Extending NUMA-BTLP Algorithm with Thread Mapping Based on a Communication Tree

Abstract
1. Introduction
2. State-of-the-Art Thread Mapping Techniques
2.1. Thread Mapping Overview
2.2. Thread Mapping Algorithms
2.2.1. Classification of Thread Mapping Algorithms
- The moment of mapping:
- The mapping method:
- ○
- algorithms which use a communication matrix to perform the mapping: Compact mapping algorithm which uses the nearest-neighbor communication pattern [3]
- ○
- ○
- algorithms that use pattern matching in matching the communication pattern with the hardware architecture: Treematch [20]
- ○
- algorithms that use a communication tree to determine the CPU affinities of the threads: NUMA-BTDM [6]
- Awareness of the underlying hardware architecture:
- ○
- ○
2.2.2. Description of Thread Mapping Algorithms
2.2.3. Software Libraries for Thread Mapping
- pthread_setaffinity_np(pthread_t thread, size_t cpusetsize, const cpu_set_t *cpuset) —sets the CPU affinity of a thread if it does not have the affinity currently
- pthread_getaffinity_np(pthread_t thread, size_t cpusetsize, const cpu_set_t *cpuset)—gets the CPU affinity of a thread and stores it in the output parameters cpuset
3. NUMA-BTLP Algorithm
3.1. Improving the Accuracy of Static Predictions on Dynamic Behavior by Eliminating Dynamic Aspects from the Static Analysis
- input data and their placement in memory
- the number of threads
- pipeline model
- work-stealing technique [25]
- thread creation and destruction
- memory allocation and deallocation
3.2. Determining the Thread Type by Static Analysis
- An autonomous thread is defined as a thread that shares no data with other threads at the same level in the thread creation hierarchy which are executed in parallel and should not benefit of the same core or of the same NUMA node as those other threads. Thus, autonomous threads can be assigned to cores as uniformly as possible. One of the criteria in achieving balanced data locality is not to exceed the average load per processing unit, which is ensured by the uniform mapping [26]
- A side-by-side thread is a thread sharing data with at least one other thread and should be mapped on every core where other threads with which the side-by-side thread shares data with are mapped. If the thread is of type side-by-side relative to the generating core, the side-by-side thread should be mapped as close as possible, e.g., on the same cores, to the generating thread and should benefit of the execution on the same core as the generating thread with priority from an autonomous thread. A thread is classified as side-by-side if:
- ○
- it executes a function that returns a value read by any other thread
- ○
- it executes a function with output parameters, which are input data of other threads
- ○
- it is created inside the body of a loop
- ○
- it contains nested threads created using pthread_create routine call
- A postponed thread is defined as a thread generated by another thread, not requiring to be executed immediately. Such threads are classified as so if they are not side-by-side relative to other threads at the same level in the thread creation hierarchy. Therefore, a postponed thread is an autonomous thread which computes non-critical data, relative to the threads at the same level in the creation hierarchy. However, it is side-by-side thread relative to the generating thread. Postponed threads meet at least one of the following criteria:
- ○
- they execute a function that returns a value not read by other threads which are currently running
- ○
- they execute a void or non-void function that has no output parameters read by threads which are currently running, or a non-void functions with previous property which, in addition, returns a value that is not used by other threads currently running
- ○
- usually the thread in not enclosed within a loop
| Algorithm 1. NUMA-BTLP static analysis [5] |
for every pthread_create call identified in the code, associated with thread A:
|
3.3. Type-Aware Tree Representation of Threads
- the root of the tree is assigned to the main thread
- a node on the i-th level of the tree which is assigned to thread ik is the child of the node on the j-th level which is assigned to thread jl, where j = i − 1, if thread ik uses the data read or written before by thread jl, ∀ i ≥ 1, ∀ 1 ≤ k ≤ ni, ∀ 1 ≤ l ≤ nj, where ni and nj are the number of nodes on level i and level j, respectively
- if both threads ik and jl use for the first time a data which is then used by the other (e.g., thread ik writes a data which is then read by thread jl and thread jl writes other data which is then read by thread ik) then the relation parent-child is established as follows: if thread ik is created first, then the thread will be the parent of thread jl and vice versa
3.4. NUMA-BTDM Algorithm
- Autonomous threads are scattered uniformly to processing units to improve balance [6]
- Postponed threads are mapped to the less loaded processing unit (considering the number of flops and iops is identified statically) [6], improving load balance. Postponed threads do not need to be executed immediately, so, mapping them on less loaded processing unit enables the possibility to apply Dynamic Voltage and Frequency Scaling(DVFS) to the unit without performance loss [5]
3.5. Setting CPU Affinity
3.6. Description of NUMA-BTLP Algorithm in Pseudo Code
| Algorithm 2. NUMA-BTLP algorithm [5] |
|
4. Comparison of the NUMA-BTLP Algorithm and Other Work
5. Materials and Methods
6. Results
6.1. Results for CPU-X Benchmark
6.1.1. Description of the Benchmark
6.1.2. Experimental Power Consumption Results
6.2. Results for Context Switch Benchmark
6.2.1. Description of the Benchmark
6.2.2. Experimental Performance Results
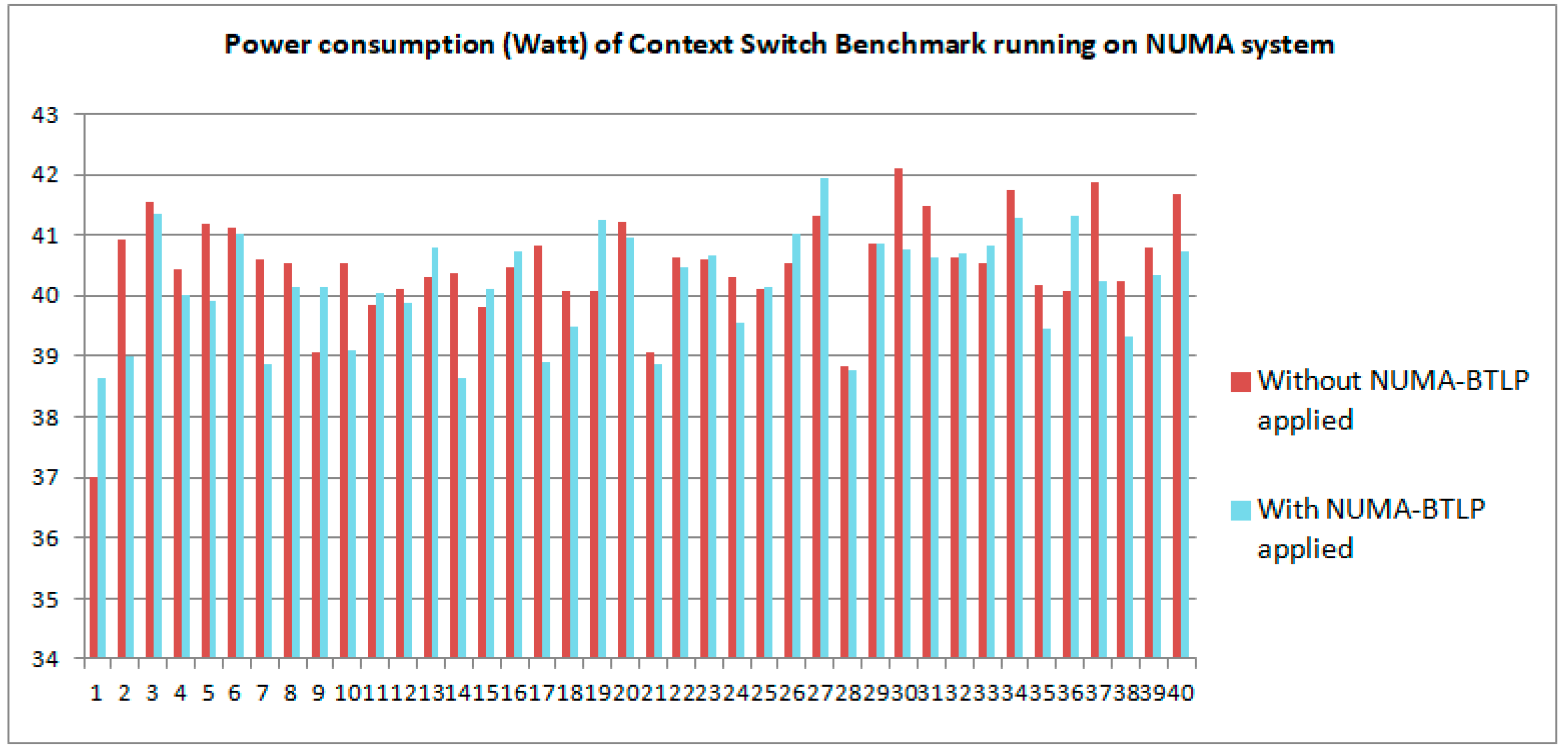
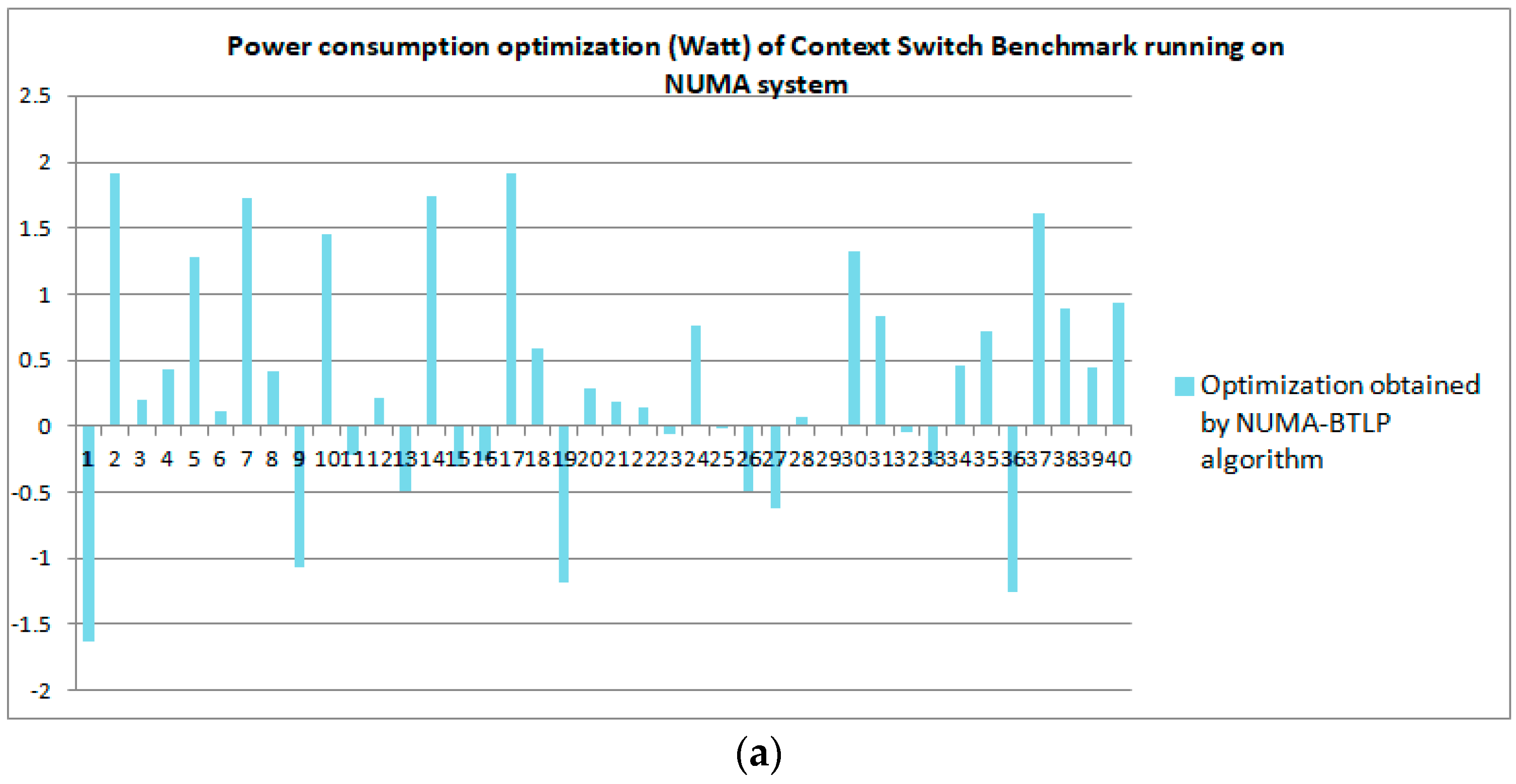
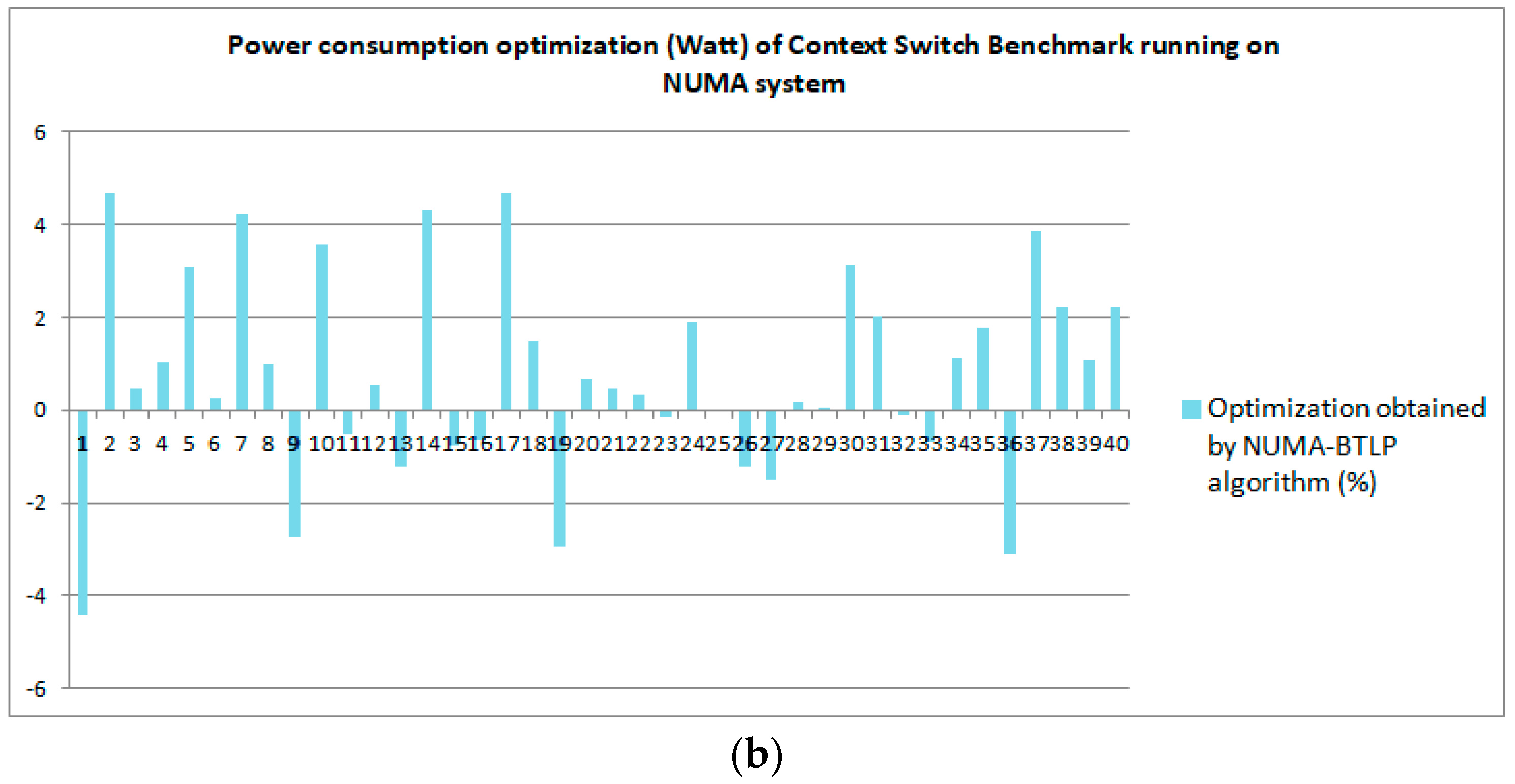
6.2.3. Experimental Power Consumption Results
7. Discussion
8. Findings and Limitations
9. Conclusions
Funding
Conflicts of Interest
References
- Introduction to Parallel Computing. Available online: https://computing.llnl.gov/tutorials/parallel_comp/ (accessed on 25 February 2018).
- Falt, Z.; Krulis, M.; Bednárek, D.; Yaghob, J.; Zavoral, F. Towards efficient locality aware parallel data stream processing. J. Univ. Comput. Sci. 2015, 21, 816–841. [Google Scholar]
- Diener, M.; Cruz, E.H.M.; Alves, M.A.Z.; Navaux, P.O.A.; Koren, I. Affinity-Based Thread and Data Mapping in Shared Memory Systems. ACM Comput. Surv. 2017, 49, 64. [Google Scholar] [CrossRef]
- Tam, D.; Azimi, R.; Stumm, M. Thread clustering: Sharing-aware scheduling on SMP-CMP-SMT multiprocessors. In Proceedings of the ACM SIGOPS Operating Systems Review, Lisbon, Portugal, 21–23 March 2007; Volume 41. [Google Scholar]
- Ştirb, I. NUMA-BTLP: A static algorithm for thread classification. In Proceedings of the 2018 5th International Conference on Control, Decision and Information Technologies (CoDIT), Thessaloniki, Greece, 10–13 April 2018; pp. 882–887. [Google Scholar]
- Știrb, I. NUMA-BTDM: A thread mapping algorithm for balance data locality on NUMA systems. In Proceedings of the 2016 17th International Conference on Parallel and Distributed Computing, Applications and Technologies (PDCAT), Guangzhou, China, 16–18 December 2016; pp. 317–320. [Google Scholar]
- Broquedis, F.; Clet-Ortega, J.; Moreaud, S.; Furmento, N.; Goglin, B.; Mercier, G.; Thibault, S.; Namyst, R. hwloc: A generic framework for managing hardware affinities in HPC applications. In Proceedings of the 2010 18th Euromicro Conference on Parallel, Distributed and Network-Based Processing, Pisa, Italy, 17–19 February 2010; pp. 180–186. [Google Scholar]
- Constantinou, T.; Sazeides, Y.; Michaud, P.; Fetis, D.; Seznec, A. Performance implications of single thread migration on a chip multi-core. ACM Sigarch Comput. Archit. News 2005, 33, 80–91. [Google Scholar] [CrossRef]
- Jeannot, E.; Mercier, G.; Tessier, F. Process placement in multicore clusters: Algorithmic issues and practical techniques. IEEE Trans. Parallel Dist. Syst. 2014, 25, 993–1002. [Google Scholar] [CrossRef]
- Wong, C.S.; Tan, I.; Kumari, R.D.; Wey, F. Towards achieving fairness in the linux scheduler. ACM Sigops Oper. Syst. Rev. 2008, 42, 34–43. [Google Scholar] [CrossRef]
- Li, T.; Baumberger, D.P.; Hahn, S. Efficient and scalable multiprocessor fair scheduling using distributed weighted round-robin. In Proceedings of the 14th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, Raleigh, NC, USA, 14–18 February 2009; ACM: New York, NY, USA, 2009; pp. 65–74. [Google Scholar]
- Das, R.; Ausavarungnirun, R.; Mutlu, O.; Kumar, A.; Azimi, M. Application-to-core mapping policies to reduce memory system interference in multi-core systems. In Proceedings of the 2013 IEEE 19th International Symposium on High Performance Computer Architecture (HPCA), Shenzhen, China, 23–27 February 2013; pp. 107–118. [Google Scholar]
- Diener, M.; Cruz, E.H.; Pilla, L.L.; Dupros, F.; Navaux, P.O. Characterizing communication and page usage of parallel applications for thread and data mapping. Perform. Eval. 2015, 88, 18–36. [Google Scholar] [CrossRef]
- Ribic, H.; Liu, Y.D. Energy-efficient work-stealing language runtimes. ACM SIGARCH Comput. Archit. News 2014, 42, 513–528. [Google Scholar]
- Armstrong, R.; Hensgen, D.; Kidd, T. The relative performance of various mapping algorithms is independent of sizable variances in run-time predictions. In Proceedings of the Seventh Heterogeneous Computing Workshop (HCW’98), Orlando, FL, USA, 30 March 1988; pp. 79–87. [Google Scholar]
- Pellegrini, F.; Roman, J. Scotch: A software package for static mapping by dual recursive bipartitioning of process and architecture graphs. In High-Performance Computing and Networking. HPCN-Europe 1996. Lecture Notes in Computer Science; Liddell, H., Colbrook, A., Hertzberger, B., Sloot, P., Eds.; Springer: Berlin/Heidelberg, Germany, 1996; Volume 1067, pp. 493–498. [Google Scholar]
- Karypis, G.; Kumar, V. Parallel multilevel graph partitioning. In Proceedings of the International Conference on Parallel Processing, Honolulu, HI, USA, 15–19 April 1996; pp. 314–319. [Google Scholar]
- Karypis, G.; Kumar, V. A fast and high quality multilevel scheme for partitioning irregular graphs. SIAM J. Sci. Comput. 1988, 20, 359–392. [Google Scholar] [CrossRef]
- Devine, K.D.; Boman, E.G.; Heaphy, R.T.; Bisseling, R.H.; Catalyurek, U.V. Parallel hypergraph partitioning for scientific computing. In Proceedings of the 20th IEEE International Parallel & Distributed Processing Symposium, Rhodes Island, Greece, 25–29 April 2006. [Google Scholar]
- Jeannot, E.; Mercier, G. Near-optimal placement of MPI processes on hierarchical NUMA architectures. In Euro-Par 2010—Parallel Processing. Euro-Par 2010. Lecture Notes in Computer Science; D’Ambra, P., Guarracino, M., Talia, D., Eds.; Springer: Berlin/Heidelberg, Germany, 2010; Volume 6272, pp. 199–210. [Google Scholar]
- Cruz, E.H.; Diener, M.; Pilla, L.L.; Navaux, P.O. An efficient algorithm for communication-based task mapping. In Proceedings of the 2015 23rd Euromicro International Conference on Parallel, Distributed, and Network-Based Processing, Turku, Finland, 4–6 March 2015; pp. 2017–2214. [Google Scholar]
- Traff, J.L. Implementing the MPI process topology mechanism. In Proceedings of the 2002 ACM/IEEE Conference on Supercomputing, Baltimore, MD, USA, 16–22 November 2002; p. 28. [Google Scholar]
- Majo, Z.; Gross, T.R. A library for portable and composable data locality optimizations for NUMA systems. ACM Trans. Parallel Comput. 2017, 3, 227–238. [Google Scholar] [CrossRef]
- Wheeler, K.B.; Murphy, R.C.; Thain, D. Qthreads: An API for programming with millions of lightweight threads. In Proceedings of the 2008 IEEE International Symposium on Parallel and Distributed Processing, Miami, FL, USA, 14–18 April 2008; pp. 1–8. [Google Scholar]
- Blumofe, R.D.; Leiserson, C.E. Scheduling multithreaded computations by work stealing. J. ACM 1999, 46, 720–748. [Google Scholar] [CrossRef]
- Diener, M.; Cruz, E.H.; Alves, M.A.; Alhakeem, M.S.; Navaux, P.O.; Heiß, H.-U. Locality and balance for communication-aware thread mapping in multicore systems. In Euro-Par 2015: Parallel Processing. Euro-Par 2015. Lecture Notes in Computer Science; Träff, J., Hunold, S., Versaci, F., Eds.; Spinger: Berlin/Heidelberg, Germany, 2015; Volume 9233, pp. 196–208. [Google Scholar]
- Xiao, Y.; Xue, Y.; Nazarian, S.; Bogdan, P. A load balancing inspired optimization framework for exascale multicore systems: A complex networks approach. In Proceedings of the 36th International Conference on Computer-Aided Design, Irvine, CA, USA, 13–16 November 2017; pp. 217–224. [Google Scholar]
- Bogdan, P.; Sauerwald, T.; Stauffer, A.; Sun, H. Balls into bins via local search. In Proceedings of the Twenty-Fourth Annual ACM-SIAM Symposium on Discrete Algorithms, New Orleans, LA, USA, 6–8 January 2013; pp. 16–34. [Google Scholar]
- Marongiu, A.; Burgio, P.; Benini, L. Vertical stealing: Robust, locality-aware do-all workload distribution for 3D MPSoCs. In Proceedings of the 2010 International Conference on Compilers, Architectures and Synthesis for Embedded Systems, Scottsdale, AZ, USA, 24–29 October 2010; pp. 207–216. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Number of Threads | Power cons. without BTLP (Watt) | Power cons. with BTLP (Watt) | Optimization (Watt) | Optimization (%) |
|---|---|---|---|---|
| 1 | 1.801 | 1.707 | 0.094 | 5.24 |
| 2 | 1.847 | 1.720 | 0.126 | 6.85 |
| 3 | 1.815 | 1.808 | 0.008 | 0.42 |
| 4 | 1.866 | 1.680 | 0.186 | 9.97 |
| 5 | 1.868 | 1.667 | 0.202 | 10.80 |
| 6 | 1.870 | 1.618 | 0.252 | 13.50 |
| 7 | 1.916 | 1.712 | 0.204 | 10.66 |
| 8 | 1.843 | 1.653 | 0.190 | 10.30 |
| 9 | 1.888 | 1.593 | 0.295 | 15.63 |
| 10 | 1.879 | 1.619 | 0.260 | 13.82 |
| 11 | 1.891 | 1.666 | 0.225 | 11.89 |
| 12 | 1.720 | 1.554 | 0.167 | 9.69 |
| Category of Statistics | Exec. Time without BTLP (s) | Exec. Time with BTLP (s) |
|---|---|---|
| Minimum | 40.56 | 40.11 |
| Average | 41.57 | 41.91 |
| Maximum | 42.16 | 42.95 |
| Variance | 0.10 | 0.45 |
| Standard deviation | 0.32 | 0.67 |
| Category of Statistics | Power cons. without BTLP (s) | Power cons. with BTLP (s) |
|---|---|---|
| Minimum | 36.99 | 38.62 |
| Average | 40.49 | 40.17 |
| Maximum | 42.09 | 41.94 |
| Variance | 0.83 | 0.75 |
| Standard deviation | 0.91 | 0.86 |
© 2018 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Știrb, I. Extending NUMA-BTLP Algorithm with Thread Mapping Based on a Communication Tree. Computers 2018, 7, 66. https://doi.org/10.3390/computers7040066
Știrb I. Extending NUMA-BTLP Algorithm with Thread Mapping Based on a Communication Tree. Computers. 2018; 7(4):66. https://doi.org/10.3390/computers7040066
Chicago/Turabian StyleȘtirb, Iulia. 2018. "Extending NUMA-BTLP Algorithm with Thread Mapping Based on a Communication Tree" Computers 7, no. 4: 66. https://doi.org/10.3390/computers7040066
APA StyleȘtirb, I. (2018). Extending NUMA-BTLP Algorithm with Thread Mapping Based on a Communication Tree. Computers, 7(4), 66. https://doi.org/10.3390/computers7040066