1. Introduction
Compressed sensing (or compressive sensing) [
1] has become a very active research direction in the field of signal processing, after the pioneering work by Candès and Tao (see [
2]). It has been successfully applied in image compression, signal processing, medical imaging, and computer science (see [
3,
4,
5,
6,
7]). Compressed sensing refers to the problem of recovering sparse signals from low dimensional measurements (see [
8]). In terms of image processing, one needs to compress the image first, then the image signal becomes sparse and its reconstruction belongs to the category of compressed sensing.
Let
denote the
d-dimensional Euclidean space. Consider a signal
. We say
x is a
k-sparse vector if
. Here, we use
to denote the set of index such that
for all
and
represents the cardinality of a set
A. By the compressed sensing theory, the recovery of a sparse signal can be mathematically described as
where
x is a
d-dimensional
k-sparse vector, and
is the measurement matrix with
. The goal of signal recovery is establishing an algorithm to approximate the unknown signal
x by using the measurement matrix
and given data
.
A well-known method in compressed sensing is basis pursuit (BP), which is also known as
minimization (see [
9]). It is defined as
By imposing a “restricted orthonormality hypothesis”, which is far weaker than assuming orthonormality and defined as the following Definition 1, the minimization program can recover x exactly. Furthermore, the target sparse signal x could be recovered with a high probability when is a Gaussian random matrix.
Definition 1. A matrix Φ
is said to satisfy the restricted isometry property at sparsity level k with the constant ifholds for all k-sparse vectors x. And, we say that the matrix Φ satisfies the restricted isometry property with parameters if . The
minimization method and related algorithms found by solving (
2) have been well studied, and they range widely in effectiveness and complexity (see [
1,
2,
10,
11,
12]). It is known that a linear program problem can be solved in polynomial time by using optimization software. However, it still takes a long time if the length of the signal is large.
Compared with the BP algorithm, greedy-type algorithms are easy to implement and have less computational complexity and fast convergence speed. Thus, greedy-type algorithms are powerful methods for the recovery of signals and are increasingly used in that field; for example, see [
13,
14,
15,
16,
17]. To recall this type of algorithm, we first recall some basic notions on sparse approximation in a Hilbert space
H. We denote the inner product of
H by
. The norm
on
H is defined by
for all
. We call a set
a dictionary if the closure of
is
H. Here
is the linear space spanned by
. We only consider normalized dictionaries, that is, for any
,
. Let
denote the set of all elements which can be expressed as a linear combination of
m elements from
We define the minimal error of the approximation of an element
as
Let a dictionary
be given. We define the collection of elements by
Then, we define
to be the closure of
in
H. Finally, we define the linear space
by
and we equip
with the norm
for all
.
The simplest greedy algorithm in
H is known as the Pure Greedy Algorithm (PGA
). We recall its definition from [
18].
Pure Greedy Algorithm (PGA(, ))
Step 1: Set .
Step 2:
-If , then stop and define for .
-If
, then choose an element
satisfying
Define the new approximation of
f as
and proceed to Step 2.
In [
19], DeVore and Temlyakov proposed the Orthogonal Greedy Algorithm (OGA
) in
H with a dictionary
. We recall its definition.
Orthogonal Greedy Algorithm (OGA(, ))
Step 1: Set .
Step 2:
-If , then stop and define for .
-If
, then choose an element
satisfying
Define the new approximation of
f as
where
is the best approximation of
f from the linear space
:= span
, and proceed to Step 2.
In fact, the OGA is one of the modifications of the PGA, improving the convergence rate. The convergence rate is one of the critical issues for the approximation power of algorithms. If
is the approximation of the target element
f by applying a greedy algorithm after
m iterations, the efficiency of the algorithm can be measured by the decay of the sequence
. It has been shown that the PGA and the OGA can achieve the convergence rates
and
for
, respectively, if the target element
f belongs to
(see [
19]).
Theorem 1. Suppose is a dictionary of H. Then, for every the following inequality holds: Theorem 2. Suppose is a dictionary of H. Then, for every the following inequality holds: It is known from [
20] that the convergence rate
cannot be improved. Thus, as a very general result for all dictionaries, the convergence rate is optimal.
The fundamental problem of signal recovery is to find out the support of the original target signal by using the model (
1). Since
N is much smaller than the dimension
d, the column vectors of the measurement matrix
are linearly dependent. Therefore, these vectors consist of a redundant system. This redundant system may be considered as a dictionary of
. It is well known that
is a Hilbert space with the usual inner product
Thus, signal recovery can be considered as an approximation problem with a dictionary in a Hilbert space. In particular, the approximation of the original signal is the solution of the following minimization problem:
where
denote the columns of
. Naturally, one can adapt greedy approximation algorithms to handle the signal recovery problem. In CS, one such method is Orthogonal Matching Pursuit (OMP) (see [
21,
22]), which is an application of OGA to the field of signal processing. Compared with the BP, the OMP is faster and it admits an ease of implementation (see [
17,
23]). We recall the definition of the OMP from [
23].
Orthogonal Matching Pursuit (OMP)
Input: An matrix , , the sparsity index k.
Step 1: Set , the index set , and .
Step 2: Define
such that
Step 3: Increment m, and return to Step 2 if .
Output: If , then output and .
It is clear from the available literature that the OMP algorithm is the most popular greedy-type algorithm being used for signal recovery. The OMP algorithm, with a high probability, can exactly recover each sparse signal by using a Gaussian or Bernoulli matrix (see [
17]). And, it is shown that the OMP algorithm can stably recover sparse signals in
under measurement noise (see [
24]). Although the OMP algorithm is powerful, the computational complexity of the orthogonality step is quite high, especially for large-scale problems. See [
25] for the detailed computation and the storage cost of the OMP. So, the main disadvantage of the OMP is its high computational cost. In particular, when the sparsity level
k of the target signal is large, OMP may not be a good choice, since the cost of orthogonalization increases quadratically with the number of iterations. Thus, in this case, it is natural to look for other greedy-type algorithms to reduce the computational cost.
In
Section 2, we propose an algorithm called Rescaled Matching Pursuit (RMP) for signal recovery. This algorithm has less computational complexity than the OMP, which means it can save resources such as storage space and computation time. In
Section 3, we analyze the efficiency of the RMP algorithm under the RIP condition. In
Section 4, we prove that the RMP algorithm can be used to find the correct support of sparse signal from a random measurement matrix with a high probability. In
Section 5, we use numerical experiments to verify this conclusion. In
Section 6, we summarize our results.
2. Rescaled Matching Pursuit Algorithm
In [
26], Petrova presented another modification of the PGA which is called the escaled pure greedy algorithm (RPGA). This modification is very simple. It simply rescales the approximation in each iteration of the PGA.
We recall the definition of the RPGA(
H,
from [
26].
Rescaled Pure Greedy Algorithm (RPGA(, ))
Step 1: Set .
Step 2:
-If , then stop and define for .
-If
, then choose an element
satisfying
with
Then, define the the new approximation of
f as
and proceed to Step 2.
The following theorem on the convergence rate of the RPGA was also obtained in [
26].
Theorem 3. Suppose is a dictionary of H. Then, for every the RPGA satisfies the following inequality: Notice that the RPGA only needs to solve a one-dimensional optimization problem at each step. Thus, the RPGA is simpler than the OGA. Together with Theorem 3, it is known that the RPGA is a greedy algorithm with minimal computational complexity to achieve the optimal convergence rate
. Based on this result, the RPGA has been applied successfully to solve the problems of convex optimization and regression, see [
27,
28,
29]. In solving these two types of problems, the RPGA performs better than the OGA. The main reason is that the RPGA has smaller computational cost than the OGA. For more detailed results about the RPGA, one can refer to [
26,
27,
28,
29,
30]. Besides, in [
31] the authors propose the Super Rescaled Pure Greedy Learning Algorithm and investigate its behavior. The success of the RPGA inspires us to consider its application in the field of signal recovery.
In the present article, we will design an algorithm based on the RPGA to recover sparse signals and analyze its performance. Suppose that x is a k-sparse signal in and is an matrix. We denote the columns of as . Then, we design the Rescaled Matching Pursuit (RMP) for sparse signal recovery.
Rescaled Matching Pursuit (RMP)
Input: Measurement matrix , vector f, the sparsity index k.
Step 1: Set , , the index set , and .
Step 2: Define
such that
Then,
where
,
, and
. Next, update the residual
Step 3: Increment m, and return to Step 2 if .
Output: If
, then output
and
. It is easy to see that
has nonzero indices at the components listed in
. If
, then we can figure out the value of
in component
through
The main procedure of the algorithm can be divided into selecting the columns of and constructing the approximation . In Step 2, the approximation is obtained by solving a one-dimensional optimization problem. In fact, is an orthogonal projection of f onto the one-dimensional space . The RMP algorithm is broadly similar to the OMP algorithm, while the computational complexity differs. For the OMP algorithm, the approximation is obtained by solving the m-dimensional least squares problem at m iteration in Step 2, which has a total cost of . For the RMP algorithm, as argued above, the approximation is obtained by solving a one-dimensional optimization problem at the m iteration in Step 2, which has a total cost of . It is not difficult to see that the computational cost is less expensive than most existing greedy algorithms, such as the OMP algorithm. That is, we can save a lot of resources such as storage space and computation time by using the RMP algorithm.
4. Signal Recovery with Admissible Measurements
Since one could not construct a deterministic matrix satisfying the RIP condition, it is natural to consider a random matrix. In practice, almost all approaches to recovering sparse signals using greedy-type methods involve some kind of randomness. In this section, we choose a class of random matrices which have good properties. This class of matrices is called admissible matrices. We first recall the definition of this class of matrices. Then, we prove that the support of a k-sparse target signal in can be recovered with a high probability by applying the RMP algorithm. This shows that RMP is a powerful method of recovering sparse signals in high-dimensional Euclidean spaces.
Definition 2. An admissible measurement matrix for a k-sparse signal in is an random matrix Φ satisfying the following conditions:
(M1) The columns of Φ are stochastically independent.
(M2) for .
(M3) Let be a sequence of k vectors whose norm do not exceed 1. If φ is a column of Φ
independent from , thenfor a positive constant . (M4) For a given submatrix Z from Φ,
the kth largest singular value satisfiesfor a positive constant .
We illustrate some points about the conditions (M3) and (M4). The above condition (M3) offers a limitation of the singular value of the submatrix, which is analogous to the RIP condition (see [
17]). Furthermore, the condition (M4) controls the inner product, since the selection of index at Step 2 of the RMP algorithm relates to the inner product. Two typical classes of admissible measurement matrices are the Gaussian matrix and Bernoulli matrix, which were first introduced by Candès and Tao for signal recovery and defined as follows (see [
2]).
Definition 3. A measurement matrix Φ is called a Gaussian measurement if every entry of Φ is selected from the Gaussian distribution , of which the density function is, for
Definition 4. A measurement matrix Φ is called a Bernoulli measurement if every entry of Φ is selected to be with the same probability, i.e., , where .
Obviously, for Gaussian and Bernoulli measurements, the properties (M1) and (M2) are straightforward to verify. We can check the other two properties using the following known results. See [
17] for more details.
Proposition 1. Suppose is a sequence of k-sparse vectors. The norm of each does not exceed 1. Choose z independently to be a random vector with entries. Then Proposition 2. Let Z be an matrix whose entries are all or else uniform on . Thenwith a probability of at least For the RMP algorithm, we derive the following result.
Theorem 6. Let x be a k-sparse signal in and Φ be an admissible matrix independent from the signal. For the given data , if the RMP algorithm selects k elements in the first iterations, the correct support of x can be found with the probability exceeding , where c is a constant dependent on the admissible measurement matrix Φ.
Proof of Theorem 6: Without a loss of generality, we may assume that the first
k components of
x are nonzero and the other remaining components of
x are zeroes. Obviously,
f can be expressed as a linear combination of the first
k columns of measurement matrix
. We decompose the measurement matrix
into two parts
, where
is the submatrix formed by the first
k columns of
, and
is the submatrix formed by the remaining
columns. For
, we assume that
and
Furthermore, we can know that
is independent from the random matrix
.
Denote
as the event where the RMP algorithm recovers all
k elements from the support of
x correctly in the first
iterations. Define
as the event where
. Then, we have
For an
N-dimensional vector
r, define
where
is a column of the matrix
. If
r is a residual vector derived by the Step 2 of the RMP algorithm and
satisfies
, it means that a column from matrix
has been selected.
If we execute the RMP algorithm with input signal x and measurement matrix for L iterations, then we obtain a sequence of residual vectors . Obviously, the residual vectors are independent from the matrix and can be considered as the functions of x and . Instead, suppose that we execute the RMP algorithm with the input signal x and matrix for L iterations. If the RMP algorithm recovers all the k elements of the support of x correctly, the columns of should be selected at each iteration. Thus, the sequence of residual vectors should be same as when we execute the algorithm with .
Therefore, the condition probability satisfies
where
is a random vector depending on
and stochastically independent from
.
Assume that
occurs. Since
is a
k-dimensional vector, then
By the basic property of singular values, we have
for any vector
r in the range of
. Thus, for vector
, we have
, where
. Then, the have the following:
for each index
.
Since the columns of
are stochastically independent from each other, we can exchange the two maxima to obtain
Obviously, each column of
is independent from
and
. By condition (M3), we have
By the property (M4), we have
Therefore, the following applies:
By using the following known inequality for
,
,
we have
We finish the proof of this theorem. □
We remark that a similar result holds for the OMP (see [
17]). So, the performance of the RMP is similar to that of the OMP in the random case. In the next section, we will verify the conclusion of Theorem 6 via numerical experiments.
5. Simulation Results
In the present section, we check the efficiency of the Rescaled Matching Pursuit (RMP) algorithm defined in
Section 2. We adopt the following model. Assume that
is the target signal. We want to recover it by using the following information:
where
is a Bernoulli measurement matrix.
In our experiments, we generate a
k-sparse signal
by randomly choosing
k components, and each of them is selected from a standard normal distribution
. We execute the RMP algorithm with a Bernoulli measurement matrix under the model (
6). We measure the performance of the RMP algorithm with the mean square error (MSE), which is defined as
where
is the estimate of the target signal
x.
The first plot,
Figure 1, displays the performances of the OMP and the RMP for an input signal with different sparsity indexes
k, different dimensions
d, and different numbers of measurements
N. The red line denotes the original signal, the blue squares represent the approximation of the RMP, and the black dots denote the approximation of the OMP.
From
Figure 1, we know that the RMP can obtain a good approximation for a sparse signal even in a high dimension or when
N is much smaller than
d. After repeating the test 100 times, we can figure out the mean square errors of the above four cases as follows:
(a) MSE(OMP) = ; MSE(RMP) =
(b) MSE(OMP) = ; MSE(RMP) =
(c) MSE(OMP) = ; MSE(RMP) =
(d) MSE(OMP) = ; MSE(RMP) =
Thus, taking a suitable number of measurements, the performance of the RMP is similar to the OMP within allowable limits.
Figure 2 shows that the RMP can approximate the 40 sparse signal well under noise, even in a high dimension, which implies that the RMP is stable with the noise.
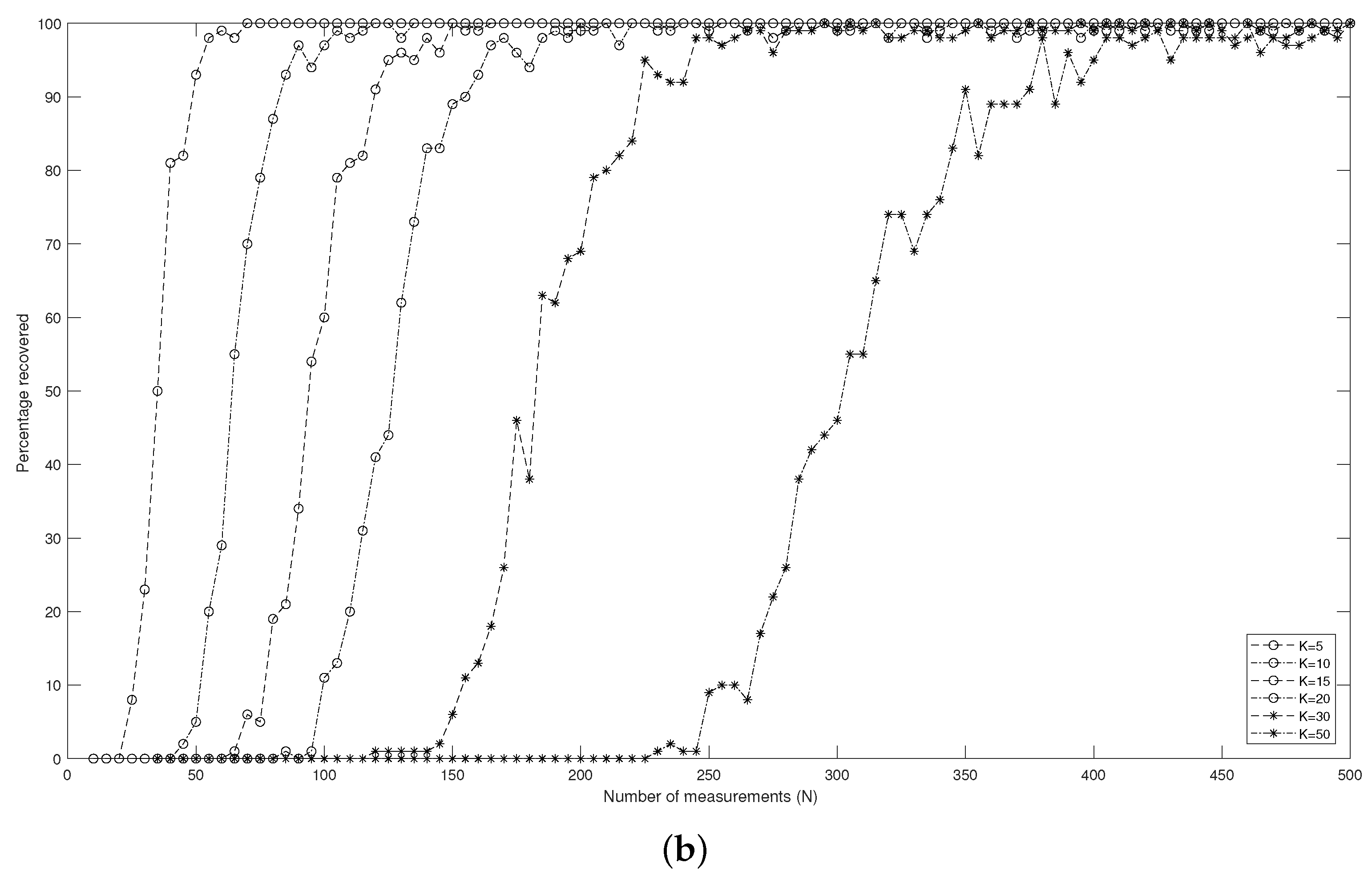
Figure 3 displays the relation between the percentage (of 100 input signals) of the support that can be determined correctly and the number
N of measurements in different dimensions
d. It reveals how many measurements are necessary to reconstruct a
k-sparse signal
with a high probability. A percentage equal to
means that support for all 100 input signals can be found. That is to say, the support of the input signal can be exactly recovered. Furthermore,
Figure 3 indicates that to guarantee the success of recovering the target signal, the number
N of the measurements must increase when the sparsity level
k increases.
The numerical experiments show that the RMP is efficient for the recovery of the sparse signals even in the noised case. The RMP can determine the support of the target signal in a high-dimension Euclidean space with a high probability, if the number N is large enough.


{kind=link}
{kind=link}
{kind=link}
{kind=link}



