
Proteomics Analysis of the Polyomavirus DNA Replication Initiation Complex Reveals Novel Functional Phosphorylated Residues and Associated Proteins




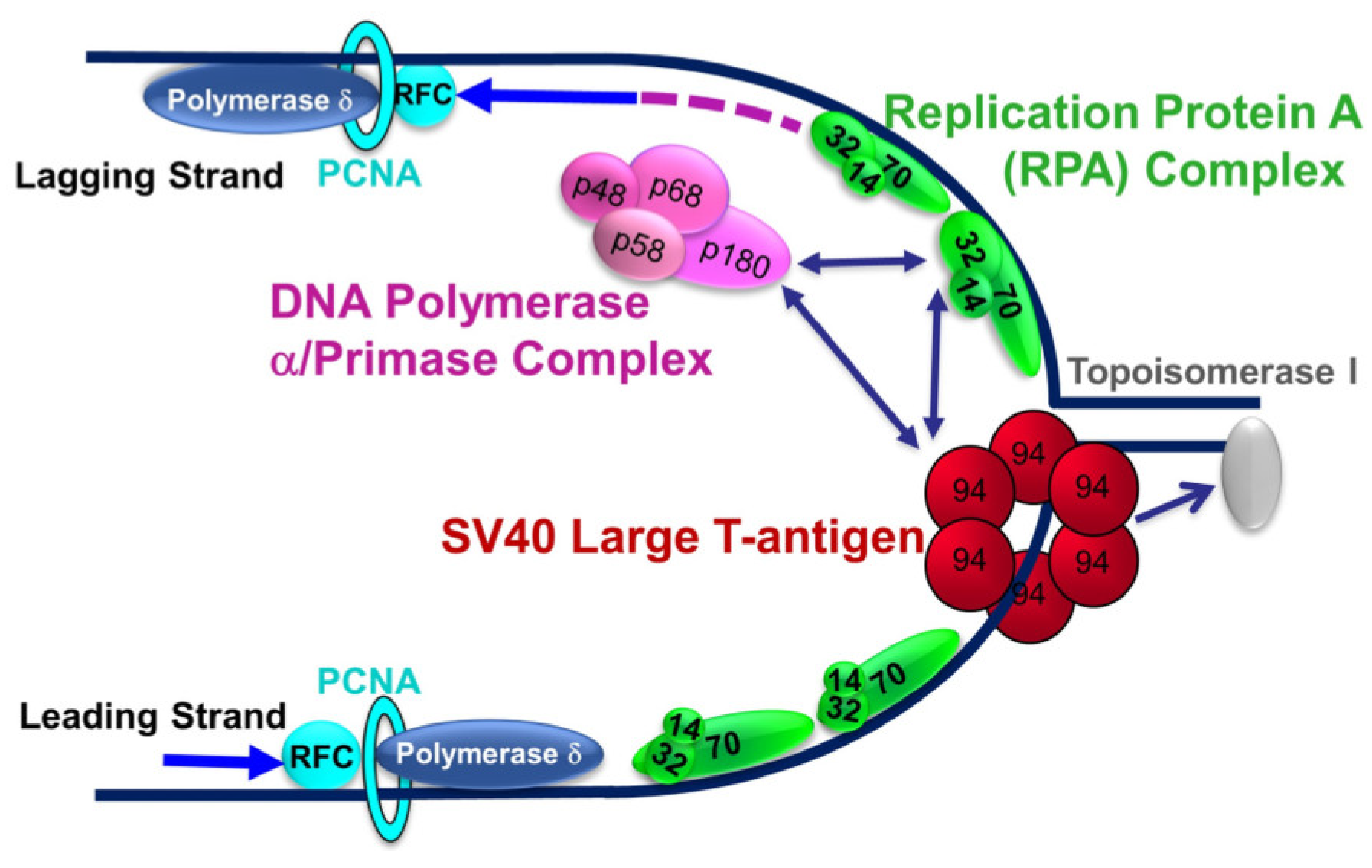{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
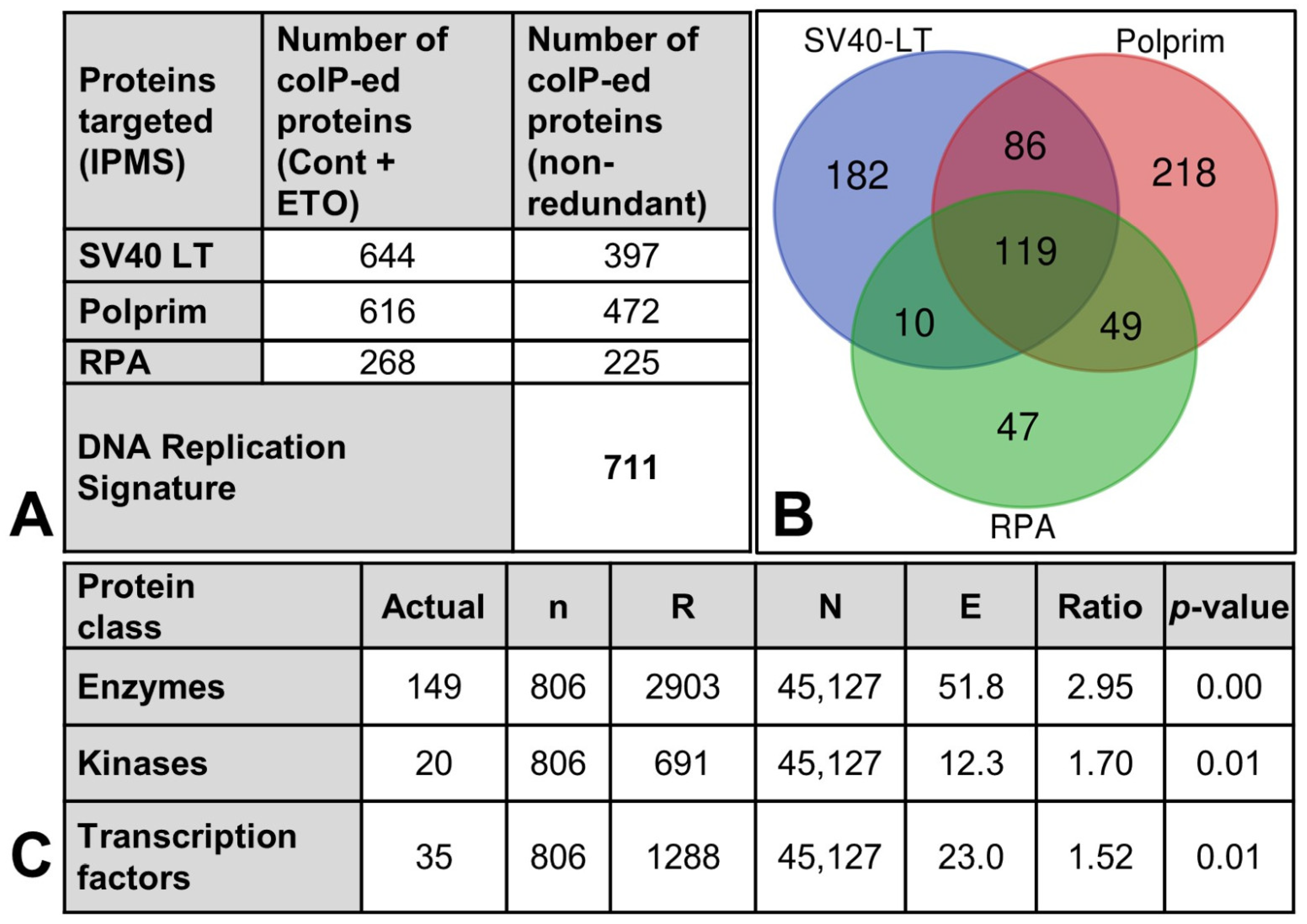{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
:1. Introduction
2. Results and Discussion
2.1. PAARs on SV40
Proteins coIP-Ed with SV40 LT
2.2. PAARs on Polprim-Complex
Proteins coIP-Ed with Polprim-Complex
2.3. PAARs on RPA-Complex
Proteins coIP-Ed with RPA-Complex
2.4. GO Enrichment Analysis
2.5. Creation and Characterization of the “DNA Replication Signature”
2.5.1. Interactome Analysis
2.5.2. Transcriptional Regulation Network Analysis
2.5.3. Corroborating Known Interactions with SV40 LT
2.5.4. Identification of a Novel LT-Associated Factor: Ets1
3. Materials and Methods
3.1. Cell-Culture and Lysate for IP
3.2. Antibodies
3.3. IP for ImmunoBlot
3.4. IP for Mass Spectrometry
3.5. Mass Spectrometry (MS)
3.6. Data Analysis
3.7. Bioinformatics-Based Analyses
3.7.1. Prediction of PAARs by In Silico Analysis (Netphos v3.1)
3.7.2. GO Enrichment Analysis
3.7.3. “DNA Replication Signature” for Global Analyses
3.7.4. Network Analysis
3.7.5. Interactome Analysis
3.7.6. Transcription Regulation Network Analysis
4. Conclusions
Supplementary Materials
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Topalis, D.; Andrei, G.; Snoeck, R. The large tumor antigen: A “Swiss Army knife” protein possessing the functions required for the polyomavirus life cycle. Antivir. Res. 2013, 97, 122–136. [Google Scholar] [CrossRef]
- Borowiec, J.A.; Dean, F.B.; Bullock, P.A.; Hurwitz, J. Binding and unwinding—How T antigen engages the SV40 origin of DNA replication. Cell 1990, 60, 181–184. [Google Scholar] [CrossRef]
- Bullock, P.A. The initiation of simian virus 40 DNA replication in vitro. Crit Rev. Biochem. Mol. Biol. 1997, 32, 503–568. [Google Scholar] [CrossRef] [PubMed]
- Fanning, E.; Knippers, R. Structure and function of simian virus 40 large tumor antigen. Annu. Rev. Biochem. 1992, 61, 55–85. [Google Scholar] [CrossRef]
- Ahuja, D.; Saenz-Robles, M.T.; Pipas, J.M. SV40 large T antigen targets multiple cellular pathways to elicit cellular transformation. Oncogene 2005, 24, 7729–7745. [Google Scholar] [CrossRef] [PubMed]
- Lee, C.; Cho, Y. Interactions of SV40 large T antigen and other viral proteins with retinoblastoma tumour suppressor. Rev. Med. Virol. 2002, 12, 81–92. [Google Scholar] [CrossRef] [PubMed]
- Damania, B.; Alwine, J.C. TAF-like function of SV40 large T antigen. Genes Dev. 1996, 10, 1369–1381. [Google Scholar] [CrossRef]
- Damania, B.; Lieberman, P.; Alwine, J.C. Simian virus 40 large T antigen stabilizes the TATA-binding protein-TFIIA complex on the TATA element. Mol. Cell Biol. 1998, 18, 3926–3935. [Google Scholar] [CrossRef]
- Valls, E.; Blanco-Garcia, N.; Aquizu, N.; Piedra, D.; Estaras, C.; de la Cruz, X.; Martinez-Balbas, M.A. Involvement of chromatin and histone deacetylation in SV40 T antigen transcription regulation. Nucleic Acids Res. 2007, 35, 1958–1968. [Google Scholar] [CrossRef]
- Gardner, S.D.; Field, A.M.; Coleman, D.V.; Hulme, B. New human papovavirus (B.K.) isolated from urine after renal transplantation. Lancet 1971, 1, 1253–1257. [Google Scholar] [CrossRef]
- Padgett, B.L.; Walker, D.L.; ZuRhein, G.M.; Eckroade, R.J.; Dessel, B.H. Cultivation of papova-like virus from human brain with progressive multifocal leucoencephalopathy. Lancet 1971, 1, 1257–1260. [Google Scholar] [CrossRef] [PubMed]
- Fanning, E.; Zhao, K. SV40 DNA replication: From the A gene to a nanomachine. Virology 2009, 384, 352–359. [Google Scholar] [CrossRef] [PubMed]
- Hurwitz, J.; Dean, F.B.; Kwong, A.D.; Lee, S.H. The in vitro replication of DNA containing the SV40 origin. J. Biol. Chem. 1990, 265, 18043–18046. [Google Scholar] [CrossRef] [PubMed]
- Kelly, T.J. SV40 DNA replication. J. Biol. Chem. 1988, 263, 17889–17892. [Google Scholar] [CrossRef]
- Simmons, D.T.; Loeber, G.; Tegtmeyer, P. Four major sequence elements of simian virus 40 large T antigen coordinate its specific and nonspecific DNA binding. J. Virol. 1990, 64, 1973–1983. [Google Scholar] [CrossRef] [PubMed]
- Li, D.; Zhao, R.; Lilyestrom, W.; Gai, D.; Zhang, R.; DeCaprio, J.A.; Fanning, E.; Jochimiak, A.; Szakonyi, G.; Chen, X.S. Structure of the replicative helicase of the oncoprotein SV40 large tumour antigen. Nature 2003, 423, 512–518. [Google Scholar] [CrossRef]
- Yardimci, H.; Wang, X.; Loveland, A.B.; Tappin, I.; Rudner, D.Z.; Hurwitz, J.; van Oijen, A.M.; Walter, J.C. Bypass of a protein barrier by a replicative DNA helicase. Nature 2012, 492, 205–209. [Google Scholar] [CrossRef]
- Foster, E.C.; Simmons, D.T. The SV40 large T-antigen origin binding domain directly participates in DNA unwinding. Biochemistry 2010, 49, 2087–2096. [Google Scholar] [CrossRef]
- Goetz, G.S.; Dean, F.B.; Hurwitz, J.; Matson, S.W. The unwinding of duplex regions in DNA by the simian virus 40 large tumor antigen-associated DNA helicase activity. J. Biol. Chem. 1988, 263, 383–392. [Google Scholar] [CrossRef]
- Wiekowski, M.; Schwarz, M.W.; Stahl, H. Simian virus 40 large T antigen DNA helicase. Characterization of the ATPase-dependent DNA unwinding activity and its substrate requirements. J. Biol. Chem. 1988, 263, 436–442. [Google Scholar] [CrossRef]
- Zhou, B.; Arnett, D.R.; Yu, X.; Brewster, A.; Sowd, G.A.; Xie, C.L.; Vila, S.; Gai, D.; Fanning, E.; Chen, X.S. Structural basis for the interaction of a hexameric replicative helicase with the regulatory subunit of human DNA polymerase alpha-primase. J. Biol. Chem. 2012, 287, 26854–26866. [Google Scholar] [CrossRef] [PubMed]
- Tsurimoto, T.; Melendy, T.; Stillman, B. Sequential initiation of lagging and leading strand synthesis by two different polymerase complexes at the SV40 DNA replication origin. Nature 1990, 346, 534–539. [Google Scholar] [CrossRef] [PubMed]
- Baranovskiy, A.G.; Babayeva, N.D.; Zhang, Y.; Gu, J.; Suwa, Y.; Pavlov, Y.I.; Tahirov, T.H. Mechanism of Concerted RNA–DNA Primer Synthesis by the Human Primosome. J. Biol. Chem. 2016, 291, 10006–10020. [Google Scholar] [CrossRef] [PubMed]
- Melendy, T.; Stillman, B. An interaction between replication protein A and SV40 T antigen appears essential for primosome assembly during SV40 DNA replication. J. Biol. Chem. 1993, 268, 3389–3395. [Google Scholar] [CrossRef] [PubMed]
- Simmons, D.T.; Gai, D.; Parsons, R.; Debes, A.; Roy, R. Assembly of the replication initiation complex on SV40 origin DNA. Nucleic Acids Res. 2004, 32, 1103–1112. [Google Scholar] [CrossRef] [PubMed]
- Uhlmann-Schiffler, H.; Seinsoth, S.; Stahl, H. Preformed hexamers of SV40 T antigen are active in RNA and origin-DNA unwinding. Nucleic Acids Res. 2002, 30, 3192–3201. [Google Scholar] [CrossRef] [PubMed]
- Simmons, D.T.; Melendy, T.; Usher, D.; Stillman, B. Simian virus 40 large T antigen binds to topoisomerase I. Virology 1996, 222, 365–374. [Google Scholar] [CrossRef] [PubMed]
- Braun, K.A.; Lao, Y.; He, Z.; Ingles, C.J.; Wold, M.S. Role of protein-protein interactions in the function of replication protein A (RPA): RPA modulates the activity of DNA polymerase alpha by multiple mechanisms. Biochemistry 1997, 36, 8443–8454. [Google Scholar] [CrossRef] [PubMed]
- Collins, K.L.; Kelly, T.J. Effects of T antigen and replication protein A on the initiation of DNA synthesis by DNA polymerase alpha-primase. Mol. Cell Biol. 1991, 11, 2108–2115. [Google Scholar] [CrossRef]
- Dornreiter, I.; Erdile, L.F.; Gilbert, I.U.; von Winkler, D.; Kelly, T.J.; Fanning, E. Interaction of DNA polymerase alpha-primase with cellular replication protein A and SV40 T antigen. EMBO J. 1992, 11, 769–776. [Google Scholar] [CrossRef]
- Dornreiter, I.; Hoss, A.; Arthur, A.K.; Fanning, E. SV40 T antigen binds directly to the large subunit of purified DNA polymerase alpha. EMBO J. 1990, 9, 3329–3336. [Google Scholar] [CrossRef] [PubMed]
- Jiang, X.; Klimovich, V.; Arunkumar, A.I.; Hysinger, E.B.; Wang, Y.; Ott, R.D.; Guler, G.D.; Weiner, B.; Chazin, W.J.; Fanning, E. Structural mechanism of RPA loading on DNA during activation of a simple pre-replication complex. EMBO J. 2006, 25, 5516–5526. [Google Scholar] [CrossRef] [PubMed]
- Loo, Y.M.; Melendy, T. Recruitment of replication protein A by the papillomavirus E1 protein and modulation by single-stranded DNA. J. Virol. 2004, 78, 1605–1615. [Google Scholar] [CrossRef] [PubMed]
- Tsurimoto, T.; Stillman, B. Functions of replication factor C and proliferating-cell nuclear antigen: Functional similarity of DNA polymerase accessory proteins from human cells and bacteriophage T4. Proc. Natl. Acad. Sci. USA 1990, 87, 1023–1027. [Google Scholar] [CrossRef] [PubMed]
- Waga, S.; Bauer, G.; Stillman, B. Reconstitution of complete SV40 DNA replication with purified replication factors. J. Biol. Chem. 1994, 269, 10923–10934. [Google Scholar] [CrossRef]
- McVey, D.; Brizuela, L.; Mohr, I.; Marshak, D.R.; Gluzman, Y.; Beach, D. Phosphorylation of large tumour antigen by cdc2 stimulates SV40 DNA replication. Nature 1989, 341, 503–507. [Google Scholar] [CrossRef] [PubMed]
- Dueva, R.; Iliakis, G. Replication protein A: A multifunctional protein with roles in DNA replication, repair and beyond. NAR Cancer 2020, 2, zcaa022. [Google Scholar] [CrossRef] [PubMed]
- Olsen, J.V.; Vermeulen, M.; Santamaria, A.; Kumar, C.; Miller, M.L.; Jensen, L.J.; Gnad, F.; Cox, J.; Jensen, T.S.; Nigg, E.A.; et al. Quantitative phosphoproteomics reveals widespread full phosphorylation site occupancy during mitosis. Sci. Signal 2010, 3, ra3. [Google Scholar] [CrossRef]
- Schub, O.; Rohaly, G.; Smith, R.W.; Schneider, A.; Dehde, S.; Dornreiter, I.; Nasheuer, H.P. Multiple phosphorylation sites of DNA polymerase alpha-primase cooperate to regulate the initiation of DNA replication in vitro. J. Biol. Chem. 2001, 276, 38076–38083. [Google Scholar] [CrossRef]
- Zhang, D.; O’Donnell, M. The Eukaryotic Replication Machine. Enzymes 2016, 39, 191–229. [Google Scholar] [CrossRef]
- Burgers, P.M.J.; Kunkel, T.A. Eukaryotic DNA Replication Fork. Annu. Rev. Biochem. 2017, 86, 417–438. [Google Scholar] [CrossRef]
- Bleichert, F.; Botchan, M.R.; Berger, J.M. Mechanisms for initiating cellular DNA replication. Science 2017, 355, 811. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.S.; Kuo, S.R.; McHugh, M.M.; Beerman, T.A.; Melendy, T. Adozelesin triggers DNA damage response pathways and arrests SV40 DNA replication through replication protein A inactivation. J. Biol. Chem. 2000, 275, 1391–1397. [Google Scholar] [CrossRef] [PubMed]
- Liu, J.S.; Kuo, S.R.; Yin, X.; Beerman, T.A.; Melendy, T. DNA damage by the enediyne C-1027 results in the inhibition of DNA replication by loss of replication protein A function and activation of DNA-dependent protein kinase. Biochemistry 2001, 40, 14661–14668. [Google Scholar] [CrossRef] [PubMed]
- Wang, Y.; Zhou, X.Y.; Wang, H.; Huq, M.S.; Iliakis, G. Roles of replication protein A and DNA-dependent protein kinase in the regulation of DNA replication following DNA damage. J. Biol. Chem. 1999, 274, 22060–22064. [Google Scholar] [CrossRef]
- Iliakis, G.; Wang, Y.; Wang, H.Y. Analysis of inhibition of DNA replication in irradiated cells using the SV40-based in vitro assay of DNA replication. Methods Mol. Biol. 1999, 113, 543–553. [Google Scholar] [CrossRef]
- King, L.E.; Fisk, J.C.; Dornan, E.S.; Donaldson, M.M.; Melendy, T.; Morgan, I.M. Human papillomavirus E1 and E2 mediated DNA replication is not arrested by DNA damage signalling. Virology 2010, 406, 95–102. [Google Scholar] [CrossRef] [PubMed]
- Imperiale, M.J. The human polyomaviruses, BKV and JCV: Molecular pathogenesis of acute disease and potential role in cancer. Virology 2000, 267, 1–7. [Google Scholar] [CrossRef] [PubMed]
- Mann, M.; Kelleher, N.L. Precision proteomics: The case for high resolution and high mass accuracy. Proc. Natl. Acad. Sci. USA 2008, 105, 18132–18138. [Google Scholar] [CrossRef]
- Homiski, C.; Dey-Rao, R.; Shen, S.; Qu, J.; Melendy, T. DNA damaged-induced phosphorylation of a viral replicative DNA helicase results in inhibition of DNA replication through attenuation of helicase function. bioRxiv 2023. [Google Scholar] [CrossRef]
- Dornreiter, I.; Copeland, W.C.; Wang, T.S. Initiation of simian virus 40 DNA replication requires the interaction of a specific domain of human DNA polymerase alpha with large T antigen. Mol. Cell Biol. 1993, 13, 809–820. [Google Scholar] [CrossRef] [PubMed]
- Huang, S.G.; Weisshart, K.; Gilbert, I.; Fanning, E. Stoichiometry and mechanism of assembly of SV40 T antigen complexes with the viral origin of DNA replication and DNA polymerase alpha-primase. Biochemistry 1998, 37, 15345–15352. [Google Scholar] [CrossRef] [PubMed]
- Murakami, Y.; Hurwitz, J. Functional interactions between SV40 T antigen and other replication proteins at the replication fork. J. Biol. Chem. 1993, 268, 11008–11017. [Google Scholar] [CrossRef] [PubMed]
- Sharma, K.; D’Souza, R.C.; Tyanova, S.; Schaab, C.; Wisniewski, J.R.; Cox, J.; Mann, M. Ultradeep human phosphoproteome reveals a distinct regulatory nature of Tyr and Ser/Thr-based signaling. Cell Rep. 2014, 8, 1583–1594. [Google Scholar] [CrossRef] [PubMed]
- Zhang, J.; Yang, P.L.; Gray, N.S. Targeting cancer with small molecule kinase inhibitors. Nat. Rev. Cancer 2009, 9, 28–39. [Google Scholar] [CrossRef] [PubMed]
- Olsen, J.V.; Macek, B. High accuracy mass spectrometry in large-scale analysis of protein phosphorylation. Methods Mol. Biol. 2009, 492, 131–142. [Google Scholar] [CrossRef] [PubMed]
- Grasser, F.A.; Scheidtmann, K.H.; Tuazon, P.T.; Traugh, J.A.; Walter, G. In vitro phosphorylation of SV40 large T antigen. Virology 1988, 165, 13–22. [Google Scholar] [CrossRef]
- Prives, C. The replication functions of SV40 T antigen are regulated by phosphorylation. Cell 1990, 61, 735–738. [Google Scholar] [CrossRef] [PubMed]
- Scheidtmann, K.H.; Echle, B.; Walter, G. Simian virus 40 large T antigen is phosphorylated at multiple sites clustered in two separate regions. J. Virol. 1982, 44, 116–133. [Google Scholar] [CrossRef]
- Fanning, E. Control of SV40 DNA replication by protein phosphorylation: A model for cellular DNA replication? Trends Cell Biol. 1994, 4, 250–255. [Google Scholar] [CrossRef]
- Weisshart, K.; Taneja, P.; Jenne, A.; Herbig, U.; Simmons, D.T.; Fanning, E. Two regions of simian virus 40 T antigen determine cooperativity of double-hexamer assembly on the viral origin of DNA replication and promote hexamer interactions during bidirectional origin DNA unwinding. J. Virol. 1999, 73, 2201–2211. [Google Scholar] [CrossRef] [PubMed]
- Cegielska, A.; Shaffer, S.; Derua, R.; Goris, J.; Virshup, D.M. Different oligomeric forms of protein phosphatase 2A activate and inhibit simian virus 40 DNA replication. Mol. Cell Biol. 1994, 14, 4616–4623. [Google Scholar] [CrossRef]
- McVey, D.; Ray, S.; Gluzman, Y.; Berger, L.; Wildeman, A.G.; Marshak, D.R.; Tegtmeyer, P. cdc2 phosphorylation of threonine 124 activates the origin-unwinding functions of simian virus 40 T antigen. J. Virol. 1993, 67, 5206–5215. [Google Scholar] [CrossRef] [PubMed]
- McVey, D.; Woelker, B.; Tegtmeyer, P. Mechanisms of simian virus 40 T-antigen activation by phosphorylation of threonine 124. J. Virol. 1996, 70, 3887–3893. [Google Scholar] [CrossRef] [PubMed]
- Xiao, C.Y.; Hubner, S.; Jans, D.A. SV40 large tumor antigen nuclear import is regulated by the double-stranded DNA-dependent protein kinase site (serine 120) flanking the nuclear localization sequence. J. Biol. Chem. 1997, 272, 22191–22198. [Google Scholar] [CrossRef]
- Hornbeck, P.V.; Zhang, B.; Murray, B.; Kornhauser, J.M.; Latham, V.; Skrzypek, E. PhosphoSitePlus, 2014: Mutations, PTMs and recalibrations. Nucleic Acids Res. 2015, 43, D512–D520. [Google Scholar] [CrossRef]
- Nasheuer, H.P.; Moore, A.; Wahl, A.F.; Wang, T.S. Cell cycle-dependent phosphorylation of human DNA polymerase alpha. J. Biol. Chem. 1991, 266, 7893–7903. [Google Scholar] [CrossRef]
- Voitenleitner, C.; Rehfuess, C.; Hilmes, M.; O’Rear, L.; Liao, P.C.; Gage, D.A.; Ott, R.; Nasheuer, H.P.; Fanning, E. Cell cycle-dependent regulation of human DNA polymerase alpha-primase activity by phosphorylation. Mol. Cell Biol. 1999, 19, 646–656. [Google Scholar] [CrossRef] [PubMed]
- Voitenleitner, C.; Fanning, E.; Nasheuer, H.P. Phosphorylation of DNA polymerase alpha-primase by cyclin A-dependent kinases regulates initiation of DNA replication in vitro. Oncogene 1997, 14, 1611–1615. [Google Scholar] [CrossRef]
- Liu, J.S.; Kuo, S.R.; Melendy, T. Phosphorylation of replication protein A by S-phase checkpoint kinases. DNA Repair 2006, 5, 369–380. [Google Scholar] [CrossRef]
- Olson, E.; Nievera, C.J.; Klimovich, V.; Fanning, E.; Wu, X. RPA2 is a direct downstream target for ATR to regulate the S-phase checkpoint. J. Biol. Chem. 2006, 281, 39517–39533. [Google Scholar] [CrossRef] [PubMed]
- Ashley, A.K.; Shrivastav, M.; Nie, J.; Amerin, C.; Troksa, K.; Glanzer, J.G.; Liu, S.; Opiyo, S.O.; Dimitrova, D.D.; Le, P.; et al. DNA-PK phosphorylation of RPA32 Ser4/Ser8 regulates replication stress checkpoint activation, fork restart, homologous recombination and mitotic catastrophe. DNA Repair 2014, 21, 131–139. [Google Scholar] [CrossRef] [PubMed]
- Lai, Y.; Zhu, M.; Wu, W.; Rokutanda, N.; Togashi, Y.; Liang, W.; Ohta, T. HERC2 regulates RPA2 by mediating ATR-induced Ser33 phosphorylation and ubiquitin-dependent degradation. Sci. Rep. 2019, 9, 14257. [Google Scholar] [CrossRef] [PubMed]
- Albert, B.; Kos-Braun, I.C.; Henras, A.K.; Dez, C.; Rueda, M.P.; Zhang, X.; Gadal, O.; Kos, M.; Shore, D. A ribosome assembly stress response regulates transcription to maintain proteome homeostasis. eLife 2019, 8, e45002. [Google Scholar] [CrossRef] [PubMed]
- Bertoli, C.; Skotheim, J.M.; de Bruin, R.A. Control of cell cycle transcription during G1 and S phases. Nat. Rev. Mol. Cell Biol. 2013, 14, 518–528. [Google Scholar] [CrossRef]
- Takeda, D.Y.; Dutta, A. DNA replication and progression through S phase. Oncogene 2005, 24, 2827–2843. [Google Scholar] [CrossRef] [PubMed]
- Huang, H.; Zhao, K.; Arnett, D.R.; Fanning, E. A specific docking site for DNA polymerase alpha-primase on the SV40 helicase is required for viral primosome activity, but helicase activity is dispensable. J. Biol. Chem. 2010, 285, 33475–33484. [Google Scholar] [CrossRef]
- Wachi, S.; Yoneda, K.; Wu, R. Interactome-transcriptome analysis reveals the high centrality of genes differentially expressed in lung cancer tissues. Bioinformatics 2005, 21, 4205–4208. [Google Scholar] [CrossRef] [PubMed]
- Shimazu, T.; Komatsu, Y.; Nakayama, K.I.; Fukazawa, H.; Horinouchi, S.; Yoshida, M. Regulation of SV40 large T-antigen stability by reversible acetylation. Oncogene 2006, 25, 7391–7400. [Google Scholar] [CrossRef]
- Uramoto, H.; Hackzell, A.; Wetterskog, D.; Ballagi, A.; Izumi, H.; Funa, K. pRb, Myc and p53 are critically involved in SV40 large T antigen repression of PDGF beta-receptor transcription. J. Cell Sci. 2004, 117 Pt 17, 3855–3865. [Google Scholar] [CrossRef]
- Utani, K.; Aladjem, M.I. Extra View: Sirt1 Acts As A Gatekeeper Of Replication Initiation To Preserve Genomic Stability. Nucleus 2018, 9, 261–267. [Google Scholar] [CrossRef] [PubMed]
- Shi, Y.; Dodson, G.E.; Shaikh, S.; Rundell, K.; Tibbetts, R.S. Ataxia-telangiectasia-mutated (ATM) is a T-antigen kinase that controls SV40 viral replication in vivo. J. Biol. Chem. 2005, 280, 40195–40200. [Google Scholar] [CrossRef] [PubMed]
- Liu, S.; Opiyo, S.O.; Manthey, K.; Glanzer, J.G.; Ashley, A.K.; Amerin, C.; Troksa, K.; Shrivastav, M.; Nickoloff, J.A.; Oakley, G.G. Distinct roles for DNA-PK, ATM and ATR in RPA phosphorylation and checkpoint activation in response to replication stress. Nucleic Acids Res. 2012, 40, 10780–10794. [Google Scholar] [CrossRef] [PubMed]
- O’Reilly, D.R. p53 and transformation by SV40. Biol. Cell 1986, 57, 187–196. [Google Scholar] [CrossRef] [PubMed]
- Lane, D.; Levine, A. p53 Research: The past thirty years and the next thirty years. Cold Spring Harb. Perspect. Biol. 2010, 2, a000893. [Google Scholar] [CrossRef] [PubMed]
- Fry, E.A.; Mallakin, A.; Inoue, K. Translocations involving ETS family proteins in human cancer. Integr. Cancer Sci. Ther. 2018, 5, 1000281. [Google Scholar] [CrossRef]
- Ebegboni, V.J.; Jones, T.L.; Brownmiller, T.; Zhao, P.X.; Pehrsson, E.C.; Rajan, S.S.; Caplen, N.J. ETS1, a target gene of the EWSR1::FLI1 fusion oncoprotein, regulates the expression of the focal adhesion protein TENSIN3. Mol. Cancer Res. 2024. [Google Scholar] [CrossRef]
- Dittmer, J. The role of the transcription factor Ets1 in carcinoma. Semin. Cancer Biol. 2015, 35, 20–38. [Google Scholar] [CrossRef]
- Yordy, J.S.; Li, R.; Sementchenko, V.I.; Pei, H.; Muise-Helmericks, R.C.; Watson, D.K. SP100 expression modulates ETS1 transcriptional activity and inhibits cell invasion. Oncogene 2004, 23, 6654–6665. [Google Scholar] [CrossRef]
- Miteva, Y.V.; Budayeva, H.G.; Cristea, I.M. Proteomics-based methods for discovery, quantification, and validation of protein-protein interactions. Anal. Chem. 2013, 85, 749–768. [Google Scholar] [CrossRef]
- Blom, N.; Sicheritz-Ponten, T.; Gupta, R.; Gammeltoft, S.; Brunak, S. Prediction of post-translational glycosylation and phosphorylation of proteins from the amino acid sequence. Proteomics 2004, 4, 1633–1649. [Google Scholar] [CrossRef] [PubMed]
- Ashburner, M.; Ball, C.A.; Blake, J.A.; Botstein, D.; Butler, H.; Cherry, J.M.; Davis, A.P.; Dolinski, K.; Dwight, S.S.; Eppig, J.T.; et al. Gene ontology: Tool for the unification of biology. The Gene Ontology Consortium. Nat. Genet. 2000, 25, 25–29. [Google Scholar] [CrossRef] [PubMed]
- GOConsortium, The Gene Ontology resource: Enriching a GOld mine. Nucleic Acids Res. 2021, 49, D325–D334. [CrossRef] [PubMed]
- Rivals, I.; Personnaz, L.; Taing, L.; Potier, M.C. Enrichment or depletion of a GO category within a class of genes: Which test? Bioinformatics 2007, 23, 401–407. [Google Scholar] [CrossRef]
- Bessarabova, M.; Ishkin, A.; JeBailey, L.; Nikolskaya, T.; Nikolsky, Y. Knowledge-based analysis of proteomics data. BMC Bioinform. 2012, 13 (Suppl. 16), S13. [Google Scholar] [CrossRef]









Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dey-Rao, R.; Shen, S.; Qu, J.; Melendy, T. Proteomics Analysis of the Polyomavirus DNA Replication Initiation Complex Reveals Novel Functional Phosphorylated Residues and Associated Proteins. Int. J. Mol. Sci. 2024, 25, 4540. https://doi.org/10.3390/ijms25084540
Dey-Rao R, Shen S, Qu J, Melendy T. Proteomics Analysis of the Polyomavirus DNA Replication Initiation Complex Reveals Novel Functional Phosphorylated Residues and Associated Proteins. International Journal of Molecular Sciences. 2024; 25(8):4540. https://doi.org/10.3390/ijms25084540
Chicago/Turabian StyleDey-Rao, Rama, Shichen Shen, Jun Qu, and Thomas Melendy. 2024. "Proteomics Analysis of the Polyomavirus DNA Replication Initiation Complex Reveals Novel Functional Phosphorylated Residues and Associated Proteins" International Journal of Molecular Sciences 25, no. 8: 4540. https://doi.org/10.3390/ijms25084540