1. Introduction
According to the World Health Organization (WHO), chronic diseases kill 40 million people each year, contributing to
of the global mortality rate [
1]. Epilepsy is one of the chronic neurological disorders characterized by the occurrence of sudden and recurrent abnormal neuronal activity in the brain called seizures [
2]. The seizures may vary from being undetectable episodes to long episodes of vigorous shaking of the body [
3]. The morbidity and mortality of epilepsy are largely associated with the sudden loss of consciousness, fatal injuries caused by unforeseen seizures, and status epilepticus, where a life-threatening seizure lasts for more than five minutes [
4].Epilepsy affects 50 million people globally, and 30–40% of this group cannot be treated with any available medicinal therapy [
4].
Advanced Implantable Medical Devices (IMD) such as Deep Brain Stimulator (DBS) [
5] and Vagus Nerve Stimulator (VNS) [
6] have been extensively researched and developed to significantly reduce the seizure frequency for the patients who do not respond to Anti-Epileptic Drugs (AED) [
4,
7,
8]. IMDs deliver electrical impulses through brain-implanted electrodes to a specific target area in the brain in order to reduce the seizure frequency. However, these IMDs deliver chronic therapy rather than acute targeted therapy, and also lack physiological feedback, which limits their efficacy [
8]. For the last 80 years, analyzing the electrical signals from the brain, namely ElectroEncephaloGraphy (EEG) and ElectroCorticoGraphy (ECoG), is a well-established method to describe the physiological process of the seizure development and its impact over different parts of the brain [
9]. EEG is a non-invasive method of measuring the electrical signals with electrodes that are placed on the surface of the scalp, whereas ECoG is an invasive method with electrodes that are placed directly on the exposed surface of the brain [
10]. The advantages of ECoG over EEG are: (i) the Signal-to-Noise Ratio (SNR) of brain signals in ECoG is higher due to the use of electrodes implanted directly on the brain’s surface (unlike EEG, which uses electrodes mounted on the scalp); (ii) collecting ECoG signal is more convenient for the patient than EEG since the patient does not have to be monitored for long periods; (iii) the impact of artifacts caused by physical movements, electrical activities, and other electrical wearable is almost negligible in ECoG signal [
10,
11]. Nonetheless, these ECoG signals are highly patient-specific and require medical intervention from experts to analyze these signals.
Applying the principles of statistics to automate the analysis of these physiological signals and to predict the onset of seizure has been researched since 1970 [
12,
13]. In the last two decades, extensive use of machine learning algorithms to detect the onset of seizure based on EEG and ECoG recordings have been reported. Machine learning algorithms such as Artificial Neural Networks (ANN) and Support Vector Machines (SVM) are used to detect seizure events, given the patient-specific EEG data analysis [
14,
15,
16]. The outcome of these algorithms can be effectively used as physiological feedback to the IMDs, which will then expectantly operate in a closed-loop fashion. As a result, the efficacy of the treatment will be improved by delivering intense targeted stimulation [
14].
However, due to the inherent uncertainty of the brain signals and because EEG and ECoG vary a lot depending on age, environments, drug intake, etc., it is extremely challenging, if not impossible, to develop a generic seizure prediction framework for all epileptic patients [
17]. In addition, in the case of epilepsy, seizure patterns for each patient not only are unique but also vary with time [
18]. As a result, a generic machine learning algorithm will not efficiently work for the same patient as well as for large patient groups [
19]. It is evident that constant intervention from a medical expert is required for the generic algorithms to work with the same accuracy in a large patient group.
A more common way to approach this problem is to collect continuous EEG and ECoG data, which captures unique seizure patterns and pre-seizure patterns for individual patients. The collected data is then used to train machine learning algorithms and to develop a patient-specific seizure prediction algorithm. However, this approach is not scalable to large patient groups as developing patient-specific machine learning models requires enormous efforts in collecting, labeling, and training the machine learning algorithms. In addition, a seizure event typically occurs for about
of a patients lifetime and, for
of the time, an epileptic patient is seizure free. This infrequency in seizure events makes it difficult to capture the naturally occurring seizure patterns that are very different from induced seizure patterns [
18].
A notable limitation of the existing methods is the complete exclusion of human-expert in the real-time seizure detection systems, since the human expertise is only utilized for labelling the recorded seizure patterns during the pre-development of the patient-specific seizure-detection systems.
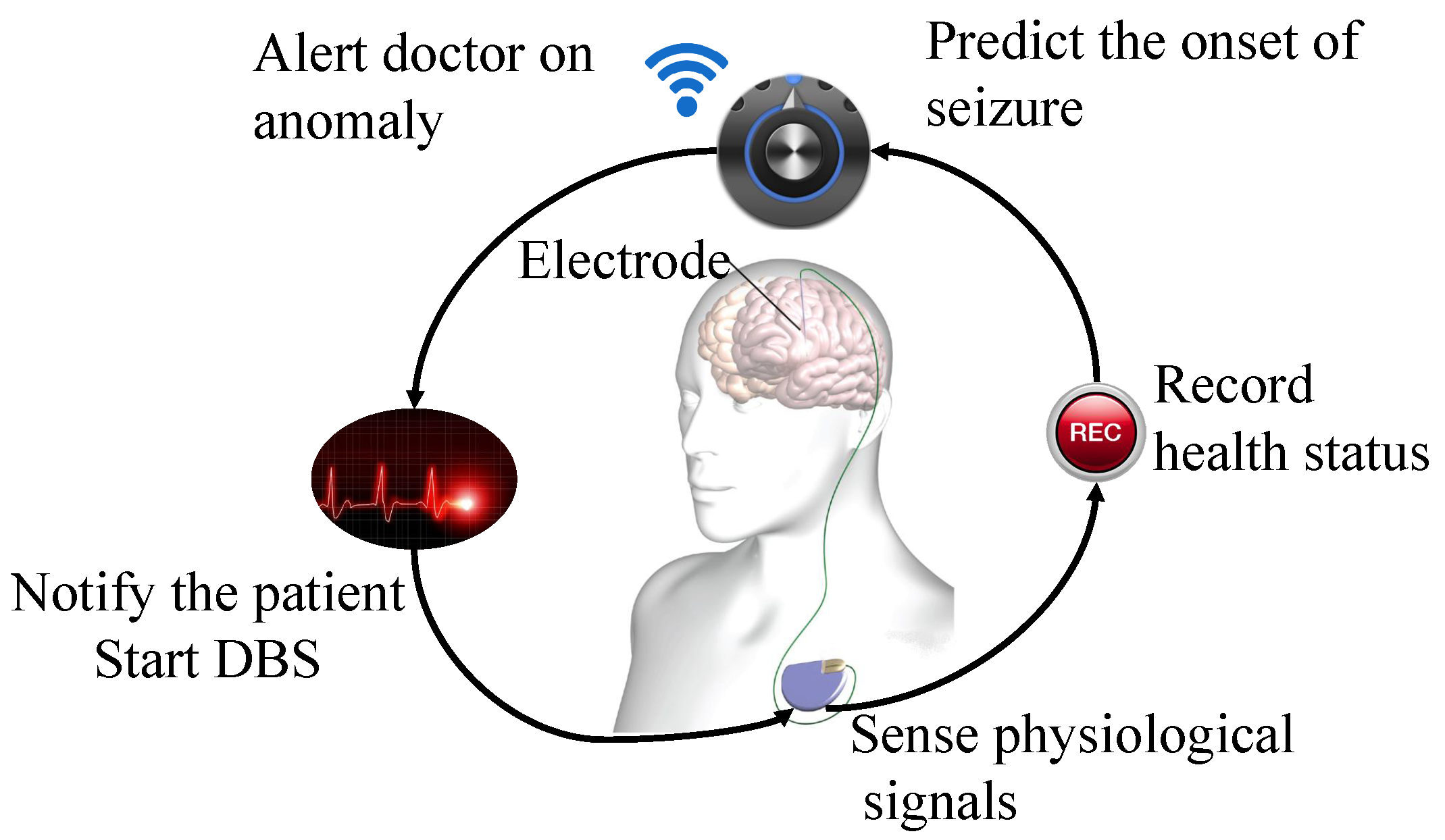
The first long-term in-man study for a stand-alone seizure advisory system, which predicts the onset of seizures, concluded that substantial disparities are found between reported and detected seizure events, with patient-specific seizure prediction algorithms [
19]. (A semi-autonomous operation of advanced medical therapies such as Deep Brain Stimulator (DBS) shown in
Figure 1.)
In order to overcome this limitation, authors of [
21] used active learning heuristics aiming to reduce the enormous efforts of labeling the data during the training of machine learning model. They developed a scalable and personalized event detection algorithm for infrequent events, like seizure detection in an epileptic patient. Although their results concluded that active learning significantly reduced the number of labels required to train a SVM classifier, the accuracy of detecting an event was not improved.
To this end, in this paper, we propose a lightweight seizure prediction framework that can run on an off-the-shelf ultra-low power hardware, yet can leverage the expert’s knowledge on handling the ambiguous ECoG data in a scalable manner. The main contributions of our paper are:
Analysis and selection of feature set based on computational time and memory usage,
Performance analysis of seven different classifiers to select the best performing classifier on a resource constrained platform,
Application of active learning heuristics and development of a probabilistic seizure prediction framework,
Performance evaluation of our algorithm based on seizure predictability through simulations.
The rest of this paper is organized as follows. In
Section 2, we present the preliminary background for our seizure prediction framework, explaining the nature of the brain signals of an epileptic patient, the main challenges of the online seizure prediction systems, and the related work. In
Section 3, we explain the principles of our seizure prediction framework and its active learning heuristics. In
Section 4, we explain simulation settings, followed by the validation metrics. In
Section 5, we present and discuss the results obtained. Finally, we conclude our work in
Section 6.
2. Preliminary Background
In this section, we briefly explain the nature of brain signals of an epileptic patient, the main challenges in seizure prediction, and the related work.
2.1. ECoGignal
In our study, we use the ECoG signals to design the prediction framework. ECoG is a type of electrophysiological monitoring that measures the electrical activity on specific locations in the brain by implanting a surface-electrode-array through invasive brain surgery [
10]. Each electrode in the array is considered as a channel of the measurement. Each channel is sampled at a constant sampling rate producing a constant number of ECoG samples per second. For example, a sampling rate of 400 Hz will produce 400 samples per second on each channel. We will study ECoG of 16 channels.
As shown in
Figure 2, the ECoG is categorized into four periods, namely ictal period, pre-ictal period, post-ictal period, and inter-ictal period [
22]. The ictal period is when the actual seizure occurs. The post-ictal is the period shortly after the ictal period when significant spikes in ECoG occur sparsely. The pre-ictal is the period before the seizure occurrence when a patient feels visual auras. The inter-ictal is the seizure-free period between two seizure events [
12]. The seizure events are detected in the ictal period. To predict the onset of the ictal period, it is important to detect the pre-ictal period. By doing so, the clinical measures to reduce the impact of seizure events can be taken. Typically, the pre-ictal period can vary from 10 min to 1 h depending on different seizure and patient types; however, there is no straightforward way to define a unique pre-ictal period for future data [
23].
By well-established conventions, the Seizure Occurrence Period (SOP) is the time period within which a seizure is expected and the Seizure Prediction Horizon (SPH) is the time period between the onset of prediction alarm and the SOP [
19,
25,
26,
27,
28]. A seizure prediction framework should analyze real-time ECoG and must generate a time series of binary data classification of pre-ictal denoted by (1) and inter-ictal denoted by (0). These binary classifications can be translated into a seizure warning, and a necessary medical treatment can be provided in real time before the onset of a seizure event. Note that SPH is clinically unknown, but it has to be longer than a pre-ictal period [
25]. Ideally, the SPH can be consistently set to the upper bound of the standard pre-ictal period, i.e., 1 h duration, so that SPH will be persistent even for shorter pre-ictal periods say, 5 or 50 min.
2.2. Challenges in Seizure Prediction
Although there exist numerous research results in the area of the seizure prediction, most of them are not suitable for real-time detection and execution on low-power devices. It is a well-established convention that EEG data will be collected at a power-deficient sensor node, and the processing of signal will be carried out on a power-surplus base station. Recently, this convention is evidently changing. With the rapid development of the IMDs, the need for seizure prediction algorithm to be able to locally run on such resource constrained environment is paramount. Most of the existing work on seizure prediction arena will neither fit in these resource-constrained hardware platform nor be able to meet the requirements for clinical applications. To this end, we summarize the limitations of seizure prediction concerning the ultra-low power IMDs as follows.
2.2.1. Ultra-Low Power Requirement
As the IMDs are continuously shrinking in size, the need for highly reliable data processing techniques is growing stronger. The physical limitation of resources such as power, and computational capability, is a barrier to run complex algorithms locally on the IMDs. An overview of the technical specification of various IMDs is presented in
Table 1. In addition, newly developed algorithms are computationally complex and require more resources to achieve high reliability. An optimum design should intelligently compromise the power consumption and the performance metrics such as reliability and accuracy.
2.2.2. Paradigm Shift from Offline to Online Learning of Seizure Patterns
Neural networks and deep learning have the potential to detect particular seizure related patterns, by extracting and learning features from EEG data without a priori knowledge of the seizure structure. However, the use of these advanced learning algorithms on the IMDs is severely limited due to their large power-hungry computation. With advances in computer architecture such as neuro-morphic computing [
34], which mimics the human brain in computations, complex computations with very low power consumption were proven to be possible. Nonetheless, these hardware platforms are still under development to be used for life-critical medical applications. This limits the immediate use of these online learning algorithms on the IMDs.
2.2.3. Uncertainty of Brain Signals
The underlying cause of seizure dynamics in the brain is still not clear. However, the brain has its own regulatory mechanism which could stabilize any abnormal activity in the brain [
35]. Because of this, deterministic seizure prediction will not be capable of accurately predicting the onset of seizure, as the seizure event could have been regulated by the brain itself. To address this issue, authors in [
18] suggest utilizing a more probabilistic approach such as regression, in which brain signals are continuously filtered through a probability model of seizure events. Moreover, EEG and ECoG are highly uncertain and are susceptible to noises from other parts of the brain that may closely resemble seizure events. The use of other bio-markers such as heart rate and blood pressure has been shown to improve the prediction accuracy [
36].
2.2.4. Expert Intervention Is Both Constructive and Destructive
In life-critical seizure prediction systems, where the brain signals are very heterogeneous and uncertain, an expert intervention is needed to overview the outcome of such systems. However, such personalized care with close monitoring of the patient by an expert is unscalable to large size of patient groups. This destructs the purpose for autonomous seizure prediction system, when the outcome of each event has to be monitored by an expert. Nonetheless, when such an autonomous system can detect the ambiguity in the signal with high confidence, an expert can intervene to assist the system with a further course of action. Minimal intervention can be constructive in cases like generic seizure prediction systems.
2.3. Related Work
A substantial amount of work has been done in detecting the ictal epochs over the last six decades [
37]. It was not until recent years that the focus of research is being shifted to detect the pre-ictal epochs, which is proven to be more helpful in prediction of seizure [
19]. A significant number of algorithms have been proposed for seizure prediction at a crowd-sourced seizure forecast competition in Kaggle, set up in the year 2014 by the American Epilepsy Society [
37]. A similar approach has been followed by the University of Melbourne together with the American Epilepsy Society in 2016 using a different dataset available in [
38]. Most of the top 10 performing algorithms in this competition used SVM based classifiers and used frequency domain features. The description and performance of the top 10 performing algorithms are described in [
37].
All of these algorithms are designed to perform well on patient-specific data and with an abundance of labelled data in the pre-ictal class. These algorithms, however, do not focus on the problem of data insufficiency and scalability to large patient groups, but rather focus on the high detection accuracy using patient-specific models. In a practical setting, it is difficult, if not impossible, to collect a large amount of such categorized data in advance for an epileptic patient. A thorough review of existing seizure prediction techniques is presented in [
39] by Gadhoumi et al. Other seizure prediction algorithms that aim to be adaptive in their seizure prediction are summarized in
Table 2.
One of the major disadvantages of these adaptive seizure prediction algorithms is that they do not have any direct mechanism to handle the ambiguous data that cannot be confidently classified into either pre-ictal class or inter-ictal class. These algorithms aim at changing classifier’s properties such as the distance threshold from the classification plane to improve the classification accuracy. In case of the seizure prediction, in which there is an abundance of ambiguous samples, a simple increase or decrease in the classifier’s threshold will not only decrease the accuracy, but also increase the misclassification rate of the minority class.
The first use of active-learning heuristics to handle the ambiguous data was presented by the authors of [
21], where they presented an outlier detector over the results of an SVM classifier and selected the samples that were far away from classification boundary.
In [
41], Gupta et al. compared different techniques for active selection and proposed a novel output-based active selection (OAS) method for the active learning framework. In OAS, a meta-classifier called the Bernoulli-Gaussian Mixture Model (BGMM), which combines the base classifier’s uncertainty along with base classifier’s outputs, is generated. The resulting BGMM model has a mixture of distributions consisting of the feature set distribution, crisp label distribution, and soft label distribution. The sub-population of the ambiguous feature set is considered as a hidden variable and identified from the overall population of feature set by estimating the parameters of feature set distribution with respect to crisp and soft label distribution. The set of features with the highest ambiguity is selected using the BGMM.
One of the main advantages of using BGMM over other active selection methods is that it combines the prediction uncertainty with the actual prediction outcome of the classifier to effectively mitigate the querying of morbid samples to be labelled by an expert [
41]. The authors applied this algorithm for the task of ensemble classification with an array of re-trainable classifiers using active learning heuristics.
2.4. Hypothesis for Our Seizure Prediction Framework
It is a well-established fact that brain signals are inherently uncertain, and pre-ictal signals may vary for different types of seizures [
16,
39,
42]. Moreover, pre-ictal signals can temporally vary for the same seizure and even for the same patient. In this study, we hypothesize that,
Gradual accumulation of pre-ictal signals would improve the overall accuracy of seizure prediction.The inclusion of expert in the system will ensure that pre-ictal signals are labelled correctly in case of ambiguity in classification. However, selecting ambiguous samples to be labelled by an expert without diminishing the autonomous property of the seizure prediction system is a crucial task. By doing so, a seizure prediction system can achieve high prediction accuracy with less number of initial training samples, i.e., with less number of pre-recorded pre-ictal data.
To this end, we aim to develop a seizure prediction framework that is capable of handling the ambiguous samples by seeking feedback from an expert. We will adapt the BGMM to be used for the task of binary classification of pre-ictal and inter-ictal periods from ECoG signals under active learning heuristics. The core of our active learner is based on this BGMM block, which will determine the feature samples that have the most ambiguity. In the following section, we present the seizure prediction framework of which our major contribution is the active learner block and its integration with the machine learning classifier in a closed-loop fashion.
3. Adaptive Seizure Prediction Framework
The main aim of our seizure prediction framework is to predict the seizure events with a minimum number of labelled data, and to be scalable for large patient groups. In addition, the complexity of the framework will be kept minimal so that it can be operated on a resource-constrained embedded platforms. As shown in
Figure 3, our prediction framework receives the raw ECoG signal over which the set of features will be extracted. The obtained feature set is forwarded to a classification model, which will classify the feature samples into two different classes of labels, i.e., pre-ictal and inter-ictal, with a degree of certainty. During initialization of our framework, the classification model is obtained from minimal labels that are generic to large patient groups. This significantly shortens the initial training periods to obtain a patient-specific classifier model, which will be used in the online phase.
To determine whether a sample is so ambiguous that an expert has to manually annotate, we designed the thresholding block. This block filters the ambiguous samples based on an optimal threshold tuned during the training phase. The threshold is the percentage of the correctly predicted labels accumulated during 1 h. If the outcome is above the threshold, a seizure alarm is triggered. Otherwise, the feature set, the stored labels, and the classification certainty are forwarded to the active learner block, which operates with a core of Bernoulli-Gaussian Mixture Model (BGMM). Labels for the ambiguous samples are obtained from an expert, and the classifier model is updated accordingly. This feedback loop through an active learner would improve the accuracy of the classifier with a minimum number of initial training labels and also the patient-specific accuracy is enhanced over time. In what follows, we elaborate on the functionality of the main building blocks of the framework.
3.1. Feature Extraction
The typical approach to analyze the ECoG data using machine learning algorithms is to pre-process the raw signal by computing features. Using features would enhance the classification accuracy and reduce the computational burden. Since the signal conversion from time-domain to frequency-domain consumes a substantial amount of power and considerable processing-time, we focus on the ECoG temporal signals to achieve low-complexity for running on embedded systems. To this end, we selected eight features, which can represent well the pre-ictal epileptiform discharges in the time domain. The features selected are listed below and their definition are stated in [
43]:
“Area—Describes the normalized positive area under the curve.
Normalized decay—Describes the chance-corrected fraction of signal that is decreasing or increasing.
Line length—Describes sum of the absolute differences between successive data points.
Mean energy—Describes mean energy across the data.
Peak amplitude—Describes the base-10 logarithm of the mean-squared amplitude of the peaks, where a peak is defined as a change from negative to positive in the signal derivative sign.
Valley amplitude—Describes the base-10 logarithm of the mean-squared amplitude of the valleys, where a valley is defined as a change from positive to negative in the signal derivative sign.
Normalized peak number—Describes the number of peaks present normalized by the average difference between adjacent data point values.
Peak variation—Describes the variation between peaks and valleys across both time and values of the data.” [43].
All the above features are computed based on samples collected during non-overlapping sliding windows. For example, a window size of 20 s of ECoG will have 8000 raw samples when sampled at 400 Hz. These time domain features will be extracted from 16 selected channel of the ECoG, which are the most informative channels [
44]. As a result for each sliding window, we will have a 128-dimensional vector (16 channels * 8 features), collectively denoted as
features.
In order to compare the effect of different time-domain and frequency-domain feature sets on classification accuracy, we will also compute the frequency-domain features over the ECoG signals. The frequency-domain set of input features represents the power-in-band properties of the ECoG signals in the commonly studied Berger’s frequency bands, Standard Delta (0–4 Hz), Theta (4–8 Hz), Alpha (8–12 Hz), Beta (12–30 Hz), and Gamma (30–100 Hz). We filter 20 s of ECoG data using a band-pass filter (2nd order Butterworth) with five frequency bands and find the power spectral density by squaring the signal (based on Plancheral theorem to skip the calculation of FFT over ECoG signals). Then, we extract a set of 80 dimensional (16 channels * 5 features) features from non-overlapping 20-s windows of raw ECoG signal, collectively denoted as features.
3.2. Classification Model
The classifier is an integral part of the prediction framework as shown in
Figure 3. We focus on binary classification problem to classify the pre-ictal data and inter-ictal data from patient-specific ECoG. The classification model is generated based on patient-specific ECoG signals. One of the crucial criteria for selecting the classification method is the memory required and the classification time of classifiers. We selected seven classifiers, namely,
k-Nearest neighbour (kNN) with k = 3,
k-Nearest neighbour (kNN) with k = 5,
Support Vector Machine (SVM),
Logistic regression,
Naive Bayes,
Linear Discriminant Analysis (LDA),
Quadratic Discriminant Analysis (QDA).
We chose three and five neighbors in kNN to generate distinct class boundaries, as a larger k makes boundaries between the classes less distinguishable. The implementation of these classifiers is fairly standard in MATLAB (2017a, MathWorks, Inc., Natick, MA, USA). The classifier is trained with features extracted over 20-s non-overlapping time windows of subject-wise ECoG signals. It is important to note that the entire original dataset will be segmented into 20-s windows and balanced to train the classifier model for different subjects. This process will be explained in detail under
Section 4.
3.3. Thresholding
The main aim of threshold block in our seizure prediction framework is to temporally analyze the output of the classifier over a period based on a pre-tuned threshold, and to decide if the signal represents the pre-ictal class or the inter-ictal class. For this, we use the segmentation of classifier’s outcome in one hour blocks, i.e., for each 20 s of the raw ECoG signals, the classifier model outputs the class, either pre-ictal or inter-ictal. This outcome is accumulated for 1 h of raw ECoG contributing to 180 classification labels. The threshold is computed based on the ratio between the percentage of the correctly predicted labels accumulated during 1 h. The threshold is computed based on the ratio of the number of correctly predicted labels accumulated during 1 h. If a threshold of is set, it means 126 out of the 180 classification labels should be classified as pre-ictal to trigger a seizure alarm. If it cannot be achieved, the feature set is forwarded to the active learner block together with the soft labels (certainty of the prediction) and crisp labels (prediction of the class) from the classifier. In our experiment, the optimal threshold of 70% was empirically found by varying it using our dataset. As shown in our experimental evaluation, the choice of 70% indeed improved the classification accuracy. In real-world scenarios, this threshold can be changed according to the requirements of the patient and the dataset.
3.4. Active Learner
In general, all pre-ictal signals are believed to be unique for each seizure, so it is impossible to capture all the expected pre-ictal signal types in a patient’s lifetime [
19]. The re-training process without new labels will not improve the accuracy of the classifier model for unknown pre-ictal signals. An expert’s knowledge is constantly needed to maintain the high accuracy in seizure prediction throughout patient’s lifetime. The advantage of applying the active-learning heuristic to the output of classifier is twofold. One is to improve the prediction accuracy by dynamically updating the classifier model, and the other is to make it scalable by frequently updating the classifier model to achieve patient-non-specific detection of pre-ictal periods. Updating the classifier model requires additional labels and a training phase to derive a model based on the newly obtained labels. In an active learning framework, these additional labels are provided by an expert (otherwise known as oracle w.r.t. active learning terminologies) by observing the ambiguous samples. The process of labeling by the expert and updating the classifier model through training is repeated until a stopping criterion is met. An important aspect of active learning in addressing the issue of expensive labelling over other semi-supervised learning is that active learning explores the instances with the most ambiguity or least confidence, whereas the latter explores the instances with least ambiguity or the most confidence. However, selecting the samples to be labelled by the expert is a crucial task, which decides the success of the active learning framework.
There are various techniques to select the ambiguous samples to be labelled. Examples include the uncertainty-based selection [
45], the margin information density criterion [
46], and the importance weighting technique [
47]. The total number of labelled pre-ictal samples is often lower than the amount of the available inter-ictal samples. Outlier based ambiguous sample selection for active learning will select morbid samplesto be classified in a multi-dimensional feature space, which results in high misclassification. A morbidset of samples is defined as the set of most uncertain samples, which would belong to the same class as predicted by a classifier model, despite the fact that they actually belong to two different classes. Selecting this morbid set of samples to be labelled by an expert will not only increase the labelling cost, but also show no significant improvement in the detection accuracy.
3.4.1. Bernoulli-Gaussian Mixture Model
To prevent morbid samples from being selected to be labelled by an expert, we use BGMM as the active selector block. BGMM will create a mixture of three probability distributions namely, ambiguous-sample and label distributions as Gaussian distributions and their certainty distribution as a Bernoulli distribution. The ambiguity of new samples will be estimated by identifying the probability of the new sample to belong to either pre-ictal or ictal class. The sample with the least probability will be selected to be labeled by an expert. In what follows, we will explain the mathematical modelling of the BGMM block with respect to our problem of ambiguous pre-ictal sample selection from ECoG signals.
Let the feature space defined by
, where
d denotes the feature dimension and
denotes the measurable set of ECoG signals. Let the binary output space defined by
. We consider the problem of estimating the joint probability density
given a set of input ECoG observations
and output seizure labels
, where
L is the total number of available labels and
N is the total number of observed ECoG samples. In our case, the labels do not fully represent the observed samples, i.e.,
, which makes the estimation of
semi-supervised [
41]. Hence, the uncertain labels of seizure are defined as
. Input ECoG observation
is represented as a marginal 2-component Gaussian mixture distribution, i.e., the inter-ictal epoch and the pre-ictal epoch, and defined as follows:
For
,
where
represents the mean and co-variances of the distribution.
The BGMM model also includes the augmented observations
and
where
and
, representing the crisp and soft labels (normalized confidence probability) of the classifier’s outcome, respectively.
K is the maximum number of times an expert can be queried for the label and is set based on the application requirement. The distributions of
are defined as follows. For
and
,
where
and
represent the
kth component of
and
, respectively, and
denotes a Bernoulli distribution for variable
z with success probability
.
From these individual distributions, the joint distribution of BGMM is defined as
with parameters
(mixture proportion),
. The estimation of these parameters is carried out using a an Expectation–Maximization (E–M) algorithm by considering the variables
as hidden variables. The cost function is defined as the error in classification due to non-optimal classifier model, i.e.,
where
is the expectation operator with respect to the probability measure
,
is the optimal classifier model and
is an estimate of the optimal classifier. The estimation of parameters
is done by an E-step and an M-step. The E-step creates a function for the expectation of the log-likelihood using the current estimate for the parameters. The M-step computes the parameters by maximizing the expected log-likelihood of the parameters estimated on the E-step, where the E-step is
where in our case,
,
is defined by
and the
is given by
The output from the BGMM is then forwarded to a
selector block, which selects the samples with least confidence or the most ambiguity, in order to be labelled by an expert. The least confident sample
is selected by
[
48].
3.4.2. Stopping Criterion
The vital step in active learning is to know when to stop querying the expert; otherwise, it will increase the labelling effort and makes the system unscalable for large patient groups. An active learner must be aware of when to stop the expert querying. For this, we monitor the confidence samples that is observed after the selector block in the active learner (
Figure 4). This confidence samples are then used as active feedback to exhibit the confidence in classification accuracy and to stop the active learner from querying the expert.
In order to achieve this, the confidence samples are monitored for each iteration of the active learner block. Querying the expert is stopped when the confidence of the samples remains the same for consecutive iterations of the active learner block. This constant confidence samples directly reflects the accuracy of the base classifier model i.e., the new labels from the expert have improved the classifier model and there are no ambiguous samples to be labelled by an expert. Thus, querying the expert must be stopped immediately.
3.5. Seizure Prediction Framework
Our prediction framework is implemented using four main functional blocks, namely,
- (i)
ExtractFeature: where the n dimensional feature-set is extracted over 20 s time window of raw ECoG signals
- (ii)
Threshold: where a prediction alarm is set, if 70% of the accumulated labels are classified as pre-ictal state,
- (iii)
Classify: where a trained semi-supervised classifier model is used to obtain the set of soft-labels and crisp-labels , from the input feature-set . In addition, the set of uncertain feature samples is obtained based on the soft and crisp-labels of the classifier model,
- (iv)
Activelearner: where a BGMM model based on the feature-set , uncertain sample-set , soft-label set , and crisp-label set is generated. An E-M algorithm is used to obtain the sample-set where the confidence of classification of each sample is determined by the probability . An active sample is selected from the samples of , which has the smallest . The pseudo-code of these individual functional blocks are shown in Algorithm 1.
| Algorithm 1 Pseudo-code of individual functions |
1: function Extract feature()
input:
output:
2: =
3: end function
4: function Classify()
input:
output:
5: for each sample in do
6: (acquire soft and crisp labels)
7: end for
8: return =
(obtain ambiguous samples)
9: end function | 10: function Threshold()
11: if then
12: return = 1
13: else
14: return = 0
15: end if
16: end function
17: function Active learner()
input:
output:
18: (Obtain BGMM model)
19: for each sample in do
20:
21: end for
22:
23: end function |
As shown in Algorithm 2, our prediction framework sequentially utilizes these functional blocks such that, for every 20 s window of raw ECoG signals, the Extract Feature function generates the set of feature vectors. This feature-set is input to the Classify function, in order to obtain the soft and crisp-labels together with the uncertain feature-subset. Based on these labels, Threshold function triggers a prediction alarm if more than 70% of the samples are labelled as pre-ictal state. If less than 70% of the labels are classified as pre-ictal, the feature-set together with soft and crisp-labels are forwarded to the active learner. The Activelearner function then selects the samples with most ambiguity and obtains the label from an expert. The classifier model is updated based on the newly obtained label and the whole procedure is repeated until the end of the ECoG signal.
| Algorithm 2 Pseudo-code of seizure prediction framework |
1: procedure Prediction(, )
2: input:
3: output: (prediction alarm)
4: repeat
5: for every 20 s window of do
6: = Extract feature()
7: = Classify
8: end for
9: while !(time == 60 mins) do
10: = (accumulate the labels for 1 h)
11: end while
12: if !(Threshold()) then
13: = Active Learner()
14: (Obtain labels)
15: update (Update base classifier model)
16: else
17: return
18: end if
19: until End of
20: end procedure |
5. Results and Discussion
In this section, we present and discuss the results.
5.1. Feature Selection
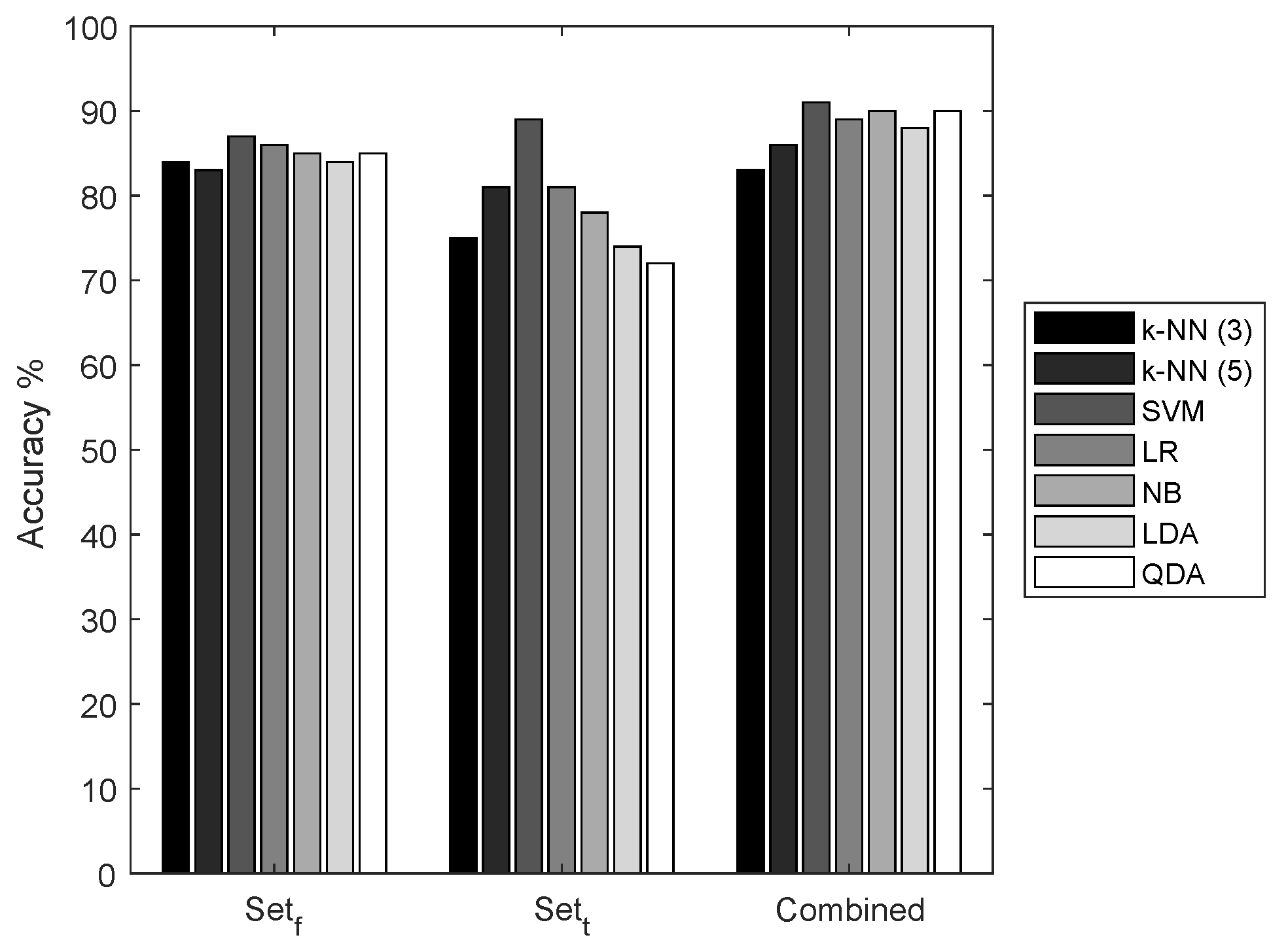
We selected two sets of features representing the time-domain characteristics and spatial-domain characteristics of the ECoG signals. We compared the performance of seven classifiers with three different feature sets,
, and a combination of sets
t and
f. It is apparent from the results shown in
Figure 5 that the combination of the feature set has the highest accuracy in all the classifiers. However,
has low performance when compared to the features of
.
For further evaluation of our seizure prediction framework, we intend to use
, mainly for two reasons: firstly, to measure the impact of the active learner on classifier accuracy. With low accuracy, the results of classifiers are not always reliable. With these empirical results, it is known that these features are not completely capable of representing the ECoG signal in higher dimensional feature space, which will result in a large number of ambiguous feature samples close to the classifier’s hyper-plane. Secondly, the calculation of these features is less complex than the other two sets. These features can be implemented in ultra-low power hardware and the power consumption can be greatly reduced when compared to the implementation of other feature sets [
50].
5.2. Evaluation of Classifier
In this section, we present and discuss the evaluation and selection of the base classifier model for our seizure prediction framework.
5.2.1. Time and Memory Consumption
We evaluate the performance of seven classifiers with the feature set in terms of classification time, i.e., the total time required to classify a 1 h block of raw ECoG signals, using the tic and toc functions of MATLAB. This timing method includes the overhead of the laptop’s background process; however, profiling of all the classifiers is carried out at the same time, with an assurance that the overheads are commonly present during all the timing measurements.
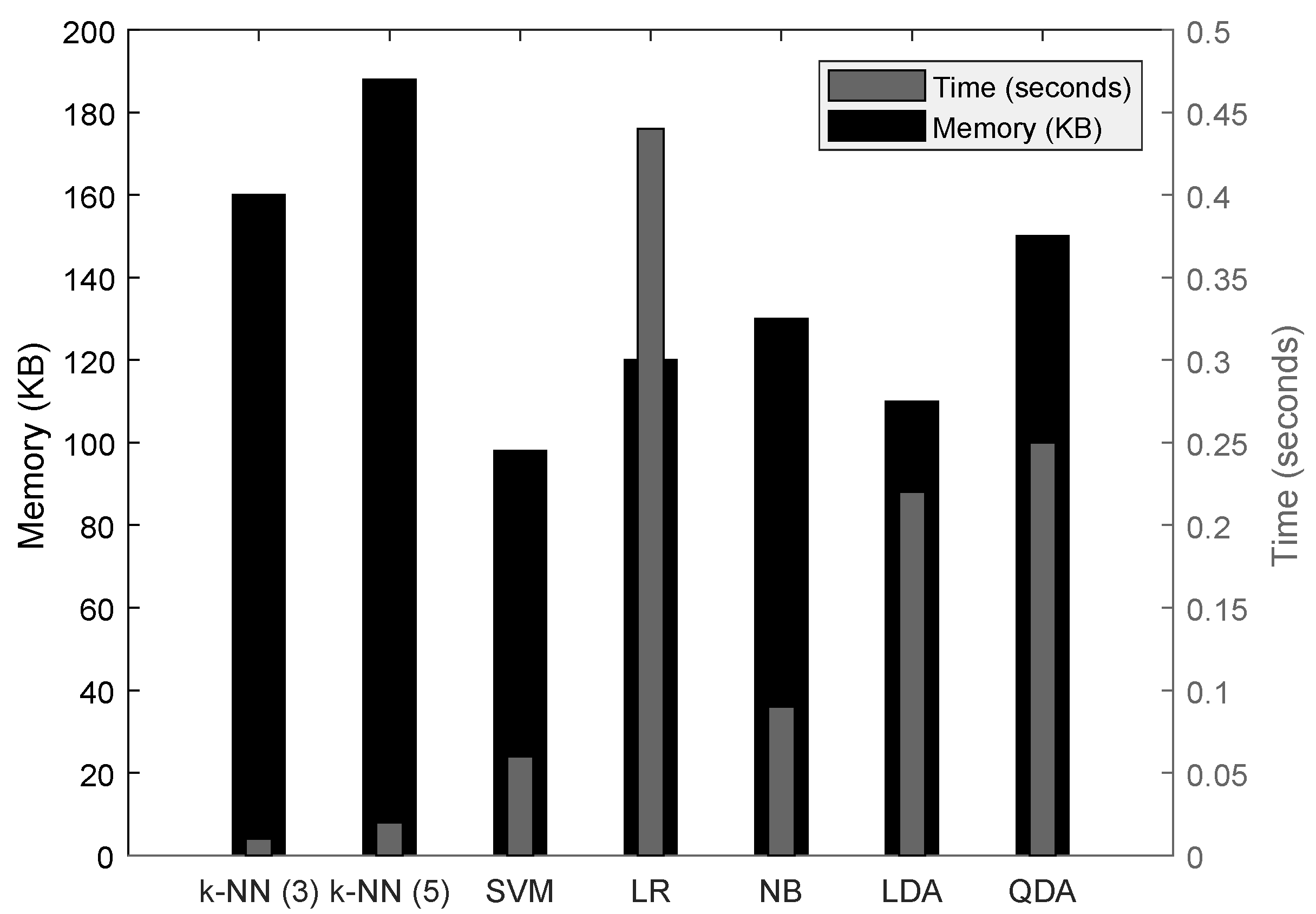
From
Figure 7, it is known that k-NN classifiers require the least time for the classification process because of the minimal computation, but they have the most memory consumption. The most suitable classifier among the list is the SVM, as it requires less memory and requires the least classification time. Based on this result, for further evaluation of the prediction framework, we choose the SVM classifier with
as the feature set extracted from 20 s of non-overlapped ECoG signals.
In SVM, together with the crisp-label, a degree of certainty, i.e., probability of the output, is also extracted after the classification process using the Platt’s scaling method [
51]. In this way, the classifier block outputs a soft-label and a crisp-label after each iteration of the feature set. These labels are forwarded to a threshold block in our prediction framework, which decides whether the classification outcome is eligible for a seizure alarm and can be used for post-processing or if the classifier model needs to be retrained through an active-learning framework.
5.2.2. Evaluation of the Base Classifier Model
In order to evaluate the performance of the classifier with respect to our segmented data, we calculate the performance in each class (pre-ictal and inter-ictal) separately. This ensures that the performance of the classifier is valid for each class. In addition, in this way, we will be able to know how much data from each class is classified as unknown for each subject. For this performance evaluation, we used the segmented data as shown in
Table 4. We discuss the results from all iterations for Dog5 dataset in this section.
In
Table 12, FPR and FNR are calculated for one hour period to match our assumption of prediction horizon. The feature samples that have a degree of certainty of more than 80% in either class is considered clear samples. These samples can be classified with high confidence into one of the classes. The remaining samples that have a lower degree of certainty are grouped as ambiguous samples. Although a perfect classifier model will have a high degree of certainty and less ambiguous samples near the hyperplane, with this superstitious certainty requirement, we intentionally increase the amount of ambiguous data. This setting will replicate the real-world scenario, where the amount of pre-ictal epochs used for training the classifier will be less than the inter-ictal epochs, naturally increasing the amount of ambiguous data or unknown classes.
From
Table 12, it is observed that each iteration using a Dog5 dataset with different validation data has different error rates. In addition, the FPR is always lower than the FNR because of the large amount of inter-ictal data that is used for training the classifier. Iteration5 has the highest number of ambiguous samples, and it is also reflected in the FPR and FNR. The number of ambiguous samples is very high i.e., 78% of the whole validation data used is grouped as ambiguous data. We choose the classifier model, which is developed based on Iteration5 for further evaluation of the active learner block.
In
Table 13, we present the performance of the classifier for inter-ictal datasets, with similar metrics. It is evident that the abundance of inter-ictal data has a positive influence on the classifier performance in terms of FPR and FNR, i.e., only a negligent amount of samples are misclassified in the inter-ictal class. In addition, most of the samples are clear and very few samples are ambiguous in all the iterations. It is observed from these results that all classifier models derived from all five of the iterations have quite similar performances for the inter-ictal class. Therefore, we choose the classifier model based on the pre-ictal performance, which is the model Iteration5 for the subject Dog5.
5.2.3. Classifier Model for Each Subjects
A similar process as explained above is used to obtain the base classifier model for each subject. The number of iterations for each subject depends on the number of available one-hour pre-ictal segments. For example, the subject Dog4 has 16 pre-ictal segments so the classifier model has been iterated for 16-fold cross-validation to find the classifier model with the most ambiguous samples as shown in
Table 5,
Table 6,
Table 7,
Table 8,
Table 9 and
Table 10. We present only the iteration that has the most ambiguous samples and its corresponding FPR and FNR are presented in this section. The results of the classifier using datasets of all subjects are presented in
Table 14. It is important to note that subjects Patient1 and Patient5 has the highest error rate because of the highest scarcity in pre-ictal data. We selected the classifier model that has the highest amount of ambiguous data in the pre-ictal class.
We also report the performance of the same classifier model with inter-ictal class in
Table 15. As explained in the case of Dog5 dataset, the abundance of data in the inter-ictal class has no influence on the selection of classifier model, which is true for all other subjects.
5.3. Threshold Value Selection
In order to select the threshold value for our seizure prediction framework, we experimented with different threshold values and measured the number of missed seizure episodes. As mentioned earlier, based on the number of classification labels that are classified as pre-ictal episodes in a 1 h period, a seizure alarm will be triggered. We varied the threshold values from 40% until 90% and calculated how many seizures are missed during the entire period. We present the results in
Figure 8, where at a 40% threshold, we have 12 missed seizures for the subjects Dog2, and three missed seizures for Patient1. At 70%, only one seizure is missed for three subjects (Patient2, Patient1, and Dog4) and all the seizures were correctly detected in the other four subjects. At and above 80%, we have correctly detected all the seizures. We will choose a 70% threshold for the rest of the evaluation because the number of accurately predicted seizures is cut off at this threshold value, and it is optimal for improving the classification performance. One may note that step-wise decreasing of the threshold values below 70% results in an increase of missed seizures. Therefore, the use of threshold values lower than 70% is not meaningful.
5.4. Evaluation of Active Learners
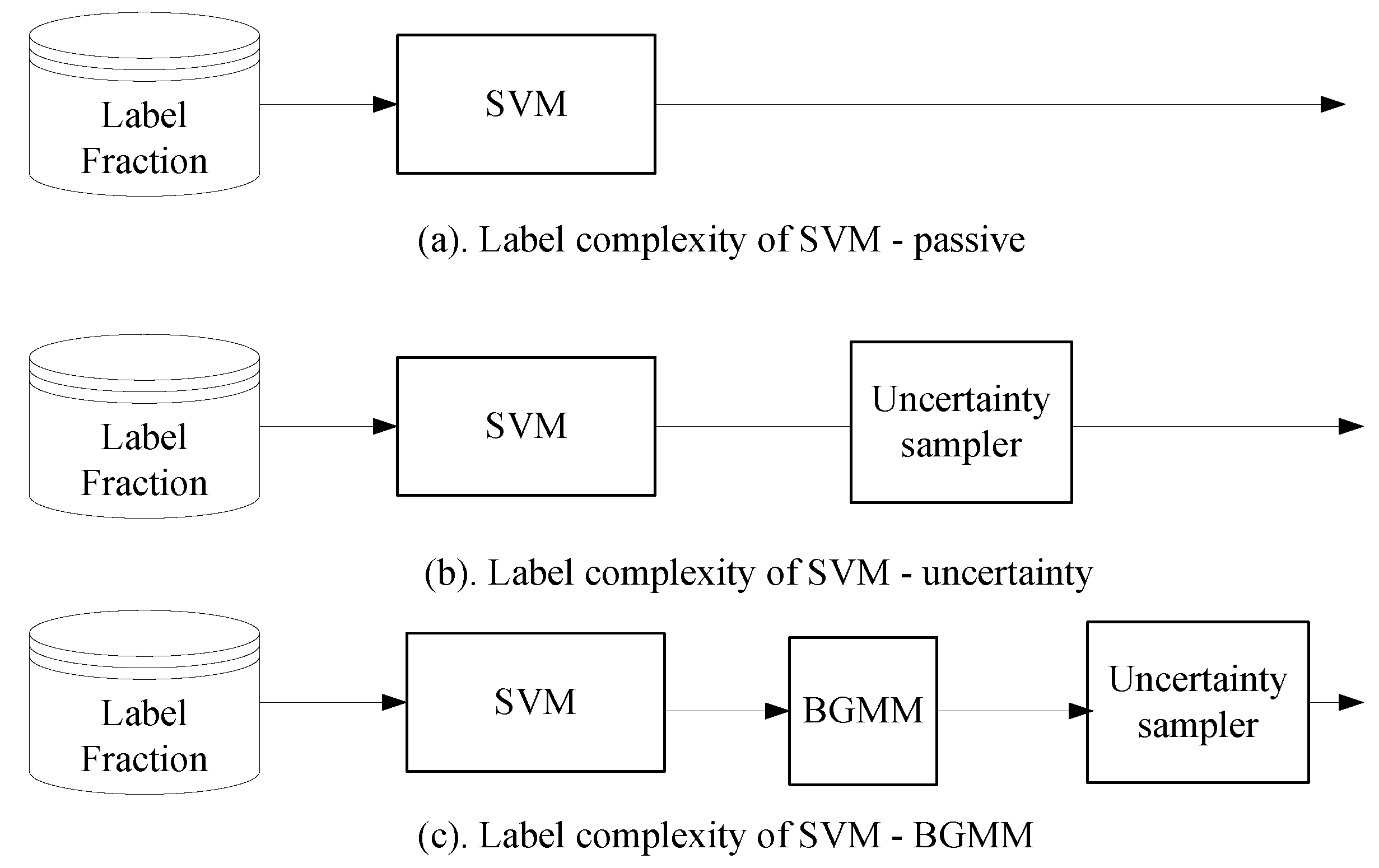
To compare the performance of the Bernoulli-Gaussian Mixture Model based active learners, we used the Support Vector Machine classifier with semi-supervised setting (or passive setting) and Support Vector Machine with just our uncertainty sampler as shown in
Figure 9.
The classifier model selected for each subject is validated with different label fractions and the label complexity is presented for each subject separately, as shown in
Figure 10. The ratios of different label fractions are derived as shown in
Table 11. The model selected from the evaluation of the classifier performance is used to evaluate the active learner block. The error rate is the complement of accuracy
of the classifier. The performance of an ideal active learning in terms of error-rate
should be close to
, whereas, in the semi-supervised case, it is
.
From
Figure 11, it is evident that, for all subjects, the active learner was able to achieve a much lower error rate than the semi-supervised SVM classifier. In
Figure 10a, BGMM-based SVM was able to achieve 37% less error rate than semi-supervised SVM, with just 10% of the labels. Although an uncertainty sampler has reduced the error rate by 17% with just 10% of the labels, the complexity is still close to
, which is not desirable. It is evident that the BGMM-based active selection has a clear improvement in the classification error when the amount of labelled data is very low. In addition, for the case of BGMM-based SVM, the error rate saturates at around 1% because of the limitation of the selected classifier model. This complexity is close to
As explained earlier, the base classifier is prone to misclassification because of the nature of pre-ictal distribution in ECoG signals. We added misclassification noise, i.e., randomly distributed label proportion, to the output of the base classifier. We used the base classifier model that was chosen to have the highest ambiguous sample, and the label fraction was fixed in a way that the number of labelled data segments used for training is always lower than the number of labelled segments used for validation.
In order to evaluate the performance of the active learner block in the presence of such misclassification, we measure the accuracy of the base classifier with three different settings as shown in
Figure 11. We measure accuracy of the classifier as a function of different noise proportions
. In the presence of noise, the base classifier in a semi-supervised setting has poor performance. In addition, the uncertainty sampler did not improve the accuracy in the presence of noise. BGMM-based SVM classifiers have significant stability against the misclassification noise. The ability of BGMM to select the active samples based on the estimation probability distribution results in clear isolation of the random noise added to the classification results. It is evident that the misclassification costs can be lowered by the BGMM model; however, choice of classifier model is important to achieve high accuracy. In addition, at very high noise proportion of above
, all the settings of the base classifier have similar accuracy in classification.
5.5. Evaluation of Seizure Prediction Framework
To compare the seizure prediction performance of our framework, we used the features, 20% labelled data with an SVM classifier that has the least memory consumption and shortest execution time. This setting is a valid representation of a low-power, less complex classifier with minimal training phase. In addition, in a practical setting, a seizure prediction framework is expected to work with such a constrained setting. We compare our seizure prediction framework with a Poisson random predictor in terms of True Prediction Rate (TPR) and False Prediction Rate (FPR). The prediction horizon is the time period between a true positive seizure warning and the actual seizure episode.
The performance of the random predictor and our seizure prediction framework is presented in
Table 16. The TPR is very low for the Poisson predictor, as it sends the seizure warnings randomly for the seizure occurrence. However, with the minimal prior knowledge, our seizure prediction framework has an average TPR of
. In addition, in case of subject Dog3, which has the highest number of seizure events, TPR is very high at
.
The prediction horizon of the Poisson predictor is completely random, as the time to raise a seizure warning can be at any random time within inter-ictal periods. This results in very high FPR, which reflects the incorrectly predicted seizure event through the pre-ictal period. In addition, with a random Poisson predictor, the prediction horizons are completely random, reflecting the random seizure events. In our seizure prediction framework, the FPR is very low, reflecting the falsely predicted seizure events, and the prediction horizon is averaged at 21.7 min for all of the subjects.
In order to evaluate our framework for clinical applicability, we calculated the false positives per hour (FP/h). Any seizure prediction to be clinically applicable must not have more than 0.15 FP/h [
52]. As shown in
Table 17, our seizure prediction tool has very low FP/h for five out of seven subjects. In the case of the Patient dataset, our seizure prediction tool has very high FP/h due to the very low number of seizures occurring over a long duration, i.e., frequency of the recurring seizures is very low. This severely limits the initial training of the model and also reduces the statistical significance between the pre-ictal and inter-ictal data.
5.6. Advantages and Limitations of Our Study
In our seizure prediction framework, we enabled an expert-in-the-loop operation, through which an expert can identify the ambiguous pre-ictal signals based on the inter-ictal and ictal episodes. To the best of our knowledge, our study is the first to use active learning heuristics to predict the onset of seizure episodes.We designed our framework to be less complex such that it has very low resource consumption in terms of memory and power. We have used time-domain features for classification, which ensures its implementation in resource-constrained IMD, compared to the frequency domain features. Although we did not present a detailed evaluation of resource consumption analysis of feature extraction and classifier model on an IMD, we relied on extensive literature to support our claim [
15,
24,
43]. Our study also has the lowest false prediction per hour measurements as shown in
Table 18 when compared with existing works. For our comparison, we selected the existing works that report the false positives per hour measurement as listed out in [
39]. Our results show that on-time prediction of seizures using IMD is plausible, and, through close collaboration with medical experts, the clinical/practical aspects of the approach can be further investigated. Nonetheless, we have indicated clinical/practical aspects such as FP/h and prediction horizon for our seizure prediction framework.
However, our study also has shortcomings. We evaluated our framework based on a small set of intra-cranial measurements. Applicability of our framework to a much broader dataset still needs to be validated. This may result in reiterating the design choices of our framework such as the selection of nonlinear time-domain features for classifier training, an adaptable threshold setting depending on the dataset, and different choices of machine learning classifiers. In the dataset used in this study little to no artefacts was present. Nonetheless, we evaluated the robustness of our framework using noise-complexity, which, in reality, could be caused by artefacts. Naturally occurring artefacts are much more random and might decrease the performance of our framework. The time-domain features are selected based on prior studies that were used for seizure prediction. Although it works perfectly in our dataset, it might not hold true for other datasets. A thorough evaluation with other datasets is needed to overcome these problems.
In this regard, it is important to mention that obtaining the intra-cranial ECoG measurements is not an easy task. An invasive surgical procedure is required to implant the electrode on the surface of the brain. Although more and more pre-recorded intra-cranial datasets are becoming available, limitations still exist in terms of poorly labelled data, lack of information about the method of measurements, and details of the seizure under study. This renders most of the dataset directly unusable for evaluating any seizure prediction system. Moreover, practical application of seizure prediction systems might introduce another set of problems such as the electrode failure, the discrepancy in brain signals, etc. The design choices must be reiterated by clinical evaluation to foresee these practical problems.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}