
An Improved Retrievability-Based Cluster-Resampling Approach for Pseudo Relevance Feedback

Abstract
:
1. Introduction
Motivation and Contribution
2. Related Work
Cluster-Based Pseudo-Relevance Feedback
3. Experimental Setup
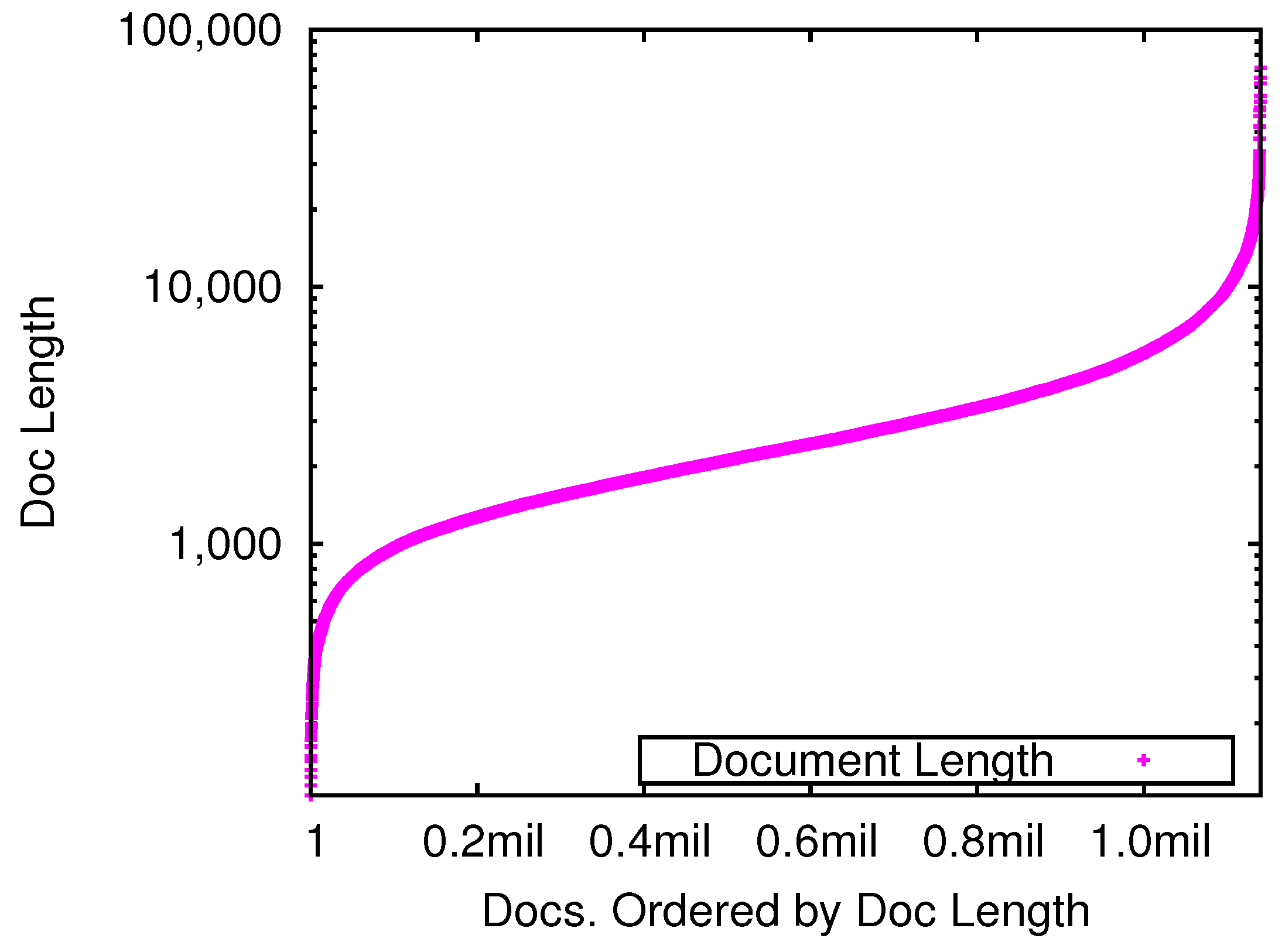
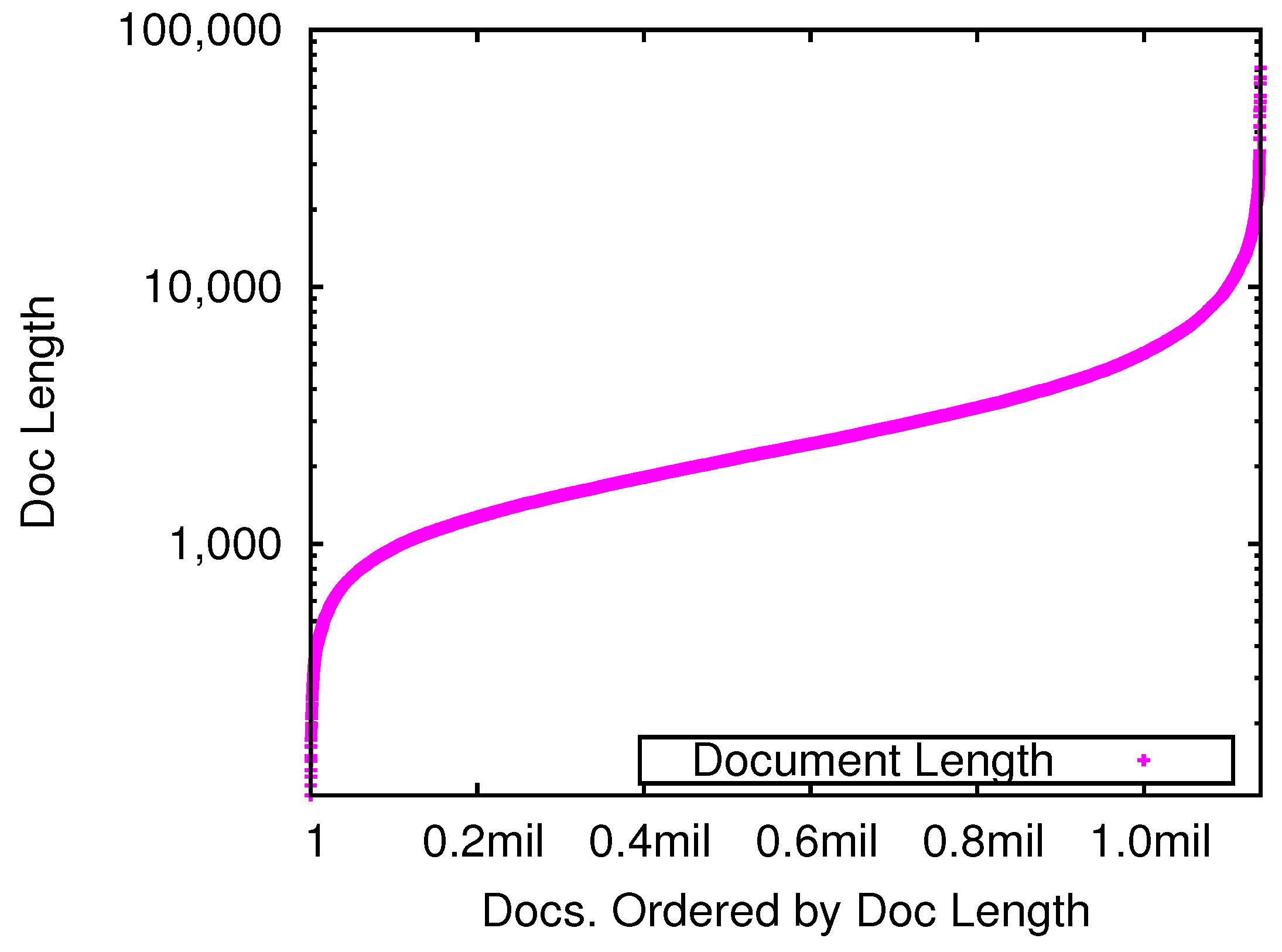
3.1. Collection
3.2. Retrieval Models
3.2.1. Standard Retrieval Models
- TFIDF: The TFIDF (term frequency inverse document frequency) is a retrieval model often used in information retrieval. It is a statistical measure used to evaluate how important a query terms is to a document. The importance increases proportionally to the number of times a term appears in the document, but is offset by the frequency of the term in the collection. The standard TFIDF retrieval model is described as follow:is the term frequency of query term t in d and is the total number of documents in the collection. represents the total number of documents containing t.
- NormTFIDF: The standard TFIDF does not normalize the term frequencies relative to document length, thus sensitive to and biased toward large absolute term frequencies. It is possible to address the length bias by using document length and defied normalized TFIDF (NormTFIDF) as:
- BM25: Okapi (Best Match Retrieval Model BM25) is arguably one of the most important and widely-used information retrieval models. It is a probabilistic function and nonlinear combination of three key attributes of a document: term frequency , document frequency and the document length . The effectiveness of BM25 is controlled by two parameters k and b. These parameters control the contributions of term frequency and document length. We used the following standard function of BM25 proposed by [4]:is the average document length in the collection from which the documents are drawn. k and b are two parameters, and they are used with and .
- SMART: The System for Manipulating and Retrieving Text (SMART) is a retrieval model in information retrieval. It is based on the vector space model. We use the following variation of SMART developed by [31] at AT&T Labs.represents the average number of occurrences of each term in the d, is the number of unique terms in d and represents the average number of unique terms per document.
3.2.2. Language Models with Term Smoothing
- Jelinek–Mercer smoothing (JM): Jelinek–Mercer smoothing [17] combines the relative frequency of a query’s term in the document d with the relative frequency of the term in the collection (D). The amount of smoothing is controlled by the λ, and it is set between 0 and 1. Small smoothing values of λ close to 0 add only the contribution of term frequencies, while large λ values reduce the effect of relative term frequencies within the documents, and more importance is given toward the relative frequencies of terms in the collection.is the probability of term t occurring in the collection . According to the suggested value of λ by [17], we use (λ with ).
- Dirichlet (Bayesian) smoothing (DirS): This smoothing technique makes smoothing dependent on the document length [17]. Since long documents allow us to estimate the language model more accurately, therefore, this technique smooths them less, and this is done with the help of a parameter μ. Since the value of μ is added in the document length, thus small values of μ retrieve less long documents. If the μ is used with large values, then the distinction for the difference between document lengths becomes less extreme, and long documents are more favored over short documents. Again, this favoritism mostly occurs in the case of long Boolean OR queries.According to [17] suggestion, we use the μ with 2000.
- Two-stage smoothing (TwoStage): This smoothing technique first smooths the document model using the Dirichlet prior probability with the parameter μ (as explained above), and then, it mixes the document model with the query background model using Jelinek–Mercer smoothing with the parameter λ [17]. The query background model is based on the term frequency in the collection. The smoothing function is therefore:where μ is the Dirichlet prior probability and λ is the Jelinek–Mercer parameter. In our experiments, we use the parameters and , respectively.
- Absolute discount smoothing (AbsDis): This technique makes smoothing by subtracting a constant from the counts of each seen term [17]. The effect of δ is similar to Jelinek–Mercer parameter λ, but differs in this sense that it discounts the seen terms’ probabilities by subtracting a constant δ instead of multiplying them by .is the set of all unique terms of d. We use the δ with .
3.2.3. Query Expansion Models
- Query expansion using language modeling (TS-LM): [32]: This method uses the top-n documents for PRF selection. The candidate terms for the expansion in the PRF are ranked according to the sum of divergences between the documents in which they occurred and the importance of the terms in the whole collection (Equation (14)),
- Query expansion using Kullback–Leibler divergence (TS-KLD): [14]: This method also uses the top-n for PRF selection. However, terms for the expansion in the PRF set are ranked according to the relative rareness of terms in the PRF set as opposed to the whole collection (Equation (13)),t is the expansion term; P is the PRF set; represents the total count of term t in the collection; C represents the total count of all terms in the collection; and is the probability of term t occurrence in the PRF set P.
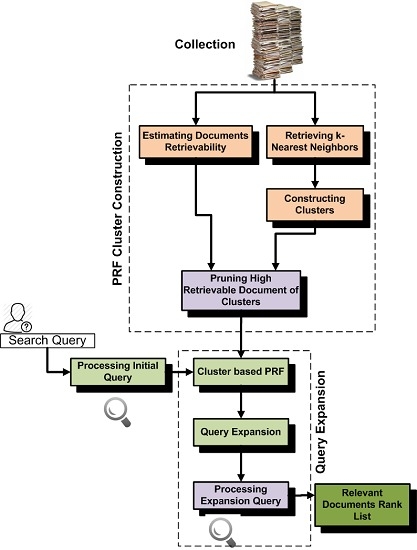
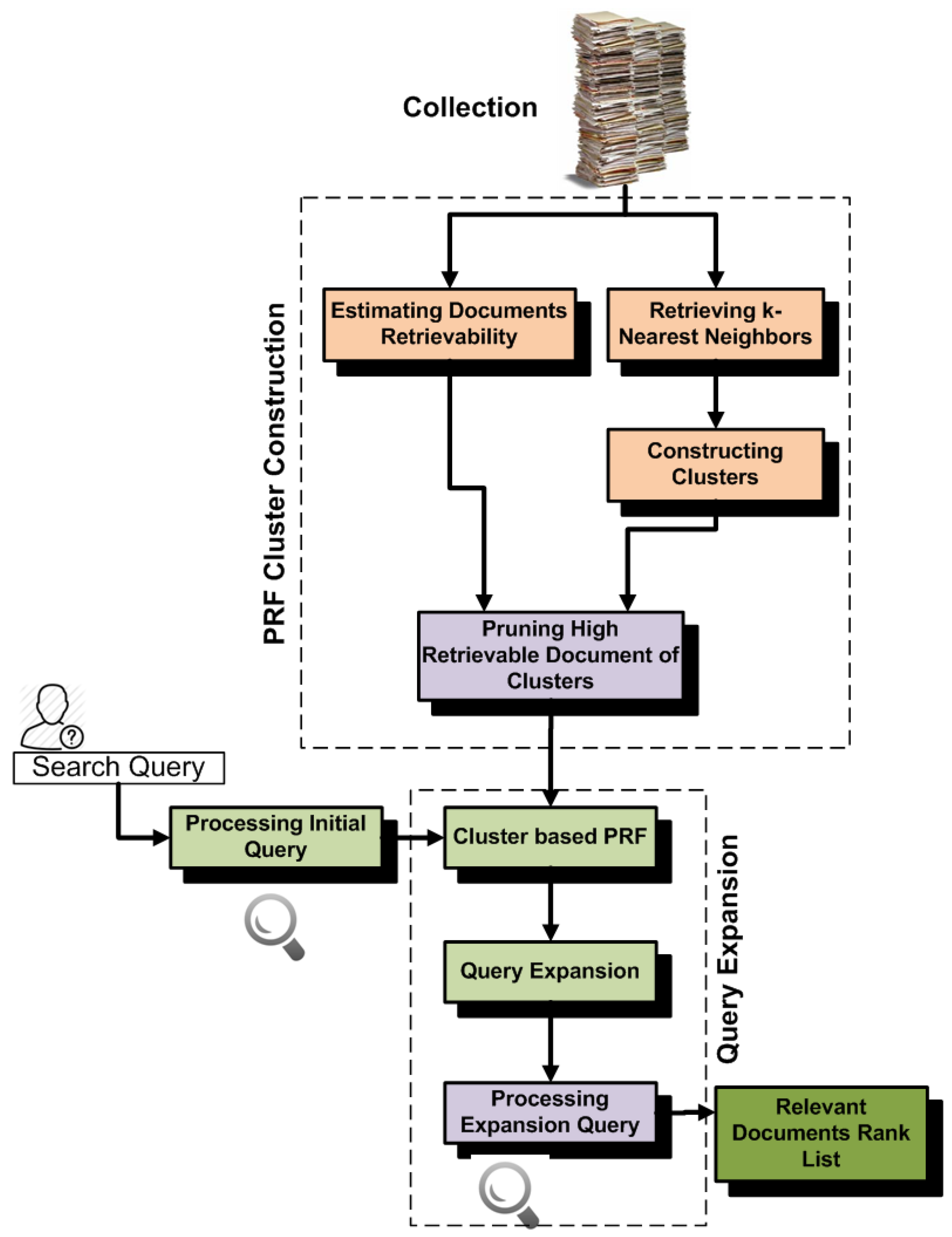
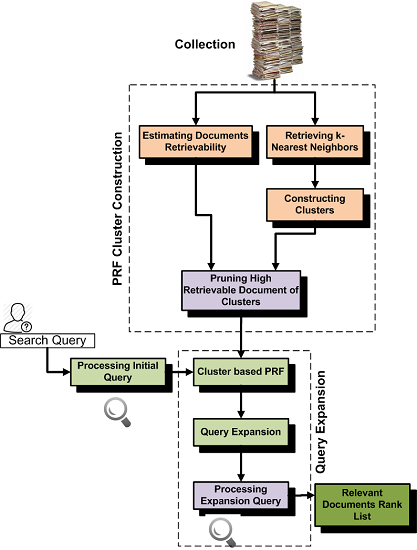
4. Cluster-Based Pseudo-Relevance Feedback
4.1. Constructing Clusters for PRF
4.2. Ranking Clusters and Selecting Documents for Relevance Feedback
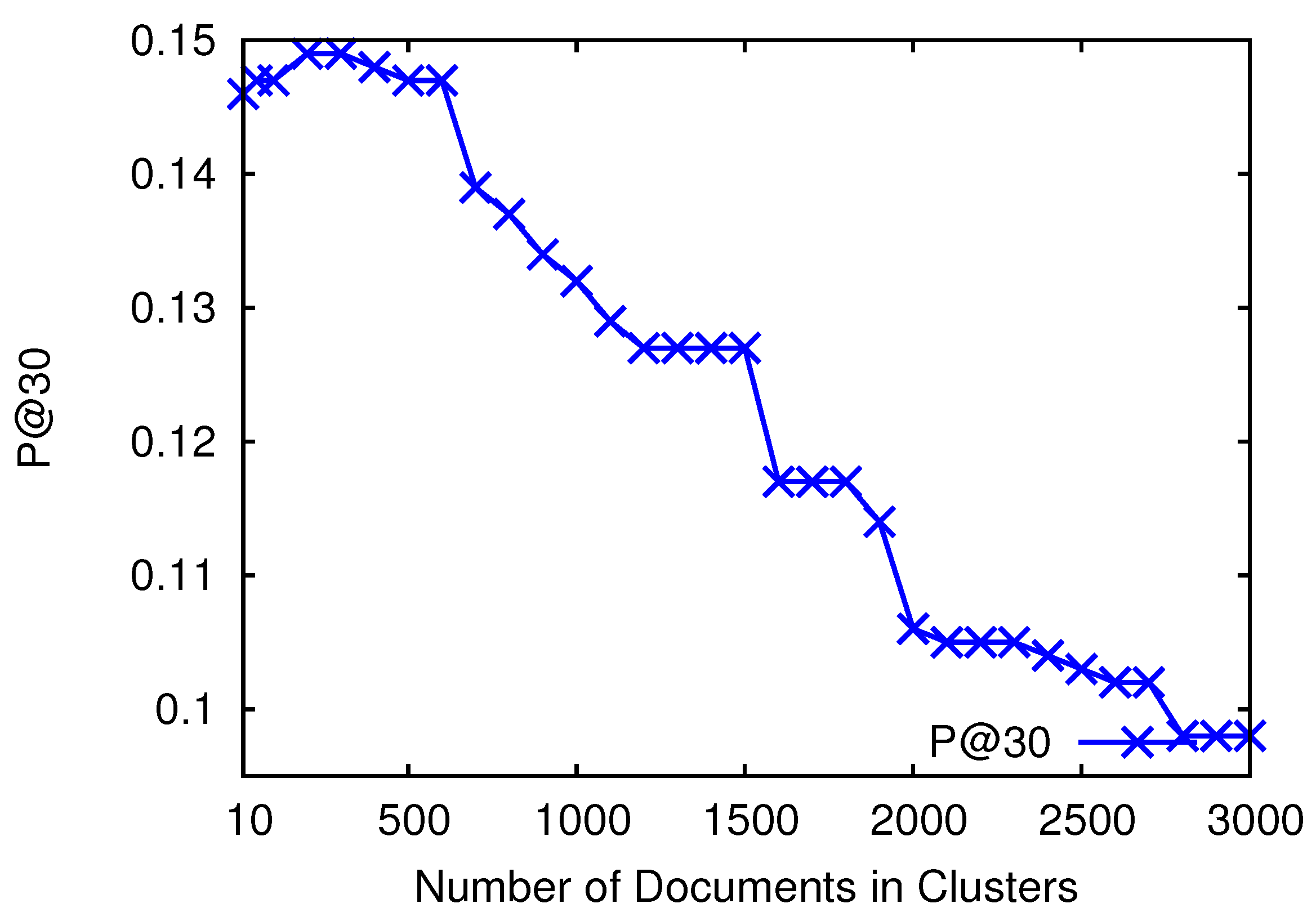
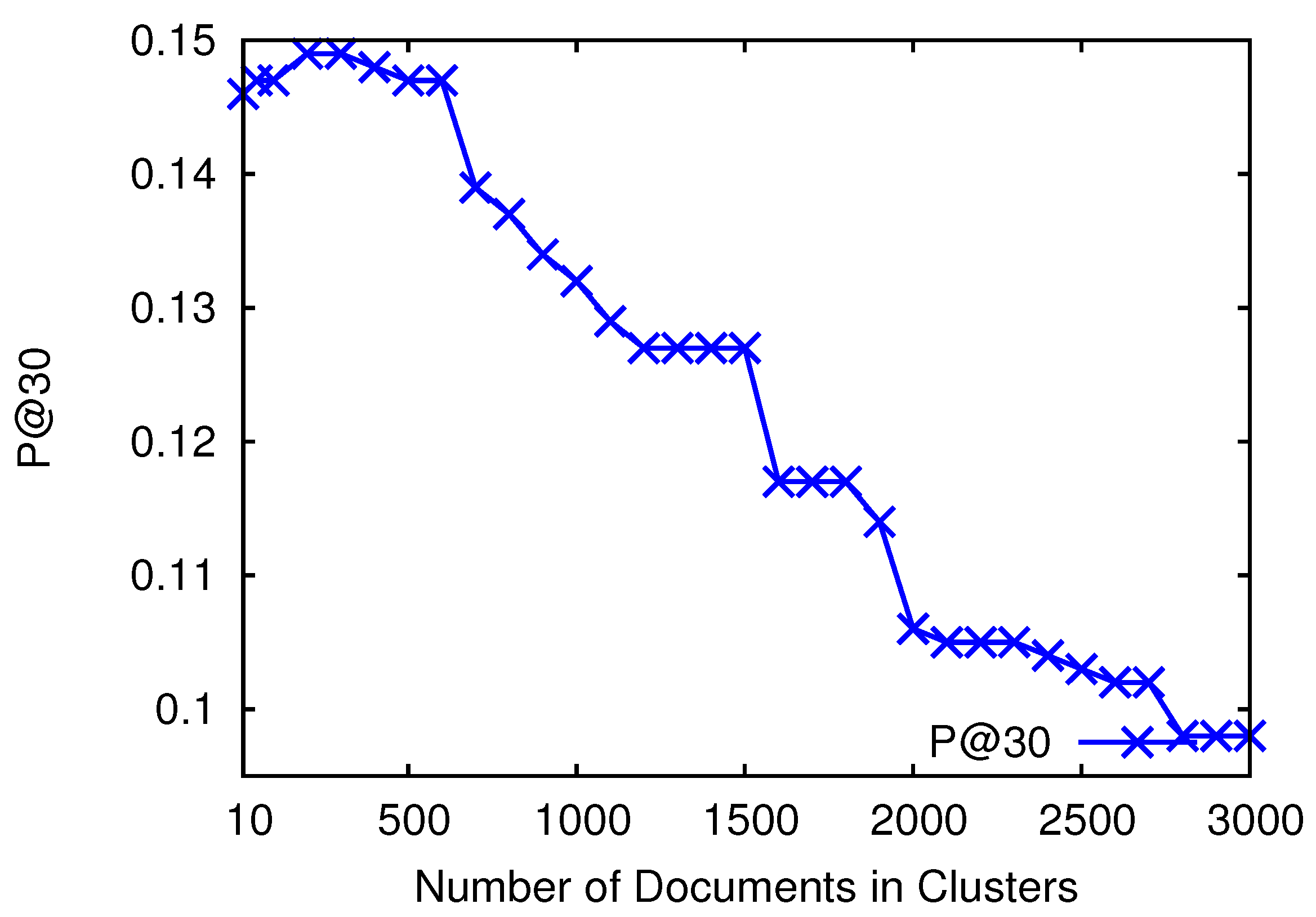
4.3. Parameter Setting for Constructing Clusters
4.4. Effectiveness Analysis
- Recall: Recall cares about all relevant (judged) documents. It is the ratio of the number of retrieved relevant documents relative to the total number of documents in the collection that are desired to be retrieved.represents the total number of relevant documents retrieved. represents the false negative, the documents that are relevant, but could not be retrieved.
- Precision: Precision is the ratio of the number of retrieved relevant documents relative to the total number of retrieved documents. Precision measures the quality of the rank lists. However, since it does not consider the total number of relevant documents, therefore, a result list consisting of just a few retrieved and relevant documents might provide higher precision than a large result list with many relevant documents.represents the false positive, the documents that are retrieved, but are not relevant. Recall and precision are always used with rank cutoff levels. In our experiments we measured the recall with and precision with rank cutoff levels.
- Mean average precision (MAP): Precision and recall are not sensitive to the ranking order of documents (i.e., they do not consider how efficiently different retrieval models retrieve the relevant documents at the top ranked positions). Average precision cares for this factor by averaging the precision values obtained after each relevant document found. Thus, a retrieval model that ranks a large number of relevant documents at the top ranked positions would provide good average precision. It is calculated using the following equation.represents the set of retrieved documents of a query q, and is the rank of a document d in . returns one, if d is a relevant judged document of q, otherwise zero. The mean average precision (MAP) is used for the average precision figures over a number of different queries.
- b-pref: The b-pref measure is designed for those situations where the relevance judgments are known to be far from complete. It was introduced in the TREC 2005 terabyte track. b-pref computes a preference relation of whether the judged relevant documents are retrieved ahead of irrelevant documents. Thus, it is based only on the relative ranks of judged documents [34]. The b-pref measure is defined as:where is the set of judged relevant documents of a query q, E is the set of all judged irrelevant documents retrieved before the last judged document rank position in q, is the rank of judged document in q and e represents the count of irrelevant documents in E retrieved before the rank position . b-pref can be thought of as the inverse of the fraction of judged irrelevant documents that are retrieved before the relevant ones.
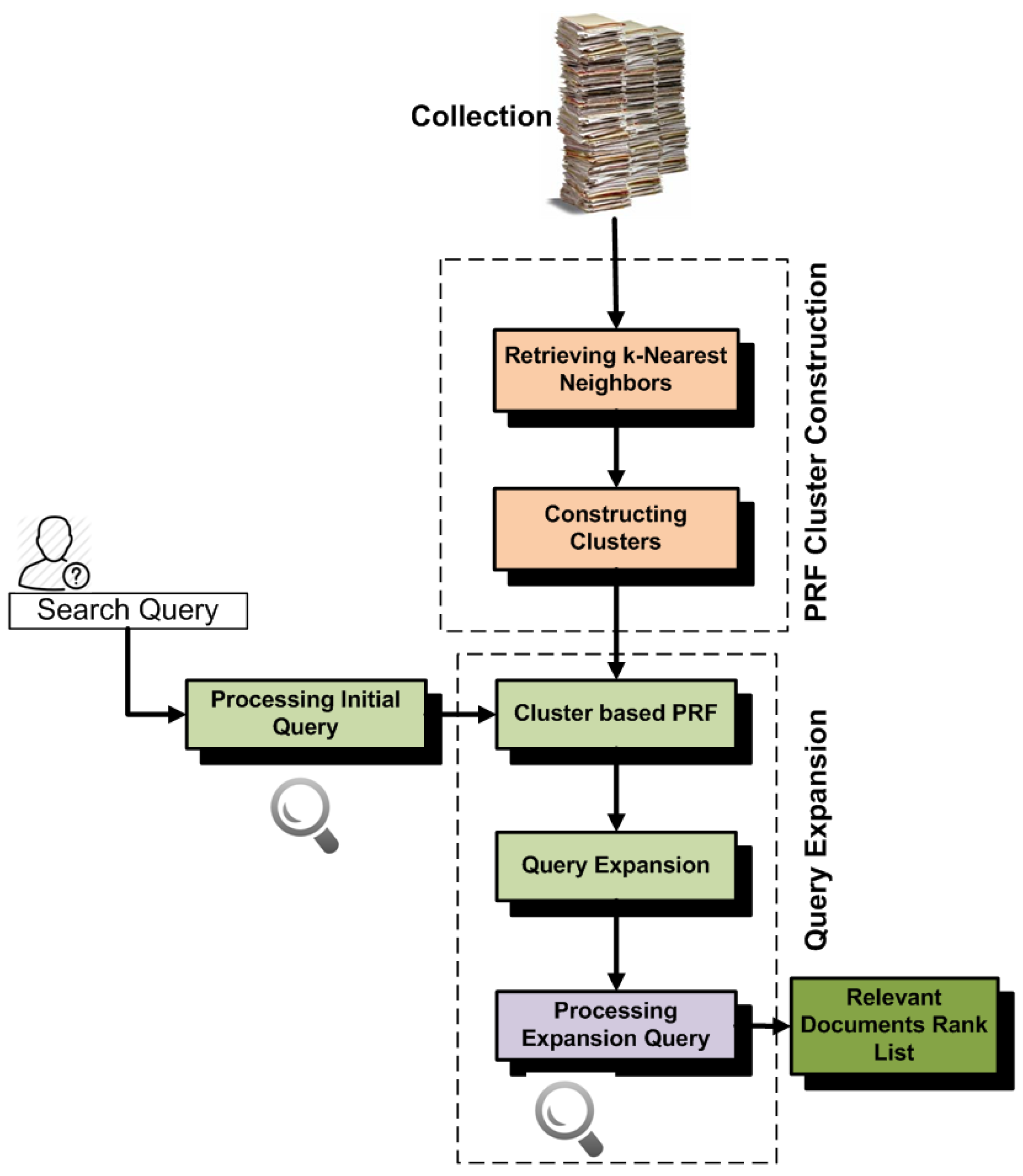
5. Retrieval Bias and Cluster-Based PRF
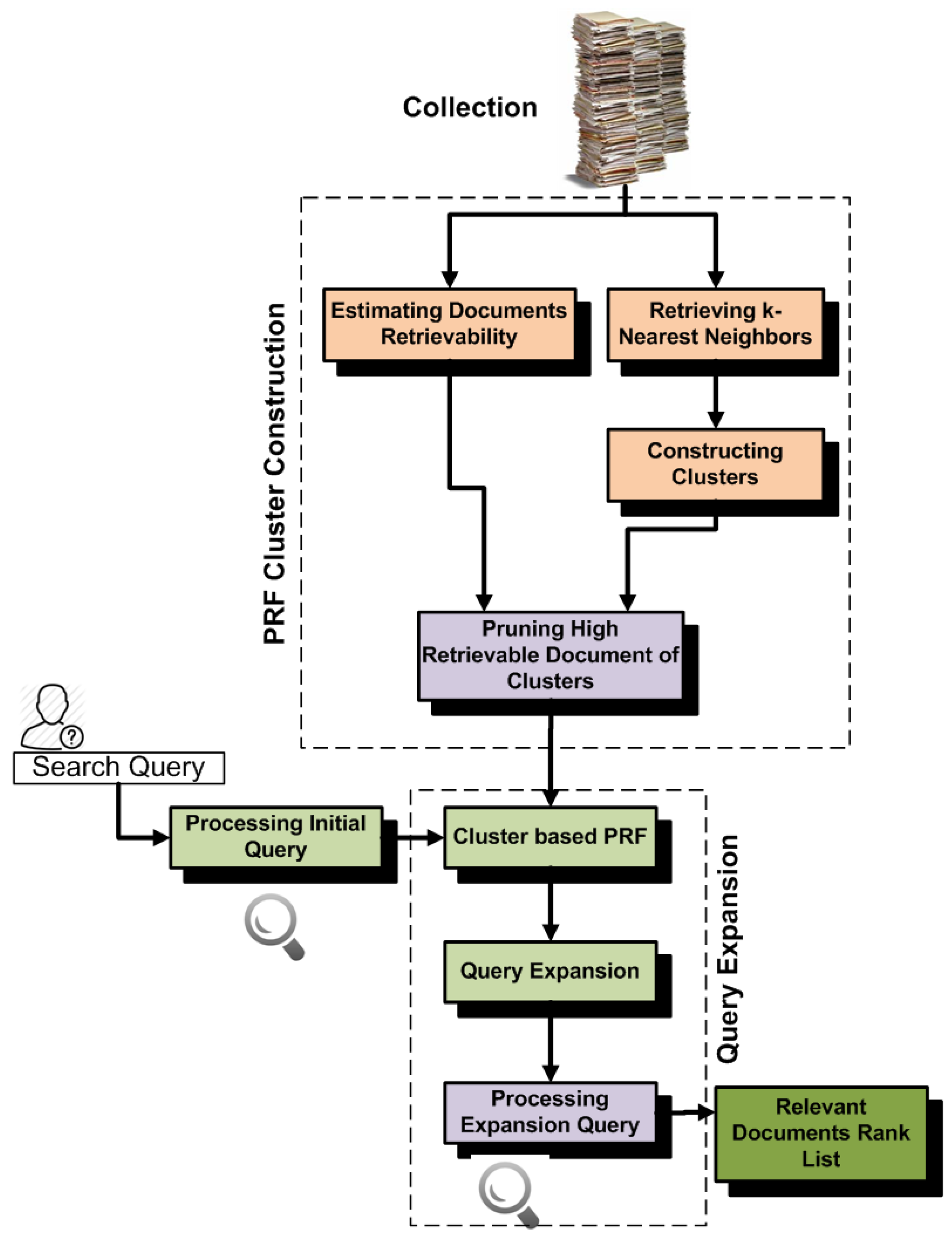
- In the first experiments, we construct clusters by retrieving k-nearest neighbors that have high similarity with centroid documents. We then partition all documents of the collection into different subsets according to their retrievability scores, and then, we analyze which subset contributes most to PRF effectiveness. These experiments help us with understanding which documents add noise in the PRF selection.
- In the second experiments, we construct clusters by retrieving k-nearest neighbors that have high similarity with the cluster centroids and that do not add noise due to retrieval bias. Basically, for these experiments, we remove high retrievable documents from the clusters. We then compare the effectiveness with the standard k-nearest neighbor approach and found high improvement.
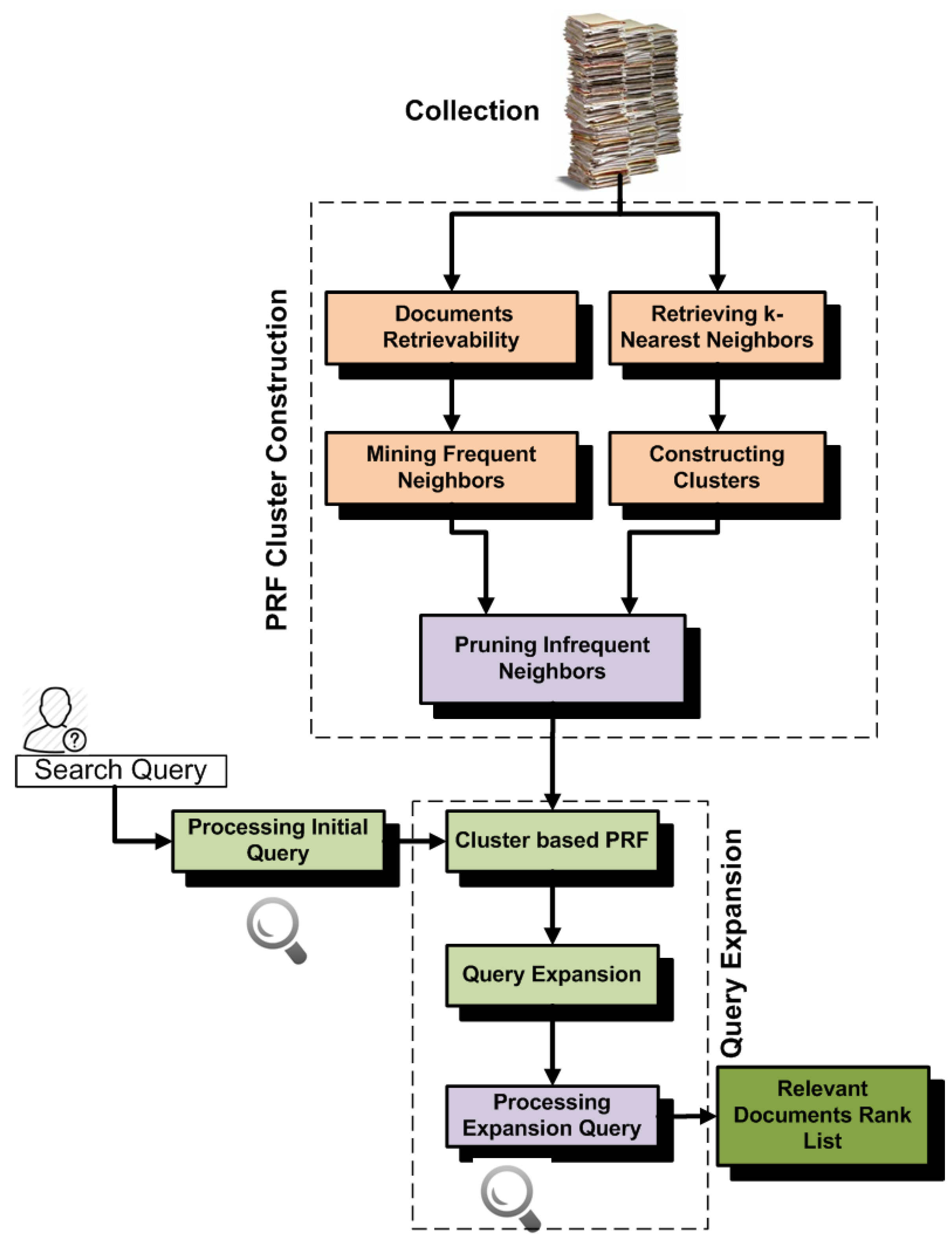
- In the third experiments, we mine frequent neighbors of clusters and construct clusters by retrieving k-nearest neighbors that have high similarity with cluster centroids and are also frequently retrieved with documents of cluster. The standard retrievability approach always penalizes high retrievable documents even if these are most relevant to the clusters and frequently retrieved with documents of the cluster. Constructing clusters by mining frequent neighbors is helpful for increasing the effectiveness. We also compare the effectiveness of this approach with the retrievability-based cluster construction approach and found high improvement.
5.1. Retrievability Measure
- there are many probable queries in Q that can be expressed in order to retrieve d and
- when retrieved, the rank r of the document d is lower than a rank cutoff (threshold) c. This is the point at which the user would stop examining the ranked list. This is a user-dependent factor and, thus, reflects a particular retrieval scenario in order to obtain a more accurate estimate of this measure. For instance, in the web-search scenario, a low c would be more accurate as users are unlikely to go beyond the first page of the results, while in the context of recall-oriented retrieval settings (for instance, legal or patent retrieval), a high c would be more accurate.
5.2. Retrievability Analysis
5.3. Retrieval Bias and PRF Effectiveness
5.4. Retrievability and Cluster-Based PRF (RetrClusPRF)
5.5. Frequent Neighbor-Based PRF (FreqNeig)
6. Conclusions
Conflicts of Interest
References
- Attar, R.; Fraenkel, A.S. Local feedback in full-text retrieval systems. J. ACM 1977, 24, 397–417. [Google Scholar] [CrossRef]
- Buckley, C.; Salton, G.; Allan, J.; Singhal, A. Automatic Query Expansion Using Smart: Trec 3; DIANE Publishing: Collingdale, PA, USA, 1994. [Google Scholar]
- Lavrenko, V.; Croft, W.B. Relevance based language models. In Proceedings of the 24th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, New Orleans, LA, USA, 9–12 September 2001; ACM: New York, NY, USA, 2001; pp. 120–127. [Google Scholar]
- Robertson, S.; Walker, S.; Beaulieu, M.; Gatford, M.; Payne, A. Okapi at trec-4. In Proceedings of the Fourth Text REtrieval Conference (TREC–4), Gaithersburg, MD, USA, 1–3 November 1995.
- Salton, G.; Buckley, C. Improving retrieval performance by relevance feedback. J. Am. Soc. Inf. Sci. 1990, 41, 288–297. [Google Scholar] [CrossRef]
- Gelfer Kalmanovich, I.; Kurland, O. Cluster-based query expansion. In Proceedings of the 32nd International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’09, Boston, MA, USA, 19–23 July 2009; pp. 646–647.
- Lee, K.S.; Croft, W.B.; Allan, J. A cluster-based resampling method for pseudo-relevance feedback. In Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’08, Singapore, 20–24 July 2008; pp. 235–242.
- Lee, K.S.; Croft, W.B. A deterministic resampling method using overlapping document clusters for pseudo-relevance feedback. Inf. Process. Manag. 2013, 49, 792–806. [Google Scholar] [CrossRef]
- Azzopardi, L.; Vinay, V. Retrievability: An evaluation measure for higher order information access tasks. In Proceedings of the 17th ACM Conference on Information and Knowledge Management, CIKM ’08, Napa Valley, CA, USA, 26–30 October 2008; pp. 561–570.
- Bashir, S.; Rauber, A. Improving retrievability of patents in prior-art search. In Proceedings of the 32nd European Conference on Advances in Information Retrieval, ECIR’2010, Milton Keynes, UK, 28–31 March 2010; Springer: Berlin/Heidelberg, Germany, 2010; pp. 457–470. [Google Scholar]
- Bashir, S.; Rauber, A. On the relationship between query characteristics and ir functions retrieval bias. J. Am. Soc. Inf. Sci. Technol. 2011, 62, 1512–1532. [Google Scholar] [CrossRef]
- Azzopardi, L.; Bache, R. On the relationship between effectiveness and accessibility. In Proceedings of the 33rd Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’10, Geneva, Switzerland, 19–23 July 2010; pp. 889–890.
- Lupu, M.; Huang, J.; Zhu, J.; Tait, J. TREC-CHEM: Large scale chemical information retrieval evaluation at trec. In SIGIR Forum; ACM: New York, NY, USA, 2009; Volume 43, Number 2; pp. 63–70. [Google Scholar]
- Croft, W.B. Advances in Information Retrieval, Recent Research from the Center for Intelligent Information Retrieval; Springer: Berlin/Heidelberg, Germany, 2000. [Google Scholar]
- Robertson, S.E.; Walker, S. Okapi/keenbow at trec-8. In Proceedings of the Eighth Text REtrieval Conference (TREC-8), Gaithersburg, MD, USA, 19–21 November 1999.
- Sakai, T.; Manabe, T.; Koyama, M. Flexible pseudo-relevance feedback via selective sampling. Trans. Asian Lang. Inf. Process. 2005, 4, 111–135. [Google Scholar] [CrossRef]
- Zhai, C.; Lafferty, J. A study of smoothing methods for language models applied to information retrieval. ACM Trans. Inf. Syst. 2004, 22, 179–214. [Google Scholar] [CrossRef]
- Cao, G.; Nie, J.-Y.; Gao, J.; Robertson, S. Selecting good expansion terms for pseudo-relevance feedback. In Proceedings of the 31st Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’08, Singapore, 20–24 July 2008; ACM: New York, NY, USA, 2008; pp. 243–250. [Google Scholar]
- Huang, X.; Huang, Y.R.; Wen, M.; An, A.; Liu, Y.; Poon, J. Applying data mining to pseudo-relevance feedback for high performance text retrieval. In Proceedings of the Sixth International IEEE Computer Society Conference on Data Mining, ICDM ’06, Washington, DC, USA, 8–22 December 2006; pp. 295–306.
- Huang, Q.; Song, D.; Ruger, S. Robust query-specific pseudo feedback document selection for query expansion. In Proceedings of the IR Research, 30th European Conference on Advances in Information Retrieval, ECIR’08, Milton Keynes, Glasgow, UK, 30 March–3 April 2008; pp. 547–554.
- Collins-Thompson, K.; Callen, J. Estimation and use of uncertainty in pseudo-relevance feedback. In Proceedings of the 30th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR’07, Amsterdam, The Netherlands, 23–27 July 2007; pp. 295–306.
- Boteanu, B.; Mironica, I.; Ionescu, B. Hierarchical clustering pseudo-relevance feedback for social image search result diversification. In Proceedings of the 13th International Workshop on Content-Based Multimedia Indexing, CBMI 2015, Prague, Czech Republic, 10–12 June 2015; pp. 1–6.
- Buckley, C.; Mitra, M.; Walz, J.; Cardie, C. Using Clustering and Superconcepts within Smart: Trec 6. Inf. Process. Manag. 1998, 36, 109–131. [Google Scholar] [CrossRef]
- Lynam, T.R.; Buckley, C.; Clarke, C.L.A.; Cormack, G.V. A multi-system analysis of document and term selection for blind feedback. In Proceedings of the Thirteenth ACM International Conference on Information and Knowledge Management, CIKM ’04, Washington, DC, USA, 8–13 November 2004; ACM: New York, NY, USA, 2004; pp. 261–269. [Google Scholar]
- Yeung, D.L.; Clarke, C.L.A.; Cormack, G.V.; Lynam, T.R.; Terra, E.L. Task-specific query expansion (multitext experiments for trec 2003). In Proceedings of the 2002 Text REtrieval Conference, Gaithersburg, MD, USA, 19–22 November 2002.
- Bashir, S.; Rauber, A. Improving retrievability of patents with cluster-based pseudo-relevance feedback documents selection. In Proceedings of the 18th ACM Conference on Information and Knowledge Management, CIKM ’09, Hong Kong, China, 2–6 November 2009; pp. 1863–1866.
- Fujita, S. Technology survey and invalidity search: A comparative study of different tasks for Japanese patent document retrieval. Inf. Process. Manag. 2007, 43, 1154–1172. [Google Scholar] [CrossRef]
- Mase, H.; Matsubayashi, T.; Ogawa, Y.; Iwayama, M.; Oshio, T. Proposal of two-stage patent retrieval method considering the claim structure. Trans. Asian Lang. Inf. Process. 2005, 4, 190–206. [Google Scholar] [CrossRef]
- Itoh, H. NTCIR-4 Patent Retrieval Experiments at RICOH. In Proceedings of the NTCIR-4 Workshop Meeting, NTCIR ’04, Tokyo, Japan, 2–4 June 2004.
- Shinmori, A.; Okumura, M.; Marukawa, Y.; Iwayama, M. Patent claim processing for readability: Structure analysis and term explanation. In Proceedings of the ACL-2003 Workshop on Patent Corpus Processing, Sapporo, Japan, 12 July 2003; Volume 20, pp. 56–65.
- Singhal, A. At&t at trec-6. Available online: http://singhal.info/trec6.pdf (accessed on 11 November 2016).
- Larkey, L.S.; Allan, J.; Connell, M.E.; Bolivar, A.; Wade, C. Umass at TREC 2002: Cross language and novelty tracks. In Proceedings of the Text Retrieval Conference (TREC), Gaithersburg, MD, USA, 19–22 November 2002; pp. 721–732.
- Liu, X.; Croft, W.B. Cluster-based retrieval using language models. In Proceedings of the 27th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR’04, Sheffield, UK, 25–29 July 2004; pp. 186–193.
- Different Evaluation Measures. Available online: http://trec.nist.gov/pubs/trec16/appendices/measures.pdf (accessed on 14 November 2016).
- Callan, J.; Connell, M. Query-based sampling of text databases. ACM Trans. Inf. Syst. (TOIS) J. 2001, 19, 97–130. [Google Scholar] [CrossRef]
- Gastwirth, J.L. The estimation of the LORENZ curve and GINI index. Rev. Econ. Stat. 1972, 54, 306–316. [Google Scholar] [CrossRef]
- He, B.; Ounis, I. Query performance prediction. Inf. Syst. 2006, 31, 585–594. [Google Scholar] [CrossRef]
- Zhao, Y.; Scholer, F.; Tsegay, Y. Effective pre-retrieval query performance prediction using similarity and variability evidence. In Proceedings of the 30th European Conference on Advances in Information Retrieval, ECIR’08, Glasgow, UK, 30 March–3 April 2008; pp. 52–64.
- Cronen-Townsend, S.; Zhou, Y.; Croft, W.B. Predicting query performance. In Proceedings of the 25th Annual International ACM SIGIR Conference on Research and Development in Information Retrieval, SIGIR ’02, Tampere, Finland, 11–15 August 2002; pp. 299–306.
- Han, J.; Pei, J.; Yin, Y. Mining frequent patterns without candidate generation. In Proceedings of the 2000 ACM SIGMOD International Conference on Management of Data, SIGMOD ’00, Dallas, TX, USA, 15–18 May 2000; pp. 1–12.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Retrieval Model | Effectiveness | |||
|---|---|---|---|---|
| MAP | b-Pref | |||
| TFIDF | 0.015 | 0.006 | 0.005 | 0.133 |
| NormTFIDF | 0.057 | 0.032 | 0.016 | 0.243 |
| BM25 | 0.121 | 0.079 | 0.037 | 0.351 |
| SMART | 0.036 | 0.016 | 0.010 | 0.210 |
| DirS | 0.144 | 0.093 | 0.045 | 0.406 |
| JM | 0.148 | 0.094 | 0.045 | 0.410 |
| AbsDis | 0.145 | 0.094 | 0.044 | 0.392 |
| TwoStage | 0.141 | 0.089 | 0.044 | 0.403 |
| TS-LM | 0.180 | 0.112 | 0.063 | 0.500 |
| TS-KLD | 0.157 | 0.097 | 0.050 | 0.429 |
| Resampling | ★0.199 | ★0.138 | ★0.081 | ★0.523 |
| TS-LM | Resampling | JM | TS-KLD | |
|---|---|---|---|---|
| TS-LM | - | 292/448 | ★493/294 | ★449/313 |
| Resampling | ★448/292 | - | ★540/281 | ★523/279 |
| JM | 294/493 | 281/540 | - | 305/371 |
| TS-KLD | 313/449 | 279/523 | 371/305 | - |
| Retrieval Model | High Quality Queries | ||
|---|---|---|---|
| NormTFIDF | 0.68 | 0.60 | 0.49 |
| BM25 | 0.55 | 0.50 | 0.43 |
| DirS | 0.59 | 0.53 | 0.46 |
| JM | 0.67 | 0.60 | 0.50 |
| AbsDis | 0.64 | 0.57 | 0.48 |
| TwoStage | 0.60 | 0.53 | 0.43 |
| TFIDF | 0.89 | 0.84 | 0.72 |
| SMART | 0.95 | 0.92 | 0.85 |
| Retrieval Model | Subset % within Top 500 Documents | Effectiveness | |||
|---|---|---|---|---|---|
| MAP | b-pref | ||||
| Partition 1 | 11% | ★0.103 | ★0.221 | ★0.150 | ★0.551 |
| Partition 2 | 14% | ★0.098 | ★0.213 | ★0.143 | ★0.546 |
| Partition 3 | 20% | 0.095 | 0.212 | 0.136 | 0.543 |
| Partition 4 | ★25% | 0.090 | 0.199 | 0.130 | 0.540 |
| Partition 5 | ★30% | 0.091 | 0.191 | 0.129 | 0.540 |
| Retrieval Model | Effectiveness | |||
|---|---|---|---|---|
| MAP | b-pref | |||
| TFIDF | 0.015 | 0.006 | 0.005 | 0.133 |
| NormTFIDF | 0.057 | 0.032 | 0.016 | 0.243 |
| BM25 | 0.121 | 0.079 | 0.037 | 0.351 |
| SMART | 0.036 | 0.016 | 0.010 | 0.210 |
| DirS | 0.144 | 0.093 | 0.045 | 0.406 |
| JM | 0.148 | 0.094 | 0.045 | 0.410 |
| AbsDis | 0.145 | 0.094 | 0.044 | 0.392 |
| TwoStage | 0.141 | 0.089 | 0.044 | 0.403 |
| TS-LM | 0.180 | 0.112 | 0.063 | 0.500 |
| TS-KLD | 0.157 | 0.097 | 0.050 | 0.429 |
| Resampling | 0.199 | 0.138 | 0.081 | 0.523 |
| RetrClusPRF | ★0.223 (+12%) | ★0.159 (+15%) | ★0.107 (+32%) | ★0.552 (+06%) |
| FreqNeigPRF | ★0.235 (+18%) | ★0.168 (+22%) | ★0.121 (+49%) | ★0.572 (+09%) |
| TS-LM | Resampling | JM | TS-KLD | RetrClusPRF | FreqNeigPRF | |
|---|---|---|---|---|---|---|
| TS-LM | - | 292/448 | 493/294 | 449/313 | 217/518 | 205/542 |
| Resampling | ★448/292 | - | ★540/281 | ★523/279 | ★321/428 | ★304/441 |
| JM | 294/493 | 281/540 | - | 305/371 | 231/589 | 201/608 |
| TS-KLD | 313/449 | 279/523 | 371/305 | - | 236/567 | 210/599 |
| RetrClusPRF | ★518/217 | ★428/321 | ★589/231 | ★567/236 | - | ★327/401 |
| FreqNeigPRF | ★542/205 | ★441/304 | ★608/201 | ★599/210 | ★401/327 | - |
© 2016 by the author; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC-BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Bashir, S. An Improved Retrievability-Based Cluster-Resampling Approach for Pseudo Relevance Feedback. Computers 2016, 5, 29. https://doi.org/10.3390/computers5040029
Bashir S. An Improved Retrievability-Based Cluster-Resampling Approach for Pseudo Relevance Feedback. Computers. 2016; 5(4):29. https://doi.org/10.3390/computers5040029
Chicago/Turabian StyleBashir, Shariq. 2016. "An Improved Retrievability-Based Cluster-Resampling Approach for Pseudo Relevance Feedback" Computers 5, no. 4: 29. https://doi.org/10.3390/computers5040029
APA StyleBashir, S. (2016). An Improved Retrievability-Based Cluster-Resampling Approach for Pseudo Relevance Feedback. Computers, 5(4), 29. https://doi.org/10.3390/computers5040029