A Topic Modeling Approach to Determine Supply Chain Management Priorities Enabled by Digital Twin Technology



Abstract
1. Introduction
2. Previous Studies
2.1. Application of the Digital Twin to the Supply Chain
- DT Technology: The main focus of DT research is the exploration of various enabling technologies, including IoT, communication protocols, data analysis technology, machine learning algorithms, DT development platforms, and security solutions.
- SCM Processes: Supply chain management processes and tasks that are analyzed using DTs include inventory management, manufacturing operations management, job scheduling, sustainability performance monitoring, and resiliency modeling.
- Management Activities: These include end-to-end visibility and transparency of goods movement and information flow, improved communication and collaboration with suppliers, supply chain risk simulation and management, and improved decision making through real-time decision support systems.
- Modeling Methods: These include specific techniques such as machine learning algorithms (reinforcement learning and neural networks), categorized as descriptive, predictive, and prescriptive methods.
- Human–AI Symbiosis: Fewer studies have examined the interaction between human decision makers and DTs in the supply chain, and the implications of this interaction.
- The Scope of DT Application: SCDTs have been studied at different stages and levels of the supply chain. The scope includes both intraorganizational and interorganizational perspectives, including production or warehouse processes.
- Business Models: SCDTs enable new business and operational models, such as collaborative platforms, cloud supply chains, and supply chain as a service.
2.2. Topic Models
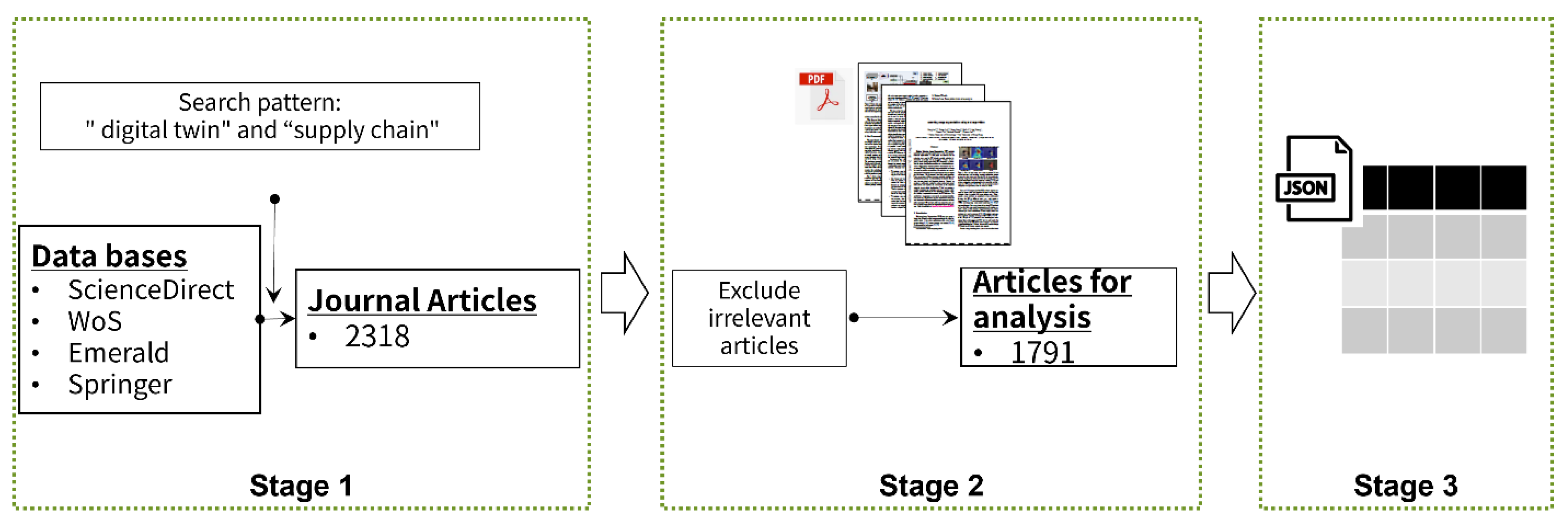
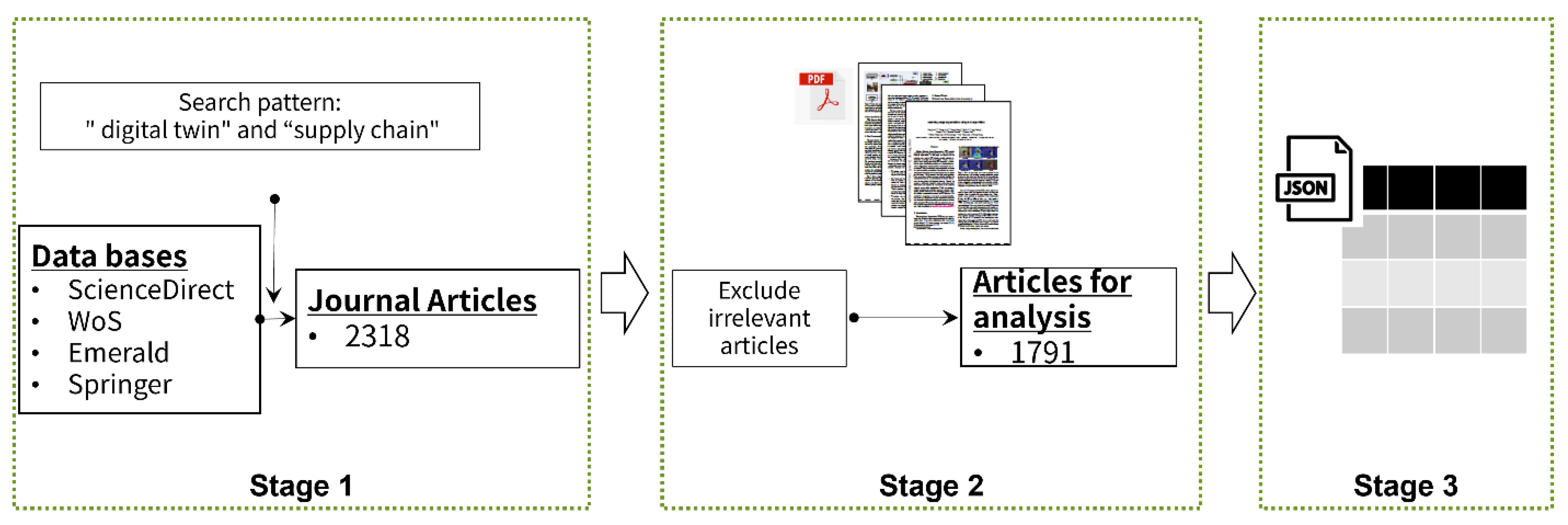
3. Data
4. Methodology
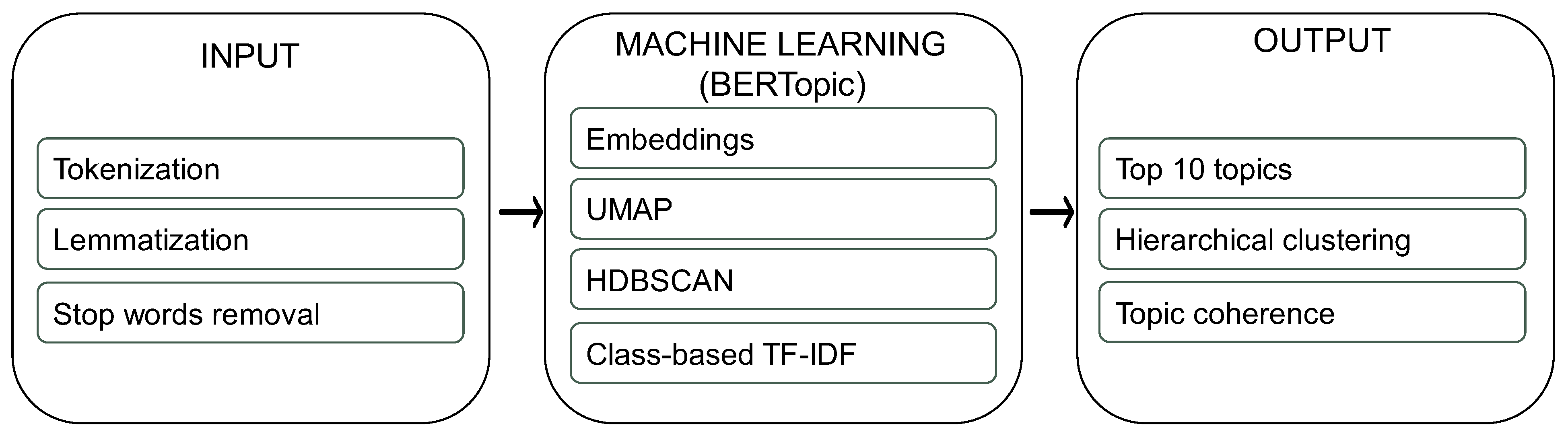
4.1. Analysis Process
4.2. Preparation of Input Data
4.3. Machine Learning Using BERTopic Model
4.3.1. Embedding
4.3.2. Uniform Manifold Approximation and Projection
4.3.3. Hierarchical Density-Based Spatial Clustering of Applications with Noise
4.3.4. Class-Based Term Frequency–Inverse Document Frequency
4.3.5. Fine-Tuning
5. Experimental Findings
5.1. Top 15 Topics
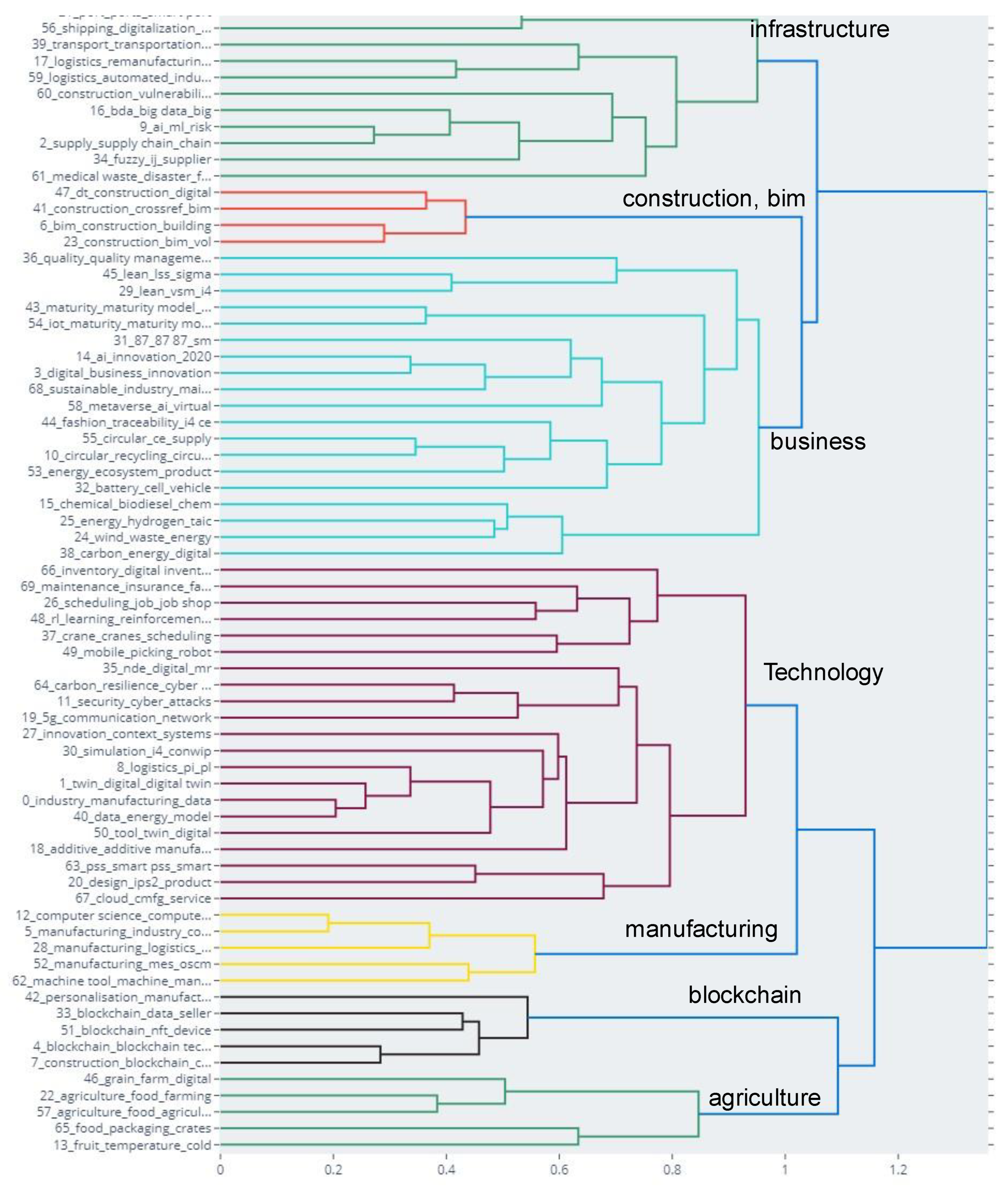
5.2. Hierarchical Clusters
5.3. Measurement of the Performance of the Model
6. Discussion
6.1. Infrastructure Domain
6.2. Construction Domain
6.3. Business Domain
6.4. Technology Domain
6.5. Manufacturing Domain
6.6. Blockchain Domain
6.7. Agriculture Domain
6.8. Comparison of Human Review and Machine Learning Results
- Compared with the human review result, this study generates new areas, such as construction, blockchain, and agriculture domains, which are not addressed in the human review results.
- The human review results put more emphasis on practicality such as management activities, processes, and methods, while the machine learning results pay more attention to macro perspectives such as infrastructure, technology, and business.
- By identifying the top keywords, the machine learning-based model was able to dig out more detailed information; for example, it identified the core technologies beyond DTs, including AI/reinforcement learning, picking robots, cybersecurity, 5G networks, the physical internet (PI), additive manufacturing, and cloud manufacturing (CMFG).
7. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Zhu, Y.; Cheng, J.; Liu, Z.; Cheng, Q.; Zou, X.; Xu, H.; Wang, Y.; Tao, F. Production Logistics Digital Twins: Research Profiling, Application, Challenges and Opportunities. Robot. Comput. Integr. Manuf. 2023, 84, 102592. [Google Scholar] [CrossRef]
- Abouelrous, A.; Bliek, L.; Zhang, Y. Digital Twin Applications in Urban Logistics: An Overview. Urban Plan. Transp. Res. 2023, 11, 2216768. [Google Scholar] [CrossRef]
- Tasche, L.; Bähring, M.; Gerlach, B. Digital Supply Chain Twins in Urban Logistics System—Conception of an Integrative Platform. Teh. Glas. 2023, 17, 405–413. [Google Scholar] [CrossRef]
- Kajba, M.; Jereb, B.; Cvahte Ojsteršek, T. Exploring Digital Twins in the Transport and Energy Fields: A Bibliometrics and Literature Review Approach. Energies 2023, 16, 3922. [Google Scholar] [CrossRef]
- Kmiecik, M. Digital Twin as a Tool for Supporting Logistics Coordination in Distribution Networks. Int. J. Supply Chain Manag. 2023, 12, 1–6. [Google Scholar] [CrossRef]
- Ivanov, D. Intelligent Digital Twin (iDT) for Supply Chain Stress-Testing, Resilience, and Viability. Int. J. Prod. Econ. 2023, 263, 108938. [Google Scholar] [CrossRef]
- Marinagi, C.; Reklitis, P.; Trivellas, P.; Sakas, D. The Impact of Industry 4.0 Technologies on Key Performance Indicators for a Resilient Supply Chain 4.0. Sustainability 2023, 15, 5185. [Google Scholar] [CrossRef]
- Astarita, V.; Guido, G.; Haghshenas, S.S.; Haghshenas, S.S. Risk Reduction in Transportation Systems: The Role of Digital Twins According to a Bibliometric-Based Literature Review. Sustainability 2024, 16, 3212. [Google Scholar] [CrossRef]
- Preut, A.; Kopka, J.-P.; Clausen, U. Digital Twins for the Circular Economy. Sustainability 2021, 13, 10467. [Google Scholar] [CrossRef]
- Peron, M. A Digital Twin-Enabled Digital Spare Parts Supply Chain. Int. J. Prod. Res. 2024, 1–16. [Google Scholar] [CrossRef]
- Sharma, A.; Kosasih, E.; Zhang, J.; Brintrup, A.; Calinescu, A. Digital Twins: State of the Art Theory and Practice, Challenges, and Open Research Questions. J. Ind. Inf. Integr. 2022, 30, 100383. [Google Scholar] [CrossRef]
- Boyes, H.; Watson, T. Digital Twins: An Analysis Framework and Open Issues. Comput. Ind. 2022, 143, 103763. [Google Scholar] [CrossRef]
- Bhandal, R.; Meriton, R.; Kavanagh, R.E.; Brown, A. The Application of Digital Twin Technology in Operations and Supply Chain Management: A Bibliometric Review. Supply Chain Manag. Int. J. 2022, 27, 182–206. [Google Scholar] [CrossRef]
- Ivanov, D. Digital Supply Chain Management and Technology to Enhance Resilience by Building and Using End-to-End Visibility during the COVID-19 Pandemic. IEEE Trans. Eng. Manag. 2021. [Google Scholar] [CrossRef]
- Nguyen, T.; Duong, Q.H.; Van Nguyen, T.; Zhu, Y.; Zhou, L. Knowledge Mapping of Digital Twin and Physical Internet in Supply Chain Management: A Systematic Literature Review. Int. J. Prod. Econ. 2022, 244, 108381. [Google Scholar] [CrossRef]
- Zhang, Z.; Guan, Z.; Gong, Y.; Luo, D.; Yue, L. Improved Multi-Fidelity Simulation-Based Optimisation: Application in a Digital Twin Shop Floor. Int. J. Prod. Res. 2022, 60, 1016–1035. [Google Scholar] [CrossRef]
- Yan, Q.; Wang, H.; Wu, F. Digital Twin-Enabled Dynamic Scheduling with Preventive Maintenance Using a Double-Layer Q-Learning Algorithm. Comput. Oper. Res. 2022, 144, 105823. [Google Scholar] [CrossRef]
- Ivanov, D. Conceptualisation of a 7-Element Digital Twin Framework in Supply Chain and Operations Management. Int. J. Prod. Res. 2023, 62, 2220–2232. [Google Scholar] [CrossRef]
- Blei, D.M.; Ng, A.Y.; Jordan, M.I. Latent Dirichlet Allocation. J. Mach. Learn. Res. 2003, 3, 993–1022. [Google Scholar]
- Deerwester, S.; Dumais, S.T.; Furnas, G.W.; Landauer, T.K.; Harshman, R. Indexing by Latent Semantic Analysis. J. Am. Soc. Inf. Sci. 1990, 41, 391–407. [Google Scholar]
- Lee, D.D.; Seung, H.S. Learning the Parts of Objects by Non-Negative Matrix Factorization. Nature 1999, 401, 788–791. [Google Scholar] [CrossRef] [PubMed]
- Hofmann, T. Probabilistic Latent Semantic Analysis. arXiv 2013, arXiv:1301.6705v1. [Google Scholar]
- Angelov, D. Top2Vec: Distributed Representations of Topics. arXiv 2020, arXiv:2008.09470v1. [Google Scholar]
- Grootendorst, M. BERTopic: Neural Topic Modeling with a Class-Based TF-IDF Procedure. arXiv 2022, arXiv:2203.05794. [Google Scholar]
- Egger, R.; Yu, J. A Topic Modeling Comparison Between LDA, NMF, Top2Vec, and BERTopic to Demystify Twitter Posts. Front. Sociol. 2022, 7, 886498. [Google Scholar] [CrossRef] [PubMed]
- Hirata, E.; Lambrou, M.; Watanabe, D. Blockchain Technology in Supply Chain Management: Insights from Machine Learning Algorithms. Marit. Bus. Rev. 2020, 6, 114–128. [Google Scholar] [CrossRef]
- Devlin, J.; Chang, M.-W.; Lee, K.; Toutanova, K. BERT: Pre-Training of Deep Bidirectional Transformers for Language Understanding. arXiv 2019, arXiv:1810.04805. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings Using Siamese BERT-Networks. arXiv 2019, arXiv:1908.10084. [Google Scholar]
- McInnes, L.; Healy, J.; Melville, J. UMAP: Uniform Manifold Approximation and Projection for Dimension Reduction. arXiv 2020, arXiv:1802.03426v3. [Google Scholar]
- Campello, R.J.G.B.; Moulavi, D.; Sander, J. Density-Based Clustering Based on Hierarchical Density Estimates. In Advances in Knowledge Discovery and Data Mining; Pei, J., Tseng, V.S., Cao, L., Motoda, H., Xu, G., Eds.; Lecture Notes in Computer Science; Springer: Berlin/Heidelberg, Germany, 2013; Volume 7819, pp. 160–172. ISBN 978-3-642-37455-5. [Google Scholar]
- Carbonell, J.; Goldstein, J. The Use of MMR, Diversity-Based Reranking for Reordering Documents and Producing Summaries. In Proceedings of the 21st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, Melbourne, Australia, 24–28 August 1998; ACM: Melbourne Australia, 1998; pp. 335–336. [Google Scholar]
- Röder, M.; Both, A.; Hinneburg, A. Exploring the Space of Topic Coherence Measures. In Proceedings of the 8th ACM International Conference on Web Search and Data Mining, Shanghai, China, 2–6 February 2015; Association for Computing Machinery: New York, NY, USA, 2015; pp. 399–408. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database | No. of Articles | Contribution | No. of Words | Contribution |
|---|---|---|---|---|
| Emerald | 274 | 15% | 2,602,587 | 12% |
| ScienceDirect | 952 | 53% | 13,566,607 | 65% |
| Springer | 362 | 20% | 2,082,070 | 10% |
| WoS | 203 | 11% | 2,751,306 | 13% |
| Total | 1791 | 100% | 21,002,570 | 100% |
| Parameter | Explanation | Utility |
|---|---|---|
| embedding model | The original BERTopic model was used for fine-tuning. | all-MiniLM-L6-v2 |
| HDBSCAN | Density clustering algorithm using the excess of mass (EOM) method to select clusters. | min_cluster_size=5, and cluster_selection _method=‘eom’ |
| UMAP | Dimensionality reduction model. ‘n_neighbors’ affects UMAP’s compromise between local and global structure preservation, whereas ‘n_components’ is the desired dimensionality of the reduced embedding domain. The degree to which UMAP can group data items near one another is governed by ‘min_dist’. Similarity computations are performed using the cosine distance. | n_neighbors=10, n_components=5, min_dist = 0.1, and metric=‘cosine’ |
| Diversity | Evaluation of the variety of the selected terms and key phrases. Diversity utility ranges from 0 to 1, where 0 is minimum and 1 is maximum. | 0.1 |
| Topic | Topic Label | Count |
|---|---|---|
| 1 | 0_industry_manufacturing_data | 345 |
| 2 | 1_twin_digital_digital twin | 176 |
| 3 | 2_supply_supply chain_chain | 108 |
| 4 | 3_digital_business_innovation | 71 |
| 5 | 4_blockchain_blockchain technology_chain | 49 |
| 6 | 5_manufacturing_industry_computer science | 36 |
| 7 | 6_bim_construction_building | 35 |
| 8 | 7_construction_blockchain_contracts | 25 |
| 9 | 8_logistics_pi_pl | 24 |
| 10 | 9_ai_ml_risk | 24 |
| 11 | 10_circular_recycling_circular economy | 23 |
| 12 | 11_security_cyber_attacks | 22 |
| 13 | 12_computer science_computer_science | 19 |
| 14 | 13_fruit_temperature_cold | 18 |
| 15 | 14_ai_innovation_2020 | 17 |
| Cluster | Domains | Characteristics |
|---|---|---|
| 1 | Infrastructure domain | Smart ports Shipping digitalization Logistics automation |
| 2 | Construction domain | Construction Building information modeling (BIM) |
| 3 | Business domain | Lean production Maturity models Innovation Sustainability Circular economy Metaverse Energy sources and use (battery, wind, biodiesel, and carbon) |
| 4 | Technology domain | AI/reinforcement learning Picking robots Cyber security Digital twins 5G network Physical internet (PI) Additive manufacturing and cloud manufacturing (CMFG) |
| 5 | Manufacturing domain | Manufacturing logistics Operations and supply chain management (OSCM) |
| 6 | Blockchain domain | Personalization Blockchain data sellers Non-fungible token (NFT) Blockchain technology |
| 7 | Agriculture domain | Agriculture food Food packaging Cold chains |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hirata, E.; Watanabe, D.; Chalmoukis, A.; Lambrou, M. A Topic Modeling Approach to Determine Supply Chain Management Priorities Enabled by Digital Twin Technology. Sustainability 2024, 16, 3552. https://doi.org/10.3390/su16093552
Hirata E, Watanabe D, Chalmoukis A, Lambrou M. A Topic Modeling Approach to Determine Supply Chain Management Priorities Enabled by Digital Twin Technology. Sustainability. 2024; 16(9):3552. https://doi.org/10.3390/su16093552
Chicago/Turabian StyleHirata, Enna, Daisuke Watanabe, Athanasios Chalmoukis, and Maria Lambrou. 2024. "A Topic Modeling Approach to Determine Supply Chain Management Priorities Enabled by Digital Twin Technology" Sustainability 16, no. 9: 3552. https://doi.org/10.3390/su16093552
APA StyleHirata, E., Watanabe, D., Chalmoukis, A., & Lambrou, M. (2024). A Topic Modeling Approach to Determine Supply Chain Management Priorities Enabled by Digital Twin Technology. Sustainability, 16(9), 3552. https://doi.org/10.3390/su16093552