Certificateless Provable Group Shared Data Possession with Comprehensive Privacy Preservation for Cloud Storage


School of Computer Engineering and Science, Shanghai University, Shanghai 200444, China
*
Author to whom correspondence should be addressed.
Future Internet 2018, 10(6), 49; https://doi.org/10.3390/fi10060049
Submission received: 5 May 2018
/
Revised: 31 May 2018
/
Accepted: 5 June 2018
/
Published: 7 June 2018
(This article belongs to the Special Issue Big Data and Internet of Thing)
Abstract
:Provable Data Possession (PDP) protocol makes it possible for cloud users to check whether the cloud servers possess their original data without downloading all the data. However, most of the existing PDP schemes are based on either public key infrastructure (PKI) or identity-based cryptography, which will suffer from issues of expensive certificate management or key escrow. In this paper, we propose a new construction of certificateless provable group shared data possession (CL-PGSDP) protocol by making use of certificateless cryptography, which will eliminate the above issues. Meanwhile, by taking advantage of zero-knowledge protocol and randomization method, the proposed CL-PGSDP protocol leaks no information of the stored data and the group user’s identity to the verifiers during the verifying process, which is of the property of comprehensive privacy preservation. In addition, our protocol also supports efficient user revocation from the group. Security analysis and experimental evaluation indicate that our CL-PGSDP protocol provides strong security with desirable efficiency.
1. Introduction
In recent years, cloud computing [1] has received considerable attention from research communities in academia, as well as industry. As an important part of cloud computing, cloud storage has become a popular choice for people to deploy their data storage, which brings a number of benefits. Users are relieved of the burden of the management of a great deal of data. Furthermore, universal data access with independent geographical location is highly convenient.
However, a number of vulnerabilities that led to various attacks have left many potential users worried [2]. Thus, many researchers focus on creating trusted cloud services that provide the necessary security guarantees. Santos et al. [3] presented a trusted cloud-computing platform (TCCP), which offers a closed box execution environment for IaaS services. TCCP guarantees confidential execution of guest virtual machines. It also enables customers to attest to the IaaS provider and to determine if the service is secure before their VMs are launched into the cloud. In 2016, Paladi et al. [4] presented a security framework for cloud infrastructure. This framework included a trusted VM launching and a domain-based stored data protection protocols. The trusted VM launching protocol is used before deploying guest VMs, and trust is established by the remotely attesting host platform configuration. Meanwhile, the domain-based storage protection protocol ensures data confidentiality in remote storage by using cryptographic methods.
Furthermore, unlike traditional storage, the cloud stored data is outside of the control of the users, which entails security risks in terms of confidentiality, integrity, and availability of data and service [5]. One of the major concerns of cloud users is the integrity of their outsourced data. Moreover, the cloud server may not be fully trusted to report incidents of data loss in order to protect its reputation [6,7,8]. As a result, it is necessary for cloud users to periodically check whether their outsourced data are stored properly. Provable Data Possession (PDP) scheme is a primitive one that can be used to convince cloud users that their data are kept intact.
As is well known, it is impractical for cloud users to frequently download all the cloud data due to the expensive cost of bandwidth. Additionally, the traditional methods for data integrity checking, like hash function and Message Authorization Code (MAC), cannot be applied directly, because the cloud server may only store the hash code of the original data in order to reduce storage costs. In 2007, Ateniese et al. [9] proposed a provable data possession scheme to check the integrity of data, which employed RSA algorithm to construct homomorphic verifiable authenticators of the data blocks, meaning that the cloud servers were able to prove the data integrity with low communication overheads and computational costs. After that, many researchers proposed corresponding system models and security models based on the first PDP scheme. Later, the POR model was introduced in Juel et al. [10], which used an error-correcting code to establish a sentinel-based POR scheme. Shacham et al. [11] developed a proof of retrievability scheme based on the BLS signature [12], which not only eliminates the constraint on checking times, but also shortens the size of authenticator. In order to support the dynamic data operation on cloud data, Ateniese et al. [13] presented a scalable and efficient provable data possession scheme based on hash functions and symmetric key encryptions. The limitation is that this scheme cannot support data block insertion. Erway et al. [14] proposed a full-dynamic PDP Scheme by utilizing the authenticated flip table. Similarly, Cash et al. [15] proposed a dynamic POR scheme that relies on oblivious RAM protocols. Wang et al. [16] made further improvements to the previous dynamic PDP schemes by using Merkle hash tree (MHT). Liu et al. [17] introduced a top-down, levelled, multi-replica, MHT-based data auditing scheme for dynamic big data storage in the cloud, which supports fully dynamic data updates and authentication of block indices.
Public verifiability is one of the most important properties for PDP schemes, which means that external verifiers are able to check the integrity of cloud data. With this practical property, cloud users can delegate the rights to check data possession to a third-party auditor (TPA) to do the periodical checking job. However, data privacy may be leaked to the TPA during the checking process, which may cause financial loss for the users who have stored confidential or sensitive data on cloud servers. Recently, a number of schemes [16,18,19,20,21,22] have been developed that allow a TPA to check the integrity of the stored data. Wang et al. [20] proposed a privacy-preserving public cloud data auditing system by combining the public key-based homomorphic authenticator with random masking. This scheme explained the definition of data privacy against the TPA. Wang et al. [21] performed further study on data privacy preservation and proposed the notion of ‘zero-knowledge public auditing’ to defeat off-line guessing threat. Yu et al. [22] enhanced the privacy of remote data integrity-checking protocol for secure cloud storage. The aforementioned schemes [16,18,19,20,21,22] all work only in the public key infrastructure (PKI) [23]-based system, which may suffer from heavy public key management. Yu et al. [24] further presented an identity-based PDP scheme to eliminate heavy public key management. This scheme leaks no information of the stored data to the TPA, but cannot protect the privacy of the user’s identity. If the data is shared by a group of users, such as a company, the TPA will know all the details of the group users’ identities.
In order to reduce the complexity of the PDP scheme, many researchers [24,25,26,27] have focused on studying identity-based PDP schemes. By utilizing identity-based cryptography (IBC) [28], there is no need for a PKI to perform complex certificate management such as distribution, storage, revocation, and verification. Unfortunately, IBC has an inherent drawback of key escrow. Wang et al. [29] first proposed a certificateless public auditing mechanism for verifying data integrity in the cloud in order to eliminate the problem of key escrow. In this scheme, Key Generation Center will generate only the partial key, so that in any case it will not compromise the user’s private key. Li et al. [30] introduced a certificateless PDP scheme for shared group data, but it lost the privacy preservation of cloud data and the user’s identity to the TPA.
Motivation: In this paper, we mainly focus on preserving the privacy of group shared data against the third-party auditor (TPA) during the integrity checking process. Suppose there is a group of users from one company who share company data on a given cloud server. Each user of the group can upload and share their data on the cloud server. The manager of the group requires a TPA to periodically check the integrity of the outsourced data, but he does not allow the TPA to extract any information related to their data, not even the identity of the group users. Users of the group may leave the company, so the problem of user revocation from the group needs to be considered. Thus, we need a primitive to meet such requirements and to guarantee the integrity of the outsourced data on the cloud server.
Our contribution: The contributions of this paper are summarized as follows:
- First, we propose a new PDP protocol (CL-PGSDP) for group shared data by utilizing certificateless cryptography [31], which eliminates the problems of certificate management and key escrow.
- Second, by making use of the idea of zero-knowledge proof protocol, the equality of discrete logarithm [32,33,34], and randomization method, we construct a privacy-preserving CL-PGSDP protocol. On the one hand, our protocol leaks no information of the group shared data to the TPA. On the other hand, all the data blocks are signed by group users to get corresponding authentication tags, and the TPA cannot learn any identity information from the challenged data block during the auditing process.
- Third, based on CDH and DL assumptions, we provide detailed security proofs of our new protocol. Additionally, our protocol supports efficient group user revocation. We perform some experiments and show the practicality of our protocol.
Organization: The rest of the paper is organized as follows: In Section 2, we review some preliminaries used in CL-PGSDP construction. In Section 3, we formalize the system model and security model of CL-PGSDP protocol. We describe the concrete construction of the CL-PGSDP protocol in Section 4. We formally prove the correctness, soundness, and comprehensive privacy preservation of our protocol in Section 5. We report the performance and implementation results in Section 6. Section 7 concludes our paper.
2. Preliminaries
In this section, we review some preliminaries knowledge used in this paper, including bilinear pairing, certificateless Cryptography, zero-knowledge proof, and Complexity assumption.
2.1. Bilinear Pairing
Denote G1 and G2 as two multiplicative groups with the prime order . g is a generator of group G1. A function is called a bilinear pairing [12] if it has the following properties:
- Bilinearity: For all . and , holds.
- Non-Degeneracy: , in which is the identity of .
- Efficient Computation: can be computed efficiently for all. .
2.2. Certificateless Cryptography
A Certificateless Cryptography (CLC) [31] scheme is specified by seven randomized algorithms.
- Setup: This algorithm takes security parameter k as input and returns the system parameters and master-key.
- Partial-Private-Key-Extract: This algorithm takes , master-key, and entity’s ID as inputs and returns a partial private key for the entity.
- Set-Secret-Value: This algorithm takes and entity’s ID as inputs and outputs this entity’s secret value .
- Set-Private-Key: This algorithm takes , entity’s ID, partial private key , and secret value as inputs and outputs private key .
- Set-Public-Key: This algorithm takes and secret value as inputs and outputs public key .
- Encrypt: This algorithm takes , message m, and public key as inputs and entity’s ID and generates ciphertext of the message m if success.
- Decrypt: This algorithm takes , , and as inputs and returns message m.
By making use of certificateless cryptography, we will construct new authenticator of data block.
2.3. Zero-Knowledge Proof
Zero-knowledge proofs [33] are defined as those proofs that convey no additional knowledge other than the correctness of the proposition in question. Here, we introduce one of the zero knowledge protocol: equality of discrete logarithm [34]. Let be a finite cyclic group with the prime order ; , are generators of . The protocol shows that a prover (P) can prove to a verifier (V) that , without leaking the secret key to V.
- P randomly chooses , and computes , then sends to V.
- V also randomly chooses and sends to P.
- P computes , in which is the secret key of P, and returns to V.
- V accepts the proof if and only if and .
2.4. Security Assumption
Discrete Logarithm (DL) problem [35]: is a multiplicative cyclic group, is a generator of . Given , compute .
Definition 1 (DL Assumption).
For any probabilistic polynomial time (PPT) algorithm , the advantage for to solve the DL problem in is negligible, which can be defined as .
Computational Deffie-Hellman (CDH) Problem [36]: is a multiplicative cyclic group, is a generator of . Given , compute .
Definition 2 (CDH Assumption).
For any PPT algorithm , the advantage for to solve the CDH problem in is negligible, which can be defined as .
The denotes a negligible value in the above definitions.
3. System Model and Security Model
In this section, we introduce the system model and security model of CL-PGSDP protocol.
3.1. CL-PGSDP System
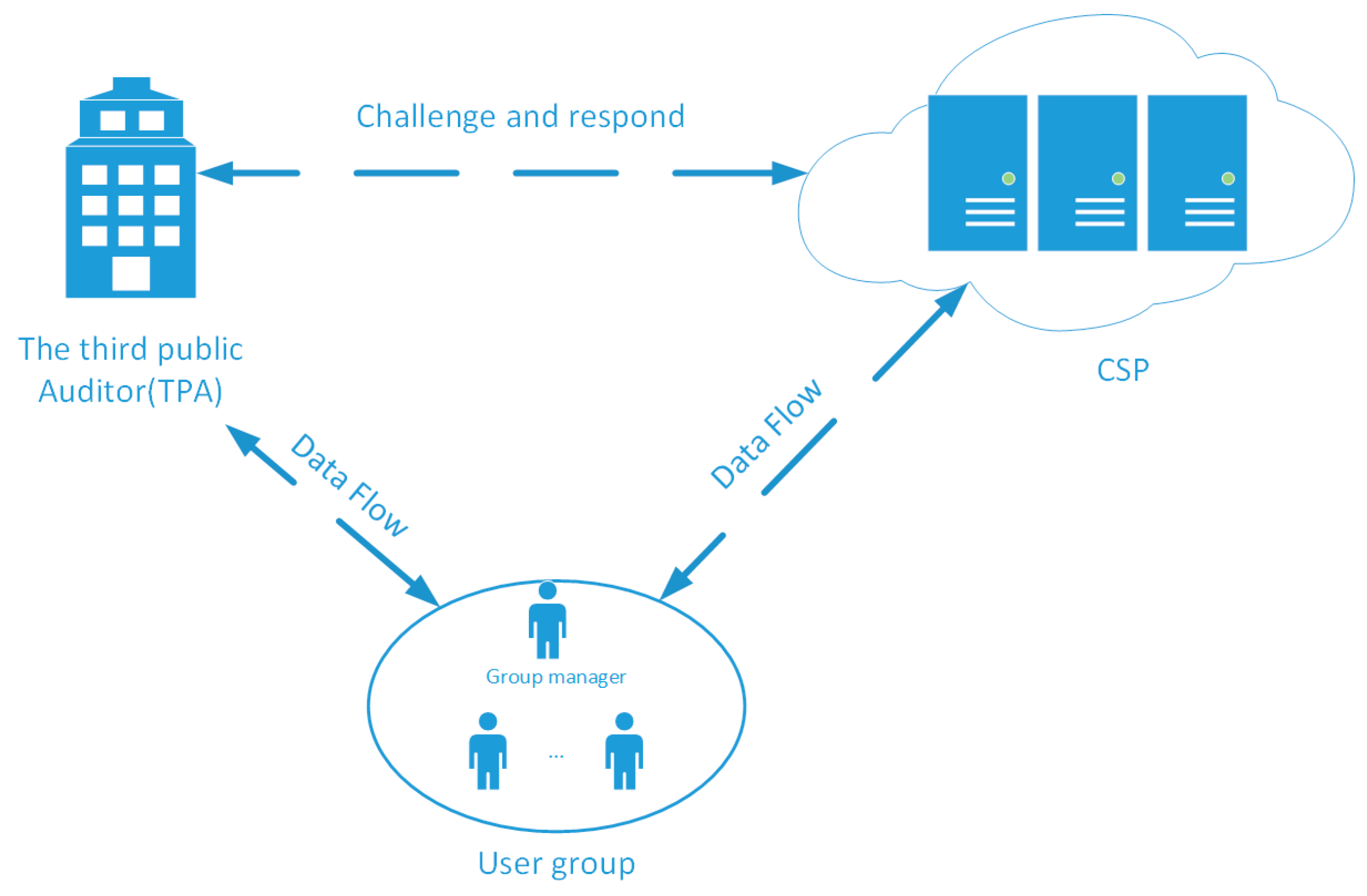
The system model of our scheme is composed of three different entities: user group, cloud service provider (CSP), and the third party public auditor (TPA). Figure 1 illustrates the relationships and interactions among the three entities of the system. The user group includes numbers of users, who have large amount of data to be stored on cloud without keeping a local copy (each user is able to upload, access, and update the outsourced group shared data). We suppose one of the users is the group manager, who sets up the system and generates system parameters. The CSP has significant storage space and computation resources and provides data storage services for cloud users. The CSP could be semi-trusted and might even hide data corruption incidents to cloud users to maintain their good reputation. The TPA has expertise and capabilities to be delegated by the cloud users to check the data possession of the cloud, but the TPA is also curious in the sense that he is willing to learn some information during the data integrity checking procedure.
3.2. System Components
Eight algorithms are involved in CL-PGSDP system.
- Setup is a probabilistic algorithm run by the group manager. It takes a security parameter λ as input and outputs the system parameters and the master key .
- Partial-Private-Key-Gen is a probabilistic algorithm run by the group manager. It takes the master key , a random value , and the identity of the user as inputs, and outputs the ’s partial private key .
- Secret-Value-Gen is a probabilistic algorithm run by the group user who randomly selects as the secret value. Thus, the private key of the group user contains two parts: secret value and partial private key .
- Public-Key-Gen is a probabilistic algorithm performed by the group user to compute the public key. It inputs the ’s secret value and outputs the ’s public key .
- Tag-Gen is a probabilistic algorithm executed by the group user to generate authentication tags for data blocks. It takes the ’s partial private key , the secret value , and the data block as inputs, and outputs the tag of .
- Challenge is a randomized algorithm run by the TPA. It takes the system parameters , a unique file name, and the count of the challenged data blocks as inputs, and outputs the challenge information .
- Proof-Gen is a probabilistic algorithm run by cloud server to obtain a data possession proof P of the challenged blocks. The inputs include , the challenged data blocks and tags of the challenged data blocks.
- Proof-Check is a deterministic algorithm run by the TPA. It inputs the proof P, the challenge information , and the user’s public key. If P is correct, this algorithm outputs 1, otherwise it outputs 0.
3.3. System Security
We consider three security properties, namely, completeness, soundness, and comprehensive privacy preservation against the TPA in our CL-PGSDP protocol.
- Completeness means the cloud server can pass the possession checking procedure as long as the cloud server properly stores the group shared data.
- Comprehensive privacy preservation means that the TPA achieves no information on the data blocks and the user’s identity during the integrity checking procedure.
- Soundness states that whenever the cloud server convinces a TPA to accept its proof, the cloud server should actually store the challenged data blocks. According to certificateless cryptography [30,31], we consider three types of probabilistic polynomial-time (PPT) adversaries, namely, A1, A2, A3, and a challenger C in our security model and define the security of our protocol by three games. The details are as follows:
Game 1: This game is played by challenger C and adversary A1 who wants to substitute the user’s public key with any other value, but A1 cannot access the master key of the system.
Setup: Challenger C runs the Setup algorithm to obtain the system parameters and the master secret key , and forwards to the adversary A1, while keeps confidential.
Queries: A1 can adaptively issue the following queries to C. C maintains the corresponding query lists, which are initially empty, and responds to the queries to A1 as follows.
- (1)
- Hash Query. A1 makes hash function queries to C for any identity ID, and C responds to the hash values to A1.
- (2)
- Partial Private Key Query. A1 adaptively chooses different ID and summits it to C for querying the partial private key of the ID. C executes the Partial-Private-Key-Gen algorithm to obtain the partial private key for the ID and sends it to A1.
- (3)
- Secret Value Query. A1 adaptively chooses different ID and summits it to C for querying the secret value of the ID. C runs the Secret-value-Gen algorithm to generate the secret value for the ID and sends it to A1.
- (4)
- Public Key Query. A1 adaptively chooses different ID and summits it to C for querying the public key of the ID. C performs the algorithm Public-key-Gen to compute the public key for the ID and sends it to A1.
- (5)
- Public Key Replacement. A1 can repeatedly select a value to replace the public key of any ID.
- (6)
- Tag Query. A1 adaptively chooses the tuple (ID, ) and submits it to C for querying the tag of the data block . C runs Tag-Gen algorithm to generate the tag of data block and sends it to A1.
Forge: Finally, A1 outputs a forged tag for the with the identity and the public key .
If the forged tag is valid after the above queries, then A1 wins the game.
Game 2: This game is played by challenger C and adversary A2 who is able to get the master key but cannot substitute the group user’s public key.
Setup: Challenger C runs the Setup algorithm to obtain the system parameters and the master secret key , and forwards and to the adversary A2.
Queries: A2 can make a number of queries to C adaptively. C maintains the corresponding query lists, which are initially empty, and responds to the queries to A2 as follows.
- (1)
- Hash Query. A2 makes hash function queries to C for any identity ID, and C responds the hash values to A2.
- (2)
- Secret Value Query. A2 adaptively chooses different ID and summits it to C for querying the secret value of the ID. C runs the Secret-value-Gen algorithm to generate the secret value for the ID and sends it to A2.
- (3)
- Public Key Query. A2 adaptively chooses different ID and summits it to C for querying the public key of the ID. C performs the algorithm Public-key-Gen to compute the public key for the ID and sends it to A2.
- (4)
- Tag Query. A2 adaptively chooses the tuple (ID, ) and submits it to C for querying the tag of the data block generated by the ID. C runs Tag-Gen algorithm to generate the tag of data block and sends it to A2.
Forge: Finally, A2 outputs a forged tag for the with the identity .
If the forged tag is valid after the above queries, then A2 wins the game.
Definition 3.
A CL-PGSDP scheme is secure against adaptive impersonation and forging tag attacks if any PPT adversary A (A1 or A2) who plays the above games with the challenger C has only negligible probability of winning the games, that is,
in which the probability is taken over all coin tosses made by A and C.
Game 3: This game is played by challenger C and adversary A3 who aims to forge the data integrity proof to cheat the TPA. A3 is regarded as the untrusted CSP. From the Definition 3, we know that it is hard to forge the tag of single data block. Thus, we will focus on the issue of whether A3 can forge the integrity proof without correct data to pass the challenge.
Setup: Challenger C runs the Setup algorithm to obtain the system parameters , the master secret key , and partial private key for all users, and only forwards to the adversary A3.
Tag Queries: A3 adaptively chooses the tuple (ID, m) and sends it to C for querying the tag of data block m. C runs the algorithm Tag-Gen to generate the tag of m and returns it to A3.
Challenge: C makes a random challenge to A3 and requests A3 to provide the corresponding data possession proof for .
Forge: For the challenge , A3 generates a proof and sends it to C. If the proof can pass the integrity verification while A3 does not possess the correct data, A3 wins the game.
Definition 4.
A CL-PGSDP scheme is secure against adaptive impersonation and forging proof attacks if any PPT adversary A who plays Game 3 with the challenger C has only negligible probability of winning the games, that is,
in which the probability is taken over all coin tosses made by A and C.
4. Our Construction
In this section, we provide a concrete construction of certificateless provable group shared data possession protocol supporting comprehensive privacy preservation for cloud storage. We suppose the number of users in the group is z, and represent the unique identity of the user , in which . Without losing the generality, we set as the group manager who will set up system and generate system parameters and the partial private keys for other users. The group shared data M is split into n blocks, denoted as . In the Partial-Private-Key-Gen algorithm, we employ short signature [12] and randomization method to produce the partial private key for each user of the group. In the Tag-Gen algorithm, we take the advantage of the idea of certificateless cryptography [31] to construct the tags of the data blocks using the partial private key and the secret value. In the challenge phase, the TPA randomly chooses some indexes of the data blocks and corresponding random values as a challenge to the CSP. In the proof generating phase, the CSP computes a response to the TPA. We utilize the idea of zero knowledge proof [33,34] to design the details of the interaction between the TPA and the CSP. The details of the proposed protocol are as follows:
- Setup. This algorithm is run by . On input of security parameter , chooses two cyclic multiplicative groups, and , with prime order , . is a generator of . There exists a bilinear map . selects three secure hash functions , , a pseudo-random permutation (PRP) , and a pseudo-random function (PRF) . initializes a public log file , which is used to record the information of the indexes of the data blocks and the information of the corresponding tag generators. randomly chooses as master secret key and as secret value, and computes . keeps the master secret key and privately, and publishes the system parameters .
- Partial-Private-Key-Gen. This algorithm is run by . When receiving the identity of the user , computes the ’s partial private key and sends and to .
- Secret-Value-Gen. This algorithm is run by group user. randomly selects as the secret value and keeps it privately.
- Public-Key-Gen. This algorithm is run by group user. uses the secret value to compute the public key .
- Tag-Gen. Each user in group can generate tags of data blocks using partial private key and secret value. Suppose user generates an authentication tag for data block . It takes ’s partial private key , the secret value , and the data block as inputs and outputs the tag of . The equation for computing tag is , in which , is the index of data block , and denotes the unique identity of data block . Each time the generates a tag for data block , will update the information in public log file with the index of , , and . Actually, is a table, and one line of it can be showed as follows:
j - The user uploads the data blocks and its tags to the CSP. The CSP can check the validation of each tag using the following equation:
- Challenge. This algorithm is run by the TPA, who randomly picks c-element subset of the set by pseudo-random permutation (PRP) ; each element in denotes the index of the challenged data block. The TPA chooses a random element for each element in by pseudo-random function (PRF) . Let be the set . To generate a challenge, the TPA will search the log file according the set to get the information . The TPA picks a random value as secret value and computes , . Let . The TPA sends the to the server.
- Proof-Gen. Upon receiving the , the CSP computes , and , then sends as a response to the from the TPA.
- Proof-Check. Upon receiving the from the CSP, the TPA first searches the publish log file to get the information and checks the equation:in which means the information of can be find from public log file by the index of data block . If the equation holds, the TPA accepts the proof; otherwise, the proof is invalid. The process of Challenge, Proof-Gen, and Proof-Check are summarized as Figure 2.
- Revocation-Tag-Gen. If user , leaves the group, and user will be the successor of . The following procedure will efficiently update the tags generated by . It needs , and the CSP online simultaneously.
- (1)
- The CSP randomly selects , and sends it to .
- (2)
- Upon receiving , computes and sends to .
- (3)
- computes and sends it to the CSP.
- (4)
- When receiving , the CSP computes . The CSP will update the tag of the data block by computing the equation , in which is the tag generated by . The proof of the correctness of algorithm Revocation-Tag-Gen is as follows:
5. Security Analysis of the New Protocol
In this section, we show that our protocol is secure with the properties of completeness, soundness, and comprehensive privacy preservation.
5.1. Completeness
If the CSP properly stores data, it can always pass the verification. The completeness of the protocol can be demonstrated as follows:
5.2. Soundness
Theorem 1.
In the random oracle model, if a PPT adversary A1 wins Game 1 defined in Section 3 with non-negligible probability , then there is an algorithm that can solve the CDH problem.
Proof of Theorem 1.
Algorithm is given ; its goal is to output . Algorithm simulates the challenger and interacts with as A1 follows.
Setup: produces the system parameters , secret key , and sets , while keeps unknown.
H1-Query: At any time, A1 can query the random oracle H1. To respond to these queries, algorithm maintains a list of tuples as Tab1. When A1 queries the oracle H1 at the identity , Algorithm responds as follows:
- (1)
- If , then algorithm retrieves the tuple and responds with to A1.
- (2)
- Otherwise, picks a random and computes . Then, it adds the tuple to Tab1 and responds with to A1.
PartialKey-Query: At any time, A1 can query partial key for any identity . If , makes the H1-Query. Otherwise, maintains a list of tuples as Tab2. When A1 queries the oracle PartialKey-Query at the identity, Algorithm responds as follows:
- (1)
- If , then algorithm retrieves the tuple and responds to A1.
- (2)
- Otherwise, computes . Then, it adds the tuple to Tab2 and responds to A1.
SecretValue-Query: At any time, A1 can query secret value for any identity , if or . firstly makes the H1-Query or PartialKey-Query for the identity . Then, randomly chooses a value as response to A1.
PublicKey-Query: At any time, A1 can query public key for any identity , if or . first makes the H1-Query or PartialKey-Query for the identity . Then, computes , in which is the secret value from SecretValue-Query and responds to A1.
H2-Query: At any time, A1 can query the random oracle H2 for . Algorithm also maintains a list of tuples as Tab3. If , then algorithm retrieves the tuple and responds to A1. Otherwise, randomly selects and computes . Then, it adds the tuple to Tab3 and responds to A1.
Tag-Query: At any time, A1 can query tag with . first checks whether , , and . If not, will compute corresponding tuple and update Tab1, Tab2, and Tab3. After that, can get corresponding information from Tab1, Tab2, and Tab3 and compute the tag for by the algorithm Tag-Gen and returns it to A1.
Forge: Eventually, A1 outputs . is the forged tag of the data block on the identity with the public key .
Analysis: If A1 wins Game 1, on the one hand, can get
according to the verification Equation (1). On the other hand, can retrieve from Tab1 and from Tab3. Thus, gets . Finally, we can derive that
which means that can solve the CDH problem with non-negligible probability . However, according to CDH assumption, the advantage for to solve the CDH problem in is negligible. Thus, A1 cannot win Game 1. This completes the proof. ☐
Theorem 2.
In the random oracle model, if a PPT adversary A2 wins Game 2 defined in Section 3 with non-negligible probability , then algorithm can solve the CDH problem.
Proof of Theorem 2.
Algorithm is given ; its goal is to output . Algorithm simulates the challenger and interacts with as A2 follows.
Setup: produces the system parameters , secret key , and sets , in which is master key. sends , , , and to A2.
H1-Query: At any time, A2 can query the random oracle H1. To respond to these queries, algorithm maintains a list of tuples as Tab1. When A2 queries the oracle H1 at the identity , Algorithm responds as follows:
- (1)
- If , then algorithm retrieves the tuple and responds with to A2.
- (2)
- Otherwise, picks a random and computes . Then, it adds the tuple to Tab1 and responds with to A2.
SecretValue-Query: Because A2 knows the master key, there is no need for A2 to query the partial key. At any time, A2 can query secret value for any identity . If , makes the H1-Query. Otherwise, maintains a list of tuples as Tab2. When A2 queries the oracle SecretValue-Query at the identity , Algorithm responds as follows:
- (1)
- If , then algorithm retrieves the tuple and responds with to A2.
- (2)
- Otherwise, randomly selects and makes . Then, it adds the tuple to Tab2 and responds with to A2.
PublicKey-Query: At any time, A2 can query public key for any identity , if or . first makes the H1-Query or PartialKey-Query for the identity . Then, computes , in which is the secret value from SecretValue-Query, and updates Tab2. responds with to A2.
H2-Query: At any time, A2 can query the random oracle H2 for . Algorithm also maintains a list of tuples as Tab3. If , then algorithm retrieves the tuple and responds to A2. Otherwise, randomly selects and computes . Then, it adds the tuple to Tab3 and responds with to A2.
Tag-Query: At any time, A2 can query tag with . first checks whether , , and . If not, will compute corresponding tuple and updates Tab1, Tab2, and Tab3. After that, can get corresponding information from Tab1, Tab2, and Tab3, and computes the tag for using the algorithm Tag-Gen and returns it to A2.
Forge: Eventually, A2 outputs . is the forged tag of the data block on the identity .
Analysis: If A2 wins Game 2, on the one hand, can get
according to the verification Equation (1). On the other hand, can retrieve from Tab1, from Tab2, and from Tab3. Thus, gets . Finally, we can derive that
which means that can solve the CDH problem with non-negligible probability . However, according to CDH assumption, the advantage for to solve the CDH problem in is negligible. Thus, A2 cannot win Game 2. This completes the proof. ☐
Theorem 3.
If the DL assumption holds, the adversary A3 wins Game 3 only at negligible probability.
Proof of Theorem 3.
Let the challenge information be . If A3 outputs and wins Game 3 at non-negligible probability, we can get the verification equation:
in which is the forged tag for the forged data block and is produced by A3. Assume the real proof is and the corresponding information is . We also get the verification equation:
Thus, we can derive from the above two verification equations that
Because A3 wins the Game 3, there exists and at least one data block . Suppose . Then, we get , which is . We can get . Based on this conclusion, the DL problem can be solved as follows: Given two elements in which , we will compute . We randomly select and let . We can get following equation:
Then, we can derive . Since , is the random value from , so the probability of is only . Therefore, we can output the right value of with non-negligible probability . This completes the proof. ☐
5.3. Comprehensive Privacy Preservation
5.3.1. Data Privacy Preservation
Upon receiving the challenge from the TPA, the cloud server responds with the proof: , in which we hide the information of and using hash function H3. Furthermore, the TPA just needs to check the following equation: , without knowing any information about data file blocks or their corresponding tags .
5.3.2. User Identity Privacy Preservation
In CL-PGSDP protocol, we design a log file that is used to record the information of the index of data block and the information of its tag generator, including the hash value and the public key of user . During the auditing process, the TPA gets the hash value for the challenged data block from the log file. Because the user identity is randomized by in Partial-Private-Key-Gen, it is impossible for the TPA to obtain user’s real identity. Therefore, the user identity cannot be known by the TPA.
6. Performance and Implementation
In this section, we give the performance analysis and experimental results of our protocol.
6.1. Performance Analysis
We summarize the computational and the communicational cost of our protocol as follows.
Computational cost: For simplicity, we denote by ExpG2 and ExpG2 the exponentiations in G1 and G2, by MultG1 and MultG2 the multiplication in G1 and G2, by P the pairing computation, and by H the map-to-point hash function, respectively. The original hash function, PRF and PRP operation, addition and multiplication on , and so on are omitted in our evaluation, because the computational cost of them is negligible. Suppose the data is split into n blocks. The main computation of the group manager is generating system parameters and partial private key for each group user. Thus, the main computational cost is 2ExpG1 + H. The primary computation of group users is generating tags for data blocks, which is the most expensive operation in our protocol, but fortunately part of it can be done offline. The cost of group users is (2n + 1) ExpG1 + nH. The dominated computation of the TPA is generating a challenge and checking the validity of a proof. We suppose all the group users have generated tags and the challenge involves their corresponding tags. Thus, the cost for the TPA is zP + zExpG2 + ExpG1 at most for one challenge. When checking a proof, the cost for the TPA is 2cExpG1 + cPG1 + cH + (c − 1) ExpG2. The main computational cost for the CSP is to generate a proof for a challenge, and the total cost is (2c − 1) MultG1 + cMultG2 + cExpG2 + cExpG1 + P. We make a detailed comparison with Li’s protocol [30] in Table 1.
Communicational cost: In the challenge phase, the TPA summits to the CSP. The CSP responds with a proof to the TPA that is a hash value from H3. Thus, the communicational cost is .
6.2. Experimental Results
To evaluate the efficiency of our proposed protocol, we conduct experiments on Ubuntu 16.04 operation system with Intel i5-6200CPU @ 2.40 GHz and 4 GB memory. We implement the algorithm in C with the Pairing-based Cryptography (PBC) library [37] and the GNU Multiple Precision Arithmetic (GMP) library [38]. We utilize the parameter a.param, which provides a symmetric pairing with the fastest speed among all default parameters. The implementation time overhead of the protocol is displayed in following two parts.
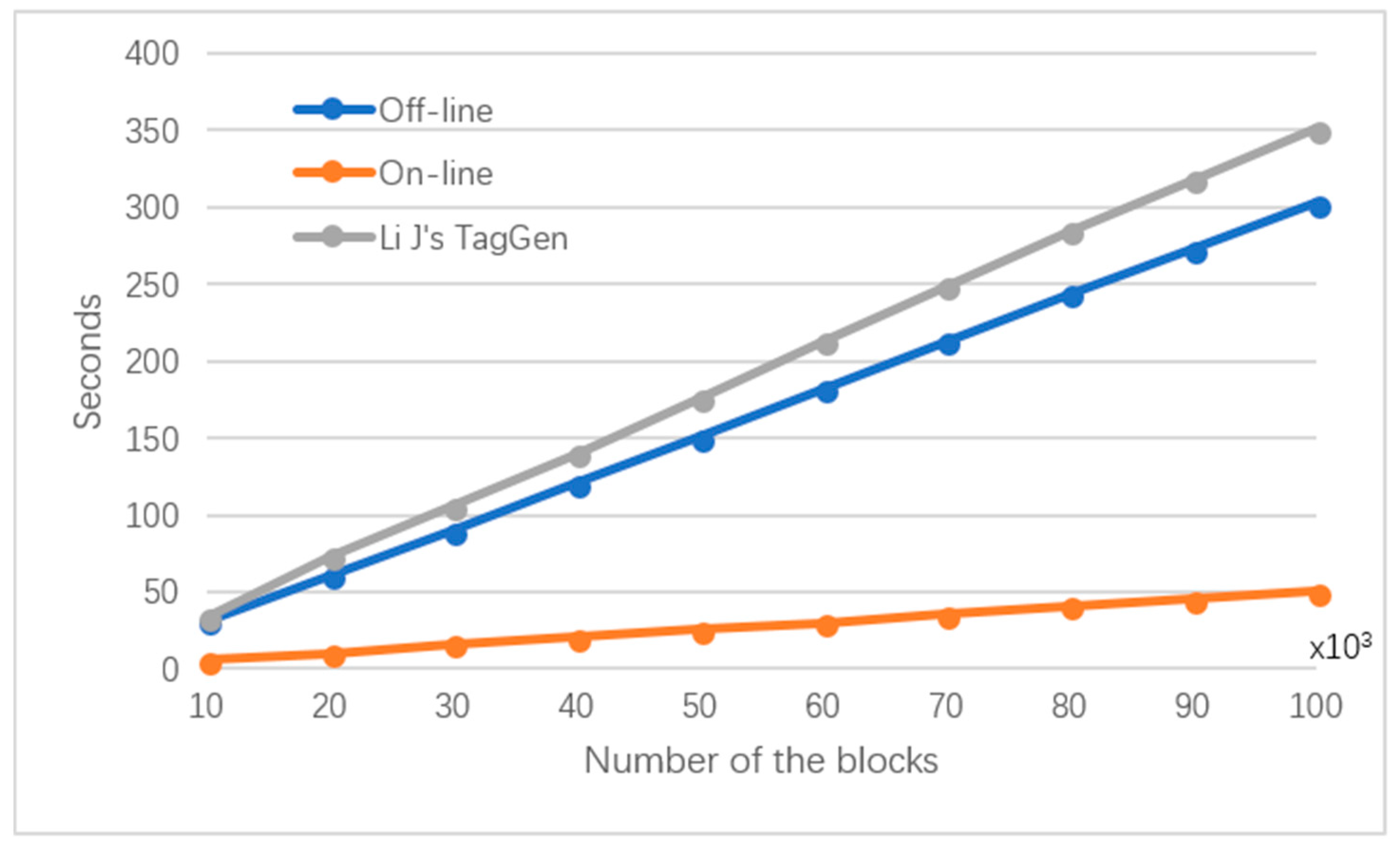
In the first part, we carry out an experiment to evaluate the tag generation cost of our protocol. We set the number of the group users at 50, and the size of data ranges from 0.2 MB to 2 MB. The order of is set at 160-bit, which has the equivalent security level of 1024-bit RSA. Hence, the number of data blocks ranges from 10,000 to 100,000. Figure 3 depicts the comparison on computation cost for tag generation. From Figure 3, we can see that the phase of tag generation of our protocol is separated into two parts: offline and online. As its computational cost is the most expensive one, the group user can preprocess , which can be conducted in offline phase. In the online phase of tag generation, group user needs to compute for each data block, which is more practical than Li’s protocol. The time cost of offline computation of tag generation for 1 MB data file is 150.5 s, while the online time cost is 25.3 s. Without loss of generality, we suppose the blocks are, on average, assigned to group users, which makes the result more acceptable. As we expected that both online and offline time of generating tags increases almost linearly with the increase of the data size. Thus, one shall be able to anticipate the time cost of generating tags for any size of data files.
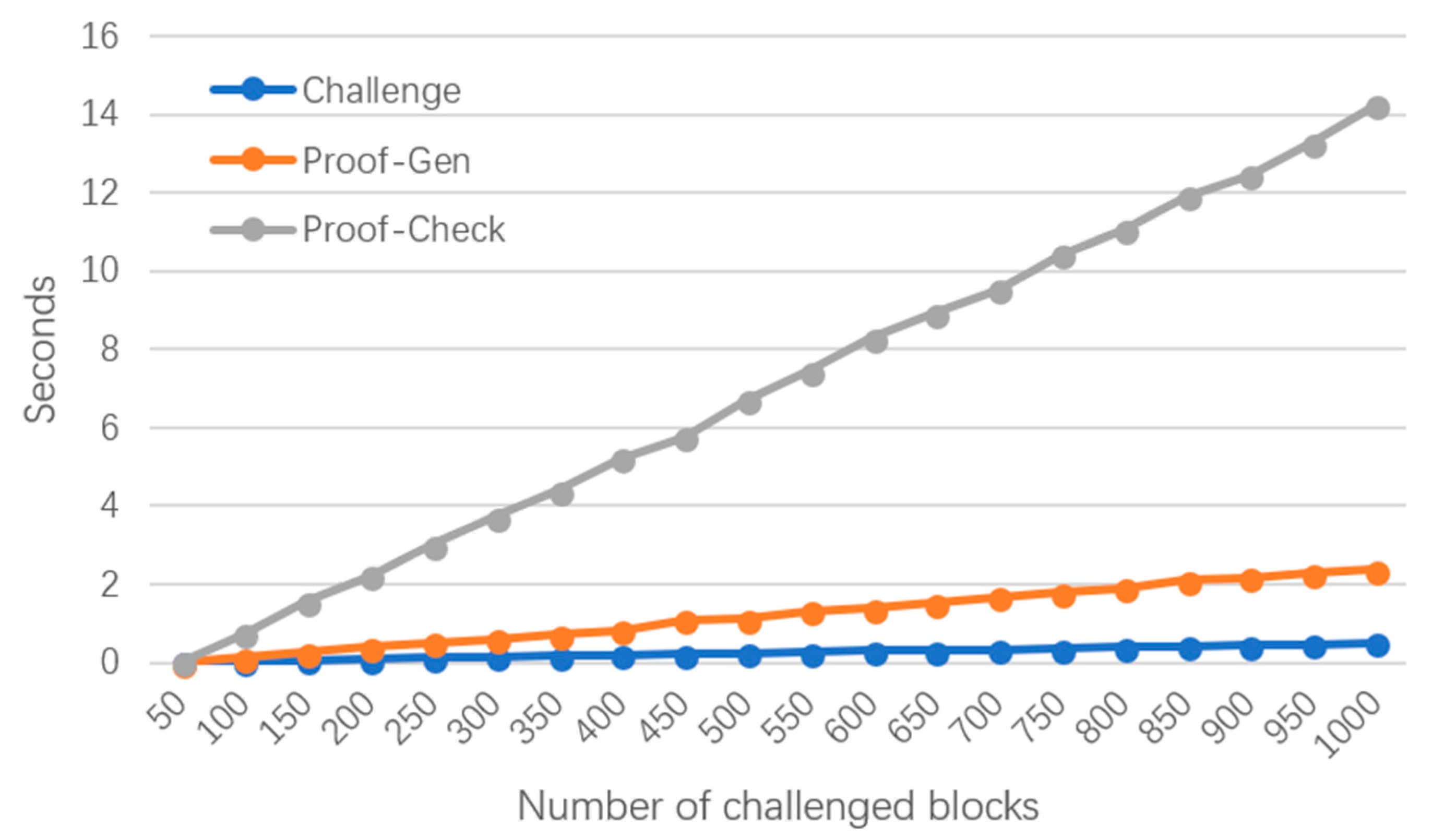
In the second part, we increase the number of challenged data blocks from 50 to 1000 with an increment of 50 for each test to see the time cost of Challenge, Proof-Gen, and Proof-Check steps. We suppose all the users in the group will get involved in generating the tags of the challenged data blocks. Figure 4 demonstrates the time cost of these three parts, which increase with the increase of the number of challenged data blocks, which is consistent with our previous computational analysis, because when the number of challenged data blocks rises, more random values in need to be produced and more need to be computed. The CSP has increasing computation on and . According to [9], if the CSP has polluted 1% of the data blocks, the TPA can achieve the probability of CSP’s misbehavior detection of at least 99% while only needing to make 460 data blocks for a challenge. We can see that it costs the TPA only about 5.75 s to verify a response and the CSP costs about 1.1 s to generate a response when the number of challenged data blocks is 460. We compare the Proof-Check performance between Li’s protocol and our protocol in Table 2. We find that our mechanism requires more checking time compared to Li’s protocol. Based on our analysis of computation cost from Table 1, we find that there are more pairing operations (P) during the phase of Proof-Check, which is consistent with our experimental results, because one pairing operation takes more time than other cryptographic operations. However, our mechanism is of comprehensive privacy preservation, while Li’s not.
7. Conclusions
In this paper, we propose a new PDP protocol for group shared data at untrusted cloud storage, which aims to solve the problems of privacy preservation, including data privacy and the group user identity privacy. By utilizing certificateless cryptography, we eliminate the issues of expensive certificate management and key escrow. We prove that our protocol is secure, and further illustrate its efficiency through practical experiments. The results show that the proposed protocol is efficient and practical.
Author Contributions
S.J. and H.Y. conceived and designed the experiments, S.J. performed the experiments, S.J. and W.S. analyzed the data, W.S. contributed analysis tools, and S.J. wrote the paper, Z.L. and S.J. revised the manuscript.
Funding
This research was partially supported by Shanghai Innovation Action Plan Project, grant number 16511101200.
Conflicts of Interest
The authors declare no conflict of interest.
References
- Mell, P.; Grance, T. The NIST Definition of Cloud Computing; Florida Entomological Society: Gaithersburg, MD, USA, 2011. [Google Scholar]
- Antonis, M.; Paladi, N.; Gehrmann, C. Security aspects of e-health systems migration to the cloud. In Proceedings of the IEEE 16th International Conference on e-Health Networking, Applications and Services (Healthcom), Natal, Brazil, 15–18 October 2014. [Google Scholar]
- Santos, N.; Gummadi, K.P.; Rodrigues, R. Towards Trusted Cloud Computing. In Proceedings of the Conference on Hot Topics in Cloud Computing, San Diego, CA, USA, 14–19 June 2009. [Google Scholar]
- Paladi, N.; Gehrmann, C.; Michalas, A. Providing user security guarantees in public infrastructure clouds. IEEE Trans. Cloud Comput. 2017, 5, 405–419. [Google Scholar] [CrossRef]
- Chu, C.; Zhu, W.; Han, J.; Liu, J.K.; Xu, J.; Zhou, J. Security concerns in popular cloud storage services. IEEE Pervasive Comput. 2013, 12, 50–57. [Google Scholar] [CrossRef]
- Miller, R. Amazon Addresses EC2 Power Outages. Available online: http://www.datacenterknowledge.com/archives/2010/05/10/amazon-addresses-ec2-power-outages (accessed on 6 June 2018).
- Yang, K.; Jia, X. Data storage auditing service in cloud computing: Challenges, methods and opportunities. World Wide Web 2012, 15, 409–428. [Google Scholar] [CrossRef]
- Kaufman, L.M. Data security in the world of cloud computing. IEEE Secur. Privacy 2009, 7, 61–64. [Google Scholar] [CrossRef]
- Ateniese, G.; Burns, R.; Curtmola, R.; Herring, J.; Kissner, L.; Peterson, Z.; Song, D. Provable data possession at untrusted stores. In Proceedings of the 14th ACM Conference on Computer and Communications Security, Alexandria, VA, USA, 29 October–2 November 2007; pp. 598–609. [Google Scholar]
- Juels, A.; Kaliski, B.S., Jr. PORs: Proofs of retrievability for large files. In Proceedings of the 14th ACM Conference on Computer and Communications Security, Alexandria, VA, USA, 29 October–2 November 2007. [Google Scholar]
- Shacham, H.; Waters, B. Compact proofs of retrievability. In Proceedings of the 14th Annual International Conference on the Theory and Application of Cryptology and Information Security, Melbourne, Australia, 7–11 December 2008; pp. 90–107. [Google Scholar]
- Boneh, D.; Lynn, B.; Shacham, H. Short signatures from the Weil pairing. In Proceedings of the 7th International Conference on the Theory and Application of Cryptology and Information Security, Gold Coast, Australia, 9–13 December 2001; pp. 514–532. [Google Scholar]
- Ateniese, G.; di Pietro, R.; Mancini, L.V.; Tsudik, G. Scalable and efficient provable data possession. In Proceedings of the 4th International Conference on Security and Privacy in Communication Networks, Istanbul, Turkey, 22–25 September 2008; p. 9. [Google Scholar]
- Erway, C.; Küpçü, A.; Papamanthou, C.; Tamassia, R. Dynamic provable data possession. In Proceedings of the ACM Transactions on Information and System Security (TISSEC), Chicago, IL, USA, 9–13 November 2009; p. 15. [Google Scholar]
- David, C.; Küpçü, A.; Wichs, D. Dynamic proofs of retrievability via oblivious RAM. J. Cryptol. 2017, 30, 22–57. [Google Scholar]
- Wang, Q.; Wang, C.; Li, J.; Ren, K.; Lou, W. Enabling public verifiability and data dynamics for storage security in cloud computing. In Proceedings of the European Symposium on Research in Computer Security, Saint-Malo, France, 21–23 September 2009; pp. 355–370. [Google Scholar]
- Liu, C.; Ranjan, R.; Yang, C.; Zhang, X.; Wang, L.; Chen, J. MuR-DPA: Top-down levelled multi-replica merkle hash tree based secure public auditing for dynamic big data storage on cloud. IEEE Trans. Comput. 2015, 64, 2609–2622. [Google Scholar] [CrossRef]
- Yuan, J.; Yu, S. Proofs of retrievability with public verifiability and constant communication cost in cloud. In Proceedings of the International Workshop on Security in Cloud Computing, Hangzhou, China, 8 May 2013; pp. 19–26. [Google Scholar]
- Wang, H. Proxy provable data possession in public clouds. IEEE Trans. Ser. Comput. 2013, 6, 551–559. [Google Scholar] [CrossRef]
- Wang, C.; Wang, Q.; Ren, K.; Lou, W. Privacy-preserving public auditing for data storage security in cloud computing. In Proceedings of the IEEE INFOCOM, San Diego, CA, USA, 14–19 March 2010; pp. 1–9. [Google Scholar]
- Wang, C.; Chow, S.S.M.; Wang, Q.; Ren, K.; Lou, W. Privacy-preserving public auditing for secure cloud storage. IEEE Trans. Comput. 2013, 62, 362–375. [Google Scholar] [CrossRef]
- Yu, Y.; Au, M.H.; Mu, Y.; Tang, S.; Ren, J.; Susilo, W.; Dong, L. Enhanced privacy of a remote data integrity-checking protocol for secure cloud storage. Int. J. Inf. Secur. 2015, 14, 307–318. [Google Scholar] [CrossRef]
- Cooper, D.; Santesson, S.; Farrell, S.; Boeyen, S.; Housley, R.; Polk, W. Internet X.509 Public Key Infrastructure Certificate and Certificate Revocation List (CRL) Profile. Available online: https://tools.ietf.org/html/rfc5280 (accessed on 6 June 2018).
- Yu, Y.; Au, M.H.; Ateniese, G.; Huang, X.; Susilo, W.; Dai, Y.; Min, G. Identity-based remote data integrity checking with perfect data privacy preserving for cloud storage. IEEE Trans. Inf. Forensics Secur. 2017, 12, 767–778. [Google Scholar] [CrossRef]
- Wang, H. Identity-based distributed provable data possession in multicloud storage. IEEE Trans. Ser. Comput. 2015, 8, 328–340. [Google Scholar] [CrossRef]
- Wang, H.; Wu, Q.; Qin, B.; Domingo-Ferrer, J. Identity-based remote data possession checking in public clouds. IET Inf. Secur. 2013, 8, 114–121. [Google Scholar] [CrossRef]
- Zhang, J.; Dong, Q. Efficient ID-based public auditing for the outsourced data in cloud storage. Inf. Sci. 2016, 343, 1–14. [Google Scholar] [CrossRef]
- Boneh, D.; Franklin, M. Identity-Based Encryption from the Weil Pairing. In Proceedings of the Annual International Cryptology Conference, Santa Barbara, CA, USA, 19–23 August 2001; pp. 213–229. [Google Scholar]
- Wang, B.; Li, B.; Li, H.; Li, F. Certificateless public auditing for data integrity in the cloud. In Proceedings of the IEEE Conference on IEEE Communications and Network Security (CNS), National Harbor, MD, USA, 14–16 October 2013; pp. 136–144. [Google Scholar]
- Li, J.; Yan, H.; Zhang, Y. Certificateless public integrity checking of group shared data on cloud storage. IEEE Trans. Serv. Comput. 2018. [Google Scholar] [CrossRef]
- Al-Riyami, S.S.; Paterson, K.G. Certificateless public key cryptography. In Proceedings of the International Conference on the Theory and Application of Cryptology and Information Security, Taipei, Taiwan, 30 November–4 December 2003; pp. 452–473. [Google Scholar]
- Goldwasser, S.; Micali, S.; Rackoff, C. The knowledge complexity of interactive proof systems. SIAM J. Comput. 1989, 18, 186–208. [Google Scholar] [CrossRef]
- Feige, U.; Fiat, A.; Shamir, A. Zero-knowledge proofs of identity. J. Cryptol. 1988, 1, 77–94. [Google Scholar] [CrossRef]
- Chaum, D.; Pedersen, T.P. Wallet databases with observers. In Proceedings of the Annual International Cryptology Conference, Santa Barbara, CA, USA, 16–20 August 1992; pp. 89–105. [Google Scholar]
- Nyberg, K.; Rueppel, R.A. Message recovery for signature schemes based on the discrete logarithm problem. In Proceedings of the Workshop on the Theory and Application of Cryptographic Techniques, Perugia, Italy, 9–12 May 1997; pp. 182–193. [Google Scholar]
- Bao, F.; Deng, R.H.; Zhu, H. Variations of diffie-hellman problem. In Proceedings of the 5th International Conference on Information and Communications Security, Huhehaote, China, 10–13 October 2003; pp. 301–312. [Google Scholar]
- Lynn, B. The Pairing-Based Cryptography Library (0.5.14), 2017. Available online: https://crypto.stanford.edu/pbc/ (accessed on 6 June 2018).
- Free Software Foundation. The GNU Multiple Precision Arithmetic Library. Available online: https://gmplib.org/ (accessed on 6 June 2018).
Figure 1.
System model of our protocol.

Figure 2.
CL-PGSDP protocol.

Figure 3.
Tag generation time for increased number of data blocks.

Figure 4.
Increasing number of challenges for fixed size of data.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Comparison with Li [30].
Table 1.
Comparison with Li [30].
| Li [30] | Our CL-PGSDP | |
|---|---|---|
| Tag Generation cost | 2nExpG1 + nH | 2nExpG1 + nH |
| Challenge cost | Negligible cost | zP + zExpG2 + ExpG1 |
| Proof Generation cost | cExpG1 + (c − z) MultG1 | (2c − 1) MultG1 + cMultG2 + cExpG2 + cExpG1 + P |
| Proof-Check cost | (z + 2) P + (c + d) ExpG1 + (c + 2d) MultG1 + dMultG2 | 2cExpG1 + cPG1 + cH + (c − 1) ExpG2 |
| Working scenario | Group data | Group data |
| Support data privacy-preserving | No | Yes |
| Support user identity privacy-preserving | No | Yes |
Table 2.
Comparison of Proof-Check with Li [30].
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Yang, H.; Jiang, S.; Shen, W.; Lei, Z. Certificateless Provable Group Shared Data Possession with Comprehensive Privacy Preservation for Cloud Storage. Future Internet 2018, 10, 49. https://doi.org/10.3390/fi10060049
AMA Style
Yang H, Jiang S, Shen W, Lei Z. Certificateless Provable Group Shared Data Possession with Comprehensive Privacy Preservation for Cloud Storage. Future Internet. 2018; 10(6):49. https://doi.org/10.3390/fi10060049
Chicago/Turabian StyleYang, Hongbin, Shuxiong Jiang, Wenfeng Shen, and Zhou Lei. 2018. "Certificateless Provable Group Shared Data Possession with Comprehensive Privacy Preservation for Cloud Storage" Future Internet 10, no. 6: 49. https://doi.org/10.3390/fi10060049
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.