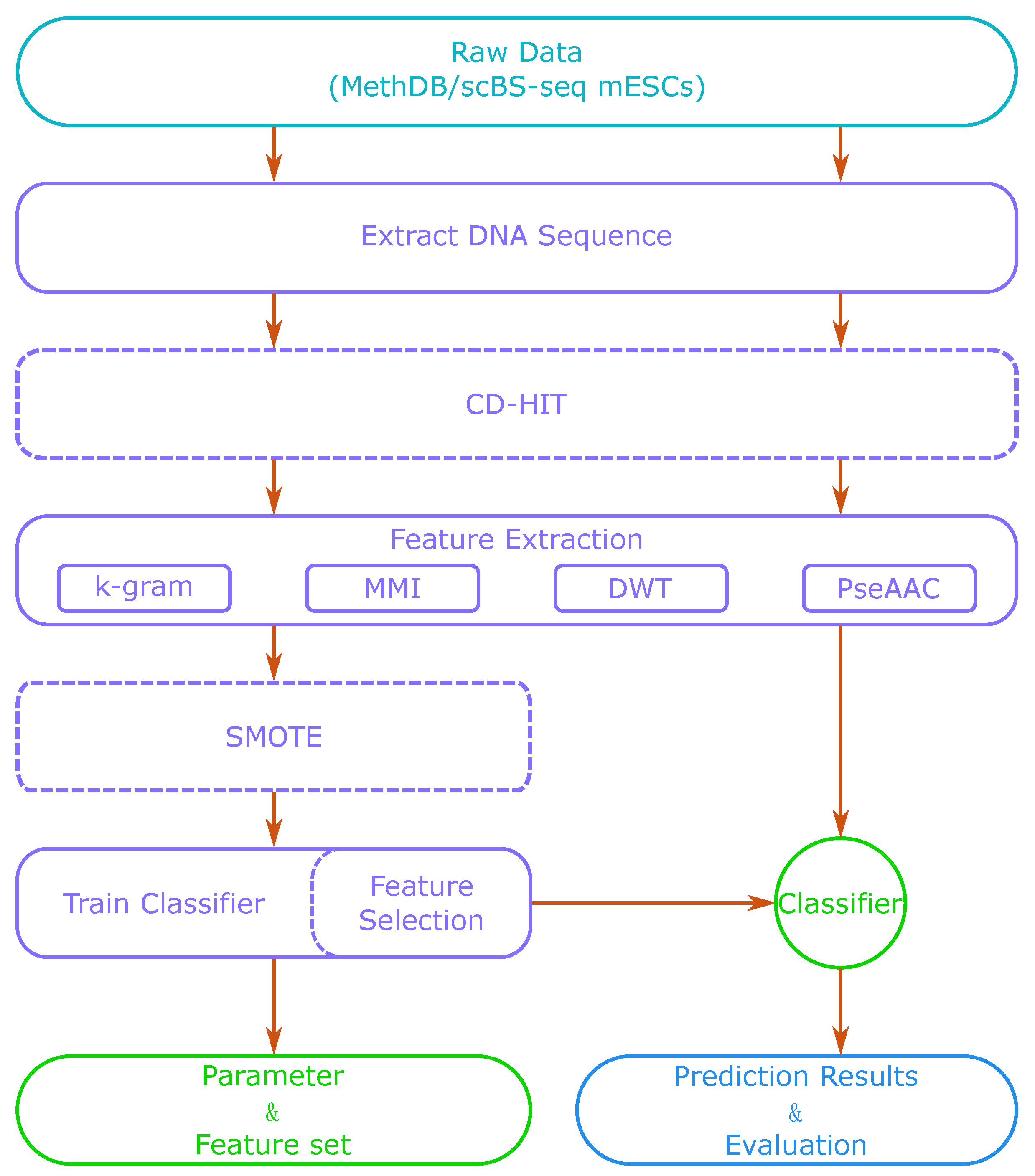
Figure 1 shows a flow chart of our method. Firstly, we extracted DNA sequences around CpG sites from a sequence database or a reference genome. Then, we used feature extraction methods to generate a feature vector. With those extracted features, we trained a classifier such as SVM or a sparse Bayesian learning model. We also adjusted the model’s parameters to obtain its best performance. After training, we could use the classifier to predict methylation states of new DNA sequences. When the dataset was small, we could also apply CD-HIT (Cluster Database at High Identity with Tolerance) and SMOTE (Synthetic Minority Over-sampling Technique) algorithms in the process to optimize the training set. Feature selection is optional, as it can increase the accuracy of prediction, but is also time-consuming.
2.1. Physicochemical Properties
There are 16 2-permutations of nucleotides, namely
,
. According to a previous research work [
37], each permutation has six physicochemical properties (Twist, Tilt, Roll, Shift, Slide, Rise) associated with its physical structure.
Table 1 lists the original values of the six physical structural properties adapted from Goni et al. (2007) [
37].
Based on the physical structural properties between two nucleotides, we can transform one
-length nucleotide sequence
to one
matrix
as in Equation (
1).
where
is the physical structural properties listed in
Table 1,
shows one 2-permutation of nucleotides located at position
i and
of sequence
L, and
means one physicochemical property.
2.2. k-Gram
The
k-gram [
38,
39] is a pair of values
, in which
v represents one feature and
c is the count of this feature. For analyzing the DNA sequence, the
v can be defined as a combination of several units of nucleotides, and
c is the number of combinations occurred in the sequence. For example, to represent a DNA sequence with 3-gram,
v belongs to the set of combination of 3 nucleotides and
c is the count of this combination in the whole sequence.
We utilize
k-gram to extract the sequence features, and the nucleotide combination list
G can be expressed as follows.
where
is 1-gram with 4 features,
is 2-gram with 16 features,
is 3-gram with 64 features,
.
Using k-gram to represent DNA segments (84 features), we can get the basic and intuitive information of the sequence with simple statistical methods. If two segments are more like each other and have more similar function, then their compositions may be more consistent. The number of each nucleotide and their combinations in a segment can directly reflect its composition.
2.3. Multivariate Mutual Information
Multivariate mutual information (MMI) has been used in many previous works [
40,
41,
42] to extract features from sequence data. Therefore, the nucleotides sequence can also be represented using MMI. Inspired by the previous research works [
29,
43], we propose an improved method to extract features of the nucleotides sequence.
In order to use multivariate mutual information on a DNA sequence, we first define 2-tuple nucleotide composition set
and a 3-tuple nucleotide composition set
as follows.
MMI in a tuple does not have a relationship with the order of nucleotides, so if two tuples have same constant but with different order, they may have he tsame information and be assigned as one type tuple. We can see from and that there does not exist the same composition with different order tuples, having 10 elements in and 20 elements in .
We define 2-tuple mutual information for the elements in
as follows:
We also define 3-tuple mutual information for the elements in
as follows:
For a specific segment, is the frequency of nucleotide occurring in this segment, as and are the frequency of 2-tuple and 3-tuple, respectively.
We use
M to denote the multivariate mutual information feature set (30 features) as follows:
2.4. Discrete Wavelet Transform
Discrete Wavelet Transform (DWT) [
34] is a transform operation where the wavelets are discretely sampled, and it can capture both the frequency and location information [
44]. This transform is the projection of signal onto the wavelet function. When applied to DNA sequence analysis, DWT can decompose the physicochemical properties of the nucleotides sequence into a list of coefficients at different resolutions, and also removes the noise information from the high-pass profiles [
30,
45].
Figure 2 is an example of 4-level discrete wavelet transform. At every level, the data can be split into a high-frequency band containing more noisy information and a low-frequency band including more useful signal, and should be transformed at the next level.
At each level of DWT, the high-frequency band and low-frequency band signals are split. We calculate the maximum, minimum, mean, and standard deviation values of each band. Additionally, the first 5 elements are more significant information to represent the sequence in the compressed low-frequency band. Then, we can get features from each level of DWT, and there are 52 features for 4-levels in the whole transformation process. Within the physical property matrix , we can extract 52 features for each property by using a 4-level DWT method. All 6 physicochemical properties can get 312 features. We use the symbol D to denote this DWT feature vector.
2.5. Pseudo Amino Acid Composition
Pseudo Amino Acid Composition (PseAAC) [
35] is a very common method used to analyze protein sequences [
31], and has been widely used in many research fields [
36,
46,
47]. We adapt PseAAC by using physicochemical properties and correlation between each tuple to fit the DNA methylation prediction.
In the physical property matrix
, there are 6 physicochemical properties and each one has 40 values that represent the physicochemical properties of the 2-tuple at the specific position. We use
to denote the
i-th column vector, and we can define the PseAAC feature as follows.
where
is the parameter of pseudo composition,
i is the index of column in matrix
,
is the
n-th value in the
i-th column of matrix
, and
is the mean value of all elements in the
i-th column.
We use
from 0 to 30, which means that
. Therefore, each column of
can be produced as 31 features. All 6 physicochemical properties (186 features) can be calculated as follows:
2.6. Sparse Bayesian Classifier
Sparse Bayesian learning is a general Bayesian framework that can obtain sparse solutions to regression and classification tasks [
48]. It uses Bayesian inference to obtain parsimonious solutions. With a probabilistic Bayesian learning framework, we can construct an accurate prediction model which offer a number of advantages over SVM, such as less computation complexity and probabilistic predictions.
In our method, we use the 612-D features to train a sparse Bayesian classifier. The 612-D features include 84-D from k-gram, 30-D from MMI, 312-D from DWT, and 186-D from PseAAC. After training, the classifier can be used to predict the methylation state of anDNA sequence. Especially, we adjust the parameters of the classifier to get better performance, as the training kernel of the sparse Bayesian learning model is a Gaussian kernel function, and the model’s iteration time is set to 5000.
3. Results
Our method can utilize the 612-D features to train a classifier and perform DNA methylation sites prediction. In order to see how well it works for methylation prediction, we tested it on a benchmark dataset and two scBS-seq datasets. On the benchmark dataset, we analyzed the importance of each feature, and then compared our method with iDNA-Methyl, Methylator, and MethCGI. For the scBS-seq datasets, DeepCpG [
27] and another method proposed by Zhang et al. [
26] were used in the comparison.
3.1. Datasets
3.1.1. Benchmark Dataset
There are many databases collecting data about methylation or deregulation. These databases provide valuable resources for researchers to do computation experiments [
49]. The database MethDB [
32] provides data about methylation sequences. It focuses on the methylated cytosines in the DNA, and currently contains
records of 5-methyl-cytosine content data as well as 6312 records of individual patterns/profiles. MethDB has been used as a benchmark dataset by many methylation predictors, like iDNA-Methyl, Methylator, MethCGI, and so on. So, we use this dataset to test and analyze our method.
We extracted DNA sequences from the MethDB to construct positive and negative datasets. The extraction process is the same as the one used by iDNA-Methyl, in which the extracted sequence has 41 base pairs and the centering nucleotide is cytosine. Based on the methylation status of the sequences’ center cytosine, we divided the sequences into a methylated set (positive dataset) and a non-methylated set (negative dataset).
Among those extracted sequences, some of them were identical or very similar to each other. The redundancy affects the accuracy of prediction, so we used CD-HIT [
50] to reduce the redundancy of datasets. According to the results of CD-HIT, if a sequence is identical to another one in the same dataset, one of these two sequences are removed. If two sequences from different dataset are identical (i.e., they are conflicting with each other), then both of them are removed. After reducing redundancy and removing conflict, there were 787 positive sequences and 1639 negative ones.
The size of the negative samples was two times that of the positive ones. This imbalanced situation of the datasets reduces the prediction’s accuracy. In order to prevent the false negative situation created by mis-predicting methylated sequences as non-methylation, we applied the SMOTE algorithm [
51] to enlarge the positive dataset [
52]. SMOTE can introduce synthetic samples by joining a real sample and its
k-nearest neighbor. After the balancing process, 852 generated samples were added to the positive dataset. Because SVM is widely used and can achieve more accurate prediction than other machine learning models, we used SVM to do classification, as the final size of samples was not very large—both were 1639 in positive and negative.
3.1.2. scBS-seq Dataset
In order to know the genome-wide prediction performance of our method, we applied it on 2 scBS-seq profiled cell datasets, which were
-cultured mESCs and serum-cultured mESCs. The
-cultured dataset is from 12 2
i-cultured mESCs and the serum-cultured dataset is from 18 serum-cultured mESCs [
33]. According to the CpG site’s position in the raw data file, we extracted sequences from the reference GRCm38 mouse genome. The extracted sequence has 201 base pairs with 100 before the site and 100 after it. Each CpG site’s methylation state is labeled according to the mapped reads. If one CpG site’s mapped reads in the raw data file had more tagged as methylated, then this site was labeled as methylated, and otherwise it was labeled as un-methylated. More specifically, the sites whose reads number were less than 4 should be discarded.
From the -cultured mESCs, we got methylated CpG sites, and un-methylated CpG sites. The serum-cultured mESCs had methylated sites and un-methylated sites. Then, we could generate positive and negative datasets using the sequences around those sites, respectively. Unlike the benchmark dataset mentioned before, these two generated scBS-seq datasets are very large in sample size. It is not realistic to remove redundancy or balance the positive and negative samples. So, we applied our method on those original datasets without other processing.
3.2. Evaluation Method
3.2.1. Target-Jackknife Cross-Validation
As a re-sampling technique, Jackknife is very useful for variance and bias estimation [
53]. The basic procedure of Jackknife cross-validation is that it iteratively singles out one sample from the dataset, then uses the remaining samples to predict the singled-out sample. So, we can get a list of prediction results by using a Jackknife test and then calculating the evaluation variables. Jackknife cross-validation is suitable to test predictors on small datasets, so we chose jackknife cross-validation to evaluate our method’s performance on the benchmark dataset.
When generating the benchmark dataset, we used the SMOTE algorithm to increase the size of the positive set. Those additional hypothetical positive samples are not from the real world. In order to correctly evaluate our method, we filtered out those synthetic ones when doing the test, meaning that the ones created by SMOTE were only involved in the training but not the testing process. This is target-jackknife cross-validation. As there were 787 samples in the original positive dataset and 1639 in the negative one, we did rounds of training and prediction, then calculated the AUC, MCC, etc.
3.2.2. Holdout Validation
The sizes of scBS-seq datasets are very large. Using jackknife cross-validation is very time-consuming. So we chose holdout validation. Holdout validation is a type of simple validation. In this validation method, the samples are randomly assigned to two sets: the training set and the test set. The size of each set is arbitrary.
In our experiment, to simplify the procedure of dividing, we used samples from chromosomes 1, 3, 5, 7, 9, and 11 as the training set and samples from chromosomes 2, 4, 6, 8, 10, and 12 as the test set. Under this strategy, the -cultured dataset had positive samples and negative samples used to train the model, and the number of samples used to test were and , respectively. The constitution of the serum-cultured dataset was positives and negatives in the training set, and positives and negatives in the test set.
3.2.3. Evaluation Criteria
To test the accuracy in predicting methylation sites, we used four statistical measurements to define its performance and effectiveness, as follows:
where true positive (TP) is the number of methylated segments that were correctly predicted as methylated sites, true negative (TN) is the number of non-methylated segments that were correctly predicted as non-methylated sites, false positive (FP) is the number of non-methylated segments that were incorrectly predicted as methylated sites, and false negative (FN) is the number of methylated segments that were incorrectly predicted as non-methylated sites.
means the overall prediction accuracy,
means Matthew’s correlation coefficient [
54],
and
are sensitivity and specificity, respectively [
55].
Besides those four criteria, we also used area under the receiver operating characteristic curve (AUC) [
56] to analyze and evaluate our method. The receiver operating characteristic graph is created by plotting true positive rate against the false positive rate at various threshold settings [
55]. A higher AUC value means that the classifier is scoring a positive instance greater than a negative instance—in other words, that this classifier is more efficient and accurate. So, the AUC can reflect the accuracy of prediction results.
3.3. Feature Analysis
The contribution of features to the classifier are not the same. In order to know the importance of each feature, we ran experiments using different combinations of features and evaluated the trained classifier. This experiment was performed on the benchmark dataset.
The experimental results are listed in
Table 2. Firstly, we used the individual feature set to train the classifier separately, and used target-jackknife cross-validation to test it. The
k-gram counts the occurrence of each nucleotide and their combination. It can get 84 features. Those features are the simplest way to represent a nucleotide sequence. Using this 84-D feature, the classifier achieved
on ACC,
on MCC,
on SN,
on SP, and
on AUC. The MMI can get 30 features. They reflect the mutual information in the sequence. This representation form is a little more complex than
k-gram, and contains deeper information. With this 30-D feature, the classifier was not as good as the
k-gram one, but had an improvement of
on SP. Among the four individual feature sets, the 312-D feature of DWT trained the best classifier with AUC reaching
, and the ACC, MCC, and SN were
,
, and
, respectively. DWT decomposes sequences into coefficients at different resolution, and also removes the noise information. So, it has better performance than other extraction methods. However, its SP value was the worst among the four individual feature sets, only reaching
while the other three individual features had SP values greater than
. From those results, we can see that DWT had a significant increase in AUC (at least
), MCC (at least
), and SN (at least
) compared to the other individual features.
We also combined four features (612-D) together to train the classifier, and the result achieved on AUC, on ACC, on MCC, on SN, and on SP. The combination was better than four individual features when evaluated on AUC, ACC, MCC, and SN. However, for the SP value, the combination was not very good, as its result was less than the best one ( by PseAAC).
We plotted the receiver operating characteristic (ROC) curves of each classifier trained by different features or their combination in
Figure 3. It is well-known that the area under the curve can be used to evaluate a classifier’s ability, and a larger area means better results. We can see that the DWT feature was the best one among four individual features. We found that MMI,
k-gram, and PseAAC did not have very much difference—at least in terms of ROC. The curve of the combination was better than the DWT’s, but the improvement was not very significant. The AUC value of the combination feature was
.
3.4. Feature Selection
From the analysis of feature importance, we can see that some of the features were more important to the classifier than others. So, in the 612-D feature vector of the four features’ combination, some items were important and some were less effective. We wanted to use a feature selection algorithm [
57] to choose the most useful features [
58], and see the performance results of a classifier trained by those features. In this experiment, the benchmark dataset was used to train and test our method, and we used SVM to do classification.
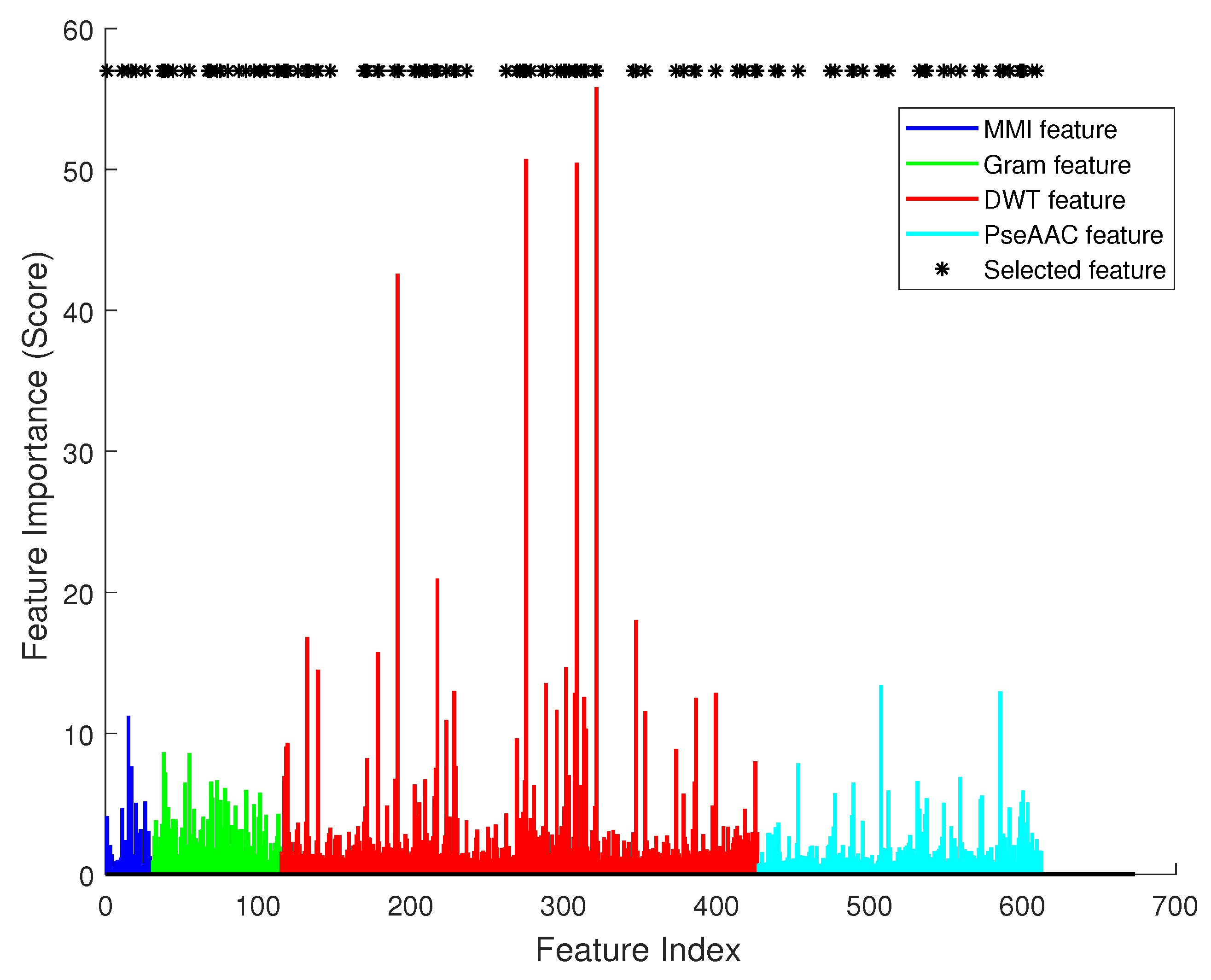
Figure 4 illustrates the effect of each single feature item. In this figure, there are 612 bars in total. The
x axis is the index of each feature, and the
y axis is the importance score calculated using SVM’s feature selection function. Asterisks mark the most significant features in feature selection. We can see that they had varied importance to the classifier, and obviously DWT had most significant effect (the red color bars).
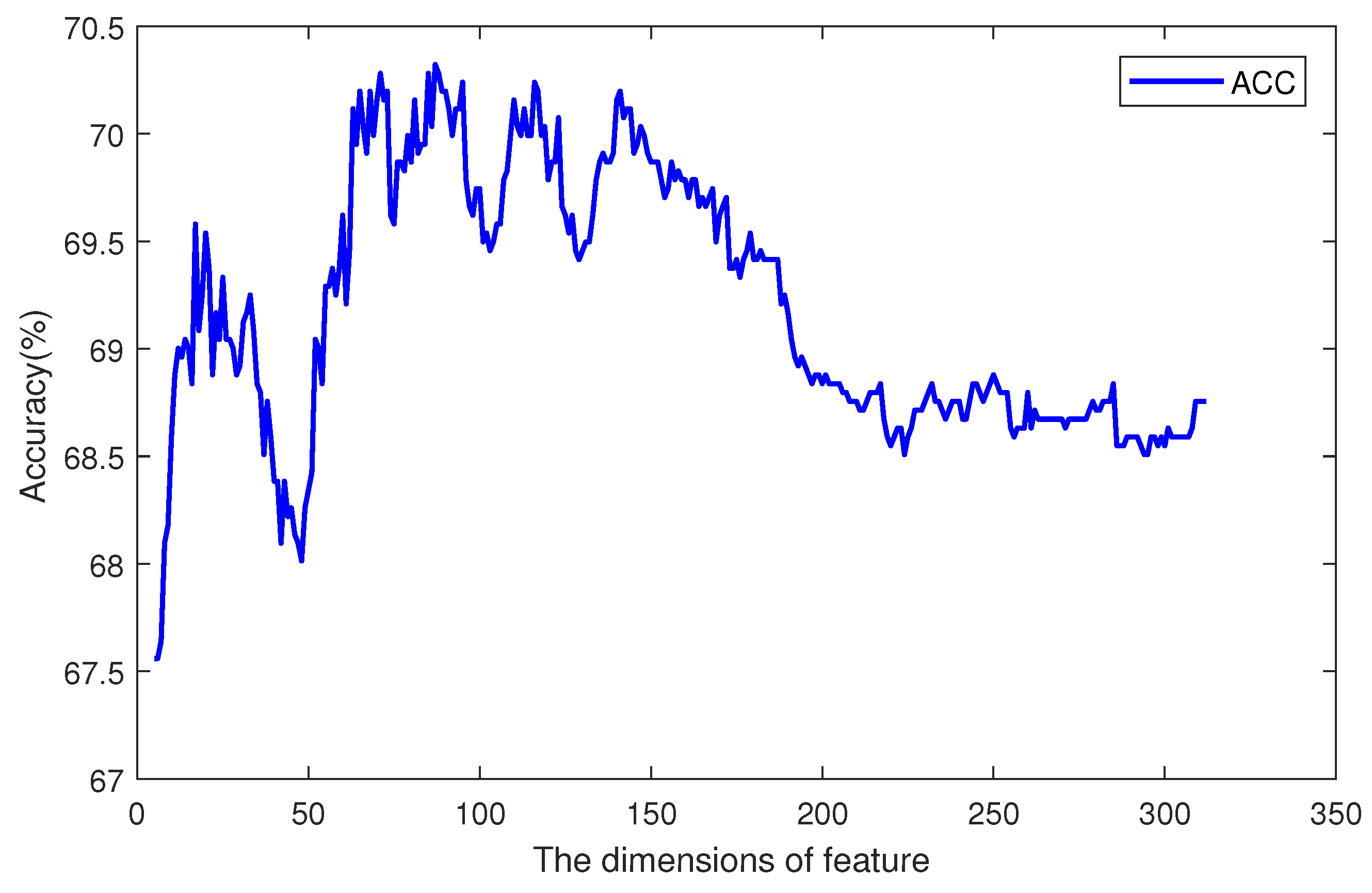
Then, we sorted the feature items by their importance scores, and iteratively increased the size of the feature vector. For every iteration, the most important one of the remaining feature items should be added to the vector, and a classifier can be trained. So, there were 612 classifiers, and each had a specific accuracy value. The tendency of accuracy is plotted in
Figure 5. The
x axis is the dimension of the feature, and the
y axis is the accuracy of the classifier. When the dimension of the feature was less than 100, increasing the feature size could improve the accuracy, but when the dimension was greater than 200, the performance of the classifier with more feature items was worse. Between dimensions 100 and 200, there was an optimal plateau. Among 612 sorted features, the first 100 ones contained different information and attributes of the sequence, so increasing the size of the feature set could provide more support to the classifier. The features from the 100th to 200th contained information which may also be included in the first 100 features. This information does not have a great effect on the prediction result. So, the accuracy kept in a certain range from
to
. The other remaining features may have had noise information, and affected the classifier’s performance. So, the curve in
Figure 5 shows an increase at first, and remains high for a period after reaching the highest point, then it decreases. The most accurate classifier was trained by using 114 significant items, which are marked in
Figure 4 by an asterisk symbol. In the optimal feature vector, 5 items were selected from feature MMI, 21 were from k-gram, 64 were from DWT, and 24 were from PseAAC.
We used the the 114-D selected feature to train a classifier, and the performance result is listed in
Table 2. From the table we can see that this classifier could achieve
on AUC,
on ACC,
on MCC,
on SN, and
on SP. Especially, with feature selection, the AUC value could increase by
than without feature selection. We plotted the ROC of this classifier in
Figure 3. The curve of the selected feature is prominent, and has significant changes from the curve of the combination feature. So, feature selection is useful in our method.
3.5. DWT Feature Analysis
According to
Figure 4, we can see that DWT features are more important than other ones in our method. We used only DWT features to train an SVM classifier and applied feature selection on them. Then, we analyzed those features further to see the properties of DWT feature extraction. This experiment was done on the original unbalanced benchmark dataset.
The accuracies of different dimensions are plotted in
Figure 6. The
x axis is the dimension of DWT features, and the
y axis is the accuracy of prediction. The total dimension of features was 312. When the dimension was 87, the accuracy reached its max value. Before point 87, the main tendency was increasing, but with a small fluctuation around point 50. After point 150, the accuracy decreased along with more features.
We analyzed these selected 87 features and found that different levels of DWT had different importance. There were 4 levels of extraction, and each level could get 78 features. With feature selection, each level contributes a different number of features. Among the 78 features from the 1st-level, 31 were selected. Selected features from the 2nd- to 4th-levels were 15, 20, and 21, respectively. From the constitution, we can see that the first level had the greatest importance and the second level was the least important level. The effects of third and fourth levels had no great difference. Those properties can help us to optimize the DWT in future works.
3.6. Performance on Benchmark Dataset
With the utilization of feature selection in our method, we compared it with three existing methods: MethCGI [
24], Methylator [
19], and iDNA-Methyl [
21]. This comparison is based on the benchmark dataset, and our method uses SVM as classifier. The results are listed in
Table 3.
Among the three reference methods, iDNA-Methyl was the best, and ACC, MCC, SN, and SP were , , , and , respectively. iDNA-Methyl had great improvements over the other two methods: ACC increased by and MCC by . Our method had a better result than those three methods in ACC, MCC, and SN. The ACC of our method was , with increment to iDNA-Methyl. The MCC of our method was , which is also better than the other methods, but the improvement was not very obvious. The SN of our method had a very significant value () compared to iDNA-Methyl () and Methylator (). When compared to other methods on SP, we could only achieve . This value was slightly lower than iDNA-Methyl’s and MethCGI’s . The Methylator’s SP was only , so our method remained better than Methylator. From these results, we can see that our method solved some of the limitations of existing methods and could get more accurate results.
3.7. Performance on scBS-seq Dataset
We also tested our method on scBS-seq profiled cells’ data. In our experiment, two datasets were used: -cultured and serum-cultured. For each dataset, we trained a list of classifiers using each single cell’s training set, and tested the classifier with the corresponding cell’s test set. The best accuracy of all the classifiers could be used as the result of our method on that dataset. Considering the large size of the samples, we used sparse Bayesian learning rather than SVM to do classification, and used hold validation to evaluate our method.
Figure 7 shows the the ROCs of our method on two datasets. Each ROC in the figure is a performance result of our method when it was trained and tested on a specific cell’s data. From the curves, we can see that in the
-cultured dataset, the curves were focused in a small region, and there was not a very large difference between each cell’s result. In the serum-cultured dataset, except for the two curves of SER-3 and SER-6, the other curves were very consistent. Since the methylation pattern of SER-3 and SER-6 deviated strongly from the remaining serum cells [
27,
33,
59], the curves of those two cells deviated from the normal ones.
The results of our method and other methods are listed in
Table 4. DeepCpG, which uses a deep neural network, was proposed by Angermueller et al. [
27]. Another method, proposed by Zhang et al., uses genome annotation marks as feature and random forests as classifier [
26], and we refer to it as RF_Zhang. All of the values in
Table 4 are the best results of each method on the specific dataset.
From
Table 4, we can see that our method was comparable with the other two methods. On dataset
-cultured cells, the AUC of our method was
while DeepCpG and RF_Zhang could only reach
and
, respectively. Besides the
improvement on AUC, our method was also better on ACC (
) and SP (0.9987). On the dataset of serum-cultured cells, our method’s performance was outstanding. The AUC of our method reached
, an increase of
from DeepCpG’s. Additionally, the MCC and SN had improvements of
and
. The ACC value was almost the same as DeepCpG’s.
5. Conclusions
In this paper, we propose a novel method for DNA methylation prediction. We designed and implemented four feature extraction methods to extract sequence and physical structure information, then used sparse Bayesian learning to do classification. The four feature extraction methods were k-gram, multivariate mutual information, discrete wavelet transform, and pseudo amino acid composition. Besides those, we also analyzed the importance of each feature, and used feature selection to improve the performance of our method. Testing on three datasets (a benchmark dataset and two scBS-seq datasets) demonstrated that our method is outstanding. The AUC values on the three datasets were , , and . When compared with other methods, our method’s AUCs on the three datasets were the greatest, and we achieved great improvements of to . Especially on the benchmark dataset, our method had on AUC, on ACC, on MCC, and on SN. Those four values are the greatest among all the methods. According to the evaluation value and comparison, our method was effective in predicting DNA methylation sites. Furthermore, the feature extraction methods used in our method are helpful for other prediction problems.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}