
Parameter Automatic Calibration Approach for Neural-Network-Based Cyclonic Precipitation Forecast Models

Abstract
:1. Introduction
2. Methodology
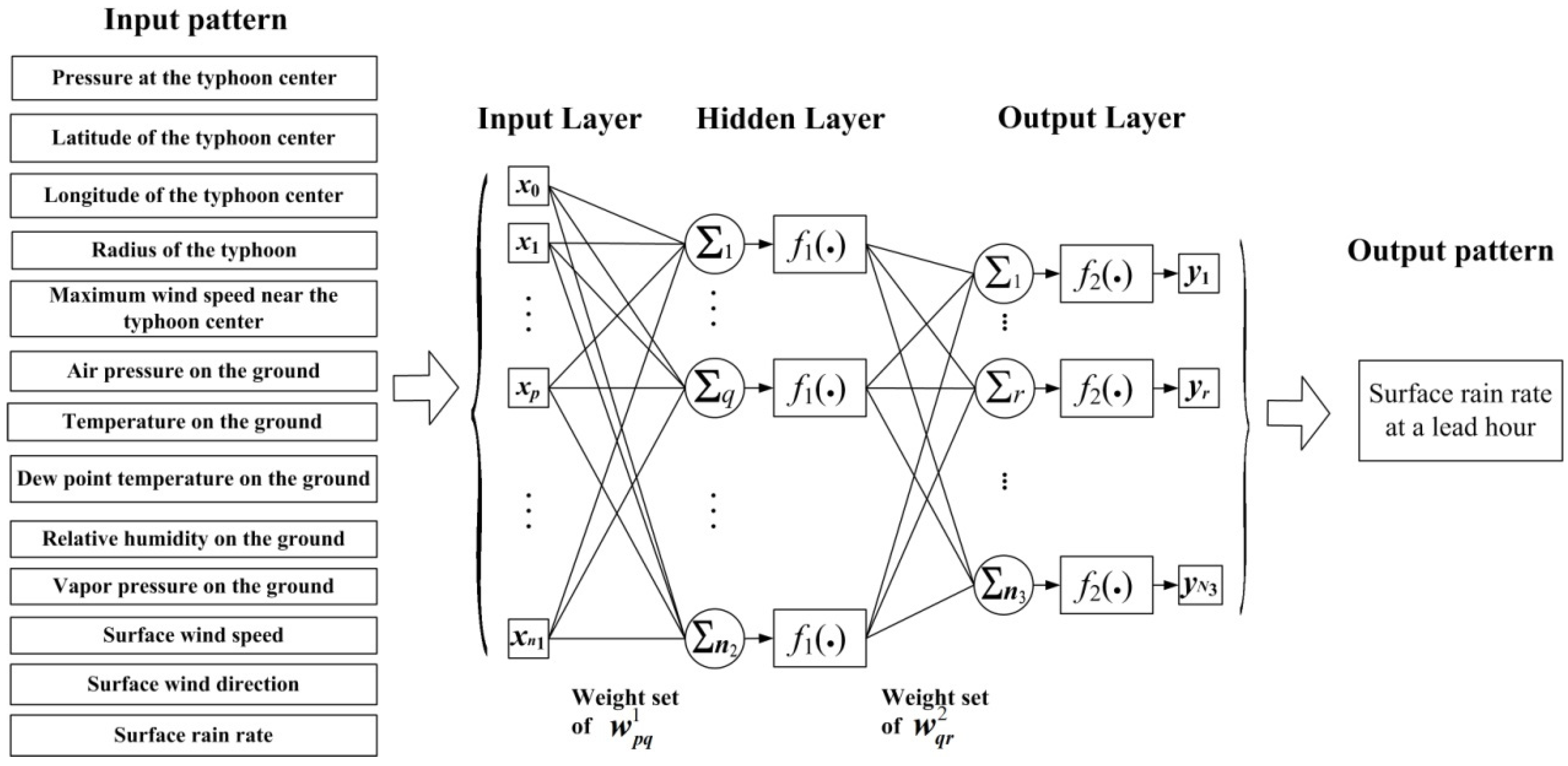
2.1. Sketch of MLP ANN

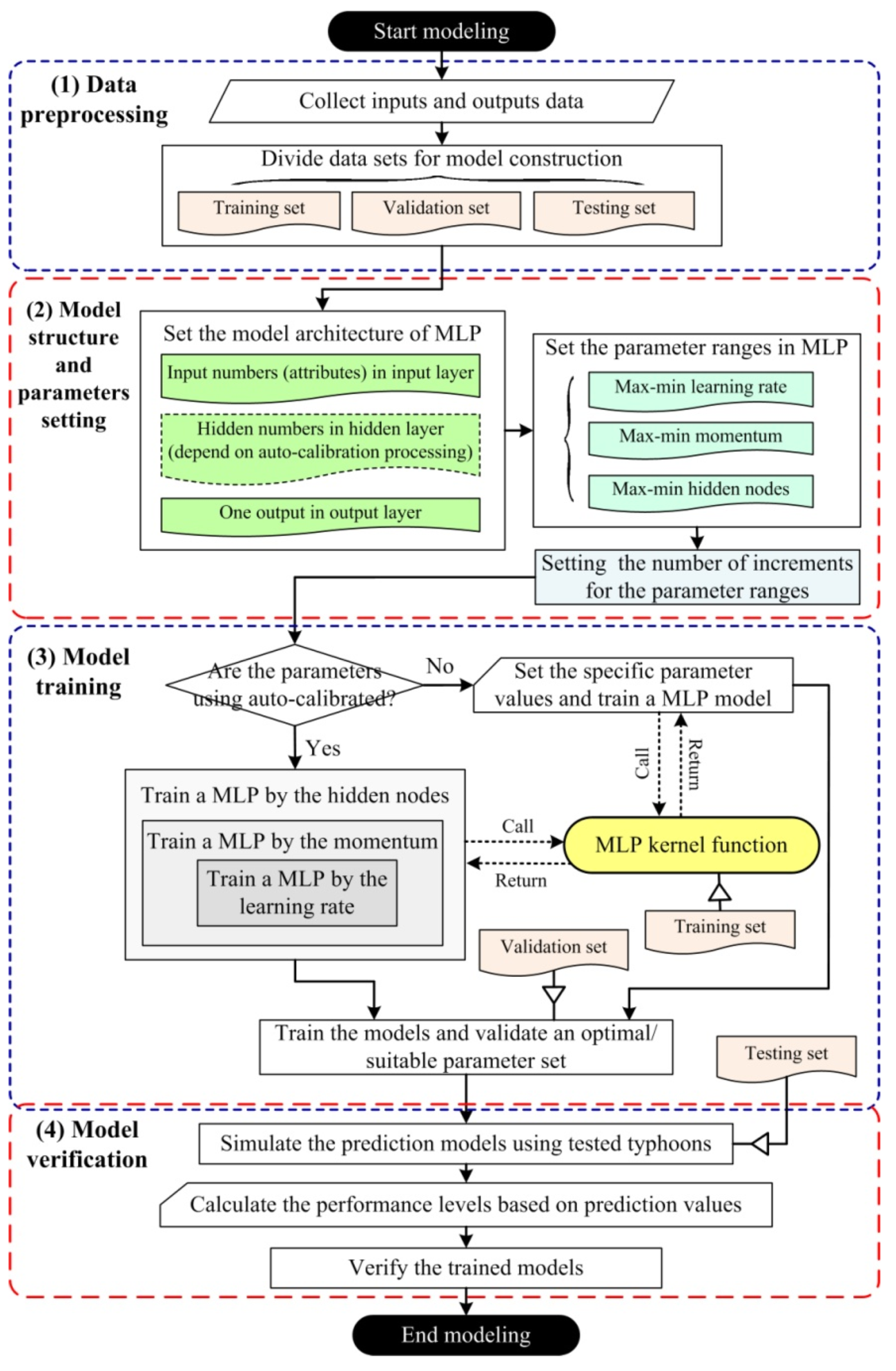
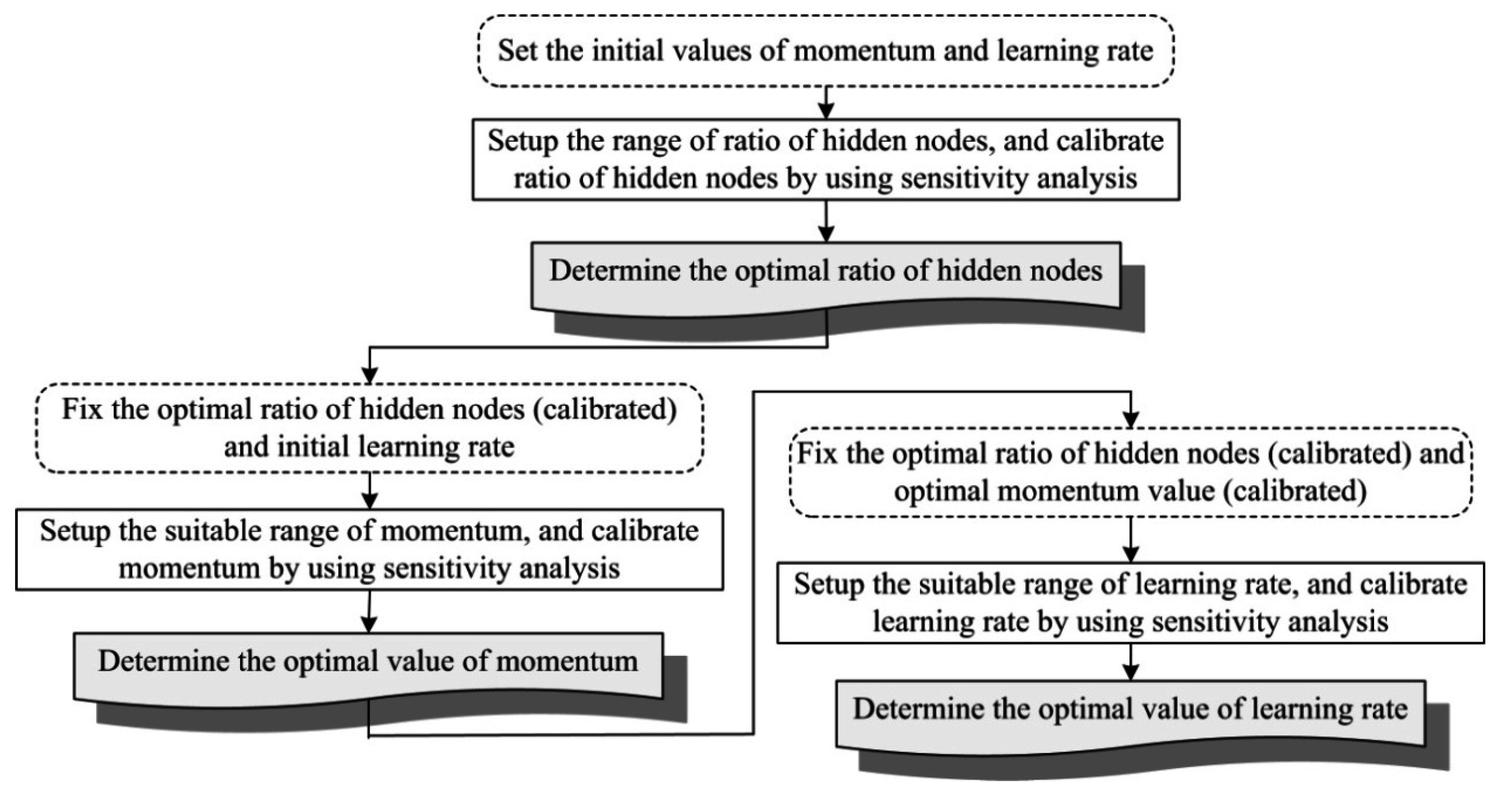
2.2. Proposed ANN–PAC Model

3. Experiment
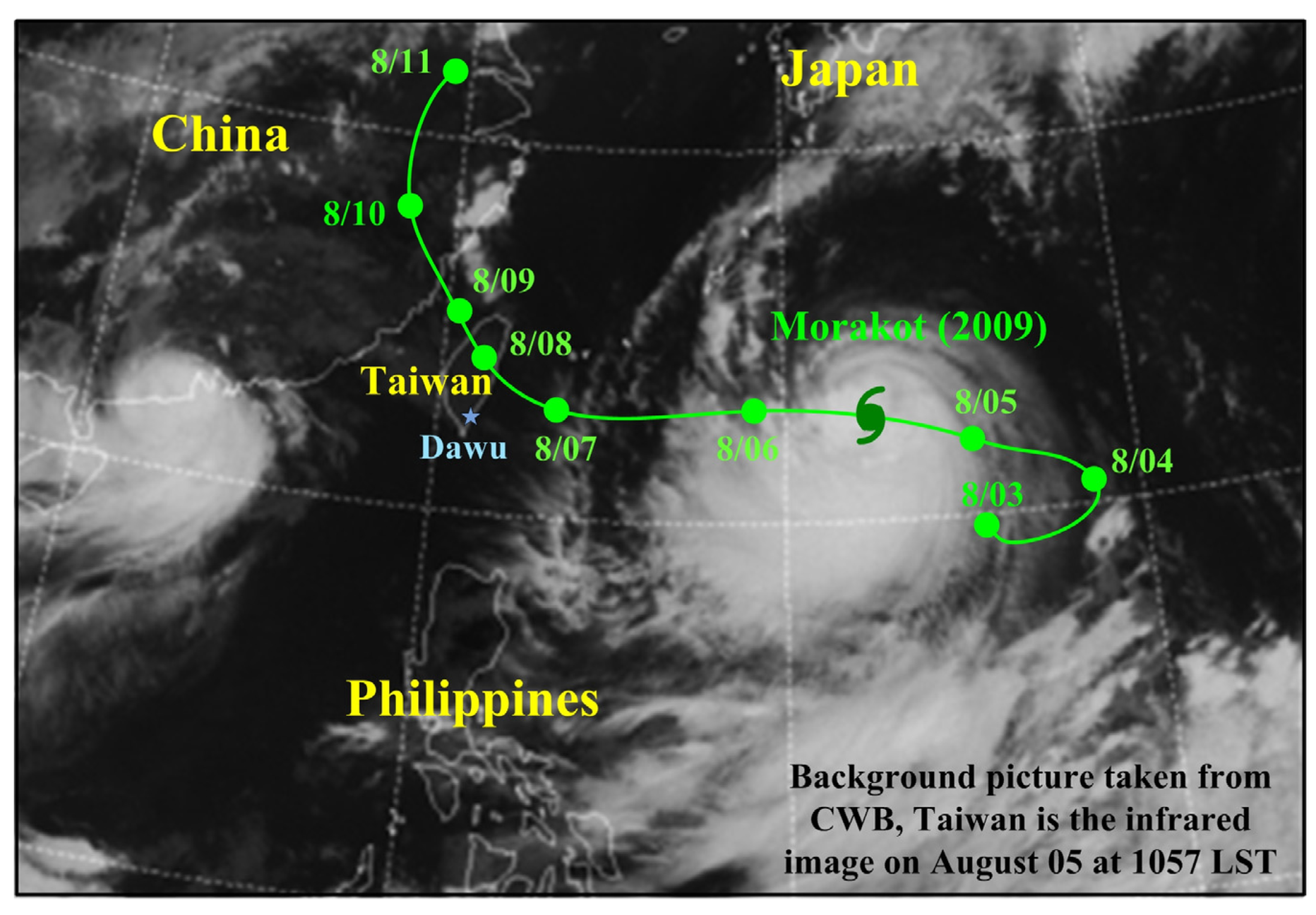
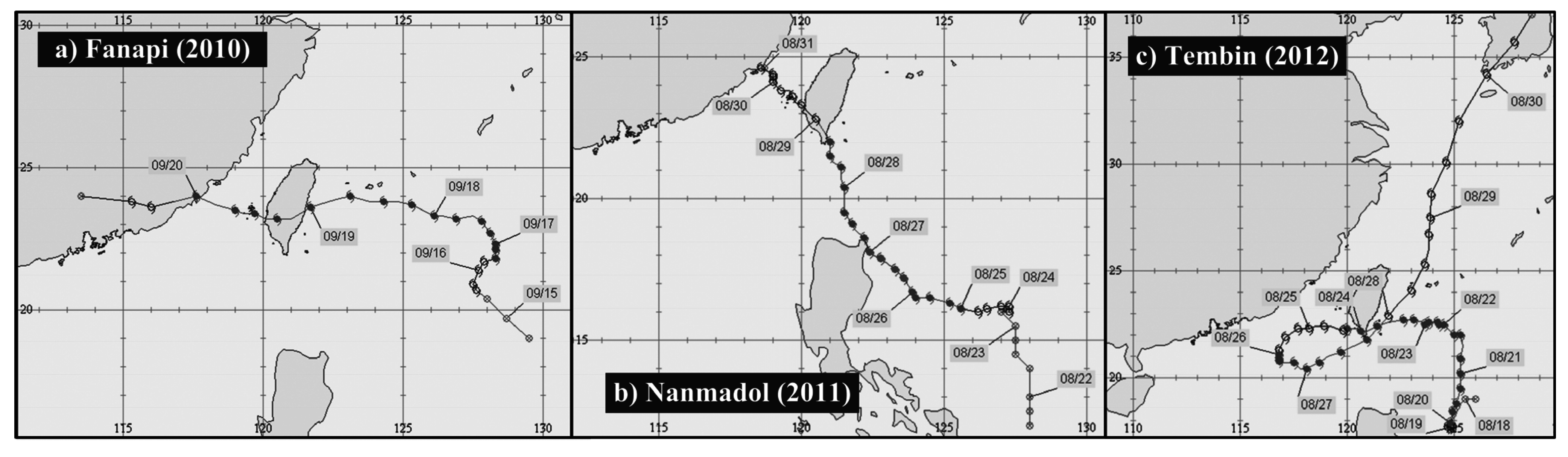
3.1. Study Area and Data


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Year | Typhoon Name | Year | Typhoon Name |
|---|---|---|---|
| 2001 | Lekima | 2007 | Pabuk, Wutip, Sepat, Wipha, Krosa |
| 2002 | Nakri | 2008 | Kalmaegi, Fung-Wong, Sinlaku |
| 2003 | Morakot, Dujuan, Melor | 2009 | Morakot |
| 2004 | Mindulle, Aere, Nanmadol | 2010 | Fanapi |
| 2005 | Haitang, Matsa, Talim, Longwang | 2011 | Nanmadol |
| 2006 | Chanchu, Billis, Kaemi, Bopha | 2012 | Tembin |
3.2. Data Division
| Data Attribute | Range | Mean |
|---|---|---|
| Pressure at typhoon center (hPa) | 912.0−1000.0 | 964.3 |
| Latitude (°N) of typhoon center (degree) | 12.0−27.8 | 23.2 |
| Longitude (°E) of typhoon center (degree) | 115.3−128.1 | 121.5 |
| Radius of typhoon (km) | 0−300.0 | 207.7 |
| Maximum wind speed near typhoon center (m℘s−1) | 7.0−16.0 | 11.9 |
| Air pressure on the ground (hPa) | 967.2−1011.3 | 995.0 |
| Temperature on the ground (°C) | 23.1−35.8 | 27.0 |
| Dew point temperature on the ground (°C) | 18.1−28.0 | 24.1 |
| Relative humidity on the ground (%) | 40.0−100.0 | 85.5 |
| Vapor pressure on the ground (hPa) | 20.8−37.8 | 30.2 |
| Surface wind speed (m·s−1) | 0.0−20.2 | 3.6 |
| Surface wind direction | 0.0−360.0 | 165.7 |
| Surface rain rate (mm·h−1) | 0.0−103.0 | 4.5 |

3.3. Modeling Using ANN–PAC

4. Evaluations and Comparisons
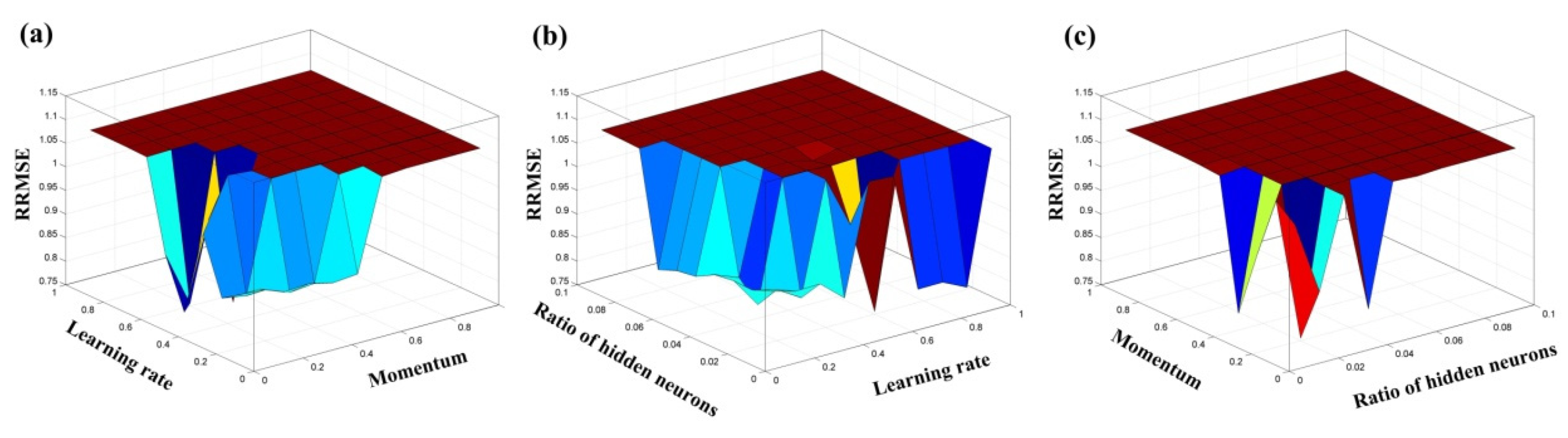
4.1. Results

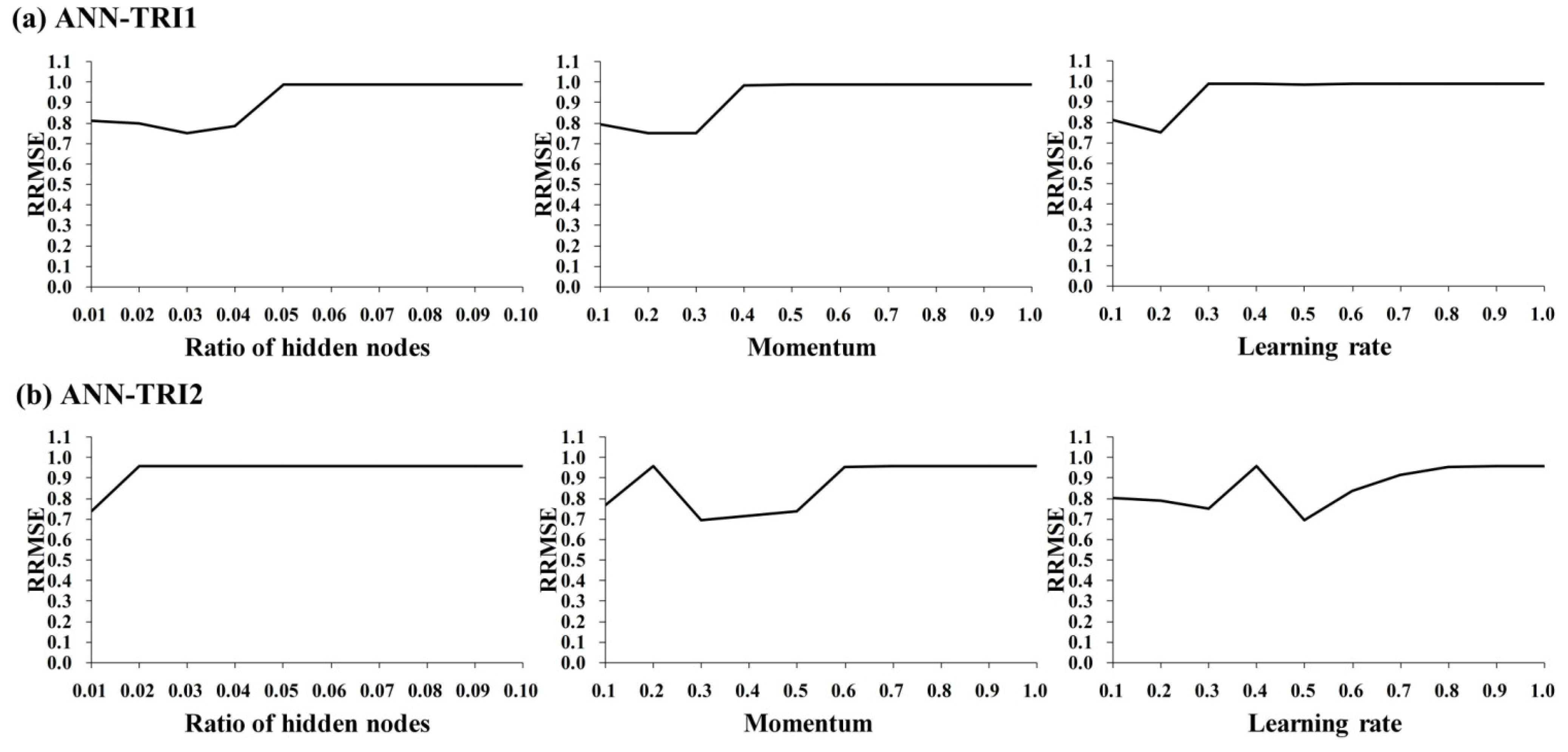
4.2. Model Scenarios


4.3. Performance Levels and Comparisons
| Subset | Model | Performance | ||
|---|---|---|---|---|
| RMAE | RRMSE | r | ||
| Validation set | ANN-PAC | 0.397 | 0.575 | 0.886 |
| ANN-TRI1 | 0.528 | 0.750 | 0.817 | |
| ANN-TRI2 | 0.482 | 0.695 | 0.832 | |
| Regressions | 0.441 | 0.708 | 0.859 | |
| Testing set | ANN-PAC | 0.429 | 0.685 | 0.824 |
| ANN-TRI1 | 0.557 | 0.901 | 0.742 | |
| ANN-TRI2 | 0.555 | 0.895 | 0.733 | |
| Regressions | 0.581 | 0.880 | 0.755 | |
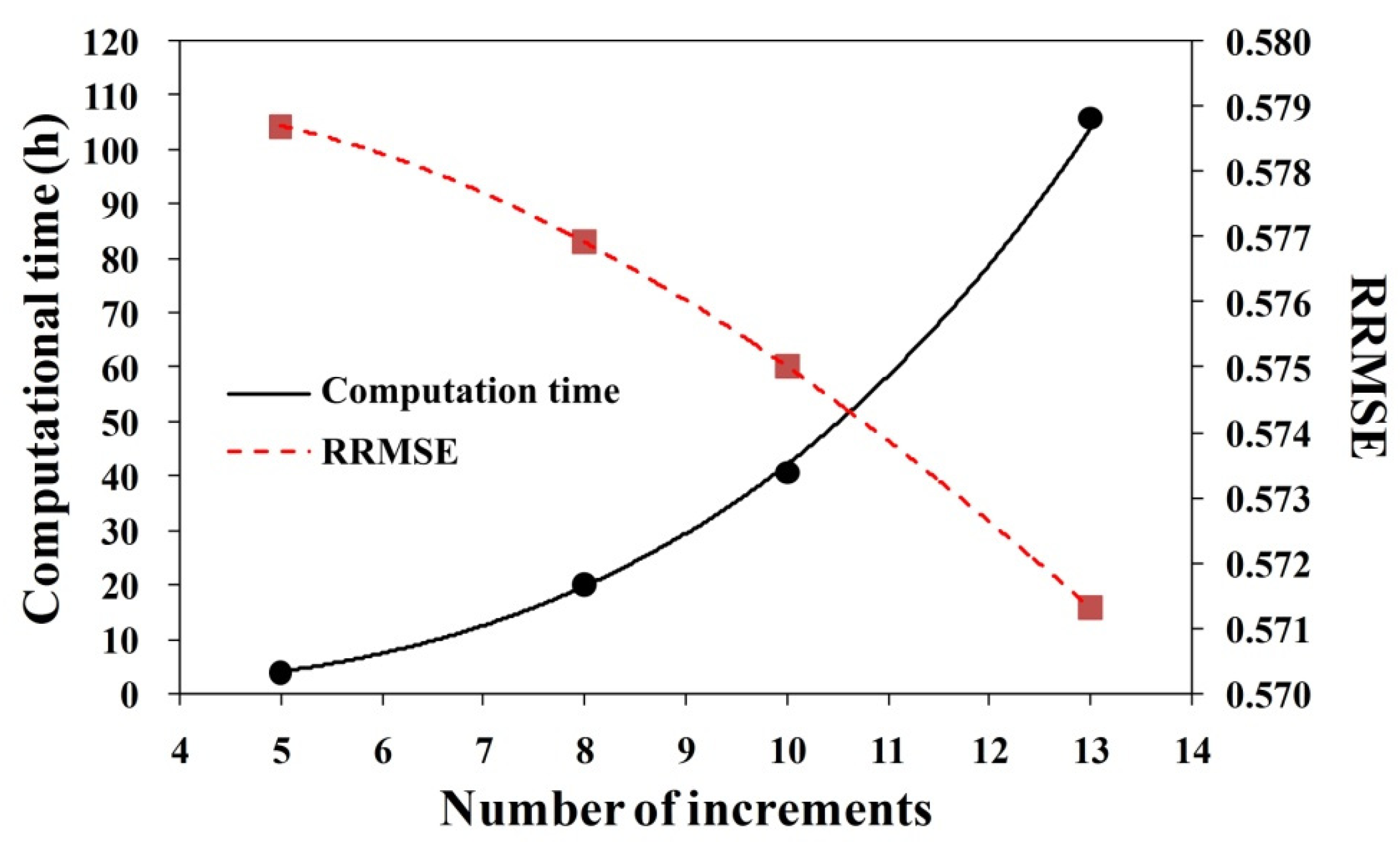
4.4. Effects of the Number of Increments

5. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
References
- Lee, C.S.; Huang, L.R.; Shen, H.S.; Wang, S.T. A climatology model for forecasting typhoon rainfall in Taiwan. Nat. Hazards 2006, 37, 87–105. [Google Scholar] [CrossRef]
- McCulloch, W.S.; Pitts, W. A logical calculus of the ideas imminent in nervous activity. Bull. Math. Biophys. 1943, 5, 115–133. [Google Scholar] [CrossRef]
- Rumelhart, D.E.; Hinton, G.E.; Williams, R.J. Learning Internal Representations by Error Propagation. In Parallel Distributed Processing; Rumelhart, D.E., McClelland, J.L., Eds.; MIT Press: Cambridge, UK, 1986. [Google Scholar]
- Asklany, S.A.; Elhelow, K.; Youssef, I.K.; El-wahab, M.A. Rainfall events prediction using rule-based fuzzy inference system. Atmos. Res. 2011, 101, 228–236. [Google Scholar] [CrossRef]
- Babovic, V. Data mining in hydrology. Hydrol. Process. 2005, 19, 1511–1515. [Google Scholar] [CrossRef]
- Chang, F.J.; Chiang, Y.M.; Tsai, M.J.; Shieh, M.C.; Hsu, K.L.; Sorooshian, S. Watershed rainfall forecasting using neuro-fuzzy networks with the assimilation of multi-sensor information. J. Hydrol. 2014, 508, 374–384. [Google Scholar] [CrossRef]
- Cheng, C.; Wang, S.; Chau, K.W.; Wu, X. Parallel discrete differential dynamic programming for multireservoir operation. Environ. Model. Softw. 2014, 57, 152–164. [Google Scholar] [CrossRef]
- Chau, K.W.; Wu, C.L.; Li, Y.S. Comparison of several flood forecasting models in Yangtze River. J. Hydrol. Eng. 2005, 10, 485–491. [Google Scholar] [CrossRef]
- Kecman, V. Learning and Soft Computing: Support Vector Machines, Neural Networks, and Fuzzy Logic Models; MIT Press: Cambridge, UK, 2001. [Google Scholar]
- Liu, W.C.; Chung, C.E. Enhancing the predicting accuracy of the water stage using a physical-based model and an artificial neural network-genetic algorithm in a river system. Water 2014, 6, 1642–1661. [Google Scholar] [CrossRef]
- Minns, W.; Hall, M.J. Artificial neural networks as rainfall-runoff models. Hydrol. Sci. J. 1996, 41, 399–417. [Google Scholar] [CrossRef]
- Surridge, B.W.J.; Bizzi, S.; Castelletti, A. A framework for coupling explanation and prediction in hydroecological modelling. Environ. Model. Softw. 2014, 61, 274–286. [Google Scholar] [CrossRef]
- Taormina, R.; Chau, K.W.; Sethi, R. Artificial neural network simulation of hourly groundwater levels in a coastal aquifer system of the Venice lagoon. Eng. Appl. Artif. Intell. 2012, 25, 1670–1676. [Google Scholar] [CrossRef]
- Vojinovic, Z.; Kecman, V.; Babovic, V. Hybrid approach for modeling wet weather response in wastewater systems. J. Water Resour. Plan. Manag. 2003, 129, 511–521. [Google Scholar] [CrossRef]
- Wang, W.C.; Xu, D.M.; Chau, K.W.; Chen, S. Improved annual rainfall-runoff forecasting using PSO–SVM model based on EEMD. J. Hydroinform. 2013, 15, 1377–1390. [Google Scholar]
- Wei, C.C. RBF neural networks combined with principal component analysis applied to quantitative precipitation forecast for a reservoir watershed during typhoon periods. J. Hydrometeorol. 2012, 13, 722–734. [Google Scholar] [CrossRef]
- Wei, C.C. Soft computing techniques in ensemble precipitation nowcast. Appl. Soft Comput. 2013, 13, 793–805. [Google Scholar] [CrossRef]
- Wei, C.C.; Hsu, N.S.; Huang, C.L. Two-Stage pumping control model for flood mitigation in inundated urban drainage basins. Water Resour. Manag. 2014, 28, 425–444. [Google Scholar] [CrossRef]
- Wu, C.L.; Chau, K.W. Prediction of rainfall time series using modular soft computing methods. Eng. Appl. Artif. Intell. 2013, 26, 997–1007. [Google Scholar] [CrossRef]
- Cai, H.; Lye, L.M.; Khan, A. Flood Forecasting on the Humber River using an Artificial Neural Network Approach. In Proceedings of the 2009 Canadian Society for Civil Engineering Annual Conference; Canadian Society for Civil Engineering: Montreal, Canada, 2009; Volume 2, pp. 611–620. [Google Scholar]
- Dai, H.C.; Macbeth, C. Effects of learning parameters on learning procedure and performance of a BPNN. Neural Netw. 1997, 10, 1505–1521. [Google Scholar] [CrossRef]
- Maier, H.R.; Dandy, G.C. Neural networks for the prediction and forecasting of water resources variables: A review of modelling issues and applications. Environ. Modell. Softw. 2000, 15, 101–124. [Google Scholar] [CrossRef]
- Chen, W.; Chau, K.W. Intelligent manipulation and calibration of parameters for hydrological models. Int. J. Environ. Pollut. 2006, 28, 432–447. [Google Scholar] [CrossRef]
- Dawson, C.W.; Abrahart, R.J.; Shamseldin, A.Y.; Wilby, R.L. Flood estimation at ungauged sites using artificial neural networks. J. Hydrol. 2006, 319, 391–409. [Google Scholar] [CrossRef]
- Jacobs, R.A. Increased rates of convergence through learning rate adaptation. Neural Netw. 1988, 1, 295–307. [Google Scholar] [CrossRef]
- Kamruzzaman, M.; Shahriar, M.S.; Beecham, S. Assessment of short term rainfall and stream flows in South Australia. Water 2014, 6, 3528–3544. [Google Scholar] [CrossRef]
- Lin, G.F.; Jhong, B.C. A real-time forecasting model for the spatial distribution of typhoon rainfall. J. Hydrol. 2015, 521, 302–313. [Google Scholar] [CrossRef]
- Pasini, A.; Pelino, V.; Potestà, S. A neural network model for visibility nowcasting from surface observations: Results and sensitivity to physical input variables. J. Geophys. Res. 2001, 106, 14951–14959. [Google Scholar] [CrossRef]
- Pasini, A.; Langone, R. Attribution of precipitation changes on a regional scale by neural network modeling: A case study. Water 2010, 2, 321–332. [Google Scholar] [CrossRef]
- Pasini, A.; Langone, R. Influence of circulation patterns on temperature behavior at the regional scale: A case study investigated via neural network modeling. J. Clim. 2012, 25, 2123–2128. [Google Scholar] [CrossRef]
- Pasini, A.; Modugno, G. Climatic attribution at the regional scale: A case study on the role of circulation patterns and external forcings. Atmos. Sci. Lett. 2013, 14, 301–305. [Google Scholar] [CrossRef]
- Wei, C.C. Forecasting surface wind speeds over offshore islands near Taiwan during tropical cyclones: Comparisons of data-driven algorithms and parametric wind representations. J. Geophys. Res. Atmos. 2015, 120, 1826–1847. [Google Scholar] [CrossRef]
- Zhang, Y.; Li, G. Long-term evolution of cones of depression in shallow aquifers in the North China Plain. Water 2013, 5, 677–697. [Google Scholar] [CrossRef]
- Sheela, K.G.; Deepa, S.N. Review on methods to fix number of hidden neurons in neural networks. Math. Probl. Eng. 2013, 2013. [Google Scholar] [CrossRef]
- Maier, H.R.; Dandy, G.C. The effect of internal parameters and geometry on the performance of back-propagation neural networks: An empirical study. Environ. Model. Softw. 1998, 13, 193–209. [Google Scholar] [CrossRef]
- Maier, H.R.; Jain, A.; Dandy, G.C.; Sudheer, K. Methods used for the development of neural networks for the prediction of water resource variables in river systems: current status and future directions. Environ. Model. Softw. 2010, 25, 891–909. [Google Scholar] [CrossRef]
- Panchal, G.; Ganatra, A.; Kosta, Y.P.; Panchal, D. Behaviour analysis of multilayer perceptrons with multiple hidden neurons and hidden layers. Int. J. Comput. Theor. Eng. 2011, 3, 332–337. [Google Scholar] [CrossRef]
- Patra, J.C.; van den Bos, A. Auto-calibration and -compensation of a capacitive pressure sensor using multilayer perceptrons. ISA Trans. 2000, 39, 175–190. [Google Scholar] [CrossRef]
- Kurt, I.; Ture, M.; Kurum, A.T. Comparing performances of logistic regression, classification and regression tree, and neural networks for predicting coronary artery disease. Expert Syst. Appl. 2008, 34, 366–374. [Google Scholar] [CrossRef]
- Imrie, C.E.; Durucan, S.; Korre, A. River flow prediction using artificial neural networks: Generalization beyond the calibration range. J. Hydrol. 2000, 233, 138–153. [Google Scholar] [CrossRef]
- Pasini, A. Artificial neural networks for small dataset analysis. J. Thorac. Dis. 2015, 7, 953–960. [Google Scholar] [PubMed]
- Prechelt, L.; Orr, G.B. Early Stopping−But When? In Neural Networks: Tricks of the Trade. Lecture Notes in Computer Science; Montavon, G., Müller, K.R., Eds.; Springer: Berlin, Germany; Heidelberg, Germany, 2012; pp. 53–67. [Google Scholar]
- Hu, T.S.; Lam, K.C.; Ng, S.T. River flow time series prediction with a range dependent neural network. Hydrol. Sci. J. 2001, 46, 729–745. [Google Scholar] [CrossRef]
© 2015 by the authors; licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lo, D.-C.; Wei, C.-C.; Tsai, E.-P. Parameter Automatic Calibration Approach for Neural-Network-Based Cyclonic Precipitation Forecast Models. Water 2015, 7, 3963-3977. https://doi.org/10.3390/w7073963
Lo D-C, Wei C-C, Tsai E-P. Parameter Automatic Calibration Approach for Neural-Network-Based Cyclonic Precipitation Forecast Models. Water. 2015; 7(7):3963-3977. https://doi.org/10.3390/w7073963
Chicago/Turabian StyleLo, Der-Chang, Chih-Chiang Wei, and En-Ping Tsai. 2015. "Parameter Automatic Calibration Approach for Neural-Network-Based Cyclonic Precipitation Forecast Models" Water 7, no. 7: 3963-3977. https://doi.org/10.3390/w7073963
APA StyleLo, D.-C., Wei, C.-C., & Tsai, E.-P. (2015). Parameter Automatic Calibration Approach for Neural-Network-Based Cyclonic Precipitation Forecast Models. Water, 7(7), 3963-3977. https://doi.org/10.3390/w7073963