
A Simulation of Image-Assisted Forest Monitoring for National Inventories

Abstract
:1. Introduction
- Yt = the volume at the beginning of year t,
- Lt = live growth during year t,
- Et = entry during year t,
- Mt = mortality during year t, and
- Ht = harvest during year t.
2. Materials and Methods
2.1. Simulated Populations
2.2. Sampling the Simulated Populations
2.3. General Estimation Approach
- the number of plots observing growth in year t,
- the product of portion of year t growing season observed by plot i and the portion of plot i area within the area of interest, and
- the value of component C observed on plot i, assignable to year t.
2.3.1. Estimation of the Weights under α = A1:
2.3.2. Estimation of the Weights under α = A2:
2.3.3. Estimation of the Weights under α = A3:
2.4. Estimation of Initial Annual Volume
2.5. Estimation Systems
2.6. Estimation System Evaluation
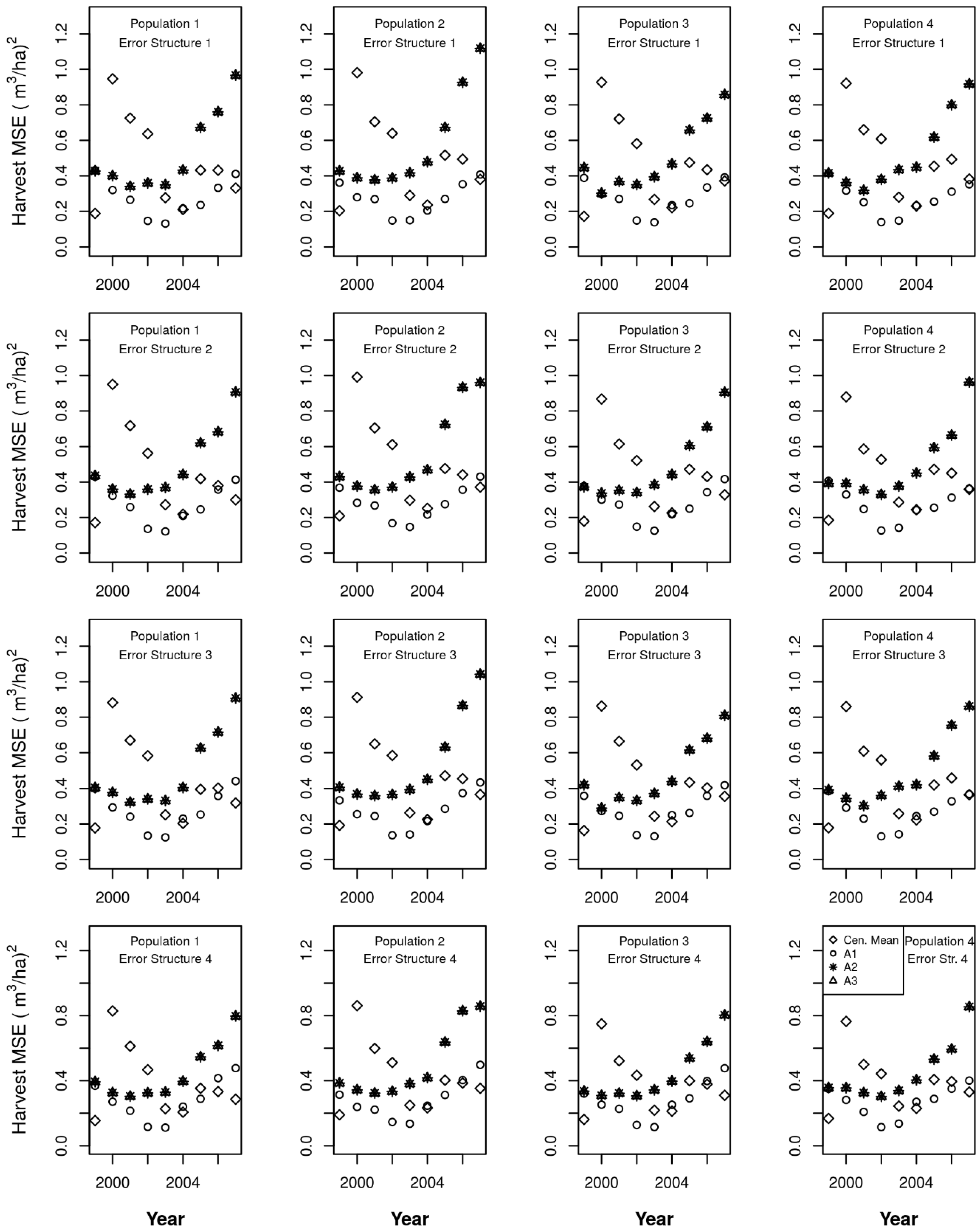
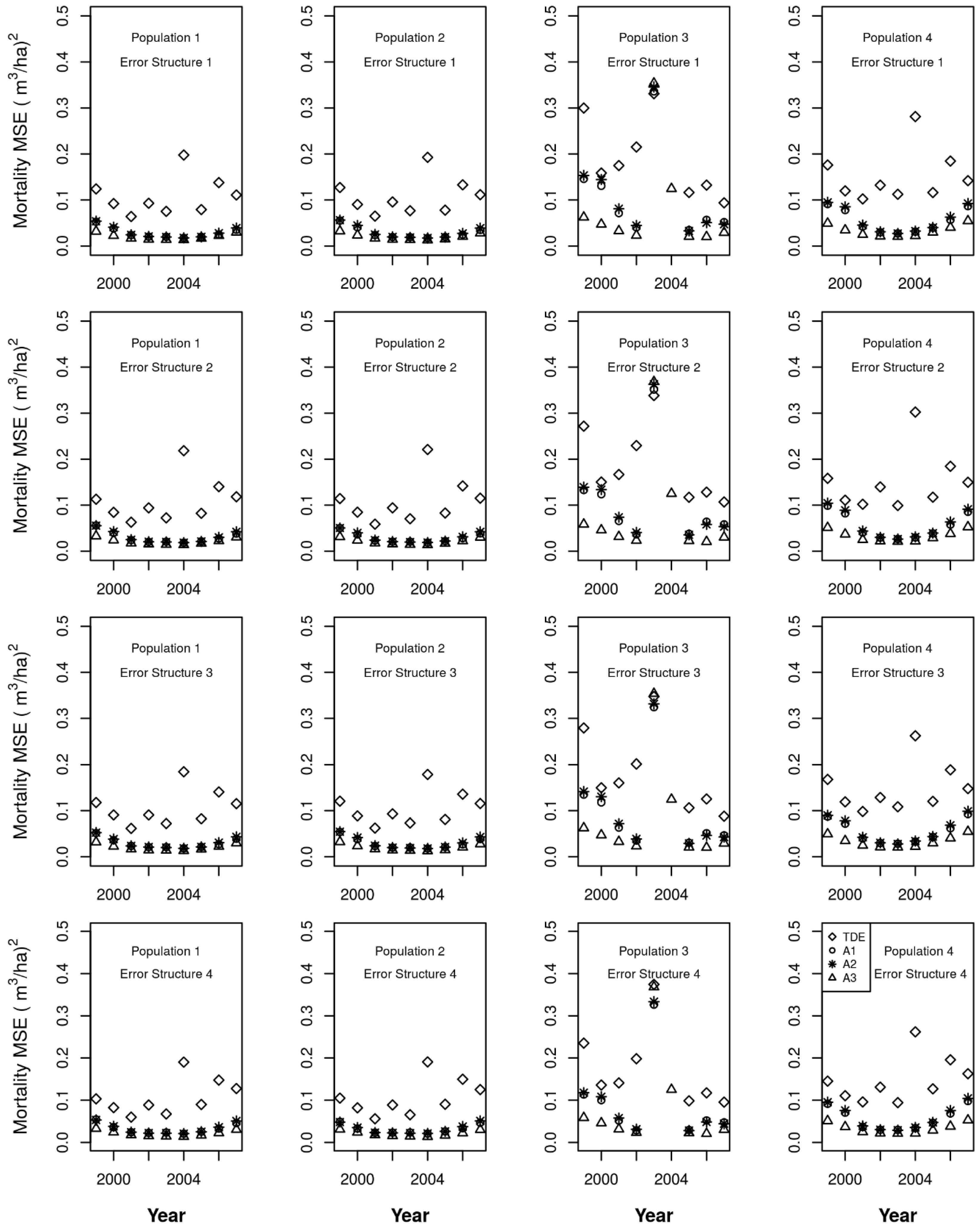
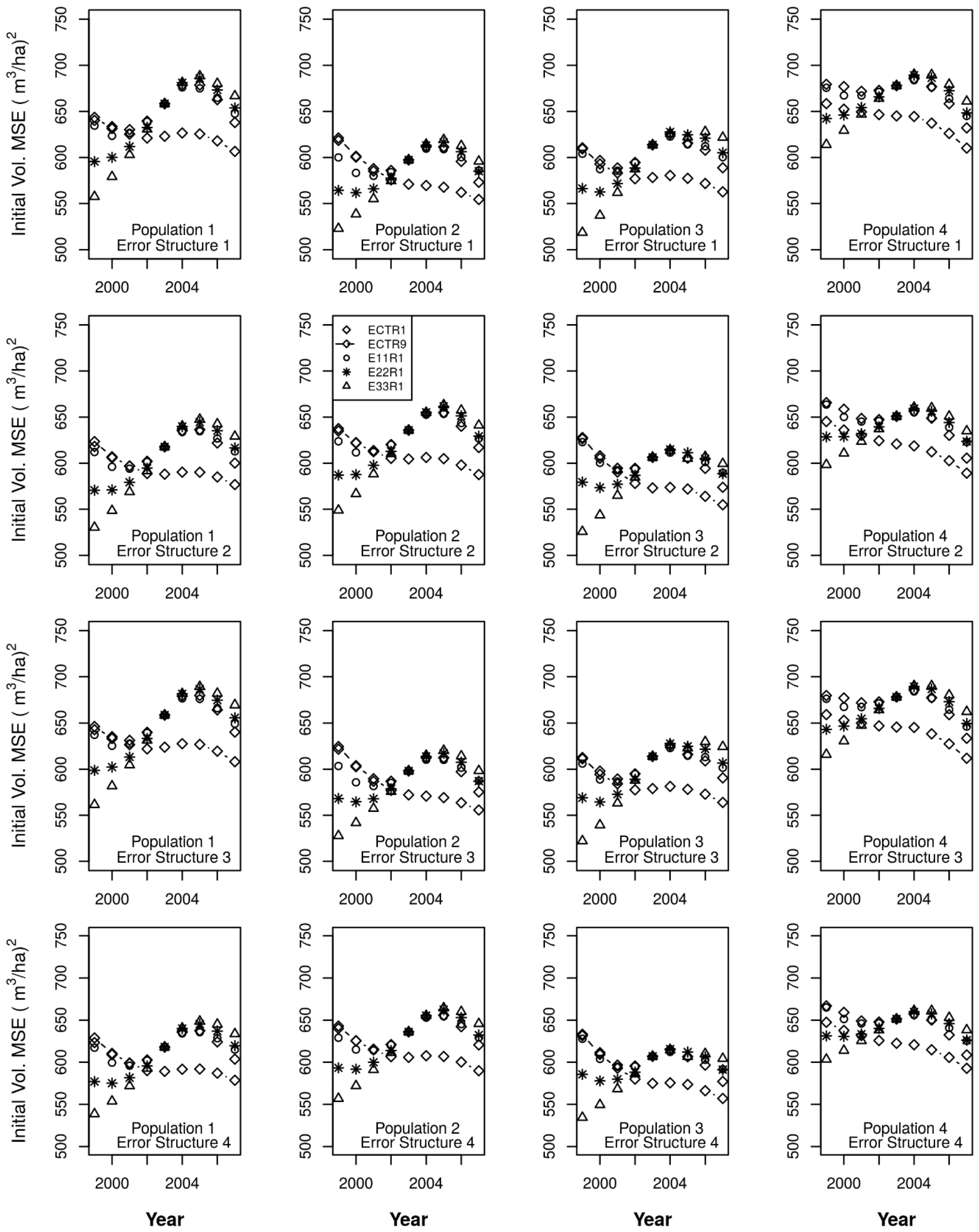
3. Results
4. Discussion
5. Conclusions
Acknowledgments
Conflicts of Interest
Appendix A. Distribution Statistics for the Four Simulated Populations

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Component | Statistic | 1998 | 1999 | 2000 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 |
| Volume | Minimum | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 1st Quartile | 0.00 | 0.00 | 0.42 | 1.89 | 4.33 | 7.11 | 9.86 | 12.56 | 14.84 | 16.47 | 17.58 | 18.59 | 19.17 | 19.59 | |
| Median | 9.91 | 14.93 | 19.98 | 25.31 | 30.71 | 35.84 | 41.21 | 45.78 | 49.51 | 53.05 | 56.53 | 59.07 | 61.52 | 63.46 | |
| Mean | 50.53 | 54.21 | 57.79 | 61.45 | 65.60 | 69.50 | 73.21 | 76.16 | 78.78 | 81.30 | 83.62 | 85.70 | 87.46 | 89.00 | |
| 3rd Quartile | 77.83 | 83.76 | 89.56 | 95.08 | 101.26 | 106.63 | 110.80 | 113.99 | 116.78 | 120.38 | 123.21 | 126.65 | 130.25 | 132.89 | |
| Maximum | 813.34 | 813.36 | 814.69 | 815.08 | 816.37 | 818.58 | 821.72 | 825.90 | 831.01 | 837.24 | 844.48 | 852.75 | 862.01 | 872.21 | |
| Live Growth | Minimum | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 1st Quartile | 0.00 | 0.00 | 0.00 | 0.00 | 0.29 | 0.66 | 0.73 | 0.66 | 0.50 | 0.22 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Median | 1.19 | 1.49 | 2.02 | 2.49 | 3.04 | 3.36 | 3.43 | 3.40 | 3.36 | 3.20 | 2.35 | 0.73 | 0.00 | 0.00 | |
| Mean | 3.57 | 3.59 | 3.79 | 4.01 | 4.27 | 4.43 | 4.49 | 4.47 | 4.48 | 4.53 | 4.13 | 3.51 | 2.75 | 1.71 | |
| 3rd Quartile | 5.30 | 5.39 | 5.70 | 6.03 | 6.35 | 6.50 | 6.65 | 6.68 | 6.72 | 6.94 | 6.56 | 5.65 | 3.94 | 0.00 | |
| Maximum | 52.52 | 50.58 | 66.35 | 58.15 | 48.79 | 39.41 | 33.73 | 35.04 | 39.47 | 43.90 | 44.57 | 41.38 | 39.08 | 46.09 | |
| Entry | Minimum | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 1st Quartile | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Median | 0.00 | 0.04 | 0.11 | 0.17 | 0.22 | 0.25 | 0.26 | 0.24 | 0.22 | 0.18 | 0.08 | 0.00 | 0.00 | 0.00 | |
| Mean | 0.45 | 0.47 | 0.52 | 0.57 | 0.62 | 0.64 | 0.65 | 0.64 | 0.63 | 0.64 | 0.57 | 0.47 | 0.35 | 0.22 | |
| 3rd Quartile | 0.46 | 0.50 | 0.58 | 0.64 | 0.72 | 0.76 | 0.78 | 0.75 | 0.72 | 0.67 | 0.56 | 0.38 | 0.16 | 0.00 | |
| Maximum | 21.21 | 21.60 | 29.03 | 27.63 | 17.04 | 12.20 | 9.91 | 11.56 | 13.28 | 15.23 | 16.71 | 15.15 | 15.01 | 14.90 | |
| Mortality | Minimum | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 1st Quartile | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Median | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.06 | 0.06 | 0.02 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Mean | 0.74 | 0.74 | 0.76 | 0.78 | 0.82 | 0.86 | 0.88 | 0.91 | 0.94 | 0.97 | 0.90 | 0.77 | 0.60 | 0.38 | |
| 3rd Quartile | 0.21 | 0.28 | 0.39 | 0.46 | 0.55 | 0.65 | 0.71 | 0.73 | 0.72 | 0.69 | 0.48 | 0.20 | 0.00 | 0.00 | |
| Maximum | 108.46 | 93.27 | 78.00 | 77.97 | 78.57 | 78.77 | 79.11 | 79.44 | 79.54 | 80.31 | 80.39 | 80.51 | 80.83 | 80.94 | |
| Harvest | Minimum | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 1st Quartile | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Median | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Mean | 0.63 | 0.75 | 0.84 | 0.99 | 1.21 | 1.45 | 1.78 | 1.99 | 2.16 | 2.20 | 1.90 | 1.55 | 1.05 | 0.55 | |
| 3rd Quartile | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Maximum | 341.31 | 373.88 | 352.31 | 358.61 | 447.97 | 466.30 | 466.29 | 462.06 | 465.60 | 483.98 | 485.19 | 498.90 | 488.34 | 510.38 | |
| Year | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Component | Statistic | 1998 | 1999 | 2000 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 |
| Volume | Minimum | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 1st Quartile | 0.00 | 0.00 | 0.40 | 1.84 | 4.23 | 6.96 | 9.60 | 12.18 | 14.36 | 15.85 | 16.85 | 17.75 | 18.27 | 18.47 | |
| Median | 9.92 | 14.91 | 19.91 | 25.21 | 30.56 | 35.64 | 40.95 | 45.44 | 49.13 | 52.52 | 55.81 | 58.18 | 60.61 | 62.44 | |
| Mean | 50.54 | 54.21 | 57.77 | 61.40 | 65.48 | 69.34 | 72.98 | 75.87 | 78.39 | 80.81 | 83.02 | 85.02 | 86.69 | 88.18 | |
| 3rd Quartile | 77.85 | 83.75 | 89.54 | 95.06 | 101.16 | 106.48 | 110.52 | 113.66 | 116.30 | 119.70 | 122.36 | 125.71 | 129.16 | 131.71 | |
| Maximum | 817.12 | 817.14 | 818.39 | 818.81 | 820.10 | 822.27 | 825.34 | 829.30 | 834.12 | 840.11 | 847.13 | 855.06 | 864.06 | 873.90 | |
| Live Growth | Minimum | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 1st Quartile | 0.00 | 0.00 | 0.00 | 0.00 | 0.29 | 0.66 | 0.72 | 0.66 | 0.49 | 0.20 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Median | 1.19 | 1.49 | 2.02 | 2.49 | 3.04 | 3.35 | 3.43 | 3.40 | 3.36 | 3.20 | 2.34 | 0.73 | 0.00 | 0.00 | |
| Mean | 3.57 | 3.59 | 3.79 | 4.01 | 4.27 | 4.43 | 4.49 | 4.46 | 4.47 | 4.52 | 4.13 | 3.51 | 2.75 | 1.71 | |
| 3rd Quartile | 5.30 | 5.39 | 5.70 | 6.03 | 6.35 | 6.50 | 6.65 | 6.68 | 6.72 | 6.94 | 6.55 | 5.64 | 3.93 | 0.00 | |
| Maximum | 53.14 | 50.99 | 64.66 | 57.50 | 48.22 | 38.87 | 34.09 | 35.12 | 39.56 | 44.20 | 44.79 | 41.08 | 39.22 | 47.07 | |
| Entry | Minimum | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 1st Quartile | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Median | 0.00 | 0.04 | 0.11 | 0.17 | 0.22 | 0.25 | 0.26 | 0.24 | 0.21 | 0.18 | 0.07 | 0.00 | 0.00 | 0.00 | |
| Mean | 0.45 | 0.47 | 0.52 | 0.57 | 0.61 | 0.64 | 0.65 | 0.64 | 0.63 | 0.64 | 0.57 | 0.47 | 0.35 | 0.22 | |
| 3rd Quartile | 0.46 | 0.49 | 0.58 | 0.64 | 0.72 | 0.76 | 0.77 | 0.75 | 0.72 | 0.67 | 0.55 | 0.38 | 0.16 | 0.00 | |
| Maximum | 21.51 | 22.06 | 29.05 | 27.55 | 16.99 | 12.11 | 9.90 | 11.63 | 13.32 | 15.21 | 16.64 | 15.13 | 14.87 | 14.81 | |
| Mortality | Minimum | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 1st Quartile | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Median | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.03 | 0.06 | 0.06 | 0.02 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Mean | 0.74 | 0.74 | 0.76 | 0.78 | 0.82 | 0.86 | 0.88 | 0.91 | 0.94 | 0.97 | 0.90 | 0.76 | 0.60 | 0.38 | |
| 3rd Quartile | 0.21 | 0.28 | 0.39 | 0.46 | 0.55 | 0.65 | 0.71 | 0.73 | 0.72 | 0.69 | 0.48 | 0.20 | 0.00 | 0.00 | |
| Maximum | 109.16 | 93.88 | 78.48 | 77.31 | 77.80 | 78.08 | 78.46 | 78.55 | 78.85 | 79.36 | 79.29 | 80.21 | 79.93 | 80.14 | |
| Harvest | Minimum | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 1st Quartile | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Median | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Mean | 0.63 | 0.75 | 0.84 | 0.99 | 1.21 | 1.45 | 1.78 | 1.99 | 2.16 | 2.20 | 1.90 | 1.55 | 1.05 | 0.55 | |
| 3rd Quartile | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Maximum | 341.31 | 373.88 | 352.31 | 358.61 | 447.97 | 466.30 | 466.29 | 462.06 | 465.60 | 483.98 | 485.19 | 498.90 | 488.34 | 510.38 | |
| Year | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Component | Statistic | 1998 | 1999 | 2000 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 |
| Volume | Minimum | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 1st Quartile | 0.00 | 0.01 | 0.53 | 2.20 | 4.87 | 8.04 | 9.14 | 10.45 | 13.06 | 14.71 | 15.80 | 16.81 | 17.40 | 17.79 | |
| Median | 10.75 | 16.13 | 20.67 | 25.56 | 30.53 | 36.24 | 40.04 | 43.26 | 47.86 | 51.44 | 54.68 | 57.17 | 59.44 | 61.53 | |
| Mean | 51.18 | 54.72 | 58.13 | 61.61 | 65.57 | 69.84 | 72.10 | 73.23 | 76.58 | 79.13 | 81.51 | 83.61 | 85.38 | 86.95 | |
| 3rd Quartile | 78.58 | 83.99 | 89.65 | 94.95 | 101.07 | 106.52 | 109.36 | 110.52 | 114.31 | 117.73 | 120.77 | 124.18 | 128.08 | 130.65 | |
| Maximum | 810.43 | 810.45 | 811.78 | 812.27 | 813.73 | 816.17 | 819.60 | 812.08 | 817.60 | 824.27 | 832.04 | 840.86 | 850.77 | 861.88 | |
| Live Growth | Minimum | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 1st Quartile | 0.00 | 0.00 | 0.00 | 0.00 | 0.36 | 0.69 | 0.63 | 0.36 | 0.42 | 0.12 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Median | 1.24 | 1.54 | 2.08 | 2.55 | 3.09 | 3.34 | 3.38 | 3.24 | 3.31 | 3.14 | 2.29 | 0.65 | 0.00 | 0.00 | |
| Mean | 3.64 | 3.64 | 3.83 | 4.05 | 4.31 | 4.42 | 4.45 | 4.35 | 4.44 | 4.48 | 4.10 | 3.48 | 2.73 | 1.70 | |
| 3rd Quartile | 5.40 | 5.48 | 5.78 | 6.10 | 6.39 | 6.48 | 6.61 | 6.59 | 6.68 | 6.90 | 6.52 | 5.59 | 3.89 | 0.00 | |
| Maximum | 53.47 | 51.13 | 65.89 | 57.70 | 48.59 | 39.46 | 33.90 | 34.73 | 39.03 | 43.61 | 45.57 | 41.61 | 39.45 | 46.75 | |
| Entry | Minimum | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 1st Quartile | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Median | 0.01 | 0.04 | 0.12 | 0.17 | 0.22 | 0.25 | 0.25 | 0.22 | 0.21 | 0.17 | 0.07 | 0.00 | 0.00 | 0.00 | |
| Mean | 0.46 | 0.48 | 0.53 | 0.58 | 0.62 | 0.64 | 0.64 | 0.62 | 0.63 | 0.63 | 0.56 | 0.47 | 0.35 | 0.22 | |
| 3rd Quartile | 0.47 | 0.51 | 0.58 | 0.65 | 0.72 | 0.77 | 0.76 | 0.73 | 0.71 | 0.66 | 0.55 | 0.37 | 0.16 | 0.00 | |
| Maximum | 21.57 | 21.53 | 29.06 | 27.40 | 17.04 | 12.08 | 10.01 | 11.73 | 13.46 | 15.31 | 16.47 | 15.15 | 15.23 | 14.56 | |
| Mortality | Minimum | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 1st Quartile | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Median | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.04 | 0.23 | 0.03 | 0.02 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Mean | 0.96 | 0.96 | 0.97 | 1.00 | 1.04 | 1.64 | 2.75 | 0.83 | 0.90 | 0.92 | 0.87 | 0.72 | 0.59 | 0.35 | |
| 3rd Quartile | 0.23 | 0.31 | 0.42 | 0.51 | 0.63 | 0.78 | 2.61 | 0.64 | 0.71 | 0.66 | 0.47 | 0.18 | 0.00 | 0.00 | |
| Maximum | 158.60 | 143.09 | 127.45 | 111.75 | 95.96 | 315.22 | 161.51 | 79.47 | 79.70 | 79.56 | 80.13 | 80.03 | 80.71 | 80.43 | |
| Harvest | Minimum | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 1st Quartile | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Median | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Mean | 0.62 | 0.76 | 0.85 | 1.00 | 1.22 | 1.44 | 1.77 | 1.95 | 2.12 | 2.18 | 1.87 | 1.54 | 1.02 | 0.54 | |
| 3rd Quartile | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Maximum | 350.75 | 351.60 | 355.06 | 363.78 | 458.23 | 457.02 | 459.82 | 472.80 | 467.02 | 495.37 | 493.21 | 490.81 | 490.98 | 489.22 | |
| Year | |||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| Component | Statistic | 1998 | 1999 | 2000 | 2001 | 2002 | 2003 | 2004 | 2005 | 2006 | 2007 | 2008 | 2009 | 2010 | 2011 |
| Volume | Minimum | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 1st Quartile | 0.00 | 0.15 | 0.60 | 1.62 | 3.11 | 4.74 | 6.43 | 7.75 | 9.01 | 9.71 | 10.08 | 10.33 | 10.26 | 10.25 | |
| Median | 11.06 | 14.47 | 17.89 | 21.40 | 25.06 | 28.49 | 31.92 | 33.89 | 36.32 | 38.53 | 40.05 | 41.35 | 42.19 | 43.05 | |
| Mean | 51.83 | 54.27 | 56.61 | 58.83 | 61.27 | 63.44 | 65.61 | 66.77 | 67.91 | 68.76 | 69.42 | 69.90 | 70.17 | 70.51 | |
| 3rd Quartile | 79.82 | 83.69 | 87.86 | 91.18 | 94.85 | 97.41 | 99.44 | 99.56 | 100.74 | 101.48 | 102.13 | 102.14 | 102.79 | 103.60 | |
| Maximum | 815.61 | 816.86 | 817.57 | 817.21 | 817.18 | 817.45 | 817.97 | 818.55 | 819.23 | 820.01 | 820.74 | 821.45 | 822.05 | 822.55 | |
| Live Growth | Minimum | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 1st Quartile | 0.00 | 0.00 | 0.00 | 0.00 | 0.22 | 0.41 | 0.43 | 0.33 | 0.23 | 0.07 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Median | 1.01 | 1.15 | 1.44 | 1.70 | 1.99 | 2.11 | 2.12 | 2.05 | 1.99 | 1.86 | 1.31 | 0.36 | 0.00 | 0.00 | |
| Mean | 2.69 | 2.58 | 2.63 | 2.70 | 2.80 | 2.82 | 2.80 | 2.72 | 2.68 | 2.67 | 2.39 | 2.01 | 1.55 | 0.95 | |
| 3rd Quartile | 3.97 | 3.86 | 3.94 | 4.04 | 4.14 | 4.14 | 4.15 | 4.09 | 4.05 | 4.11 | 3.82 | 3.21 | 2.18 | 0.00 | |
| Maximum | 51.69 | 49.21 | 42.81 | 36.57 | 30.42 | 24.38 | 21.25 | 21.70 | 23.99 | 26.41 | 26.11 | 23.87 | 22.74 | 26.14 | |
| Entry | Minimum | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 1st Quartile | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Median | 0.02 | 0.05 | 0.10 | 0.14 | 0.18 | 0.20 | 0.20 | 0.18 | 0.16 | 0.13 | 0.05 | 0.00 | 0.00 | 0.00 | |
| Mean | 0.40 | 0.41 | 0.44 | 0.47 | 0.50 | 0.51 | 0.51 | 0.49 | 0.48 | 0.48 | 0.42 | 0.35 | 0.26 | 0.16 | |
| 3rd Quartile | 0.42 | 0.43 | 0.49 | 0.53 | 0.58 | 0.61 | 0.60 | 0.58 | 0.55 | 0.51 | 0.41 | 0.28 | 0.12 | 0.00 | |
| Maximum | 17.15 | 21.96 | 16.19 | 12.39 | 15.27 | 12.33 | 7.75 | 8.98 | 10.34 | 11.61 | 12.58 | 11.41 | 11.46 | 10.77 | |
| Mortality | Minimum | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 1st Quartile | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Median | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.04 | 0.07 | 0.06 | 0.02 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Mean | 0.88 | 0.87 | 0.89 | 0.93 | 0.97 | 1.02 | 1.03 | 1.06 | 1.09 | 1.11 | 1.03 | 0.85 | 0.66 | 0.41 | |
| 3rd Quartile | 0.25 | 0.34 | 0.45 | 0.54 | 0.64 | 0.76 | 0.83 | 0.85 | 0.84 | 0.79 | 0.56 | 0.23 | 0.00 | 0.00 | |
| Maximum | 123.71 | 107.31 | 90.42 | 88.78 | 90.63 | 91.76 | 93.19 | 94.74 | 95.85 | 97.15 | 98.07 | 98.83 | 99.90 | 100.50 | |
| Harvest | Minimum | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 |
| 1st Quartile | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Median | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Mean | 0.63 | 0.76 | 0.81 | 0.97 | 1.18 | 1.39 | 1.65 | 1.84 | 1.95 | 1.97 | 1.69 | 1.38 | 0.92 | 0.49 | |
| 3rd Quartile | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | 0.00 | |
| Maximum | 349.75 | 363.14 | 358.10 | 360.22 | 449.39 | 452.14 | 454.02 | 468.62 | 448.86 | 488.82 | 499.46 | 487.89 | 495.86 | 491.62 | |
References
- Roesch, F.A.; Coulston, J.W.; van Deusen, P.C.; Podlaski, R. Evaluation of image-assisted forest monitoring: A simulation. Forests 2015, 6, 2897–2917. [Google Scholar] [CrossRef]
- Eastaugh, C.S.; Hasenauer, H. Biases in volume increment estimates derived from successive angle count sampling. For. Sci. 2013, 59, 1–14. [Google Scholar] [CrossRef]
- Bechtold, W.A.; Patterson, P.L. The Enhanced Forest Inventory and Analysis Program-National Sampling Design and Estimation Procedures; US Department of Agriculture Forest Service, Southern Research Station: Asheville, NC, USA, 2005.
- Massey, A.; Mandallaz, D.; Lanz, A. Integrating remote sensing and past inventory data under the new annual design of the Swiss National Forest Inventory using three-phase design-based regression estimation. Can. J. Res. 2014, 44, 1177–1186. [Google Scholar] [CrossRef]
- Vidal, C.; Bélouard, T.; Hervé, J.-C.; Robert, N.; Wolsack, J. A new flexible forest inventory in France. In Proceedings of the Seventh Annual Forest Inventory and Analysis Symposium, Portland, OR, USA, 3–6 October 2005; McRoberts, R.E., Reams, G.A., van Deusen, P.C., McWilliams, W.H., Eds.; Department of Agriculture Forest Servic: Washington, DC, USA, 2007; pp. 67–73. [Google Scholar]
- Roesch, F.A. An alternative view of continuous forest inventories. For. Sci. 2008, 54, 455–464. [Google Scholar]
- Corona, P. Consolidating new paradigms in large-scale monitoring and assessment of forest ecosystems. Environ. Res. 2016, 144, 8–14. [Google Scholar] [CrossRef] [PubMed] [Green Version]
- Eriksson, M. Compatible and time-additive change component estimators for horizontal-point-sampled data. For. Sci. 1995, 41, 796–822. [Google Scholar]
- Roesch, F.A. Toward robust estimation of the components of forest population change. For. Sci. 2014, 60, 1029–1049. [Google Scholar] [CrossRef]
- Smith, R.L. Ecology and Field Biology, 3rd ed.; Harper & Row: New York, NY, USA, 1980; pp. 34–116. [Google Scholar]
- Raj, D. Sampling Theory; McGraw-Hill: New York, NY, USA, 1968. [Google Scholar]
- Walton, G.S.; DeMars, C.J. Empirical Methods in the Evaluation of Estimators; USDA Forest Service Research Paper NE-272; USDA Forest Service, Northeastern Forest Experiment Station: Upper Darby, PA, USA, 1973.
- Cassel, C.M.; Särndal, C.E.; Wretman, J.H. Foundations of Inference in Survey Sampling; John Wiley & Sons: New York, NY, USA, 1977. [Google Scholar]
- Cochran, W.G. Sampling Techniques, 3rd ed.; John Wiley & Sons: New York, NY, USA, 1977. [Google Scholar]







| Component | Population | |||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||||
| α | β | α | β | α | β | α | β | |
| E | 0.95 | 0.05 | 0.95 | 0.05 | 0.95 | 0.05 | 0.95 | −0.05 |
| L | 0.95 | 0.05 | 0.95 | 0.05 | 0.95 | 0.05 | 0.90 | −0.10 |
| M | 0.95 | 0.05 | 0.95 | 0.05 | 0.95 | 0.05 | 0.80 | 0.20 |
| H | 0.95 | 0.05 | 0.90 | 0.10 | 0.95 | 0.05 | 0.95 | 0.05 |
| Component | Sampling Error Structure | |||||||
|---|---|---|---|---|---|---|---|---|
| 1 | 2 | 3 | 4 | |||||
| b | d | b | d | b | d | b | d | |
| Y, E | 1.00 | 0.01 | 1.00 | 0.03 | 1.00 | 0.05 | 1.00 | 0.10 |
| L, M, H | 1.00 | 0.01 | 0.99 | 0.03 | 0.98 | 0.05 | 0.95 | 0.10 |
© 2016 by the author; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Roesch, F.A. A Simulation of Image-Assisted Forest Monitoring for National Inventories. Forests 2016, 7, 204. https://doi.org/10.3390/f7090204
Roesch FA. A Simulation of Image-Assisted Forest Monitoring for National Inventories. Forests. 2016; 7(9):204. https://doi.org/10.3390/f7090204
Chicago/Turabian StyleRoesch, Francis A. 2016. "A Simulation of Image-Assisted Forest Monitoring for National Inventories" Forests 7, no. 9: 204. https://doi.org/10.3390/f7090204
APA StyleRoesch, F. A. (2016). A Simulation of Image-Assisted Forest Monitoring for National Inventories. Forests, 7(9), 204. https://doi.org/10.3390/f7090204