2.2. Fixed Range Normalization
As mentioned in the previous section,
GS is a function of two metrics,
WV and
MI.
WV measures intra-segment variability and can be considered as an undersegmentation evaluation metric. It is reasonably assumed that as spectral variance within objects decreases, so does undersegmentation.
WV is described in Equation (1):
where
n is the number of segments,
is the variance and
the area for each segment, respectively. In a similar fashion,
MI is used as an oversegmentation evaluation metric. As
MI decreases, neighboring objects are more spectrally discrete from their neighbors and as such, oversegmentation is assumed to also decrease.
MI is the most widely used indicator of spatial autocorrelation in modern geography and is typically represented as in Equation (2) [
35]:
where
n is the number of data points
, zi =
xi −
,
is the mean value of
x,
M =
and
wij is the element of the matrix of spatial proximity
M, which depicts the degree of spatial association between the points
i and
j [
36]. In the above description
x refers to the value of the variable we are testing for spatial autocorrelation—in this case a spectral band. The matrix of spatial proximity was constructed by using the common borders approach. In detail,
wij = 1 when
j shares a boundary with
i and
wij = 0 elsewhere [
37]. The normalization of these two measures (0–1 range) follows the implementation of Espindola et al. [
19]:
where
Xn is the normalized
WV (or
MI),
Xmax is the maximum
WV (or
MI) value of all candidate segmentations,
is the minimum
WV (or
MI) value of all candidate segmentations and
X is the
WV (or
MI) value of the current segmentation. The
GS is the sum of these normalized values:
As the optimal value of
GS is critically affected by the range of the considered segmentations, Böck et al. [
31] proposed to use a fixed minimum and maximum segmentation range based on the most extreme empirical and theoretical values of
WV and
MI, respectively. For
WV, the finest scale that can be achieved is when each image pixel represents a segment and thus, having a variance value of zero. On the contrary, the end range is defined by the situation were the whole image consists of a segment that can be derived by computing image variance. For
MI, the two extreme values of −1 and 1 are chosen in a way that corresponds to situations where maximum negative and positive spatial autocorrelation is achieved.
The main flaw of this approach rests in the fact that it mixes theoretical distributions with empirical data. To further elaborate on this, let us imagine the situation were WV is in the absolute maximum, i.e., image variance. In this case, the computation of MI is not possible as it requires a neighboring network and thus, the equivalent value for MI is unknown. Similarly, when the value of MI is −1, the true value of WV is unknown. Moreover, it may not be plausible that an RS image can have a MI of −1 and more so to arbitrarily assume that it would correspond to a WV value of image variance. On the contrary, with maximum negative autocorrelation, WV values might be particularly low. As such, not only do these values not correspond to each other, but also it is unknown if these values can actually be produced from empirical data.
For the traditional implementation of normalization [
20] this is not a problem as both
WV and
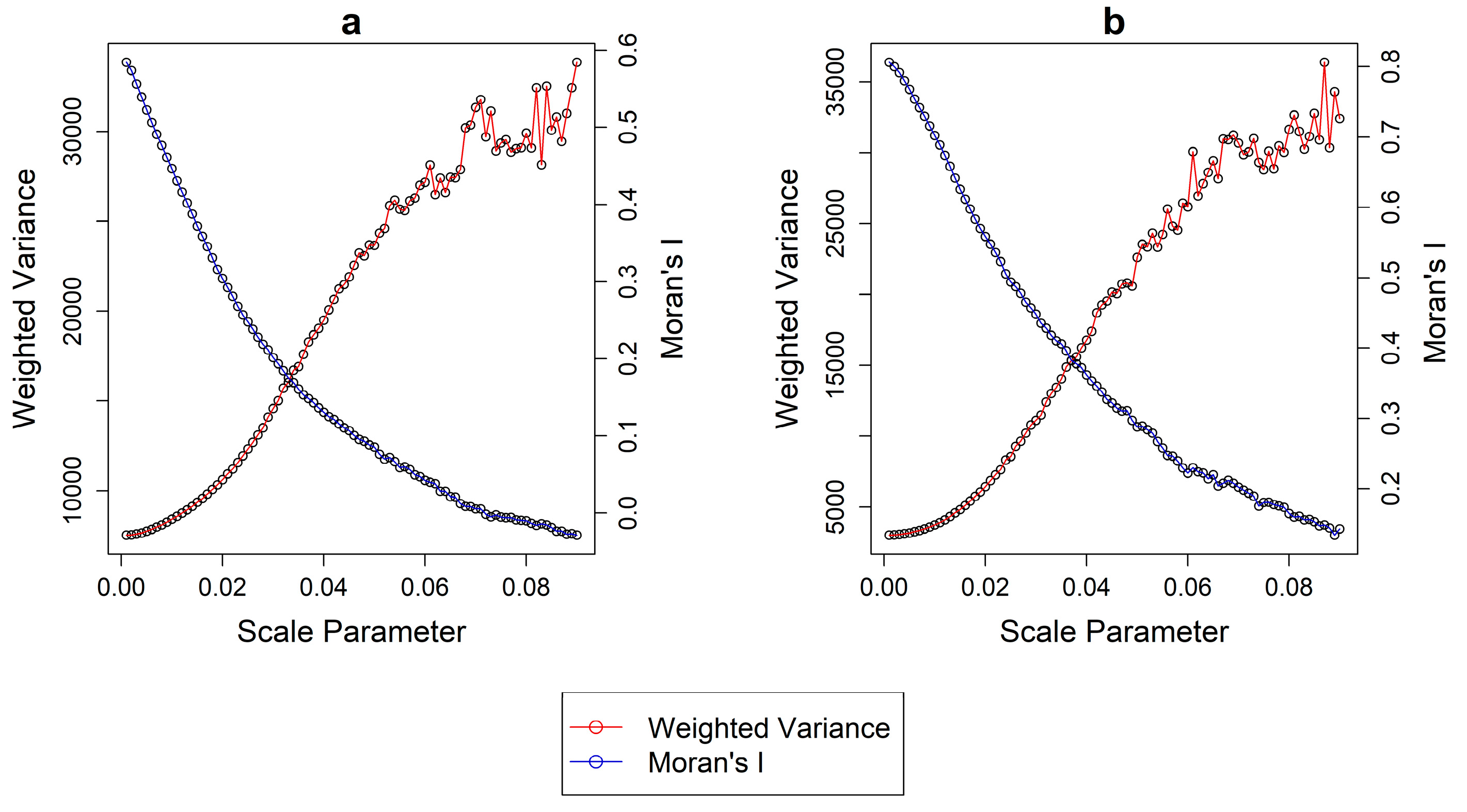
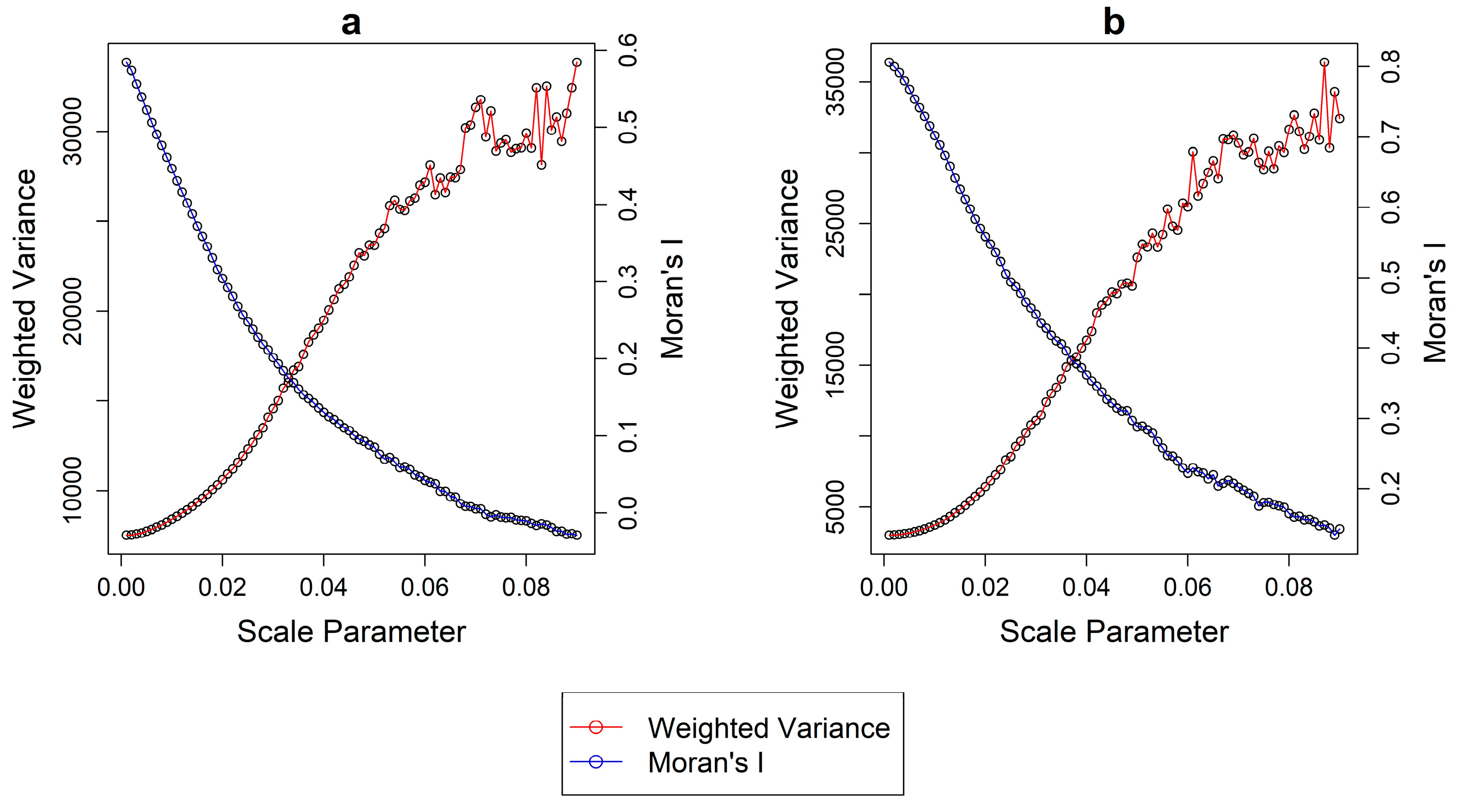
MI values are known for each segmentation. To illustrate this, we applied the approach in the two regions of interest (ROI). We computed 90 segmentations with an incrementing scale parameter starting from an extremely fine scale to an extremely coarse one. It should be noted that the scale parameter here is different from the one of eCognition [
38]. In the “i.segment” module of GRASS, the decisive merging “threshold” parameter ranges from 0 to 1, with 0 leading to the creation of no segments at all, while 1 represents the merging of all pixels. In the case of the two ROIs in this image, values between 0.001 and 0.09 include all relevant segmentations as suggested by the extreme shift of
MI and
WV in
Figure 2. Finally, a step of 0.001 was used.
Table 1 shows the absolute values of
WV and
MI for each case study, respectively. It should be noted that we employed a multiband approach where each of the metrics was computed per single band and then averaged the results [
20,
34].
By applying the normalization procedure using these values as the min/max, spurious results were produced.
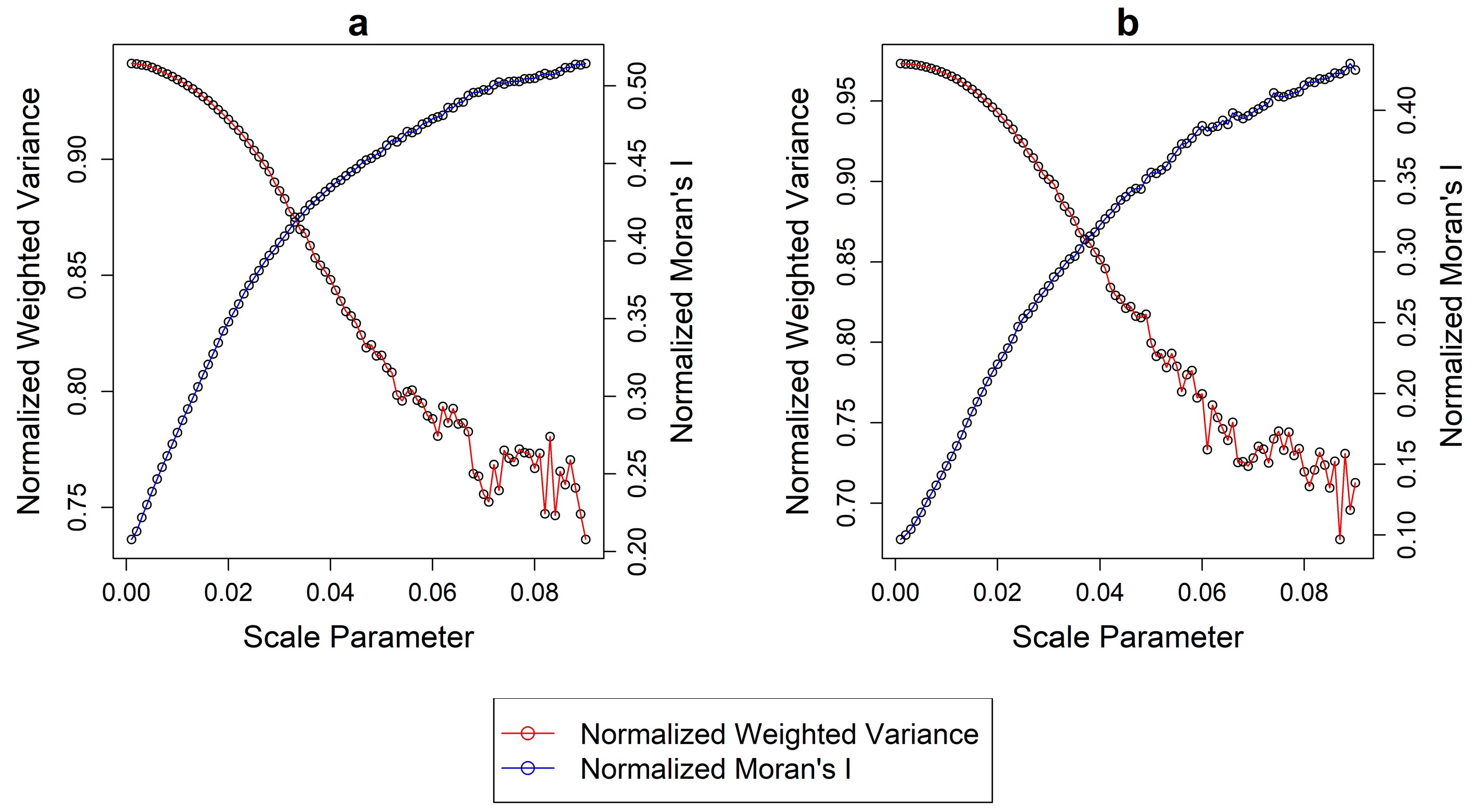
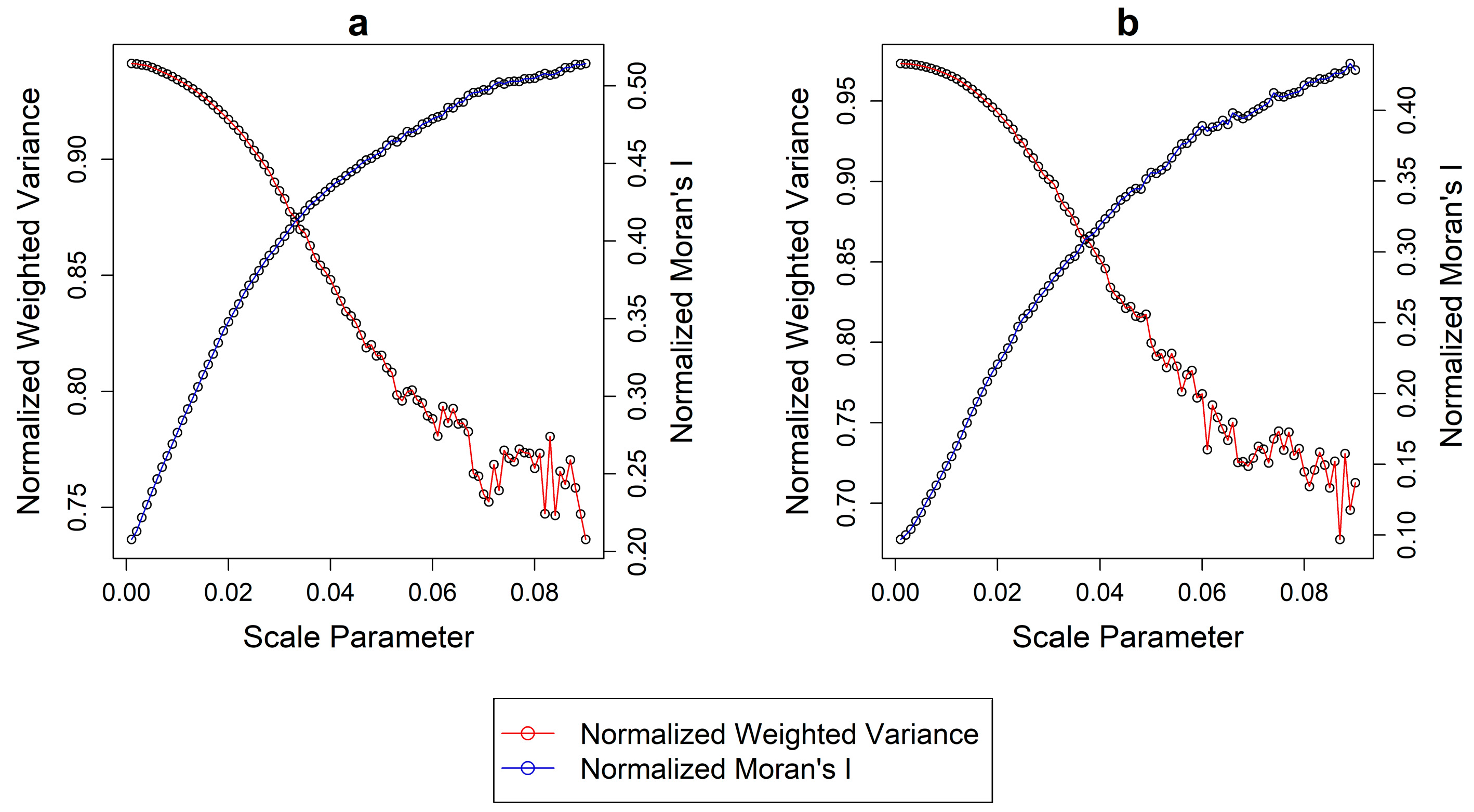
Figure 3 illustrates the Normalized Weighted Variance (
WVn) and Normalized Moran’s I (
MIn) plotted against each segmentation scale in a similar fashion as before. It is evident that the range of values (i.e.,
MIn maximum–
MIn minimum) of the two metrics is intrinsically different among them and in both regions. The range of
WVn for the two regions is 0.20 and 0.29, respectively. On the contrary the same values for
MIn are 0.31 and 0.34. In a normalization process, unequal ranges in the values is an indicator of bias towards one or the other metrics. This suggests that by using the FT method the
GS is biased towards
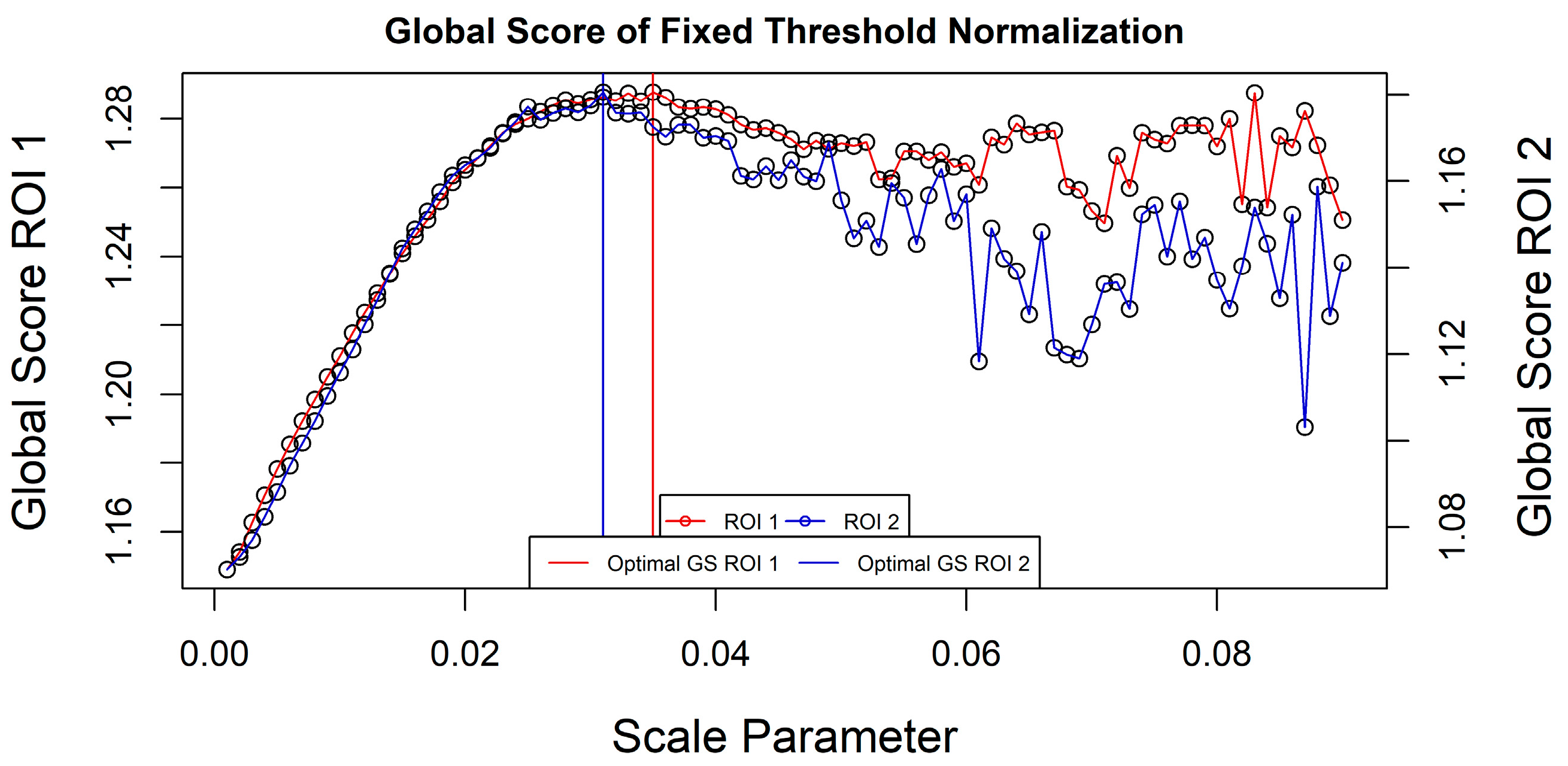
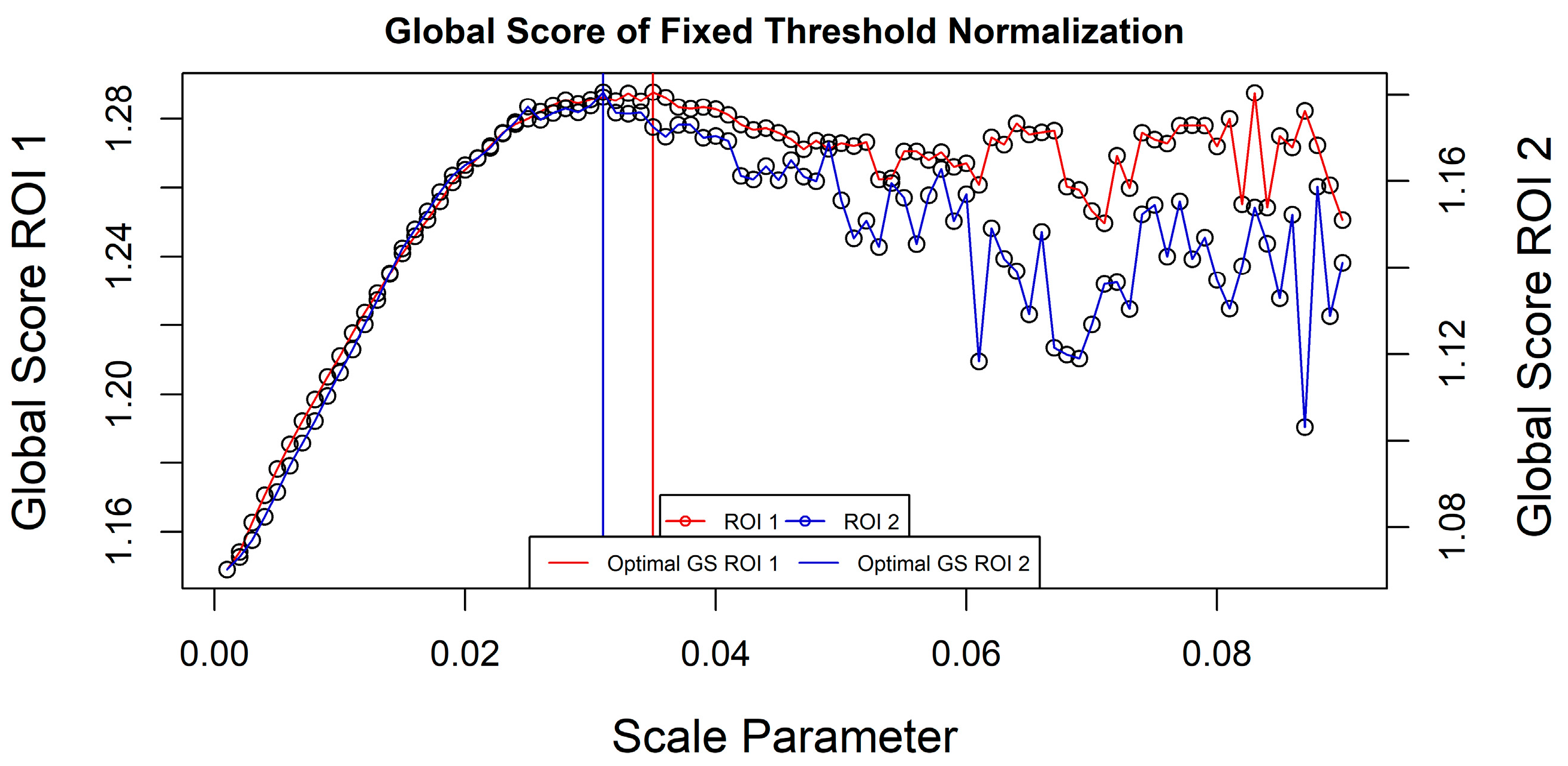
MI (which has a larger range) and as such, segmentations with potentially undersegmented objects might be suggested as optimal. The optimal
GS values for ROI 1 was found with a scale parameter of 0.035 while for ROI 2 a scale value of 0.031 was suggested as suitable (
Figure 4).
2.3. Selection of Relevant Ranges Based on Local Regression (LOESS) Trend Analysis
Given the methodological concerns that come with the approach described above, an alternative solution is to focus on selecting relevant ranges for the normalization before computing the
GS in an objective and meaningful manner. Our proposed solution revolves around detecting variability shifts in the rate of change of
WV and
MI values. Erratic behavior in these trends can suggest the maximum limit for a reasonable segmentation range to be considered for normalization. The rate of change of variability and autocorrelation metrics such as
WV and
MI are useful indicators that can detect changes (e.g., shift to oversegmented scales). Drǎguţ et al. [
18] used the rate of change in Local Variance to suggest optimal segmentation parameters with the ESP tool. Instead, we are looking for segmentation ranges to apply the traditional
GS USPO procedure.
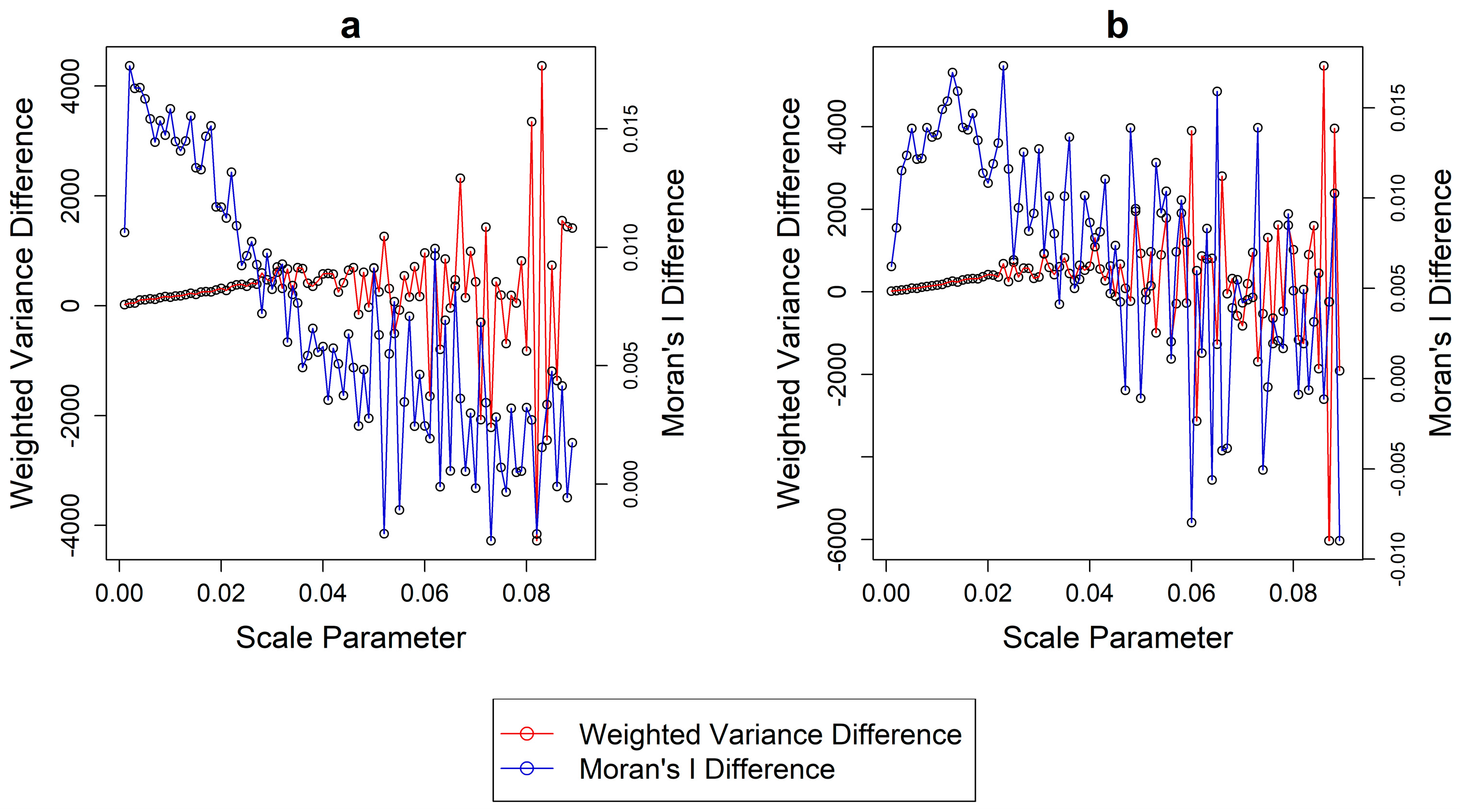
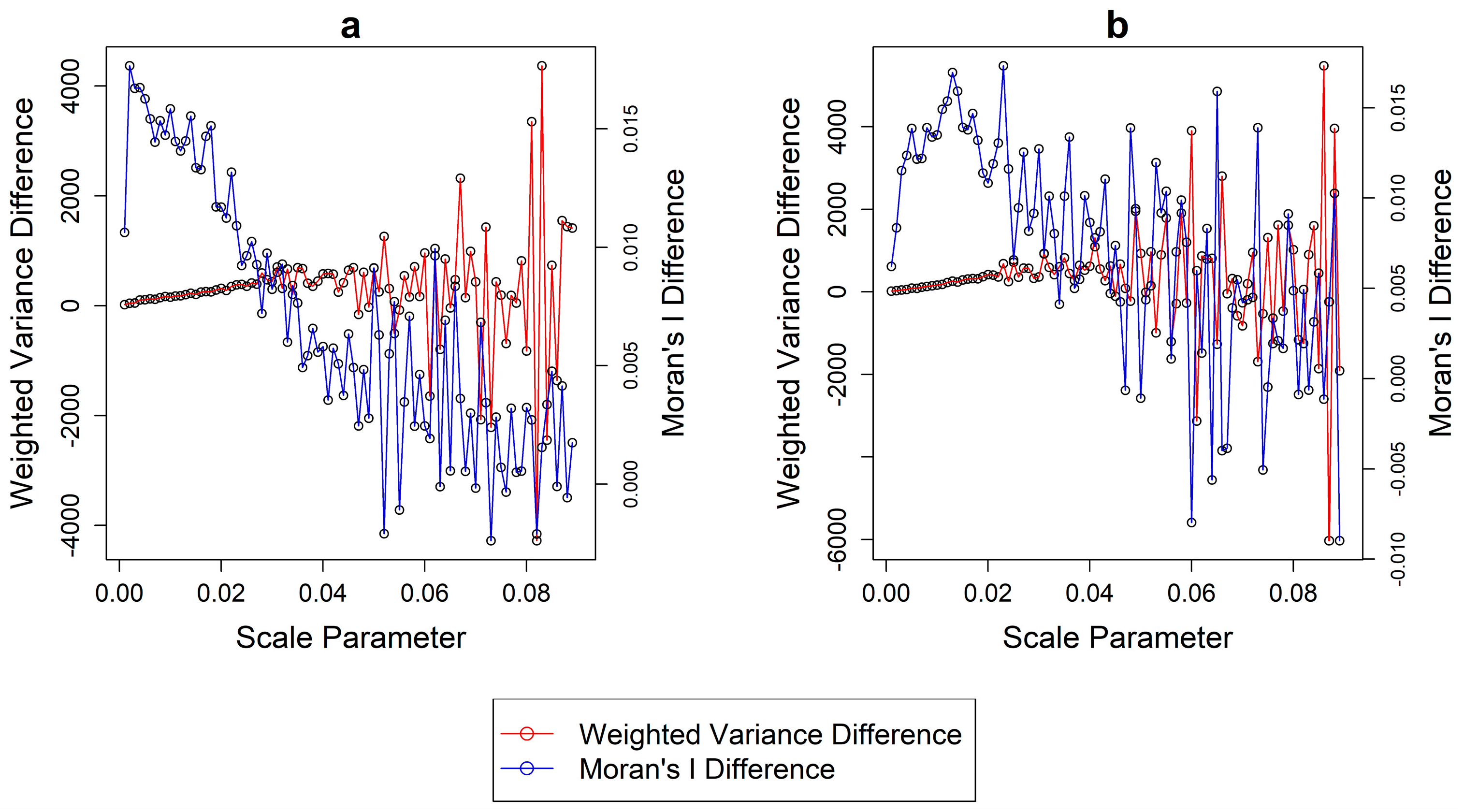
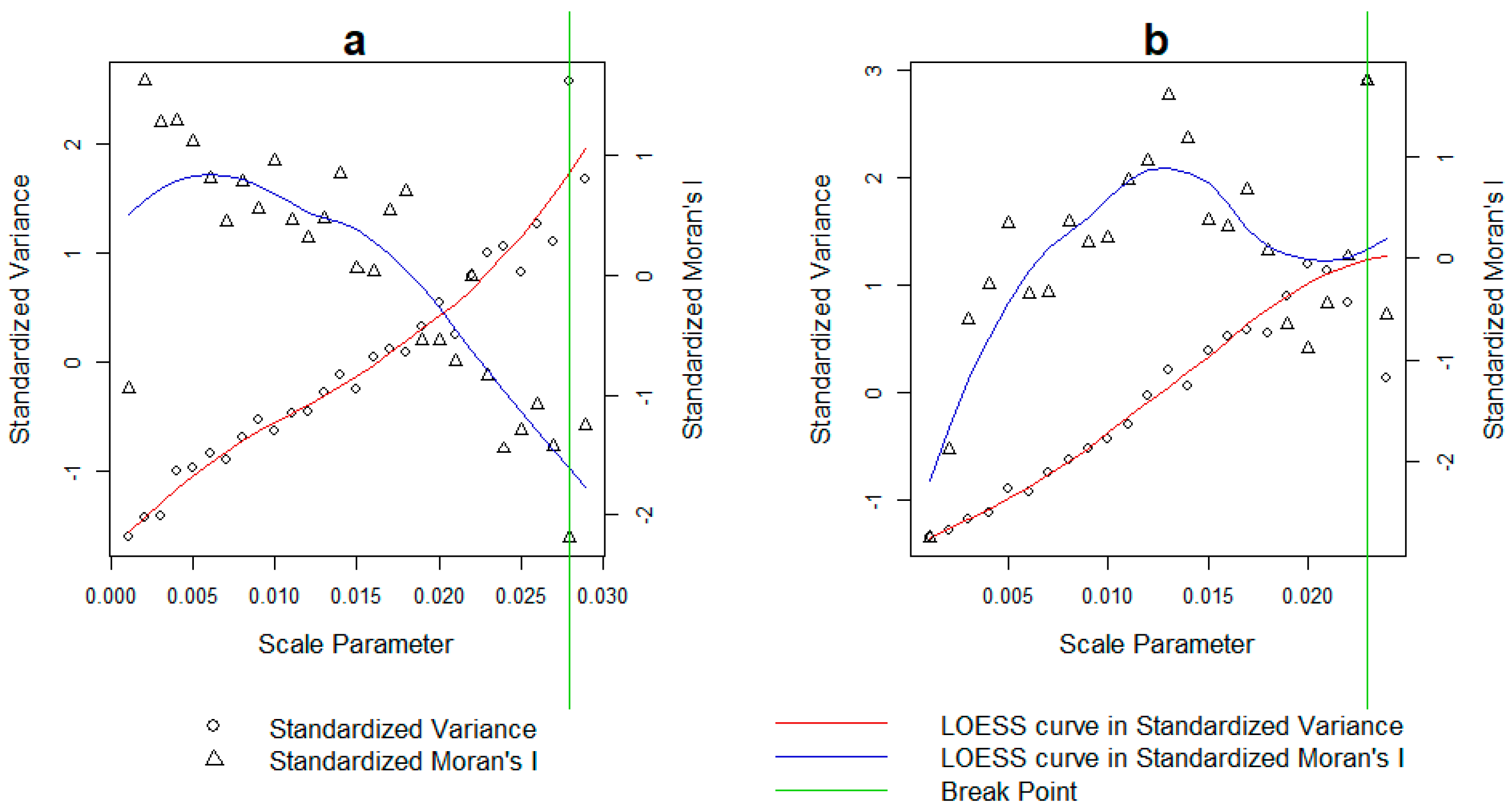
Figure 5 shows the difference for each of the two metrics from each segmentation layer and the next and for each ROI, respectively. Notably, erratic behavior and instability is found for both metrics starting at a segmentation scale of 0.020, which becomes apparent visually after a scale value of 0.030 and onwards, in both datasets. Including segmentations beyond this value can add bias to the normalization process as the rates of change for both metrics display an intrinsically unstable behavior. This is due to the large, sudden and irregular changes in the objects size and composition in too heavily undersegmented layers.
Since computing an extremely large amount of segmentations, investigating the trends and visually assessing the point of instability might be a subjective process and time inefficient, we propose an automated solution based on Local Regression (LOESS) curve fitting. LOESS partitions data into subsets and fits a low degree polynomial in each one of them. As a local regression technique, LOESS-based models are suitable methods to detect significant breaks in trends of various data [
39]. The salient steps of our solution are described as follows:
Selection of a segmentation to act as minima (fine scale) and a step value as user-based inputs. A very low scale parameter, which produces very oversegmented results, is appropriate for this task. The results of LOESS are sensitive to the step between each segmentation as the algorithm is more efficient when a lot of data points are given and as such, a very small step parameter is required in order for the trends to manifest. In our case, we used a segmentation produced from a scale parameter of 0.001 as minimum range with the same value as a step. Tests with a step parameter higher than 0.003 failed to provide reasonable results.
Consider an initial amount of segmentations and compute MI and WV values for each one. For the LOESS curve to produce meaningful results, at least a few segmentations (n~10) should be produced, as it is a local fitting method that operates in subsets of the input data.
Computing the difference of
MI (
MID) and
WV (
WVD) between a segmentation and the next coarser one:
where
MIi is the
MI value of the current segmentation and
MIi+1 the value of the next coarser one, and
WVi is the
WV value of the current segmentation and
WVi+1 the value of the next coarser one.
Standardizing the differences of each metric (standard deviation of 1 and mean of 0) as shown in Equation (7):
where
is the current value for
MID (or
WVD),
is the mean value of the
MID (or
WVD) for considered segmentations and
SD their standard deviation.
Fit a LOESS curve to the standardized differences with a second-degree polynomial. The results of the fit are sensitive to the span parameter, which controls the degree of smoothing. The default value (0.75) of the loess package in R statistical software was used.
Examine the residuals between the LOESS predictions and the raw values. Since the data are standardized, the residuals correspond to standard deviations. Residuals that are sufficiently high for both MIDS and WVDS are indicators of a break in the trends. As a rule of thumb, we can assume that a significant shift in the trends manifests when the residuals are higher than 0.4 (larger than 0.4 times a standard deviation) for both MI and WV at the same time while the sum of their absolute residuals is larger than 1. This rule assures both individual and combined evaluation of the trends.
Selecting the segmentation that satisfies the previous rule as the maximum range. If the criteria are not satisfied, compute an additional coarser segmentation by incrementing the scale parameter, and repeat from step 3.
The proposed solution is conservative in nature, as it requires the minimum amount of segmentations to be computed to select an adequate range rather than an arbitrary fixed one. In ROI 1 the criteria were satisfied at a segmentation with a scale parameter of 0.028 (
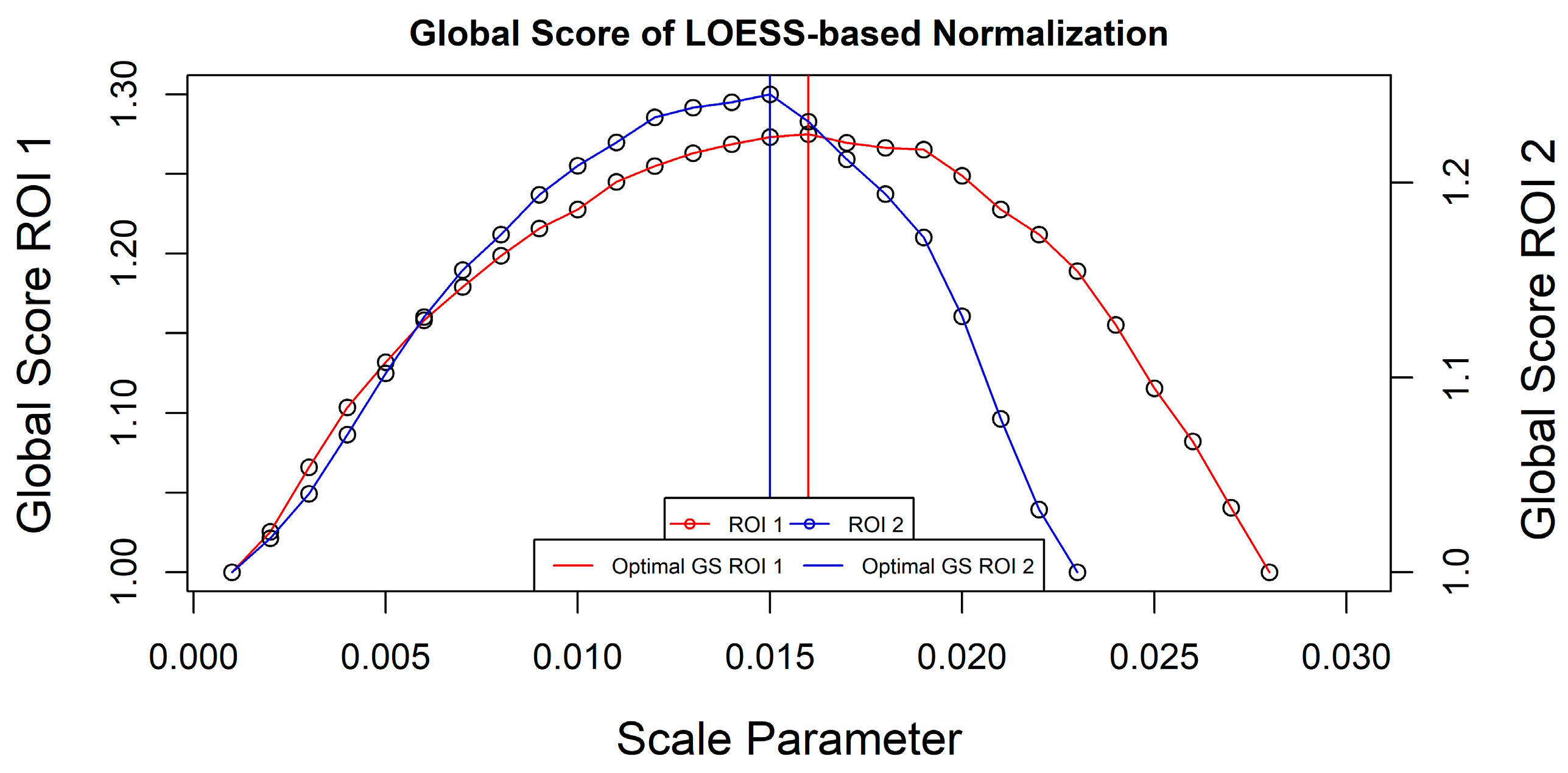
Figure 6). As a reminder, this value represents the maximum value used for the normalization. Applying this value, the optimization of the
GS was found at a scale of 0.016 (
Figure 7). For the second region, the maximum limit for normalization was 0.023 and the
GS was optimized at a segmentation produced with a scale parameter of 0.015.
2.4. Validation Scheme
To investigate the efficiency of the FT approach and the potential improvement of the proposed LOESS technique we employed a two-step validation scheme. First, we computed segmentation goodness metrics (discrepancy measures) to directly measure the quality of each segmentation method. These metrics are based on overlaying operations between produced segments and reference objects and are extensively described in several studies [
4,
16,
40,
41,
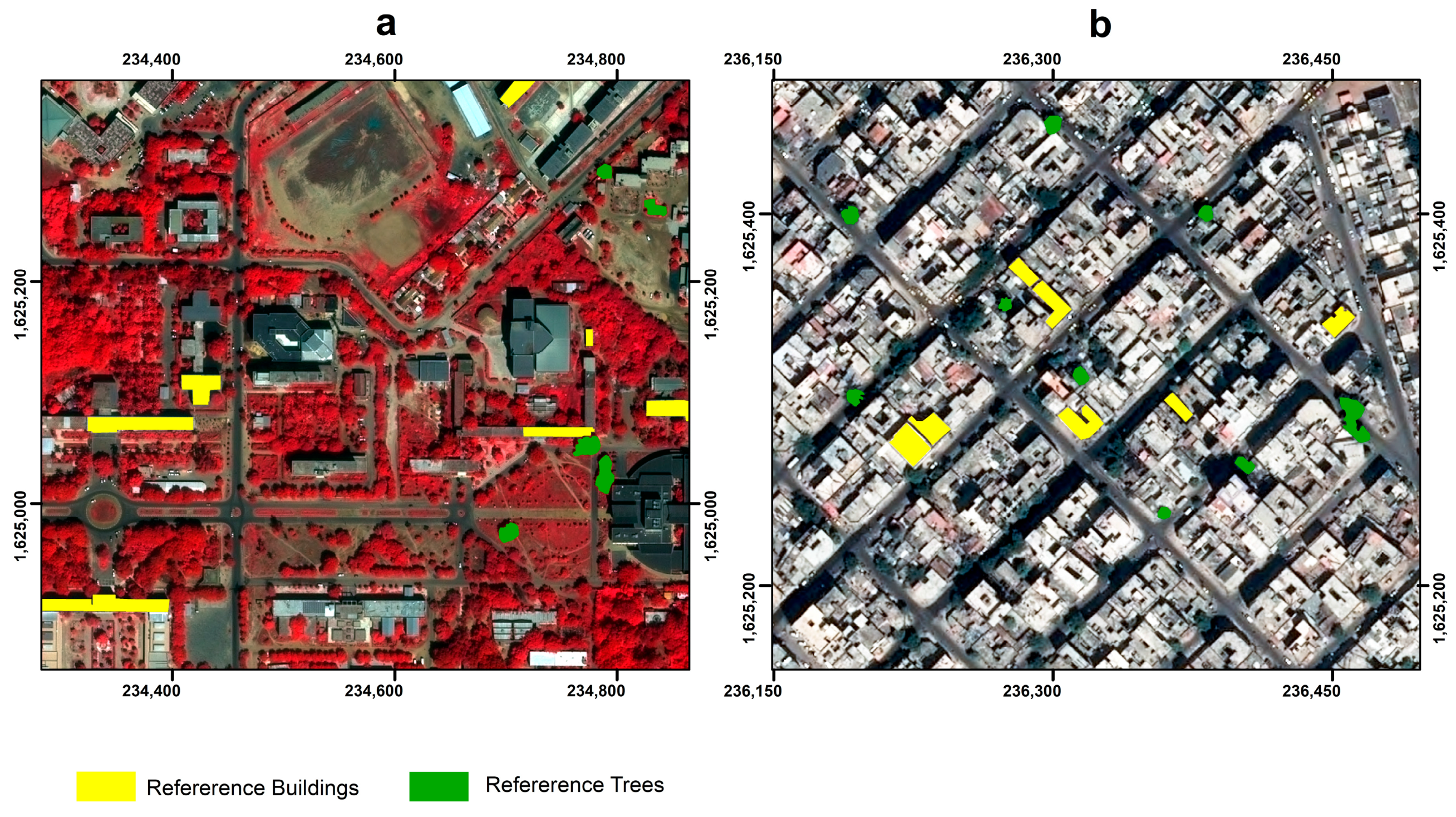
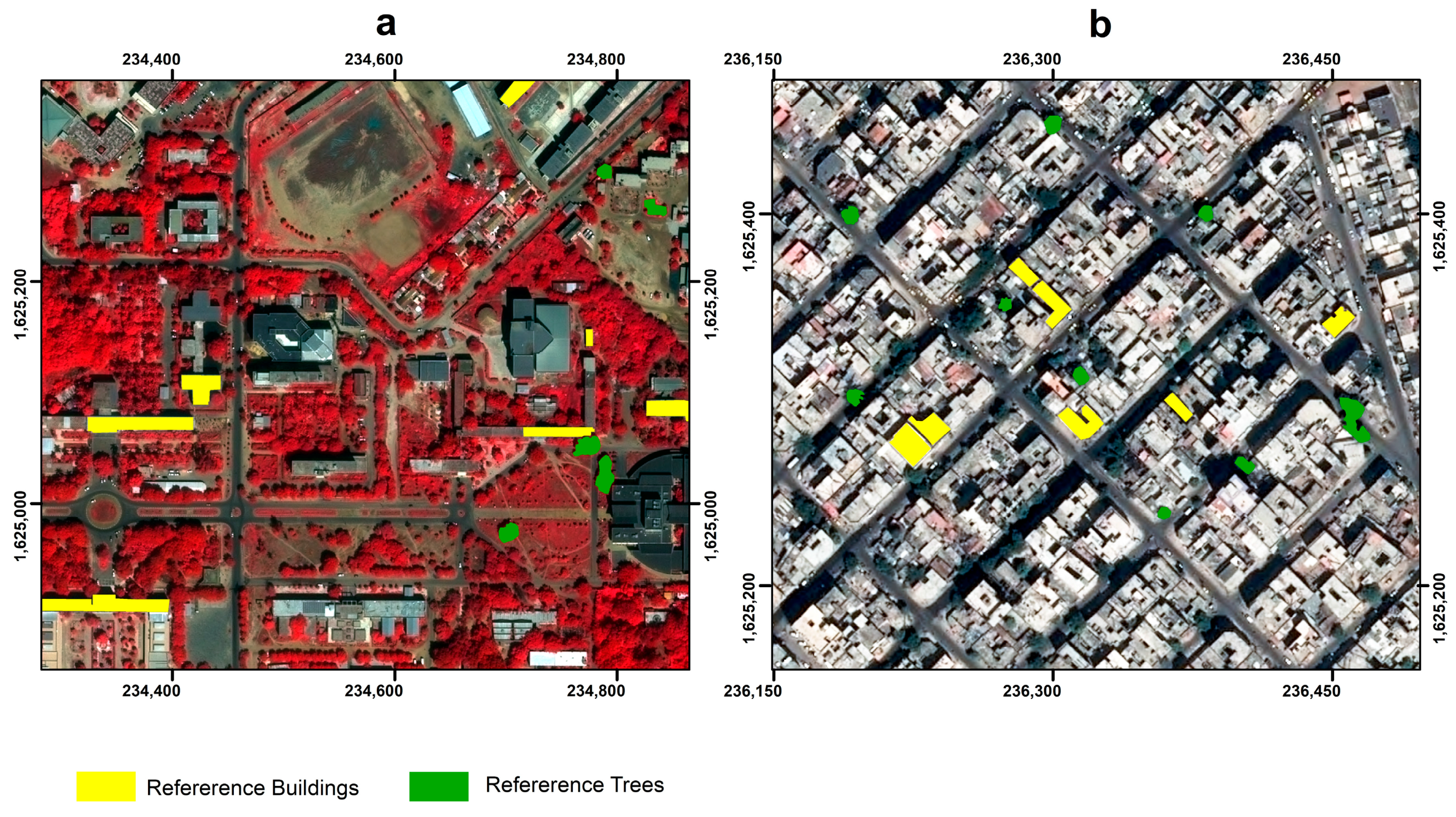
42]. We manually digitized 20 objects of interest in each ROI for the buildings and tree categories to serve as reference polygons. The objects were derived from the pool of training data used for LULC classification (
Figure 8,
Table 2). Afterwards, we computed the
Area Fit Index (
AFI) [
43], which is an area-based metric and the
MergeSum (
MS) [
16],
which is a combined measure that jointly evaluates over/under segmentation. For
AFI, values > 0 indicate oversegmentation, values < 0 indicate undersegmentation with the ideal value (perfect fit) being 0. For
MS, values closer to 0 indicate a better segmentation performance.
The second measure we used to evaluate the two methods is through the results of a LULC classification of the two ROIs. To do so, we collected 440 points across both ROIs through random sampling and we labeled them according to the specifications of the two-level classification scheme described in
Table 2. The objects underlaying the training points received the corresponding class value. Undersegmented objects were discarded, so the training sample size for each method was not exactly the same, as it would depend on the degree of undersegmentation of the image. A Random Forest (RF) classifier was used to perform the classification. Regarding the parameters of the RF models, 500 trees were selected, while the number of features to be examined at each tree node was determined from cross-validation to be 5. We used the complement of the out of the bag error (OOB; ~30% hold out training sample for each tree) as a proxy for the overall accuracy (OA; i.e., OA = 1 − OOB). The OOB has been suggested as a robust metric that can be utilized as an alternative of using an independent test set [
44]. For the scope of the study, which is comparative and not aimed on maximizing performance, the OOB was found appropriate as it has been used successfully in recent research [
45]. We considered 60 features as input to the classifier and namely descriptive statistics (min, max, median, mean, standard deviation, range, sum, 90th percent, first and third quartiles) for each spectral band, the nDSM and the NDVI, as well as geometrical covariates such as compactness, perimeter and area.
The analysis was performed with an Intel® Xeon® CPU E5-2690 (2.90 GHz, 2 processors, 16 cores, 32 processing threads) and 96 GB of RAM. The average time for the “i.segment” module of GRASS to produce a segmentation for a single scale parameter is 34 and 28 s for each ROI, respectively. For performing the USPO procedure as proposed by the authors, roughly 15 (ROI 1) and 11 (ROI 2) minutes are required. This includes the computation of the actual segmentation layer proposed by the USPO as well as descriptive files regarding the MI, WV and GS values for each considered scale parameter. The processing time requirements reported above refer to non-parallelized, single thread versions. If parallelized using the specifications of our hardware, the whole process for both ROIs at the same time would require approximately 4 min.

 ,
, 






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}