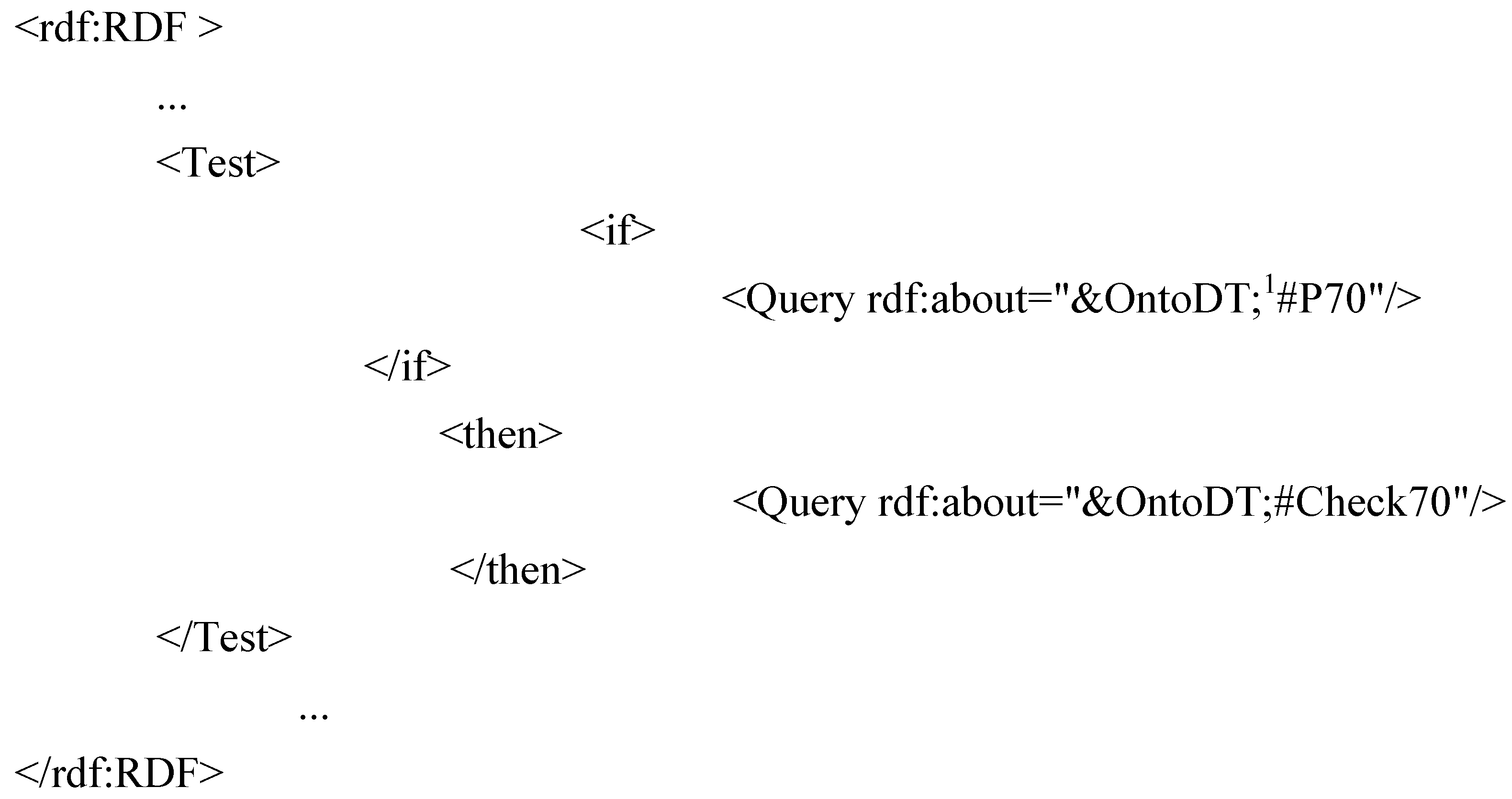1. Introduction
Regulations in the Building Industry are becoming increasingly complex and involve more than one technical area, covering products, components and project implementations. They also play an important role in ensuring the quality of a building, and minimizing its environmental impact. As a consequence of this complexity; checking the conformity of a new product against the existing regulations is becoming more complex for industrials every day. In this general context, the research communities of the Knowledge Engineering and Semantic Web play a key role in providing models and techniques to simplify access to technical regulatory information, facilitate its appropriation, and support professionals in its implementation.
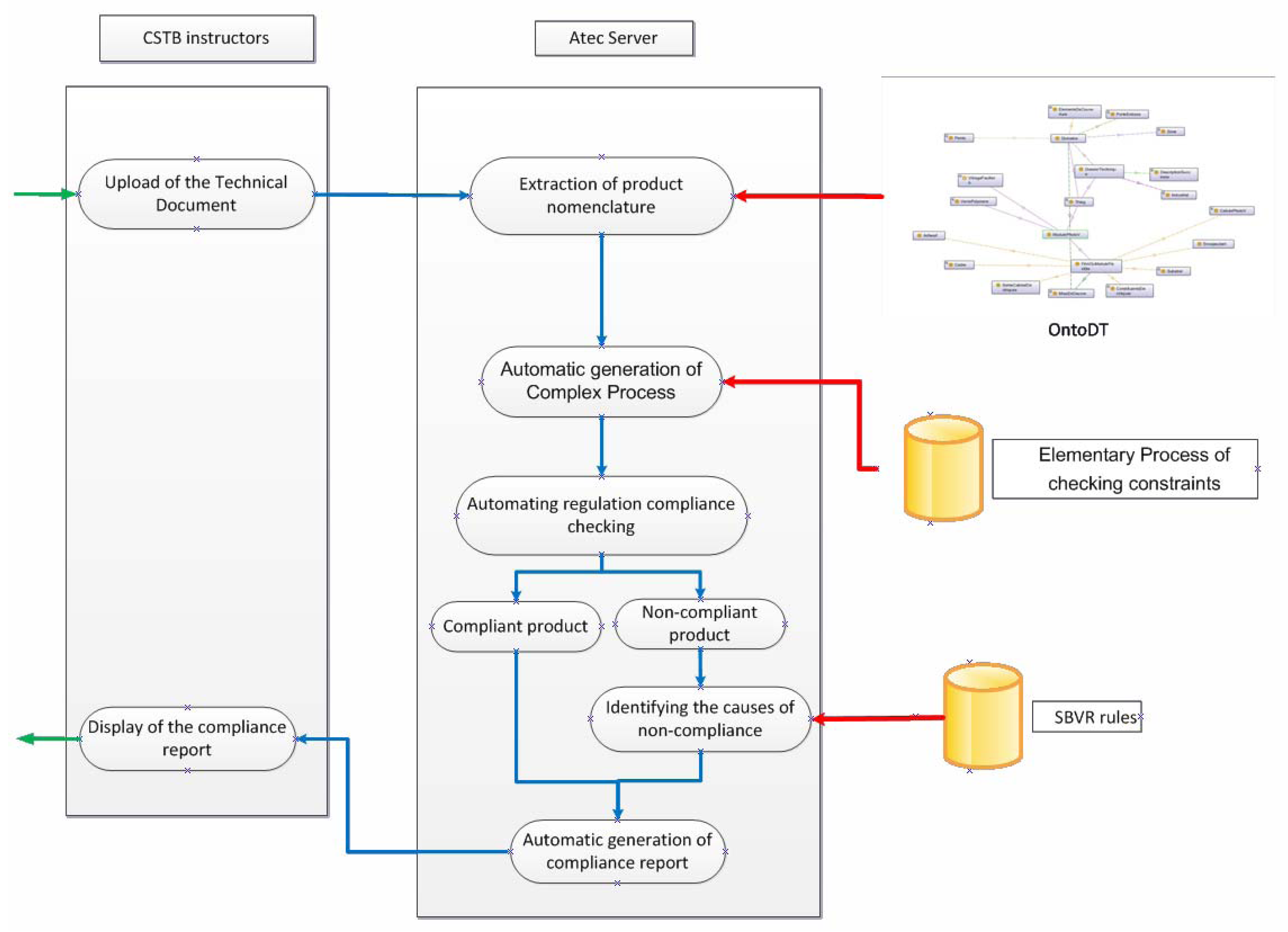
In this article, we address the different issues linked to compliancy, checking specifically the production of Technical Advice (so-called “ATec” in French). An ATec is a document containing technical information on the usability of a product, material, component of construction or even an innovative process of construction. However, this new product or new process must comply with existing regulatory documents. ATec was chosen as a study model for this project because CSTB has the mastership and a wide experience in these types of technical documents. We were able to lead interviews on the CSTB site of Sophia-Antipolis with experts directly involved in the drafting of these ATec in the field of photovoltaic panels.
2. Selected Regulatory Documents
2.1. Importance and Difficulties Linked to Regulations
The regulations are written and applied by humans and are therefore vulnerable to human error. They can at times be incomplete, contradictory, or arbitrarily complex. This has at least one direct consequence in the present scope. If we want to automate the verification process of compliancy of a new product, the textual knowledge and the corresponding constraints contained in these documents have to be translated (and transformed) into rules understandable by machines and, thus processable.
2.2. The Technical Guides
In this paper, we will illustrate our approach by not considering direct standards or regulatory documents, but Technical Guides (TG). These TGs are documents edited by the CSTB that explain regulatory documents; they do not replace the regulations. The TGs are a complement to the regulatory documents, offering the industrials easier reading and understanding of the technical rules of construction. Also, they collect detailed executions featuring a wide range of situations. The TGs are also the documents of reference that help verify the validity of the technical information provided by the manufacturers. All of the structural and dimensional variables for the validation of a product are encompassed within the TGs. Our goal is to formalize the knowledge they contain as constraints database, exploitable by knowledge-based systems.
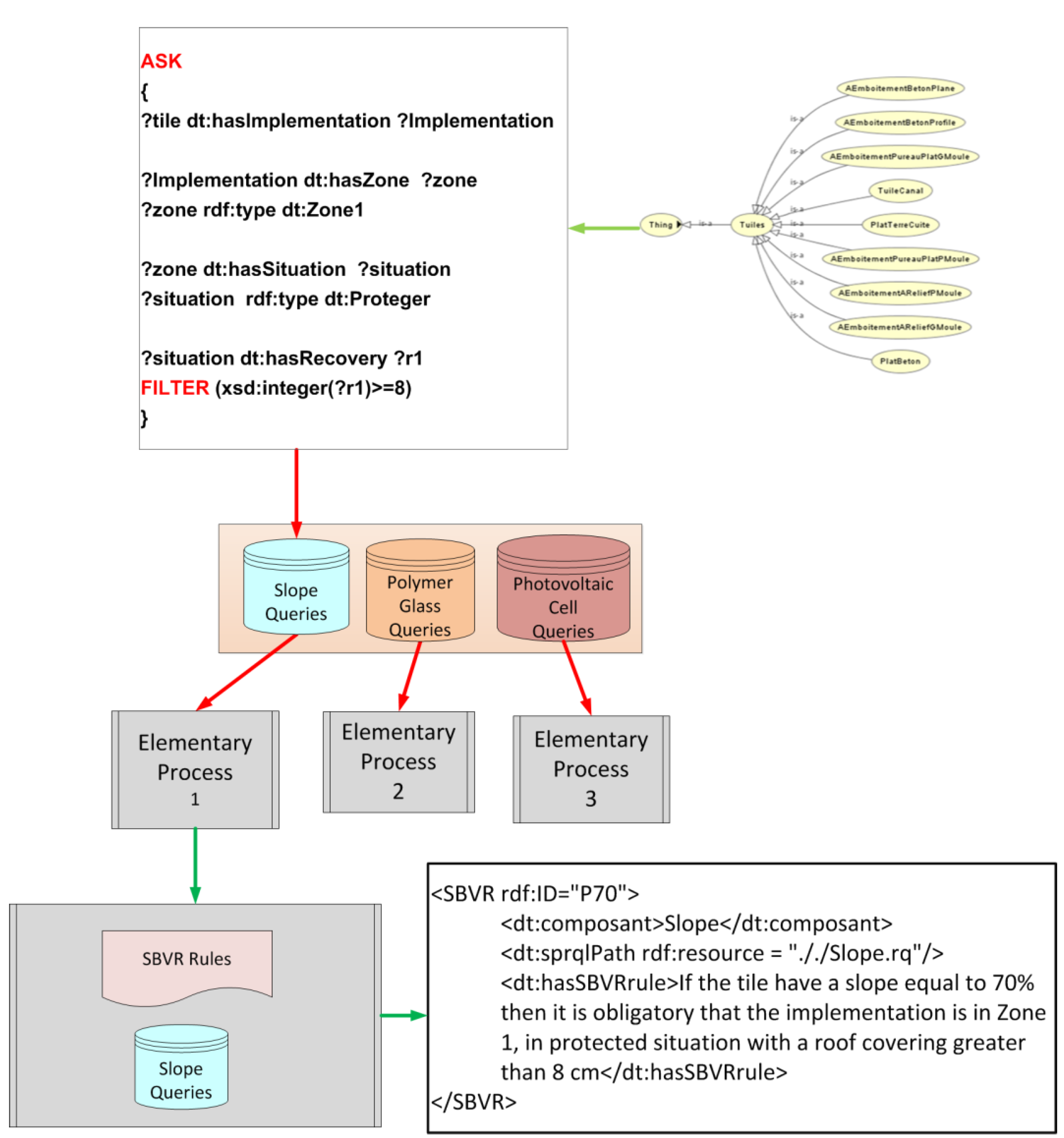
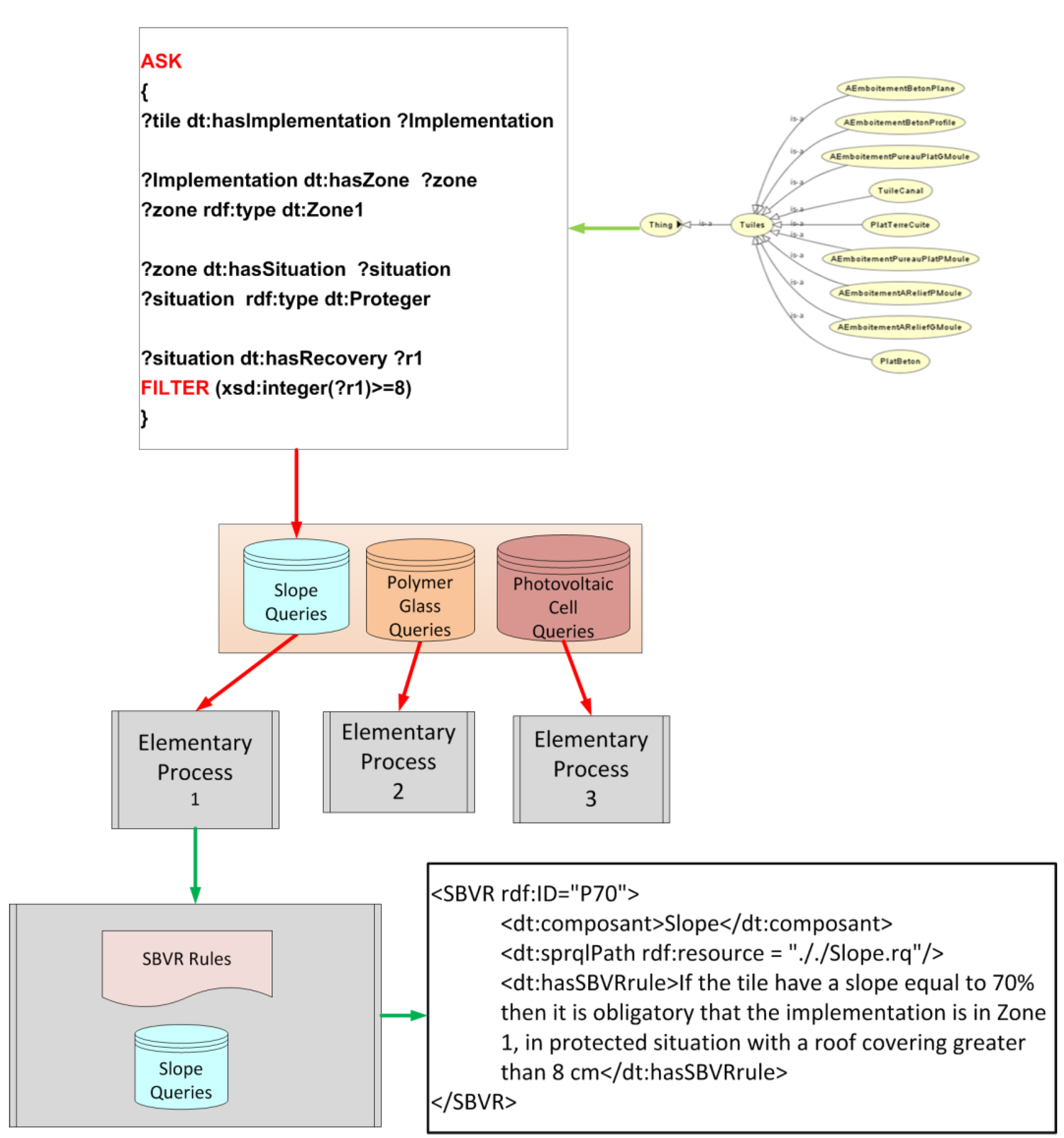
We use the TG “The tile roofs” issued by CSTB as a study model. This guide of 107 pages outlines the different types of tiles and their characteristics. It defines their status of implementation and verification of various criteria, such as slope tiles, support or climatology of their place of installation. Monitoring these instructions is of utmost importance because non-conformance with a requirement leads to a negative on the Technical Assessment Technical Paper.
According to the TG “The tile roofs”, we were able to identify nine different types of tile, with different intrinsic characteristics. Each tile has a manufacturing area and a shape, an implementation that depends on the slope and support, and raises an attachment.
The regulatory constraints existing in these TGs are used to decide whether the procedures used by manufacturers meet their obligations.
2.3. The Technical Advice (ATec)
As already introduced in the first chapter, an ATec corresponds to an innovative product or process and it mainly contains a technical description (made by industrial wanting to promote its new product or process). The structure of an ATec is always the same and it consists of three parts:
• An overview and identification of the assessment, which could be considered as an administrative part.
• The technical assessment itself, formulated by a group of experts from CSTB. Basically, only two options are possible in this section. It should be answered clearly if the element or process described is acceptable or not.
• The technical document (TD) of the product or process which must be delivered in the technical assessment. Fulfilling this part is devoted to the industrial who wants to promote an innovative product or process. For several reasons, this is the most difficult part that requires efforts from the industrial and time from CSTBs’ experts.
Therefore, we are particularly interested in assisting the creation of the TD.
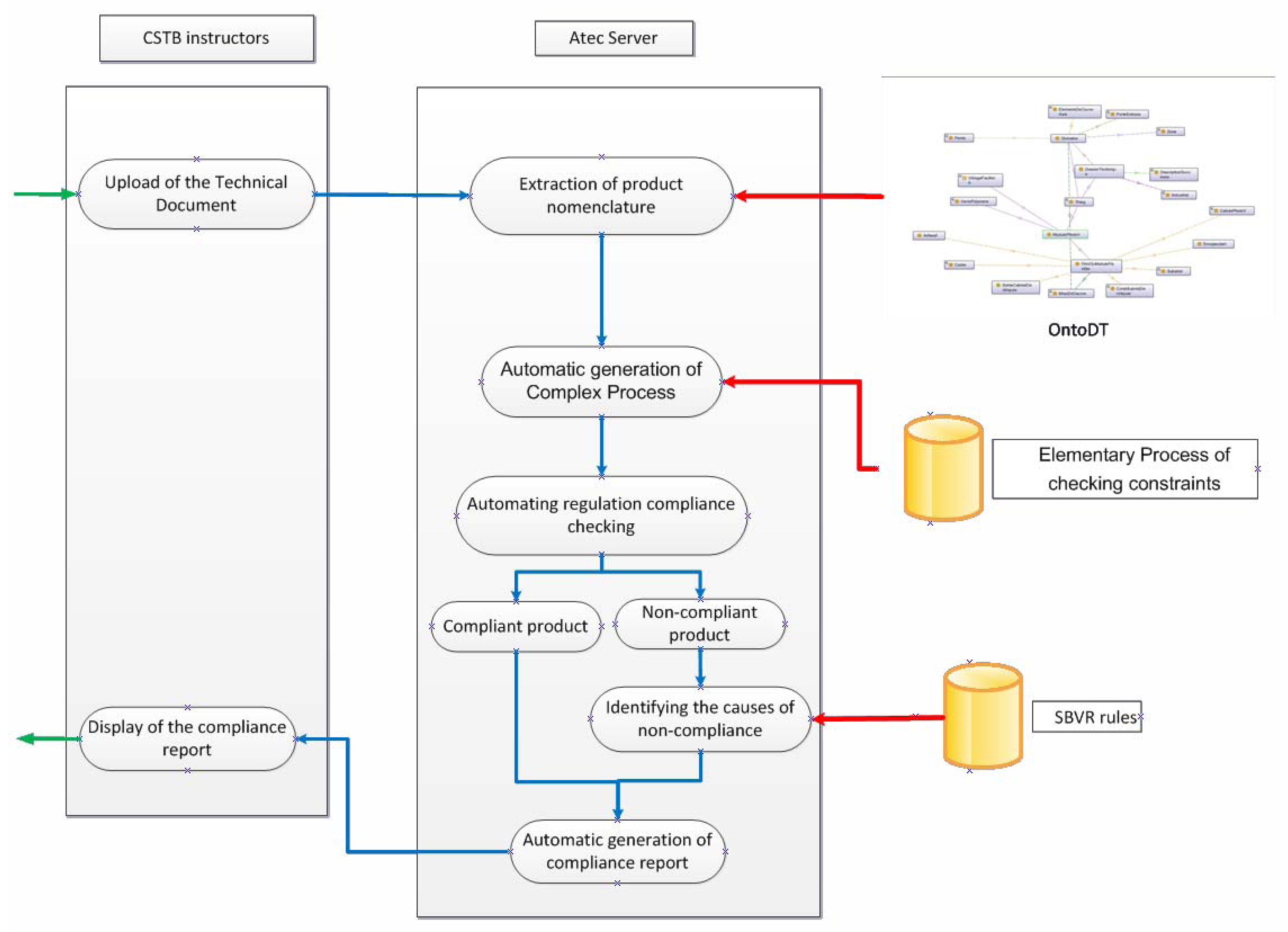
An ATec is drafted at the request of an industrial. The industrial sends a request to the relevant department within the CSTB and in return, the CSTB sends back a template of the TD to the industrial. It is a Word document which contains chapters, text and instructions. This template is supposed to be self-sufficient but it is apparent that industrials fail to properly prepare the template in order to create a good TD. A dialogue between CSTB and the applicant is therefore necessary before reaching an acceptable version of the TD. As a direct consequence, this leads to a long casework, which takes approximately 6 to 8 months and requires an effort from both sides that must be reduced to a minimum.
3. Modeling Technical Documents
The regulations as well as the TD are written in a flat textual format that is understandable. The corner stone of our approach is to develop a common framework allowing structured and semantically rich representations of regulation contents and product or process structures. After reviewing various studies related to technical regulations and after having interviewed experts involved in the elaboration of ATec, we defined a generic process for the verification of the TD. This process is a formalization of practices followed by CSTBs’ experts. In the continuation of the work performed at CSTB [
5], about ontology building and conformity checking of construction projects [
6], we propose to model the process of elaborating the TD using an ontology-based approach.
We represent the regulatory constraints using the above mentioned ontology as the source for a controlled vocabulary and we defined a methodology to transform the rules expressed from natural language (which is the case for regulation) to semi-formal language (SBVR) and to a formal language (SPARQL). This part will be explained in
Section 4 of the current article.
3.1. The OntoDT Ontology
In order to disambiguate the semantic attached to the terms; we defined an ontology of the considered domain. We defined an ontology, so-called “OntoDT”, to represent both the structure of the TD but also the vocabulary used in the considered technical field.
We have studied the TDs issued by a group within CSTB that is responsible for validating the ATec concerning photovoltaic panels. The OntoDT ontology contains an exhaustive list of terms from the photovoltaic domain merged with the other terms extracted from a thesaurus developed by CSTB for the building industry which is called the REEF [
7].
We developed a model for tiles based on information collected from a dedicated Technical Guide named “The tile roofs”. Each tile is represented in concept and integrated into our ontology, OntoDT. The ontology includes all the semantics reflecting structural and dimensional criteria of a tile; the criteria are represented by properties.
As a result, our ontology has 138 classes and 48 properties formalized in the OWL Lite language; 35% of these classes are created from REEF terms. The remaining 65% are concepts more specific than those of the REEF thesaurus, which contains general concepts of the building industry. In its current state, it lacks specific terms relative to a particular field (Photovoltaic). However, it remains in constant evolution.
3.2. Modeling the Technical Document
We use our ontology, OntoDT, to model the semantics conveyed by the TD into a formal interpretable knowledge. We translated the template of the TD to a set of forms interconnected to each other. The product to be described is decomposed into a set of sub elements called “components”. These components are identified in the OntoDT and thus linked by semantic relationships to other components. These relationships will guide the concatenation of the corresponding forms. In other words, in an application developed on this basis, the user will be guided in the process according to the information entered in the forms. The way the forms follow on from each other is determined by the ontology and by data entered by the user.
For example, a PV glass polymer module (a component) is part of a PV panel (the product). This glass polymer module is composed of several elements: polymer film, photovoltaic cell, etc. (elements).
To model this composition, each concept representing a component, an element or a product is defined by an axiom. Axioms are used in the definition of an ontological class, they are of the A ⊆ B form, where A is a primitive concept (Product) and B description composed concept. For instance, (
Figure 1) provides the definition of the class PolymerGlass in the OWL language: it is a subclass of the class PVPanel and of a class defined as the intersection of the classes of the instances having components of classElectricCable, Frame, PVCell,
etc.
Figure 1.
Example of owl code used to define a concept.
Figure 1.
Example of owl code used to define a concept.
We have described the interdependencies between the different concepts modeling the interactions or interdependencies between parts of PV modules. These have a number of intrinsic characteristics (length, weight, manufacturer, etc.) represented in our modeling by properties attached to the corresponding concepts.
Once the industrial fills in the form relative to a concept with all the elements relative to its definition, they are stored in an RDF annotation file. By doing so, we acquire an interoperable representation of a TD, reusable in other systems. The use of the RDF model will allow us to later to check the conformity of the TD with the standards of the photovoltaic domain.
3.3. Modeling the Process of Writing a Technical Document
The question which now arises is how to model the process itself of completing the TD, in order to produce a dynamic sequence of forms to fill in. The dynamicity of the forms depends on the way previous forms are filled out; we want to adjust to the information provided without requiring the industrial to complete irrelevant parts of the TD.
Our approach is to initially ask for high-level information (name the type of product, etc.) then browse the explicit dependency rules in the ontology to seek all information required for a product. From the information provided by the industrial, the domain ontology is used to determine the next iteration. The industrial will have to, in an initial form, choose a product among all those concerned with the photovoltaic field. Using this information, based on our ontology, we determine the list of components used in its manufacture and we offer a list of corresponding forms.
The dynamics of the sequence of forms relies upon a SPARQL query pattern presented in (
Figure 2) which we initiate to query the ontology to determine the next form. More precisely, by using this query template, we query a product on its composition by questioning its definition. The concepts involved in its definition are returned by the query and necessitate more information that must be provided by the industrial through entry forms generated on the fly. The chaining of forms thus depends on the query results: each form corresponds to one or more elements of the result.
Figure 2.
Extract of the SPARQL query pattern.
Figure 2.
Extract of the SPARQL query pattern.
For example, the query below searches the ontology on the definition of the concept “PolymerGlass”. First, this query pattern checks if the component contains one or several elements (rdfs:subClassOf, owl:intersectionOf). Second, it iterates all the elements corresponding to the nomenclature of the component (rdf:rest*/rdf:first). Third, it returns all the elements as results (owl:someValuesFrom).
The result is that “PolymerGlass” is a module which has as components a “Frame”, a “PVCell”, etc.
Result: [Frame, PVCell, PolymereFilm, InnerGlass…]
At each step of the process of writing a TD, we display a form to the industrial for entering information related to a concept belonging to the result of such a query. If this concept is already defined, the same query template is initiated with a new query in order to provide the industrial with new forms matching the components involved in the definition of the current concept. The same query pattern is recursively instantiated until reaching terminal concepts, i.e., primitive concepts (with no definition).
As a result, the industrial browses our ontology to complete all components of its product by filling out the forms provided; only relevant questionnaires are displayed.
3.4. Generation of Structured Annotations
To validate our approach, we developed a tool to assist the production of TD. This application has been developed in J2EE. It conforms to the three-tier architecture. The first third consists of a web page on the client side (GUI) that supports various forms to fill in by the industrial. The second third on server side is a SERVLET [
8] containing a business code that interacts with the GUI part and the business part. It is connected to the KGRAM [
9] semantic engine to query the ontological knowledge that represents the TD and generates the RDF model of the filled TD. The last third is relative to the data. It includes the ontology of the TD and information of the product stored as RDF annotations.
Our tool provides the industrials with a rich and interactive interface based on a sequence of forms. All along the drafting process, the industrial is guided in his choices by the OntoDT ontology and the system adapts and goes through the ontology to seek progressively more specific information. These sequences of forms are orchestrated through SPARQL queries that run on the ontology.
At the end of the sequence of forms, two files are generated: a human readable file containing the information filled in by the industrial, and a semantic description of the document in RDF. This will be exploited to help in writing the technical assessments itself, by automatically checking the conformity of the information in the TD with the regulatory texts of the domain.
4. Modeling Business Rules
Within the vast field of regulatory modeling, one standard fits our problem particularly well. Focussing on the transformation of regulatory documents [
10,
11,
12], this standard is the SBVR standard. SBVR stands for “Semantics of Business Vocabulary and Business Rules”. It is an Object Management Group (OMG) [
13] standard whose ultimate objective is to provide a meta-model that allows establishing data exchange interfaces for tools that create, organize, analyze and use vocabularies and business rules [
14,
15]. The SBVR meta-model facilitates the validation, analysis, alignment, and fusion of business rules for different tools of different constructors. The development of an SBVR base is done in two steps: the development of a business vocabulary and the writing of business rules based on the terms and concepts defined in the vocabulary.
SBVR controlled vocabularies consist of hierarchies of concepts specific to a certain domain, their relationships, definitions and synonyms. SBVR rules are based upon the Predicate Logic: they capture the “what” of business rules, rather than the “how”, in other words the semantics of business rules, not the way they must be executed. SBVR is not an executable formalism; it is particularly addressed to business experts. It uses a controlled natural language that all business experts understand. It does not have a specific rule format.
In this paper, our SBVR examples are presented following the SBVR-based Structured English [
14], using several font styles:
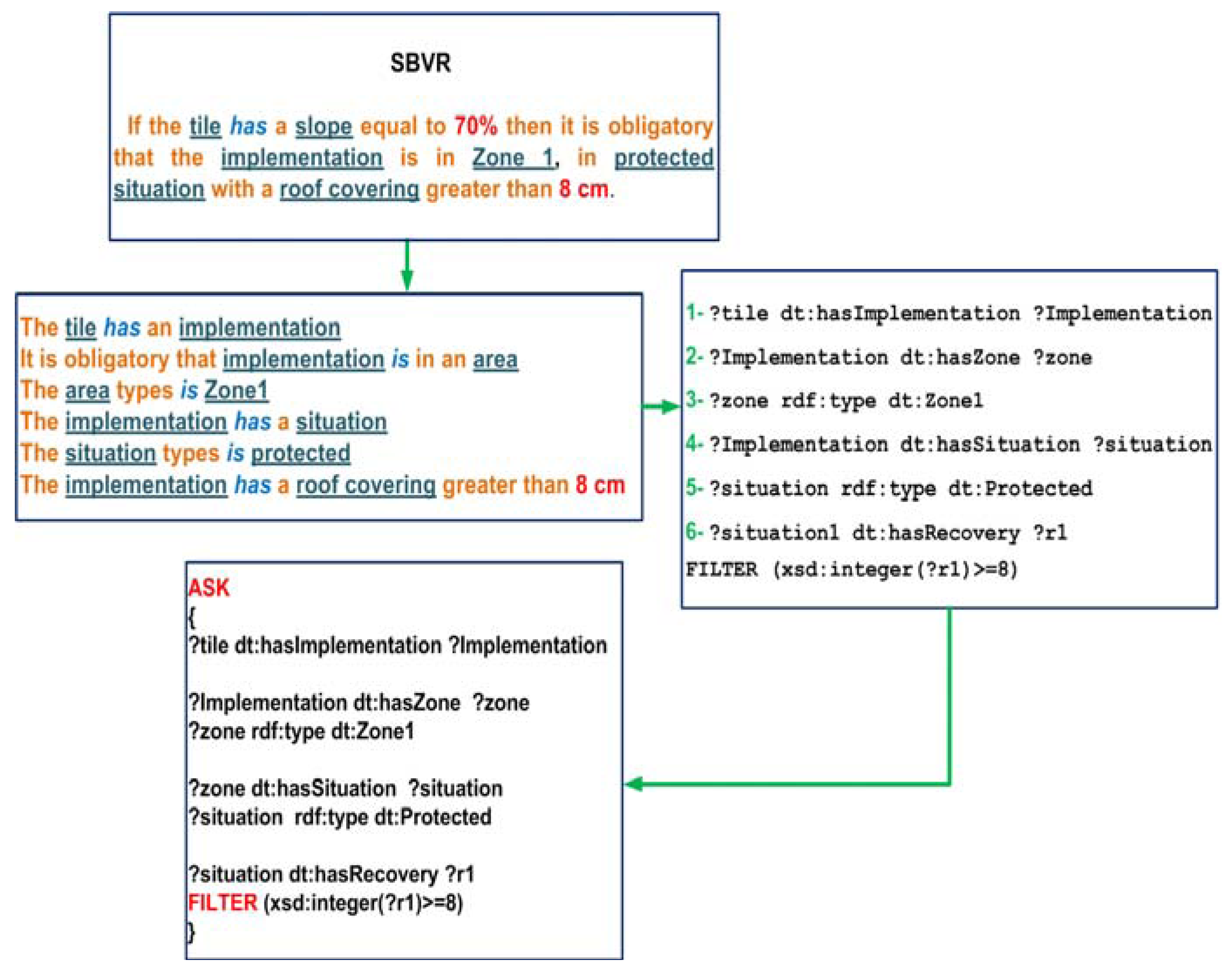
4.3. Representation of Regulatory Constraints in SPARQL
We aim to model the way experts use CSTB guides and try to automate their know-how. It forces us to follow their interpretation and to establish a formal representation of regulations. SBVR describes the concepts and requirements regardless of their implementation. We chose to represent constraints into “ASK” SPARQL queries. This formalization allows the automation of the conformance of a document against these constraints (see
Figure 5).
Figure 5.
Transforming SBVR into SPARQL queries
Figure 5.
Transforming SBVR into SPARQL queries
To perform a transformation of SBVR rules into SPARQL queries we followed a number of defined steps and used a controlled-vocabulary, in our case we used OntoDT.
As an example the following SBVR rules:
Step 1: We decompose the SBVR rule into a set of single sentences in order to decompose the different constraints expressed. So we can identify the antecedent and the consequent of our “if-then” rules as follows (
Table 1):
Table 1.
Decomposing SBVR rules into Antecedent and Consequent.
Table 1.
Decomposing SBVR rules into Antecedent and Consequent.
| Rules parts | English |
|---|
| Antecedent | ![Futureinternet 04 00830 i006]() |
| Consequent | ![Futureinternet 04 00830 i007]() |
Step 2: We transform, into triple pattern, each formulation expressed in the antecedent and consequence. We used all concepts and properties of OntoDT (
Table 2).
Table 2.
Transforming SBVR rules into SPARQL triple pattern.
Figure 6.
SPARQL query of the antecedent (Example 1).
Figure 6.
SPARQL query of the antecedent (Example 1).
Figure 7.
SPARQL query of the consequent (Example 1).
Figure 7.
SPARQL query of the consequent (Example 1).
Step 4: Construction of the RDF annotation of the SBVR (
Figure 8).
Figure 8.
RDF annotation of the SBVR (Example 1)
Figure 8.
RDF annotation of the SBVR (Example 1)
5. Modeling of the Verification Process of Regulatory Constraints
5.1. Process Model
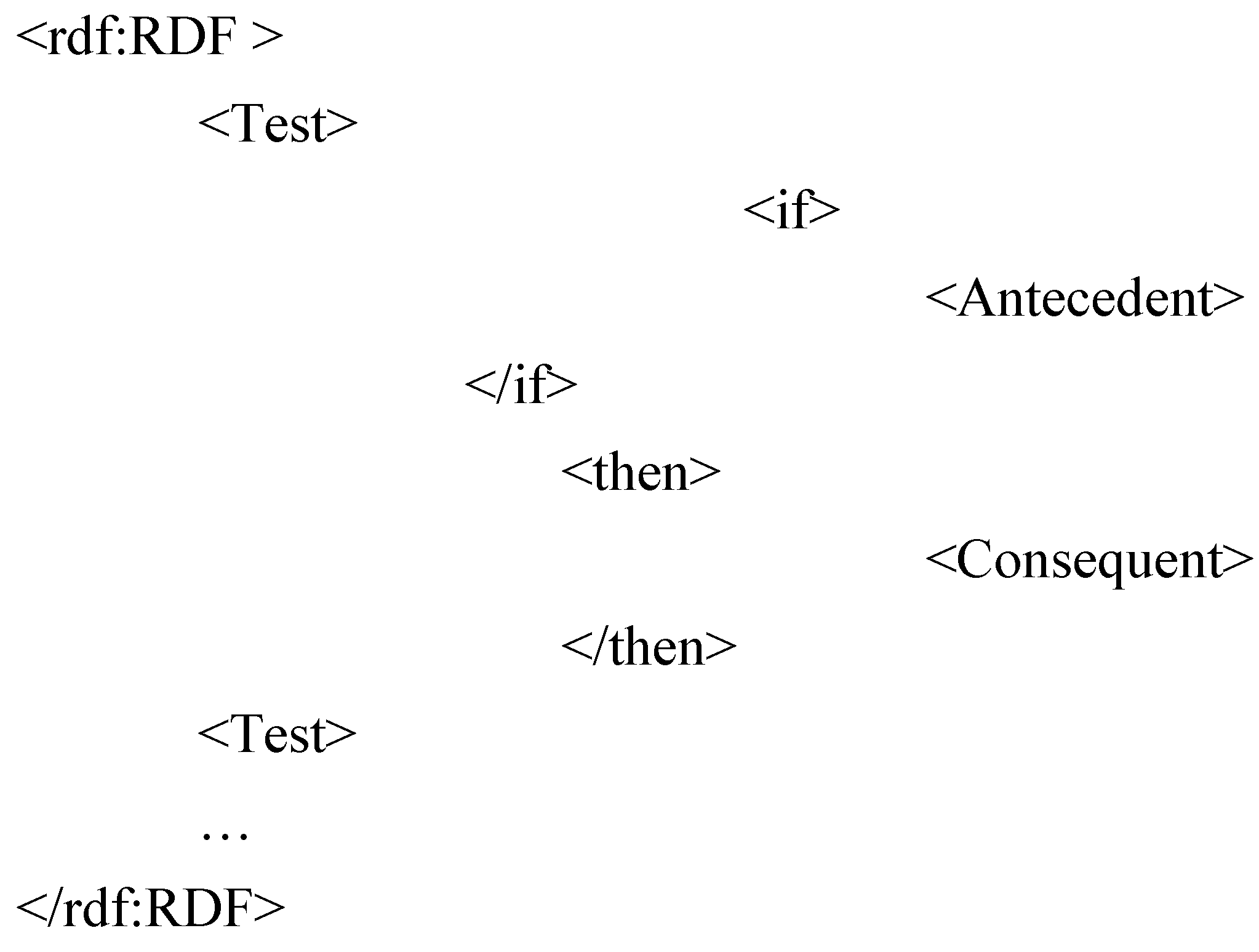
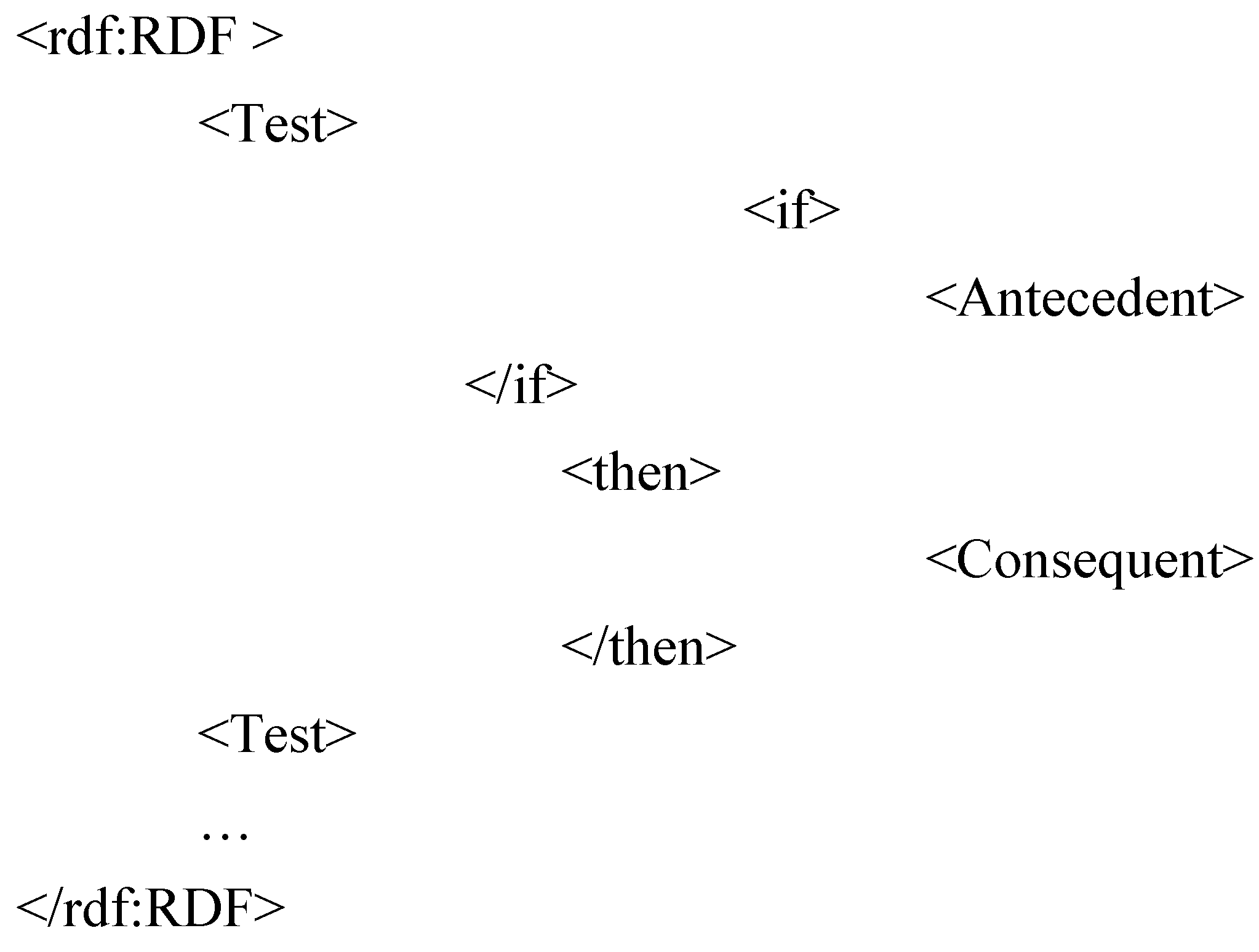
We proceeded with interviewing our experts, who are responsible for managing ATec in order to capture their knowledge and then to propose a process model representing the way they work. Our model enables building an RDF description of the sequence of constraint verifications performed to control a given TD.
The RDFS schema of our model comprises four properties: body, if, then and or else, and eight classes: Pipeline, Pipe, Load, Query, Rule, RuleBase, Test and And, among which the class Pipeline models a process definition and the class Pipe models a call for a process. The execution of queries (Query) or rules (Rule, RuleBase) can be conditional (Test) and a process description can recursively call for other processes (Pipe), including itself. This recursive feature is used in the modeling of complex processes calling for one or several elementary processes.
The abstract syntax of a process is defined by the following grammar:
We have developed a process engine based on the KGRAM semantic engine [
9] with the following principle: it analyses a process definition represented in our model and dynamically constructs and executes a sequence of SPARQL queries or rules. It thus enables supervision, coordination and sequential execution a set of queries and rules. The process management relies on a set of predefined SPARQL queries such as the one presented in (
Figure 9), dedicated to the management of the body of a process, which enables listing all the components of a process and their types:
Figure 9.
A SPARQL query template to interpret a process RDF representation.
Figure 9.
A SPARQL query template to interpret a process RDF representation.
For instance, let us consider the validation process which RDF representation is presented in (
Figure 10). Once this RDF data is loaded, our process engine executes the above query template (
Figure 9) the resource of class Pipeline is identified and the resources denoting sub-processes involved in its definition are listed. Each of these sub-processes is recursively handled in order to identify the operations to be performed. Note that we do not use the whole process model since our process representations do not involve rules: in our case, the only basic operations are queries.
Figure 10.
Extract of the RDF representation of a verification process
Figure 10.
Extract of the RDF representation of a verification process
Let us detail the handling of such a RDF description. The process engine interprets a resource of type Load (line 4) by loading the RDF description of a TD (located at the URI in argument) whose validity is to be checked. It interprets a resource of type Query (line 7) by loading the SPARQL query located at the URI and executing it on the loaded RDF description of a TD.
A resource of type Test (line 5) calls for the instantiation and execution of the query template presented in (
Figure 11) which enables identifying the value of the “if, then” and “or else” properties and their types. The process engine then first executes the ASK query denoted by the value of the “if” property and, depending on a TRUE or a FALSE answer, it recursively interprets the RDF description of the process denoted by the value of the “then” property or by the value of the “or else” property, if any.
Figure 11.
A SPARQL query template for identifying conditional sub-processes.
Figure 11.
A SPARQL query template for identifying conditional sub-processes.
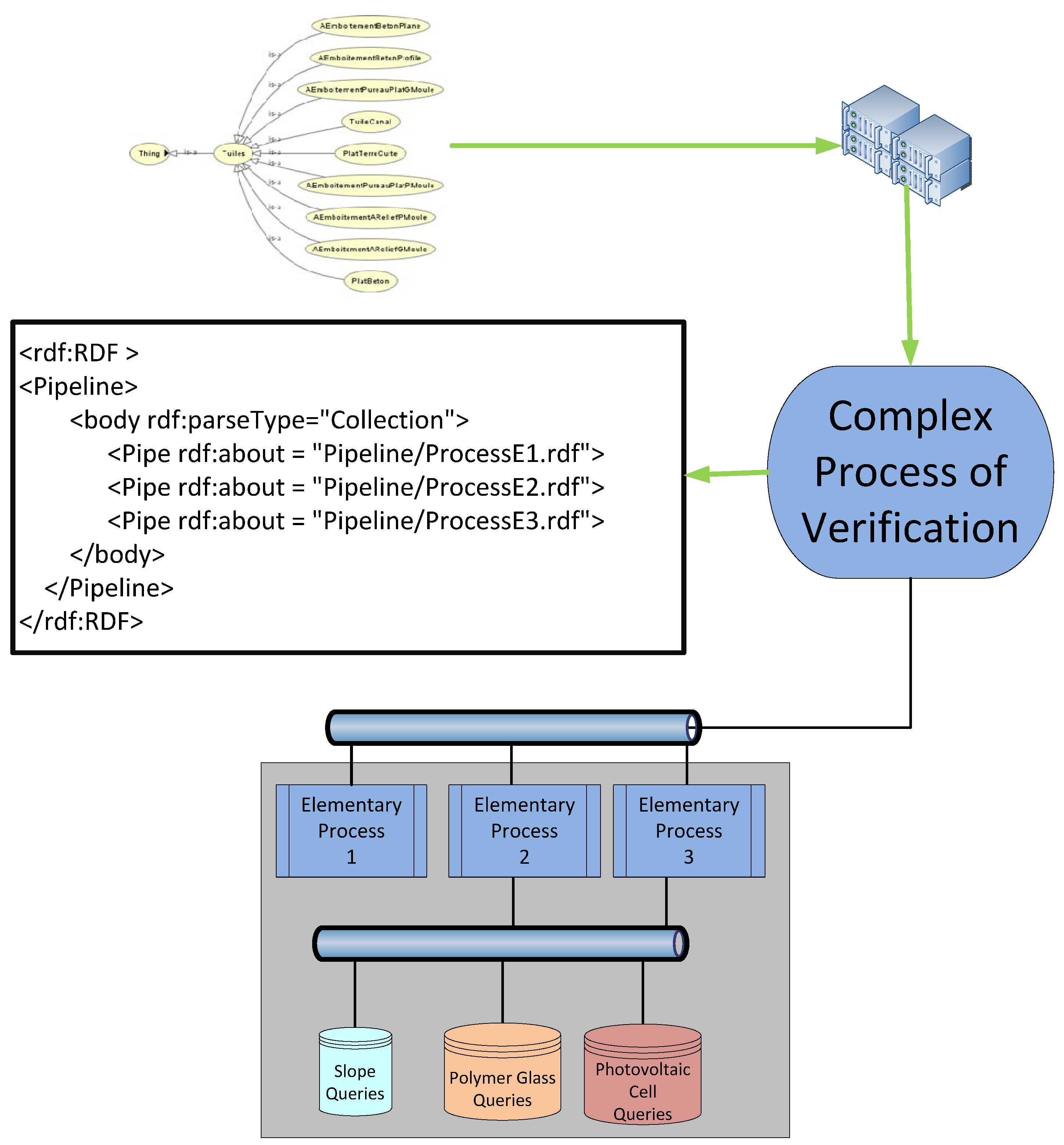
5.2. Elementary and Complex Processes
We distinguish between elementary and complex processes. A process is said to be elementary if it consists in the verification of the attributes of a component described in a TD which is denoted in our ontology by an atomic class. A process is said to be complex if it is associated to a component defined in the ontology as a combination of sub-components. In that case, the process consists in the verification of the attributes of the components and the verification of those of its sub-components.
For instance, the validation process associated to a tile (
Figure 12) is elementary: its RDF description calls for the execution of SPARQL queries testing its structural and dimensional criteria (the slope, the material, the form,
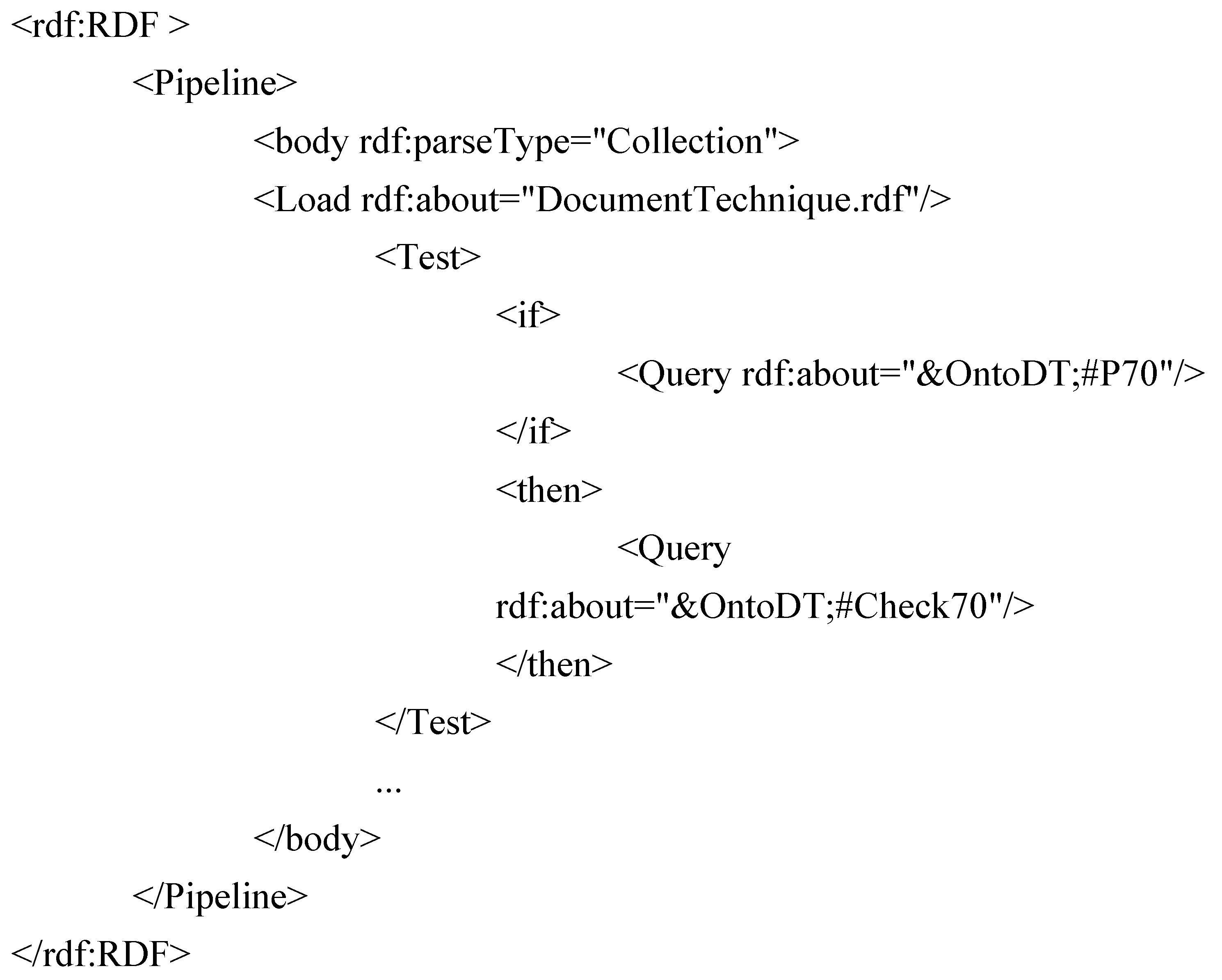
etc.). In contrast, the validation process associated to PV glass polymer module is complex: its RDF description presented in (
Figure 14) calls for the interpretation of the description of its sub-processes relative to the verification of its sub-components [Cadre, CellulePhotoV, FilmPolymere, VerreInterieur] (
Section 3.3).
Figure 12.
Elementary process of checking constraints.
Figure 12.
Elementary process of checking constraints.
Such an RDF description of a complex process is automatically and dynamically generated, by using a SPARQL query template (
Figure 13) querying the definition of the component to be validated in the OntoDT ontology.
Figure 13.
A SPARQL query template for generating a complex process.
Figure 13.
A SPARQL query template for generating a complex process.
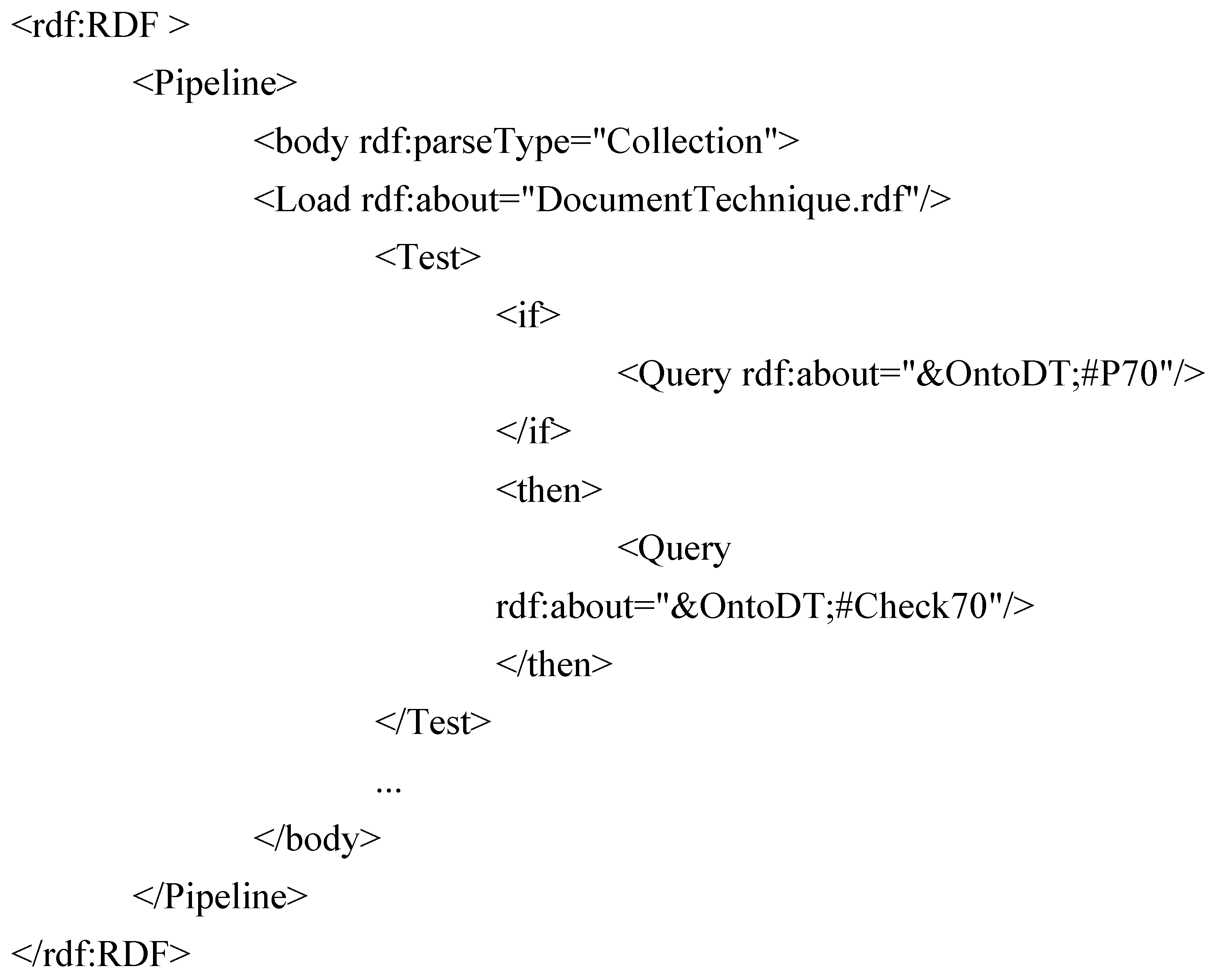
The interpretation and execution of such a process consists of the recursive interpretation of the description of its sub-processes. To be precise, in case of a complex process involving sub-processes, the process engine interprets the resource of type Pipe denoting a sub-process by loading its RDF description accessible at the URI and recursively interpreting it (see
Figure 14).
Figure 14.
Complex process of checking constraints.
Figure 14.
Complex process of checking constraints.
6. State of the Art
Regulatory modeling is a vast research area. The authors of [
17] have undertaken initial work on the structure of rules in decision tables. Decision trees were later applied in building industry, specifically in the design of steel buildings [
18]. The SASE system [
19], was developed to provide a complete hierarchical structure to classify families of related regulations or codes. A major study of these early approaches is provided in [
20]. In addition, let us cite [
21] who have developed the REGNET application to determine the applicability of building regulations in some given conditions, based on a question and answer interface.
Up to now, more recent work focuses on the rigorous extraction of requirements from regulations [
22,
23,
24]. Authors presented a methodology for extracting stakeholder rights and obligations from regulations. Also, regulatory modeling was discussed under two different approaches. The first one aims to automatically analyze the rules and to confront the complexity of natural language [
16,
25]. In a second approach, regulatory constraints are directly written according to a normalizing model, with the help of domain experts, which facilitates their translation into formal models [
26,
27]. We propose a third approach, which takes into account the regulations written in natural language, offers a tool for writing TDs and automatically analyses the content of these documents and their conformance to regulation.
On the other hand, various efforts have been made to apply conformance rules to the representations of construction projects, using the structures of drawings specially coded (IFC) or textual descriptions [
5,
28,
29]. When compared to these works, the originality of our approach lies in the combination of formal representations and SBVR rules from which they are derived to explain the rules themselves or the decision making. Our approach extends conformance checking with the explanation of the decision making.
7. Results and Limitations
We validated our approach on “real use case” at CSTB. We used TG which summarize the main requirements of seven Unified Technical Document (DTU) currently applied in France. We designed our rules database by extracting regulation constraints and transformed them into semi-formal language (SBVR) and formal language (SPARQL) using many steps. These transformations have been handled manually by domain experts. They were able to model 100% of TG constraints into SBVR.
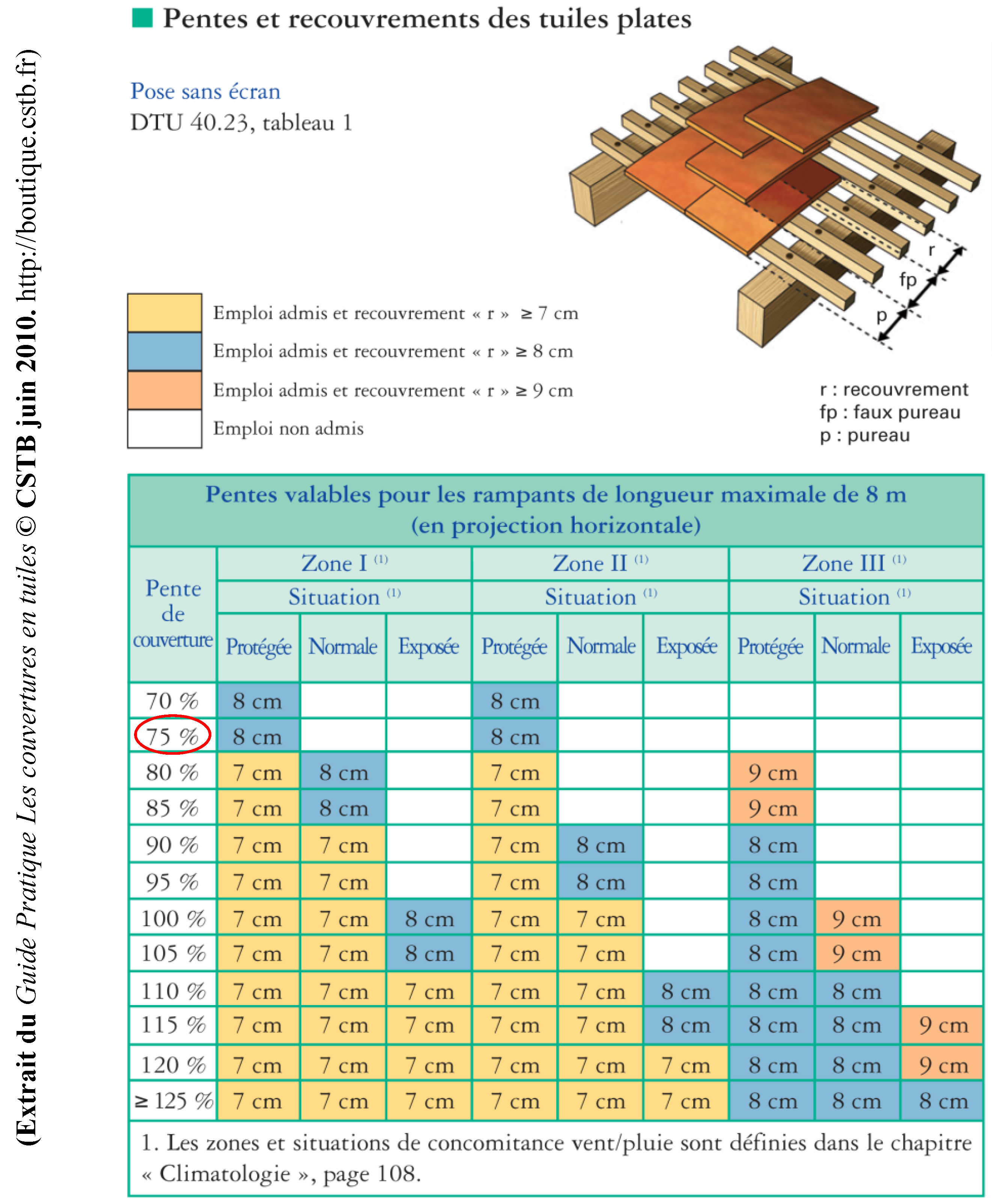
Although the interpretation of experts helps in translating most of the constraints from text to SBVR, some of them remain non-transformable into SPARQL. These cases correspond to the “fuzzy” constraints that contain information defined in a qualitative way (e.g., “a short distance”), or that contain “common knowledge” [
5] (e.g., “The recovery of the ridge tiles is in the opposite direction of the winds rain dominant”—Technical guides, “The tile roofs” page 75).
The current limitation of our technical guides is that they collect detailed execution data featuring a wide range of situations. These types of rules are called “Implementation rules”, easily representable in SBVR, are the largest part of the rules that cannot be formalized in SPARQL. These rules represent a large proportion of regulatory constraints identified in the TGs (in this case 70%).
Example of implementation rules (
Table 3):
Table 3.
Transforming implementation rules into SBVR formulation.
Table 3.
Transforming implementation rules into SBVR formulation.
| Implementation rules | SBVR formulation |
|---|
| «In the case of Canal tile, it typically runs in a mortar or flashing bardelis embedded and sealed in the wall.» Technical guides “The tile roofs” page76 [30]. | ![Futureinternet 04 00830 i015]() |
As final results, with the help of CSTB experts, we identified about 177 SPARQL queries and 177 elementary processes. This result is about 30% of the SBVR rule modeled.
8. Conclusions
In this paper, we have presented an approach and a tool to assist in compiling regulation and technical documents in the construction industry and partially automate regulation conformance checking. We propose a domain ontology, OntoDT, representing concepts involved in the description of technical documents and regulations. We combine SBVR and semantic web languages representing a controlled vocabulary and formalize regulatory constraints extracted from the Practical Guides edited by CSTB. These two complementary representations both are based on the OntoDT ontology and are associated in RDF annotations. The SBVR-based representation of regulations presented to the users, reduces ambiguity. RDF and SPARQL based formalizations enable automating regulation conformance checking. Finally, we propose a process model to organize regulations extracted from Technical Guides. A regulation conformance checking process is associated to each basic component involved in a technical document and a whole checking process is automatically built in based on the RDF description of the technical document and the component definitions in the OntoDT ontology.
We have developed a tool for representing technical documents and another one for their regulation conformance checking. They have been evaluated by CSTB instructors who have validated both the granularity of the information required and the OntoDT ontology. Our regulation conformance checking tool is a component of an assistance tool in writing technical advices, which we have developed for CSTB instructors and which is not detailed within this paper. Our models of regulation, technical documents and conformance checking process have been evaluated through the evaluation of this tool. CSTB instructors have validated the messages provided by our tool.
A major perspective of our work is the identification of regulations which cannot be completely formalized and their inclusion through SBVR representations in a semi-automatic conformance checking process.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
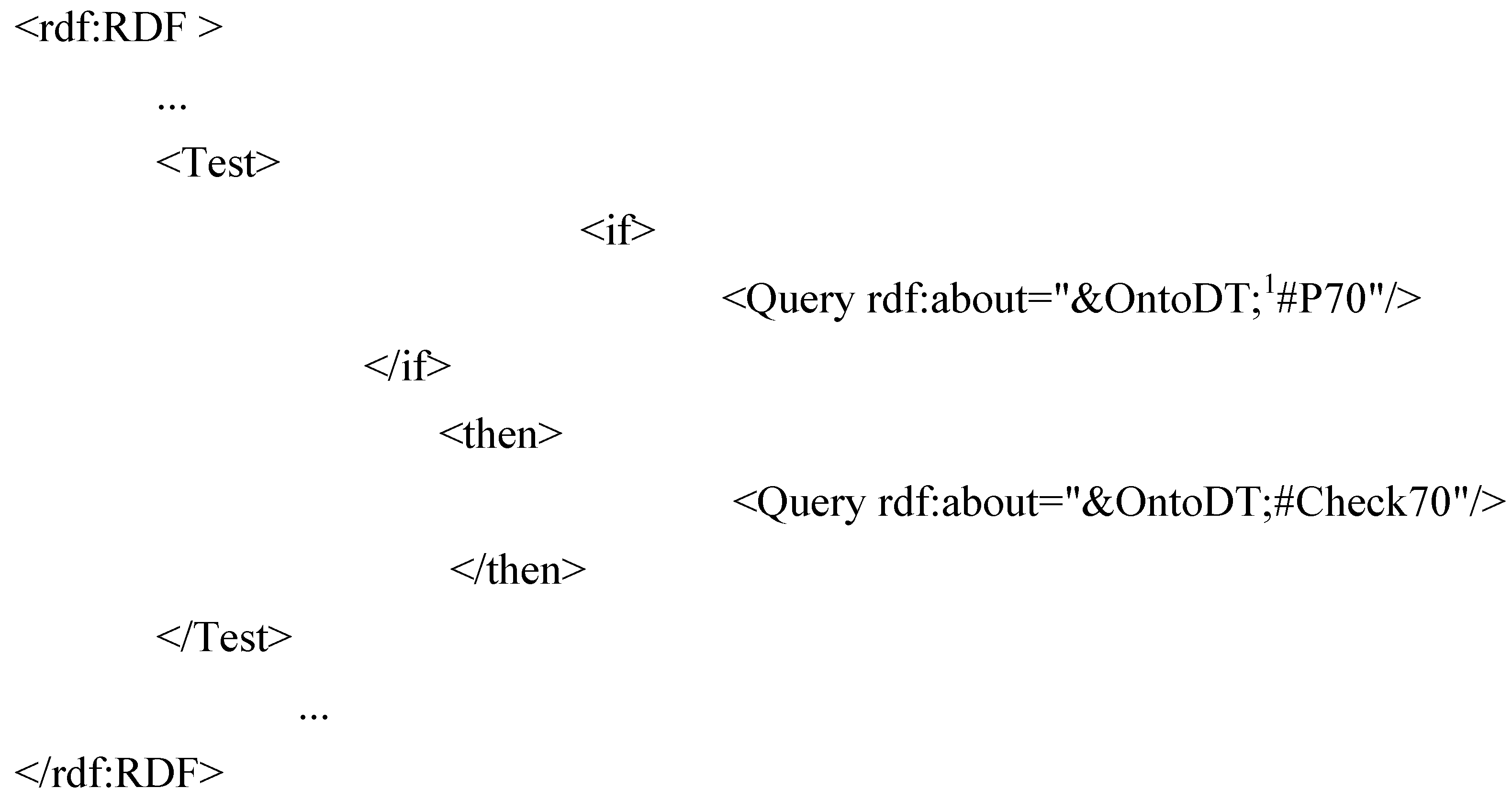{kind=link}
{kind=link}
{kind=link}
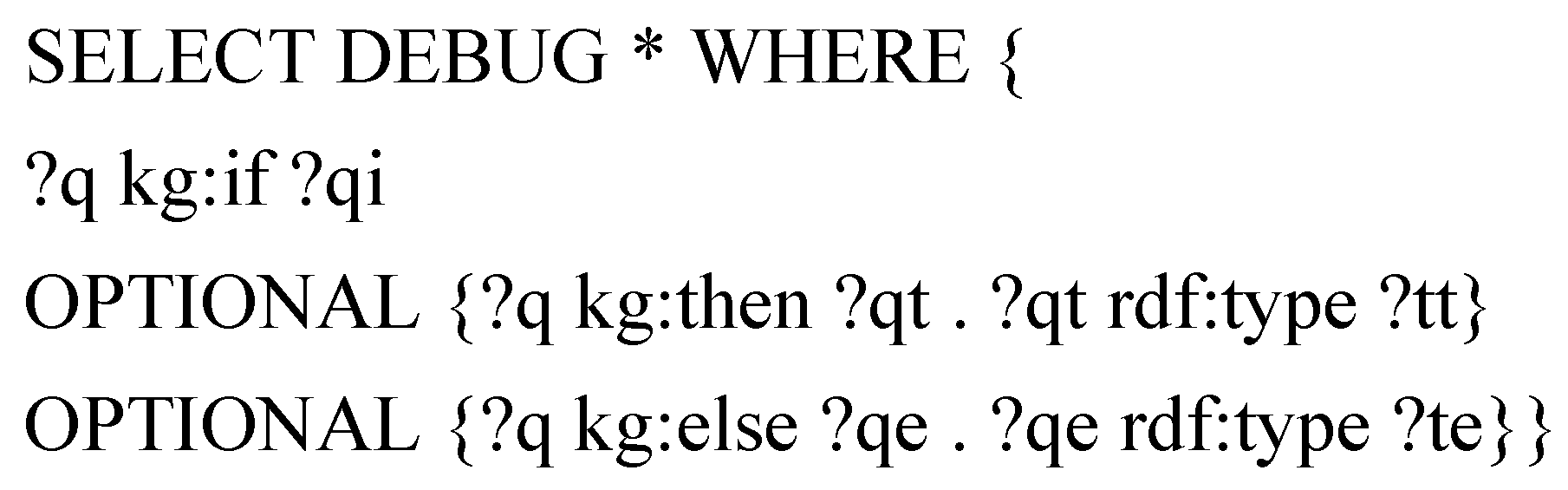{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}