1. Introduction
Time series forecasting methods are quantitative techniques that analyze historical data of a variable for predicting its values. Traditional forecasting methods [
1,
2,
3,
4,
5,
6,
7] use statistical techniques to estimate the future trend of a variable starting from numerical datasets. Many time series data contain seasonal patterns that have regular, repetitive and predictable changes that happen sequentially in a period of time which could be a year, a season, a month, a week, etc.
Different approaches have been developed to deal with trend and seasonal time series. Traditional approaches, such the moving average method, additive and multiplicative models, Holt-Winters exponential smoothing, etc. [
3,
4,
5,
7], use statistical methods for removing the seasonal components: they decompose the series into trend, seasonal, cyclical and irregular components [
8]. Other statistical approaches are based on the Box–Jenkins model, called Autoregressive Integrated Moving Average (ARIMA) [
3,
5,
7,
9]. In the first phase of ARIMA, an auto-correlation analysis is performed for verifying if the series is non-stationary. Then, the series is transformed into a stationary series formed by the differences between the value at the actual moment and the value at the previous moment.
The main limitation of the seasonal ARIMA model is the fact that the process is considered to be linear. Many soft computing models have been presented in the literature for capturing nonlinear characteristics in seasonal time series, e.g., Support Vector Machine (SVM) [
10,
11] used for wind speed prediction [
12], air quality forecasting [
13], and rainfall forecasting [
14]. SVM utilizes a kernel function to transform the input variables into a multi-dimensional feature space, and then the Lagrange multipliers are used for finding the best hyperplane to model the data in the feature space. The main advantage of an SVM method is that that the solution is unique and there are no risk to move towards local minima, but some problems remain as the choice of the kernel parameters which influences the structure of the feature space, affecting the final solution. Another method is based on an Artificial Neural Network (ANN) [
8,
15,
16,
17]. The most widely used ANN architectures for forecasting problems are given by multi-layer Feed Forward Network (FNN) architectures [
18,
19], where the input nodes are given by the successive observations of the time series; that is, target
yt is a function of the values
yt−1,
yt−2, …,
yt−p, where
p is the number of input nodes.
A variation of FNN is the Time Lagged Neural Network (TLNN) architecture [
20,
21], where the input nodes are the time series values at some particular lags. For example, in a time series having the month as seasonal period, the neural network used for forecasting the parameter value at the time
t can contain input nodes corresponding to the lagged values at the time
t − 1,
t − 2, ..,
t − 12. The key point is that an ANN can be considered a nonlinear auto-regression model. ANNs are inherently nonlinear and can accurately model complex characteristics in data patterns with respect to linear approaches such as ARIMA models. One of the main problems in the ANN forecasting models is the selection of appropriate network parameters. This operation is crucial since it strongly affects the final results. Furthermore, the presence of a high number of network parameters in the model can produce overtraining of data, giving rise to incorrect forecasting solutions.
To reduce the problems present in the SVM and ANN approaches, some authors have recently developed some hybrid models, e.g., genetic algorithms and tabu search (GA/TS) [
11] and the Modified Firefly Algorithm (MFA).
In [
22], a Discrete Wavelet Transform (DWT) algorithm is used to decompose the time series into linear and nonlinear components. Afterwards, the ARIMA and the ANN models are used to forecasting separately the two components.
In [
23], the authors present four seasonal forecasting models: an adaptive ANN model that uses a genetic algorithm for evolving the ANN topology and the back-propagation parameter called ADANN (Automatic Design of Artificial Neural Networks), a SVM seasonal forecasting model and two hybrid ANN and SVM models based on linguistic fuzzy rules. The authors compare the four methods with the traditional ARIMA method, showing that the results under the four methods are comparable with the ones obtained using ARIMA. The best results are obtained by using the ADANN algorithm based on linguistic fuzzy rules but ANN-based methods are complex to manage and require more computational effort.
Various fuzzy modeling approaches are proposed in literature and applied in different fields for data analysis and knowledge exploring (for examples, see [
24,
25,
26,
27]).
To overcome the high computational complexity and the heavy dependence on the input parameters of the ANN models, a soft computing forecasting method based on fuzzy transforms [
28] (for short, F-transforms) is presented in [
29]. This method was applied to the North Atlantic Oscillation (NAO) data time series. The results are better than the ones obtained using the well known Wang–Mendel method [
30] and Local Linear Wavelet Neural Network (LLWNN) techniques.
F-transforms are a powerful flexible method to be applied in various domains such as image compression [
31], detection of attribute dependencies in data analysis [
32] and extraction of the trend cycle of time series [
33].
Strictly speaking, in [
29], a forecasting index is calculated with respect to the data of the training set: if this index is smaller than or equal to an assigned threshold, the algorithm is stopped; otherwise, it is iterated by taking a finer fuzzy partition of the variable domain.
When a fuzzy partition is settled, the algorithm controls that the training dataset is sufficiently dense with respect to the fuzzy partition; that is, each fuzzy set of the fuzzy partition has at least a non-zero membership degree in some point.
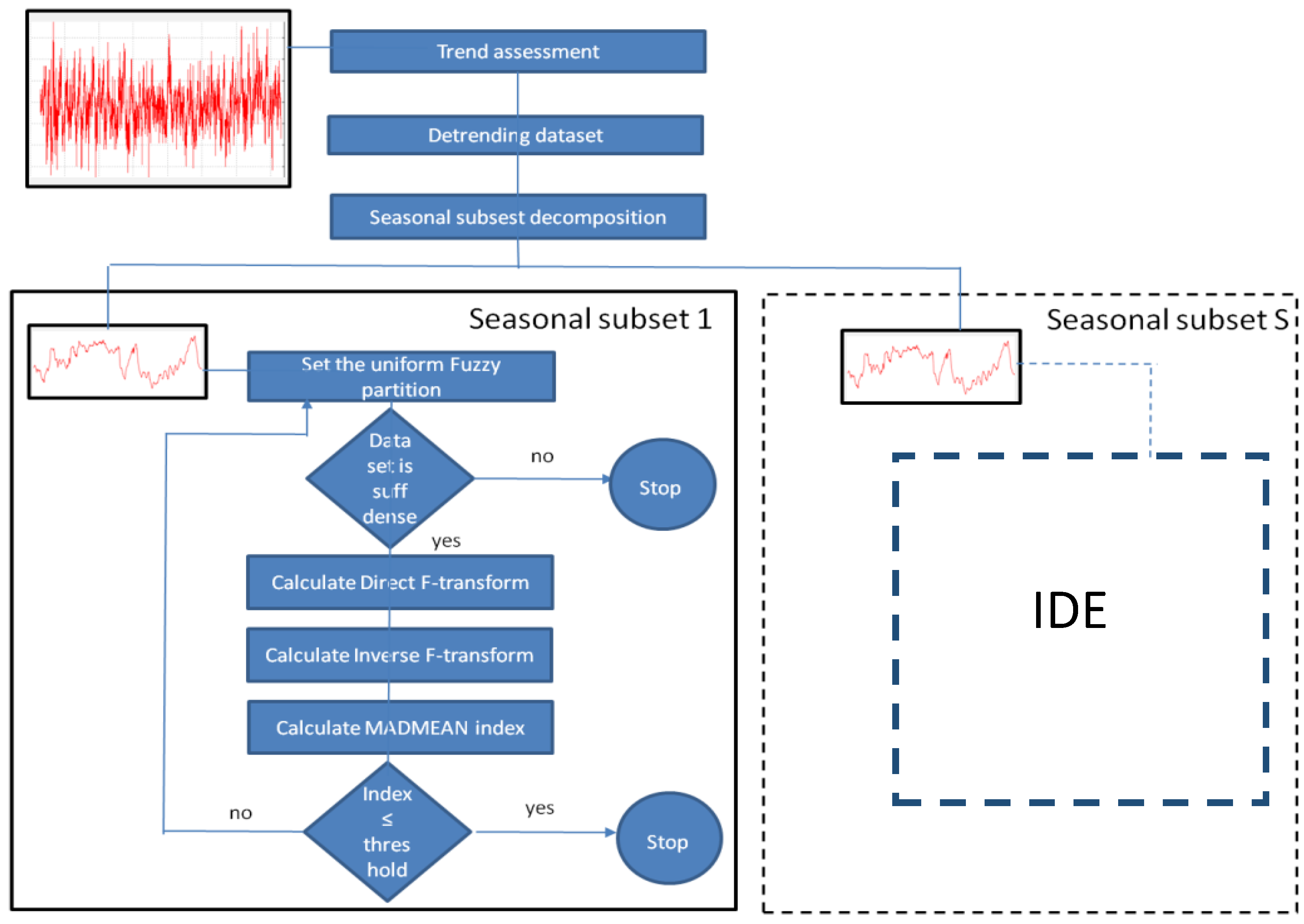
Here, we give a forecasting method based on F-transforms for seasonal time series analysis called Time Series Seasonal F-transform (TSSF). We give a partition of the time series dataset into seasonal pattern components. A seasonal pattern is related to a fixed period of the time series fluctuations: the seasonality is set on a fixed period such as year, month, week, etc. In the TSSF model, we assume that the different components affect the time series. We use the best polynomial fit for estimating the trend of the time series. After de-trending the data by subtracting the trend from the time series dataset, we find a fuzzy partition of the dataset into seasonal subsets to which we apply the F-transforms by checking that the chosen partition is optimal for the density of the training data. In [
29,
32], the authors have developed this process: in particular, four forecasting indexes are proposed for assessing the quality of the results: Mean Absolute Deviation (MAD), Mean Absolute Percentage Error (MAPE), Root Mean Square Error (RMSE) and Mean Absolute Deviation Mean (MADMEAN). An optimal fuzzy partition is found by calculating the corresponding RMSE and MADMEAN: if at least one of the two indices does not exceed a respective threshold, then the process stops and the given fuzzy partition is considered optimal.
1.1 TSSF Method for Forecasting Analysis
In the TSSF method, we essentially adopt the same procedure, but we prefer to use the MADMEAN index because this index is more robust than other forecasting indexes, as proven in [
34]. We emphasize that the dimension of the optimal fuzzy partition can vary with the seasonal subset. In
Figure 1, the TSSF method is synthetized in detail.
In the assessment phase, the best polynomial fit is applied for determining the trend in the training data. After de-trending the dataset, the time series is decomposed into S seasonal subsets to which the F-transform forecasting iterative method is applied. Initially, a coarse grained uniform fuzzy partition is fixed. If the subset is not sufficiently dense with respect to the fuzzy partition, the F-transform sub-process applied on the seasonal subset stops, else the MADMEAN index is calculated and, if it is greater than an assigned threshold, the F-transform sub-process is iterated considering a finer uniform fuzzy partition. The output is given by the inverse F-transforms obtained for each seasonal subset at the end of the corresponding sub-process.
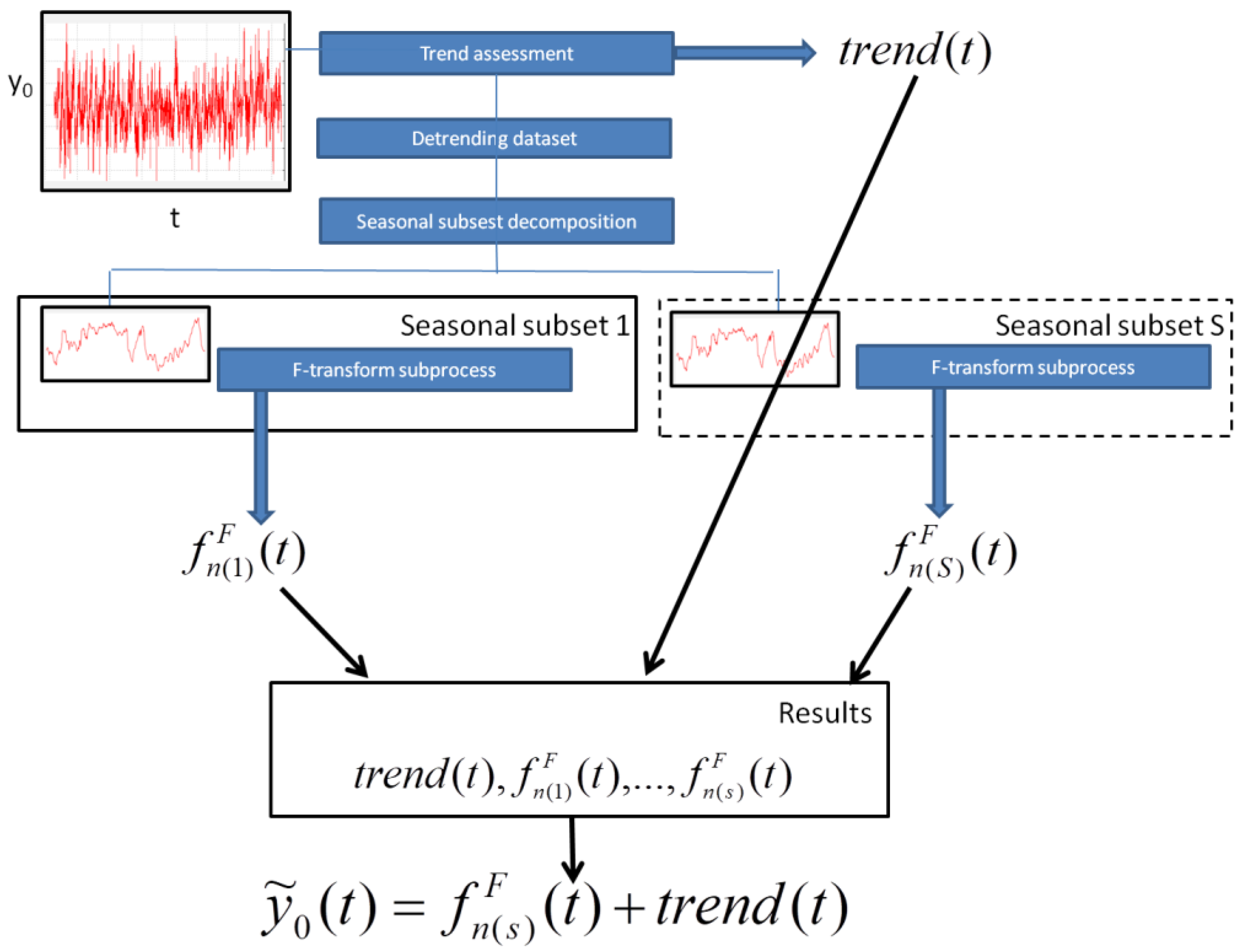
To forecast a value of a parameter
y0 at the time
t, we calculate the
sth seasonal subset of cardinality
n(
s), in which the time
t is inserted. Then, we consider the
sth inverse F-transform
. The forecasted value of the parameter is given by the formula
, where
trend(
t) is the value of the polynomial trend at the time
t.
Figure 2 illustrates the application of the TSSF for forecasting analysis.
For sake of completeness, we recall the concept of F-transform in
Section 2.
Section 3 contains the F-transform-based prediction method. In
Section 4, we describe our TSSF method applied on the climate dataset of Naples (Italy) (
www.ilmeteo.it/portale/archivio-meteo/Napoli) whose results are given in
Section 5 that contain also comparisons with average seasonal variation, ARIMA and the traditional prediction F-transform methods.
Section 6 reports the conclusions.
2. Direct and Inverse F-Transform
Following the definitions and notations of [
28], let
n ≥ 2 and
x1,
x2, …,
xn be points of [
a,
b], called nodes, such that
x1 =
a <
x2 < … <
xn =
b. The family of fuzzy sets
A1, …,
An: [
a,
b] → [0,1], called basic functions, is a fuzzy partition of [
a,
b] if the following hold:
- -
Ai(xi) = 1 for every i =1,2, …,n;
- -
Ai(x) = 0 if x [xi−1,xi+1] for i = 2, …,n − 1;
- -
Ai(x) is a continuous function on [a,b];
- -
Ai(x) strictly increases on [xi−1, xi] for i = 2, …, n and strictly decreases on [xi,xi+1] for i = 1, …, n − 1;
- -
A1(x) +…+ An(x) = 1 for every x [a,b].
The fuzzy sets {A1(x),…,An(x)} form an uniform fuzzy partition if n ≥ 3 and xi = a + h∙(i − 1), where h = (b − a)/(n − 1) and i = 1, 2, …, n (that is the nodes are equidistant);
- -
Ai(xi − x) = Ai(xi + x) for every x [0,h] and i = 2, …, n − 1;
- -
Ai+1(x) = Ai(x − h) for every x [xi, xi+1] and i = 1,2, …, n − 1.
Here, we are only interested in the discrete case, i.e., for functions
f defined on the set
P of points
p1, ...,
pm of [
a,
b]. If
P is sufficiently dense with respect to the given partition {
A1,
A2, …,
An}, i.e., for each
i {1,…,
n} there exists an index
j {1,…,m} such that
Ai(
pj) > 0, we define {
F1,
F2, …,
Fn} as the discrete direct F-transform of
f with respect to {
A1,
A2, …,
An}, where
Fi is given by
for
i = 1, …,
n. Similarly we define the discrete inverse F-transform of
f with respect to {
A1, A
2, …,
An} by setting
for every
j {1, …,
m}. We can extend the above concepts to functions in
k (≥2) variables. In the discrete case, we assume that the function
f(
x1,
x2, …,
xk) is defined on m points
pj = (
pj1,
pj2, …,
pjk)
[
a1,
b1] × [
a2,
b2] × … × [
ak,
bk] for
j = 1,…,
m. We say that
P = {(
p11,
p12, …,
p1k), …, (
pm1,
pm2, …,
pmk)} is sufficiently dense with respect to the fuzzy partitions
of [
a1,
b1], …, [
ak,
bk], respectively, if for each k-tuple {
h1, …,
hk}
{1, …,
n1} × … × {1, …,
nk}, there exists a point
pj = (
pj1,
pj2, …,
pjk) in
P,
j = 1, …,
m, such that
.
In this case, we define the (
h1,
h2,…,
hk)-
th component
of the discrete direct F-transform of
f with respect to the basic Function (3) as
Now, we define the discrete inverse F-transform of
f with respect to the Function (3) to be the following function by setting for each point
pj = (
pj1,
pj2,…,
pjk)
[
a1,
b1] × … × [
ak,
bk]:
for
j = 1, …,
m. The following theorem holds [
28]:
Theorem 1. Let f(x1,x2,…,xk) be given on the set of points P = {(p11,p12, …, p1k) ,(p21, p22, …, p2k), …,(pm1, pm2, …, pmk)} [a1,b1] × [a2,b2] × … × [ak,bk]. Then, for every ε > 0, there exist k integers n1 = n1(ε), …, nk = nk(ε) and k related fuzzy partitions (3) of [a1,b1], …, [ak,bk], respectively, such that the set P is sufficiently dense with respect to them and for every pj = (pj1, pj2, …, pjk) in P, j = 1, …, m, the following inequality holds: 3. F-Transform Forecasting Method
We now describe the F-transform forecasting algorithm presented in [
29]. Let
M be assigned input–output pairs data (
x(j),
y(j)) in the following form:
for
j = 1, 2, …,
M. The task is to generate a fuzzy rule-set from the
M pairs (
x(j),
y(j)) to determine a mapping
f from the input-space R
n into the output-space R. We assume that the
lie in
for every
i = 1, …, n, and
y(1),
y(2), …,
y(M) in [
y−,
y+]. The F-transform forecasting method calculates a function
, which approximates the data. Similar to in [
32], we create a partition of
ni fuzzy sets for each domain
, hence we construct the respective direct and inverse F-transforms (Equations (3) and (4)) to estimate an approximation of
f. We illustrate this forecasting method in the following steps:
- (1)
Give a uniform partition composed by
ni fuzzy sets (
ni ≥ 3)
of the domain
of each variable
xi,
i = 1, …,
n. If
are the nodes of each interval
, each function
Ais is defined in the following way for
s = 1, …,
ni:
where
,
,
and
.
- (2)
If the dataset is not sufficiently dense with respect to the fuzzy partition, i.e., if there exists a variable
xi and a fuzzy set
Ais of the corresponding fuzzy partition such that
for each
r = 1, …,
M, the process stops otherwise calculate the
n1∙
n2∙…∙
nk components of the direct F-transform of
f with Equation (3) by setting
k =
n,
, …,
and
, obtaining the following quantity:
- (3)
Calculate the discrete inverse F-transform as
to approximate the function
f.
- (4)
Calculate the forecasting index as
If Equation (11) is less or equal to an assigned threshold, then the process stops; otherwise, a finer fuzzy partition is taken and the process restarts from the step 2.
In [
29], four forecasting indices, RMSE, MAPE, MAD, MADMEAN, were proposed, but we prefer to use MADMEAN, which is the best one in terms of accuracy, as proven in [
34].
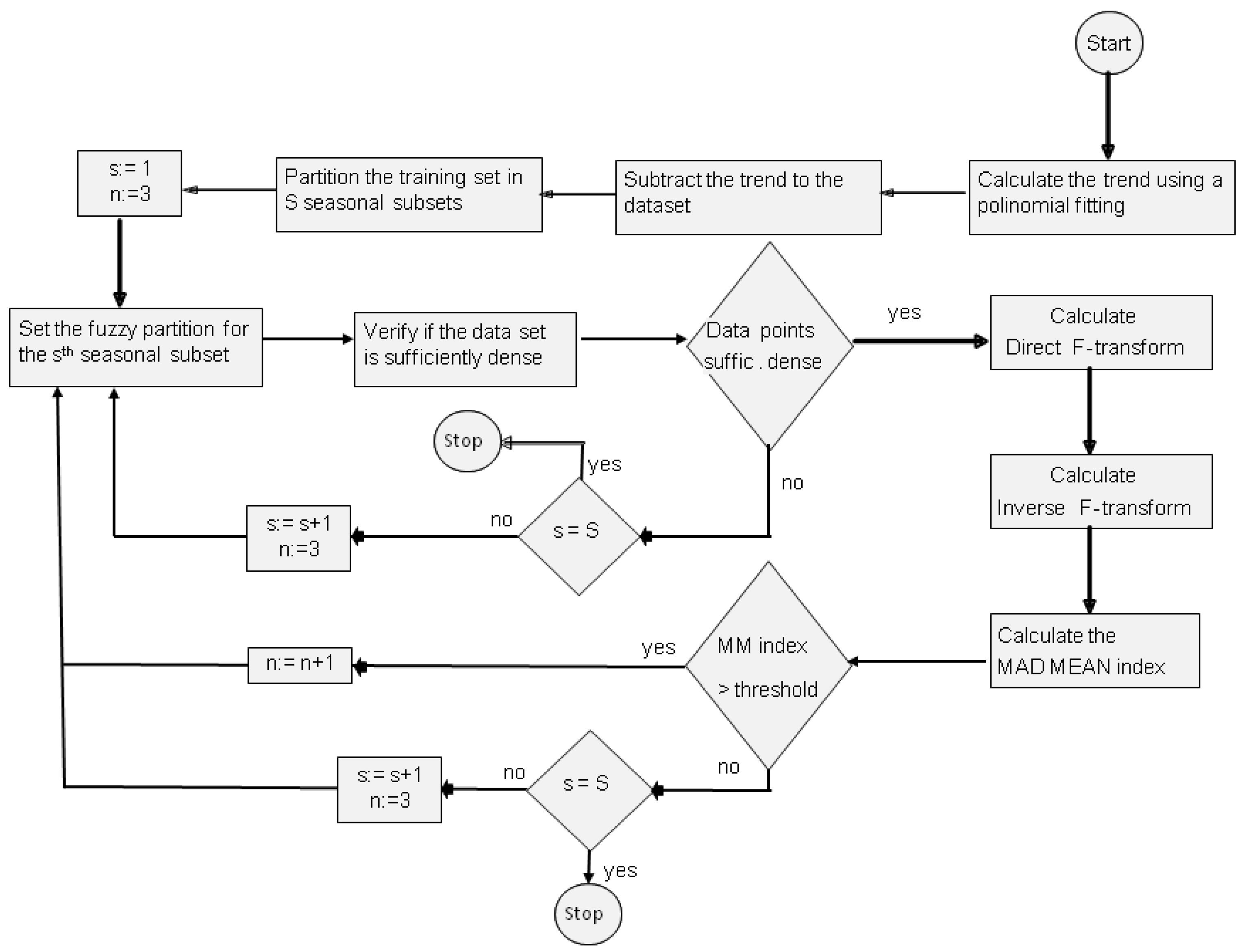
4. TSSF Method
We consider time series of data formed from observations of an original parameter y0 measured at different times. The dataset is formed by M measure pairs as .
Our aim is to evaluate seasonal fluctuations of a time series by using the F-transform method. First, we use a polynomial fitting for calculating the trend of the phenomenon with respect to the time. Afterwards, we subtract the trend from the data obtaining a new dataset of the fluctuations y(j), being . After de-trending the dataset, we use a partition into S subsets, being S considered as seasonal period. Each subset represents the seasonal fluctuation with respect to the trend.
The seasonal data subset is composed by
Ms pairs, expressing the fluctuation measures of the parameter
y0 at different times: (
t(1),
y(1)), (
t(2),
y(2)) .... (
t(Ms),
y(Ms)), where
y(j) is given by the original measure
at the time
t(j) minus the trend calculated at that time. The formulae of the corresponding one-dimensional directed and inverse F-transforms, considering
n basic functions, are given as
respectively. The inverse F-transform (13) approximates the seasonal fluctuation at the time
t. In our method, we start with three basic functions and verify that the subset of data is sufficiently dense with respect to this fuzzy partition. After calculating the directed and inverse F-transform with Equations (12) and (13), respectively, we calculate the (MADMEAN)
s index for the
sth fluctuation subset of data given as
If Equation (14) is greater than an assigned threshold, than the process is iterated considering a fuzzy partition of dimension
n:=
n + 1; otherwise, the iteration process stops. Our algorithm is illustrated in
Figure 3.
For the
sth fluctuation subset, we obtain the inverse F-transform by using the following
n(
s) basic functions:
For evaluating the value of the parameter
y0 at the time
t in the
sth seasonal period, we add to
the trend calculated at the time
t, i.e.,
trend(
t), obtaining the following value:
For evaluating the accuracy of the results, we can use the MADMEAN index given by
For sake of completeness, we describe also the values of the above-cited indices:
- -
Root Mean Square Error (RMSE) is defined as:
- -
Mean Absolute Percentage Error (MAPE) is defined as:
- -
Mean Absolute Deviation (MAD) is defined as:
The TSSF algorithm is schematized in
Appendix A. To evaluate the MADMEAN threshold, we consider a pre-processing phase in which we apply the
k-cross-validation technique to control the presence of over-fitting in the learning data. We set a seasonal subset and we apply a random partition in
k folds. The union of
k − 1 subsets is used as training set and the other subset is used as validation set. Then we consider a fuzzy partition with
n = 3 and apply Equation (17) to the training set calculating the MADMEAN index; then we apply Equation (18) to the validation test to calculate the RMSE index. We repeat this process for all the
k folds, obtaining the mean MADMEAN and RMSE indexes as
where MADMEAN(
n) and RMSE(
n) are the mean MADMEAN and RMSE using the fuzzy partition size
n, respectively.
We repeat this process using many values of n. Then, we plot in a graph the RMSE(n) by varying n. The threshold value is set as the mean MADMEAN obtained in correspondence of the value n for which there is a plateau in the RMSE graph.
In next section, we present the results of tests in which the TSSF algorithm is applied to seasonal time series. In our tests, we apply the pre-processing phase described below in which we partition the dataset in
k folds, setting
k = 10. Comparisons are pointed out with respect to ARIMA, the F-transform methods and SVM and ADANN proposed in [
23].
5. Experiments on Time Series Data
In a first experiment, we use a dataset composed from climate data (mean, maximum and minimum temperature, pressure, speed of the wind, etc., measured every day) of Naples (Italy) collected at the webpage:
www.ilmeteo.it/portale/archivio-meteo/Napoli. The following main climate parameters are measured every thirty minutes: Min temperature (°C), Mean temperature (°C), Max temperature (°C), Dew point (°C), Mean humidity (%), Mean view (km), Mean wind speed (km/h), Max wind speed (km/h), Gust of wind (km/h), Mean pressure on sea level (mb), Mean pressure (mb), and Millimeters of rain (mm).
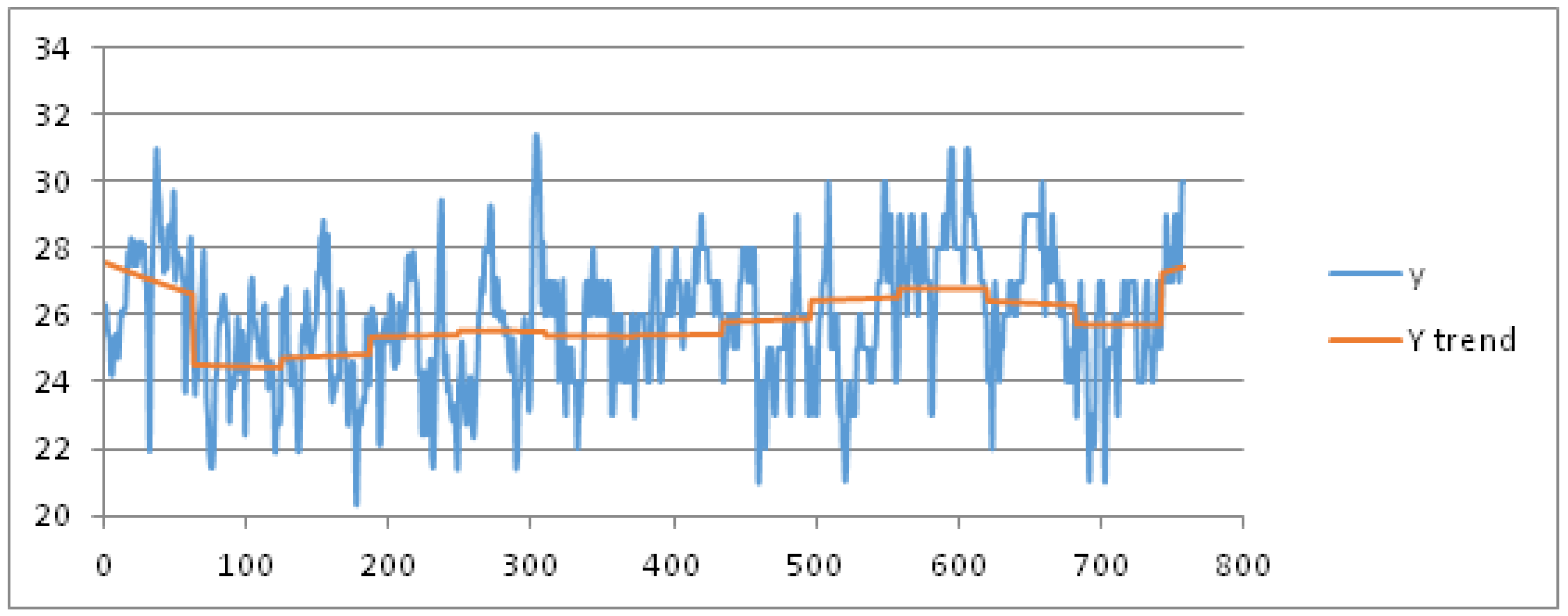
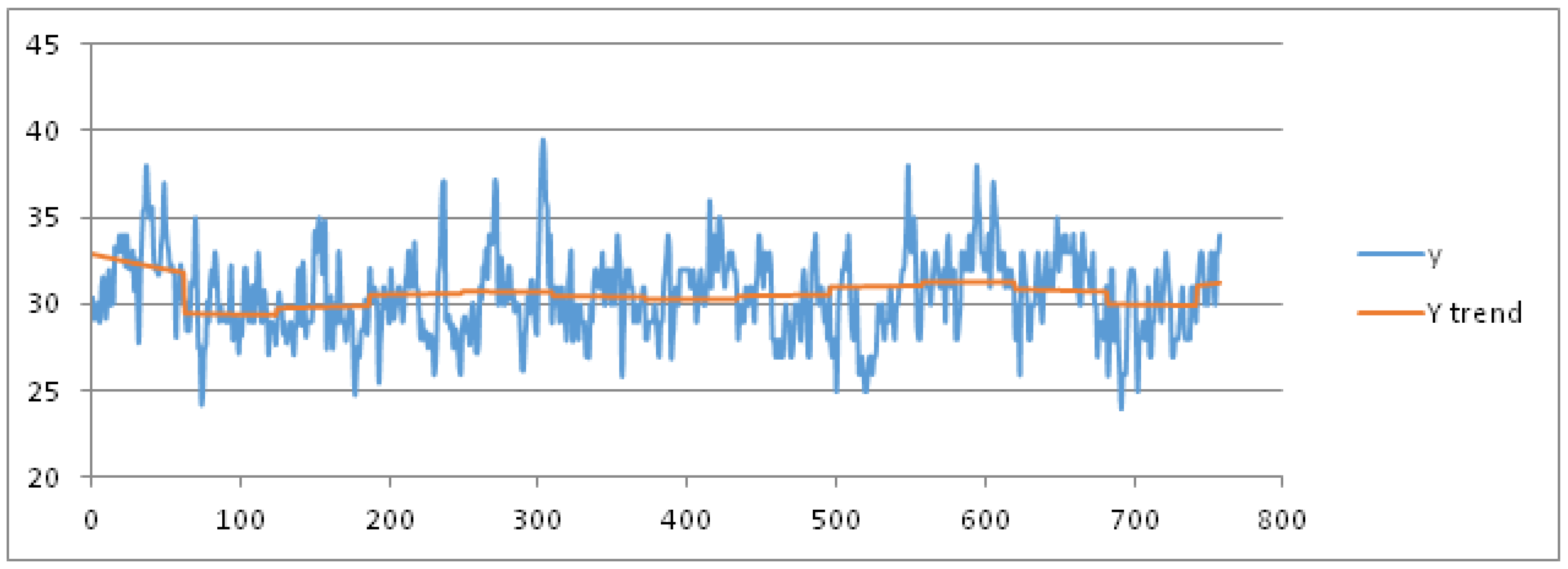
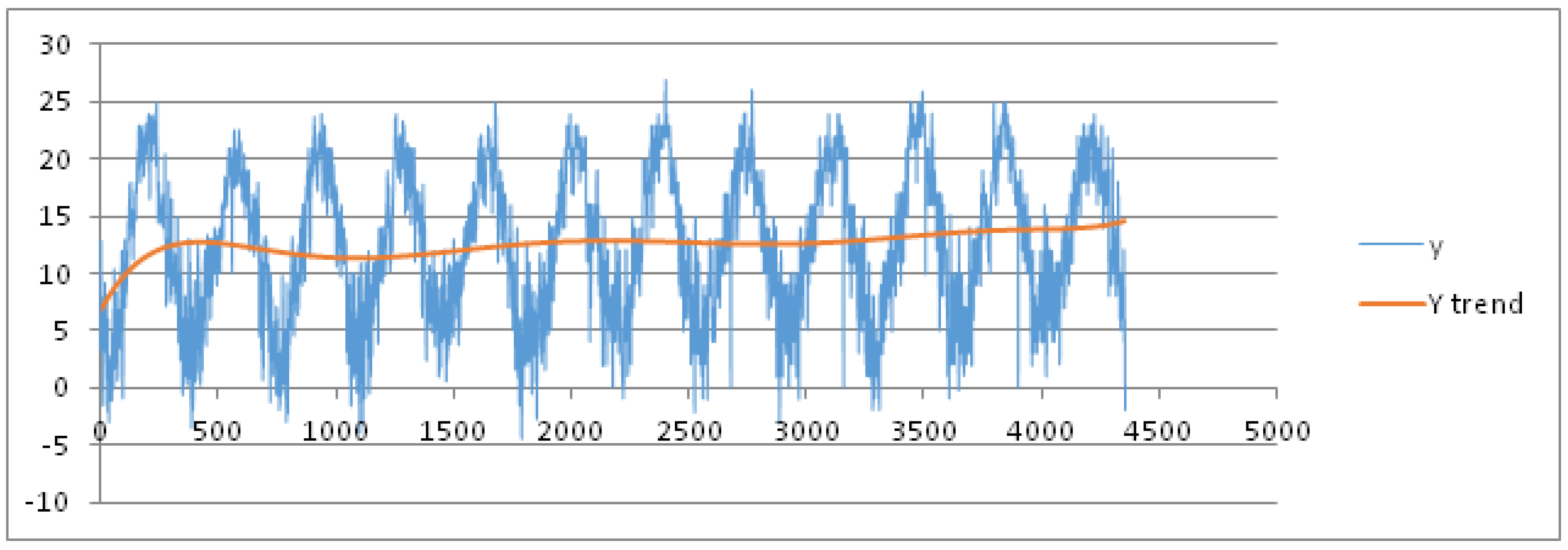
For sake of brevity, we limit the results for the parameters mean, max and min temperature. As training dataset, we consider these data recorded in the months July and August from 1 July 2003 to 16 August 2015, hence for 806 days represented as abscissas (via a number ID) in
Figure 4 and
Figure 5, respectively. The daily mean and max temperature is represented on the ordinate axis in
Figure 4 and
Figure 5, respectively. We obtain the best fit polynomial of nine degree (
) (red color in
Figure 4 and
Figure 5) whose coefficients are given in
Appendix B.
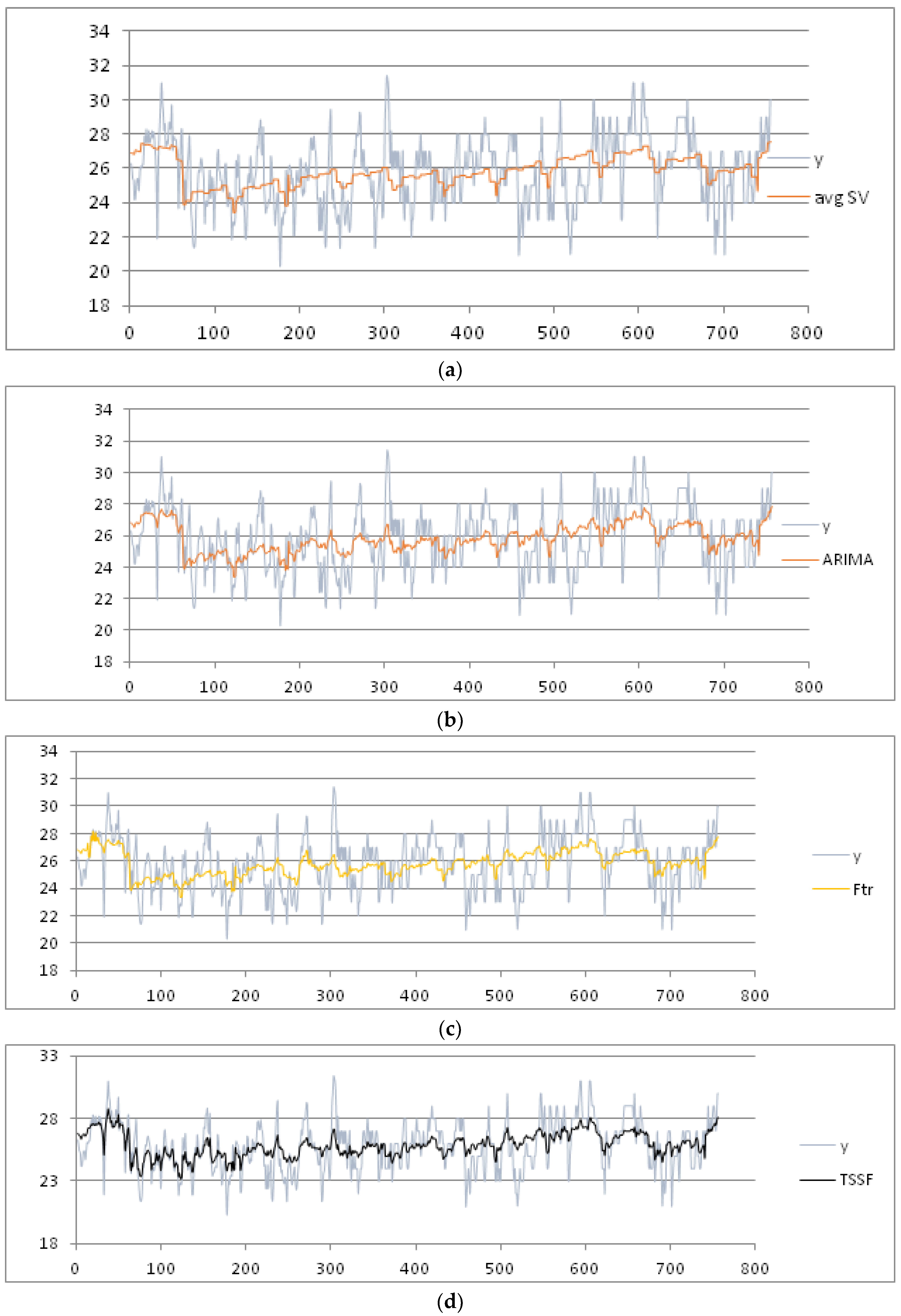
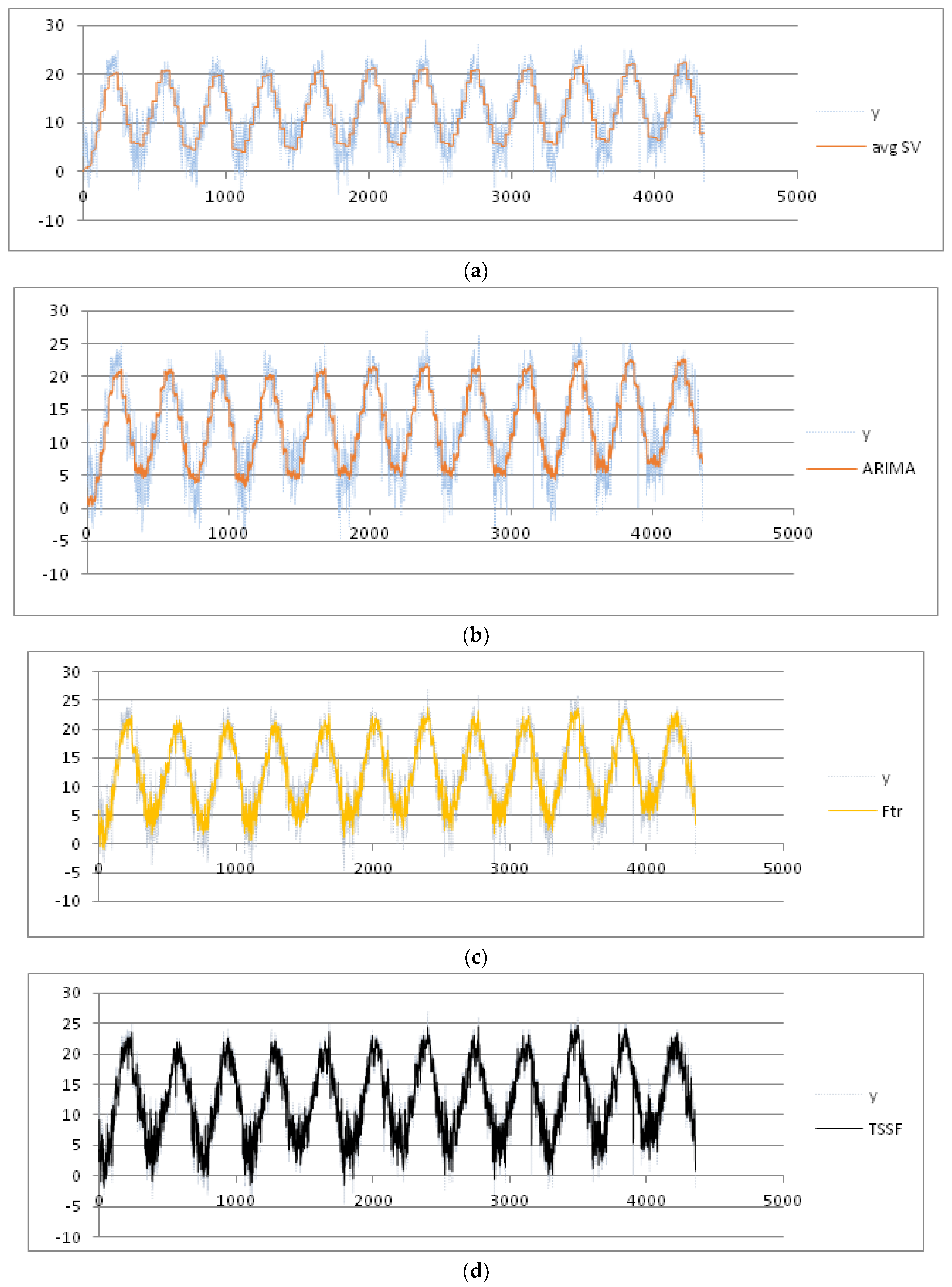
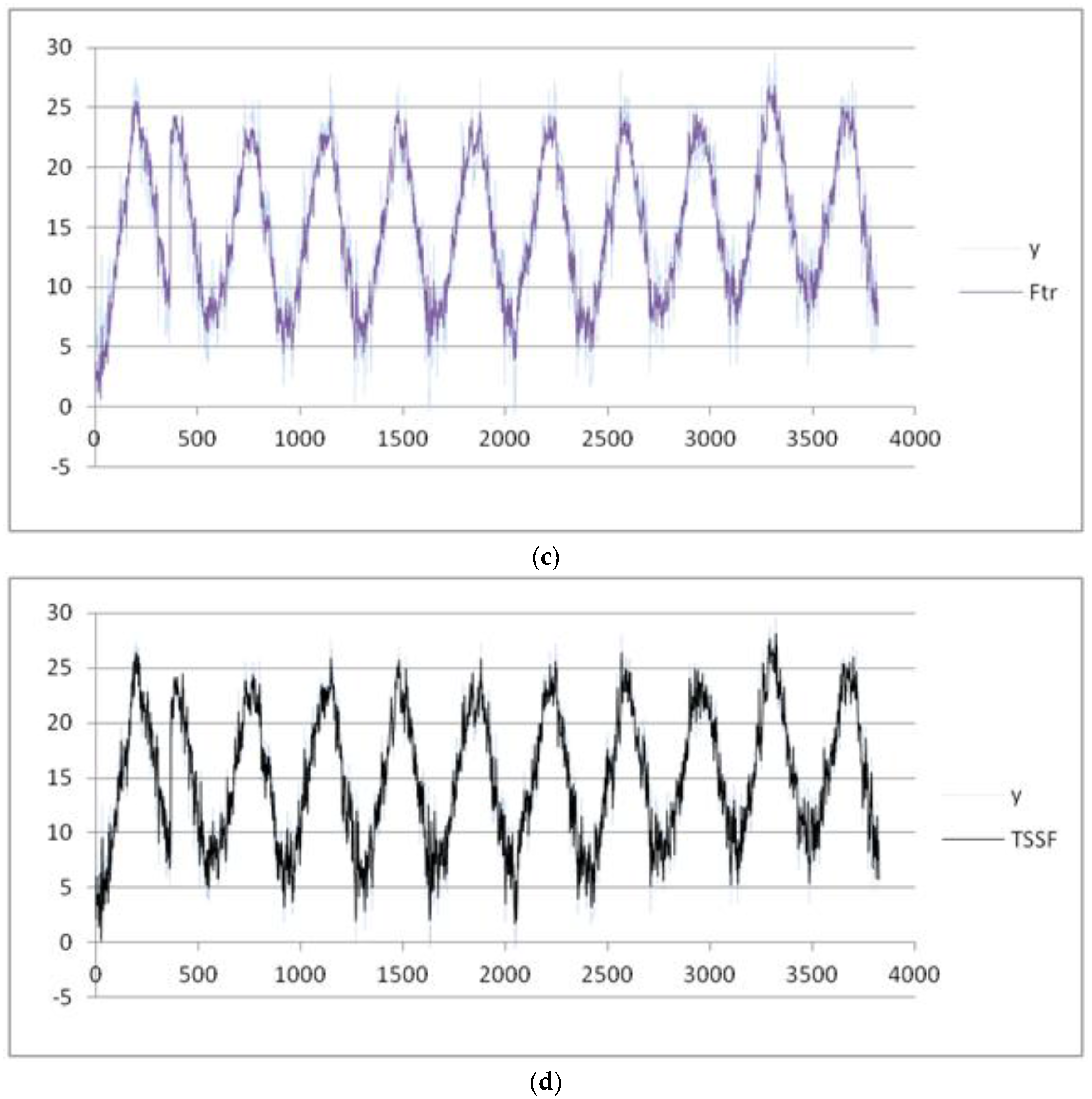
We consider the week as seasonal period, partitioning the data set into nine seasonal subsets: Week 27 (1 July) to Week 36 (31 August). After applying the pre-processing phase, we set the threshold of the MADMEAN index to the value 5. Then, we apply the TSSF algorithm to the daily mean and max temperature. We also give the results of the other three methods, plotted in
Figure 6a–d and
Figure 7a–d , respectively:
- (1)
Average seasonal variation method [
3] (labeled as avgSV): This method calculates the mean seasonal variation for each seasonal period and adds the mean seasonal variation to the trend value.
- (2)
Seasonal ARIMA method: In our experiments, we used the forecasting tool ForecastPro [
35]. As highlighted in [
23], this tool is well known for ensuring the best performance in the use of forecasting ARIMA models.
- (3)
F-transform prediction method [
29]: This is applied to the complete dataset (labeled as F-transforms).
In
Table 1, we show the four indices obtained using the four methods. The best results for the mean temperature are obtained using the TSSF method, with a MADMEAN of 4.22.
In
Table 2, we show the four indexes obtained using the four methods. The best results for the max temperature are obtained using TSSF, with a MADMEAN of 4.53.
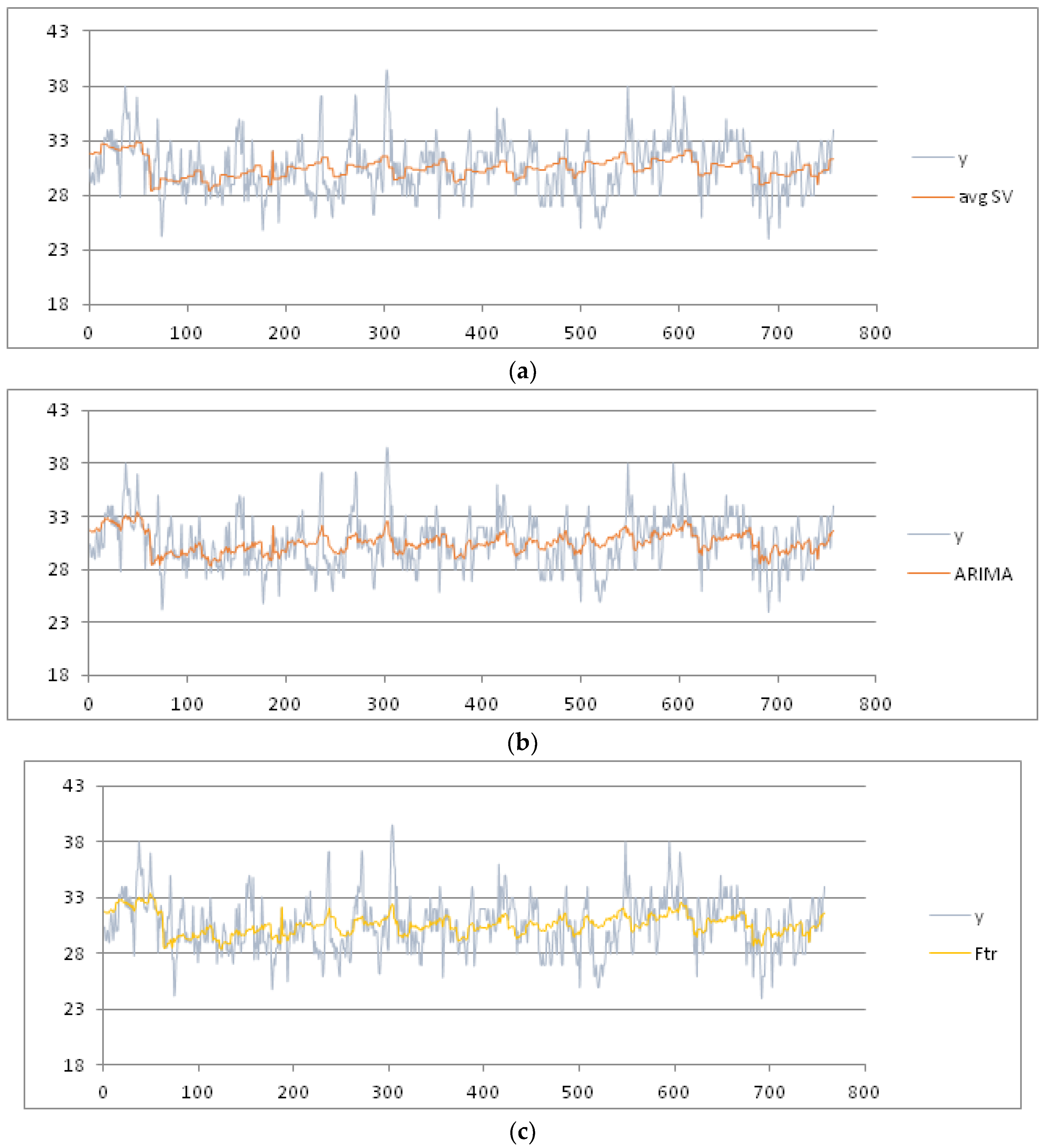
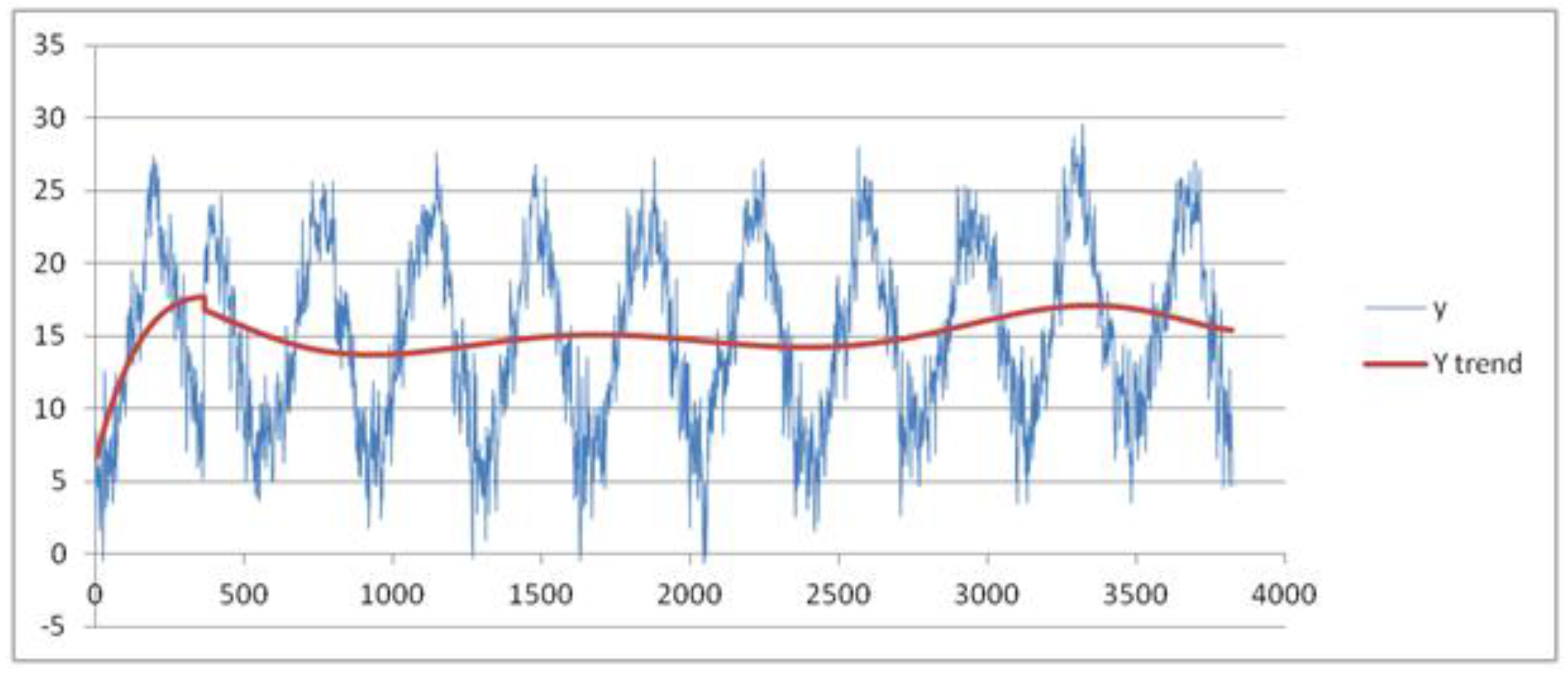
We now present the results of other experiments in which the variation of the min temperature is explored during the years. We assume the month as seasonal period: the training dataset is formed by all the measures recorded from 1 January 2003 to 31 December 2015. It is partitioned into 12 seasonal subsets corresponding to 12 months of a year. After applying the pre-processing phase, we set the threshold of the MADMEAN index to the value 6. In
Figure 8, we show the data and the trend obtained using a best fit polynomial of nine degree (see
Appendix A).
As we can observe in
Figure 8, the seasonality of the data seems to be more evident than in the two previous examples. In
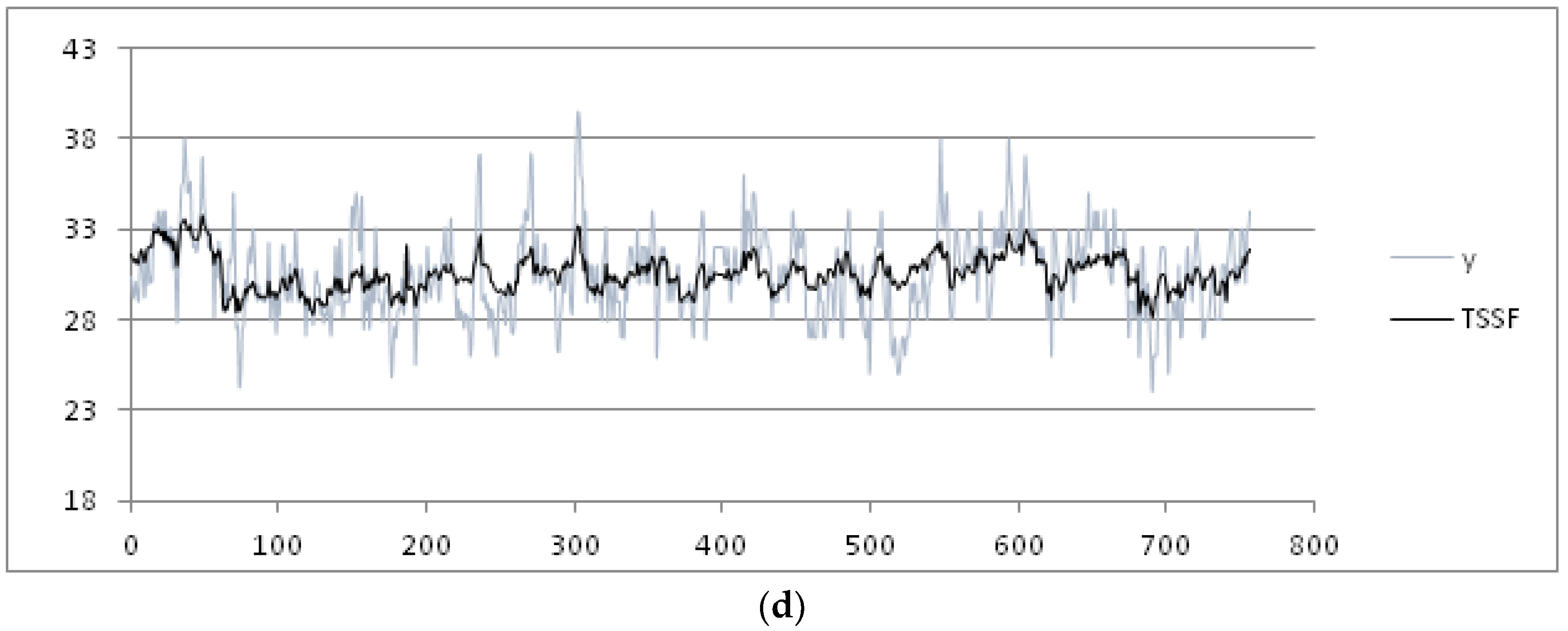
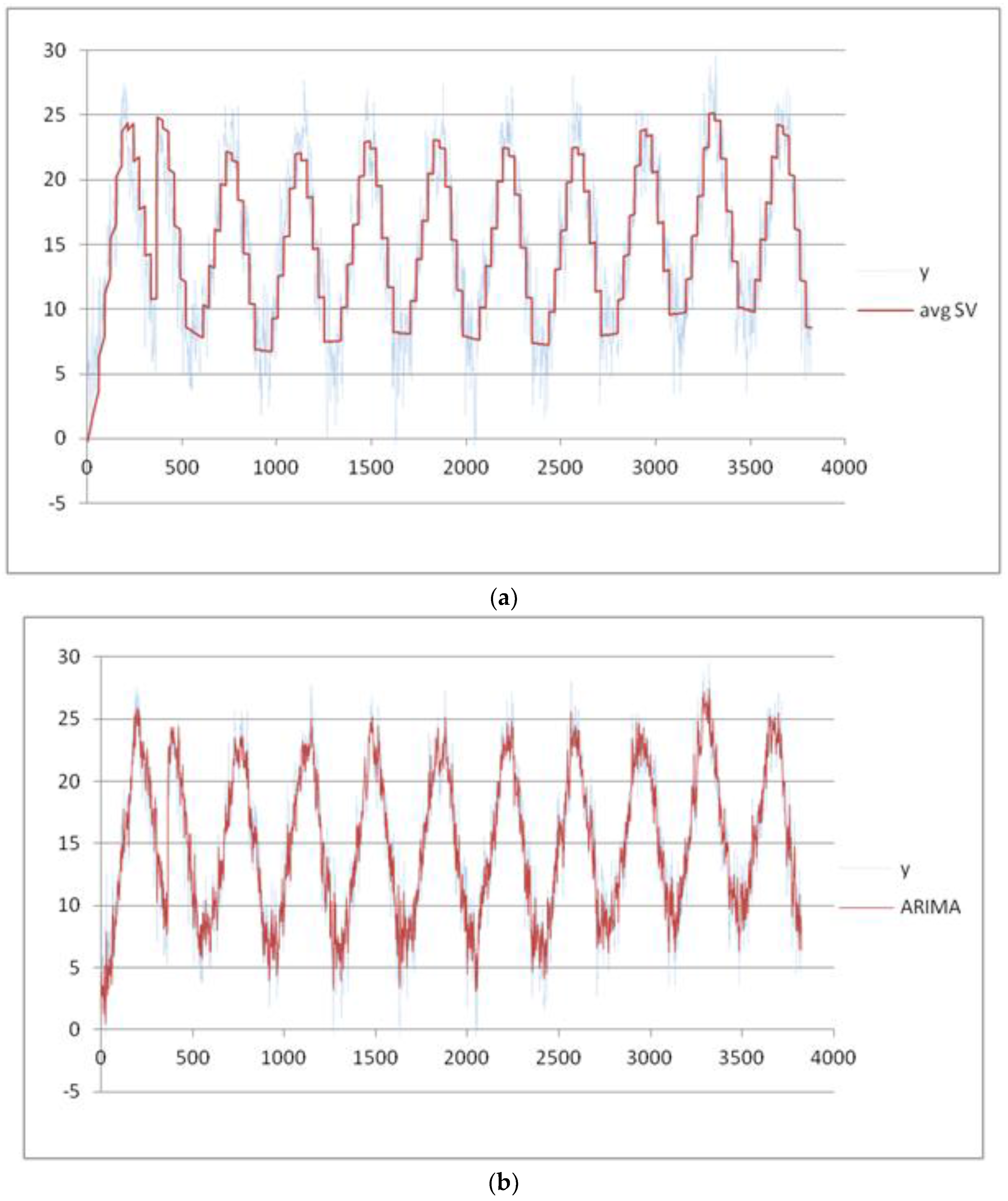
Figure 9a–d, we plot the final results using the four forecasting methods.
In
Table 3, we show the indices obtained using the four methods. MAPE is not measurable because there are measures of min temperature equal to 0.00. The best results for the min temperature are obtained using the TSSF, with a MADMEAN of 5.26.
The results in
Table 3 show that the TSSF is more efficient when the seasonality of the data is more pointed, such as the mean temperature time series. To test the reliability of the forecasting results obtained using the four forecasting methods, we have considered test datasets containing the measure of the analyzed parameter in a next time period and calculating the RMSE obtained with respect to the forecasted values. For the mean and max temperature parameters, we use a test dataset formed by the mean and max daily temperatures measured in the temporal interval 17 August 2015–31 August 2015. For the min temperature parameter, we use a test dataset formed by the min daily temperatures measured in the temporal interval 1 January 2015–31 August 2015. We apply the test datasets, measuring the RMSE obtained using the four methods. In addition, we also show the RMSE calculated by applying the SVM and ADANN algorithms proposed in [
23], as shown in
Table 4.
These results confirm that the performances obtained using the TSSF algorithm are better than the ones obtained using the avgSV, ARIMA and F-transform methods: the most reliable results are obtained for the third parameter, in which the seasonality is more regular. In addition, the performance obtained by applying SVM and ADANN algorithms to the first two time series improve those obtained by adopting the TSSF algorithm, but, in the third case, where the time series has best regularity, RMSE obtained using the TSSF, SVM and ADANN algorithms are indeed comparable.
The analyzed data concern the measures (°C) of the daily mean temperature during the period 1 January 2006–31 December 2016. The month is considered as the seasonal period; the dataset is partitioned into 12 seasonal subsets corresponding to the 12 months of a year. After applying the pre-processing phase, we set the threshold of the MADMEAN index to the value 5.2.
In
Figure 10, we show the data and the trend obtained using a best fit polynomial of nine degree (see
Appendix A and
Appendix B). In
Figure 11a–d, the results obtained using the four methods are plotted.
In
Table 5, we show the four indexes obtained using the four methods. The best results for the mean temperature are obtained using TSSF, with a MADMEAN of 3.83.
The results in
Table 5 confirm the ones obtained for the min temperature parameters in the weather dataset of Naples (
Table 3): the TSSF gives better results than the ARIMA and F-transform algorithms, and is more efficient when the seasonality of the data is more regular. To test the reliability of the results obtained in
Table 5, we have considered a test dataset containing the measure of the daily mean temperature during the period 1 January 2017–19 March 2017 and calculating the RMSE obtained with respect to the forecasted values. In
Table 6, we show the RMSE measured in the ix methods for each parameter.
The results in
Table 6 confirm that the performances obtained using the TSSF algorithm are better than the ones obtained using the avgSV, ARIMA and F-transform methods. Moreover, the performance of the TSSF algorithm is comparable with the ones obtained using the SVM and ADANN algorithms, as the time series shows a regular seasonality.
In
Table 7, we show the tests results obtained for the mean temperature using the seasonal datasets of the daily mean temperature measured by other stations in the district of Genova; the data were downloaded from the Liguria Region webpage “Ambiente in Liguria”. In each experiment, the season parameter is given by the month of the year.
Table 7 confirms the results of
Table 6. The performances of the TSSF algorithm are better than the ones obtained using the avgSV, ARIMA and F-trasform methods and comparable with the ones obtained with the SVM and ADANN algorithms: the reason for this is that none of the time series in
Table 7 has significant irregular variations.

















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}