Developing a Data Mining Based Model to Extract Predictor Factors in Energy Systems: Application of Global Natural Gas Demand

 ,
, 
 and
and
Abstract
1. Introduction
2. Literature Review
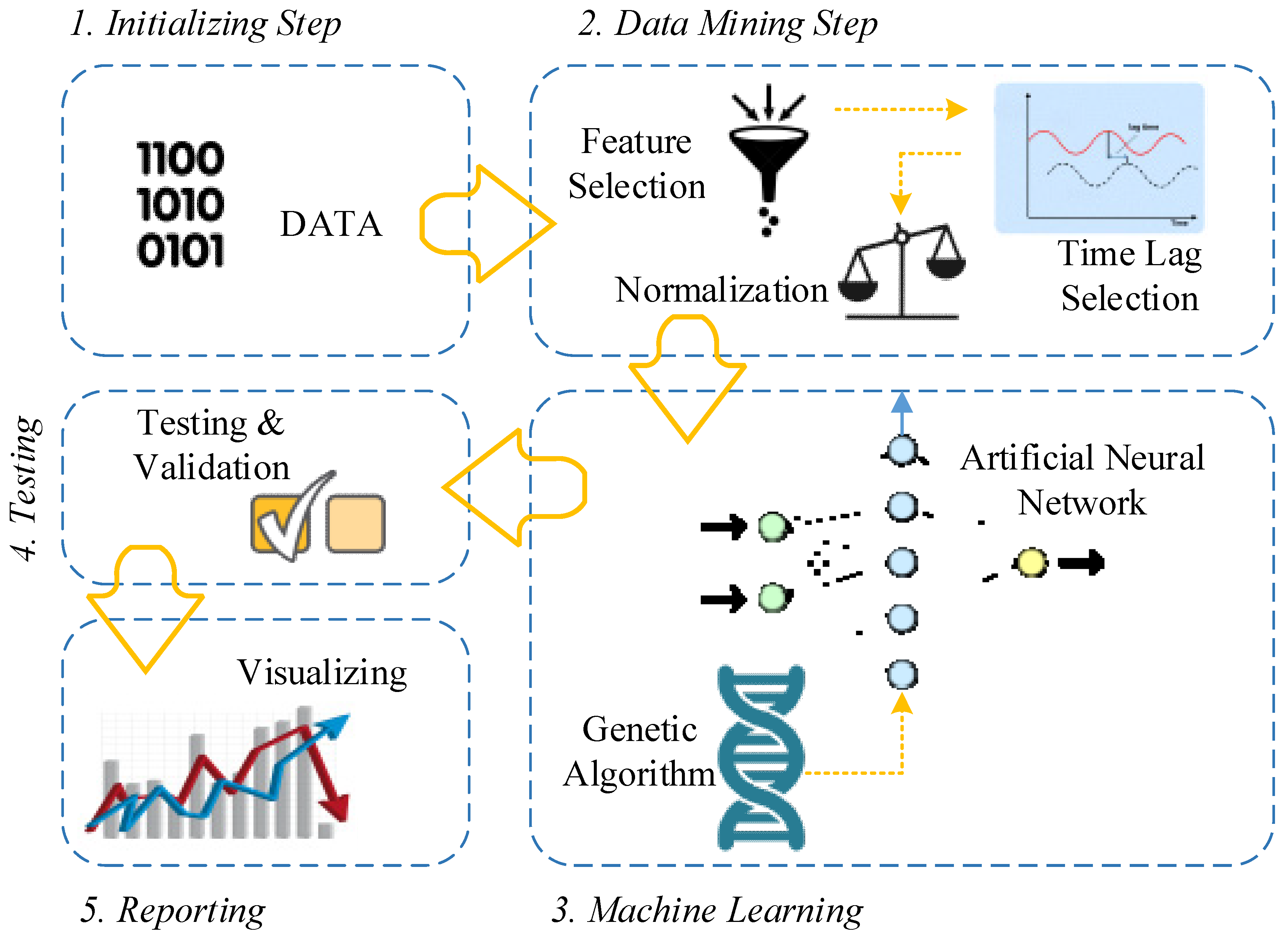
3. The Methodology of Research
3.1. Input Preparation
3.1.1. Data Gathering
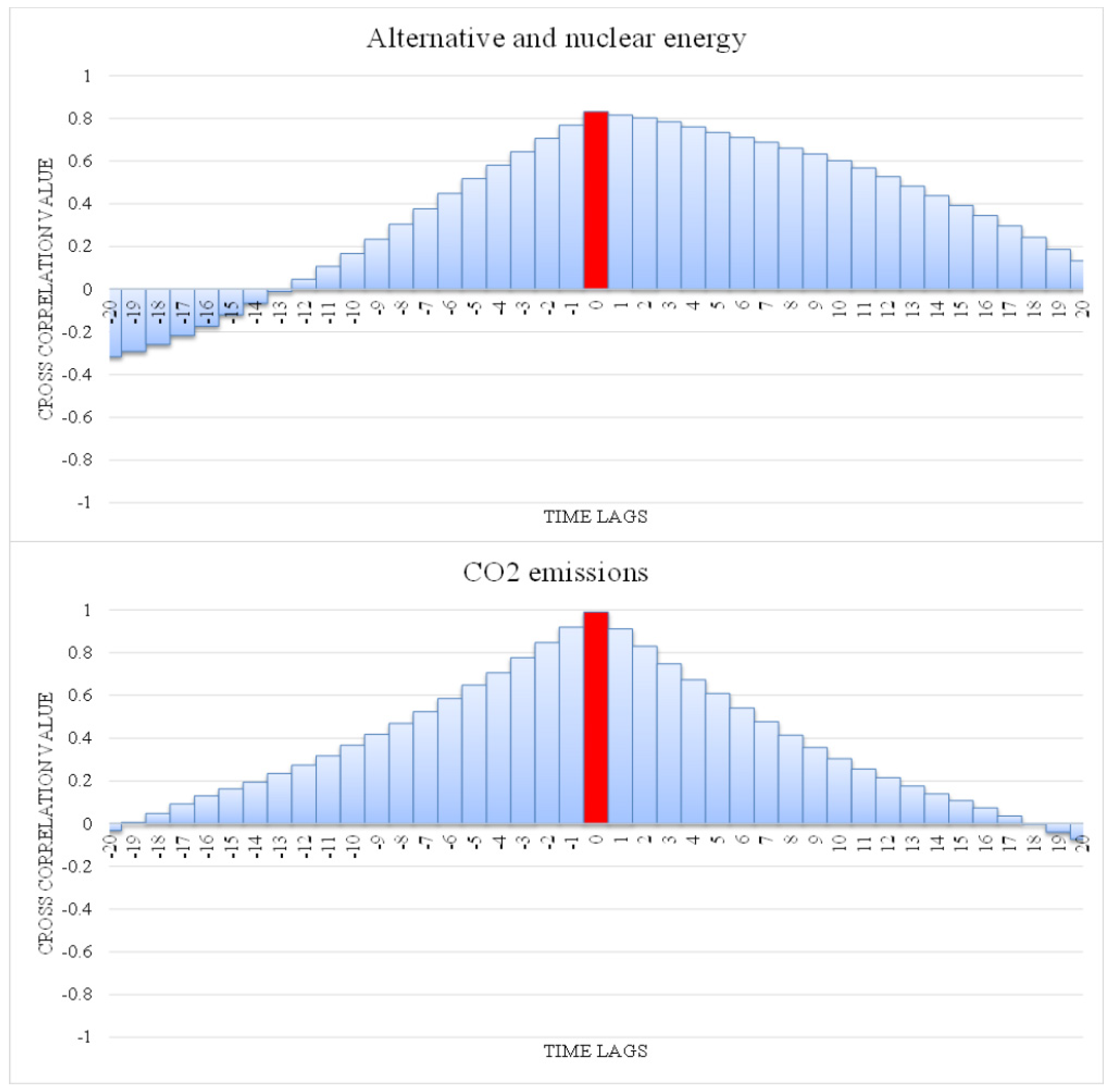
3.1.2. Data Preprocessing (Feature Selection, Lag Selection and Data Normalization)
3.2. Designing the Forecasting Framework
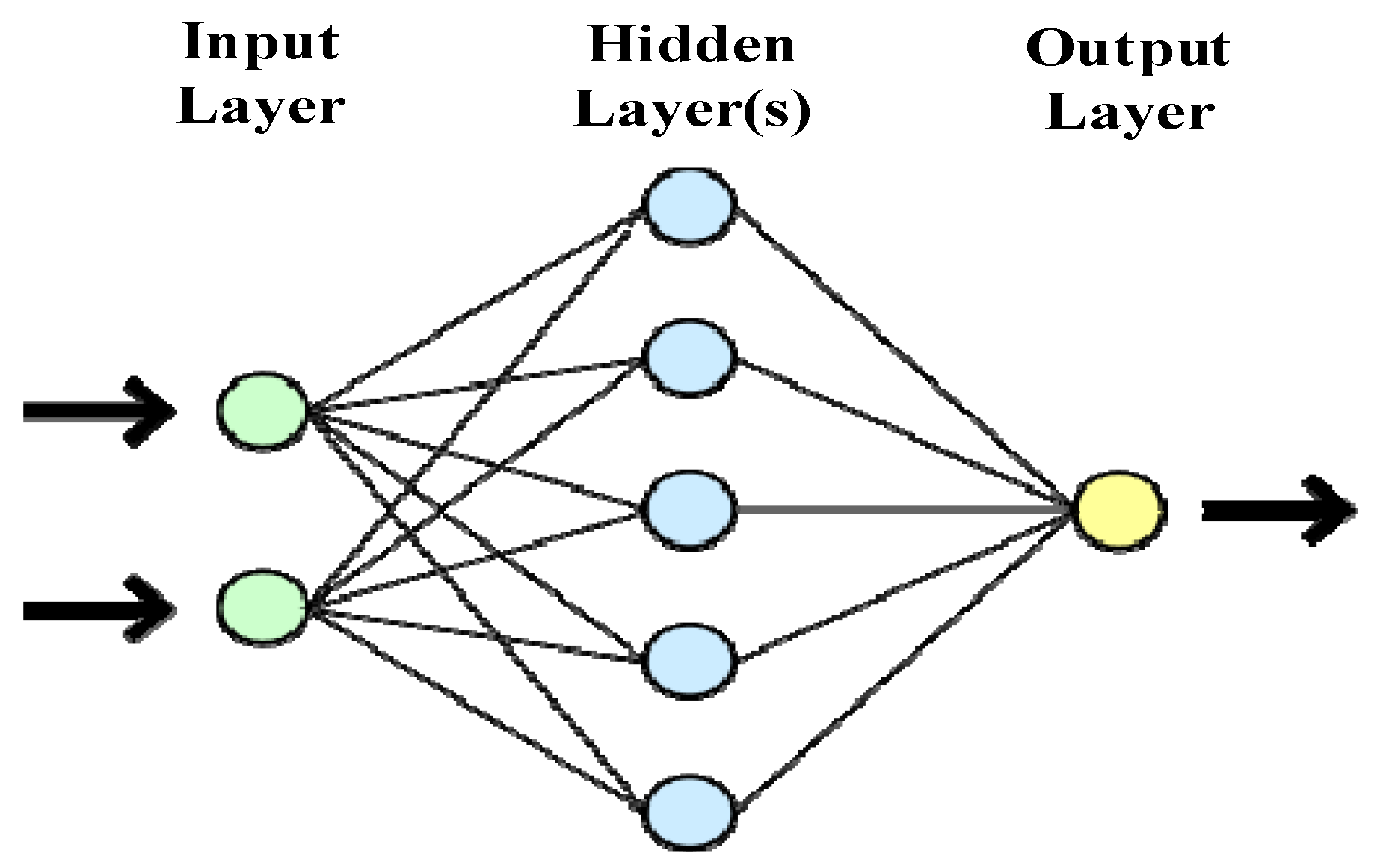
3.2.1. Artificial Neural Network
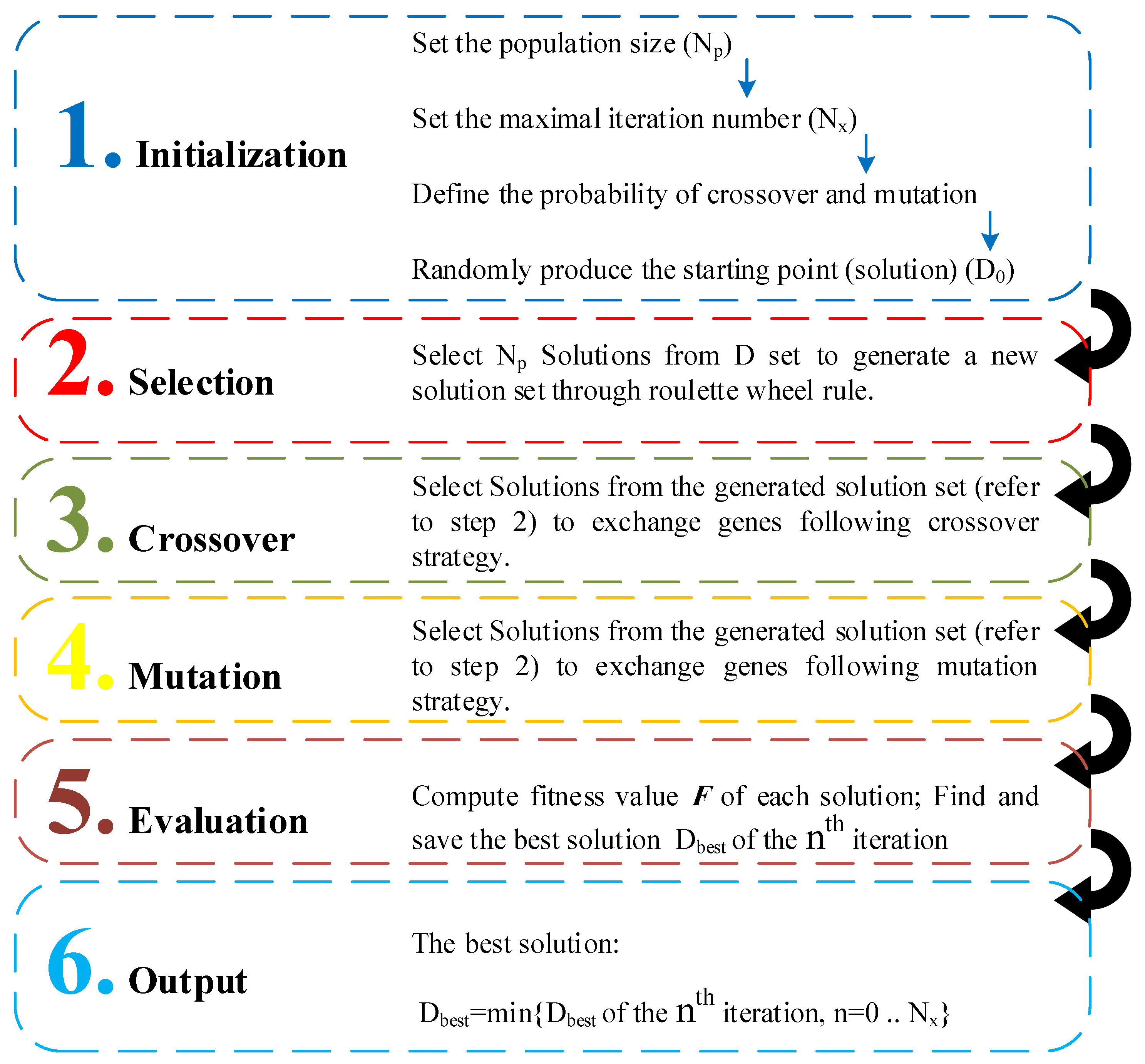
3.2.2. Genetic Algorithm
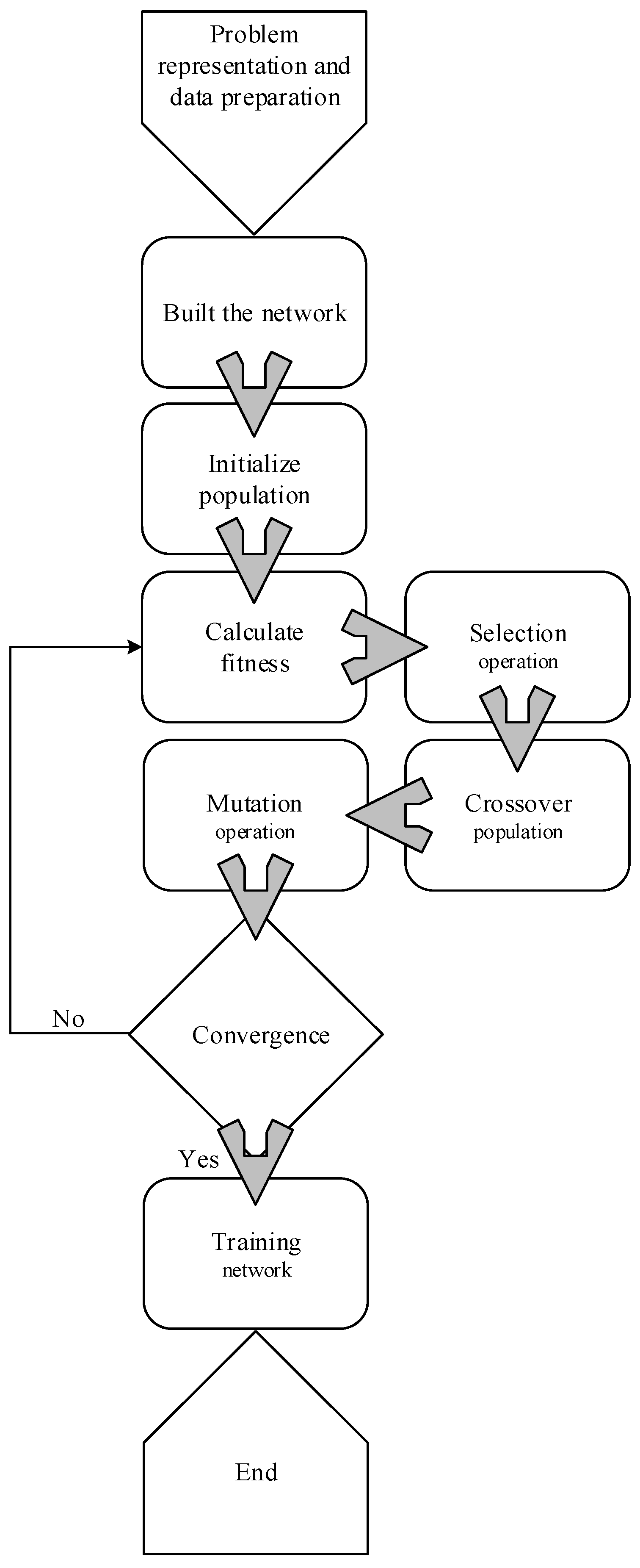
3.2.3. Genetic Neural Network
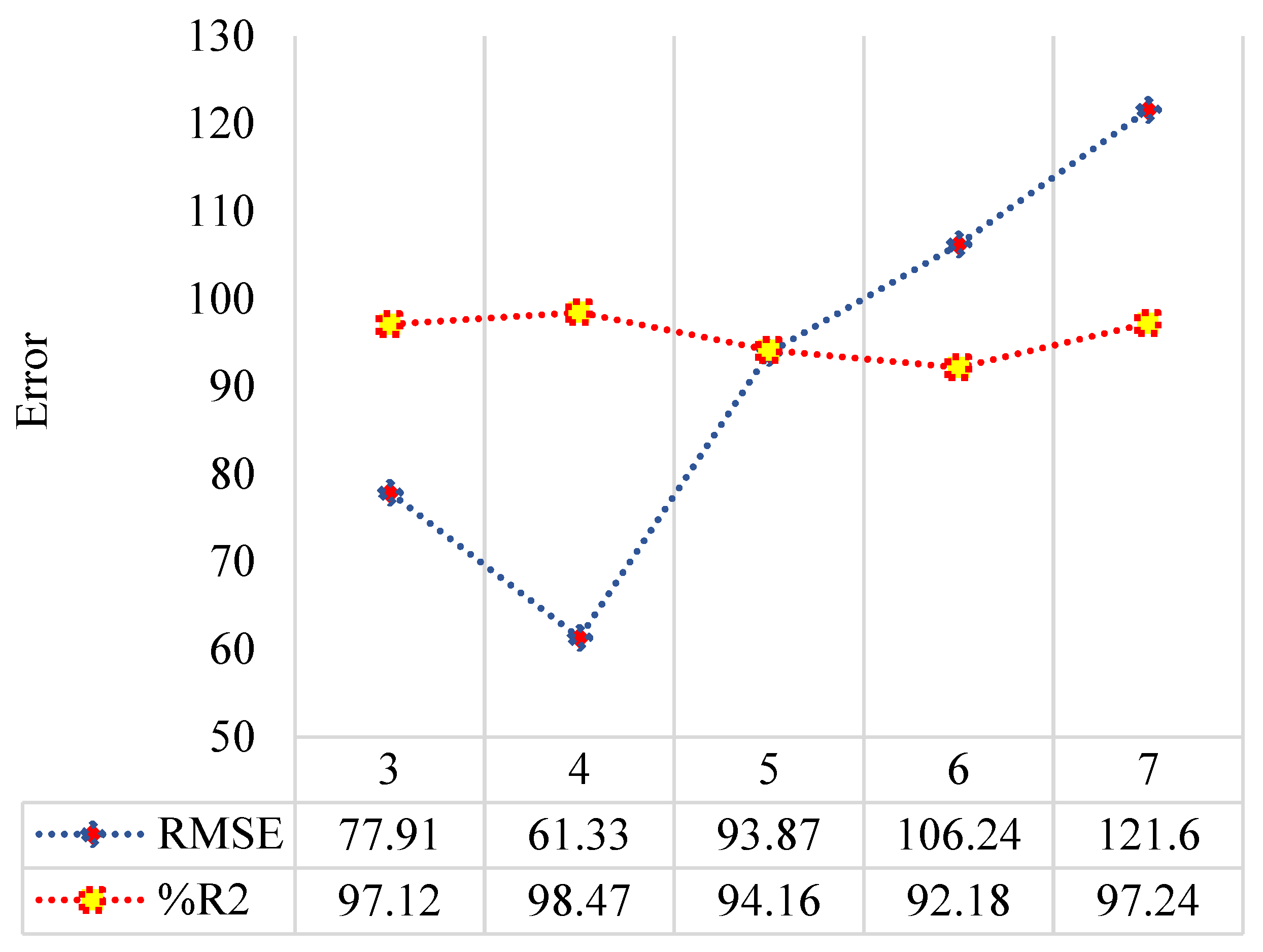
3.2.4. The Architecture of the ANN
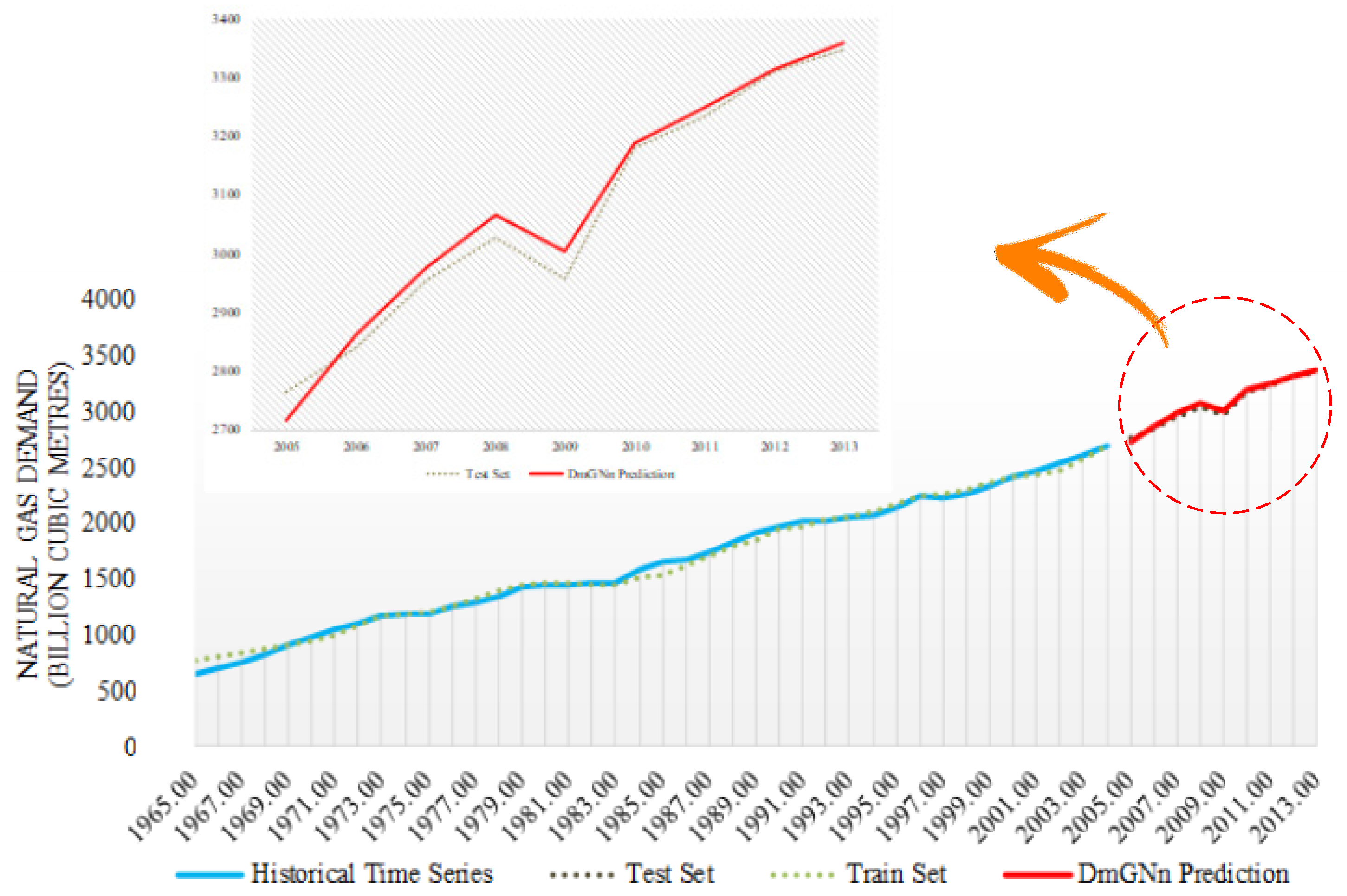
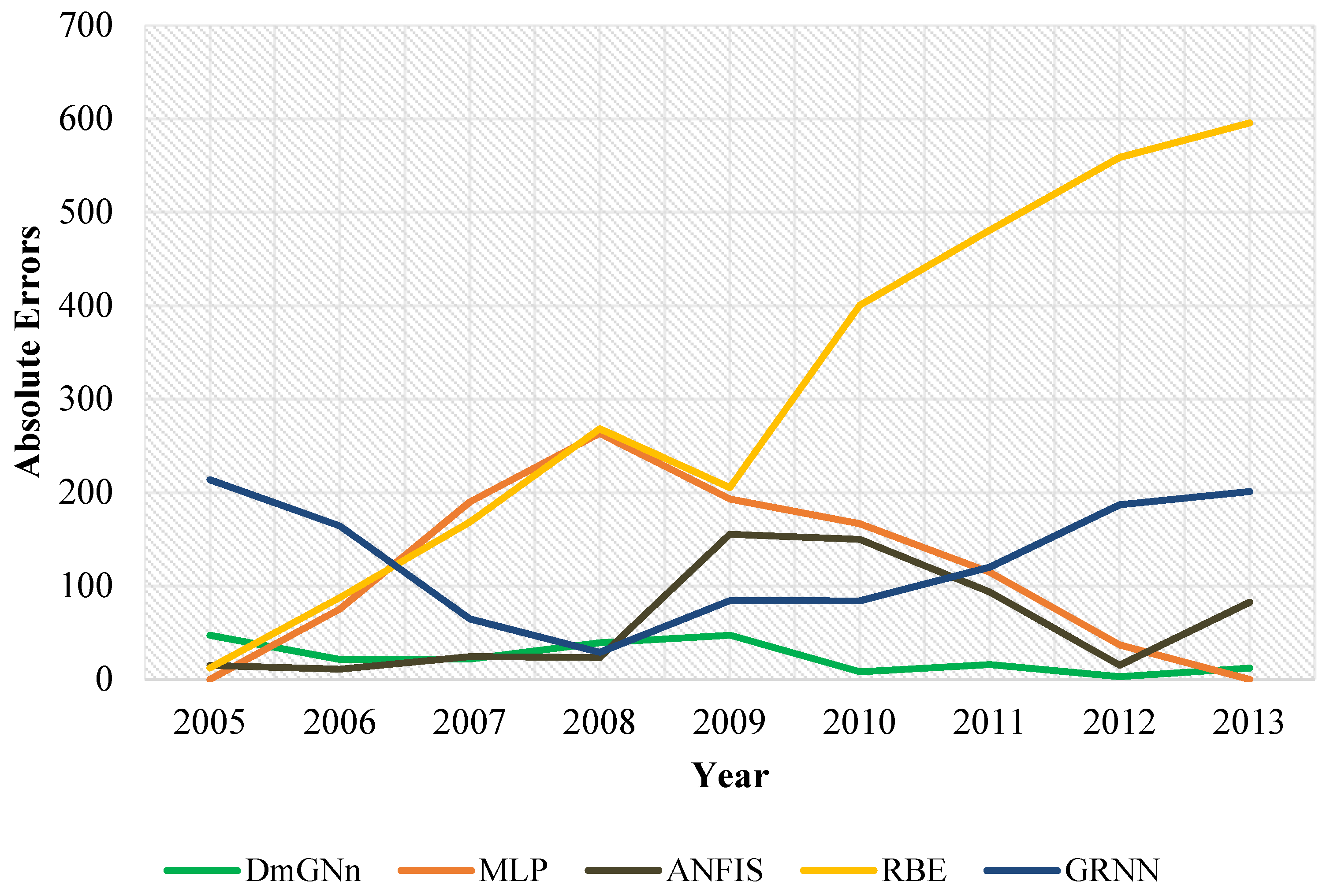
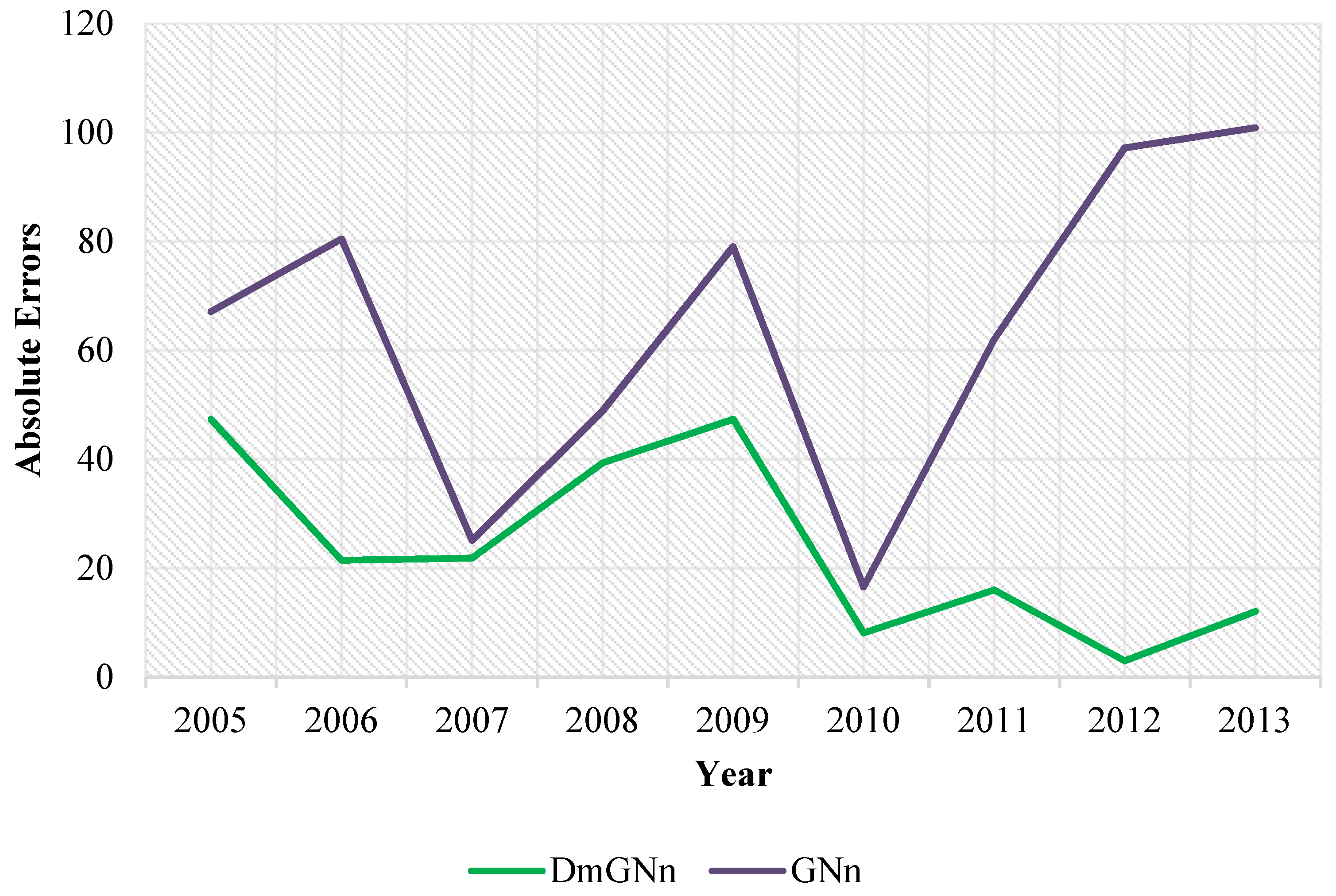
4. Outputs and Results
5. Conclusions
Author Contributions
Funding
Conflicts of Interest
References
- BP. Statistical Review of World Energy; BP: London, UK, 2016. [Google Scholar]
- IEA. World Energy Outlook; IEA: Paris, France, 2016. [Google Scholar]
- EIA. Annual Energy Outlook; EIA: Paris, France, 2017.
- Alipour, M.; Hafezi, R.; Ervural, B.; Kaviani, M.A.; Kabak, O. Long-term policy evaluation: Application of a new robust decision framework for Iran’s energy exports security. Energy 2018, 157, 914–931. [Google Scholar] [CrossRef]
- EIA. Annual Energy Outlook; EIA: Paris, France, 2016.
- Hafezi, R.; Akhavan, A.; Pakseresht, S. Projecting plausible futures for Iranian oil and gas industries: Analyzing of historical strategies. J. Nat. Gas Sci. Eng. 2017, 39, 15–27. [Google Scholar] [CrossRef]
- Alipour, M.; Hafezi, R.; Amer, M.; Akhavan, A.N. A new hybrid fuzzy cognitive map-based scenario planning approach for Iran’s oil production pathways in the post-sanction period. Energy 2017, 135, 851–864. [Google Scholar] [CrossRef]
- Hafezi, R.; Akhavan, A.; Pakseresht, S. The State of Competition in Natural gas Market Application of Porter’s Five Forces for NIGC, In Proceedings of the International Gas Union Research Conference (IGRC), Rio de Janeiro, Brazil, 24–26 May 2017.
- Hafezi, R.; Bahrami, M.; Akhavan, A.N. Sustainability in development: Rethinking about old paradigms. World Rev. Sci. Technol. Sustain. Dev. 2017, 13, 192–204. [Google Scholar] [CrossRef]
- Hafezi, R.; Akhavan, A.N.; Pakseresht, S.; Wood, D.A. A Layered Uncertainties Scenario Synthesizing (LUSS) model applied to evaluate multiple potential long-run outcomes for Iran’s natural gas exports. Energy 2019, 169, 646–659. [Google Scholar] [CrossRef]
- Alipour, M.; Alighaleh, S.; Hafezi, R.; Omranievardi, M. A new hybrid decision framework for prioritizing funding allocation to Iran’s energy sector. Energy 2017, 121, 388–402. [Google Scholar] [CrossRef]
- Gheyas, I.A.; Smith, L.S. Feature subset selection in large dimensionality domains. Pattern Recognit. 2010, 43, 5–13. [Google Scholar] [CrossRef]
- Kim, Y.; Street, W.N.; Menczer, F. Feature selection in data mining. Data Min. Oppor. Chall. 2003, 3, 80–105. [Google Scholar]
- Guyon, I.; Elisseeff, A. An introduction to variable and feature selection. J. Mach. Learn. Res. 2003, 3, 1157–1182. [Google Scholar]
- Koller, D.; Sahami, M. Toward Optimal Feature Selection; Stanford InfoLab: Stanford, CA, USA, 1996. [Google Scholar]
- Bishop, C.M. Pattern Recognition and Machine Learning; Springer: Berlin, Germany, 2006. [Google Scholar]
- Hafezi, R.; Shahrabi, J.; Hadavandi, E. A bat-neural network multi-agent system (BNNMAS) for stock price prediction: Case study of DAX stock price. Appl. Soft Comput. 2015, 29, 196–210. [Google Scholar] [CrossRef]
- Hafezi, R.; Akhavan, A.N. Forecasting Gold Price Changes: Application of an Equipped Artificial Neural Network. AUT J. Model. Simul. 2018, 50, 71–82. [Google Scholar]
- Kourou, K.; Exarchos, T.P.; Exarchos, K.P.; Karamouzis, M.V.; Fotiadis, D.I. Machine learning applications in cancer prognosis and prediction. Comput. Struct. Biotechnol. J. 2015, 13, 8–17. [Google Scholar] [CrossRef]
- Dessì, D. A Recommender System of Medical Reports Leveraging Cognitive Computing and Frame Semantics, in Machine Learning Paradigms; Springer: Berlin, Germany, 2019; pp. 7–30. [Google Scholar]
- Panapakidis, I.P.; Dagoumas, A.S. Day-ahead natural gas demand forecasting based on the combination of wavelet transform and ANFIS/genetic algorithm/neural network model. Energy 2017, 118, 231–245. [Google Scholar] [CrossRef]
- Kazemi, S.; Hadavandi, E.; Mehmanpazir, F.; Nakhostin, M. A hybrid intelligent approach for modeling brand choice and constructing a market response simulator. Knowl. Based Syst. 2013, 40, 101–110. [Google Scholar] [CrossRef]
- Júnior, S.E.R.; de Oliveira Serra, G.L. A novel intelligent approach for state space evolving forecasting of seasonal time series. Eng. Appl. Artif. Intell. 2017, 64, 27–285. [Google Scholar]
- Ervural, B.C.; Beyca, O.F.; Zaim, S. Model Estimation of ARMA Using Genetic Algorithms: A Case Study of Forecasting Natural Gas Consumption. Procedia Soc. Behav. Sci. 2016, 235, 53–545. [Google Scholar] [CrossRef]
- Zhu, L.; Li, M.S.; Wu, Q.H.; Jiang, L. Short-term natural gas demand prediction based on support vector regression with false neighbours filtered. Energy 2015, 80, 428–436. [Google Scholar] [CrossRef]
- Xu, N.; Dang, Y.; Gong, Y. Novel grey prediction model with nonlinear optimized time response method for forecasting of electricity consumption in China. Energy 2016, 118, 473–480. [Google Scholar] [CrossRef]
- Bianco, V.; Scarpa, F.; Tagliafico, L.A. Scenario analysis of nonresidential natural gas consumption in Italy. Appl. Energy 2014, 113, 392–403. [Google Scholar] [CrossRef]
- Baldacci, L.; Golfarelli, M.; Lombardi, D.; Sami, F. Natural gas consumption forecasting for anomaly detection. Expert Syst. Appl. 2016, 62, 190–201. [Google Scholar] [CrossRef]
- Zavanella, L.; Zanoni, S.; Ferretti, I.; Mazzoldi, L. Energy demand in production systems: A Queuing Theory perspective. Int. J. Prod. Econ. 2015, 170, 393–400. [Google Scholar] [CrossRef]
- Baumeister, C.; Kilian, L. Real-time analysis of oil price risks using forecast scenarios. IMF Econ. Rev. 2011, 62, 119–145. [Google Scholar] [CrossRef]
- Dilaver, Ö.; Dilaver, Z.; Hunt, L.C. What drives natural gas consumption in Europe? Analysis and projections. J. Nat. Gas Sci. Eng. 2014, 19, 125–136. [Google Scholar] [CrossRef]
- Li, J.; Dong, X.; Shangguan, J.S.; Hook, M. Forecasting the growth of China’s natural gas consumption. Energy 2011, 36, 1380–1385. [Google Scholar] [CrossRef]
- Suganthi, L.; Samuel, A.A. Energy models for demand forecasting—A review. Renew. Sustain. Energy Rev. 2012, 16, 1223–1240. [Google Scholar] [CrossRef]
- Aras, H.; Aras, N. Forecasting residential natural gas demand. Energy Sources 2004, 26, 463–472. [Google Scholar] [CrossRef]
- Erdogdu, E. Natural gas demand in Turkey. Appl. Energy 2010, 87, 211–219. [Google Scholar] [CrossRef]
- Gori, F.; Ludovisi, D.; Cerritelli, P. Forecast of oil price and consumption in the short term under three scenarios: Parabolic, linear and chaotic behaviour. Energy 2007, 32, 1291–1296. [Google Scholar] [CrossRef]
- Kumar, U.; Jain, V. Time series models (Grey-Markov, Grey Model with rolling mechanism and singular spectrum analysis) to forecast energy consumption in India. Energy 2010, 35, 1709–1716. [Google Scholar] [CrossRef]
- Akkurt, M.; Demirel, O.F.; Zaim, S. Forecasting Turkey’s natural gas consumption by using time series methods. Eur. J. Econ. Political Stud. 2010, 3, 1–21. [Google Scholar]
- Sen, P.; Roy, M.; Pal, P. Application of ARIMA for forecasting energy consumption and GHG emission: A case study of an Indian pig iron manufacturing organization. Energy 2016, 116, 1031–1038. [Google Scholar] [CrossRef]
- Fagiani, M.; Squartini, S.; Gabrielli, L.; Spinsante, S. A review of datasets and load forecasting techniques for smart natural gas and water grids: Analysis and experiments. Neurocomputing 2015, 170, 448–465. [Google Scholar] [CrossRef]
- Shi, G.; Liu, D.; Wei, Q. Energy consumption prediction of office buildings based on echo state networks. Neurocomputing 2016, 216, 478–488. [Google Scholar] [CrossRef]
- Zhang, W.; Yang, J. Forecasting natural gas consumption in China by Bayesian model averaging. Energy Rep. 2015, 1, 216–220. [Google Scholar] [CrossRef]
- Taşpınar, F.; Celebi, N.; Tutkun, N. Forecasting of daily natural gas consumption on regional basis in Turkey using various computational methods. Energy Build. 2013, 56, 23–31. [Google Scholar] [CrossRef]
- Dalfard, V.M.; Asli, M.N.; Asadzadeh, S.M.; Sajjadi, S.M.; Nazari-Shirkouhi, A. A mathematical modeling for incorporating energy price hikes into total natural gas consumption forecasting. Appl. Math. Model. 2013, 37, 5664–5679. [Google Scholar] [CrossRef]
- Bianco, V.; Scarpa, F.; Tagliafico, L.A. Analysis and future outlook of natural gas consumption in the Italian residential sector. Energy Convers. Manag. 2014, 87, 754–764. [Google Scholar] [CrossRef]
- Gorucu, F. Evaluation and forecasting of gas consumption by statistical analysis. Energy Sour. 2004, 26, 267–276. [Google Scholar] [CrossRef]
- O’Neill, B.C.; Desai, M. Accuracy of past projections of US energy consumption. Energy Policy 2005, 33, 979–993. [Google Scholar] [CrossRef]
- Adams, F.G.; Shachmurove, Y. Modeling and forecasting energy consumption in China: Implications for Chinese energy demand and imports in 2020. Energy Econ. 2008, 30, 1263–1278. [Google Scholar] [CrossRef]
- Ramanathan, R. A multi-factor efficiency perspective to the relationships among world GDP, energy consumption and carbon dioxide emissions. Technol. Forecast. Soc. Chang. 2006, 73, 483–494. [Google Scholar] [CrossRef]
- Lu, W.; Ma, Y. Image of energy consumption of well off society in China. Energy Convers. Manag. 2004, 45, 1357–1367. [Google Scholar] [CrossRef]
- Hunt, L.C.; Ninomiya, Y. Primary energy demand in Japan: An empirical analysis of long-term trends and future CO 2 emissions. Energy Policy 2005, 33, 1409–1424. [Google Scholar] [CrossRef]
- Iniyan, S.; Suganthi, L.; Samuel, A.A. Energy models for commercial energy prediction and substitution of renewable energy sources. Energy Policy 2006, 34, 2640–2653. [Google Scholar] [CrossRef]
- Sözen, A.; Arcaklioğlu, E.; Özkaymak, M. Turkey’s net energy consumption. Appl. Energy 2005, 81, 209–221. [Google Scholar] [CrossRef]
- Ermis, K.; Midilli, A.; Dincer, I.; Rosen, M.A. Artificial neural network analysis of world green energy use. Energy Policy 2007, 35, 1731–1743. [Google Scholar] [CrossRef]
- Sözen, A.; Arcaklioglu, E. Prediction of net energy consumption based on economic indicators (GNP and GDP) in Turkey. Energy Policy 2007, 35, 4981–4992. [Google Scholar] [CrossRef]
- Sözen, A.; Gülseven, Z.; Arcaklioğlu, E. Forecasting based on sectoral energy consumption of GHGs in Turkey and mitigation policies. Energy Policy 2007, 35, 6491–6505. [Google Scholar] [CrossRef]
- Geem, Z.W.; Roper, W.E. Energy demand estimation of South Korea using artificial neural network. Energy Policy 2009, 37, 4049–4054. [Google Scholar] [CrossRef]
- Forouzanfar, M.; Doustmohammadi, A.; Menhaj, M.B.; Hasanzadeh, S. Modeling and estimation of the natural gas consumption for residential and commercial sectors in Iran. Appl. Energy 2010, 87, 268–274. [Google Scholar] [CrossRef]
- Ekonomou, L. Greek long-term energy consumption prediction using artificial neural networks. Energy 2010, 35, 512–517. [Google Scholar] [CrossRef]
- Rodger, J.A. A fuzzy nearest neighbor neural network statistical model for predicting demand for natural gas and energy cost savings in public buildings. Expert Syst. Appl. 2014, 41, 1813–1829. [Google Scholar] [CrossRef]
- Aydinalp-Koksal, M.; Ugursal, V.I. Comparison of neural network, conditional demand analysis, and engineering approaches for modeling end-use energy consumption in the residential sector. Appl. Energy 2008, 85, 271–296. [Google Scholar] [CrossRef]
- Aramesh, A.; Montazerin, N.; Ahmadi, A. A general neural and fuzzy-neural algorithm for natural gas flow prediction in city gate stations. Energy Build. 2014, 72, 73–79. [Google Scholar] [CrossRef]
- Szoplik, J. Forecasting of natural gas consumption with artificial neural networks. Energy 2015, 85, 208–220. [Google Scholar] [CrossRef]
- Soldo, B.; Potocnik, P.; Simunovic, G.; Saric, T.; Govekar, E. Improving the residential natural gas consumption forecasting models by using solar radiation. Energy Build. 2014, 69, 498–506. [Google Scholar] [CrossRef]
- Izadyar, N.; Ong, H.C.; Shamshirband, S.; Ghadamian, H.; Tong, C.W. Intelligent forecasting of residential heating demand for the District Heating System based on the monthly overall natural gas consumption. Energy Build. 2015, 104, 208–214. [Google Scholar] [CrossRef]
- González-Romera, E.; Jaramillo-Morán, M.Á.; Carmona-Fernández, D. Forecasting of the electric energy demand trend and monthly fluctuation with neural networks. Comput. Ind. Eng. 2007, 52, 336–343. [Google Scholar] [CrossRef]
- Kampelis, N.; Tsekeri, E.; Kolokotsa, D.; Kalaitzakis, K.; Isidori, D.; Cristalli, C. Development of demand response energy management optimization at building and district levels using genetic algorithm and artificial neural network modelling power predictions. Energies 2018, 11, 3012. [Google Scholar] [CrossRef]
- Akpinar, M.; Adak, M.; Yumusak, N. Day-ahead natural gas demand forecasting using optimized abc-based neural network with sliding window technique: The case study of regional basis in turkey. Energies 2017, 10, 781. [Google Scholar] [CrossRef]
- Zheng, D.; Shi, M.; Wang, Y.; Eseye, A.F.; Zjamg, J. Day-ahead wind power forecasting using a two-stage hybrid modeling approach based on scada and meteorological information, and evaluating the impact of input-data dependency on forecasting accuracy. Energies 2017, 10, 1988. [Google Scholar] [CrossRef]
- Lee, Y.S.; Tong, L.I. Forecasting energy consumption using a grey model improved by incorporating genetic programming. Energy Convers. Manag. 2011, 52, 147–152. [Google Scholar] [CrossRef]
- Ozturk, H.K.; Ceylan, H.; Hepbasli, A.; Utlu, Z. Estimating petroleum exergy production and consumption using vehicle ownership and GDP based on genetic algorithm approach. Renew. Sustain. Energy Rev. 2004, 8, 289–302. [Google Scholar] [CrossRef]
- Yu, F.; Xu, X. A short-term load forecasting model of natural gas based on optimized genetic algorithm and improved BP neural network. Appl. Energy 2014, 134, 102–113. [Google Scholar] [CrossRef]
- Askari, S.; Montazerin, N.; Zarandi, M.F. Forecasting semi-dynamic response of natural gas networks to nodal gas consumptions using genetic fuzzy systems. Energy 2015, 83, 252–266. [Google Scholar] [CrossRef]
- Kovačič, M.; Šarler, B. Genetic programming prediction of the natural gas consumption in a steel plant. Energy 2014, 66, 273–284. [Google Scholar] [CrossRef]
- Mousavi, S.M.; Mostafavi, E.S.; Hosseinpour, F. Gene expression programming as a basis for new generation of electricity demand prediction models. Comput. Ind. Eng. 2014, 74, 120–128. [Google Scholar] [CrossRef]
- Fan, G.F.; Wang, A.; Hong, W.C. Combining grey model and self-adapting intelligent grey model with genetic algorithm and annual share changes in natural gas demand forecasting. Energies 2018, 11, 1625. [Google Scholar] [CrossRef]
- Toksarı, M.D. Ant colony optimization approach to estimate energy demand of Turkey. Energy Policy 2007, 35, 3984–3990. [Google Scholar] [CrossRef]
- Ünler, A. Improvement of energy demand forecasts using swarm intelligence: The case of Turkey with projections to 2025. Energy Policy 2008, 36, 1937–1944. [Google Scholar] [CrossRef]
- De, G.; Gao, W. Forecasting China’s Natural Gas Consumption Based on AdaBoost-Particle Swarm Optimization-Extreme Learning Machine Integrated Learning Method. Energies 2018, 11, 2938. [Google Scholar] [CrossRef]
- Paudel, S.; Elmitri, M.; Counturier, S.; Nhuyen, P.H.; Kamphius, R.; Lacarrirere, B.; Corre, O.L. A relevant data selection method for energy consumption prediction of low energy building based on support vector machine. Energy Build. 2017, 138, 240–256. [Google Scholar] [CrossRef]
- Amasyali, K.; El-Gohary, N. Building Lighting Energy Consumption Prediction for Supporting Energy Data Analytics. Procedia Eng. 2016, 145, 511–517. [Google Scholar] [CrossRef]
- Azadeh, A.; Zarrin, M.; Beik, H.R.; Bioki, T.A. A neuro-fuzzy algorithm for improved gas consumption forecasting with economic, environmental and IT/IS indicators. J. Pet. Sci. Eng. 2015, 133, 716–739. [Google Scholar] [CrossRef]
- Sun, J. Energy demand in the fifteen European Union countries by 2010—A forecasting model based on the decomposition approach. Energy 2001, 26, 549–560. [Google Scholar] [CrossRef]
- Tao, Z. Scenarios of China’s oil consumption per capita (OCPC) using a hybrid Factor Decomposition–System Dynamics (SD) simulation. Energy 2010, 35, 168–180. [Google Scholar] [CrossRef]
- Alcántara, V.; del Río, P.; Hernández, F. Structural analysis of electricity consumption by productive sectors. The Spanish case. Energy 2010, 35, 2088–2098. [Google Scholar]
- Liu, X.; Moreno, B.; García, A.S. A grey neural network and input-output combined forecasting model. Primary energy consumption forecasts in Spanish economic sectors. Energy 2016, 115, 1042–1054. [Google Scholar] [CrossRef]
- Huang, Y.; Bor, Y.J.; Peng, C.Y. The long-term forecast of Taiwan’s energy supply and demand: LEAP model application. Energy Policy 2011, 39, 6790–6803. [Google Scholar] [CrossRef]
- Shabbir, R.; Ahmad, S.S. Monitoring urban transport air pollution and energy demand in Rawalpindi and Islamabad using leap model. Energy 2010, 35, 2323–2332. [Google Scholar] [CrossRef]
- Rout, U.K.; Vob, A.; Singh, A.; Fahl, U.; Blesl, M.; Gallachoir, B.P.O. Energy and emissions forecast of China over a long-time horizon. Energy 2011, 36, 1–11. [Google Scholar] [CrossRef]
- Wang, Z.X.; Ye, D.J. Forecasting Chinese carbon emissions from fossil energy consumption using non-linear grey multivariable models. J. Clean. Prod. 2017, 142, 600–612. [Google Scholar] [CrossRef]
- Zeng, B.; Li, C. Forecasting the natural gas demand in China using a self-adapting intelligent grey model. Energy 2016, 112, 810–825. [Google Scholar] [CrossRef]
- Shaikh, F.; Ji, Q. Forecasting natural gas demand in China: Logistic modelling analysis. Int. J. Electr. Power Energy Syst. 2016, 77, 25–32. [Google Scholar] [CrossRef]
- Zurada, J.M. Introduction to Artificial Neural Systems; West Publishing Company: St. Paul, MN, USA, 1992; Volume 8. [Google Scholar]
- Hall, M.A. Correlation-Based Feature Selection for Machine Learning; The University of Waikato: Harmilton, New Zealand, 1999. [Google Scholar]
- Hall, M.A. Correlation-Based Feature Selection of Discrete and Numeric Class Machine Learning; The University of Waikato: Harmilton, New Zealand, 2000. [Google Scholar]
- Liew, V.K.S. Which Lag Length Selection Criteria Should We Employ? Econ. Bull. 2004, 3, 1–9. [Google Scholar]
- Sola, J.; Sevilla, J. Importance of input data normalization for the application of neural networks to complex industrial problems. IEEE Trans. Nucl. Sci. 1997, 44, 1464–1468. [Google Scholar] [CrossRef]
- Patro, S.; Sahu, K.K. Normalization: A Preprocessing Stage; Cornell University: Ithaca, NY, USA, 2015. [Google Scholar]
- Jayalakshmi, T.; Santhakumaran, A. Statistical normalization and back propagation for classification. Int. J. Comput. Theory Eng. 2011, 3, 1793–8201. [Google Scholar]
- Schalkoff, R.J. Artificial Neural Networks; McGraw-Hill Higher Education: New York, NY, USA, 1997. [Google Scholar]
- Holland, J.H. Genetic algorithms. Sci. Am. 1992, 267, 66–72. [Google Scholar] [CrossRef]
- FazelZarandi, M.H.; Hadavandi, E.; Turksen, I.B. A Hybrid Fuzzy Intelligent Agent-Based System for Stock Price Prediction. Int. J. Intell. Syst. 2012, 27, 1–23. [Google Scholar]
- Han, J.; Pei, J.; Kamber, M. Data Mining: Concepts and Techniques; Elsevier: Amsterdam, The Netherlands, 2011. [Google Scholar]
- Arsenault, E.; Bernard, J.T.; Carr, C.W.; Genest-Laplante, E. A total energy demand model of Québec: Forecasting properties. Energy Econ. 1995, 17, 163–171. [Google Scholar] [CrossRef]
- Tolmasquim, M.T.; Cohen, C.; Szklo, A.S. CO 2 emissions in the Brazilian industrial sector according to the integrated energy planning model (IEPM). Energy Policy 2001, 29, 641–651. [Google Scholar] [CrossRef]
- Intarapravich, D.; Johnson, C.J.; Li, B.; Long, S.; Pezeshki, S.; Prawiraatmadja, W.; Tang, F.C.; Wu, T.K. 3 Asia-Pacific energy supply and demand to 2010. Energy 1996, 21, 1017–1039. [Google Scholar] [CrossRef]
- Raghuvanshi, S.P.; Chandra, A.; Raghav, A.K. Carbon dioxide emissions from coal based power generation in India. Energy Convers. Manag. 2006, 47, 427–441. [Google Scholar] [CrossRef]
- Mackay, R.; Probert, S. Crude oil and natural gas supplies and demands up to the year AD 2010 for France. Appl. Energy 1995, 50, 185–208. [Google Scholar] [CrossRef]
- Parikh, J.; Purohit, P.; Maitra, P. Demand projections of petroleum products and natural gas in India. Energy 2007, 32, 1825–1837. [Google Scholar] [CrossRef]
- Nel, W.P.; Cooper, C.J. A critical review of IEA’s oil demand forecast for China. Energy Policy 2008, 36, 1096–1106. [Google Scholar] [CrossRef]
- Zhang, M.; Mu, H.; Li, G.; Ning, Y. Forecasting the transport energy demand based on PLSR method in China. Energy 2009, 34, 1396–1400. [Google Scholar] [CrossRef]
- Dincer, I.; Dost, S. Energy and GDP. Int. J. Energy Res. 1997, 21, 153–167. [Google Scholar] [CrossRef]
- Kankal, M.; Akpinar, A.; Komurcu, M.I.; Ozsahin, T.S. Modeling and forecasting of Turkey’s energy consumption using socio-economic and demographic variables. Appl. Energy 2011, 88, 1927–1939. [Google Scholar] [CrossRef]
- Suganthi, L.; Jagadeesan, T. A modified model for prediction of India’s future energy requirement. Energy Environ. 1992, 3, 371–386. [Google Scholar] [CrossRef]
- Suganthi, L.; Williams, A. Renewable energy in India—A modelling study for 2020–2021. Energy Policy 2000, 28, 1095–1109. [Google Scholar] [CrossRef]
- Ceylan, H.; Ozturk, H.K. Estimating energy demand of Turkey based on economic indicators using genetic algorithm approach. Energy Convers. Manag. 2004, 45, 2525–2537. [Google Scholar] [CrossRef]
- Canyurt, O.E.; Ozturk, H.K. Application of genetic algorithm (GA) technique on demand estimation of fossil fuels in Turkey. Energy Policy 2008, 36, 2562–2569. [Google Scholar] [CrossRef]
- Persaud, A.J.; Kumar, U. An eclectic approach in energy forecasting: A case of Natural Resources Canada’s (NRCan’s) oil and gas outlook. Energy Policy 2001, 29, 303–313. [Google Scholar] [CrossRef]
- Wang, J.; Lin, Y.I.; Hou, S.Y. A data mining approach for training evaluation in simulation-based training. Comput. Ind. Eng. 2015, 80, 171–180. [Google Scholar] [CrossRef]
- Kononenko, I.; Šimec, E.; Robnik-Šikonja, M. Overcoming the myopia of inductive learning algorithms with RELIEFF. Appl. Intell. 1997, 7, 39–55. [Google Scholar] [CrossRef]
- Ghiselli, E.E. Theory of Psychological Measurement; McGraw-Hill: New York, NY, USA, 1964. [Google Scholar]
- Kohavi, R.; John, G.H. Wrappers for feature subset selection. Artif. Intell. 1997, 97, 273–324. [Google Scholar] [CrossRef]
- Rich, E.; Knight, K. Artificial Intelligence; McGraw-Hill: New York, NY, USA, 1991. [Google Scholar]
- Freitag, D. Greedy Attribute Selection. In Proceedings of the eleventh International Conference, New Brunswick, NJ, USA, 10–13 July 1994. [Google Scholar]
- Parras-Gutierrez, E.; Rivas, V.M.; Garcia-Arenas, M.; Jesus, M.J. Short, medium and long term forecasting of time series using the L-Co-R algorithm. Neurocomputing 2014, 128, 433–446. [Google Scholar] [CrossRef]
- Winker, P. Optimized multivariate lag structure selectio. Comput. Econ. 2000, 16, 87–103. [Google Scholar] [CrossRef]
- Shahrabi, J.; Hadavandi, E.; Asadi, S. Developing a hybrid intelligent model for forecasting problems: Case study of tourism demand time series. Knowl. Based Syst. 2013, 43, 112–122. [Google Scholar] [CrossRef]
- Burnham, K.P.; Anderson, D.R. Multimodel inference: Understanding AIC and BIC in Model Selection. Sociol. Methods Res. 2004, 33, 261–304. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; McClelland, J.L.; Group, P.R. Parallel Distributed Processing: Explorations in the Microstructures of Cognition. Volume 1: Foundations; The MIT Press: Cambridge, MA, USA, 1986. [Google Scholar]
- Hadavandi, E.; Shahrabi, J.; Hayashi, Y. SPMoE: A novel subspace-projected mixture of experts model for multi-target regression problems. Soft Comput. 2016, 20, 2047–2065. [Google Scholar] [CrossRef]
- Hadavandi, E.; Shahrabi, J.; Shamshirband, S. A novel Boosted-neural network ensemble for modeling multi-target regression problems. Eng. Appl. Artif. Intell. 2015, 45, 204–219. [Google Scholar] [CrossRef]
- Kourentzes, N. Intermittent demand forecasts with neural networks. Int. J. Prod. Econ. 2013, 143, 198–206. [Google Scholar] [CrossRef]
- Teixeira, J.P.; Fernandesa, P.O. Tourism Time Series Forecast -Different ANN Architectures with Time Index Input. Procedia Technol. 2012, 5, 445–454. [Google Scholar] [CrossRef]
- Yadav, A.K.; Chandel, S. Solar radiation prediction using Artificial Neural Network techniques: A review. Renew. Sustain. Energy Rev. 2014, 33, 772–781. [Google Scholar] [CrossRef]
- Zhang, J.; Chen, R.H.; Wang, M.J.; Tian, W.X.; Su, G.H.; Qiu, S.Z. Prediction of LBB leakage for various conditions by genetic neural network and genetic algorithms. Nucl. Eng. Des. 2017, 325, 33–43. [Google Scholar] [CrossRef]
- Biswas, M.R.; Robinson, M.D.; Fumo, N. Prediction of residential building energy consumption: A neural network approach. Energy 2016, 117, 84–92. [Google Scholar] [CrossRef]
- Anemangely, M.; Ramezanzadeh, A.; Tokhmechi, B. Shear wave travel time estimation from petrophysical logs using ANFIS-PSO algorithm: A case study from Ab-Teymour Oilfield. J. Nat. Gas Sci. Eng. 2017, 38, 373–387. [Google Scholar] [CrossRef]
- Zendehboudi, A.; Li, X.; Wang, B. Utilization of ANN and ANFIS models to predict variable speed scroll compressor with vapor injection. Int. J. Refrig. 2017, 74, 473–485. [Google Scholar] [CrossRef]
- Abdi, J.; Moshiri, B.; Abdulhai, B.; Sedigh, A.K. Forecasting of short-term traffic-flow based on improved neurofuzzy models via emotional temporal difference learning algorithm. Eng. Appl. Artif. Intell. 2012, 25, 1022–1042. [Google Scholar] [CrossRef]
- Fath, A.H. Application of radial basis function neural networks in bubble point oil formation volume factor prediction for petroleum systems. Fluid Phase Equilibria 2017, 437, 14–22. [Google Scholar] [CrossRef]
- Mohammadi, R.; Ghomi, S.F.; Zeinali, F. A new hybrid evolutionary based RBF networks method for forecasting time series: A case study of forecasting emergency supply demand time series. Eng. Appli. Artif. Intell. 2014, 36, 204–214. [Google Scholar] [CrossRef]
- Heidari, E.; Sobati, M.A.; Movahedirad, S. Accurate prediction of nanofluid viscosity using a multilayer perceptron artificial neural network (MLP-ANN). Chemom. Intell. Lab. Syst. 2016, 155, 73–85. [Google Scholar] [CrossRef]
- Park, J.; Kim, K.Y. Meta-modeling using generalized regression neural network and particle swarm optimization. Appl. Soft Comput. 2017, 51, 354–369. [Google Scholar] [CrossRef]
- Hu, R.; Wen, S.; Zeng, Z.; Huang, T. A short-term power load forecasting model based on the generalized regression neural network with decreasing step fruit fly optimization algorithm. Neurocomputing 2017, 221, 24–31. [Google Scholar] [CrossRef]
- Lotfinejad, M.M.; Hafezi, R.; Khanali, M.; Hossenini, S.S. A Comparative Assessment of Predicting Daily Solar Radiation Using Bat Neural Network (BNN), Generalized Regression Neural Network (GRNN), and Neuro-Fuzzy (NF) System: A Case Study. Energies 2018, 11, 1188. [Google Scholar] [CrossRef]
- Chai, T.; Draxler, R.R. Root mean square error (RMSE) or mean absolute error (MAE)?—Arguments against avoiding RMSE in the literature. Geosci. Model Dev. 2014, 7, 1247–1250. [Google Scholar] [CrossRef]
- Willmott, C.J.; Matsuura, K. Advantages of the mean absolute error (MAE) over the root mean square error (RMSE) in assessing average model performance. Clim. Res. 2005, 30, 79–82. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Approaches | References | |
|---|---|---|
| Classical computational extrapolation | Time series | [24,25,31,34,35,36,37,38,39,40,41,42,43] |
| Regression | [28,44,45,46,47] | |
| Econometrics | [48,49,50,51,52] | |
| Expert systems and learning models | Artificial neural network (ANN) | [21,40,53,54,55,56,57,58,59,60,61,62,63,64,65,66,67,68,69] |
| Genetic programming (GP) | [21,24,40,58,65,67,69,70,71,72,73,74,75,76] | |
| Ant colony optimization | [77] | |
| Particle swarm optimization (PSO) | [26,78,79] | |
| Support vector machine (SVM) | [25,40,59,64,80,81] | |
| Fuzzy inference system (FIS) | [21,44,62,73,82] | |
| Others | Decomposition approach | [83,84] |
| Input-output model | [85,86] | |
| Bottom-up model | [87,88,89] | |
| Grey method | [26,37,76,86,90,91] | |
| Logistic model | [92] | |
| Type of Models | Pros & Cons |
|---|---|
| Classic price modeling/forecasting |
|
| Time series models |
|
| Learning forecasting models |
|
| Qualitative based forecasting models |
|
| Title | Unit | Reference(s) | Source |
|---|---|---|---|
| Alternative and Nuclear Energy | % of total energy use | Proposed by authors | World Bank |
| CO2 Emissions | metric tons per capita | [49] | World Bank |
| CO2 Emissions | Kt | World Bank | |
| Energy Imports, Net | % of energy use | Proposed by authors | World Bank |
| Fossil Fuel Energy Consumption | % of total | [104] | World Bank |
| GDP Growth | annual % | [49,55,59,77,78,105,106,107,108,109,110,111,112,113] | World Bank |
| GDP per Capita | current US$ | World Bank | |
| Population Growth | annual % | [46,52,53,77,78,105,107,108,109,112,113,114,115,116,117] | World Bank |
| Urban Population | person | [105,111] | World Bank |
| Gold Price | 10:30 A.M.in London Bullion Market, US$ | Proposed by authors | World Bank |
| Natural Gas Production | billion cubic meters | Proposed by authors | British Petroleum |
| Oil Consumption | million tones | Proposed by authors | British Petroleum |
| Crude Oil Prices | US dollars per barrel ($2013) | [52,104,106,112,114,115,118] | British Petroleum |
| Error Title | Abbreviation | Formula |
|---|---|---|
| R-squared | R2 | * |
| Mean Absolute Error | MAE | |
| Mean Absolute Percentage Error | MAPE | |
| Mean Bias Error | MBE | |
| Root Mean Square Error | RMSE |
| Models | Characteristics | R2 | MAE | MAPE | MBE | RMSE |
|---|---|---|---|---|---|---|
| DmGNn | Number of Neurons = 4; Maximum generation = 100; Cross Over Probability = 0.8; Mutation Probability = 0.05; | 0.9847 | 52.19 | 1.69 | 13.54 | 61.33 |
| MLP | Maximum Epochs = 200; Train Parameter Goal = 1 × 10−7; | 0.8241 | 115.59 | 3.80 | −44.85 | 145.61 |
| ANFIS | FIS Generation Approach: FCM; Number of Clusters = 10; Partition Matrix exponent = 2; | 0.8494 | 63.45 | 1.89 | 21.31 | 84.31 |
| RBF | Spread Value = 0.17; | 0.0018 | 308.64 | 10.42 | −308.64 | 366.51 |
| GRNN | Spread Value = 1; | 0.9864 | 127.63 | 4.17 | −4.03 | 142.12 |
| Input Protocol | R2 | MAE | MAPE | MBE | RMSE |
|---|---|---|---|---|---|
| Processed data | 0.9847 | 52.19 | 1.69 | 13.54 | 61.33 |
| Raw data | 0.9679 | 79.96 | 2.61 | 2.66 | 94.21 |
© 2019 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hafezi, R.; Akhavan, A.N.; Zamani, M.; Pakseresht, S.; Shamshirband, S. Developing a Data Mining Based Model to Extract Predictor Factors in Energy Systems: Application of Global Natural Gas Demand. Energies 2019, 12, 4124. https://doi.org/10.3390/en12214124
Hafezi R, Akhavan AN, Zamani M, Pakseresht S, Shamshirband S. Developing a Data Mining Based Model to Extract Predictor Factors in Energy Systems: Application of Global Natural Gas Demand. Energies. 2019; 12(21):4124. https://doi.org/10.3390/en12214124
Chicago/Turabian StyleHafezi, Reza, Amir Naser Akhavan, Mazdak Zamani, Saeed Pakseresht, and Shahaboddin Shamshirband. 2019. "Developing a Data Mining Based Model to Extract Predictor Factors in Energy Systems: Application of Global Natural Gas Demand" Energies 12, no. 21: 4124. https://doi.org/10.3390/en12214124
APA StyleHafezi, R., Akhavan, A. N., Zamani, M., Pakseresht, S., & Shamshirband, S. (2019). Developing a Data Mining Based Model to Extract Predictor Factors in Energy Systems: Application of Global Natural Gas Demand. Energies, 12(21), 4124. https://doi.org/10.3390/en12214124