
Deep Learning Approach for Car Detection in UAV Imagery





Abstract
:1. Introduction
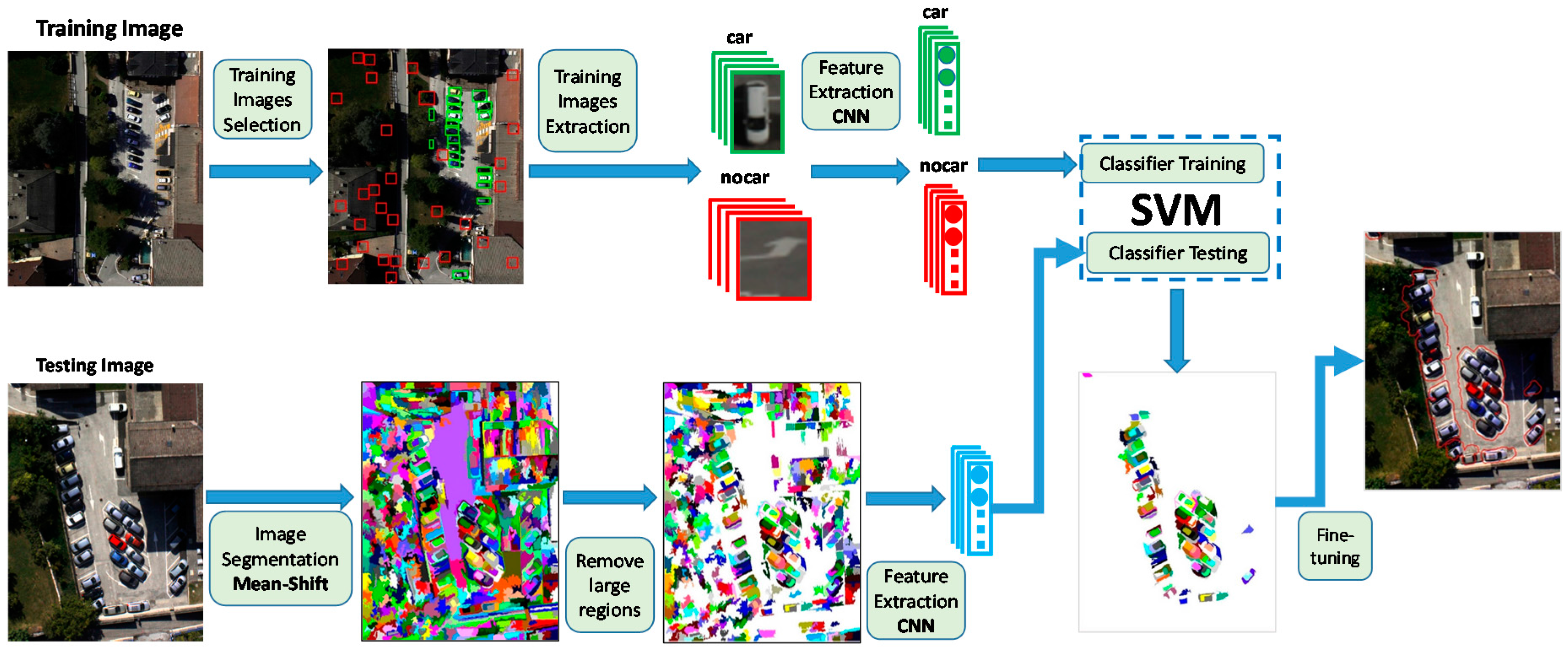
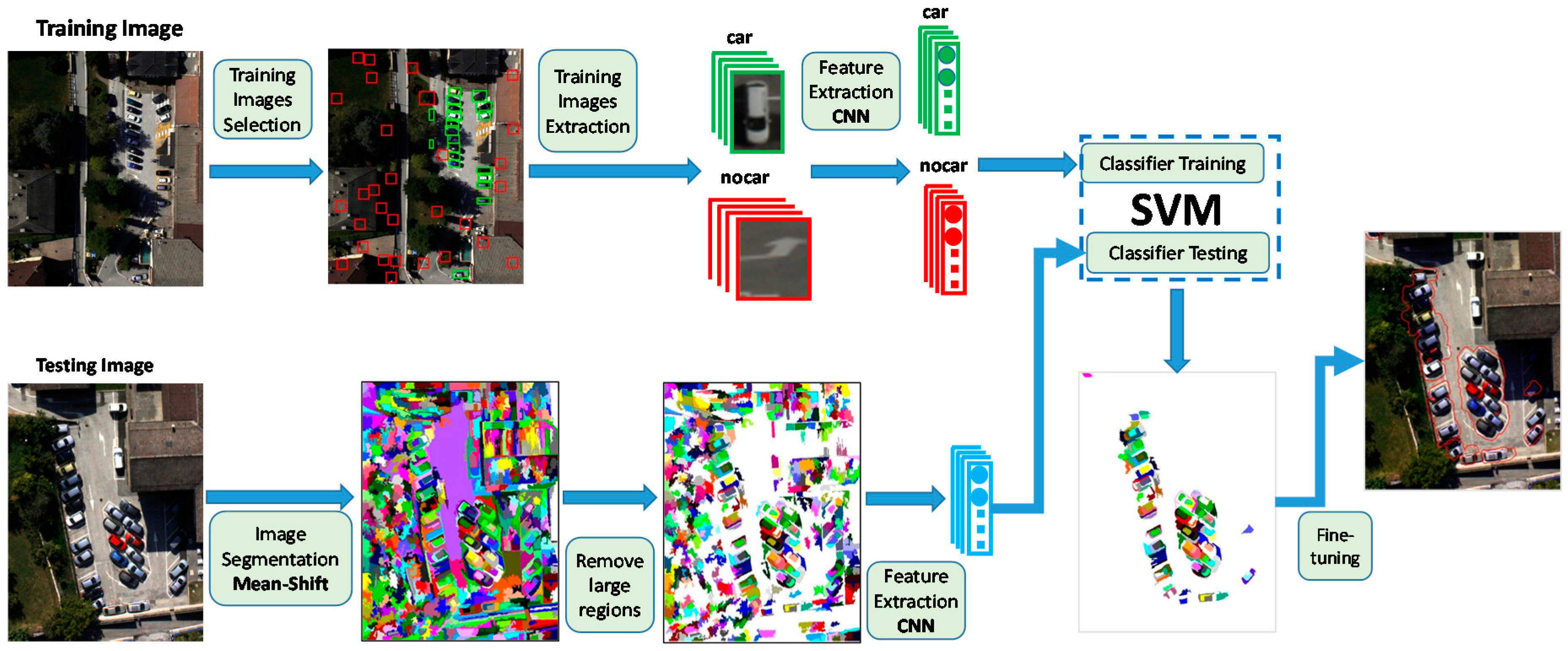
2. Methodology
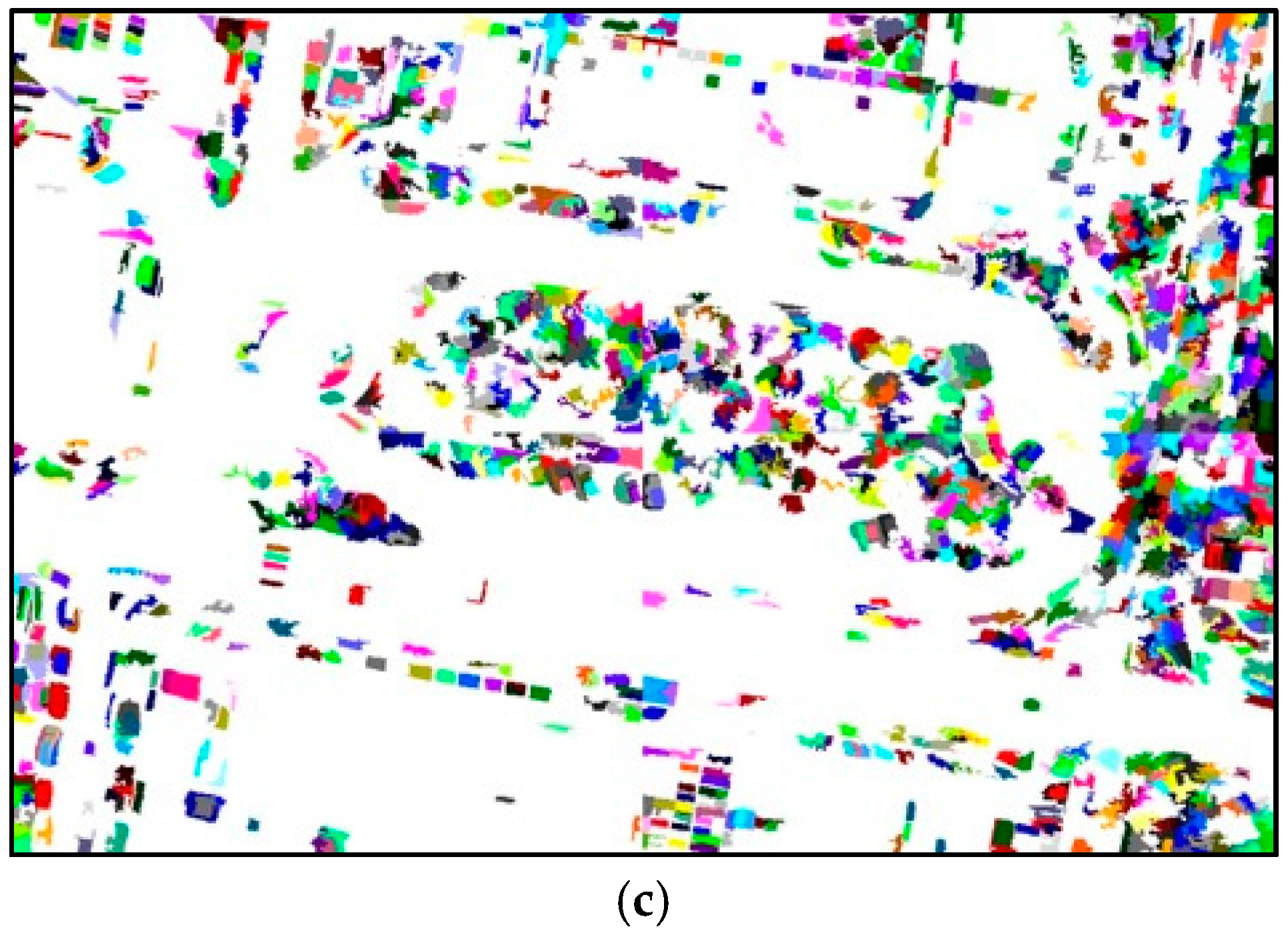
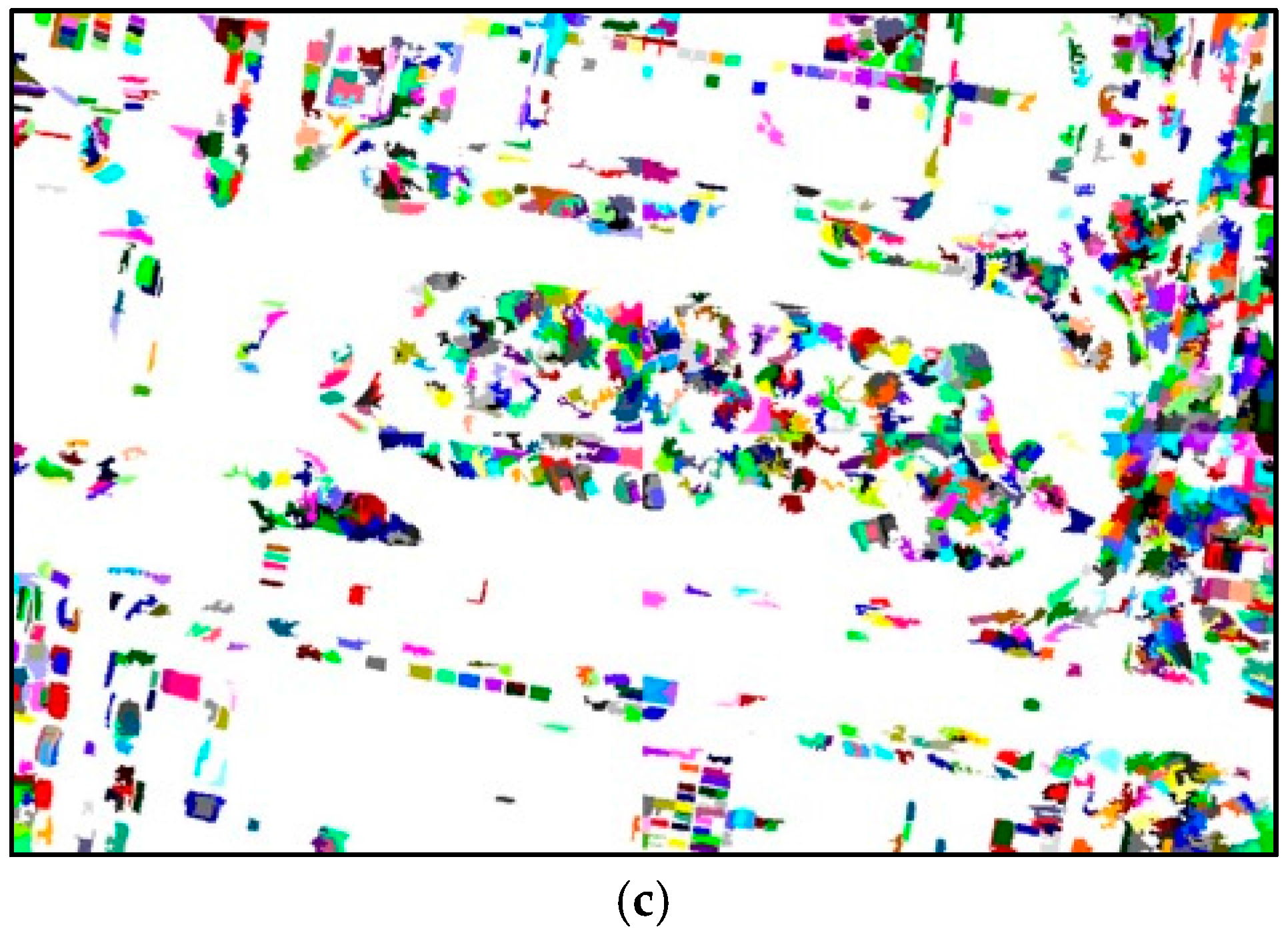
2.1. Over-Segmentation of the UAV Image
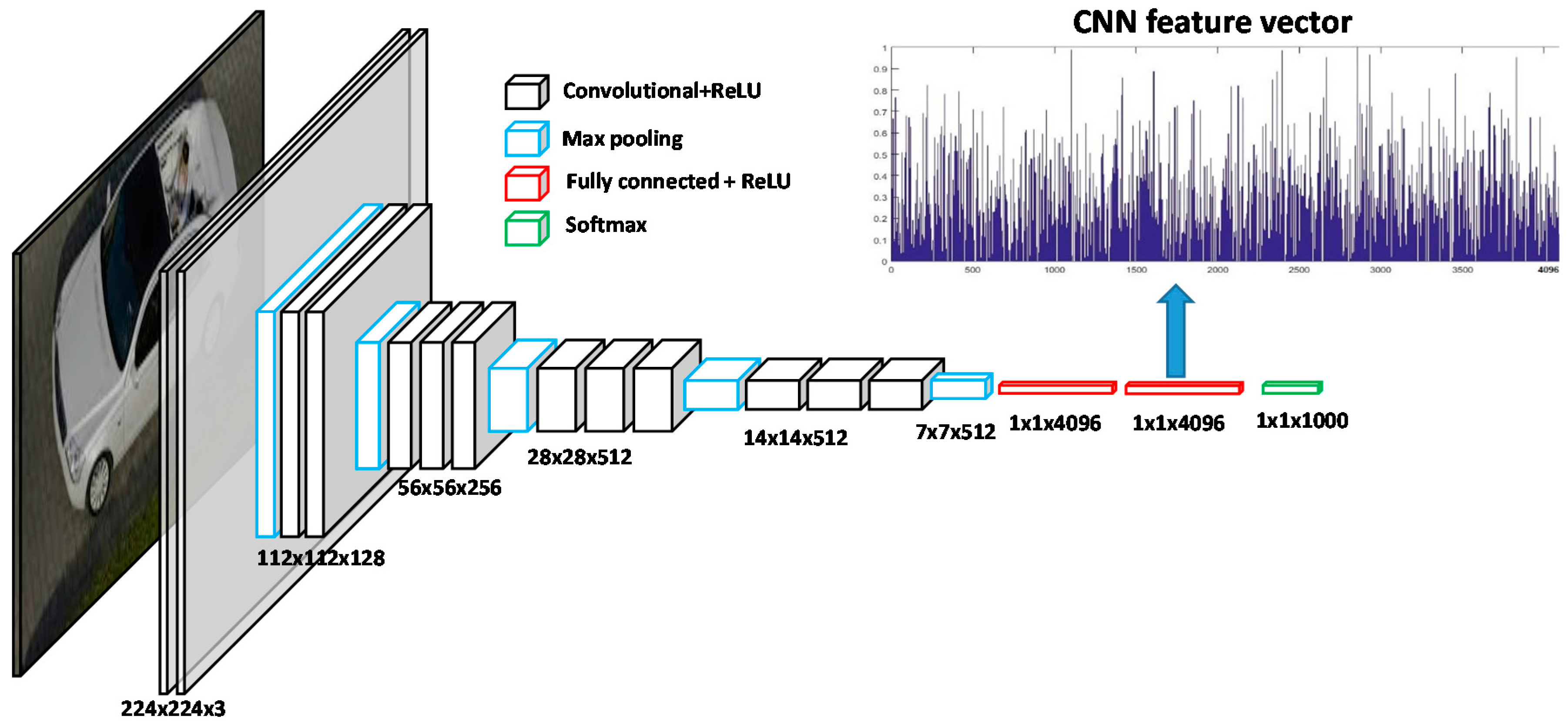
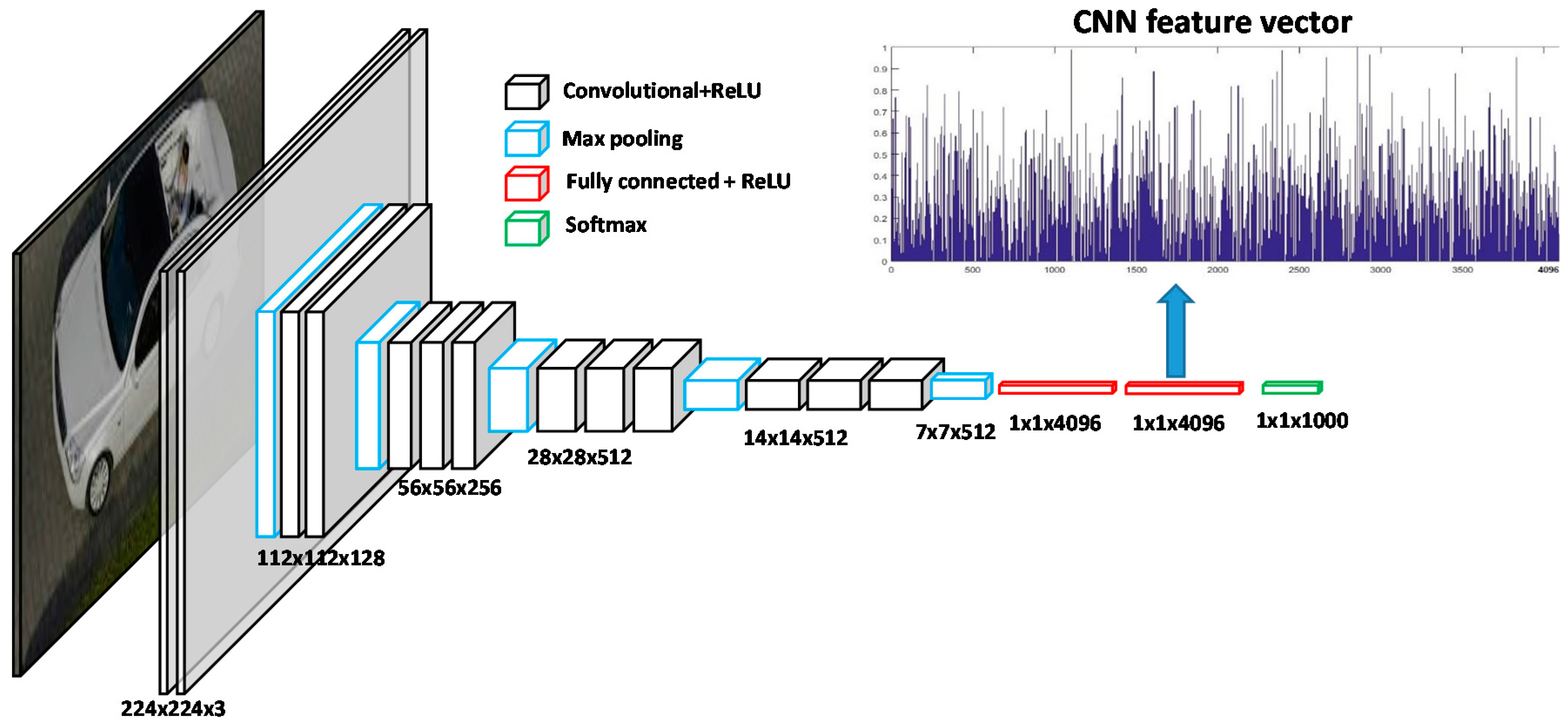
2.2. Feature Extraction with Pre-Trained CNNs
2.3. Region Classification with a Linear SVM
2.4. Fine-Tuning the Detection Result
3. Results
3.1. Dataset Description and Experiment Setup
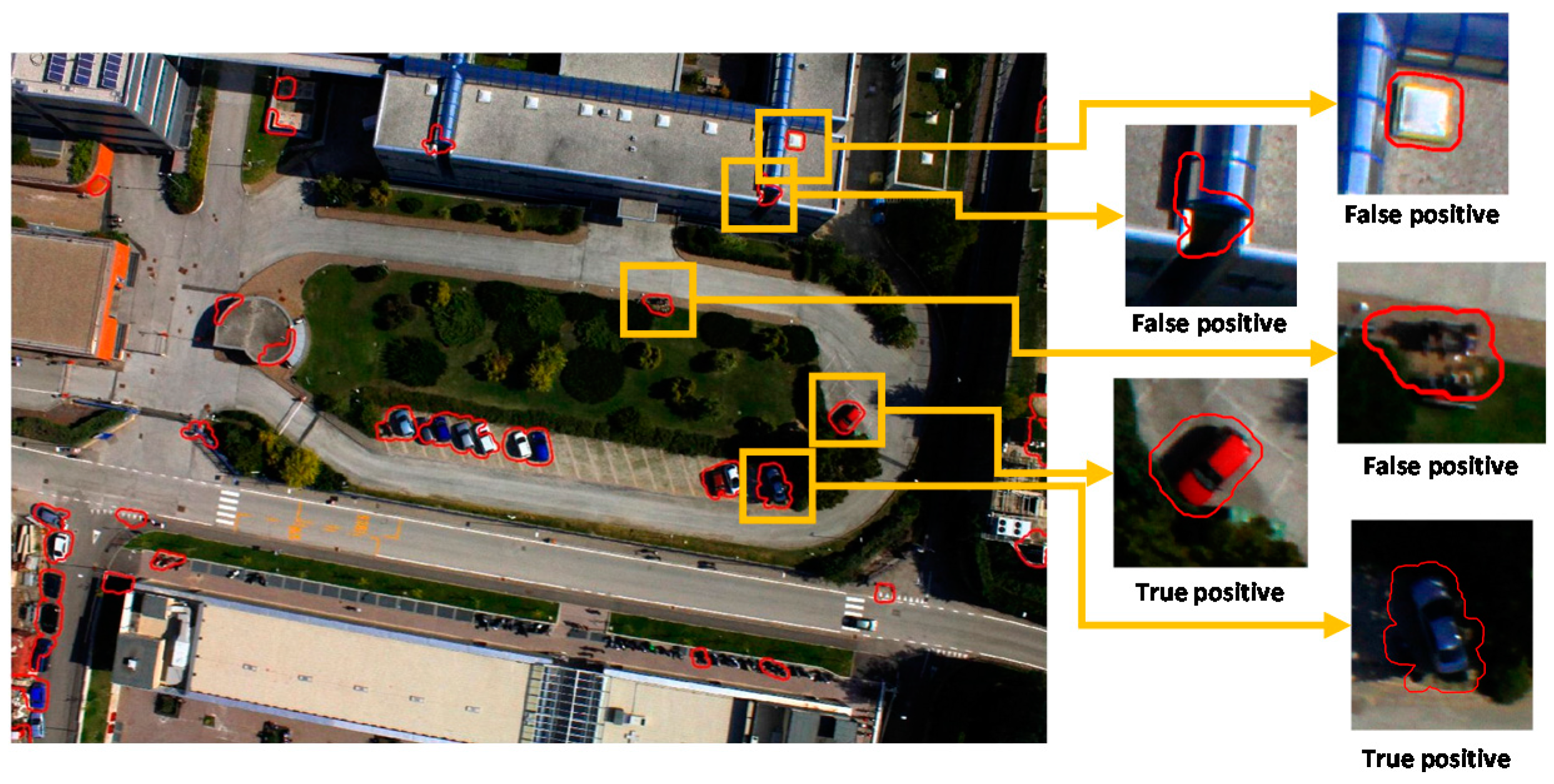
3.2. Assessment Method
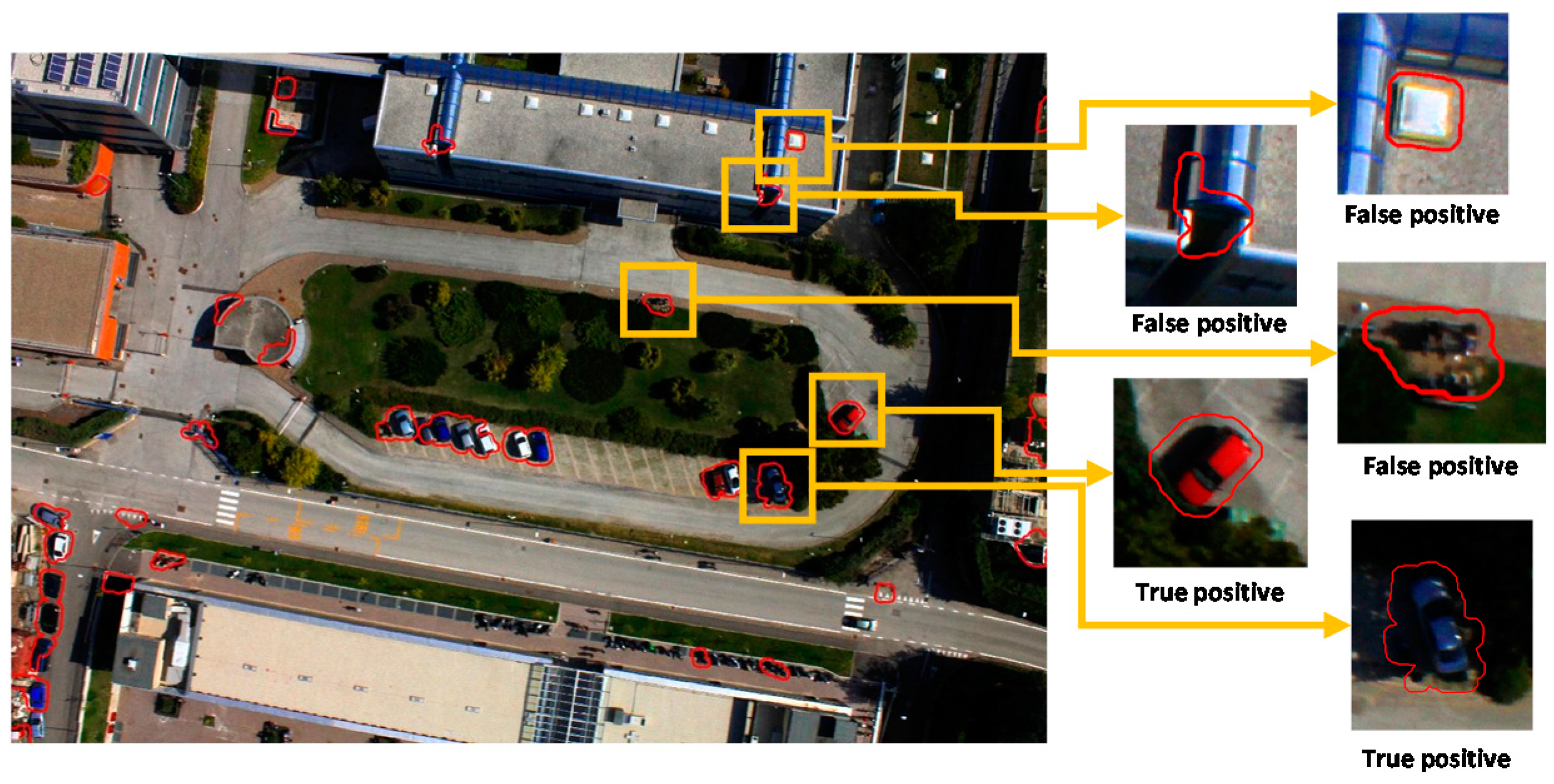
3.3. Detection Results
4. Discussions
4.1. Sensitivity Analysis with Respect to the Window Size
4.2. Comparison with State-of-the-Art
5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Colomina, I.; Molina, P. Unmanned aerial systems for photogrammetry and remote sensing: A review. ISPRS J. Photogramm. Remote Sens. 2014, 92, 79–97. [Google Scholar] [CrossRef]
- Berni, J.; Zarco-Tejada, P.J.; Suarez, L.; Fereres, E. Thermal and Narrowband Multispectral Remote Sensing for Vegetation Monitoring From an Unmanned Aerial Vehicle. IEEE Trans. Geosci. Remote Sens. 2009, 47, 722–738. [Google Scholar] [CrossRef]
- Uto, K.; Seki, H.; Saito, G.; Kosugi, Y. Characterization of Rice Paddies by a UAV-Mounted Miniature Hyperspectral Sensor System. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2013, 6, 851–860. [Google Scholar] [CrossRef]
- Püschel, H.; Sauerbier, M.; Eisenbeiss, H. A 3D Model of Castle Landenberg (CH) from Combined Photogrammetric Processing of Terrestrial and UAV-based Images. Int. Arch. Photogramm. Remote Sens. Spat. Inf. Sci. 2008, 37, 93–98. [Google Scholar]
- Moranduzzo, T.; Mekhalfi, M.L.; Melgani, F. LBP-based multiclass classification method for UAV imagery. In Proceedings of the 2015 IEEE International Geoscience and Remote Sensing Symposium (IGARSS), Milan, Italy, 26–31 July 2015; pp. 2362–2365. [Google Scholar]
- Lin, A.Y.-M.; Novo, A.; Har-Noy, S.; Ricklin, N.D.; Stamatiou, K. Combining GeoEye-1 Satellite Remote Sensing, UAV Aerial Imaging, and Geophysical Surveys in Anomaly Detection Applied to Archaeology. IEEE J. Sel. Top. Appl. Earth Obs. Remote Sens. 2011, 4, 870–876. [Google Scholar] [CrossRef]
- Moranduzzo, T.; Melgani, F. A SIFT-SVM method for detecting cars in UAV images. In Proceedings of the 2012 IEEE International Geoscience and Remote Sensing Symposium, Munich, Germany, 22–27 July 2012; pp. 6868–6871. [Google Scholar]
- Moranduzzo, T.; Melgani, F. Automatic Car Counting Method for Unmanned Aerial Vehicle Images. IEEE Trans. Geosci. Remote Sens. 2014, 52, 1635–1647. [Google Scholar] [CrossRef]
- Moranduzzo, T.; Melgani, F. Detecting Cars in UAV Images With a Catalog-Based Approach. IEEE Trans. Geosci. Remote Sens. 2014, 52, 6356–6367. [Google Scholar] [CrossRef]
- Moranduzzo, T.; Melgani, F.; Bazi, Y.; Alajlan, N. A fast object detector based on high-order gradients and Gaussian process regression for UAV images. Int. J. Remote Sens. 2015, 36, 37–41. [Google Scholar]
- Zhao, T.; Nevatia, R. Car detection in low resolution aerial image. In Proceedings of the Eighth IEEE International Conference on Computer Vision (ICCV 2001), Washington, WA, USA, 7–14 July 2001. [Google Scholar]
- Moon, H.; Chellappa, R.; Rosenfeld, A. Performance analysis of a simple vehicle detection algorithm. Image Vis. Comput. 2002, 20, 1–13. [Google Scholar] [CrossRef]
- Kluckner, S.; Pacher, G.; Grabner, H.; Bischof, H.; Bauer, J. A 3D Teacher for Car Detection in Aerial Images. In Proceedings of the 2007 IEEE 11th International Conference on Computer Vision, Rio de Janeiro, Brazil, 14–21 October 2007; pp. 1–8. [Google Scholar]
- Holt, A.C.; Seto, E.Y.W.; Rivard, T.; Gong, P. Object-based Detection and Classification of Vehicles from Highresolution Aerial Photography. Photogrammetric Engineering and Remote. Photogramm. Eng. Remote Sens. 2009, 75, 871–880. [Google Scholar] [CrossRef]
- Shao, W.; Yang, W.; Liu, G.; Liu, J. Car detection from high-resolution aerial imagery using multiple features. In Proceedings of the 2012 IEEE International Geoscience and Remote Sensing Symposium, Munich, Germany, 22–27 July 2012; pp. 4379–4382. [Google Scholar]
- Chen, X.; Xiang, S.; Liu, C.-L.; Pan, C.-H. Vehicle Detection in Satellite Images by Hybrid Deep Convolutional Neural Networks. IEEE Geosci. Remote Sens. Lett. 2014, 11, 1797–1801. [Google Scholar] [CrossRef]
- Leitloff, J.; Rosenbaum, D.; Kurz, F.; Meynberg, O.; Reinartz, P. An Operational System for Estimating Road Traffic Information from Aerial Images. Remote Sens. 2014, 6, 11315–11341. [Google Scholar] [CrossRef]
- Xu, Y.; Yu, G.; Wang, Y.; Wu, X.; Ma, Y. A Hybrid Vehicle Detection Method Based on Viola-Jones and HOG + SVM from UAV Images. Sensors 2016, 16, 1325. [Google Scholar] [CrossRef] [PubMed]
- Hinton, G.; Osindero, S.; Teh, Y. A Fast Learning Algorithm for Deep Belief Nets. Neural Comput. 2006, 18, 1527–1554. [Google Scholar] [CrossRef] [PubMed]
- Vincent, P.; Larochelle, H.; Bengio, Y.; Manzagol, P.-A. Extracting and Composing Robust Features with Denoising Autoencoders. In Proceedings of the 25th International Conference on Machine Learning, Helsinki, Finland, 5–9 July 2008; ACM: New York, NY, USA, 2008; pp. 1096–1103. [Google Scholar]
- Swietojanski, P.; Ghoshal, A.; Renals, S. Convolutional Neural Networks for Distant Speech Recognition. IEEE Signal Process. Lett. 2014, 21, 1120–1124. [Google Scholar]
- Lampert, C.H.; Blaschko, M.B.; Hofmann, T. Beyond sliding windows: Object localization by efficient subwindow search. In Proceedings of the 2008 IEEE Conference on Computer Vision and Pattern Recognition, Anchorage, AK, USA, 23–28 June 2008; pp. 1–8. [Google Scholar]
- Vedaldi, A.; Gulshan, V.; Varma, M.; Zisserman, A. Multiple kernels for object detection. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 27 September–4 October 2009; Volume 1, pp. 606–613. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 24–27 June 2014; pp. 580–587. [Google Scholar]
- Wang, X.; Yang, M.; Zhu, S.; Lin, Y. Regionlets for Generic Object Detection. IEEE Trans. Pattern Anal. Mach. Intell. 2015, 37, 2071–2084. [Google Scholar] [CrossRef] [PubMed]
- Uijlings, J.R.R.; Van De Sande, K.E.A.; Gevers, T.; Smeulders, A.W.M. Selective Search for Object Recognition. Int. J. Comput. Vis. 2013, 104, 154–171. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards Real-Time Object Detection with Region Proposal Networks. IEEE Trans. Pattern Anal. Mach. Intell. 2016. [Google Scholar] [CrossRef] [PubMed]
- Cheng, Y. Mean shift, mode seeking, and clustering. IEEE Trans. Pattern Anal. Mach. Intell. 1995, 17, 790–799. [Google Scholar] [CrossRef]
- Comaniciu, D.; Meer, P. Mean shift: A robust approach toward feature space analysis. IEEE Trans. Pattern Anal. Mach. Intell. 2002, 24, 603–619. [Google Scholar] [CrossRef]
- Boykov, Y.; Funka-Lea, G. Graph Cuts and Efficient N-D Image Segmentation. Int. J. Comput. Vis. 2006, 70, 109–131. [Google Scholar] [CrossRef]
- Jianbo Shi, J.; Malik, J. Normalized cuts and image segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2000, 22, 888–905. [Google Scholar] [CrossRef]
- Vedaldi, A.; Soatto, S. Quick Shift and Kernel Methods for Mode Seeking. In Computer Vision—ECCV 2008; Forsyth, D., Torr, P., Zisserman, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2008; Volume 5305, pp. 705–718. [Google Scholar]
- Vincent, L.; Soille, P. Watersheds in digital spaces: An efficient algorithm based on immersion simulations. IEEE Trans. Pattern Anal. Mach. Intell. 1991, 13, 583–598. [Google Scholar] [CrossRef]
- Levinshtein, A.; Stere, A.; Kutulakos, K.N.; Fleet, D.J.; Dickinson, S.J.; Siddiqi, K. TurboPixels: Fast superpixels using geometric flows. IEEE Trans. Pattern Anal. Mach. Intell. 2009, 31, 2290–2297. [Google Scholar] [CrossRef] [PubMed]
- Farabet, C.; Couprie, C.; Najman, L.; Le Cun, Y. Learning Hierarchical Features for Scene Labeling. IEEE Trans. Pattern Anal. Mach. Intell. 2013, 35, 1915–1929. [Google Scholar] [CrossRef] [PubMed]
- Brosch, T.; Tam, R. Efficient Training of Convolutional Deep Belief Networks in the Frequency Domain for Application to High-resolution 2D and 3D Images. Neural Comput. 2015, 27, 211–227. [Google Scholar] [CrossRef] [PubMed]
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. Imagenet classification with deep convolutional neural networks. In Advances in Neural Information Processing Systems; MIT Press: Cambridge, MA, USA, 2012. [Google Scholar]
- Simonyan, K.; Zisserman, A. Very Deep Convolutional Networks for Large-Scale Image Recognition. In Proceedings of the 3rd International Conference on Learning Representations, San Diego, CA, USA, 7–9 May 2015. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Test Image | Size | Regions | Within Range | Cars Present | TP | FP | Pacc | Uacc | Acc |
|---|---|---|---|---|---|---|---|---|---|
| Image 1 | 2626 × 4680 | 4666 | 4006 | 56 | 47 | 4 | 83.9% | 92.2% | 88.0% |
| Image 2 | 2424 × 3896 | 3114 | 2483 | 31 | 26 | 10 | 83.9% | 72.2% | 78.0% |
| Image 3 | 3456 × 5184 | 4623 | 1282 | 19 | 14 | 7 | 73.7% | 66.7% | 70.2% |
| Image 4 | 3456 × 5184 | 6473 | 2165 | 16 | 13 | 0 | 81.3% | 100.0% | 90.6% |
| Image 5 | 3456 × 5184 | 6666 | 1994 | 5 | 4 | 2 | 80.0% | 66.7% | 73.3% |
| Window Size in Pixels | % of Average Car Size | TP | FP | Pacc | Uacc | Acc | Cars Present |
|---|---|---|---|---|---|---|---|
| 60 × 60 | 30% | 18 | 2 | 60.0% | 90.0% | 75.0% | 30 |
| 80 × 80 | 40% | 24 | 1 | 80.0% | 96.0% | 88.0% | 30 |
| 100 × 100 | 50% | 25 | 1 | 83.3% | 96.2% | 89.7% | 30 |
| 120 × 120 | 60% | 26 | 3 | 86.7% | 89.7% | 88.2% | 30 |
| 140 × 140 | 70% | 27 | 3 | 90.0% | 90.0% | 90.0% | 30 |
| 160 × 160 | 80% | 29 | 3 | 96.7% | 90.6% | 93.6% | 30 |
| 180 × 180 | 90% | 26 | 5 | 86.7% | 83.9% | 85.3% | 30 |
| 200 × 200 | 100% | 27 | 8 | 90.0% | 77.1% | 83.6% | 30 |
| Proposed Method | Method in [9] | |||||||||
|---|---|---|---|---|---|---|---|---|---|---|
| Test Image | Size | Cars Present | TP | FP | Acc | Time (s) | Cars Present | TP | FP | Acc |
| Image 1 | 2626 × 4680 | 51 | 43 | 4 | 87.9% | 1592 | 51 | 35 | 10 | 73.2% |
| Image 2 | 2424 × 3896 | 31 | 26 | 10 | 78.0% | 815 | 31 | 20 | 15 | 60.8% |
| Image 3 | 3456 × 5184 | 19 | 14 | 7 | 70.2% | 416 | 19 | 16 | 30 | 59.5% |
| Image 4 | 3456 × 5184 | 15 | 12 | 0 | 90.0% | 726 | 15 | 14 | 17 | 69.2% |
| Image 5 | 3456 × 5184 | 3 | 2 | 2 | 58.3% | 657 | 3 | 2 | 39 | 35.8% |
| Total | 119 | 97 | 23 | 119 | 87 | 111 | ||||
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ammour, N.; Alhichri, H.; Bazi, Y.; Benjdira, B.; Alajlan, N.; Zuair, M. Deep Learning Approach for Car Detection in UAV Imagery. Remote Sens. 2017, 9, 312. https://doi.org/10.3390/rs9040312
Ammour N, Alhichri H, Bazi Y, Benjdira B, Alajlan N, Zuair M. Deep Learning Approach for Car Detection in UAV Imagery. Remote Sensing. 2017; 9(4):312. https://doi.org/10.3390/rs9040312
Chicago/Turabian StyleAmmour, Nassim, Haikel Alhichri, Yakoub Bazi, Bilel Benjdira, Naif Alajlan, and Mansour Zuair. 2017. "Deep Learning Approach for Car Detection in UAV Imagery" Remote Sensing 9, no. 4: 312. https://doi.org/10.3390/rs9040312
APA StyleAmmour, N., Alhichri, H., Bazi, Y., Benjdira, B., Alajlan, N., & Zuair, M. (2017). Deep Learning Approach for Car Detection in UAV Imagery. Remote Sensing, 9(4), 312. https://doi.org/10.3390/rs9040312