
Probabilistic Graphical Framework for Estimating Collaboration Levels in Cloud Manufacturing



Abstract
:1. Introduction
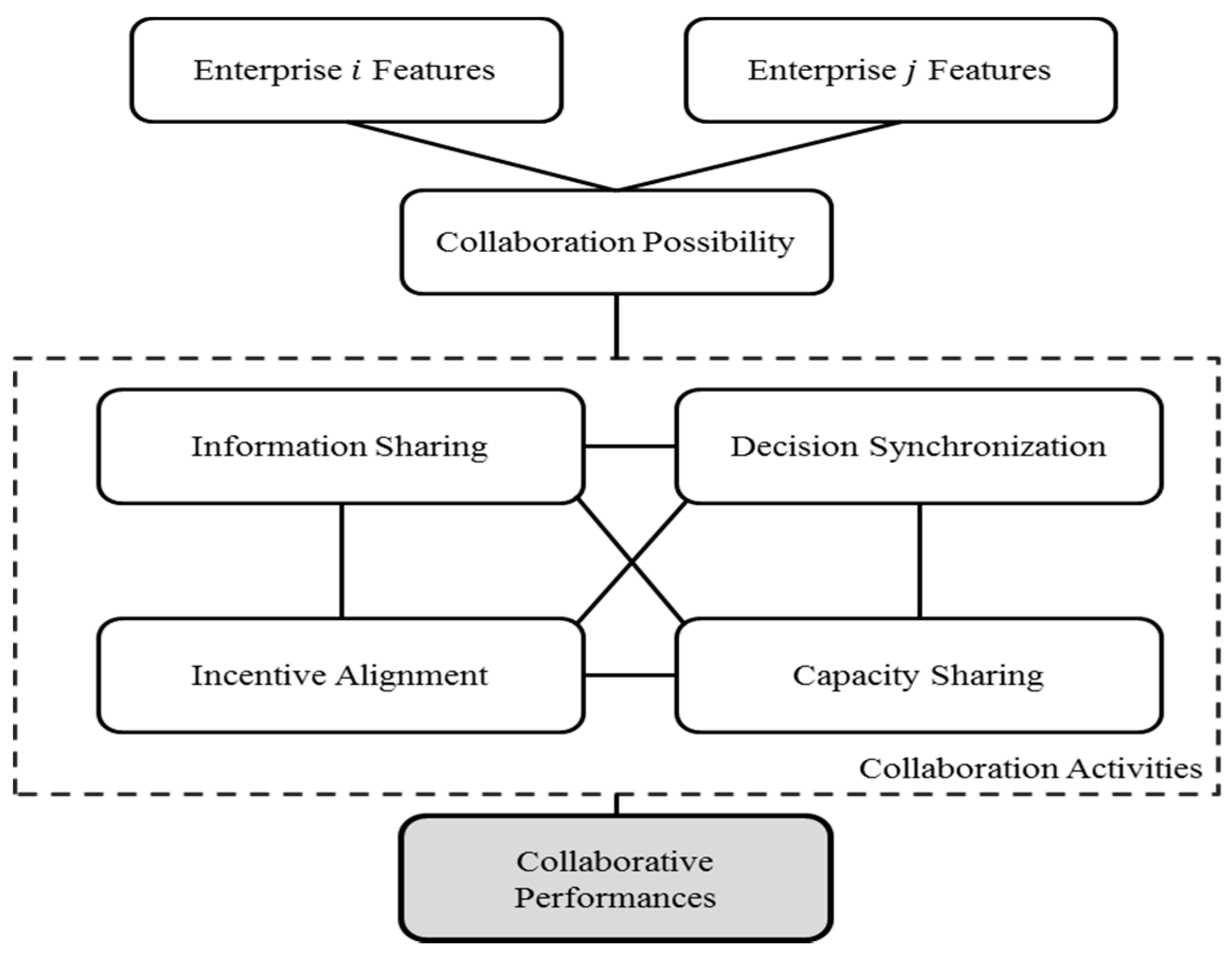
2. Proposed Framework
2.1. Defining Variables and Their Relationships
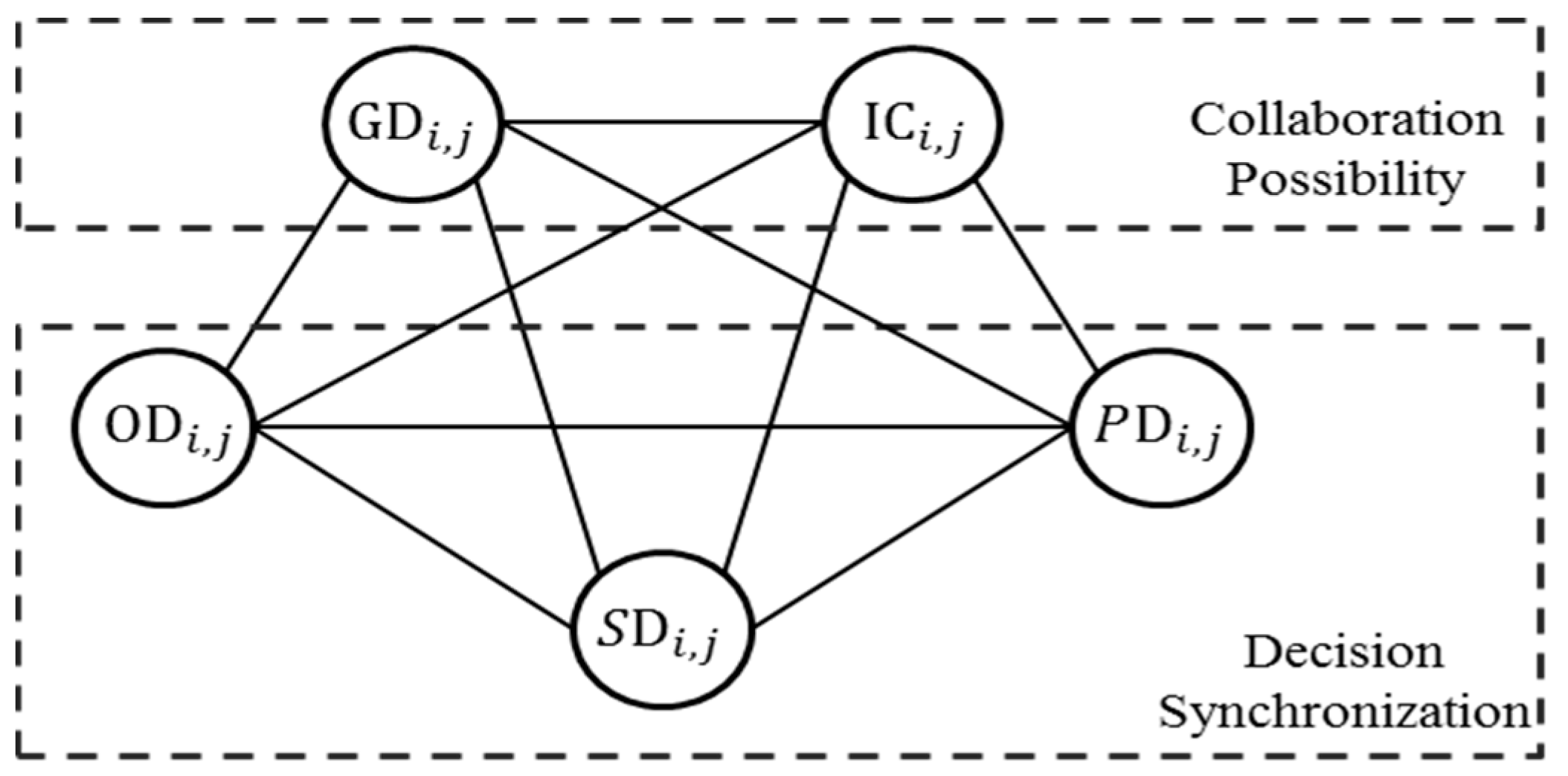
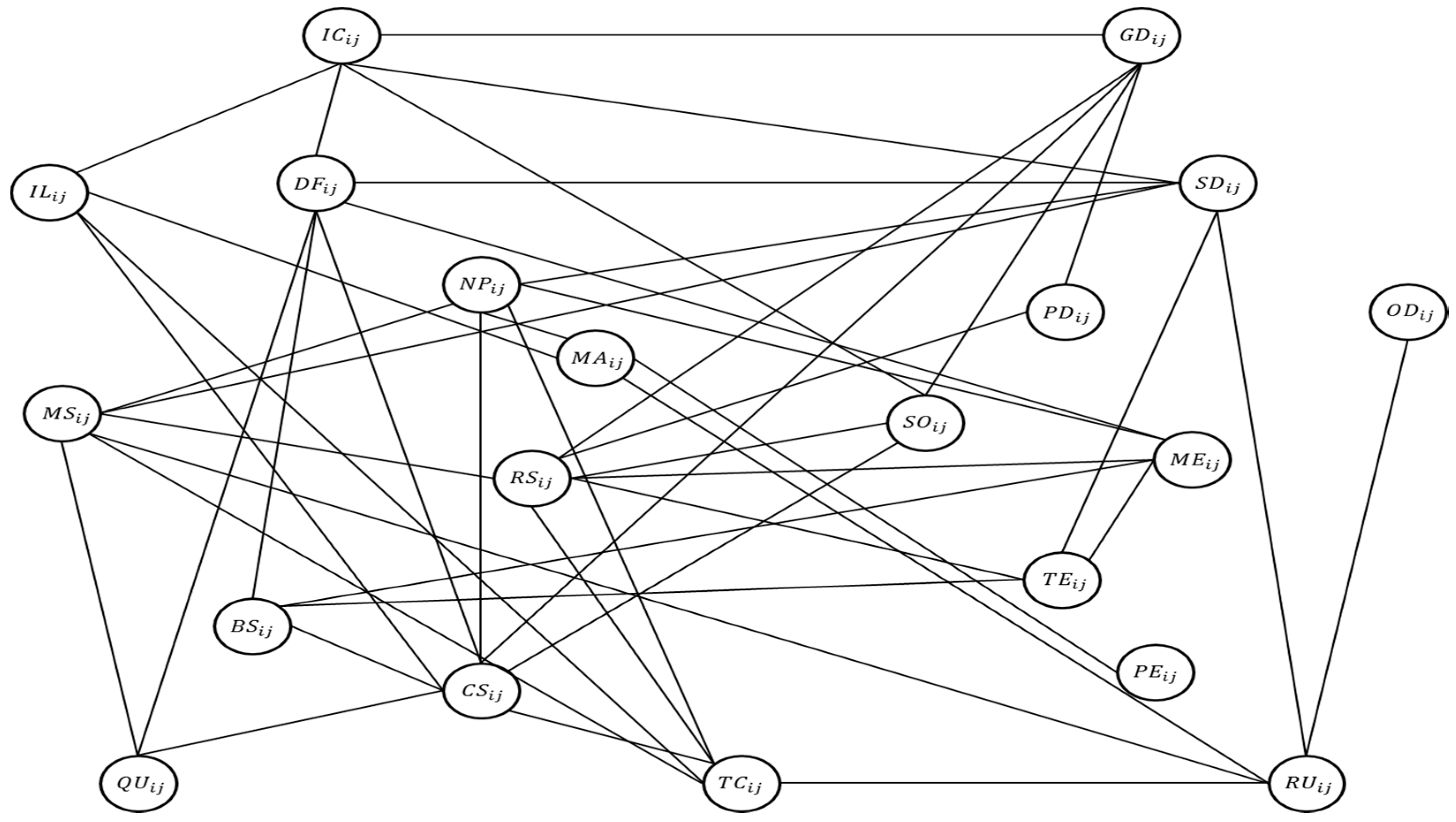
2.2. Designing the Probabilistic Graphical Model
2.3. Collecting Data
- Q. Which type of manufacturing service does your company provide?(1) Assembly (2) Machining (3) Molding (4) Fabrication (5) Prototyping
- Q. Specify the company names that your company has collaborations with.( )
- Q. How much has your company shared inventory with “Company A”?(1) Never (2) Rarely (3) Sometimes (4) Often (5) Always
- Q. How much has your quality improved through collaboration with “Company B”?(1) Never (2) Little (3) Somewhat (4) Much (5) A Great Deal
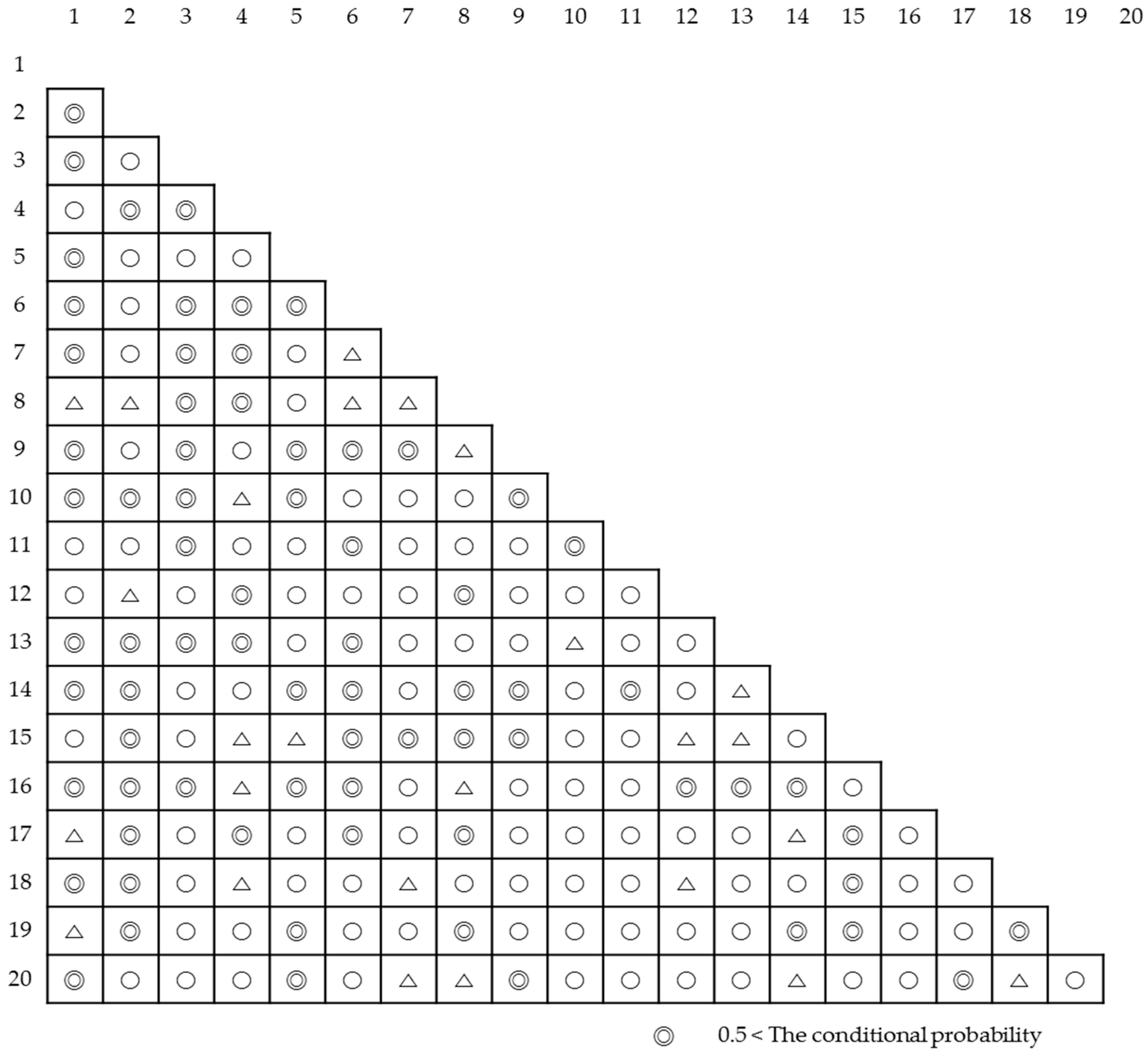
2.4. Learning Probabilistic Graphical Model
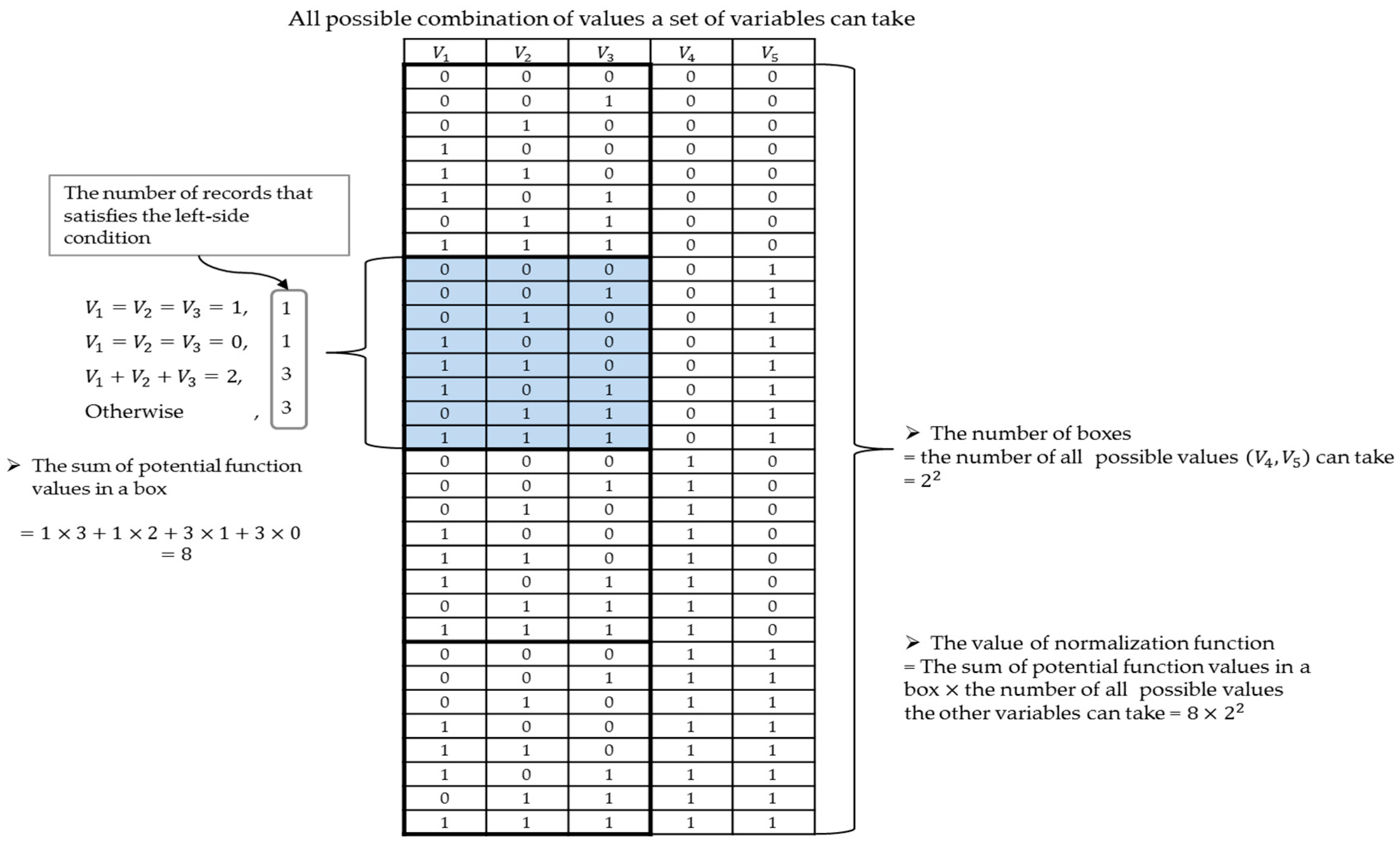
2.5. Estimating Collaboration Level
3. Illustrative Example
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Ehie, I.C.; Olibe, K. The effect of R&D investment on firm value: An examination of US manufacturing and service industries. Int. J. Prod. Econ. 2010, 128, 127–135. [Google Scholar]
- Váncza, J.; Monostori, L.; Lutters, D.; Kumara, S.R.; Tseng, M.; Valckenaers, P.; van Brussel, H. Cooperative and responsive manufacturing enterprises. CIRP Ann. Manuf. Technol. 2011, 60, 797–820. [Google Scholar] [CrossRef]
- Simatupang, T.M.; Sridharan, R. The collaborative supply chain. Int. J. Logist. Manag. 2002, 13, 15–30. [Google Scholar] [CrossRef]
- Camarinha-Matos, L.M. Collaborative networked organizations in manufacturing. IFAC Proc. Volumes 2007, 40, 187–198. [Google Scholar] [CrossRef]
- Li, B.H.; Zhang, L.; Wang, S.L.; Tao, F.; Cao, J.W.; Jiang, X.D.; Song, X.; Chai, X.D. Cloud manufacturing: A new service-oriented networked manufacturing model. Comput. Integr. Manuf. Syst. 2010, 16, 1–7. [Google Scholar]
- Jiang, P.; Ding, K. Social manufacturing: A new way to support outsourcing production. In Proceedings of the 2nd International Conference on Innovative Design and Manufacturing, Taipei, Taiwan, 12–14 December 2012.
- Rao, Y.; Li, P.; Shao, X.; Wu, B.; Li, B. A CORBA-and MAS-based architecture for agile collaborative manufacturing systems. Int. J. Computer Integr. Manuf. 2006, 19, 815–832. [Google Scholar] [CrossRef]
- Wu, D.; Greer, M.J.; Rosen, D.W.; Schaefer, D. Cloud manufacturing: Drivers, current status, and future trends. In Proceedings of the ASME 2013 International Manufacturing Science and Engineering Conference collocated with the 41st North American Manufacturing Research Conference, San Diego, CA, USA, 15–21 November 2013.
- Wu, D.; Rosen, D.W.; Wang, L.; Schaefer, D. Cloud-based design and manufacturing: A new paradigm in digital manufacturing and design innovation. Comput. Aided. Des. 2015, 59, 1–14. [Google Scholar] [CrossRef] [Green Version]
- Bi, Z.M.; Wang, L. Manufacturing paradigm shift towards better sustainability. In Cloud Manufacturing; Springer: London, UK, 2013. [Google Scholar]
- Xu, X. From cloud computing to cloud manufacturing. Robot. Cim-Int. Manuf. 2012, 28, 75–86. [Google Scholar] [CrossRef]
- Jassbi, J.; Di Orio, G.; Barata, D.; Barata, J. The impact of cloud manufacturing on supply chain agility. In Proceedings of the 12th IEEE International Conference on Industrial Informatics, Porto Alegre RS, Brazil, 27–30 July 2014.
- Singh, A.; Mishra, N.; Ali, S.I.; Shukla, N.; Shankar, R. Cloud computing technology: Reducing carbon footprint in beef supply chain. Int. J. Prod. Econ. 2015, 164, 462–471. [Google Scholar] [CrossRef]
- Ren, L.; Zhang, L.; Tao, F.; Zhao, C.; Chai, X.; Zhao, X. Cloud manufacturing: from concept to practice. Enterp. Inf. Syst. 2015, 9, 186–209. [Google Scholar] [CrossRef]
- Xing, K.; Qian, W.; Zaman, A.U. Development of a cloud-based platform for footprint assessment in green supply chain management. J. Clean. Prod. 2016, 139, 191–203. [Google Scholar] [CrossRef]
- Golightly, D.; Sharples, S.; Patel, H.; Ratchev, S. Manufacturing in the cloud: A human factors perspective. Int. J. Ind. Ergonom. 2016, 55, 12–21. [Google Scholar] [CrossRef]
- Ren, L.; Cui, J.; Wei, Y.; Laili, Y.; Zhang, L. Research on the impact of service provider cooperative relationship on cloud manufacturing platform. Int. J. Adv. Manuf. Technol. 2016, 86, 2279–2290. [Google Scholar] [CrossRef]
- Argoneto, P.; Renna, P. Supporting capacity sharing in the cloud manufacturing environment based on game theory and fuzzy logic. Enterp. Inf.Syst. 2016, 10, 193–210. [Google Scholar] [CrossRef]
- Ahn, G.; Park, Y.J.; Hur, S. The Dynamic Enterprise Network Composition Algorithm for Efficient Operation in Cloud Manufacturing. Sustainability 2016, 8, 1239. [Google Scholar] [CrossRef]
- Liu, Y.; Zhang, L.; Tao, F.; Wang, L. Resource service sharing in cloud manufacturing based on the Gale–Shapley algorithm: Advantages and challenge. Int. J. Computer Integr. Manuf. 2015. [Google Scholar] [CrossRef]
- Li, W.; Zhu, C.; Ngai, E.C.H.; Yang, L.T.; Shu, L.; Sheng, Y. Facilities collaboration in cloud manufacturing based on generalized collaboration network. In Proceedings of the 2015 11th International Conference on Heterogeneous Networking for Quality, Reliability, Security and Robustness, Taipei, Taiwan, 19–20 August 2015.
- Cheng, Z.; Zhan, D.; Zhao, X.; Wan, H. Multitask oriented virtual resource integration and optimal scheduling in cloud manufacturing. J. Appl. Math. 2014. [Google Scholar] [CrossRef]
- Ming, Y.; Grabot, B.; Houé, R. A typology of the situations of cooperation in supply chains. Comput. Ind. Eng. 2014, 67, 56–71. [Google Scholar] [CrossRef] [Green Version]
- Ding, H.; Zhao, Q.; An, Z.; Tang, O. Collaborative mechanism of a sustainable supply chain with environmental constraints and carbon caps. Int. J. Prod. Econ. 2016, 181, 191–207. [Google Scholar] [CrossRef]
- Min, S.; Roath, A.S.; Daugherty, P.J.; Genchev, S.E.; Chen, H.; Arndt, A.D.; Glenn Richey, R. Supply chain collaboration: What’s happening? Int. J. Logist. Manag. 2005, 16, 237–256. [Google Scholar] [CrossRef]
- Acharya, U.R.; Fujita, H.; Sudarshan, V.K.; Mookiah, M.R.K.; Koh, J.E.; Tan, J.H.; Hagiwara, Y.; Chua, C.K.; Junnarkar, S.M.; Vijayananthan, A.; et al. An integrated index for identification of fatty liver disease using radon transform and discrete cosine transform features in ultrasound images. Inform. Fusion. 2016, 31, 43–53. [Google Scholar] [CrossRef]
- Barratt, M. Understanding the meaning of collaboration in the supply chain. Supply Chain Manag. 2004, 9, 30–42. [Google Scholar] [CrossRef]
- Khan, M.; Hussain, M.; Saber, H.M. Information sharing in a sustainable supply chain. Int. J. Prod. Econ. 2016, 181, 208–214. [Google Scholar] [CrossRef]
- Bian, W.; Shang, J.; Zhang, J. Two-way information sharing under supply chain competition. Int. J. Prod. Econ. 2016, 178, 82–94. [Google Scholar] [CrossRef]
- Galbreth, M.R.; Kurtuluş, M.; Shor, M. How collaborative forecasting can reduce forecast accuracy. Oper. Res. Lett. 2015, 43, 349–353. [Google Scholar] [CrossRef]
- Wiengarten, F.; Humphreys, P.; Cao, G.; Fynes, B.; McKittrick, A. Collaborative supply chain practices and performance: Exploring the key role of information quality. Supply Chain Manag. 2010, 15, 463–473. [Google Scholar] [CrossRef]
- Seok, H.; Nof, S.Y. Collaborative capacity sharing among manufacturers on the same supply network horizontal layer for sustainable and balanced returns. Int. J. Prod. Res. 2014, 52, 1622–1643. [Google Scholar] [CrossRef]
- Anbanandam, R.; Banwet, D.K.; Shankar, R. Evaluation of supply chain collaboration: A case of apparel retail industry in India. Int. J. Prod. Perf. Manag. 2011, 60, 82–98. [Google Scholar] [CrossRef]
- Rota, C.; Pugliese, P.; Hashem, S.; Zanasi, C. Assessing the level of collaboration in the Egyptian organic and fair trade cotton chain. J. Clean. Prod. 2016. [Google Scholar] [CrossRef]
- Ramanathan, U.; Gunasekaran, A.; Subramanian, N. Supply chain collaboration performance metrics: A conceptual framework. Benchmarking Int. J. 2011, 18, 856–872. [Google Scholar] [CrossRef]
- Inaam, Z.; Abderrahman, M.; Yasmina, H. A framework of Performance Assessment of Collaborative Supply Chain. IFAC-PapersOnLine 2016, 49, 845–850. [Google Scholar] [CrossRef]
- Koller, D.; Friedman, N. Probabilistic Graphical Models: Principles and Techniques; MIT Press: Cambridge, MA, USA, 2009. [Google Scholar]
- Jordan, M.I. An introduction to graphical models. Unpublished work. 1997. [Google Scholar]
- Van der Biest, K.; D’Hondt, R.; Jacobs, S.; Landuyt, D.; Staes, J.; Goethals, P.; Meire, P. EBI: An index for delivery of ecosystem service bundles. Ecol. Indic. 2014, 37, 252–265. [Google Scholar] [CrossRef]
- Ahn, G.; Hur, H. Continuous Conditional Random Field Model for Predicting the Electrical Load of a Combined Cycle Power Plant. Ind. Eng. Manag. Syst. 2016, 15, 148–155. [Google Scholar] [CrossRef]
- Wang, X.V.; Xu, X.W. An interoperable solution for Cloud manufacturing. Rob. Comput. Integr. Manuf. 2013, 29, 232–247. [Google Scholar] [CrossRef]
- MFG.com. Available online: http://www.mfg.com (accessed on 17 November 2016).
- Simatupang, T.M.; Wright, A.C.; Sridharan, R. The knowledge of coordination for supply chain integration. Bus. Process Manag. J. 2002, 8, 289–308. [Google Scholar] [CrossRef]
- Baihaqi, I.; Sohal, A.S. The impact of information sharing in supply chains on organisational performance: An empirical study. Prod. Plan. Control 2013, 24, 743–758. [Google Scholar] [CrossRef]
- Lotfi, Z.; Mukhtar, M.; Sahran, S.; Zadeh, A.T. Information sharing in supply chain management. Procedia Technol. 2013, 11, 298–304. [Google Scholar] [CrossRef]
- Sari, K. Investigating the value of reducing errors in inventory information from a supply chain perspective. Kybernetes 2015, 44, 176–185. [Google Scholar] [CrossRef]
- Wu, L.; Chuang, C.H.; Hsu, C.H. Information sharing and collaborative behaviors in enabling supply chain performance: A social exchange perspective. Int. J. Prod. Econ. 2014, 148, 122–132. [Google Scholar] [CrossRef]
- Barratt, M.; Barratt, R. Exploring internal and external supply chain linkages: Evidence from the field. J. Oper. Manag. 2011, 29, 514–528. [Google Scholar] [CrossRef]
- Kumar, G.; Nath Banerjee, R. Supply chain collaboration index: An instrument to measure the depth of collaboration. Benchmarking Int. J. 2014, 21, 184–204. [Google Scholar] [CrossRef]
- Bruque-Cámara, S.; Moyano-Fuentes, J.; Maqueira-Marín, J.M. Supply chain integration through community cloud: Effects on operational performance. J. Purch. Supply Manag. 2016, 22, 141–153. [Google Scholar] [CrossRef]
- Liao, S.H.; Kuo, F.I. The study of relationships between the collaboration for supply chain, supply chain capabilities and firm performance: A case of the Taiwan’s TFT-LCD industry. Int. J. Prod. Econ. 2014, 156, 295–304. [Google Scholar] [CrossRef]
- Sigala, M. A supply chain management approach for investigating the role of tour operators on sustainable tourism: The case of TUI. J. Clean. Prod. 2008, 16, 1589–1599. [Google Scholar] [CrossRef]
- Lehoux, N.; D’Amours, S.; Langevin, A. Inter-firm collaborations and supply chain coordination: Review of key elements and case study. Prod. Plan. Control 2014, 25, 858–872. [Google Scholar] [CrossRef]
- Cachon, G.P. The allocation of inventory risk in a supply chain: Push, pull, and advance-purchase discount contracts. Manag. Sci. 2004, 50, 222–238. [Google Scholar] [CrossRef]
- Rivera, L.; Sheffi, Y.; Knoppen, D. Logistics clusters: The impact of further agglomeration, training and firm size on collaboration and value added services. Int. J. Prod. Econ. 2016, 179, 285–294. [Google Scholar] [CrossRef]
- Koufteros, X.A.; Vonderembse, M.A.; Doll, W.J. Examining the competitive capabilities of manufacturing firms. Struct. Equ. Modeling 2002, 9, 256–282. [Google Scholar] [CrossRef]
- Murphy, K.P. Machine Learning: A Probabilistic Perspective; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dimension | Variable | Explanation | Values | References |
|---|---|---|---|---|
| Enterprise Features | Service type enterprise i provides | p: Type p service (p =1,2,3,4) | [2,42] | |
| Manufacturing resources of enterprise i | q: Type resource q (q = 1,2,3,4) | [2,42] | ||
| Geographical location of enterprise i | r: Region (r = 1,2,3) | [2,42] | ||
| Collaboration Possibility | Interchangeability and composability of services enterprises i and j provide | 1: Interchangeable or composable 0: Otherwise | - | |
| Geographical distance between enterprises i and j | 1: They are closely located 0: Otherwise | - | ||
| Information Sharing | Inventory level sharing between enterprises i and j | 1: They have shared inventory level 0: Otherwise | [31,34,43,44,45,46,47,50] | |
| Collaborative demand forecasting between enterprises i and j | 1: They have collaboratively forecasted demand 0: Otherwise | [31,44,45,46] | ||
| New product development plan sharing between enterprises i and j | 1: They have shared new product development plan 0: Otherwise | [31,35,45,48,49] | ||
| Manufacturing schedule sharing between enterprises i and j | 1: They have shared manufacturing schedules 0: Otherwise | [35,44,48,49,50] | ||
| Information of manufacturing ability sharing between enterprises i and j | 1: They have shared manufacturing ability 0: Otherwise | [44,45,48,50] | ||
| Decision Synchronization | Operational decision synchronization between enterprises i and j | 1: They have collaboratively made a decision regarding operational issues 0: Otherwise | [31,43,49,51,52] | |
| Strategic decision synchronization between enterprises i and j | 1: They have collaboratively made a decision regarding strategic issues 0: Otherwise | [31,35,49,51,52] | ||
| Policy decision synchronization between enterprises i and j | 1: They have collaboratively made a decision regarding policy issues 0: Otherwise | [34,43] | ||
| Incentive Alignment | Cost sharing between enterprises i and j | 1: They have shared cost 0: Otherwise | [3] | |
| Benefit sharing between enterprises i and j | 1: They have shared benefit 0: Otherwise | [53] | ||
| Risk sharing between enterprises i and j | 1: They have shared risk 0: Otherwise | [53,54] | ||
| Capacity Sharing | Manufacturing equipment sharing between enterprises i and j | 1: They have shared manufacturing equipment 0: Otherwise | [25,35,41,49] | |
| Storage sharing between enterprise and | 1: They have shared storage 0: Otherwise | [25,35,41,49] | ||
| Technology sharing between enterprises and | 1: They have shared technology 0: Otherwise | [25,35,41,49] | ||
| Personnel sharing between enterprises and | 1: They have shared personnel 0: Otherwise | [41] | ||
| Collaborative Performance | Quality improvement of both enterprises and | 1: They have experienced quality improvement through collaboration 0: Otherwise | [33,42,56] | |
| Total cost reduction of both enterprises and | 1: They have experienced total cost reduction through collaboration 0: Otherwise | [33,45,49,56] | ||
| Resource utilization improvement of both enterprises and | 1: They have experienced resource utilization improvement through collaboration 0: Otherwise | [45] |
| Clique | Variables | Weight |
|---|---|---|
| 0.5004 | ||
| 0.9768 | ||
| 0.8985 | ||
| 0.7800 | ||
| 0.8391 | ||
| 0.7346 | ||
| 0.6401 | ||
| 0.8228 | ||
| 0.8540 | ||
| 0.7149 | ||
| 0.4255 | ||
| 0.9206 | ||
| 0.8757 | ||
| 0.4294 | ||
| 0.8521 | ||
| 0.8038 | ||
| 0.9946 | ||
| 0.1193 | ||
| 0.8209 | ||
| 0.5309 | ||
| 0.9671 | ||
| 0.6952 | ||
| 0.2307 | ||
| 0.7174 | ||
| 0.6907 | ||
| 0.8250 | ||
| 0.9906 |
| Variable | Value | Variable | Value | Variable | Value |
|---|---|---|---|---|---|
| 0 | 0 | 0 | |||
| 1 | 0 | 1 | |||
| 1 | 1 | 1 | |||
| 1 | 0 | 1 | |||
| 1 | 0 | 0 | |||
| 0 | 1 | 1 | |||
| 1 | 1 |
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license ( http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ahn, G.; Park, Y.-J.; Hur, S. Probabilistic Graphical Framework for Estimating Collaboration Levels in Cloud Manufacturing. Sustainability 2017, 9, 277. https://doi.org/10.3390/su9020277
Ahn G, Park Y-J, Hur S. Probabilistic Graphical Framework for Estimating Collaboration Levels in Cloud Manufacturing. Sustainability. 2017; 9(2):277. https://doi.org/10.3390/su9020277
Chicago/Turabian StyleAhn, Gilseung, You-Jin Park, and Sun Hur. 2017. "Probabilistic Graphical Framework for Estimating Collaboration Levels in Cloud Manufacturing" Sustainability 9, no. 2: 277. https://doi.org/10.3390/su9020277