
Building Extraction from Terrestrial Laser Scanning Data with Density of Projected Points on Polar Grid and Adaptive Threshold


Abstract
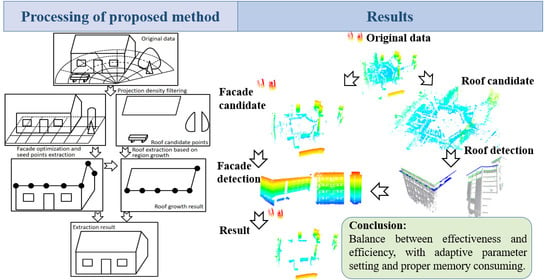
:
1. Introduction
- (1)
- Point density variation usually has more of an effect on TLS data than MLS data. The targets in an MLS scene are mainly located on the side of street; thus, the distances from different buildings to the scanner or the trajectory are similar, and the point density is relatively homogeneous. However, the case in a TLS scene can be very different, as the ranges of different objects may vary significantly, e.g., the point spacing may vary from 2 cm to 50 cm in a scene with the angular resolution of 0.02° and the largest scanning distance of 150 m. For each cell, the DoPP depends both on height difference and point density. As point density decreases with the increasing distance [37], it may occur in TLS data that a low but close object has a denser distribution of horizontally projected points than a high object from a long distance. This means that a fixed DoPP threshold may not work for data with large density variation, which holds particularly for TLS data.
- (2)
- It is hard to construct an intuitive and simple relation between the threshold and the geometric characteristics of a building, making it difficult to set a reasonable DoPP threshold [26]. Some methods partially solve this problem by calculating the point number on the surface of the farthest buildings with the lowest height [24,25]. However, this method requires a thorough knowledge of the scene in order to obtain necessary parameters for threshold calculation, e.g., the perpendicular horizontal distance from the scanner to the farthest building surface and the lowest building height. Moreover, the threshold result is still a fixed value.
- (3)
- The roof points can hardly be recognized by a DoPP method because the roof is visible from ground view only obliquely and has a more scattered horizontal point distribution.
- (I)
- We utilize a polar grid, instead of the commonly used rectangular grid, to adapt to the density variation in TLS data. The polar grid has a more balanced point distribution, as a similar number of laser beams pass through each cell;
- (II)
- We generate an adaptive DoPP threshold for each cell. After DoPP filtering, we construct an object-oriented decision tree by combining different grid features to further refine the filtering results;
- (III)
- Our method can extract roof points with region growing based on the seed points extracted from the facade points.
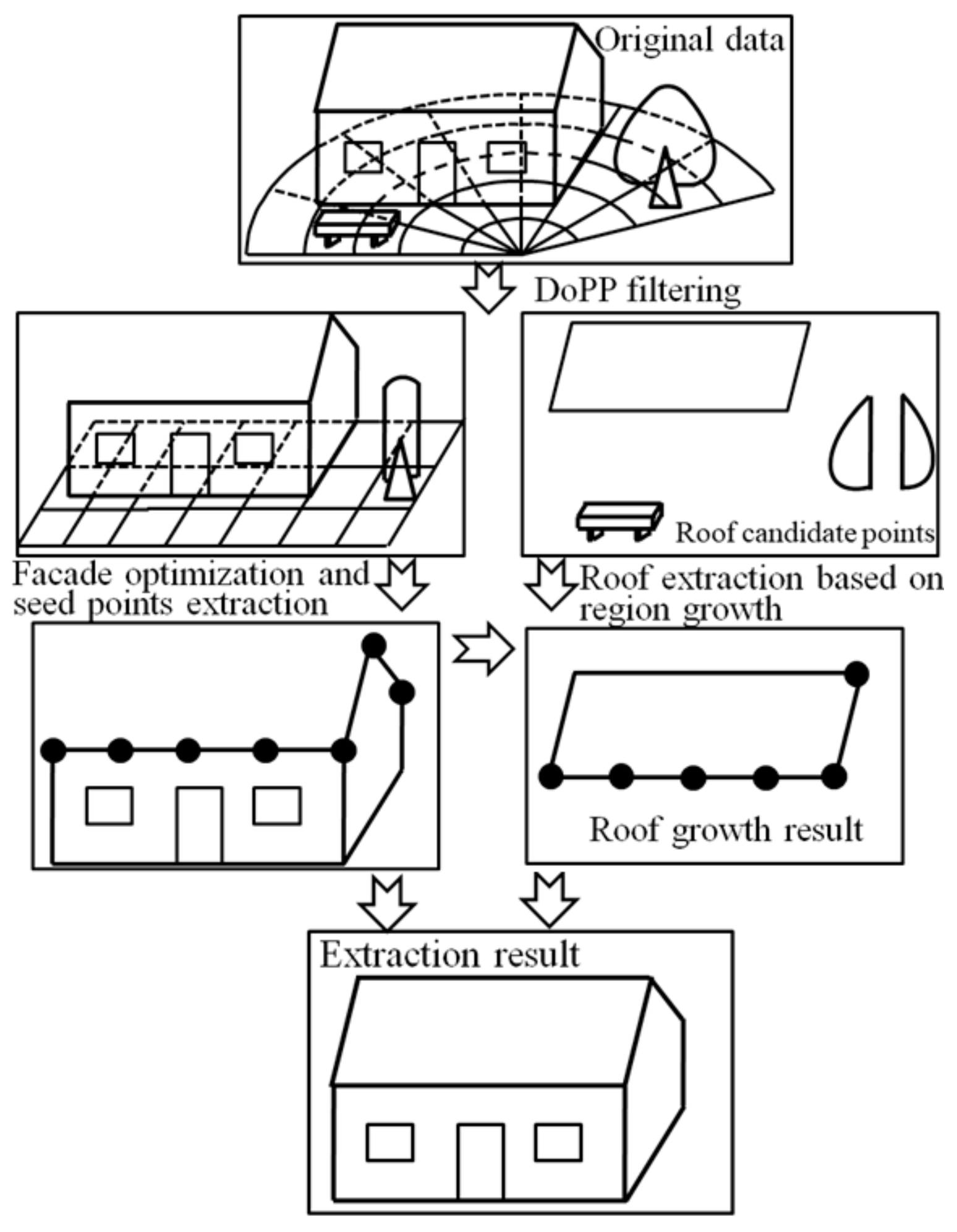
2. Methodology
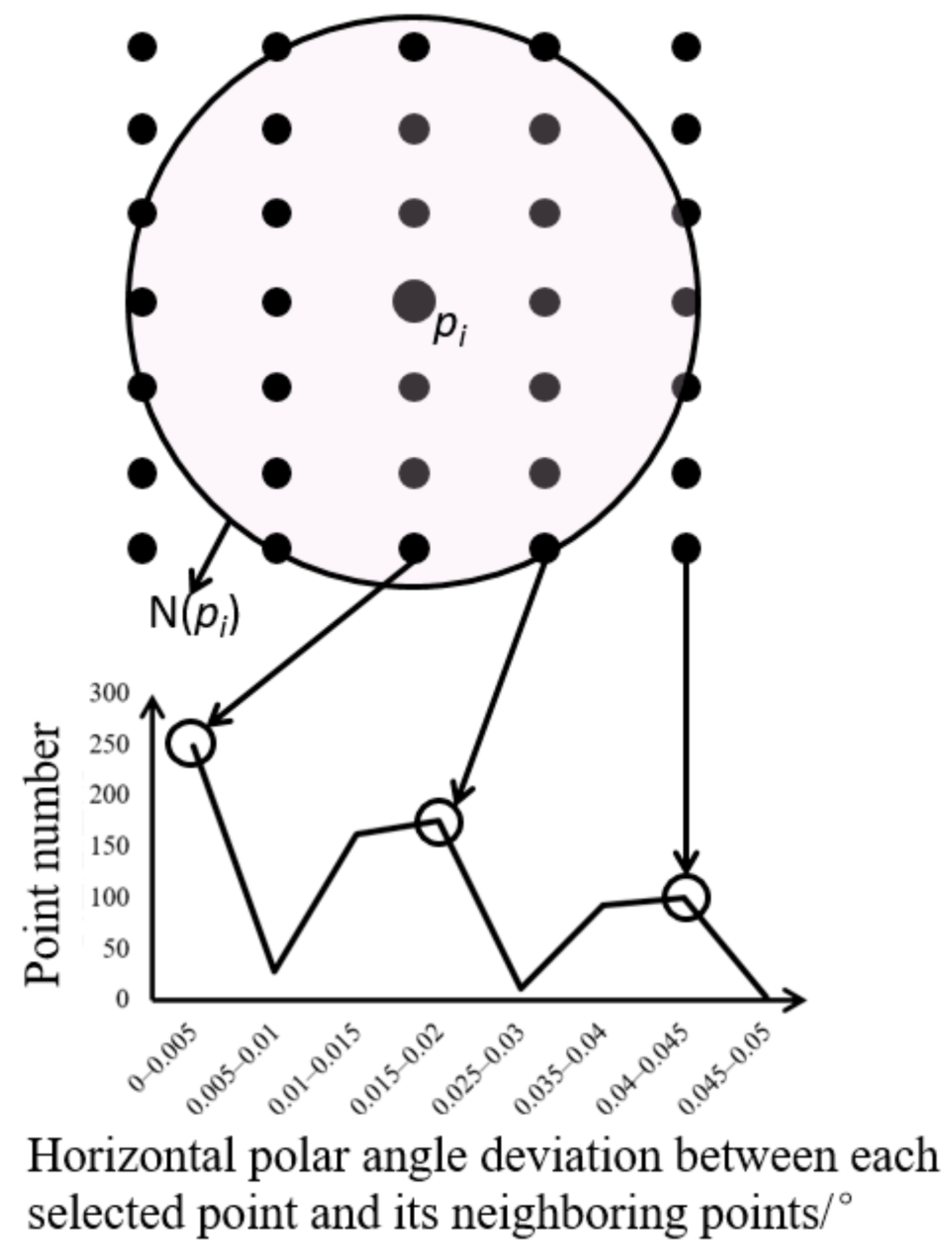
2.1. Generation of Polar Grid
2.2. DoPP Filtering Based on Adaptive Threshold
2.3. Facade Extraction Based on Grid Features
- (1)
- Height difference. This is the difference between the maximum and minimum z-coordinate of each object. Facades should have larger height difference than theoretical minimum height, which is 3.5 m, as analyzed in the contents following Equation (7). This feature is consistent with basic knowledge of the real world and easy to calculate, so we use it to remove the objects with a higher DoPP than np but a height less than 3.5 m, such as walls, pedestrians, hardscapes, some pole-like objects and the side of a large car.
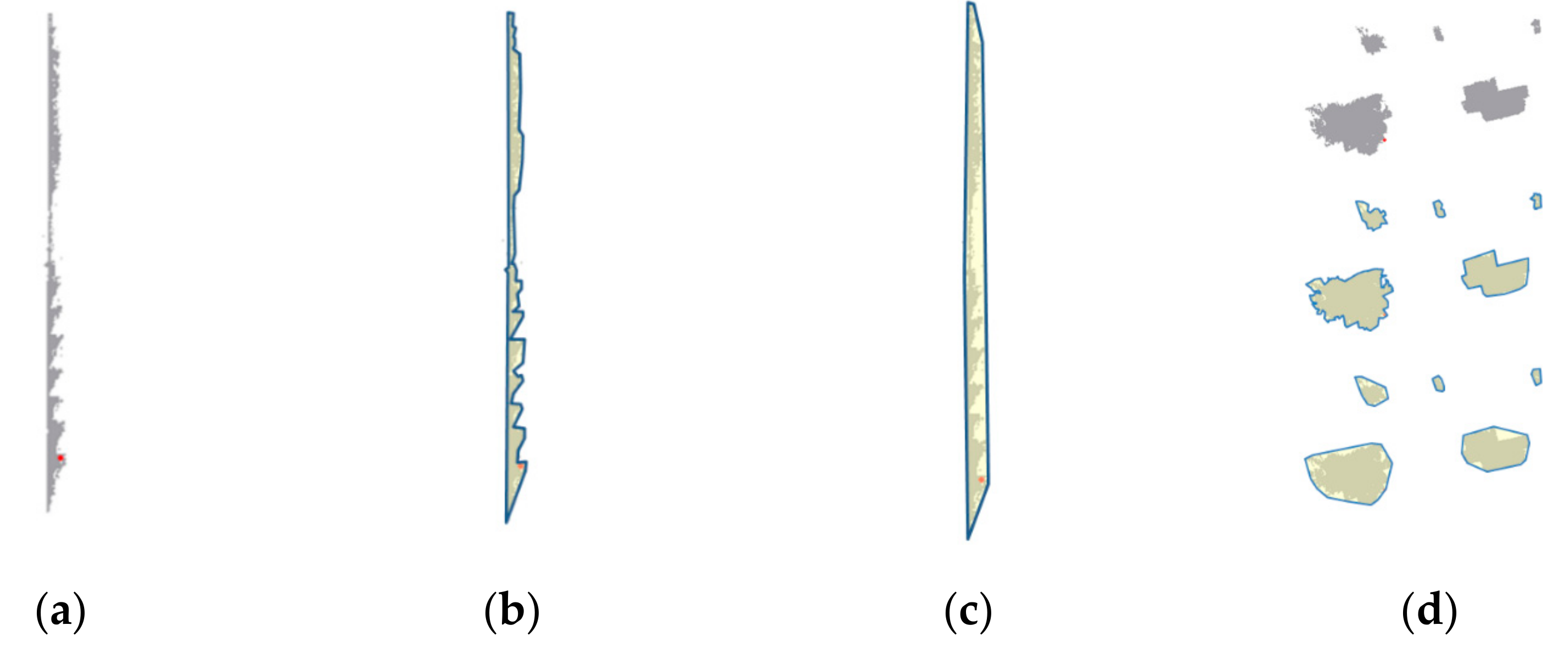
- (2)
- Horizontal Hollow Ratio. It has been indicated in previous studies that this feature can be utilized for building extraction in ALS [52] and MLS [28] data. As the laser beam cannot penetrate the facade surface and the roof cells have been filtered utilizing DoPP filtering, the hollow regions also exist behind the facade from the bottom view of the TLS data. In the study of [28], the horizontal hollow ratio is calculated as the ratio of projection area to convex hull area:
- (3)
- Compactness. After horizontal hollow ratio filtering, some facades are still mixed with non-building objects, such as trees and pole-like objects. Many of those objects are commonly isolated and the corresponding projections appear as circular shapes, while facades have a long and thin shape. The geometry difference can be measured by compactness [54], which is calculated as:
- (4)
- Model-based planar ratio. The objects preserved by compactness in the last step will show a long and thin shape, just like the usual shape of a building. But the objects formed by several connected compact targets are also preserved, e.g., the projection of a series of connected thick tree crowns may be recognized as a facade object only based on compactness. Considering the limitation of compactness, we add information about the remaining objects. A plane model is estimated for each cell group based on the RANSAC method [55]. A cell group is labeled as representing a building when the ratio of the points on the plane model is larger than 80%, which is the same setting as used in [38]. By checking the global geometric characteristics of the whole points in one cell group, the model-based planar ratio can distinguish the single-wall facade from other objects satisfactorily. A possible problem of this feature, however, is that the planar ratio may be smaller than 80% when the facade is not planar or consists of a long wall and a short wall. As a result, this kind of facade may still be recognized as a non-facade object even after filtering with the horizontal hollow ratio and the model-based planar ratio.
- (5)
- Point-based planar ratio. To extract the remaining facades after the aforementioned processing, we make a point-level insight for the cell groups left in the previous steps, following the knowledge that most parts of a common building surface are planar and have a smooth shape. The local geometry of the neighborhood of one point can be described using dimensionality features [31], which are calculated based on the eigenvalues of the local covariance matrix:
2.4. Roof Points Extraction
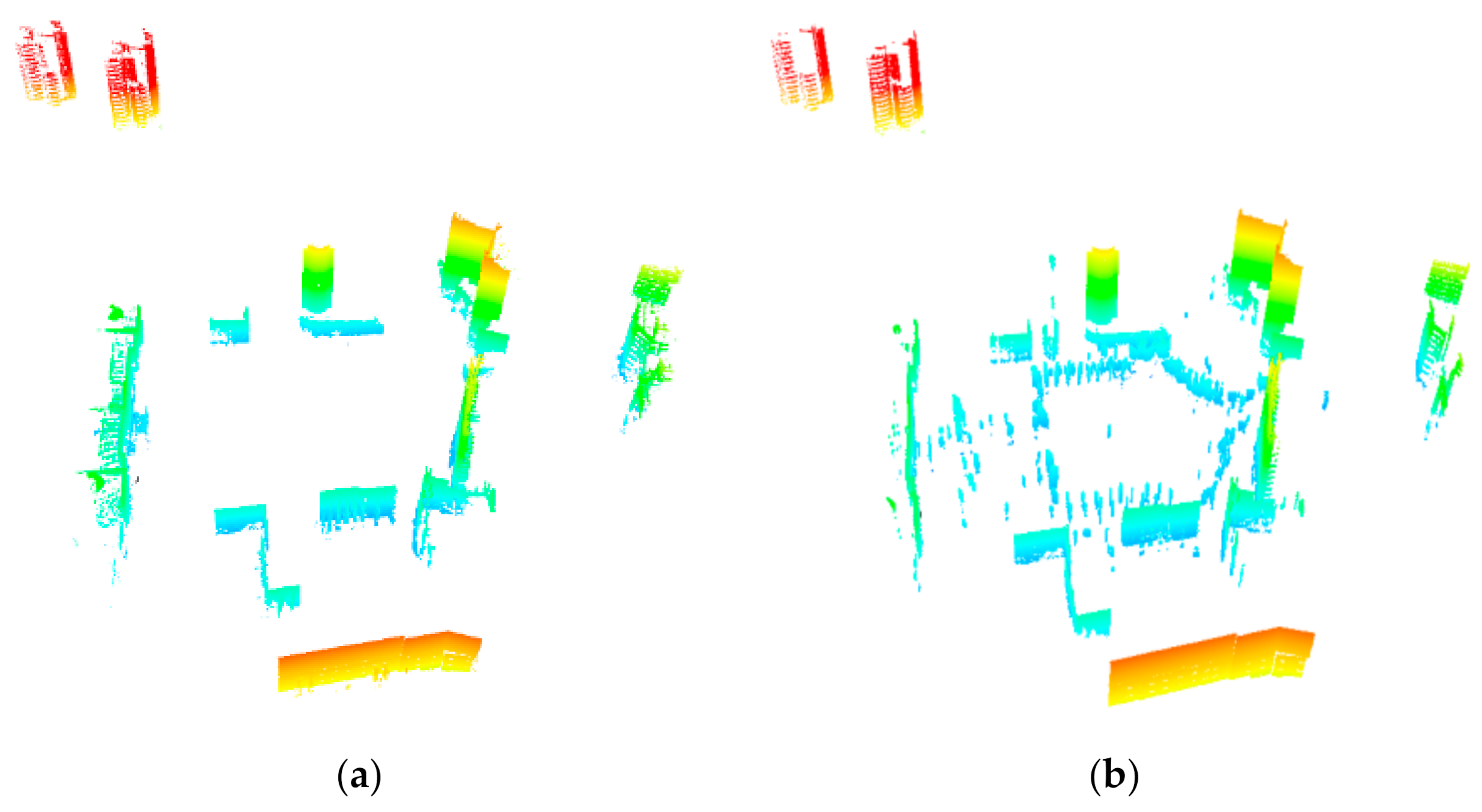
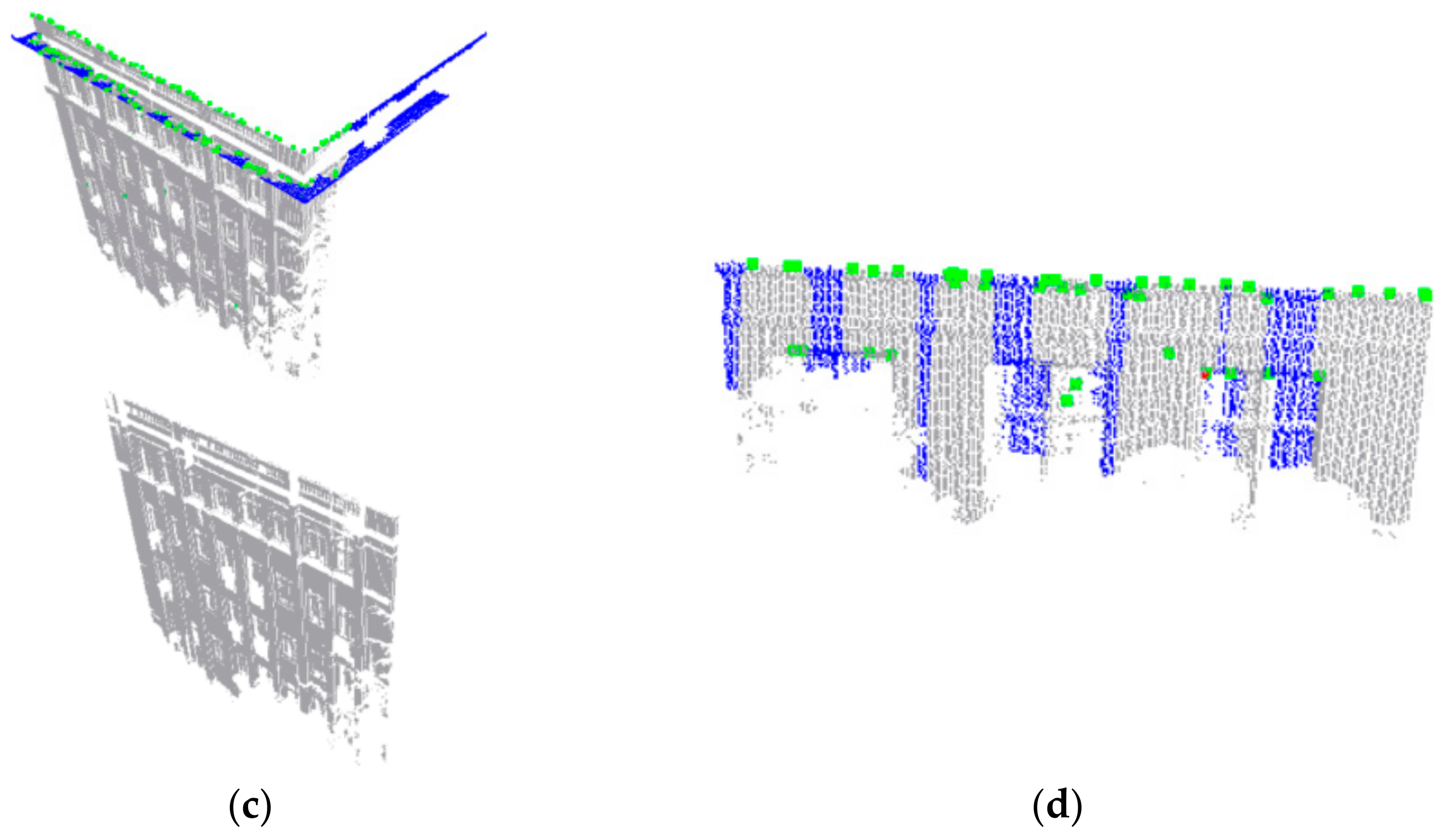
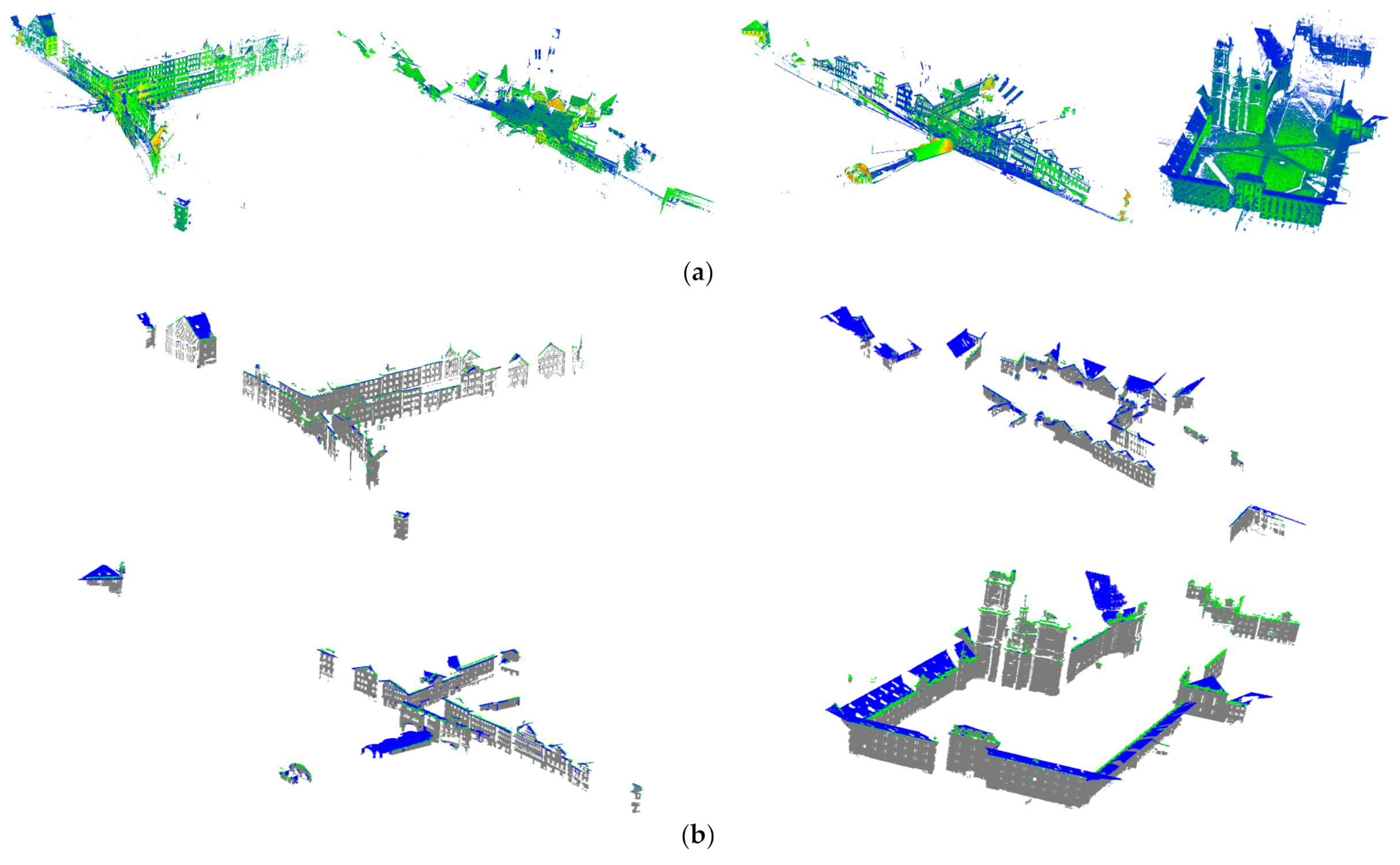
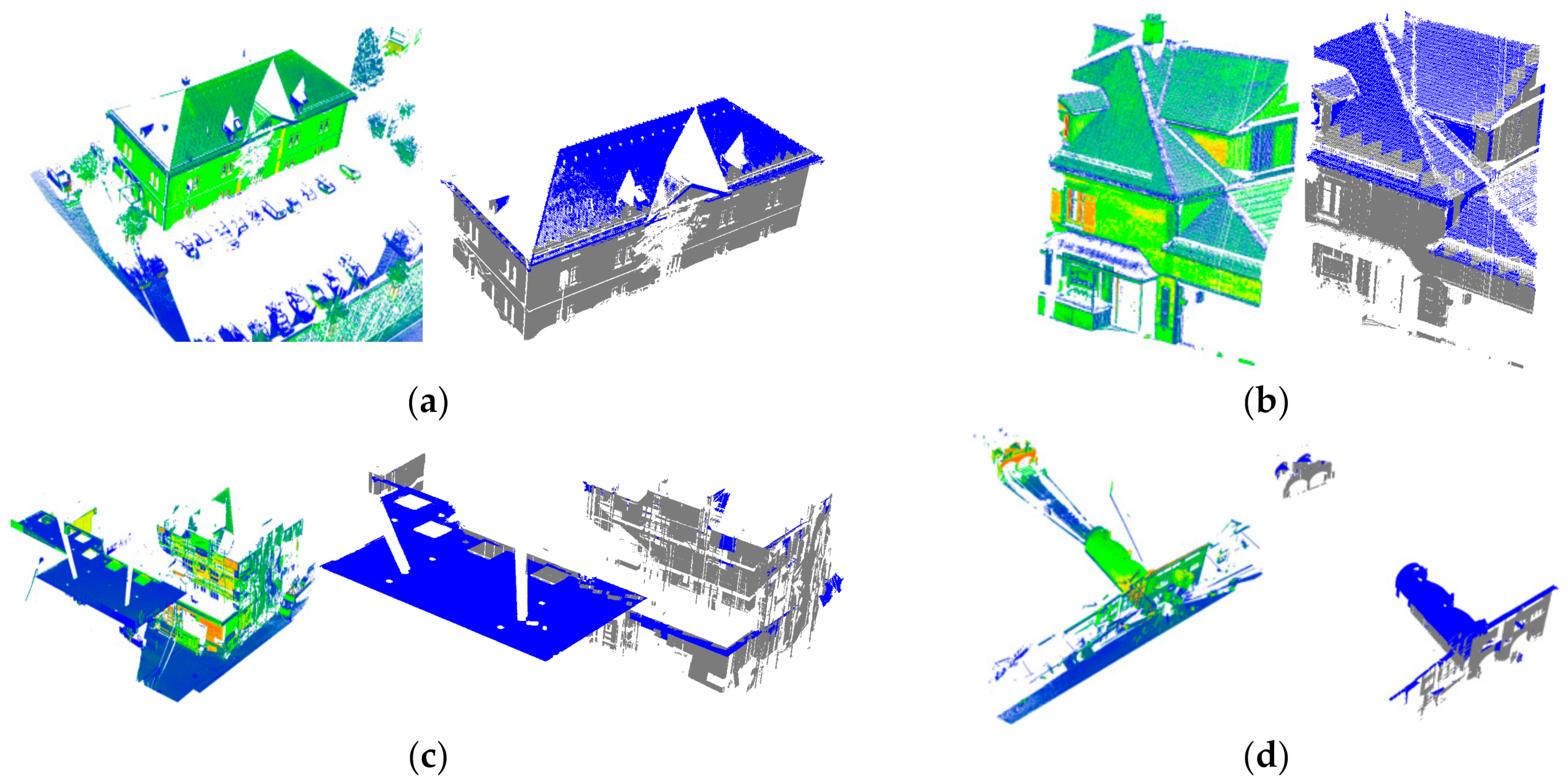
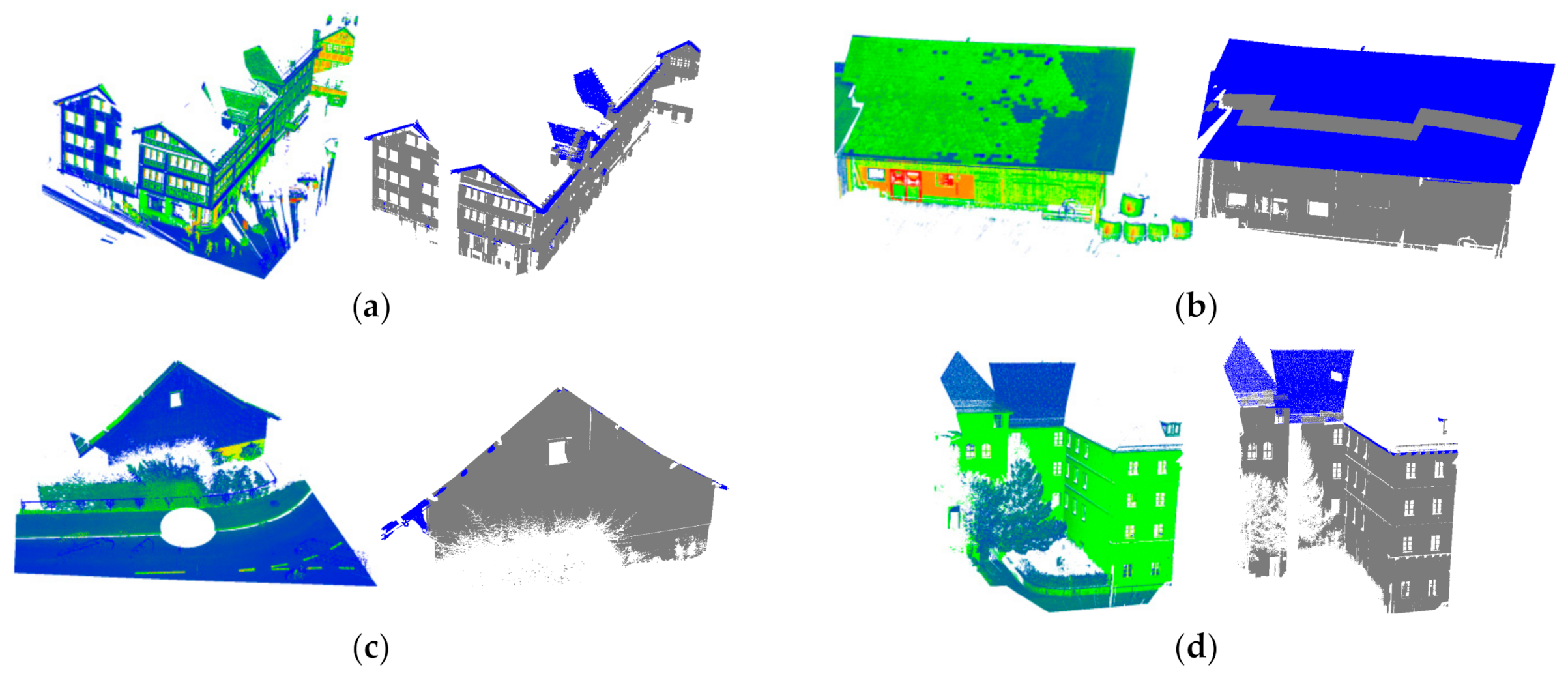
3. Experimental Results and Discussion
3.1. Datasets
3.2. Comparison with Other Methods on the First Dataset
3.3. Parameters Test
3.4. Test on the Second Dataset
4. Discussion
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
References
- Chen, D.; Wang, R.; Peethambaran, J. Topologically aware building rooftop reconstruction from airborne laser scanning point clouds. IEEE J. Trans. Geosci. Remote Sens. 2017, 55, 7032–7052. [Google Scholar] [CrossRef]
- He, M.; Zhu, Q.; Du, Z.; Hu, H.; Ding, Y.; Chen, M. A 3D shape descriptor based on contour clusters for damaged roof detection using airborne LiDAR point clouds. Remote Sens. 2016, 8, 189. [Google Scholar] [CrossRef] [Green Version]
- Yu, B.; Liu, H.; Wu, J.; Hu, Y.; Zhang, L. Automated derivation of urban building density information using airborne lidar data and object-based method. Landsc. Urban Plan. 2010, 98, 210–219. [Google Scholar] [CrossRef]
- Qin, R.; Gruen, A. 3D change detection at street level using mobile laser scanning point clouds and terrestrial images. ISPRS J. Photogramm. Remote Sens. 2014, 90, 23–35. [Google Scholar] [CrossRef]
- Du, S.; Zhang, Y.; Zou, Z.; Xu, S.; He, X.; Chen, S. Automatic building extraction from LiDAR data fusion of point and grid-based features. ISPRS J. Photogramm. Remote Sens. 2017, 130, 294–307. [Google Scholar] [CrossRef]
- Huang, J.; Zhang, X.; Xin, Q.; Sun, Y.; Zhang, P. Automatic building extraction from high-resolution aerial images and LiDAR data using gated residual refinement network. ISPRS J. Photogramm. Remote Sens. 2019, 151, 91–105. [Google Scholar] [CrossRef]
- Tomljenovic, I.; Höfle, B.; Tiede, D.; Blaschke, T. Building extraction from airborne laser scanning data: An analysis of the state of the art. Remote Sens. 2015, 7, 3826–3862. [Google Scholar] [CrossRef] [Green Version]
- Lai, X.; Yang, J.; Li, Y.; Wang, M. A Building Extraction Approach Based on the Fusion of LiDAR Point Cloud and Elevation Map Texture Features. Remote Sens. 2019, 11, 1636. [Google Scholar] [CrossRef] [Green Version]
- Zarea, A.; Mohammadzadeh, A. A novel building and tree detection method from LiDAR data and aerial images. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2015, 9, 1864–1875. [Google Scholar] [CrossRef]
- Che, E.; Jung, J.; Olsen, M.J. Object recognition, segmentation, and classification of mobile laser scanning point clouds: A state of the art review. Sensors 2019, 19, 810. [Google Scholar] [CrossRef] [Green Version]
- Pu, S.; Vosselman, G. Knowledge based reconstruction of building models from terrestrial laser scanning data. ISPRS J. Photogramm. Remote Sens. 2009, 64, 575–584. [Google Scholar] [CrossRef]
- Yang, B.; Dong, Z. A shape-based segmentation method for mobile laser scanning point clouds. ISPRS J. Photogramm. Remote Sens. 2013, 81, 19–30. [Google Scholar] [CrossRef]
- Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. 2000, 22, 888–905. [Google Scholar]
- Xia, S.; Wang, R. Extraction of residential building instances in suburban areas from mobile LiDAR data. ISPRS J. Photogramm. Remote Sens. 2018, 144, 453–468. [Google Scholar] [CrossRef]
- Lim, E.H.; Suter, D. 3D terrestrial LIDAR classifications with super-voxels and multi-scale Conditional Random Fields. Comput.-Aided Des. 2009, 41, 701–710. [Google Scholar] [CrossRef]
- Aijazi, A.K.; Checchin, P.; Trassoudaine, L. Segmentation based classification of 3D urban point clouds: A super-voxel based approach with evaluation. Remote Sens. 2013, 5, 1624–1650. [Google Scholar] [CrossRef] [Green Version]
- Yang, B.; Dong, Z.; Zhao, G.; Dai, W. Hierarchical extraction of urban objects from mobile laser scanning data. ISPRS J. Photogramm. Remote Sens. 2015, 99, 45–57. [Google Scholar] [CrossRef]
- Li, B.J.; Li, Q.Q.; Shi, W.Z.; Wu, F.F. Feature extraction and modeling of urban building from vehicle-borne laser scanning data. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2004, 35, 934–939. [Google Scholar]
- Hammoudi, K.; Dornaika, F.; Paparoditis, N. Extracting building footprints from 3D point clouds using terrestrial laser scanning at street level. ISPRS/CMRT09 2009, 38, 65–70. [Google Scholar]
- Fan, H.; Yao, W.; Tang, L. Identifying man-made objects along urban road corridors from mobile LiDAR data. IEEE Geosci. Remote Sens. Lett. 2013, 11, 950–954. [Google Scholar] [CrossRef]
- Hernández, J.; Marcotegui, B. Point cloud segmentation towards urban ground modeling. In Proceedings of the 2009 Joint Urban Remote Sensing Event, Shanghai, China, 20–22 May 2009; IEEE: Piscataway, NJ, USA, 2009; pp. 1–5. [Google Scholar]
- Cheng, L.; Tong, L.; Wu, Y.; Chen, Y.; Li, M. Shiftable leading point method for high accuracy registration of airborne and terrestrial LiDAR data. Remote Sens. 2015, 7, 1915–1936. [Google Scholar] [CrossRef]
- Zheng, H.; Wang, R.; Xu, S. Recognizing street lighting poles from mobile LiDAR data. IEEE Trans. Geosci. Remote Sens. 2016, 55, 407–420. [Google Scholar] [CrossRef]
- Cheng, L.; Tong, L.; Li, M.; Liu, Y. Semi-automatic registration of airborne and terrestrial laser scanning data using building corner matching with boundaries as reliability check. Remote Sens. 2013, 5, 6260–6283. [Google Scholar] [CrossRef] [Green Version]
- Cheng, X.; Cheng, X.; Li, Q.; Ma, L. Automatic registration of terrestrial and airborne point clouds using building outline features. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2018, 11, 628–638. [Google Scholar] [CrossRef]
- Yang, B.; Wei, Z.; Li, Q.; Li, J. Automated extraction of street-scene objects from mobile lidar point clouds. Int. J. Remote Sens. 2012, 33, 5839–5861. [Google Scholar] [CrossRef]
- Gao, S.; Hu, Q. Automatic extraction method of independent features based on elevation projection of point clouds and morphological characters of ground object. In Proceedings of the 2014 Third International Workshop on Earth Observation and Remote Sensing Applications (EORSA), Changsha, China, 20 October 2014; IEEE: Piscataway, NJ, USA, 2014; pp. 86–90. [Google Scholar]
- Wang, Y.; Cheng, L.; Chen, Y.; Wu, Y.; Li, M. Building point detection from vehicle-borne LiDAR data based on voxel group and horizontal hollow analysis. Remote Sens. 2016, 8, 419. [Google Scholar] [CrossRef] [Green Version]
- Yang, B.; Wei, Z.; Li, Q.; Li, J. Semiautomated building facade footprint extraction from mobile LiDAR point clouds. IEEE Geosci. Remote Sens. Lett. 2012, 10, 766–770. [Google Scholar] [CrossRef]
- Gao, J.; Yang, R. Online building segmentation from ground-based LiDAR data in urban scenes. In Proceedings of the 2013 International Conference on 3D Vision-3DV 2013, Seattle, WA, USA, 29 June–1 July 2013; IEEE: Piscataway, NJ, USA, 2013; pp. 49–55. [Google Scholar]
- Weinmann, M.; Jutzi, B.; Hinz, S.; Mallet, C. Semantic point cloud interpretation based on optimal neighborhoods, relevant features and efficient classifiers. ISPRS J. Photogramm. Remote Sens. 2015, 105, 286–304. [Google Scholar] [CrossRef]
- Demantké, J.; Mallet, C.; David, N.; Vallet, B. Dimensionality based scale selection in 3D lidar point clouds. Int. Arch. Photogr. Remote Sens. Spat. Inf. Sci. Laser Scanning 2011, 38, 97–102. [Google Scholar] [CrossRef] [Green Version]
- Weinmann, M.; Jutzi, B.; Mallet, C. Semantic 3D scene interpretation: A framework combining optimal neighborhood size selection with relevant features. ISPRS Ann. Photogramm. Remote Sens. Spat. Inf. Sci. 2014, 2, 181. [Google Scholar] [CrossRef] [Green Version]
- Brodu, N.; Lague, D. 3D terrestrial lidar data classification of complex natural scenes using a multi-scale dimensionality criterion: Applications in geomorphology. ISPRS J. Photogramm. Remote Sens. 2012, 68, 121–134. [Google Scholar] [CrossRef] [Green Version]
- Niemeyer, J.; Rottensteiner, F.; Soergel, U. Contextual classification of lidar data and building object detection in urban areas. ISPRS J. Photogramm. Remote Sens. 2014, 87, 152–165. [Google Scholar] [CrossRef]
- Atik, M.E.; Duran, Z.; Seker, D.Z. Machine Learning-Based Supervised Classification of Point Clouds Using Multiscale Geometric Features. Int. J. Geo-Inf. 2021, 10, 187. [Google Scholar] [CrossRef]
- Chen, M.; Pan, J.; Xu, J. Classification of Terrestrial Laser Scanning Data with Density-Adaptive Geometric Features. IEEE Geosci. Remote Sens. Lett. 2018, 15, 1795–1799. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, L.; Tong, X.; Du, B.; Wang, Y.; Zhang, L.; Zhang, Z.; Liu, H.; Mei, J.; Xing, X.; et al. A three-step approach for TLS point cloud classification. IEEE J. Trans. Geosci. Remote Sens. 2016, 54, 5412–5424. [Google Scholar] [CrossRef]
- Pirotti, F.; Guarnieri, A.; Vettore, A. Ground filtering and vegetation mapping using multi-return terrestrial laser scanning. ISPRS J. Photogramm. Remote Sens. 2013, 76, 56–63. [Google Scholar] [CrossRef]
- Ghamisi, P.; Hoefle, B. LiDAR data classification using extinction profiles and a composite kernel support vector machine. IEEE Geosci. Remote Sens. Lett. 2017, 14, 659–663. [Google Scholar] [CrossRef]
- Schmidt, A.; Niemeyer, J.; Rottensteiner, F.; Soergel, U. Contextual classification of full waveform lidar data in the Wadden Sea. IEEE Geosci. Remote Sens. Lett. 2014, 11, 1614–1618. [Google Scholar] [CrossRef]
- Liu, H.; Motoda, H.; Setiono, R.; Zhao, Z. Feature selection: An ever evolving frontier in data mining. In Proceedings of the Feature Selection Data Mining, Hyderabad, India, 21 June 2010; pp. 4–13. [Google Scholar]
- Cortes, C.; Vapnik, V. Support-vector networks. Mach. Learn. 1995, 20, 273–297. [Google Scholar] [CrossRef]
- Chang, C.C.; Lin, C.J. LIBSVM: A library for support vector machines. ACM Trans. Intell. Syst. Technol. (TIST) 2011, 2, 1–27. [Google Scholar] [CrossRef]
- Breiman, L. Random forests. Mach. Learn. 2001, 45, 5–32. [Google Scholar] [CrossRef] [Green Version]
- Zhang, Z.; Zhang, L.; Tong, X.; Mathiopoulos, P.T.; Guo, B.; Huang, X.; Wang, Z.; Wang, Y. A multilevel point-cluster-based discriminative feature for ALS point cloud classification. IEEE J. Trans. Geosci. Remote Sens. 2016, 54, 3309–3321. [Google Scholar] [CrossRef]
- Landrieu, L.; Raguet, H.; Vallet, B.; Mallet, C.; Weinmann, M. A structured regularization framework for spatially smoothing semantic labelings of 3D point clouds. ISPRS J. Photogramm. Remote Sens. 2017, 132, 102–118. [Google Scholar] [CrossRef] [Green Version]
- Qi, C.R.; Su, H.; Mo, K.; Guibas, L.J. Pointnet: Deep learning on point sets for 3d classification and segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 652–660. [Google Scholar]
- Li, Y.; Bu, R.; Sun, M.; Wu, W.; Di, X.; Chen, B. Pointcnn: Convolution on x-transformed points. Adv. Neural Inf. Process. Syst. (NIPS) 2018, 31, 820–830. [Google Scholar]
- Zhang, W.; Qi, J.; Wan, P.; Wang, H.; Xie, D.; Wang, X.; Yan, G. An easy-to-use airborne LiDAR data filtering method based on cloth simulation. Remote Sens. 2016, 8, 501. [Google Scholar] [CrossRef]
- Che, E.; Olsen, M. Fast ground filtering for TLS data via Scanline Density Analysis. ISPRS J. Photogramm. Remote Sens. 2017, 129, 226–240. [Google Scholar] [CrossRef]
- Aljumaily, H.; Laefer, D.; Cuadra, D. Big-data approach for three-dimensional building extraction from aerial laser scanning. J. Comput. Civ. Eng. 2015, 30, 04015049. [Google Scholar] [CrossRef]
- Otsu, N. A threshold selection method from gray-level histograms. Automatica. IEEE J. Trans. Syst. Man Cybern. 1975, 11, 23–27. [Google Scholar]
- Touya, G. A road network selection process based on data enrichment and structure detection. Trans. GIS 2010, 14, 595–614. [Google Scholar] [CrossRef] [Green Version]
- Fischler, M.; Bolles, R. Random Sample Consensus: A Paradigm for Model Fitting with Applications to Image Analysis and Automated Cartography. Commun. ACM 1981, 24, 381–395. [Google Scholar] [CrossRef]
- Hackel, T.; Savinov, N.; Ladicky, L.; Wegner, J.; Schindler, K.; Pollefeys, M. Semantic3D.net: A new Large-scale Point Cloud Classification Benchmark. arXiv 2017, arXiv:1704.03847. [Google Scholar]
- Piegl, L.; Tiller, W. Algorithm for finding all k nearest neighbors. Comput.-Aided Des. 2002, 34, 167–172. [Google Scholar] [CrossRef]
- Lin, H.; Gao, J.; Zhou, Y.; Lu, G.; Ye, M.; Zhang, C.; Liu, L.; Yang, R. Semantic decomposition and reconstruction of residential scenes from LiDAR data. ACM Trans. Graph. 2013, 32, 1–10. [Google Scholar] [CrossRef]
- Li, Z.; Zhang, L.; Mathiopoulos, P.; Liu, F.; Zhang, L.; Li, S. A hierarchical methodology for urban facade parsing from TLS point clouds. ISPRS J. Photogramm. Remote Sens. 2017, 123, 75–93. [Google Scholar] [CrossRef]
















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description | Value | Basis |
|---|---|---|---|
| N | Number of laser beams in one cell to calculate angular size | 1: First dataset and parameter test: 5∗n with n = 1, 2, ...10 2: Second dataset: 10 | 1: For test purpose 2: Empirically based on parameter test result |
| ρG | Radial size | 1: First dataset and parameter test: (0.1 m, 2 m) with interval of 0.1 m 2: Second dataset: 0.5 m | 1: For test purpose 2: Empirically based on parameter test result |
| np | DoPP threshold | Automatic | Equation (7) |
| - | Height difference threshold | 3.5 m | Basic knowledge of real world |
| TH | Threshold of HHR | Min{0.4, OTSU result} | 0.4: to avoid a very large threshold in case only single-facade buldings exist |
| TC | Threshold of Compactnee | Max{0.65, OTSU result} | 0.65: to avoid a very small threshold in case only facade cells exist |
| - | Threshold of planar ratio | 80% | Previous work in [38] |
| Method | Threshold | Completeness | Correctness |
|---|---|---|---|
| Proposed method | Adaptive threshold | 89.95% ± 8.71% | 80.74% ± 10.73% |
| Original DoPP | Fixed threshold | 88.42% ± 4.47% | 58.74% ± 6.22% |
| Empirical threshold | 91.65% | 64.82% |
| Method | TP | FP | FN | Completeness | Correctness |
|---|---|---|---|---|---|
| Method in [26] | 10 | 15 | 5 | 67% | 40% |
| Method in [28] | 11 | 2 | 4 | 73% | 85% |
| Original DoPP | 9 | 6 | 6 | 60% | 60% |
| Proposed method | 14 | 2 | 1 | 93% | 88% |
| Method | Completeness | Correctness | F1 | Time/s |
|---|---|---|---|---|
| The proposed method | 91.8% | 99.8% | 95.6% | 970 |
| Classification method | 93.1% | 95.3% | 94.2% | >3600 |
| Stage | Complexity | Meaning of the Symbols |
|---|---|---|
| DoPP filtering | O(N1) | N1 is the number of non-ground points. |
| Facade extraction (not including planar ratio calculation) | O(N2) | N2 is the number of points after DoPP filtering; N2 < N1. |
| Facade extraction (model-based planar ratio calculation) | O(N3) | Theoretically, N3 is the rough point number of long and thin non-facade objects and facades which are not multi-wall type; N3 < N2. |
| Facade extraction (point-based planar ratio calculation) | O(kN4log2 N4 + N4) | Theoretically, N3 is the rough point number of long and thin objects, which cannot be fitted with one plane; k is the nearest neighbor; N4 < N3. |
| Roof extraction | O(kN5log2 N5 + N5) | Theoretically, N5 is the rough point number of roof points; N5 < N1–N2. |
Publisher’s Note: MDPI stays neutral with regard to jurisdictional claims in published maps and institutional affiliations. |
© 2021 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, M.; Liu, X.; Zhang, X.; Wang, M.; Zhao, L. Building Extraction from Terrestrial Laser Scanning Data with Density of Projected Points on Polar Grid and Adaptive Threshold. Remote Sens. 2021, 13, 4392. https://doi.org/10.3390/rs13214392
Chen M, Liu X, Zhang X, Wang M, Zhao L. Building Extraction from Terrestrial Laser Scanning Data with Density of Projected Points on Polar Grid and Adaptive Threshold. Remote Sensing. 2021; 13(21):4392. https://doi.org/10.3390/rs13214392
Chicago/Turabian StyleChen, Maolin, Xiangjiang Liu, Xinyi Zhang, Mingwei Wang, and Lidu Zhao. 2021. "Building Extraction from Terrestrial Laser Scanning Data with Density of Projected Points on Polar Grid and Adaptive Threshold" Remote Sensing 13, no. 21: 4392. https://doi.org/10.3390/rs13214392