A Local Approximation Approach for Processing Time-Evolving Graphs

Abstract
:1. Introduction
- -
- We developed a new optimization approach to reduce the response time in the distributed time-evolving graph systems by providing a novel local computing model instead of the global computing model.
- -
- We designed a prediction method for the PageRank algorithm to guess the messages from remote computing nodes and thereby combined the predicted messages and the local messages to update the vertices of the newly-constructed snapshot. This ensures a smaller relative error between the results of the computation by using the local computing model and the results of the computation by using the global computing model.
- -
- We were able to reduce the response time by 22% for the SSSP algorithm and 7% for the PageRank algorithm on average compared to the incremental computing framework of GraphTau [12].
2. Background
2.1. Incremental Computing Model
2.2. Potential Advantages of Local Approximation
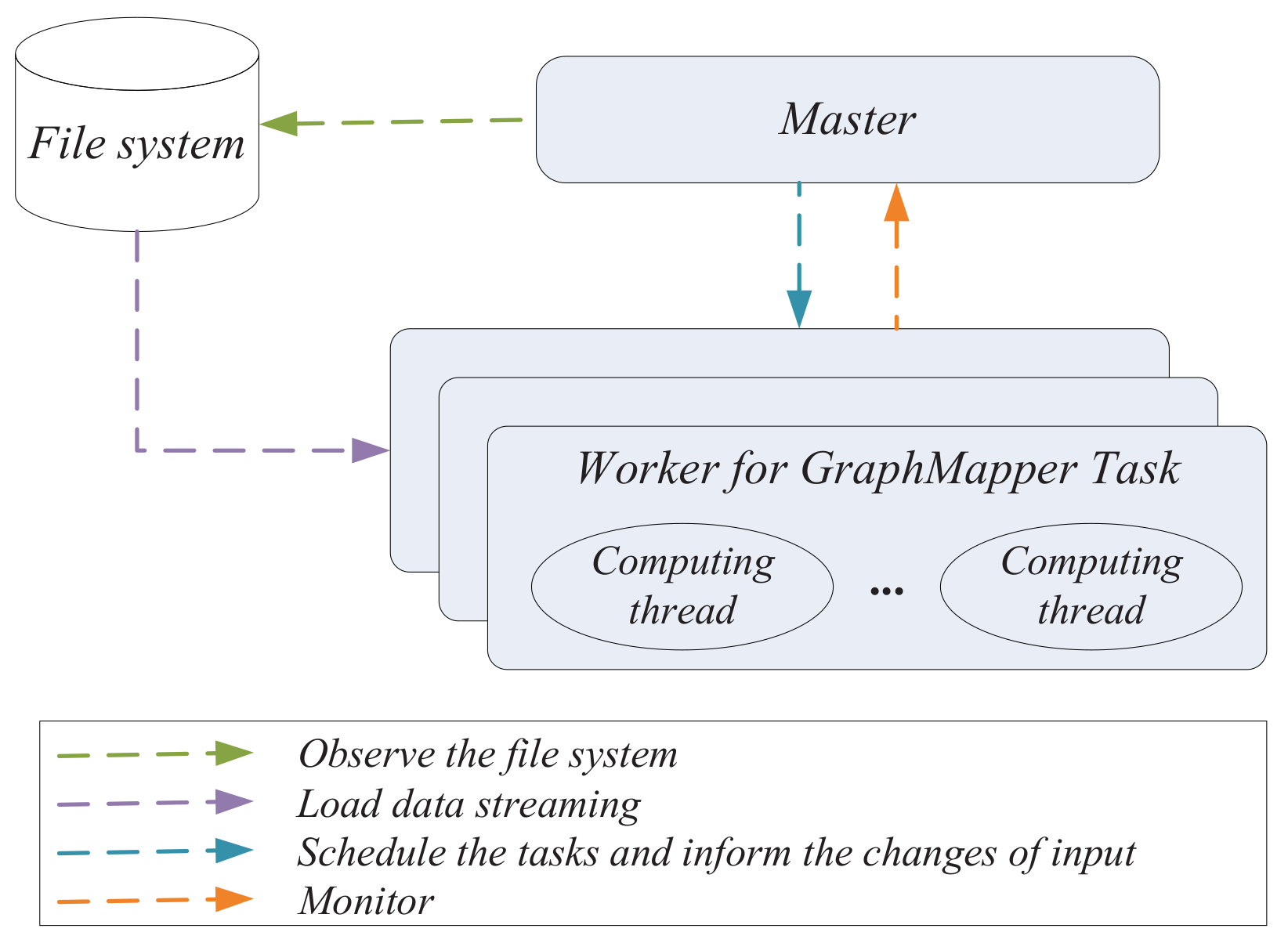
3. System Design
3.1. LocalAppro System
3.2. Message Passing Model
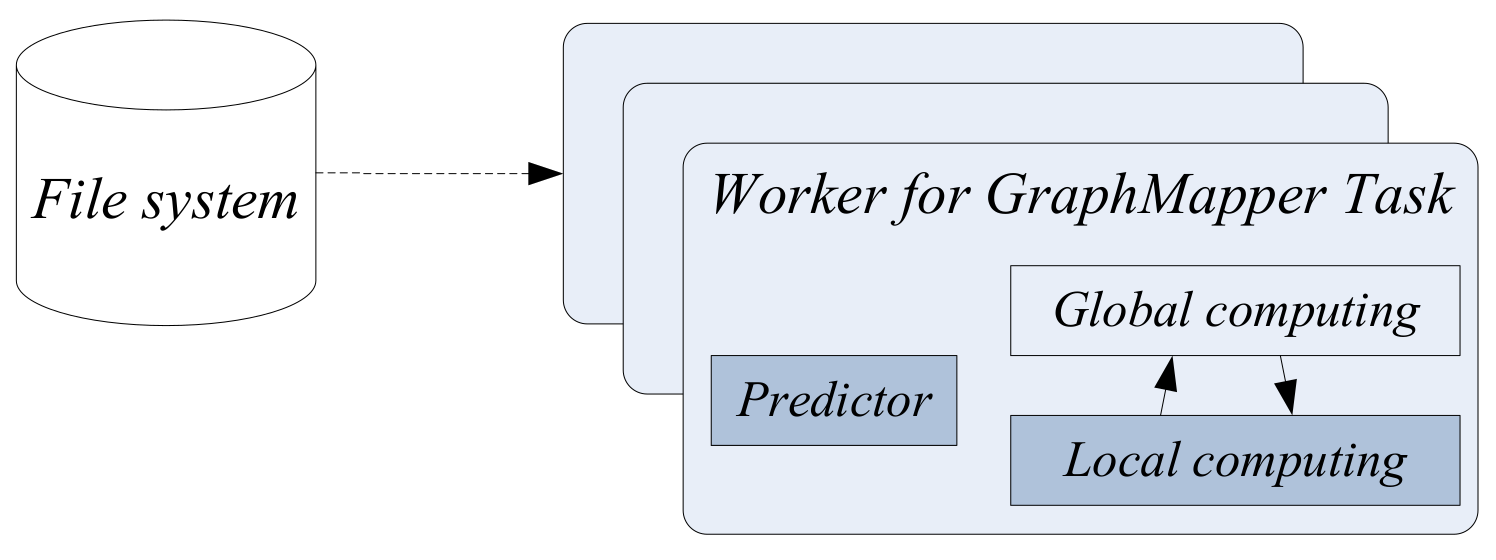
4. Local Approximation
4.1. Local Computing Model
4.2. Algorithms with the Local Computing Model
4.2.1. SSSP Algorithm
| Algorithm 1 SSSP algorithm with local computing model |
| Input: Vertex v |
| Output: |
| SSSPComputation (Vertex v){ |
| 1. ← initialization(v); |
| 2. ← getInEdges(v); |
| 3. for each vertex u ∈ |
| 4. ← findMinimum(,getValue(u)+getWeight(u,v)); |
| 5. end for |
| 6. if < getValue(v) |
| 7. setValue(v,); |
| 8. end if |
| 9. return ;} |
4.2.2. PageRank Algorithm
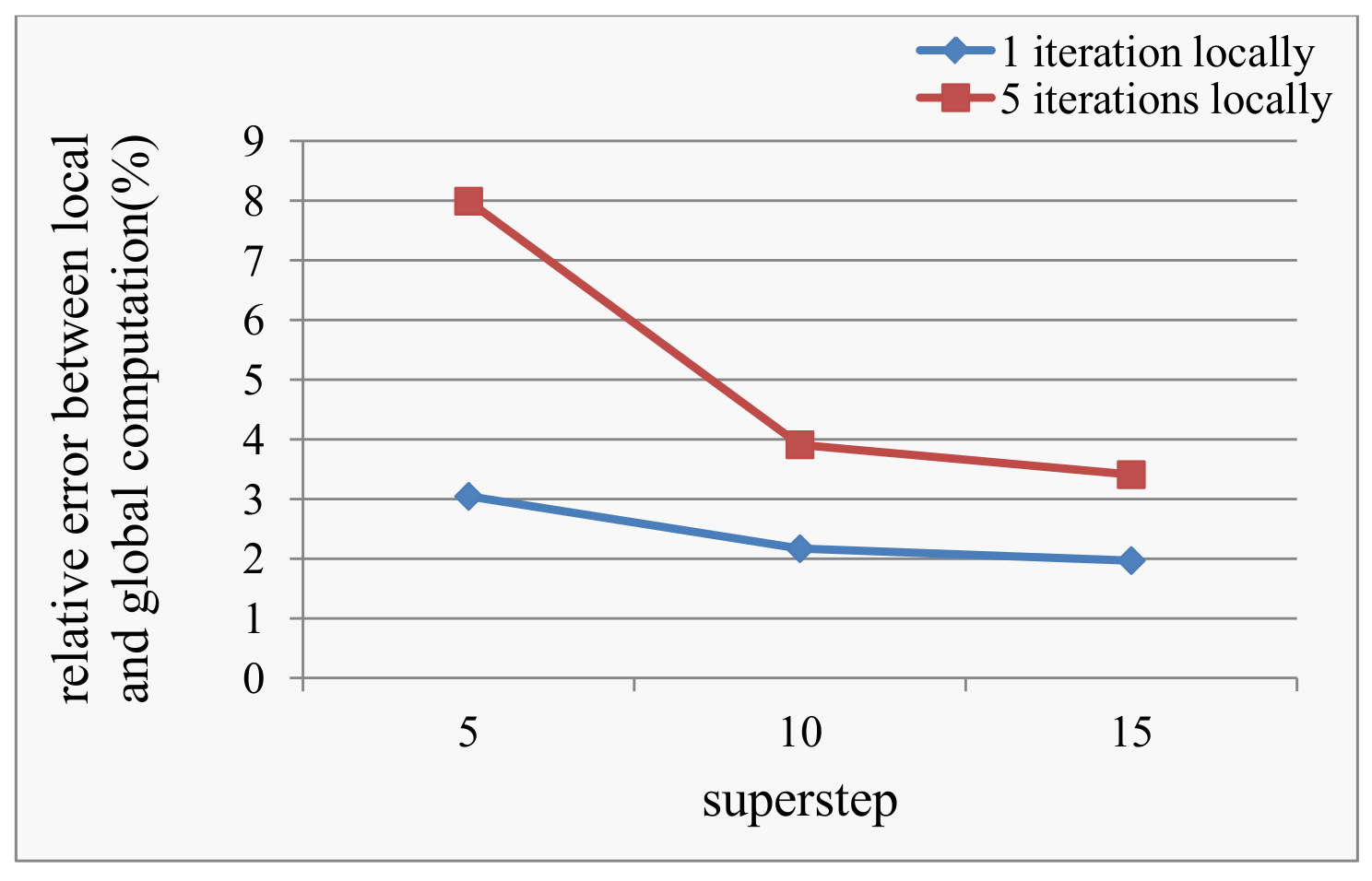
- For the vertices that have been in the old snapshot, based on Formula (5) above, the sum of the messages from the remote neighbors of the vertex v multiplied by d at superstep t can be described as Formula (7). We make the assumption that the messages from the remote neighbors of the vertex v gradually increase with the pattern that the increasing rate gradually decreases. Thereby, we predict the sum of the remote messages by using Formula (8) with the local messages. We set to be 0.05 in our implementation.
- For the newly-inserted vertices, we make the assumption that the neighbors of the new vertices are uniformly distributed in each computing node; thereby, we predict the sum of the remote messages as the sum of the local messages.
| Algorithm 2 PageRank algorithm with local computing model |
| Input: Vertex v |
| Output: |
| PageRankComputation (Vertex v){ |
| 1. ← 0; |
| 2. ← getInEdges(v); |
| 3. for each vertex u ∈ |
| 4. ← getNumEdges(u); |
| 5. ← +getValue(u)/; |
| 6. end for |
| 7. ← d*; |
| 8. ← d*predict(v); |
| 9. ← ++(1-d)/N |
| 10. setValue(v,); |
| 11. return ;} |
5. Evaluation
5.1. Experimental Setup
5.2. Performance Study
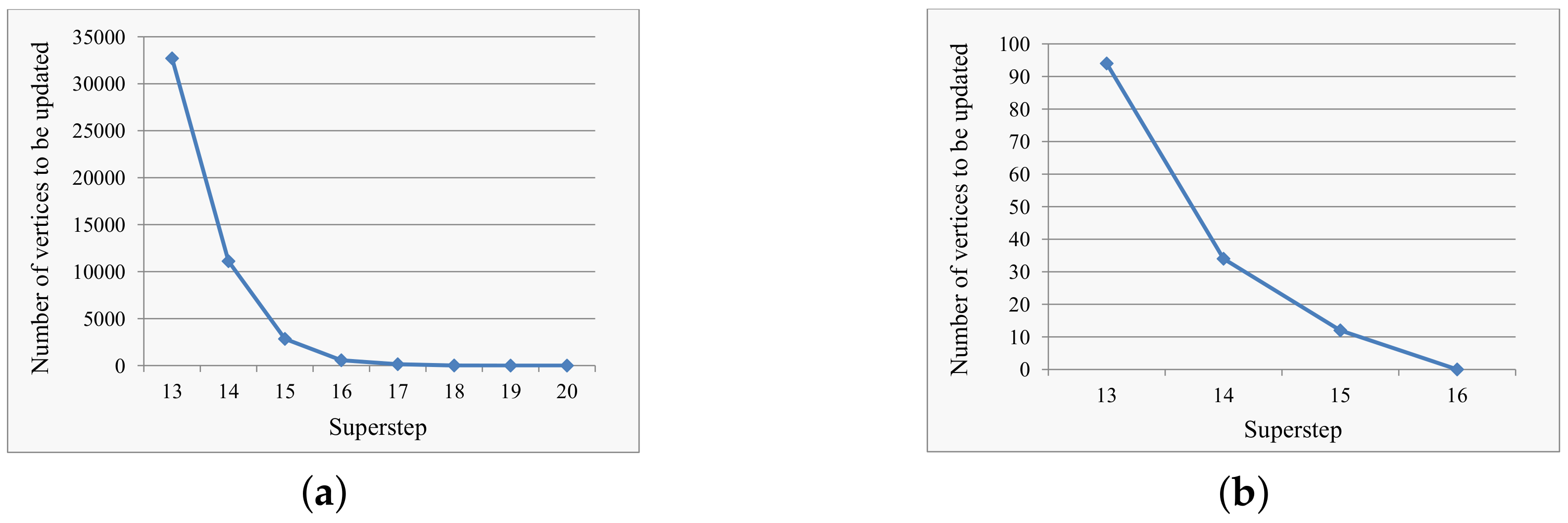
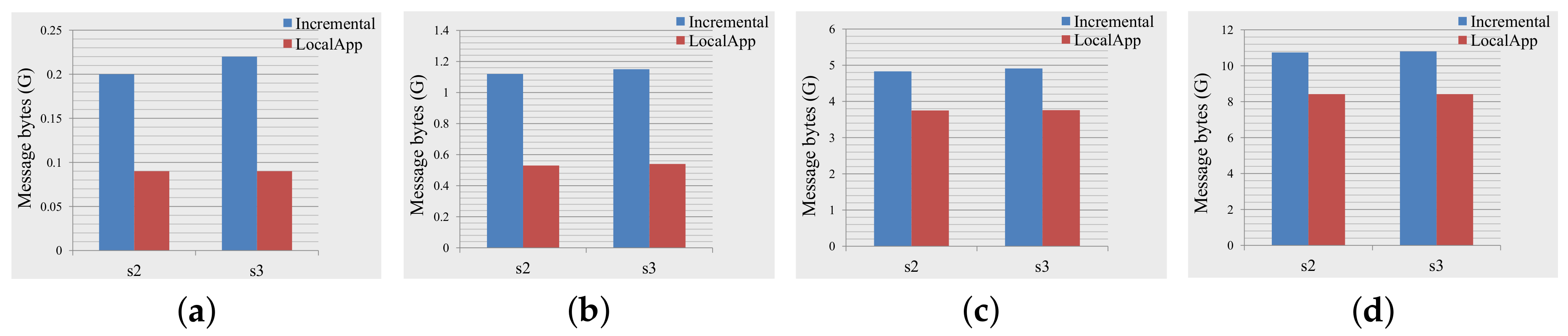
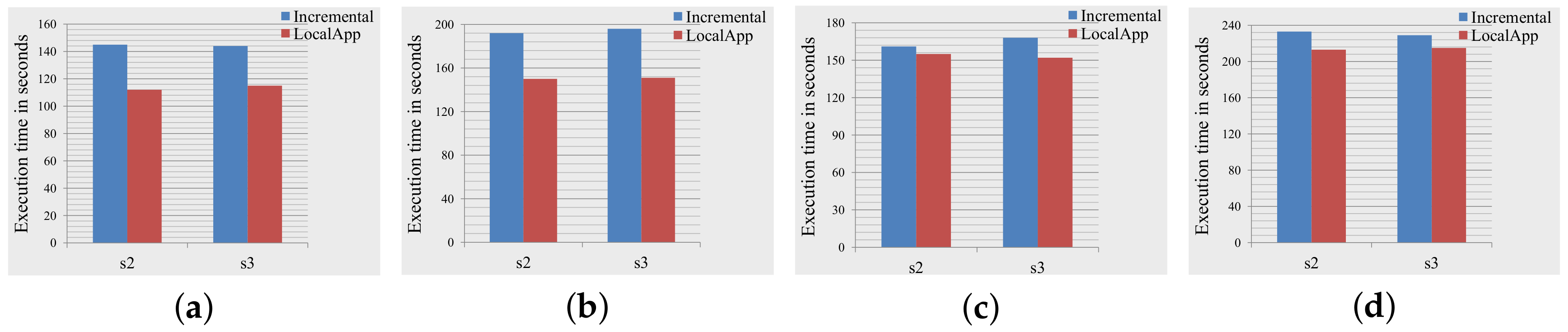
5.2.1. Communication Overhead and Response Time
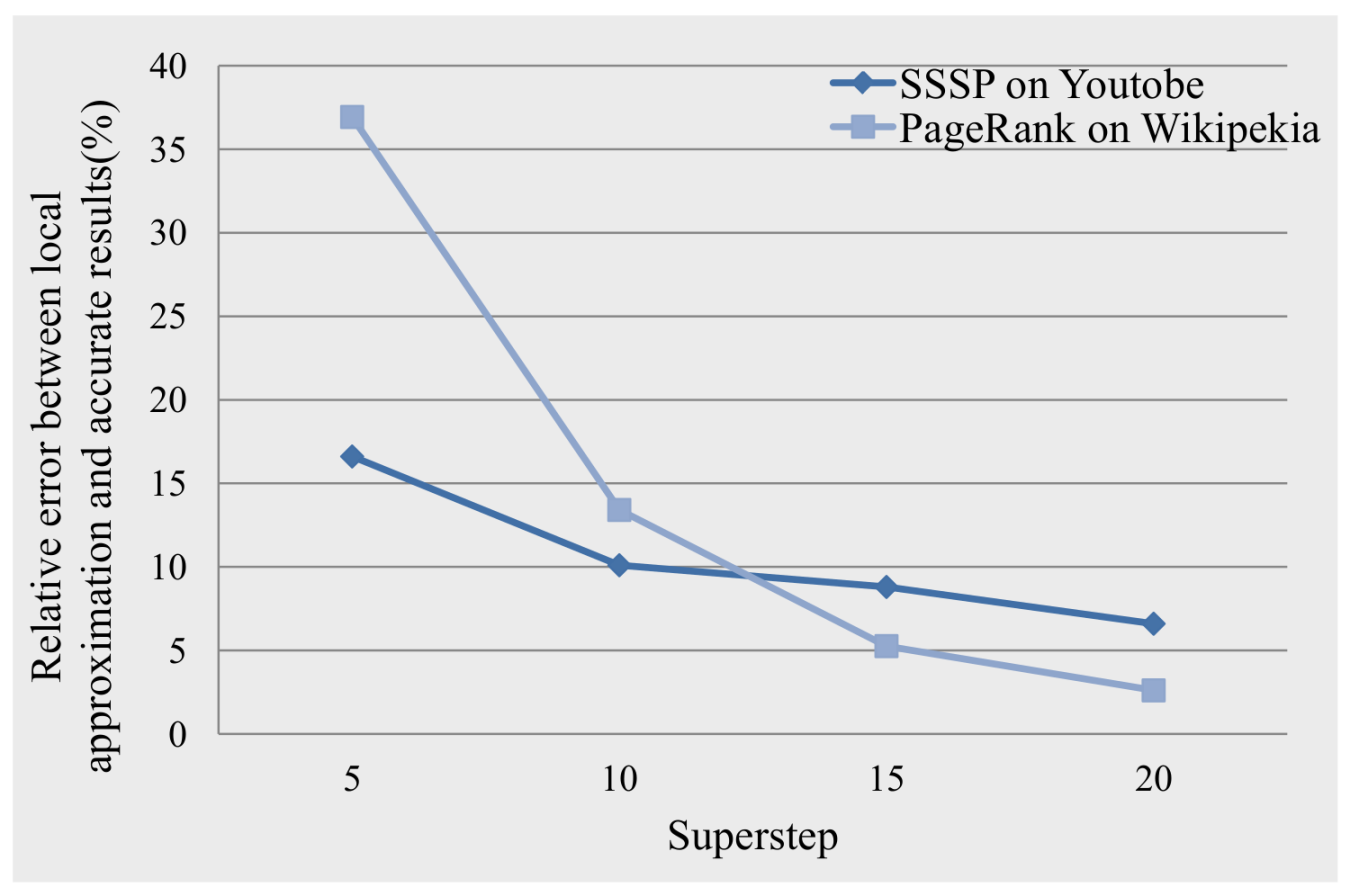
5.2.2. Local Approximation Error Analysis
6. Related Work
6.1. Distributed Time-Evolving Graph Computing Systems
6.2. Asynchronous Graph Systems
7. Conclusions and Future Work
Author Contributions
Funding
Acknowledgments
Conflicts of Interest
References
- Malewicz, G.; Austern, M.H.; Bik, A.J.; Dehnert, J.C.; Horn, I.; Leiser, N.; Czajkowski, G. Pregel: A system for large-scale graph processing. In Proceedings of the 2010 ACM SIGMOD International Conference on Management of Data (SIGMOD’10), Indianapolis, IN, USA, 6–10 June 2010; pp. 135–146. [Google Scholar]
- McCune, R.R.; Weninger, T.; Madey, G. Thinking like a vertex: A survey of vertex-centric frameworks for large-scale distributed graph processing. ACM Comput. Surv. 2015, 48, 25. [Google Scholar] [CrossRef]
- Gonzalez, J.E.; Low, Y.; Gu, H.; Bickson, D.; Guestrin, C. PowerGraph: Distributed Graph-Parallel Computation on Natural Graphs. In Proceedings of the 10th USENIX Symposium on Operating Systems Design and Implementation (OSDI’12), Hollywood, CA, USA, 8–10 October 2012; pp. 17–30. [Google Scholar]
- Gonzalez, J.E.; Xin, R.S.; Dave, A.; Crankshaw, D.; Franklin, M.J.; Stoica, I. GraphX: Graph processing in a distributed dataflow framework. In Proceedings of the 11th USENIX Symposium on Operating Systems Design and Implementation; Broomfield, CO, USA, 6–8 October 2014, pp. 599–613.
- Kang, U.; Tsourakakis, C.E.; Faloutsos, C. PEGASUS: A Peta-scale graph mining system implementation and observations. In Proceedings of the 2009 Ninth IEEE International Conference on Data Mining, Miami, FL, USA, 6–9 December 2009; pp. 229–238. [Google Scholar]
- Leskovec, J.; Kleinberg, J.M.; Faloutsos, C. Graphs over time: Densification laws, shrinking diameters and possible explanations. In Proceedings of the eleventh ACM SIGKDD International Conference on Knowledge Discovery in Data Mining (KDD’05), Chicago, IL, USA, 21–24 August 2005; pp. 177–187. [Google Scholar]
- Gaito, S.; Zignani, M.; Rossi, G.P.; Sala, A.; Zhao, X.; Zheng, H.; Zhao, B.Y. On the bursty evolution of online social networks. In Proceedings of the First ACM International Workshop on Hot Topics on Interdisciplinary Social Networks Research (HotSocial’12), Beijing, China, 12–16 August 2012; pp. 1–8. [Google Scholar]
- Vaquero, L.M.; Cuadrado, F.; Ripeanu, M. Systems for near real-time analysis of large-scale dynamic graphs. arXiv, 2014; arXiv:1410.1903. [Google Scholar]
- Murray, D.G.; Mcsherry, F.; Isaacs, R.; Isard, M.; Barham, P.; Abadi, M. Naiad: A timely dataflow system. In Proceedings of the Twenty-Fourth ACM Symposium on Operating Systems Principles (SOSP’13), Farminton, PA, USA, 3–6 November 2013; pp. 439–455. [Google Scholar]
- Morshed, S.J.; Rana, J.; Milrad, M. Real-time Data analytics: An algorithmic perspective. In Proceedings of the IEEE International Conference on Data Mining, Barcelona, Spain, 12–15 December 2016; pp. 311–320. [Google Scholar]
- Cheng, R.; Hong, J.; Kyrola, A.; Miao, Y.; Weng, X.; Wu, M.; Yang, F.; Zhou, L.; Zhao, F.; Chen, E. Kineograph: Taking the pulse of a fast-changing and connected world. In Proceedings of the 7th ACM European Conference on Computer Systems (EuroSys’12), Bern, Switzerland, 10–13 April 2012; pp. 85–98. [Google Scholar]
- Iyer, A.P.; Li, L.E.; Das, T.; Stoica, I. Time-evolving graph processing at scale. In Proceedings of the 4th International Workshop on Graph Data Management Experience and Systems (GRADES’16), Redwood Shores, CA, USA, 24–24 June 2016. [Google Scholar]
- Cai, Z.; Logothetis, D.; Siganos, G. Facilitating real-time graph mining. In Proceedings of the Fourth International Workshop on Cloud Data Management (CloudDB’12), Maui, HI, USA, 29 October 2012. [Google Scholar]
- Shi, X.; Cui, B.; Shao, Y.; Tong, Y. Tornado: A system for real-time iterative analysis over evolving data. In Proceedings of the 2016 International Conference on Management of Data (SIGMOD’16), San Francisco, CA, USA, 26 June–1 July 2016; pp. 417–430. [Google Scholar]
- Valiant, L.G. A bridging model for parallel computation. Commun. ACM 1990, 33, 103–111. [Google Scholar] [CrossRef]
- Apache. Apache Giraph. 2012. Available online: http://giraph.apache.org/ (accessed on 7 January 2015).
- Dean, J.; Ghemawat, S. MapReduce: simplified data processing on large clusters. Commun. ACM 2008, 51, 107–113. [Google Scholar] [CrossRef]
- Konect. Konect Network Dataset. 2017. Available online: http://konect.uni-koblenz.de/ (accessed on 21 May 2017).
- Das, T.; Zhong, Y.; Stoica, I.; Shenker, S. Adaptive stream processing using dynamic batch sizing. In Proceedings of the ACM Symposium on Cloud Computing (SOCC’14), Seattle, WA, USA, 3–5 November 2014; pp. 1–13. [Google Scholar]
- Low, Y.; Gonzalez, J.E.; Kyrola, A.; Bickson, D.; Guestrin, C.E.; Hellerstein, J. Graphlab: a new framework for parallel machine learning. arXiv, 2014; arXiv:1408.2041. [Google Scholar]
- Zhang, Y.; Gao, Q.; Gao, L.; Wang, C. Maiter: an asynchronous graph processing framework for delta-based accumulative iterative computation. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 2091–2100. [Google Scholar] [CrossRef]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Notation | Description |
|---|---|
| Represents a graph where V is the set of the vertices and E is the set of the edges | |
| Represents a subgraph present in the same computing node where a specified vertex v is located, where is the set of the vertices and is the set of the edges in this subgraph. | |
| Represents a subgraph present in the different computing node where a specified vertex v is located, where is the set of the vertices and is the set of the edges in this subgraph. |
| Dataset | Stream | Size (MB) | Description | ||
|---|---|---|---|---|---|
| YouTube | s1 | 2,438,091 | 6,294,386 | 106 | The social network of YouTube users and their friendship connections. |
| s2 | 361,085 | 840,673 | 17 | ||
| s3 | 714,061 | 1,888,816 | 36 | ||
| Wikipedia-small | s1 | 1,092,282 | 16,810,630 | 181 | The hyperlink network of the English Wikipedia with edge arrival times. |
| s2 | 338,588 | 1,259,596 | 19 | ||
| s3 | 529,574 | 2,565,247 | 35 | ||
| Wikipedia | s1 | 1,631,890 | 37,675,911 | 545 | The hyperlink network of the English Wikipedia with edge arrival times. |
| s2 | 367,747 | 1,233,340 | 22 | ||
| s3 | 336,098 | 2,261,332 | 39 |
| Algorithm | Dataset | Snapshot | Relative Error (%) |
|---|---|---|---|
| SSSP | YouTube | s2 | 8.67 |
| s3 | 16.59 | ||
| Wikipedia | s2 | 2.39 | |
| s3 | 4.17 | ||
| PageRank | Wikipedia-small | s2 | 5.61 |
| s3 | 8.06 | ||
| Wikipedia | s2 | 5.26 | |
| s3 | 6.14 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Ji, S.; Zhao, Y. A Local Approximation Approach for Processing Time-Evolving Graphs. Symmetry 2018, 10, 247. https://doi.org/10.3390/sym10070247
Ji S, Zhao Y. A Local Approximation Approach for Processing Time-Evolving Graphs. Symmetry. 2018; 10(7):247. https://doi.org/10.3390/sym10070247
Chicago/Turabian StyleJi, Shuo, and Yinliang Zhao. 2018. "A Local Approximation Approach for Processing Time-Evolving Graphs" Symmetry 10, no. 7: 247. https://doi.org/10.3390/sym10070247
APA StyleJi, S., & Zhao, Y. (2018). A Local Approximation Approach for Processing Time-Evolving Graphs. Symmetry, 10(7), 247. https://doi.org/10.3390/sym10070247