A Minimal-Sensing Framework for Monitoring Multistage Manufacturing Processes Using Product Quality Measurements †



Abstract
:
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
1. Introduction
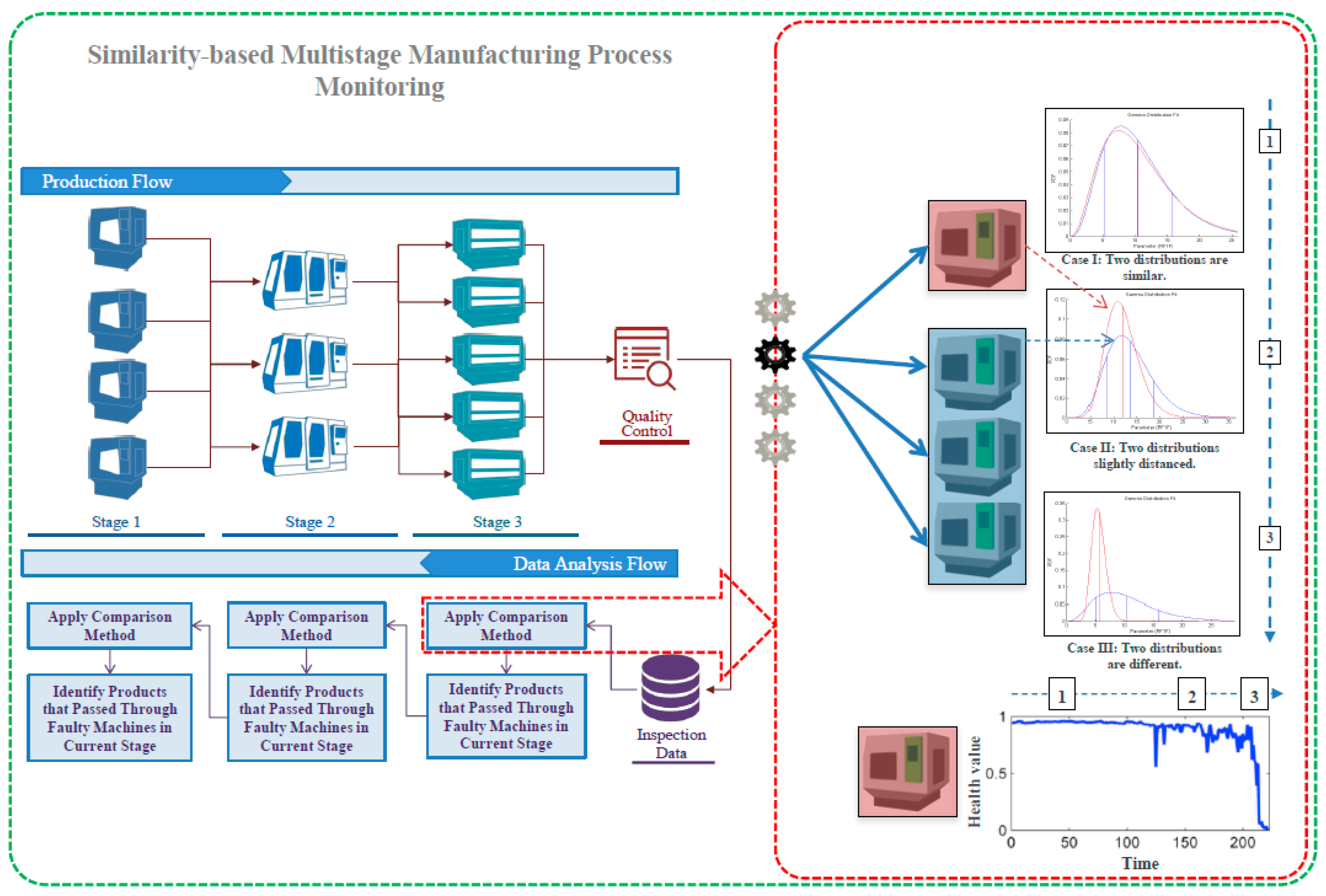
2. Theoretical Background
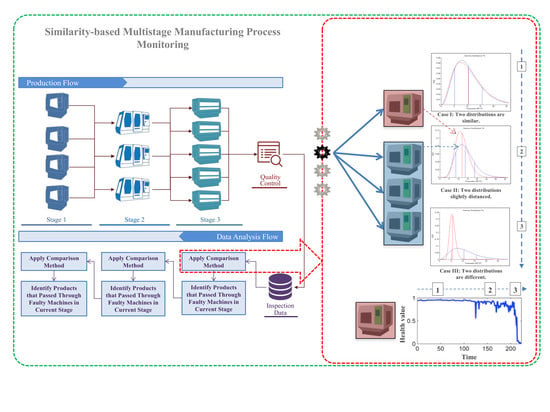
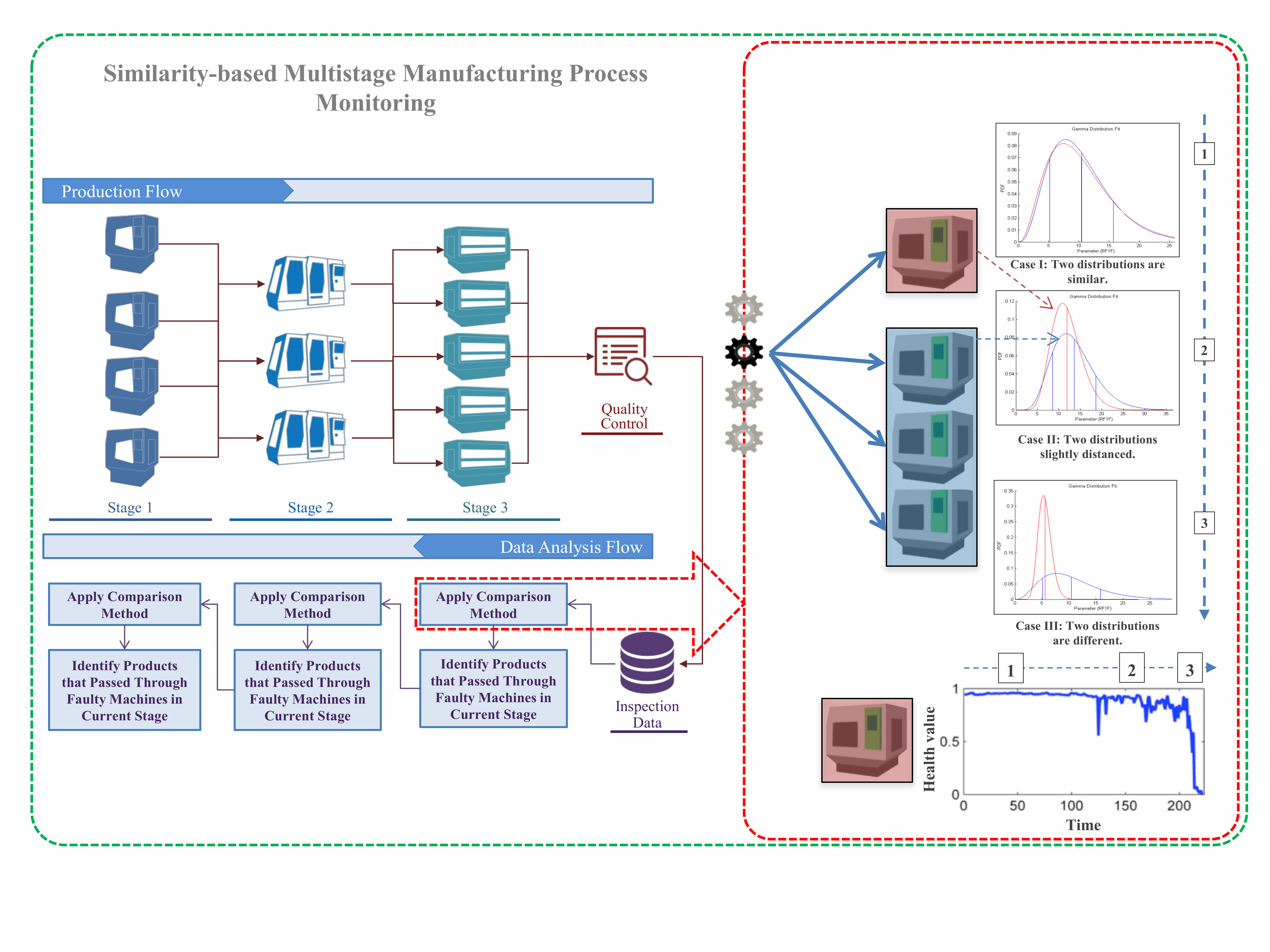
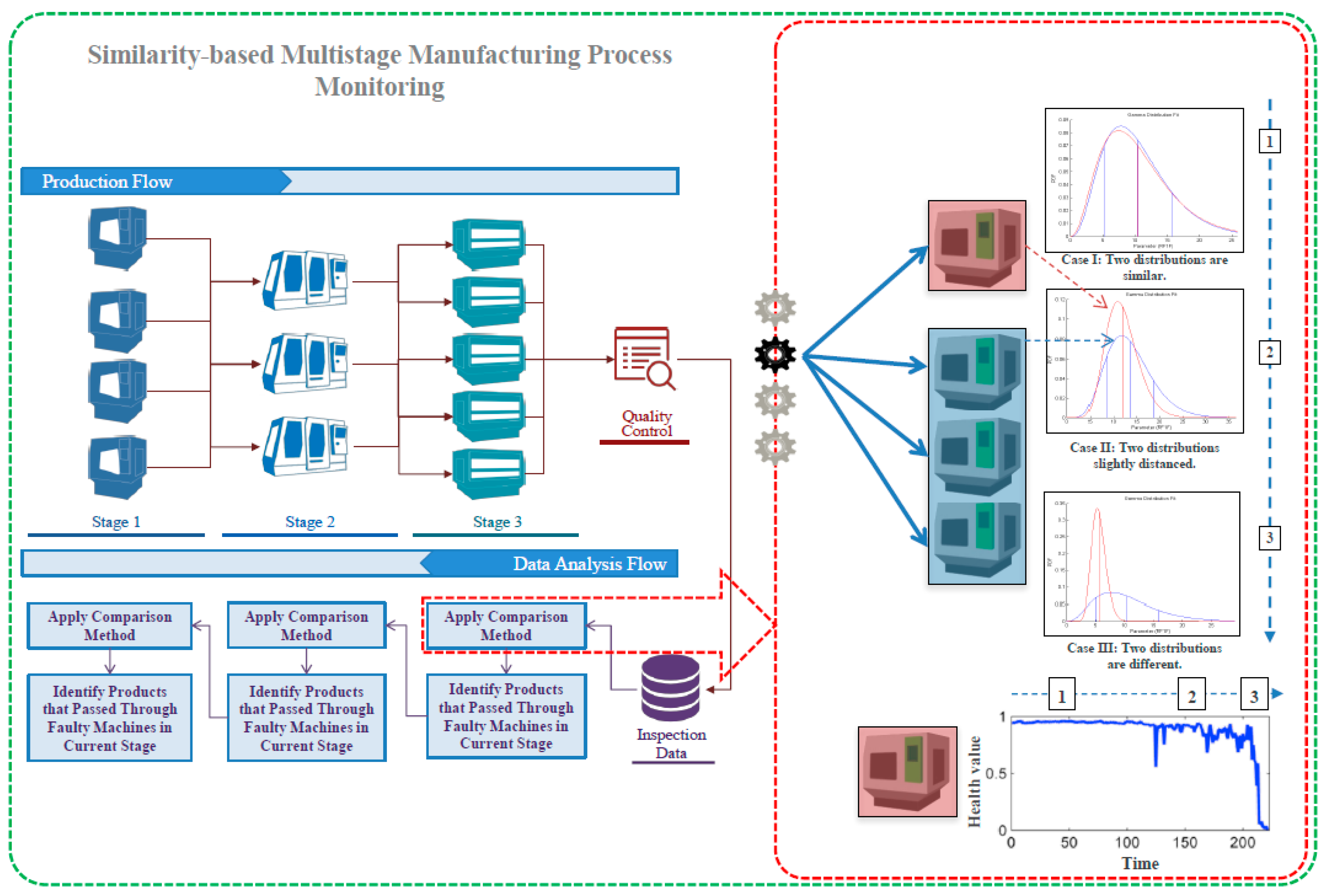
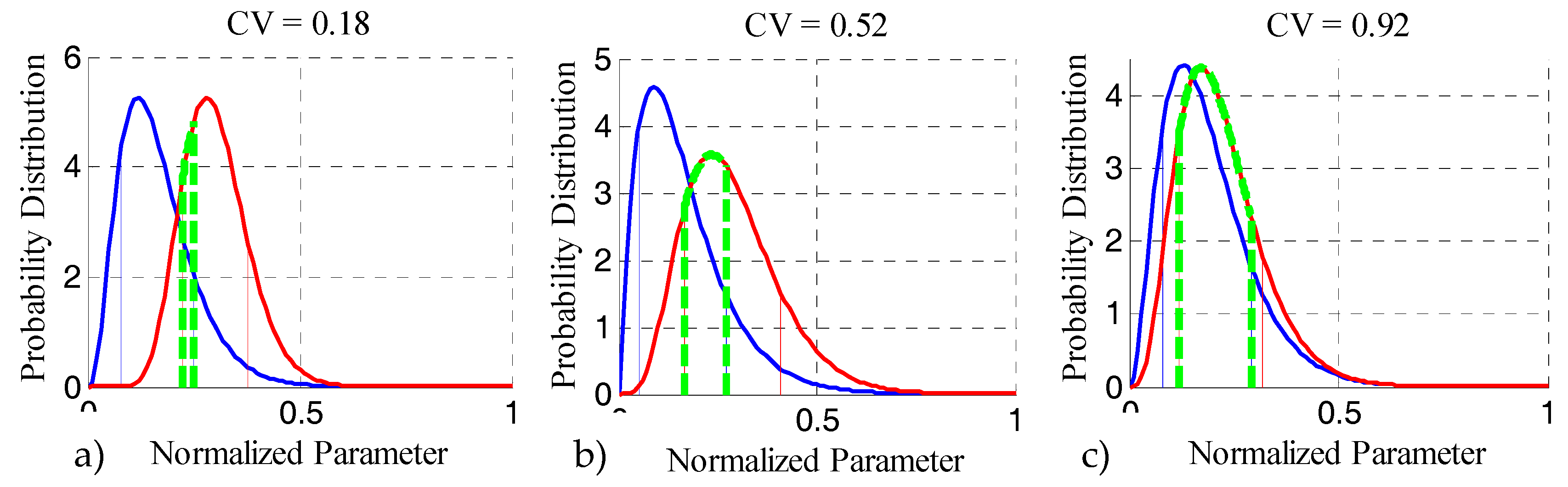
2.1. Intuition and General Framework
2.2. Mathematical Description
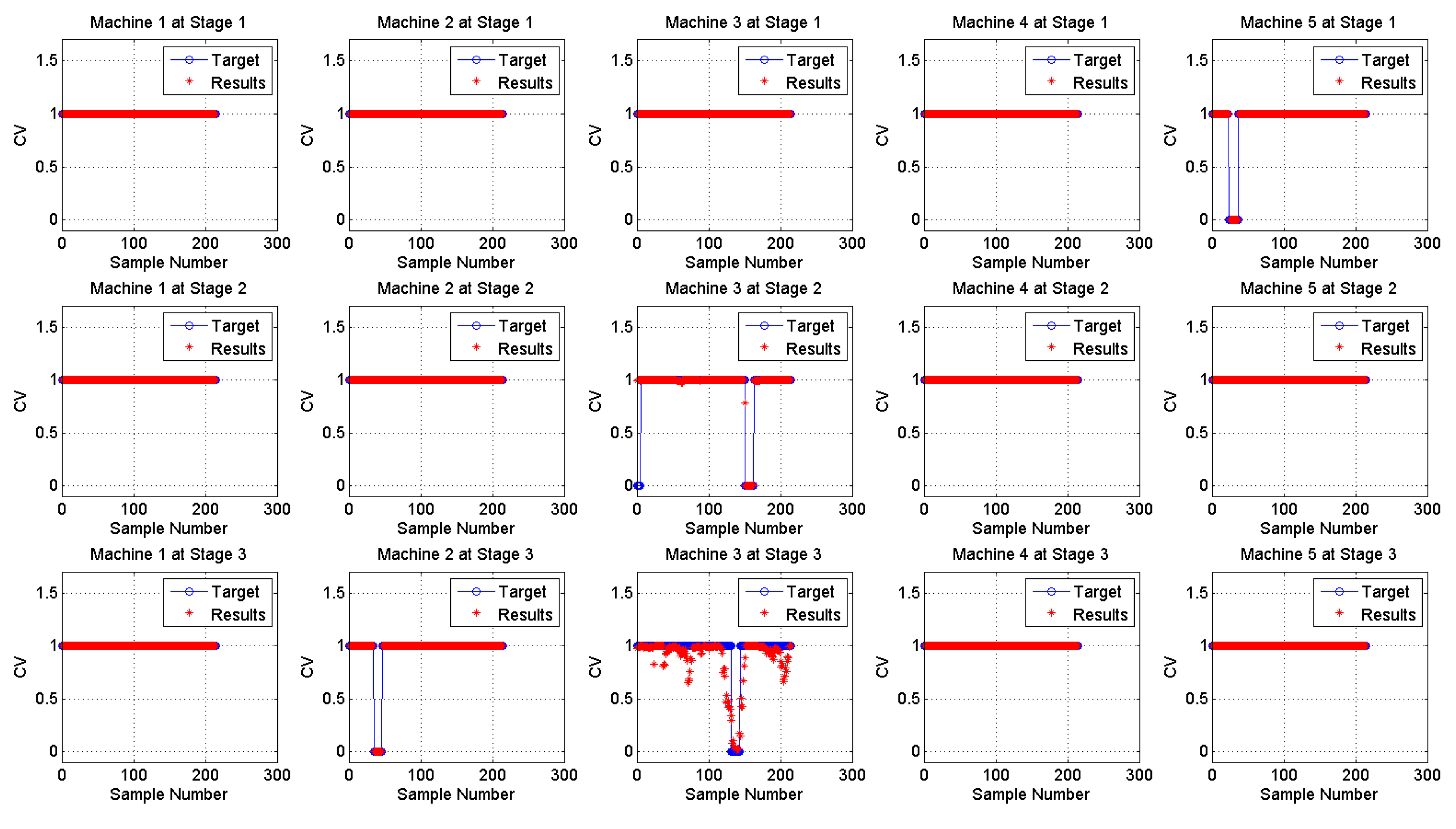
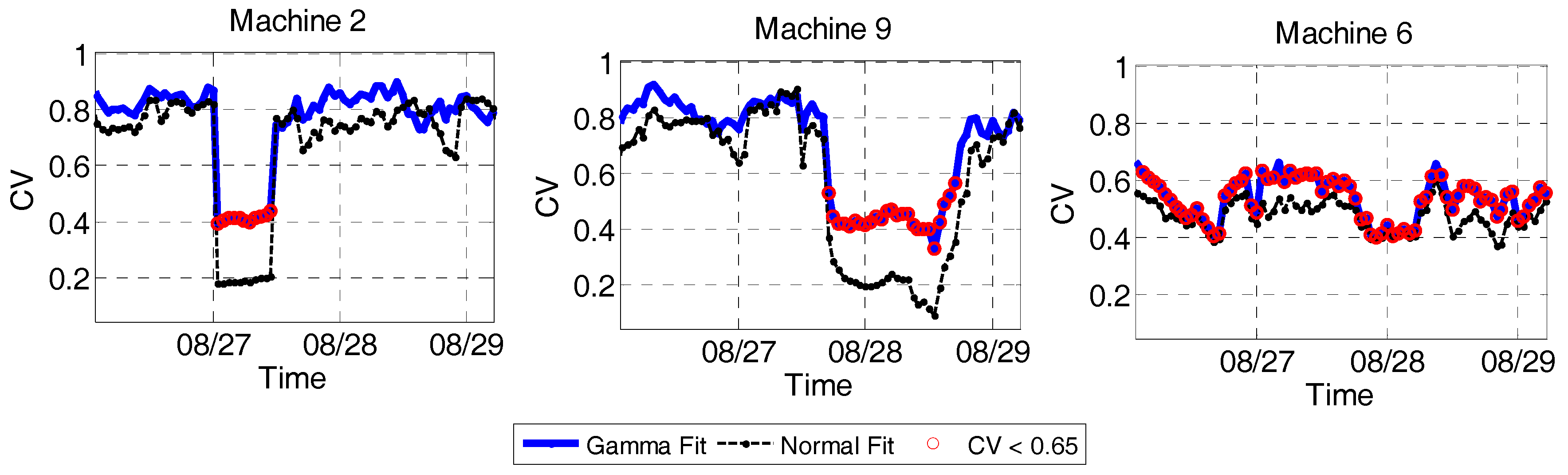
3. Experiment and Validation
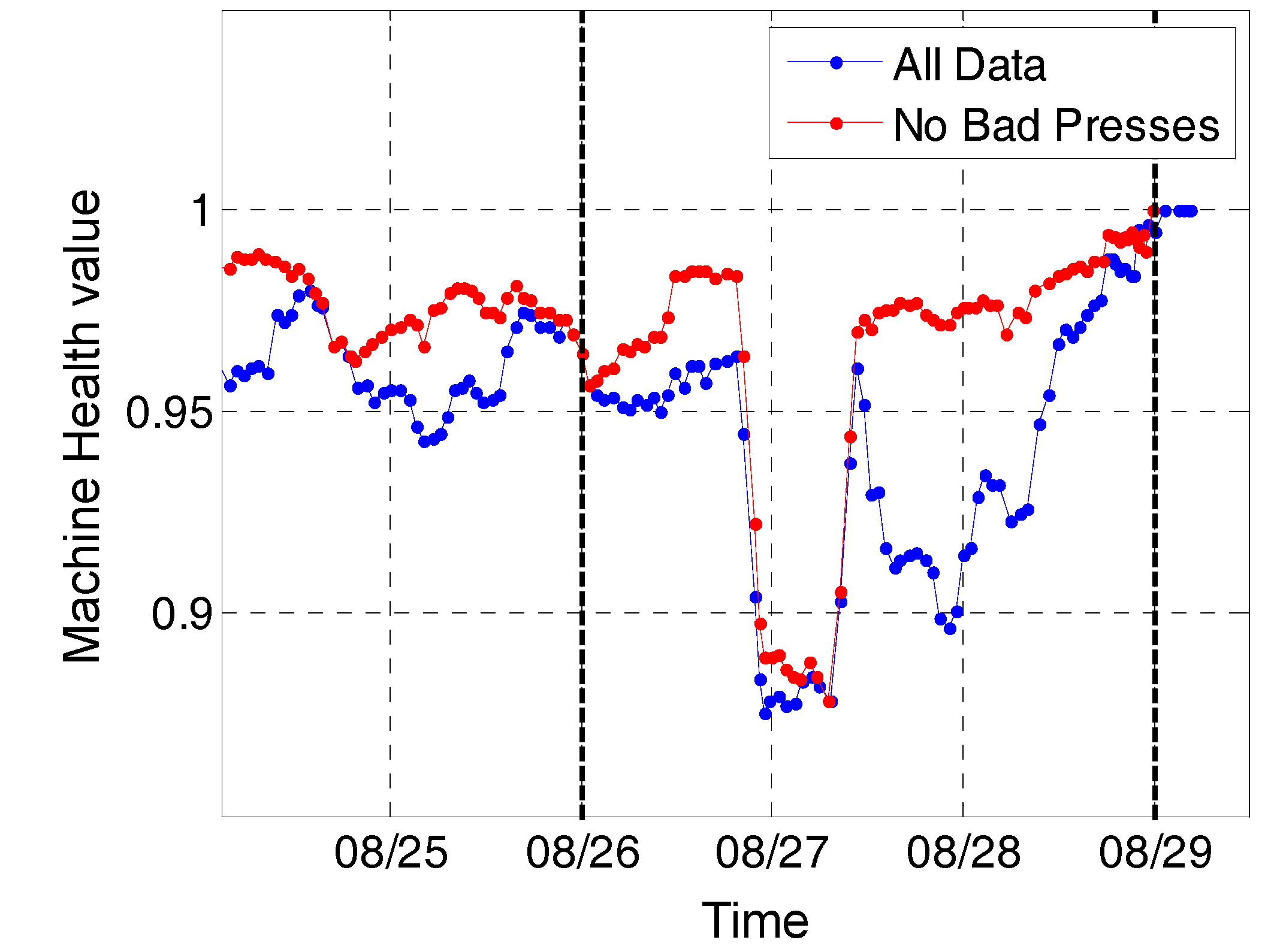
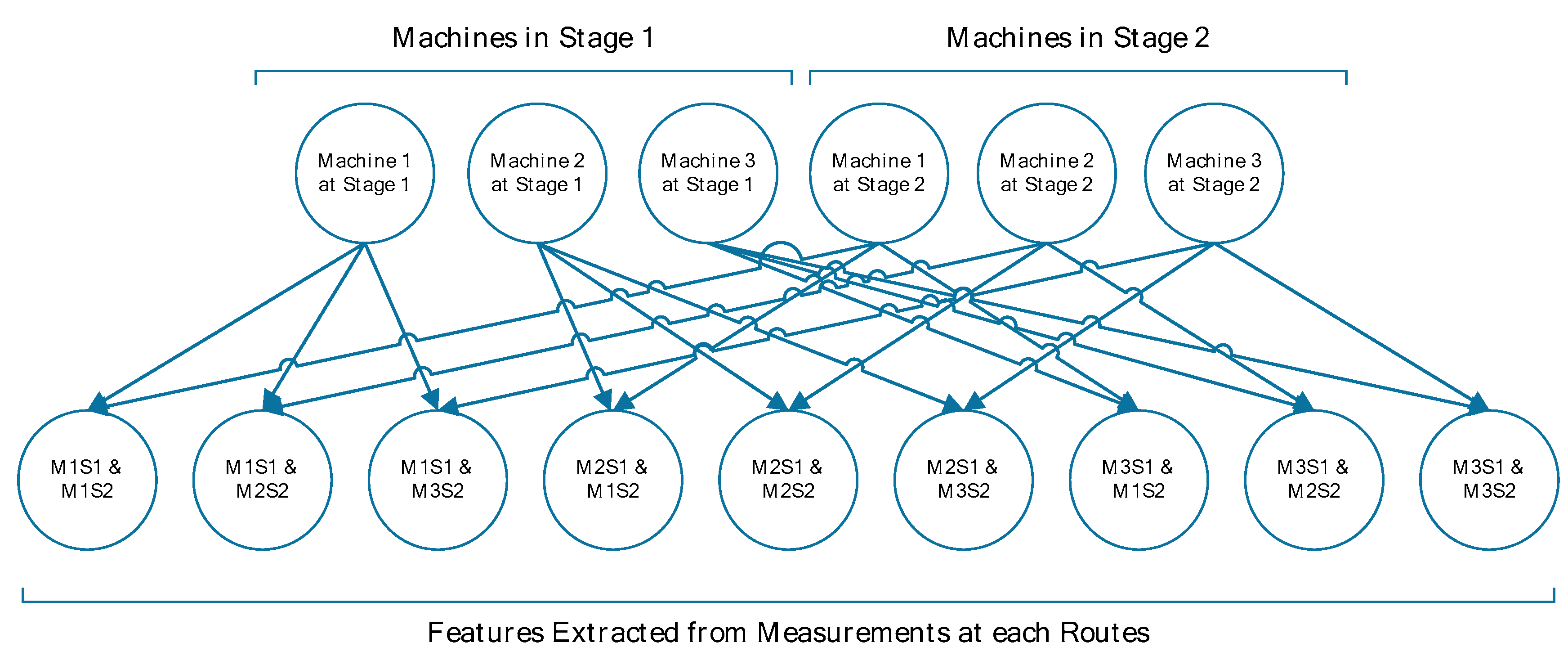
3.1. Data Description
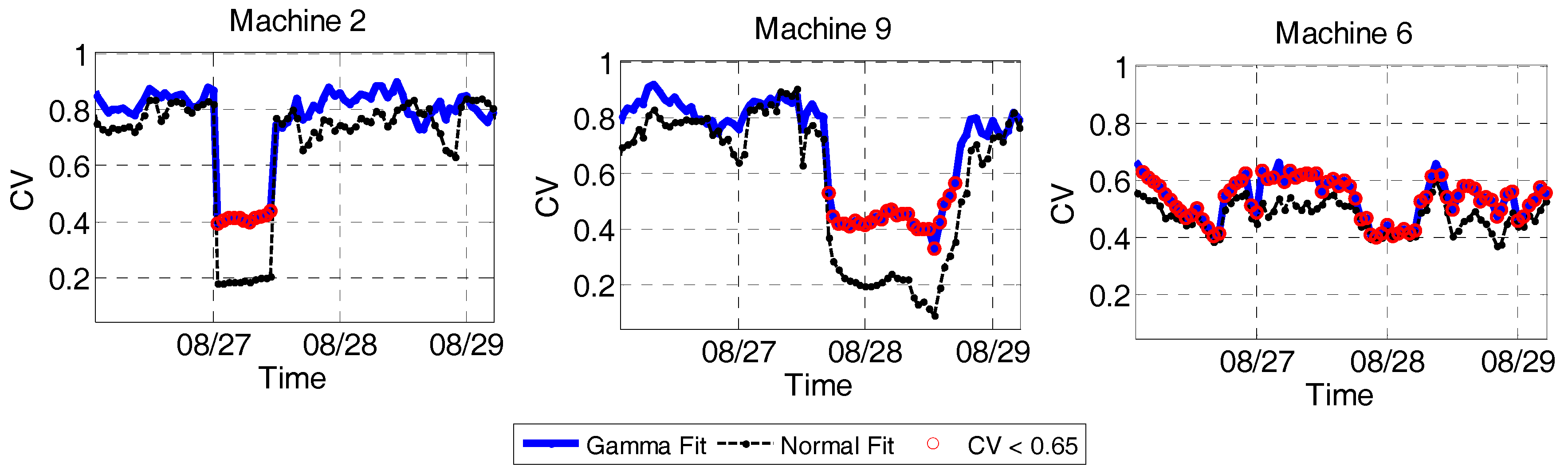
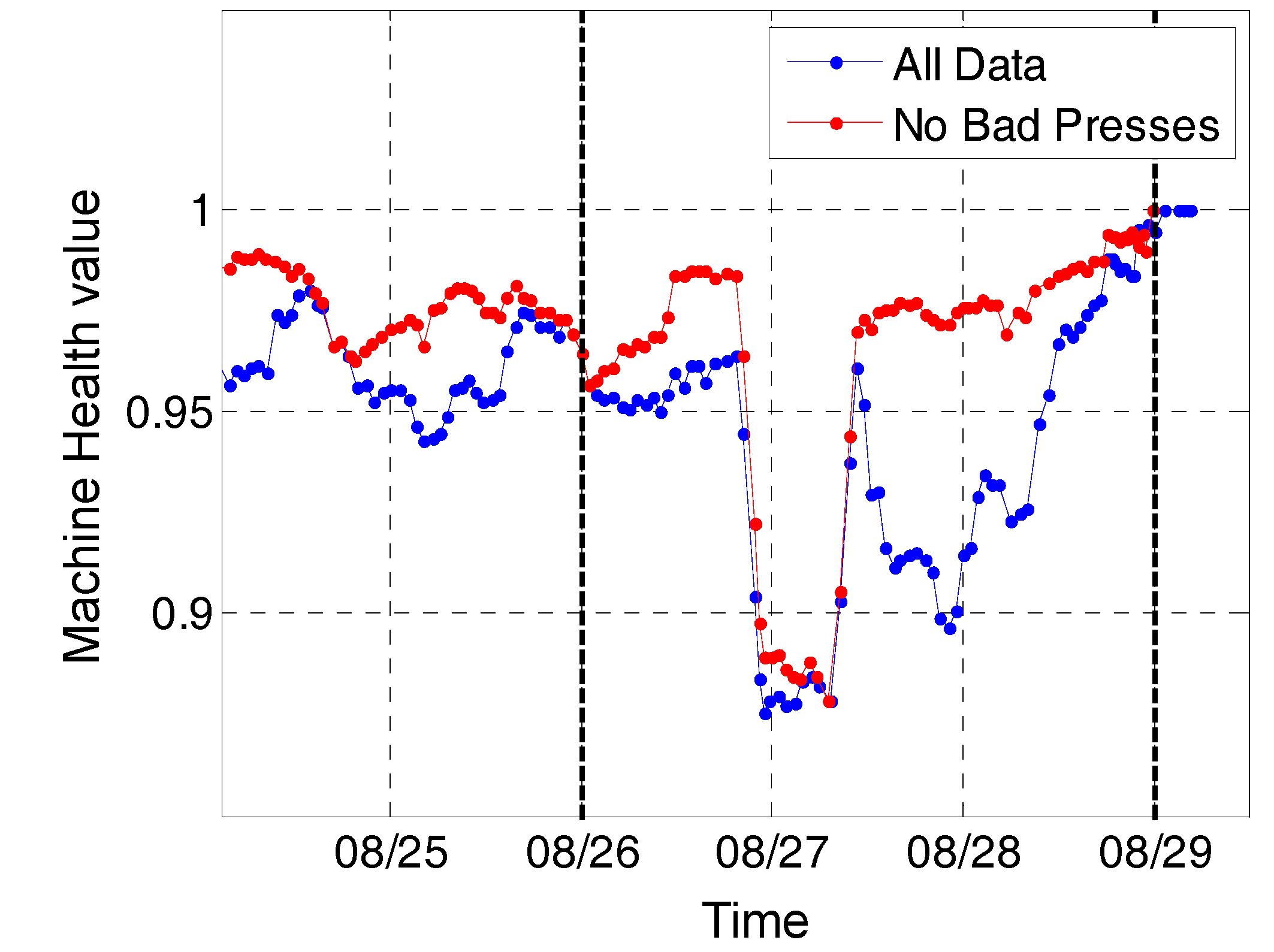
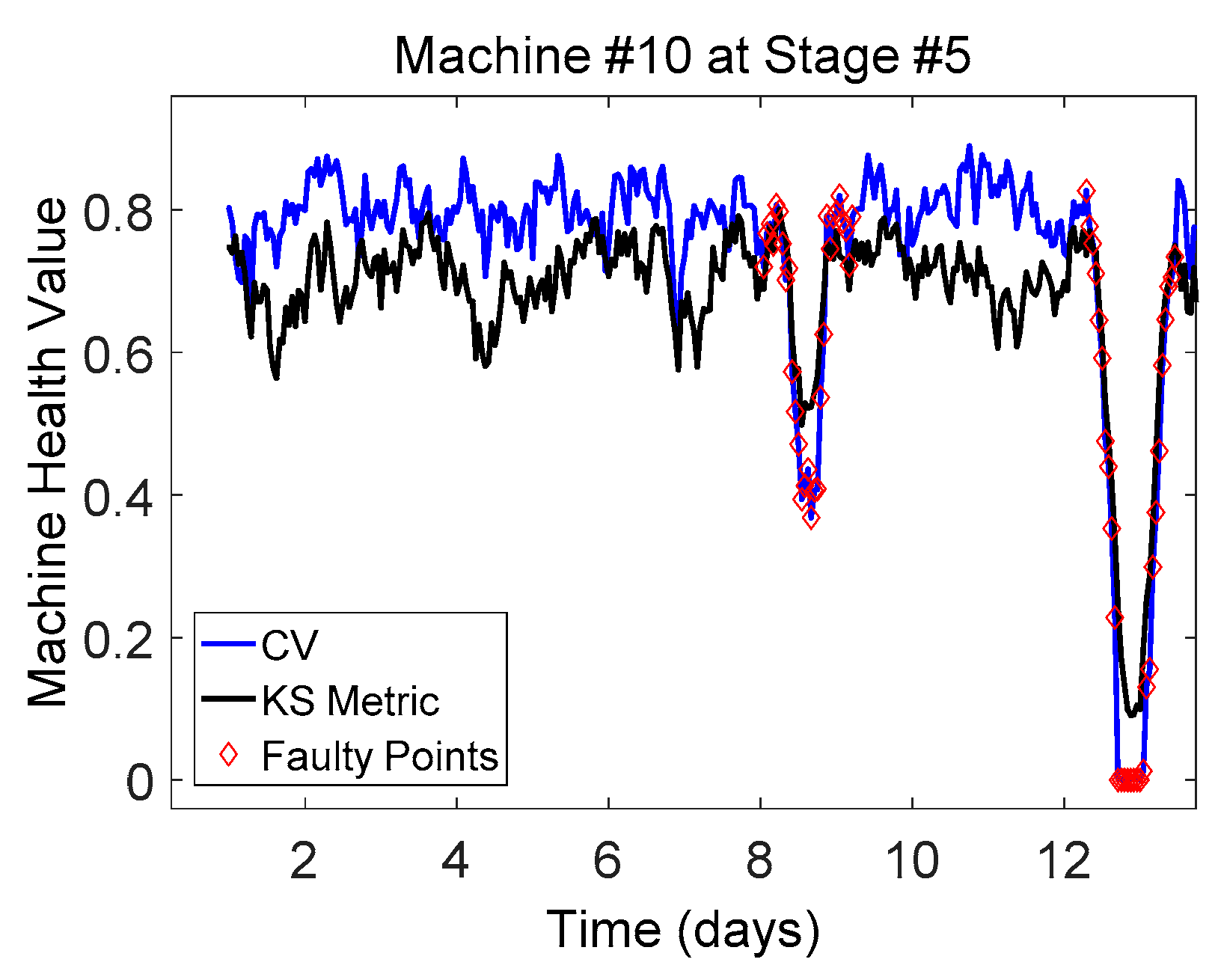
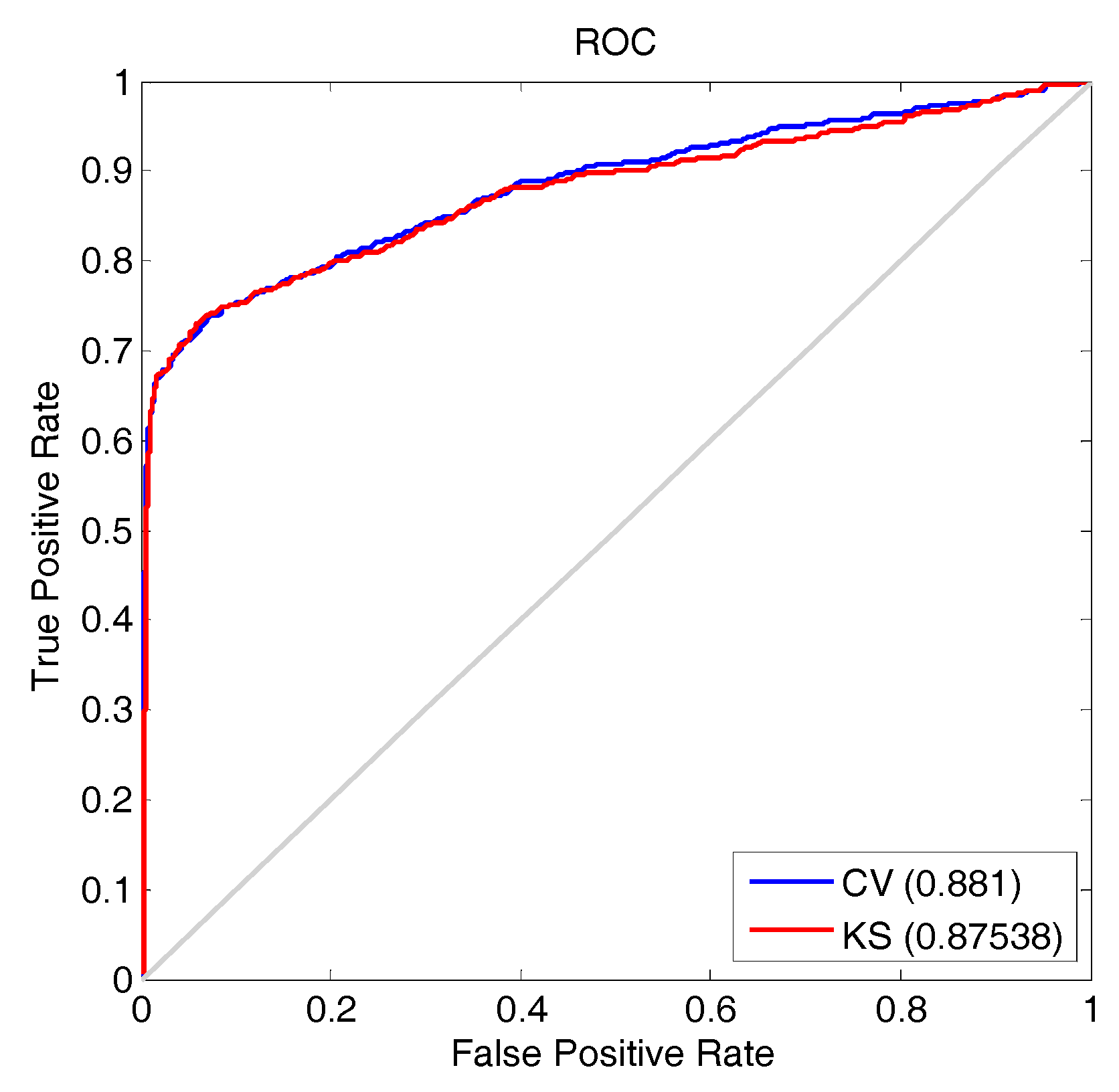
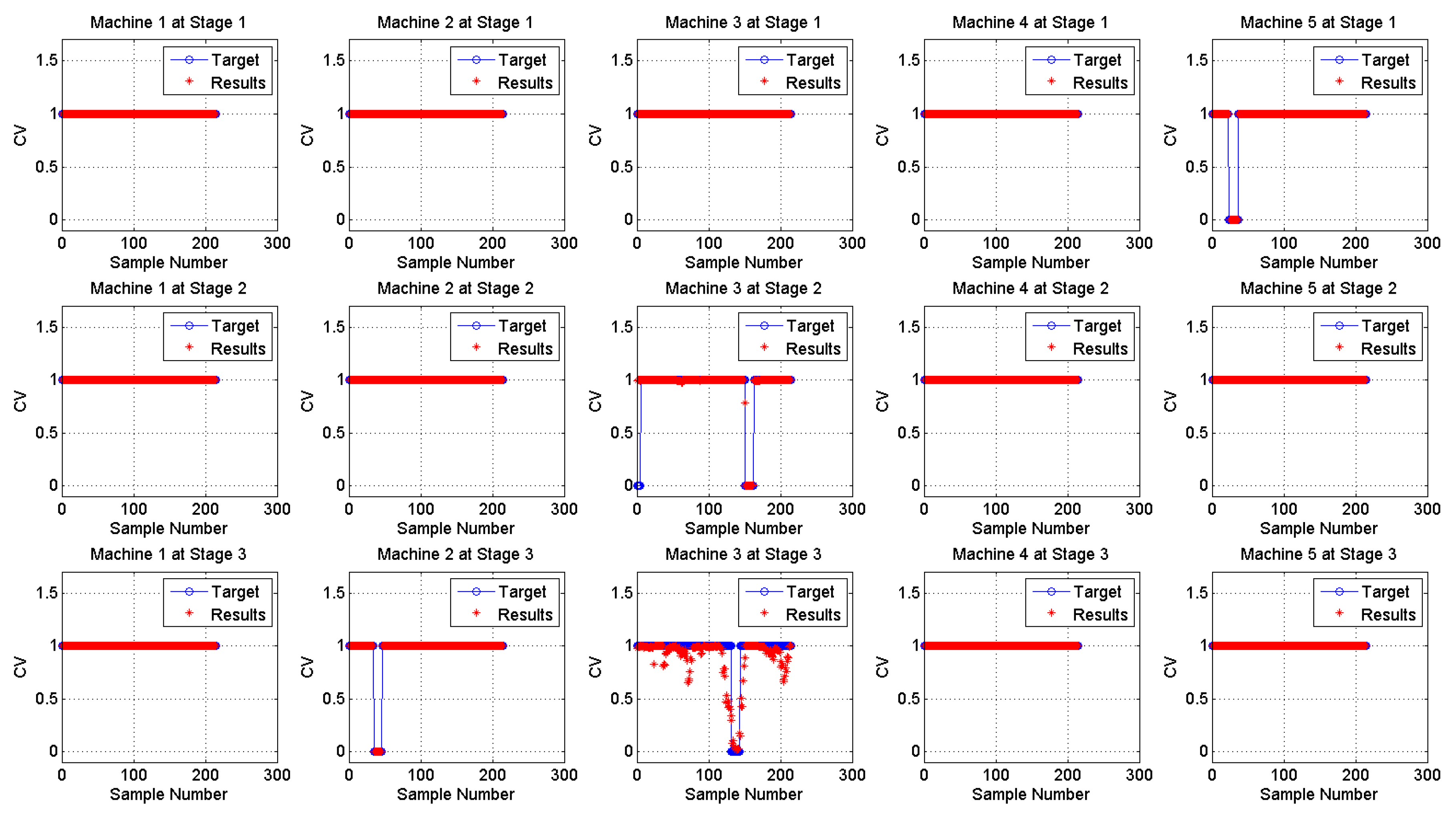
3.2. Results and Discussion
4. Evaluation and Benchmarking
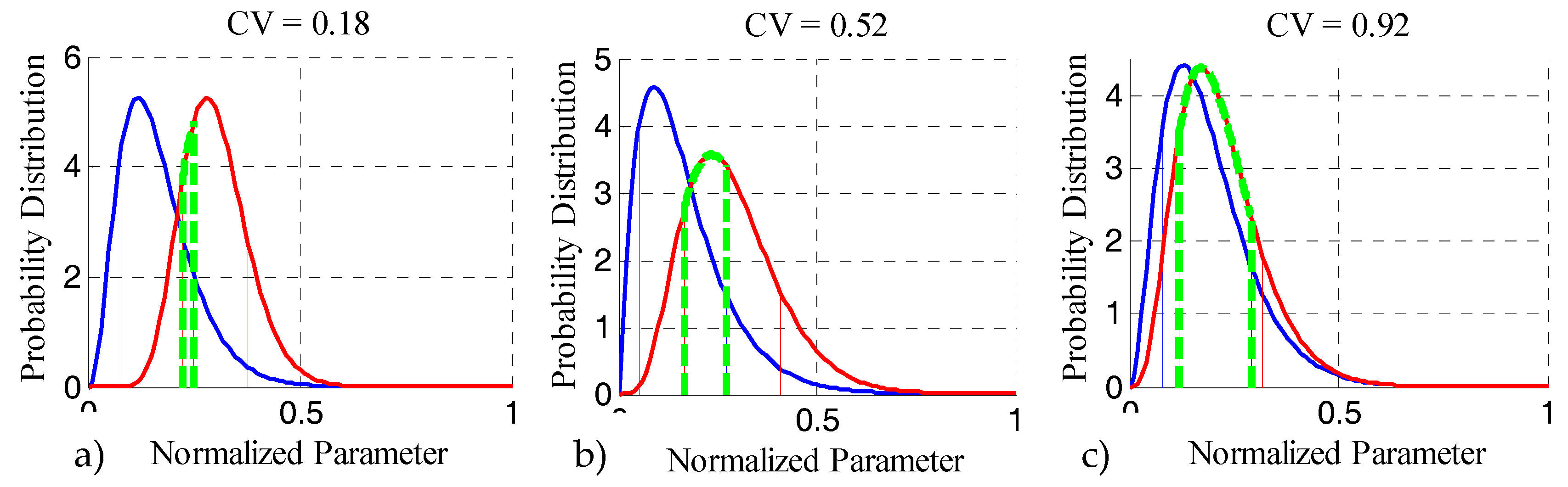
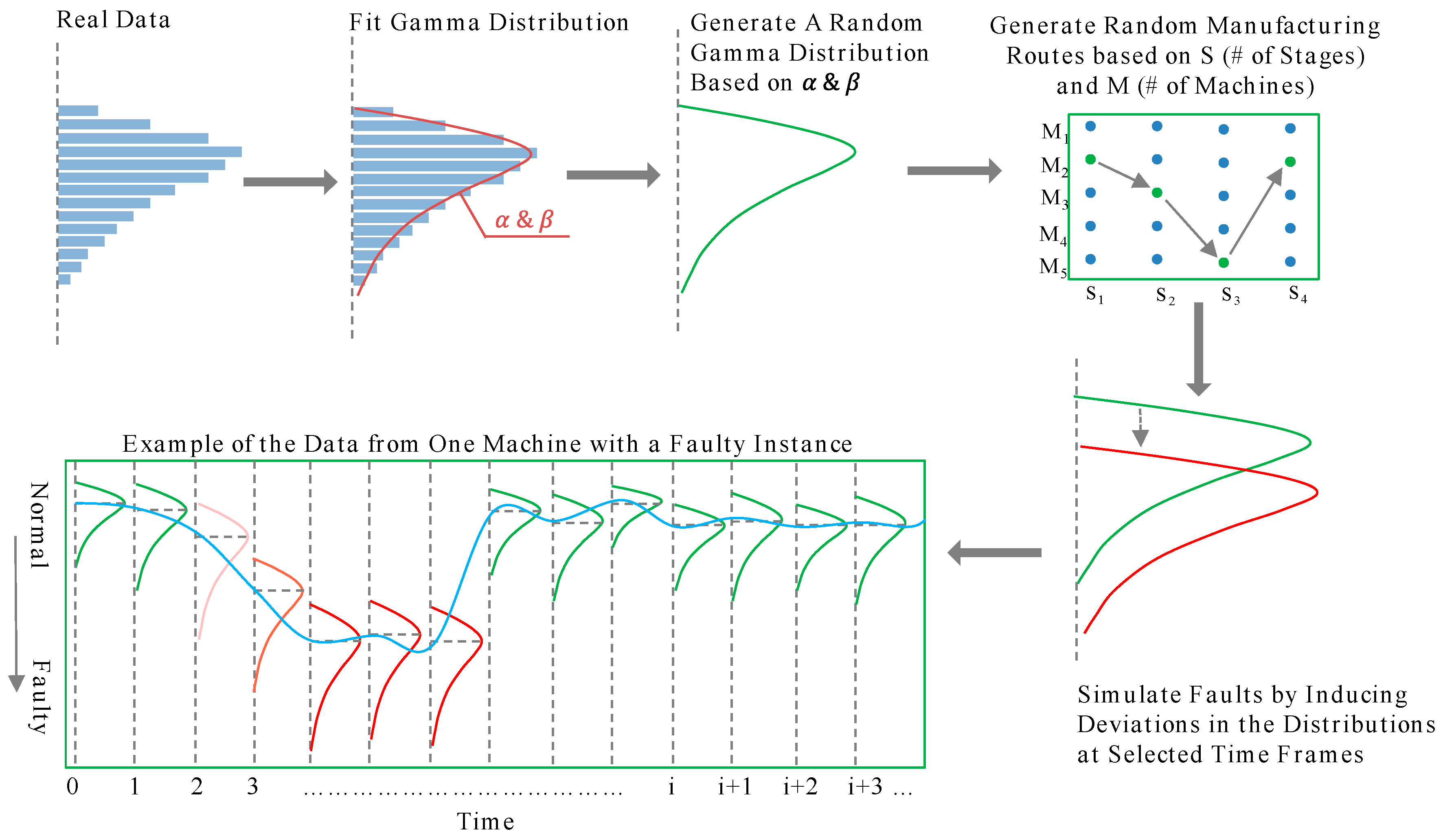
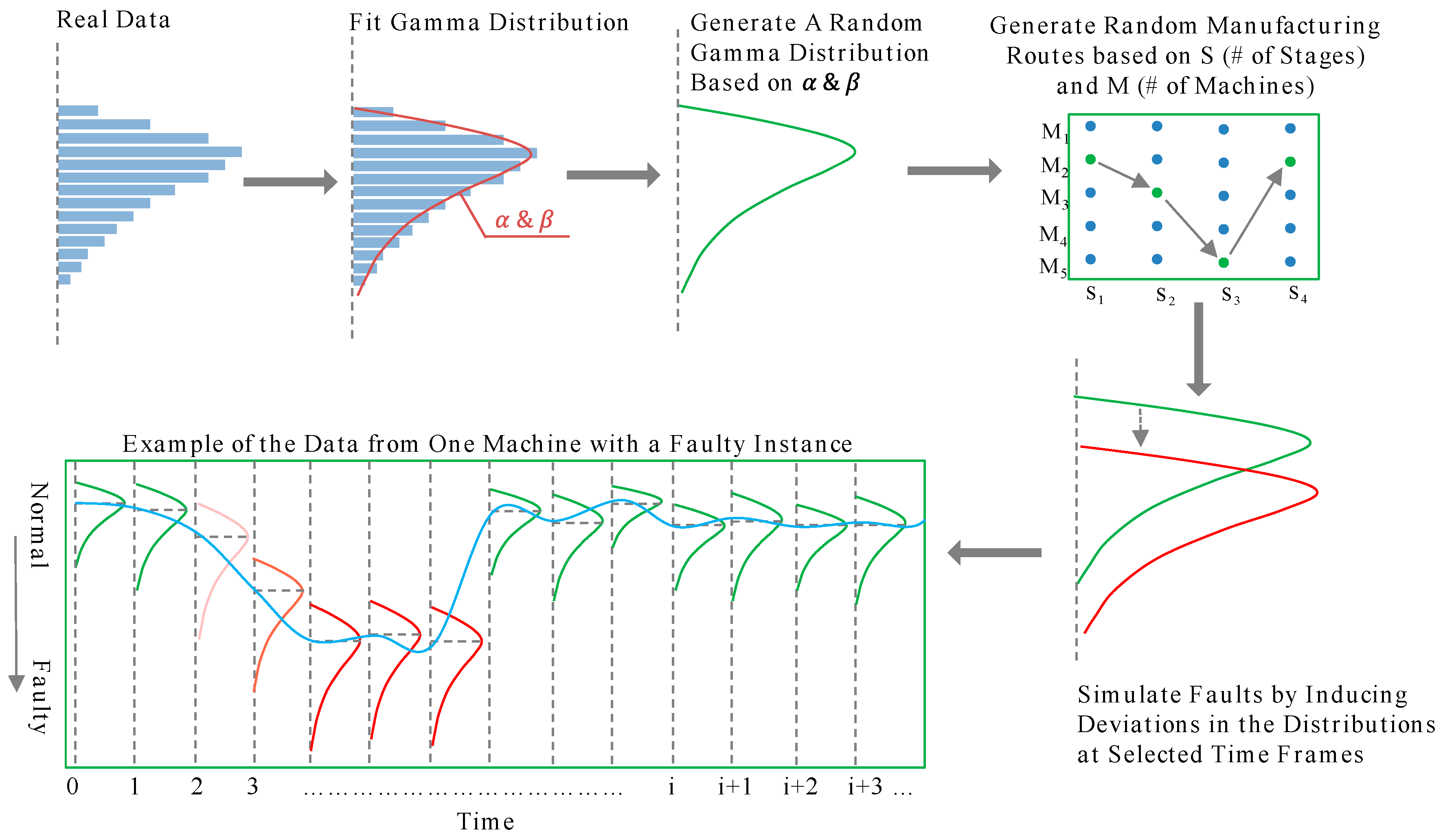
4.1. Data Simulation Using the Monte-Carlo Technique
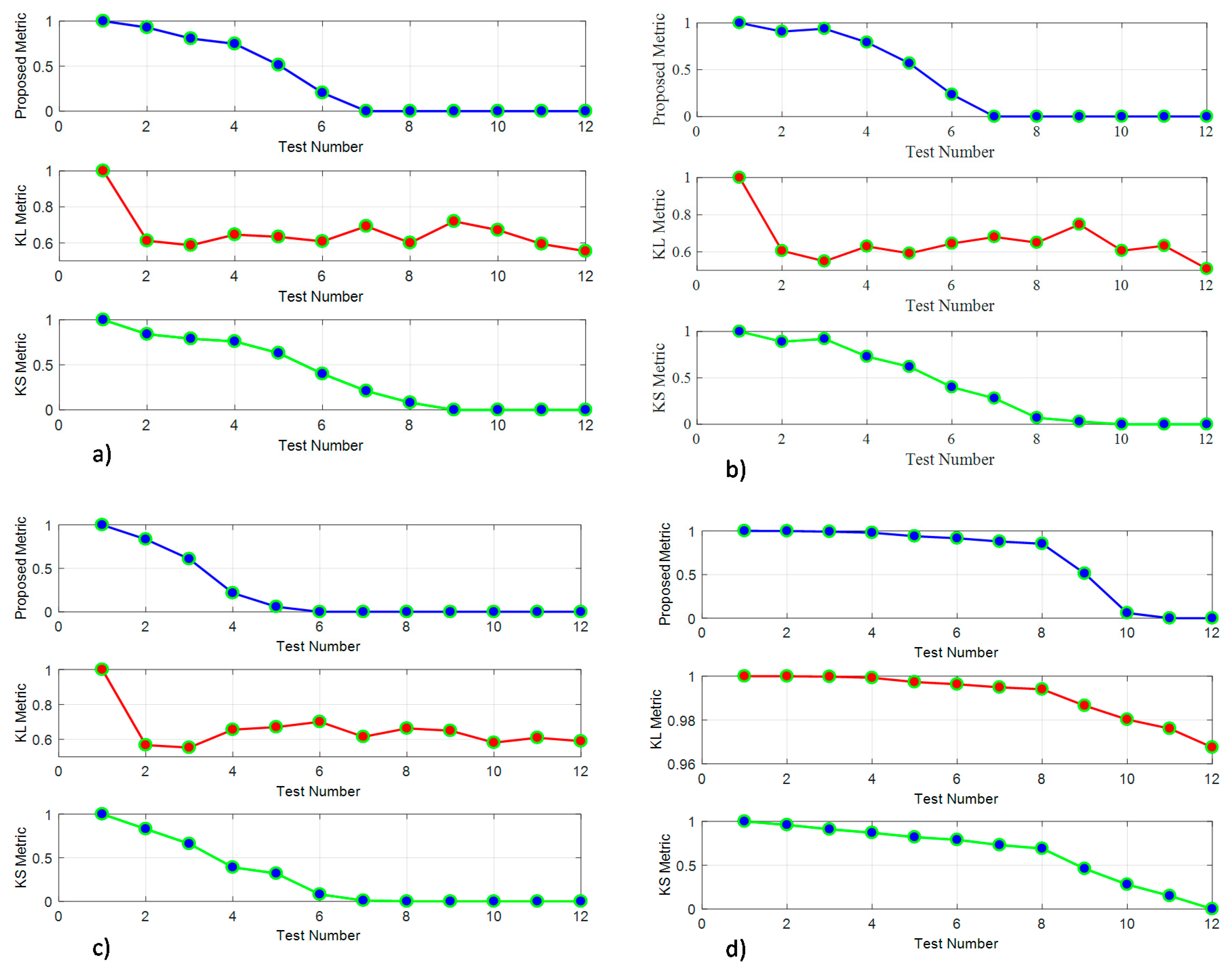
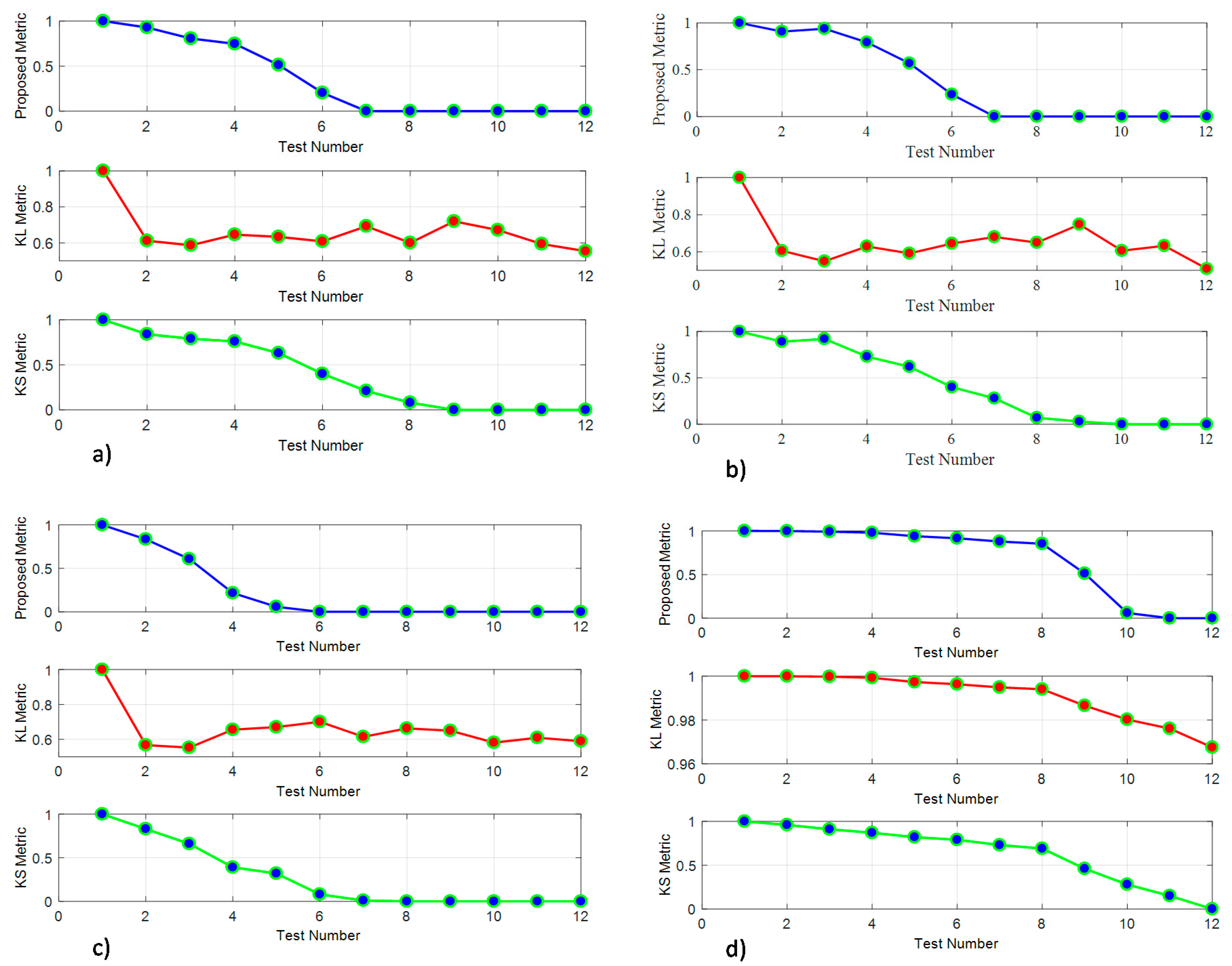
4.2. Benchmark with Distribution Comparison Techniques
- Increasing the gamma distribution’s shape parameter while keeping the scale parameter more or less constant.
- Increasing the gamma distribution’s scale parameter while keeping the shape parameter more or less constant.
- Increasing both shape and scale parameters at the same time.
- Linear shifting the values of one of the distributions.
4.3. Evaluation of the Proposed Method
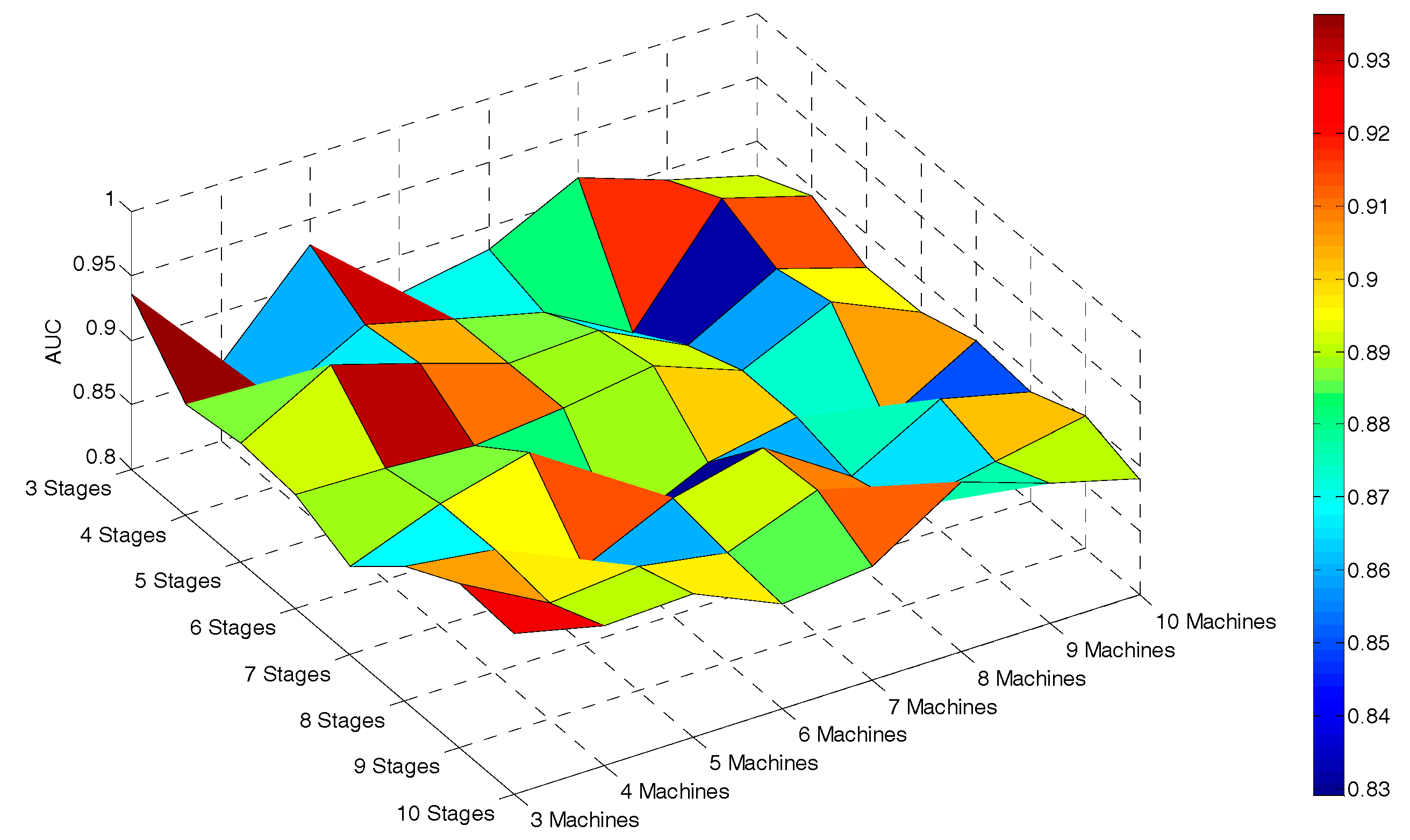
4.4. The Impact of the Process Scale
5. Bayesian Networks as an Alternative Method
6. Summary and Conclusions
Author Contributions
Conflicts of Interest
References
- Djurdjanovic, D.; Mears, L.; Niaki, F.A.; Haq, A.U.; Li, L. State of the Art Review on Process, System, and Operations Control in Modern Manufacturing. J. Manuf. Sci. Eng. 2017. [Google Scholar] [CrossRef]
- Ceglarek, D.; Shi, J. Fixture failure diagnosis for autobody assembly using pattern recognition. J. Eng. Ind. 1996, 118, 55–66. [Google Scholar] [CrossRef]
- Shu, L.; Tsung, F. Multistage process monitoring and diagnosis. In Proceedings of the 2000 IEEE International Conference on Management of Innovation and Technology (ICMIT 2000), Singapore, 12–15 November 2000. [Google Scholar]
- Chen, T.; Zhang, J. On-line multivariate statistical monitoring of batch processes using Gaussian mixture model. Comput. Chem. Eng. 2010, 34, 500–507. [Google Scholar] [CrossRef] [Green Version]
- Tsung, F.; Li, Y.; Jin, M. Statistical process control for multistage manufacturing and service operations: A review. In Proceedings of the IEEE International Conference on Service Operations and Logistics, and Informatics (SOLI’06), Shanghai, China, 21–23 June 2006. [Google Scholar]
- Wolbrecht, E.; D’ambrosio, B.; Paasch, R.; Kirby, D. Monitoring and diagnosis of a multistage manufacturing process using Bayesian networks. Ai Edam 2000, 14, 53–67. [Google Scholar] [CrossRef]
- Zhou, S.; Ding, Y.; Chen, Y.; Shi, J. Diagnosability study of multistage manufacturing processes based on linear mixed-effects models. Technometrics 2003, 45, 312–325. [Google Scholar] [CrossRef]
- Zhou, S.; Huang, Q.; Shi, J. State space modeling of dimensional variation propagation in multistage machining process using differential motion vectors. IEEE Trans. Robot. Autom. 2003, 19, 296–309. [Google Scholar] [CrossRef]
- Shi, J.; Zhou, S. Quality control and improvement for multistage systems: A survey. IIE Trans. 2009, 41, 744–753. [Google Scholar] [CrossRef]
- Ceglarek, D.; Shi, J.; Wu, S. A knowledge-based diagnostic approach for the launch of the auto-body assembly process. J. Manuf. Sci. Eng. 1994, 116, 491–499. [Google Scholar] [CrossRef]
- Hu, S.J.; Wu, S. Identifying sources of variation in automobile body assembly using principal component analysis. Trans. NAMRI/SME 1992, 20, 311–316. [Google Scholar]
- Liu, S.C.; Hu, S.J. Variation simulation for deformable sheet metal assemblies using finite element methods. J. Manuf. Sci. Eng. 1997, 119, 368–374. [Google Scholar] [CrossRef]
- Lucas, J.M.; Saccucci, M.S. Exponentially weighted moving average control schemes: Properties and enhancements. Technometrics 1990, 32, 1–12. [Google Scholar] [CrossRef]
- Montgomery, D.C. Introduction to Statistical Quality Control; John Wiley & Sons: Hoboken, NJ, USA, 2007. [Google Scholar]
- Neubauer, A.S. The EWMA control chart: Properties and comparison with other quality-control procedures by computer simulation. Clin. Chem. 1997, 43, 594–601. [Google Scholar] [PubMed]
- Page, E. Continuous inspection schemes. Biometrika 1954, 41, 100–115. [Google Scholar] [CrossRef]
- Rato, T.J.; Reis, M.S. Statistical Process Control of Multivariate Systems with Autocorrelation. In Computer Aided Chemical Engineering; Elsevier: Amsterdam, The Netherlands, 2011; pp. 497–501. [Google Scholar]
- Reynolds, M.R.; Amin, R.W.; Arnold, J.C.; Nachlas, J.A. Charts with variable sampling intervals. Technometrics 1988, 30, 181–192. [Google Scholar] [CrossRef]
- Reynolds, M.R.; Amin, R.W.; Arnold, J.C. CUSUM charts with variable sampling intervals. Technometrics 1990, 32, 371–384. [Google Scholar] [CrossRef]
- Roberts, S. Control chart tests based on geometric moving averages. Technometrics 1959, 1, 239–250. [Google Scholar] [CrossRef]
- Hu, S.J.; Koren, Y. Stream-of-variation theory for automotive body assembly. CIRP Ann. Manuf. Technol. 1997, 46, 1–6. [Google Scholar] [CrossRef]
- Shi, J. Stream of Variation Modeling and Analysis for Multistage Manufacturing Processes; CRC Press: Boca Raton, FL, USA, 2010. [Google Scholar]
- Woodall, W.H.; Montgomery, D.C. Some current directions in the theory and application of statistical process monitoring. J. Qual. Technol. 2014, 46, 78. [Google Scholar] [CrossRef]
- Cheng, S.; Azarian, M.H.; Pecht, M.G. Sensor systems for prognostics and health management. Sensors 2010, 10, 5774–5797. [Google Scholar] [CrossRef] [PubMed]
- Ardakani, H.D.; Phillips, B.; Bagheri, B.; Lee, J. A New Scheme for Monitoring and Diagnosis of Multistage Manufacturing Processes Using Product Quality Measurements. In Proceedings of the Annual Conference of the Prognostics and Health Management Society, Coronado, CA, USA, 18–24 October 2015. [Google Scholar]
- Karandikar, J.M.; Abbas, A.E.; Schmitz, T.L. Tool life prediction using Bayesian updating. Part 2: Turning tool life using a Markov Chain Monte Carlo approach. Precis. Eng. 2014, 38, 18–27. [Google Scholar]
- Niaki, F.A.; Ulutan, D.; Mears, L. Parameter inference under uncertainty in end-milling γ′-strengthened difficult-to-machine alloy. J. Manuf. Sci. Eng. 2016, 138, 061014. [Google Scholar] [CrossRef]
- Gözü, E.; Karpat, Y. Uncertainty analysis of force coefficients during micromilling of titanium alloy. Int. J. Adv. Manuf. Technol. 2017, 93, 839–855. [Google Scholar] [CrossRef]
- Siegel, D.; Lee, J. An Auto-Associative Residual Processing and K-Means Clustering Approach for Anemometer Health Assessment. In International Journal of Prognostics and Health Management Volume 2; Lulu Press, Inc.: Morrisville, NC, USA, 2011. [Google Scholar]
- Doucet, A.; Wang, X. Monte Carlo methods for signal processing: A review in the statistical signal processing context. IEEE Signal Process. Mag. 2005, 22, 152–170. [Google Scholar] [CrossRef]
- Kar, C.; Mohanty, A. Application of KS test in ball bearing fault diagnosis. J. Sound Vib. 2004, 269, 439–454. [Google Scholar] [CrossRef]
- Kullback, S.; Leibler, R.A. On information and sufficiency. Ann. Math. Stat. 1951, 22, 79–86. [Google Scholar] [CrossRef]
- Johnson, D.; Sinanovic, S. Symmetrizing the kullback-leibler distance. Available online: https://scholarship.rice.edu/bitstream/handle/1911/19969/Joh2001Mar1Symmetrizi.PDF?sequence=1&isAllowed=y (accessed on 15 December 2017).
- Nannapaneni, S.; Mahadevan, S.; Rachuri, S. Performance evaluation of a manufacturing process under uncertainty using Bayesian networks. J. Clean. Prod. 2015, 113, 947–959. [Google Scholar] [CrossRef]
- Leng, D.; Thornhill, N.F. Process Disturbance Cause & Effect Analysis Using Bayesian Networks. IFAC-PapersOnLine 2015, 48, 1457–1464. [Google Scholar]
- Du, S.; Yao, X.; Huang, D. Engineering model-based Bayesian monitoring of ramp-up phase of multistage manufacturing process. Int. J. Prod. Res. 2015, 53, 4594–4613. [Google Scholar] [CrossRef]
- Zhao, W. A Probabilistic Approach for Prognostics of Complex Rotary Machinery Systems. Ph.D. Thesis, University of Cincinnati, Cincinnati, OH, USA, 2015. [Google Scholar]
© 2018 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (http://creativecommons.org/licenses/by/4.0/).
Share and Cite
Davari Ardakani, H.; Lee, J. A Minimal-Sensing Framework for Monitoring Multistage Manufacturing Processes Using Product Quality Measurements. Machines 2018, 6, 1. https://doi.org/10.3390/machines6010001
Davari Ardakani H, Lee J. A Minimal-Sensing Framework for Monitoring Multistage Manufacturing Processes Using Product Quality Measurements. Machines. 2018; 6(1):1. https://doi.org/10.3390/machines6010001
Chicago/Turabian StyleDavari Ardakani, Hossein, and Jay Lee. 2018. "A Minimal-Sensing Framework for Monitoring Multistage Manufacturing Processes Using Product Quality Measurements" Machines 6, no. 1: 1. https://doi.org/10.3390/machines6010001
APA StyleDavari Ardakani, H., & Lee, J. (2018). A Minimal-Sensing Framework for Monitoring Multistage Manufacturing Processes Using Product Quality Measurements. Machines, 6(1), 1. https://doi.org/10.3390/machines6010001