
Analysis of a Similarity Measure for Non-Overlapped Data



Abstract
:1. Introduction
1.1. Background and Motivation
1.2. Data Description
- Two data, and for , denotes a universe of discourse. and have values at the same support whether it is same or not. It means direct operation such as summation or subtract is possible between two values.
- On the other hand, they are classified as non-overlapped data. It is rather difficult to attain operation results between two data in different supports. In this paper, we propose a similarity design for such non-overlapped data with the help of preprocessing.
- In general, data—especially big data—provide a large amount of information, and groups of data are located close to or far from each other geometrically. The information analysis on neighbor data is used to design the non-overlapped data in this paper.
2. Preliminaries on Similarity Measure
- (S1)
- , for
- (S2)
- , if and only if
- (S3)
- , for
- (S4)
- , if , then and
- (D1)
- , for
- (D2)
- ,
- (D3)
- ,
- (D4)
- , if , then and .
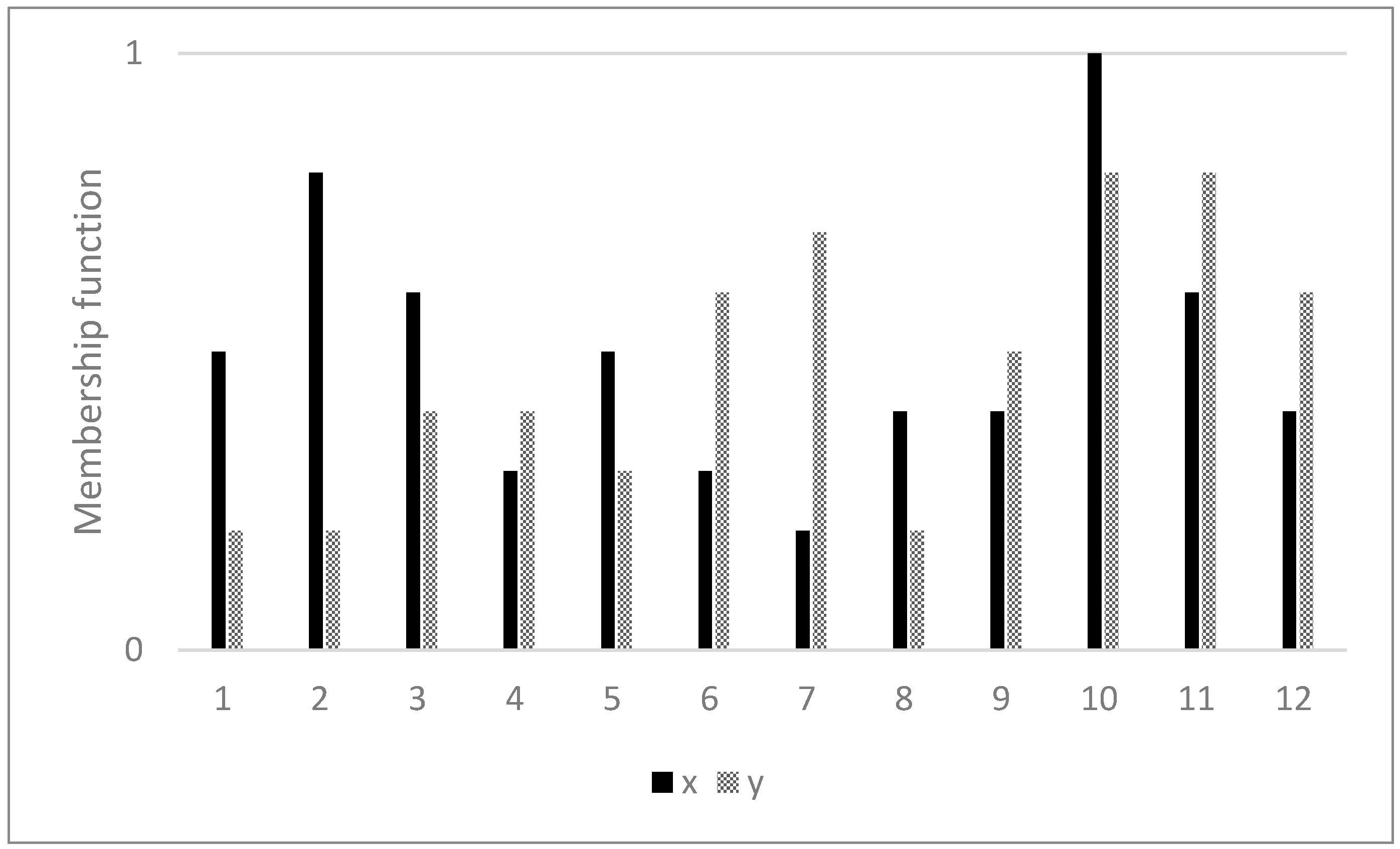
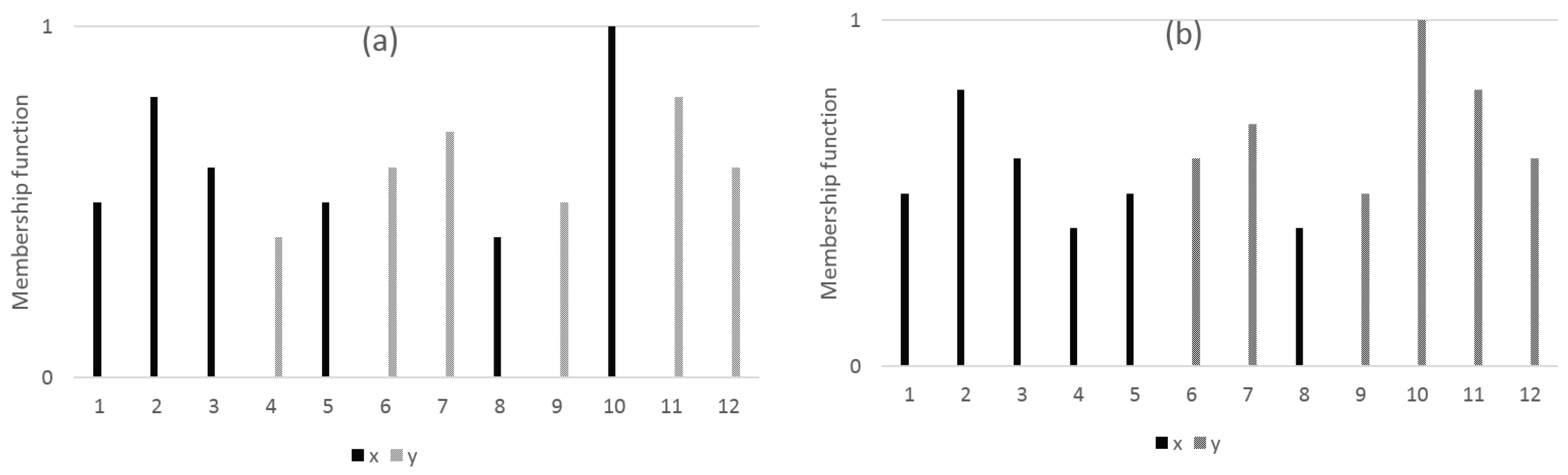
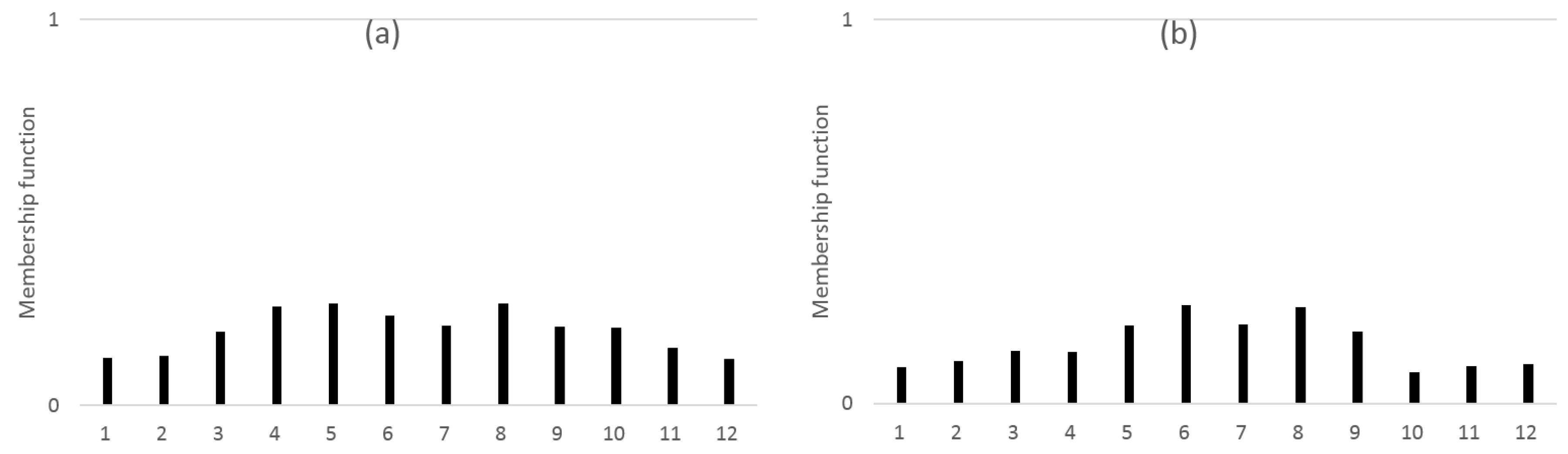
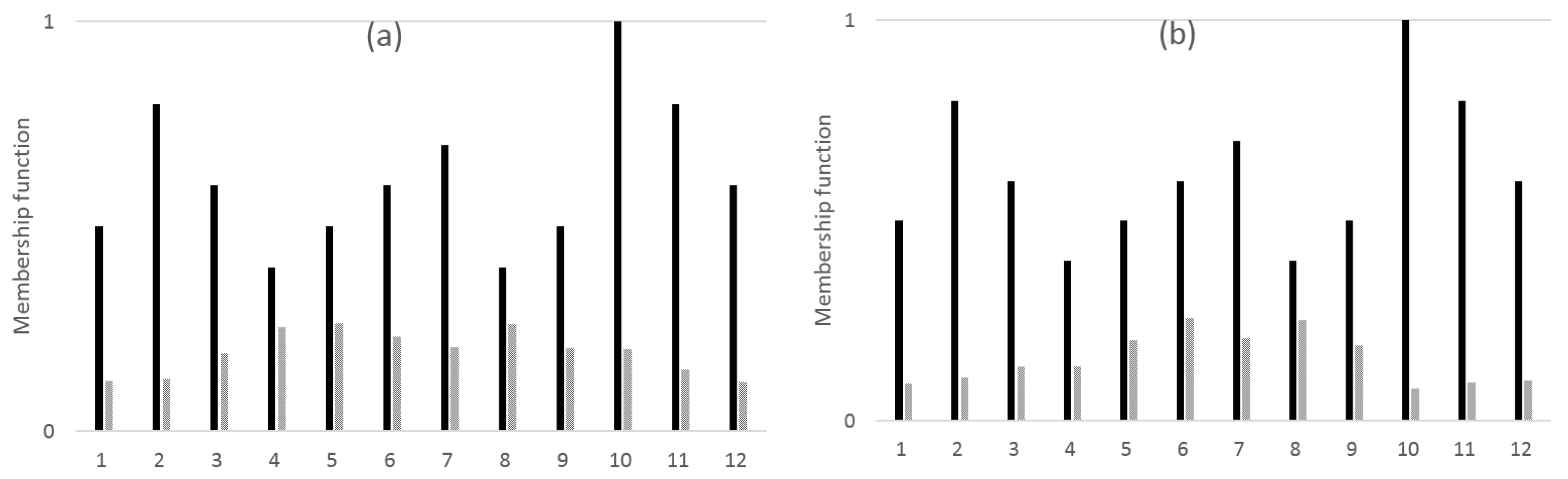
3. Similarity Measure on Non-Overlapped Data
3.1. Data Transformation and Application to Similarity Measure
3.2. Similarity Measure Design Using Neighbor Information
4. Conclusions
Acknowledgments
Author Contributions
Conflicts of Interest
Appendix A. Proof of Theorem 1
- (S1):
- It is clear from Equation (1) itself, hence is satisfied.
- (S2):
- is clear. Hence, (S2) is satisfied.
- (S3):
- It is also clear because:
- (S4):
- From Equation (1), because:it is guaranteed that .
Appendix B. Proof of Theorem 2
- (S1)
- It is clear from Equation (2) itself, hence .
- (S2)
- Because:
- (S2)
- is satisfied.
- (S3)
- This property is satisfied because:
- (S4)
- From Equation (2), because:it is guaranteed that . Similarly, because:is also satisfied.
Appendix C. Derivation of Equations (12) and (13)
References
- Zadeh, L.A. Fuzzy sets and systems. In Proceedings of the Symposium on System Theory; Polytechnic Institute of Brooklyn: New York, NY, USA, 1965; pp. 29–37. [Google Scholar]
- Dubois, D.; Prade, H. Fuzzy Sets and Systems; Academic Press: New York, NY, USA, 1988. [Google Scholar]
- Kovacic, Z.; Bogdan, S. Fuzzy Controller Design: Theory and Applications; CRC Press: Boca Raton, FL, USA, 2005. [Google Scholar]
- Plataniotis, K.N.; Androutsos, D.; Venetsanopoulos, A.N. Adaptive Fuzzy systems for Multichannel Signal Processing. Proc. IEEE 1999, 87, 1601–1622. [Google Scholar] [CrossRef]
- Fakhar, K.; El Aroussi, M.; Saidi, M.N.; Aboutajdine, D. Fuzzy pattern recognition-based approach to biometric score fusion problem. Fuzzy Sets Syst. 2016, 305, 149–159. [Google Scholar] [CrossRef]
- Pal, N.R.; Pal, S.K. Object-background segmentation using new definitions of entropy. IEEE Proc. 1989, 36, 284–295. [Google Scholar] [CrossRef]
- Kosko, B. Neural Networks and Fuzzy Systems; Prentice-Hall: Englewood Cliffs, NJ, USA, 1992. [Google Scholar]
- Liu, X. Entropy, distance measure and similarity measure of fuzzy sets and their relations. Fuzzy Sets Syst. 1992, 52, 305–318. [Google Scholar]
- Bhandari, D.; Pal, N.R. Some new information measure of fuzzy sets. Inf. Sci. 1993, 67, 209–228. [Google Scholar] [CrossRef]
- De Luca, A.; Termini, S. A Definition of nonprobabilistic entropy in the setting of fuzzy entropy. J. Gen. Syst. 1972, 5, 301–312. [Google Scholar]
- Hsieh, C.H.; Chen, S.H. Similarity of generalized fuzzy numbers with graded mean integration representation. In Proceedings of the 8th International Fuzzy Systems Association World Congress, Taipei, Taiwan, 17–20 August 1999; Volume 2, pp. 551–555. [Google Scholar]
- Chen, S.J.; Chen, S.M. Fuzzy risk analysis based on similarity measures of generalized fuzzy numbers. IEEE Trans. Fuzzy Syst. 2003, 11, 45–56. [Google Scholar] [CrossRef]
- Lee, S.H.; Pedrycz, W.; Sohn, G. Design of Similarity and Dissimilarity Measures for Fuzzy Sets on the Basis of Distance Measure. Int. J. Fuzzy Syst. 2009, 11, 67–72. [Google Scholar]
- Lee, S.H.; Ryu, K.H.; Sohn, G.Y. Study on Entropy and Similarity Measure for Fuzzy Set. IEICE Trans. Inf. Syst. 2009, E92-D, 1783–1786. [Google Scholar] [CrossRef]
- Lee, S.H.; Kim, S.J.; Jang, N.Y. Design of Fuzzy Entropy for Non Convex Membership Function. In Communications in Computer and Information Science; Springer: Berlin, Germany, 2008; Volume 15, pp. 55–60. [Google Scholar]
- Dengfeng, L.; Chuntian, C. New similarity measure of intuitionistic fuzzy sets and application to pattern recognitions. Pattern Recognit. Lett. 2002, 23, 221–225. [Google Scholar] [CrossRef]
- Li, Y.; Olson, D.L.; Qin, Z. Similarity measures between intuitionistic fuzzy (vague) set: A comparative analysis. Pattern Recognit. Lett. 2007, 28, 278–285. [Google Scholar] [CrossRef]
- Couso, I.; Garrido, L.; Sanchez, L. Similarity and dissimilarity measures between fuzzy sets: A formal relational study. Inf. Sci. 2013, 229, 122–141. [Google Scholar] [CrossRef]
- Li, Y.; Qin, K.; He, X. Some new approaches to constructing similarity measures. Fuzzy Sets Syst. 2014, 234, 46–60. [Google Scholar] [CrossRef]
- Lee, S.; Sun, Y.; Wei, H. Analysis on overlapped and non-overlapped data. In Proceedings of the Information Technology and Quantitative Management (ITQM2013), Suzhou, China, 16–18 May 2013; Volume 17, pp. 595–602. [Google Scholar]
- Lee, S.; Wei, H.; Ting, T.O. Study on Similarity Measure for Overlapped and Non-overlapped Data. In Proceedings of the Third International Conference on Information Science and Technology, Yangzhou, China, 23–25 March 2013. [Google Scholar]
- Lee, S.; Shin, S. Similarity measure design on overlapped and non-overlapped data. J. Cent. South Univ. 2014, 20, 2440–2446. [Google Scholar] [CrossRef]
- Host-Madison, A.; Sabeti, E. Atypical Information Theory for real-vauled data. In Proceedings of the 2015 IEEE International Symposium on Information Theory (ISIT), Hong Kong, China, 14–19 June 2015; pp. 666–670. [Google Scholar]
- Host-Madison, A.; Sabeti, E.; Walton, C. Information Theory for Atypical Sequence. In Proceedings of the 2013 IEEE Information Theory Workshop (ITW), Sevilla, Spain, 9–13 September 2013; pp. 1–5. [Google Scholar]
- Pemmaraju, S.; Skiena, S. Computational Discrete Mathematics: Combinatorics and Graph Theory with Mathematica; Cambridge University: Cambridge, UK, 2003. [Google Scholar]
{kind=link}
{kind=link}
{kind=link}
{kind=link}
© 2017 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lee, S.; Cha, J.; Theera-Umpon, N.; Kim, K.S. Analysis of a Similarity Measure for Non-Overlapped Data. Symmetry 2017, 9, 68. https://doi.org/10.3390/sym9050068
Lee S, Cha J, Theera-Umpon N, Kim KS. Analysis of a Similarity Measure for Non-Overlapped Data. Symmetry. 2017; 9(5):68. https://doi.org/10.3390/sym9050068
Chicago/Turabian StyleLee, Sanghyuk, Jaehoon Cha, Nipon Theera-Umpon, and Kyeong Soo Kim. 2017. "Analysis of a Similarity Measure for Non-Overlapped Data" Symmetry 9, no. 5: 68. https://doi.org/10.3390/sym9050068
APA StyleLee, S., Cha, J., Theera-Umpon, N., & Kim, K. S. (2017). Analysis of a Similarity Measure for Non-Overlapped Data. Symmetry, 9(5), 68. https://doi.org/10.3390/sym9050068