1. Introduction
Construction projects have become increasingly large and complex, and they require precise and accurate analysis of data to establish reliable construction plans [
1,
2,
3]. Reliable construction plans ensure that resources such as materials, labor, and equipment can be allocated appropriately prior to actual operations. This saves time and money and can secure the sustainability of the construction project [
4]. Construction plans established before starting construction are important indicators of how to utilize such resources effectively during the construction period. This makes it possible to implement efficient progress management [
5,
6]. Accurate progress management must be performed to deliver a project on time, especially in the construction phase. Comparing the actual performance to the plans can be done to improve workflows and mitigate rework and delays [
7]. Deviations in progress from the plan can be detected by monitoring activities, which can be used for more accurate determination of feasible time information for future start and finish dates of later activities [
8,
9].
Progress monitoring is conventionally performed based on the final total cost. In South Korea, most construction companies use the Cost Breakdown Structure (CBS) to monitor construction progress [
10]. The Earned Value Management System (EVMS) is another method of progress monitoring based on costs and is widely used worldwide in current construction projects. However, this method is time-consuming, and the analysis is conducted at only the project or activity levels but not the operation level among the hierarchy levels in construction management [
11]. Analysis at the project or activity level is generally conducted by comparing the total cost actually spent at the completion date to the planned cost. Such information is not reliable or useful for establishing effective strategies due to the lack of information in the early stages of the construction [
11,
12].
To overcome this limitation, this study proposes a material-based progress monitoring methodology using data extracted from daily work reports, which have generally been used to report actual construction progress by contractors at the operation level in regard to the actual material delivered and installed at construction sites. The total amount of material required to finish the operation is determined by quantity take-off from the drawings and specifications. This measure is considered to be a more accurate estimate than cost, which might vary substantially depending on when it is estimated [
13]. Accordingly, material-based progress monitoring is expected to provide a more reliable reference since the estimated material quantities show little variance compared to the estimated cost. Quantified comparative results were obtained using three predictive methods: Multiple Regression Analysis (MRA), an Artificial Neural Network (ANN), and the Auto-Regressive Moving Average (ARIMA).
Using MRA and ANN, the relationship between materials and labor was analyzed to develop prediction models by setting the materials as a dependent variable and labor as an independent variable. The results show how much labor must be involved to complete the remaining work. ARIMA is applied to make predictions based on the relationship between materials and time flow. The results of these three methods could assist in determining a proper predictive method for material-based progress monitoring based on the characteristics of each job site.
3. Materials and Methods
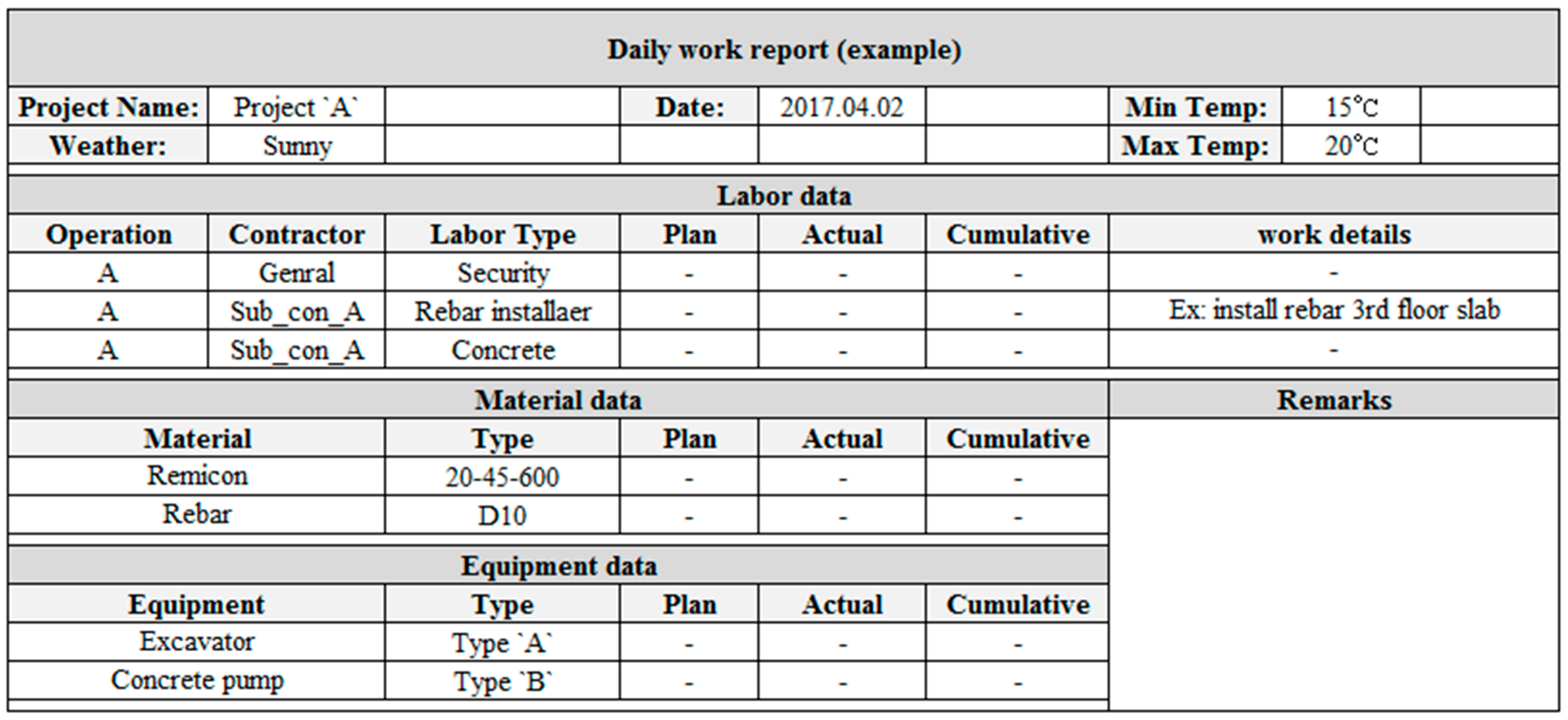
The daily work report is a document written by the general contractors and sub-contractors. In South Korea, this document is generally used to estimate the amount of work done to measure the amount of payment required based on the unit cost of each item. The daily work reports are stored in written documents or commercial software. Major construction companies in South Korea have also developed web-based systems for more efficient management of the documents.
Work reports contain massive amounts of quantitative data that can be analyzed and provide significant information for construction projects. The daily work reports used in this study were collected from web based systems, and an example of a report template is shown in
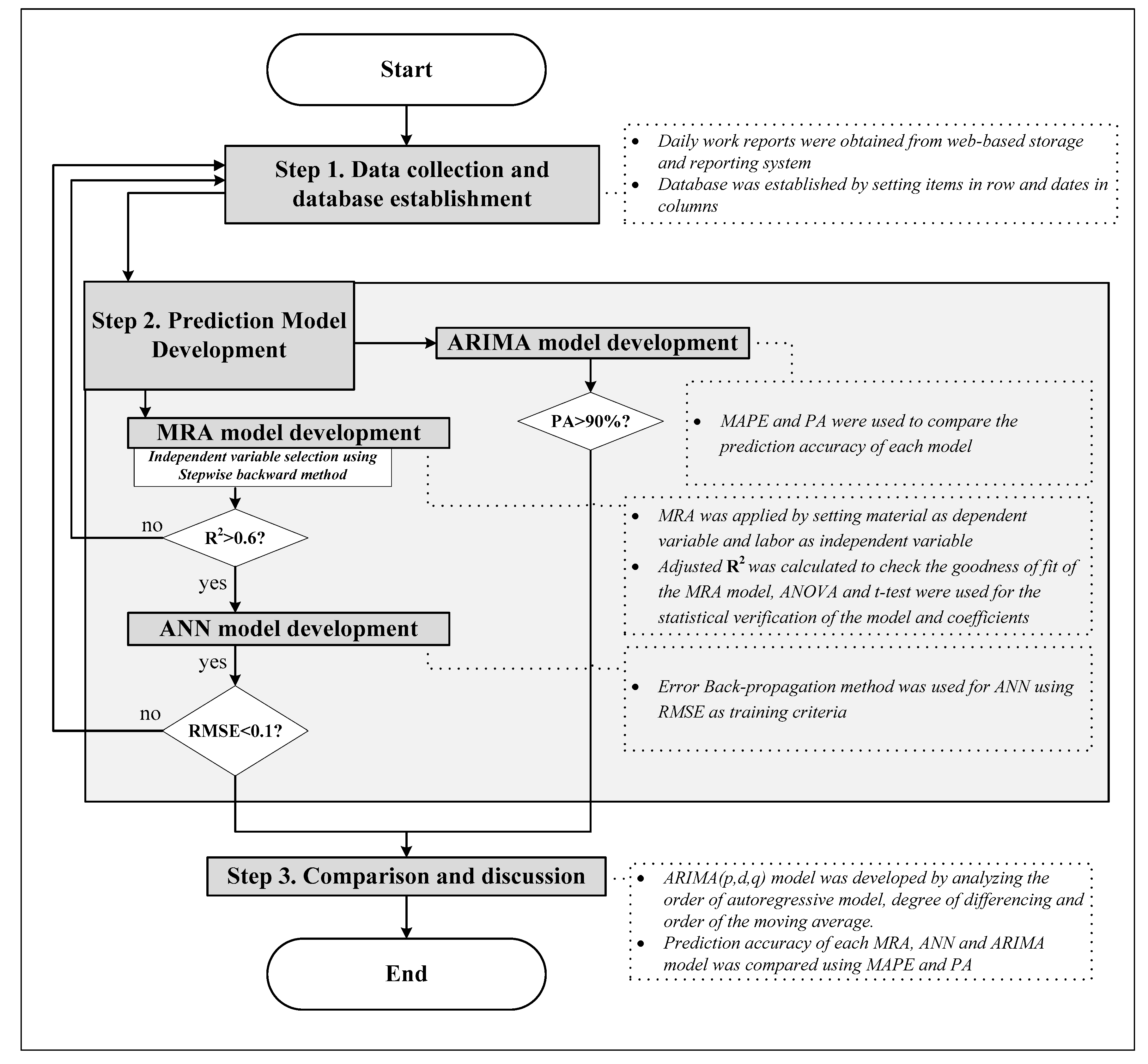
Figure 1. Predictive methods are used in this study to analyze specific trends of the cumulative amount of material, which must be managed to compare the current amount used with the total amount required to finish the operation. This analysis is similar to that of EVMS, where the cumulative cost is the main comparison criterion for planned cost versus actual cost. The duration of the operation can be predicted by estimating the time required for the actual cumulative amount of material to reach the total amount estimated based on the quantity take-off. The analysis procedure is shown in
Figure 2.
MRA is a statistical method that has been widely applied in various fields. The method considers the relationship between dependent and independent variables and suggests a prediction model and has been analyzed and developed in various studies [
25,
26,
27]. MRA has advantages of suggesting prediction models in the form of simple equations and providing statistical results that show the relationship between each independent and dependent variable. Analysis of variance (ANOVA) was used to verify the MRA models, and a
t-test was used to verify the coefficients. The multicollinearity was tested using the Variance Inflation Factor (VIF), and the Durbin–Watson statistic was used to test the autocorrelation of the dependent variable. Equation (1) is a typical formula of MRA models:
where
is a constant value,
is a coefficient of
,
is an independent variable, and
is the dependent variable.
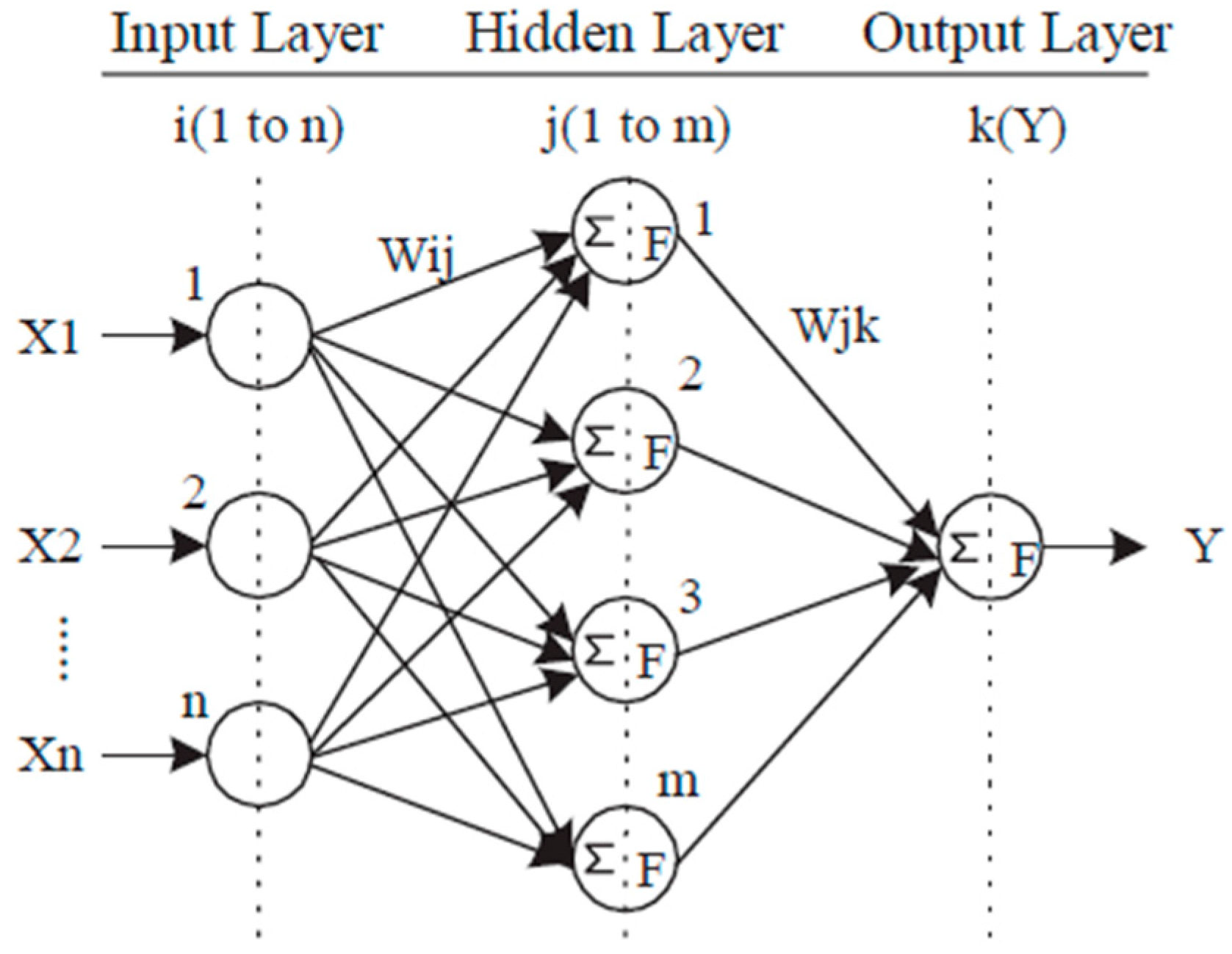
An ANN is a computer system that simulates the learning process of human neurons. Among the various training methods, the Back Propagation Network (BPN) method is the most widely used because of its effectiveness and short learning time [
28]. The BPN method was used to develop a prediction model with the basic network structure shown in
Figure 3 [
29]. The neurons in the input layer do not perform calculations, while the neurons in the hidden layer perform summations and functions. There are various functions for such ANN structures, but this study uses the hyperbolic tangent function. The mathematical expression for the basic structure of the BPN is shown in Equation (2):
where
is the output of the neuron,
is the threshold of the neuron, and
is the transfer function.
The main task of the ANN is to update the connection weights until the total error reaches a desired value that is defined by the user. An appropriate target error must be defined so that the system will converge. Although the ANN provides precise predictive results, it does not provide the same results as MRA. The ANN results vary according to the training. However, the prediction results are generally more accurate than those of MRA. An ANN was developed using a sensitivity analysis of the number of neurons in the hidden layer, error back-propagation, and thresholds that give the lowest root mean square error (RMSE). Equation (3) is used to calculate the RMSE:
ARIMA is used to analyze the trends of datasets that change based on the same time units, such as weeks, months, or years. ARIMA is designed for stationary time series of data with constant statistical properties such as the mean and variance. Prior to developing ARIMA models, the periodic variations and systematic changes must be identified and removed [
30], which was done using an autocorrelation function (ACF). In general, ACFs for non-stationary data differ significantly, depending on the number of time lags. This can be solved by using a differencing method to calculate the differences of the series and create a new series. The original data can be changed from non-stationary to stationary by identifying the appropriate amount of differences.
The order of the autoregressive and moving average are deduced based on the behavior of the ACF and the partial autocorrelation function (PACF). The ARIMA is then deduced based on the autoregressive moving average (ARMA) for a non-stationary dataset that has been changed to a stationary dataset. Equation (4) is a typical form of ARMA models:
where
is a constant value,
is the forecast target variable at time
t;
and
are the coefficients of the AR and MA models;
is the forecast value of
at time (
); and
. The model identification procedure based on ACF and PACF is shown in
Table 1.
Since the original material and labor data are not time series data, a time series dataset was obtained by calculating the cumulative amount of material as Equation (5):
ARIMA models were tested by changing the order of the autoregressive model (), degree of differencing (), and order of the moving average (). The model with the highest prediction accuracy was selected.
The data extracted from the daily work reports were divided into three groups. A dataset of the last four weeks was set aside for later comparison of the ARIMA models to the MRA and ANN. For the rest of the data, 90% were used to develop the MRA and ANN models, and 10% were used for verification. All of the models were implemented using the computer language R version 3.2.4 in R Studio. The
function was used for MRA,
was used for ANN, and
was used for ARIMA. The prediction accuracy of each model was calculated using Equations (6) and (7) based on the mean absolute percentage error (MAPE) and prediction accuracy (PA):
A case study using actual data was conducted with focus on the structural operation, which represents over 50% of the total duration of a construction project [
31]. Lee (2009) suggests that the structural operation represents 40–60% of the total project cost [
32]. This study focuses on the rebar installation, which is the most labor-intensive part of the structural operation. This is important because if the operations are more labor-intensive, stronger relationships are expected between materials and labor. Accordingly, a part of the database related to rebar installation was used to apply the predictive methods. As a result, a dataset representing 37 weeks was obtained with one material item (rebar) and five labor items. The data were obtained from an office building project in a metropolitan area in Yongin, Kyeonggi-Do, South Korea. The main properties of the project are summarized in
Table 2.
A set of 699 daily work reports was obtained for the case study. The reports include 35 types of materials, 26 types of equipment, and 90 types of labor used during 699 calendar days. A matrix-form database consisting of 151 rows and 699 columns was established based on the quantitative data extracted from the reports. The data are summarized in
Table 3.
is the amount of rebar in units of tons;
is the amount of labor dealing with metal;
is the amount of foremen;
is the amount of rebar installers;
is the amount of labor dealing with concrete; and
is the amount of labor dealing with forms (installation and dismantling).
4. Results
The MRA models were first developed by setting the amount of rebar () as a dependent variable and the amounts of labor (–) as independent variables. A stepwise backward method was used to develop the models. This method is used to obtain the best dependent variables to use in the MRA model. The results provide a model with an of 0.654, an adjusted of 0.607, and a standard error of the estimate of 15.713. The Durbin–Watson statistics were calculated as 1.186, which means that there was no severe autocorrelation.
The ANOVA results show that the model is adequate (
F-statistics: 13.846,
p-value: 0.000).
,
, and
were chosen as a result of the stepwise backward method. The
t-test results of the coefficients are summarized in
Table 4. All VIF values are lower than 10, which means that there is no multicollinearity between the dependent variables. The resulting MRA model is shown in Equation (8).
The ANN was then applied by setting
as a dependent variable and
,
, and
as independent variables. A sensitivity analysis was carried out for the number of neurons in the hidden layer, and the best model was produced using two neurons. The resulting RMSE was 9.992.
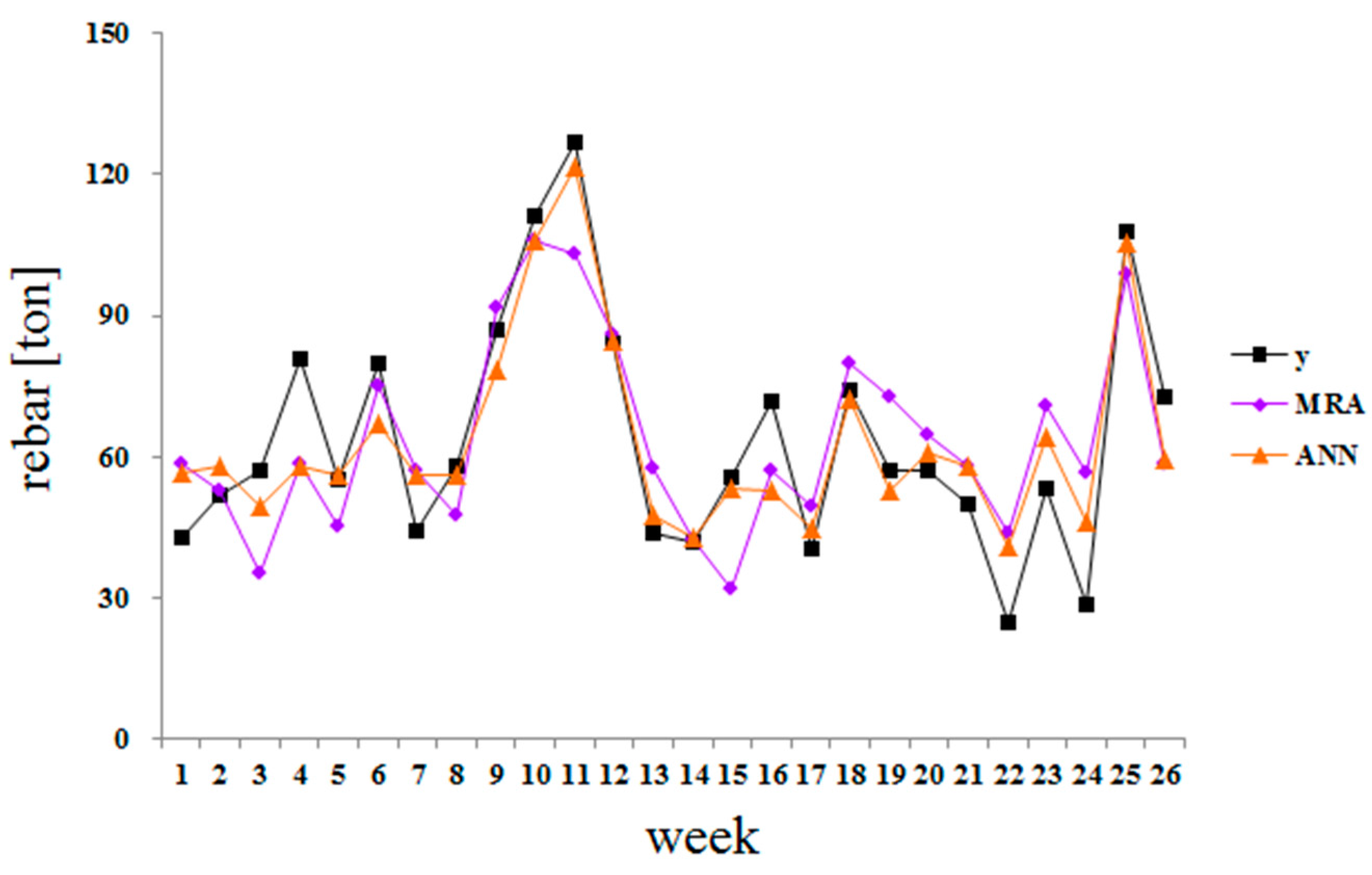
Table 5 shows the MAPE and PA values of the MRA and ANN for both the training and test data, and
Figure 4 shows a graph comparing the actual values to the estimated values.
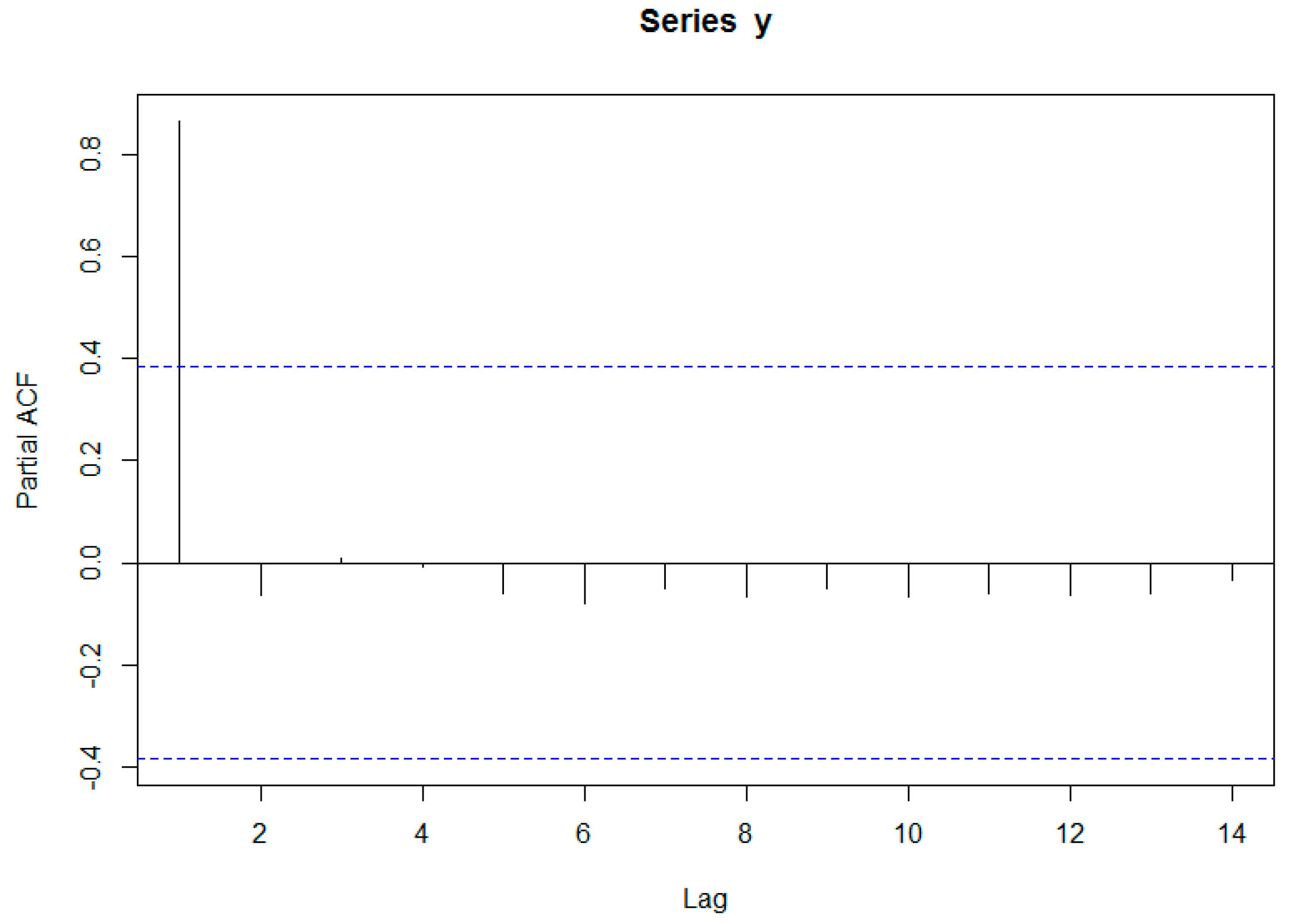
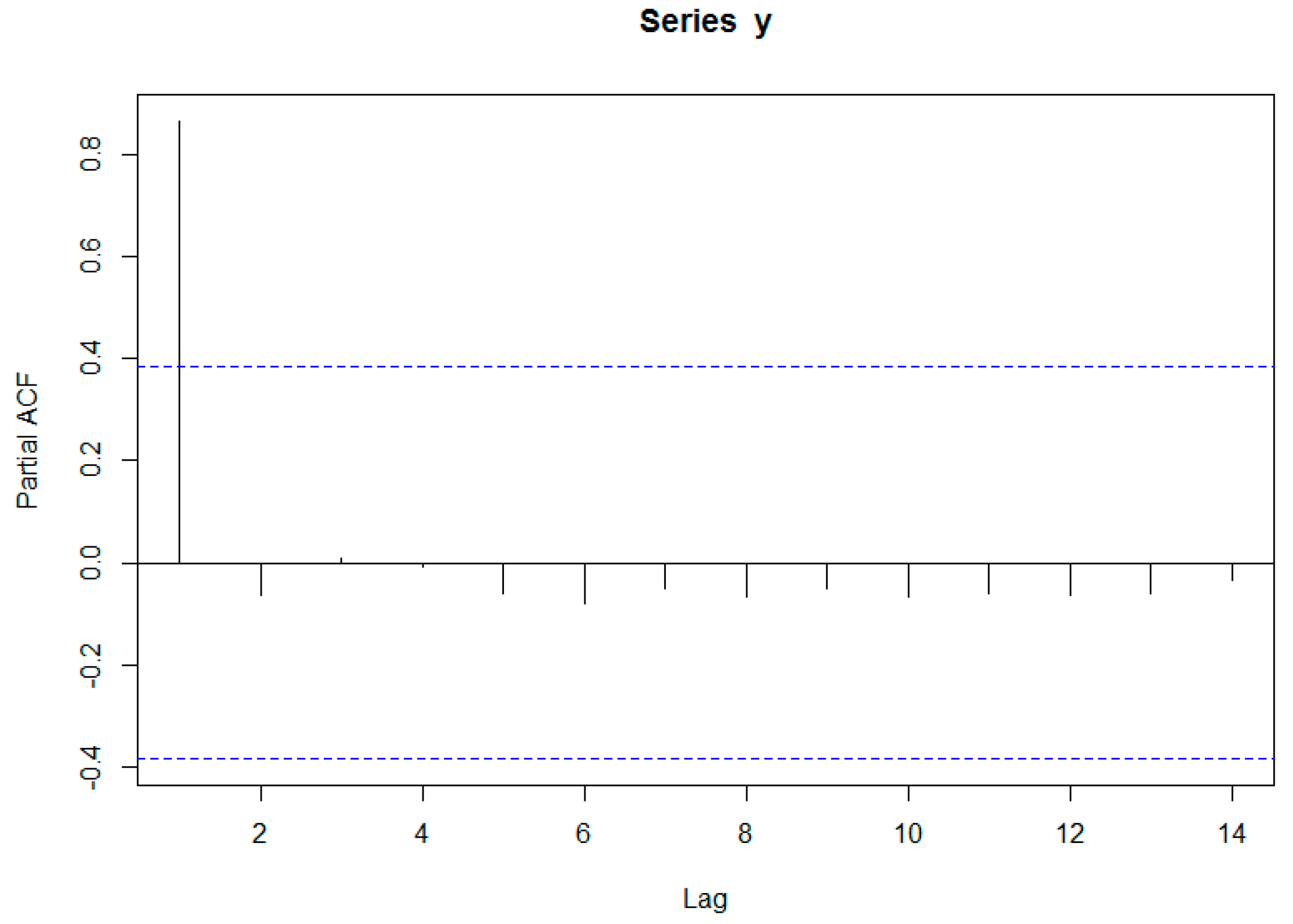
For the ARIMA models, the ACF and PACF were plotted to investigate whether or not differencing is required, as shown in
Figure 5 and
Figure 6.
is the cumulative amount of rebar calculated by Equation (5).
As shown in
Figure 5, the ACF decreased very slowly, which indicates that the data are not stationary and require differencing. One differencing was sufficient to make the rebar data stationary. The results show that AR(1) is the most adequate model. Accordingly, after adding a differencing term, the ARI(1,1) model was selected as the most adequate. The final model can be expressed as Equation (9):
where
is the AR(1) parameter estimate, which was computed as 0.31. The constant
is 64.26, and
is an error term. The MAPE of the model was calculated as 3.62, and PA was 96.38%.
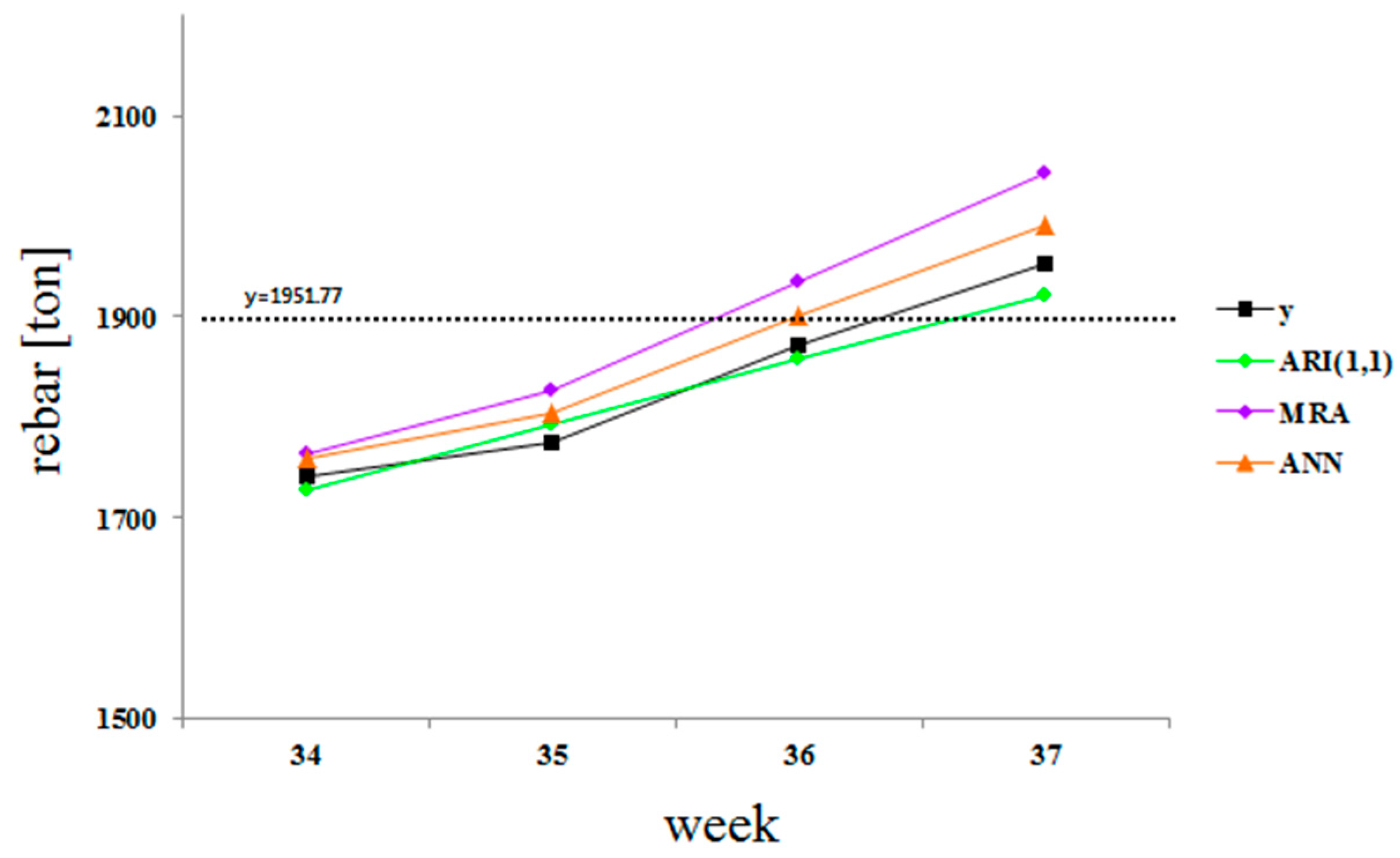
The MRA, ANN, and ARI(1,1) models were then tested to predict the duration for the remaining work. The actual operation was conducted in 37 weeks. Data from the first 33 weeks were used to develop and verify the models. The cumulative amount of rebar installed until week 33 was estimated as 1656.44 tons, and the total amount of rebar estimated for completion was 1951.77 tons. Therefore, the MRA and ANN were tested by applying the actual amount of labor to these models and determining if the prediction results match 1951.77 tons. The results were compared with the prediction results of the ARI(1,1) model, which predicts the cumulative amount of rebar based on the time series trend.
Figure 7 shows a graph of the results, and
Table 6 shows the MAPE and PA calculated for the four-week period.
5. Discussion
The analysis carried out in the previous chapter dealt with the application of Step 2. In
Figure 2, MRA and ANN were used to develop predictive models based on the relationship of material and labor. The estimated values by MRA and ANN were recomputed as cumulative data using Equation (5) for the comparison with ARIMA. ARIMA was used to develop predictive models based on the time series trend of material. The results show that ARI(1,1) had the best prediction accuracy of 98.99%, followed by 84.27% for ANN. MRA had the lowest prediction accuracy of 61.27%. The ARI(1,1) model successfully estimated the duration for remaining work with 98.99% accuracy. Thus, the model could be used to predict that four more weeks are required to finish the remaining work for this operation if the current trend in the amount of material used is maintained. The MRA and ANN models could also be used after modification in future studies.
These results indicate that the rebar installation is more affected by the time series trend than the relationship with the amount of labor. For further development of the research methodology, other prediction methods must be tested to obtain higher prediction accuracy than that of the typical ANN and MRA. Despite the low prediction accuracy of MRA, this step was essential for deducing the most significant independent variables, which were used to develop ANN models. Unlike MRA, ANN produced an acceptable prediction accuracy that can be used for adjusting the labor management plans for remaining work. Personnel at a construction site can use these models as reliable references for the estimation of the amount of labor required to finish the remaining work.
The amount of time required to finish the remaining work can be also determined by the ARI(1,1) model. The results of the case study show that a similar time series trend continued until the end of the operation. Thus, ARI(1,1) produced high prediction accuracy. However, more projects must be analyzed to suggest more generalized results. Considering that the case study was a typical office building project in a metropolitan area, different projects with more repetitive operations are expected to result in higher prediction accuracy for MRA and ANN. This is expected due to the higher size of data samples, which has a significant influence on the prediction accuracy of the models. Accordingly, future studies are needed to optimize the prediction results for both the amount of labor and time series trends for practical applications in construction projects.
The proposed methodology shown in this study could also be used in the planning phase prior to construction. The developed prediction models could be used as a reliable reference for similar construction projects in the future for more reliable labor and progress management. This procedure requires systemization of the suggested methodology to generate a database automatically based on the quantitative data stored in daily work reports. Such systems can be used for developing prediction models for various types of projects.
6. Conclusions
This study has proposed a material-based progress management method using predictive methods based on MRA, ANN, and ARIMA, which were quantitatively compared. The results have shown that the time series trend has more of an impact than the amount of labor. However, the methods used for the relationship analysis of materials and labor were typical types of MRA and ANN. It is expected that higher prediction accuracy can be achieved by applying enhanced MRA and ANN models such as nonlinear regression, as well as other training methods for ANN rather than the traditional BPN.
This study also presented how to use these methods as a reliable reference for construction site managers for effective scheduling. In general, decision making for such purposes is done based on the experience of the practitioners, which cannot be neglected. However, reference models such as those suggested in this study should also be used to avoid critical misjudgments that could result in serious cost overruns and delays. The proposed methods are expected to contribute to the further development of Project Management Information Systems (PMIS) for general contractors and construction managers, which can be used effectively for scheduling based on actual data analysis.
The contributions of this study can be summarized from two main perspectives. The data deduced from daily work reports can provide significant information on the progress management in construction sites. Also, the typical types of MRA, ANN, and ARIMA can be used efficiently for construction data, which generally produce lower prediction accuracy than in other industries. The new approach to progress management based on materials is expected to be more accurate than using cost since variance is smaller.
More cases and more methods must be tested in future work, since the present study analyzed only one project as a case study. Moreover, systemization of the proposed methodology is expected to be very beneficial for the enhancement of current PMIS systems for general contractors, who have massive amounts of daily work report data. The development of a system that automatically extracts material and labor data from daily work reports will provide a better chance for the analysis of various types of construction projects and will help to secure sustainable management of construction data for future projects.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}