1. Introduction
The code is available at
https://github.com/Li-ZK/CIR-FSD-2022 (accessed on 29 June 2022). Object detection has always been a research hotspot in remote sensing and computer vision fields. In the past few years, object detection has made significant progress due to the rapid development of deep convolutional neural networks (CNNs). A series of excellent object detection algorithms based on CNN have emerged in natural scene images [
1,
2]. The object detection frameworks are generally divided into two main types according to whether they contain region proposals, i.e., one-stage and two-stage detectors. One-stage detectors, represented by the You Only Look Once (YOLO) series [
3,
4,
5,
6,
7], directly generate class-related bounding boxes and their probabilities at each spatial location. In contrast, two-stage detectors, represented by the region-based CNN (R-CNN) series [
8], including Fast R-CNN [
9] and Faster R-CNN [
10], adopt a region proposal algorithm to improve the performance of object detection.
Compared with natural scene images, remote sensing images (RSIs) have the characteristics of arbitrary directions, different object sizes and complex backgrounds. To deal with the problems mentioned above, researchers have proposed many excellent solutions based on CNN [
11]. Wu et al. [
12] proposed an Optical Remote Sensing Imagery detector (ORSIm detector) that incorporates feature extraction, feature learning, fast image pyramid matching, and boosting strategies. Qian et al. [
13] incorporated a multi-level feature fusion module into the existing hierarchical deep network, which can fully use the multi-level features. Cheng et al. [
14] proposed a two-stage oriented detector for detecting arbitrary-oriented objects in RSIs. They generated high-quality oriented proposals through an oriented RPN, and refined these proposals through an oriented R-CNN head. Yang et al. [
15] proposed a sampling fusion network to improve sensitivity to small objects. They use a supervised multi-dimensional attention network to attenuate the noise in remote sensing images and highlight object information. Zheng et al. [
16] proposed a multitask learning network that treats each small-scale training dataset as a task. They utilize shared branches to extract shared features across tasks to better adapt to remote sensing images.
Although the object detection method based on CNN has achieved great success, training a deep detector usually requires sufficient annotation data. Collecting annotated data in the real world is time-consuming and expensive, which makes it difficult to obtain enough annotated data. This raises considerable attention about learning efficient detectors with limited training samples. Chen et al. [
17] proposed a low-shot transfer detector for object detection in few-shot cases, which transfers rich source domain knowledge to the target domain. Xu et al. [
18] designed a cross-domain ship detection method, which can transfer labeled optical ship images to unlabeled SAR images. Wu et al. [
19] designed a multi-source active fine-tuning network to achieve vehicle detection without the requirement for well-annotated samples. Few-shot object detection (FSOD) has gradually become an effective mechanism to address this issue, which can learn new concepts from limited training samples.
Currently, FSOD is mainly divided into three categories: meta-learning-based, metric-learning-based, and fine-tuning-based approaches [
20,
21]. Meta-learning [
22,
23,
24,
25] usually utilizes many episodes to learn task-agnostic notions (e.g., meta-parameters), which might be meaningful for quickly adapting to a new session. Kang et al. [
22] used a meta feature learner to extract meta-features from the query images and designed a reweighting module to acquire the global features of the support images. Li et al. [
23] designed a meta-learning model with multiscale architecture to solve the inherent scale fluctuations in remote sensing images by introducing feature pyramid network (FPN) [
26]. Cheng et al. [
25] designed a prototype learning network (PLN) to obtain the prototypes of each class, and used the prototypes to guide a region proposal network to generate higher-quality proposals, which can more effectively choose foreground objects from complicated backgrounds in RSIs. Meta-learning approaches divide so many small tasks and design a complex episodic training scheme, which can cause a lot of training time and more memory with an increasing number of categories in the support set.
Metric-learning [
27,
28,
29] focuses on learning a robust encoding function and a rating function that measure the similarity of a query image’s embedding vectors to each category prototype. Karlinsky et al. [
28] proposed a novel metric-learning-based method for representing each category that uses a mixed model with multiple modes, and they take the centers of these modes as the category’s representative vectors. During the training process, the method concurrently learns the embedding space, the model weights and the representative vectors for each category. Yang et al. [
29] found that negative proposals, especially hard negative ones, are essential for learning an embedding space. Therefore, they introduced a new metric learning framework inference scheme based on negative and positive representations. The embedding space representing the positive and negative vectors in both methods is learned by utilizing a triplet loss [
30]. Metric-learning approaches require the use of training data to learn a robust collection of class prototypes as task-specific parameters, which makes building robust class prototypes problematic when the dataset contains numerous outliers (such as occlusion).
Recently, Two-stage Fine-tune Approach (TFA) has shown great potential in the field of FSOD [
31]. Compared to meta-learning and metric-learning approaches, TFA can yield competitive performance through a simple fine-tuning strategy. TFA utilizes a simple two-stage treatment on Faster R-CNN, which freezes the pre-trained weights in the first stage and fine-tunes the last layers in the second stage. Wu et al. [
32] proposed a scale-aware network based on TFA to distinguish positive–negative exemplars by combining the FPN with object pyramids. Zhang et al. [
33] proposed a novel data hallucination-based approach to address the problem of lack of variety in training data, which efficiently transfers common patterns of within-category variation from base categories to novel categories. Zhao et al. [
34] designed a path-aggregation multiscale few-shot detector for remote sensing images (PAMS-Det), which can mitigate the scale scarcity in novel categories by adding a path-aggregation module. In addition, PAMS-Det designed an involution backbone to improve the classification ability of the object detector in remote sensing images. Huang et al. [
35] designed a shared attention module and a balanced fine-tuning strategy to cope with large size variations and improve the classification accuracy. Li et al. [
36] designed a few-shot correction network to eliminate false positives caused by class confusion. This can improve the limitation of TFA for classifier rebalancing. Sun et al. [
37] introduced contrastive learning into TFA to learn contrastive-aware object proposal embeddings, which is helpful to classify the detected objects. Sun et al. observed that the positive anchors for novel objects received relatively low scores from region proposal network, resulting in fewer positive anchors passing non-maximum suppression (NMS) and becoming proposals. The low-score positive anchors for novel objects are mostly regarded as background noise, which introduces the problem of foreground–background imbalance.
Due to various object sizes and cluttered backgrounds, it is still a challenging problem to identify foreground objects from complex backgrounds in remote sensing images, even with the help of the aforementioned FSOD methods. Firstly, the receptive field of FPN is insufficient to capture rich context information for objects of different sizes since the effective receptive fields of CNN are substantially smaller than the expected receptive fields [
38,
39], which may lead to the failure of FPN to detect objects correctly. Yang et al. [
40] proposed Densely connected Atrous Spatial Pyramid Pooling (DenseASPP) for semantic segmentation of street scenes and achieved remarkable success. They used the dilated convolution to obtain different receptive fields and used the dense connections to aggregate multiple atrous-convolved features as the final feature representation. In addition, due to the complexity of RSIs, excessive background noise might override the target information, and the boundary between the targets will become blurred, which will lead to missed detection. Wang et al. [
41] designed a multiscale refinement FPN and nonlocal-aware pyramid attention to suppress background noise and focus more on the valuable object features. Finally, because of the scarcity of samples in novel categories, it is difficult to obtain the positive anchors for novel categories, which implicitly introduces the foreground-background imbalance problem. In this article, to tackle the above challenges, we introduce a fine-tuning-based method for few-shot object detection, which designs a novel context information refinement few-shot detector (CIR-FSD) for remote sensing images. In order to better extract discriminative context features, we devise a context information refinement (CIR) module. In CIR, firstly, the dilated convolutions and dense connections are used to capture rich context information from different receptive fields. Then, a binary map is used as supervision labels to refine context information, which can suppress the noise and enhance the object information. In addition, baseline TFA usually needs to freeze all parameters trained on base categories and fine-tune only the box classification layer and regression layer on novel categories, which prevents RPN from learning the features related to novel categories. In our method, in addition to the box classifier and regressor, RPN is also fine-tuned on base and novel categories, which can increase the confidence of positive anchors for novel categories. Further, we relax the constraint of NMS on the confidence of anchors. Fine-tuning RPN and relaxing NMS can obtain more positive anchors for novel categories, which can alleviate the imbalance between the foreground and background. Our main contributions are highlighted as follows:
- (1)
We design a novel context information refinement few-shot detector for remote sensing images, which can effectively detect objects of different scales and cluttered objects in complex backgrounds with a few annotated samples.
- (2)
A CIR module is designed to obtain rich context information from different receptive fields and refine it at the same time, which can learn discriminative context features.
- (3)
Our proposed method increases the confidence of positive anchors for novel categories by fine-tuning RPN, and relaxes the constraint of NMS on the confidence of anchors, which can obtain more positive anchors for novel categories to alleviate the imbalance between the foreground and background.
2. The Proposed RSI Few-Shot Object Detection Framework
2.1. Overall Architecture
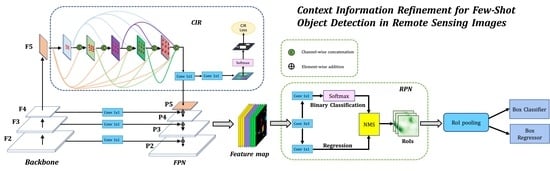
Depending on the high accuracy and recall, a two-stage detector is widely employed for object detection in the remote sensing of images, such as various improved algorithms based on the popular Faster R-CNN [
10]. Shivappriya et al. [
42] applied the Additive Activation Function (AAF) to Faster R-CNN to improve the efficiency of object detection. In the mainstream detection frameworks (i.e., Detectron2 [
43] and MMDetection [
44]), two-stage object detector generally includes multiple modules, such as Backbone, FPN [
26], RPN and Roi Feature Extractor. These detectors usually generate region of interests (RoIs) using independent RPN, and then further classify these RoIs and accurately regress them as the final results. As shown in
Figure 1, our proposed network architecture is built upon the popular detector Faster R-CNN. First, the images in the training set are fed into the Backbone for basic feature extraction. Then a CIR module is implemented for extracting discriminative context features. Next, these features are processed by a top-down module and lateral connections in FPN to generate multi-scale feature maps for objects of various sizes. These multi-scale feature maps are fed into the RPN for RoIs generation. Finally, these RoIs are pooled to a uniform scale and perform the final classification and regression tasks. The total loss function of the network is as follows:
where the first term denotes RPN loss, the second term represents classifier loss, the third term expresses regression loss, and the fourth term denotes CIR loss. The equilibrium parameter lambda represents the coefficient of CIR loss, which is taken as 0.35 in experiments and more details are described in
Section 3.2.
2.2. Two-Stage Fine-Tuning Strategy
Usually, the dataset of the experiment is divided into a training set and a test set . Under the few-shot detection scenario, the categories in the are divided into base categories and novel categories , . To train a robust model, the basic categories require as many samples as feasible, whereas the novel categories usually contain several annotated samples. To make full use of the rich prior knowledge embedded in large-scale samples and transfer this knowledge to a few novel samples, the training of our CIR-FSD is divided into two stages: base training stage and few-shot fine-tuning stage.
In the first stage, the network is trained on the base categories with abundant labels to learn prior knowledge. For each sample (, ) in , is an image () and is the label of the image . It is generally considered that such prior knowledge is stored in the feature extraction modules, such as Backbone, CIR, FPN, RoI feature extractor, etc., so that the parameters of these models are usually frozen.
In the second stage, both prior knowledge learned from base categories and new knowledge related to novel categories are utilized to detect the targets of novel classes. For several instances (, ) in , is the instances of the image (), is the label of the instances , and the maximum number of instances per category was set to k (k is generally no more than 20).
In our CIR-FSD, RPN acts as a binary classification network responsible for filtering out possible foreground objects from the background. If the RPN parameters are kept frozen, novel categories can easily be taken as background due to their low confidence. Different from the feature extraction module that is only responsible for extracting category-independent features, RPN needs to extract category-related features. To have the discriminative ability to identify novel categories from complex backgrounds, RPN needs to learn the knowledge of novel categories. Therefore, we improve RPN to enhance the confidence of novel categories in the fine-tuning stage. More novel categories are separated from the background and treated as foreground. In addition, the box classifier and regressor in the first stage are designed for base categories, and we also fine-tune them in the second stage to adapt to novel categories.
In the process of fine-tuning, the base categories often introduce catastrophic forgetting problems as it receives less attention, and there is a great deal of research examining this difficulty. Wang et al. [
45] proposed a new online continual learning dataset and evaluation metrics, which can sufficiently evaluate catastrophic forgetting. Fan et al. [
46] proposed a novel fine-tuning method, called Retentive R-CNN, which avoids catastrophic forgetting by combining pretrained RPN and fine-tuned RPN. Guirguis et al. [
47] propose a constraint-based fine-tuning approach to mitigate catastrophic forgetting. To prevent catastrophic forgetting, we used a few images from the base categories for fine-tuning, which preventing the model from overfitting the novel categories. For model testing, we test our CIR-FSD method on the test set
. Algorithm 1 depicts the whole training and testing process.
| Algorithm 1 Process of Training and Testing for the CIR-FSD |
- 1:
Create a large-scale training set out of base classes, and a small-scale training set out of novel classes, . - 2:
Construct a testing set for evaluation. - 3:
Initialize the parameters in the Backbone module, CIR module, FPN module, and RoI Feature extractor module. - 4:
for each sample do - 5:
Base training. - 6:
end for - 7:
Keep the network parameters fixed. - 8:
for k instances per class do - 9:
Few-shot fine-tuning. - 10:
end for - 11:
for each sample do - 12:
Generate bounding boxes and category scores on each image. - 13:
Calculate the accuracy and recall of all correctly identified objects. - 14:
end for
|
2.3. Context Information Refinement
It is generally believed that a large receptive field can capture richer contextual information. However, the receptive field of the feature pyramid network is insufficient to capture the contextual information for objects of different sizes. In particular, excessive background noise in complex remote sensing images can result in an overabundance of object data and a blurring of object boundaries. To address these problems, we designed a new CIR module to learn the discriminative context features, which can classify objects correctly and localize objects precisely. Specifically, as shown in
Figure 2, we adopt the backbone of Faster R-CNN (i.e., Resnet-101 [
48]) to implement the feature extractor. Then, the output feature maps of the backbone network are fed into our CIR, which is composed of multi-path dilated convolutional layers with rates of 3, 6, 12, 18, and 24 to obtain multiple receptive fields.
After applying multi-path dilated convolution to ResNet-101, the multiple feature maps in various receptive fields can be derived. In particular, deformable convolutions are introduced into each path, which can adapt to different scales and shapes of RSI objects. In addition, in our CIR, dense connections are adopted between each dilated convolutional layer, which can fuse better multi-scale context information. Finally, the output of the last dilated layer is sent into a 1 × 1 convolutional layer to fuse the multi-scale features. The structural details of the CIR implementation are described in
Section 3.2.
To better refine context information, the output of the last dilated layer is also sent into two 1 × 1 convolutional layers to learn a two-channel saliency map, which indicates the foreground and background scores, respectively. Then, the value of the saliency map is normalized to between [0,1] by executing the Softmax function. We take a binary map obtained from ground truth as the supervision label, and then calculated the CIR loss between the binary map and the saliency map to suppress noise and enhance object information. In our method, CIR loss is essentially cross-entropy loss, and it is calculated as follows:
where
h and
w denote the feature map’s width and height,
and
denote the prediction of mask’s pixel and label respectively, and Latt is pixelwise Softmax cross-entropy.
2.4. Improved RPN
RPN is considered to be a category-independent network, which uses foreground–background classifier to select RoIs without considering their exact category, as shown in
Figure 3. To prevent over-fitting, most prior studies believed that a pre-trained RPN could produce high-quality suggestions for a new assignment. As a result, they tended to freeze all parameters of such an RPN. We found that this strategy prevents RPN from learning features related to the novel categories, resulting in low confidence of the positive anchors for novel classes. Meanwhile, NMS in RPN tends to treat the novel categories as background, resulting in foreground–background imbalance. To alleviate the imbalance between the foreground and background, the RPN is fine-tuned in the fine-tuning stage and the constraint of NMS is relaxed on the confidence of positive anchors.
As shown in
Figure 4, for the convenience of presentation, we utilize the original image to replace the input feature map. The yellow cross in the picture depicts the feature map’s stride relative to the original image, and the green box represents the anchor generated by the RPN. Let the size of the
ith feature map generated by FPN be
, where
W and
H denote the feature map’s width and height, respectively, and
C denotes the number of the feature channels.
In each feature map, anchor boxes are first generated by anchor generator, corresponding to the anchors around the yellow cross in the figure. For visualization, we do not draw all the anchors around the yellow cross. Usually, there are nine different anchors around each yellow cross, consisting of three sizes and three ratios. These anchors perform classification and regression tasks via 3 × 3 convolution and 1 × 1 convolution, respectively. Then, RPN randomly selects the top m positive anchors that may contain objects in each level, and denotes their probability of containing objects. Usually, an intersection over union (IoU) threshold t is set to distinguish foreground and background. If an anchor satisfies , it is treated as foreground, otherwise as background.
To retain more positive anchors for novel categories, we improve the RPN. Specifically, we double the preset
m and propose a relaxed NMS (R-NMS). The IoU threshold
t is slightly reduced to allow more anchors to be selected, and more potential targets will be relieved of inhibitions. Finally, these anchors are fine-tuned into RoIs, and RPN selects the top
n RoIs to the subsequent networks for a more refined bounding box regression and multi-classification. To compensate for positive anchors, we slightly increase the value of
n. In RPN, the loss is a sum of the classification and bounding box regression losses, where the classification loss is calculated by cross-entropy and the regression loss is as follows:
where
u denotes the foreground anchors,
denotes the prediction,
denotes the ground thuth, and the positions of the boxes are denoted by
. Fine-tuning RPN and relaxing NMS can obtain more positive anchors for novel categories, thus improving the ability of RPN to adapt to novel classes with fewer samples.
4. Discussion
The proposed CIR-FSD was evaluated in experiments and compared with the state-of-the-art FSOD methods. Experimental results demonstrate the proposed method’s efficiency on the DIOR and NWPU VHR-10 datasets.
According to the ablation experiments in
Table 5, compared with the TFA [
31], TFA + CIR improves mAPs for novel categories on the DIOR [
49] dataset by 4.4%, 4.9%, and 3.1% in 5-shot, 10-shot, and 20-shot settings, respectively, which fully indicates that CIR extracts more robust context features conducive to object detection. After adding F-RPN, the mAPs for novel categories in 5-shot, 10-shot, and 20-shot are improved by 1.6%, 0.3% and 1.4%, respectively. Finally, after adding R-NMS, the mAPs of our proposed method are improved by 1.5%, 1.3% and 1.2% for novel categories in 5-shot, 10-shot, and 20-shot, respectively. With the above improvements, compared with the TFA, the proposed method improves mAPs for novel categories on the DIOR dataset by 7.5%, 6.5% and 5.7% in 5-shot, 10-shot, and 20-shot settings, respectively. Therefore, CIR, F-RPN and R-NMS are efficient and indispensable in the proposed method.
The comparison results of base classes are shown in
Table 3 and
Table 4. Our method, TFA and PAMS-det [
34] are based on fine-tuning, while FSRW [
22] and FSODM [
23] are based on meta-learning. For base categories, in most cases, the mAPs of the fine-tuning-based few-shot methods are better than that of all meta-learning-based few-shot methods. Especially on the larger dataset DIOR, the mAPs of the fine-tuning-based methods are much better than that of all meta-learning-based methods. The above analysis shows that compared with the meta-learning-based methods, the fine-tuning-based methods sacrifice less accuracy on base categories.
As can be seen from
Table 3 and
Table 4, our CIR-FSD exceeds all competitive methods. The results of comparative experiments demonstrate the advantages of our proposed method, which are discussed separately below.
First of all, it can be seen from
Table 3 and
Table 4 that the performance of YOLO v5 [
7] and Faster R-CNN [
10] without few-shot-based settings is much worse than that of the few-shot-based methods. For the DIOR dataset, YOLO v5 and Faster R-CNN can only achieve a mAP of 0.15 and 0.18 in the 20-shot setting, which is worse than the mAP of 0.33 obtained by our proposed method in 5 shots. Similarly, for NWPU VHR-10 [
50] dataset, YOLO v5 and Faster R-CNN can only achieve mAP of 0.20 and 0.24 in the 10-shot setting, which is even lower than our proposed method’s mAP of 0.54 in the 3-shot setting. YOLO v5 and Faster R-CNN perform terribly in detecting objects of novel classes, demonstrating that few-shot-based methods can effectively address the challenge of novel-class object detection without a sufficient number of bounding box annotations.
Secondly, as can be seen from
Table 3 and
Table 4, RepMet, FSRW and TFA are designed for detecting common objects in optical pictures (such as bicycles, cars, and chairs), and their performance is inferior than that designed for RSIs object detection in most cases. The fundamental reason for this is that objects in RSIs have greater scale variation and spatial resolution than that in optical images, which makes object detection with only a few annotated samples more challenging. Compared with FSRW, FSODM designs a multi-scale feature extraction module and a novel FSOD architecture to address the inherent scale variances problem in RSIs. Compared with TFA, PAMS-Det improves classification by using the involution operator and shape bias, and it creates a multi-scale module to better localization in remote sensing images.
Thirdly, FSODM, PAMS-Det and our proposed method are specially optimized for detecting objects in RSIs. PAMS-Det and our proposed CIR-FSD are based on fine-tuning, while FSODM is based on meta-learning. As you can see from
Table 3 and
Table 4, the fine-tuning-based methods are superior to the meta-learning-based method. Compared with two methods based on fine-tuning TFA and PAMS-det, our proposed method shows superior performance. TFA and PAMS-Det only fine-tune box classifier and regressor, while our proposed method fine-tunes RPN, finetune box classifier and regressor. More importantly, the CIR module we designed extracts more robust context features, which can capture rich context from different receptive fields and enhance the object information. Take the three-shot setting as an example, the mAP of our CIR-FSD is 8% higher than TFA and 5% higher than PAMS-Det on the DIOR dataset, while the mAP of our CIR-FSD is 25% higher than TFA and 17% higher than PAMS-Det on the NWPU dataset.
To sum up, in this study, we design a novel context information refinement few-shot detector for remote image object detection. Detailed experiments and analyses show the advantages of the proposed method. Although our method can bring high improvement to horizontal region detection, it cannot address the rotation detection boundary problem. In the future, we will make our method solve the rotation detection boundary problem while dealing with the horizontal region detection.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}