The results of the condition monitoring strategy are presented and grouped in three different subsections.
Section 4.2 includes the quantity of samples that are correctly classified and the number of missing faults and false alarms.
Section 4.3 and
Section 4.4 present the results as a percentage. On one hand,
Section 4.3 comprises both the specificity and the sensitivity, together with the false-positive and the false-negative rates. On the other hand,
Section 4.4 contains the true rate of both false positives and false negatives. Finally,
Section 4.5 includes a discussion on the level of significance
of the test. Based on that discussion, in the multivariate case, it will be seen that the level of significance can be reduced—therefore reducing the ratio of false alarms—without affecting the overall performance of the fault detection strategy.
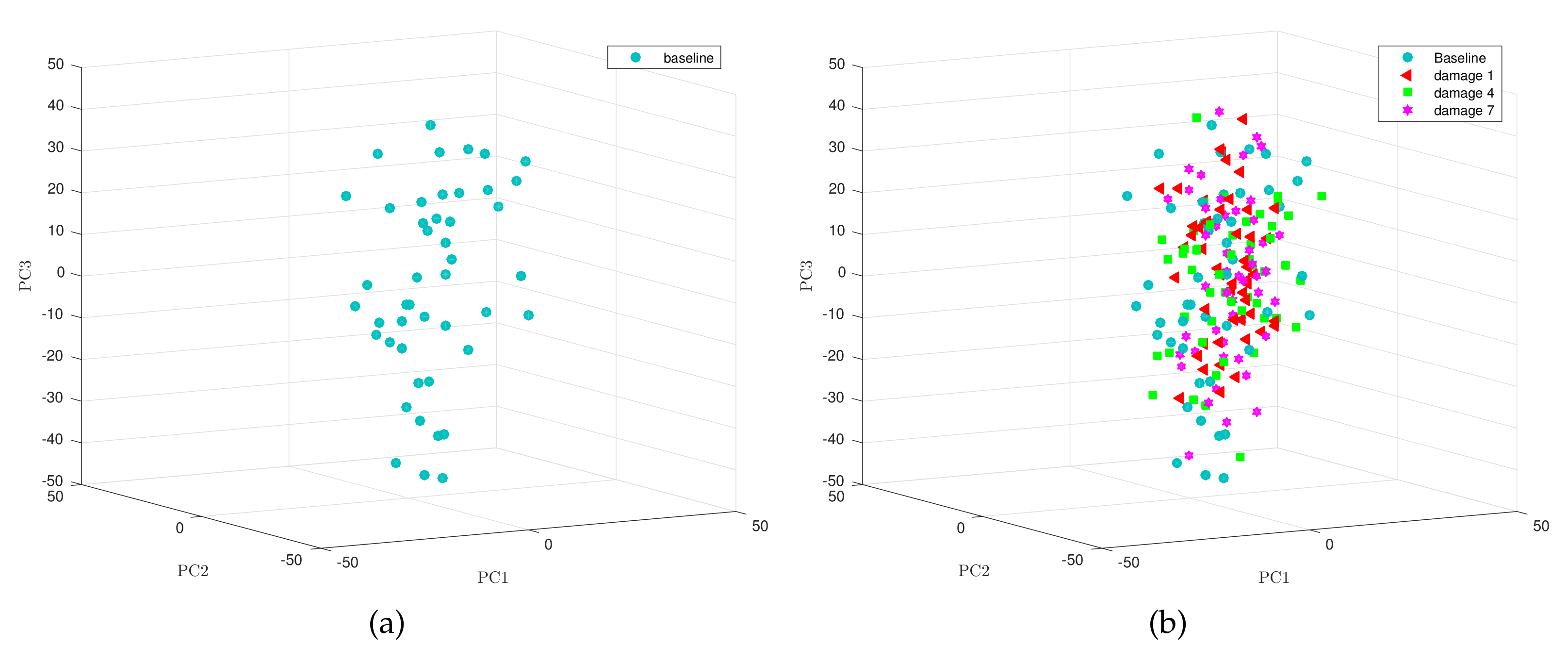
4.1. Multivariate Normality
To properly apply the condition monitoring strategy described in
Section 3, and more precisely, the multivariate hypothesis testing outlined in
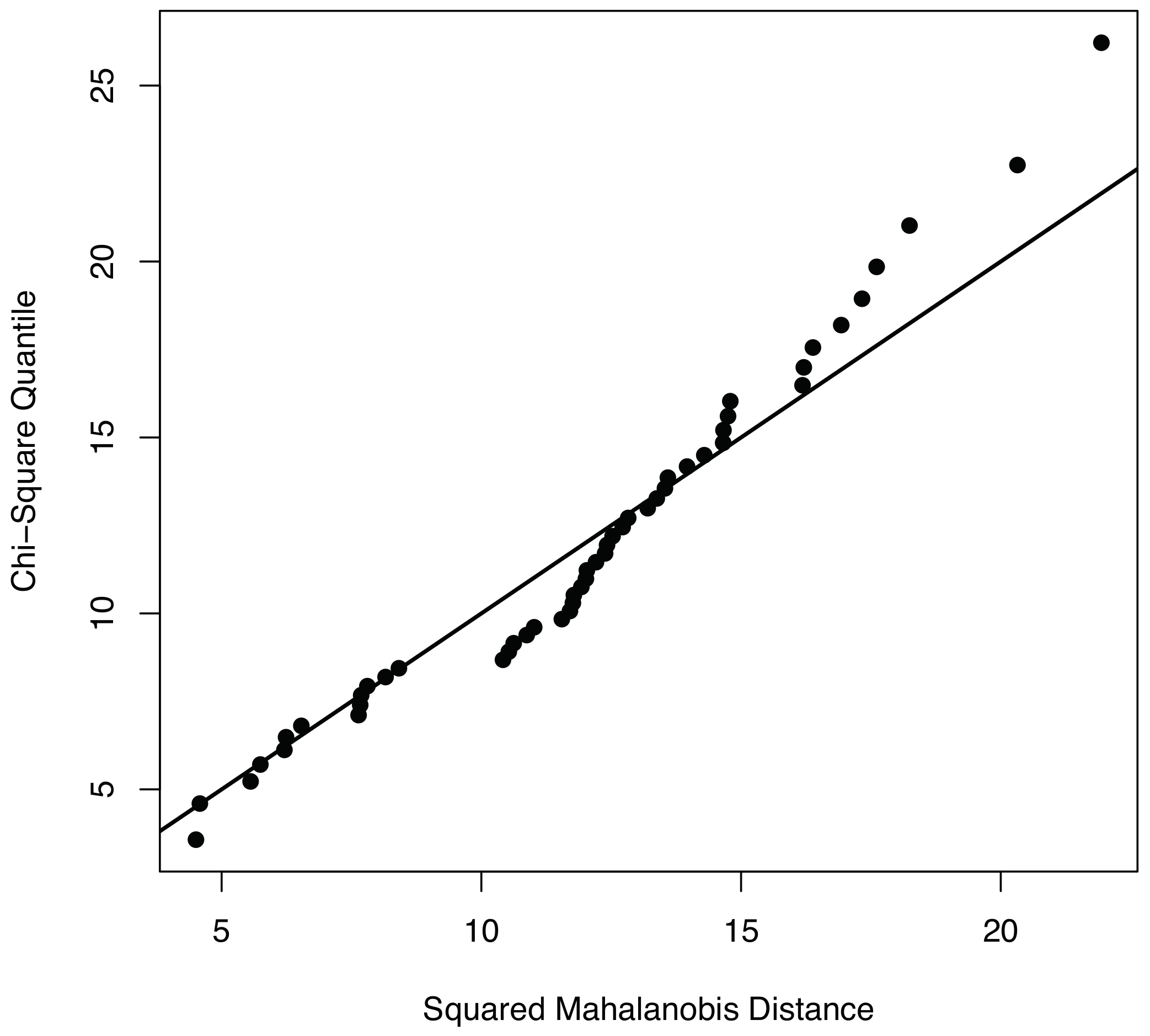
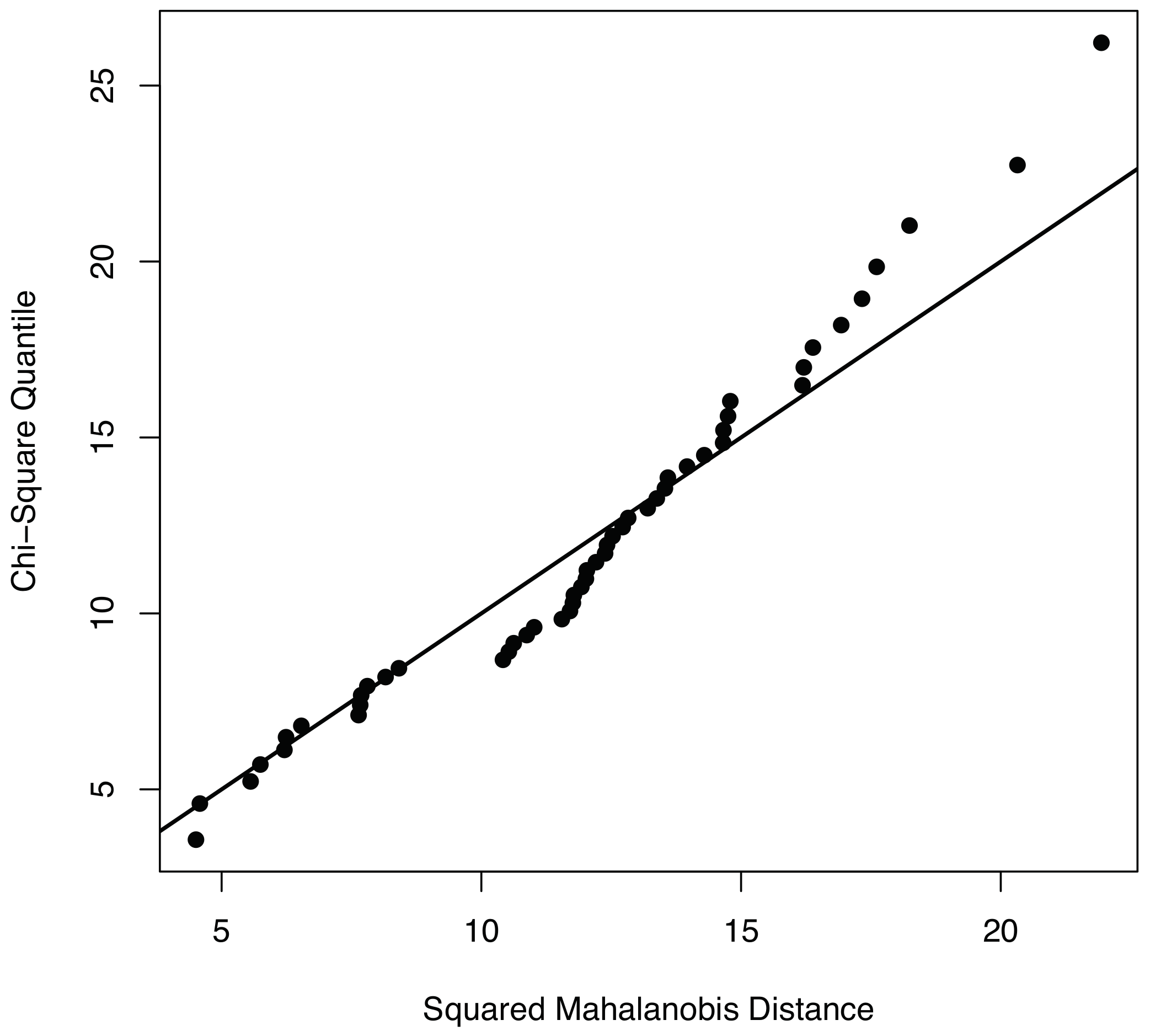
Section 3.3.1, measured data should be compatible with a multivariate normal distribution. To visually show the normality of the data used to validate the condition monitoring strategy, we use both the
Q–
Q plots and the contour plots. With respect to the
Q–
Q plots, it can be observed in
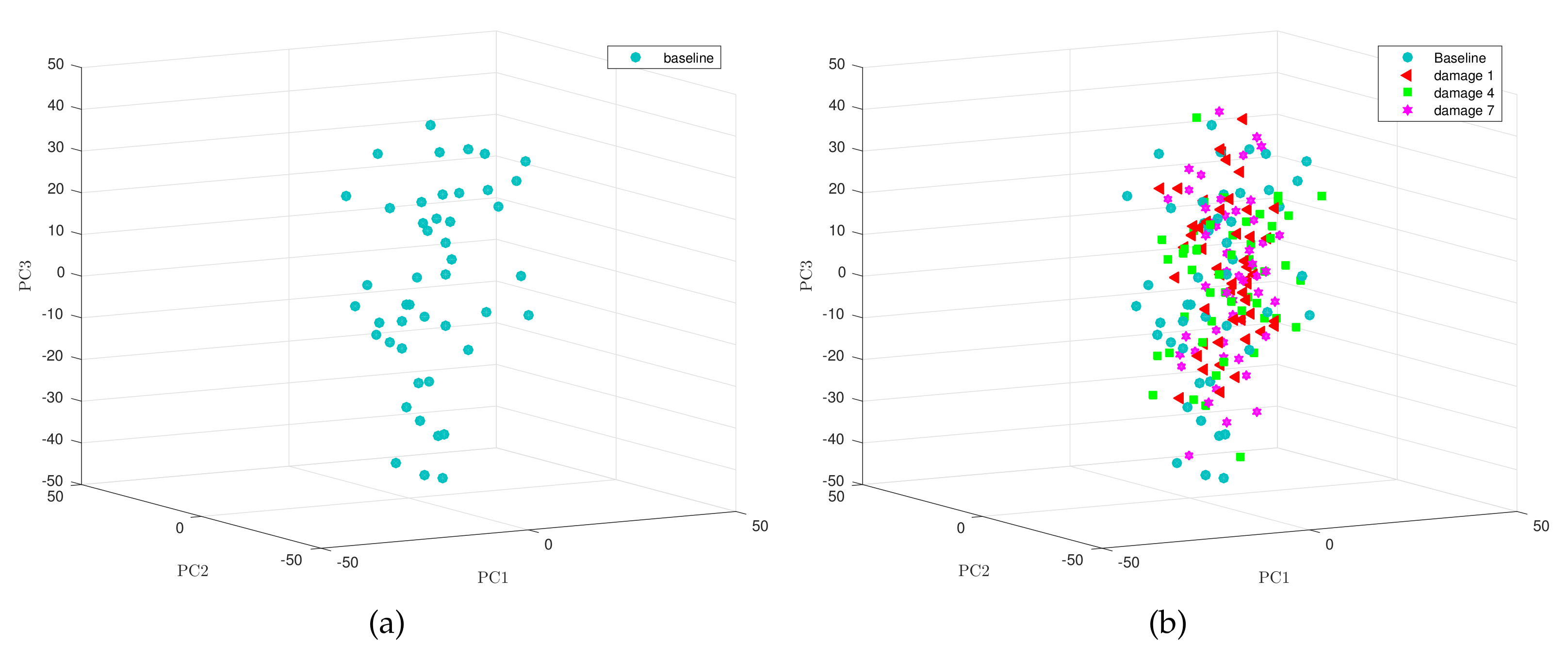
Figure 4 that the points of the sample related to fault number 1—using the first twelve principal components—are distributed closely following the bisectrix, thus indicating the multivariate normality of the data. Moreover, a contour plot for the data we consider in this work is given in
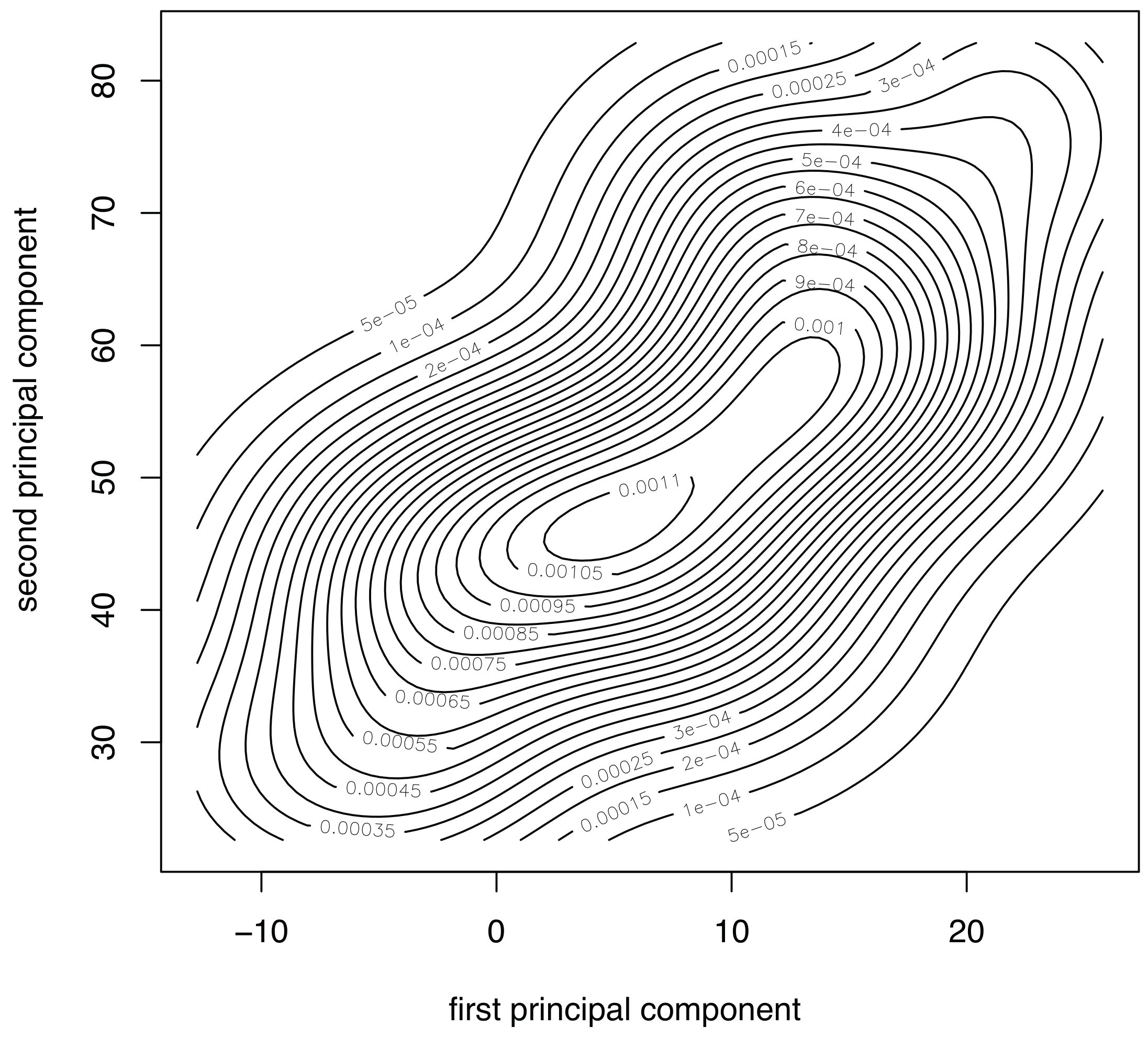
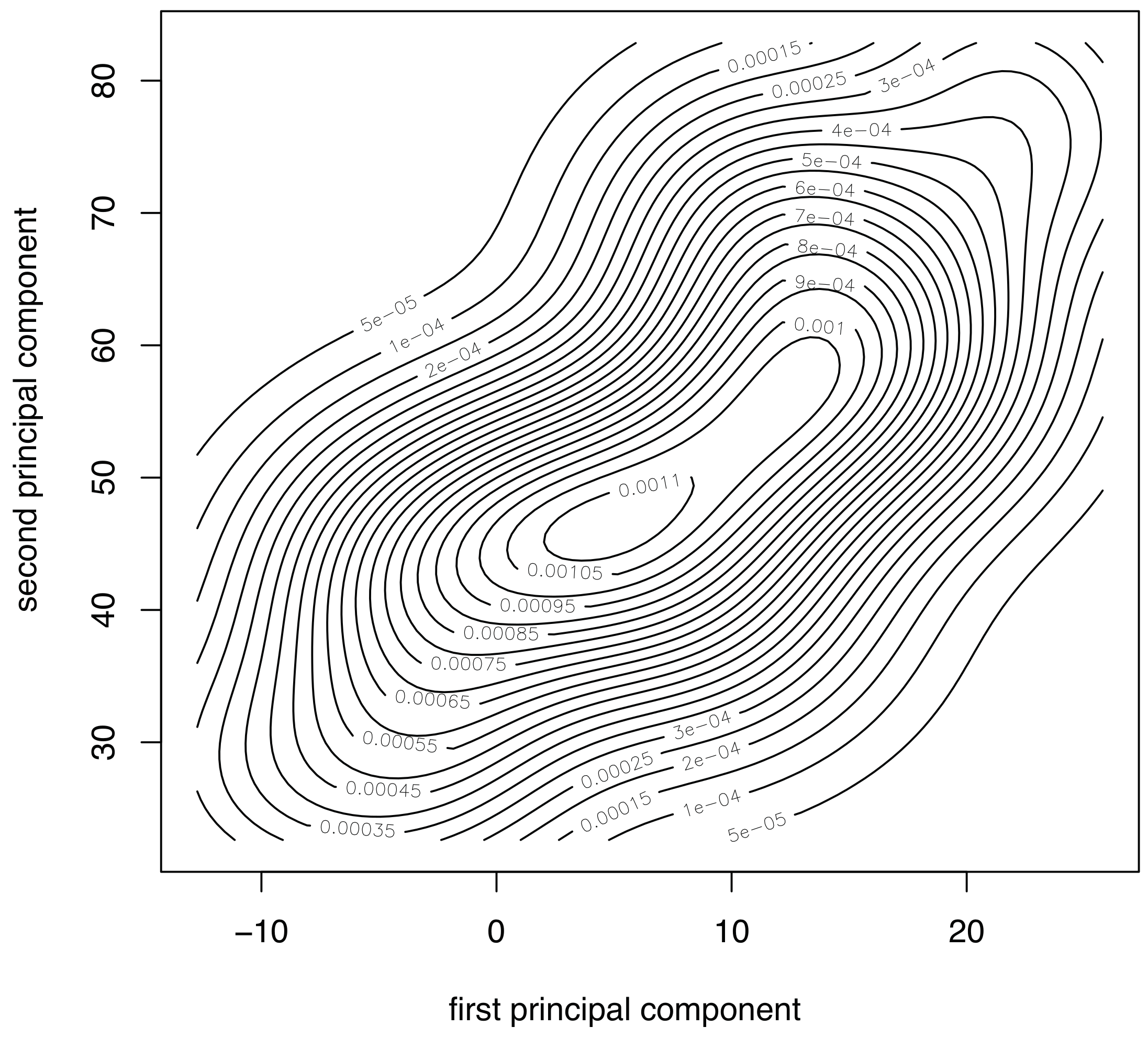
Figure 5. More accurately,
Figure 5 represents the contour plot for the sample corresponding to fault number 4, and principal components 1 and 2. The contour lines are similar to ellipses of a normal bivariate distribution that means that the distribution in this case is, again, consistent with the assumption of multinormality. Although the graphical approaches can be useful to visually show the normality, a formal test for multivariate normality should be applied. However, since there is no single most powerful test it is recommended to perform several tests to assess the multivariate normality. Consequently, we will consider the three most widely used normality tests:
- (i)
Mardia’s;
- (ii)
Henze-Zirkler’s; and
- (iii)
Royston’s
multivariate normality tests. A brief explanation of these methods can be found in [
16].
Table 3 summarizes the results of the three normality tests when considering the first two principal components, the first seven principal components and the first twelve principal components.
4.2. Type I and Type II Errors
The condition monitoring strategy presented in
Section 3 is carried out considering a total of 24 samples of
elements each, according to the following distribution:
All samples are obtained with different wind data sets with turbulence intensity set to
and generated with TurbSim [
34]. The generated wind data has the following characteristics: Kaimal turbulence model, logarithmic profile wind type, mean speed of
m/s simulated at hub height, and a roughness factor of
m. Each sample of
elements comes from the measures obtained from the
sensors detailed in
Table 1 during
s, where
and the sampling time is
s. This sampling time represents a sampling ratio of 80 Hz. Although Lind et al. [
14] propose a more realistic sampling ratio of 1 Hz, they also agree with the fact that a mixed system, combining SCADA and conventional high frequency sensors is expected in the near future. The measures are arranged in a
matrix
as in Equation (
23). As it can be observed, the number of rows of matrix
equals the number of elements in the sample. Therefore, the first element of the sample is the projection of the first row of matrix
into one or more principal components; the second element of the sample is the projection of the second row of matrix
into one or more principal components, and so on. When the projection is performed into a
single principal component, the sample is then equivalent to a set of real numbers. However, when the projection is performed into more than one principal component, the sample can be considered as a set of
dimensional vectors, where
is the number of principal components that are considered jointly. One of the main contributions of this paper is that the condition monitoring strategy is based on multivariate statistical hypothesis testing applied to this set of
dimensional vectors.
The main goal of this section is to show the benefits of the multivariate statistical hypothesis testing with respect to the univariate case. To this end, we present the results when the measured data is projected into the first, the second and the third principal component, separately. Basically, when the sample is a set of real numbers, the condition monitoring is based on the univariate hypothesis testing presented in [
33]. These results will be compared with a new condition monitoring strategy where the measured data is projected into: (i) the first
and the second principal component, jointly; (ii) the seven first principal components, jointly; and (iii) the twelve principal components, jointly.
These 24 samples plus the baseline sample of elements are used to test for the equality of means (in the univariate case) or to test for the plausibility of a value for a normal population mean vector (in the multivariate case), with a level of significance in both cases. Each sample of elements is categorized as follows:
- (i)
number of samples from the healthy wind turbine (healthy sample) which were classified by the hypothesis test as ‘healthy’ (fail to reject / accept );
- (ii)
faulty sample classified by the test as ‘faulty’ (reject / accept );
- (iii)
samples from the faulty structure (faulty sample) classified as ‘healthy’; and
- (iv)
faulty sample classified as ‘faulty’.
The results –organized according to the scheme in
Table 4– are presented in
Table 5. It can be stressed, from
Table 5, that the sum of the columns is constant: 16 samples in the first column (healthy wind turbine) and 8 more samples in the second column (faulty wind turbine).
Table 5 includes the results using both the univariate hypothesis testing fault detection strategy developed in [
33] (for the first, second and third score) and the multivariate hypothesis testing presented in this work (scores 1 to 2, 1 to 7 and 1 to 12, jointly). It is worth noting that, for a fixed level of significance
, all decisions are correct when the first twelve scores are considered jointly. In the other cases, two kinds of misclassifications are presented: (i) type I error; and (ii) type II error. The type I error, also known as false positive or false alarm, occurs when the wind turbine is working correctly but the condition monitoring strategy infers that there is some problem. The level of significance
is , at the same time, the probability of committing this type of error. Additionally, the type II error, also known as false negative or missing fault, appears when the wind turbine is not working properly but the strategy classifies it as healthy. The probability of committing this type of error is called
. This value is closely related to the sensitivity of the test, as it will be seen in
Section 4.3.
4.3. Sensitivity and Specificity
As in [
33], two more statistical measures are considered to examine the efficiency of the test. On one hand, the
sensitivity—or the power of the test—is defined as the fraction of samples from the faulty wind turbine that are correctly classified as such. On the other hand, the
specificity of the test is defined as the fraction of samples from the healthy structure which are correctly classified. Both the specificity and the sensitivity can be expressed in terms of the level of significance
and the real number
defined in
Section 4.2, as it is specified in
Table 6.
The specificity and sensitivity of both the univariate hypothesis testing and the multivariate case with respect to the 24 samples—arranged as shown in
Table 6—have been included in
Table 7.
For the univariate case, the results in
Table 7 show that the average value of the sensitivity is
, which is far from the desired value of
. The average value of the specificity is
, which is very close to the expected value of
. However, in the multivariate case, the average values of the sensitivity and the specificity are
and
, respectively. Although the average specificity in the univariate case is slightly greater than the average specificity in the multivariate case, the sensitivity in the multivariate case is undoubtedly better than the sensitivity in the univariate case. The proposed methodology thus surpasses the performance of the fault detection strategy based on univariate hypothesis testing.
4.4. Reliability of the Results
Two more statistical measures that can be used to assess the performance of the proposed condition monitoring strategy are the true rate of false negatives and the true rate of false positives. These two measures—rooted in Bayes’ theorem [
35]—are described in
Table 8. More precisely, the true rate of false negatives is the fraction of samples from the faulty wind turbine that have been mistakenly identified as healthy. Contrarily, the true rate of false positives is the fraction of sample from the healthy wind turbine that have been mistakenly identified as faulty.
For the univariate case, the results in
Table 9 show that the average value of the true rate of false negatives is
, which is far from the desired value of
. The average value of the true rate of false positives is
. However, in the multivariate case, the average values of the true rate of false negatives and the true rate of false positives are
and
, respectively. Although the average value of the true rate of false positives in the univariate case is similar to the same magnitude in the multivariate case, the true rate of false negatives in the multivariate case is clearly better. Once more the proposed methodology outperforms the fault detection strategy based on univariate hypothesis testing.
4.5. Discussion on the Level of Significance
The performance of the proposed condition monitoring strategy through principal component analysis and multivariate statistical hypothesis testing depends on:
the number of elements of each sample;
the number
of columns of each sub-matrix—corresponding to a sensor—in matrix
in Equation (
23).
the number of principal components considered jointly; and
the level of significance of the multivariate hypothesis testing.
The effect on the overall performance of the proposed method of the choice of
and
L is exhaustively discussed on [
30] for the univariate case though the results can be easily extrapolated to the multivariate case. The influence of the number
s of principal components considered jointly is also accurately examined in [
16]. As it is expected, the more number of principal components are considered, the better results are obtained.
The choice of the level of significance is of an extreme importance too. Therefore, for the choice of , two considerations have to be taken into account:
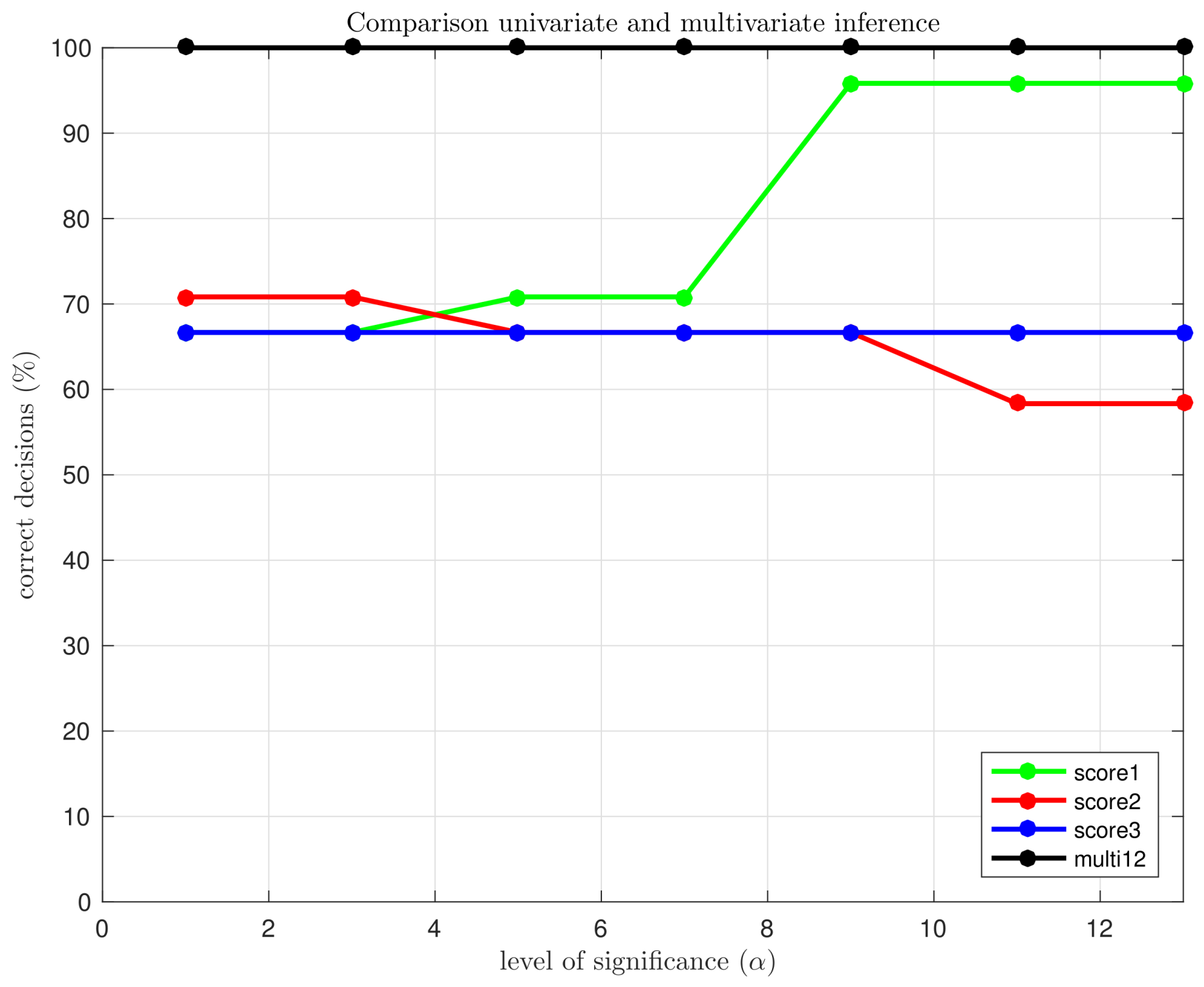
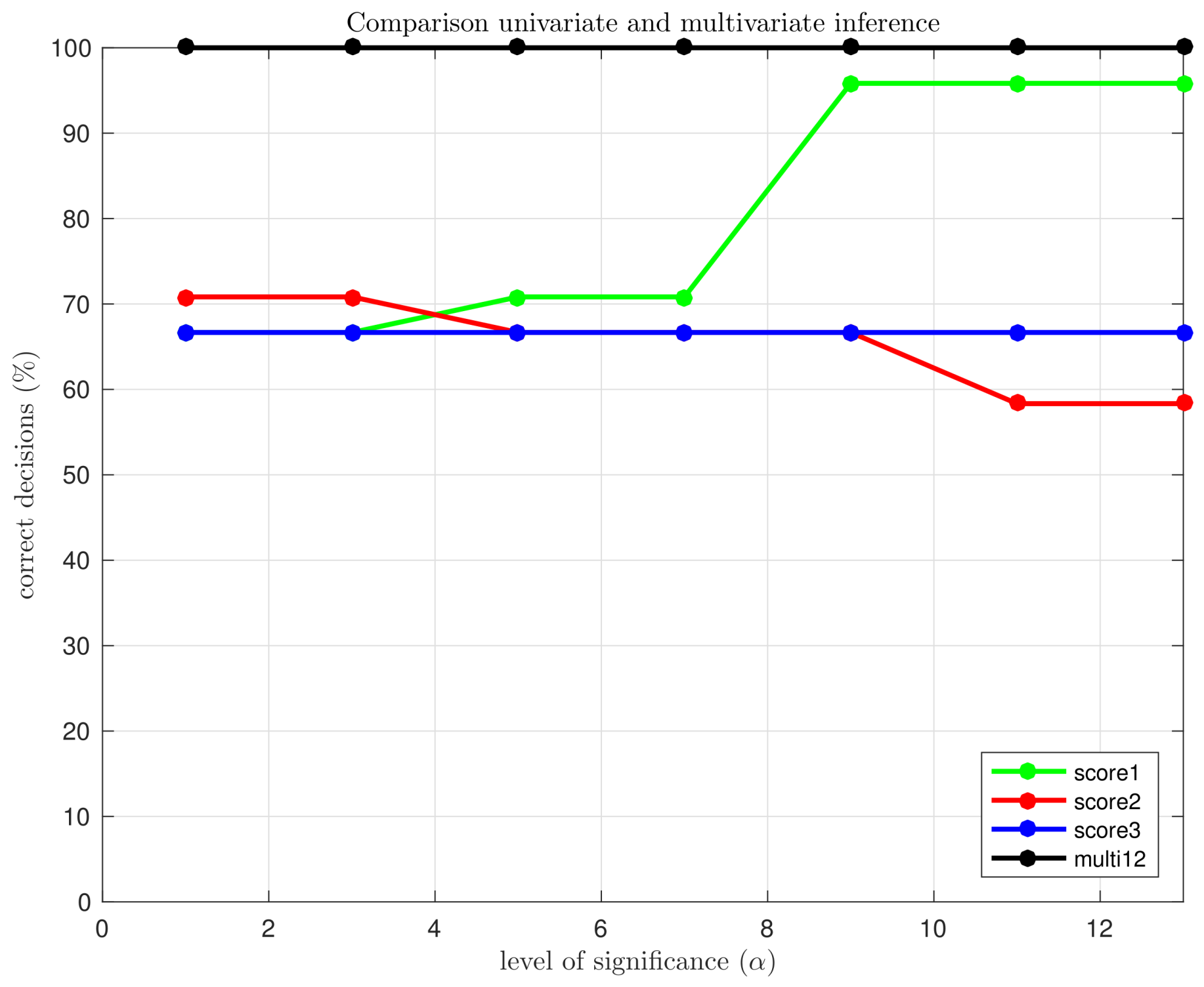
Consequently, a small level of significance is desired, but an excessively small level of significance would lead to a higher rate of missing faults. For that reason, the question is: how small the level of significance can be selected without affecting the rate of missing faults? In
Figure 6 we have depicted the percentage of correct decisions using the multivariate hypothesis testing fault detection strategy with the first twelve principal components (jointly) and the univariate hypothesis testing, for the first, the second and the third principal components (separately), as a function of the level of significance
. It can be clearly observed that, in the univariate case, if the level of significance is reduced from
to
, the overall performance is degraded. However, in the multivariate case, the reduction of the level of significance—and thus the reduction of type I errors—does not affect the fault detection strategy, keeping the percentage of correct decisions at
.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}