Joint Adaptive Coding and Reversible Data Hiding for AMBTC Compressed Images

1
School of Electrical and Computer Engineering, Nanfang College of Sun Yat-Sen University, Guangzhou 510970, China
2
School of Information Engineering, Guangdong University of Technology, Guangzhou 510006, China
*
Author to whom correspondence should be addressed.
Symmetry 2018, 10(7), 254; https://doi.org/10.3390/sym10070254
Submission received: 1 May 2018
/
Revised: 18 May 2018
/
Accepted: 31 May 2018
/
Published: 2 July 2018
(This article belongs to the Special Issue Emerging Data Hiding Systems in Image Communications)
Abstract
:This paper proposes a joint coding and reversible data hiding method for absolute moment block truncation coding (AMBTC) compressed images. Existing methods use a predictor to predict the quantization levels of AMBTC codes. Equal-length indicators, secret bits and prediction errors are concatenated to construct the output code stream. However, the quantization levels might not highly correlate with their neighbors for predictive coding, and the use of equal-length indicators might impede the coding efficiency. The proposed method uses reversible integer transform to represent the quantization levels by their means and differences, which is advantageous for predictive coding. Moreover, the prediction errors are better classified into symmetrical encoding cases using the adaptive classification technique. The length of indicators and the bits representing the prediction errors are properly assigned according to the classified results. Experiments show that the proposed method offers the lowest bitrate for a variety of images when compared with the existing state-of-the-art works.
1. Introduction
The rapid development of internet technology has made data security a key consideration for data transmission or content protection. While most digital data can be transmitted over the internet, transmitted data is also exposed to the risks of illegal access or interception. A solution to these problems is to employ a data hiding method, in which secret data are embedded into a digital media to cover the presence of embedment, or to protect the transmitted contents. Data hiding methods for images can be classified into irreversible [1,2,3] and reversible [4,5,6,7] methods. The cover images of both methods are distorted to obtain stego images. However, the distortions of irreversible methods are permanent, and thus, they are not suitable for applications where no distortions are allowed. In contrast, reversible methods recover the original images from the distorted versions after extracting the secret data. Since the original image can be completely recovered, reversible data hiding (RDH) methods have special applications, and much research has been devoted to investigating data hiding methods of this type.
Reversible data hiding method can be applied to images in spatial or compressed domains. The spatial domain methods embed data into a cover image by altering its pixel values. The difference expansion scheme proposed by Tian [8] and the histogram shifting scheme proposed by Ni et al. [9] are two well-known methods of this type. Many recent works [4,5,6,7] have exploited the merits of [8,9] to propose improved methods with better embedding efficiency. In contrast, compressed domain methods modify the coefficients of compressed codes [10], or use the joint neighborhood coding (JNC) [11] scheme to embed data bits into the compressed code stream. Up to now, RDH methods have been applied to vector quantization (VQ) [12,13], joint photographic experts group (JPEG) [14], and absolute moment block truncation coding (AMBTC) [15,16,17,18,19] compressed images. AMBTC [20] is a lossy compression method which re-represents an image block by a bitmap and two quantization levels. As AMBTC requires insignificant compaction costs while achieving satisfactory image quality, some researchers have investigated RDH methods and their applications [21,22,23] in this format.
Zhang et al. [16] in 2013 proposed an RDH for AMBTC compressed images. In their method, the different quantization levels are classified into eight cases, which in turn are recorded by three-bit indicators. By re-representing the AMBTC codes, secret data are embedded into the compressed code stream. Sun et al. [17] also proposed an efficient method using JNC. This method predicts pixel values and obtains prediction errors, which are then classified into four cases. Secret bits, two-bit indicators, and prediction errors are concatenated to construct the output code stream. Hong et al. [18] in 2017 modified the prediction and classification rules from Sun et al.’s work and proposed an improved method with a lower bitrate. However, their method also uses two-bit indicators to represent four categories of prediction errors. The use of equal-length indicators might not efficiently represent the encoding cases, leading to an increase in bitrate. In 2018, Chang et al. [19] also proposed an interesting method to improve Sun et al.’s work. In their method, a neighboring quantization level of the current quantization level, x, is selected as the prediction value, p, to predict x. The prediction error is obtained by performing the exclusive OR operation between the binary representations of p and x, and then the result is converted to its decimal representation. Since the calculated prediction errors are all positive, the sign bits are not required to record them.
In this paper, we propose a new RDH method for AMBTC compressed codes. With the proposed method, the AMBTC compressed image can be recovered, and the embedded data can be completely extracted. Unlike the aforementioned methods that embed data into quantization levels, the proposed method transforms the quantization levels into means and differences, which are used for carrying data bits. Moreover, the classifications of prediction errors are adaptively assigned, and varied length indicators are utilized to effectively reduce the bitrate. The experimental results show that the proposed method achieves the lowest bitrate when compared to recently published works. The rest of this paper is organized as follows. Section 2 briefly introduces the AMBTC compression method as well as Hong et al.’s work. Section 3 presents the proposed method. The experimental results and discussions are given in Section 4, while concluding remarks are addressed in the last section.
2. Related Works
This section briefly introduces the AMBTC compression method. Hong et al.’s work that was published recently is also introduced in this section.
2.1. AMBTC Compression Technique
The AMBTC compression technique partitions an image, I, into blocks of size . The averaged value, , of each block, , where N is the total number of blocks, is calculated. AMBTC uses the lower and upper quantization levels, denoted by and , respectively, and a bitmap, , to represent the compressed code of block . and are calculated by rounding the averaged result of pixels in with values smaller than, and larger than, or equal to, , respectively. The j-th bit in , denoted by , is set to ‘1’ if . Otherwise, is set to ‘0’. Every block is processed in the same manner, and the final AMBTC code, , is obtained. The decoding of AMBTC codes can be done by simply replacing the bits valued ‘0’ by and the bits valued ‘1’ by . A simple example is given below. Let = [23,45,46,47; 43,47,77,80; 88,86,78,90; 78,80,68,70] be an image block to be compressed, where the semicolon denotes the end-of-row operator. The averaged value of is 65.38. The averaged value of pixels with values larger than or equal to 65.38 is 79.50. Therefore, we obtain . Likewise, the averaged value of pixels with values less than 65.38 is 41.83 and thus, . Finally, the bitmap obtained is = [0000; 0011; 1111; 1111]. The decoded AMBTC block of the compressed code {42,80, [0000; 0011; 1111; 1111]} is [42,42,42,42; 42,42,80,80; 80,80,80,80; 80,80,80,80].
2.2. Hong et al.’s Method
In 2017, Hong et al. [18] proposed an efficient data hiding method for AMBTC compressed images. Their method uses the median edge detection (MED) predictor to obtain the prediction values as follows. Let x be the to-be-predicted upper or lower quantization level, and , , and be the quantization levels to the upper, left, and upper left of x, respectively. The MED predictor predicts x using the following rule to obtain the prediction value. p:
The prediction error, e, calculated by , is classified into four categories using the centralized error division (CED) technique. Two-bit indicators, ‘00’, ’01’, ‘10’, and ‘11’, are used to specify four corresponding encoding cases. The first case occurs when . In this case, the prediction error does not need bits to be recorded. The n-bit secret data, , and the indicator ‘00’ are concatenated together and output the result, ||00 to the code stream, CS. The second case occurs if . In this case, the bitstream, ||01||, is outputted to the CS, where represents the k-bit binary representation of , and the symbol || is the concatenation operator. Similarly, if (the third case), ||10|| is outputted to the CS. The last case occurs when or . In this case, ||11|| is output. The detailed encoding and decoding procedures can be found in [18].
3. Proposed Method
The existing RDH methods for AMBTC compressed images [16,17,18,19] all perform predictions on the quantization levels of AMBTC codes. The prediction errors are classified into categories. The secret data bits, indicators, and prediction errors are then concatenated and output to the code stream. For the JNC technique, better prediction often results in a smaller bitrate since fewer bits are required to record the prediction errors. However, the existing methods all perform the prediction on two quantization levels, which might not correlate enough to obtain a good prediction result. Moreover, this classification of prediction errors does not consider their distributions and assigns the same classification rules to different images. Improper classification might lead to a significant increase in bitrate. The proposed method transforms pairs of quantization levels into their means and differences using the reversible integer transform (RIT). The transformed means and differences are generally more correlated than the quantization levels, and thus, they are more suitable for predictive coding. The prediction errors are adaptively classified according to their distribution, ensuring that fewer bits are required to record them. Techniques used this paper will be separately introduced in the following two subsections.
3.1. Reversible Integer Transform of Quantization Levels
A pair of quantization levels can be transformed into their mean, , and difference, , using transform:
where is the floor operator. The transformation in Equation (2) is reversible since the pair of quantization levels, , can be recovered by the inverse transform:
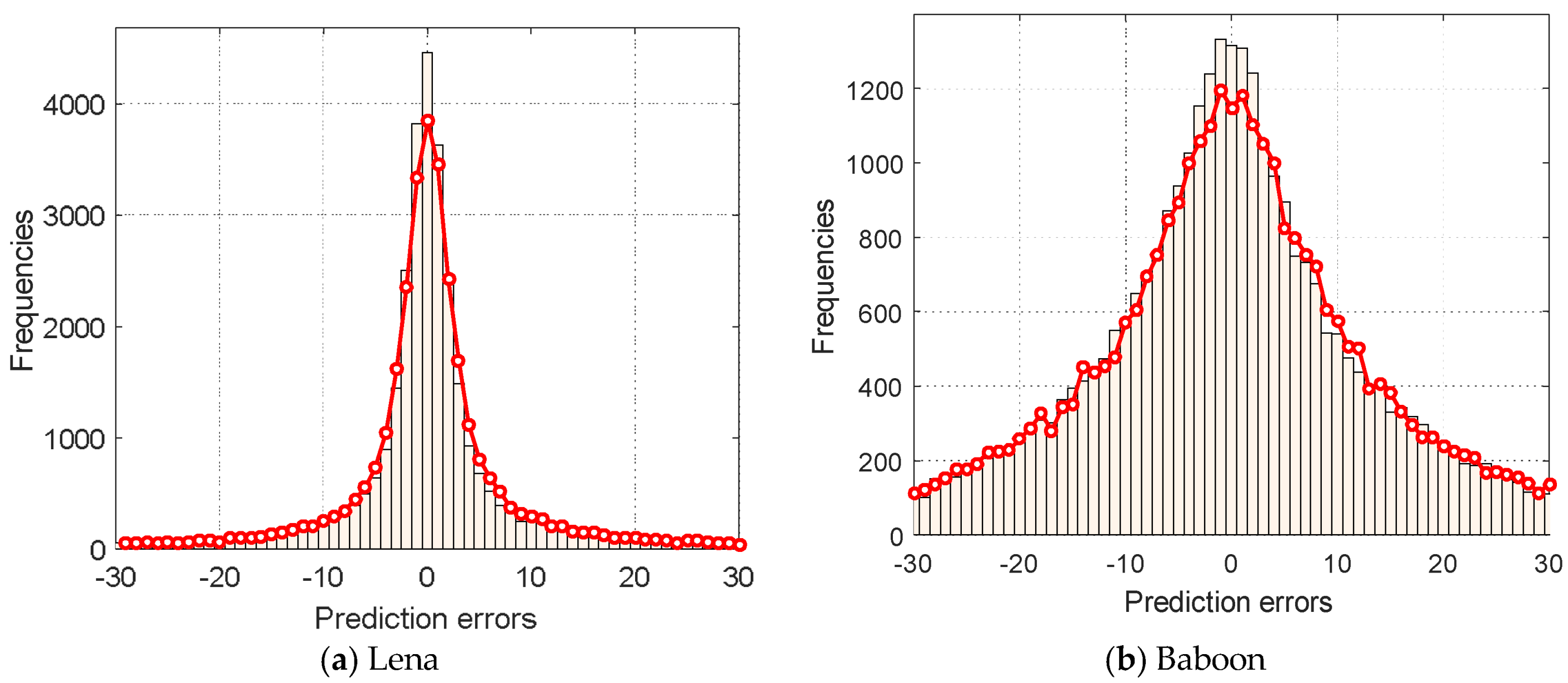
Since the mean operation has a tendency to reduce the noise, and the difference operation tends to reduce the variation in neighboring quantization levels, the transformed means and differences are often more correlated than the quantization levels. Therefore, the prediction performed on the means and differences will improve the prediction accuracy. Figure 1 shows the distribution of prediction errors for the Lena and Baboon images using the MED predictor. In this figure, the red line with circle marks is the predictor that is applied on the upper and lower quantization levels, whereas the histogram is the prediction result when the predictor is applied on the transformed means and differences. As seen from Figure 1, the peak of the histogram is higher than that of the red circle line for both Lena and Baboon images. In fact, the experiments on other test images also obtain similar trends, indicating that the transformed means and differences are more amenable for predictive coding.
3.2. Adaptive Case Classification Technique
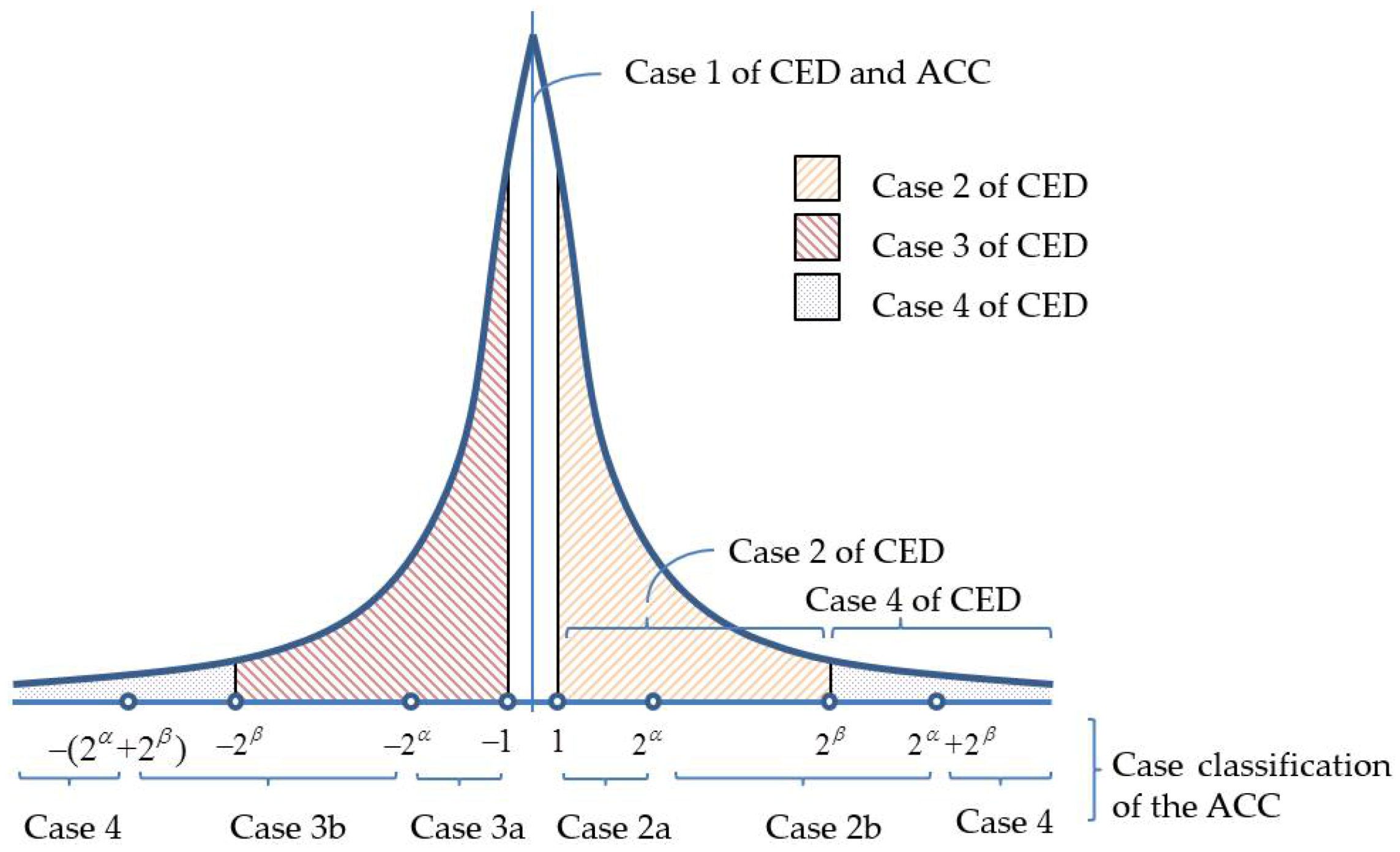
In Hong et al.’s CED technique [18], the encoding of a prediction error, , is classified into four cases. If (case 2), is encoded by a plus a two-bit indicator. Therefore, a total of bits are required to encode a case-2 prediction error. Figure 2 shows a typical prediction error histogram, and the distribution has a sharp peak at zero and decays exponentially towards two sides. The prediction errors fall in case 2 of [18] is shaded by ![Symmetry 10 00254 i001]() and each requires bits to record its value. However, the occurring frequencies of prediction errors in the range of vary significantly. Within this range, the occurring frequency is the highest at , in general, and decreases exponentially towards . Therefore, the recording of prediction errors using bits in this range with unbalanced frequencies is likely to increase the bitrate. The encoding of case 3 prediction errors, used in [18], also had similar problems.
and each requires bits to record its value. However, the occurring frequencies of prediction errors in the range of vary significantly. Within this range, the occurring frequency is the highest at , in general, and decreases exponentially towards . Therefore, the recording of prediction errors using bits in this range with unbalanced frequencies is likely to increase the bitrate. The encoding of case 3 prediction errors, used in [18], also had similar problems.
 and each requires bits to record its value. However, the occurring frequencies of prediction errors in the range of vary significantly. Within this range, the occurring frequency is the highest at , in general, and decreases exponentially towards . Therefore, the recording of prediction errors using bits in this range with unbalanced frequencies is likely to increase the bitrate. The encoding of case 3 prediction errors, used in [18], also had similar problems.
and each requires bits to record its value. However, the occurring frequencies of prediction errors in the range of vary significantly. Within this range, the occurring frequency is the highest at , in general, and decreases exponentially towards . Therefore, the recording of prediction errors using bits in this range with unbalanced frequencies is likely to increase the bitrate. The encoding of case 3 prediction errors, used in [18], also had similar problems.We propose an adaptive case classification (ACC) technique to better classify the encoding cases. By dividing cases 2 and 3 used in the CED technique into sub-cases, the overall encoding efficiency can be significantly increased. Let x be the to-be-encoded elements and p be the prediction value of x using the MED predictor. The prediction error, e, can be calculated by . Similar to the CED, the ACC classifies into case 1, and no bits are required to record the prediction errors. Case 2 in the proposed ACC technique is sub-divided into case 2a () and case 2b (), where and () are the number of bits used to record the prediction errors of cases 2a and 2b, respectively. Similarly, case 3a () and case 3b () are the subcases of case 3, and the ACC respectively uses and bits to record the prediction errors of these two cases. Finally, case 4 occurs when or . In this case, we directly record the eight-bit binary representation of x. We use two- or three-bit indicators to indicate the encoding cases. The indicator used for each case, the associated ranges of prediction errors, and the corresponding code length (exclude the secret data) are shown in Table 1.
The advantages of using the ACC over the CED technique are as follows. When , bits are required to record the prediction errors in the CED technique. However, the ACC technique only requires bits plus one extra bit to distinguish the sub-case. As a result, the ACC technique saves bits if . When , both techniques require bits to record the prediction errors. However, the ACC technique requires one more bit to distinguish the sub-case. When , the CED technique requires eight bits to record the prediction errors whereas the ACC technique requires only bits. Therefore, in this range, the ACC technique saves bits. Although the analyses above are focused on case 2 of Hong et al.’s CED technique, the results also hold for case 3 in their method since the prediction error histograms are often symmetrically distributed.
Since all of the prediction errors can be obtained by pre-scanning the transformed means and differences, the bitrate can be pre-estimated prior to the encoding and embedding processes. Therefore, the best parameters, denoted by and , that minimize the bitrate can be simply obtained by varying their values within a small range while pre-estimating the bitrate. According to our experiments, setting and is sufficient to obtain the best values. Figure 3 shows the effect of the proposed ACC technique applied on the Lena image with and . In this figure, the red dots and red circles represent that the proposed method saves and bits when recording the prediction errors, respectively. In contrast, the blue cross marks represents that one more bit is required in the proposed ACC technique to record the prediction errors. As shown in this figure, the number of red dots and circles is significantly more than that of blue cross marks, indicating that the ACC technique indeed effectively reduces the bitrate.
3.3. The Embedding Procedures
In this section, we describe the embedment of secret data, S, in detail. Let be the AMBTC codes to be embedded. An empty array, CS, is initialized to store the code stream. The MED predictor described in Section 2.2 is employed to predict the visited elements. The step-by-step embedding procedures are listed as follows.
- Step 1:
- Transform the quantization levels, and , into means, , and differences, , using the RIT technique, as described in Section 3.1.
- Step 2:
- Visit and sequentially, and use the ACC technique described in Section 3.2 to find the best and values, such that the estimated code length is minimal.
- Step 3:
- Convert the elements in the first row and the first columns of and to their eight-bit binary representations. The converted results are appended to the CS.
- Step 4:
- Scan the rest elements in using the raster scanning order and use the MED predictor (Equation (1)) to predict scanned . Let be the prediction value and calculate the prediction error .
- Step 5:
- Extract n-bit secret data, , from S. In accordance with , one of the four encoding cases is applied:
- Case 1:
- If , the bits ||00 are append to the code stream, CS.
- Case 2:
- If , append the bits, ||010||, to the CS, where is the binary representation of y. If , append ||011|| to the CS.
- Case 3:
- If , append the bits, ||100||, to the CS. If , append ||101|| to the CS.
- Case 4:
- If or , append the bits, ||11||, to the CS.
- Step 6:
- Repeat Steps 4–5 until all means, , are encoded.
- Step 7:
- Use the same procedures listed in Steps 4–6 to encode the differences, , and append the encoded result to the CS.
- Step 8:
- Append the bitmap, , to the CS, to construct the final code stream, .
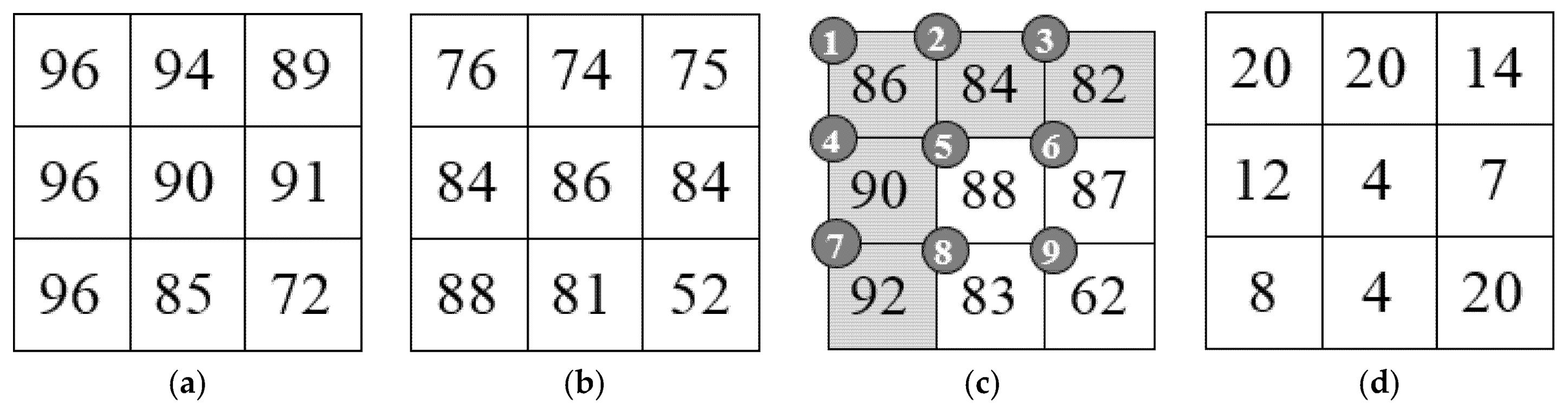
We use a simple example to illustrate the embedding procedures of the proposed method. Suppose the AMBTC codes consist of upper and lower quantization levels, as shown in Figure 4a,b, respectively. Let = ‘10111001’ be the secret data and suppose , . Firstly, we convert the quantization levels into means, , and differences, , using Equation (2). The converted results are shown in Figure 4c,d.
To encode the means and embed S, convert the elements in the first row and the first column (elements numbered 1, 2, 3, 4, and 7) of are converted to their eight-bit binary representations. In this example, we only focus on the encoding of elements , , , and (the elements numbered 5, 6, 8, and 9). To encode , we use Equation (1) to predict and obtain the prediction value, . Therefore, we have the prediction error, , which is classified into case 1, and the associated indicator is . Two bits, , are extracted from S, and and the case 1 indicator are concatenated, to obtain the codes for the fifth element, 10||00. The prediction value, , of is 86, and thus, . Since , case 2a should be applied to encode . The third and fourth bits, , are extracted from S, and , the case 2a indicator ‘010’ and the bits binary representation of are concatenated, giving 11||010||00. To encode , since and , we have to use case 3b to encode . is extracted from S, and , the case 3b indicator ‘101’, and the binary representation of are concatenated, giving 10||101||0010. Finally, since the prediction value of is , we have , which is categorized as case 4. Therefore, the encoded result of is 01||11||00111110. The coded results of , , , and are concatenated and the code stream 1000||1101000||101010010||011100111110 is obtained. The code stream of can be encoded using the similar manner, but the detailed steps for this are omitted in this example.
3.4. The Extraction and Recovery Procedures
Once the receiver has the final code stream, , the embedding parameters, , , and n, the embedded secret data, S, can be extracted, and the original AMBTC codes, , can be recovered. The detailed extraction and recovery procedures are listed as follows.
- Step 1:
- Prepare empty arrays , , , , and S for storing the reconstructed lower quantization levels, upper quantization levels, means, differences, and secret data, respectively.
- Step 2:
- Read eight bits sequentially from and convert them into integers. Place the converted integers in the first row and the first column of .
- Step 3:
- Read the next n bits from and append them to S.
- Step 4:
- Visit the unrecovered means, , in using the raster scanning order. Use Equation (1) to predict , and obtain the prediction value, .
- Step 5:
- Read the next two bits, , from , and use the following rules to recover :
- Case 1:
- If ‘00’, .
- Case 2:
- If ‘01’, read the next bit, , from . If = ‘0’, read the next bits, , from . The mean, , is recovered by , where represents the decimal value of bitstream y. If = ‘1’, read the next bits from . The mean, , is recovered.
- Case 3:
- If ‘10’, read the next bit, , from . If = ‘0’, read the next bits, , from . The mean, , is recovered by . If = ‘1’, read the next bits, , from . The mean, , is recovered.
- Case 4:
- If = ‘11’, read the next eight bits from , and the mean,, is recovered.
- Step 6:
- Perform Steps 3–5 until all the means are recovered.
- Step 7:
- Recover the differences and extract data bits embedded in . The procedures are similar to Steps 2–6.
- Step 8:
- Extract the remaining bits in and rearrange them to obtain . Transform and into and using Equation (3); the original AMBTC codes, , can be reconstructed.
We continue the example given in Section 3.3 to illustrate the procedures of the extraction of S and the recovery of the quantization levels. Suppose the first row and the first column of the means have been recovered (see Figure 4c), and the code stream, CS, to be decoded is 1000||1101000||101010010||011100111110. The first two bits, = ‘10’, are read from CS and placed in an empty array S. The MED predictor is used to predict ; we have . The next two bits are ‘00’, and thus, the prediction error is . Therefore, . The next two bits, ‘11’, are read and appended to S. The next two bits, ‘01’, are read from CS, and the next bit read is ‘0’. Therefore, is encoded using case 2a. The next bits, = ‘00’, are read from CS; we have . Since , we have . The next two bits are read from CS and appended to S. Because the next three bits from CS are ‘101’, is encoded using case 3b. The next bits, = ‘0010’, are read from CS; we have . Therefore, , where is obtained using the MED predictor. Finally, two bits, ‘01’, are read from CS and appended to S. The next two bits are ‘11’, and thus, can be obtained by converting the next eight bit to its decimal representation; we have Therefore, the means, , can be recovered (Figure 4c). Similarly, the differences, , can also be recovered (Figure 4d). Finally, according to Equation (3), the original upper and lower quantization levels can be recovered from and . The recovered quantization levels are shown in Figure 4a,b.
4. Experimental Results
In this section, we conduct several experiments and compare the results with some other state-of-the-art works to evaluate the performance of the proposed method. Six grayscale images shown in Figure 5, including Lena, Tiffany, Jet, Peppers, Stream, and Baboon, were used as the test images to generate the AMBTC codes. These images can be obtained from [24].
The peak signal-to-noise ratio (PSNR) metric was used to measure the quality of AMBTC compressed image. To make a fair comparison, the pure bitrate, , metric, which is defined by
was used to measure the embedding performance, where and are the length of final code stream, , and secret data, S, respectively. In fact, the pure bitrate measures the number of bits required to record a pixel in the original image. Therefore, this metric should be as low as possible.
4.1. Performance Evaluation of the Proposed Method
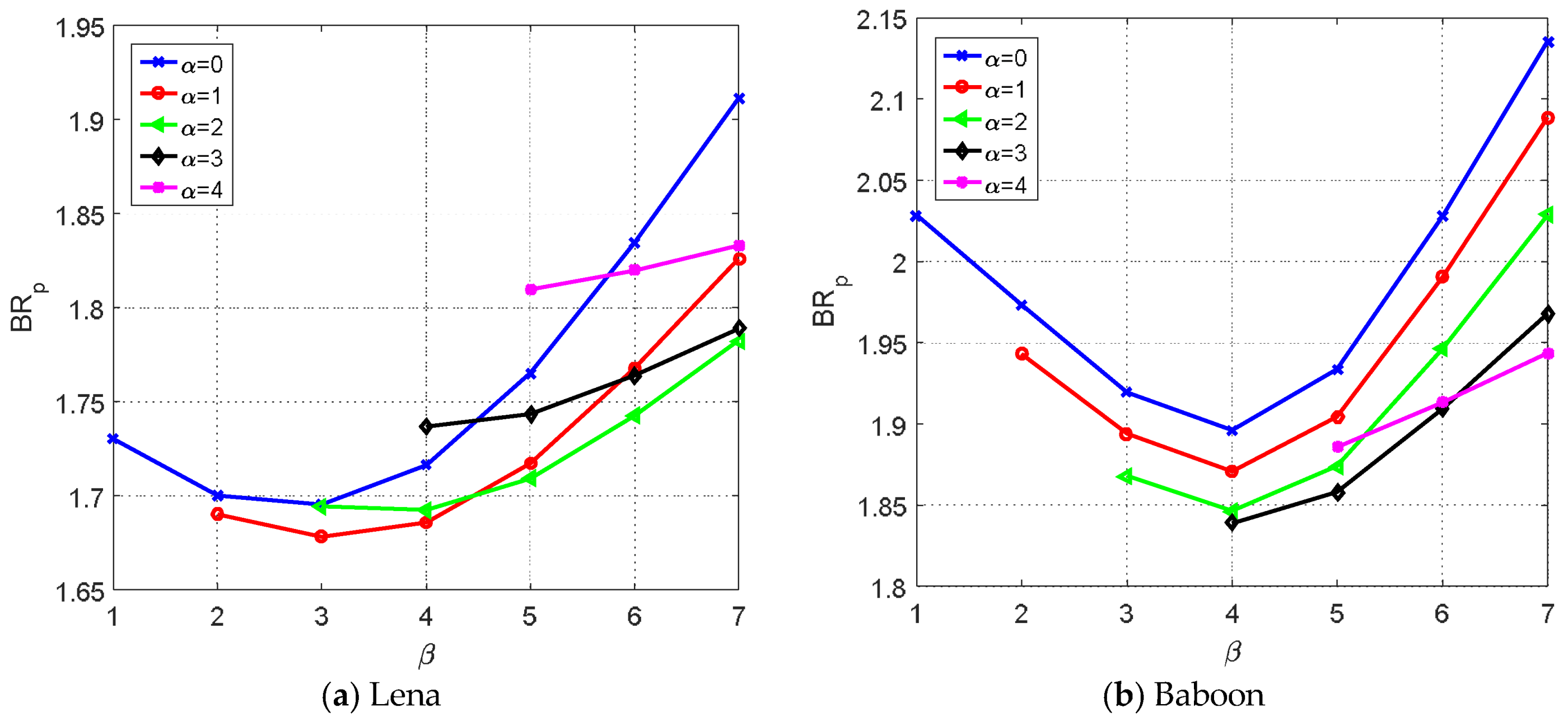
Figure 6a,b shows the pure bitrate, , versus parameter under various for the Lena and Baboon images. As seen from the figures, setting and for the Lena image achieved the lowest bitrate. However, and had to be set for the Baboon image to achieve the best result. This is because the prediction error histogram of the Lena image is sharper than that of the Baboon image, forcing the ACC technique to select smaller and values. In contrast, the prediction error histogram of the Baboon image is flatter than that of the Lena image, and thus larger and are selected.
Table 2 gives the best and values for the six test images. Notice that the values of and tended to be smaller for smooth images than those of complex images.
The proposed method classifies prediction errors into four encoding cases, and each case requires a different number of bits to record the prediction error. Figure 7 shows the distributions of these cases when the ACC technique is applied on the transformed means with and . In this figure, the red circles, blue crosses, green dots, and black squares representing the corresponding means are encoded using case 1, 2a or 3a, 2b or 3b, and 4, respectively.
Figure 7 shows that the smooth parts of the Lena images are filled with red circles and blue crosses, indicating that they are encoding using case 1, 2a, or 3a. The texture areas or edges of the Lena image are filled with black squares, meaning that the complex parts of the Lena image are encoded by case 4. It is interesting to note that most of the green dots are in the vicinity of the black squares. This indicates that the areas occupied by the green dots are less complex than those of black squares and thus, the corresponding means are encoded by case 2b or 3b.
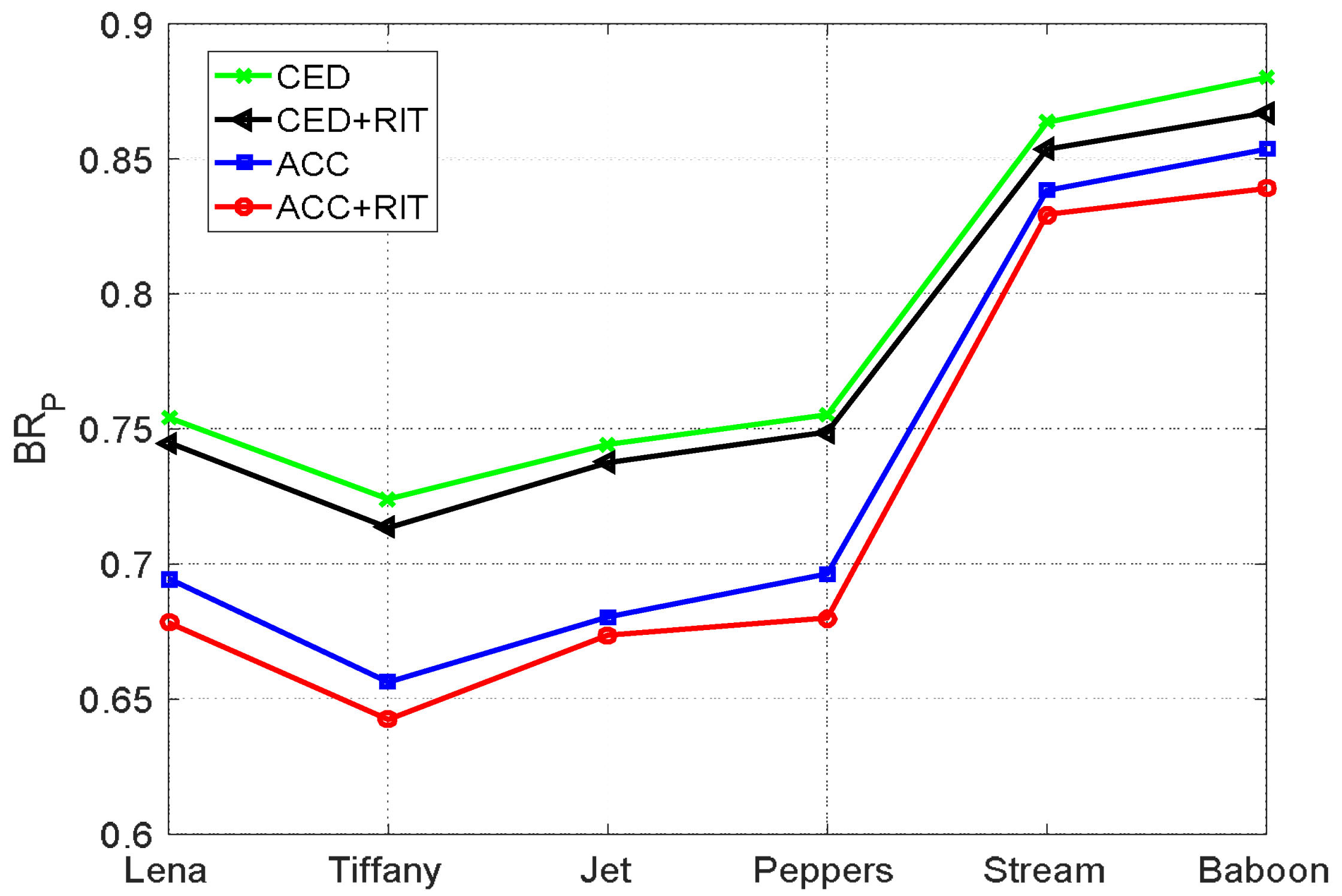
The proposed method uses the RIT technique to convert quantization levels into means and differences, and the ACC technique is then applied to encode the transformed values. To see how these two techniques affect the encoding performance, the pure bitrate is plotted in Figure 8 for all test images under various combinations of techniques. In this figure, the lines labeled ‘CED’ indicate that the CED technique with was applied on the prediction errors obtained from predicting the quantization levels. In contrast, ‘CED + RIT’ represents that the CED was applied on the prediction errors obtained from the proposed RIT technique. The line labeled ‘ACC’ indicates that the ACC technique was applied on the two quantization levels, and ‘ACC + RIT’ is the result when both ACC and RIT techniques have been applied. For the ACC technique, the best and listed in Table 2 were used.
As seen from Figure 8, the bitrate obtained by the ‘CED’ method was the largest. When the CED together with the RIT technique was applied, all the bitrates of the six test images were reduced, meaning that the transformed means and differences are more suitable for predictive coding than the original quantization levels. However, when the ACC technique was applied on the quantization levels, the reduction in bitrate was more significant, indicating that the ACC technique reduces the bitrate considerably. The best result was achieved when both ACC and RIT techniques were applied. It is interesting to note that the improvement of smooth images is more significant than that of complex images when using the proposed ‘ACC + RIT’ technique. The reason for this is that the proposed method saves bits when the predication errors are categorized as case 2a or 3a but requires one additional bit when they are categorized as case 2b or 3b. Since the prediction errors categorized as case 2a or 3a are more frequent in smooth images than complex images, we can infer that the proposed method works better for smooth images.
4.2. Comparison with Other Works
In this section, we compare some related works that have been published recently, including Zhang et al.’s [16], Sun et al.’s [17], Hong et al.’s [18], and Chang et al.’s [19] methods. In Zhang et al.’s method, eight cases for coding the differences are implemented to achieve the best result. In Sun et al.’s and Hong et al.’s methods, the best embedding parameters are set to obtain the lowest bitrate, as suggested in their original paper. In Chang et al.’s method, the exclusive OR operation is employed to generate the prediction errors. In the proposed method, the best and that minimize the bitrate are selected for embedment. All the settings used ensured that the best performance could be achieved for each compared method. The results are shown in Table 3.
In Table 3, the PSNR metric measured the image quality of AMBTC compressed images. The payload was designed such that each quantization level carried two data bits, apart from methods that can only carry one bit per quantization level (e.g., Zhang et al.’s method). The embedding efficiency is defined by , which indicates how many secret data bits can be carried per bit of code stream. Therefore, the larger the embedding efficiency, the better the performance is. We also compared the pure bitrate for all the methods. The results show that the proposed method achieves the highest embedding efficiency with the lowest pure bitrate. This is due to the subtly transformation of the quantization levels into means and differences, and the performance of predictive coding together with the ACC technique on the transformed domain. In contrast, the other compared methods all perform the prediction on the original quantization level, and the encoding cases are not adaptively designed. Therefore, their achieved pure bitrates are higher than that of the proposed method.
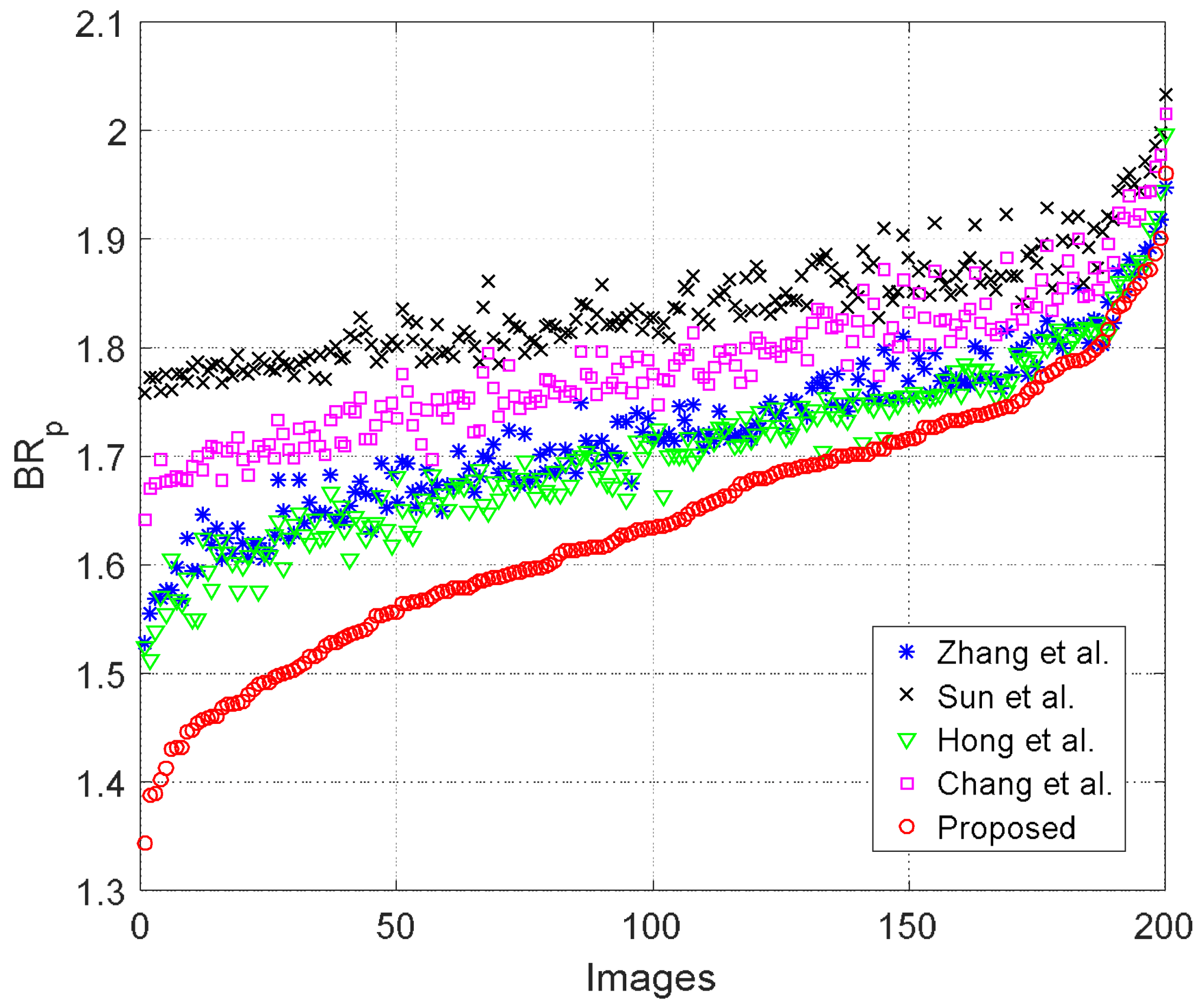
To further evaluate the performance, we also performed the test on 200 grayscale images with a size of obtained from [25]. To make a better comparison, we obtained the pure bitrate of each method, and sorted the pure bitrates obtained by the proposed method in ascending order. The bitrates of other compared methods were then rearranged using the sorted order of the proposed method. The results are shown in Figure 9.
Since the pure bitrate of a smooth image is lower than that of a complex one, we can surmise that the images on the left-hand side are smoother than the right-hand side images. As seen from Figure 9, the reduction in pure bitrate was more significant for smooth images than complex ones. Nevertheless, the proposed method offered the lowest pure bitrate for all of the 200 test images, indicating that the proposed RIT and ACC techniques are indeed more efficient than other state-of-the-art works.
5. Conclusions
In this paper, we proposed an efficient data hiding method for AMBTC compressed images. The quantization levels were first transformed into means and differences. The adaptive classification technique was then applied to classify the prediction errors into four cases with two sub-cases to efficiently encode the prediction errors. Because the classification range is determined by the distribution of prediction errors, the size of the resultant code stream was effectively reduced. The experimental results show that the proposed method not only successfully recovers the original AMBTC codes and extracts the embedded data, but also provides the lowest bitrate when compared to other state-of-the-art works.
Author Contributions
W.H. conceived the overall idea of this article and wrote the paper, X.Z. proposed the main idea of the embedding technique, carried out the experiments, and analyzed the data. S.W. proofread the manuscript and authenticated the data set.
Acknowledgments
This work was supported in part by National NSF of China (No. 61201393, No. 61571139), New Star of Pearl River on Science and Technology of Guangzhou (No. 2014J2200085).
Conflicts of Interest
The authors declare no conflict of interest.
References
- Hong, W.; Chen, T.S. A Novel Data Embedding Method Using Adaptive Pixel Pair Matching. IEEE Trans. Inf. Forensics Secur. 2012, 7, 176–184. [Google Scholar] [CrossRef]
- Liu, Y.; Chang, C.C.; Huang, P.C.; Hsu, C.Y. Efficient Information Hiding Based on Theory of Numbers. Symmetry 2018, 10, 19. [Google Scholar] [CrossRef]
- Xie, X.Z.; Lin, C.C.; Chang, C.C. Data Hiding Based on A Two-Layer Turtle Shell Matrix. Symmetry 2018, 13, 47. [Google Scholar] [CrossRef]
- Hong, W.; Chen, T.S.; Chen, J. Reversible Data Hiding Using Delaunay Triangulation and Selective Embedment. Inf. Sci. 2015, 308, 140–154. [Google Scholar] [CrossRef]
- Chen, J. A PVD-Based Data Hiding Method with Histogram Preserving Using Pixel Pair Matching. Signal Process. Image Commun. 2014, 29, 375–384. [Google Scholar] [CrossRef]
- Chen, H.; Ni, J.; Hong, W.; Chen, T.S. High-Fidelity Reversible Data Hiding Using Directionally-Enclosed Prediction. IEEE Signal Process. Lett. 2017, 24, 574–578. [Google Scholar] [CrossRef]
- Lee, C.F.; Weng, C.Y.; Chen, K.C. An Efficient Reversible Data Hiding with Reduplicated Exploiting Modification Direction Using Image Interpolation and Edge Detection. Multimedia Tools Appl. 2017, 76, 9993–10016. [Google Scholar] [CrossRef]
- Tian, J. Reversible Data Embedding Using a Difference Expansion. IEEE Trans. Circuits Syst. Video Technol. 2003, 13, 890–896. [Google Scholar] [CrossRef]
- Ni, Z.; Shi, Y.Q.; Ansari, N.; Su, W. Reversible Data Hiding. IEEE Trans. Circuits Syst. Video Technol. 2006, 16, 354–362. [Google Scholar]
- Chen, J.; Hong, W.; Chen, T.S.; Shiu, C.W. Steganography for BTC Compressed Images Using No Distortion Technique. Image Sci. J. 2010, 58, 177–185. [Google Scholar] [CrossRef]
- Chang, C.C.; Kieu, T.D.; Wu, W.C. A Lossless Data Embedding Technique by Joint Neighboring Coding. Pattern Recognit. 2009, 42, 1597–1603. [Google Scholar] [CrossRef]
- Kieu, D.; Rudder, A. A Reversible Steganographic Scheme for VQ Indices Based on Joint Neighboring and Predictive Coding. Multimedia Tools Appl. 2016, 75, 13705–13731. [Google Scholar] [CrossRef]
- Lin, C.C.; Liu, X.L.; Yuan, S.M. Reversible Data Hiding for VQ-Compressed Images Based on Search-Order Coding and Sate-Codebook Mapping. Inf. Sci. 2015, 293, 314–326. [Google Scholar] [CrossRef]
- Chang, C.C.; Liu, X.L.; Lin, C.C.; Yuan, S.M. A High-Payload Reversible Data Hiding Scheme Based on Histogram Modification in JPEG Bitstream. Imaging Sci. J. 2016, 7, 364–373. [Google Scholar]
- Hong, W. Efficient Data Hiding Based on Block Truncation Coding Using Pixel Pair Matching Technique. Symmetry 2018, 10, 36. [Google Scholar] [CrossRef]
- Zhang, Y.; Guo, S.Z.; Lu, Z.M.; Luo, H. Reversible Data Hiding for BTC-Compressed Images Based on Lossless Coding of Mean Tables. IEICE Trans. Commun. 2013, 96, 624–631. [Google Scholar] [CrossRef]
- Sun, W.; Lu, Z.M.; Wen, Y.C.; Yu, F.X.; Shen, R.J. High Performance Reversible Data Hiding for Block Truncation Coding Compressed Images. Signal Image Video Process. 2013, 7, 297–306. [Google Scholar] [CrossRef]
- Hong, W.; Ma, Y.; Wu, H.C.; Chen, T.S. An Efficient Reversible Data Hiding Method for AMBTC Compressed Images. Multimedia Tools Appl. 2017, 76, 5441–5460. [Google Scholar] [CrossRef]
- Chang, C.C.; Chen, T.S.; Wang, Y.K.; Liu, Y. A Reversible Data Hiding Scheme Based on Absolute Moment Block Truncation Coding Compression Using Exclusive OR Operator. Multimedia Tools Appl. 2018, 77, 9039–9053. [Google Scholar] [CrossRef]
- Lema, M.; Mitchell, O. Absolute Moment Block Truncation Coding and Its Application to Color Image. IEEE Trans. Commun. 1984, 32, 1148–1157. [Google Scholar] [CrossRef]
- Hong, W.; Chen, M.; Chen, T.S.; Huang, C.C. An Efficient Authentication Method for AMBTC Compressed Images Using Adaptive Pixel Pair Matching. Multimedia Tools Appl. 2018, 77, 4677–4695. [Google Scholar] [CrossRef]
- Chen, T.H.; Chang, T.C. On The Security of A BTC-Based-Compression Image Authentication Scheme. Multimedia Tools Appl. 2017, 77, 12979–12989. [Google Scholar] [CrossRef]
- Malik, A.; Sikka, G.; Verma, H.K. An AMBTC Compression Based Data Hiding Scheme Using Pixel Value Adjusting Strategy. Multidimensional Syst. Signal Process. 2017, 1–18. [Google Scholar] [CrossRef]
- The USC-SIPI Image Database. Available online: http://sipi.usc.edu/database (accessed on 29 March 2018).
- BOWS-2 Image Database. Available online: http://bows2.gipsa-lab.inpg.fr (accessed on 29 March 2018).
Figure 1.
Comparison of the distribution of prediction errors.

Figure 2.
Case classification of centralized error division (CED) and the proposed adaptive case classification (ACC).
Figure 2.
Case classification of centralized error division (CED) and the proposed adaptive case classification (ACC).

Figure 3.
Bit-saving comparisons of the ACC and CED techniques.

Figure 4.
Quantization levels and transformed means and differences. (a) Upper quantization levels; (b) Lower quantization levels; (c) Means and (d) Differences.
Figure 4.
Quantization levels and transformed means and differences. (a) Upper quantization levels; (b) Lower quantization levels; (c) Means and (d) Differences.

Figure 5.
Six test images.

Figure 6.
Comparisons of pure bitrate under various combinations of and .

Figure 7.
The distribution of encoding cases for the Lena image.

Figure 8.
Pure bitrate comparisons of combinations of techniques.

Figure 9.
Pure bitrate comparison of 200 test images.


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Table 1.
Indicators and the range of cases.
| Case | Indicator | Range of Prediction Errors | Code Length | |
|---|---|---|---|---|
| case 1 | ‘00’ | 2 | ||
| case 2 | case 2a | ‘010’ | ||
| case 2b | ‘011’ | |||
| case 3 | case 3a | ‘100’ | ||
| case 3b | ‘101’ | |||
| case 4 | ‘11’ | or | ||
Table 2.
The combination of and to achieve the lowest bitrates.
| Images | Lena | Tiffany | Jet | Peppers | Stream | Baboon |
|---|---|---|---|---|---|---|
| (1,3) | (1,3) | (1,3) | (1,3) | (3,4) | (3,4) | |
| 1.68 | 1.64 | 1.67 | 1.68 | 1.83 | 1.84 |
Table 3.
Comparisons with other works.
| Metric | Methods | Lena | Tiffany | Jet | Peppers | Stream | Baboon |
|---|---|---|---|---|---|---|---|
| PSNR | 33.24 | 35.77 | 31.97 | 33.42 | 28.59 | 26.98 | |
| Payload | [16] | 32,768 | 32,768 | 32,768 | 32,768 | 32,768 | 32,768 |
| [17] | 64,008 | 64,008 | 64,008 | 64,008 | 64,008 | 64,008 | |
| [18] | 64,516 | 64,516 | 64,516 | 64,516 | 64,516 | 64,516 | |
| [19] | 64,008 | 64,008 | 64,008 | 64,008 | 64,008 | 64,008 | |
| Proposed | 64,516 | 64,516 | 64,516 | 64,516 | 64,516 | 64,516 | |
| Embedding Efficiency | [16] | 0.066 | 0.067 | 0.066 | 0.065 | 0.062 | 0.063 |
| [17] | 0.116 | 0.118 | 0.116 | 0.116 | 0.111 | 0.112 | |
| [18] | 0.123 | 0.125 | 0.124 | 0.123 | 0.117 | 0.116 | |
| [19] | 0.118 | 0.121 | 0.119 | 0.118 | 0.112 | 0.113 | |
| Proposed | 0.128 | 0.130 | 0.128 | 0.128 | 0.119 | 0.118 | |
| Pure Bitrate | [16] | 1.77 | 1.75 | 1.76 | 1.79 | 1.88 | 1.87 |
| [17] | 1.86 | 1.82 | 1.86 | 1.86 | 1.95 | 1.94 | |
| [18] | 1.75 | 1.72 | 1.74 | 1.76 | 1.86 | 1.88 | |
| [19] | 1.82 | 1.78 | 1.80 | 1.83 | 1.94 | 1.92 | |
| Proposed | 1.68 | 1.64 | 1.67 | 1.68 | 1.83 | 1.84 |
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
MDPI and ACS Style
Hong, W.; Zhou, X.; Weng, S. Joint Adaptive Coding and Reversible Data Hiding for AMBTC Compressed Images. Symmetry 2018, 10, 254. https://doi.org/10.3390/sym10070254
AMA Style
Hong W, Zhou X, Weng S. Joint Adaptive Coding and Reversible Data Hiding for AMBTC Compressed Images. Symmetry. 2018; 10(7):254. https://doi.org/10.3390/sym10070254
Chicago/Turabian StyleHong, Wien, Xiaoyu Zhou, and Shaowei Weng. 2018. "Joint Adaptive Coding and Reversible Data Hiding for AMBTC Compressed Images" Symmetry 10, no. 7: 254. https://doi.org/10.3390/sym10070254
Note that from the first issue of 2016, this journal uses article numbers instead of page numbers. See further details here.