
Research on Annual Runoff Prediction Model Based on Adaptive Particle Swarm Optimization–Long Short-Term Memory with Coupled Variational Mode Decomposition and Spectral Clustering Reconstruction

Abstract
:1. Introduction
2. Methodology
2.1. VMD Model
- Establish a variational problem: The marginal spectrum of each modal function ak(t) is solved by applying the Hilbert transform; subsequently, the exponential term of each modal center frequency bk is incorporated to complete the modulation of the fundamental band of ak(t). Finally, the bandwidth of each mode is determined by using the Gaussian smoothing method, and a variational problem with constraints is formulated as follows:
- 2.
- Solve the variational problem: The aforementioned constrained problem is converted to an unconstrained problem by employing penalty factor α and Lagrange multiplier λ:
2.2. Spectral Clustering (SC) Model
2.3. APSO-LSTM Model
- Initialization of model parameters: The initial matrix of each optimization parameter in the LSTM algorithm is constructed, and the initial values of other insensitive parameters, population size, population dimension, learning factor, etc., in the APSO algorithm are determined.
- The particle populations X (learning rate, LSTM layer, max epochs) are randomly generated, and the initial velocity and initial position of the particles are defined.
- The values of LSTM parameters are assigned. The model networks under different parameters are trained, and each training process is recorded.
- According to the fitness function, the optimal particle fitness value is selected by calculating and comparing the fitness value of each particle. The velocity and position of the particle itself are updated according to Equations (12) and (13), respectively.
- When the selected maximum number of iterations has been reached, the minimum value of MSE at this time is picked as the optimization result of the objective function. The optimal particle population location is the output. The obtained parameters are assigned to the LSTM model. The trained optimization model is adopted to predict the runoff volume, and then the prediction results can be achieved.
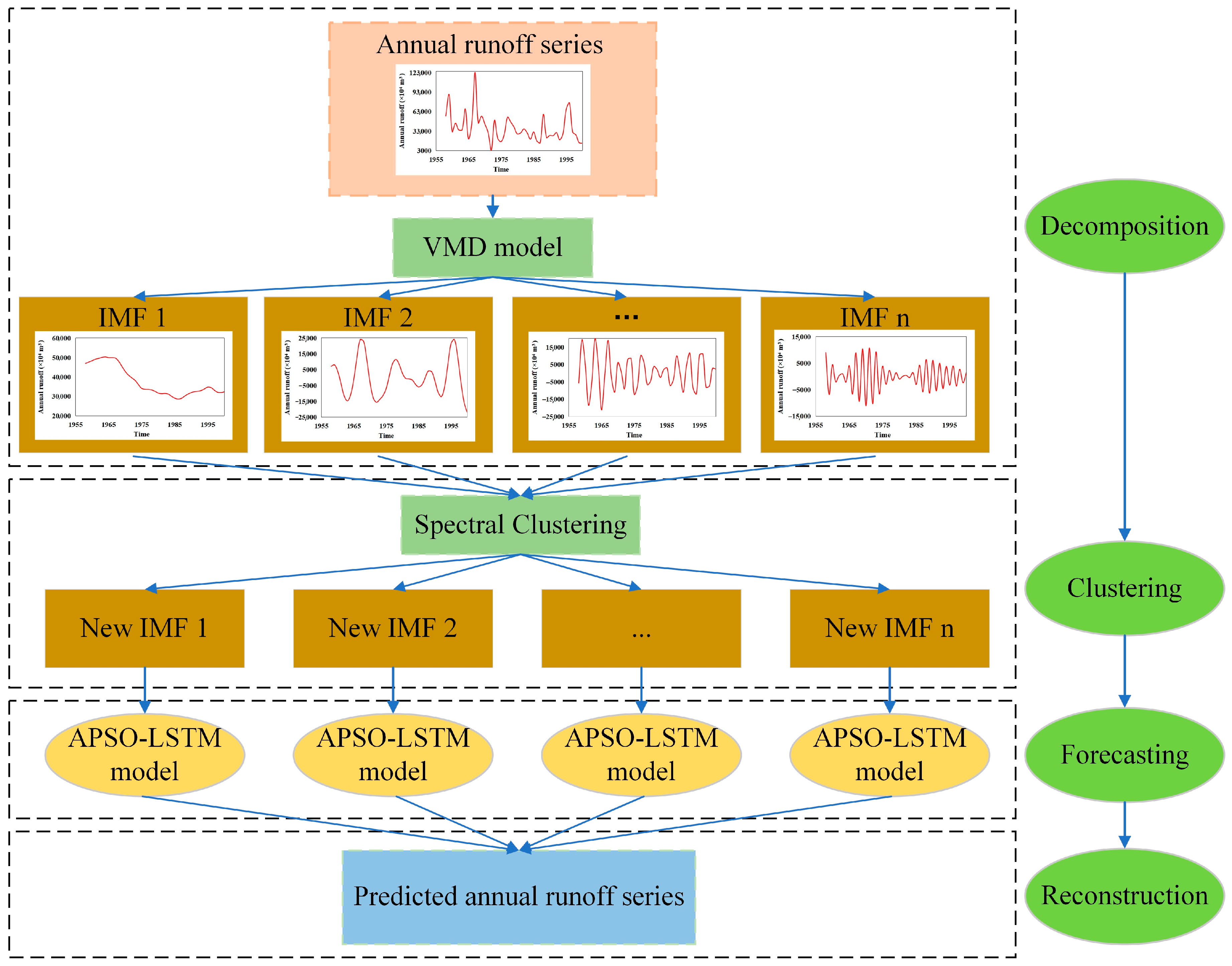
2.4. VMDSC-APSO-LSTM Model
3. Evaluation of the Model
4. Application and Analysis
4.1. Study Area and Data
4.2. Decomposition of Annual Runoff Series
4.3. Clustering Grouping of IMFs
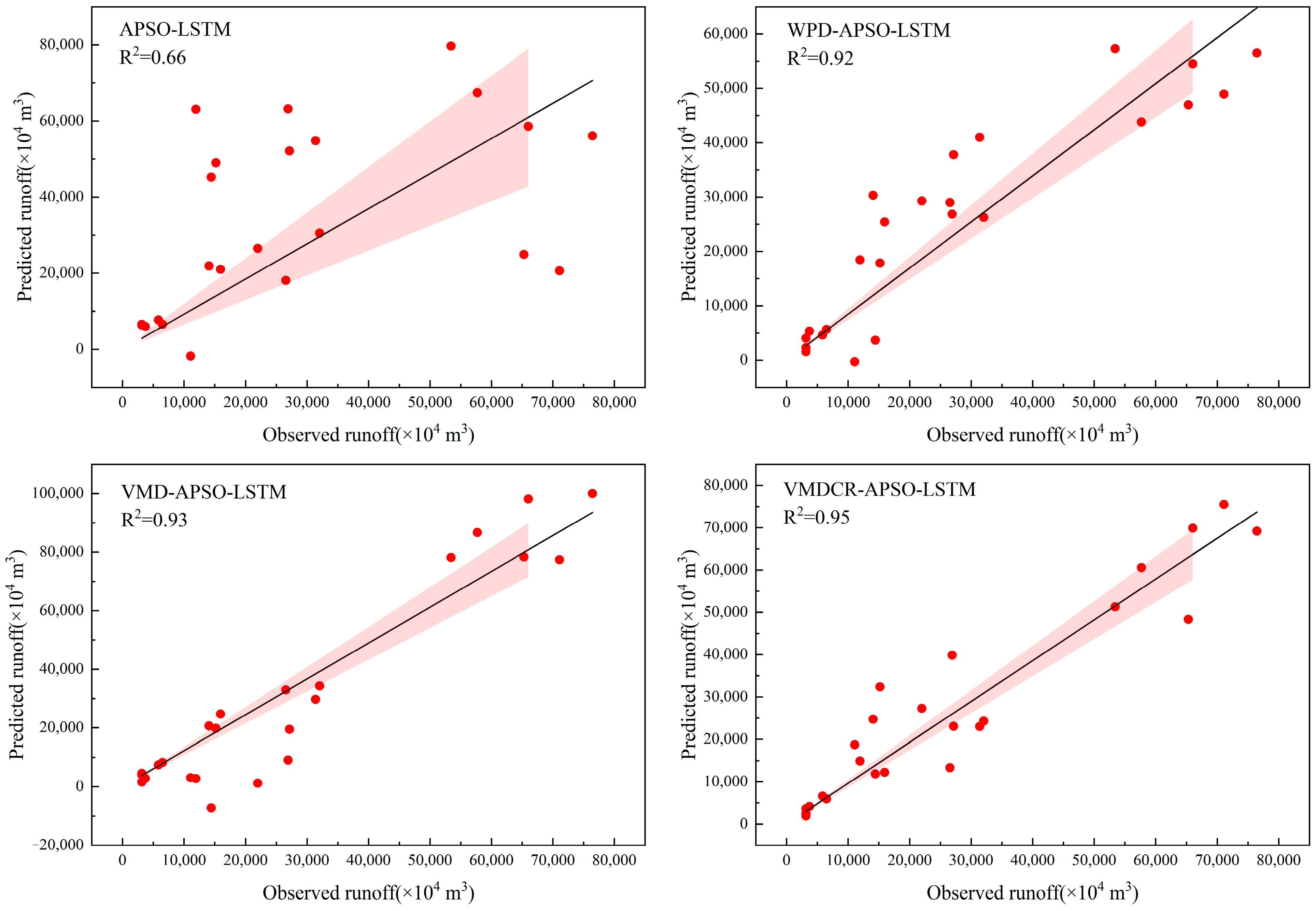
4.4. Prediction Results and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, Y.; Xu, H.; Li, Y.; Liu, L.; Hu, Z.; Xiao, C.; Yang, T. Climate change impacts on runoff in the Fujiang River Basin based on CMIP6 and SWAT model. Water 2022, 14, 3614. [Google Scholar] [CrossRef]
- Zhang, W.; Furtado, K.; Zhou, T.; Wu, P.; Chen, X. Constraining extreme precipitation projections using past precipitation variability. Nat. Commun. 2022, 13, 6319. [Google Scholar] [CrossRef] [PubMed]
- Bolorinos, J.; Rajagopal, R.; Ajami, N.K. Do water savings persist? Using survival models to plan for long-term responses to extreme drought. Environ. Res. Lett. 2022, 17, 094032. [Google Scholar] [CrossRef]
- Taniguchi, K.; Kotone, K.; Shibuo, Y. Simulation-based assessment of inundation risk potential considering the nonstationarity of extreme flood events under climate change. J. Hydrol. 2022, 613, 128434. [Google Scholar] [CrossRef]
- Cho, K.; Kim, Y. Improving streamflow prediction in the WRF-Hydro model with LSTM networks. J. Hydrol. 2022, 605, 127297. [Google Scholar] [CrossRef]
- Song, C.M. Data construction methodology for convolution neural network based daily runoff prediction and assessment of its applicability. J. Hydrol. 2022, 605, 127324. [Google Scholar] [CrossRef]
- Zhao, X.; Lv, H.; Lv, S.; Sang, Y.; Wei, Y.; Zhu, X. Enhancing robustness of monthly streamflow forecasting model using gated recurrent unit based on improved grey wolf optimizer. J. Hydrol. 2021, 601, 126607. [Google Scholar] [CrossRef]
- Han, D.; Liu, P.; Xie, K.; Li, H.; Xia, Q.; Cheng, Q.; Wang, Y.; Yang, Z.; Zhang, Y.; Xia, J. An attention-based LSTM model for long-term runoff forecasting and factor recognition. Environ. Res. Lett. 2023, 18, 024004. [Google Scholar] [CrossRef]
- Shi, W.; Wang, N.; Wang, M.; Li, D. Revised runoff curve number for runoff prediction in the Loess Plateau of China. Hydrol. Process. 2021, 35, e14390. [Google Scholar] [CrossRef]
- Yan, B.; Mu, R.; Guo, J.; Liu, Y.; Tang, J.; Wang, H. Flood risk analysis of reservoirs based on full-series ARIMA model under climate change. J. Hydrol. 2022, 610, 127979. [Google Scholar] [CrossRef]
- Zhang, J.; Yan, H. A long short-term components neural network model with data augmentation for daily runoff forecasting. J. Hydrol. 2023, 617, 128853. [Google Scholar] [CrossRef]
- Wang, X.; Wang, Y.; Yuan, P.; Wang, L.; Cheng, D. An adaptive daily runoff forecast model using VMD-LSTM-PSO hybrid approach. Hydrol. Sci. J. 2021, 66, 1488–1502. [Google Scholar] [CrossRef]
- Li, F.-F.; Cao, H.; Hao, C.-F.; Qiu, J. Daily streamflow forecasting based on flow pattern recognition. Water Resour. Manag. 2021, 35, 4601–4620. [Google Scholar] [CrossRef]
- Li, Y.; Wang, D.; Wei, J.; Li, B.; Xu, B.; Xu, Y.; Huang, H. A medium and long-term runoff forecast method based on massive meteorological data and machine learning algorithms. Water 2021, 13, 1308. [Google Scholar] [CrossRef]
- Adaryani, F.R.; Mousavi, S.J.; Jafari, F. Short-term rainfall forecasting using machine learning-based approaches of PSO-SVR, LSTM and CNN. J. Hydrol. 2022, 614, 128463. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, W.; Xu, D.; Zhao, Y.; Zang, H. A compound approach for ten-day run of prediction by coupling wavelet denoising, attention mechanism, and LSTM based on GPU parallel acceleration technology. Earth Sci. Inform. 2024, 17, 1281–1299. [Google Scholar] [CrossRef]
- Gauch, M.; Kratzert, F.; Klotz, D.; Nearing, G.; Lin, J.; Hochreiter, S. Rainfall-runoff prediction at multiple timescales with a single Long Short-Term Memory network. Hydrol. Earth Syst. Sci. 2021, 25, 2045–2062. [Google Scholar] [CrossRef]
- He, X.; Luo, J.; Li, P.; Zuo, G.; Xie, J. A hybrid model based on variational mode decomposition and gradient boosting regression tree for monthly runoff forecasting. Water Resour. Manag. 2020, 34, 865–884. [Google Scholar] [CrossRef]
- Wang, W.; Wang, B.; Chau, K.W.; Xu, D. Monthly runoff time series interval prediction based on WOA-VMD-LSTM using non-parametric kernel density estimation. Earth Sci. Inform. 2023, 16, 2373–2389. [Google Scholar] [CrossRef]
- Demir, I.; Xiang, Z.; Demiray, B.; Sit, M. WaterBench-Iowa: A large-scale benchmark dataset for data-driven streamflow forecasting. Earth Syst. Sci. Data 2022, 14, 5605–5616. [Google Scholar] [CrossRef]
- Liu, W.; Cao, S.; Chen, Y. Applications of variational mode decomposition in seismic time-frequency analysis. Geophysics 2016, 81, V365–V378. [Google Scholar] [CrossRef]
- Xu, Z.; Mo, L.; Zhou, J.; Fang, W.; Qin, H. Stepwise decomposition-integration-prediction framework for runoff forecasting considering boundary correction. Sci. Total Environ. 2022, 851, 158342. [Google Scholar] [CrossRef] [PubMed]
- Chen, S.; Ren, M.; Sun, W. Combining two-stage decomposition based machine learning methods for annual runoff forecasting. J. Hydrol. 2021, 603, 126945. [Google Scholar] [CrossRef]
- Shahram, H.; Hossein, Z.; Andrea, C.; Saeid, L. Offshore wind power forecasting based on WPD and optimised deep learning methods. Renew. Energy 2023, 218, 119241. [Google Scholar]
- Wei, H.; Wang, Y.; Liu, J.; Cao, Y. Monthly Runoff Prediction by Combined Models Based on Secondary Decomposition at the Wulong Hydrological Station in the Yangtze River Basin. Water 2023, 15, 3717. [Google Scholar] [CrossRef]
- Dragomiretskiy, K.; Zosso, D. Variational mode decomposition. IEEE Trans. Signal Process. 2014, 62, 531–544. [Google Scholar] [CrossRef]
- Abdoos, A.A. A new intelligent method based on combination of VMD and ELM for short term wind power forecasting. Neurocomputing 2016, 203, 111–120. [Google Scholar] [CrossRef]
- Von Luxburg, U. A tutorial on spectral clustering. Stat. Comput. 2007, 17, 395–416. [Google Scholar] [CrossRef]
- Qiao, G.; Yang, M.; Zeng, X. Monthly-scale runoff forecast model based on PSO-SVR. J. Phys. Conf. Ser. 2022, 2189, 012016. [Google Scholar] [CrossRef]
- Gobashy, M.; Abdelazeem, M. Metaheuristics inversion of self-potential anomalies. In Self-Potential Method: Theoretical Modeling and Applications in Geosciences; Springer: Cham, Switzerland, 2021; pp. 35–103. [Google Scholar]
- Tamilmani, G.; Varma, C.P.; Devi, V.B.; Babu, G.R. Medical image segmentation using grey wolf-based u-net with bi-directional convolutional LSTM. Int. J. Pattern Recognit. Artif. Intell. 2024, 38, 2354025. [Google Scholar] [CrossRef]
- Fakhar, M.S.; Kashif, S.A.R.; Liaquat, S.; Rasool, A.; Padmanaban, S.; Iqbal, M.A.; Baig, M.A.; Khan, B. Implementation of APSO and improved APSO on non-cascaded and cascaded short term hydrothermal scheduling. IEEE Access 2021, 9, 77784–77797. [Google Scholar] [CrossRef]
- Wen, L.; Song, Q. ELCC-based capacity value estimation of combined wind-storage system using IPSO algorithm. Energy 2023, 263, 125784. [Google Scholar] [CrossRef]
- Fang, W.; Huang, S.; Ren, K.; Huang, Q.; Huang, G.; Cheng, G.; Li, K. Examining the applicability of different sampling techniques in the development of decomposition-based streamflow forecasting models. J. Hydrol. 2019, 568, 534–550. [Google Scholar] [CrossRef]
- Hao, Y.; Lu, J.; Peng, G.; Wang, M.; Li, J.; Wei, G. F10.7 Daily forecast using LSTM combined with VMD method. Space Weather 2024, 22, e2023SW003552. [Google Scholar] [CrossRef]
- Gendeel, M.; Yuxian, Z.; Aoqi, H. Performance comparison of ANNs model with VMD for short-term wind speed forecasting. IET Renew. Power Gener. 2018, 12, 1424–1430. [Google Scholar] [CrossRef]
- GB/T22482-2008; Ministry of Water Resources. Hydrology Information Forecast Specification. China Standards Press: Beijing, China, 2009. (In Chinese)










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name of Parameters | Meaning of Parameters | Type of Parameters | Range of Values |
|---|---|---|---|
| Learning rate | Initial learning rate | float | [0.001, 0.1] |
| LSTM layer | Number of LSTM neurons | int | [20, 200] |
| Max epochs | Maximum number of iterations | int | [20, 200] |
| Serial Number | Model | Implication |
|---|---|---|
| S1 | APSO-LSTM | Optimization of long short-term memory network model by adaptive particle swarm optimization |
| S2 | VMD-APSO-LSTM | Optimization of long short-term memory network model by adaptive particle swarm optimization based on variational mode decomposition and reconstruction |
| S3 | WPD-APSO-LSTM | Optimization of long short-term memory network model by adaptive particle swarm optimization based on wavelet decomposition and reconstruction |
| S4 | VMDSC-APSO-LSTM | Optimization of long short-term memory network model by adaptive particle swarm optimization based on variational mode decomposition and spectral clustering. |
| Station | Zhaishang Station | Lancun Station | Fenhe Reservoir Station | Shangjingyou Station |
|---|---|---|---|---|
| 200 | 300 | 900 | 800 |
| Station | Indicators | S1 | S2 | S3 | S4 |
|---|---|---|---|---|---|
| Zhaishang Station | NSE | −0.07 | 0.39 | 0.75 | 0.87 |
| RMSE | 24,948.33 | 18,887.16 | 11,962.67 | 8722.91 | |
| MAE | 23,470.33 | 15,216.65 | 10,851.92 | 7229.79 | |
| Lancun Station | NSE | −1.49 | 0.47 | 0.75 | 0.90 |
| RMSE | 35,011.80 | 16,075.52 | 11,043.59 | 6905.67 | |
| MAE | 30,257.54 | 14,475.16 | 8550.40 | 5891.22 | |
| Fenhe Reservoir Station | NSE | 0.18 | 0.49 | 0.60 | 0.72 |
| RMSE | 17,748.42 | 14,024.10 | 12,402.17 | 10,481.04 | |
| MAE | 12,186.56 | 11,023.81 | 11,035.34 | 9205.33 | |
| Shangjingyou Station | NSE | −2.54 | -0.01 | 0.24 | 0.73 |
| RMSE | 2618.11 | 1395.83 | 1212.89 | 726.03 | |
| MAE | 2348.73 | 1360.30 | 1167.03 | 679.19 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Chang, J.; Jin, H.; Zhao, Z.; Zhu, X.; Cai, W. Research on Annual Runoff Prediction Model Based on Adaptive Particle Swarm Optimization–Long Short-Term Memory with Coupled Variational Mode Decomposition and Spectral Clustering Reconstruction. Water 2024, 16, 1179. https://doi.org/10.3390/w16081179
Wang X, Chang J, Jin H, Zhao Z, Zhu X, Cai W. Research on Annual Runoff Prediction Model Based on Adaptive Particle Swarm Optimization–Long Short-Term Memory with Coupled Variational Mode Decomposition and Spectral Clustering Reconstruction. Water. 2024; 16(8):1179. https://doi.org/10.3390/w16081179
Chicago/Turabian StyleWang, Xueni, Jianbo Chang, Hua Jin, Zhongfeng Zhao, Xueping Zhu, and Wenjun Cai. 2024. "Research on Annual Runoff Prediction Model Based on Adaptive Particle Swarm Optimization–Long Short-Term Memory with Coupled Variational Mode Decomposition and Spectral Clustering Reconstruction" Water 16, no. 8: 1179. https://doi.org/10.3390/w16081179