
Improved Fault Classification and Localization in Power Transmission Networks Using VAE-Generated Synthetic Data and Machine Learning Algorithms


 , , , and
, , , and
Abstract
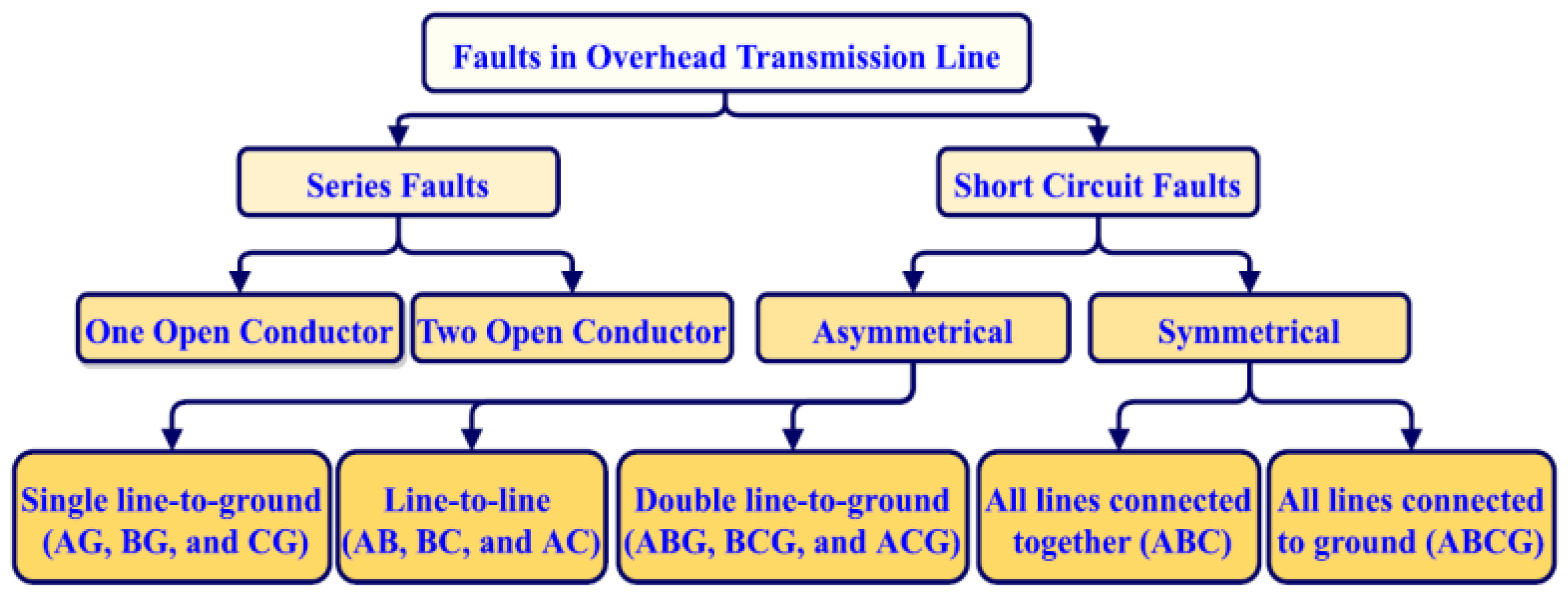
:1. Introduction
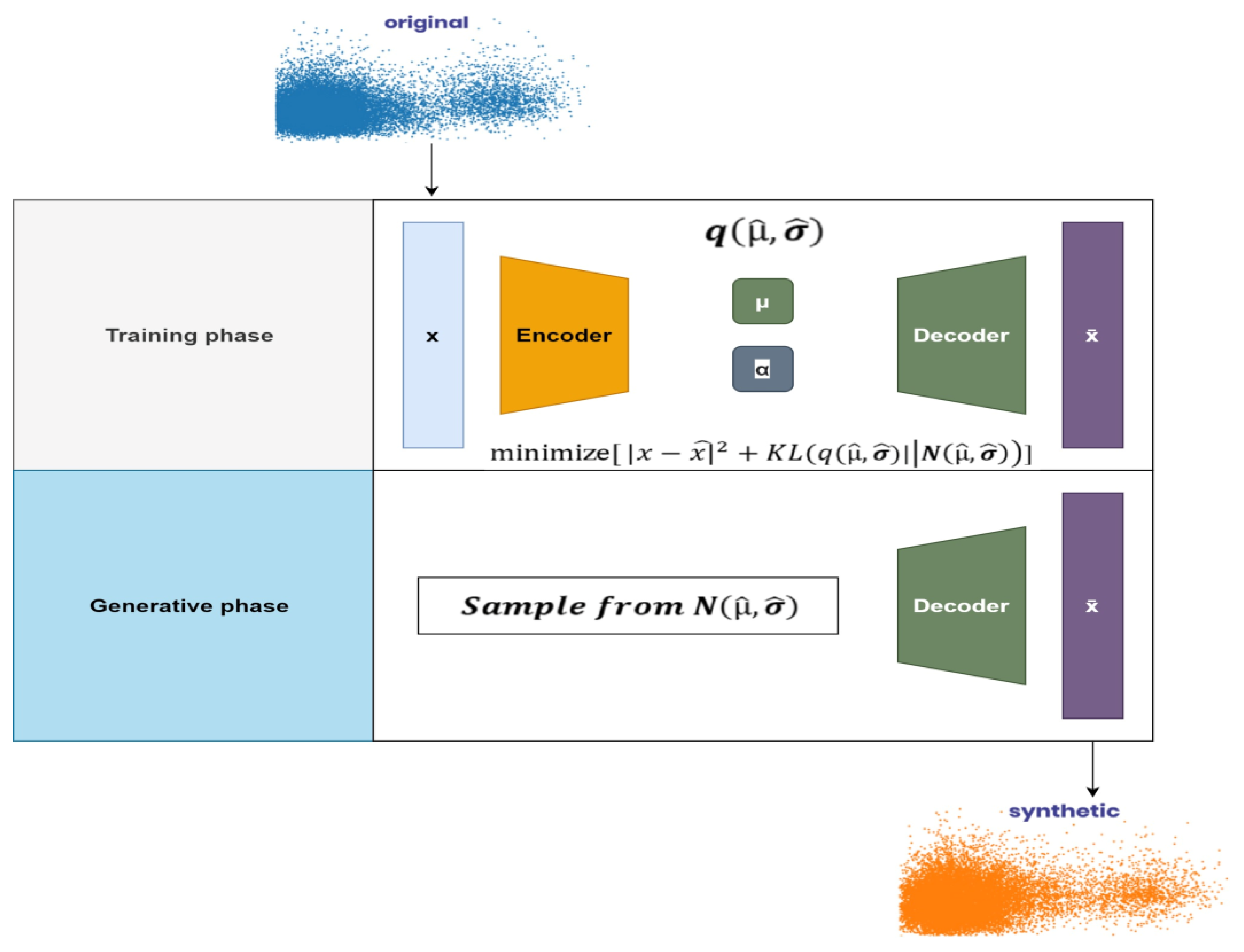
1.1. Variational Autoencoders
1.2. Data Synthesis
1.3. Forward Feature Selection
- Introduction of variational autoencoders VAE for generation of synthetic data for transmission lines fault classification and localization that can improve the classification accuracy better than traditional methods.
- The technique is cost-effective and practical since it eliminates the requirement for a large volume of labeled real-world data.
- Demonstrates the capacity to detect faults in real-time and respond quickly, which can reduce the likelihood of power outages and improve grid dependability.
- Highlights the system’s ability to save time and effort by reducing the frequency of human monitoring and intervention.
- Tuned proposed machine learning architectures for greater accuracy compared to standard methods.
- Shows how machine learning techniques using enhanced synthetic data can accurately classify power transmission network issues.
- Research publications with scientific information contain limitations due to their design, methodology, and context.
- Predictions may be distorted by selected data points due to selection bias and the generated dataset must have 5000 data points to produce acceptable results.
- The proposed architectures require feature selection and hyperparameter adjustment and measurement errors also impact algorithm performance and lead to dataset inaccuracies.
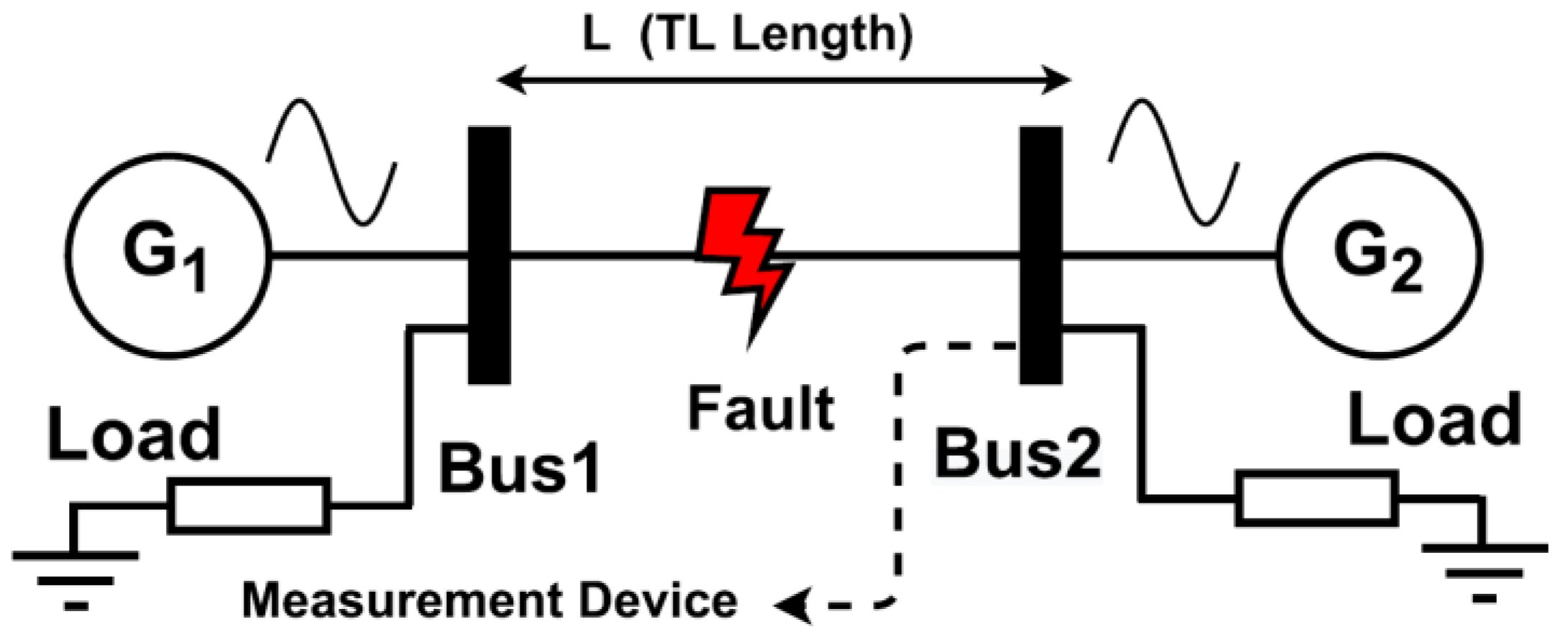
2. Modeling of 220 KV Transmission Networks
Data Preparation and Extraction
3. The Use of Cat-Boost Architecture for Fault Classification and Localization
Dataset Training Employing Cat-Boost Architecture
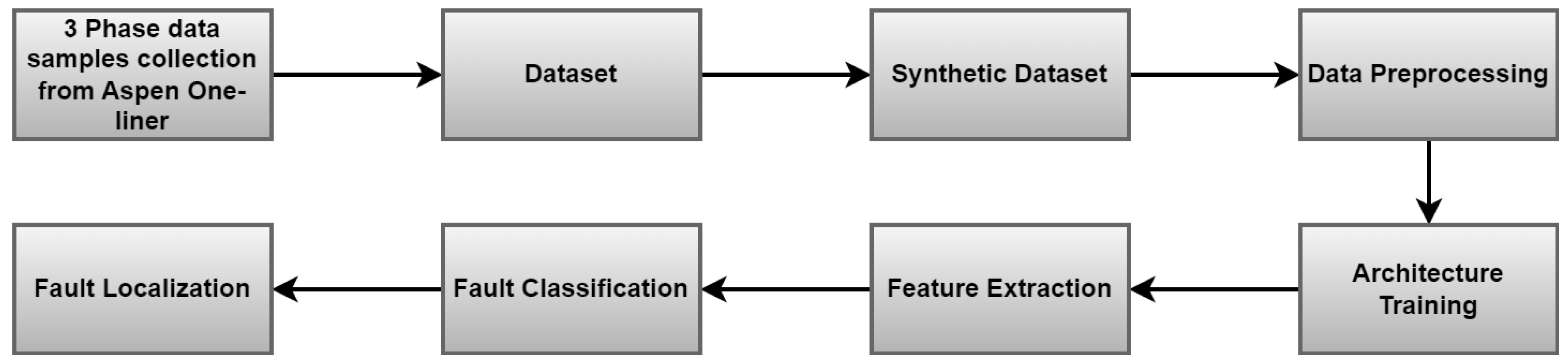
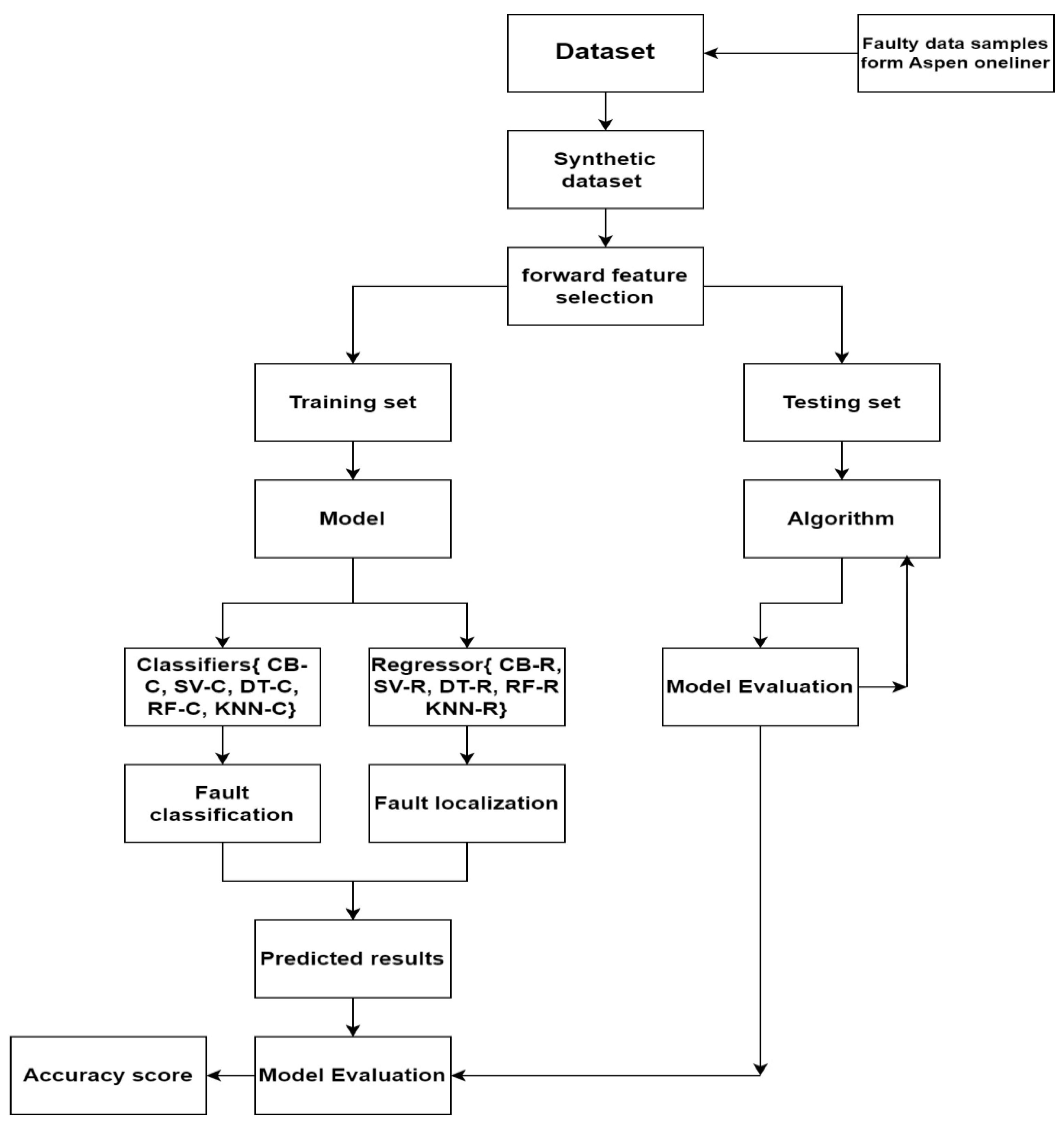
4. Proposed Methodology
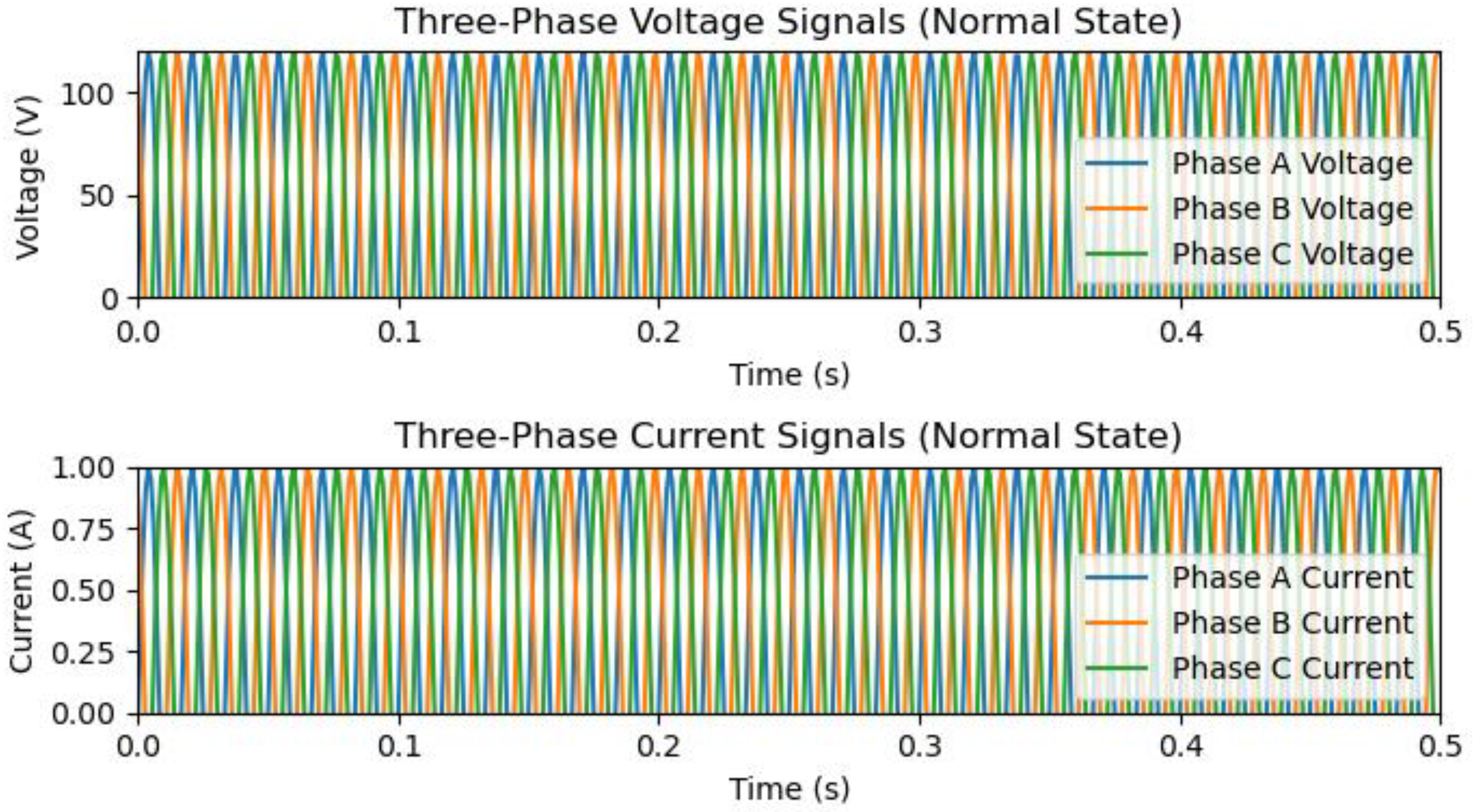
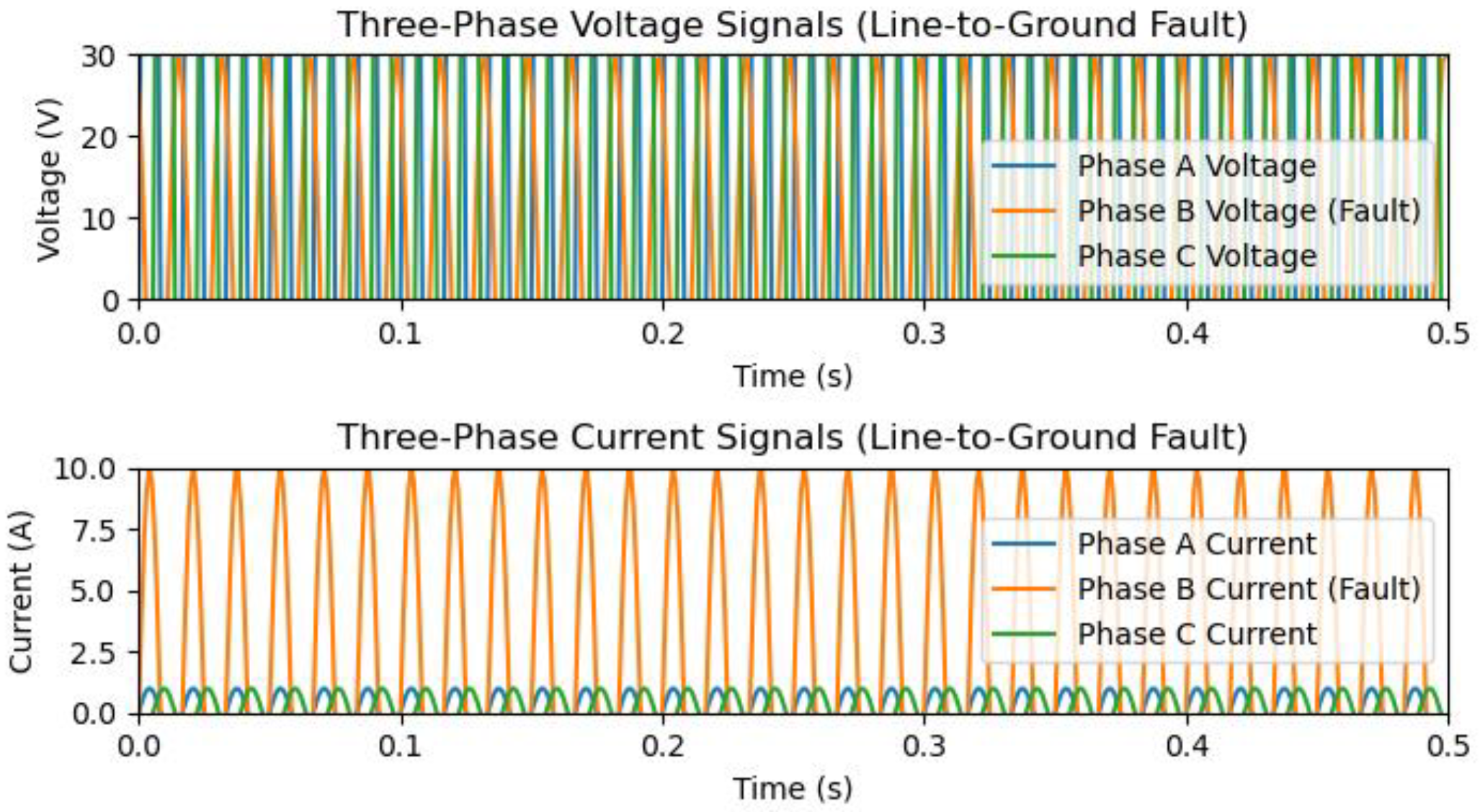
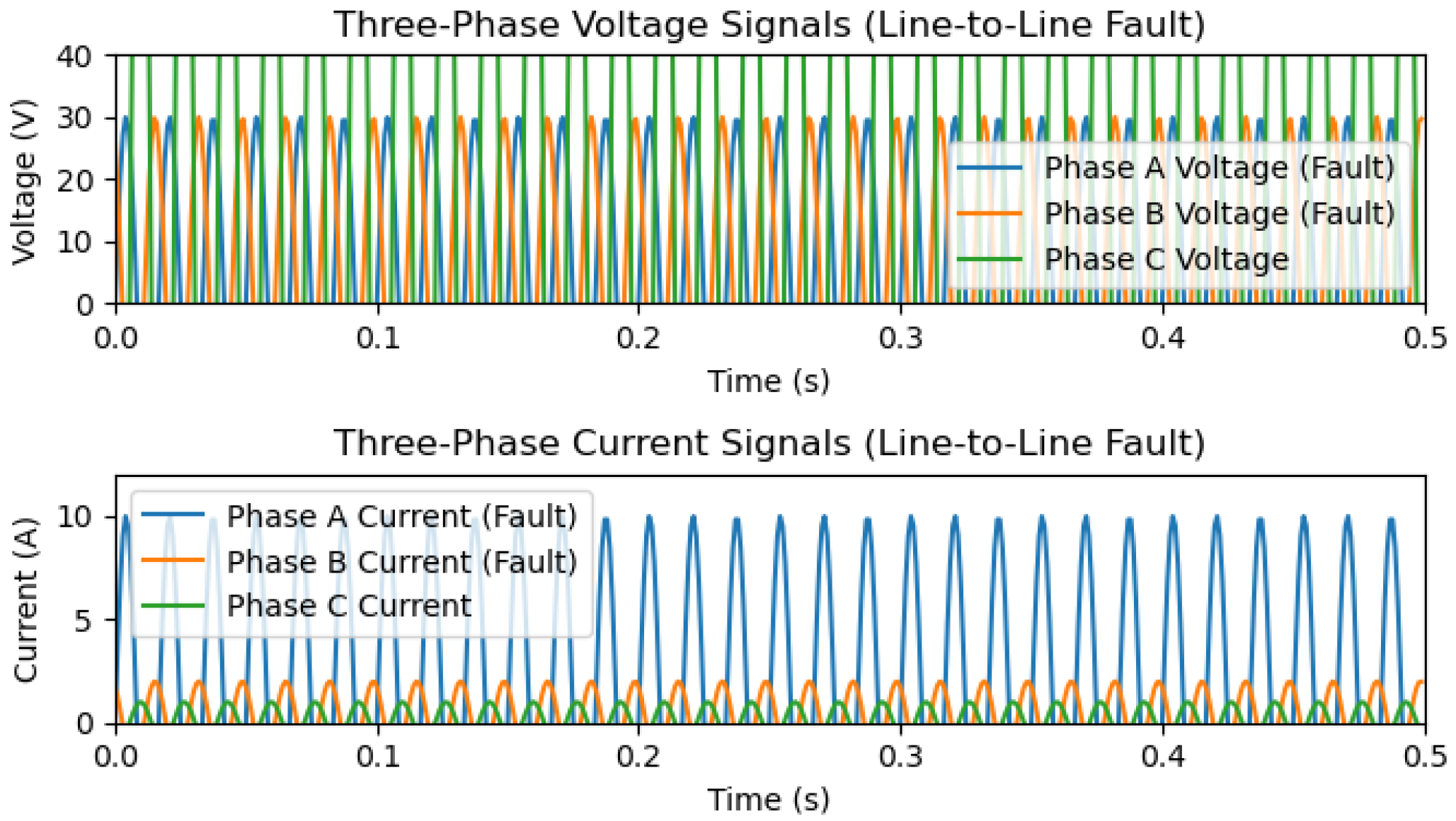
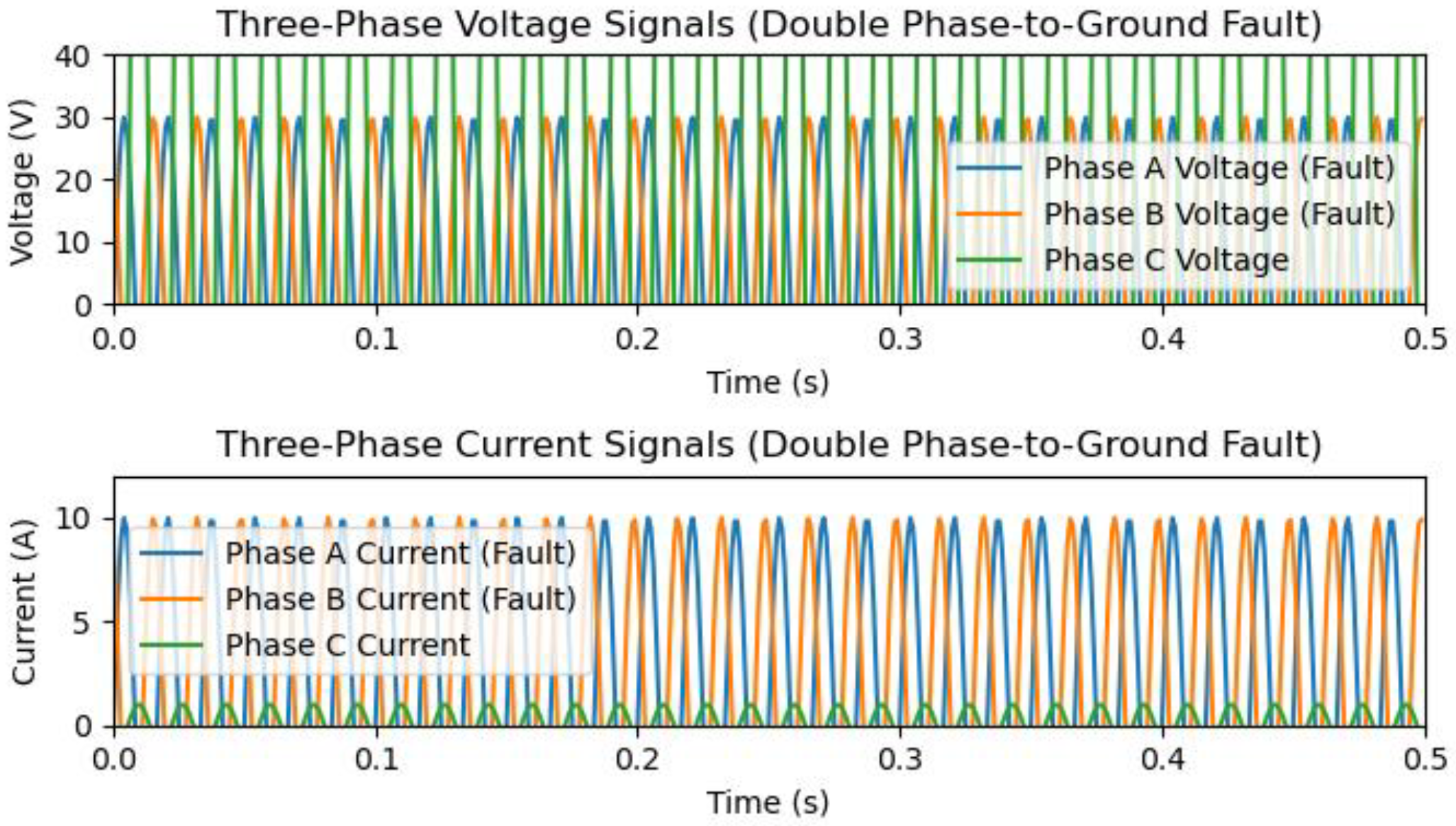
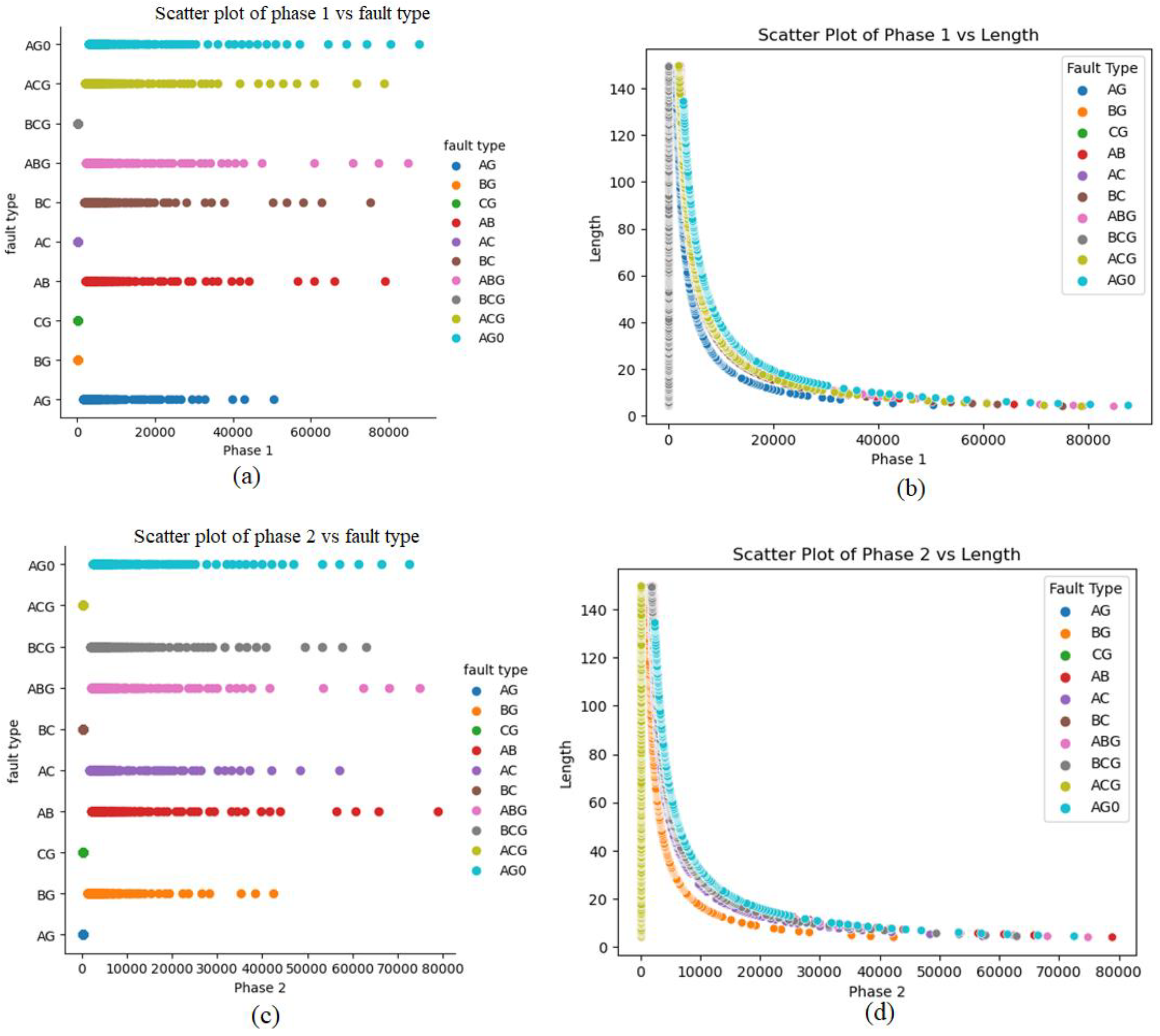
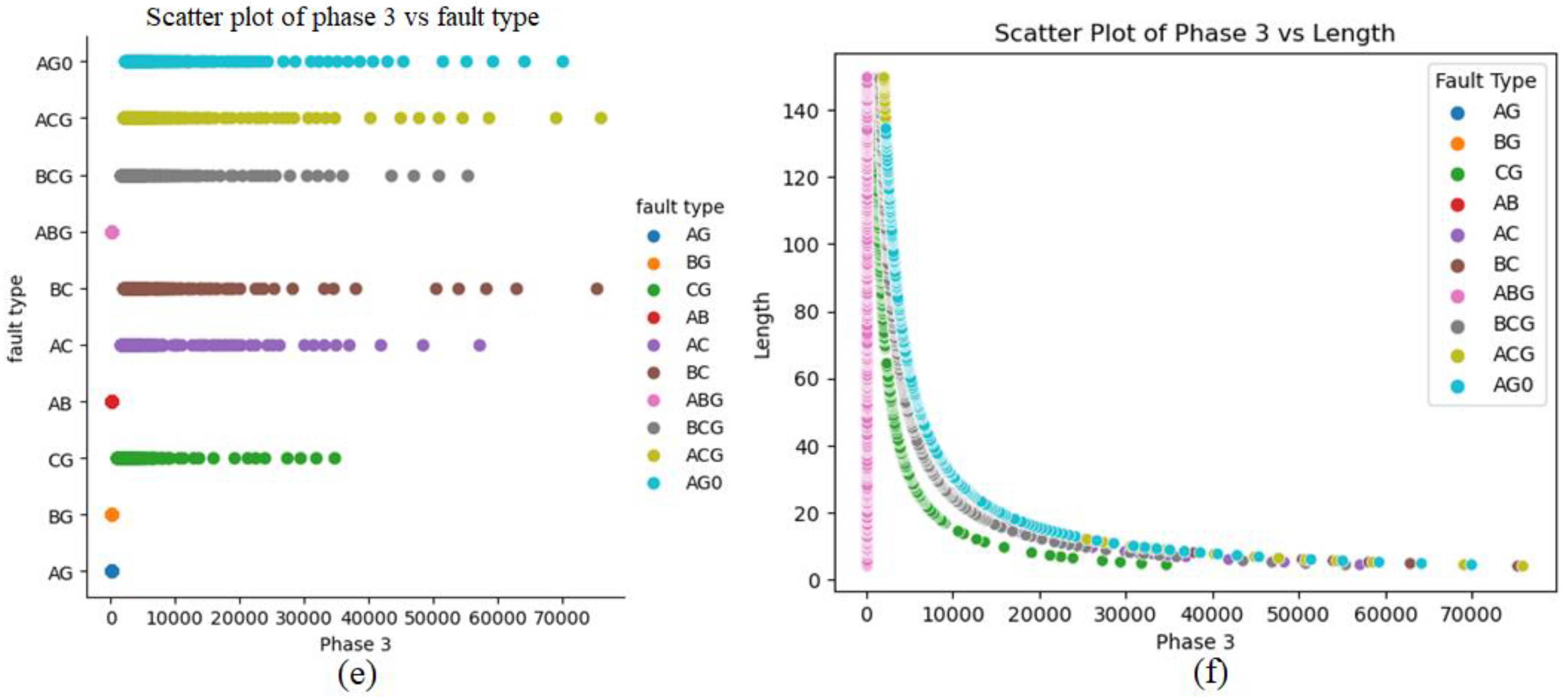
5. The Process of Data Generation and Simulation for T/L with Aspen One-Liner
Data Splitting
6. Performance Evaluation and Comparative Analysis
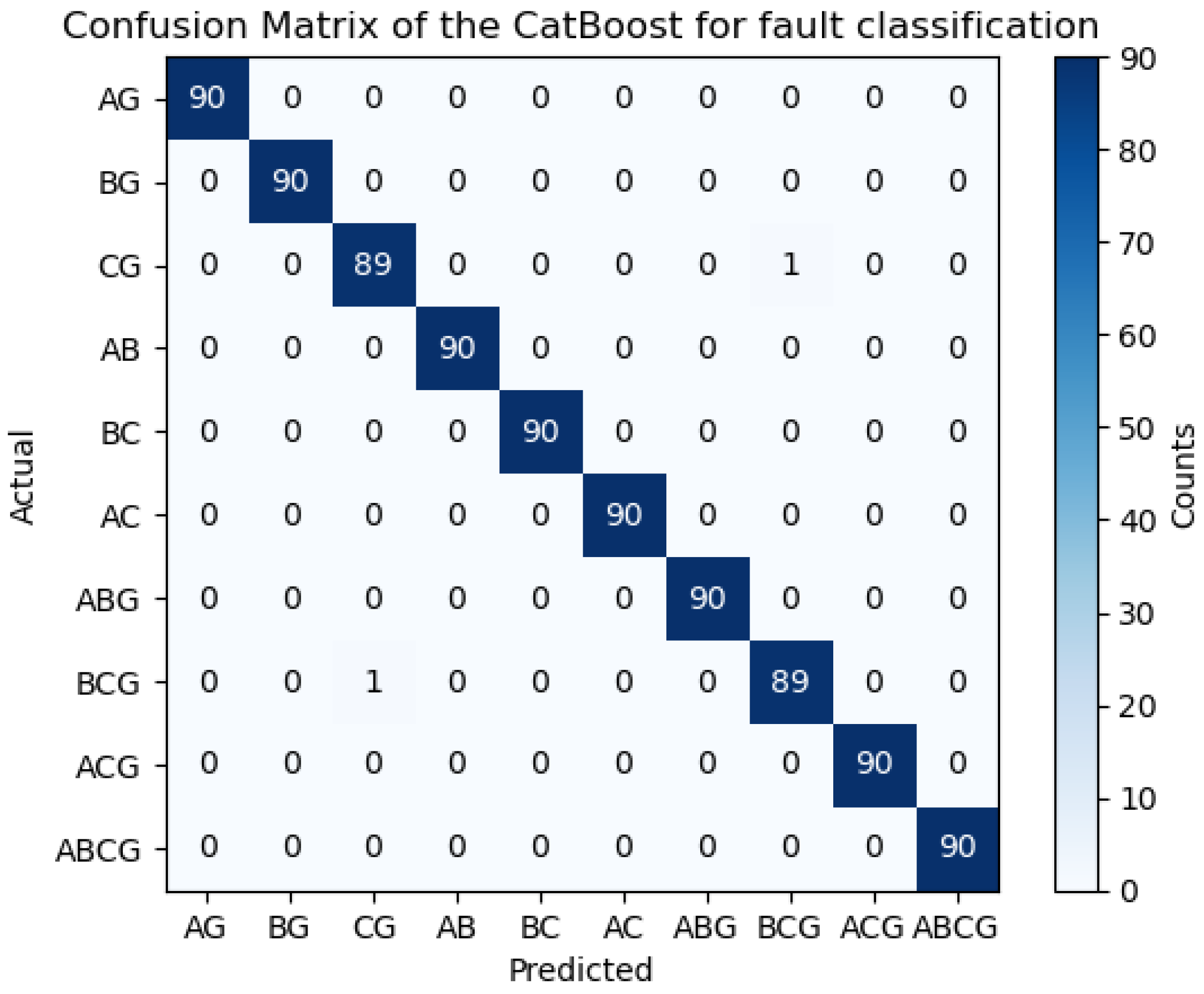
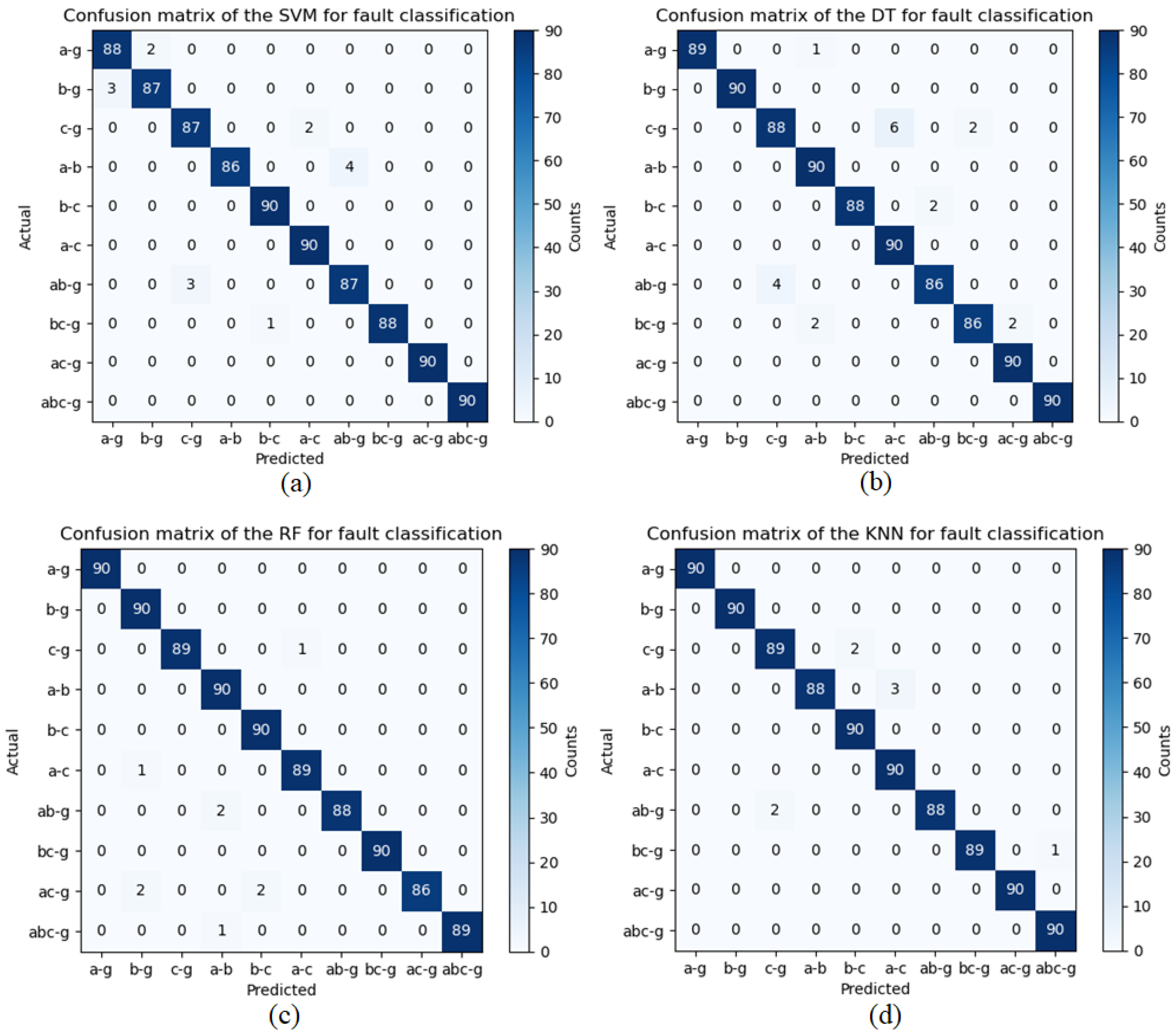
6.1. Confusion Matrixes for Predictive Modeling of Classification Algorithms
6.2. Models Hyperparameters Tuning
6.3. Performance Evaluation Parameters for Classification Models
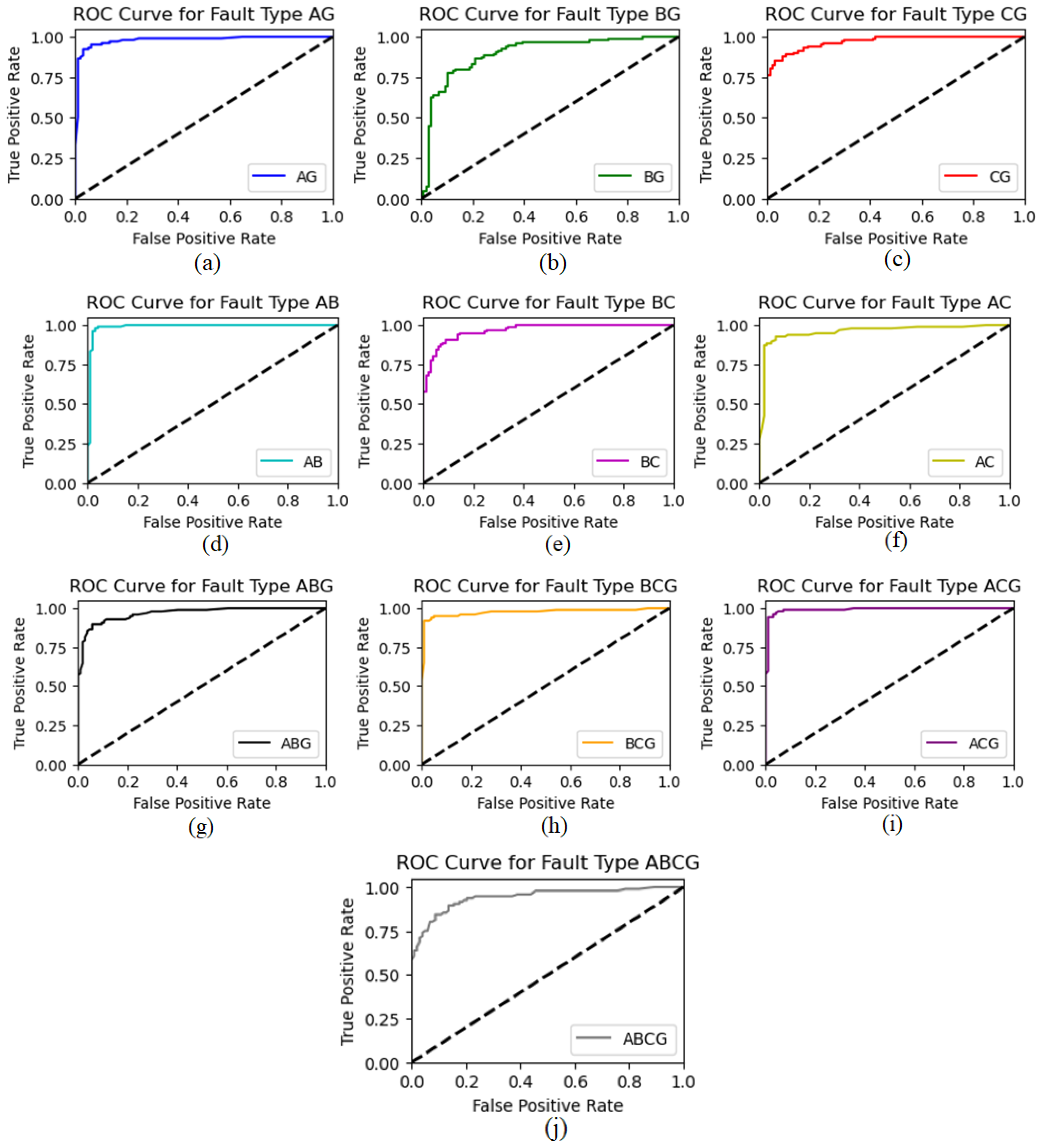
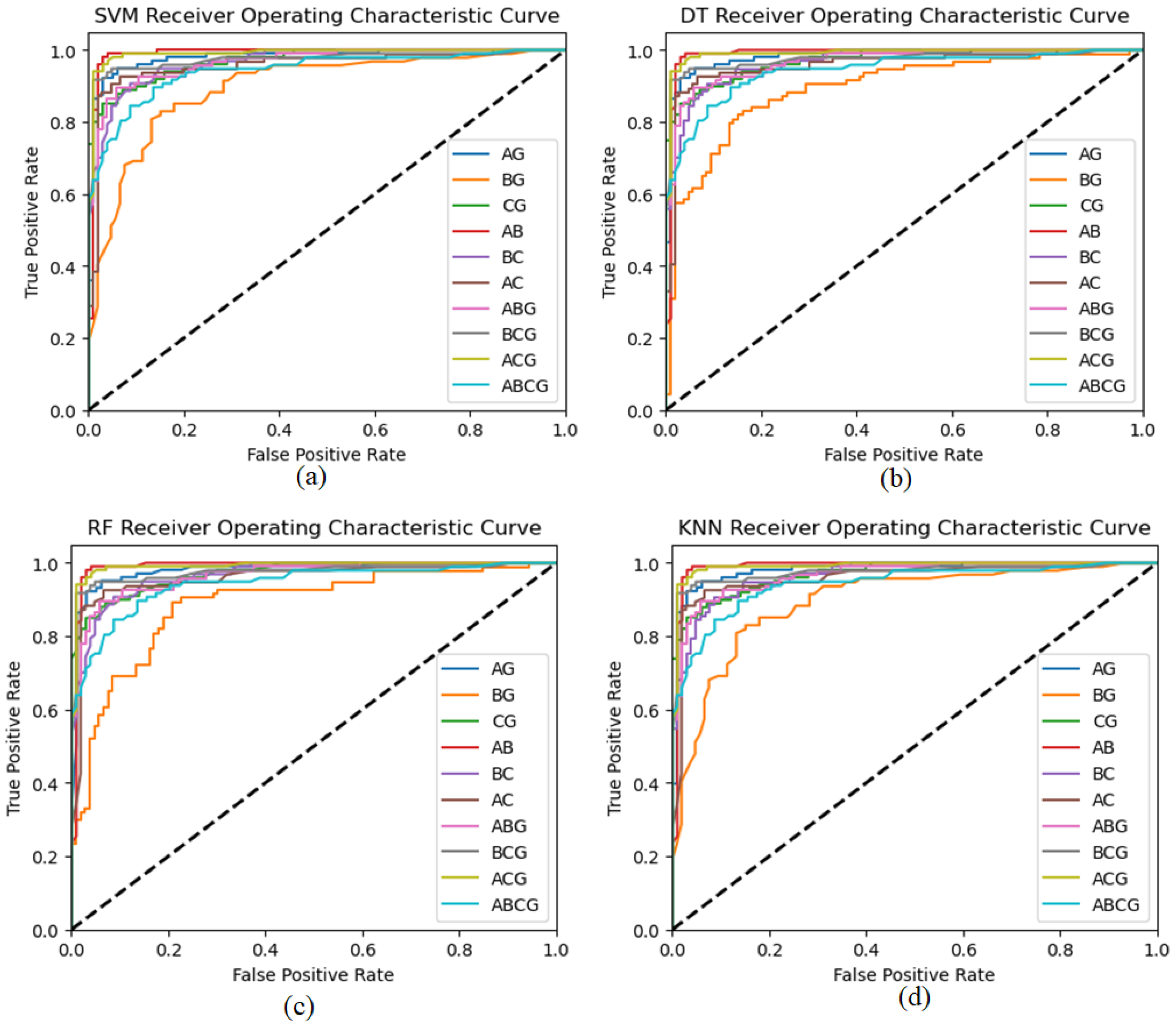
6.4. Receiver Operating Characteristic (ROC) Analysis for Proposed Architectures
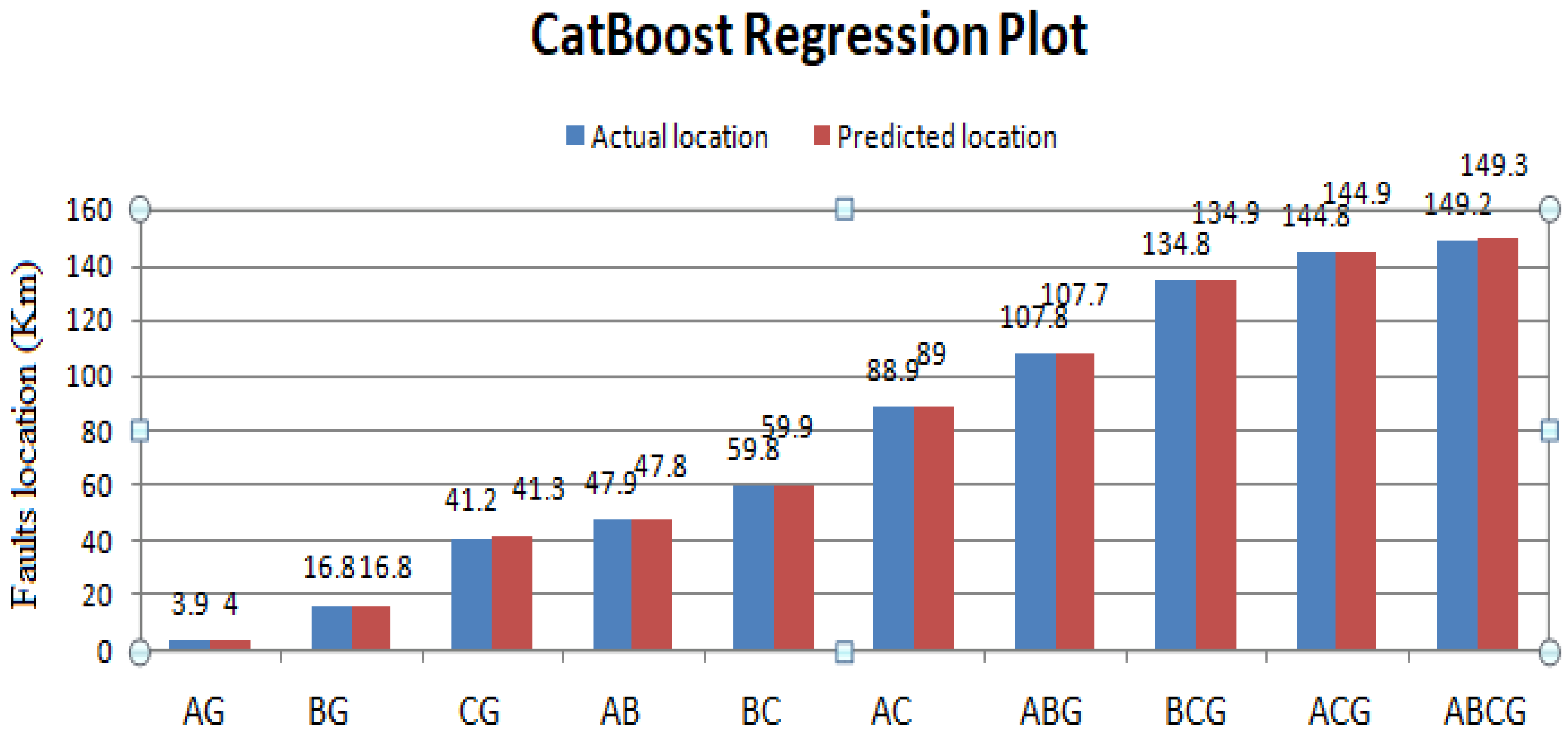
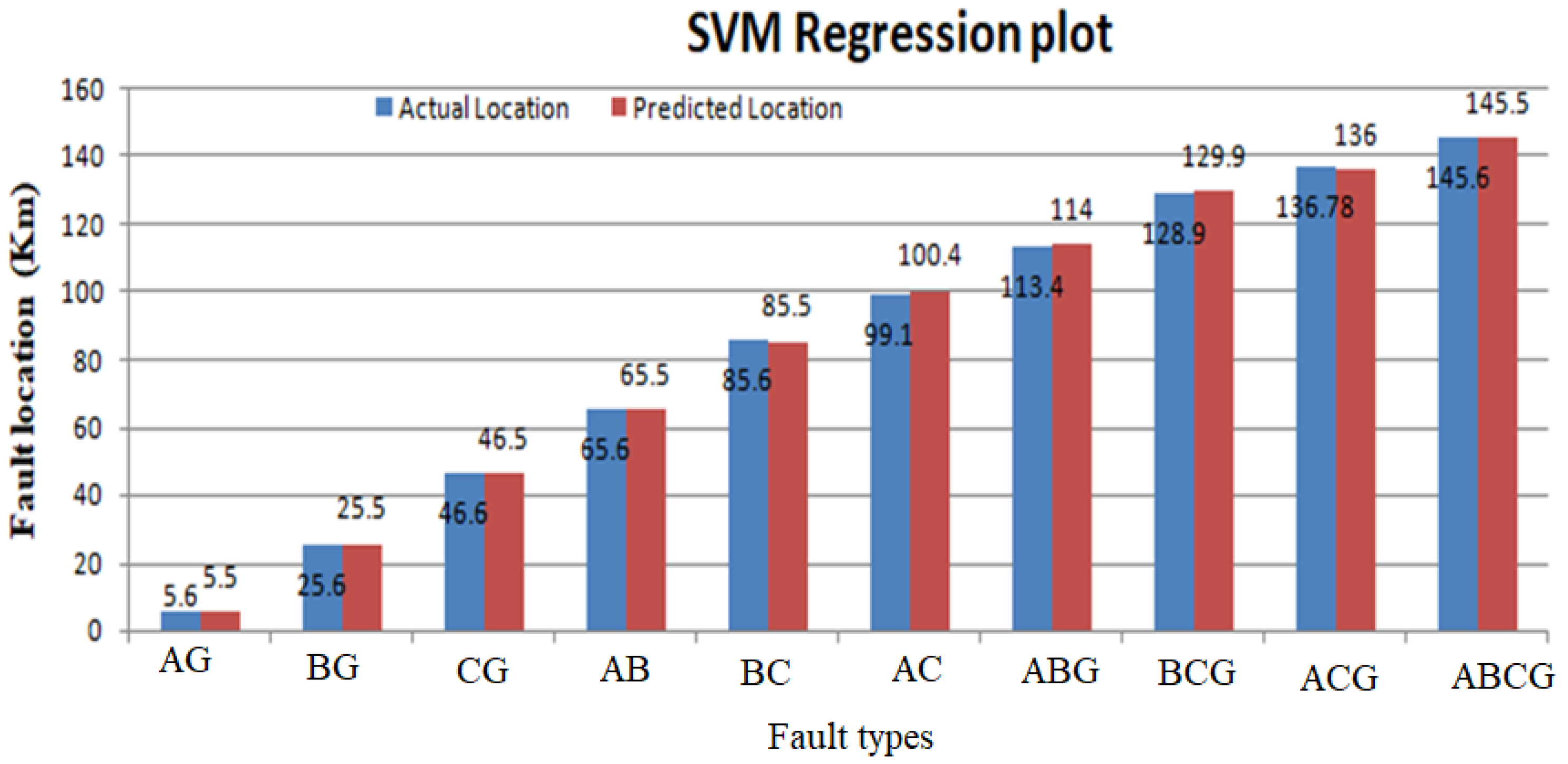
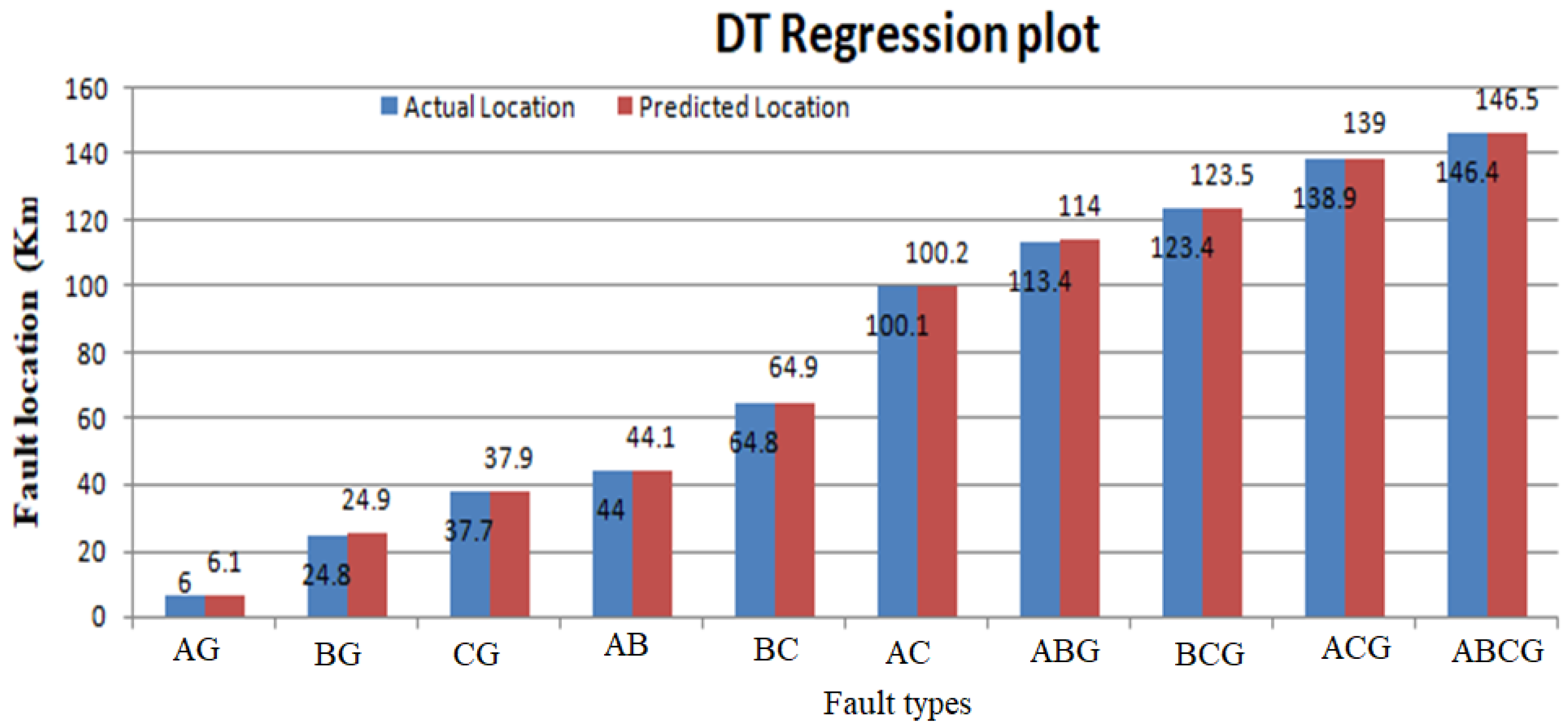
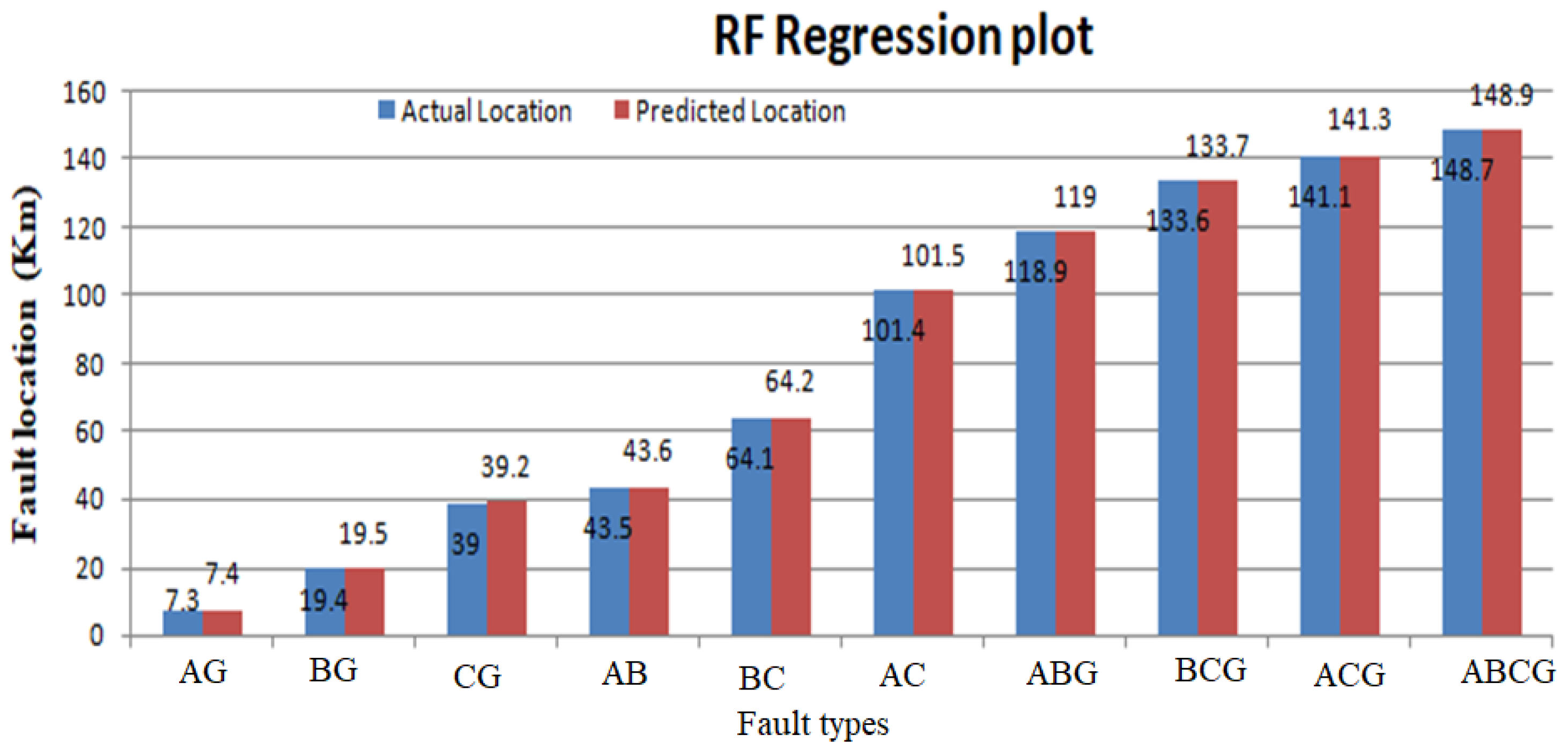
6.5. Fault Localization Results
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Dinsdale, N.J.; Wiecha, P.R.; Delaney, M.; Reynolds, J.; Ebert, M.; Zeimpekis, I.; Thomson, D.J.; Reed, G.T.; Lalanne, P.; Vynck, K.; et al. Deep learning enabled design of complex transmission matrices for universal optical components. ACS Photonics 2021, 8, 283–295. [Google Scholar] [CrossRef]
- Vaish, R.; Dwivedi, U.; Tewari, S.; Tripathi, S. Machine learning applications in power system fault diagnosis: Research advancements and perspectives. Eng. Appl. Artif. Intell. 2021, 106, 104504. [Google Scholar] [CrossRef]
- Kothari, D.P. Power system optimization. In Proceedings of the 2012 2nd National Conference on Computational Intelligence and Signal Processing (CISP), Guwahati, India, 2–3 March 2012; IEEE: Piscataway, NJ, USA, 2012; pp. 18–21. [Google Scholar]
- Raja, H.A.; Kudelina, K.; Asad, B.; Vaimann, T.; Kallaste, A.; Rassõlkin, A.; Van Khang, H. Signal Spectrum-Based Machine Learning Approach for Fault Prediction and Maintenance of Electrical Machines. Energies 2022, 15, 9507. [Google Scholar] [CrossRef]
- Raja, H.A.; Asad, B.; Vaimann, T.; Kallaste, A.; Rassolkin, A.; Belahcen, A. Custom Simplified Machine Learning Algorithms for Fault Diagnosis in Electrical Machines. In Proceedings of the 2022 International Conference on Diagnostics in Electrical Engineering (Diagnostika), Pilsen, Czech Republic, 6–8 September 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 1–4. [Google Scholar]
- Vaimann, T.; Rassõlkin, A.; Kallaste, A.; Pomarnacki, R.; Belahcen, A. Artificial intelligence in monitoring and diagnostics of electrical energy conversion systems. In Proceedings of the 2020 27th International Workshop on Electric Drives: MPEI Department of Electric Drives 90th Anniversary (IWED), Moscow, Russia, 27–30 January 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1–4. [Google Scholar]
- Tirnovan, R.-A.; Cristea, M. Advanced techniques for fault detection and classification in electrical power transmission systems: An overview. In Proceedings of the 2019 8th International Conference on Modern Power Systems (MPS), Cluj Napoca, Romania, 21–23 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–10. [Google Scholar]
- Swana, E.F.; Doorsamy, W.; Bokoro, P. Tomek link and SMOTE approaches for machine fault classification with an imbalanced dataset. Sensors 2022, 22, 3246. [Google Scholar] [CrossRef] [PubMed]
- Zhang, T.; Xia, P.; Lu, F. 3D reconstruction of digital cores based on a model using generative adversarial networks and variational auto-encoders. J. Pet. Sci. Eng. 2021, 207, 109151. [Google Scholar] [CrossRef]
- Razghandi, M.; Zhou, H.; Erol-Kantarci, M.; Turgut, D. Variational autoencoder generative adversarial network for Synthetic Data Generation in smart home. In Proceedings of the ICC 2022-IEEE International Conference on Communications, Seoul, Republic of Korea, 16–20 May 2022; IEEE: Piscataway, NJ, USA, 2022; pp. 4781–4786. [Google Scholar]
- Almeida, A.R.; Almeida, O.M.; Junior BF, S.; Barreto LH, S.C.; Barros, A.K. ICA feature extraction for the location and classification of faults in high-voltage transmission lines. Electr. Power Syst. Res. 2017, 148, 254–263. [Google Scholar] [CrossRef]
- Godse, R.; Bhat, S. Mathematical morphology-based feature-extraction technique for detection and classification of faults on power transmission line. IEEE Access 2020, 8, 38459–38471. [Google Scholar] [CrossRef]
- Al Kharusi, K.; El Haffar, A.; Mesbah, M. Fault detection and classification in transmission lines connected to inverter-based generators using machine learning. Energies 2022, 15, 5475. [Google Scholar] [CrossRef]
- Swetapadma, A.; Mishra, P.; Yadav, A.; Abdelaziz, A.Y. A non-unit protection scheme for double circuit series capacitor compensated transmission lines. Electr. Power Syst. Res. 2017, 148, 311–325. [Google Scholar] [CrossRef]
- Zhang, C.; Kuppannagariy, S.; Kannany, R.; Prasanna, V. Generative adversarial network for synthetic time series data generation in smart grids. In Proceedings of the 2018 IEEE International Conference on Communications, Control, and Computing Technologies for Smart Grids, Aalborg, Denmark, 29–31 October 2018; pp. 1–6. [Google Scholar]
- Razghandi, M.; Zhou, H.; Erol-Kantarci, M.; Turgut, D. Smart Home Energy Management: VAE-GAN synthetic dataset generator and Q-learning. arXiv 2023, arXiv:2305.08885. [Google Scholar] [CrossRef]
- Jain, S.; Seth, G.; Paruthi, A.; Soni, U.; Kumar, G. Synthetic data augmentation for surface defect detection and classification using deep learning. J. Intell. Manuf. 2022, 33, 1007–1020. [Google Scholar] [CrossRef]
- Xu, W.; Yuan, K.; Li, W.; Ding, W. An emerging fuzzy feature selection method using composite entropy-based uncertainty measure and data distribution. IEEE Trans. Emerg. Top. Comput. Intell. 2022, 7, 76–88. [Google Scholar] [CrossRef]
- Ghanem, W.A.H.M.; Ghaleb, S.A.A.; Jantan, A.; Nasser, A.B.; Saleh, S.A.M.; Ngah, A.B.; Alhadi, A.C.; Arshad, H.; Saad, A.-M.H.Y.; Omolara, A.E.; et al. Cyber intrusion detection system based on a multiobjective binary bat algorithm for feature selection and enhanced bat algorithm for parameter optimization in neural networks. IEEE Access 2022, 10, 76318–76339. [Google Scholar] [CrossRef]
- Espejo, R.; Lumbreras, S.; Ramos, A. A complex-network approach to the generation of synthetic power transmission networks. IEEE Syst. J. 2018, 13, 3050–3058. [Google Scholar] [CrossRef]
- Ogar, V.N.; Hussain, S.; Gamage, K.A. Transmission line fault classification of multi-dataset using catboost classifier. Signals 2022, 3, 468–482. [Google Scholar] [CrossRef]
- Wu, J.; Li, Q.; Chen, Q.; Zhang, N.; Mao, C.; Yang, L.; Wang, J. Fault diagnosis of the HVDC system based on the CatBoost algorithm using knowledge graphs. Front. Energy Res. 2023, 11, 1144785. [Google Scholar] [CrossRef]
- Kouziokas, G.N. SVM kernel based on particle swarm optimized vector and Bayesian optimized SVM in atmospheric particulate matter forecasting. Appl. Soft Comput. 2020, 93, 106410. [Google Scholar] [CrossRef]
- Parisi, L. m-arcsinh: An Efficient and Reliable Function for SVM and MLP in scikit-learn. arXiv 2020, arXiv:2009.07530. [Google Scholar]
- Khan, P.W.; Byun, Y.-C. Multi-fault detection and classification of wind turbines using stacking classifier. Sensors 2022, 22, 6955. [Google Scholar] [CrossRef]
- Ekici, S. Support Vector Machines for classification and locating faults on transmission lines. Appl. Soft Comput. 2012, 12, 1650–1658. [Google Scholar] [CrossRef]
- Johnson, J.M.; Yadav, A. Complete protection scheme for fault detection, classification and location estimation in HVDC transmission lines using support vector machines. IET Sci. Meas. Technol. 2017, 11, 279–287. [Google Scholar] [CrossRef]
- Fei, C.; Qin, J. Fault location after fault classification in transmission line using voltage amplitudes and support vector machine. Russ. Electr. Eng. 2021, 92, 112–121. [Google Scholar]
- Quinlan, J.R. Decision trees and decision-making. IEEE Trans. Syst. Man Cybern. 1990, 20, 339–346. [Google Scholar] [CrossRef]
- Daniya, T.; Geetha, M.; Kumar, K.S. Classification and regression trees with gini index. Adv. Math. Sci. J. 2020, 9, 1857–8438. [Google Scholar] [CrossRef]
- Chen, K.; Huang, C.; He, J. Fault detection, classification and location for transmission lines and distribution systems: A review on the methods. High Volt. 2016, 1, 25–33. [Google Scholar] [CrossRef]
- Chen, Y.Q.; Fink, O.; Sansavini, G. Combined fault location and classification for power transmission lines fault diagnosis with integrated feature extraction. IEEE Trans. Ind. Electron. 2017, 65, 561–569. [Google Scholar] [CrossRef]
- Han, S.; Williamson, B.D.; Fong, Y. Improving random forest predictions in small datasets from two-phase sampling designs. BMC Med. Inform. Decis. Mak. 2021, 21, 322. [Google Scholar] [CrossRef]
- Zhu, Y.; Peng, H. Multiple Random Forests Based Intelligent Location of Single-Phase Grounding Fault in Power Lines of DFIG-Based Wind Farm. J. Mod. Power Syst. Clean Energy 2022, 10, 1152–1163. [Google Scholar] [CrossRef]
- Chakraborty, D.; Sur, U.; Banerjee, P.K. Random forest based fault classification technique for active power system networks. In Proceedings of the 2019 IEEE International WIE Conference on Electrical and Computer Engineering (WIECON-ECE), Bangalore, India, 15–16 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 1–4. [Google Scholar]
- van de Leur, R.R.; Bos, M.N.; Taha, K.; Sammani, A.; Yeung, M.W.; van Duijvenboden, S.; Lambiase, P.D.; Hassink, R.J.; van der Harst, P.; Doevendans, P.A.; et al. Improving explainability of deep neural network-based electrocardiogram interpretation using variational auto-encoders. Eur. Heart J.-Digit. Health 2022, 3, 390–404. [Google Scholar] [CrossRef]
- Mahdavi, M.; Choubdar, H.; Rostami, Z.; Niroomand, B.; Levine, A.T.; Fatemi, A.; Bolhasani, E.; Vahabie, A.-H.; Lomber, S.G.; Merrikhi, Y. Hybrid feature engineering of medical data via variational autoencoders with triplet loss: A COVID-19 prognosis study. Sci. Rep. 2023, 13, 2827. [Google Scholar] [CrossRef]
- Ahmed, T.; Longo, L. Examining the size of the latent space of convolutional variational autoencoders trained with spectral topographic maps of EEG frequency bands. IEEE Access 2022, 10, 107575–107586. [Google Scholar] [CrossRef]
- Farhadyar, K.; Bonofiglio, F.; Zoeller, D.; Binder, H. Adapting deep generative approaches for getting synthetic data with realistic marginal distributions. arXiv 2021, arXiv:2105.06907. [Google Scholar]
- Wan, Z.; Zhang, Y.; He, H. Variational autoencoder based synthetic data generation for imbalanced learning. In Proceedings of the 2017 IEEE Symposium Series on Computational Intelligence (SSCI), Honolulu, HI, USA, 27 November–1 December 2017; IEEE: Piscataway, NJ, USA, 2017; pp. 1–7. [Google Scholar]
- Anh, D.T.; Pandey, M.; Mishra, V.N.; Singh, K.K.; Ahmadi, K.; Janizadeh, S.; Dang, N.M. Assessment of groundwater potential modeling using support vector machine optimization based on Bayesian multi-objective hyperparameter algorithm. Appl. Soft Comput. 2023, 132, 109848. [Google Scholar] [CrossRef]
- Passos, D.; Mishra, P. A tutorial on automatic hyperparameter tuning of deep spectral modelling for regression and classification tasks. Chemom. Intell. Lab. Syst. 2022, 223, 104520. [Google Scholar] [CrossRef]
- Chicco, D.; Jurman, G. The advantages of the Matthews correlation coefficient (MCC) over F1 score and accuracy in binary classification evaluation. BMC Genom. 2020, 21, 1–13. [Google Scholar] [CrossRef]
- Martínez-Camblor, P.; Pérez-Fernández, S.; Díaz-Coto, S. The area under the generalized receiver-operating characteristic curve. Int. J. Biostat. 2021, 18, 293–306. [Google Scholar] [CrossRef]






















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Algorithm | Type | Use Case | Pros | Cons |
|---|---|---|---|---|
| Support Vector Machines | Supervised | Classification Regression | Effective handling of outliers through kernel tricks | Creates problems with noisy & large datasets |
| Decision Trees | Supervised | Classification Regression | Highly interpretable and easy to implement | Small changes in data create different tree structures |
| Random Forests | Supervised | Classification Regression | Implement ensemble averaging for predictions | Less interpretable due to the large number of Decision Trees |
| K-Nearest Neighbors | Supervised | Classification Regression | Minimum assumptions for data distribution | Computational cost and sensitivity of K |
| Parameter | Unit | Value |
|---|---|---|
| Phase to phase (voltages) | KV | 220 |
| Source resistance (Rs) | Ohms (Ω) | 0.7896 |
| Source inductance (Ls) | Henry (H) | 13.43 × 10−2 |
| Fault incipient angle (φ) | Degrees | 0° and −30° |
| Fault resistance (Ron) | Ohms (Ω) | 0.001 |
| Ground resistance (Rg) | Ohms (Ω) | 0.01 |
| Snubber resistance (Rsn) | Ohms (Ω) | 0.9 × 10−4 |
| Fault capacitance (Cs) | Farad (F) | infinite |
| Switching time | Seconds | b/w 0.1 and 0.2 |
| Sequence Parameters | Unit | Value |
|---|---|---|
| Positive and negative sequence resistances (R1 and R2) | Ohms/Km | 0.01154 |
| Zero sequence resistance (Ro) | Ohms/Km | 0.3165 |
| Positive and negative sequence capacitance (C1, C2, and C3) | nF/Km | 10.14 |
| Zero sequence capacitance (Co) | nF/Km | 5.7853 |
| Positive and negative sequence inductances (L1, L2, and L3) | mH/KM | 0.7945 |
| Zero sequence capacitance (Lo) | mH/KM | 2.9981 |
| Hyperparameter | Description | Value |
|---|---|---|
| Iterations | No. of boosting iterations | 1000 |
| Depth | Depth of the tree | 6 |
| Learning rate | Learning rate | 0.1 |
| Loss function | LS for classification/regression | Log loss/RMSE |
| Class weight | List of categorical features | 0.01, 0.001, 0.9, 0.0001 |
| Verbose | Print progress every X iterations | |
| Random strength | Search randomly a certain number of combinations | 0.1 |
| Fault Type | Fault Label |
|---|---|
| Line-to-ground | AG |
| Line-to-ground | BG |
| Line-to-ground | CG |
| Double line-to-ground faults | ABG |
| Double line-to-ground faults | BCG |
| Double line-to-ground faults | ACG |
| Line-to-line faults | AB |
| Line-to-line faults | BC |
| Line-to-line faults | AC |
| Three line-to-ground faults | ABC-G |
| Attributes | Training Dataset | Testing Dataset |
|---|---|---|
| Fault types | All kinds of shunt faults | All kinds of shunt faults |
| Fault resistances | 0, 25, 50, 75, 100, 150 | 0, 25, 50, 75, 100, 150 |
| Fault distances | Increments of 4.4 km to 150 km | Increments of 4.4 km to 150 km |
| Size | 14,400 | 4498 |
| Hyper-Tuning Parameters for SVM | Hyper-Tuning Parameters for DT | ||
|---|---|---|---|
| Tuning parameters | Values | Parameters | Values |
| Kernel function | linear | Criterion | entropy |
| Regularization parameter (C) | 0.1 | Splitter | best |
| Kernel Coefficient (gamma) | 0.1 | max_depth | 90 |
| Coefficient of kernel | 1 | min_samples_split | 3 |
| Validation accuracy | 1 | min_samples_leaf | 2 |
| max_features | 5 | ||
| ccp_alpha | 0.01 | ||
| Hyper-Tuning Parameters for Random Forest | Hyper-Tuning Parameters for KNN | ||
| Parameters | Values | Parameters | Values |
| Criterion | entropy | n_neighbors | 3 |
| Splitter | best | weights | distance |
| max_depth | 90 | metric | Euclidean |
| min_samples_split | 3 | ||
| min_samples_leaf | 2 | ||
| max_features | 5 | ||
| Machine Learning Model | Fault Types | No. of Test Data Samples | Accurately Classified Samples | Misclassified Samples | Accuracy % |
|---|---|---|---|---|---|
| SVM | LG (a-g, b-g, c-g) | 270 | 268 | 2 | 99.25 |
| LL (a-b, b-c, c-a) | 270 | 266 | 4 | 98.51 | |
| LL-G (ab-g, bc-g, ac-g) | 270 | 266 | 4 | 98.51 | |
| LLL (abc) | 90 | 90 | 0 | 100 | |
| DT | LG (a-g, b-g, c-g) | 270 | 261 | 9 | 96.66 |
| LL (a-b, b-c, c-a) | 270 | 268 | 2 | 97.74 | |
| LL-G (ab-g, bc-g, ac-g) | 270 | 262 | 8 | 98.95 | |
| LLL (abc) | 90 | 90 | 0 | 100 | |
| RF | LG (a-g, b-g, c-g) | 270 | 269 | 1 | 99.62 |
| LL (a-b, b-c, c-a) | 270 | 269 | 1 | 99.62 | |
| LL-G (ab-g, bc-g, ac-g) | 270 | 267 | 3 | 98.88 | |
| LLL (abc) | 90 | 89 | 1 | 99.62 | |
| KNN | LG (a-g, b-g, c-g) | 270 | 269 | 1 | 99.62 |
| LL (a-b, b-c, c-a) | 270 | 269 | 1 | 99.62 | |
| LL-G (ab-g, bc-g, ac-g) | 270 | 267 | 3 | 98.88 | |
| LLL (abc) | 90 | 90 | 0 | 100 |
| Classifier | Accuracy | Precision | Recall | F1 Score |
|---|---|---|---|---|
| SVM | 0.99 | 0.99 | 0.99 | 0.98 |
| DT | 0.97 | 0.98 | 0.97 | 0.98 |
| RF | 0.99 | 0.99 | 0.99 | 0.99 |
| KNN | 0.98 | 0.99 | 0.97 | 0.98 |
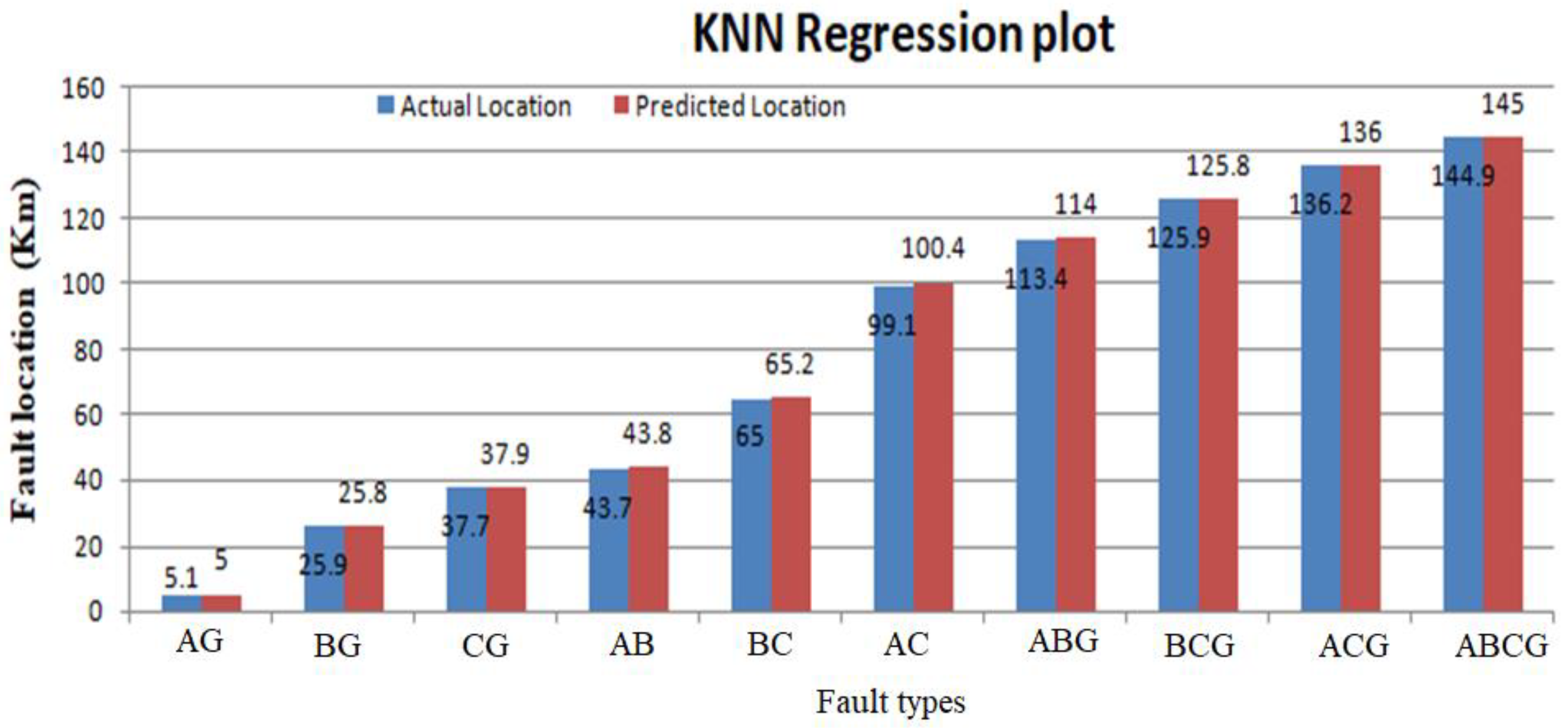
| Machine Learning Model | True Fault Distance | Predicted Fault Distance | % of Error |
|---|---|---|---|
| SVM | 116.9 | 115.6 | 1.3 |
| 104.4 | 103.7 | 0.63 | |
| 52.4 | 51.5 | 0.9 | |
| 115.1 | 113.8 | 1.36 | |
| DT | 21.6 | 21.2 | 0.4 |
| 114.2 | 112.8 | 1.4 | |
| 74.4 | 73.3 | 0.7 | |
| 50.0 | 49.2 | 0.8 | |
| RF | 61.2 | 59.7 | 1.5 |
| 48.1 | 47.6 | 0.58 | |
| 103.3 | 102.4 | 0.92 | |
| 146.4 | 145.9 | 0.9 | |
| KNN | 115.6 | 114.8 | 0.8 |
| 104.4 | 103.9 | 0.48 | |
| 112.8 | 112.2 | 0.6 | |
| 21.2 | 20.2 | 0.99 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Khan, M.A.; Asad, B.; Vaimann, T.; Kallaste, A.; Pomarnacki, R.; Hyunh, V.K. Improved Fault Classification and Localization in Power Transmission Networks Using VAE-Generated Synthetic Data and Machine Learning Algorithms. Machines 2023, 11, 963. https://doi.org/10.3390/machines11100963
Khan MA, Asad B, Vaimann T, Kallaste A, Pomarnacki R, Hyunh VK. Improved Fault Classification and Localization in Power Transmission Networks Using VAE-Generated Synthetic Data and Machine Learning Algorithms. Machines. 2023; 11(10):963. https://doi.org/10.3390/machines11100963
Chicago/Turabian StyleKhan, Muhammad Amir, Bilal Asad, Toomas Vaimann, Ants Kallaste, Raimondas Pomarnacki, and Van Khang Hyunh. 2023. "Improved Fault Classification and Localization in Power Transmission Networks Using VAE-Generated Synthetic Data and Machine Learning Algorithms" Machines 11, no. 10: 963. https://doi.org/10.3390/machines11100963