1. Introduction
Land-surface temperature (LST) is a very important parameter in the geosciences, which plays a fundamental role in land–atmosphere interaction and is a key parameter in global environmental change in terms of its effect on global hydrology, ecology and biogeochemical processes [
1,
2,
3]. LSTs also play an important role in the field of surface radiation and energy balance, drought monitoring, global and regional climate-change analysis, ecosystem modelling, surface-water thermal simulation, etc. [
4,
5,
6,
7]. In addition, remotely sensed LST is widely used in studying the surface urban heat island (SUHI), which can assess the SUHI effect [
8] and find the correlation between LST and SUHI, e.g., the exact impact of temporal aggregation on LST and SUHI [
9]. Liu et al. demonstrated that both biophysical and building-wall characteristics significantly influence the spatiotemporal variations of LST [
10]. As a result, the question of how to obtain LST data/information economically and efficiently is of great interest to many disciplines in the natural sciences.
LST retrieval via remote-sensing (RS) methods can greatly improve the range of measurement and reduce the amount of work otherwise involved. Indeed, LST retrieval is a popular focus in current RS research. Spaceborne RS instruments that obtain high-precision LST data have been used in the field of quantitative RS research since the 1980s [
11]. At present, the RS data that are applied to LST retrieval are provided by several instruments including the Thematic Mapper/Enhanced Thematic Mapper (TM/ETM+), the Advanced Spaceborne Thermal Emission and reflection Radiometer (ASTER), the Moderate-ResOlution Imaging Spectroradiometer (MODIS), and the Advanced Very High Resolution Radiometer (AVHRR).
At the same time, the split-window algorithm (SWA) for retrieving LSTs from satellite thermal infrared RS data, the single-window algorithm/single-channel algorithm, and the temperature/emissivity separation algorithm have also been established [
12,
13,
14,
15]. However, most split-window algorithms are aimed at processing National Oceanic and Atmospheric Administration (NOAA) and AVHRR data, and a long time series of LST products is lacking. In addition, the coefficients of the split-window algorithm are mostly “local”, i.e., the algorithm coefficients depend on specific research areas and sensors. Therefore, our team members performed a large-scale radiation transmission simulation in which they fitted and tested more than 10 kinds of commonly used split-window algorithms. In their analysis, they selected nine split-window algorithms with high precision, low sensitivity and practicability, and built an integrated algorithm that used Bayesian weighted-model averaging (BMA) [
16].
Incorporating global LST retrieval with an integrated algorithm based on the BMA model often involves a large number of long time-scale RS data calculations. To perform these calculations, the interactive data language (IDL) code is used, and several components have been specifically developed in the IDL environment to visualize images (ENVI) by the Exelis Visual Information Solutions (VIS) corporation. The traditional stand-alone IDL program is not capable of such tasks [
17,
18], and as the amount of RS data increases, it is difficult to process the data quickly with IDL programs in stand-alone environments. Thus, Exelis VIS offers the ENVI services engine (ESE) to provide IDL and ENVI image-processing services on a cluster or cloud-computing environment [
19]. However, for real-world applications, an RS image-processing program usually contains one or more algorithms. If a parallel algorithm is implemented within the IDL program, it will take a lot of development time. Using ESE does save on development time, but commercial products are expensive and can be a financial burden. Fortunately, the emergence and application of different high-performance computing (HPC) technologies, e.g., the cluster-based parallel computing [
20,
21,
22,
23,
24], graphics processing unit (GPU) based computing [
25,
26,
27,
28,
29], and cloud computing [
30,
31,
32,
33,
34,
35,
36] etc., makes large-scale data processing possible, which can greatly improve processing efficiency.
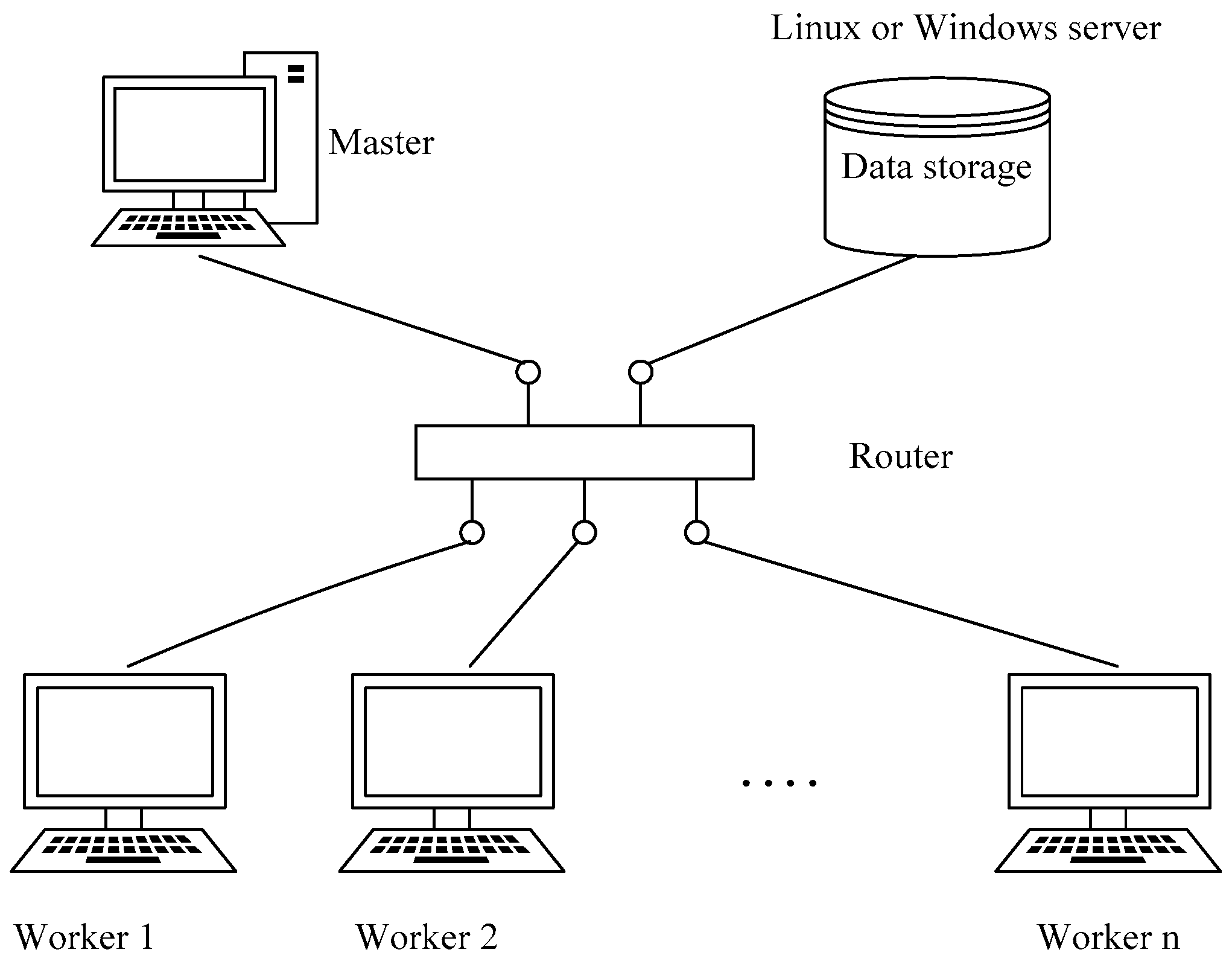
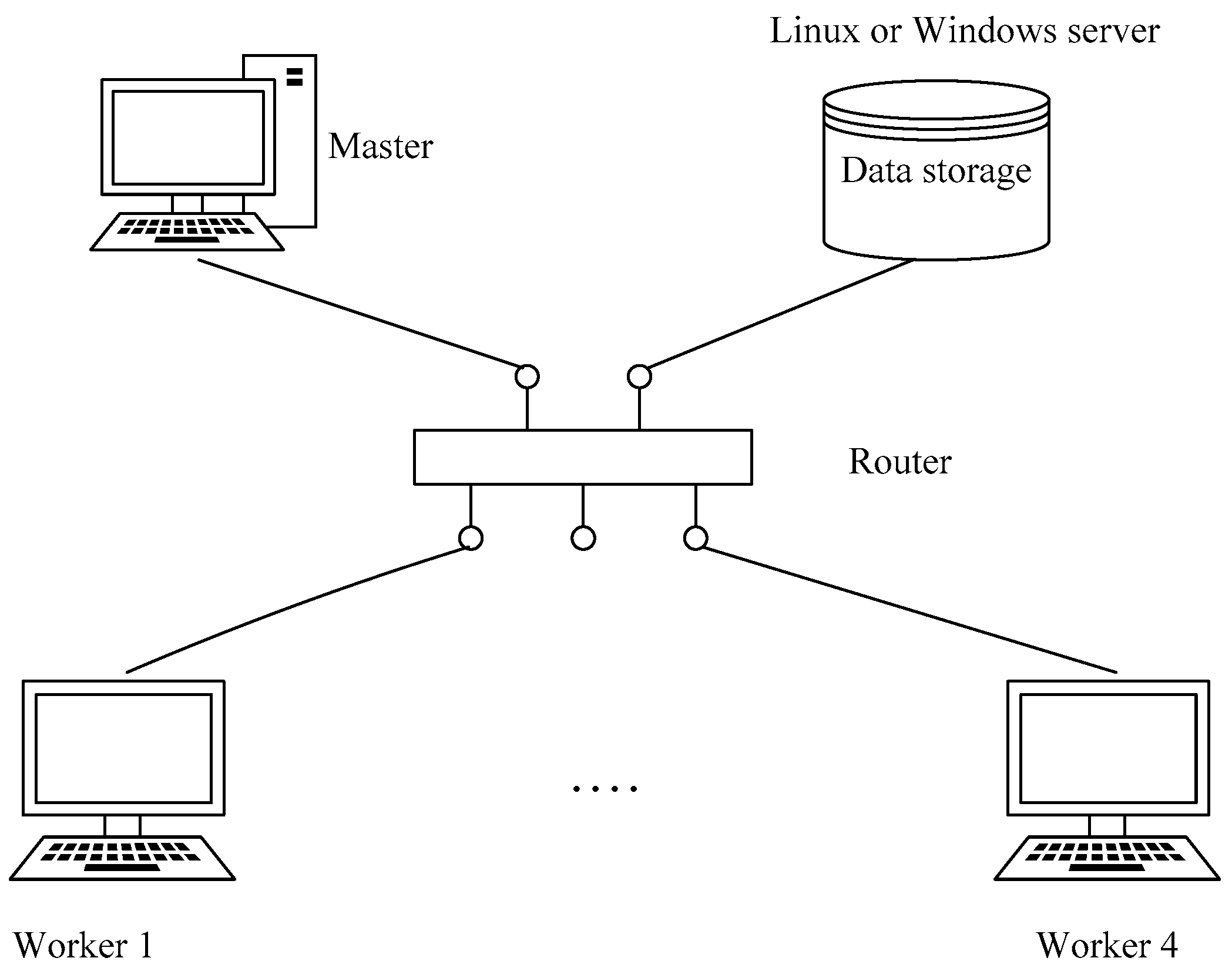
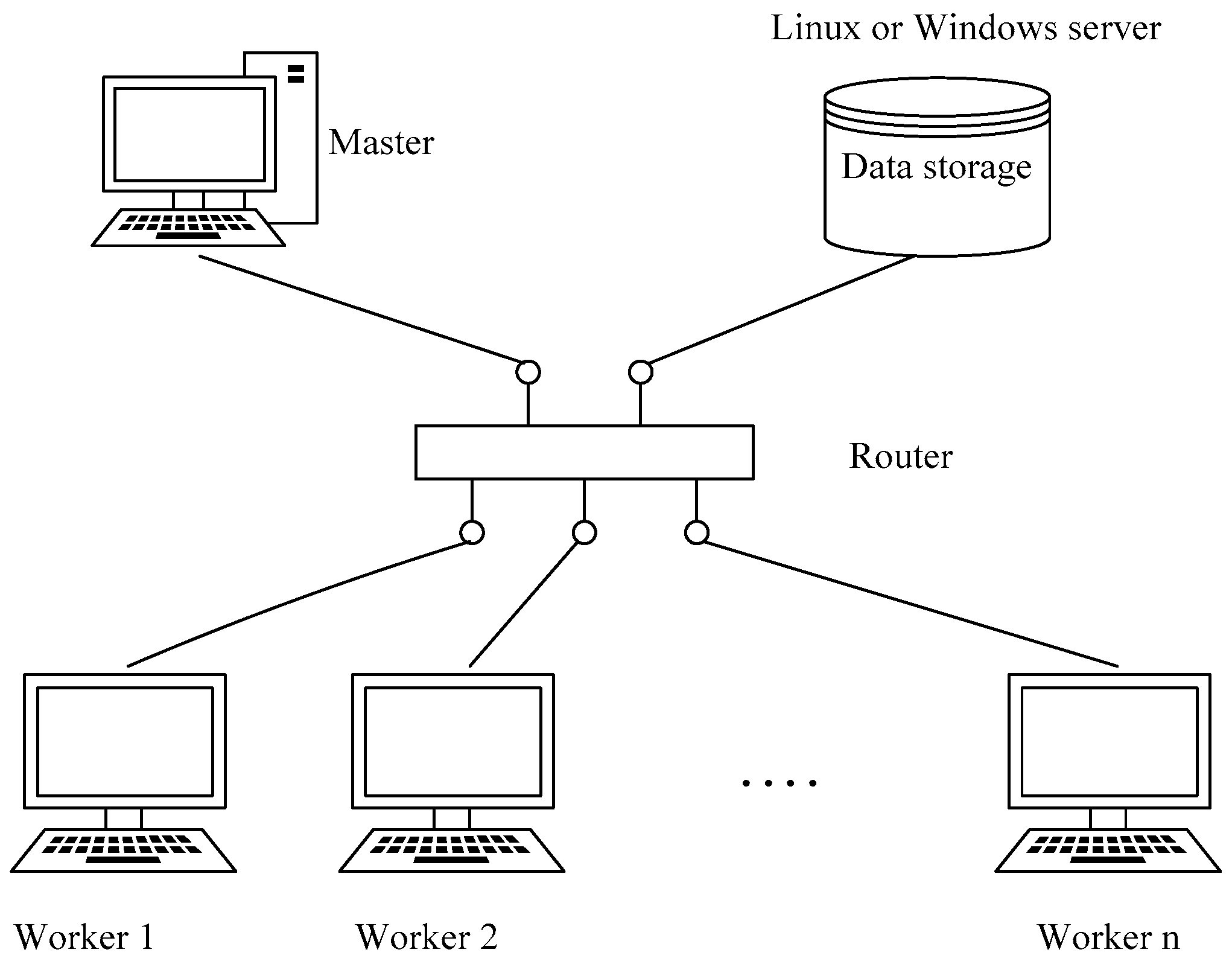
HPC systems are usually based on Linux. Existing LST-retrieval software needs to use IDL and other related, dependent environments. In upgraded versions of the IDL language environment, the latest version of ENVI is either unavailable or troublesome to deploy on Linux platforms. On the other hand, ENVI works well in the Windows operating system, and the widespread use of Windows makes it easier to build clusters of existing decentralized resources, which can save on costs and improve resource utilization.
There are a few existing studies that have used Windows-based clusters to develop their parallel algorithm or for parallel data processing. For example, Pan et al. used spare computers to form a “private cloud” in order to achieve a multi-computer parallel-computing framework for application in geophysical exploration [
37]. Zheng used a Windows-based Beowulf cluster and a message passing interface (MPI) to study the application of parallel computing to seismic-damage analysis with RS images [
38]. Moreover, Tie et al. applied parallel-computing technology and an MPI in a Windows cluster to batch process RS images, and proposed a simple parallel scheme for LST retrieval [
39]. Unfortunately, this investigation only proposed the basics of the parallel-processing method and there were still some unaddressed issues such as storage and performance bottlenecks and fault tolerances.
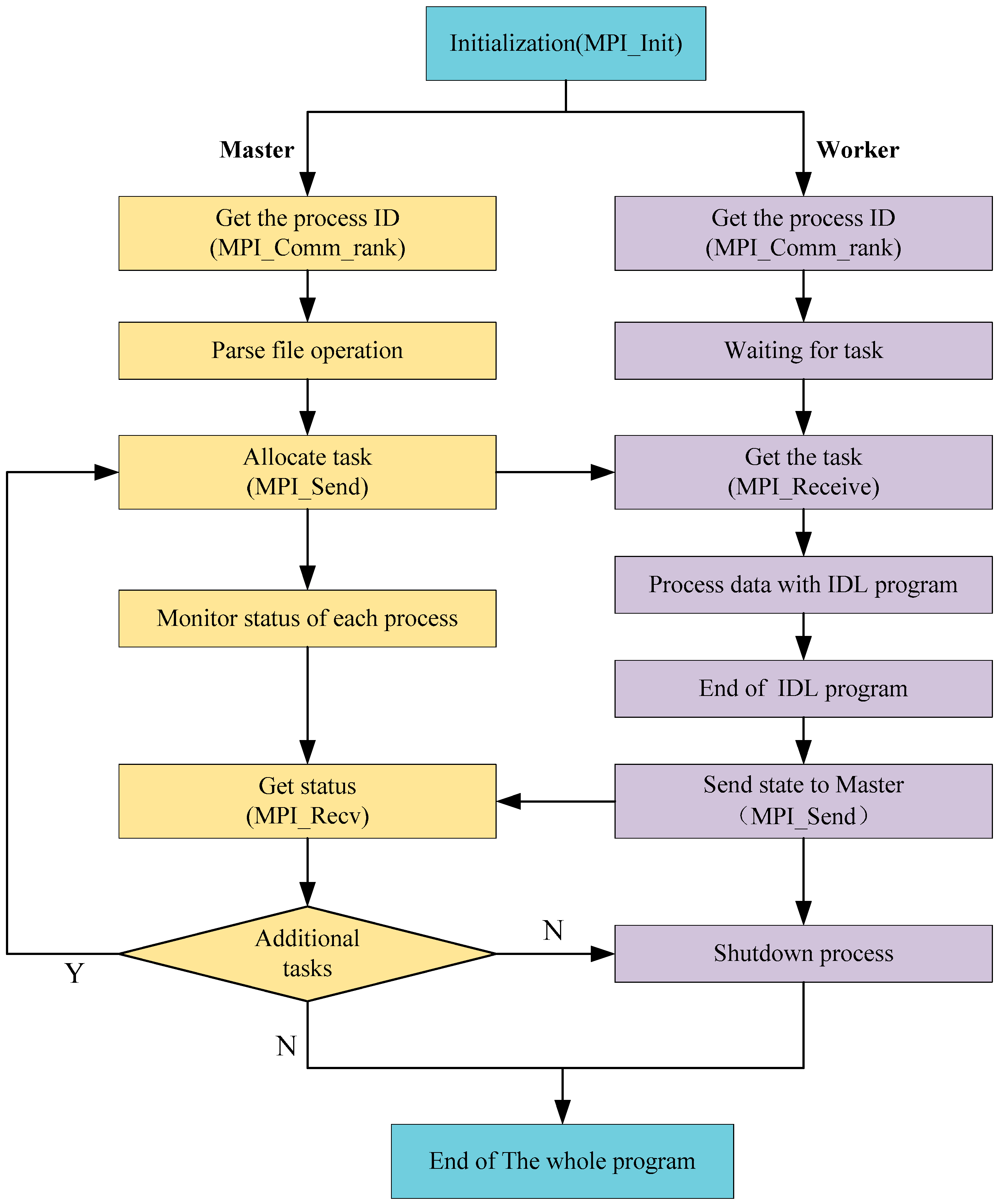
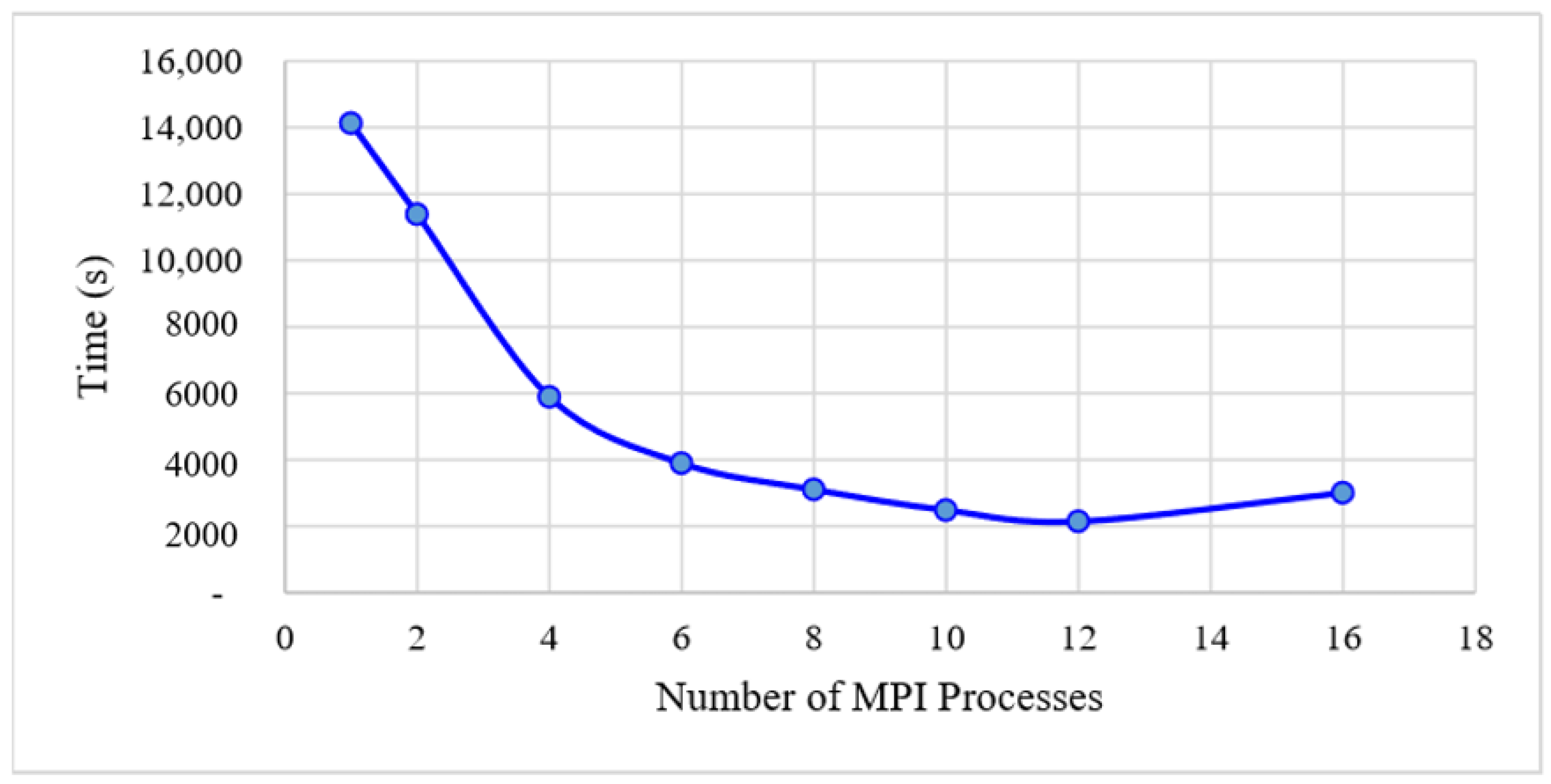
In summary, to meet the demands of LST retrieval from thermal infrared data, and improve the efficiency of the retrieval, our aim is to use MODIS time-series RS data for LST retrieval. We propose a parallel algorithm for LST retrieval at the process level using an MPI parallel-programming model, which enables us to perform high-performance LST retrieval in a distributed memory environment with the Windows operating system. Furthermore, our research aims to solve the aforementioned, unaddressed problems present in previous study.
In addition to the LST parameter in global environmental and climate change, there are some other surface-temperature (ST) parameters such as sea-surface temperature (SST), lake-surface temperature, etc. The large-scale retrieval of these ST parameters are also applied to the large time-series RS data considered here. Compared with the retrieval of LSTs, existing research on SST retrieval has been around for a few decades. In 1980, McMillin pioneered the split-window approach to calculate SSTs on the basis of the 4th and 5th channels of AVHRR [
40]. In 1985, McClain et al. proposed a single, linear multi-channel sea surface temperature method [
41]. In 1999, Kumar et al. proposed the Miami pathfinder algorithm for SST that is suitable for processing MODIS data [
42]. In 2004, Qin proposed a single-window method, specifically for the infrared channel of the TM6 satellite, which can also be applied to SST retrieval [
43]. In recent years, many scholars have also studied the various factors that influence the SST retrieval procedure [
44,
45].
Meanwhile, lake-surface temperatures are monitored by satellites and numerous related works have been published in recent years. For instance, Livingstone used an RS image-retrieval method to reveal the relationship between the temperature of a lake in Australia and the local climate over a period of 80 years [
46]. Pour et al. used MODIS images to retrieve the temperature of frozen Arctic lakes [
47]. Moreover, Woolway et al. showed the relevance of lake-surface temperatures in relation to LST retrieval as it can be used to compare with LSTs, which is common in climatology [
48]. Actually, all these algorithms have been improved and applied to lake-surface temperature retrieval based on LST or SST retrieval algorithms [
49]. However, the parameters of different types of minerals vary from region to region, and from lake to lake. Thus, the required parameters for modelling one type of environment are often incompatible for modelling similar environments in different areas. Therefore, how to select parameters that are more suitable, and hence make the lake-surface temperature retrieval more accurate, has been a difficult obstacle to overcome in these studies. As such, our designed approach that adopts HPC for global LST retrieval by using large-scale RS data processing will, hopefully, be beneficial to the field, and can be applied to these, and others, ST-retrieval applications.
2. Background and Experimental Data Issue
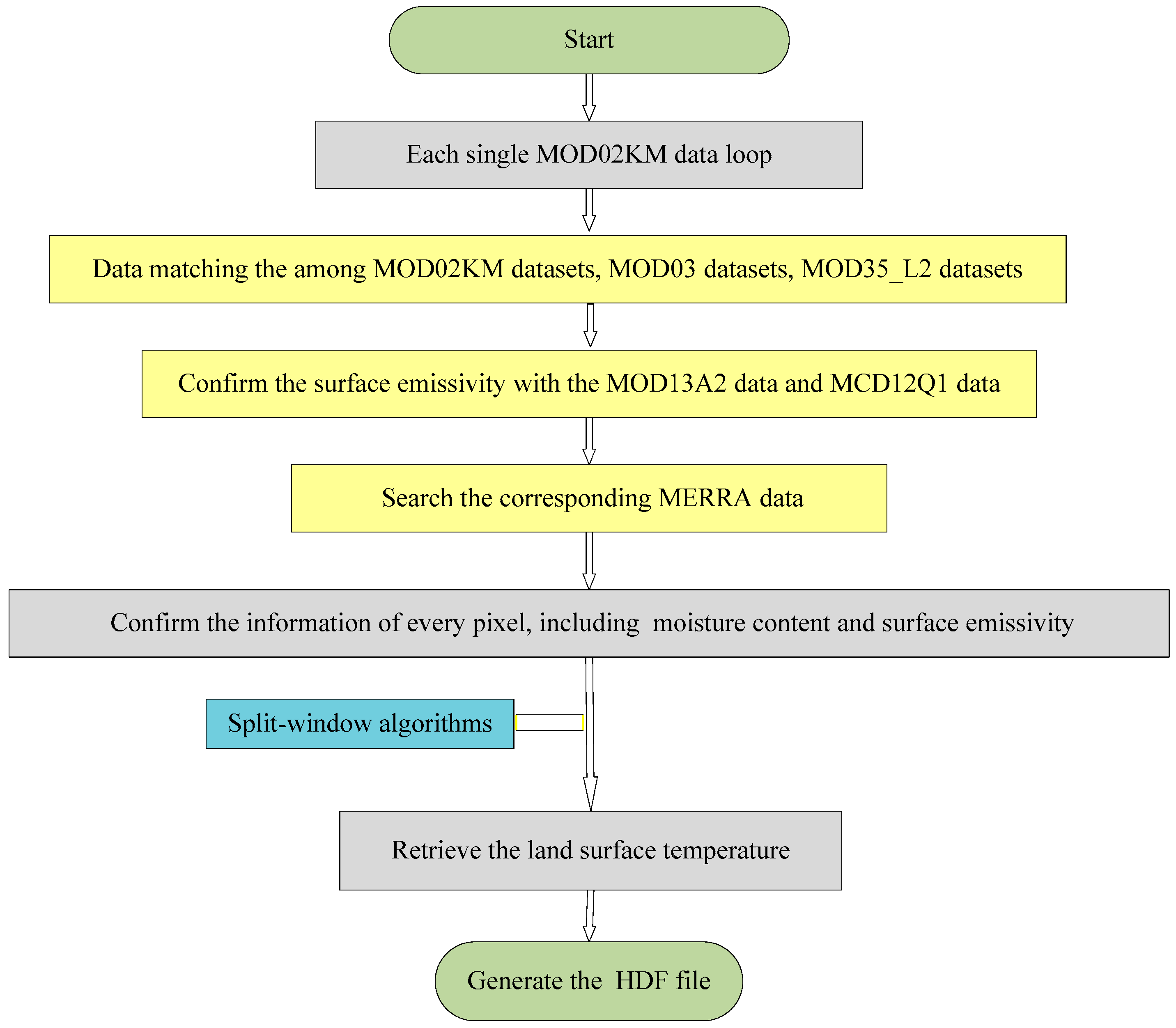
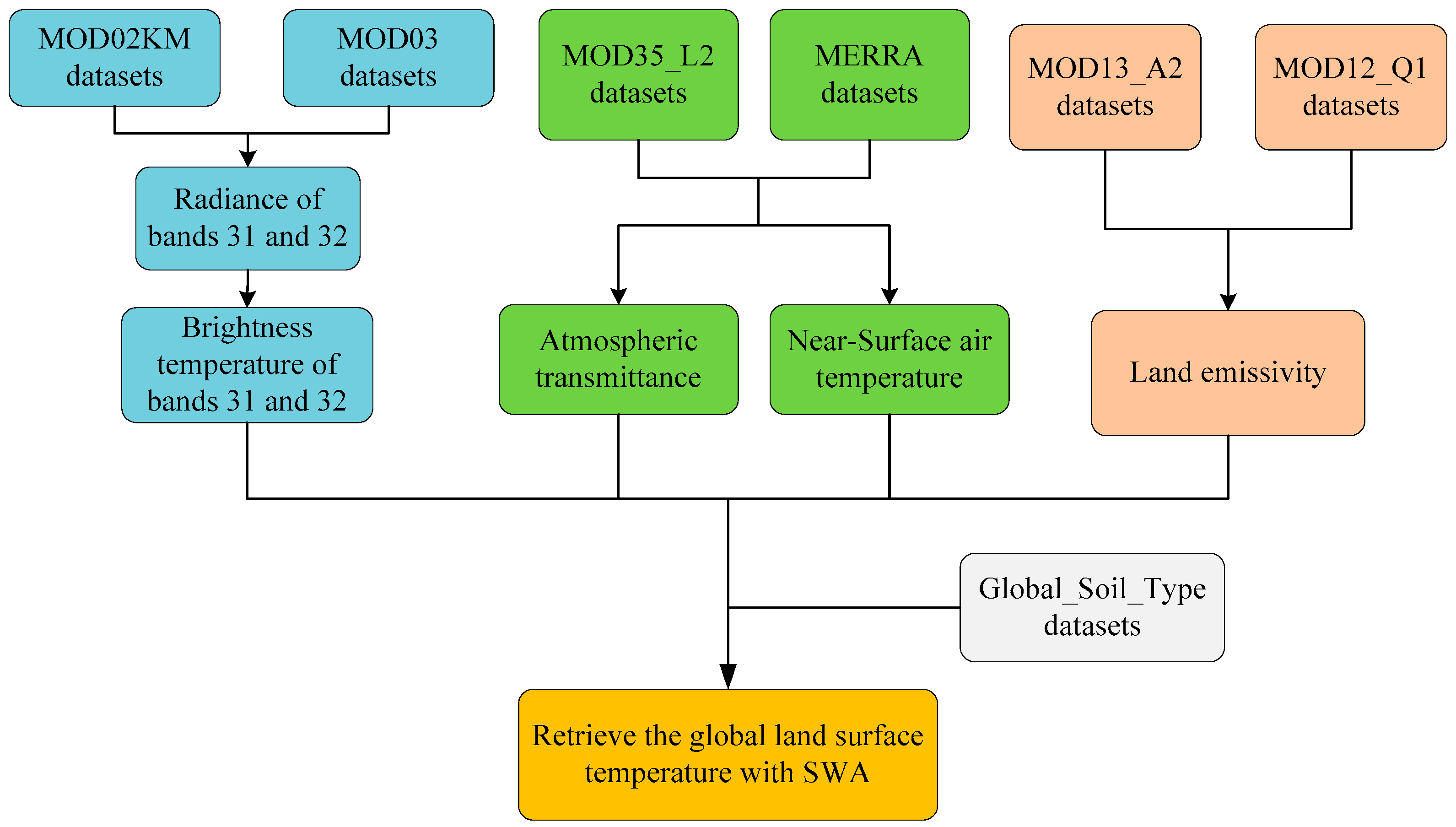
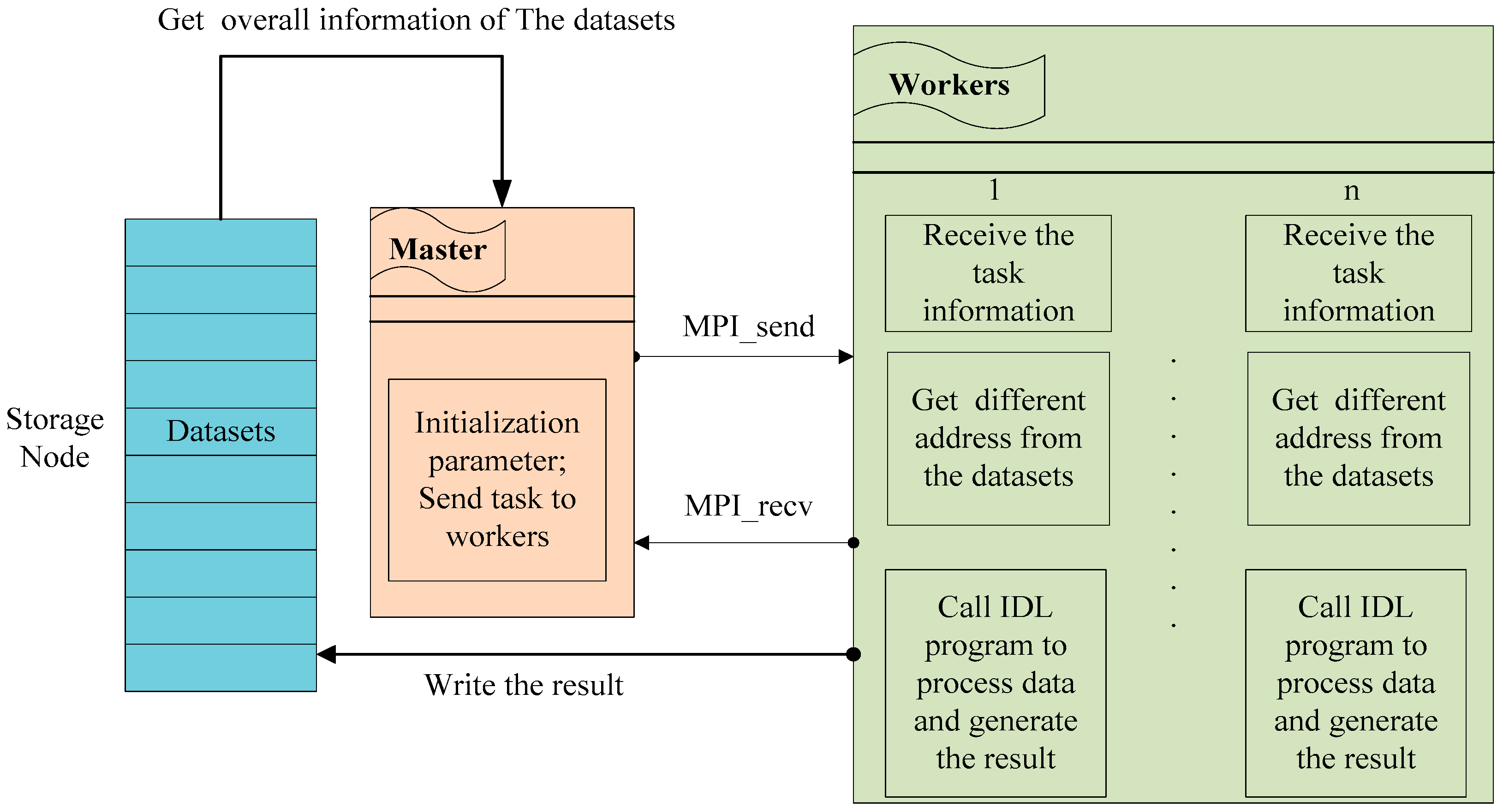
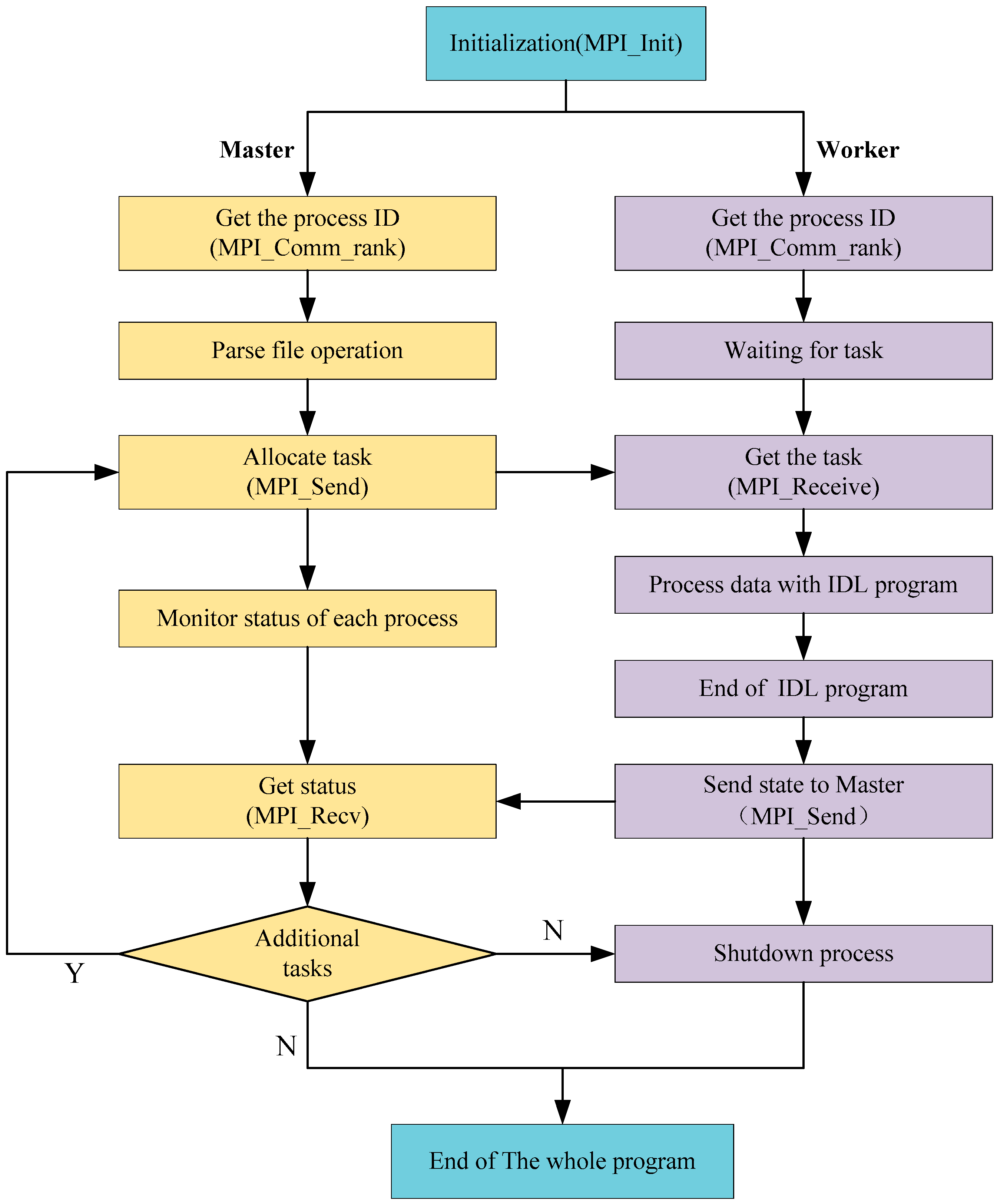
This work was supported by a National High-Technology Research and Development Program (863) entitled “Generation and application of global products of essential land variables of global ecological system and surface-energy balance”. The entire project aims to use multi-source RS data to produce global products that represent essential land variables, and which in turn can provide a database and technical support for researchers to make decisions about global change. Our results include: (1) the global products of essential land variables for 33 years (from 1982 to 2014), including the leaf-area index, emissivity, surface albedo, and photosynthetically active radiation; and (2) another eight products for four representative years (1983, 1993, 2003 and 2013), which involve shortwave radiation downstream of photosynthetically active radiation, LSTs, net long-wave radiation, net radiation (daytime), vegetation coverage, gross primary productivity, and latent heat [
24]. Within this big project, our work is mainly focused on creating a new and integrated LST-retrieval algorithm that is suitable for generating long time series of LST products based on RS data, because these products have extremely important practical value for climate-change modeling, surface radiation and regional/global energy balance. In our sub-project, we are required to generate day-to-day LST products for a total of four periods (the years 1983, 1993, 2003 and 2013). The spatial resolution of the data in the years 1983 and 1993 is 5 km, while the others (2003, 2013) are 1 km. To carry out the task, we took the following steps: (1) based on a large-scale radiation transmission simulation, we selected several LST-retrieval algorithms from the existing split-window algorithms. These selected algorithms have advantages such as high precision, low sensitivity on the initial values of the inputted parameters, and highly practicability; (2) then, we built an integrated algorithm with a BMA model, as the BMA method has several advantages related to the integration of surface long-wave radiation models [
50] and evapotranspiration model integration [
51].
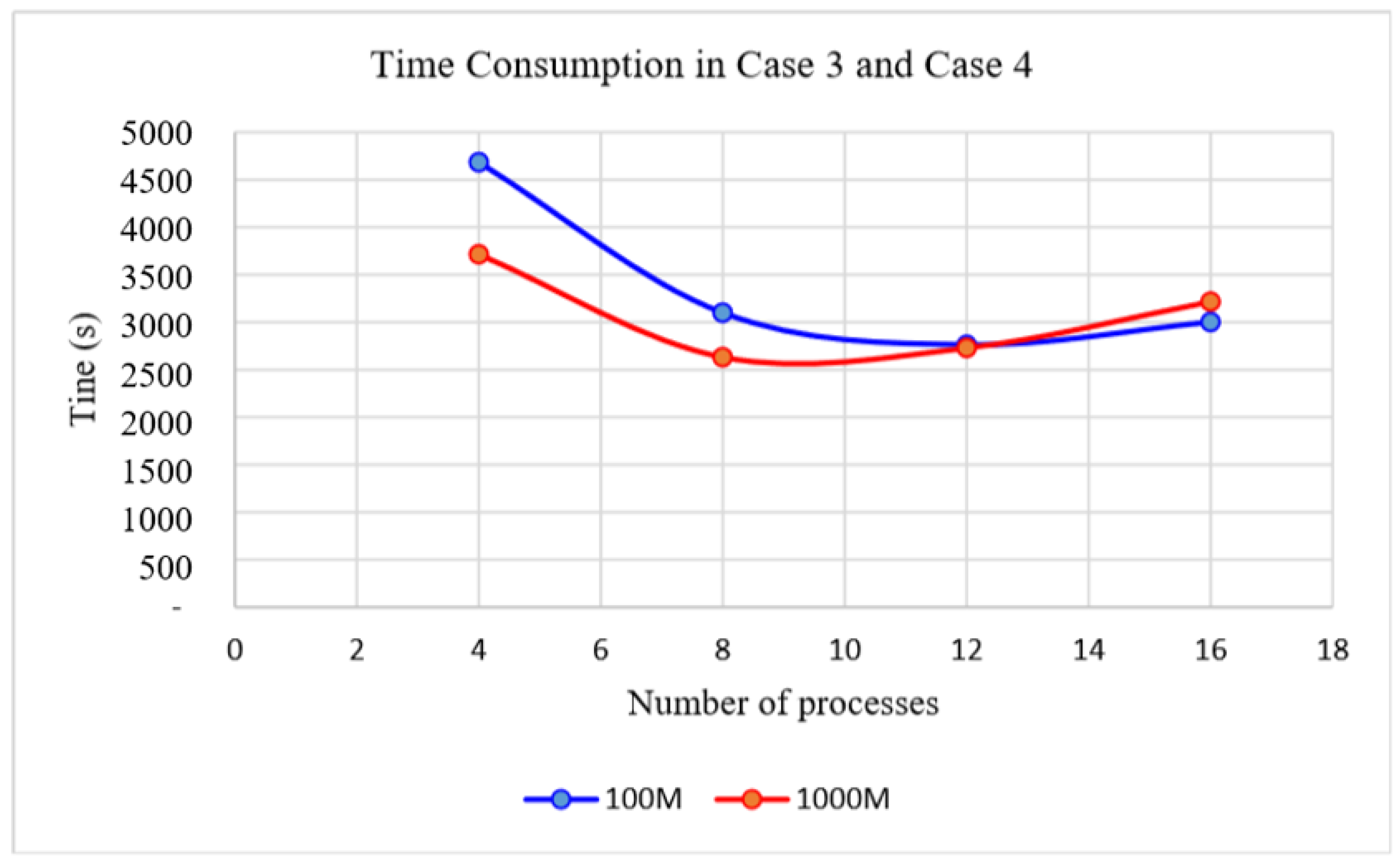
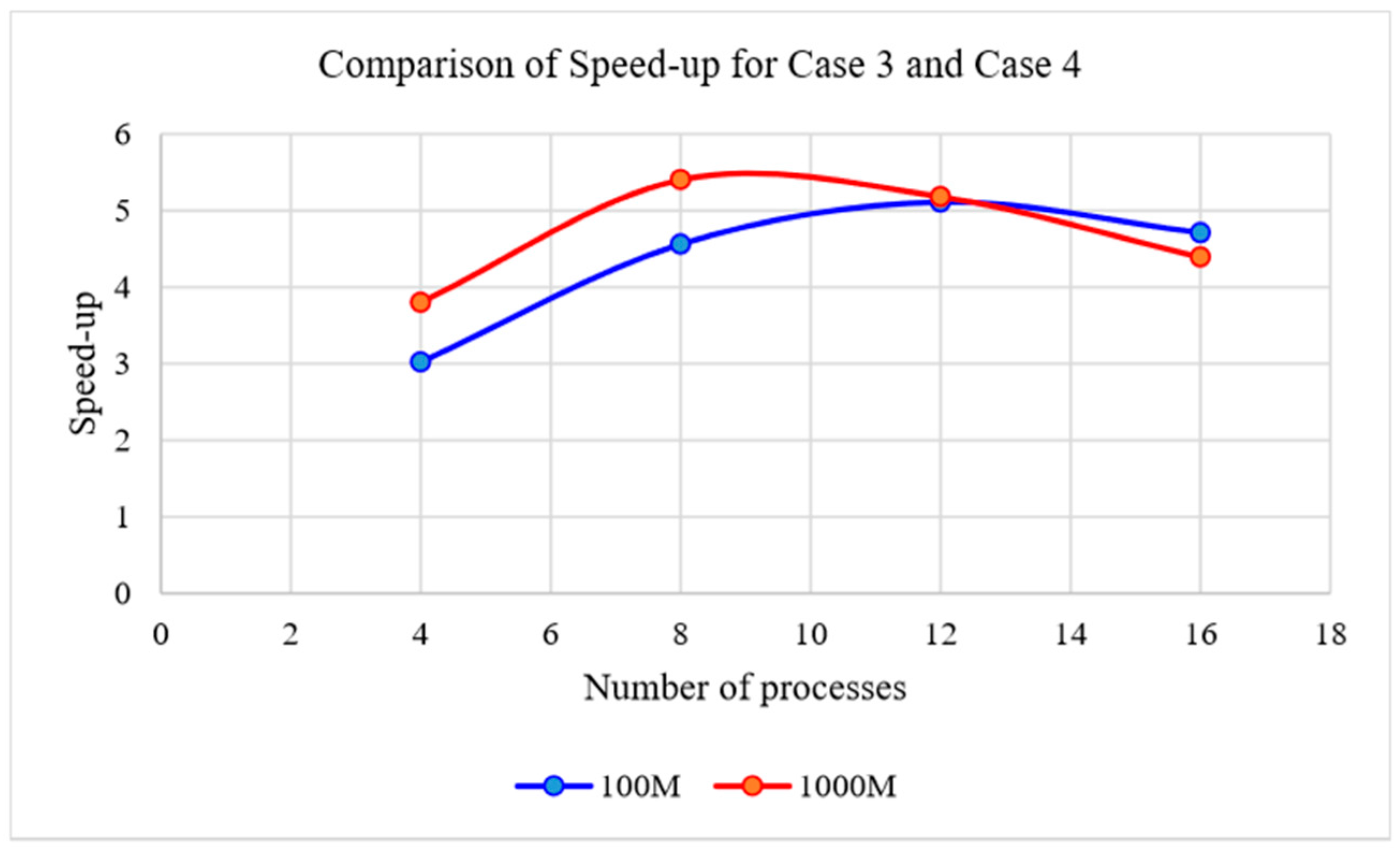
We note that, in the data-processing stage, we need to process four years’ worth of data, while there are ~10 scenes of data from each day. To verify the feasibility of our approach quickly, we needed to experiment with some part of the data in advance in order to obtain a complete and reliable flow for our proposed HPC method. In this study, we chose only one scene from a single day of data. Therefore, we used 64 days of data for the experiments. Because this paper focuses on verifying the feasibility of the method, and it is impractical to demonstrate using the entire project data in this paper, the experiment data investigated here is only a small part of the entire data collected by the whole project.





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}