Prediction of Coding Intricacy in a Software Engineering Team through Machine Learning to Ensure Cooperative Learning and Sustainable Education


Abstract
:1. Introduction
1.1. Research Questions
- (1)
- Can we predict the coding intricacy level efficiently among software teams working on the same software project?
- (2)
- Can cooperative learning and ESD be achieved by predicting the high coding intricacy level among teams?
2. Related Work
2.1. Difficulties in Learning Programming
2.2. Performance Prediction of Students in an E-Learning System
2.3. ML for Predicting Programming Learning
2.4. Potential Limitations in the Literature
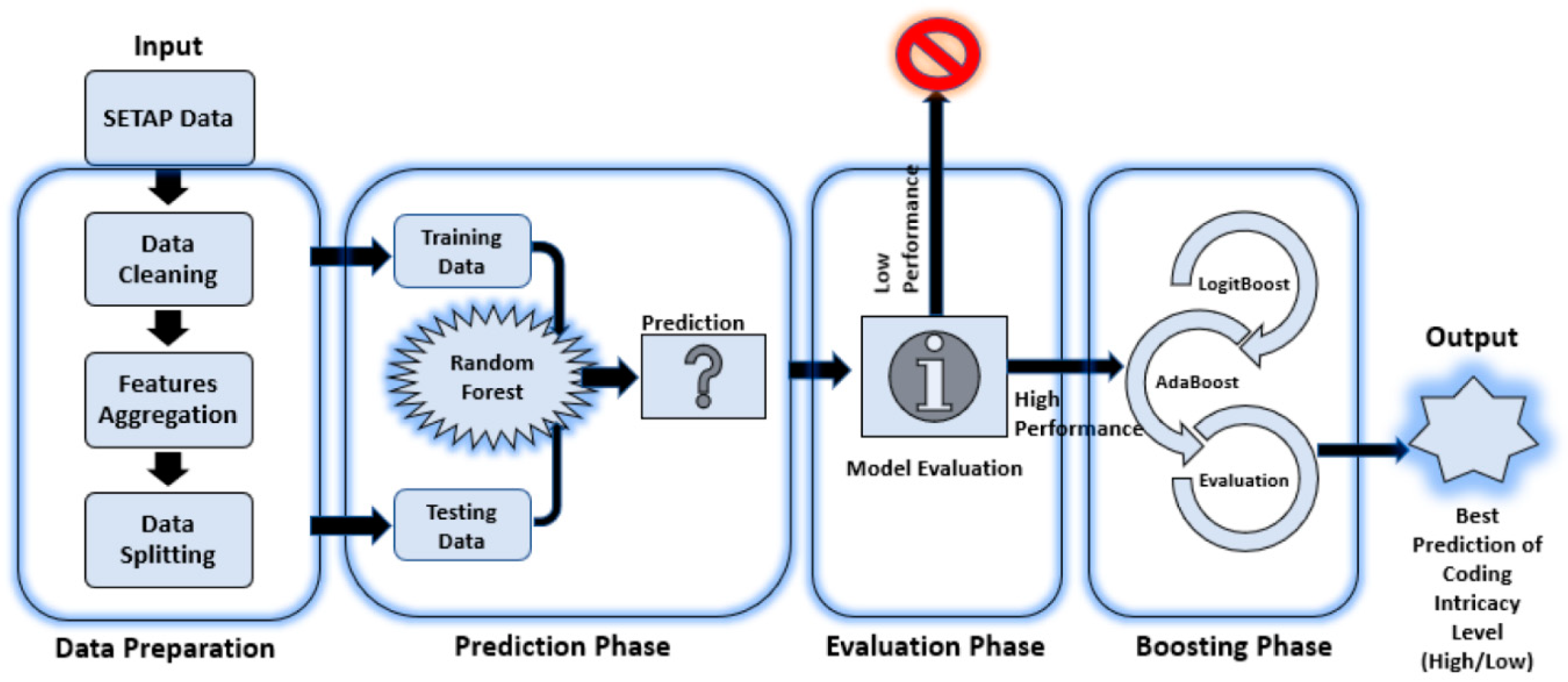
3. Materials and Methods
- (1)
- Data Preparation
- (2)
- Prediction Phase
- (3)
- Evaluation Phase
- (4)
- Boosting Phase
3.1. Data Preparation
3.1.1. Data Cleaning
3.1.2. Features Aggregation
3.1.3. Data Splitting
3.2. Prediction Phase
3.3. Evaluation Phase
3.4. Boosting Phase
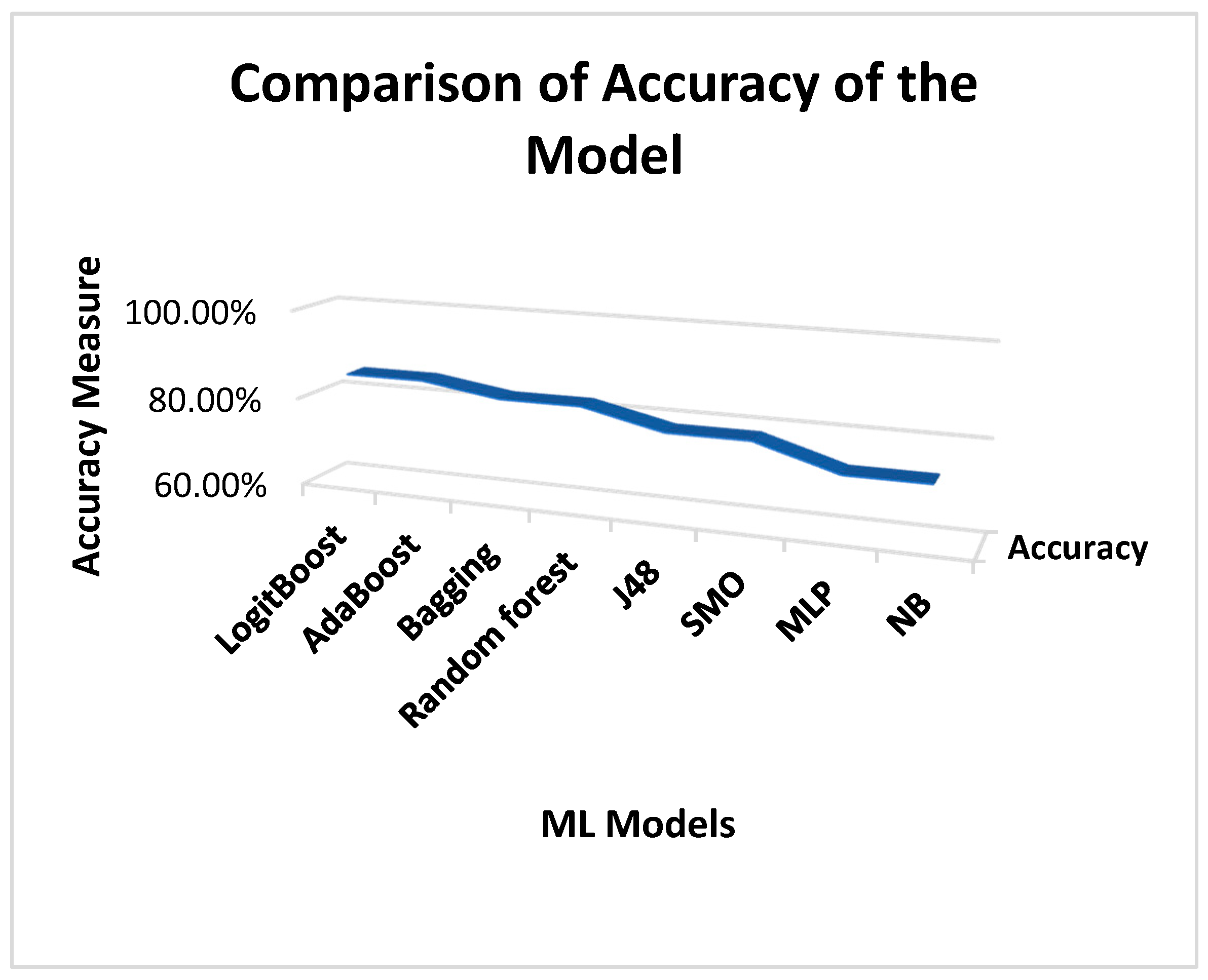
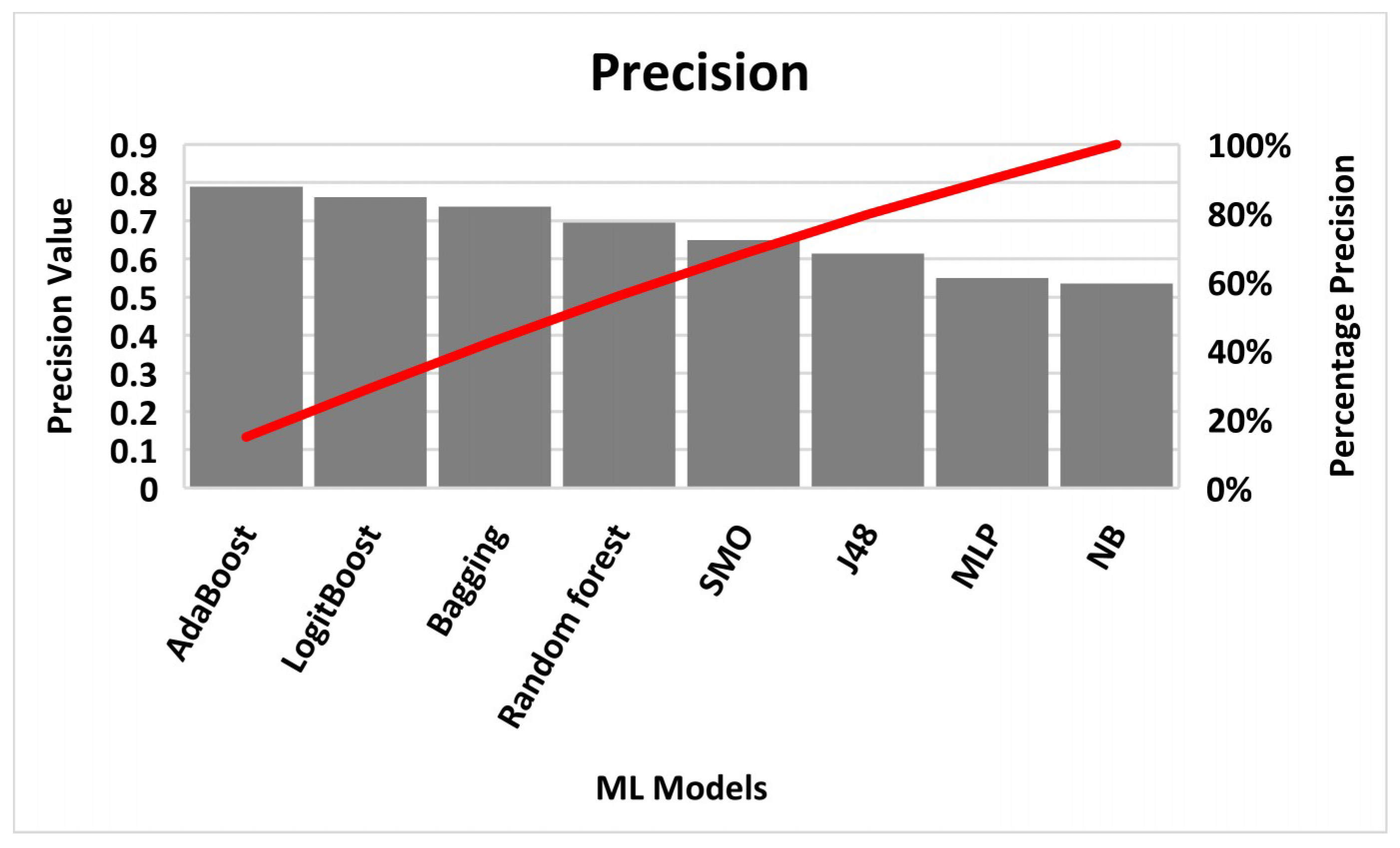
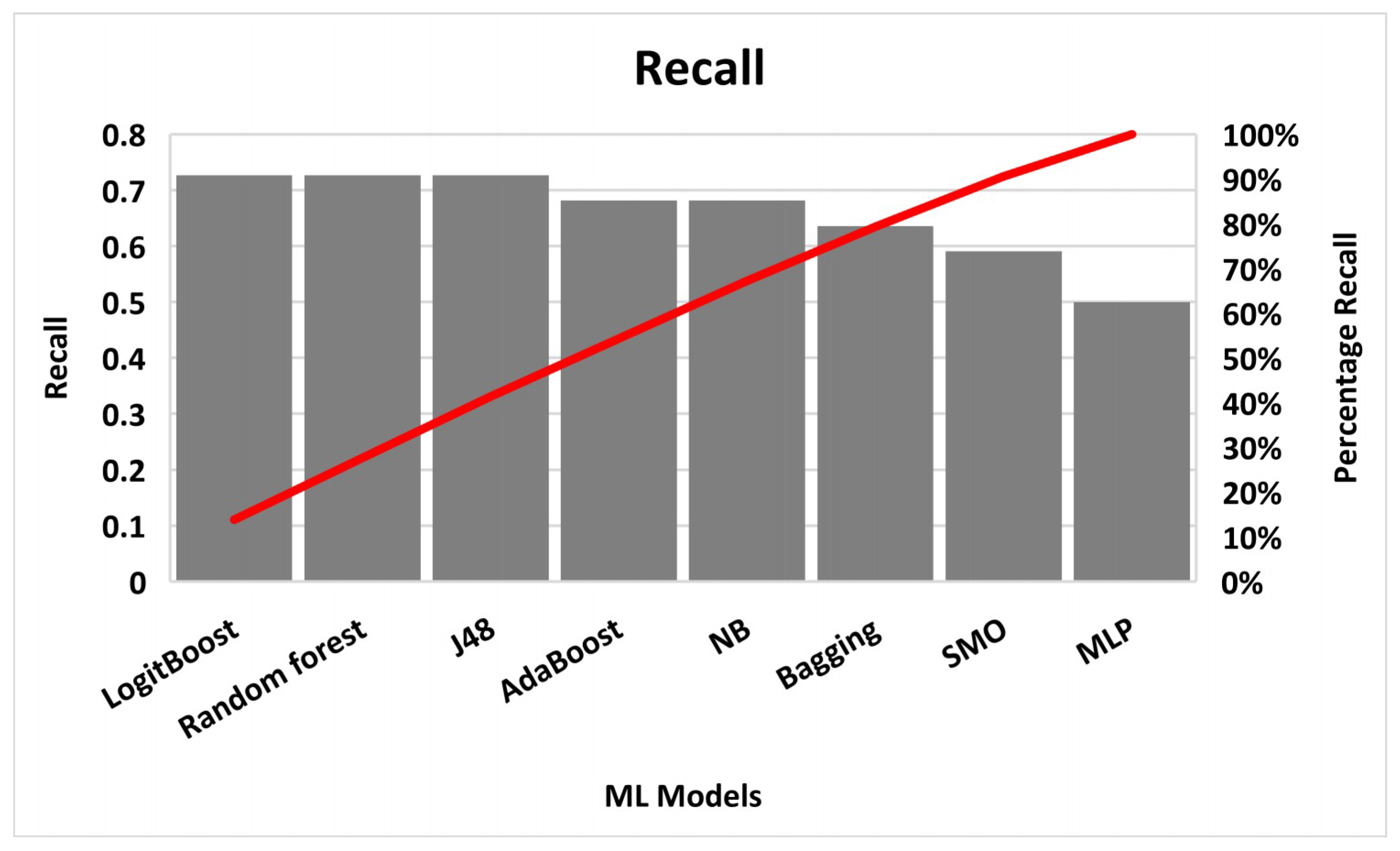
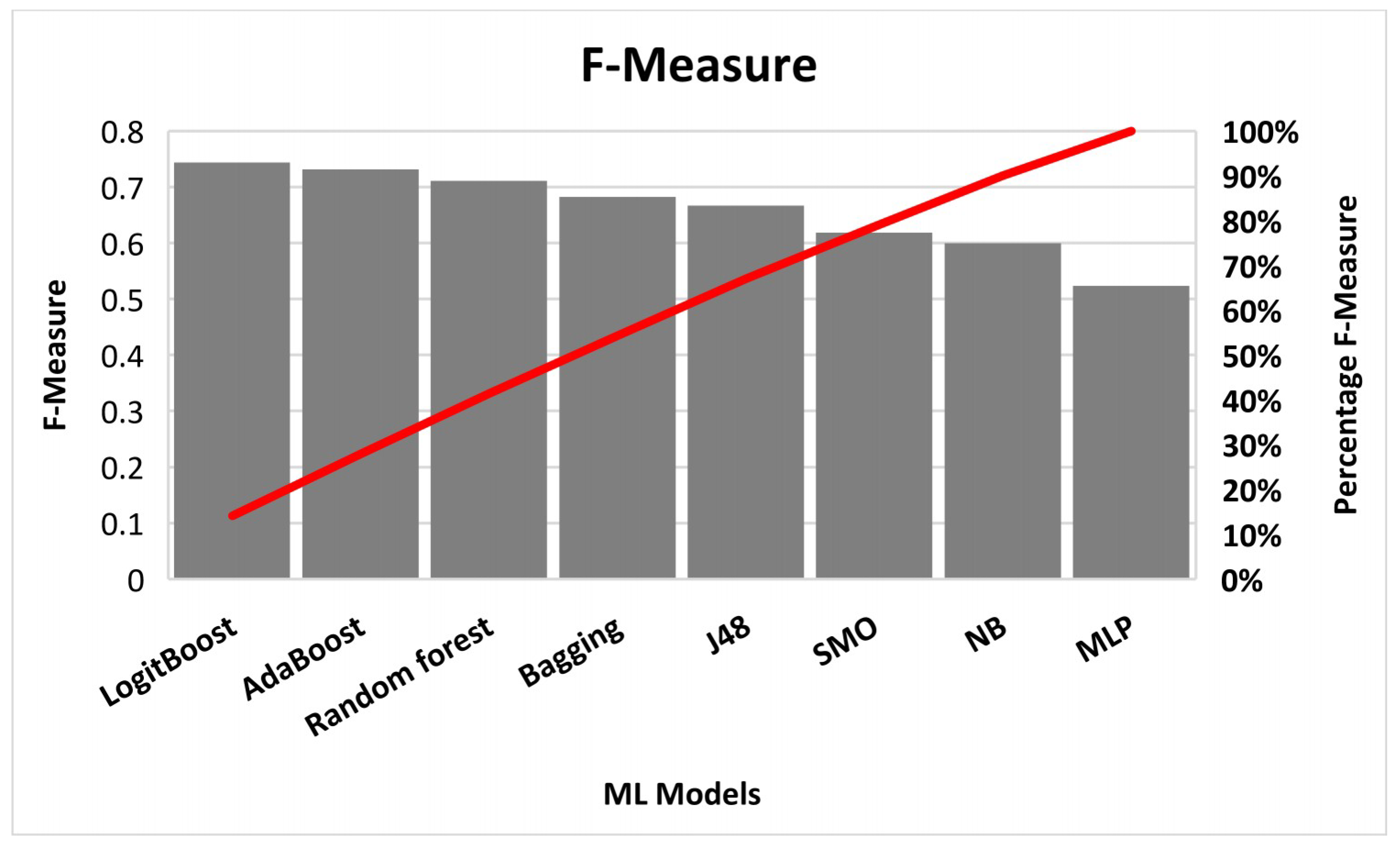
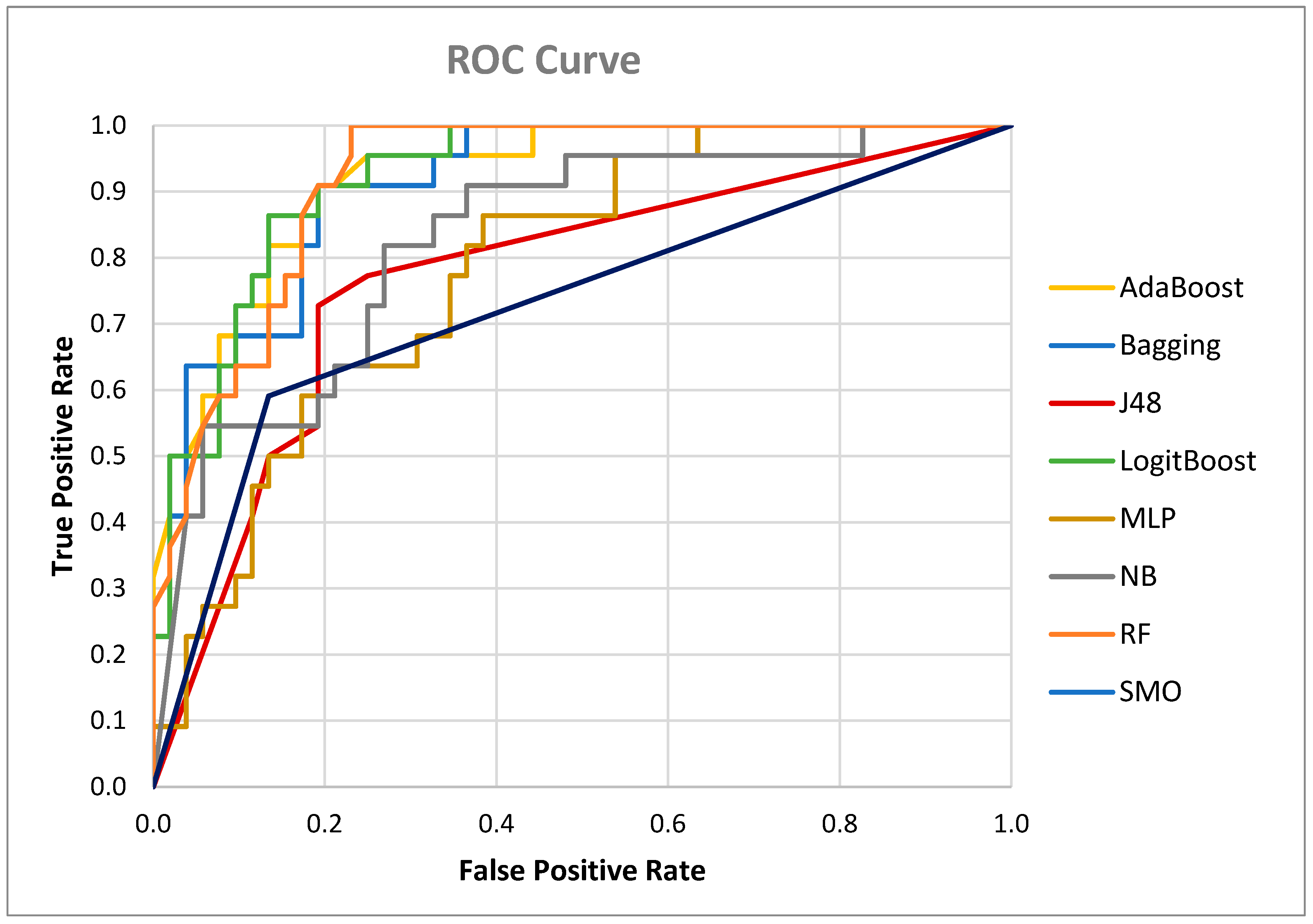
4. Results
5. Discussion
- (1)
- Can we predict the coding intricacy level efficiently among software teams working on the same software project in a term?Yes, through the proposed approach of boosting of an RF model, coding intricacy levels of different teams working on the same project in a term can be predicted. Results of the proposed approach verdict its efficiency by thoroughly comparing it with other effective approaches of ML. Through the proposed strategy, 85.14% accuracy was achieved.
- (2)
- Can cooperative learning and ESD goals be achieved by predicting the coding intricacy level among teams?Yes, predictions about students can help as a second eye for the instructors to perceive the apprehensions of the students. Predicting the coding intricacy level of software engineering teams is an aid for assisting the instructors in determining the students’ concerns, which otherwise could be very difficult. Student–instructor healthy discussions and support sessions can help resolve the issues that are leading to high coding intricacy. Peer support and guidance can help address issues of high intricacy level. Thus, the prediction of coding intricacy levels is directly influencing the learning space. It would be a great source for producing a cooperative learning environment [55]. This will eventually lead towards the accomplishment of the goals of ESD by optimizing the educational environment.
6. Conclusions and Future Work
Author Contributions
Funding
Conflicts of Interest
References
- United Nations. Sustainable Development Goals. Available online: http://www.undp.org/content/undp/en/home/sustainable-development-goals.html (accessed on 15 September 2020).
- UNESCO Roadmap for Implementing the Global Action Programme on Education for Sustainable Development. Available online: https://unesdoc.unesco.org/ark:/48223/pf0000230514 (accessed on 15 September 2020).
- Ricardo, V.; Azizpour, H.; Leite, I.; Balaam, M.; Dignum, V.; Domisch, S.; Felländer, A.; Max, L.; Tegmark, S.D.; Nerini, F.F. The role of artificial intelligence in achieving the Sustainable Development Goals. Nat. Commun. 2020, 11, 1–10. [Google Scholar]
- Laurence, H.; Johannesen, M. The role of academic management in implementing technology-enhanced learning in higher education. Technol. Pedagog. Educ. 2020, 29, 129–146. [Google Scholar]
- Chien-wen, S.; Ho, J.-T. Technology-enhanced learning in higher education: A bibliometric analysis with latent semantic approach. Comput. Hum. Behav. 2020, 104, 106177. [Google Scholar]
- Denner, J.; Werner, L.; Ortiz, E. Computer games created by middle school girls: Can they be used to measure understanding of computer science concepts? Comput. Educ. 2012, 58, 240–249. [Google Scholar] [CrossRef]
- Miikka, K.; Mäntylä, M.; Farooq, U.; Claes, M. Time pressure in software engineering: A systematic review. Inf. Softw. Technol. 2020, 121, 106257. [Google Scholar]
- Lior, F.; Pinchovski, B. It is about time: Bias and its mitigation in time-saving decisions in software development projects. Int. J. Proj. Manag. 2020, 38, 99–111. [Google Scholar]
- Cristobal, R.; Ventura, S. Educational data mining and learning analytics: An updated survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2020, 10, e1355. [Google Scholar]
- Sung-Shun, W.; Liu, Y.; Dai, J.; Chuang, Y.-C. A Novel Improvement Strategy of Competency for Education for Sustainable Development (ESD) of University Teachers Based on Data Mining. Sustainability 2020, 12, 2679. [Google Scholar]
- Mehwish, N.; Zhang, W.; Zhu, W. Early Prediction of a Team Performance in the Initial Assessment Phases of a Software Project for Sustainable Software Engineering Education. Sustainability 2020, 12, 4663. [Google Scholar]
- Ibtissam, A.; Jeghal, A.; Radouane, A.; Yahyaouy, A.; Tairi, H. A robust classification to predict learning styles in adaptive e-learning systems. Educ. Inf. Technol. 2020, 25, 437–448. [Google Scholar]
- Khe Foon, H.; Hu, X.; Qiao, C.; Tang, Y. What predicts student satisfaction with MOOCs: A gradient boosting trees supervised machine learning and sentiment analysis approach. Comput. Educ. 2020, 145, 103724. [Google Scholar]
- Eyal, R.; Henderikx, M.; Yoram, K.; Kalz, M. What are the barriers to learners’ satisfaction in MOOCs and what predicts them? The role of age, intention, self-regulation, self-efficacy and motivation. Australas. J. Educ. Technol. 2020, 36, 119–131. [Google Scholar]
- Abdessamad, C.; Faddouli, N.-E.E. BERT and Prerequisite Based Ontology for Predicting Learner’s Confusion in MOOCs Discussion Forums. In International Conference on Artificial Intelligence in Education; Springer: Berlin/Heidelberg, Germany, 2020; pp. 54–58. [Google Scholar]
- Mubarak, A.A.; Cao, H.; Ahmed, S.A. Predictive learning analytics using deep learning model in MOOCs’ courses videos. Educ. Inf. Technol. 2020. [Google Scholar] [CrossRef]
- Moreno-Marcos, P.M.; Muñoz-Merino, P.J.; Maldonado-Mahauad, J.; Pérez-Sanagustín, M.; Alario-Hoyos, C.; Kloos, C.D. Temporal analysis for dropout prediction using self-regulated learning strategies in self-paced MOOCs. Comput. Educ. 2020, 145, 103728. [Google Scholar] [CrossRef]
- Ya, Z.; Xu, Z. Multi-Model Stacking Ensemble Learning for Dropout Prediction in MOOCs. J. Phys. Conf. Ser. 2020, 1607, 012004. [Google Scholar]
- Ruth, C.; Ruiz-Garcia, J.C. Improving learner engagement in MOOCs using a learning intervention system: A research study in engineering education. Comput. Appl. Eng. Educ. 2020. [Google Scholar] [CrossRef]
- Min, L.; Hew, K.F. Examining learning engagement in MOOCs: A self-determination theoretical perspective using mixed method. Int. J. Educ. Technol. High. Educ. 2020, 17, 1–24. [Google Scholar]
- Yongqiang, S.; Guo, Y.; Zhao, Y. Understanding the determinants of learner engagement in MOOCs: An adaptive structuration perspective. Comput. Educ. 2020, 157, 103963. [Google Scholar]
- Ruiqi, D.; Benckendorff, P.; Gannaway, D. Learner engagement in MOOCs: Scale development and validation. Br. J. Educ. Technol. 2020, 51, 245–262. [Google Scholar]
- UCISETAP Database at UC Irvine Machine Learning Archive. Available online: https://archive.ics.uci.edu/ml/datasets/Data+for+Software+Engineering+Teamwork+Assessment+in+Education+Setting (accessed on 18 July 2020).
- Durak, H.Y. The effects of using different tools in programming teaching of secondary school students on engagement, computational thinking and reflective thinking skills for problem solving. Technol. Knowl. Learn. 2020, 25, 179–195. [Google Scholar] [CrossRef]
- Pérez, B.; Rubio Á, L. A project-based learning approach for enhancing learning skills and motivation in software engineering. In Proceedings of the 51st ACM Technical Symposium on Computer Science Education, Portland, OR, USA, 11–14 March 2020; pp. 309–315. [Google Scholar]
- Türker, P.M.; Pala, F.K. The Effect of Algorithm Education on Students’ Computer Programming Self-Efficacy Perceptions and Computational Thinking Skills. Int. J. Comput. Sci. Educ. Sch. 2020, 3, 19–32. [Google Scholar]
- Aissa, M.; Al-Kalbani, M.; Al-Hatali, S.; BinTouq, A. Novice Learning Programming Languages in Omani Higher Education Institution (Nizwa University) Issues, Challenges and Solutions. In Sustainable Development and Social Responsibility; Springer: Berlin/Heidelberg, Germany, 2020; Volume 2, pp. 143–148. [Google Scholar]
- Albluwi, I.; Salter, J. Using static analysis tools for analyzing student behavior in an introductory programming course. Jordanian J. Comput. Inf. Technol. 2020. [Google Scholar] [CrossRef]
- Mozahem, N.A. Using Learning Management System Activity Data to Predict Student Performance in Face-to-Face Courses. Int. J. Mob. Blended Learn. 2020, 12, 20–31. [Google Scholar] [CrossRef]
- Xu, B.; Yan, S.; Jiang, X.; Feng, S. SCFH: A Student Analysis Model to Identify Students’ Programming Levels in Online Judge Systems. Symmetry 2020, 12, 601. [Google Scholar] [CrossRef]
- Hooshyar, D.; Pedaste, M.; Yang, Y. Mining Educational Data to Predict Students’ Performance through Procrastination Behavior. Entropy 2020, 22, 12. [Google Scholar] [CrossRef] [Green Version]
- Rastrollo-Guerrero, J.L.; Gómez-Pulido, J.A.; Durán-Domínguez, A. Analyzing and Predicting Students’ Performance by Means of Machine Learning: A Review. Appl. Sci. 2020, 10, 1042. [Google Scholar] [CrossRef] [Green Version]
- Yaacob, W.W.; Sobri, N.M.; Nasir, S.M.; Norshahidi, N.D.; Husin, W.W. Predicting Student Drop-Out in Higher Institution Using Data Mining Techniques. J. Phys. Conf. Ser. 2020, 1496, 012005. [Google Scholar] [CrossRef]
- Ninrutsirikun, U.; Imai, H.; Watanapa, B.; Arpnikanondt, C. Principal Component Clustered Factors for Determining Study Performance in Computer Programming Class. Wirel. Pers. Commun. 2020. [Google Scholar] [CrossRef]
- Lin, P.H.; Chen, S.Y. Design and Evaluation of a Deep Learning Recommendation Based Augmented Reality System for Teaching Programming and Computational Thinking. IEEE Access 2020, 8, 45689–45699. [Google Scholar] [CrossRef]
- Trevizan, B.; Chamby-Diaz, J.; Bazzan, A.L.; Recamonde-Mendoza, M. A comparative evaluation of aggregation methods for machine learning over vertically partitioned data. Expert Syst. Appl. 2020. [Google Scholar] [CrossRef]
- Tadayoshi, F. Estimation of prediction error by using K-fold cross-validation. Stat. Comput. 2011, 21, 137–146. [Google Scholar]
- Oshiro, T.M.; Perez, P.S.; Baranauskas, J.A. How many trees in a random forest? In International Workshop on Machine Learning and Data Mining in Pattern Recognition; Springer: Berlin/Heidelberg, Germany, 2012; pp. 154–168. [Google Scholar]
- Skurichina, M.; Duin, R.P. Bagging, boosting and the random subspace method for linear classifiers. Pattern Anal. Appl. 2002, 5, 121–135. [Google Scholar] [CrossRef]
- Bhargava, N.; Sharma, G.; Bhargava, R.; Mathuria, M. Decision tree analysis on j48 algorithm for data mining. Proc. Int. J. Adv. Res. Comput. Sci. Softw. Eng. 2013, 3, 1114–1119. [Google Scholar]
- Shevade, S.K.; Keerthi, S.S.; Bhattacharyya, C.; Murthy, K.R.K. Improvements to the SMO algorithm for SVM regression. IEEE Trans. Neural Netw. 2000, 11, 1188–1193. [Google Scholar] [CrossRef] [Green Version]
- Wu, Z.; Pan, S.; Chen, F.; Long, G.; Zhang, C.; Philip, S.Y. A comprehensive survey on graph neural networks. IEEE Trans. Neural Netw. Learn. Syst. 2020. [Google Scholar] [CrossRef] [Green Version]
- Sen, P.C.; Hajra, M.; Ghosh, M. Supervised classification algorithms in machine learning: A survey and review. In Emerging Technology in Modelling and Graphics; Springer: Berlin/Heidelberg, Germany, 2020; pp. 99–111. [Google Scholar]
- Fawcett, T. An introduction to ROC analysis. Pattern Recognit. Lett. 2006, 27, 861–874. [Google Scholar] [CrossRef]
- Viera, A.J.; Joanne, M.G. Understanding interobserver agreement: The kappa statistic. Fam. Med. 2005, 37, 360–363. [Google Scholar]
- Sagi, O.; Rokach, L. Ensemble learning: A survey. Wiley Interdiscip. Rev. Data Min. Knowl. Discov. 2018, 8, e1249. [Google Scholar] [CrossRef]
- Ying, C.; Qi-Guang, M.; Jia-Chen, L.; Lin, G. Advance and prospects of AdaBoost algorithm. Acta Autom. Sin. 2013, 39, 745–758. [Google Scholar]
- Pham, B.T.; Prakash, I. Evaluation and comparison of LogitBoost Ensemble, Fisher’s Linear Discriminant Analysis, logistic regression and support vector machines methods for landslide susceptibility mapping. Geocarto Int. 2019, 34, 316–333. [Google Scholar] [CrossRef]
- Stevenson, W.J. Supercharging your Pareto analysis. Qual. Prog. 2000, 33, 51. [Google Scholar]
- Moreno-Marcos, P.M.; Pong, T.C.; Muñoz-Merino, P.J.; Kloos, C.D. Analysis of the factors influencing learners’ performance prediction with learning analytics. IEEE Access 2020, 8, 5264–5282. [Google Scholar] [CrossRef]
- Rajabalee, B.Y.; Santally, M.I.; Rennie, F. A study of the relationship between students’ engagement and their academic performances in an eLearning environment. E-Learn. Digit. Media 2020, 17, 1–20. [Google Scholar] [CrossRef]
- Jacobs, G.M.; Ivone, F.M. Infusing Cooperative Learning in Distance Education. TESL-EJ 2020, 24, 1. [Google Scholar]
- Pigozzi, M.J. Quality in education defines ESD. J. Educ. Sustain. Dev. 2007, 1, 27–35. [Google Scholar] [CrossRef]
- Van Ryzin, M.J.; Roseth, C.J. The Cascading Effects of Reducing Student Stress: Cooperative Learning as a Means to Reduce Emotional Problems and Promote Academic Engagement. J. Early Adolesc. 2020. [Google Scholar] [CrossRef]
- Topping, K.J. Peer Tutoring and Cooperative Learning. Oxf. Res. Encycl. Educ. 2020. [Google Scholar] [CrossRef]
- Cañabate, D.; Serra, T.; Bubnys, R.; Colomer, J. Pre-Service Teachers’ Reflections on Cooperative Learning: Instructional Approaches and Identity Construction. Sustainability 2019, 11, 5970. [Google Scholar] [CrossRef] [Green Version]
- Lozano, R.; Merrill, M.Y.; Sammalisto, K.; Ceulemans, K.; Lozano, F.J. Connecting Competences and Pedagogical Approaches for Sustainable Development in Higher Education: A Literature Review and Framework Proposal. Sustainability 2017, 9, 1889. [Google Scholar] [CrossRef] [Green Version]
- Berglund, T. Student Views of Environmental, Social and Economic Dimensions of Sustainable Development and Their Interconnectedness: A Search for the Holistic Perspective in Education for Sustainable Development; Karlstads Universitet: Karlstad, Sweden, 2020. [Google Scholar]
- Hoogeveen, P.; Winkels, J. Het Didactische Werkvormenboek. Variatie en Differentiatie in de Praktijk. In Teaching Methods Book. Variation and Differentiation in Practice; Uitgeverij Van Gorcum: Assen, The Netherlands, 1996. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ROC Area | Interpretation |
|---|---|
| More than 0.9 | Exceptional |
| From 0.9 to 0.8 | Good |
| From 0.8 to 0.7 | Acceptable |
| From 0.7 to 0.6 | Reasonable |
| Less than 0.6 | Poor |
| Kappa Value | Interpretation |
|---|---|
| 0.61–0.80 | Considerable agreement between predicted and actual labels |
| 0.41–0.60 | Moderate agreement between predicted and actual labels |
| 0.21–0.40 | Fair agreement between predicted and actual labels |
| 0.01–0.20 | No to a slight agreement between predicted and actual labels |
| values ≤0 | No agreement between predicted and actual labels |
| Model | Accuracy | RMSE | Kappa |
|---|---|---|---|
| RF | 82.43% | 0.3430 | 0.5850 |
| Bagging | 82.43% | 0.3541 | 0.5623 |
| J48 | 78.38% | 0.4584 | 0.5083 |
| SMO | 78.38% | 0.4650 | 0.4686 |
| MLP | 72.97% | 0.5023 | 0.3357 |
| NB | 72.97% | 0.5059 | 0.4003 |
| Model | Accuracy | RMSE | Kappa |
|---|---|---|---|
| LogitBoost | 85.14% | 0.3380 | 0.6395 |
| AdaBoost | 85.14% | 0.3431 | 0.6297 |
| RF | 82.43% | 0.3430 | 0.5850 |
| Model | True Positive Rate | False Positive Rate | ROC Area |
|---|---|---|---|
| LogitBoost | 0.727 | 0.096 | 0.922 |
| AdaBoost | 0.682 | 0.077 | 0.920 |
| Bagging | 0.636 | 0.096 | 0.911 |
| Random forest | 0.727 | 0.135 | 0.920 |
| J48 | 0.727 | 0.192 | 0.771 |
| SMO | 0.591 | 0.135 | 0.728 |
| MLP | 0.500 | 0.173 | 0.783 |
| NB | 0.682 | 0.250 | 0.828 |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2020 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Naseer, M.; Zhang, W.; Zhu, W. Prediction of Coding Intricacy in a Software Engineering Team through Machine Learning to Ensure Cooperative Learning and Sustainable Education. Sustainability 2020, 12, 8986. https://doi.org/10.3390/su12218986
Naseer M, Zhang W, Zhu W. Prediction of Coding Intricacy in a Software Engineering Team through Machine Learning to Ensure Cooperative Learning and Sustainable Education. Sustainability. 2020; 12(21):8986. https://doi.org/10.3390/su12218986
Chicago/Turabian StyleNaseer, Mehwish, Wu Zhang, and Wenhao Zhu. 2020. "Prediction of Coding Intricacy in a Software Engineering Team through Machine Learning to Ensure Cooperative Learning and Sustainable Education" Sustainability 12, no. 21: 8986. https://doi.org/10.3390/su12218986